

서론
수집 데이터 및 분석
1. 1톤 트럭 데이터 수집 및 특성 분석
2. Micro-Trip 클러스터링
대표운행사이클 도출 및 실운행기록과의 특성 비교
1. 대표운행사이클 도출
2. 실 운행기록과의 특성 비교
결론
서론
차량의 표준화된 성능과 배기가스 배출량 등을 평가하기 위해 각국에서는 현지 사정에 적합한 공인시험 주행모드를 개발하여 사용하고 있다. 우리나라에서도 디젤자동차의 배출가스를 측정하기 위해 D-13 등의 테스트 모드를 개발하였으나, 일반적으로 공개되는 공인연비를 측정하기 위해서는 미국에서 개발하여 다수의 국가에서 사용 중인 FTP(Federal Test Procedure)-75 모드를 주로 사용하고 있다. 그러나 이는 국내 환경이 적절히 반영되어 있다고 보기 어렵고, 특히 빈번한 주 ‧ 정차와 가 ‧ 감속 등의 주행 특성을 갖는 소형 택배 트럭과 같은 특이형태의 주행패턴을 가지는 운행차량의 성능을 평가하는 것에는 어려움이 있다.
이와 같이 지역 및 통행수단이 가지는 다양성으로 인해 각 상황에 적합한 차량의 성능을 평가할 수 있는 주행모드에 대한 연구(Hung et al., 2007; Kamble et al., 2009; Han et al., 2012)들은 지속적으로 이루어졌다. 이 중 다양한 가상의 가 ‧ 감속 패턴 및 속도를 고려하는 유럽의 NEDC 주행모드와 일본의 J10-15등의 모드를 제외하고는 FTP-75로 대표되는 대부분의 주행모드(Tong et al., 1999; Amirjamshidi and Roorda, 2015; Arun et al., 2017)들이 실제 환경에서 발생한 데이터들의 통계적 특성-특정지역, 특정시간대에서 빈번히 발생하는 주행패턴, 최고속도, 평균속도, 정체성향 등-을 분석하여 이를 바탕으로 대표적인 주행모드를 도출하고 있다.
그러나 이와 같은 통계적 분석에 따른 성능평가 주행모드의 한계를 극복하고자 데이터 처리의 효율성과 실 데이터의 효과적인 반영을 목적으로 하는 클러스터링 방법을 사용한 연구도 이루어졌다. Fotouhi and Montazeri-Gh(2013)은 테헤란에서 AVL(Advanced Vehicle Location) System을 통해 수집한 차량의 위치 정보를 사용하여 주행특성을 추출하고, 클러스터링하여 정체주행(Congested traffic condition) ‧ 도심주행(Urban traffic condition) ‧ 준도심주행(Extra urban traffic condition) ‧ 고속주행(Highway traffic condition)의 네 가지 그룹으로 나눈 후, 이를 바탕으로 각 클러스터의 중심에서 가까운 주행(trip)부터 충분한 길이가 될 때까지 기록을 붙여 각 그룹별 주행모드를 도출하였다.
본 연구에서는 배송업무로 인한 도심주행을 주로 하여 저속운행과 잦은 가다-서다 운행 행태를 보이는 소형 택배 트럭의 대표적인 운행 사이클을 개발하여 관련 차량의 성능을 평가하고 유사업종에서 활용 가능한 친환경 차량의 개발 시, 주요 부품의 성능 수준을 결정하는데 기여하는 것을 목적으로 하여, 빅데이터 클러스터링 기반의 대표운행사이클을 개발한다. 이를 위하여 Fotouhi and Montazeri-Gh(2013)에서 사용한 K-means clustering와 주행모드 도출 방법을 활용하여, 소형 택배 트럭과 같이 비교적 특수한 상황의 운행패턴을 가지는 차량의 성능 평가용 주행모드를 개발하고자 각 클러스터별 주행기록이 아닌 클러스터의 특성을 반영하는 하나의 주행모드를 개발하는 방안을 제시한다.
본 논문의 구성은 다음과 같다. 2장에서는 수집된 데이터 및 이들 데이터를 바탕으로 주행의 기본단위를 설정하는 방법과 클러스터링을 설명한다. 3장에서는 클러스터 된 주행 데이터를 바탕으로 대표운행사이클을 도출하는 방법을 논하고, 택배 트럭의 일일 주행 궤적 자료와의 비교를 통해 유사성을 살펴본다. 마지막으로 4장에서는 연구의 활용방안 및 한계점에 관해 서술한다.
수집 데이터 및 분석
디지털운행기록계(Digital TachoGraph, DTG)는 차량에 부착하여 이동거리, 속도, RPM, 종 ‧ 횡방향 가속도, 브레이크 작동 여부, 위 ‧ 경도 및 GPS 방위각 등의 정보를 수집하는 장치로, 현재 사업용 차랑에 의무적으로 부착되어 초 단위의 운행정보를 전자식 기억장치에 자동으로 기록하고 있다. 이처럼 DTG는 차량으로부터 다수의 운행 특성을 저장하기 때문에 클러스터링에 사용할 특성을 비교적 다양하게 사용할 수 있다는 장점이 있다. 더불어 특정 업체나 지역에 국한된 특정 차량으로부터의 주행기록을 수집하는 것이 아닌, 사업용 차량으로 사용되고 있는 적재중량 1톤 이하 트럭으로부터 발생한 주행기록이 의무적으로 제출된 가운데 랜덤하게 샘플을 추출하여 연구에 사용할 수 있어 표본수집으로부터 발생할 수 있는 편향(bias)를 최소화 할 수 있어 본 연구에 사용하기에 적합한 데이터라 할 수 있다.
다음에서는 적재중량 1톤 이하 트럭의 DTG 데이터를 수집 및 가공, 클러스터링 알고리즘을 사용하는 대표운행사이클 도출 방법에 대해 소개하고자 한다.
1. 1톤 트럭 데이터 수집 및 특성 분석
본 연구에서는 2017년 4월 발생하여 제출된 적재중량 1톤 이하 소형트럭 318대의 DTG 데이터를 수집하여 사용하였다. 총 65,050,870개의 궤적 GPS 좌표를 통해 지도상에 나타낸 그림은 Figure 1과 같다. Figure 1을 보면 수집된 주행기록은 전국에 걸쳐 분포하였으며, 수집된 데이터의 기본 주행 특성은 Table 1과 같이 나타났다.
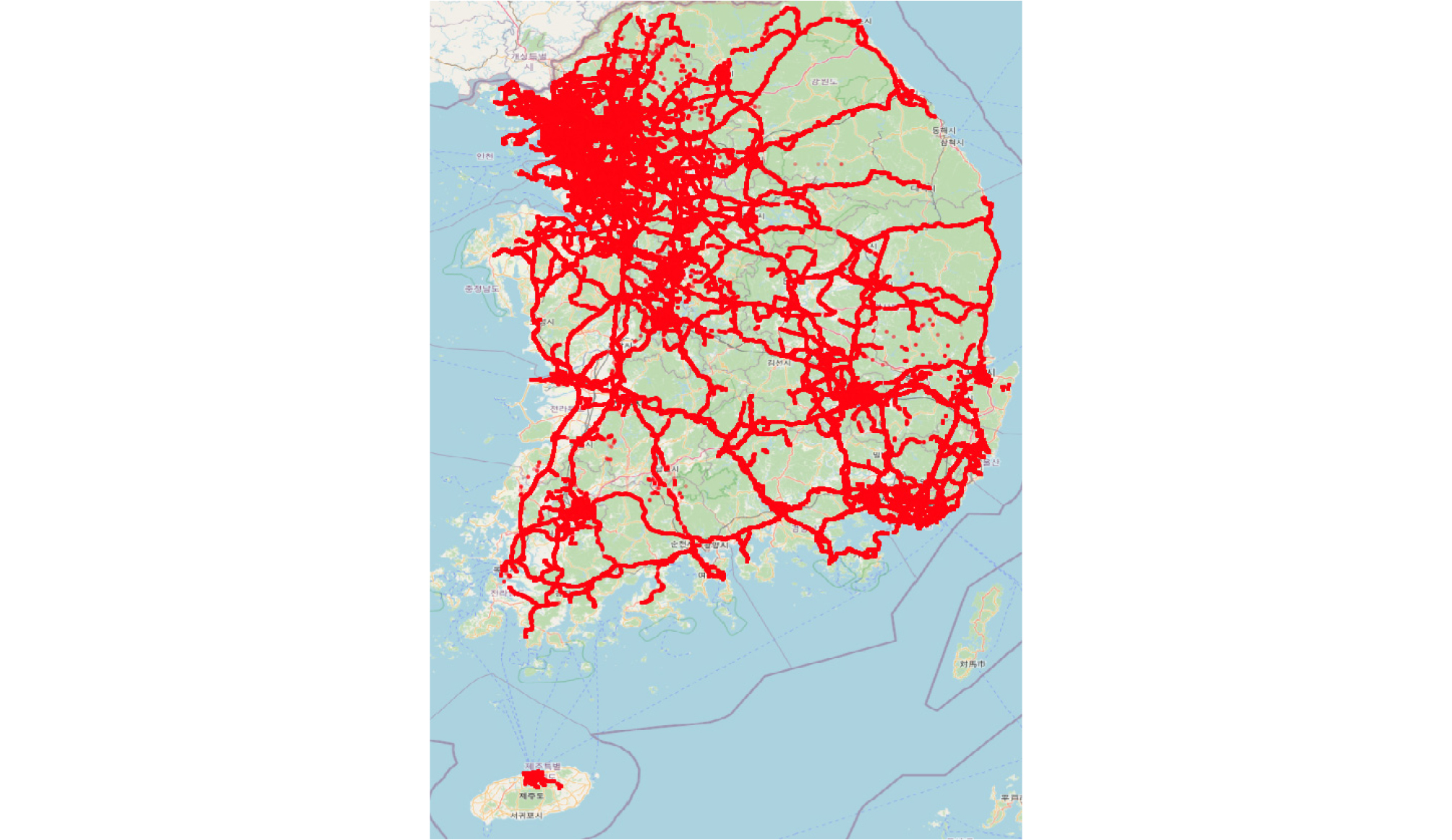
Table 1.
Characteristics of data
2017년 4월 기준 적재중량 1톤 이하 소형 트럭은 총 2,828,335대 이며, 이 중 DTG 기록 제출 대상인 등록된 사업용 차량은 총 120,631대가 있다. 따라서 수집된 샘플은 전체 모집단의 0.26%가량으로 샘플률이 낮아 이를 보완하기 위하여 차량의 개별적 특성을 최소화하며 운행구간의 특성이 반영될 수 있도록 주행을 분할하여, 분할된 주행 기록을 micro-trip으로서 정의하고, 이를 단위로 하는 분석방법을 적용하였다. 소형트럭의 주행기록에서는 일반 차량의 주행과는 다르게 주로 시내를 주행하고 다수의 배송지점을 방문하여 잦은 정차(속도 0km/hr) 상황을 확인할 수 있다. 이러한 정차 상태를 기준으로 정차와 다음 출발 사이의 구간을 micro-trip으로 정의1)하고 기록계의 오작동이 없는 구간에 대하여 총 293,425개의 micro-trip을 생성하였다.
2. Micro-Trip 클러스터링
수집된 micro-trip의 운행 특성을 잘 나타낼 수 있는 각각 평균 속도, 최대속도, 최대 가속도, 최대 감속도, 이동 거리에 대한 가속 횟수 비율, 전체 시간에 대한 가속 시간의 비율의 6개 특성이 선정되었고, 이를 각 micro-trip에 대해 계산하여 6차원 벡터를 형성하였으며, 이 6차원 벡터는 각 micro-trip의 특성 벡터가 된다. 본 연구에서는 이 특성 벡터를 바탕으로 데이터를 분류하기 위하여 K-means 클러스터링 방법을 사용하였다.
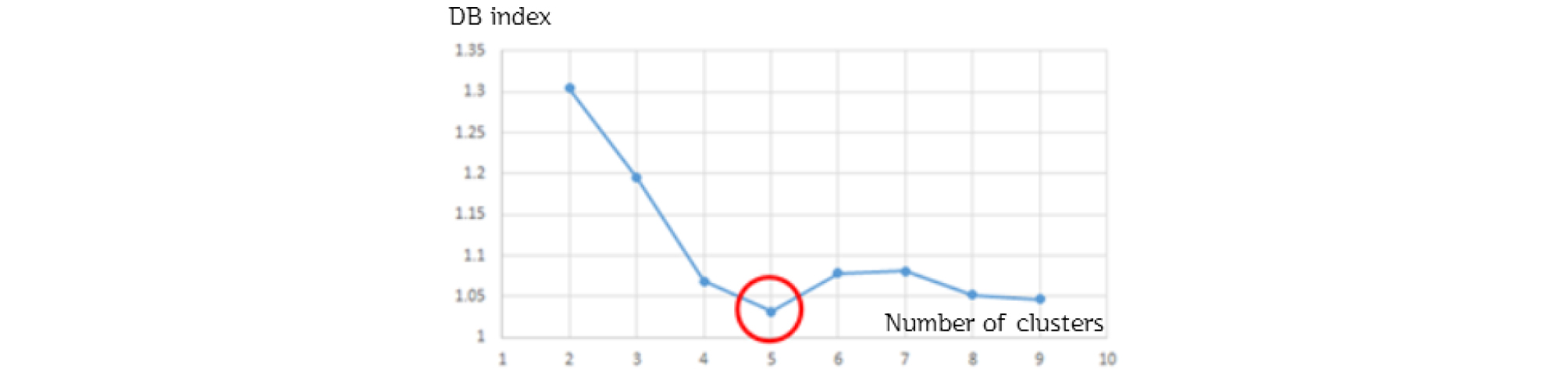
K-means 클러스터링 방법은 가장 널리 이용되는 클러스터링 방법으로, 연산 비용이 적게 사용되기 때문에 Large-scale의 데이터 처리에 적합하며, 초기 Initial point를 도메인에 적합한 값으로 지정하면 효율적인 연산이 가능하다. 또한, 각 cluster의 대표값이 centroid의 좌표로서 나타나기 때문에 최종 대표 운행 사이클을 생성할 때 선택하는 micro-trip의 기준을 직관적으로 수립할 수 있는 장점이 있다. K-means 클러스터링 방법은 클러스터의 개수 K를 연구자가 임의로 설정해야 한다는 단점이 있으나 본 연구에서는 클러스터 평가(Davies Bouldin Index)로 임의성을 제거하였으며, 그 결과 5개의 군집이 적합한 것으로 나타났다. 이는 대상 차량이 실 주행하는 환경을 고려할 때 정체-도심-준도심-고속 운행으로 4개 이상의 군집이 적절할 것으로 예상했던 가설과도 일치하였다.
K-means 클러스터링 방법은, 주어진 데이터를 벡터 공간 위에서 K개의 영역으로 분할하는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작하며, 레이블이 달려 있지 않은 입력 데이터를 분류한다. 알고리즘의 초기 단계에서, 각 벡터는 각 클러스터의 중심벡터 집합 중에서 유클리드 거리가 최소인 중심벡터를 중심벡터로 갖는 클러스터 에 포함되도록 결정된다. 임의의 p-차원 특성 벡터 와 k번째 클러스터의 중심벡터 사이의 p-차원 유클리드 거리(l)는 다음과 같이 계산된다.
| $$l=\parallel{\vec\mu}_k-\vec x\parallel_p=\sqrt[p]{\sum_{i=1}^n(\mu_k-x_i)^P}$$ | (1) |
임의의 위치에 K개의 클러스터(cluster)와 클러스터 중심을 위치시키고, 데이터셋의 각 벡터를 K개의 클러스터 중심 중 유클리드 거리가 가장 가까운 곳에 있는 클러스터 중심이 속해있는 클러스터에 할당한다. 이후, 각 클러스터에 포함되는 데이터셋의 평균값을 해당 클러스터의 클러스터 중심으로 업데이트하는데, 이와 같은 과정을 반복하여 클러스터 중심이 더 이상 변하지 않고 수렴할 때까지 반복한다. 이때 각 벡터와 해당 클러스터의 중심벡터 사이의 유클리드 거리의 합으로서 밀집도 혹은 비용 함수(Equation 2)가 정의된다. 는 클러스터에 포함된 특성 벡터를 나타내며, 는 클러스터의 중심 벡터를 나타낸다. 밀집도는 데이터셋이 클러스터 중심으로부터 분산되어 있으면 높은 값을 가지고, 비슷한 특성들이 함께 모여 있으면 낮은 값을 가지므로, 이를 척도로 하는 평가 지표인 Davies Bouldin Index(이하 DB Index)를 사용하여 적절한 클러스터의 개수 K의 결정이 가능하다.
| $$\mathrm{cos}t(K)=\sum_{n=1}^{N_k}\parallel x_n-\mu_k\parallel_p$$ | (2) |
Davies Bouldin Index는 최적 클러스터 개수를 결정하는 데 사용되며, 클러스터 내(inner-cluster) 유사도가 높고, 클러스터 간(inter-cluster) 유사도가 낮은 클러스터들을 생성하는 클러스터링 알고리즘은 낮은 Davies-Bouldin Index 값을(Equation 3) 가지게 된다.
이때, ,는 해당 클러스터의 밀집도를 나타내는 척도이며, 은 두 클러스터가 얼마나 분리되었는지를 나타내는 척도를 나타낸다. 는 클러스터에 포함된 특성 벡터의 개수를 나타내고, 클러스터 중심과 데이터 간의 거리를 유클리드 거리로 계산할 때, p는 2이다. 계산된 K값에 대한 DB Index의 기울기가 변하는 지점에서의 K값을 최적 클러스터 개수로 결정한다(elbow method). 알고리즘은 비용 함수가 지역 최솟값(local minimum)을 가질 때 중단되므로 클러스터의 평가는 해당 K값에 대해 여러 번 반복하여 최소의 DB Index을 가질 때의 K-means 클러스터링 결과를 사용한다. DB Index를 분석한 결과, 첫 번째 변곡점으로 최적 클러스터 개수는 5개로 도출(Figure 2) 되었는데, 6개 이상의 더 높은 개수의 클러스터로 분할하는 경우, 기 분리된 클러스터를 재분할하는 방향으로 알고리즘이 동작하게 된다. 클러스터링을 실시한 후 이를 다시 출현 비율로 분할하여 대표운행사이클을 생성하는 현재 방식에서는 클러스터 개수의 추가는 최종 대표 사이클 생성에 큰 영향을 미치지 않게 되며, 이는 실제로 클러스터를 6개 이상으로 나누어 클러스터링을 수행했을 때, 고속주행에 해당하는 데이터가 추가되는 결과를 보였다.
따라서 5개의 클러스터를 가지는 K-means 클러스터링을 실시하였으며, 그 결과는 Table 2와 같다.
대표운행사이클 도출 및 실운행기록과의 특성 비교
1. 대표운행사이클 도출
대표운행사이클은 각 특성 벡터가 클러스터의 중심 벡터에 해당하는 micro-trip을 이어 붙여 생성한다. 2장에서 도출한 각 클러스터의 중심 micro-trip을 해당 클러스터에 포함된 micro-trip 개수에 비례하는 확률을 통해 추출하여 제작하였다. 이때, 클러스터링이 완료된 후, K개의 클러스터 각각에 포함되는 micro-trip의 개수를 각각 라 하면, micro-trip 총 개수는 이고, 대표운행사이클에 포함시킬 중심 추출 확률은 이다. 기존에 사용되는 연비 평가용 주행사이클의 총 주행 거리 또는 총 주행 시간과 비슷한 수준이 될 때까지 클러스터 중심 micro-tip을 위 확률을 통해 추출하고, 추출이 완료된 후 이를 임의의 순서로 배치하여 대표 운행 사이클 제작을 완료한다.
본 연구에서는 2017년 서울시 도심 평균 속도가 19km/h로, 평균 속도가 19km/h 이상인 클러스터에 대하여 비(非) 시내 주행으로 간주하여 클러스터 4와 5를 제외하였다. 이는 수집된 적재중량 1톤미만 트럭 DTG 데이터에는 용달 차량도 일부 포함되어 있어 외곽지역, 장거리 고속주행 등을 포함하고 있기 때문에, 이들 특성을 제외하기 위하여 평균속도가 낮은 클러스터 1, 2, 3만을 사용하여 대표운행사이클을 생성하였다. 이에 클러스터 출현비율은 1, 2, 3 순서대로 11.54:44.23:44.23(6:23:23)이고, 전체 사이클의 길이는 주로 통용되는 공인연비 사이클인 FTP-75와 유사하게 2,500초 근처에서 형성되도록 하였다. 또한, 클러스터 1, 2, 3의 유휴 시간 비율인 0.48을 적용하여 사이클 길이의 48%는 정차하고 있는 상태인 유휴상태를 유지할 수 있도록 구성하였으며, 도출된 대표운행사이클의 속도-시간 그래프는 Figure 3과 같다.
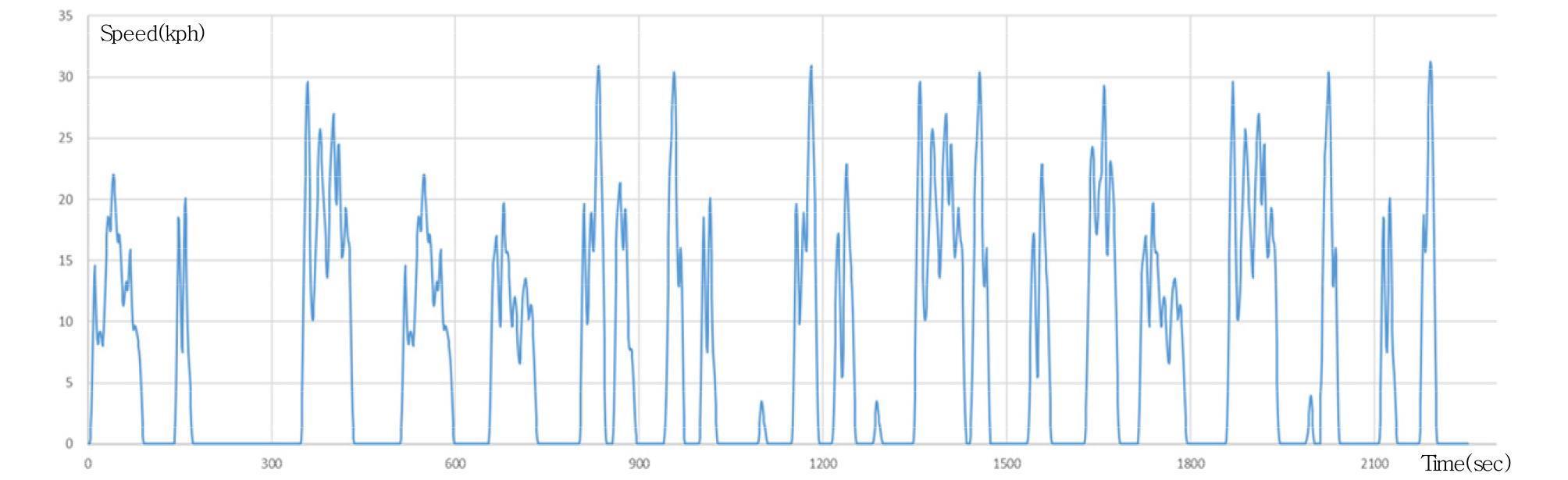
본 연구에서 생성한 대표운행사이클은 길이가 2,254초, 평균 속도가 6.86km/h로 2017년 2/4분기에 조사된 택배 차량 평균 운행속도 5.9km/h(KOTI, 화물운송시장동향)와 유사하게 도출되어 생성된 대표운행사이클이 소형 택배 트럭의 운행 특성을 다소간에 반영하고 있는 것으로 판단되나, 더 상세한 비교를 위하여 아래에서는 실 운행기록과의 특성을 구체적으로 비교하고자 한다.
2. 실 운행기록과의 특성 비교
도출된 대표운행사이클의 평균속력 및 유휴비율 등의 실제 택배 차량의 운행행태와의 비교를 위하여 임의 선정된 차량의 운행궤적을 검토하였다. 시내 주행 비율이 높은 트럭을 대상으로 주요 정차지역 및 정차시간, 평균속력, 유휴비율 등을 산정하였다. Figure 4의 A트럭의 경우 평균속력이 7.58km/h, 유휴비율이 0.52, Figure 5의 B트럭은 평균속력 10.37km/h, 유휴비율 0.46, Figure 6의 C트럭은 평균속력 7.95km/h 유휴비율 0.47로 나타났다.
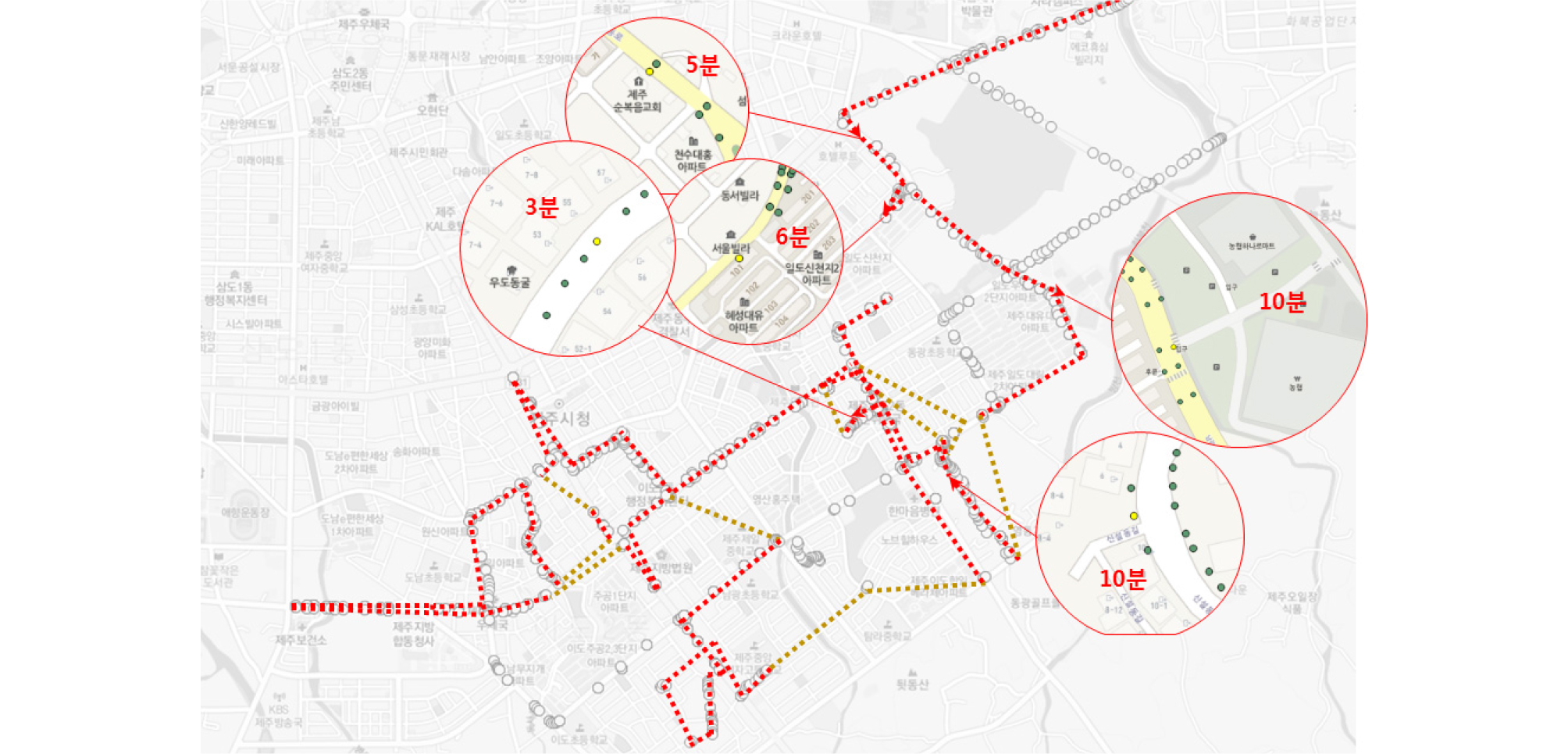
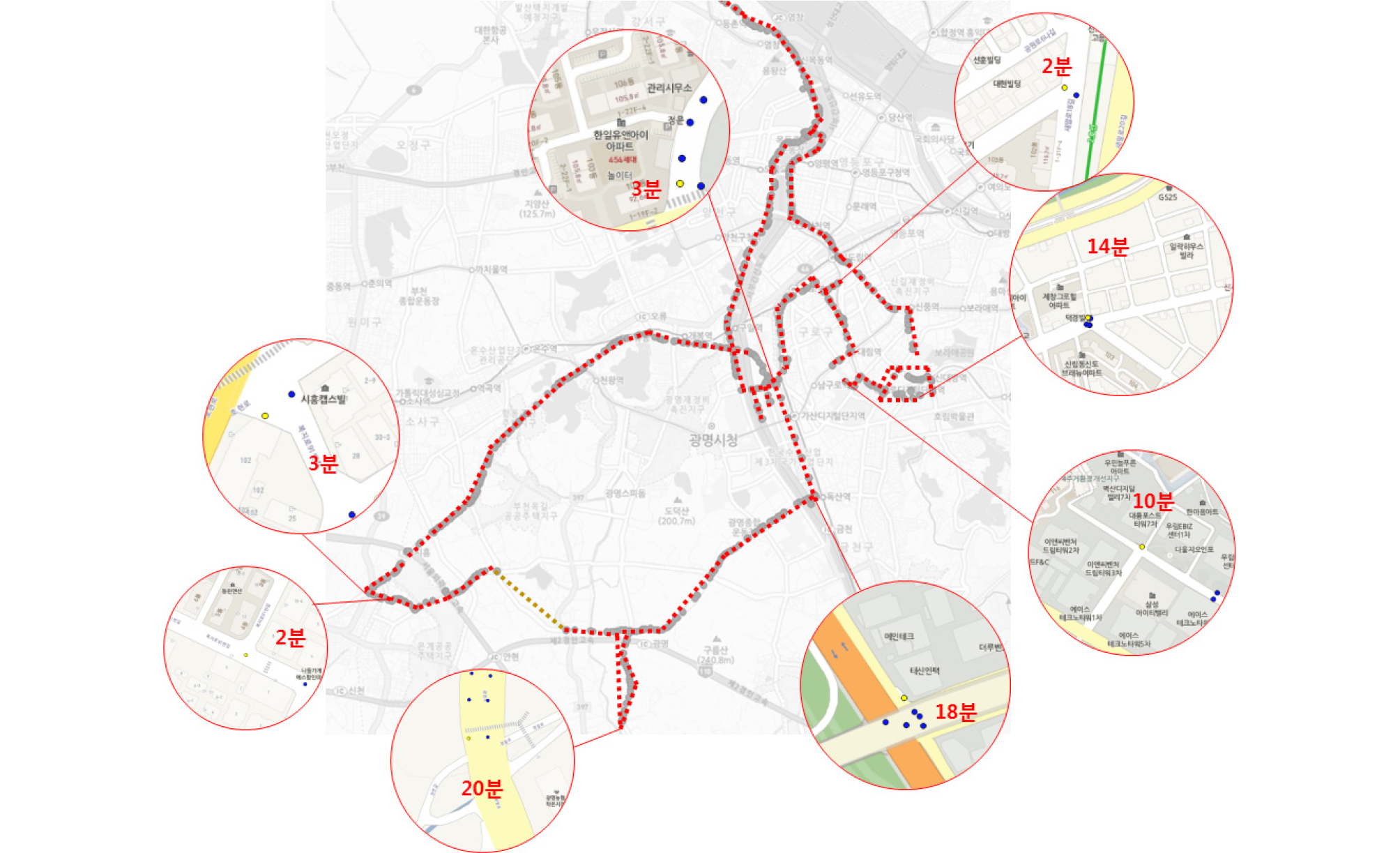
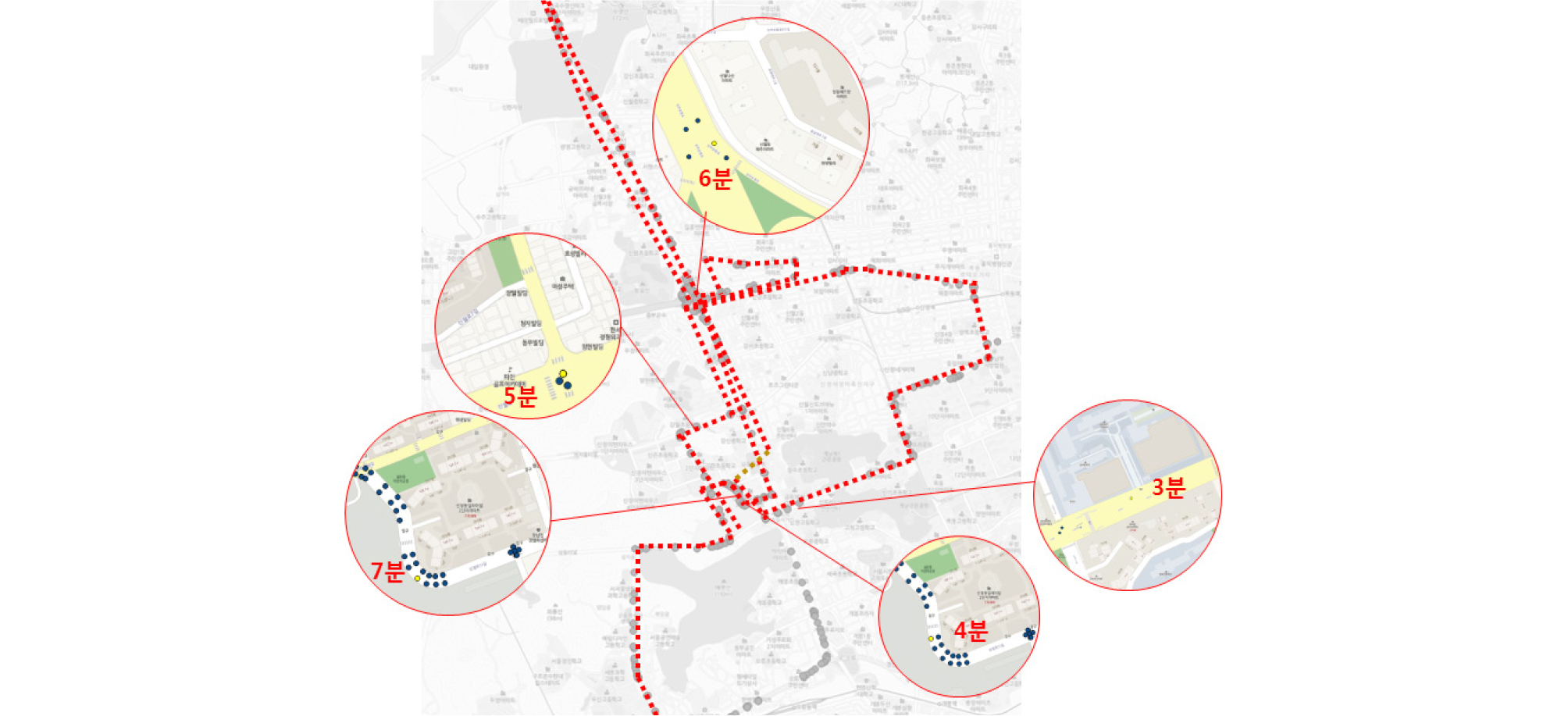
실제 운행궤적과의 비교 결과, 화물운송시장동향 조사 결과에 비해 트럭의 일일 실 운행 데이터와 대표운행사이클의 더 높은 평균속력을 갖는 것으로 나타났는데, 이는 화물운송시장동향 조사의 경우 전체 운행시간 대비 전체 주행거리를 바탕으로 산정하여, 엔진 정지 시에도 속도가 0으로 간주되어 전체적인 평균속력이 낮아지게 되고, 실운행궤적의 경우에는 시내주행 뿐 아니라, 차고지 등에서 배달지역까지 이동 등 일부 고속주행이 가능한 구간 등이 포함되어 있어 시내 저속주행구간을 가정한 대표운행사이클에 비해서도 다소 평균 속력이 높이 나타난 것으로 판단된다. 유휴비율은 실운행궤적에서 도출된 비율과 원데이터인 micro-trip단위의 유휴비율이 유사하여 대표운행사이클에 반영된 유휴비율이 실제 운행을 반영한 것을 확인하였다.
결론
본 연구에서는 기존의 일반적인 성능평가용 주행모드의 한계를 극복하고, 상황과 차종에 적합한 성능평가 주행모드를 개발하기 위하여 특수한 주행패턴을 가지는 소형택배트럭의 운행궤적을 바탕으로 대표적인 운행 사이클을 도출하였다.
이를 위해서 적재중량 1톤 이하 트럭의 DTG 데이터를 수집하여, 이를 출발 및 정차 포함, 다음 출발 이전까지의 micro-trip으로 가공, K-means 알고리즘을 통하여 클러스터링을 실시하였다. 도출된 클러스터 중 고속운행의 클러스터를 제외하고 출현비율에 맞추어 길이 2,254초, 평균속력6.86km/h, 유휴비율 0.48의 대표운행사이클을 도출하였다. 이를 검증하기 위하여 실제 택배 트럭의 궤적을 검토하여 유사한 형태를 보이는 것을 확인하였다. 그러나 제시된 트럭 3대의 운행경로만으로 전체 소형 택배 트럭의 운행 특성을 검토하기에는 한계가 있으며 향후 추가적인 검토가 필요하다.
본 연구에서 도출된 대표운행사이클은 소형 택배 트럭이 가지는 주행특성을 반영하고 있어, 기존의 경유를 사용하는 소형 택배트럭을 하이브리드 혹은 전기차로 개조하는데 각 부품별 성능을 산정하거나 평가하는데 활용될 수 있다. 특히 연구에서 사용된 방법론을 사용하면 충분한 데이터 확보 시 특정 차종이나 특정 업종에 대한 대표운행사이클을 개발할 수 있으며, 이를 활용하여 해당 차량의 성능평가 및 유사차종의 부품개발 시 성능결정의 가이드라인을 제안 할 수도 있다.
더불어, 최근 지속가능한 교통을 위한 친환경 자동차에 관한 관심이 높아지며, 연구 ‧ 개발이 활발히 이루어지고 시장 내 점유율도 높아지고 있음에도 불구하고 이러한 친환경 차량의 성능을 평가하는 테스트용 주행모드에 대한 연구는 미비한 실정이다. 특히 저단에서 전기모터를 동력원으로 사용하는 하이브리드 자동차와 같은 전기자동차의 경우에는 정지 상태에서부터 최대 토크를 낼 수 있어(Yang et al., 2014) 내연기관과는 다른 동력사용 패턴을 보이기 때문에 성능평가를 위한 별도의 주행모드에 대한 필요가 증대되고 있다. 본 연구에서 소형 택배 트럭을 위한 대표운행사이클을 도출한 방법을 활용한다면, 하이브리드 자동차 및 전기자동차와 같은 새로운 동력원을 가지는 차종에 관한 성능평가용 주행모드를 개발할 수 있다. 또한 중 ‧ 장거리 운송에 주로 사용되는 중 ‧ 대형 트럭에 대하여서도 동일한 방법을 사용하여 해당 운행 특성에 적합한 운행 사이클을 도출 할 수 있다. 본 연구에서 개발한 대표운행사이클뿐 아니라 방법론을 활용하여 도출되는 각 목적에 적합한 운행사이클들을 실 운행기록의 특성들과 비교분석하여 신뢰성을 확보한다면 연비 공인시험기관인 한국교통안전공단 자동차안전연구원, 한국자동차연구원등에서 해당 차종 및 목적등에 적합한 연비시험을 시행하고 인증할 수 있는 방안도 도출 할 수 있을 것이다.
그러나 본 연구는 두 가지의 수집된 데이터에 의한 한계를 가진다. 본 연구에서 사용한 DTG 데이터에는 차종에 해당하는 변수가 누락되어, 소형 택배트럭과 달리 비교적 장거리를 운행하고, 정차횟수가 적은 용달차량의 운행이 혼재해 있다. 클러스터링을 통하여 고속주행을 제외하기는 하였으나, 실제 택배트럭이 아닌 차량의 시내주행 특성이 일부 반영되어 있을 가능성이 존재한다. 또한, 현재 수집된 데이터는 1달(4월)동안의 운행기록으로 타 계절에서 발생 가능한 기상효과(강수, 적설 등)에서 운행되는 패턴을 반영하지 못했을 가능성이 있다.
1) 기존 연구(Haan and Keller, 2001; Fotouhi and Montazeri-Gh, 2013)에서는 대체로 micro-trip을 정차와 정차 사이의 운행기록으로 정의하고 있으나, 본 연구에서는 정차하고 있는 시간(stop duration)에 대해서도 함께 고려하기 위하여 출발로부터 다음 출발 이전까지의 운행기록을 micro-trip으로 정의하였다.
