

서론
선행연구
데이터 개요 및 수집
연구방법론
1. 데이터 분석
2. 특성 가공
3. 학습 및 테스트 자료 설명
4. 랜덤 포레스트 기반 노면 상태 예측 기술
연구 결과
1. 노면 상태 예측 결과
2. 노면 상태 예측 결과 표출
결론 및 향후 연구
서론
교통사고분석시스템(Koroad, 2019)에서 제공하는 통계에 따르면, 2018년 교통사고 발생 건수는 2017년보다 813건이 증가하였다. 맑은 날 교통사고 발생 건수는 2017년도 대비 3,169건이 감소하였지만, 비가 내린 날 3,526건, 눈이 내린 날 320건으로 강수가 발생하였을 때 사고 발생 건수가 2017년도보다 증가하였다. 강수가 발생하면 교통사고 발생 건수가 증가하는 것뿐만 아니라, 발생한 교통사고의 심각도에도 영향을 미친다. Jung et al.(2010)의 연구에 따르면, 젖은 노면이 건조한 노면보다 마찰력이 낮아진다고 한다. 노면이 젖어 마찰력이 낮아지면, 차량의 제동거리가 증가하게 되고, 건조한 노면에서의 사고보다 2-3배 더 심각한 피해를 받을 수 있다(Harold and Hakkert, 1987). 강수 발생에 따른 교통사고 빈도 및 심각도의 감소를 위해 유지 보수 활동을 계속하고 있지만, 운전자의 도로 위험에 대한 인식 역시 높아질 필요가 있다(Jonas et al., 2000). Lee et al.(2018)에 따르면, 비가 내리면 운전자들이 급정지의 비율이 다른 날씨보다 높아지고, 이러한 급격한 운전 행동의 변화는 교통사고를 발생시킬 수 있는 요인이 된다. 따라서 도로의 관리를 철저하게 함과 동시에 운전자가 도로의 위험도를 인지하고 급격한 운전 행동의 변화를 줄이기 위한 지속적인 노력이 필요하다.
본 연구를 통해 기여할 수 있는 바는 두 가지로 정의할 수 있다. 첫 번째로, 기상 변화로 인한 노면의 상태를 광역적으로 예측함으로써, 기상으로 인해 노면 안전도가 취약해진 지점에 대한 도로 관리적 측면에서의 대응이 가능하도록 한다. 예를 들면, 노면이 결빙될 가능성이 있는 지역에 대한 제설 및 제빙 작업을 사전에 진행할 수 있다. 두 번째로 차량의 통행이 없는 도로에 대한 노면 상태 예측을 통해 운전자에게 사전에 통보할 수 있다. 최근 노면 상태 예측 연구는 주로 차에 장착한 저비용 소형 센서 정보를 통해 노면 상태를 예측하는데 집중하고 있다. 하지만 인적이 드물거나 차량 통행이 장시간 없던 경우, 처음 해당 지역을 통과하는 차량에게 노면의 상태에 대한 정보를 공유할 수는 없다. 본 연구에서는 이러한 장시간 인적이 없는 도로에 대해 광역적인 예측을 통해 운전자에게 노면의 상태를 알려줄 수 있다.
본 연구의 목적은 제안하는 시공간 특성이 노면 상태를 예측함에 있어 충분한 설명력을 갖는지를 입증하는 것이다. 이를 위해 본 연구에서는 의사 결정 나무 기반의 랜덤 포레스트 모델을 사용하였다. 랜덤 포레스트의 기반이 되는 의사 결정 나무는 Lee et al.(2018)에서 입증한 바와 같이 노면의 상태를 예측할 때 높은 정확도를 보일 뿐만 아니라, 특성 중요도나 의사 결정 나무를 도식화 할 수 있어 해석 능력이 뛰어나 제안한 특성의 효율성을 입증하는데 가장 적합한 모델이다. 하지만 의사 결정 트리 하나만 사용할 경우, 다양한 경우의 수를 고려하기 어렵기 때문에 과대 적합이 발생할 수 있다(Zhao, 2016). 따라서 본 연구에서는 다수의 의사 결정 트리를 사용하는 랜덤 포레스트를 사용하여 데이터를 학습하였다.
선행연구
노면 상태 예측 연구는 예측하는 공간의 범위에 따라 특정 지점을 예측하는 지점 예측과 넓은 공간적 범위를 가진 범위 예측으로 분류된다.
특정 지점의 노면 상태를 예측하는 연구들은 주로, 특정 신호를 검출하는 장비를 사용하여 관측된 정보와 노면 상태와의 관계를 분석(Shao et al., 1994)하고 노면의 상태를 예측한다. 지점의 노면 예측을 위해서는 지점 노면의 직접적인 정보가 필요하다. 지점의 노면 정보는 적외선 온도 센서(Mats et al., 2012), 압전센서(Kang et al., 2019), RWIS (Road Weather Information System)(Tobias, 2018), 스마트폰 카메라(Pan et al., 2018) 등으로 수집된다.
범위 예측은 기존에 측정된 노면 상태를 이용하여 시공간적으로 예측하지 않은 지역의 노면 상태를 예측하는 것으로 주로 AWS와 같은 기상 정보를 통해 예측한다. Lee(2016)은 에스케이(SK)에서 운영 중인 AWS에서 관측되는 기상 정보를 활용하여 정릉터널 주변 도로의 노면 상태를 예측하였다. Li(2010)은 중국의 호북 지방에 위치한 3개 도시에서 수집된 기상 정보를 활용하여 노면 상태를 예측하였다. 그뿐만 아니라, 지역 단위로 예측할 경우, 반드시 도로의 상태나 주변 구조물과 같은 주변 환경에 대해 고려가 필요하다. Yeo et al.(2018)은 여름철 노면 상태에 영향을 주는 요인들을 추출하기 위해 기상 정보 이외에 도로 기하구조 정보, 교통정보 등의 입력 변수들을 사용하여 내부 순환로의 노면 상태를 예측하였다. Lee et al.(2018) 역시 내부 순환로의 노면 상태를 예측하였으나, 기상 정보 이외에 기상 및 도로 기하구조 정보를 가공하여 시간과 예측 지역의 물 수용력에 대한 특성을 추가하였다. 그 외에도 범위 예측은 광역적으로 예보된 기상 정보를 사용하여 노면 상태를 예측하기도 한다. Cheresnick et al.(2018)은 대기 기상 모델을 사용하여 현재와 미래에 대한 광역적인 노면상태 예측이 가능하도록 하였다. Kangas et al.(2015)은 레이더(Radar)에서 예보된 강수량 정보와 도로 기상 센서(Road Weather Sensor, RWS)를 사용하여 핀란드 전역의 노면 상태를 1시간 단위로 예측하였다.
데이터 개요 및 수집
노면 상태 예측을 위해 기상정보와 노면상태 정보를 수집하였으며 데이터 수집 항목은 Table 1과 같다.
Table 1. Description of collected data
기상 정보는 노면 상태 정보와의 상관관계를 구하기 위한 기초 데이터로 활용된다. 기상 정보는 기상청에서 운영 중인 자동기상관측장비(Automatic Weather System, AWS) 데이터를 사용하였다. AWS는 기온, 습도, 풍향, 풍속, 강수량, 기압 등을 자동으로 관측하는 장비이며 기상청은 전국의 기상상황을 상세하기 위해 494개소의 AWS를 운영하고 있으며, 본 연구에서는 연구 대상 지역인 서울, 경기, 인천 지역에 설치되어있는 96개소의 AWS 데이터만 활용하였다.
노면 정보는 Kim et al.(2017)이 제안한 빅데이터 시스템과 RCM411(Teconer, 2016) 노면 센서를 사용하여 수집하였다. RCM411은 차량에 부착하여, 이동 중에 노면온도, 노면상태, 수막두께, 마찰 값 등의 노면 정보를 실측하는 센서로써, 이동형 센서 중 높은 노면 상태 분류 정확도로 노면의 상태를 검출한다(Johan et al., 2016). 노면 센서에서 측정된 데이터는 노면 상태 수집 지점과 함께, 노면 센서와 연동된 스마트폰의 수집 어플리케이션을 통하여 빅데이터 시스템으로 매초 마다 전송된다. 예측 모델의 훈련 및 검증, 분석에 사용한 데이터는 총 3,223,484개이며, 총 수집 기간은 2015년 11월부터 2016년 3월 사이의 기간 중, 총 148일간 수집하였다.
연구방법론
1. 데이터 분석
본 연구에서는 다양한 노면 상태 정보 중 결빙 상태 노면에 대한 분석을 집중적으로 하였다. 결빙 데이터 전체 노면 상태 중에서 유지 시간이 가장 길고, 발생하는 곳이 국지적이기 때문에 시공간 분석에 있어 가장 적합한 노면 상태이기 때문이다. 분석은 시간에 따른 분석과 공간에 따른 분석으로 진행되었으며, 각 분석 결과를 바탕으로 각 특성에 대한 시공간적 설명력을 갖도록 가공하였다.
시간에 따른 결빙 노면 상태 분석 결과, 노면은 7일 이전에 발생한 강수에 의해 결빙될 수 있다는 것을 확인하였다. 뿐만 아니라, 최근 발생한 강수 이전의 강수에 대한 정보 역시 현재 노면 상태를 예측하는데 필요할 수 있다는 결론을 내렸다. 대표적인 사례가 3월 12일 발생한 결빙 노면 상태인데, 이날 수집한 데이터는 건조 상태가 49,674개, 습윤 상태 14,530개, 젖은 상태 508개, 결빙 상태 14,770개이다. 특이한 점은 3월 12일을 기준으로 7일 이전인 3월 5일에 일 강우 46.61mm의 많은 비가 발생하였으며, 2월 28일과 29일에 눈이 내렸다는 것이다. 그리고 Table 2와 같이 3월 5일부터 3월 12일까지 평균 온도가 0도를 유지하고 있어, 결빙된 노면이 현재까지도 유지될 확률이 높은 온도 상태를 갖고 있었다. 위와 같은 결론을 바탕으로 본 연구에서는 기상에 대한 특성에 시간적 설명력을 부여할 때, 수일 전에 발생한 강수 정보를 고려하며 가장 최근 강수량이외에도 그 이전에 발생한 강수량까지 고려할 수 있도록 가공하였다.
Table 2. Per day precipitation and average temperature from 5 March to 12 March
| 12 Mar. | 11 Mar. | 10 Mar. | 9 Mar. | 8 Mar. | 7 Mar. | 6 Mar. | 5 Mar. | |
| Precipitation (mm) | 0 | 0 | 0 | 0 | 0 | 0 | 0.05 | 46.61 |
| Avg. temperature (°C) | 0.52 | -0.04 | -0.13 | 0.13 | 0.67 | 1.92 | 1.86 | 2.73 |
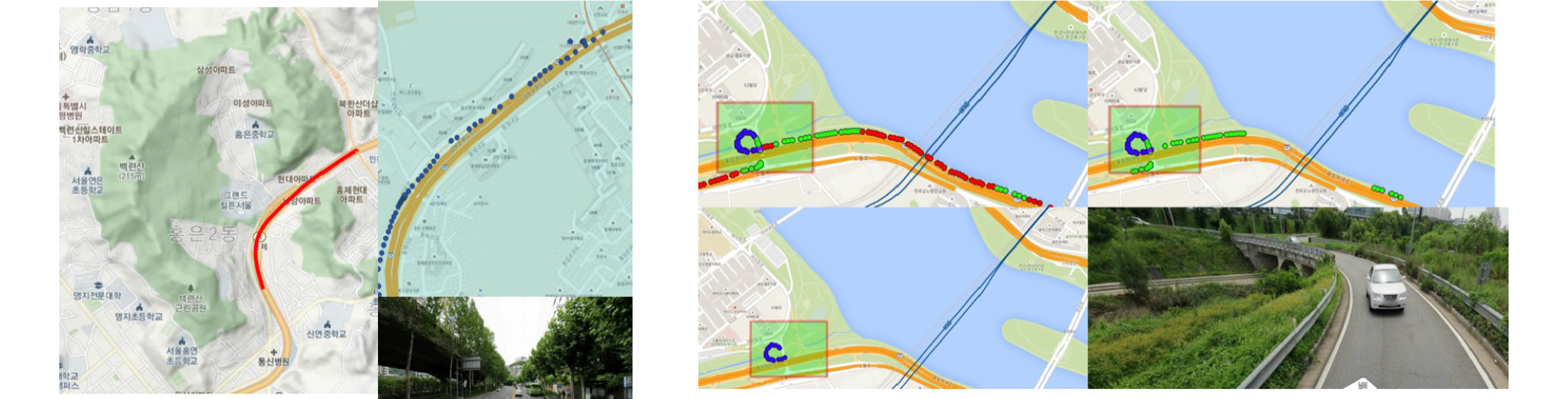
공간에 따른 결빙 노면 상태 분석 결과, 노면은 주변 환경의 변화에 따라 노면의 상태가 달라질 수 있음을 확인하였다. 대표적인 사례로는 Figure 1과 같이 서대문 구청에서 홍은 사거리로 가는 구간과 여의 상류 IC 부근의 올림픽 대로에서 노들로로 진입하는 구간인데, 먼저 서대문 구청에서 홍은 사거리로 가는 구간은 도로 옆에 홍제천이 흘러 습도가 높고, 위로는 내부 순환로가 지나가기 때문에 도로에 그늘이 형성되어 있으며, 지형적으로 산에 둘러싸여 다른 주변 환경들보다 낮은 온도를 형성한다. 워싱턴 대학교(Washington University, 2019)에 따르면 저지대의 도로는 주변보다 낮은 온도를 형성하기 때문에 노면이 결빙될 가능성이 높으며, 강이나 천 주변에는 습도가 높아 안개나 서리로 인한 도로 결빙이 발생할 수도 있다. 뿐만 아니라, 건물이나 가로수 등 그림자를 형성하는 구조물이 있는 도로의 경우 그늘을 형성하기 때문에 노면의 변화가 느려 젖어 있거나 결빙된 노면의 상태가 오랜 시간 유지될 수 있다. 두 번째 여의 상류 IC부근의 경우, 해당 구간 밑으로 작은 천이 흘러 구간 중간에 교량이 존재하며, 오르막 구조로 되어있어 높은 지대의 비가 흘러내릴 수 있는 기하적 구조를 갖고 있었다. 주변 환경적 측면에서는 옆에 한강이 흘러 습도가 높으며, 주변에 구조물이 없어 한강에서 불어오는 바람의 영향을 받을 수 있다. 위 사례와 같이 교량이나 다리 같은 경우, 다른 도로들보다 열을 쉽게 뺏기기 때문에 노면이 결빙될 확률이 높다. 이처럼 도로 위의 결빙된 노면은 주변 환경적인 요소로 인해 발생할 수 있으므로, 정확하고 광역적으로 노면 상태를 예측하기 위해서는 주변 환경을 설명할 수 있는 특성이 필요하다. 따라서 본 연구에서는 주변 환경적 특성을 고려하기 위해 좌표 정보를 모톤 코드로 차원 축소하여 특성으로 활용하였다.
2. 특성 가공
노면 상태 예측에는 기상요소의 지속성에 대해 고려가 필요하다. 비가 그치고 시간이 지나면 노면은 마른다. 만약 온도가 높다면 노면이 빨리 마르고, 영하의 날씨에는 노면이 결빙된다. 또한, 여름철에는 노면이 마르기 전에 다시 비가 내릴 수 있으며, 겨울철에는 얼어있는 도로에 다시 비가 내릴 수 있다. 강수량이 높으면, 노면이 건조될 때까지의 많은 시간이 필요하다. 반대로 강수량이 낮으면, 더 빨리 노면이 건조된다.
특성에서 이러한 기상요소의 지속성에 대해 고려하기 위해, Figure 2와 같이 다중 강수 정보를 가공하였다. 다중 강수량 정보를 가공하기 위해서, 과거 자동 기상 관측소에서 측정한 정보를 관측 시점을 기준으로 역추적하여 강수가 발생한 구간을 찾는다. 강수량이 0이거나 증가하지 않는 구간이 발생하면 마지막 동일 값이 발생한 지점을 강수 발생 시점으로 지정한다. 다중 강수량 정보 특성 가공은 강수 정보뿐만 아니라, 시간 관련 정보도 반환한다. 시적 거리(Time Distance)는 강우 발생 시점으로부터 관측 시점 또는 그다음 강우 발생 시점까지의 시차를 의미한다. 이 시적 거리를 사용하여 각 강수량 정보는 강수 강도 형태로 가공된다.

온도 정보는 강수 발생 시점(Precipitation start time)과 관측 시점(Sensing time) 사이의 온도 값들을 평균, 표준 편차, 1사 분위, 3사 분위, 최솟값, 최댓값의 기초 통계 정보로 변환한다. 평균 온도는 총 강수량과 시적 거리가 비슷할 경우, 온도에 의한 노면 상태 변화 속도가 가속되는 정도를 설명하는 변수로 사용한다. 표준 편차는 두 지점 사이의 온도 변화 정도로 중간에 결빙되거나, 변화 속도가 가속되는 정도를 추가로 설명한다. 1사 분위와 3사 분위, 최솟값, 최댓값은 두 시점 사이에서 낮은 온도 또는 높은 온도가 유지된 정도를 표현하여, 노면이 결빙되거나 노면 위 수분의 증발이 가속될 가능성에 대한 설명 변수로 사용한다.
본 연구에서 공간적인 설명력을 갖는 특성을 학습시키기 위해서 좌표 정보를 활용하였다. 좌표정보를 사용하여 주변 환경 정보를 학습하는 이유는 다음과 같다. 우선 좌표정보를 활용하면 기상 정보가 같지만 서로 다른 노면 상태를 갖는 데이터를 분류할 수 있다. 예를 들어, 특정 시점에서의 기상 정보는 같은 AWS를 참조하는 경우 그 값이 같지만, 수집한 위치에 따라 노면 상태는 다를 수 있다. 이는 수집한 위치에 따라 주변 환경이 달라져, 노면의 상태 역시 달라졌다는 것을 의미한다. 즉, 노면 상태를 수집한 위치의 좌표정보에 따라 동일 시점의 동일 기상 정보에 대해 노면의 상태가 달라진다고 할 수 있다. 따라서 예측 모델은 이 좌표정보를 사용하여 동일 시점에 같은 기상 정보를 갖는 데이터들이 좌표정보가 달라짐에 따라 노면 상태가 달라진다는 것을 학습할 수 있다. 결론적으로 공간상의 위치에 따라 노면의 상태가 달라질 수 있음을 예측 모델이 학습한다는 의미이며, 이는 공간상의 위치가 달라짐에 따라 변하는 주변 환경을 학습한다고 할 수 있다.
예측 모델에서 학습할 좌표정보는 모톤 코드로 색인한 값을 사용하였다. 모톤 코드는 2차원의 좌표정보를 1차원으로 색인하는 알고리즘으로, Figure 3과 같이 특정 영역을 일정 크기의 격자로 나누고 왼쪽 아래 격자부터 Z 모양의 순서대로 색인 값을 정의한다. 만약 좌표정보가 특정 격자에 포함되면, 좌표정보는 해당 격자가 갖는 색인 값으로 표현할 수 있다. 본 연구에서는 서울특별시, 경기도, 인천광역시를 포함하는 영역에 대해 하나의 격자가 가로 16미터, 세로 8미터의 범위를 포함하도록 구성하였다.
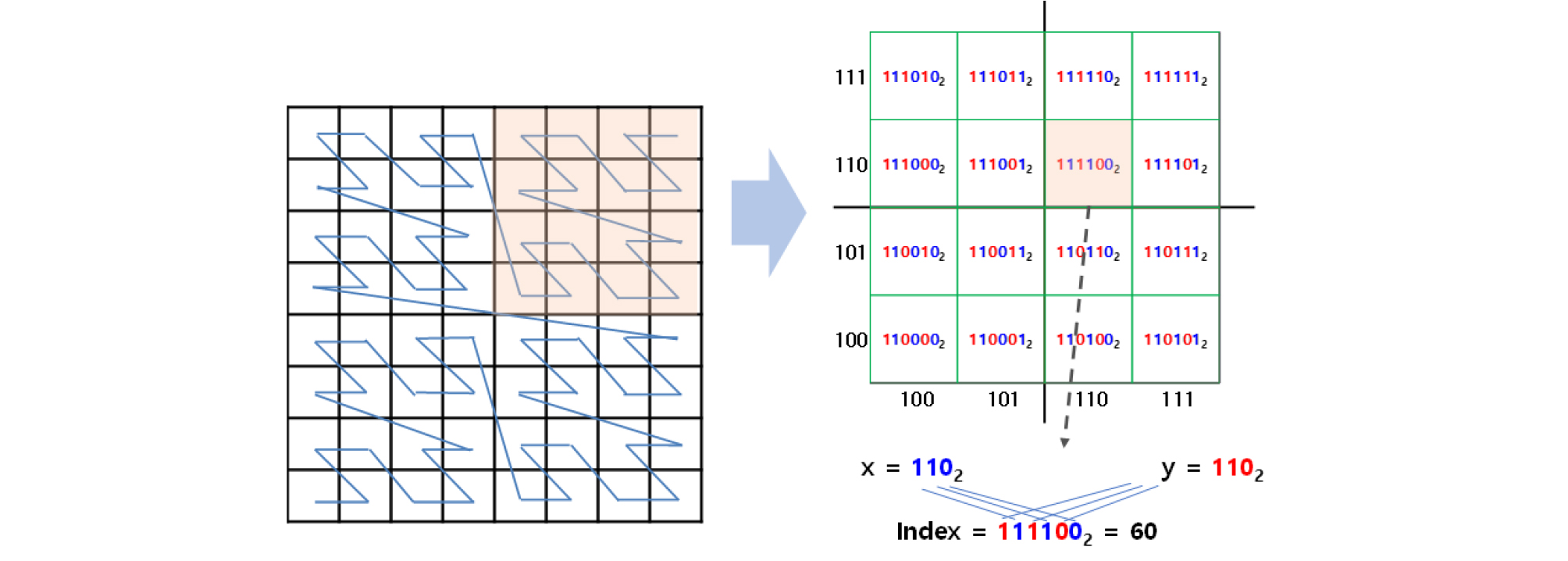
본 연구에서 좌표정보 대신 모톤 코드를 사용하는 이유는 과대 적합을 방지하기 위함이다. 먼저, 모톤 코드를 사용함으로써 좌표가 갖는 공간에 대한 설명력을 유지하면서, 2차원의 특성이 1차원으로 축소된다. 차원이 축소됨으로써, 랜덤 포레스트에서 사용하는 의사 결정 나무에서 분기에 고려해야 할 특성이 감소하고, 그에 따른 과대 적합을 피할 수 있다. 이처럼 차원 축소의 일환으로 모톤 코드를 사용한 이유는 결빙되었거나 아직 건조되지 않는 노면이 발생하는 구간이 Figure 4와 같이 구간의 형태로 나타나기 때문이다.
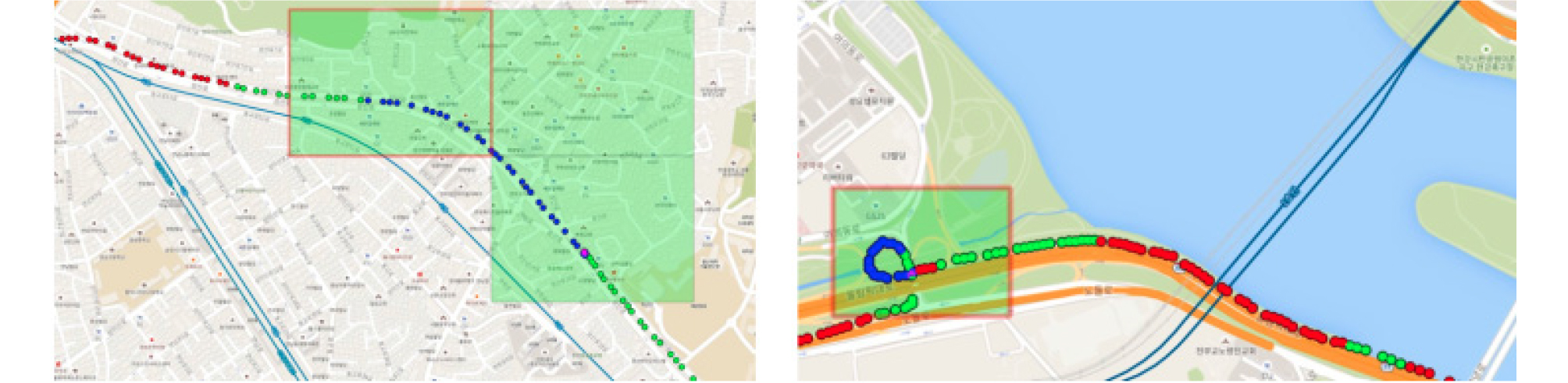
해당 도로 구간에 대해 랜덤 포레스트에서 사용하는 의사 결정 나무로 분기 조건을 정의한다면, 구간의 최소지점과 최대 지점 좌표에 대해 각각 2번의 분기가 발생하므로 총 4번의 분기가 필요하다. 만약 모톤 코드를 사용하여 축소한 경우, 최대 2번의 분기가 발생하며, 만약 동일한 노면 상태가 하나의 색인에 속하는 경우 한 번의 분기만으로 노면 상태를 분류할 수 있다. 의사 결정 나무와 같은 트리 기반 모델의 경우, 트리의 깊이가 깊어질수록 과대 적합을 유발하기 때문에, 불필요한 분기 발생을 최소화하는 것이 필요하다. 이와 같은 의미에서 모톤 코드를 사용한 좌표 정보의 차원 축소는 랜덤 포레스트에서의 과대 적합을 방지할 수 있다. 하지만 모톤 코드로 생성한 색인이 포함하는 지역 범위가 클 경우, 너무 많은 주변 환경 정보와 노면 상태 정보를 하나의 색인이 포함할 수 있기 때문에, 적절한 크기의 색인 범위로 학습하는 것이 필요하다.
3. 학습 및 테스트 자료 설명
위 특성 가공을 통해 생성된 새로운 설명 변수들은 Table 3과 같다.
Table 3. Dependent variable created by feature engineering
모델이 학습할 데이터의 종속 변수는 노면의 상태이며, 독립 변수는 강우량, 온도, 공간 색인 정보를 사용한다. 강우량과 온도는 직전 몇 번째까지의 강수량 정보를 고려할 것인지에 따라 다른데, 본 연구에서는 직전 5번째 발생한 강수량까지 고려하였다. 공간 정보는 모톤 코드를 이용하여 각 데이터의 좌표 정보를 공간 색인 정보로 변환한다. 따라서 지점 단위로 수집한 데이터는 공통된 면적 단위의 공간 색인 정보를 갖게 된다. 이로 인해, 만약 종속 변수 및 독립 변수가 동일한 데이터들이 발생할 수 있지만, 별도의 중복 제거 과정을 수행하지 않았다. 그 이유는 대상 지역은 유사한 기상 상황이 발생하였을 때 해당 노면 상태일 확률이 높다는 것을 의미하기 때문이다. 종속 변수는 건조, 습윤, 젖음, 살얼음, 결빙 등 5가지의 참값을 갖는다. 데이터 셋의 수는 수집한 데이터의 총 수와 동일하게 3,223,484개를 사용하였다.
4. 랜덤 포레스트 기반 노면 상태 예측 기술
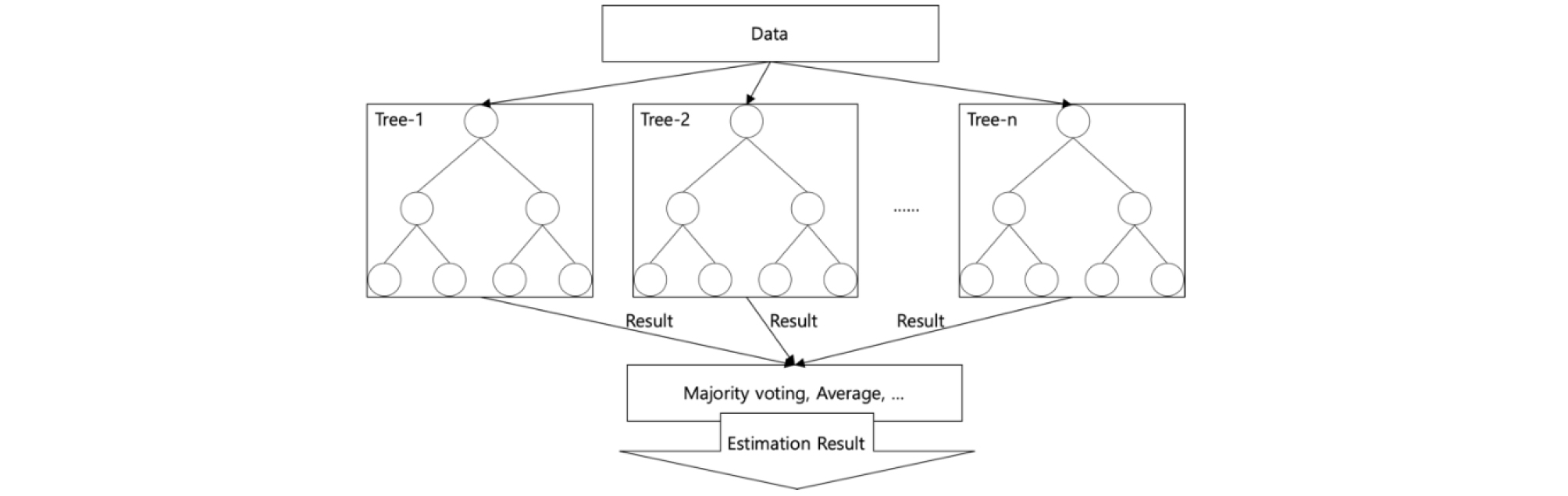
랜덤 포레스트는 앙상블(ensemble) 기계 학습 기법 중 하나로, 앙상블은 여러 개의 기계학습 모델을 서로 다르게 학습시킨 후, 각 모델에서 예측한 결과에 대해서 다수결이나 평균값 등을 사용하여 하나의 예측 결과를 도출하는 방식이다. 그 중 랜덤 포레스트는 의사 결정 나무와 같은 트리 기반 예측 모델들에 대한 앙상블 기법이다. 의사 결정 나무는 규칙 기반 모델로써, 최상위 노드와 중간 노드, 말단 노드로 구성된다. 최상위와 중간 노드는 특정 조건에 따른 데이터의 분기점을 학습하고, 말단 노드에서는 해당 노드에 존재하는 데이터의 종속 변수의 각 그룹에 대한 비율 정보를 갖고 있다. 테스트 데이터가 최상위 노드로 들어오면, 대상 데이터는 각 노드에서 학습한 조건에 의해 분기된다. 말단 노드에 도착하면, 대상 노드에 존재하는 종속 변수의 그룹 중 가장 비율이 높은 그룹으로 결과를 예측한다(Figure 5).
본 연구에서 랜덤 포레스트를 사용하는 이유는 랜덤 포레스트의 기반이 되는 의사 결정 나무의 장점을 활용함과 동시에 의사결정 트리만 사용했을 때 발생할 수 있는 과대 적합에 대한 이슈를 해결하기 위해서다. 의사 결정 트리 사용하여 노면 상태를 예측할 때 갖는 장점은 해석 능력과 정확도이다. Lee et al.(2018)의 실험 결과 노면 상태 예측에 있어 K-근접 이웃(KNN, K-Nearest Neighber)과 의사 결정 트리와 같은 논리 및 통계 기반 모델의 예측 성능이 인공 신경망이나 SVM (Support Vector Machine)보다 높았다. Yeo et al.(2018)은 메트랩(Matlab)에서 지원하는 기계 학습 기법들에 대해 예측 성능을 실험한 결과, 배깅(Bagging) 트리나 랜덤 포레스트와 같은 의사 결정 나무 기반 앙상블 모델의 예측 성능이 높았다.
의사 결정 트리는 위와 같이 예측 정확도면에서도 효율적이나, 학습한 모델에 대한 해석적인 측면에서도 장점을 갖고 있다. 특성 중요도는 모델에 대한 특성의 영향력을 판단하는 척도로 주로 사용하며, 이를 통해 불필요한 특성을 제외하거나, 추가적인 특성 가공을 진행할 수 있다. 따라서 본 연구에서 제안하는 시공간 특성이 노면 상태를 예측하기 위한 충분한 설명력을 갖추었는지 판단하기 위해서는 모델을 선택함에 있어, 해석 능력에 대한 측면도 고려할 필요가 있기 때문에 랜덤 포레스트를 기법을 사용하여 데이터를 학습하였다.
Zhao(2016)에 따르면, 랜덤 포레스트는 하나의 의사 결정 트리만 사용했을 때 발생할 수 있는 과대 적합을 해결하는 방법 중 하나라고 설명하고 있다. Mcgoavern et al.(2010)도 자체 개발한 시공간 의사 결정 트리를 활용한 SRRF (Spatiotemporal Relational Random Forest)를 통해 하나의 의사 결정 트리를 사용했을 때 발생할 수 있는 과대 적합의 이슈를 방지하고 있다. 본 연구에서도 노면 상태 예측을 다수의 의사 결정 트리를 통해 수행함으로써 과대 적합의 이슈를 방지하고자 한다.
연구 결과
1. 노면 상태 예측 결과
노면 상태 예측 정확도는 2회의 교차 검증을 통해 측정하였다. 1차 교차검증을 통해 최적의 파라미터를 사용하였다. 2차 교차 검증을 통해 특성 가공된 데이터를 학습한 예측 모델의 정확도는 Table 4와 같다. 에프1-스코어로 예측 모델검증 결과 전체 평균은 95%의 정확도를 보였다. 노면 상태에 따른 예측 정확도는 수집한 데이터의 양이 많은 건조(dry) 상태와 젖음(wet) 상태에 대해서는 95%이상의 정확도를 보였으며, 가장 적은 양의 데이터를 학습한 살얼음(slush) 상태의 에프1-스코어가 85%, 그다음으로 적은 결빙 상태가 92%의 정확도를 보였다.
Table 4. F1-Score of prediction model
| State | Precision | Recall | F1-score |
| Dry | 0.97 | 0.97 | 0.97 |
| Moist | 0.92 | 0.92 | 0.92 |
| Wet | 0.95 | 0.95 | 0.95 |
| Slush | 0.81 | 0.89 | 0.85 |
| Ice | 0.92 | 0.93 | 0.92 |
| Total average | 0.95 | 0.95 | 0.95 |
Figure 6과 같이, 노면 상태 예측을 위해 사용한 특성의 중요도에서는 공간 색인의 중요도가 20% 이상으로 가장 높았다. 다중 강수량 정보는 각 강수량 정보가 모델 예측에 기여한 정도는 낮지만, 모든 강수량 정보가 모델 예측을 위한 조건으로 활용되었다는 점에서 과거의 강수 기록들이 현재의 노면 상태에 영향을 미친다고 해석할 수 있다. 온도 관련 특성은 직전의 평균 온도와 표준 편차가 가장 많은 영향력을 미쳤는데, 이는 노면이 마르거나 결빙되는 데에는 직전의 강수 발생 시점부터 관측 시점 사이의 온도에 의한 영향이 가장 크다고 해석할 수 있다. 하지만 그보다 더 과거의 온도 정보 역시 모델 예측에 조금은 영향을 미친다. 이는 과거에 결빙된 도로에 비가 내린 후 영하의 날씨가 유지된다면, 현재 노면의 상태가 결빙될 가능성이 크기 때문일 것이라고 해석할 수 있다.
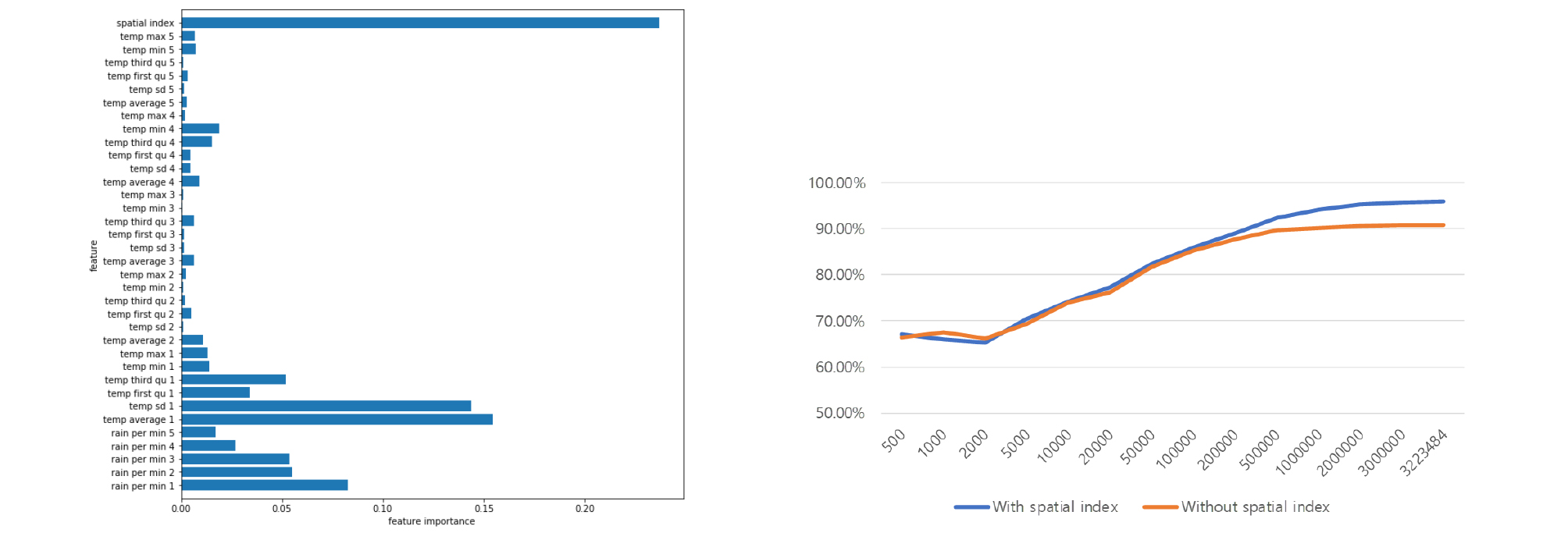
모톤 코드를 사용한 공간 색인이 노면 상태 예측에 있어 정확도를 향상시키는데 미치는 영향은 적다. Figure 6과 같이 사용한 데이터의 양이 적을 때에는 공간 색인에 대한 특성이 있는 모델과 없는 모델이 비슷한 예측 정확도를 보인다. 하지만 데이터의 양이 50만 개를 넘어가면서 공간 색인이 있는 모델과 없는 모델의 예측 정확도의 차이가 증가하기 시작한다. 이는 공간 색인을 통해 모델이 대상 영역의 공간에 대한 학습을 위해 필요한 데이터의 수를 감소시킬 수 있다고 할 수 있다.
2. 노면 상태 예측 결과 표출
Figure 7은 특정 일자에 대해 예측한 노면 상태를 지도상에 표출한 결과이다. 하나의 상자는 데이터 한 개를 의미하며, 상자의 색은 노면 상태를 의미한다. 표출에 사용한 날들은 대부분 비나 눈이 내리고 1-2일이 지났으며, 대부분의 노면의 상태가 습윤 또는 결빙 상태로 있을 것이라 예상하였다. 표출 결과, 표출 지역의 노면의 상태는 대부분 건조 또는 습윤 상태였으며, 결빙된 노면에 대해서는 예측하지 않았다. 일부 지역에 대해서는 상행과 하행의 노면의 상태가 습윤과 건조로 다르게 예측하였으며, 평지 구간에서 저지대 구간으로 진입하면서 건조 상태에서 습윤 상태로 예측하는 것도 확인하였다.
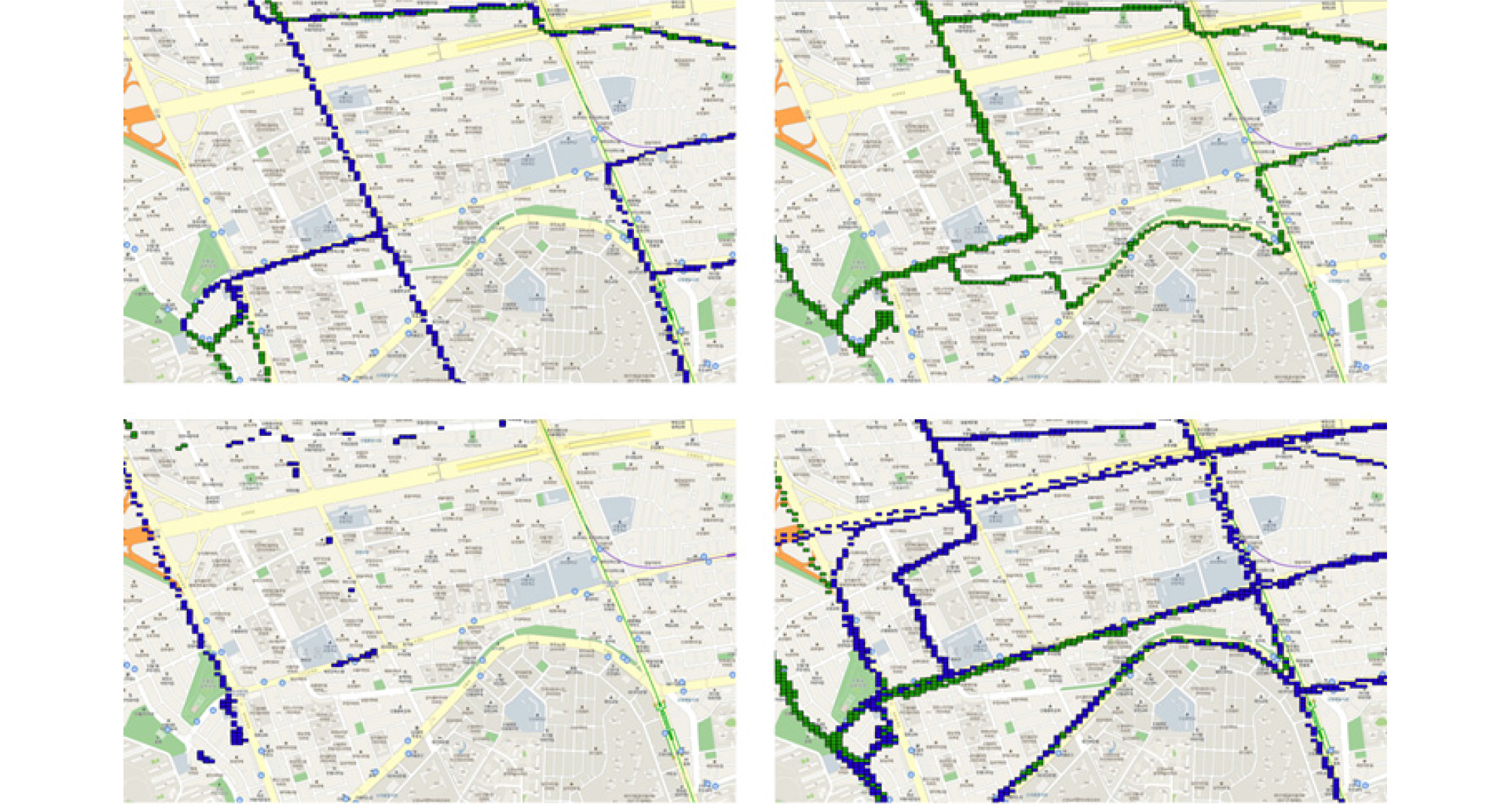
Figure 7.
Representation of prediction results for 10 Dec 2015 (top left), 19 Jan 2016 (top right), 16 Feb 2016 (bottom left) 14 Mar 2016 (bottom right) each. Each box corresponds to one predicted data and its color indicates condition of road surface (dry=blue, moist=green, wet=red, slush=yellow, ice=black)
결론 및 향후 연구
본 연구에서는 서울, 경기, 인천 지역에 대해 기상 및 노면 상태 정보를 수집하고, 특성 가공을 통해 시공간에 대한 설명력이 부여된 독립변수를 생성하였다. 기상 정보는 다중 강수량 정보를 생성하여, 과거 발생한 강수량이 현재 노면 상태에 미칠 영향력에 대해 고려하였고, 특성 중요도를 통해 과거의 강수량 정보가 현재의 노면 상태를 판별하기 위한 조건으로 활용할 수 있음을 확인하였다. 온도 특성 중에서는 직전의 평균 온도와 그 표준 편차가 노면의 상태에 영향을 줄 수 있다는 것을 확인하였다. 공간 관련 특성인 모톤 코드 기반 공간 색인 정보는 공간상의 위치에 따라 달라지는 노면의 상태에 대해 고려하였다. 실험 결과, 공간 색인 정보는 학습한 데이터의 양에 따라 예측 효율이 향상하는 것을 확인하였으며, 충분한 양의 데이터를 학습하였을 때에는 모든 특성 중에서 모델 예측에 가장 많은 영향을 미친다는 것을 확인하였다. 본 연구는 넓은 범위의 지역에 대한 노면 상태를 예측할 수 있다는 점에서 그 의의가 있으며, 사고 위험도가 높은 도로에 대한 추가적인 관리나 운전자가 인지하지 못하는 지점의 도로 위험성을 알리는데 활용할 수 있다. 본 연구에서 제안한 색인 정보를 통한 공간 학습은 해당 격자에서 수집한 충분한 양의 데이터가 존재해야 하므로, 광역적 예측을 위해서는 많은 양의 데이터가 필요하다. 주변 환경 공간에 관한 연구가 지속적인 진행이 된다면 적은 양의 데이터로 학습하지 않은 공간에서의 노면 상태 예측이 가능할 것으로 보인다. 기상 정보의 경우, 만약 노면 상태와 기상 정보 사이의 더 깊이 있는 분석이 진행된다면, 본 연구보다 더 효율적인 기상 관련 특성을 가공할 수 있을 것으로 생각한다.
