

서론
방법론
1. Elliptic Bivariate Relationship
2. 본 연구 활용 교통류 예측 방법론
3. SHAP(SHapley Additive exPlanations)
사례분석
1. 분석방법 및 데이터
2. 교통량 예측결과
3. 변수 중요도 산정결과
결론
서론
교통류 소통상태를 파악하는 것은 고속도로 교통관리의 필수요소이며(Zhang and Kabuka, 2018; Wu et al., 2018), 특히 교통량 예측을 통해 교통수요를 선제적으로 파악하는 것은 효과적인 교통관리를 위해 매우 중요하다. 기존의 고속도로 교통량 예측은 시계열 분석이나 비모수 회귀모형에 교통량, 통행속도 등의 교통류 변수를 활용하는 방법으로 수행되어 왔다. 그중에서도 전통적으로 활용된 방법은 historical average algorithms(Smith and Demetsky, 1997)과 smoothing techniques(Smith and Demetsky, 1997; Williams et al., 1998)이다. Davis et al.(1990)과 Hamed et al.(1995)은 교통류 예측에 ARIMA와 같이 수리통계의 기본 원리에 근거한 예측 방법을 도입하였으며, 자기회귀 모형과 이동 평균법 모형을 모두 포괄하는 ARIMA 모형은 시계열 예측에서 우수한 성능을 보였다. 하지만 ARIMA 모형은 평균값에 집중하여 극단값을 놓치는 경향이 있어 혼잡교통류(congested flow)에서 자유류(free flow)로의 전환을 포착하지 못한다는 한계 역시 지적된 바 있다. Kalman filter 알고리즘은 Okutani and Stephanedes(1984)에 의해 교통류 예측에 효과적이라는 사실이 처음 입증되었다. Stathopoulos and Karlaftis(2003)은 ARIMA보다 kalman filter가 교통 데이터 모델링에 우수함을 입증하였다. 그러나 kalman filter는 교통류 상태가 급변하는 상황에서 반응이 느리다는 한계가 있다. 이후 교통류 예측은 시계열 예측(Cheng et al., 2012), 회귀 및 함수 근사(Dunne and Ghosh, 2012), 클러스터링(Chiabaut and Faitout, 2021), 베이지안 추론(Ghosh et al., 2007)등 복잡한 예측 알고리즘을 개발하고 검증하는 연구가 주를 이루고 있다.
최근에는 빅데이터 수집 및 활용이 가능해지면서 XGBoost, Long Short-Term Memory(LSTM) 등의 머신러닝 및 딥러닝 모형을 활용하는 연구사례도 많다. 머신러닝 및 딥러닝 모형은 일반적으로 전통적인 시계열 예측 방법들을 활용한 모형에 비해 예측력이 우수한 것으로 알려져 있지만, 예측결과에 대한 해석이 어렵다는 한계가 있다(Polson and Sokolov, 2017; Vlahogianni et al., 2014; Xu et al., 2016). 예측결과를 적절히 활용하고 모형을 보완, 개선하기 위해서는 모형의 원리를 이해하는 것이 필수적이며, 이는 예측의 정확도만큼이나 중요한 요소라고 할 수 있다(Lundberg and Lee, 2017). SHapley Additive exPlanations(SHAP)는 이러한 머신러닝 및 딥러닝 기반 모형들의 예측결과를 해석하는 방법 중 하나로서, 게임이론(game theory)을 바탕으로 모형에 적용된 설명변수들의 변수 중요도를 계산하는 방법이다. SHAP을 활용한다면 각 설명변수들이 예측결과에 미치는 영향을 정량적으로 파악할 수 있기 때문에 머신러닝 및 딥러닝 모형의 한계점을 일부 극복할 수 있을 것으로 판단된다(Lundberg and Lee, 2017).
본 연구의 목적은 교통류 소통상태를 파악하는 새로운 방법 중 하나인 elliptic bivariate relationship(Ka et al., 2020)이 머신러닝 및 딥러닝 기반의 교통류 예측모형에 적용될 수 있음을 보이는 것이다. Ka et al.(2020)은 고속도로 구간에서 관측되는 Vehicle Accumulation(VA)과 Travel Time(TT) 간 타원형 패턴(Oh et al., 2019)을 이용하여, 교통류 소통상태를 파악할 수 있는 두 가지 파라미터를 제시한 바 있다. 선행연구에서 제시된 두 가지 파라미터들을 이용하면, 현재 교통류의 정체강도를 파악할 수 있을 뿐만 아니라 현재 교통류의 정체가 심화되고 있는 단계인지 혹은 회복되고 있는 단계인지 여부를 알 수 있다. 이렇듯 교통류 측면에서 유용한 의미를 지니는 파라미터들이 머신러닝 및 딥러닝 모형에 적용되었을 때에도 중요한 설명변수로서 작동할 수 있을지에 대한 분석을 수행하는 것은 의미가 있을 것으로 판단된다.
따라서 본 연구는 실제 검지기 데이터를 활용하여 elliptic bivariate relationship의 두 가지 파라미터들을 도출하고 일반적인 교통류 변수들(교통량, 속도)과 함께 예측모형의 설명변수로 적용한다. 다음, elliptic bivariate relationship 파라미터를 적용한 모형과 적용하지 않은 모형의 예측력을 비교하고, SHAP을 활용하여 두 파라미터들의 변수 중요도를 일반적인 교통류 변수들과 비교함으로써 elliptic bivariate relationship의 적용성을 분석한다.
방법론
1. Elliptic Bivariate Relationship
Figure 1은 선행연구(Ka et al., 2020)에서 제시한 elliptic bivariate relationship의 개념에 대해 설명하고 있다. 정체가 발생하는 고속도로상 두 지점에서 수집되는 지점검지데이터를 활용하여 VA와 TT를 계산할 수 있으며, 두 변수로 이루어진 2차원 공간에 시간의 흐름에 따른 교통상태의 변화를 표현하면 타원 형태의 패턴이 나타난다. 본 연구는 VA와 TT 산정에 있어 Equations 1, 2, 3과 같이 선행연구의 정의를 준용한다.
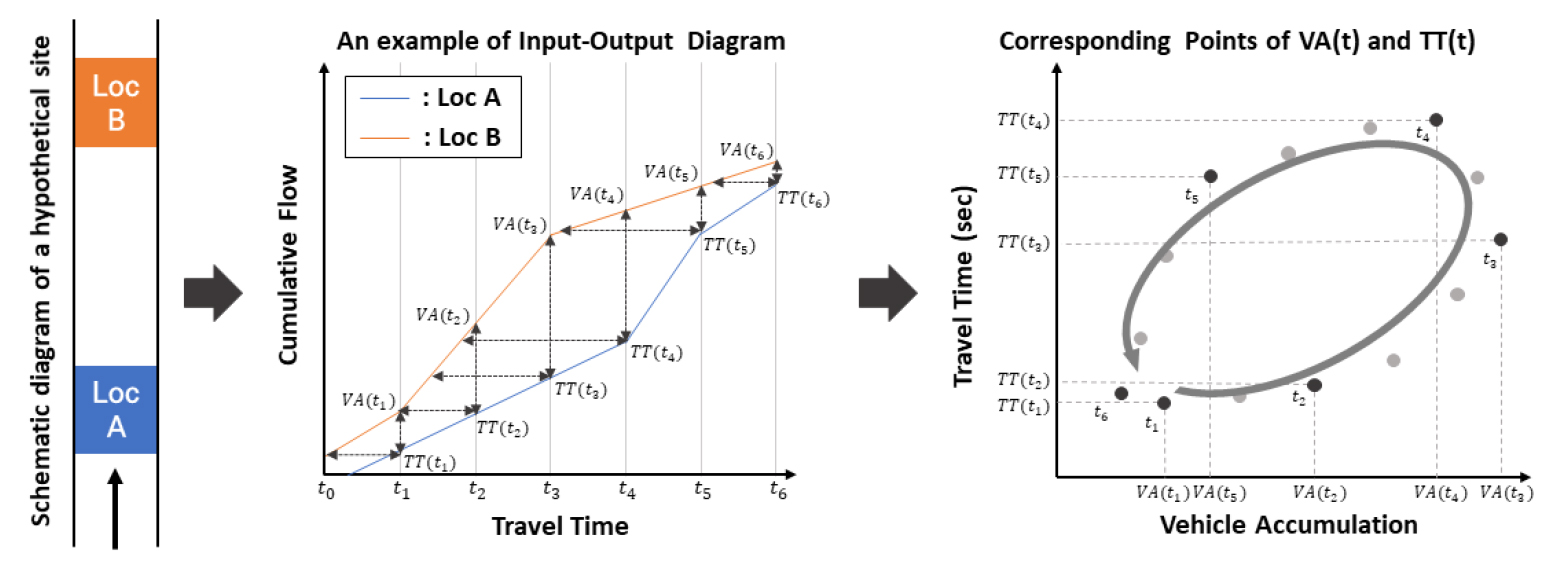
Figure 1.
Elliptic bivariate relationship between vehicle accumulation and travel time (Ka et al., 2020)
여기서, : 시간 t에서의 segment i의 통행시간
: 시간 t에서의 segment i 내 차량 대수
: 시간 t에서의 segment i 내 차량의 평균속도
: 시간 t에서의 segment i의 구간교통량
: 시간 t에서의 segment i의 밀도
: segment i의 길이
선행연구(Ka et al., 2020)는 elliptic bivariate relationship으로부터 교통류 측면에서 의미를 가지는 파라미터들을 도출하기 위해, VA-TT 평면상에서의 이동을 표현하는 변환행렬(transformation matrix)을 분해(decomposition)했을 때 얻어지는 값들의 의미를 파악하였다.
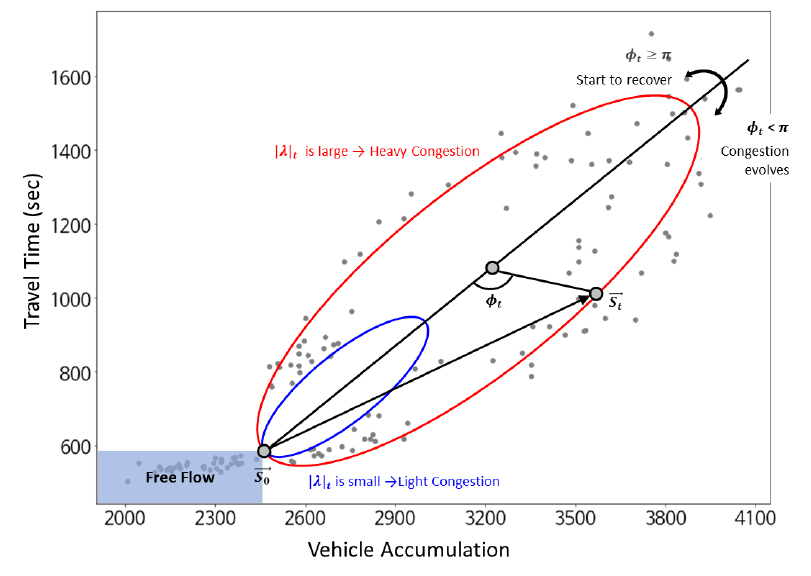
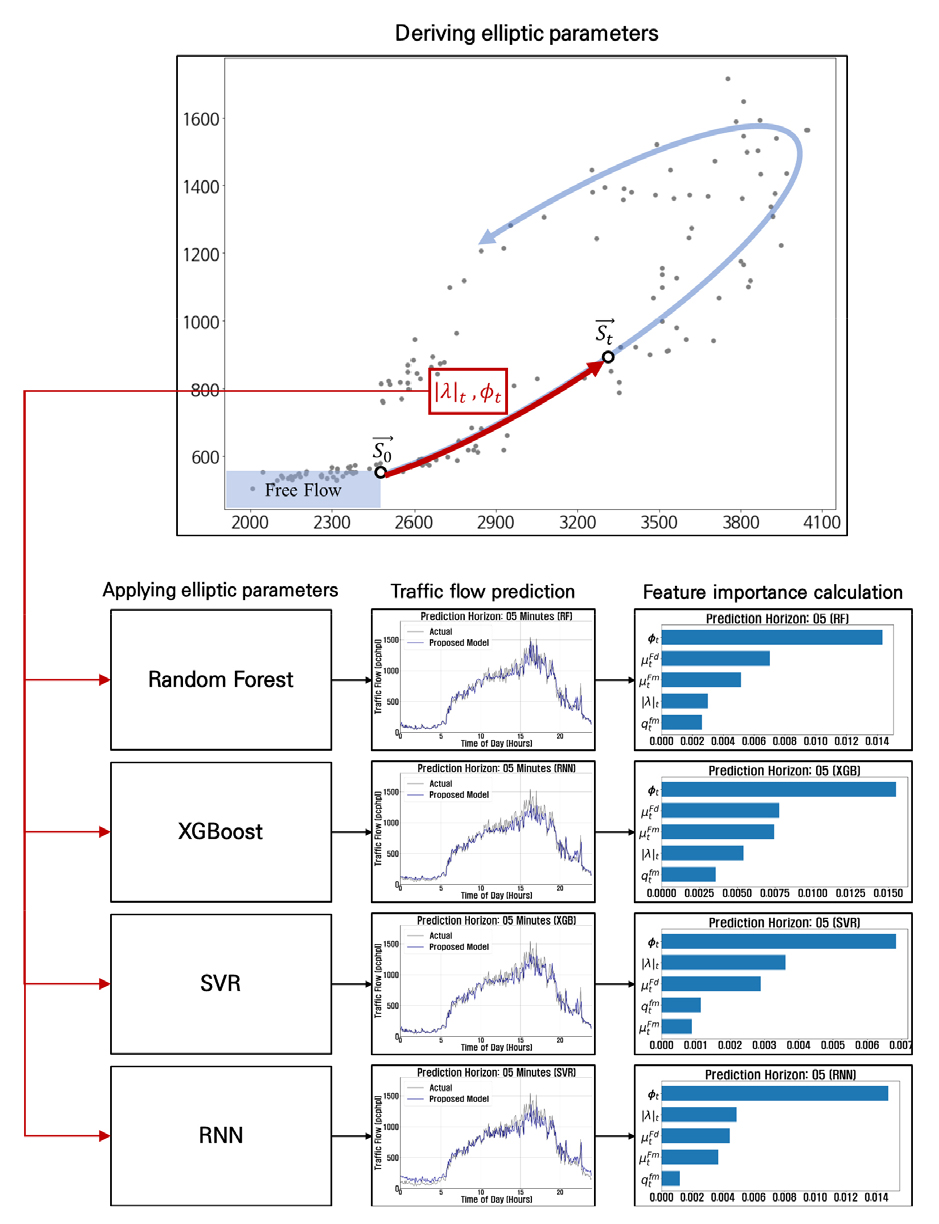
Figure 2에서 현재 교통류 상태 가 자유류 소통상태인 로부터 행렬 에 의해 이동된 상태라고 할 때, 이다. 이때, 와 가 임의의 타원 위의 점이라면 Equation 4와 같이 복소 고유값 분해가 가능하다. 변환행렬은 Equation 4와 같이 행렬 와 로 분해될 수 있는데, 는 각 점들이 놓여있는 타원의 기하적 특성을 표현하며 는 가 로부터 얼마나 변화했는지를 나타낸다. 행렬 는 Equation 4에서 나타내고 있는 바와 같이 만큼의 회전과 만큼의 스케일링 조합으로 표현될 수 있다. 즉, 와 는 현재의 교통류 상태 를 정의하는 파라미터가 된다.
여기서, , : 각각 reference ellipse의 장축과 단축의 길이
,: 의 고유값(eigenvalue) 및 에 대응하는 고유 벡터(eigenvector)
, : 의 실수부(real part) 및 허수부(imaginary part)
: 타원의 기울기
변환행렬 분해를 통해 도출한 와 는 VA-TT 평면상에서 교통류 상태를 정의할 수 있다. 먼저 는 를 기준으로 현재 교통류 상태가 정체가 심화되고 있는 단계인지, 혹은 회복되고 있는 단계인지를 의미한다. Figure 2를 참고하면 의 값이 일 때를 기준으로 하여 일 때는 정체가 심화, 일 때는 회복되고 있음을 알 수 있다. 또한, 가 클수록 교통류 상태가 더 큰 타원을 따라 이동하며 이는 곧 정체의 강도가 세지는 것을 의미한다. 이 두 가지 파라미터가 가지는 교통류 측면에서의 의미는 교통량을 예측함에 유용한 정보로써 활용될 수 있을 것으로 판단되며, 해당 파라미터들은 실시간으로 계산할 수 있어 실시간 예측에 적합할 것으로 판단된다. 본 연구는 실제 데이터를 적용한 사례분석을 통해 데이터 기반의 검토를 수행하고자 한다.
2. 본 연구 활용 교통류 예측 방법론
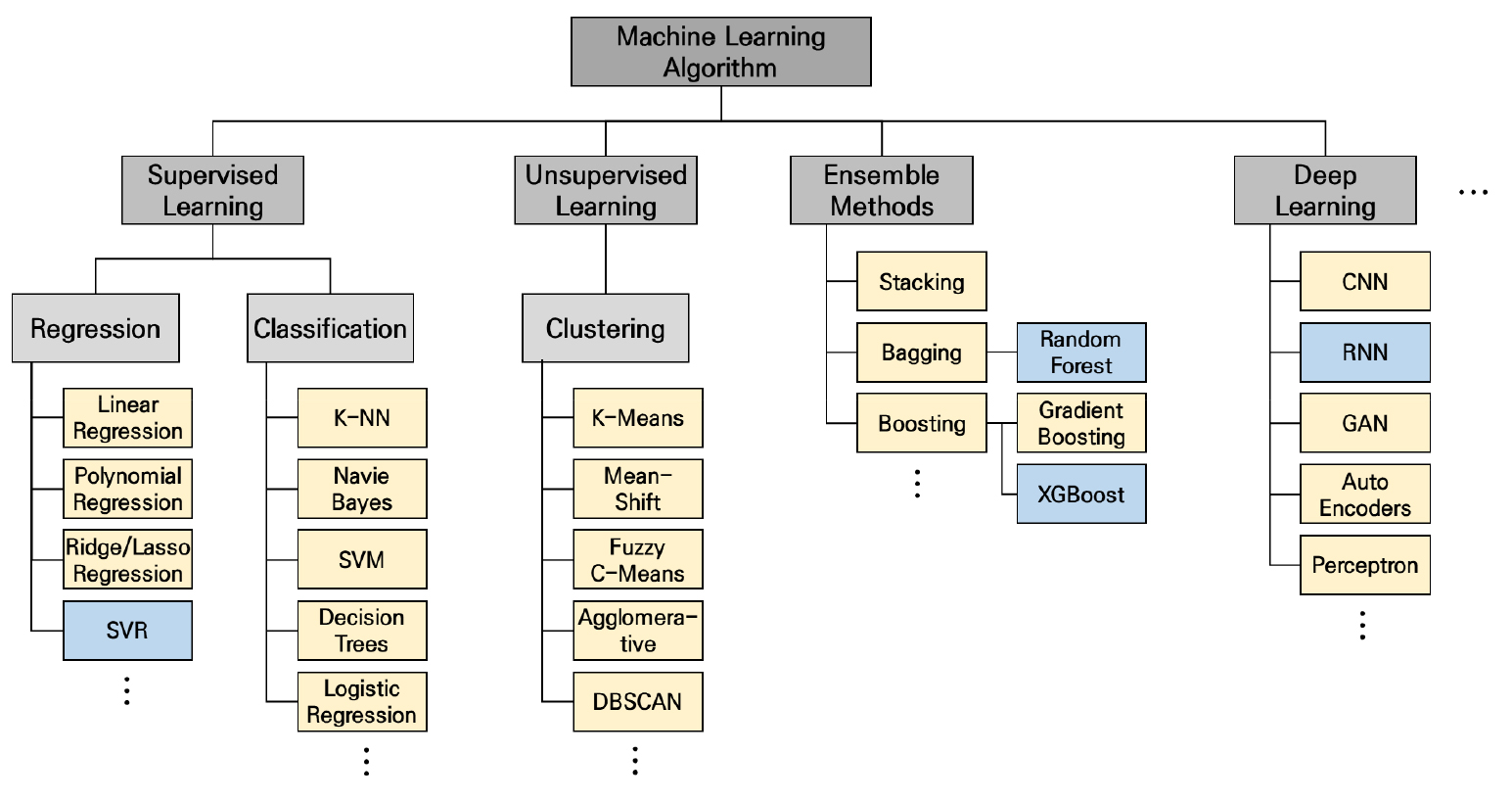
본 연구의 주된 목적은 elliptic bivariate relationship 파라미터들이 머신러닝 기반의 실시간 교통량 예측모형에 적용될 수 있음을 보이는 것이다. Figure 3과 같은 다양한 종류의 머신러닝에서 elliptic bivariate relationship 파라미터들의 적용성을 검토해보기 위해 서로 다른 유형의 4가지 예측 방법론을 선정하였다. 선정된 방법론은 앙상블 기반 배깅(bagging) 기법의 랜덤 포레스트(random forest)와 부스팅(boosting) 기법의 XGBoost(eXtreme Gradient Boost), 지도 학습의 SVR(Support Vector Regressor), 딥러닝 알고리즘의 RNN(Recurrent Neural Network)이다.
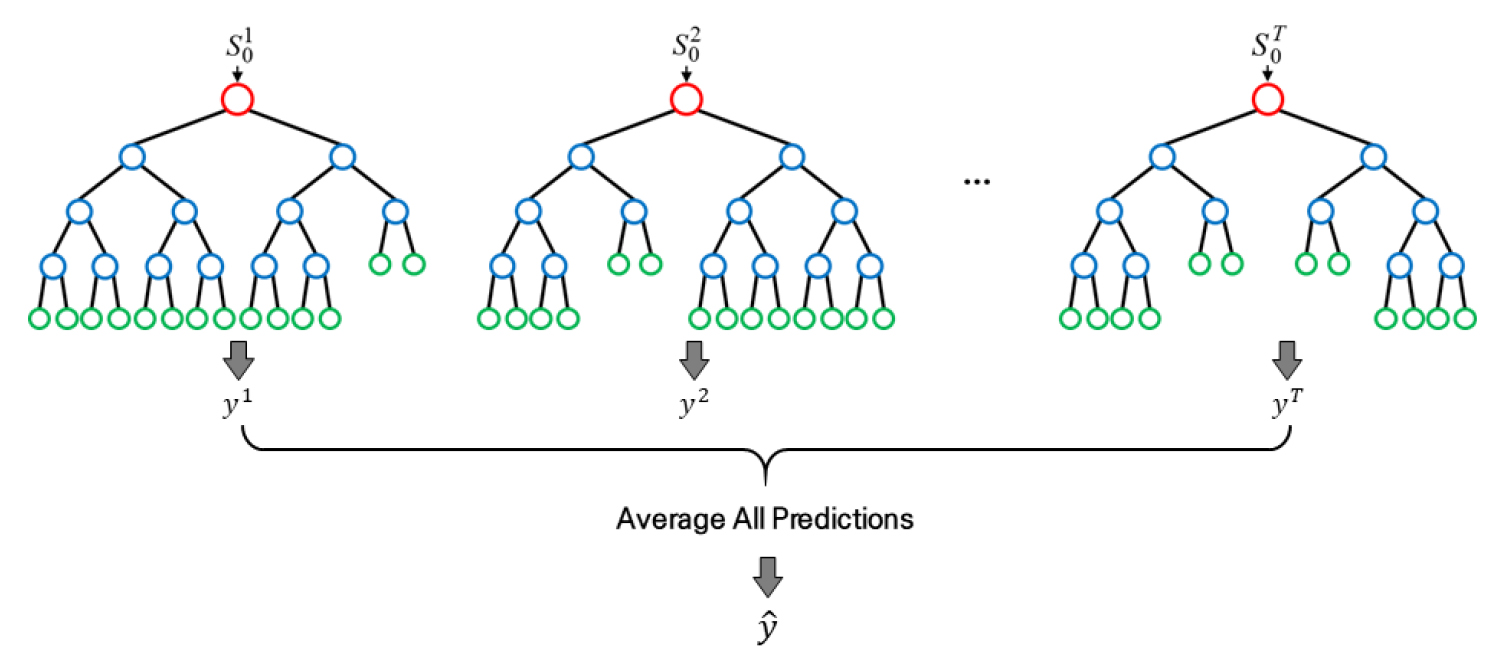
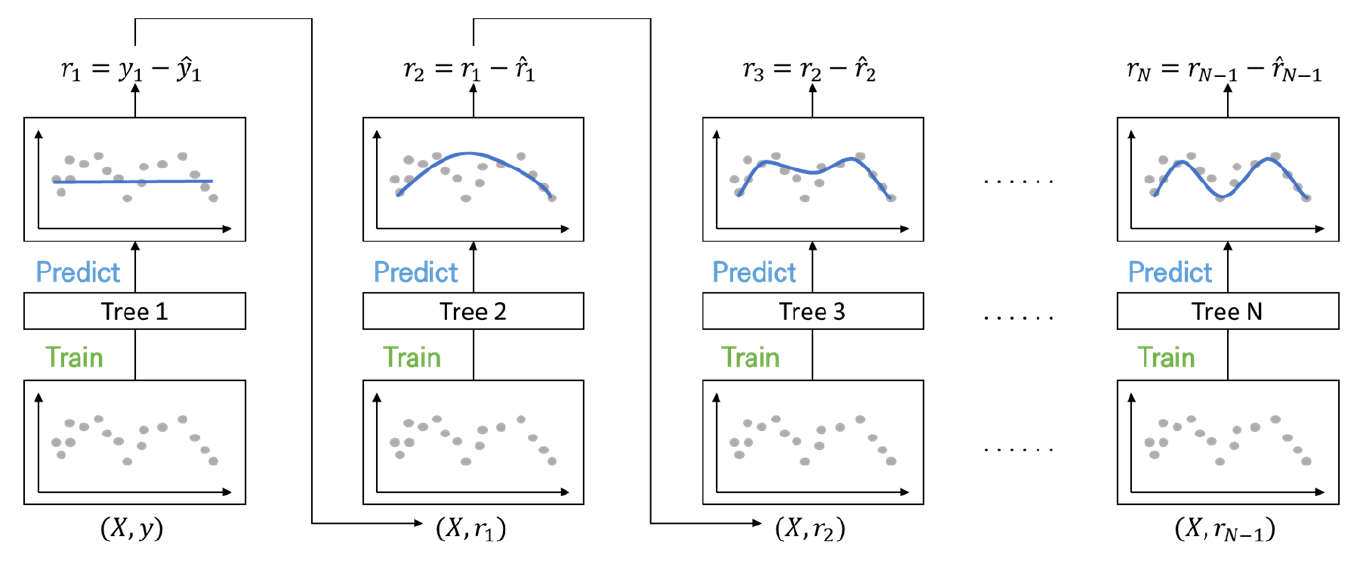
랜덤 포레스트는 여러 의사결정 나무(decision tree)로 이루어진 앙상블 기반 알고리즘이다(Figure 4). 일반적인 의사결정 나무는 학습 데이터에 따라서 생성되는 결과가 매우 달라서, 단일 의사결정 나무만을 사용하여 일반화하기에는 어려움이 있다. 랜덤 포레스트는 배깅을 활용하여 조금씩 다른 훈련 데이터에 대해 훈련된 다수의 의사결정 나무에서 나오는 결과값의 평균을 사용하여 예측 정확도를 높인 알고리즘이다(Biau and Scornet, 2016).
eXtreme Gradient Boost(XGBoost)는 여러 개의 의사결정 나무를 조합하여 예측하는 앙상블 기반 모형 중 부스팅 알고리즘의 한 종류이다(Figure 5). XGBoost는 그래디언트 부스팅(gradient boosting)의 학습시간이 오래 걸리고 과적합이 발생하기 쉽다는 단점을 개선한 알고리즘으로 병렬 처리로 학습하여 학습 속도가 그래디언트 부스팅보다 빠르고 자체적인 과적합 규제 기능이 있어 강한 내구성을 갖춘 알고리즘이다(Chen and Guestrin, 2016).
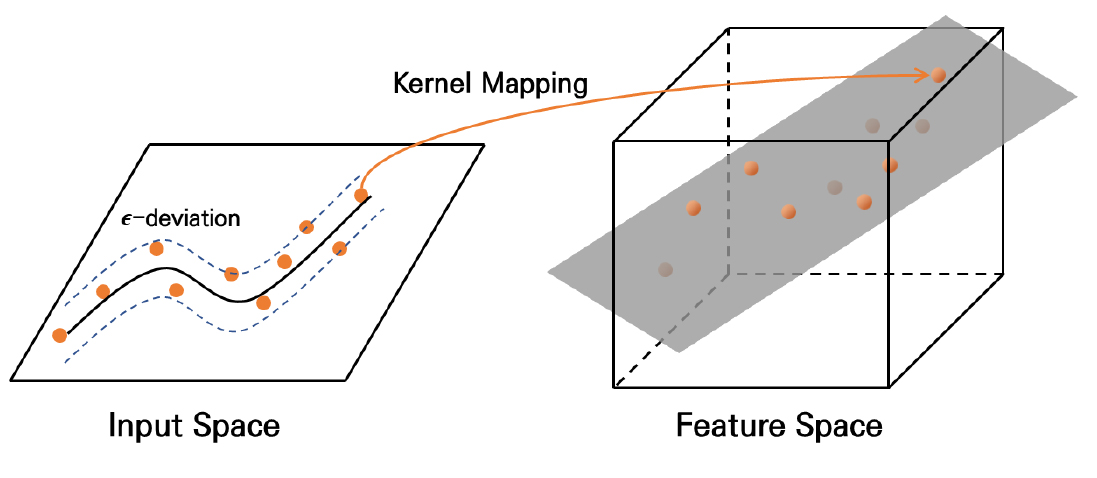
SVR은 학습 데이터의 분류 예측에 활용되는 서포트 벡터 머신(Support Vector Machine, SVM)에 손실함수를 도입하여, 분류 예측을 회귀 예측으로 변환한 방법이다. SVR은 최대한 큰 마진을 갖는 초평면을 구하는 SVM과는 달리, 예측값과 실측값 간 차이를 오차허용률 내로 최대한 많이 유지하는 것을 목표로 한다(Figure 6). SVR은 비선형 회귀 문제의 경우, 커널 함수를 사용하여 원공간(input space)에서의 입력값을 매핑 함수를 통해 고차원 형상공간(feature space)에 사상시켜 고차원 선형 회귀문제로 변환 후 회귀 분석을 수행한다(Smola and Schölkopf, 2004).
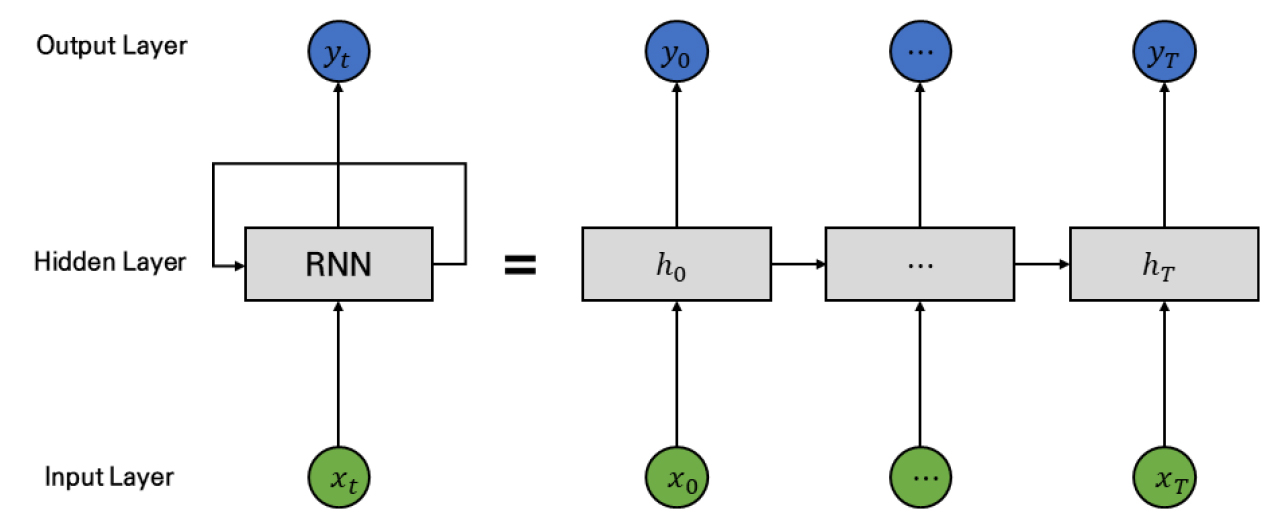
RNN는 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 신경망 내부의 메모리에 저장하여 다음 입력값이 들어오면 은닉층 노드의 계산에 활용하는 순환형 구조를 띤 신경망이다(Figure 7). RNN은 이전 메모리에 저장된 값을 고려하여 연산하기 때문에 입력값의 시계열적 동적 특징을 모델링 할 수 있도록 해준다는 장점이 있다. 하지만 RNN은 장기 의존성 문제(the problem of long-term dependencies)가 있어 비교적 짧은 시퀀스만 효과적으로 처리할 수 있다는 단점 또한 있다(Medsker and Jain, 1999).
3. SHAP(SHapley Additive exPlanations)
예측모형의 결과값을 올바르게 해석하는 것은 해당 모형에 신뢰를 제공할 수 있으며 예측결과에 대한 근거를 제공한다는 점에서 매우 중요하다(Lundberg and Lee, 2017). 최근 많은 분야에서 활용되고 있는 머신러닝 혹은 딥러닝 모형은 복잡한 구조로 되어 있어서 예측 성능은 좋지만, 모형의 예측 과정을 설명하기 어렵다는 한계점이 있다. 기존의 앙상블 기반 모형에서도 변수 중요도를 계산할 수 있으나, 해당 변수가 결과값에 미치는 영향을 정확하게 확인할 수 없으며, 기준을 잡는 방법에 따라 중요한 변수가 달라져 신뢰할 수 없다는 단점이 있다. 이러한 문제들을 보완하고자 개발된 방법이 바로 SHAP이다. SHAP은 각 설명변수 간 독립성을 근거로 각 설명변수가 결과값을 예측하는 데 기여한 정도를 수치로 제공하는 기법으로 모든 머신러닝 모형의 결과를 설명할 수 있다는 장점이 있다. 위와 같은 SHAP의 특성을 활용한다면 각 교통량 예측모형에서 설명변수들이 교통량 예측 결과값에 대해 얼마나 기여하였는지 확인할 수 있으며 이를 통해 elliptic bivariate relationship 파라미터들의 머신러닝 모형 적용성을 분석할 수 있을 것이다.
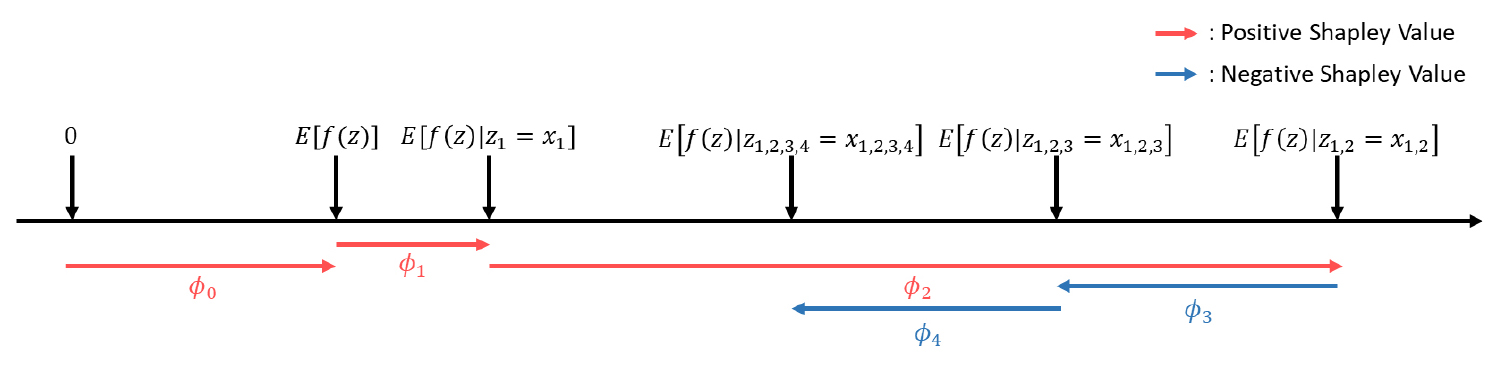
SHAP은 게임이론을 활용하여 임의의 설명변수에 대한 변수 중요도를 알기 위해 설명변수의 조합을 구성하고, 해당 설명변수의 유무에 따라 발생하는 결과값의 차이를 바탕으로 shapley value를 계산한다. Shapley value는 각 설명변수가 학습에 포함되었을 때, 모형의 성능에 어떤 영향을 미치는지 나타낸 값이다(Figure 8). Lundberg and Lee(2017)는 임의의 설명변수의 shapley value가 단일 값을 갖기 위해 가져야 할 조건 세 가지를 제시하였다. Equation 5는 기존 모형 로부터 생성된 결과를 설명하기 위해 생성한 가 각 설명변수들의 shapley value를 활용하여 표현될 수 있어야 한다는 의미이고, Equation 6는 단순화된 입력값이 0이면 변수 중요도 도 0이 되어야 한다는 의미이다. 마지막으로 Equation 7은 모형이 에서 으로 바뀌었을 때, 설명변수 의 영향력이 더 커졌다면, 의 설명 모형에서 설명변수 에 대한 계수가 의 설명변수 에 대한 계수보다 더 커야한다는 것을 의미한다.
여기서, 설명하고자 하는 기존 모형
: 를 설명하기 위해 단순화한 설명 모형
: 에 들어가는 입력값
: 의 단순화한 형태로 에 들어가는 입력값
: 설명변수 의 shapley value
: 단순화된 input의 설명변수 개수
: 을 단순화한 입력값으로 ()
: 설명변수 가 제외된 집합
Equation 8은 성질 1, 2, 3(Equations 5, 6, 7)을 만족할 때, 설명변수 의 shapley value를 계산하는 수식이다.
여기서, 에서 0이 아닌 원소의 개수
사례분석
1. 분석방법 및 데이터
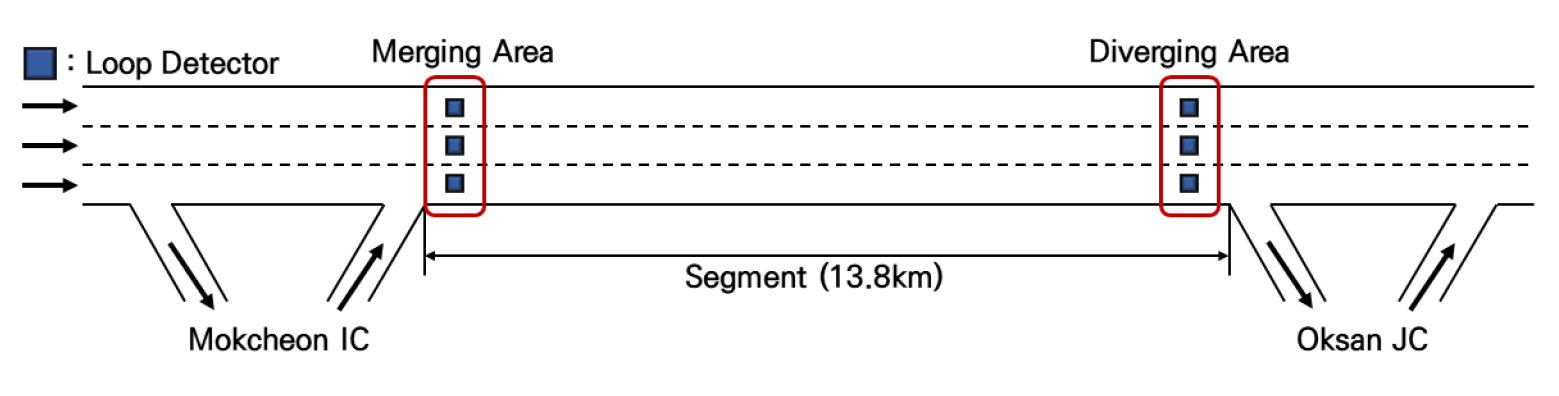
본 연구는 경부고속도로 하행 목천 IC부터 옥산 JC 구간을 공간적 범위로 선정하였으며 공간 범위의 개략도는 Figure 9와 같다. 데이터는 한국도로공사에서 제공하는 5분 집계단위 VDS 데이터를 사용하였으며, 공간 범위 내에 존재하는 9개의 검지기 중 합류부와 분류부에 가장 인접한 검지기의 교통류 데이터를 사용하였다.
본 연구에서는 랜덤 포레스트, XGBoost, SVR, RNN을 활용하여 전체 시간대에 대한 5분 후, 15분 후, 30분 후 교통량 예측을 진행하였으며, 교통량 예측 시 사용한 설명변수와 종속변수의 의미는 Table 1과 같다. 각 검지기 데이터는 5분 간격으로 측정되었으며, 2022년 1월 1일부터 2022년 4월 14일까지 총 104일 치 데이터를 학습시키고 2022년 4월 15일의 교통량을 예측하였다. 성능 평가 지표로는 Mean Absolute Percentage Error(MAPE)를 사용하였다. MAPE는 실제값과 예측값 사이의 오차가 실제값에서 차지하는 비율을 나타낸 지표로 0에 가까울수록 예측력이 좋다고 해석할 수 있다.
Table 1.
Data for prediction
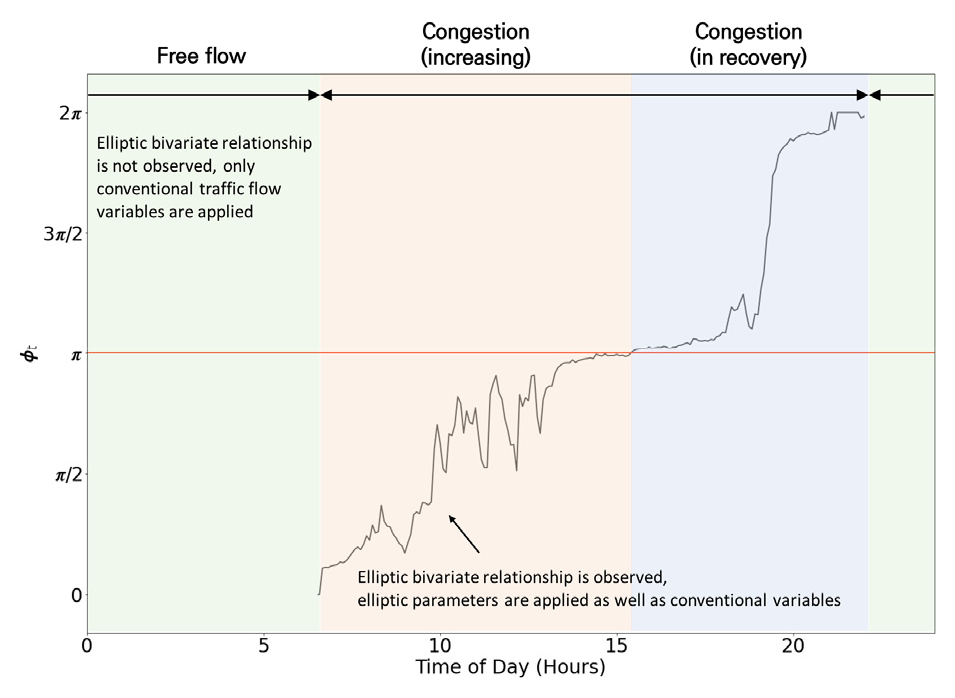
선행연구(Ka et al., 2020)에 의하면 VA와 TT 간의 elliptic bivariate relationship은 교통류가 자유류를 벗어나기 시작하여 정체를 거쳐 회복하는 시간 동안 나타난다. 따라서 심야시간대 등 정체가 전혀 발생하지는 않는 상황에서는 elliptic bivariate relationship 파라미터의 값을 도출할 수 없으며 예측모형에 적용이 불가하다는 한계점이 있다. 본 연구의 예측모형은 elliptic bivariate relationship이 관측되지 않는 비정체상황에 대해서는 교통량, 속도 등 기존 교통류 변수를 예측모형에 적용하며, elliptic bivariate relationship 파라미터가 도출되는 상황에서는 와 를 설명변수로서 추가적으로 적용하게 된다.
Figure 10은 본 연구의 분석사례에 대한 의 값이며, 본 연구의 사례분석 절차를 종합적으로 나타내면 Figure 11과 같다.
2. 교통량 예측결과
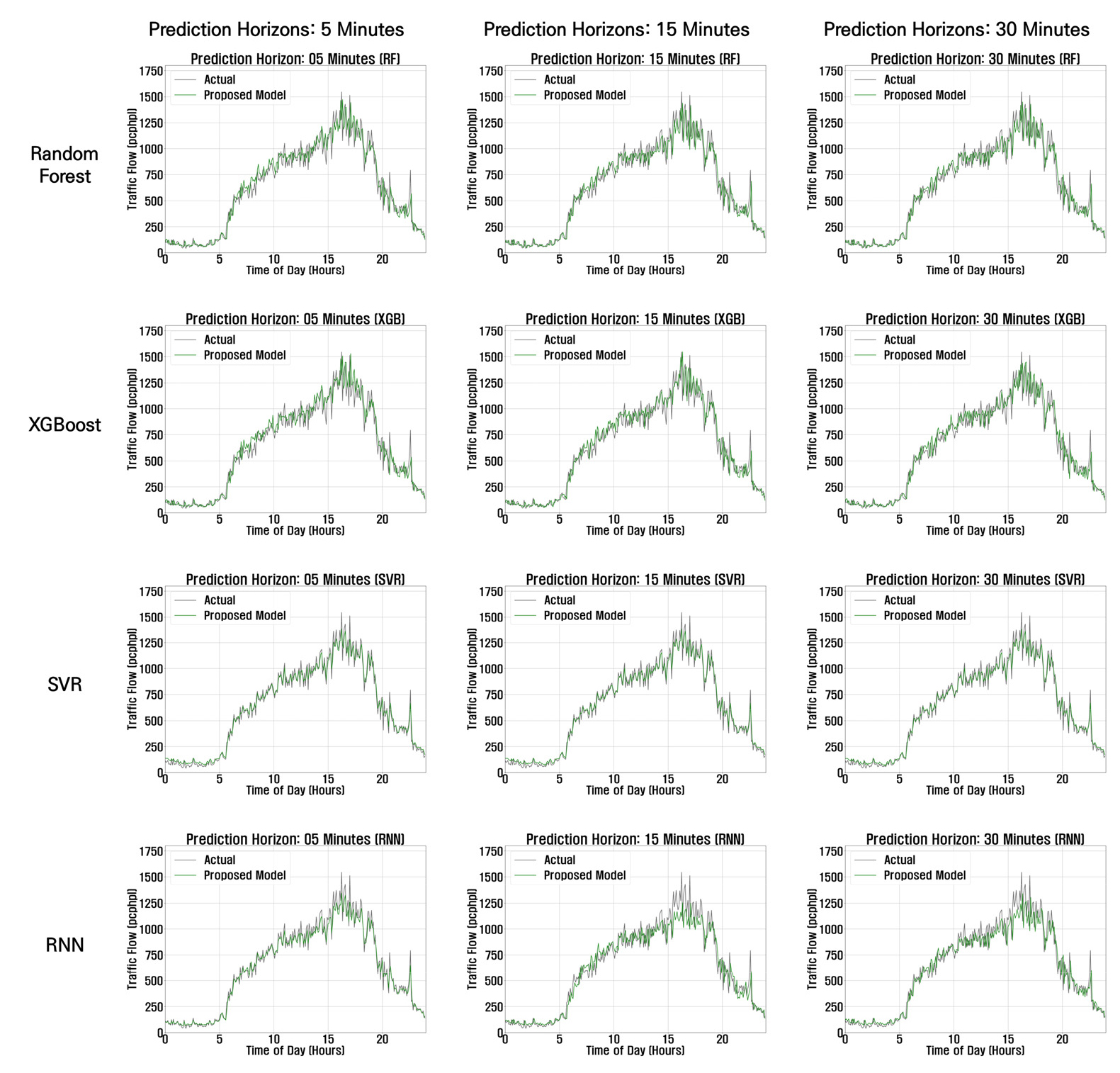
본 연구에서는 elliptic bivariate relationship 파라미터들을 활용한 예측모형과 활용하지 않은 예측모형의 결과 비교를 수행하였다. Table 2는 elliptic bivariate relationship 파라미터들의 포함 여부에 따른 정체 시간대의 MAPE이고, Figure 12는 2022년 4월 15일의 실제 교통량과 예측모형별 예측 교통량을 그래프로 표현한 것이다. Elliptic bivariate relationship 파라미터들을 포함한 예측모형의 평균적인 MAPE는, 5분 후 예측모형은 9.6%, 15분 후 예측모형은 9.8%, 30분 후 예측모형은 9.9%로 나타났다. 이는, 예측 시간 간격이 커질수록 예측력이 점점 낮아지는 것을 의미한다. 해당 결과를 기존의 예측모형과 비교해 보면, 제안한 예측모형이 5분 후, 15분 후, 30분 후 예측 모두 MAPE가 약 2.4% 정도 낮은 것으로 나타났다. 이는 모든 예측 시간대에서 elliptic bivariate relationship 파라미터들을 포함한 모형의 예측력이 높음을 의미한다.
또한, 예측모형에 사용한 알고리즘별 분석결과를 비교한 결과, 각 예측모형의 평균적인 MAPE는 랜덤 포레스트가 9.7%, XGBoost가 9.6%, SVR이 9.8%, RNN이 10.0%로 나타났다. 즉, 랜덤 포레스트와 XGBoost와 같은 앙상블 기반 모형들이 가장 우수한 성능을 보였으며, 그 뒤로 RNN과 SVR이 유사한 예측 성능을 갖음을 확인하였다. 네 가지 예측모형에 대해 상대적인 개선 정도의 차이가 있긴 하였지만, MAPE를 기준으로 elliptic bivariate relationship 파라미터들을 포함함에 따라 MAPE가 2.1%(XGBoost의 5분 후 예측모형)부터 2.8%(RNN의 30분 후 예측모형)까지, 평균 약 2.4% 감소하는 것을 확인할 수 있다.
Table 2.
MAPE (%) for each prediction model
본 연구는 예측모형이 적용된 전체시간을 정체의 양상에 따라 세분화하여 예측결과를 분석하고자 하였으며, elliptic bivariate relationship 파라미터 의 의미를 바탕으로 하여 가 도출되지 않는 상황을 비정체, 인 상황을 정체 심화단계, 인 상황을 정체 회복단계로 구분하였다. Tables 3, 4, 5는 각각 비정체, 정체 심화단계, 정체 회복단계에 대한 예측결과를 보여주고 있는데, 비정체의 경우에는 전술한 바와 같이 예측모형에 elliptic bivariate relationship 파라미터들이 적용될 수 없으며 결과적으로 기존의 교통류 변수들만을 사용한 모형과 차이가 없게 된다. 또한, 비정체상황의 MAPE가 정체상황의 MAPE보다 높은 것을 확인할 수 있었다. 이는, 비정체상황이 정체상황에 비해 교통량이 적기 때문에 MAPE 산정 시 과대추정된 결과로 보인다. 반면, 정체 시에는 예측모형의 설명변수로서 elliptic bivariate relationship 파라미터들이 추가 적용되었는데, 정체 심화단계의 경우 예측모형의 MAPE가 평균적으로 약 1.2%가 감소하였으며 정체 회복단계의 경우 예측모형 MAPE가 평균적으로 약 2.0% 감소하였다. 이는 정체의 진행상태와 정체의 크기를 나타내는 와 를 적용함으로써 교통류가 정체상태일 때 예측모형의 성능을 개선할 수 있음을 보여주는 결과이다.
Table 3.
MAPE (%) for each prediction model in uncongested state
Table 4.
MAPE (%) for each prediction model in congested state (congestion increases, )
Table 5.
MAPE (%) for each prediction model in congested state (congestion is relieved, )
3. 변수 중요도 산정결과
Figure 13과 Table 6는 자기 회귀 변수인 를 제외한 나머지 설명변수의 변수 중요도를 계산한 결과이다. 분석결과, 예측모형에 적용된 설명변수 중 의 중요도가 가장 높은 것으로 나타났으며 의 중요도 역시 일반적인 교통류 변수와 유사하거나 다소 높은 수준인 것으로 확인되었다. 의 경우 모든 예측모형에서 가장 높은 변수 중요도를 갖는 것으로 나타났다. 동일한 교통량이나 속도가 관측되더라도, 현재의 교통류가 정체 심화단계인지 혹은 회복단계인지 여부에 따라 교통류 상태가 다를 수 있다는 점을 고려할 때 이러한 결과는 합리적인 것으로 판단된다. 정체강도를 의미하는 파라미터인 의 경우, 보다는 변수 중요도가 낮게 산정되었으나 다른 교통류 변수(속도, 교통량)와 유사한 수준의 중요도를 갖는 것으로 나타났다.
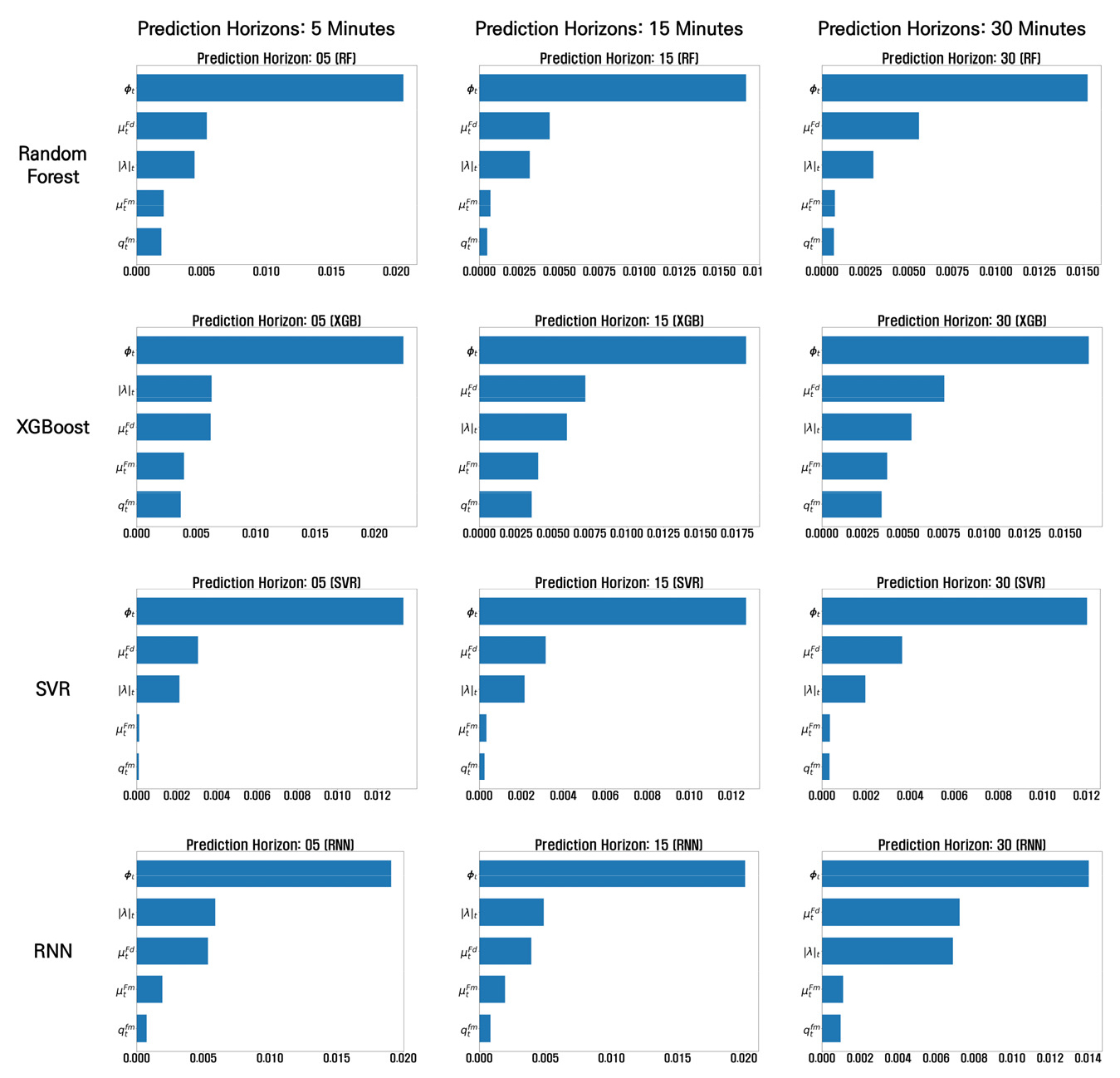
Table 6.
Feature importance for each prediction model
결론
본 연구는 교통류 상태를 파악하는 새로운 방법 중 하나인 vehicle accumulation과 travel time 간의 elliptic bivariate relationship(Ka et al., 2020)을 머신러닝 및 딥러닝 기반 교통량 예측모형에 적용하였다. 선행연구에 의하면 elliptic bivariate relationship의 두 가지 파라미터 중 는 현재 교통류 상태가 정체가 심화되고 있는 단계인지, 정체로부터 회복되고 있는 단계인지 여부를 나타내며,는 현재의 정체강도를 의미한다. 본 연구는 두 파라미터의 다양한 유형의 예측모형에 대한 적용성 검토를 위해 배깅, 부스팅, 딥러닝 등의 분류에 해당하는 방법론들을 활용하였으며, 실제 교통데이터를 이용하여 사례분석을 수행하였다.
분석결과, elliptic bivariate relationship의 두 가지 파라미터들을 적용한 예측모형의 오차율이 일반적인 교통류 변수(속도, 교통량)만을 적용한 모형 대비 최소 2.1%부터 최대 2.8%까지 일관적으로 감소하였으며, 정체의 단계별로 비교 분석한 결과에서도 예측모형의 오차율이 일관성 있게 개선되는 것을 확인할 수 있었다. 또한, SHAP을 이용하여 예측모형에 적용된 변수들의 중요도를 산정한 결과, 와 가 교통량 예측에 있어 상당한 영향을 미치는 것으로 나타났다. 는 특히, 모든 모형에서 변수 중요도가 가장 높은 것으로 나타났다. 이는 현재 정체 단계를 나타내는 가 교통량 예측에 가장 중요도가 크다는 것을 의미하며, 평균속도와 교통량이 같더라도 현재 교통류의 정체가 심화단계인지 또는 회복단계인지에 따라 다르게 변화할 수 있음을 시사한다. 나머지 파라미터인는 일반적인 교통류 변수(속도, 교통량)와 비슷한 정도의 변수 중요도를 보였으며, 이는 정체강도 역시 교통류 예측에 영향을 미칠 수 있음을 의미한다.
결론적으로 교통류 측면에서 유용한 의미를 갖는 elliptic bivariate relationship 파라미터들인 와 가 교통량 예측모형에서도 유용한 설명변수로 활용될 수 있음이 데이터 기반 분석을 통해 확인되었다. Elliptic bivariate relationship 파라미터들을 활용한 향후연구로는 단일 고속도로 구간이 아닌 고속도로 네트워크, 도시부 교차로 등 다양한 공간적 범위에 대한 분석이 가능할 것이다.
