

서론
선행연구
1. 교통사고 요인 분석 연구
2. 이미지·LiDAR 데이터 기반 인공지능 활용 교통안전 연구
3. 데이터 기반 시나리오 생성 연구
4. 연구 차별성
자율주행차 도심부 사고 시나리오 생성 방법론
1. 사고 취약상황 정의
2. 프로브 차량 실주행 데이터 수집 및 3D-LiDAR PCD 운동학적 속성 추출
3. 사고 유발 물체 검출 및 변수 중요도 추출 모델
분석 결과
1. 심층 인공 신경망 학습 및 결과
2. 랜덤 포레스트 학습 및 결과
자율주행차 도심부 시나리오 생성 및 토의
1. Logical 시나리오 생성
2. 토의
결론 및 향후 연구
서론
자율주행자동차(이하 자율주행차)는 부분적으로 또는 완전히 네비게이션, 제어 및 위험 상황 회피가 가능한 차량으로 정의된다. SAE(Society of Automotive Engineers, 이하 SAE)에 따르면 자율주행차는 자율주행시스템이 없는 0단계부터 완전 자율주행시스템이 탑재된 5단계까지 총 여섯 가지 단계로 구분되며, 3단계부터 인간 운전자의 개입이 최소화되고 단계가 높아질수록 자율주행차 스스로 다양한 상황을 대처할 수 있어야 한다. 자율주행차는 속도를 유지하면서 차량 간 거리를 줄일 수 있어 도로 용량 증대 및 이동성 향상 효과가 기대되며, 인적요인으로 인한 사고의 90%를 예방할 수 있을 것으로 예측된다(Lee et al., 2019; Singh, 2015; Wagner, 2016; Liu et al., 2018; Khattak et al., 2020; Kang et al., 2019; Kang et al., 2020; Kang et al., 2022a; Kang et al., 2022b). 그러나 이러한 긍정적인 효과는 자율주행차 도입이 일정 수준 이상을 넘어 자율주행차가 일부 상용화 되었을 경우에 발생할 수 있다(Liu et al., 2018; Ye et al., 2018; Amirgholy et al., 2020). 자율주행차 도입 초창기의 경우, 일반자동차와의 혼재상황으로 예상치 못한 사고 상황들이 발생할 가능성이 존재한다(Goodall, 2014). 이처럼 다양한 기술적 진보가 자율주행차 상용화를 앞당기고 있으나, 단순히 기술만으로 새로운 모빌리티를 도입하는 것에는 한계가 존재하여 자율주행차의 안전성을 보장할 수 있는 체계가 요구된다.
자율주행차의 안전성을 보장하기 위해 기존 자동차 안전도 평가에 자율주행차가 포함되어 자율주행 시스템(Autonomous Driving System, 이하 ADS)이 평가받기 시작하였다. 자동차 안전도 평가(New Car Assessment Program, 이하 NCAP)는 일반자동차의 충돌실험을 통해 안전도를 측정하고 이를 소비자에게 해당 자동차의 안전도에 관한 정보를 제공하는 제도로, 자율주행차의 경우 전방 충돌 방지 보조 시스템(Forward Collision-Avoidance Assist, 이하 FCA), 차로 유지 보조 시스템(Lane Following Assist, 이하 LFA) 등을 평가하고 있다. 그러나, 자율주행차는 인간이 운전하는 일반차량과 달리 복잡한 환경에서 특정 상황을 스스로 대응할 필요가 있어 다양한 환경에서의 평가가 요구되어 단순한 환경에서 기술을 평가하는 것에는 한계가 존재한다. 이에 따라 실제 도로 운행 및 시뮬레이션 등을 통해 다양한 환경을 고려할 수 있는 시나리오 접근법이 제시되고 있다. 시나리오 접근법은 지식 기반 접근법(Knowledge-based extraction)과 데이터 기반 접근법(Data-driven extraction)으로 구분된다(Riedmaier et al., 2020). 지식 기반 접근법의 경우, 온톨로지 방식을 활용하여 전문가 지식을 통해 빠르게 시나리오 카탈로그를 생성할 수 있으나 실재하는 데이터가 아닌 지식만으로 구성되어 시나리오 자체에 대한 대표성의 문제가 제기될 수 있다. 반면, 데이터 기반 접근법은 실제 사고 데이터 및 머신러닝 등을 활용하여 시나리오를 생성하여 시나리오 대표성의 문제를 극복할 수 있으나, 데이터 정제 및 인공지능 등의 요건을 충족하지 못할 경우 시나리오를 생성할 수 없다는 전제조건이 존재한다. 또한 자율주행차는 고속도로 및 도심도로 환경에서 ODD(Operational Design Domain)가 상이하기 때문에 고속도로와 도심도로를 나누어 시나리오를 제시할 필요가 있다. 특히 도심도로의 경우. 상대적으로 인지해야하는 객체(차량, 보행자, 표지판 등)가 많으며 객체 간 상호작용이 발생하여 사고 빈도가 높아 자율주행차 도심부 상용화를 위한 시나리오가 필수적으로 요구된다(Son et al., 2021).
이에 본 연구는 도심부 대상의 자율주행차 평가 시나리오를 제시하기 위해 데이터 기반 접근법을 토대로 시나리오를 제시하고자 한다. 특히, 3D-LiDAR PCD를 활용하여 주변 차량의 운동학적 데이터를 추출하여 사고유발차량 검출 및 변수 중요도 파악을 통해 자율주행차 안전성을 평가할 수 있는 시나리오 개발하고자 한다.
본 연구는 다음과 같이 진행된다; 2장에서 사고 요인 및 인공지능, 시나리오 연구를 고찰하여 본 연구의 차별성을 제시한다. 3장에서는 logical 시나리오를 개발하기 위한 데이터 수집 및 운동학적 속성 추출, 인공지능 활용 방안, 안전성 평가 시나리오 작성 방식을 제시한다. 4장은 제시한 방법론을 통해 인공지능 학습을 진행하고 이를 토대로 도심부 자율주행차 logical 시나리오를 5장에서 제시한다. 종합적으로 6장에서 결론을 짓는다.
선행연구
1. 교통사고 요인 분석 연구
일반적으로 교통사고 연구는 도로 교통사고를 발생시키는 요인들을 추출하는 연구로 이루어져 있으며, 대부분 인적(운전자), 도로 상태 및 환경 요인으로 구분된다(Chen et al., 2020; Theofilatos et al., 2012; Park et al., 2007; Lee and Ahn, 2006; Lee and Lee, 2017; Eboli et al., 2020; Harith et al., 2019). 인적 요인에는 운전자의 연령, 운전 습관 및 운전자의 행동이 포함되며, 도로 요인은 교차로, 평균 차선 수 및 도로 폭, 평균 일일 교통량, 교통 신호 및 도로 시설물 등이 포함되고, 환경 요인에는 날씨, 시간 및 조명 등이 포함된다. 이러한 요인들이 다양한 교통사고를 설명할 수는 있으나, 사실 교통사고에서 가장 지배적인 요인은 차량이다. 즉, 가장 중요한 요인은 특정 변수에 영향을 받았는지 여부에 관계없이 차량 그 자체인 것이다. 따라서 실제 주행 차량의 운동학적 변수인 거리, 속도, 가속도에 초점을 맞출 필요가 있다.
운동학적 변수에 중점을 둔 여러 연구에서는 거리, 속도, 가속도가 교통사고를 일으키는 주요 요인임을 확인하였으며, 이를 활용하여 다양한 연구를 수행하였다 (Eboli et al., 2016; John et al., 2019; Watanabe et al., 2012; Bauernschuster and Rekers, 2022; Eshetu, 2019; Gota et al., 2019; Wang et al., 2006; Ali et al., 2021; Lee et al., 2021). 속도와 가속도가 차량의 운동을 설명하는 가장 필수적인 매개변수임을 확인하고, 운전자의 위험한 운전행동을 분류하기 위한 방안을 제안하였으며(Eboli et al., 2016), 정확한 차량 간 거리 및 속도, 가속도 측정이 FCA 성능을 향상시킬 수 있는 방안임을 제시하였다(Wang et al., 2020) 또한, 도로 위 차종 및 차량 크기(Watanabe et al., 2012; Bumrungsup and Kanitpong, 2022), 도로 위 사고 유발 차량의 상대적 위치(Hussain et al., 2018; Ilić et al., 2019) 등이 사고 유발 및 심각도에 영향을 미치는 요인인 것으로 나타났다.
2. 이미지·LiDAR 데이터 기반 인공지능 활용 교통안전 연구
최근 다양한 분야에서 인공지능을 접목하여 활용하고 있으며, 교통분야에서도 사고 예방 및 교통 흐름 예측 등으로 인공지능을 활용하고 있다. 대부분 이미지 데이터를 활용하여 사고 상황을 사전에 예측하는 연구로(Thakurdesai and Aghav, 2020; Hsu et al., 2020; Yu et al., 2020; Rahman et al., 2020; Choi et al., 2021), YOLO(Hsu et al., 2020), Mask R-CNN(Hsu et al., 2020), CNN-LSTM(Yu et al., 2020)등의 방법론을 활용하고 있다. 그러나 단순 이미지 데이터의 경우 사각지대가 존재하고 시공간을 동시에 고려하지 못하여 LiDAR(Light Detection and Ranging) 데이터를 활용하여 이를 보완하고 있다. LiDAR 데이터는 Point Cloud Data(이하 PCD)로 이루어져 있으며, PCD 내 개별적인 점들의 집합을 통해 특정 물체를 식별할 수 있다. LiDAR를 활용한 연구에서는 3D-LiDAR 데이터를 2D로 투영하여 이미지 데이터화하여 사용하는 연구가 존재하며, 이들은 YOLO 및 CNN(Ponnaganti et al., 2021; Lee et al., 2020) 방식을 통해 물체를 식별하고 있다. 나아가 3D-LiDAR 데이터 자체를 활용하는 연구에서는 공간적 특징을 명확하게 확인하여 정확도를 향상시켰다(Wang et al., 2020; Yuan et al., 2021; Yahya et al., 2020). 또한 단순 이미지 데이터에 3D-LiDAR 데이터를 퓨전하여 물체 식별 정확도를 향상시키는 연구도 제시되고 있다(Sakic et al., 2020; Pang et al., 2022; Choi and Kim, 2021). 이처럼 3D-LiDAR PCD를 활용하여 물체를 식별하는 시스템은 카메라 데이터를 보완할 수 있어 실제 자율주행 상용화에 필수적인 기술이다.
3. 데이터 기반 시나리오 생성 연구
데이터 기반 시나리오 생성 연구를 살펴보기 이전에, 자율주행차 안전성 평가 시나리오를 집중적으로 고려한 PEGASUS 프로젝트의 안전성 평가 시나리오를 검토하였다(PEGASUS project, 2019). PEGASUS 프로젝트는 독일 연방에서 BMW, Audi 등과 함께 자율주행 기능의 안전성에 대한 체계적인 방식과 요구사항을 개발하였다. 이는 실험(Test) 시나리오를 생성하기 위한 6개의 정보 레이어를 정의하고, 각 레이어에는 기능 요구사항, 교통 흐름, 위치, 위험 상황 설명, 도로 선형, 객체 이동 등을 제시할 수 있는 항목이 존재한다. 이를 통해 교통 사고 중 발생할 수 있는 사고 상황에 대해 자율주행차의 안전성을 평가할 수 있는 Functional, Logical, Concrete Scenario를 정의하였다.
Functional 시나리오는 도로 네트워크, 차선 폭, 속도 제한, 정지 및 이동 객체, 날씨 조건, 차량 동작 등과 같은 가장 높은 추상화 수준의 정보를 포함하며, logical 시나리오는 functional 시나리오에서 기술된 요소에 대한 정확한 값 범위를 설정해야한다. 특히, logical 시나리오의 4번째 레이어는 위험 상황에 관여하는 목표차량(Ego), 대상 차량(Actor), 인접 차량(Neighboring), 보행자와 같은 행위자들의 이동을 기술해야하며, 해당 레이어에서 행위자들의 거리, 차종, 초기 차선 및 위험 상황 동안 행위자의 움직이는 속도 범위를 제시해야한다. Logical 시나리오는 실험 시나리오를 제시하기 위한 중요 단계로 실제 거리, 속도 등의 변수 범위를 필수적으로 파악할 필요가 있다. Concrete 시나리오는 최종적인 자율주행차 안전성 평가를 하기 위한 실험 시나리오를 제시하기 위해 logical 시나리오에서 설정된 범위값들 내에서 값들의 조합을 통해 특정 변수값을 지정해야 한다(Figure 1).
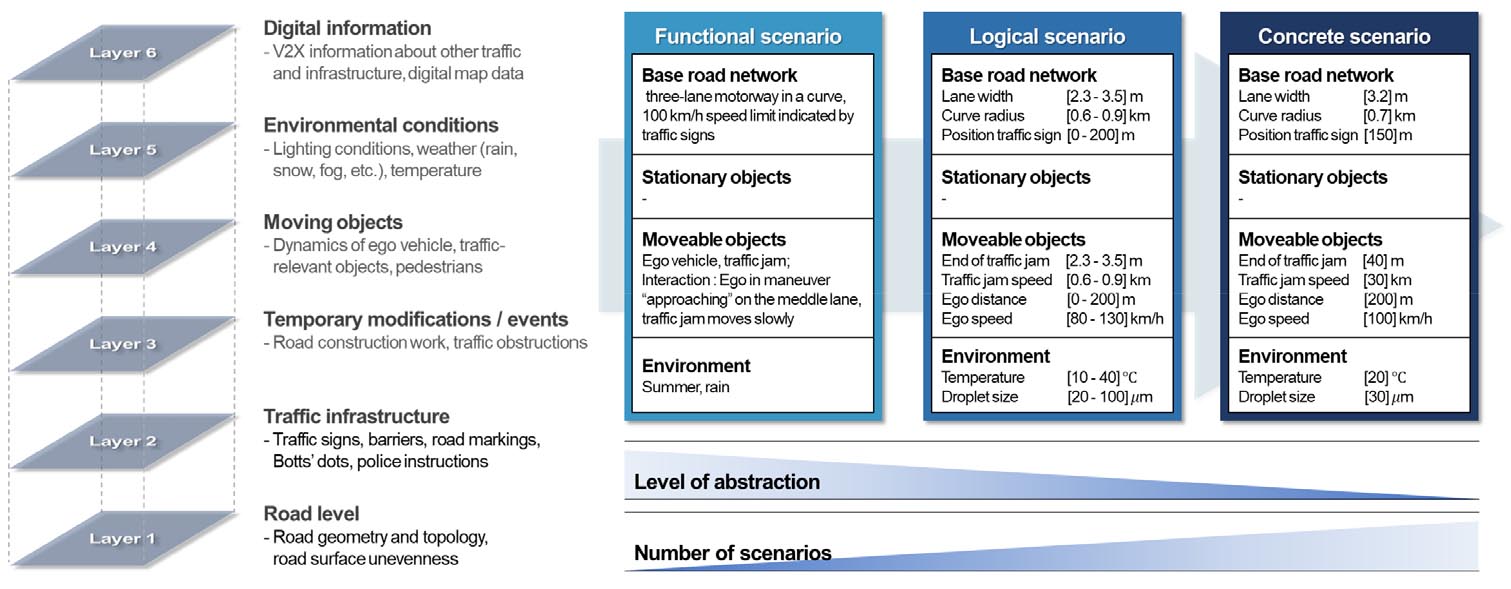
PEGASUS 프로젝트와 같이 자율주행차 안전성을 보장할 수 있는 체계가 요구되어 세계적으로 자율주행차 안전성 평가가 진행되고 있으며(Euro NCAP, KNCAP, CNCAP), 특히, 다양한 평가 방식 중 환경요소의 변화를 효과적으로 반영할 수 있는 시나리오 접근법이 주목받고 있다(Riedmaier et al., 2020). 이에 따라 다양한 시나리오 연구가 제시되고 있으며, 그 중 시나리오 대표성을 확보할 수 있는 데이터 및 인공지능을 활용한 데이터 기반 시나리오 접근 연구가 제안되고 있다. 시나리오를 제시하기 위해 활용하는 데이터는 자율주행차 데이터와 일반차량 데이터가 존재한다. 자율주행차 데이터의 경우, 실제 주행에 대한 데이터를 제공하고 있는 기관이 존재하지 않기 때문에 대부분 캘리포니아 교통관리국(California Department of Motor Vehicles, 이하 CA DMV)에서 제공하는 자율주행차 사고 보고서 데이터를 활용하고 있다. 자율주행차 사고 보고서를 기반으로 토픽 모델링을 통해 사고를 분석하고 시나리오를 제시하였으며(Alambeigi et al., 2020), 시퀀스 및 클러스터링 분석을 통해 자율주행차 사고 특징을 추출하고 시나리오를 제시하였다(Song et al., 2021). 또한 CA DMV에서 제공하는 제어권 해제 보고서(Disengagement report)를 결합하여 시나리오를 제시한 연구도 확인되었다(Favarò et al., 2017). 그러나, CA DMV 데이터를 활용한 대다수의 연구에서 보고서 내 추출할 활용 변수에 대한 한계와 충분한 데이터셋의 누적(300건)을 한계로 지적하고 있다. 이에 따라 기존 일반차량 데이터를 활용하여 시나리오를 제시하는 연구가 제안되고 있다. Yuan et al.(2020)은 일반 차량의 사고 데이터를 기반으로 ANN(Artificial Neural Network)을 활용하여 4,320개의 시나리오를 제시하였으며, 5개의 고위험 시나리오를 도출하였다. 사고 시나리오를 도출하기 위해 시간, 날씨, 도로 유형, 속도 제한 등 사고 요인을 다양하게 활용하였으며, 추출된 시나리오를 기반에서 사고 빈도와 확률분포를 고려하여 5개의 고위험 시나리오를 제시하였다. Kang et al.(2022a)은 일반 차량 사고 데이터를 기반으로 Vision Transformer(이하 ViT)를 활용하여 사고 취약상황을 분류하고 사고 취약상황 시나리오를 제시하였다. 사고 상황을 TTC(Time-To-Collision, 이하 TTC)로 4가지(Normal, Pre-collision, Collision, Post-collision) 상황으로 분류하고 ViT 학습을 통해 94%의 분류 정확도를 도출하여 사고 취약상황의 functional 시나리오를 제시하였다.
4. 연구 차별성
선행연구는 대부분 교통사고 요인을 인적, 도로, 환경적 요인으로 분석하는 것이 주된 연구였으며 차량 요인을 분석한 연구라도 기존에 수집된 데이터나 자차 데이터만을 활용하여 주변 차량의 행동을 고려할 수 없는 한계가 존재하였다. 본 연구는 실제 프로브 차량을 통해 자체적으로 데이터를 수집하였으며, 자차 데이터와 함께 주변 차량 데이터를 추출하여 활용하였다. 또한 인공지능을 활용한 연구에서도 단순 이미지 데이터를 활용하거나 3D-LiDAR를 활용하여도 단순 물체(점 집합)를 검출하는 연구에 그쳐있다. 본 연구는 3D-LiDAR PCD 내 존재하는 점들의 특성에 주목하고, 이를 통해 물체로 추정되는 객체의 운동학적 특성을 추출하여 활용하였다. 시나리오 생성 선행연구는 시나리오 생성 목적보다 데이터/모델 정확도에 초점이 맞추어져 있었으며, 특정 시나리오 포맷없이 고속도로/도심부 환경의 단순한 시나리오만을 제시하는 것에 그쳐 있다. 본 연구는 상대적으로 인지해야하는 주변 객체가 많이 존재하는 도심부 환경에서 자율주행차 안전성 평가에 실질적으로 적용될 수 있는 시나리오를 개발하고자 실질적인 변수값을 포함하고 있는 구체적인 시나리오를 제시하였다.
본 연구는 실제 수집한 자차 및 주변 차량 데이터 중 3D-LiDAR PCD를 활용하여 운동학적 데이터(거리, 속도, 가속도)를 추출하고, 이를 기반으로 사고유발 차량을 탐지하여 보다 상세한 값을 제공하는 도심부 시나리오를 제시하는 것에 차별성을 가진다.
자율주행차 도심부 사고 시나리오 생성 방법론
Figure 2과 같이, 3D-LiDAR PCD 기반 운동학적 속성을 활용한 자율주행차 안전성 평가 시나리오 생성을 위한 전체적인 프레임워크는 4가지로 구성된다.
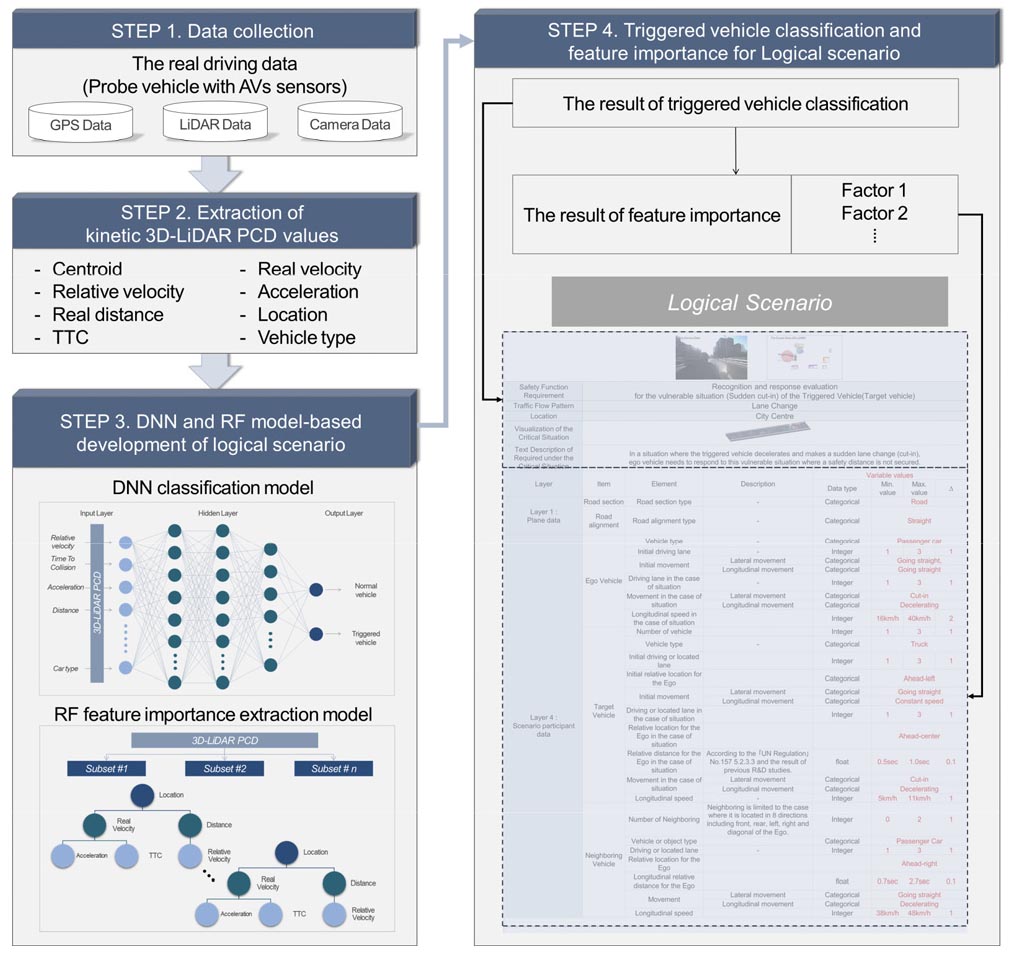
1. 자율주행차 센서 탑재 프로브 차량을 통한 데이터 수집
2. 3D-LiDAR PCD를 활용한 점들의 운동학적 속성 추출
3. 사고 유발 객체 검출을 위한 심층인공신경망 활용 및 변수 중요도 추출을 위한 랜덤포레스트 활용
4. Step 3 기반 자율주행차 안전성 평가 변수 값 제공 범위 시나리오 제시
1. 사고 취약상황 정의
교통사고 데이터는 개인정보 등의 문제로 접근이 제한되어 있으며, 일반 주행 상황에 비해 매우 희소한 데이터이기 때문에 데이터 불균형 문제가 발생한다. 또한 이전 연구들은 교통사고 환경에 초점을 맞추어 분석하였으나, 대부분의 교통사고 데이터는 사고 이후의 데이터(Post accident)이기 때문에 사고 발생 시점의 속성을 파악하는 것에는 한계가 존재한다. 이에 따라 사고 상황이 아닌 사고로 이어질 수 있는 상황에 집중하는 연구가 제시되고 있다. Talebpour et al.(2014)는 ‘Near-crash’라는 용어를 사용하였으며, 이는 다른 차량의 비정상적인 행동이나 움직임에 대응하거나 충돌을 회피하기 위해 운전자가 대응을 할 필요가 있는 상황으로 정의하였다. Wu et al.(2018) 또한 ‘Near-crash’ 용어를 사용하였으며, 마찬가지로 운전자가 잠재적인 위협에 직면할 때 급격하게 회피하는 기동(긴급 제동 및 조향제어)을 수행하는 상황으로 정의하였다.
본 연구는 실제 교통사고가 발생하기 전에 사고로 이어질 가능성이 높은 상황에서 사고를 사전에 예방하기 위한 자율주행차 안전성 평가 시나리오를 제시하고자, 사고 취약상황을 정의하고 이에 초점을 맞추었다. 이에 따라 사고 취약상황(Critical situation)은 일반 주행상황에서 운전자가 주변 객체에 의해 회피가 필요하다 판단하여 급감속, 급제동, 정지 등의 운행행태로 변화하는 위축된 상황(Flinched)으로 정의하였다(Table 1).
Table 1.
Definition of Critical Situation Level
2. 프로브 차량 실주행 데이터 수집 및 3D-LiDAR PCD 운동학적 속성 추출
본 연구에서는 실제 자율주행차에 탑재되어 있는 센서를 프로브 차량에 탑재하여 실주행 데이터를 수집하였다(Table 2). 프로브 차량을 운전하는 운전자가 도로를 주행 중에 주변 차량 및 환경으로부터 회피해야하는 상황이 발생하면 버튼을 눌러 해당 상황을 표기하도록 설정하였다(Figure 3). 이러한 데이터는 60초의 영상으로 600 프레임으로 구성되어 있으며(10fps), 특정 회피 상황이 포함되어 있는 데이터는 300번째 프레임에 저장되어 있다.
Table 2.
The Sensor of the Probe Vehicle

본 연구에서는 수집한 실주행 데이터를 모두 스크리닝하여 데이터를 선별하는 작업을 진행하였다. 2022년 9월까지 총 8,200여개 데이터셋(4,930,000 프레임)을 수집하였으며, 취약상황 정의에 따라 프로브 차량이 주변 차량 및 환경에 영향을 받아 감속, 급제동, 정지하는 상황의 데이터를 선별하여 추출하였다(Table 3). 카메라 데이터를 통해 상황을 확인한 결과, 프로브 차량이 감속하는 상황은 대부분 주변 차량이 계속하여 프로브 차량 주행 차로 위로 컷인하거나 컷 아웃하는 상황이었으며, 급제동 및 정지 상황은 교통량이 많은 상황에서 프로브 차량 주행 차로 위로 급작스럽게 컷인하는 상황으로 확인되었다.
Table 3.
The Collected Dataset and Composition
| Driving Behavior | Data (%) |
| Constant Speed | 7,670 (92.54%) |
| Decelerating | 483 (5.83%) |
| Sudden Brake | 72 (0.86%) |
| Stopped | 63 (0.76%) |
| Total | 8,288 (100%) |
취약상황 데이터를 기반으로 운동학적 속성을 추출하기 위해 연구 설계 시, 점들의 개별적 속성에 집중하고자 t 프레임과 다음 프레임(t+1) 간의 점의 위치를 벡터화하고자 하였으나, 프로브 차량에 탑재되어있는 LiDAR 센서는 회전하며 빛을 쏘는 형태로 프레임 간 점들이 일대일 대응하지 않는 것으로 확인되었다. 이에 따라 개별적인 점들을 전처리를 하지 않을 경우, 유의미한 속성을 파악하는 것에 한계가 존재하였다. 이에 따라 물체로 추정되는 점들을 클러스터링하여 프로브 차량 주변 객체로 인식하여 해당 객체의 운동학적 속성을 추출하고자 하였다. 주변 객체의 운동학적 속성을 추출하는 단계는 Figure 4과 같이 3단계로 구분된다.
1. 불필요한 연산 및 정확한 클러스터링을 위한 3D-LiDAR PCD 관찰 공간 설정
2. 정확한 클러스터링 및 운동학적 속성 추출을 위한 Plan Segmentation
3. 프로브 차량 주변 객체를 클러스터링을 통한 객체의 운동학적 속성 추출
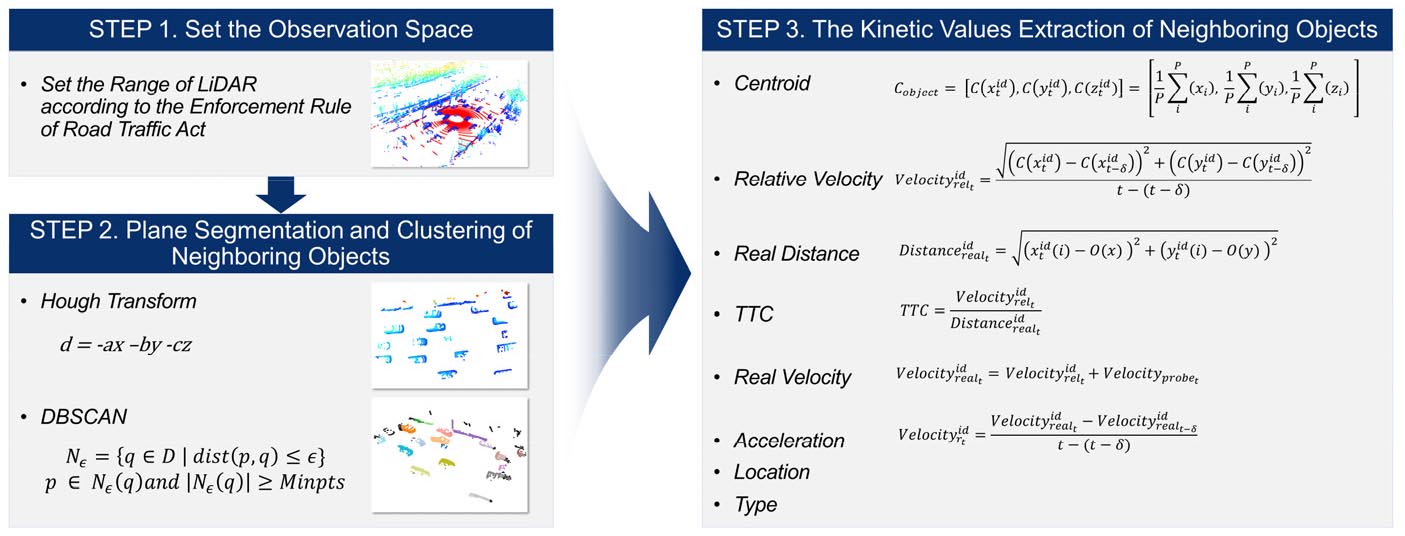
도로교통법 시행규칙 제 15조에 따르면 차로의 폭원은 최소 2.75m, 최대 3.5m로 규정되어있어, 본 연구에서는 차로 변경 등 다양한 도로 상황을 고려하여 한 차로 당 4.0m로 가정하여 범위를 설정하였다. 이에 따라 프로브 차량의 주행차로와 각 양쪽 2차로를 포함할 수 있도록 원점을 기준으로 20m를 관찰공간으로 설정하였으며(5차로), 도심도로 환경은 고속환경이 아니므로 전후방 범위 또한 20m의 범위로 제한하였다(40m × 40m).
LiDAR는 프로브 차량 주변 객체의 점들을 수집하기 때문에 원하는 객체만 정확히 클러스터링하는 것은 한계가 존재한다. 이에 본 연구는 클러스터링 오차를 최소화하기 위해 차량이 주행하는 도로 지면에서 나오는 점들을 제거하고자 Plane Segmentation(이하 PS)을 진행하였다. PS 기법은 3D PCD를 분석하여 데이터의 의미있는 평면으로 분리하는 과정으로 도로, 건물, 지면 등 원하지 않는 평면을 제거하여 관심 대상에 집중할 때 효과적으로 활용될 수 있다. 본 연구에서는 PS 기법 중 평면을 찾는 것에 효과적인 Hough Transform 기법을 활용하였다. 각 점 P(x, y, z)와 해당 점의 법선 벡터 N(a, b, c)를 사용하여 Hough 공간에서 평면의 매개변수 (d)를 계산하고 누적시켜 해당 평면을 찾고 해당 평면 속에 해당하는 포인트들을 제거한다(Equation 1).
여기서,
공간 D의 평면을 의 형태로 표현할 때,
: 평면의 매개변수
: 평면의 법선 벡터
: 원점으로부터 평면까지의 거리
도로 지면의 점들을 제거하고 대상 객체를 클러스터링하기 위해 DBSCAN(Density-Based Spatial Clustering of Applications with Noise) 기법을 활용하였다. DBSCAN 기법은 밀도 기반의 공간 클러스터링 알고리즘으로 데이터 점들 간의 거리와 밀도를 기반으로 클러스터를 찾는 기법이다. DBSCAN은 노이즈를 효과적으로 구분할 수 있으며 클러스터의 모양과 개수에 상관없이 작동하는 장점이 존재한다. DBSCAN은 클러스터를 결정하기 위해 Equation 2와 같이 최소거리 (eps)가 결정 기준으로 작용하고 클러스터를 구성하기 위해 클러스터 내 점의 개수는 Equation 3과 같이 필요한 최소 개수(Minpts) 이상 존재하여야 한다. 본 연구에서 활용하는 3D-LiDAR의 경우 주변 유사한 객체들을 클러스터하고, 대부분 클러스터 되는 점들의 밀도가 유사하여 객체들을 분류하는 것에 적합할 것으로 판단하였다(Ester et al., 1996).
여기서,
: 포인트 p의 (Neighborhood)
: 데이터 집합
: (Neighborhood)에 포함된 포인트 개수
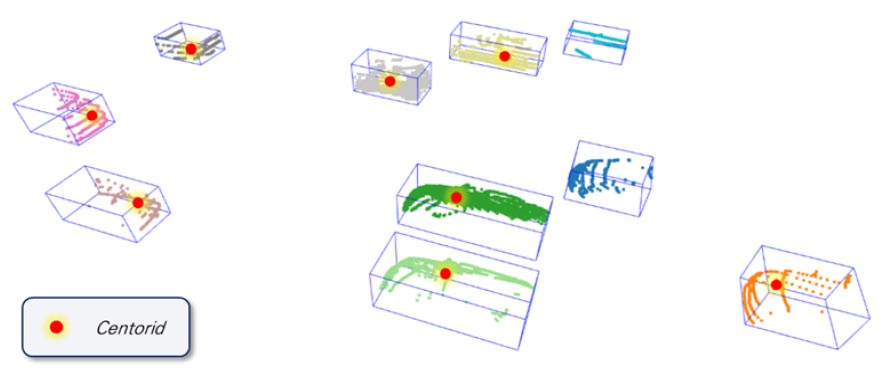
운동학적 속성을 추출하기 위해 클러스터링된 객체들을 구성하는 점들을 대표할 수 있는 대푯값으로 무게중심(Centroid, Center of Gravity)을 활용하였다. 무게중심을 활용하여 추출한 운동학적 속성은 사고 요인분석 연구 등에서 요인으로 고려되는 차량 간 거리, 상대 속도, 실제 속도, 가속도, TTC(Time-to-Collision), 차량 위치, 차종으로 선정하였다.
해당 객체를 대표할 수 있는 무게중심은 Equation 4를 통해 계산하였다(Figure 5).
여기서,
: Ego vehicle 주변 객체
: 프레임(상황)
: t 프레임 내 해당 객체(id)를 구성하는 점(x, y, z) 좌표값
: t 프레임 내 해당 객체(id)의 무게중심
: 해당 객체의 모든 점의 개수
무게중심을 활용하여 객체의 상대속도를 추출하였다. LiDAR 센서가 프로브차량 중앙루프에 탑재되어있어 객체의 상대속도는 LiDAR 데이터에서의 객체 속도이다. 이를 위해 t 프레임에서 해당 객체의 위치와 이전 프레임()에서 객체의 위치를 통해 상대 거리를 계산하였으며 z값은 무시하였다. 계산된 상대거리는 절댓값으로 계산되므로 운행 방향에 따라 부호를 고려해야하며, 상대 속도는 상대 거리와 프레임 간격(시간)을 통해 계산하였다(Equation 5).
여기서,
: t 프레임에서의 해당 객체 상대 속도
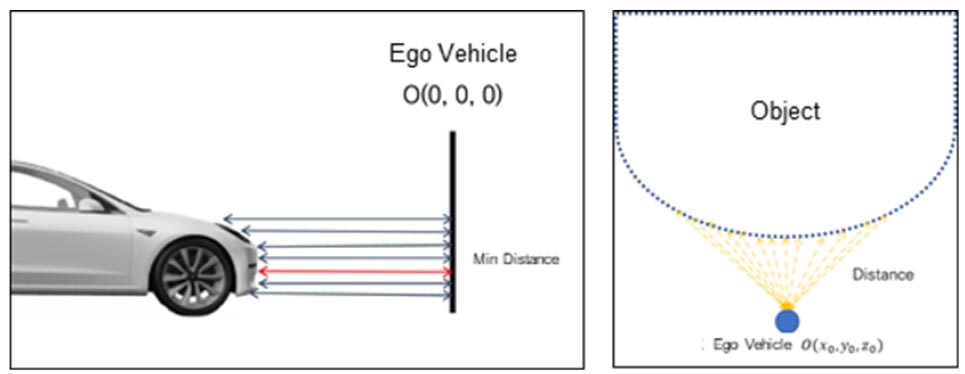
차량 간 실제 거리를 추출하기 위해 프로브 차량의 위치와 해당 객체의 거리를 계산하였다(Equation 6). 무게중심이 객체들을 대표하는 점이지만, 실제 거리를 산정하기 위해서 무게중심이 아닌 실제 차량의 제원을 고려하였다. 이에 따라, 본 연구에서는 차량에서 튀어나온 범퍼 부분을 고려하여 프로브 차량과 해당 객체가 지닌 점 간의 최단 거리를 실제 거리로 산정하였다. 이를 위해 z좌표(차량 높이)가 LiDAR가 탑재되어있는 중앙 루프보다 낮은 값부터 계산하였다(Figure 6).
여기서,
: t 프레임에서의 해당 객체와 프로브 차량 간 실제 거리
: t 프레임 내 해당 객체(id)를 구성하는 점
: 프로브 차량 위치(Origin)
TTC는 운행 차량이 주변 차량과 충돌하는 시간을 의미하며(Kiefer et al., 2006), 충돌 위험 또는 현재 상황이 계속될 경우 충돌 전까지 시간을 측정한다. TTC는 차량 간 거리를 상대속도로 나눈 값으로 정의되며, 교통사고 유발 차량을 감지하기 위해 TTC를 고려할 필요가 있다. 이에 따라 앞서 구한 상대속도(Equation 5)와 실제 차량 간 거리(Equation 6)를 활용하여 TTC를 계산하였다(Equation 7).
상대 속도와 함께 주변 차량의 실제 주행 속도를 계산하기 위해 LiDAR 데이터와 함께 수집되는 프로브 차량의 GPS를 활용하였다. 프로브 차량이 주행 중일 때, 주변 객체의 실제 속도는 프로브 차량의 실제속도에 상대속도(방향 포함)를 더한 값으로 계산할 수 있다(Equation 8).
여기서,
: 해당 객체의 실제 속도
: 해당 객체의 상대 속도(Equation 5)
: 프로브 차량의 실제 속도(GPS)
실제 속도를 기반으로 해당 객체의 가속도를 계산하였다(Equation 9). 가속도 계산을 위해 t 프레임에서 해당 객체의 실제 속도와 이전 프레임()에서 객체의 실제 속도를 통해 해당 객체의 가속도를 계산하였다.
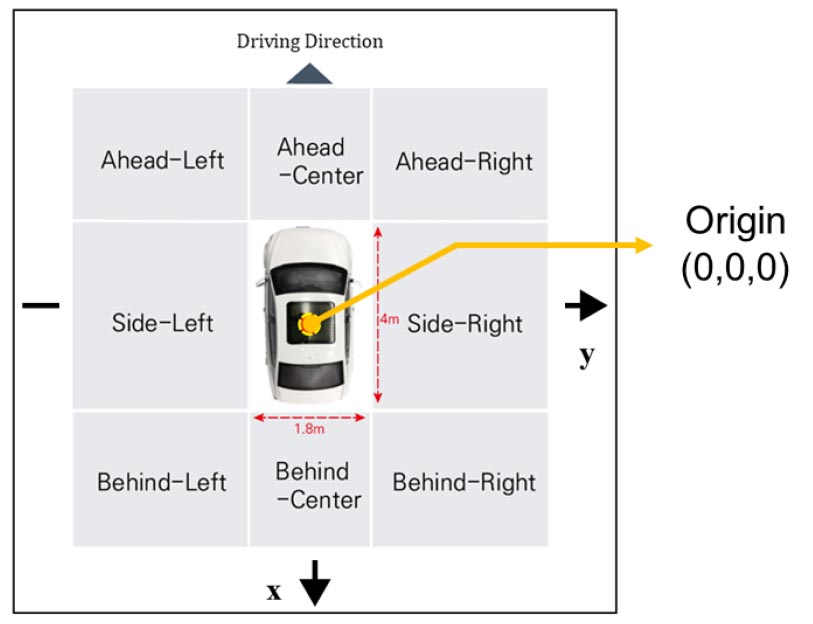
사고 예방하기 위한 ADAS의 기술은 주변 객체의 위치를 필수적으로 식별할 필요가 있다(Hussain et al., 2018). 이에 따라 주변 객체의 위치 속성을 추출하고자 프로브 차량을 기준으로 객체의 무게중심을 활용하였다. 프로브 차량의 규격이 폭 1.5m-2.0m, 전장이 3.5m-5.0m임을 감안하여 폭을 1.8m, 전장을 4.0m로 가정하였다. 프로브 차량을 기준으로 객체의 중심점이 프로브 차량보다 앞에 있을 경우 Ahead 등으로 구분하여, 총 8가지의 위치로 제시하였다. 예를 들어 해당 객체의 무게중심의 좌표가(-5, 3, 1)일 경우, Figure 7에 따라 Ahead-Right로 판단할 수 있다.
또한, 운동학적 속성과 더불어 교통사고와 차종의 상관관계를 고려하여(Bumrungsup and Kanitpong, 2022), 군집화된 각 객체의 형태를 식별하여 차종을 추가적으로 확인하였다(Figure 8). 활용하는 데이터에서 확인된 차량의 형태로는 승용차(Figure 7-Left), 버스(Figure 7-Mid), 화물차(Figure 7-Right)가 존재한다.

추출한 운동학적 속성을 종합하여 인공지능 학습을 위한 입력 데이터는 Table 4와 같다. 범주형 데이터의 경우 one-hot 인코딩을 진행하였으며, 실제 속도 계산을 위해 생성한 상대 속도의 실제 값을 입력 데이터로 사용하는 것이 아닌 상대 속도의 절댓값과 부호로 구분하여 입력 데이터로 활용하였다. 또한 주행 상황에서 대부분 사고유발차량 뿐만 아닌 다른 객체들이 다양하게 존재하므로 앞서 산정한 범위 내 객체를 모두 확인하였으며, 데이터 수집 시 해당 상황 및 사고유발차량을 표기해 놓은 상황설명서를 기반으로 일반차량과 사고유발차량을 라벨링하여 학습을 진행하였다.
Table 4.
The Input Dataset of Preprocessed Kinetic 3D-LiDAR PCD Set for Learning and Sample
3. 사고 유발 물체 검출 및 변수 중요도 추출 모델
본 연구에서는 운동학적 요소를 학습시켜 사고유발차량을 추출하고, 운동학적 요소 중 큰 영향력을 가진 요소를 추출하여 시나리오를 수립하고자 DNN(Deep Neural Network) 모델과 RF(Random Forest) 모델을 활용하였다. DNN 모델은 여러 개의 은닉층(Hidden layer)을 포함한 인공신경망(Artificial Neural Network, ANN) 구조를 가진 알고리즘이다. 기본적인 구조는 입력층(Input layer), 은닉층, 출력층(Output layer)으로 이루어져 있으며, 각 층은 여러 개의 뉴런(Neuron)으로 구성된다. 입력층은 입력 데이터를 받아들이고, 출력층은 최종 예측값을 출력하며, 은닉층은 입력 데이터에서 복잡한 특징(feature)을 추출하고, 이를 토대로 최종 예측값을 결정한다. DNN 모델은 기본적인 요소들을 계층적으로 구성하고, 상위 층에서는 하위 층들의 특성들을 수렴시킴으로써 복잡한 비선형 관계들을 모델링할 수 있다. 또한 입력 변수들 간의 비선형적인 결합은 연속형 또는 범주형 변수에 관계없이 쉽게 분석할 수 있으며, 자동 특징 추출 기능을 통해 변수 선택에 대한 고려사항을 최소화할 수 있다(Kang et al., 2020).
RF 모델은 의사결정나무(Decision Tree)를 여러개 모아 결합한 앙상블(Ensemble) 학습 모델이다(Breiman, 2001). 랜덤 포레스트는 각 의사결정나무 모델이 학습 데이터의 일부를 무작위로 선택하여, 서로 다른 하위 데이터셋(subset)을 이용해 학습한다. 이는 각각의 의사결정나무들이 서로 다른 특징(feature)들을 고려하여 모델링을 수행하게 되므로, 전체 모델의 예측 성능이 향상될 수 있다. RF 모델은 모델의 예측 결과를 결합하여 최종 예측값을 도출하며, 이 때, 각 의사결정나무의 예측값에 가중치를 부여하거나 다수결 방식으로 예측값을 결정할 수 있다. RF 모델은 다양한 종류의 데이터에 대해서 높은 성능을 보이며, 모델 학습 시간도 짧아서 대용량 데이터에도 적합한 장점이 존재한다. 또한, 변수의 중요도를 계산하여 모델 학습에 사용된 변수들의 영향력을 파악할 수 있으며, Mean Decrease Impurity(MDI), Mean Decrease Accuracy, Permutation Importance 등의 변수 중요도 방식이 존재한다. 그 중 Permutation Importance 기법은 각 변수를 무작위로 섞어서 모델을 재학습하고, 이를 토대로 나머지 데이터셋을 예측하는 방식이다. 이는 각 변수가 모델의 성능 개선에 얼마나 기여하는지를 측정할 수 있으며, 변수가 해당 모델에 어느 정도의 영향을 미치는지 확인할 수 있다.
본 연구에서는 추출한 주변 객체들의 운동학적 속성을 활용하여 DNN 모델학습 및 RF 모델학습을 통해 사고유발차량을 검출하고, 사고유발차량 검출에 중요하게 활용되는 변수의 중요도를 파악하여 자율주행차 안전성 평가 시나리오를 제시하고자 한다. 특히, 단순 functional 시나리오를 제시하는 것을 넘어 거리, 속도, 가속도를 파악하여 logical 시나리오를 제시하고자 한다.
분석 결과
본 연구에서 활용한 DNN 모델은 역전파 알고리즘(Rumelhart et al., 1986)과 SGD(Stochastic Gradient Descent)를 기반으로 사고 유발 차량 모델을 학습시켰다. 학습 및 테스트 데이터의 비율은 8:2로 설정하였으며, Sigmoid 함수(Bridle,1990)를 사용할 때 기울기 소실을 방지하기 위해 ReLU(Rectified Linear Unit) 함수(Nair and Hinton, 2010)를 사용하였다. 안정적인 학습을 위해 배치 크기는 64로 설정하였으며 과적합을 최소화하기 위해, 검증 데이터의 정확도가 100 epoch 이내에 수렴하는 지점에서 Early stopping을 설정하였다. 또한, DNN 모델은 사용 데이터, 은닉 층의 수, 은닉 층 유닛 개수에 따라 상이하기 때문에 본 연구에서는 최적의 모델을 선정하고자 다양하게 변형하여 학습을 진행하였다.
DNN 모델 및 RF 모델의 평가를 위해 4가지 지표를 사용하였으며, 이를 기반으로 혼동행렬을 제시하고 테스트 데이터 샘플을 확인하였다; Accuracy(Equation 9), (2) Precision(Equation 10), Recall(Equation 11), f1-score(Equation 12). True Positive(TP)은 모델이 positive 클래스를 정확하게 예측한 결과이며, True Negative(TN)은 모델이 negative 클래스를 정확하게 예측한 결과이다. False Positive(FP)은 모델이 positive 클래스를 잘못 예측한 결과이며, False Negative(FN)은 모델이 negative 클래스를 잘못 예측한 결과이다.
1. 심층 인공 신경망 학습 및 결과
실험적으로 은닉층 및 해당 unit 수를(128, 64, 32)로 설정했을 때 가장 높은 예측 성능을 확인하였으며, 다른 은닉층 및 유닛 설정은 93-95%의 정확도가 확인되었다. Kang et al.(2020)은 DNN을 사용하여 교통 사고 가해자와 피해자의 심각도를 예측하고 최대 85%의 정확도를 도출하였다. Yu et al.(2020)은 CNN-LSTM을 사용하여 고위험, 비충돌 상황을 예측하고 78%의 Recall을 보였으며, Yuan et al.(2020)은 ANN을 사용하여 사고 시나리오를 예측하고 해당 시나리오 발생 확률을 82.4%의 정확도로 예측했다. 본 연구와 같이 사고 유발 차량을 분류/예측하는 연구는 확인되지 않았으나 유사한 사고 상황에서 분류 연구 결과, 운동학적 3D-LiDAR PCD를 사용할 경우 보다 정확한 예측이 가능함을 확인할 수 있다.
가장 높은 정확도를 나타낸 모델의 혼동 행렬 확인 결과(Table 5), 사고 유발 차량은 81.4%의 정확도로 분류될 수 있으며 사고와 무관한 차량은 98.5%의 정확도로 분류될 수 있음을 확인하였다. 또한, 사고유발차량이 아닌 것으로 오인한 FN이 사고유발차량으로 오인한 FP보다 많은 것으로 나타나 이를 추가적으로 분석하기 위해 정상적인 분류 상황(TP와 TN)과 비정상적인 분류 상황(FP와 FN)에 해당하는 데이터를 검토하였다.
Table 5.
The Result of Highest Model (128, 64, 32) and Confusion Matrix
| Metric | Highest Model Result (128, 64, 32) (%) | 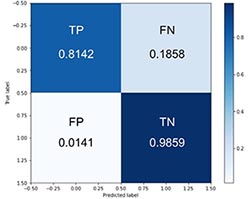 |
| Precision | 90.60 | |
| Recall | 81.41 | |
| F1-score | 85.76 | |
| Accuracy | 96.13 |
정상적으로 사고유발차량을 분류한 상황은 Figure 9과 같다. 프로브 차량이 두 번째 차선을 주행하던 중, 트럭이 첫 번째 차선에서 갑자기 차선 변경을 시도하는 상황이다. 233번째 프레임에서 프로브 차량은 48km/h의 평균 속도로 정상 주행하며, 세 번째 차선에서 주행 중인 인접 차량(normal vehicle)을 주시하고 있다. 254번째 프레임에서, 프로브 차량은 갑자기 차선 변경을 시도하는 사고 유발 차량(트럭)을 인식하였다. 트럭은 45km/h의 도로 평균 속도 상황에서 11km/h 속도로 주행하고 있으며 이에 따라 TTC가 1.0초인 상황을 유발시켰다. 260번째 프레임에서 TTC는 0.47초로 급감하였으며 이에 대응하기 위해 프로브 차량은 세 번째 차선으로 급변경을 시도하였다. 그러나, 일반적인 주행 상황에서 세 번째 차선에서 인접 차량이 주행하고 있어 프로브 차량은 2차선에 급정지하였다. 이 때, 인접 차량도 속도가 48km/h에서 39.6km/h로 감소하였으며 TTC는 2.7에서 0.7로 급감하여 사고를 유발할 수 있는 취약 상황이었다. 결과적으로 갑작스럽게 차선을 변경하는 트럭이 사고로 이어질 수 있는 상황을 유발하는 사고 유발 차량으로 분류되었다. 사고 유발 차량의 움직임으로 인해 프로브 차량과 인접 차량의 속도, TTC, 위치 등이 급격하게 변화되는 것을 확인할 수 있다.
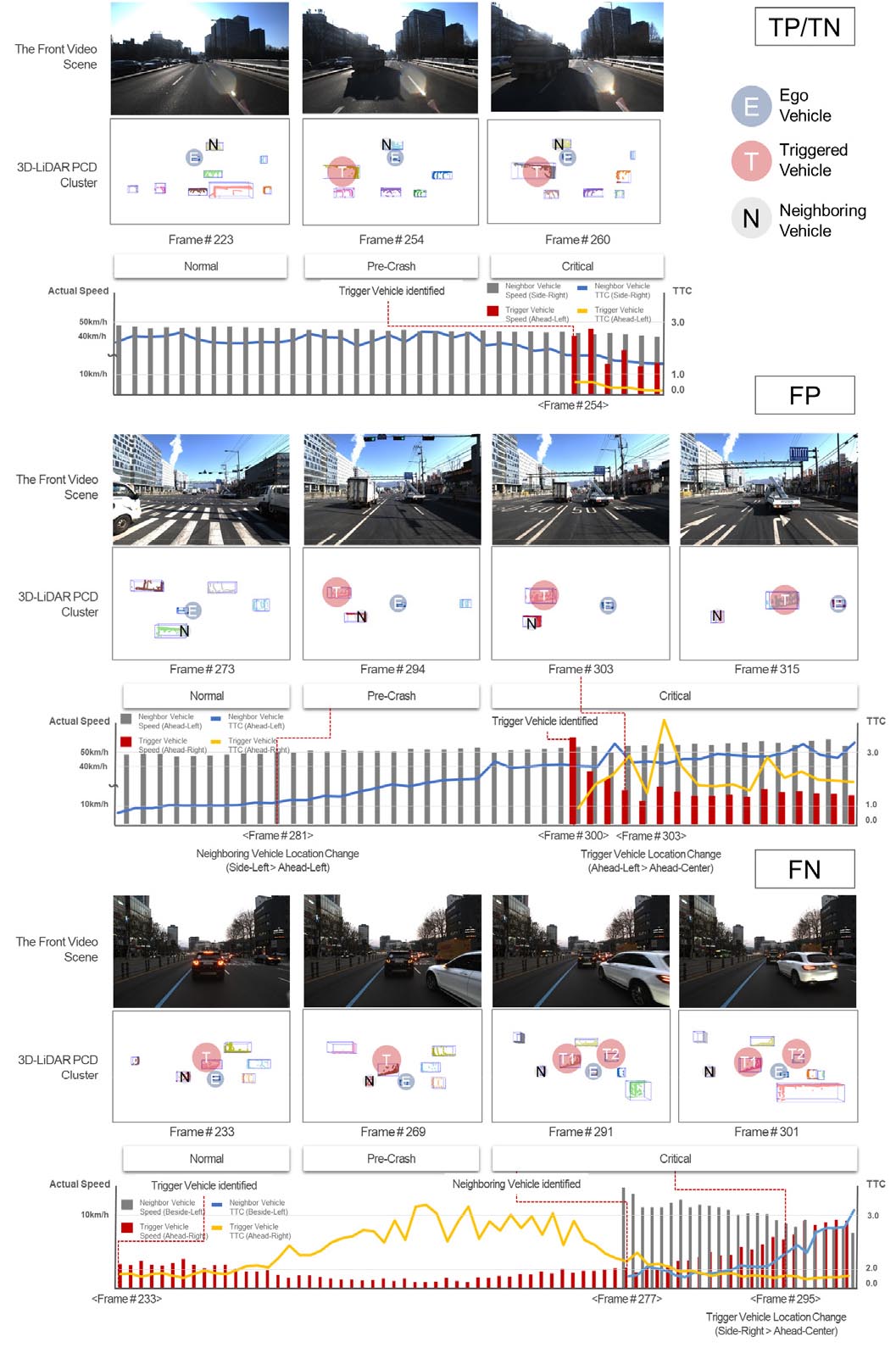
FP로 분류된 상황은 프로브차량이 정상 주행 상황(273번째 프레임)에서 좌측 인접 차량을 주시하며 45km/h의 속도로 주행하고 있다. 300번째 프레임에서 프로브 차량이 사고 유발 차량을 인식하였으며 프로브 차량 주행 차선으로 변경하였다. 303번째 프레임에서 사고 유발 차량의 속도가 65km/h에서 25km/h로 급감하였으나 TTC는 1.1에서 2.0으로 증가하고 위치는 Ahead-left에서 Ahead-center로 변경되었다. 이처럼 속도가 급격히 감소하고 TTC가 증가하면서 빠르게 위치 변경을 완료한 경우, 모델은 취약한 상황에서 사고 유발 차량을 일반 차량을 혼동한 것으로 나타났다.
FN로 분류된 상황은 233번째 프레임에서 첫 번째 사고 유발 차량(1st)이 우측 인접 차량으로 인식되었고, 2.7km/h 및 TTC 2.8 상황에서 차선 변경을 시도하고 있었다. 277번째 프레임에서 인접 차량은 11km/h 및 TTC 1.6초 상황에서 차선을 변경하는 것이 확인되었으며, 모델은 이를 두 번째 사고 유발차량으로 판단하였다. 296번째 프레임에서 첫 번 째 사고 유발차량의 위치가 Right에서 Ahead-center로 이동하였으며, 해당 상황은 301번째 프레임에서 7.5km/h 및 TTC 2.5초에서 종료되었다. 이는 빠른 속도와 낮은 TTC를 가진 주변 인접차량 또한 추가적인 사고유발 차량으로 인식될 수 있음을 의미하며, 이는 인간이 고려하지 못한 객체를 AI의 활용을 통해 확인할 수 있음을 의미한다.
2. 랜덤 포레스트 학습 및 결과
RF 모델을 사용하여 사고 유발 차량 검출을 수행한 결과, 전반적인 측정치 DNN 모델과 유사한 것으로 나타났다. 전체적인 지표에서 약 1-2%정도 차이가 존재하나 84%의 F1-score 및 95%의 정확도가 확인되었다(Table 6). 유사한 사고 상황 분류 연구 결과, Gao et al.(2018)은 운동학적 변수를 사용하여 RF 모델의 사고 위험 상황을 분류하였으며 76%의 Recall 값을 보였다. Gao의 경우 단순 속도, 가속도에 집중한 입력 데이터를 활용하여 그 외 변수를 고려하지 않은 차이로 본 연구에서의 결과값이 5% 정도 높은 것으로 나타났다. 본 연구와 같이 사고 유발차량을 분류/예측하는 연구는 확인되지 않았으나, 유사한 사고 상황 분류 연구와 같이 운동학적 속성 중 속도와 가속도 뿐만 아니라 거리, 상대 속도, TTC 등 그 외 운동학적 속성이 결과에 영향을 미치는 요인일 수 있음을 의미하며, 해당 데이터에서 DNN 성능 대비 RF 모델 성능이 떨어지지 않음을 확인하였다.
Table 6.
The Accuracy of Random Forest Model
| Metric | Result (%) |
| Precision | 91.19 |
| Recall | 78.37 |
| F1-score | 84.12 |
| Accuracy | 95.24 |
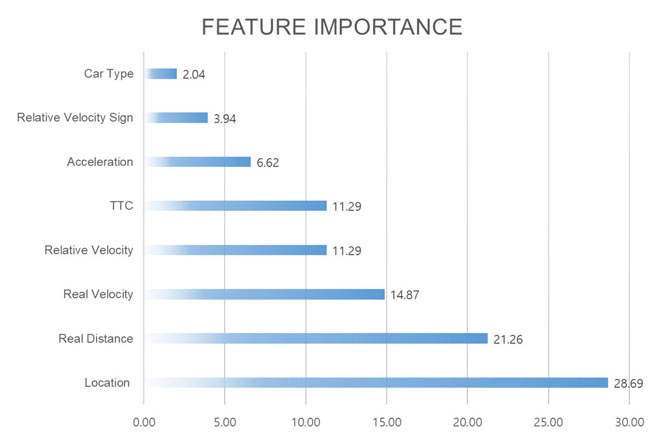
추가적으로 RF 모델 결과를 통해 가장 영향력 있는 요소를 Feature Impotrance 기법(이하 FI)을 활용하여 추출하였다(Figure 10). 사고 유발 차량을 분류하는 것에 가장 중요한 요소는 Location(차량 위치), Real Distance(실제 거리), Real/Relative Velocity(실제, 상대 속도), TTC로 확인되었다. 특히, 사고 유발 차량의 상대적 위치 요소 중요도가 30%에 근접하였다. 이는 주변 차량의 주행 행동을 예측할 때 활용되는 기준으로 작용하며, 이를 통해 차량의 행태 및 경로를 예측할 수 있기 때문으로 판단된다(Mozaffari et al., 2020; Hubmann et al., 2017). 차량 간의 상호작용이 발생하는 범위는 주변 차량의 위치에 따라 변화하며, 차량 간의 거리, 속도 등이 이어지는 매개변수로 나타난다. 이는 주변 차량의 주행 행태에 따라 실시간으로 변화하는 지표이기 때문에 안전성 평가에 필수적으로 제시될 필요가 있다.
자율주행차 도심부 시나리오 생성 및 토의
1. Logical 시나리오 생성
DNN 및 RF 모델 결과에서 확인된 TP 샘플 및 FI 결과를 토대로 logical 시나리오를 생성하였으며, 다음과 같은 과정을 따른다.
1. 사고유발차량으로 잘 분류된 TP 및 TN 차량이 존재하는 사고취약상황을 선정한다.
2. FI 결과를 확인하고 해당 속성값 logical 시나리오 요소로 활용한다.
3. 실제 데이터에서 선정된 시나리오 요소를 추출하여 시나리오를 작성한다.
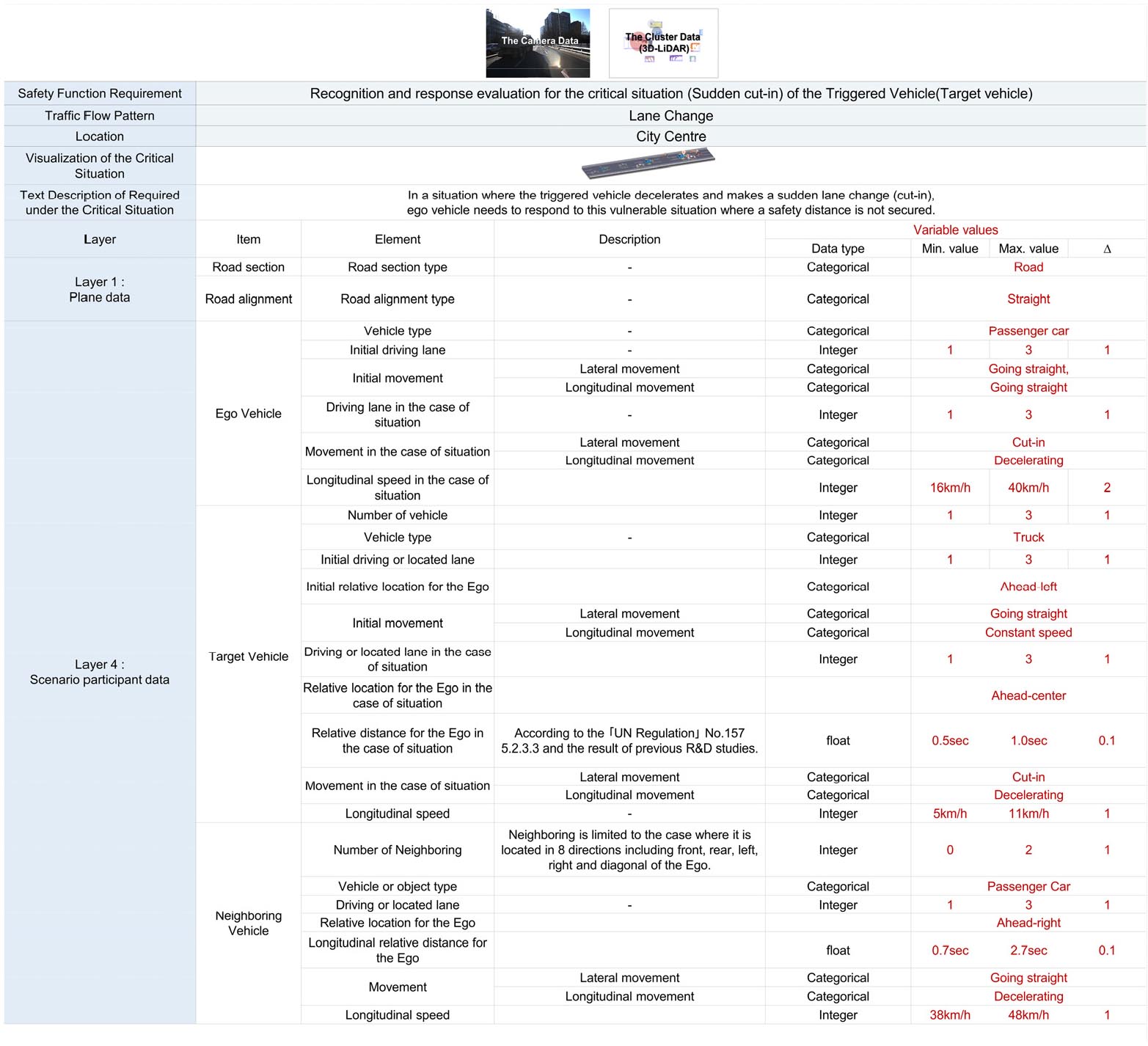
본 연구에서는 차량 간 상호작용이 가장 활발하게 발생하고 사고로 이어질 수 있는 cut-in 상황을 선정하였으며, 이는 앞서 확인한 TP/TN 샘플로 이를 통해 logical 시나리오를 생성하였다. FI 확인 결과, 위치, 거리, 속도, TTC가 가장 중요한 요소로 확인되었으며 이를 logical 시나리오에 필수적으로 포함하였다. Logical 시나리오는 PEGASUS 프로젝트에서 제시한 바와 같이 여섯 개의 레이어로 구성되어 있으며, 특히 레이어 4인 시나리오 참여자 데이터에는 목표 차량, 대상차량(사고유발차량), 인접차량이 핵심 요소로 위치해있다. 이는 차량 유형, 초기 주행 차선 위치 및 취약 상황에서의 움직임, 속도 등과 같은 세부정보를 지정해주어야 하며, 해당 요소의 범위값을 표시해야 한다(Ko et al., 2022).
시나리오 해당 상황 및 범위 값에 대한 추출은 다음과 같다 : 자율주행차가 2차선을 주행 중일 때, 1차선으로 갑자기 사고 유발 차량(트럭)이 cut-in을 시도하였다. 갑작스러운 cut-in에 대응하기 위해 자율주행차는 3차선으로 방향을 전환하고 차선을 변경하려 했으나, 3차선에서 지나가는 근접 차량으로 인해 급정지하였다. 자율주행차는 40km/h로 주행하고 있었으며 트럭이 갑자기 cut-in을 시도하는 것을 인식하고 속도를 16km/h로 낮추었다. 이때 트럭은 5-11km/h 속도로 주행하고 있었으며, 자율주행차와의 거리는 최대 9m, 최소 5m였다. 자율주행차 순간적인 차선변경 상황에서의 주변 차량은 45km/h의 평균 속도로 주행하다 38km/h로 속도를 줄여 지나갔으며, 자율주행차는 그 자리에 정지하였다. 해당 상황의 자율주행차 안전성 평가를 위한 logical 시나리오는 Figure 11과 같이 제시할 수 있다.
2. 토의
자율주행차 도입을 위해 안전성 평가 시나리오 연구와 프로젝트가 진행되고 있다. 기존 시나리오 연구는 사고 후 데이터를 기반으로 전문가들이 개입하여 빠르게 카탈로그를 확보할 수 있으나 대표성이 부족하며, 예측할 수 없는 무수한 시나리오를 몇 명의 전문가로 보완하기 어렵다는 한계가 존재하였다(Kang et al., 2022c; Erdogan et al., 2019). 이에 따라, AI 기술을 도입하여 실제 운전 데이터를 기반으로 대표성을 확보하고 무수한 시나리오를 생성하기 위한 연구가 이어지고 있다(Jenkins et al., 2018). 이러한 추세를 따라, 본 연구에서는 AI 기법을 활용하여 실주행 3D-LiDAR PCD를 확보하고, 운동학적 변수를 추출하여 logical 시나리오를 제시하여 실질적인 값을 제시하였다. 그러나 AI의 도입으로 특정 영역을 설명할 수 없는 블랙박스 문제가 발생하는 등 설명 가능성에 대한 결점이 여전히 존재하며, 이는 신뢰성과 이어질 수 있어 필수적으로 보완이 요구된다. 이에 따라, XAI(eXplainable Artificial Intelligence)를 활용하여 설명력을 보완할 수 있는 시나리오 작성 방안을 고려해야 할 필요가 있으므로 사항이 충족되어야 한다.
1. 실제 주행 데이터(3D-LiDAR PCD)를 활용하여 신뢰성과 구체성 확보
2. AI 도입을 통한 무수한 시나리오 생성
3. XAI 도입을 통한 설명 가능성 확보
본 연구에서는 이러한 요구사항을 충족시키기 위해 두 조건을 고려하였으나, 설명 가능성을 확보하지 못해 추가적인 방법론을 고려하였다. 추가 연구에서는 사용한 학습 모델 및 데이터에 대한 설명력을 확보하기 위해 XAI 연구에서 활발하게 사용되는 LIME(Local Interpretable Model-agnostic Explanations, Ribeiro et al., 2016) 및 SHAP(Shapley Additive exPlanations, Lundberg and Lee, 2017) 알고리즘 등을 도입할 필요가 있다. XAI를 도입할 경우, 본 연구에서 활용한 FI 방법을 넘어 데이터 속성이 미치는 음/양의 영향(Negative and positive impact)을 확인할 수 있으며 데이터 속성 간의 상관관계를 보다 자세하게 설명할 수 있어 기존 인공지능 연구에서 결여된 시나리오의 설명가능성을 보장할 수 있을 것으로 기대된다.
결론 및 향후 연구
본 연구는 사고 취약 상황을 유발하는 차량을 분류하고 자율주행차 안전성 평가를 위한 logical 시나리오를 제시하였다. 3D-LiDAR PCD를 활용하여 단순 프로브 차량의 속성만을 추출하지 않고, 주변 차량의 운동학적 속성을 추출하여 활용하였다. 운동학적 속성을 입력 데이터로 활용하여 DNN 및 RF 모델에 적용하였으며, 학습 결과를 토대로 logical 시나리오의 중요 변수를 제시하고 이에 대한 실질적인 범위 값을 제시하였다.
이에 따라 본 논문의 주요 기여점은 다음과 같다. 첫째, 3D-LiDAR PCD 및 운동학적 데이터 추출의 중요성을 파악하였다. 기존 사고 관련 연구에서는 주변 환경에서 중요한 요인을 추출하고 결과를 제시하였으나, 교통사고는 차량 간 상호작용의 부정적인 결과이기 때문에 차량 자체를 고려하는 것이 필수적이다. 이에 따라 자차뿐만 아니라 주변 차량의 속성도 추가적으로 활용할 수 있어야 한다. 따라서, LiDAR의 개별적인 점에 초점을 맞추어 운동학적 속성을 추출하는 것이 중요하다. 둘째, 실제 주행 데이터에 기반한 logical 시나리오를 제시하였다. 시나리오란 고차원적이며 명확한 평가를 요하는 상황을 전달하기 위한 것으로, 추상도가 높은 functional 시나리오는 구체적이지 않기 때문에 실질적인 안전성 평가에 중요한 역할을 하지 않는다. 이에 따라 자율주행차 상용화를 위해서는 신뢰성과 구체적인 요소 값이 포함된 logical 시나리오로 필수적으로 제시해야한다. 이전 AI 기반 시나리오 연구 대부분은 단순히 functional 시나리오만 제시하거나, 시나리오 제시를 위한 간단한 프레임워크만을 제시한 경우가 대부분이다. 따라서 본 연구는 실주행 데이터와 AI를 활용하여 실제값을 제시한 logical 시나리오를 제시한 것에 의의가 있다.
반면, 본 연구에서 고려하지 못한 것은 활용한 실주행 데이터 자체가 자율주행차 센서를 탑재한 ‘일반차량’ 데이터라는 것이다. 현재 자율주행차 실운행 데이터의 접근성은 매우 제한되어 있어 캘리포니아 차량관리국(CA DMV)에서 제공되는 자율주행차 사고 보고서에 한정된다. 이를 활용한 연구가 다양하게 진행되고는 있으나, 현재 데이터의 개수가 충분하지 못한 한계가 존재하여 본 연구에서는 해당 데이터를 사용하지 않았다. 향후 자율주행차 운행 데이터를 확보하여 본 연구의 흐름과 동일하게 진행하여 본 연구 결과와 비교할 수 있을 것으로 판단된다. 더불어 토의에서 제시한 바와 같이, 자율주행차의 신뢰성 향상 및 수용성 증진을 위해서는 시나리오를 통한 안전성 확보가 필수적으로 요구되지만, 시나리오 그 자체의 신뢰성 이슈가 존재할 수 있으므로 이를 자세하게 설명할 수 있는 설명가능한 인공지능을 추가적으로 도입할 필요가 있다. 향후 연구에서는 SHAP 방법론을 도입하여 logical 시나리오를 넘어 구체적인 변수값을 지정할 수 있는 concrete 시나리오를 제시하고자 할 수 있을 것으로 기대된다.
본 연구에 기반하여 향후 연구로 logical 시나리오 생성 연구들의 방법론 및 프레임워크를 비교분석할 수 있으며, 앞서 제시한 XAI 기법을 활용하여 보다 설명력 높은 시나리오를 생성하는 연구를 수행할 수 있다. 더 나아가, logical 시나리오를 넘어 특정값을 지정해야하는 concrete 시나리오를 선별하기 위해 TTC 등 KPI(Key Performence Indicator)를 설정하는 surrogate measure를 선정하는 연구를 추가적으로 수행할 수 있을 것으로 기대된다.
