

서론
수요응답형 대중교통(DRT) 서비스는 기존 버스 서비스의 비효율성을 개선할 수 있는 효율적인 대안으로 널리 인정받고 있다(Schasché and Sposato, 2021; Kim et al., 2023). DRT는 시간적으로 고정된 스케줄과 공간적으로 고정된 정류장 및 노선 운영 대신 스케줄, 정류장, 노선 등을 유연하게 운영함으로써 기존 버스 서비스의 문제점을 상당 부분 해소할 수 있다. 승객이 필요한 시간과 장소에서 필요한 만큼만 서비스를 제공하고, 최대한 빠르게 경로를 따라 이동한다. 운송 서비스 제공 업체는 불필요한 차량 운행 거리를 줄여 운행비용을 절감할 수 있다. 승객은 대기시간과 불확실성을 줄이면서 언제 어디서나 이동할 수 있어 만족도가 높아진다. 지방자치단체(지자체)는 기본적인 이동권을 보장하고 지역 교통 서비스 제공업체에 대한 보조금을 절약함으로써 주민들로부터 더 나은 평가를 받을 수 있다.
그러나 현재 운행 중인 DRT의 서비스가 완벽하지 않아 몇몇 풀어야 하는 문제들이 있다. 성공적인 DRT 운영의 핵심은 대기시간을 줄이고 우회율을 낮게 유지하여 사용자 만족도를 유지하는 것이다. 그런데 역설적이게도 승객이 너무 증가하면 대기시간과 우회율이 덩달아 증가하여, DRT의 편리함이란 특성과 충돌하는 일이 발생할 수 있다. 더 큰 문제는 이동 수요의 불균형으로 인해 이러한 불편이 서비스 지역 내에서 불균등하게 발생한다는 것이다. 도심에는 더 많은 기능이 집중되어 있기 때문에 도시의 외곽 지역보다 더 많은 이동이 발생한다. DRT 차량은 시내에서 이동 수요가 많은 지점을 더 자주 이동하기 쉽다. 이로 인해 수요가 많은 지역에서만 차량 왕복을 하는 동안 도심 외곽 지역에서 오는 승객의 호출 수요에 대응하지 못하는 일이 발생할 수 있다. 본 연구는 이러한 현상을 ‘늪 현상’으로 명명하고, 이를 완화하는 방안을 고민하고자 한다.
선행연구
1. 관련연구 고찰
DRT 서비스 관련하여 최근 많은 연구 결과가 보고되고 있다. 여기에는 DRT 개요(Schasché and Sposato, 2021; Kim et al., 2023), 성능 평가(Papanikolaoua et al., 2017; Torgal et al., 2021; Write, 2013; Smacker and Grsso, 2020), 농촌 DRT(Kirsimaa and Suik, 2020; Sorensen et al., 2021; ITF, 2021; Imhof and Blattler, 2023), 여러 종류의 DRT(Kim, 2022; Kagho et al., 2021), 시뮬레이션 중심 분석(Huang et al., 2020; Markov, 2021), DRT 이용 결정 요인(Saxena, 2020) 등 다양한 내용들이 있다. 이렇듯 DRT에 대한 연구가 활성화하는 추세는 이 신규교통서비스에 대한 수요가 전반적으로 증가하고 있음을 반영한다. 그러나 우리가 아는 한, 이상에서 논의한 서비스 지역 내의 불균등한 서비스 제공 관련 문제들은 지금까지 주목받지 못했다. 실시간 버스 라우팅, 기존 및 신규 DRT 서비스의 공동 최적화 방법, 시공간적 택시 배차 알고리즘, DRT 실패 원인 등 늪 현상과 관련된 문제를 분석한 연구 결과들(Melis and Sorensen, 2022; Zhao et al., 2023; Santani et al., 2008; Enoch et al., 2006)은 보고된 바 있다. 그러나 이러한 관련 연구들은 DRT 차량이 이동 수요가 낮은 외곽 지역의 요청을 제대로 서비스하지 못하는 근본적인 이유를 주제로 하고 있지 않다.
DRT 서비스 제공의 불균등성은, DRT 서비스의 근본적인 목적 중 하나가 이동 수요가 낮은 외곽 지역에 적정 수준의 이동 서비스를 제공하는 것이기 때문에 개선이 필요하다. 서비스 공급자의 입장에서는 서비스를 한정된 구간에 집중하는 것이 낮은 공차율 등으로 효율적일 수 있지만, 대중교통 이용자나 공공서비스 관리의 주체인 지자체로서는 보완이 필요한 측면이 있다.
2. 본 연구의 차별성
늪 현상이란 고밀도 수요 지역에서의 많은 호출로 인해 DRT 차량이 고밀도 수요 지역을 벗어나지 못해, 교통 취약지역인 저밀도 수요 지역의 호출을 수용할 수 없는 상태를 말한다. 늪에서는 DRT 차량이 일정 구간 내에서만 이동하고 해당 구간을 거의 벗어나지 못한다. 이에 따라 해당 구간 밖에 있는 지역에서 시작하거나 끝나는 이동 수요는 너무 오래 기다리거나 최단 경로에서 너무 많이 우회해야 하기 때문에 서비스를 받기가 어렵다. 이 때문에 이동 형평성 제고라는 DRT 도입의 근본적인 목적 중 하나인 기존 대중교통 대비 서비스 개선이 잘 작동하지 않을 수 있다.
늪 문제를 완화하기 위한 즉각적 해결책은 늪 내에서 발생하는 수요에 대한 서비스를 제한하는 것이다. 그러나 늪 지역의 정류장들은 DRT 사업자에게는 수익 증대 기회일 수 있어, 이러한 제한은 서비스 공급자에게 불이익을 강제할 수 있다는 점에서 논란의 여지가 있다. 이에 대해서는, 역할 분담으로 이러한 제한을 극복하는 안을 제시할 수 있다. 고정된 시간과 공간에서 상시적으로 수요가 많은 정류장 간의 이동 서비스는 일반 운송 사업자의 사업 영역에 포함시키고, 시간과 공간에서 불규칙적으로 발생하고 수요가 비교적 적은 정류장으로(부터)의 이동 서비스는 DRT의 관심사인 탄력적 운행 시간 및 노선을 갖는 등의 운영 방식을 생각할 수 있다.
배차 제한 정책이 도입되면 전체 서비스 지역에 보다 고르게 서비스를 제공하기 위해 운행이 제한되는 정류장의 집합인 ‘레드존’을 어떻게 설정해야 하는지의 문제가 중요하게 된다. 레드존에는 특정 통행 규칙이 적용된다. 레드존에서 외부로 나가거나 외부에서 레드존으로 진입하는 통행은 허용되지만, 레드존 내부의 정류장 간 통행은 금지된다. 이러한 정류장 세트를 지정하는 것은 DRT서비스를 새로운 지역에 도입하기 전이 바람직하며, 이를 통해 늪지대 외부 승객의 불만을 사전에 줄임으로써 서비스의 신뢰성을 높일 수 있다. 그런데 서비스 제공의 균등성 수준이 다른 레드존은 매우 다양하게 정의될 수 있기 때문에, 이 중 최적의 레드존을 설정하는 것은 결코 쉬운 일이 아니다.
또 다른 논란의 여지가 있는 문제는 본 연구에서 서비스 제공의 균등성을 뜻하는 ‘최적’ 레드존의 정의이다. 늪은 DRT 서비스의 불균등한 제공에서 비롯된다. 최적화가 정류장의 DRT 수요의 ‘비율’을 따라 수요가 많은 지역에 가중치를 둔다면, 최적화의 결과는 늪 문제를 오히려 심화시킬 수 있다. 본 연구는 따라서 서비스 지역 내 정류장 간의 이동 수요 분포에 관계없이 모든 버스 정류장에 동등하게 서비스를 제공하는 것으로 가정한다.
본 연구는 이동 수요 분포에 대한 정보를 바탕으로, 수요에 대응하는 차량의 이동을 추론하는 방법을 제안하고자 한다. 이를 통해 도출된 결과는 최적의 ‘레드존’ 소속 정류장을 찾아 차량 이동이 가능한 한 고르게 분산되고 ‘늪’이 약화되도록 하는 반복적인 최적 레드존 탐색에 활용할 것이다.
연구방법
이 장에서는 차량이 위치한 정류장에서 도달 가능한 이용자가 위치한 지점을 경유하여 이용자가 가고자 하는 목적지까지의 수요대응형 차량의 이동을 표현하고 최적 레드존을 검색하는 방법을 개발하고자 한다. 이를 위해 필요한 정보는 출발지-목적지 정류장 간 승객 이동 수요와 이동 시간, 차량 배차 제한 여부, 대기 중인 이용자에게 차량이 접근할 수 있는 최대 시간 등이다. 여기서, 배차 제한은 출발지와 목적지의 정류장이 모두 ‘레드존’이라 불리는 특정 구간 안에 있는 수요는 서비스에서 배제하는 것을 의미한다.
이 방법은 두 개의 연속적 작업으로 구성된다. 먼저 각 정류장에 대해 해당 정류장의 차량이 도달 가능한 출발지 정류장을 통해 목적지 정류장까지 갈 확률을 나타내는 전환행렬을 제시한다. ‘도달 가능’ 정류장이란 이용자가 위치한 출발지의 정류장이 현재 차량이 위치한 정류장으로부터 허용된 시간 범위 내에 있고, 목적지와 출발지의 정류장 중 최소 하나는 레드존 영역의 밖에 있어야 함을 의미한다. 전환행렬은 전체 이동 수요 대비 각 목적지 정류장의 이동 수요 비율을 반영하여 각 정류장에 있는 차량이 도달 가능한 출발지 정류장을 통해 목적지 정류장까지 갈 확률 행렬을 생성한다.
그런 다음 각 정류장에 차량이 나타날 확률 행렬을 정류장 확률 지도로 변환한다. 이 지도는 차량 출현 확률이 매우 높은 버스 정류장을 2D 공간에서 식별하는 데 사용된다. 전체 정류장의 차량 출현 확률에서 가장 큰 비중을 차지하는 늪 정류장의 집합을 ‘늪지대’로 정의한다. 유전자 알고리즘을 이용하여, 소속 정류장 집합이 서로 다른 여러 개의 레드존을 생성하고 정류장 간 차량 출현 확률의 차이를 최소화하는 최적의 레드존을 확인한다. 이 작업은 해당 지역에서의 DRT 서비스 출시 전에 수행할 수 있다는 점에서 의미가 크다.
1. 연구질의
Q1: 이용자의 이동 수요 분포와 정류장 간 이동 시간 비용에 대한 정보만 주어졌을 때 DRT 차량이 현재 위치에서 승객의 목적지까지 이동할 확률을 미리 계산할 수 있는가?
Q2: 정류장 간 DRT 차량 존재의 확률적 편차를 최소화하는 반복 프로세스를 사용하여 최적의 레드존을 찾을 수 있는가?
2. 전환행렬
Figure 1의 MAT은 위의 첫 번째 작업을 설명하고 있다. 레드존 정류장 RZ가 주어지면 MAT는 원래의 정류장간 이동 수요인 D를 DR로 변경하고, 서비스에서 레드존 내 이동을 제외한다. DR은 이용자의 출발지가 각 목적지에 도착할 확률이 각 출발지마다 1로 합산되는 DRN으로 변환된다. 최대 허용 대기시간 Wmax가 주어지면 MAT는 이동 시간 행렬 Z를 참조하여 차량의 현재 위치 정류장으로부터 이용자가 대기하는 출발지 정류장까지 각 차량의 가용성을 조사하여 현재 차량 위치에서 이용 가능한 경우 1을, 그렇지 않으면 0을 부여한다. 그러면 F는 현재 차량 위치에서 이용자의 출발지까지의 확률의 행 합이 1이 되는 확률 행렬인 FN으로 변환된다.
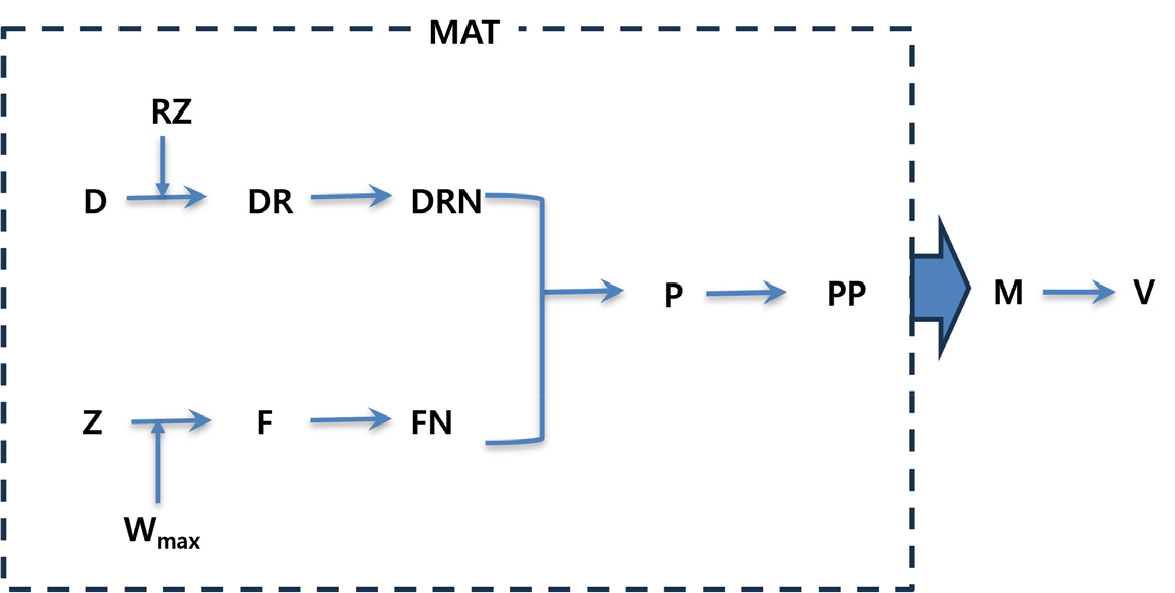
Figure 1.
Procedure of transition matrices and probability matrix
Note: RZ=red zone bus stops; D=demand matrix; DR=D with red zone policy; DRN=DR with normalization of each row; Wmax=maximum allowed waiting time; Z=travel time matrix; F=feasibility mask matrix with Wmax appled to Z; FN=F with normalization of each row; P=transition probability matrix; PP=P reflected with travel demand sum for each destination (Dj); M=probability of vehicles at each bus stop; V=variance of probabilities of vehicles at bus stops.
그런 다음 P는 FN과 DRN이 동시에 만족하는 확률 행렬을 제공한다. 이렇게 하여 MAT는 최종적으로 P의 각 행에 대한 이동 수요의 비율을 반영하는 PP를 생성한다. 다음으로 이 PP를 차량 출현 확률 정보가 포함된 각 정류장의 위치가 2D상에 배열된 지도 M으로 변환한다. 레드존 영역이 다르면 정류장마다 차량 출현 확률 분포가 달라진다. 그럼 각 레드존 영역 내의 정류장 집합의 최적성을 차량 출현 확률의 분산값 크기로 평가할 수 있다.
더욱 구체적으로, D는 정류장간 평균 이동 수요의 OD 행렬로서, dij로 구성되며, i=j이면, dij=0이다. Z는 정류장간 평균 통행시간의 임피던스 행렬로, zij로 구성되며, i=j이면, zij=0이다. RZ는 레드존 정류장으로, rzi로 구성되며, 정류장 i 가 레드존에 포함되면 rzi=1, 아니면 rzi=0의 값을 갖는다. DR은 drij의 OD 행렬로서, 정류장 i 나 j 중 하나라도 레드존에 포함되지 않으면 drij=dij, 모두 레드존에 포함되면 drij=0의 값을 갖는다. DRN은 DR을 표준화한 행렬로, drnij = drij / Σj drij로 구성되며, 행의 합 Σj drnij = 1이다. F는 feasibility mask로서, fri로 구성되며, zri < Wmax이면 fri=1, 아니면 fri=0이다. 또한, 정류장 r 은 차량의 현재 위치, 정류장 i 는 이용자 현재 위치를 나타낸다. FN은 표준화 F로서, fnri = fri / Σi fri로 구성되어, 행의 합 Σi fnri=1이다.
P는 차량의 전환행렬로서 prj로 구성되어 있다. 여기서 prj는 정류장 r의 차량이 정류장 i에 갈 것으로 선택될 확률과 정류장 i가 목적지 j에 갈 확률의 결합확률로서, Equation 1과 같이 정의된다.
여기서, q는 이용자가 위치한 정류장 i로부터 최대 허용 접근시간 내에 있는 차량 위치 가능 정류장을 나타낸다. 만일 그러한 q중 하나가 실제 차량이 있는 r이라면 수식의 오른편이 prj에 더해지는 것이다.
주어진 prj에서 PP는 차량이 r에서 j로 통행할 확률인 pprj로 구성된다. 이는 서비스 지역 전체 정류장의 통행수요를 모두 합한 총통행수요 대비 r번째 정류장 통행수요의 비율을 Equation 2와 같이 반영한다.
M이 서비스 지역 정류장의 지도로서 각 정류장의 상대빈도를 표시한다고 하자. 즉 정류장 i에서 차량이 있을 확률은 Equation 3과 같다.
V는 정류장의 상대빈도의 분산인 Equation 4로 계산된다.
3. 유전자 알고리즘
최적의 레드존은 (1)레드존 내 이동 수요에 대한 차량 배차 서비스 제한, (2)서비스를 호출한 이용자에게 차량이 접근할 수 있는 최대 허용 시간이라는 제약조건 하에서 차량의 정류장별 출현 빈도의 정류장 간 차이가 최소화되도록 하는 레드존이다. 일반적으로, 서비스 지역 내 서로 다른 레드존 즉 서로 다른 정류장 집합을 만드는 방법의 수는 매우 많다. 본 연구는 표준적인 유전자 알고리즘(Koza, 1992)을 채택하여 수많은 레드존 후보 중 최적의 것을 찾도록 설계하였다(Figure 2).

모집단은 미리 정해진 수의 유기체로 구성된다. 유기체 또는 문자열은 0 또는 1 의 값을 갖는 유전자 또는 정류장의 배열로 구성되며, 여기서 1은 레드존 영역 내에 있는 정류장, 그렇지 않은 경우 0이다. 배열의 길이는 서비스 영역의 정류장 수로 정한다. 유기체의 선택은 복원추출이며, 추출은 유기체의 품질에 따라 확률적으로 이루어진다. 이 문제 영역에서 레드존 영역의 품질은 Equation 4가 표현한 정류장 간 차량 출현 확률의 분산의 크기에 반비례한다. 고품질의 유기체 선택 확률이 높지만, 품질이 낮은 유기체가 선택될 수도 있다. 본 연구는 돌연변이, 교차, 복제 등의 유전자 변환을 통해 최종 세대까지 세대마다 최적의 유기체 즉 분산량이 가장 작은 최적의 레드존을 찾는다. 즉 유기체를 구성하는 정류장들이 갖는 0 또는 1의 값이 문제 영역과 무관하게(domain free) 유전자 변환되면 해당 유기체는 새롭게 정의되는 것이고, 이렇게 새롭게 정의된 유기체들이 표현하는 새로운 RZ에 의해 문제 영역의(domain specific) 함수인 Equation 1에서 Equation 4에 의해 해당 유기체의 목적함수 값인 V가 새롭게 계산되어 다른 유기체들과 다음번의 유전자 변형 과정에 선택되기 위한 경쟁을 벌이게 된다. 전환행렬에 의한 유기체(즉 레드존의 크기, 모양, 위치) 평가, 즉 ‘evaluate newly generated population’은 더 이상의 개선된 유기체가 나타나지 않거나 정해진 반복회수를 채울 때까지 while 문에 의해 반복적으로 이루어진다.
연구지역 및 자료
본 연구는 충청북도 청주시 오송의 실제 통행 수요 데이터에 위의 전환행렬 계산과 레드존 설정 방법을 적용하였다. 오송은 40.74 km2의 면적, 13개 법정리에 2022년 현재 약 24,000명의 주민이 살고 있다. 각 세부지역마다 인구밀도가 다르기 때문에 평균 통행수요 수준도 다르다. 면사무소가 위치한 중앙리는 인구가 많고 평균 연령이 주변 리들에 비해 낮다.
이 지역의 여러 주민들은 불규칙한 운행 스케줄과 낮은 운행 횟수 등 높지 않은 서비스 수준의 대중교통으로 인해 불편을 겪어왔다. 이에 청주시는 주민들에게 더 나은 대중교통 서비스를 제공하기 위해 대안적 대중교통 교통서비스 도입을 결정하였으며, DRT 서비스 플랫폼 업체가 2022년 10월 오송에서 188개의 정류장에서 총 4대의 DRT 차량으로 시범서비스를 시작하였다. DRT 서비스의 유형은 노선운행 방법에 따르면 고정노선형, 경로이탈형, 준다이나믹형, 다이나믹형(Song et al., 2009), 운영 방식에 따르면 실시간 호출형, 고정노선형, 하이브리드형 등 여러 기준으로 구분할 수 있다. 청주의 DRT는 실시간 호출의 완전 다이나믹형을 채택하고 있다. 2023년 5월부터 이 시범사업은 본 사업으로 전환되었다. 이러한 성공으로 현재는 오송을 포함해 청주시 주변부를 둘러싼 11개 면 각각에서 이 서비스를 운영하고 있다.
연구 지역인 오송은 이동 수요의 분포가 고르지 않아 서비스 지역의 외곽에 거주하는 주민들이 서비스를 받기 어려워 불만이 많을 것이 예상되었다. 전체 서비스 지역의 중앙에 있는 제한된 구간에 수요가 너무 많아 차량이 해당 구간을 빠져 나오는 것이 매우 어려울 것이기 때문이었다. 즉 차량이 해당 지역을 벗어나지 못하고 호출 빈도가 높은 구간인 늪 안쪽에서만 돌아다닐 가능성이 컸다. 이렇게 되면 늪 밖의 잠재적 이용자들은 서비스를 이용하고 싶어도 긴 대기시간과 우회율 때문에 이용을 못 하게 되는 경우가 빈번할 것이었다.
이러한 이유로 서비스 플랫폼 업체는 Figure 3과 같이 사업 시작부터 레드존 규제를 설치한 후 레드존 내의 정류장간 이동 요청은 모두 서비스하지 않았다. 이로 인해 제한된 지역 내 차량 이동의 집중은 전반적으로 완화되었고, 서비스는 늪 밖으로 확산되었다. 그런데 문제는 신규 서비스 지역에서 서비스를 시작하기 전에는 해당 지역 특성의 차이로 인해 레드존의 모양, 크기, 위치를 어떻게 설치할지 미리 알 수 없다는 것이다. 오송의 예에서처럼, 시작부터 설정했던 레드존이 늪 문제를 최적으로 풀었던 것인지는 확인하지 않았었다.
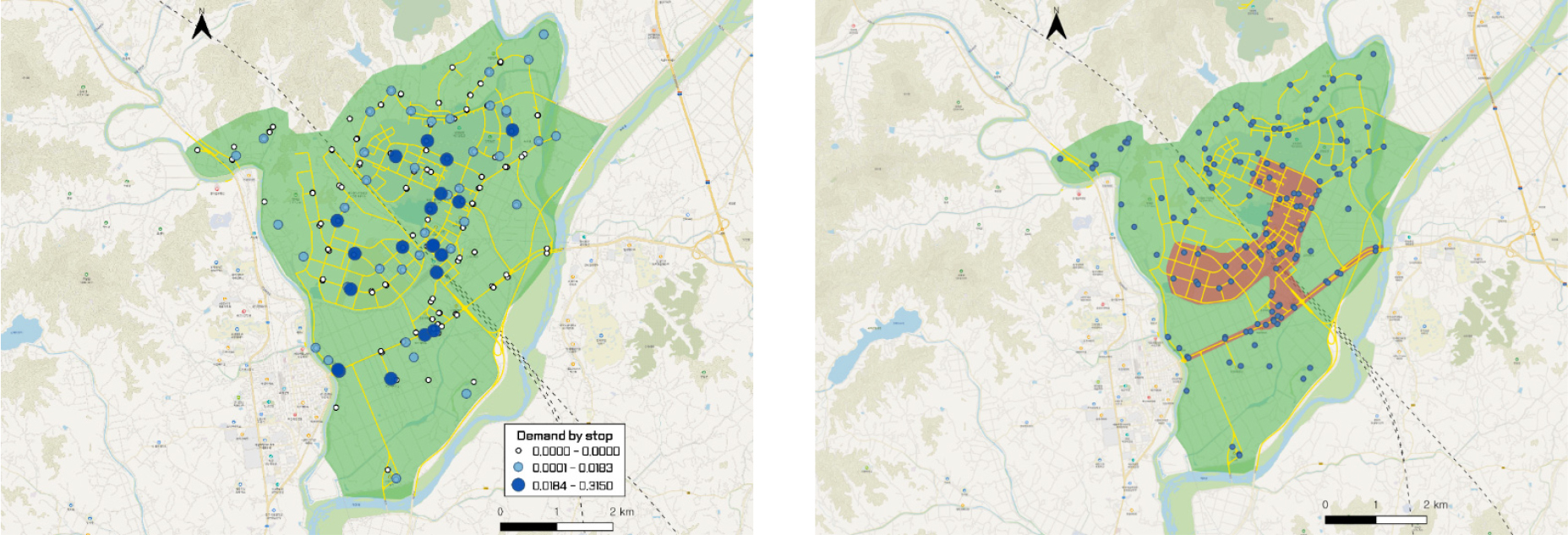
위 문제에 대한 답을 얻기 위해, 본 연구는 2023년 1월-7월 30일 간의 정류장별 하루 평균 수요 데이터를 분석에 사용하였다. 특히 데이터 수집 기간 기준으로 이미 운영 중이었던 레드존 정책으로 인해, DRT 수요는 원래 수요가 아닌 억제된 수요였으며, 따라서 늪의 초기 상태와 이후 레드존 구성에 의한 변화를 시뮬레이션하기 위해, 데이터에서의 레드존 내 정류장간 수요를 각 70%씩 추가 설정하여 분석에 투입하였다.
분석결과
1. 연산 예
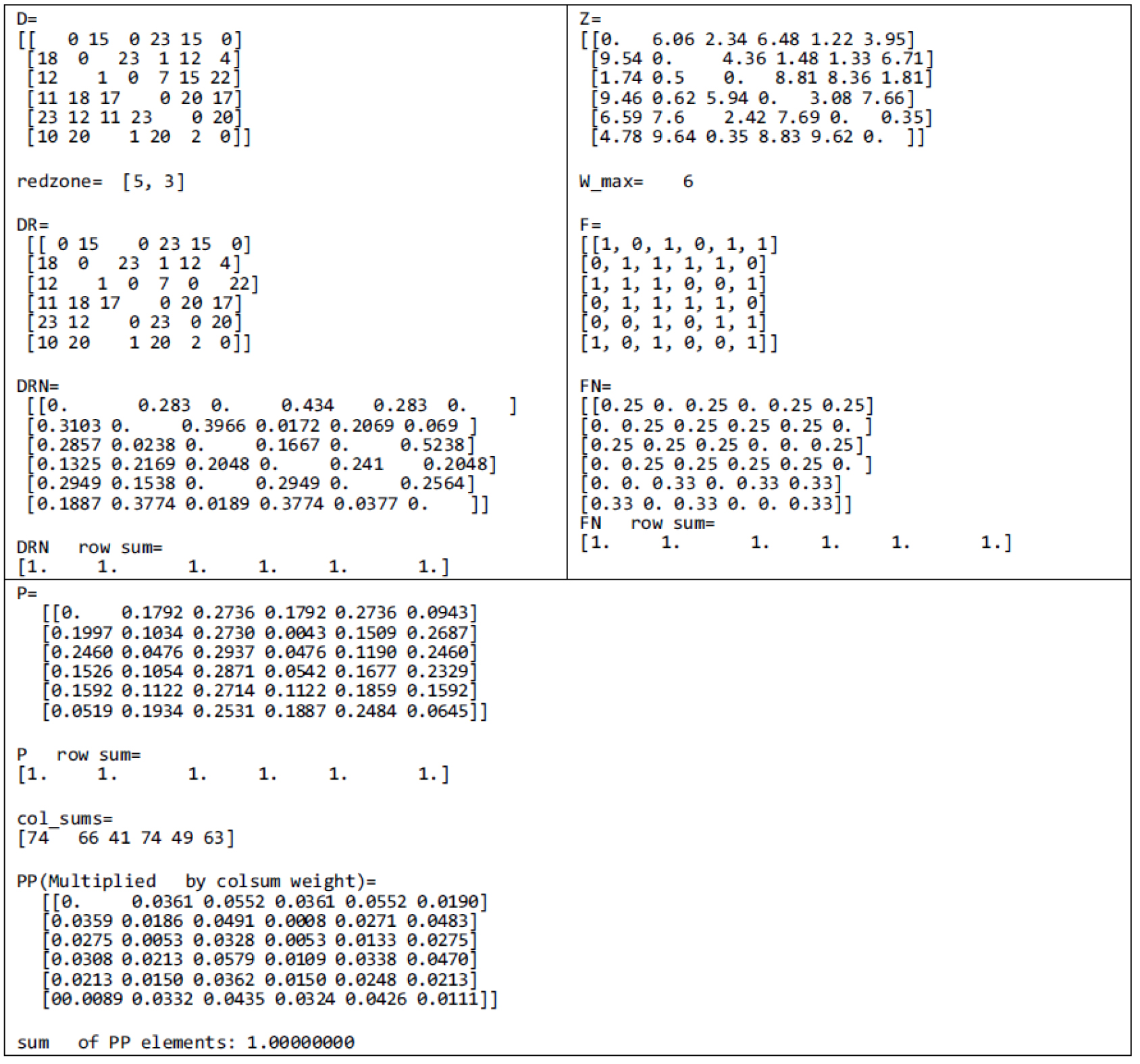
여기서는 가상의 데이터를 이용하여 현재 차량 위치에서 이용자가 요청한 목적지까지 차량이 이동할 확률을 계산하는 방법을 설명한다. 가상의 데이터에는 이용자의 정류장별 이동 수요와 정류장간 이동 시간의 OD 행렬의 정보가 있다. 여기에는 레드존 규정 및 허용되는 최대 대기 시간이 적용된다. 간단히 설명하자면, 본 연구에서는 가상의 서비스 지역에서 DRT 서비스를 제공하는 정류장 6개를 설정하였다. 레드존 정류장은 3번과 5번으로, 이 두 정류장 사이를 이동하고자 하는 수요에는 서비스를 제공하지 않는다. 차량의 현재 위치에서 이용자의 출발지 정류장까지 도착할 때까지 허용되는 최대 대기 시간은 6분으로 설정하였다. 이상은 계산 과정을 제시하기 위한 임의의 시뮬레이션 설정이다.
Figure 4는 이동 수요 D와 이동 시간 Z의 원래 값을 결합하여 Figure 1의 절차에 따라 이용자가 도달 가능한 출발지를 통해 한 위치에서 승객의 목적지까지 차량이 이동할 확률을 나타내는 행렬 PP를 생성하는 것을 보여준다. P는 F(차량에서 출발지까지)행 합과 D(출발지에서 목적지까지)행 합의 조합으로, 각 행에서 차량에서 출발지로, 다시 출발지에서 목적지로의 이동 행렬이 생성된다. 또한 PP는 승객의 총이동수요 대비 각 목적지의 비율을 반영하기 위해 목적지 수요 규모에 따라 가중치가 부여된다. 6개의 정류장 모두 이동 수요가 0이 아니므로 P의 행합은 1이고 PP의 총합은 1이다. 이동 수요가 없는 정류장이 있는 경우 P와 PP의 행 합계는 1보다 작아진다. 매우 많은 혹은 무수히 많은 solution candidate들 중 더 나은 하나를 선택하는 본 연구의 도메인 특성에 따라, 이 예제는 본 연구가 제안한 계산 방법이 실제 어떻게 구현되는가를 보여주는 내용으로 한정한다. 본 연구의 방법이 과연 정답을 정확히 재생산하는가를 알아보기 위해 가능한 모든 대안을 나열하고 그 중 최적의 대안을 해로 결정하는 방법은 domain-free GA의 수행성을 평가하는 것으로, 본 연구에서는 검토하지 않는다.
2. 실제 사례
청주시 오송읍의 188개 정류장간 실제 이동 수요 데이터에 앞 절에서 논의한 방법론을 적용하였다. 먼저 연구지역 및 자료 장의 논의에 근거하여 정류장간 이동 시간과 이동 수요의 188×188 OD 행렬을 추출하였다. 2024년 9월 현재 오송읍의 평균 대기시간은 20분이었다. 이에 최대 허용 대기 시간을 20분으로 설정했다. 이하에서는 정류장 간 DRT 차량 출현 확률의 편차를 최소화하는 최적의 레드존 소속 정류장을 찾고자 한다.
연구방법 장에서 설명한 대로, 검토할 수 있는 가능한 레드존 정류장 집합은 매우 많아, 본 연구는 이들 중 최적의 레드존을 찾기 위한 유전자 알고리즘을 설계하였다. 우리의 유전자 변형 프로세스에서 한 세대의 모집단은 100개의 유기체, 즉 문자열로 구성된다. 각 문자열은 188개의 유전자 또는 정류장으로 구성되며, 각 정류장이 레드존 구역에 있는지 여부를 나타낸다. 유전자 변형 프로세스는 2000회 세대 혹은 1000회 이상 목적함수값 불변의 조건에서 종료하는 것으로 설정하였다. 각 유전자 변형 세대에서 복제 연산자 선택 확률은 15%, 교차 연산자는 55%, 돌연변이 연산자는 30%로 설정하였다. 복제 연산자가 선택되면 문자열의 30%, 교차 연산자면 40%, 돌연변이 연산자면 20%를 선택하여 해당 연산자에 의해 유전자가 변형된다. 문자열 선택은 Equation 5의 룰렛휠(Koza, 1992)에 따라 100개의 문자열에 대해 복원추출로 수행하였다.
여기서, Si는 레드존 문자열로 문자열 i를 선택할 확률, Vi는 레드존 문자열로 문자열 i를 선택한 경우의 정류장 간 DRT 차량 출현 확률의 분산, n은 한 세대 내의 문자열의 수이다.
Equation 5에 의해 선택된 문자열은 선택된 유전자 연산자에 의해 유전자 변형을 거친다. 선택되지 않은 다른 모든 문자열은 그대로 다음 유전자 변형 세대로 넘겨진다. 본 연구에서, 유전자 연산자의 작동은 다음과 같다. 본 연구는 원포인트 교차 연산자를 채택하여, 무작위로 하나의 교차점을 선택해 교차점에서 문자열 간의 정보를 교환한다. 돌연변이는 선택한 문자열의 각 셀(=정류장)을 5%의 확률로 0에서 1로, 혹은 1에서 0으로 변경하도록 하였다. 이들은 모두 GA에서 도메인 지식이 불필요한 일반화 매개변수이다.
이러한 유전 연산자 외에 도메인 특정의 매개변수 하나를 설정하였는데, 레드존 영역의 정류장 수를 전체 정류장 수의 10% 이내로 제한하는 것이다. 이는 모든 정류장을 레드존 구간에 할당하면 확률의 편차가 작아지는 반면 DRT 서비스가 어떤 정류장에도 제대로 제공되지 않는 비합리적 답안을 피하기 위함이다. 만일 위의 유전자 연산자가 전체 정류장의 10% 이상을 레드존으로 설정한 ‘불법적’인 문자열을 만들어내면, 우리의 GA는 ‘합법적’인 문자열을 만들어낼 때까지 변형을 반복하였다. 각 세대의 유전자 변형 평가 점수는 가장 분산이 작은 문자열의 분산 값으로 간주하였다. 변형 프로세스가 종료되면 정류장 간 DRT 차량 출현 확률의 편차를 가장 작게 만들어주는 문자열을 최적의 레드존으로 간주하였다. 이상에서 설정한 유전자 알고리즘의 파라미터들은 Koza(1992)를 포함한 분자생물학에서의 여러 선행연구들이 빈번하게 채택하는 수치들이다. 이와 다른 파라미터 값들을 설정하면 분석 결과에 어느 정도 차이가 있을 수 있다. 유전자 파라미터의 최적화는 본 연구의 연구 주안점을 넘어서는 것으로, 결론에서는 이를 후속 연구로 제안할 것이다.
정류장 간에 DRT 차량이 나타날 확률의 분산은 Figure 5에서와 같이, 유전자 변형 프로세스의 세대가 진행됨에 따라 감소하였다. 수치들은 각 세대 최상의 레드존 설정에 따른 분산 값이다. 이는 점점 더 개선된 레드존이 점진적으로 분산을 줄이고 늪의 영향을 약화시킨다는 것을 의미한다. 1회의 프로세스 시행으로는 일반적인 결론을 확인하기는 어렵기 때문에, 본 연구는 5회의 유전자 변형 프로세스를 진행하였고, 이로부터 최소화를 원하는 목적함수 값의 평균과 표준편차의 값을 확인하였다. 각 유전자 변형 프로세스의 종료 조건을 2000회 세대(generation=iteration) 혹은 1000회 이상 목적함수값 불변으로 설정하였으며, 프로세스별로 24시간이 소요되었으며, 각 프로세스의 목적함수 값과 수렴 시 세대 횟수는 0.01839(2000회), 0.01880(1758회), 0.01794(1458), 0.01837(1999회), 0.01818 (1579회)로서, 평균 0.0184, 표준편차 0.00032였다. 대체로, 1000 세대 전후로 0.018과 0.019 구간 내에서 안정적으로 수렴함을 볼 수 있다. 즉 1회의 프로세스로도 대체로 안정적인 해 값을 찾을 수 있음을 확인할 수 있다.
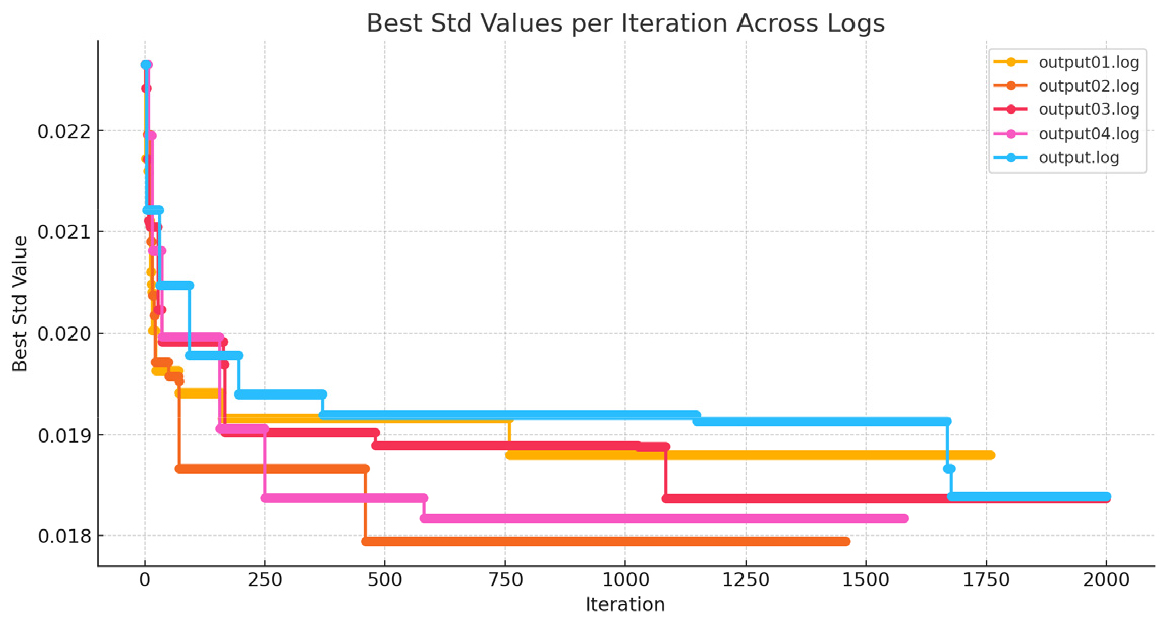
Figure 6는 위 5회의 유전자 프로세스 시행 중 마지막 5회차의 시행을 예시하였다. 해당 프로세스의 running time은 24시간 4분 18초였다. 그림은 유전자 변형 프로세스가 각 세대마다 구성한 레드존을 표현하고 있는데, 여기서 늪은 소속 정류장의 차량 출현 확률의 합이 전체의 40% 이상인 영역으로 설정한 것이다. GA 프로세스에 의한 레드존 최적화는 결과적으로 기존의 늪 현상 발생 지역에 밀도가 높은 레드존 정류장이 중첩되어 본 연구가 지향한 바, DRT 사업 개시 전 바람직한 레드존 설정으로 서비스 공급의 형평성을 추구하는 목적을 상당부분 달성하고 있음을 확인할 수 있었다.
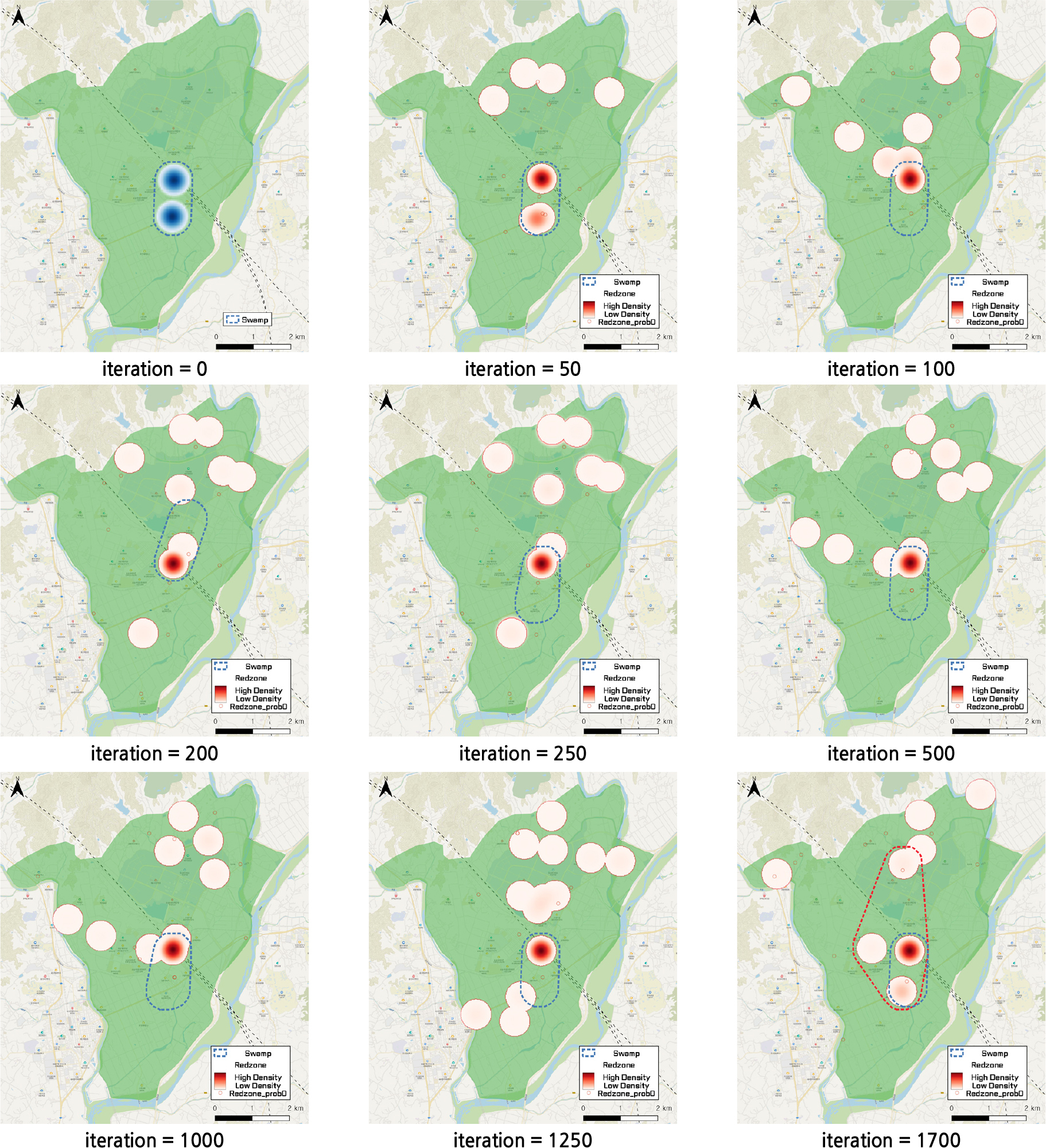
첫째, 가장 뚜렷한 사실로서, GA 프로세스가 종료 조건에 도달하면 밀도가 높은 최적화된 레드존 정류장이 명확한 영역을 형성하였다. 둘째, 프로세스의 최적화에 따라 늪은 레드존에 의해 성공적으로 둘러싸이게 되었다. 셋째, 레드존 영역은 늪을 포락하는 것을 넘어 그 주변으로 설정이 되었다. 이는 본 분석에서의 프로세스의 목적이 GA가 늪 영역을 정확히 찾아내는 것 자체가 아니라 늪 영역과의 중첩을 통해 서비스 이용의 형평성을 제고하는 데 있기 때문에 설명 가능한 결과이다. 넷째, 레드존의 재설정에 의해 영향을 받은 늪의 크기와 위치의 변화를 확인할 수 있었다. 본 분석은 레드존 정류장의 개수를 작게 설정하였기 때문에 늪의 변화 규모가 제한적이었으나, 레드존 정류장의 개수를 더 많이 설정하였다면 유전자 변형 프로세스에 의해 늪 영역의 변화 역시 유도되었을 것으로 보인다. 현재 시뮬레이션에서는 188개의 정류장 중 GA 프로세스가 매 세대마다 20개의 레드존 정류장을 설정하게 되어 있는데, 이는 전체 OD 짝 개수인 188*187 = 35156 개의 불과 1%인 20*19 = 380 개의 OD 짝을 설정하는 것으로서, 레드존 설정으로 인한 늪 자체의 구성 변화를 유도하기에는 지나치게 적은 수치로 보인다. 예를 들어 전체 OD 짝의 10% 이상을 설정할 수 있는 규모의 레드존이라면, 그로 인한 늪의 영향 약화를 예상할 수 있다. 여기서, 늪 크기는 늪에 속하는 정류장을 둘러싸고 있는 500m 버퍼 영역의 합으로 설정하였다. 다섯째, 결국 가장 중요하게는, GA 프로세스가 지정한 레드존 정류장이 늪 영역에 중첩되면서 목적함수인 서비스 이용의 분산이 감소하여 본 분석 프로세스의 의도가 구현됨을 확인할 수 있었다. 여섯째, 본 연구가 제안한 방법으로 탐색한 최적의 레드존 정류장이 Figure 3에서처럼 일단 사업 시행 후 사후적으로 설정한 레드존과 대부분의 면적을 공유한다는 것이다. 이는 본 연구가 제안한 사업시행 전 레드존 설정 방법이 신규서비스에 대한 이용자의 잠재적 불만을 줄이고 운영효율성을 높일 수 있음을 뜻한다.
이상의 분석 결과에 따라, 앞서의 연구방법 장에서 제시한 두 개의 연구 질의에 다음의 답변이 가능하다.
A1: 정류장 간 승객의 이동 수요 분포와 이동 시간 비용에 대한 정보만 주어졌을 때, DRT 차량이 현재 차량 위치에서 승객의 목적지까지 이동할 확률을 사전 계산하는 것이 가능했다.
A2: 반복적인 유전자 변형 프로세스를 사용하여, 정류장간 수요 반응 차량 확률의 분산을 최소화하는 최적의 레드존을 찾을 수 있었다.
결론 및 토의
본 연구는 정류장 간 이동 수요 분포 정보만 주어졌을 때 각 정류장에서 DRT 차량이 나타날 확률을 추론하는 계산 방법을 개발하고자 하였다. 이 계산법은 유전자 알고리즘의 적합도 정보를 제공하여 최적의 서비스 제한 정류장 집합인 레드존 구간을 구성하여 서비스 지역의 정류장에 DRT 서비스를 가능한 한 균등하게 제공할 수 있음을 확인하였다. 이 방법은 DRT 서비스를 실제 시작하기 전에 해당 지역에서 사전적으로 실행할 수 있음이 중요하다. 이는 특히 레드존 밖에 거주하는 사용자의 만족도를 높일 수 있다는 점에서 주목할 만한 방법이다.
본 연구의 이론적 기여는, DRT 서비스 이전에 측정된 정류장 간 이동 수요 분포 정보와 통행비용 정보만 있으면, 서비스를 시작하여 차량을 운행하기 전에 서비스 지역 내 정류장 간의 차량 이동의 전환행렬을 계산할 수 있다는 것이다. 또한 유전자 알고리즘을 사용하여 모양과 위치에서 최적인 레드존 영역을 찾아낼 수 있다. 정책적으로, 본 연구가 제안한 방법을 사용하여 대중교통 서비스 제공의 형평성을 개선할 수 있다. 차량 운영의 효율적인 알고리즘을 활용하여, 주민의 만족도가 개선되고 지자체의 지역 운수업체에 대한 보조금을 감소시킬 수도 있다.
향후 연구 주제는 다음과 같다. 첫째, 본 연구가 제안한 방법은 최대 대기 시간 범위 내에 있는 DRT 차량이 이용자에게 서비스를 제공할 확률이 차량 간에 동일하다고 암묵적으로 가정한다. 보다 현실적으로는, 더 가까운 차량이 승객을 태울 권리가 있거나, 적어도 가까운 차량이 승객을 태울 확률이 더 높다는 것을 반영하도록 방법을 고도화할 필요가 있다. 둘째, 제안된 방법의 타당성 마스킹 행렬에는 우회율 허용 조건이 포함되어 있지 않다. 비록 서비스 이용의 시간과 공간이 자유롭다고 하여도, 긴 우회에 의한 이동 시간 증가는 이용자가 바라지 않는 일일 것이다.
셋째, 본 연구에서 채택한 유전자 알고리즘의 파라미터는 분자생물학에서의 선행연구들이 빈번히 채택하는 수치들이었으나, 상이한 파라미터 세트들에 따른 유전자 알고리즘의 안정성 및 분석결과의 신뢰성 등을 주제로 한 보완 연구가 필요하다. 넷째, 현재 방법은 늪 발생 현상을 정류장의 입장에서 하루 동안의 발생 확률을 매크로하게 검토하고, 그에 따른 레드존 영향의 시뮬레이션을 진행하였으나, 이용자 입장의 마이크로한 모델링을 통해 늪 발생 확률과 레드존 영향의 시뮬레이션 결과의 사실성을 제고할 필요가 있다. 정류장 입장의 모델링에 더해 이용자 입장의 시뮬레이션을 추가하는 것이 연구 결과의 적용 가능성을 더 높일 것으로 사료된다.
다섯째, 레드존 운영으로 인한 공공의 잉여를 측정하는 방법을 명시적으로 정의해야 한다. 늪 문제를 완화하기 위해 레드존의 배차를 제한하는 대중교통 서비스는 효율적인 운영으로 인해 훨씬 낮은 비용으로 교통이 열악한 지역에 거주하는 주민들의 이동을 돕는다. 그러나 이 서비스 방식은 서비스 제공 업체가 승객당 이동 거리가 짧은 늪지대에서 더 많은 승객과 더 낮은 운영비용으로 높은 수익을 올릴 수 있는 기회를 박탈하는 것이다. 늪지대에 대한 레드존 정책 적용을 정당화하기 위해서는, 이익이 손실보다 커야 한다. 이로부터 레드존 설정의 현실성이 확보될 것이다. 더구나 이는 레드존 내부 이용자의 서비스 저하의 문제도 잠재적으로 갖고 있다. 따라서 공공의 잉여를 측정하는 방식을 통해 본 연구가 분석한 이용자와 운영자 입장의 손익 개념을 넘어 공공의 입장에 의한 손익 개념을 함께 고려하는 복합 목적의 최적화 방안을 지향할 필요가 있다. 마지막으로, 본 연구는 본 연구가 설정한 서비스 제공의 형평성을 개선시키도록 레드존의 분포를 변형시킨 결과 레드존과 늪이 중첩되는 것을 확인할 수 있었으나, 이것이 레드존 도입에 의한 DRT 운영 수행성 측면의 지표들에 어떤 영향을 주는지 분석하지 않았다. 예를 들어 레드존 도입 이전과 이후에 전체 승객대기시간, 전체 승객요청 처리건수 등 시스템의 퍼포먼스가 어떻게 변화할지를 확인할 수 있다면, 형평성과 운영효율성의 상호관련성을 파악하는 데 필요한 정보를 정리할 수 있을 것이다. 이는 레드존 설정에 의한 다양한 영향들에 대한 폭넓은 이해를 가능케 할 것이다.
