

서론
택시 수요는 인구 구조, 토지 이용, 물가와 같은 사회경제적 요인뿐만 아니라, 타 대중교통 및 택시 공급 정책, 기상 상황 등 다양한 요인들에 의해 복합적으로 영향을 받는다. 이러한 복합적인 요인들이 반영된 택시수요예측의 정확성은 교통 시스템의 효율성을 유지하는 데 필수적이며, 이를 통해 택시 배차를 최적화하고, 택시공급의 과잉 또는 부족 문제를 최소화할 수 있다. 특히, COVID-19 팬데믹과 같은 예기치 않은 사회적 이슈는 택시 이용 수요의 급격한 감소를 초래하며, 택시 산업 전반에 침체를 불러왔다. 이는 단순히 운전자들의 수익 감소를 넘어서, 시민들의 이동 편의성과 도시 교통 시스템의 효율성을 저해하는 심각한 문제로 확대되었다.
서울시와 같은 대도시의 택시 이용수요를 정확히 추정하는 것은 효율적인 배차 전략과 지속 가능한 교통 정책 마련을 위해 필수적이다. 이를 위해 기존 국내외 연구에서는 택시 수요예측에 회귀분석, 시계열 분석 등 전통적인 통계적 방법뿐만 아니라, 머신러닝, 딥러닝 기반의 다양한 빅데이터 분석 기법도 활발히 적용해 왔다. 이러한 고도화된 분석 기법들은 대규모 데이터를 처리하고 숨겨진 패턴을 효과적으로 발견하는 데 유용하지만, 변수 간의 비선형적 관계를 해석하거나, 시간과 공간적 특성을 정밀하게 반영하는 데 한계가 있다.
택시 수요는 인구밀도, 토지 이용, 환경요인과 같은 다양한 사회경제적 요소뿐만 아니라, 날씨 변화, 지역 특성과 같은 외부 요인에 의해 복합적으로 영향을 받는다. 이들 요인은 비선형적인 상호작용을 통해 수요 예측의 불확실성을 증대시킨다. 예를 들어, 기상 변화나 특정 이벤트가 택시 수요에 미치는 영향은 일관된 선형적 관계로 설명할 수 없다. 따라서 택시 수요의 비선형적인 특성을 분석하는 것은 복잡한 상호작용을 반영하고 예측의 정확성을 높이는 데 필수적인 접근 방법이다. 이러한 비선형성 분석을 통해 예외적인 상황을 고려한 보다 정교한 예측이 가능해지며, 이를 정책 수립에 실질적으로 활용할 수 있다.
따라서 본 연구는 이러한 기존 방법론의 한계를 극복하기 위해 다변량 함수 다항식(MFP, Multivariate Functional Polynomial) 모델을 활용하였다. MFP 모델은 변수 간 비선형적 관계를 효과적으로 반영할 수 있을 뿐만 아니라, 시간적·공간적 특성을 동시에 고려할 수 있는 접근 방법이다. 이를 통하여 정확하고 해석 가능한 택시 이용수요를 추정하고, 서울시의 지속 가능한 택시 정책 마련에 실질적인 기여를 하는데 궁극적인 목적이 있다.
본 연구의 시·공간적 분석범위는 서울시의 각 행정구역(구) 단위로 설정하여 총 25개 구로 설정하였으며, 시간적 범위로는 2023년 일 년간의 서울시 택시 승하차 통행 데이터를 활용하였다. 이를 통해 행정 구역별 택시 이용현황 및 이용수요를 추정하였으며, 시간적 범위를 일 단위로 세분화하여 계절적 요인, 평일 및 주말, 공휴일과 같이 요일에 따른 택시 이용 패턴을 심층으로 분석하였다. 이러한 분석을 바탕으로 시간적·공간적 특성을 반영한 이용수요 추정 모델을 구축함으로써, 서울시의 택시 이용에 대한 더욱 신뢰성 있는 결과를 예측하고자 하였다.
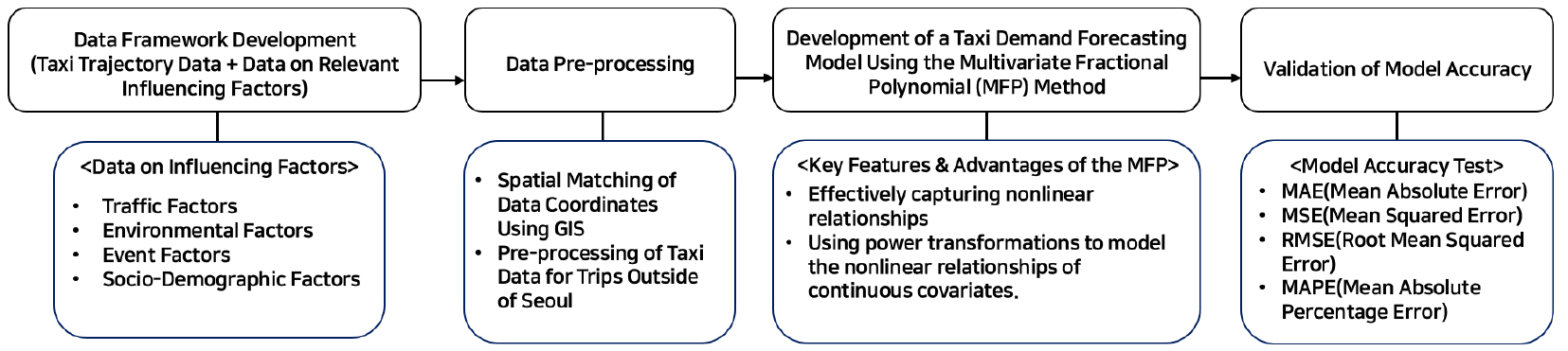
본 연구의 과정은 총 4개의 단계로 수행되었으며, 각 단계별 연구내용은 Figure 1과 같다. 첫째, 택시 승하차 통행 데이터를 기반으로 택시 이용수요에 영향을 미치는 교통, 환경, 이벤트, 사회·인구학적 요인 등을 결합한 융합 데이터를 구축하였으며, 이를 통해 이용패턴 분석 및 예측에 필요한 기초 데이터의 틀을 마련하였다. 둘째, 수집된 데이터를 전처리하고 누락된 데이터를 보완하는 작업을 진행하였다. 이 과정에서 택시통행궤적의 GIS 좌표매칭을 통해 공간적 일관성을 확보하였으며 분석 가능한 형태로 데이터를 정제하였다. 세 번째는 구축된 데이터를 바탕으로 MFP(Multivariate Fractional Polynomial) 모델을 제시하였다. MFP 모델은 독립 변수와 종속 변수 간의 비선형적 관계를 효과적으로 반영할 수 있도록 각 변수의 최적 분수 다항식을 선택하여 수요예측 모델링을 진행하였으며, 비선형적인 수요 패턴을 보다 정교하게 설명하고자 하였다. 마지막으로는 MAE(Mean Absolute Error), MSE(Mean Squared Error), RMSE(Root Mean Squared Error), MAPE(Mean Absolute Percentage Error) 등 모델 성능 평가 지표 값을 산정하여 모델의 정확도를 검증하고 회귀모델과 비교하였다.
선행연구
택시 이용수요 추정은 국내외에서 다양한 접근 방법을 통해 연구되고 있으며, 최근 빅데이터, 인공지능(AI), 기계 학습(ML) 기술의 발전으로 예측의 정확성과 신뢰성이 크게 향상되고 있다. 이러한 기술적 발전은 대규모 데이터를 효과적으로 처리하고 복잡한 패턴을 분석하는 데 유용하며 이를 기반으로 다양한 접근 방법 기반의 이용 수요예측모델들이 개발되고 있다. 본 연구에서는 국내외 선행연구들을 고찰함으로써, 국내외 택시 수요추정 연구의 현황과 주요 수요추정 방법론들을 살펴보고자 하였다. 특히, 기존 연구들이 활용한 데이터의 특성과 분석 기법을 비교·분석하여, 택시 이용수요 추정 연구에 있어 중요한 시사점을 도출함과 동시에 기존 방법론의 한계점을 보완하고, 새로운 접근 방식을 제안하고자 한다.
국내 택시 이용수요는 서울특별시, 부산광역시, 대전광역시 등과 같은 대도시를 공간적 범위로 설정하여 추정되었으며 DTG, GPS, 택시호출 데이터 등을 수집 및 활용하여 택시 이용현황 분석 및 이용수요를 추정해왔다. 주요 선행연구들을 살펴보면, 다양한 데이터와 방법론이 활용되었으며, 각 연구는 고유한 변수를 외생 변수로 설정하여 수요 패턴을 모델링 했다. 대표적으로 Lee et al.(2022)은 서울시를 공간적 범위로 설정하고, 2019년 장애인 콜택시 호출 및 차량 데이터를 기반으로 GCN(Graph Convolution Network), RNN(Recurrent Neural Network)의 방법론을 활용하여 택시 이용수요를 예측하였다. 이 과정에서 호출 시각, 승하차 시간대, 출발지 및 도착지 정보, 차량 상태 등의 다양한 변수를 외생 변수로 활용하여 이용수요 패턴을 모델링 하였다. Kim and Kang(2019)의 연구에서는 서울시를 공간적 범위로 설정하여 2016년 9월에서 10월 사이의 콜택시 빅데이터를 분석하였으며, 택시 이용수요 패턴을 모델링 하였다. 이 연구에서는 요일, 휴일 및 전일 휴일 여부 등의 변수를 활용하여 TGNET(Temporal- Guided Network) 방법론을 적용한 것이 특징이다. Kim et al.(2021)은 서울시 택시 운행 데이터, 행정구역 정보, 택시 승차대 데이터를 기반으로 K-means 클러스터링을 활용하여 택시 이용수요를 예측하였다. 이 연구는 과거 택시 이용 수요 데이터를 외생 변수로 활용하여 수요 패턴을 모델링 한 점에서 과거 데이터의 활용 가능성을 잘 보여주고 있다. Yoon et al.(2018)은 2015년에서 2018년까지 SKT 택시 운행 데이터와 2014년에서 2017년까지 데이터 광장의 택시 운행 데이터를 분석하여, 기상 상태 변수를 활용한 Cluster-Based predictor 방법론으로 택시 이용수요를 모델링 하였다. 이 연구는 날씨 요인이 택시 수요에 미치는 영향을 심층적으로 분석한 사례로, 이용수요 예측에 기상 데이터를 통합하는 접근 방식을 제시하였다.
국외 택시 이용수요 예측 연구는 미국, 중국, 유럽 등 주요 대도시를 대상으로 주로 진행되어 왔다. 이들 연구에서는 택시 통행 및 궤적 데이터, 환경 데이터, 사회인구 데이터 등 다양한 데이터를 종합적으로 활용하였으며, 계량경제 분석 모델뿐만 아니라 Long Short-Term Memory(LSTM), Extreme Gradient Boosting(XGB), Convolutional Neural Network(CNN), Extreme Gradient Boosting(XGB) 등의 딥러닝 기법이 적용되었다. 또한, 인구, 1인당 소득, 기상상황, 시·공간적 요인 등 택시 이용수요와 관련된 다양한 영향요인들을 분석하여 기존 수요 데이터와 융합함으로써 보다 정교하고 실효성 있는 예측 모델을 개발하였다.
Gangrade et al.(2022)은 택시 이용 수요예측을 위해 시카고를 공간적 범위로 설정하고 Neighborhood Proximity Based Model(NPBM) 방법론을 활용하여 택시 운행 기록, 관심 지점 데이터, 사회인구학적 데이터를 분석하였다. 이 연구는 예측 과정에서 관심 지점의 위치, 지역 인구 및 1인당 소득 등 외생변수를 고려하여 이용 수요예측의 정밀성을 높이고자 하였다. Zhao et al.(2022)의 연구에서는 뉴욕 맨해튼을 분석 대상으로 설정하고 Hybrid Dynamic Graph Convolutional Network(HDGCN) 방법론을 활용하여 택시 운행데이터를 분석하였다. 예측 과정에서 지역 간 상관관계를 고려하여 보다 정확한 이용수요를 도출하고자 하였다. Liu and Chen(2022)은 중국 시안을 공간적 범위로 설정하고 Extreme Gradient Boosting(XGB) 방법론을 활용하여 택시 GPS, 환경 및 POI(Point of Interest) 데이터를 분석하였다. 예측 과정에서 시간, 환경, 공급량 등 외생변수를 고려한 것이 특징이다. Luo et al.(2022)은 미국 뉴욕과 중국 청두를 공간적 범위로 설정하고 Spatial Temporal Diffusion Convolutional Networks(ST-DCN) 방법론을 활용하여 시공간별 택시 운행데이터를 분석하였다. Askari et al.(2020)은 포르투갈 포르투를 공간적 범위로 설정하고 Long Short-Term Memory(LSTM) 방법론을 활용하여 포르투 택시의 궤적 데이터를 분석하였다. 해당 연구는 POI와 택시 이용수요 데이터를 통합하여 예측의 신뢰성을 제고하고자 하였다.
이렇듯 국내외 연구에서는 다양한 데이터를 활용한 택시 이용수요 예측이 진행되어 왔으며, 특히 외생변수를 반영한 딥러닝 기법을 융합한 방법론이 주로 적용되고 있다. 기존의 연구들은 딥러닝 기반의 방법론을 통해 변수 변환 과정을 제시하고 있으나, 이러한 과정에서 어떤 변환이 최적의 결과를 도출하는지 직관적으로 이해하기 어려운 한계가 있다. 이는 딥러닝 기법의 본질적인 특성인 ‘블랙박스(Black Box)’ 문제로 인해 변수 변환의 근거와 결과를 명확하게 해석하는데 제한이 따르기 때문이다. 반면, 본 연구에서 제시하는 MFP 모델은 기존 접근법과 차별화되며, 변수에 대한 다양한 수학적 변환을 통해 비선형 관계를 직관적으로 설명할 수 있다. 이는 정책목표에 따라 영향요인을 구체적으로 개선할 수 있는 분석 기반을 제공한다는 점에서 의의를 가진다. 따라서 택시 이용수요와 관련된 영향요인 간의 비선형적 관계를 보다 명확하게 반영할 수 있으며, 기존의 딥러닝 기반 방법론에서 직관적 해석이 어려운 변수 변환 과정을 효과적으로 분석할 수 있다. 또한, 비전문가들도 쉽게 이해하고 활용할 수 있어 실용적인 측면에서 높은 적용 가능성을 기대할 수 있다.
데이터 구축 프로세스
본 연구에서 수집한 택시 승하차 통행 데이터는 수집 일시, 교통사업자명, 차량 등록번호, 운수종사자 자격번호, 부제번호, 주행거리(m), 영업거리(m), 공차거리(m), 영업시간(초), 요금, 호출료, 할증 여부, 결제 수단, 승·하차 시각(연도, 월, 일, 시, 분, 초), 승·하차 위치(X·Y 좌표), 승·하차 지역 정보(시·군·구·읍·면·동) 등의 다양한 세부 정보를 포함하고 있다. 이 중 택시 이용 수요 분석에 실질적으로 필요한 항목을 추출한 결과, 주행거리, 공차거리, 영업거리, 영업시간, 승·하차 시각, 승·하차 위치, 승·하차 지역 정보 등이 선정되었다. 다만, 주행거리, 공차거리, 영업거리 변수들은 택시 수요 예측에 직접적인 영향을 미치기보다는 택시 공급 및 운영 효율성 분석에 더 적합하다고 판단되어, 수요 예측 모델 구축 단계에서는 제외하였다.
택시 이용수요에 영향을 미치는 요인으로는 교통 요인(지하철, 버스 등 대중교통 이용률 등), 환경적 요인(기상상태, 미세먼지 등), 이벤트 요인(특정 행사, 공휴일, 긴급상황 등), 사회·인구학적 요인(유동인구, 경제활동 등)을 고려하였다. 각 요인은 분기별, 월별, 일별, 시간대별로 수집 가능한 범위 내에서 활용되었으며 세부 데이터는 시공간적으로 일관성을 유지하며 분석 가능한 형태로 정제되었다.
서울시 25개소 구별 시간대(0-23시)에 따른 승·하차 대수와 O-D(Origin-Destination) 데이터를 구축하기 위해서는 기본적으로 승·하차 위치(구 단위) 정보가 필요하다. 그러나 택시 운행데이터 중 일부 승·하차 위치 정보가 누락이 된 경우가 있으므로 승차 또는 하차 위치에 대한 정보가 없는 데이터는 서울시 행정구역(구) 지도와 승·하차 위치 좌표 간의 매칭을 통해 해당 위치의 누락된 서울시 구 정보를 수집하였다.
매칭이 완료된 데이터와 승·하차 위치 정보가 포함된 데이터를 통합한 후, 시간대별 승·하차 대수를 추출하였다. 이 과정에서 자정 시간대를 기준으로 전월과 익월로 넘어가는 데이터를 처리하기 위해, 전월의 마지막 날 자정 이후에 발생한 데이터 샘플을 익월의 데이터셋에 결합하여 시간대별 승·하차 대수를 정확히 반영하였다. Figure 2는 GIS를 활용한 데이터 매칭 과정을 시각적으로 나타내며, 누락된 승·하차 위치 정보를 보완하고 일관성 있는 데이터셋을 구축하기 위해 수행된 절차를 보여준다.

MFP를 활용한 택시수요예측 방법론
계량 경제모형은 통계적 분석을 기반으로 하며 변수 간의 관계를 명확히 하여 해석 가능성을 높여주는 강점을 지닌다. 이를 통해 정책 결정자나 연구자는 모델의 결과를 쉽게 이해하고 적용할 수 있으며, 특정 변수의 변화가 결과에 미치는 영향을 분석할 수 있다. 또한, 적은 양의 데이터로도 유효한 분석을 수행할 수 있으며, 모델의 복잡성을 조절하여 과적합의 위험을 줄일 수 있다. 이러한 특성은 특히 다양한 사회적, 경제적 변수가 작용하는 택시 이용수요 예측과 같은 복잡한 문제에 효과적이다. 특히 MFP(Multivariate Fractional Polynomial) 모델은 연속형 공변량의 비선형성을 효과적으로 모델링하고 변수 선택과 함수 형태 선택을 통합하여 분석의 예측 정확도와 적합성을 향상시키는데 유용하다(Royston and Sauerbrei, 2003). 이 모델은 통계적 기법을 활용하여 다양한 요인의 영향을 통합적으로 고려하며, 복잡한 데이터의 패턴과 관계를 효과적으로 파악할 수 있다. 이를 통해 해석력과 실질적인 적용 가능성을 모두 충족시키는 역할을 할 수 있다. 또한 MFP 모델은 변수 간의 인과적 관계를 명확히 분석할 수 있어 해석이 용이하며 소규모 데이터 환경에서도 효과적으로 사용되는 장점이 있다. 반면, 모델의 변수 간 관계를 설정하는 과정에서 적절한 변수 설정이 필요하며, 초기 데이터 구축과정에서 추가적인 분석이 요구된다.
본 연구에서는 이러한 배경을 바탕으로, 객관적이고 신뢰성 있는 택시 이용수요 모델 산정을 위해 MFP(Multivariate Fractional Polynomial) 모델을 적용하였다. MFP 모델은 다변량 데이터에서 연속형 변수 간 비선형 관계를 효과적으로 모델링 할 수 있는 기법으로, 변수에 대한 거듭제곱 변환을 확장하여 연속형 공변량의 비선형 관계를 정교하게 설명한다(Royston and Altman, 1994). 일반적인 거듭제곱 모델은 Box와 Tidwell(1962)에 의해 제안되었으며, Royston과 Altman(1994)은 이 단순 거듭제곱 모델을 공식화하여 1차 분수 다항식(FP1)으로 정의한 후, 더 높은 차수의 분수 다항식으로 확장하였다.
반면 MFP(Multivariate Fractional Polynomial) 모델은 차수 m의 분수 다항식(FP) 함수에 대한 일반화에서, 로 표현하면 인덱스 이 거듭제곱 으로 대체되어(Royston and Altman, 1994)과 같이 나타낼 수 있다.
여기서, : 거듭제곱의 차수, : 각 항에 추정된 회귀계수, : 번째 항에서 의 변환 형태 : 차수 의 분수 다항식 함수
Royston and Altman(1994)이 제안한 바에 따르면, 거듭제곱은 제한된 집합 에서 선택되며, 이때 는 을 나타낸다. 이 집합은 변환(=1)이 포함되지 않으나, 역수, 로그, 제곱근, 제곱 변환 등이 포함된다. 는 Equation 2와 같은 형식을 취한다.
택시수요예측결과
Table 1과 같이 본 연구에서는 택시 이용수요 추정을 위해 교통 요인, 환경적 요인, 이벤트, 사회·인구학적 요인들을 설명변수로, 2023년 서울시 승·하차 통행데이터 기반으로 집계된 택시 이용수요를 종속변수로 구축하였다. 요일 데이터를 처리할 때, 참조 변수를 일요일로 설정하고 나머지 요일을 더미 변수로 포함하여 분석을 진행하였다. 더미 변수는 범주형 변수를 모델에 포함시키기 위한 방법으로, 요일별 차이를 개별적으로 추정할 수 있게 한다.
Table 1.
Variable name transformation
각 변수의 기초통계량은 Table 2에서 보여주는 바와 같다. 요일 변수 및 이벤트 요인은 0과 1로 구성된 더미변수(Dummy variable)이며, 택시 이용 건수(승차기준), 생활인구(명/분기), 기온(°F/일), 강수량(mm/일), 미세먼지(/일), 유동인구(명/일), 코로나 확진자 수(명/일), 버스 및 지하철 승·하차 이용 대수(건/일), 주거인구(명/일)는 일별 데이터로 점포 개·폐업 수(개소/분기), 총 점포 수(개소/분기)는 분기 데이터로 직장인구(명/년)는 연간 데이터, 승용차(대/월), 승합차(대/월), 화물차(대/월), 특수차(대/월), 이륜차 등록 대수(대/월), 관광객 수(명/월)는 월별 데이터로 구성하였다. 코로나 확진자 수를 나타내는 변수는 데이터 활용 기간이 2023년으로, COVID-19의 영향이 미미할 것으로 예상되는 시점이지만 특정 지역과 시간대에는 COVID-19로 인한 잔존 영향이 있을 가능성을 고려하였다. 특히 택시 수요가 대중교통 기피 현상 등으로 여전히 영향을 받을 수 있다고 판단하여, 코로나 확진자 수를 변수에 포함시켜 분석을 진행하였다.
Table 2.
Summary statistics of variable characteristics
Table 3은 MFP(Multivariate Fractional Polynomial) 모델로 분석한 결과를 제시한다. 구축된 MFP 모델은 택시 이용수요와 영향변수들 간의 비선형적 관계를 효과적으로 반영하기 위해 각 변수의 최적 분수 다항식 변환을 적용한 결과를 포함하며, 각 변수들은 모두 신뢰수준 99%하에서 통계적으로 유의한 결과를 보였다.
Table 3.
MFP (Multivariate Fractional Polynomial) model analysis results
| Variable | Descriptions | Coeff. | S.E. | t | P>|t| |
| Monday | Monday | -0.13255 | 0.00827 | -16.04 | < 0.001** |
| Tuesday | Tuesday | -0.07763 | 0.00841 | -9.23 | < 0.001** |
| Wednesday | Wednesday | -0.06769 | 0.00821 | -8.24 | < 0.001** |
| Thursday | Thursday | -0.03767 | 0.00809 | -4.66 | < 0.001** |
| Weekend | Weekend | 0.08494 | 0.01707 | 4.97 | < 0.001** |
| Holiday | Holiday | 0.06764 | 0.02223 | 3.04 | < 0.003** |
| Ilogs_1 | -1,417,458 | 358,350.2 | -3.96 | < 0.001** | |
| Ilogs_2 | 574,884 | 145,573.2 | 3.95 | < 0.001** | |
| Ilogt_1 | -0.02073 | 0.00325 | -6.38 | < 0.001** | |
| Ilogt_2 | 0.01243 | 0.00194 | 6.41 | < 0.001** | |
| Iprcp_1 | -0.00284 | 0.00070 | -4.06 | < 0.001** | |
| Ilogm_1 | -0.22119 | 0.06911 | -3.20 | < 0.001** | |
| Icpt_1 | -0.06258 | 0.00801 | -7.82 | < 0.001** | |
| Icpt_2 | -0.00668 | 0.00086 | -7.81 | < 0.001** | |
| Ilogsa_1 | 0.56541 | 0.03703 | 15.27 | < 0.001** | |
| Constant | - | 13.44598 | 0.00786 | 1,710.63 | < 0.001** |
Ilogs_1과 Ilogs_2는 생활인구 변수(Sum-people)의 분수 다항식 변환 결과를 나타내며 2차 다항식이 유의미하게 기여하는 것으로 나타났다. Ilogs_1은 생활인구의 증가가 택시 수요에 미치는 영향을 낮은 생활인구 수준에서의 민감도를 중심으로 설명하며, Ilogs_2는 생활인구 증가율의 완화 효과를 비선형적으로 반영함을 알 수 있다. 생활인구 변수(Ilogs_1: β = -1417458, p < 0.01; Ilogs_2: β = 574854, p < 0.01)는 생활인구가 증가함에 따라 초기에는 수요가 급격히 증가하지만, 일정 수준을 초과하면 증가율이 둔화되는 경향을 정량적으로 보여준다. Ilogt_1과 Ilogt_2는 기온 변수(Tem)에 대한 변환 결과로 기온과 택시 수요 간 비선형적 관계를 설명하기 위하여 변형되었다. 기온 변수의 파라미터(Ilogt_1: β = -0.020703, p < 0.01; Ilogt_2: β = 0.214307, p < 0.01)를 통해 Ilogt_1은 극단적인 기온에서의 택시 수요 감소를 설명하며, Ilogt_2는 적정 온도 범위에서 수요의 증가 경향을 나타낸다는 것을 확인할 수 있다. 이는 기온이 낮거나 높을수록 택시 이용이 감소하고, 쾌적한 기온에서는 이용이 증가하는 계절적 특성을 반영한다. Iprcp_1은 강수량 변수(Prcp)의 분수 다항식 변환 결과를 나타낸다. 강수량 변수(Iprcp_1: β = -0.002389, p < 0.05)는 강수량 증가가 택시 이용 수요를 유의미하게 증가시키는 비선형적 관계를 설명하며, 소량의 강수에서도 택시 이용이 민감하게 반응하는 특성을 보여준다. Ilogm_1은 유동인구 변수(mopeople)의 변환 결과로 유동인구 증가가 택시 수요에 미치는 직접적이고 비례적인 영향을 나타낸다. 유동인구 변수의 파라미터(Ilogm_1: β = -0.221158, p < 0.01)는 log(유동인구)-14.5952의 값이 1단위 증가 시 평균적으로 택시수요가 0.221 단위 감소하는 것을 보여주며, 도시 내 보행 밀도가 높을수록 타 대중교통시설수 및 접근성이 높아 상대적으로 택시 이용수요에 감소 영향을 미치는 요인임을 보여준다. Icpt_1과 Icpt_2는 코로나 확진자 변수(cpt)의 변환 결과로, 팬데믹 상황에서 확진자 수 증가가 택시 이용 수요를 감소시키는 비선형적 특성을 정량화한 것이다. COVID-19 확진자 수의 파라메터(Icpt_1: β = -0.062515, p < 0.01; Icpt_2: β = -0.006681, p < 0.01)를 통하여 COVID-19 확진자 수의 급격한 증가가 택시 이용에 영향을 미치는 것으로 분석되었다. 또한 Icpt_1과 Icpt_2의 변형된 변수식은 각각 , 로 COVID-19 확진자 수가 증가할수록 택시 이용수요는 증가하는 경향을 보여주고 있다. 이는 확진자 수 증가로 인해 대중교통 이용을 기피하고, 개인적인 이동 수단으로 택시를 선호하게 되면서 택시 이용이 증가한 결과로 해석된다. Ilogsa_1은 지하철 승하차 이용 대수 변수(subway_sum)의 변환 결과로, 대중교통 이용과 택시 이용 간의 상호 대체적 관계를 나타낸다. 변수를 로그 변환을 함으로써 데이터의 스케일을 정규화하고 유의미한 관계를 보이는 것으로 나타났다. 지하철 승·하차 이용 대수의 파라미터(Ilogsa_1: β = 0.565413, p < 0.01)는 대중교통 이용 증가가 택시 수요를 대체하는 관계를 보여준다. 이 결과는 택시와 대중교통 간의 밀접한 상호작용이 있다는 것을 나타내며, 대중교통 인프라 변화가 택시 산업에 미치는 영향을 이해하는 데 중요한 정보를 제공한다는 것을 시사한다. 마지막으로 시간 요인은 평일, 주말, 공휴일로 구분되며, Table 3의 분석 결과에서 보여주듯이 주말과 공휴일에는 택시 이용수요가 양의 상관관계를 보이는 것으로 나타났다. 특히, 주말(β = 0.089435, p < 0.01)과 공휴일(β = 0.065741, p < 0.01)은 주중에 비해 택시 이용수요가 통계적으로 유의미하게 증가하였으며, 이는 여가 활동과 이동량이 증가하는 반면 대중교통공급이 감소되는 요일 특성을 반영하는 것으로 볼 수 있다.
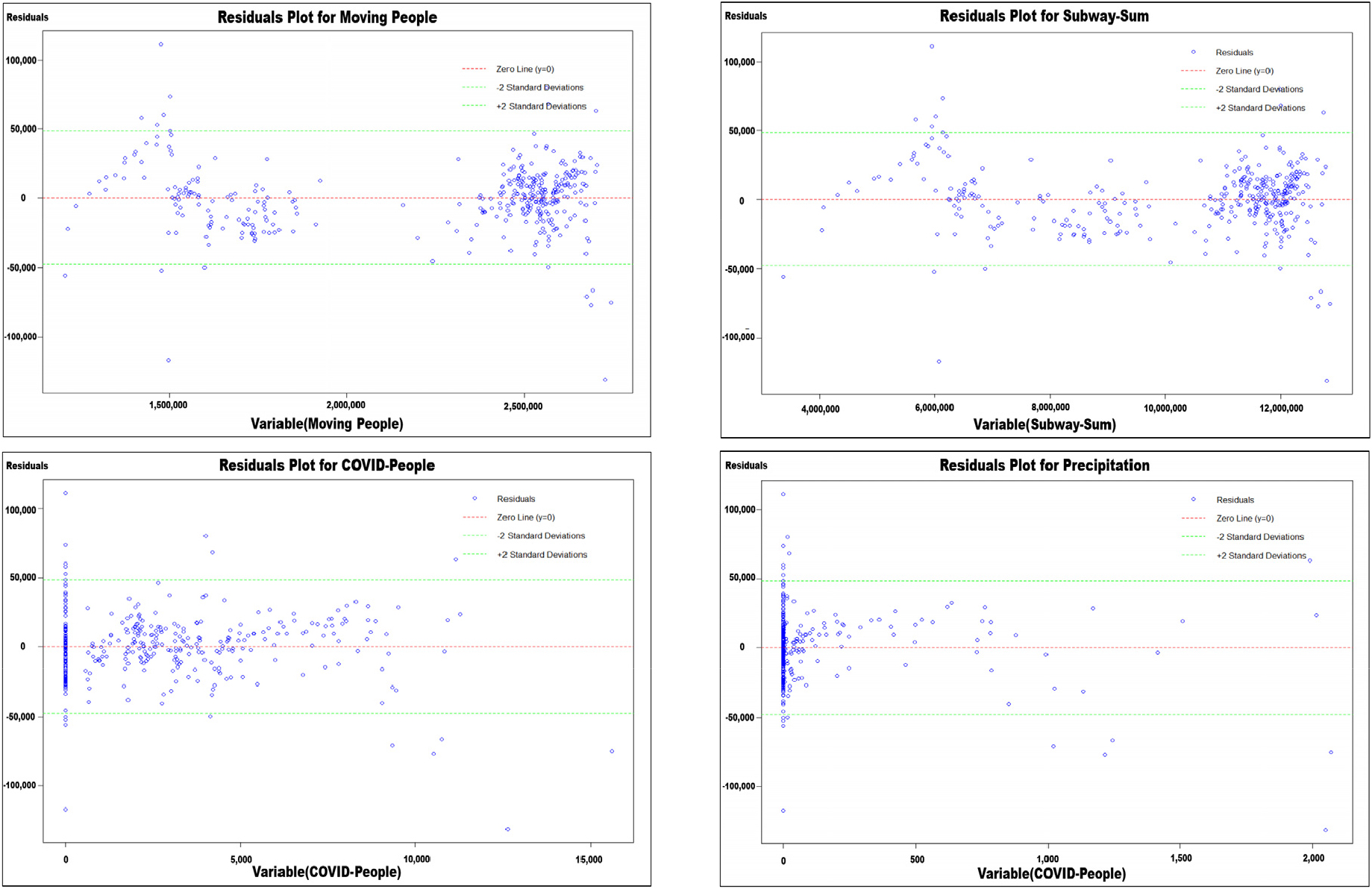
본 연구에 적용된 MFP(Multivariate Fractional Polynomial) 모델은 변수 간 비선형성을 반영하므로, 잔차 분석을 통해 모델이 각 독립변수의 값에 대해 종속변수를 얼마나 정확하게 예측했는지를 평가할 수 있다. Figure 3은 도출된 MFP 모델에서 유의한 변수로 도출된 유동인구, 생활인구, 주거인구, 코로나 확진자 수, 강수량, 지하철 승하차 이용 대수의 Residuals Plot을 나타낸다. 그래프의 X축은 독립변수의 값을 나타내며, Y축은 종속변수의 실제값과 예측값 간의 차이(잔차, Residuals)를 보여준다.
이는 각 변수의 값이 X값으로 입력되었을 때, 해당 변수가 택시 이용수요에 미치는 영향을 평가하기 위한 분석을 시각적으로 나타낸 것이다. Hauer(2015)는 신뢰수준 95%의 데이터는 평균으로부터 ±2 표준편차 범위 내에 존재해야 한다고 주장했으며, MFP 모델에 적용된 각 변수들의 오차의 분포 또한 ±2·표준편차에 대부분 분포하는 것을 확인할 수 있다. 잔차가 특정 패턴 없이 무작위로 분포하는 것은 MFP 모델이 독립변수와 종속변수 간의 관계를 비선형적으로 적절히 반영하였음을 의미하며, 이는 모델이 독립변수의 다양한 범위에 걸쳐 안정적인 성능을 유지한다는 것을 보여준다.
2023년 기준 관련 데이터를 MFP 모델에 적용하여 예측한 결과, 서울시 택시 이용수요는 실제값 총 251,797,551건/년 보다 165,578건이 적은 251,633,545건/년으로 추정되었다. 반면 비교를 위해 구축한 다중 선형회귀 모델을 통해 예측한 결과는 실제 수요인 251,797,551건/년에 비해 255,001건이 적은 251,542,550건/년으로 도출되었으며, LSTM 모델을 통해 예측한 결과는 실제 수요인 251,797,551건/년에 비해 435,300건이 적은 250,875,221건/년으로 추정되었다.
본 연구에서 제시한 모델의 성능을 평가하기 위해 평균 절대 오차(MAE, Mean Absolute Error), 평균 제곱 오차(MSE, Mean Squared Error), 평균 제곱근 오차(RMSE, Root Mean Squared Error), 평균 절대 백분율 오차(MAPE, Mean Absolute Percentage Error) 회귀 성능 평가지표를 사용하였다. 회귀성능평가지표로 도출된 값은 0에 가까울수록 예측 정확도가 우수한 모델임을 나타낸다. Table 4는 다중 회귀 분석 모델, MFP 모형과 LSTM 모델의 예측 성능을 비교한 결과로, MFP 모형은 나머지 두 모형과 비교하여 평균 절대 오차(MAE), 평균 제곱 오차(MSE), 제곱근 평균 제곱 오차(RMSE), 평균 절대 백분율 오차(MAPE) 지표에서 예측의 정확도가 더 높게 나타났다. 딥러닝 기반 LSTM 모형은 MFP 모형에 비해 다소 낮은 성능을 보였는데 이는 본 연구에서 사용한 관측치의 제한적인 규모가 영향을 미친 것으로 판단된다. 즉, LSTM 모델은 빅데이터에서 더 강력한 학습 능력을 발휘하는 반면, 소규모 데이터에서는 성능이 제한될 수 있음을 시사한다. 이러한 결과는 데이터 규모와 모델 선택 간의 상관관계를 강조함과 동시에 소규모 데이터 환경에서는 통계 기반 모델(MFP 모델)이 보다 적합할 수 있음을 보여준다.
Table 4.
Performance evaluation metrics for multiple linear regression and MFP models
Table 5는 택시 이용수요가 과대 추정된 날짜와 과소 추정된 날짜 상위 5개를 보여준다. 분석 결과, 과대 추정은 대규모 행사, 연말 및 연초와 같은 이벤트 요인과 관련된 날짜에서 발생한 것으로 나타났다. 반면, 과소 추정은 명절과 연휴, 전시 및 공연 등이 있는 날짜에서 예측의 오차가 발생한 것으로 나타났다. 이러한 결과는 이벤트 관련 변수들이 MFP 모형에서 통계적으로 유의하지 않은 것으로 나타나 모형에서 제외된 것이 주요 원인으로 판단된다. 즉, 이벤트 요인 변수는 예측 모델링 과정에서 충분히 반영되지 못했기 때문에 오차에 영향을 미친 것으로 해석할 수 있다.
Table 5.
Top 5 dates with positive and negative errors (Unit : cases)
결론
본 연구는 서울시 일일 택시 이용수요를 추정하기 위하여 다변량 분수 다항식(MFP, Multivariate Fractional Polynomial) 방법론을 적용하여 기존에 제기되어 왔던 선형 회귀모형 및 딥러닝 기반 방법론의 한계를 극복하고자 하였다. 택시 이용수요는 시간적, 사회·인구학적, 교통, 환경, 이벤트 요인 등 다양한 변수에 의해 영향을 받는 복잡한 비선형적 특성을 지니고 있다. 본 연구는 이러한 특성을 효과적으로 반영하기 위해 MFP 모형의 적합성을 평가하고 활용하였다.
본 연구에서 개발된 일 단위 및 구 단위 택시 수요 예측 모형은 다양한 교통 정책 및 운영 전략에 활용될 수 있는 실질적인 기초 자료를 제공한다. 특히, 변수 간의 비선형적 관계를 정밀하게 반영하면서도 직관적으로 해석할 수 있도록 설계되어, 실무에서 정책 결정을 내리는 사용자들이 예측 결과를 쉽게 이해하고 이를 기반으로 결정을 내릴 수 있는 장점이 존재한다. 대표적인 활용 방안으로는 요일별 택시 배차 최적화 전략 설계, 구별 택시 공급-수요 불균형 문제 해결, 공휴일 및 이벤트 대응 계획 수립, 기상 상황에 따른 운영 최적화 등 다양한 교통 운영 전략과 정책 수립에 활용될 수 있다.
연구의 주요 결과에 따르면, 생활인구, 유동인구, 기온, 강수량, COVID-19 확진자 수와 같은 요인들이 택시 이용수요에 통계적으로 유의미한 영향을 미치는 것으로 분석되었다. 특히, MFP 모형은 기존 선형 회귀모형 대비 예측 정확도를 크게 개선하였으며, 예측 성능 지표(MAE, MSE, RMSE, MAPE)에서도 우수한 성능을 보여준다는 것을 확인하였다. 이러한 결과는 MFP 모형이 다양한 변수의 영향을 효과적으로 반영하고, 변수의 형태 변환을 통해 계절적 변화와 특정 시간대의 수요 변동을 예측하는데 적합하다는 것을 보여주는 것뿐만 아니라, 택시 정책 수립과 운수업계의 의사결정 과정에서 실질적인 도움을 제공할 수 있는 해석 가능성과 실용성을 겸비하고 있음을 보여준다.
본 연구를 통하여 다음과 같은 시사점을 도출하였다. 첫째, MFP 모형은 시간적·공간적 특성을 동시에 고려함으로써 이벤트와 같은 비정상적 변수들이 택시 이용수요에 미치는 영향을 분석하는 데 유용하다. 둘째, 기후와 인구 구조 변화, 대중교통 이용량 등의 요인이 택시 이용수요에 미치는 영향을 정량적으로 파악함으로써 변화에 대비한 정책적 대안을 제시할 수 있다. 셋째, 택시 공급과 수요 간 불균형 문제를 해결하기 위한 기초자료뿐만 아니라 실질적인 접근법으로 활용이 가능하다. 즉, 효율적인 배차 전략, 대중교통 인프라의 최적화, 그리고 수요 기반의 유연한 가격 정책 설계 등 다양한 응용 가능성을 제공할 수 있다는 것을 보여준다.
한편, 본 연구에서 구축한 택시 수요 예측모형은 이벤트 요인의 통계적 유의성이 낮아 특정 날짜에서 발생한 수요 과대 및 과소 추정 문제를 발견하였으며, 이는 이벤트 변수의 정교한 설계와 추가 보완이 필요함을 시사한다. 더불어, 분석의 범위가 일별 데이터를 중심으로 이루어진 점에서 시간대별 이용수요 변동을 반영하지 못한 한계가 있었다. 따라서 향후 연구에는 시간대별 데이터를 활용한 추가 연구를 통해 택시 이용수요의 미시적 시간 패턴을 파악하고 보다 실질적인 수요-공급 관리 방안을 제시해야 할 것이다. 또한 공간적 자기상관과 시계열적 특성을 통합적으로 고려하여 모형을 고도화함으로써 도시 전역의 택시 이용수요 분포를 정밀히 이해하고 정책 수립 및 실무 활용 시보다 강력한 도구로써 활용해야 한다. 더 나아가, 다양한 도시 환경과 국제적 사례를 적용하여 모형의 보편성과 확장 가능성을 검증한다면 택시 수요예측 연구의 응용 범위를 넓히는 데 기여할 수 있을 것으로 기대한다. 또한 향후 연구에서는 서울시뿐만 아니라 다양한 지역의 택시 승하차 통행 데이터를 확보하고 각 지역의 교통 환경, 인구밀도, 대중교통 접근성 등을 독립변수로 추가함으로써 보다 현실적인 모형을 구축할 필요가 있다. 이를 통해 각 지역별 특성을 반영할 수 있는 수요예측을 하고, 정책 적용의 효율성을 더욱 향상시킬 수 있을 것이다.
