

서론
기존문헌 고찰
1. 첨두 ‧ 비첨두 교통량 비율 및 지속시간 관련 문헌
2. 통행량 변동 관련 연구
3. 내비게이션 자료 활용 관련 연구
연구 방법 및 평가
통행거리별 패턴 분석
1. 연구 기초자료
2. 통행거리별 구분
3. 통행거리별 구분에 따른 첨두 ‧ 비첨두 ‧ 심야 군집화 및 현행지침 비교
시간대별 통행패턴 분석
1. 통행거리 그룹 시간대별 교통량 집중률 패턴 분석
2. k-means 클러스터링 결과 평가 및 최적 클러스터링 k값 제시
내비게이션 통행패턴 구분 분석 결과 통행배정 적용방법 제시
결론
서론
SOC(Social Overhead Capital) 사업을 추진하는데 있어 대규모의 사업비가 투자됨에 따라, 사업 추진 이전에 정부 혹은 지자체들은 국가재정법, 지방재정법 등을 근거로 삼아 타당성 조사를 수행하고 있다. 도로 및 교통부분 사업의 타당성조사를 수행하는데 있어, 교통수요 분석의 예측 결과는 사회적 편익을 포함한 경제성 분석 결과에 영향을 주게 된다. (예비)타당성 조사의 분석 결과가 중앙 및 지방정부의 사회간접자본 투자 의사결정에 영향을 많이 주고 있어 교통수요예측의 정확성이 더욱 중요하게 부각이 되어 왔으며, 예측 정확성 향상을 위한 교통자료, 분석방법 및 해석에 대한 개선 및 발전시키기 위한 연구들이 진행되어 왔다.
거시적 교통 수요추정 방법으로 교통수요 4단계 예측모형이 국제적으로 가장 보편적으로 사용되고 있으며, 4단계 모형은 통행빈도선택, 통행목적지선택, 교통수단선택 및 경로선택과 같은 통행자의 가장 기본적인 행태를 단계별로 나누어서 통행발생모형, 통행분포모형, 수단선택모형, 노선선택모형에 의해 분석하고 있다. 우리나라의 수요예측모형은 통행발생모형, 통행분포모형, 수단선택모형의 결과를 KTDB(Korea Transport Data Base)에서 제공하고 있으며 이후 노선선택모형에서의 통행배정 시 기본시간단위를 전일 혹은 첨두 ‧ 비첨두로 구분하여 수행하도록 지침으로 제시하고 있다. 기본시간 단위는 분석의 대상이 되는 도로사업의 관측교통량을 조사하고 관측교통량이 첨두 특성을 갖는지 검토하여, 첨두의 특성을 갖는다면 KTDB의 1일 기준 OD자료를 첨두 ‧ 비첨두로 대표되는 1시간 통행량 비율과 지속시간을 고려하여 환산하여 구축된 대표 첨두시와 비첨두시의 1시간 OD를 입력 자료로 네트워크 분석이 이루어지고 있다. 첨두 ‧ 비첨두의 지속시간과 교통량 비율은 한국교통원구원(KOTI)이 정부를 위탁을 받아 지침과 자료를 제공하고 있다.
KTDB에서 배포하는 OD자료는 가구통행실태조사를 기반으로 작성되며, 가구통행실태조사의 표본율은 재정적 한계로 인해 과거에는 약 2%, 현재는 1%로 매우 낮은 실정으로 시간적으로나 비용적 측면에서 표본율을 더 증가시키는 것은 어려운 실정이다. 이러한 가구통행실태조사의 낮은 표본율을 보완하는 방법으로 교통관련 빅데이터가 주목을 받고 있다. 정보통신 기술이 발달함에 따라 모든 분야에서 빅데이터가 이슈가 되고 있고, 교통 분야에서 주목하는 빅데이터는 휴대폰자료, 내비게이션자료, TCS자료, 지점상시교통량자료, 교통카드자료 등이 있다. 전수 자료로는 TCS자료와 지점상시교통량자료가 있지만 TCS자료는 고속도로를 이용하는 차량에 대해서만 전수 자료라는 한계점이 있으며, 지점상시교통량자료는 특정지점을 통과하는 교통량만 알 수 있어, 최초 출발지점과 최종 도착지점 및 경로에 대한 정보를 알 수 없다는 한계점이 존재한다. 내비게이션 자료는 표본자료라는 한계점과 전수화를 위한 내비게이션 시장점유율 모집단 자료를 필요로 한다는 단점이 존재하지만, 출발 ‧ 도착 지점과 통행경로의 공간적 정보와 출발 ‧ 도착시간 및 통행시간이라는 시간적 정보를 비교적 정확하게 얻을 수 있는 이점이 있다.
실제 통행을 하는데 있어서 통행자들은 통행자의 사회경제적 특성, 통행목적, 출발-도착지점 간 교통서비스 수준 그리고 통행거리(통행시간)와 같은 요소를 고려하며 출발시각을 선택하고 있다. 이와 같은 통행자 및 통행특성을 반영한 현실적 분석을 위해서는 출발시각 선택행태에 영향을 주는 요인과 출발시각 교통자료가 필요하나, 기존의 정통적 조사방법에 따른 자료에는 그와 같은 정보를 내포하지 않아 교통존 기반의 거시적 네트워크 분석에 한계점이 존재하여 왔다. 또한 현재 첨두, 비첨두 지속시간 및 집중률 적용하는 것에 있어서 분석지역의 집중률을 네트워크 상 모든 지점의 모든 OD쌍에 대해 일괄적으로 적용한다는 한계점이 있다.
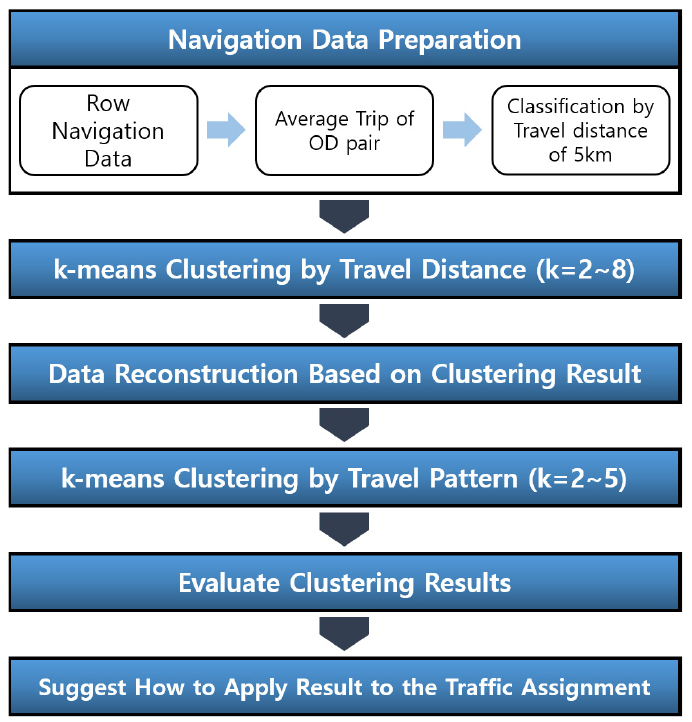
본 연구는 내비게이션 이용자 데이터를 활용하여 단거리, 중거리 및 장거리와 같이 통행거리별로 대표적인 하루 24시간대에 걸친 출발시각 기준 시간대별 교통량 집중률의 분포 패턴을 분석하여 통행거리별 첨두 ‧ 비첨두 시간대 교통량 집중률을 자료기반(data-based)으로 정확히 파악하고자 하였다. 이렇게 통행거리별 차이가 나는 출발시각 기준의 시간대별 교통량을 융합하고, 단거리-중거리-장거리 통행을 모두 반영한 하루의 시간대별 교통량 집중비율 분포를 분석하고, 분석의 용이성을 위해 유사한 교통량 집중률을 보이는 시간대를 그룹화하여 구분해서 정적 통행배정을 위한 대표 1시간의 OD 교통량 자료를 구축하고자 하였다. 이와 같은 유사 통행 패턴을 보이는 시간대 그룹별 OD 교통량을 입력 자료로 네트워크 노선배정(traffic assignment)을 분석할 경우 각 링크별(특정 하나의 도로구간) 상을 오가는 출발시각 기준의 단거리에서 장거리의 시간대별 교통량 집중률을 현실적으로 제대로 반영한 분석이 가능하게 하는 것이 본 연구의 목적이다. 본 연구의 흐름은 Figure 1과 같다.
기존문헌 고찰
1. 첨두 ‧ 비첨두 교통량 비율 및 지속시간 관련 문헌
「도로 ‧ 철도 부문 사업의 예비타당성조사 표준지침 수정 ‧ 보완 연구(제5판)」(Korea Development Institute, 2008)와 「교통시설 투자 평가지침(제6차 개정)」(Ministry of Land, Infrastructure and Transport, 2017)에서는 통행배정을 위한 기본 시간 단위를 첨두 ‧ 비첨두 시간대의 대표 1시간 OD를 이용한 방법과 전일 평균적 교통량으로 대표되는 1시간 OD를 이용하는 방법을 제시하였다. 지침서에서는 기본적으로 지역 간 도로의 첨두 지속시간은 10시간, 첨두 1시간 집중률은 7%로 제시하였다. 비첨두 지속시간은 9시간으로, 비첨두 1시간 교통량 집중률은 2.5%로 가정하였다. 주요 광역권의 경우에도 지역의 교통 특성에 적합한 집중률 값을 적용해야한다고 제시하였다. 따라서 「도로 ‧ 철도 부문 사업의 예비타당성조사 표준지침 수정 ‧ 보완 연구(제5판)」(Korea Development Institute, 2008)과 「교통시설 투자 평가지침(제6차 개정)」(Ministry of Land, Infrastructure and Transport, 2017)을 인용하여 지역 간 도로 및 주요 광역권 도로의 첨두 ‧ 비첨두 지속시간 및 평균 집중률을 정리하면 Table 1과 같다.
Table 1.
Regional peak ‧ nonpeak duration and concentration ratio
2. 통행량 변동 관련 연구
Kim(2016)에서는 노선배정 모형의 예측 오차의 원인으로 KTDB 자료기반 분석 오차를 입력 자료의 오차, 공간 집합화 네트워크 표현 방식에 따른 오차, 교통패턴 변동에 대한 대푯값 설정에 따른 오차, 교통류모형 단순화에 따른 오차, 노선선택 행태 집합화에 따른 오차로 구분하여 설명하였다. 교통패턴의 계절별, 시간대별 변동은 무시하고 1년의 하루 대푯값 개념으로 구축한 KTDB OD 자료로 노선배정 분석한 링크 예측 교통량을 연평균 교통량(AADT 혹은 AAWDT)로 해석하는데 오차가 발생 할 수 있다는 점을 지적하였다.
Jung et al.(2009)에서는 지점교통량 자료를 통계학적 방법을 활용하여 평균과 표준편차를 이용하여 시간대별 교통량을 구분하는 방법을 제시하였다. 해당 연구에서는 지점별로 24시간 동안의 시간대별 교통량 조사 결과를 사용하였다.
Kim and Chang(2012)에서는 2009년 수시교통량 자료를 혼합군집분석 모형을 활용하여 첨두 ‧ 비첨두 ‧ 심야에 대한 지속시간과 시간대별 집중률을 제시하였다. 해당 연구에서는 한국건설기술연구원에서 제공하는 2009년 24시간 전국 수시조사 교통량 자료를 이용하여 차종 별 구분을 지어 분석을 진행하였다. 연구결과 전 차종을 기준으로 첨두 지속시간 12시간, 집중률 6.08%, 비첨두 지속시간 4시간, 집중률 4.09%, 마지막으로 심야의 경우는 지속시간 8시간, 집중률 1.33%로 연구결과를 제시하였다.
3. 내비게이션 자료 활용 관련 연구
Park et al.(2015b)에서는 차량 내비게이션 자료를 이용하여 통행수요량과 패턴 분석 결과를 KTDB OD의 정확도 평가에 활용할지에 대해 연구하였다. 해당연구에서는 현대 Mnsoft의 2013년 11월 1일부터 2014년 1월 31일, 총 87일 동안 수집된 내비게이션 자료를 사용하였다. 인구 10만명당 내비게이션 자료 비율과 차량 1만대당 내비게이션 자료 비율 분석 결과, 지역에 따라 다른 비율과 발생 및 도착존 기준으로 하여 자료 발생의 차이가 있어 이를 OD 전수화 과정에 반영해야 하는 것으로 판단하였다.
Park et al.(2015a)에서는 내비게이션 데이터를 활용하여 KTDB OD의 통행 분포를 검토하였다. 해당 연구에서는 2013년 11월부터 2014년 1월까지 화, 수, 목 40일 동안의 현대 Mnsoft의 자료를 사용하였다. 내비게이션 OD에는 존재하나 KTDB OD에서는 통행이 0인 OD쌍이 존재하는 것으로 확인되었다. 도시부와 지방부로 구분하였을 때, 내비게이션 OD와 KTDB OD의 불일치가 도시부에서 높게 나타나 도시부 통행이 과소 예측되거나 오차가 발생하는 것으로 판단하였다.
Park and Oh(2016)에서는 내비게이션 빅데이터를 융합하여 수시조사 자료의 AADT 추정시 발생하는 오차를 감소시켜 신뢰도 개선 방안을 제시하였다. 해당 연구에서는 내비게이션 중 전국 고속도로, 지방도, 시군도 도로를 대상으로 과거 10년 이상의 자료와 약 800만대 차량의 통행 데이터를 보유하고 있는 SK T-map자료의 활용 가능성도 함께 제시하였다.
연구 방법 및 평가
이 연구에서는 내비게이션 이용자들의 통행 데이터를 출발시각 기준으로 통행거리별로 하루 24시간대에 걸쳐 시간 통행량 집중률 분포가 통계학적으로 서로 상이하게 구분될 수가 있는가가 본 논문의 핵심 주제 중에 하나이다. 따라서 관측된 자료를 통해서 통행거리를 그룹화 할 때 유사한 출발시각별 교통량 집중률 패턴을 찾을 필요가 있다. 또한 통행거리 그룹별로 다른 시간대별 집중률 패턴을 모두 융합하여 하루 24시간대를 유사한 교통량 집중률 시간대로 그룹화 하는 과정도 다시 수행할 필요가 있다. 이와 같은 과정에 분류분석이 필요하게 되는데 본 연구에서 적용한 기법은 k-means 클러스터링 방법이다. k-means 클러스터링은 분할 클러스터링의 대표적인 알고리즘으로 데이터 개별 자료의 속성이 많고 데이터 밀도가 낮을 경우 분할 클러스터링을 사용하는 것이 유용한 것으로 알려져 있다. k-means 클러스터링은 다른 클러스터링 기법에 비해 이상치의 영향이 큰 문제점이 있지만 본 연구에서의 집중률 자료는 이상치의 값이 없고 군집에 개수에 따라 유의미한 해석이 가능하기 때문에 k-means 클러스터링 방법을 사용하였다.
24시간을 k개의 그룹으로 분류한 k-means 클러스터링 결과를 평가하는 방법으로는 실루엣 계수와 BIC, Elbow Method, 절편 없는 단순회귀분석을 사용하여 적합성을 판단하였다. 즉 통행거리 그룹별 24시간 시간대별 평균 교통량 집중률과 클러스터링 결과에 따른 거리별 평균 교통량 집중률의 유사한 정도를 상관분석과 단순회귀분석을 실시하여 상관분석과 단순회귀분석의 기울기와 롤 분석하여 적합성을 판단하였다. 상관계수의 값이 1에 가깝게 나타날수록, 그리고 회귀모형의 기울기가 1에 가까울수록 클러스터링의 결과가 적합한 것으로 해석된다. 또한 BIC 분석과 Elbow 분석을 통하여 군집별 상이성을 분석하여 적정 클러스터링 개수를 도출하였다.
위의 k-means 클러스터링 결과를 평가하여 도출된 k값을 바탕으로 결정한 통행거리 그룹별 시간대별 교통량 집중률 패턴을 전일 OD에 적용하여 각 패턴별 OD를 구축하여 해당 OD자료를 입력 자료로 한 노선배정(traffic assignment)을 통하여 하루 시간대별 교통량 변동 패턴을 현실적으로 예측하고자 한다.
통행거리별 패턴 분석
1. 연구 기초자료
이 연구에서는 Table 2와 같은 원자료 형태의 SK T-map 이용자의 위치 정보 기반 내비게이션 자료를 사용하였다. 사용된 SK T-map 자료는 2016년 7월 1일부터 2017년 6월 30일까지의 기간 365일의 자료이며, 이 자료는 출발시각 기준으로 30분 단위로 집계하였다. 적용한 공간적 범위는 국가교통정보센터에서 제공하는 표준노드링크를 기반으로 하는 전국을 대상으로 하였으며, 출발, 도착 링크의 위치에 따라 교통존의 단위인 읍면동 단위로 집계하였다. 내비게이션 자료는 차량의 대수 단위(vehicle unit)로 집계 되었으며, 집계된 각 OD 교통량(vehicle trip)의 통행시간을 분 단위로 평균과 표준편차를 집계하였고, OD간 통행거리는 Km단위로 평균과 표준편차를 집계하였다.
Table 2.
Navigation row data format
수집된 내비게이션 자료를 시간대별 교통량 집중률 자료를 구축하기 위하여 출발시각 기준의 OD별 하루 시간대별 교통량 자료를 먼저 구축하였다. 전국 대상 분석에서 적용하는 교통존 규모와 일치시키기 위해 읍면동 단위에서 시군구 단위의 247개 교통존 단위로 병합하였다. 시군구 단위 교통존 OD별로 내비게이션 자료는 일주일 패턴이 평일(월-금)과 주말(토, 일)에 따라 일정한 패턴을 보이고 있으므로 365일 자료 중에 평일 261일의 자료를 사용하여 시간대별 평균 교통량과 AAWDT(Annual Average Weekday Traffic) 교통량으로 분류 정리하였다. 출발시각 기준으로 하루 24시간의 각 시간대별로 00분부터 59분까지 발행한 통행을 집계하여 시간대별 평균 교통량 자료를 구축하였다. 내비게이션 자료는 표본 자료라는 한계로 실제 OD쌍이 존재하지만 데이터상의 실제 통행거리 집계가 없는 OD쌍이 존재한다. 또한 공간적 집계단위가 교통존 단위로 변환되면서 분석의 용이성 및 일관성, 지역간 통행에서는 출발 지점의 미세한 거리적 차이는 출발 시각 선택에 큰 영향을 주지 않을 것이라는 점을 고려하며 거시적 차원의 불변 기준치을 위해 통행거리는 교통존 Centroid 간의 직선거리로 표준화 시킨 통행거리로 변환하여 OD별 통행거리 자료를 구축하였다. 247개 교통존 간에는 60,762개의 OD쌍(pair)이 존재하게 된다. 구축된 자료의 형식은 Table 3과 같다.
Table 3.
Average traffic volume for each time interval of a day between origin and destination
OD쌍을 통행거리는 5km 단위로 구분하여 집계하였으며, 350km 이상의 통행은 하나의 범주로 묶어서 Table 4와 같이 통행거리를 집계하여 자료를 구축하였다.
Table 4.
Average hour traffic volume rate to daily traffic volume by travel distance
2. 통행거리별 구분
통행은 최종 활동 목적지에서 활동 시작 시각을 고려하여 출발 시각을 결정하게 된다. 따라서 통행시간에 영향을 주는 통행 거리와 활동 목적 종류에 따라 통상적으로 통행자들은 통행시간에 소요될 시간을 감안하여 출발시각을 선택함으로 통행거리에 따라 출발시간대별 교통량 분포 역시 차이가 있을 것으로 고려된다. 따라서 출발지점과 도착지점 간 통행거리에 따라 출발시각이 다르다는 점을 반영하기 위해 하루의 시간대별 교통량 집중률 분포가 유사한 OD간 거리를 k-means 클러스터링으로 그룹화 분석하여 거리로 그룹화된 OD그룹별로 시간대별 교통량 집중률 분포패턴 자료를 구축 분석하였다.
본 연구에서는 데이터마이닝 플랫폼인 RapidMiner를 사용하여 군집화 분석을 수행하였다. 즉 5km단위로 OD간 통행거리를 집계하고, k-means 클러스터링 분석을 통해 내비게이션 자료 하루 중 시간대별 교통량 집중률의 24시간대 분포가 유사한 OD간 거리구간별 그룹을 나누는 분석이 수행되었다. Figure 2는 RapidMiner의 k-means 클러스터링 결과로 각 통행거리 패턴별 집중률 그래프를 나타낸다.
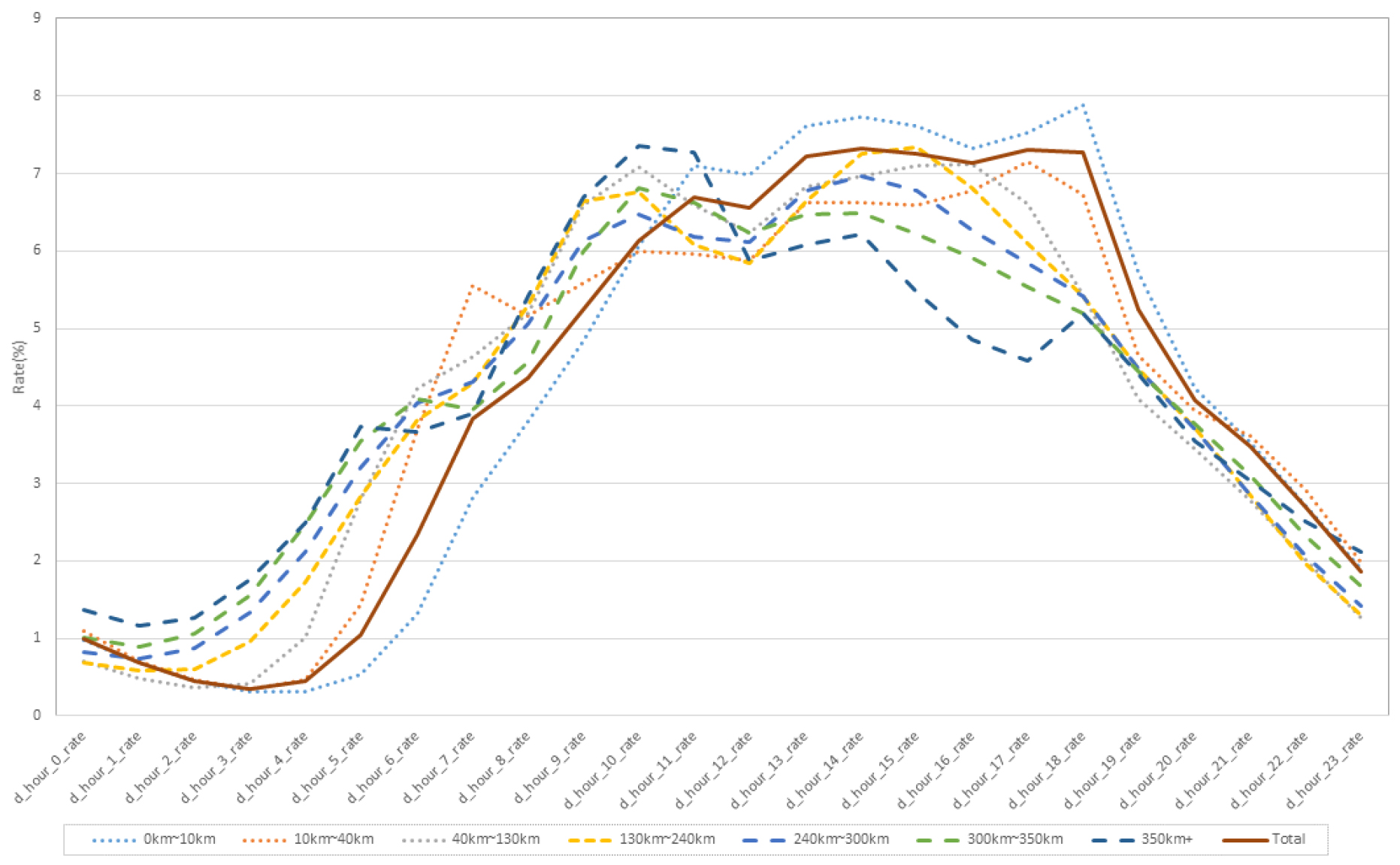
그룹의 개수인 k에 따른 ASW(Average Silhouette Width) 도출결과는 Table 5로 정리 할 수 있으며 수치상으로 k=3의 경우 ASW가 가장 높게 나왔다. 하지만 본 연구에서는 350km 이상의 거리를 나누는 것 보다는 350km 이하에 대해 좀 더 정교하게 분류 분석 하는 것이 해석상 의미성이 더 높고 통행시간 관점에서 통행자의 출발시각 선택행태 측면에서 더 명확한 행태 임계점에 대한 해석이 가능하다고 판단하여 k=7로 7개의 OD간 거리구간별 그룹으로 군집화 하였다.
Table 5.
ASW (Average Silhouette Width) of distance clustering
| k | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| ASW (Average Silhouette Width) | 0.37 | 0.44 | 0.39 | 0.40 | 0.37 | 0.38 | 0.29 |
클러스터링 결과 Table 6과 같이 각각의 임계점을 도출할 수 있었으며, 10-40km 거리를 가진 OD쌍의 AAWDT가 803,274.59대로써 가장 많은 교통량을 보였다. 또한, OD간 거리별 교통량 비율을 정리하면 Table 7과 같다. 각 거리구간별 집중률을 그래프로 표현하면 Figure 2와 같이 나타낼 수 있다.
Table 6.
Clustering results by travel distance
Table 7.
Traffic ratio of travel distance
3. 통행거리별 구분에 따른 첨두 ‧ 비첨두 ‧ 심야 군집화 및 현행지침 비교
시간대별 교통량 집중률 차이를 반영하기 위해 국내외에서 보편적으로 하루를 첨두, 비첨두 및 심야 3개의 시간대로 나누어, 각 시간대의 대표 1시간 교통량 패턴으로 시간대별 교통량 변동을 단순화하여 분석을 하고 있다. 하지만 분석의 단순화를 위한다고는 하지만 이와 같은 3개 시간대 구간으로 나누어 분석하는 것이 적합하게 현실의 시간대별 교통량 분포를 반영하고 있는지에 대해서 실측 자료를 가지고 확인 분석이 필요하다고 고려된다. 그래서 본 연구에서는 통행거리별 출발시각 선택의 차이를 반영한 상태에서 시간대별 집중률이 유사한 하루 중 시간대를 일단 3개로 하는 그룹화 분석 수행하였다.
기존에 제시된 첨두 ‧ 비첨두 지속시간과 비율은 「도로 ‧ 철도 부문 사업의 예비타당성조사 표준지침 수정 ‧ 보완 연구(제5판)」(Korea Development Institute, 2008)에서 제시한 값을 사용하였다. 본 연구에서는 일단 현행 지침과 비교를 위해서 내비게이션 자료를 활용하여 k=3인 k-means 클러스터링을 이용하였으며 구분된 3개의 그룹 중 평균 교통량 비율이 가장 큰 그룹을 첨두시, 평균 교통량 비율이 가장 낮은 그룹을 심야로 해석하여 첨두 ‧ 비첨두 ‧ 심야의 3개 그룹으로 구분하여 분석해 보았다. 즉 지침에서 첨두 ‧ 비첨두 ‧ 심야를 구분하는 방법에 대한 정확한 명시가 없어 3개의 그룹으로 고정하여 그룹화를 하여 첨두 ‧ 비첨두 ‧ 심야로 해석하여 분석 결과를 비교하였다. 지속시간은 그룹에 소속된 시간의 합으로 정의하였다.
첨두 ‧ 비첨두 ‧ 심야의 3개 시간대로 시간대 구간을 구분한 결과는 Table 8, Table 9와 같다. 첨두시간대는 각 통행거리 그룹에 대해지속시간이 10시간, 11시간, 혹은 12시간으로 분석 결과가 나왔으며, 통행거리 그룹 간에 지속시간은 같아도 하루 중 해당 시각에는 차이가 나는 경우도 있다. 내비게이션 자료 전체로 분석할 경우는 첨두 지속시간이 10시간으로 나타났다. 첨두시간대의 평균 교통량 비율은 장거리로 갈수록 낮아지게 분석되었으며 지침의 7%보다 낮게 분석되었다. 비첨두시간대의 지속시간도 5시간, 6시간 혹은 7시간으로 나타났으며, 역시 지속시간은 같아도 해당 시간대는 다른 경우도 있다. 그리고 내비게이션 자료 전체 자료의 비첨두 지속시간은 7시간으로 지침의 9시간 보다 낮게 분석되었다. 비첨두시간대의 평균 교통량 비율의 경우 통행거리 그룹별로 3.66에서 4.09%로 지침의 2.5%보다 높게 분석되었다. 심야시간의 지속시간은 7시간 혹은 8시간으로 분석되었으며, 역시 같은 지속시간이라도 통행거리 그룹별로 해당 시간대는 차이가 나는 경우도 존재한다. 그리고 전체 데이터의 심야시간대 지속시간도 7시간으로 지침의 5시간 보다 높게 분석 되었다. 심야시간대의 평균 교통량 비율은 장거리로 갈수록 높아지게 결과가 나왔다.
Table 8.
Peak ‧ non-peak ‧ night classification result of navigation data
Table 9.
Summary of peak ‧ non-peak ‧ night classification analysis result
도시교통에 있어서는 전형적으로 하루에 오전 첨두와 오후 첨두로 구분되어 보이는데 내비게이션 자료에서는 Table 7과 같이 오전과 오후의 첨두가 뚜렷하게 구분되지 않게 분석 결과가 나왔다. 이것은 출퇴근 통행과 같은 반복적인 통행의 경우 통행자들이 너무 익숙하여 내비게이션을 잘 사용하지 않는다는 특성과 OD교통량을 네트워크 분석 시 교통존의 내부 통행을 고려하지 않는다는 점을 고려해서 내비게이션 자료 중 내부통행 자료는 제거하여서 출퇴근 통행과 같이 오전과 오후 첨두 특성이 확연히 구분되는 자료가 누락되어서 나타난 현상이라고 고려된다. 이와 같이 단거리 통행 및 반복되는 통행 자료가 포함되지 않은 내비게이션 자료의 한계를 고려하고, 통행거리별 특성 반영된 시간대 그룹별 집중률 및 지속시간 분석 결과와 지침에서 제시한 값에 차이가 나는 것으로 고려가 된다.
시간대별 통행패턴 분석
1. 통행거리 그룹 시간대별 교통량 집중률 패턴 분석
본 연구에서는 또한 시간대별 집중률이 유사한 하루 중 시간대를 몇 개의 그룹으로 그룹화 하는 것이 가장 적합한가에 대한 분석도 수행하였다. 즉 하루를 유사 집중률 패턴을 보이는 시간대 구간으로 나누어 각 시간대 구간의 OD자료를 구축할 수 있도록 하고자 하는 것이다. 그럼으로써 각 시간대 구간의 대표 1시간 OD 자료를 이용하여 네트워크 분석 수행을 가능하게 함으로써 하루의 시간대 집중률 패턴을 좀 더 현실적으로 반영하고자 하는 목적이다. 그래서 출발시각 기준 하루 24시간의 각 시간대별 집중률 분포가 유사한 OD거리별 그룹화 된 앞의 절 분석 결과를 바탕으로 하루 중 시간 집중률이 유사한 시간대 그룹을 나누는 그룹화 분석을 추가적으로 수행하였다. 즉 하루를 첨두, 비첨두 및 심야의 3개 시간대로 나누는 것보다 더 현실적인 시간대별 집중률 변동 패턴을 잘 표현할 수가 있도록 하루를 몇 개의 시간대로 나누는 것이 더 적합한지를 분석을 한 것이다.
그래서 본 연구에서는 OD 거리에 따른 출발시각 차이를 반영하면서 하루 중 통행량 집중률이 유사한 시간대 그룹으로 구분하는 분석을 수행하였다. 즉, 출발시각을 기준으로 구분된 24개의 데이터와 OD 거리별 데이터의 조합 속성인 24×7의 데이터 셋으로 k-means 클러스터링 분석을 수행한 것이다.
Dursun Delen(2016)에서는 사전 지식으로 군집의 개수를 알 수 없을 때 군집분석 이전의 k값을 설정하는 Heuristic 방법들을 제시하였다. 본 연구에서도 그 방법을 활용하여 군집 개수의 초기 값을 설정하고 그 주변의 다양한 군집수를 시도하며 시행착오도 거치면서 탐색했던 것 가운데 통계학적으로 가장 최적의 군집 수로 나타나는 것으로 결정하였다. 특히 데이터 개수가 n인 경우에 k를 계산하는 방법을 사용하였으며 계산 방법은 Equation 1과 같다.
본 연구의 경우 n은 24시간에 해당되므로 24가 되며, Equation 1에 n값을 넣으면 k의 값은 3.46으로 산출된다. 이렇게 산출된 k값을 참고하면서, 또한 행태적 논리성을 반영하여 본 연구에서는 탐색 시도 할 k값의 범위를 2부터 5까지로 결정하였다.
k값을 순차적으로 2에서 5까지 하나 씩 고정시켜 가며 7개의 통행거리 구간 그룹에 대해 24시간의 24개 시간 구간별 집중률 자료를 속성으로 하여 k-means 클러스터링 분석을 실시하였다. 클러스터링 분석 결과를 가지고 7개 통행거리 그룹 간 시간대 집중률 조합 패턴이 유사한 패턴을 구분 분류하였으며, 구분된 패턴별로 단위 시간당 평균 집중률과 지속시간을 산출했다. 이와 같은 클러스터링 분석 결과는 Table 10과 Table 11에 요약 정리되어 있다.
k=2의 결과를 보면 집중률 조합패턴 2-1의 지속시간은 13시간, 조합패턴 2-2는 11시간으로 나타났으며 각 통행거리별로 평균 집중률은 각각 5.9%와 2.0%로 나타났다. 조합패턴 2-1의 평균 집중률 조합패턴은 통행거리가 길어질수록 집중률은 낮아지게 분석된 것이며, 조합패턴 2-2의 평균 집중률은 통행거리가 길어질수록 높아지게 패턴으로 나왔다.
Table 10.
Traffic pattern classification result of navigation data by distance
Table 11.
Summary of traffic pattern classification analysis result
k=3의 경우는 통행거리 그룹 간 집중률 조합패턴 3-1의 지속시간이 10시간, 조합패턴 3-2는 6시간, 조합패턴 3-3은 8시간으로 나타났으며, 평균 집중률은 각각 6.3%, 4.0%, 1.4%로 나타났다. 상세한 내용은 Table 10에 정리되어 있다.
k=4의 경우, 조합패턴 4-1의 지속시간은 10시간, 조합패턴 4-2는 4시간, 조합패턴 4-3은 4시간, 조합패턴 4-4는 6시간으로 나타났다. 평균 집중률은 각각 6.3%, 4.4%, 2.9%, 1.1%로 나타났다.
k=5의 경우는 조합패턴 5-1의 지속시간이 6시간, 조합패턴 5-2는 4시간, 조합패턴 5-3은 4시간, 조합패턴 5-4는 4시간, 조합패턴 5-5는 6시간으로 나타났다. 평균 집중률은 각각 6.4%, 6.3%, 4.4%, 2.9%, 1.1%로 분석 결과가 나왔다.
2. k-means 클러스터링 결과 평가 및 최적 클러스터링 k값 제시
여러 개의 그룹 수 k값에 대한 클러스터링 분석 결과 중 가장 현실적으로 통행거리에 따른 출발시각 차이 행태를 반영하면서 시간대별 교통량 집중률 차이 분포를 잘 설명할 수 있는 시간대 그룹 구분 개수에 대해 분석을 하였다. 이와 같은 적합한 그룹 개수를 찾기 위한 평가 방법으로는 SAS를 사용해 내비게이션 자료의 통행거리 그룹별 하루의 각 시간대 구간의 평균 교통량 집중률과 클러스터링 분석 결과에서 추정된 집중률의 유사한 정도를 비교하는 방법과 클러스터링 평가 지표를 적용하였다. 즉 Elbow method와 ASW(Average Silhouette Width), 상관계수 분석 그리고 Equation 2와 같은 절편이 없는 단순회귀모형 분석을 이용해 평가하였다.
여기서, k : 클러스터 개수(본 연구는 k=2에서 부터 k=5까지를 차례로 시도 함)
d : 통행거리그룹 d
h : 하루 0시부터 24시간까지의 1시간 구간으로 h번째 출발시간대
a : 계수
: 통행거리 그룹 d의 h 시간대 평균교통량 집중률
: 클러스터 개수 k일 때 통행거리 그룹 d의 h 시간대가 속한 패턴의 평균 집중률
특정의 클러스터 개수 k의 경우에 대하여 통행거리그룹 7개와 24개의 조합 7×24개 총 168개의 와의 상관계수를 도출하였고 또한 회귀분석을 수행하여 회귀식의 기울기 a와 을 계산하였다. 상관계수의 값이 1에 가깝게 나타날수록 모든 시간대에서 시간대별 집중률과 클러스터링 분석 결과 도출된 해당 집중률 조합패턴의 평균 집중률과 유사하다고 해석될 수 있는 것이다. 마찬가지로 Equation 2의 절편 없는 단순회귀모형에서 기울기가 1에 가깝게 나올수록 두 값 간의 차이가 없다고 해석될 수 있다.
Figure 3과 같이 군집내, 군집간 상이성을 보는 BIC 분석 결과 다양한 군집의 크기, 형태에서 적정 군집의 개수가 3-4개로 도출되었으며, Figure 4의 Elbow method의 분석결과 군집내 상이성이 크게 감소하는 클러스터링의 개수는 3개로 도출되었다. ASW(Average Silhouette Width) 산출 결과는 Table 12와 Table 13에 요약되어 있듯이 k=2일 때 ASW는 0.61로 가장 높았으며 k가 증가할수록 감소하며 k=5일 때 0.38로 가장 낮게 분석 결과가 나왔다. ASW의 변화율은 k가 2에서 3으로 변할 때가 -9.84%로 다른 군집 개수의 변화의 경우보다 가장 낮은 규모로 변화하는 것으로 분석되었다.
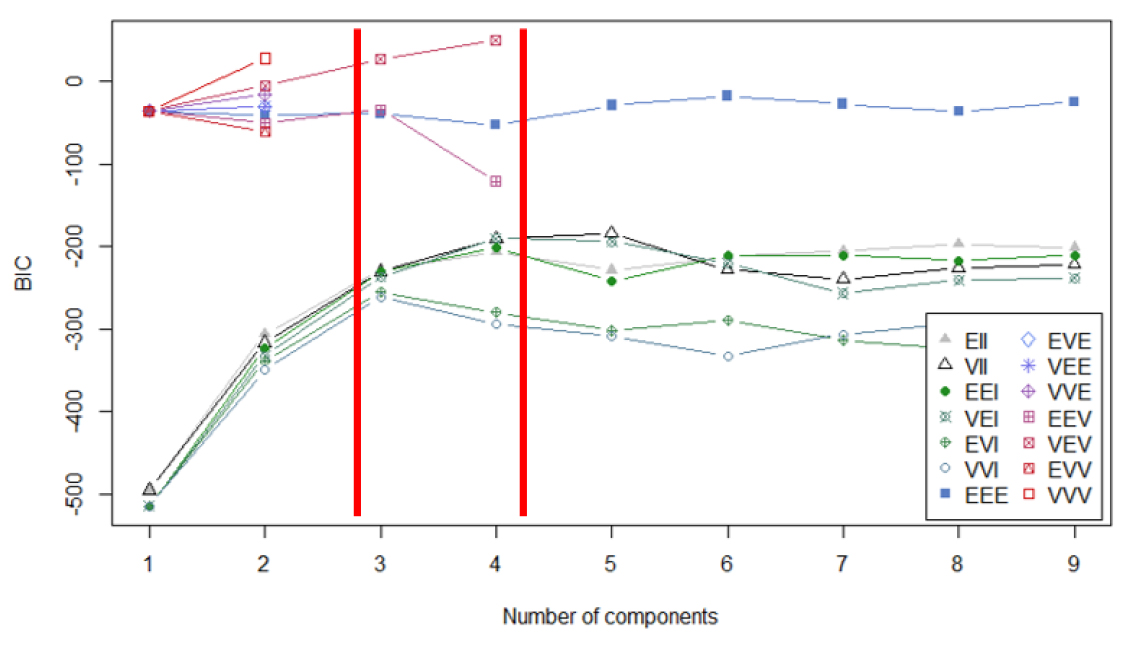
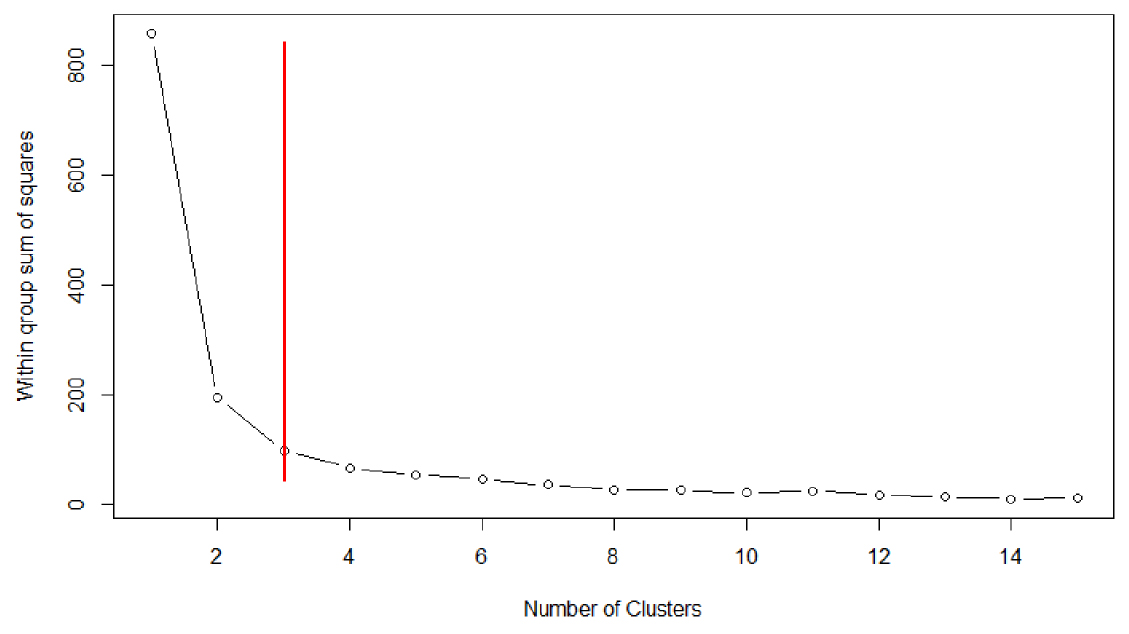
Table 12.
Summary of traffic pattern classification
| k | ASW(Average Silhouette Width) | ASW rate of change | Pearson’s correlation | |
| 2 | 0.61 | 2→4 | -9.84% | 0.8799 |
| 3 | 0.55 | 0.9448 | ||
| 4→5 | -16.36% | |||
| 4 | 0.46 | 0.9608 | ||
| 5→6 | -17.39% | |||
| 5 | 0.38 | 0.9683 | ||
Table 13.
Summary of simple linear regression result
Table 12, Table 13, Table 14의 상관분석결과를 보면 논리적으로 예상할 수가 있듯이 군집의 세분화가 할수록 상관계수가 높게 나오게 된다. 즉 k=2의 경우 상관계수 값이 0.8799, k=3은 0.9448, k=4는 0.9608, k=5는 0.9683로 나타났으며, 군집수가 증가할수록 상관계수 값의 증가 정도가 점차 작아지게 증가하게 분석되었다. 회귀분석의 결과에서는 모든 군집 개수 k값에 대해 기울기가 1이라는 귀무가설에 대해 통계학적으로 충분히 기각할 수 있게 t-value가 충분히 크고 따라서 P-value 값도 0.0001보다 작게 분석 결과가 나와 클러스터링에 의한 군집 분류에 의한 시간대별 집중률은 관측치를 매우 유사하게 설명하고 있다고 판단할 수가 있다. 결정계수 의 값도 k=2의 경우 0.9483, k=3은 0.9754, k=4는 0.9824, k=5는 0.9857로 모든 군집 개수의 경우에서 매우 높은 값으로 시간대별 집중률 변동패턴을 군집분류의 각 패턴에 의해 그 변동이 잘 설명되고 있음을 알 수가 있다. 논리적 예상과 마찬가지로 군집 개수가 증가할수록 결정계수 의 값 역시 증가하게 분석 결과가 나왔으며, 군집 개수가 증가될수록 그 증가율 폭은 점차 작아지는 것을 알 수 있다. Figure 5는 k=2, k=5 일때의 회귀식 그래프를 나타낸다.
Table 14.
Summary of clustering evaluation results
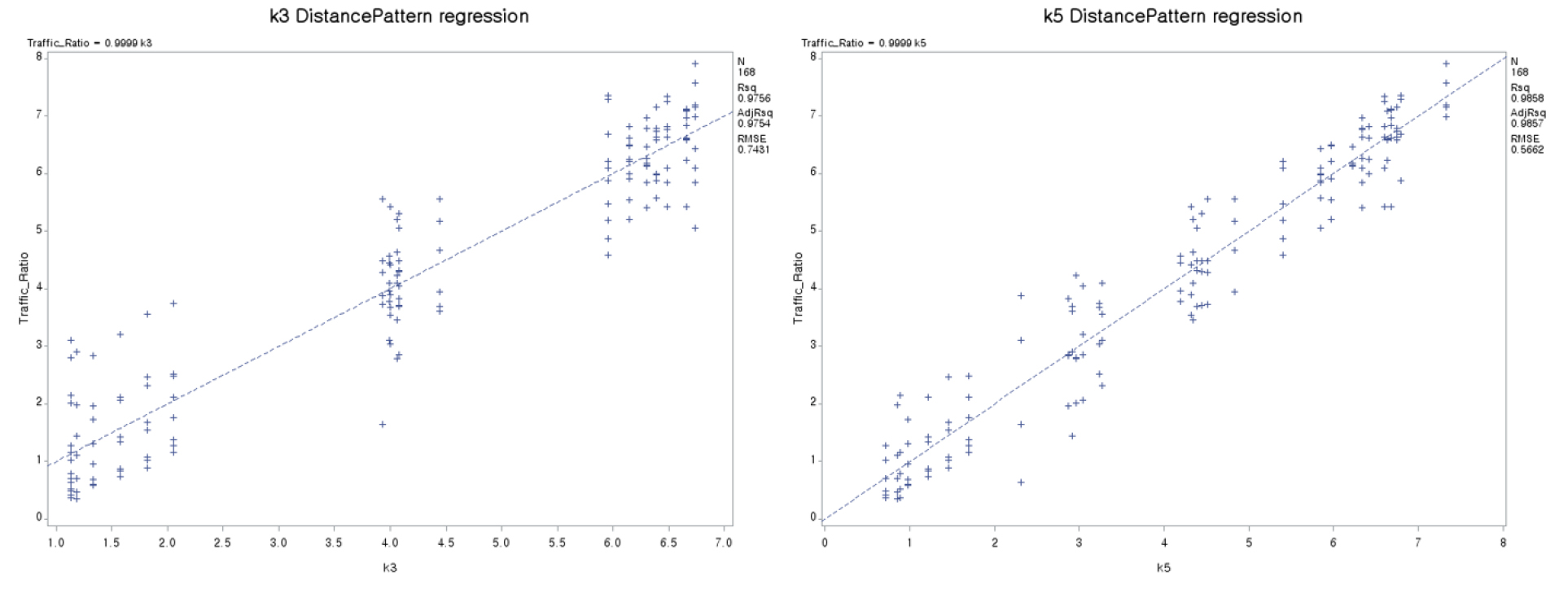
이상의 분석 결과에서 알 수 있듯이 군집 개수 k값이 증가함에 따라, 즉 현상 패턴을 상세히 구분할수록 상관계수와 회귀모형의 수정결정계수 이 증가하여 내비게이션 자료의 실측 현상을 점차 잘 설명하는 것으로 분석 결과가 나왔다. 하지만 군집 개수가 증가할수록 그 설명력의 향상 정도는 점차 줄어드는 것도 알 수가 있다. 따라서 군집 개수가 증가함에 따른 OD 자료의 시간대별 개수 증가에 의한 모형 분석의 복잡성 증가와 상세화를 통한 모형 설명력의 증가 간의 상쇄효과(trade-off)를 고려하며 하루 시간대별 군집의 적합한 개수를 결정할 필요가 있다. 현재 우리나라의 경우 하루의 시간대별 그룹을 나누어 분석할 경우 첨두시, 비첨두시 그리고 심야의 3개 시간대 그룹으로 통상 분석하고 있다. 즉 각 시간대 구간의 네트워크 상 평균 통행량을 예측 분석하기 위해서는 3개 시간대의 OD자료를 구축하고 3회의 노선배정(traffic assignment)을 수행하게 된다. 또한 각 시간대별 교통량 집중률 패턴에 따라 편익 산출도 3차례 수행하여야 전형적 하루의 교통량 패턴과 편익을 산출할 수 있게 된다. 즉 하루 중 시간대별 교통량 변동 패턴을 상세히 나누어 여러 개의 시간대 그룹과 집중률 조합패턴을 적용할 경우 통계학적 설명력은 향상됨을 앞의 분석에서 파악할 수는 있었으나, 반면에 분석 시간대별 그룹이 증가할수록 구축해야 할 시간대별 OD 수도 증가하게 되고, 또한 노선배정과 편익 산출의 횟수도 증가하여 많은 분석 노력을 요구하게 된다. 그렇다면 세분화에 의한 복잡성 증가에 의한 분석 노력과 시간의 증가에 비해 하루 시간대별 교통량 변화 패턴의 묘사 정확성 증대가 크지 않을 경우는 불필요하게 상세성을 높일 필요는 없을 것이다. 반면에 상세성을 높일 경우 노력에 비해 정확성 향상 효과가 크다면 하루 시간대 그룹을 좀 더 상세히 구분하여 분석하는 것이 바람직할 것이다. 그래서 본 연구는 앞의 통계적 분석 결과를 바탕으로 분석의 복잡성과 분석결과의 현실 정확성 사이에서 하루 중 적합한 시간대별 그룹 개수를 결정하고자 하였다.
BIC 분석의 경우 다양한 군집의 크기, 분산, 모양의 분석결과 3-4개의 군집이 적정하다고 나타났으며 Elbow method의 경우 군집이 3개 이상일 때부터 군집 내 상이성의 변화가 미비했다. ASW의 경우는 k=2일 때 그 값이 1에 가장 가깝게 분석 결과가 나온 반면에 k=4부터는 ASW가 0.5미만으로 군집간 구별성이 많이 떨어지는 것을 알 수가 있다. 군집 개수를 증가시킬 때의 ASW의 변화율을 검토하면 k가 2에서 3으로 변할 때 -9.84%로 가장 낮게 도출되어 군집 개수가 2개일 때와 3개일 때의 차이는 크게 나지 않는 것으로 분석 결과가 나온 것이다. 또한 상관분석 결과와 회귀분석의 결과를 볼 때 모든 그룹 개수에서 높은 상관계수 값과 좋은 회귀분석 결과를 보여주고 있다. 다만 군집 개수가 증가할수록 상관계수와 회귀분석 결과가 점차 좋아지지만, 그 좋아지는 정도를 분석해 볼 경우 k=2에서 k=3으로 군집 개수를 증가시킬 때가 상관계수와 회귀모형의 수정결정계수 의 값이 가장 크게 증가함을 알 수가 있다. 분석의 복잡성과 분석결과 정확성 간의 상쇄효과와 통계학적 의미성을 종합하여 고려할 때 하루의 시간대를 3개 그룹으로 구분하는 k=3일 때의 클러스터링 결과가 현실 정책분석에 적용하게에 가장 적합하다고 본 연구에서는 판단하였다. 또한, 이론적으로는 시간간격범주(Time slice)가 위의 분석과 다르게 매시간으로 짧을수록 정확성은 향상되겠지만 현재 모집단의 참값을 알 수 없어 실재 시간대별 통행 배정결과의 검증이 불가 하였으며, 본 연구는 현재 대규모 교통시설투자 정책을 분석하기 위한 정적 통행배정 OD자료 구축에 초점을 두어 분석을 진행하였다. 따라서 현재 우리나라에서 적용하고 있는 첨두, 비첨두, 심야시간대의 3개 구간 시간대 그룹으로 분석하는 것과 같이, 클러스터링 분석을 통한 7개의 OD간 거리를 고려하여 출발시각 차이를 반영하고, 통행거리별 유사 집중률 패턴이 반영된 3개의 시간대 그룹으로 분석하는 것이 실무적 분석 용이성도 반영하면서 분석 결과의 정확성도 충분히 향상시키는 시간대 구분이라고 본 연구에서는 판단했다.
내비게이션 통행패턴 구분 분석 결과 통행배정 적용방법 제시
본 연구에서 OD간 통행거리별 출발시각 차이를 반영하여 클러스터링 분석한 결과로 도출한 하루 중 1시간 교통량 집중률 조합패턴이 유사한 3개 시간대 그룹의 7개 OD 통행거리별 시간 교통량 집중률과 지속시간은 Table 14와 같다. 3개의 시간대 그룹의 유사 집중률 조합패턴을 활용하여 각 3개 시간대 그룹에 대한 OD 자료 구축 방법을 간단한 예시로 개념을 설명하고자 한다. 전일 OD 교통량에 각 시간대별의 통행거리별 교통량 집중률 조합패턴을 적용하여 해당 시간대 그룹의 OD를 구축함으로써 3개의 대표적 시간대별 OD자료를 입력 자료구축이 가능하다. 이와 같은 OD자료로 수행한 노선배정(traffic assignment)을 수행하여 하루 시간대별 교통량 변동패턴을 좀 더 현실적으로 예측 분석을 가능하게 할 것이다. 이때 정적 분석에서 사용하는 교통량-지체 함수(VDF)가 적용이 가능하며 만약 동적 OD자료 구축 후 통행배정 수행에는 새로운 교통량-지체 함수(VDF)에 관한 추가 연구가 필요하다.
Table 15.
Average traffic ratio and duration time of k=3
단순화된 예시로써 6개의 가상 교통존을 가정하였다. Table 15는 본 연구의 결과로써 하루의 3개 시간대 그룹에 대한 각 통행거리 그룹의 교통량 집중률 조합패턴 자료를 정리한 것이며, Table 16은 본 연구에서 예시로 가정한 6개의 교통존 OD 간의 통행거리에 따라 각 OD쌍에 대해 해당 거리그룹을 할당 정리한 것과 6개의 교통존간의 OD 교통량을 정리한 것이다. 각 시간대 그룹별로 대표 1시간의 OD 교통량 자료 구축은 하루 교통량 OD에 각 OD쌍의 통행거리에 해당하는 해당 시간대의 집중률을 곱함으로써 해당 시간대 그룹의 해당 OD쌍의 교통량 자료를 구축할 수 있다. 예시 자료를 이용하여 이와 같이 계산하여 시간대 그룹 1과 2 그리고 3에 대해 구축하여 정리한 것이 각각 Table 17, Table 18과 Table 19에서 표현한 것이다. 이렇게 구축된 3개의 각 시간대 그룹별 OD 교통량 자료를 입력 자료로 노선배정 분석을 수행할 경우 통행거리별 출발시각 차이를 반영한 네트워크상의 각 링크의 시간대별 교통량 분석과 예측이 가능하게 된다.
Table 16.
Example OD table of application method
Table 17.
OD table of Pattern 1
Table 18.
OD table of Pattern 2
Table 19.
OD table of Pattern 3
결론
도로 및 철도와 같은 교통시설투자 사업의 경제적 타당성을 평가하기 위해 필수적으로 수행되고 있는 교통수요 분석 결과의 정확성 향상이 필요하다는 논의는 지속되어 왔다. 자료의 부정확성은 교통 수요분석의 오차에 영향을 주는 원인들 중 하나로 KTDB의 OD자료는 가구통행실태조사를 바탕으로 구축되는데 1-2%의 낮은 표본율과 짧은 조사기간이 한계점으로 인식되어있다. 정보통신기술이 급격하게 발달함에 따라 전수에 가까운 빅데이터에 대한 기대와 빅데이터 자료들의 교통 분야 활용에 대한 연구가 활발하다. 이 연구 또한 교통 빅데이터 중 하나인 내비게이션 이용자 통행 자료를 활용한 시간대별 통행량 분포 패턴에 관한 연구이며, 경로보다는 출발 ‧ 도착 지점과 시각에 의한 도로 이용 시간대에 초점을 맞췄다.
KDI 도로철도 표준 지침 및 타 기관 지침에서 지역별로 시간대별 집중률과 지속시간을 장래 수요 예측 및 편익과 같은 사업시행 시 효과를 측정할 때 적용하도록 지침을 주고 있다. 하지만 네트워크 상 모든 지점과 모든 OD쌍에 대해 분석 지역의 첨두시와 비첨두시와 같은 특정 시간대 그룹의 통행량 집중률이 동일하다는 경직적인 가정을 하고 있다. 하지만 통행이 발생하는 시점은 직장활동, 쇼핑활동, 위락여가활동, 업무활동 등과 같이 다양한 활동들이 시작되는 시점과 장소, 그리고 해당 활동 목적지로 향하는 출발지점과의 거리에 따라 통행자의 출발시각이 선택됨에 따라 하루 중 시간대별 교통량 집중률을 획일적으로 동일하게 적용하는 것은 현실 현상과 다를 수가 있다. 따라서 본 연구에서는 내비게이션의 실측 자료를 활용하여 통행거리별 출발시각 선택의 차이를 반영하여 네트워크상의 OD쌍 거리별로 하루 중 시간대별 교통량 집중률이 유사한 시간대 그룹을 현실적으로 구분하고자 하였다.
본 연구에서는 KTDB 네트워크 및 존체계와 연계분석 가능하도록 내비게이션 데이터의 실제 출발점 및 도착점을 교통존 체계로 집계하고 통행거리를 계산하여 출발시각 기준으로 통행거리별 시간대별 교통량 분포를 분석하였다. 통행거리를 5km 단위로 나눈 후 하루 시간대별 교통량 집중률 분포패턴이 유사한 통행거리 군집그룹을 2개에서 8개 그룹 개수를 차례로 클러스터링 분석을 수행하였다. 그리고 ASW(Average Silhouette Width) 분석에 의한 지표 검토와 통행거리별 명확한 군집의 형성을 함께 고려하여 최종적으로 7개 통행거리 군집그룹 개수가 적절한 것으로 판단 결정하였다. 즉 0-10km, 10-40km, 40-130km, 130-240km, 240-300km, 300-350km, 그리고 350km 이상의 7개 통행거리 구간의 그룹 개수로 나누었을 때 시간대별 교통량 집중률 패턴이 그룹 간에는 차별화되며, 그룹 내에서는 유사한 패턴을 보이는 것으로 분석되었다.
시간대별 집중률 패턴이 유사한 시간대 그룹을 찾기 위해 앞에서 분류한 각 7개의 통행거리 그룹별로 하루 24개의 1시간 구간별 교통량 집중률 자료 즉 7⨯24의 행렬자료를 가지고 각 집중률 조합패턴이 유사한 그룹은 2개에서 5개로 점차 증가시키며 클러스터일 분석을 수행하였다. 분석 결과를 가지고 Elbow 분석, ASW 분석, 상관분석, 절편 없는 회귀분석을 수행한 결과와 실무적 분석 용이성 측면을 함께 고려하여 최종적으로 하루를 3개의 시간대 그룹으로 적합한 것으로 판단되었다. 또한 7개의 통행거리그룹으로 구성되는 각 시간대의 집중률 조합패턴이 유사한 3개 각 시간대 그룹의 정적 통행배정을 위한 교통량 OD 자료를 구축하는 방법을 본 논문에서 간단한 예시를 통해 설명하였다. 즉 OD의 거리별 출발시각 선택 차이를 반영한 하루의 3개 시간대 그룹에 대한 OD를 구축하여 통행거리별 출발시각의 차이가 반영된 네트워크상의 각 도로구간(링크) 교통량을 좀 더 현실적으로 정확하게 예측할 수 있는 네트워크 노선배정(traffic assignment) 분석을 가능하게 하고자 한 것이다.
물론, 설문조사 보다 표본율은 높지만 내비게이션 자료도 모집단이 아니고 표본 자료라는 한계는 계속 존재하고 있다. 이는 내비게이션의 이용률에 따라서 분석의 결과가 차이가 날 수 있는 부분으로 현실과 차이가 존재함을 나타낸다. 특정한 통행패턴을 반복적으로 나타나는 시간대별 통행 분포는 보정을 필요로 하며 이는 표본자료가 아닌 모집단의 신뢰할 수 있는 자료가 요구되는데, 요구를 만족시키는 자료를 구할 수 없어 보정을 수행할 수 없다는 한계가 존재한다. 또한 도시교통의 출퇴근 통행과 같이 반복적 통행경우에 익숙한 경로정보로 내비게이션을 사용하지 않는 경우가 많아 오전, 오후 첨두의 자료가 누락되는 경우가 있다는 한계점도 본 연구의 분석에서 나타났다. 따라서 출퇴근 통행과 같은 단거리 통행에 대해서는 가구통행실태조사 자료를 이용해 보완하는 등의 추가적인 연구가 필요하다. 향후, 내비게이션 자료의 수집 ‧ 가공의 완결성이 높아질수록 다양한 방법론 응용 등 다양한 활용 가능성이 증대되어 정교성 ‧ 정확성 증대가 기대된다. 다른 수단(버스, 화물차 등) 통행 설명을 위한 휴대폰 자료 및 DTG 자료 등 상호보완적 기능을 갖는 자료 간의 융합으로 더욱 정확성과 정교성을 높이는 연구가 진행될수록 본 연구가 장래에는 의미를 가질 것이다.
본 연구는 이와 같은 한계성을 감안하고, 통행거리 및 경로 그리고 출발 ‧ 도착시각에 관한 정보를 제공할 수 있는 자료 중 가장 표본율이 높은 내비게이션 자료를 활용하여, 정책분석의 정확성을 기존보다 제고시키기 위한 방안과 확장 가능성을 제시하는 것에 기여할 수 있을 것으로 고려된다.
