

서론
선행연구
서울시 생활이동데이터
1. 서울시 생활이동데이터
잠재계층분석
1. 잠재계층분석(Latent Class Analysis, LCA)
2. 모델 적합도
3. 그룹 식별 결과
결론 및 한계
서론
전통적인 4단계 교통수요 예측의 첫 단계는 통행발생(trip generation)이다. 여기서는 교통존(Traffic Analysis Zone)별로 얼마나 많은 통행량이 유출되고 유입되는지를 결정한다. 특히 통행을 크게 가구기반통행(Home-based trip)과 비가구기반통행(Non-home-based trip)으로 나눈다(Ortuzar and Willumsen, 2008). 가구기반통행은 통행의 출발지 혹은 도착지가 집인 경우를 의미하고 비가구기반통행은 출발지와 도착지가 집이 아닌 통행을 의미한다. 이렇게 가구를 기준으로 통행의 유형을 나누는 이유는 가구기반통행이 다른 유형의 통행과 성격이 다르고 예측에 필요한 설명변수도 다르기 때문이다. 주로 가구기반 통행은 통근통행이나 통학통행처럼 필수적인 통행인 경우가 많고 비가구 통행은 업무통행, 쇼핑통행, 여가통행처럼 선택적으로 이루어지는 경우가 많다. 대표적인 가구기반통행인 통근통행은 가구 특성이 중요한 설명변수로 활용되고 비가구기반 통행인 업무통행은 상업용지의 면적이 중요한 설명변수가 된다. 이 밖에도 통행의 유형은 첨두, 비첨두 등 시간에 따라 구분하기도 하고 통행자의 사회경제적 특성에 따라 구분하기도 한다. 승용차 통행, 지하철 통행 등 교통수단별로 구분하기도 한다(Ortuzar and Willumsen, 2008).
우리나라도 교통체계효율화법에 근거해 5년마다 시행하는 가구통행실태조사에서 통행 목적을 배웅, 업무, 귀가, 출근, 등교, 학원수업, 쇼핑, 여가, 외식, 친지방문, 기타 등으로 구분하고 있고, 수단별로는 보행, 자전거, 이륜차, 승용차, 버스, 지하철 등으로 구분한다. 이러한 통행 분류체계는 가구통행 설문조사 항목 등 미리 정해 놓은 양식에 그대로 반영된다. 따라서 설문조사 결과를 이용하면 통행 유형별 특성을 바로 확인할 수 있다. 가령 업무통행 등 통행목적별 통행시간이나 거리의 특성을 알 수 있다.
하지만 사전에 통행유형을 설정하지 않더라도 이미 이루어진 통행자료를 이용하여 어떤 통행유형이 두드러지게 나타났는지 사후적으로 추론하는 것도 가능하다. 예를 들어 이동통신 데이터를 이용하여 통행의 유형을 추정할 수 있다. 스마트폰 등 개인이 사용하는 이동통신장치와 연결된 기지국의 위치와 연결시간 등의 정보를 이용하면 사람들의 통행 출발지와 도착지, 출발시간, 도착시간 등을 알 수 있다. 이런 세부 데이터를 이용하면 어떤 유형의 통행이 주로 나타나는지 추정해 볼 수 있다. 이는 마치 주성분분석(Principle Component Analysis, Ghosh, 1991)을 통해 공분산이 큰 변수들의 조합으로 관찰되지 않은 잠재변수의 특성을 찾아내는 것과 유사하다.
본 연구는 기존의 가구통행실태 조사 결과가 아닌 서울시에서 제공하는 생활이동데이터1)를 이용하여 관측된 통행들 중에서 두드러진 통행유형을 찾고자 한다. 생활이동데이터는 스마트폰 이용자들의 위치와 체류시간을 이용하여 사람들의 야간 상주지역과 주간 상주지역의 위치를 추정하고 이를 기반으로 서울시 행정동별로 통행을 집계하여 제시하고 있다. 이 데이터에는 통행 목적이나 이용한 교통수단 정보는 없다. 단순히 출발지와 목적지, 출발시간, 도착시간, 통행자의 성별과 연령 등의 정보만 알 수 있다. 대신 통행 데이터의 샘플 수는 기존 가구통행실태조사 자료보다 훨씬 많은 빅데이터 수준이다. 한 달 통행데이터가 2천 4백 7십만 건에 이른다. 제한된 정보이지만 이를 이용하면 유사한 성격을 갖는 통행의 유형을 더 많은 표본을 이용하여 분석할 수 있는 장점이 있다.
분석방법으로는 일반적으로 사용되는 기술적 통계모형(descriptive model)이 아니라 자료에 내포된 특징을 찾아내는 설명적 통계모형(explanatory model)중 하나인 잠재계층분석(Latent Class Analysis) 기법을 활용한다. 이 기법은 비지도학습(unsupervised learning) 기법 중 하나로 데이터의 세부 내용을 근거로 공통된 패턴을 가진 계층을 유형화한다. 심리학, 의학분야에서 이미 광범위하게 사용되는 통계적 방법이다. 일반적으로 잠재계층분석에서는 주어진 표본이 지닌 다양한 설명변수 값의 범주에 따라 가상의 계층(class)에 속할 확률을 계산하고 이후 계층의 특징을 해석하는 방식으로 연구를 수행한다. 따라서 직접적으로 조사되지 않았지만 자료에 내재된 계층의 특징을 알 수 있는 장점이 있다. 교통분야에서는 Rafiq and McNally(2021)과 Kim and Choo(2019) 등의 연구에서 수단선택과 관련한 통행자 유형을 분류한 것이 대표적이다.
이후 논문의 구성은 다음과 같다. 우선 통행유형 특징 및 잠재계층분석과 관련된 기존 연구를 고찰하고, 서울시 생활이동데이터 수집방법과 주요 특성을 소개한 후, 이를 이용한 잠재계층분석 결과를 제시한다. 특히 서울시 생활이동데이터에서 나타난 통행유형을 찾고 그 의미를 분석한다.
선행연구
선행연구는 통행특성을 분석한 연구와 잠재계층분석을 교통분야에 적용한 연구로 나누어 살펴본다. 우선 통행특성 분석과 관련해서 Oh(2014)는 2010년 가구통행실태조사 자료를 이용하여 통근통행, 통학통행, 쇼핑통행, 여가통행의 특성을 사용된 교통수단, 통행거리 측면에서 비교하였다. 통근통행은 보행 비중이 낮고, 승용차 비중이 높았으며 평균통행거리도 긴 것으로 나타났다. 통학통행은 보행의 비중이 63.9%로 가장 높게 나타났으며 통행거리도 상대적으로 짧게 나타났다. Bin et al.(2012)는 미혼청년기, 가족형성기, 자녀교육기, 자녀청년기, 자녀독립기, 노년기 등 생애주기별 통근통행시간에 영향을 주는 요소를 살펴보았다. 평균통행시간은 자녀교육기가 1시간42분으로 가장 높았으며 노년기는 1시간 9분으로 가장 낮았다. Alexander et al.(2015)는 통신데이터를 이용하여 기종점 통행량, 출근통행량 등을 추정하고 이를 국가 통행량 조사 내용과 비교하였다. 그 결과 주중 일일 통행량은 통신데이터 추정값과 국가통행량 조사값이 각각 2.11과 2.10 백만 통행으로 유사하게 나타났다. 평균통행거리도 각각 9.67마일과 10.72마일로 크게 차이나지 않았다. 이 연구는 통신데이터를 이용해 통행실태조사를 보완하거나 정확도를 높이는데 활용될 수 있음을 잘 보여주었다.
교통분야에서 잠재계층분석 기법은 통행의 유형을 구분하고 그 특성을 파악하는데 활용되고 있다. 우선 Molin et al.(2016)은 네덜란드의 18세 이상 대중교통 이용자를 대상으로 한 설문조사 자료를 이용해 다수단을 선택하는(목적 통행을 위해 여러 교통수단을 이용하는 경우) 통행자 그룹을 잠재계층분석으로 식별하고, 해당 그룹의 연령, 소득, 차량소유 여부 등 인구사회학적 특징을 분석하였다. 그 결과 승용차와 다수단을 모두 선호하는 기혼 남성 그룹, 승용차 위주로 이용하는 기혼 남성 그룹, 자전거 위주의 다수단을 선호하는 젊은 비혼 여성 그룹, 자전거와 차량을 주로 이용하는 자녀가 있는 저학력 기혼 여성 그룹, 대중교통 중심의 다수단을 선호하는 젊은 그룹 등이 식별되었다. Davis et al.(2018)은 캘리포니아 가구통행조사 자료를 이용한 잠재계층분석을 통해 비통근 통행 중 장거리 통행의 유형을 식별했다. 비중이 높은 순서대로 각각 당일 여행, 주말 장기 여행, 승객 통행, 비즈니스 출장, 휴가 등으로 구분되었다. Delbosc and Naznin(2019)는 호주 빅토리아주의 21-25세 청년을 대상으로 한 설문조사 데이터를 사용해 잠재계층분석으로 인구사회학적 특징과 차량 및 대중교통 이용 빈도 등의 모빌리티 패턴을 식별하고 비교하였다. 우선 생애주기별 특성에 따라 전형적 그룹, 전형적 단계에 진입하는 그룹, 독립적 그룹, 차량 소유 또는 소유하지 않은 채로 사회진입이 늦어진 그룹으로 구분하였다. 부모로부터 독립하고 기혼자가 많은 전형적 단계의 그룹일수록 차량 이용과 시내 거주 경향이 컸고 독립적 그룹은 높은 차량 이용률을 보였다. 차량이 없고 사회진출이 늦어진 그룹은 대중교통 및 보행 이용률이 가장 높은 것으로 분석되었다. Kroesen(2019)는 보행, 자전거 등의 활력통행(active travel)으로 이동한 거리가 건강위험요인과 가지는 관계를 잠재계층분석을 통해 분석하였다. 그 결과 활력 통행이 많고 앉아서 생활하는 습관과 흡연, 음주 수준이 낮은 그룹, 활력 통행으로 통근하는 그룹, 신체활동이 많으나 활력 통행이 적은 그룹, 활동 수준이 낮은 그룹과 건강에 해로운 습관을 가진 그룹이 식별되었다. Rafiq and McNally (2021)은 2017년 미국의 가구통행조사 자료를 활용한 잠재계층분석으로 대중교통 이용자의 유형을 식별하고 비교하였다. 그 결과 주거지에서 직장으로만 이동하는 단순 통근자, 여러 교통수단을 이용하거나 출장지로 이동하는 기타 통근자, 여러 교통수단을 이용해 직장 및 기타 목적지로 이동하는 통행자, 단순 비통근 통행자, 여러 목적지로 이동하는 복잡한 통행을 하는 비통근 통행자로 구분되었다. 국내 연구로 Kim and Choo(2019)는 2010년 서울시 가구통행실태조사 자료를 활용하여 출근통행에 대한 잠재계층을 토지이용특성을 이용하여 두 가지로 분석하였다. 첫 번째 계층은 승용차와 대중교통의 분담율이 비슷하고 주거시설이 많은 지역이고, 두 번째 계층은 대중교통 분담률이 높고 토지이용이 업무 및 상업시설인 경우로 나타났다.
한편, 서울시 생활이동데이터를 이용해 도시와 교통특성을 분석한 연구도 늘어나고 있다. Park et al.(2022)는 PageRank 알고리즘을 적용하여 도시활력을 정량적으로 평가하였다. 도시활력은 통근 통행과 비통근 통행으로 나누어 평가하였다. 분석결과 토지이용과 건축물 나이가 다양할수록, 건축물 평균나이가 적을수록, 교차로 밀도가 높고 가로경관을 안전하게 인식할수록 도시활력이 높은 것으로 나타났다. Lee and Lee(2022)은 커뮤니티 디텍션 기법을 활용해 여러 행정동을 하나의 커뮤니티 생활권으로 정의하고, 계층적 클러스터링을 통해 생활권역을 업종 구성에 따라 분류하였다. 이후 클러스터별로 코로나19 전후의 통근 패턴 변화를 분석하였다. 생활권은 특징 없음, 제조업, 보건·교육, 정보통신·전문과학기술, 금융 등 5개 유형으로 분류되었다. 이 중 제조업에 특화된 클러스터는 코로나19 이후에도 통근 통행량이 유지된 반면 정보통신업 및 전문과학기술서비스업, 금융업에 특화된 클러스터는 통근 통행량이 줄어든 것으로 나타났다.
본 연구는 가구통행 실태조사 자료가 아닌 통신 데이터에서 추출한 생활이동데이터를 이용하여 서울시에서 주로 나타나는 통행의 특징을 분석해 본다는 의미가 있다. Alexander et al.(2015)처럼 통신 데이터를 이용하여 통행실태를 파악한다는 차원에서 유사하지만 잠재분석기법을 적용하여 통신 데이터에 내재된 주요 통행유형을 파악한다는 점에서 차이가 난다. 또한 생활이동데이터는 가구통행실태조사 데이터와 달리 표본수가 매우 많은 빅데이터 성격을 가지므로 현실을 더 정확히 파악할 수 있는 장점도 있다.
서울시 생활이동데이터
1. 서울시 생활이동데이터
서울시 생활이동데이터는 KT 모바일 데이터를 활용해 추정한 통행량을 우리나라 전체 인구의 통행량으로 보정한 데이터이다. KT 휴대폰을 사용하는 사람 중 LTE와 5G 가입자의 신호에 기반해 KT의 시장점유율 및 LTE/5G 가입 비율 등을 고려하는 보정 과정을 거친다. 서울시 생활이동데이터를 활용하면 시간대 및 행정동 단위로 보정된 인구수와 10분 단위의 평균통행시간을 알 수 있다. 출발지 및 도착지는 체류 유형에 따라 주간 상주지, 야간 상주지 및 기타 지역으로 분류되어 행정동 코드와 함께 제공된다. 80대 이상 및 10세 미만을 제외한 모든 연령에 대한 5세 단위와 성별 통행패턴도 파악할 수 있다. 본 연구에 사용된 변수는 Table 1에 제시되어 있다. 이 데이터는 서울 열린 데이터 광장(data.seoul.go.kr)에서 수집할 수 있다.
Table 1.
Data description and sample of Seoul Living Migration Data (from data.seoul.go.kr)
서울시 생활이동데이터는 개인을 식별할 수 없는 집계 데이터로 4단계를 거쳐 수집된다. 1단계로 휴대폰이 특정 기지국과 주고받는 신호를 통해 대략적인 위치를 추정한 후 기지국과 연결된 시간 정보를 바탕으로 가입자의 이동 혹은 체류 상태가 추정된다. 2단계에서 새벽 5시를 기준으로 주간 상주지와 야간 상주지를 구분한다. 새벽 5시 이후 체류시간이 길면 주간 상주지로, 새벽 5시 이전의 체류시간이 길면 야간 상주지로 분류한다. 3단계에서는 KT 가입자의 수를 전체 인구로 전수화하기 위한 보정계수를 적용한다. 이를 위해 KT 휴대폰 시장점유율 보정계수, KT 가입자 내 LTE 및 5G 서비스 가입률 보정계수, KT 휴대폰 전원이 켜져 있는 비율의 보정계수를 차례로 적용한 뒤 마지막으로 연령 및 성별 추가 보정을 거친다. 연령별 보정 시 휴대폰 사용 비율이 낮은 10세 미만이나 80세 이상의 경우에는 한 명의 휴대폰 사용자가 열 배 가깝게 확대 보정되는 경우도 있다. 마지막 단계는 기지국 단위의 이동을 집계 공간 단위로 산출하고 평균통행시간을 계산한다.
서울시 생활이동데이터는 한 달에 수집되는 행의 개수가 약 1억 개에 달하기 때문에 분석에 소요되는 시간을 줄이기 위해 분석 기간을 한 달로 제한했다. 12개월 중 월간 통행량이 가장 많은 22년 8월 한 달 동안 서울시 내부에서 발생한 통행만 추출해 분석하였다. 주중과 주말 통행을 구분하기 위해 화요일, 수요일, 목요일에 발생한 통행을 주중 통행으로, 토요일과 일요일에 발생한 통행을 주말 통행으로 구분하였다(Table 2). 월요일과 금요일 통행은 주중 통행에서 제외하였다. 월요일과 금요일은 주말과 붙어있어 화, 수, 목요일과는 통행패턴이 조금 다르게 나타나기 때문이다. 도착시간은 6개 범주로 분류하였다. 이른 오전 출근시간인 07:00-09:00시, 09:00-11:00시, 점심식사 시간인 11:00-14:00시, 14:00-17:00시, 퇴근 및 저녁식사 시간인 17:00-20:00시, 20:00-24:00시로 구분하였고 통행량이 극히 적은 새벽 시간대는 분석에서 제외하였다.
Table 2.
The number of categories by variables
기종점 목적지 유형은 야간 상주지에서 다시 야간 상주지로, 또는 야간 상주지에서 주간 상주지나 기타 장소로 이동하는 HH, HW, HE 유형, 주간 상주지에서 다시 주간 상주지로, 또는 주간 상주지에서 야간 상주지나 기타 장소로 이동하는 WW, WH, WE 유형, 기타 장소에서 다시 기타장소로, 또는 기타장소에서 주간 상주지나 야간 상주지로 이동하는 EE, EW, EH 유형의 통행을 모두 포함하였다. 평균통행시간은 20분 미만 단거리 통행 및 60분 이상 장거리 통행을 제외하고는 10분 단위로 분류하였다. 개인 특성으로는 성별에 따라 2개 범주, 연령에 따라 6개 범주를 구분하였다. 통행패턴이 거의 동일한 10대와 표본이 매우 적은 80대 이상을 분석에서 제외하였고, 나머지 연령을 10세 단위로 분류하였다.
데이터 가공 결과 총 24,697,645건의 샘플이 수집되었다. Table 3에 제시된 것처럼 전체적으로 여성이 남성보다 관측 수가 더 많았고 연령대가 젊을수록 관측 수가 많았다. 성별로는 여성이 15,217,352건(61.6%)으로 남성 9,480,293건(38.3%)에 비해 약 570만 건 더 많았다. 연령별로는 비교적 젊은 20대, 30대에서 각각 575만 건, 506만 건으로 23.3%, 20.5%를 차지해 가장 많았고, 70대는 270만 건으로 가장 적은 10.9%를 차지했다. 50대와 60대는 약 330만 건으로 13%를 차지했고, 40대는 458만 건으로 18.6%를 차지했다. 주중 데이터는 관측 일수가 화, 수, 목 등 3일이고 주말 데이터는 토, 일 등 2일에 그치기 때문에 주중 데이터가 19,225,256 건으로 77.8%를 차지하고, 주말 데이터는 5,472,388건으로 22.2%를 차지하였다. 도착시간은 모든 시간대에 고르게 분포되는 경향이 있었고 퇴근시간인 17:00-20:00에 가장 많은 5,935,334 건으로 24.0%를 차지하고, 20:00-24:00에 가장 적은 2,973,565 건으로 12.0%를 차지했다.
Table 3.
The number of samples by variables
통행 기종점 유형의 상당수인 16,493,277건(66.8%)은 출발지 혹은 도착지가 야간 상주지인 통행이었고 나머지 8,204,368건(33.2%)은 출발지 혹은 도착지가 주간 상주지와 기타 장소와 연관된 통행이었다. 통행시간은 20분-60분 범위에서 비교적 고르게 분포되었고, 평균통행시간이 60분 이상인 장거리통행이 9,945,696 건(40.3%)으로 가장 많았고, 20분 이하 단거리 통행은 1,484,405 건(6.0%)으로 가장 작게 관측되었다.
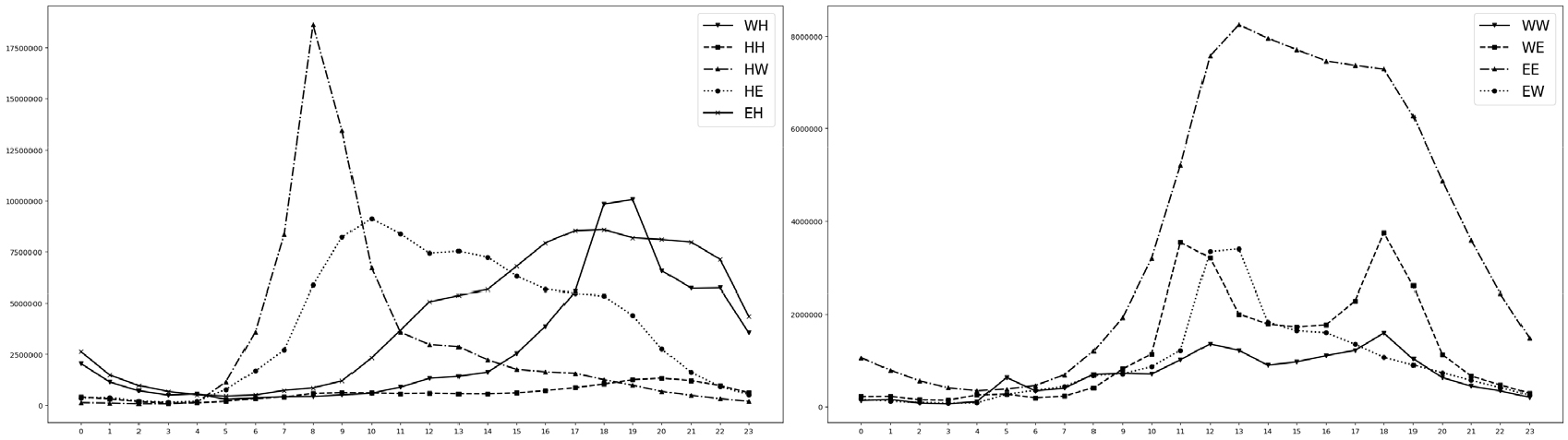
모든 연령의 통행을 기종점 유형별로 합계하여 시간별로 나타낸 결과는 Figure 1과 같다. 가로축은 1시간 단위 시간을, 세로축은 통행량을 나타낸다. 우선 주간 상주지와 야간 상주지를 오가는 통행(HW)이 출퇴근 시간에 첨두현상을 보인다. 출근 시간인 08-09시에 야간 상주지에서 주간 상주지로 가는 통행량이 가장 높았고, 퇴근시간인 오후 5시 이후에는 주간 상주지에서 야간 상주지로 이동하는 통행량이 크게 늘었다. 점심 및 저녁 시간에는 식사 및 사교활동을 위해 이동하는 직장인이 늘면서 주간 상주지에서 기타 지역으로 통행하는 통행(WE)이 두드러졌다. 야간 상주지에서 기타장소로 이동하는 통행(HE)은 출근시간 혼잡을 피해 10-11시 사이 가장 많았고, 오후와 저녁 시간 동안 야간 상주지로 돌아오는 패턴을 보였다. 기타 장소에서 주간 상주지로 이동하는 통행(EW)은 점심시간대(12-14시)에 가장 높고 시간이 지날수록 통행량이 줄어들었다.
잠재계층분석
1. 잠재계층분석(Latent Class Analysis, LCA)
잠재계층분석은 군집분석의 일종으로 데이터에 숨은 잠재적 계층(latent class)을 찾아내는 분석 방법이다. 일반적인 군집분석(clustering analysis)처럼 같은 계층(class)에 속하는 자료들은 동질적이고 다른 계층에 속하는 자료와는 차이가 나도록 구분한다(Sinha et al., 2022). 사전에 특정한 학습과정 없이 계층을 구분한다는 차원에서 비지도(unsupervised) 학습으로 볼 수 있다. 하지만 잘 알려진 k-평균 클러스터링(k-means clustering)이나 계층적 군집분석(hierarchical clustering)과는 중요한 차이를 갖는다. k-평균 클러스터링이 유사한 관측치를 계층 혹은 군집별로 할당하는 기술적(descriptive) 기법이라면, 잠재계층분석은 데이터의 구조(군집의 개수, 속성의 개수, 속성별 범주값 등)에 관한 확률 모델을 관측치에 적합시키는 설명적(explanatory) 기법이기 때문이다(Linzer and Lewis, 2011). 따라서 유사성에 기반한 전통적 군집분석에서는 특정 관측치가 오직 한 계층에만 배타적으로 속할 수 있는 반면, 잠재계층분석에서는 관측치가 특정 군집, 특정 속성에 속할 확률이 추정된다.
본 연구에서는 잠재계층분석을 사용하여 서울시 생활이동데이터에 담긴 주요 통행유형을 파악하고자 한다. 이 자료는 가구통행 실태조사 자료처럼 통행의 목적이나 수단 등을 구체적으로 제시하지 않았기 때문에 일반적인 목적통행의 공간적, 시간적 분포를 알기 어렵다. 하지만 잠재계층분석 기법을 이용하면 특징적인 통행유형을 분류할 수 있다.
잠재계층분석에서는 각 관측치가 지닌 여러 범주형 변수(categorical variables)에 대한 선택 조합을 이용해서 전체 관측치 안에 있는 상호 배타적인(mutually exclusive) 잠재계층(latent classes)을 찾아낸다. 이를 위해 개별 관측치(member)가 특정 계층에 속할 확률(the class membership probability)과 특정 계층에 속하는 관측치가 범주형 변수별로 응답할 확률(the class-conditional probability)을 이용해 우도함수(likelihood function)를 만들고 이를 최대화하는 방식으로 파라미터를 추정한다. 한편, 잠재계층분석 모델에는 범주형 변수가 일반적으로 사용되었지만 연속형 변수를 사용하는 방법도 개발되어 활용되고 있다(Sinha et al., 2021; Davis et al., 2018). Rafiq and McNally(2021)는 범주형 변수일 경우 특정 관측치가 나타날 우도함수 를 Equation 1과 Equation 2와 같이 정리하였다.
여기서, 는 한 관측치가 특정 계층에 속할 확률(the class membership probability)
는 계층 에 속하는 관측치(observation)가 설명변수에서 번째 응답을 할 확률(the class-conditional probability)
= 1 또는 0
=1 만약 관측치 가 번째 범주형 변수에서 번째 응답을 할 경우
= 0, 그 외의 경우
여기서 ,
Equation 1을 기반으로 N개의 관측치에 대해 우도함수를 만들면 Equation 2와 같다.
2. 모델 적합도
본 연구에서는 계층의 개수를 2개에서부터 5개까지 하나씩 추가해 가며 모형의 적합도를 평가하였다. 따라서 Equation 1의 계층(class) 갯수를 의미하는 는 2, 3, 4, 5로 늘려나갔으며. 범주형 변수에 해당하는 속성의 개수인 의 값은 성별은 2가 되고, 연령은 6, 도착시간은 6 등을 적용하였다. 일반적으로 잠재계층모형에서는 적합도를 평가할 때 AIC(Akaike Information Criterion), CAIC(Consistent Akaike Information Criterion), BIC(Bayesian Information Criterion), 그리고 SSABIC(Sample-Size Adjusted Bayesian Information Criterion) 등을 사용한다. 이 값은 Table 4에 보이는 것처럼 계층의 개수가 2개에서 5개로 증가하면서 지속적으로 감소했다. 해당 지표들은 작은 값을 나타낼수록 더 적합한 모델임을 의미한다. 또 다른 평가 지표인 LMR-LRT(Lo-Mendell-Rubin Likelihood Ratio Test)은 p-value를 통해 모델의 적합도를 나타내며, 측정 결과 군집 개수를 2개로 설정한 경우부터 5개로 설정한 모형까지 0.001수준에서 모두 유의한 것으로 나타났다. 모형이 개인을 특정 집단으로 얼마나 정확히 분류하는가에 대한 판단 기준인 Relative Entropy 값은 군집 개수를 2개로 설정한 모형이 0.928으로 가장 높았고, 5집단 모형이 0.837로 가장 낮은 것으로 나타났다. Relative Entropy 값은 특정 계층의 분류가 1 혹은 0을 나타내는 경우는 매우 적기 때문에, 일반적으로 0.7이상의 값을 가질 경우 비교적 정확히 분류되었다고 간주한다(Nagin, 2005). 다양한 지표의 통계적 기준과 유의성을 고려할 때 최적 계층의 수는 5개로 판단된다.
Table 4.
Goodness of fit
3. 그룹 식별 결과
Table 5는 전체 통행자료를 다섯 개 계층으로 분류할 경우의 결과를 보여준다. 계층 1일 확률이 24.9%로 가장 많고, 계층 5일 확률이 10.2%로 가장 낮은 것으로 나타났다. 각 계층은 통행 특성 측면에서 차별성이 뚜렷하다.
우선 계층 1은 일반적인 통근 통행의 특징을 잘 보여준다. 20대에서 50대 사이 통행일 확률이 81.7%를 차지하고 주중 통행일 확률이 96.3%를 차지한다는 점이 그렇다. 도착시간이 오전 9시까지일 확률이 61.2%, 11시까지로 늘리면 98.1%나 된다는 점, 야간 상주지에서 주간 상주지 통행(HW)일 확률이 98%나 차지한다는 점이 이를 잘 보여준다. 통행시간 측면에서는 60분 이상 장시간 통행 확률이 46.4%로 5개 계층 중 가장 높은 비중을 차지한다.
Table 5.
Result of LCA with 5 classes
계층 2는 고령자 통행의 특징을 잘 보여준다. 우선 60세 이상 통행 비중이 68.3%나 된다. 도착시간 측면에서는 첨두시간을 벗어난 오전 9시부터 오후 5시까지가 83.4%를 차지한다. 즉 대부분의 통행이 오전, 오후 첨두시간을 피해서 이루어진다. 또한 야간 상주지에서 기타지역 통행(HE)이 48%로 가장 높은 비중을 차지한 점도 고령자 통행의 특징으로 볼 수 있다. 대신 오전 첨두시간 통행 비율은 6.2%로 낮다. 통행시간 측면에서는 20분 미만의 단거리 통행이 15.2%나 된다. 여성의 통행 비중이 81%나 된다는 점도 특이하다. 기존 연구에서도 고령자는 첨두시간을 피해 비첨두시간에 통행이 집중되며(Kim et al., 2021; Szeto et al., 2017), 통행거리와 통행시간이 감소하고(Shirgaokar et al., 2020; Kim and Kwon, 2020; Yang et al., 2018), 통행목적에서 통근 통행의 비중은 감소하고 쇼핑·여가·오락 통행이 증가하는 특징이 있는 것으로 나타난다(Han et al., 2020; Choo et al., 2013).
계층 3은 귀가 통행의 특징을 잘 보여준다. 주중 통행일 확률이 92.7%이고, 도착시간이 오후 5시 이후일 확률이 96%나 된다. 주간 상주지에서 야간 상주지로 통행(WH)할 확률이 67.1%, 기타 지역에서 야간 상주지로 통행(EH) 확률도 25.8%이다. 통행시간도 60분 이상일 확률이 40.3%로 가장 높다. 계층 4는 여가 통행의 특징을 잘 보여준다. 주말 통행일 확률이 58%로 주중보다 높고, 연령별로는 20대에서 50대일 확률이 92.3%로 고령자 통행일 확률은 낮다. 도착시간 측면에서도 오후 2시부터 8시까지일 확률이 61.7%나 된다. 통행 목적은 기타지역에서 기타지역 통행(EE)일 확률이 62.5%나 된다. 마지막으로 계층 5는 업무통행의 특징을 잘 보여준다. 주중 통행일 확률이 99.8%나 되고 남성의 통행일 확률이 62.6%로 여성일 확률 37.4%보다 훨씬 높다. 연령별로는 20대에서 50대일 확률이 91.4%나 되고 업무시간이 11시에서 14시 사이 통행일 확률 비중이 65.5%나 된다. 또한 주간 상주지에서 기타지역(WE)일 확률이 36.2%, 기타지역에서 기타지역 통행(EE)일 확률이 36.2%로 가장 높다. 통행시간 측면에서는 50분 미만의 단거리 통행일 확률이 73.7%를 차지한다.
결론 및 한계
본 연구에서는 KT 모바일 데이터에 기반한 서울시 생활이동데이터 24,697,645 표본을 잠재계층분석을 통해 두드러진 통행유형을 파악하였다. 그 결과 통행을 5개의 계층으로 분류하였을 때 가장 통계적으로 적절한 것으로 나타났다. 또한 5개 통행은 선택확률이 높은 순으로 통근 통행, 고령자 통행, 귀가 통행, 여가 통행, 업무통행 등으로 해석되었다. 빅데이터로 볼 수 있는 생활이동데이터 분석 결과 두 가지 시사점이 발견되었다. 이는 기존의 가구통행실태조사 데이터에 기반한 교통분야 잠재계층분석과 차별화되는 내용이다.
첫째, 기존의 가구통행실태조사에서 중요하게 다뤄왔던 통근통행, 귀가통행, 여가통행 업무 통행 등이 중요한 통행 유형인 것으로 확인되었다. 이는 가구통행실태조사에서 사용하는 조사항목이 적절함을 의미한다.
둘째, 잠재계층분석 결과에서 가장 눈에 띄는 점은 고령자 통행이 통근 통행 다음으로 중요한 통행유형이라는 점이다. 고령자 통행은 그동안 중요하게 다뤄지지 않았지만 빅데이터로 볼 수 있는 생활이동데이터 분석을 통해 중요한 통행임이 새롭게 발견되었다. 이는 잠재계층분석이 관측치의 기술통계에서는 알 수 없는 잠재된 계층의 특징을 알게 해주는 설명적 모형(explanatory model)이기 때문이다.
고령자 통행이 중요한 유형으로 나타난 이유는 최근 65세 이상 인구가 크게 늘어났기 때문으로 보인다. 또한 고령자의 사회적 활동이 예전과 크게 다르다는 점도 영향을 끼쳤을 것이다. 이는 교통 측면에서 고령자를 중요한 통행 계층으로 인식하고 이들을 위한 맞춤형 정책이 개발될 필요가 있음을 보여준다. 가령, 고령자 지하철 무료요금 제도는 이런 측면에서 고령자의 통행 활동을 지원하는 긍정적인 효과가 있다. 다만 크게 늘어나는 고령자 통행량을 고려할 때 무료화로 인한 운영 비용의 증가도 큰 부담이 될 것으로 보인다. 지하철 무료화에 소요되는 재원을 보다 합리적으로 사용하여 고령자의 이동 서비스는 향상시키고 지하철 운영부담은 낮추는 정책 개발이 중요한 시점이다.
본 연구는 잠재계층분석을 수행할 때 범주(category)의 계층을 구분하지 않은 한계가 있다. 일반적인 잠재계층분석에서는 사회경제적 변수에 해당하는 연령, 성별 등의 변수로 계층에 속할 확률을 별도로 계산하고 다른 변수로만 통행특성을 설명하는 것이 일반적이지만 본 연구에서는 연령과 성별 등의 변수도 통행특성을 설명하는 변수로 사용하였다. 다만 이같은 접근 방식으로 고령자 통행이 다른 연령대와 확연히 구분되는 통행특성이 있음을 발견할 수 있었다. 향후 연구에서 상위 계층과 하위 계층을 구분하여 분석한 결과가 유사한 결과를 도출하는지 확인할 필요가 있다. 한편, 사회경제적 변수로 토지이용, 용적률, 밀도 등 토지이용특성도 반영될 필요가 있다.
또한 교통체계효율화법에 근거해 5년마다 시행하는 가구통행실태조사 데이터를 이용한 잠재계층분석 결과와 비교할 필요가 있다. 이를 통해 본 연구에서 제시한 잠재계층 유형과 어떤 차이점이 있는지 파악하면 연구 결과의 타당성을 확인할 수 있을 것이다. 가구통행실태조사 자료는 서울시 생활이동데이터보다 상세한 정보를 담고있어 보다 다양하고 의미있는 통행 유형을 찾을 수 있을 것으로 기대된다. 한편 본 연구에서 중요한 통행 유형으로 나타난 고령자 통행의 세부적인 특징을 가구통행 실태조사를 통해 정리하고 고령자 통행만을 대상으로 잠재계층분석을 실시하여 독특한 세부 통행유형이 있는지 확인할 필요도 있다. 마지막으로 서울시 생활이동데이터를 교통조사를 보완하거나 세부적 통행 패턴을 파악하는데 활용할 수 있는 방안에 대한 연구가 더 적극적으로 이루어질 필요가 있다.
