

서론
선행연구
제주도 도로 교통 현황 검토
연구방법론
1. 데이터 수집 및 전처리
2. 후보 모형 개요
3. 모형 성능 평가
분석 결과
1. 모형 성능 평가 결과
2. SHAP Summary Plot
3. SHAP Dependence Plot
4. SHAP Waterfall Plot
결론
서론
제주특별자치도(제주도)는 매년 1,000만 명이 넘는 관광객이 방문하는 국내 대표 관광지로, 이에 따른 교통량 급증과 자동차 등록 대수 증가가 지속되고 있다(JTO, 2024). 공공데이터포털 통계에 따르면 제주 지역 자동차 등록 대수는 2024년 말 기준 약 71만 대를 초과한 것으로 확인되고 있다(MOLIT, 2024a). 이러한 차량 증가는 도로 혼잡, 주차난 뿐만 아니라 도로 기반 시설의 조기 노후화를 야기하고, 이는 유지관리 비용 증가로 이어질 수 있다. 실제로 제주시에서는 포트홀 관련 민원이 매년 3,000~4,000건 수준으로 발생하는 것으로 보고되고, 최근 3년간 포트홀 보수 건수도 2021년 2,980건, 2022년 1,584건, 2023년 2,497건으로 집계되는 등 도로 파손 이슈가 반복적으로 제기되고 있다(Kim, 2024). 또한, 제주시 관계자에 따르면 노후화된 도로를 적기에 보수하기 위해서는 연간 약 300억 원 규모의 예산이 필요하나, 관련 예산은 2022년 60억 원, 2023년 57억 원, 2024년 40억 원으로 편성되었다(Kim, 2024). 이러한 예산 제약은 유지관리 우선순위 설정의 중요성을 더욱 부각할 것으로 사료된다. 특히, 도로는 국민 생활환경과 산업 활동의 기반 시설로서 관리의 중요성이 강조되어 왔다(Lee and Sun, 2020). 따라서 제한된 유지관리 예산을 고려할 때, 유지보수가 필요할 것으로 추정되는 구간을 선제적으로 식별할 수 있는 예측 기반의 도로 유지관리 체계가 요구될 것으로 판단된다.
한편 포장도로의 성능 저하는 교통량, 교통 하중, 재료 특성, 기후 조건, 유지관리 전략 등에 의해 영향을 받는 것으로 알려져 있다. 또한, 적시에 유지보수가 이루어지지 않을 경우 도로 수명이 단축되고 보수 비용이 급증할 수 있다(Famewo and Shokouhian, 2025). 이에 따라 국내외에서는 포장관리시스템(PMS; Pavement Management System) 고도화를 위해 도로 성능 저하 및 보수 시점을 예측하는 다양한 모형들이 제안되고 있다(Kwon et al., 2002; Kim et al., 2015; Lee and Sun, 2020; Kuruvachalil et al., 2025).
제주도는 해양성 기후, 잦은 강우, 해안에 인접한 도로 비율이 높다는 점에서 일반 내륙 도시와는 다른 도로 교통 특성을 가지며, 이에 착안하여 도로 결빙, 교통사고 요인, 건축물의 시각적 차폐도 등을 분석한 다양한 연구들이 수행되었으나(예 : Lee et al., 2018; Oh et al., 2016; Park and Kim, 2004), 제주도 도로 교통 현황과 보수 작업을 연계하여 보수 수요를 직접적으로 예측하는 연구는 선례가 부족한 실정이다.
이에 본 연구는 1) 기존의 도로 교통량과 도로 포장 파손 간의 관계를 규명한 선행연구를 검토하고, 2) 제주도 도로 교통 환경의 현황을 파악하여, 3) 제주도 도로·교통·기상 환경의 지역적 특성을 반영할 수 있는 데이터셋을 구축하고, 4) 도로 유지보수 기록을 종속 변수로 정의하여, 5) 유지보수 발생 가능성을 정량적으로 검토하고자 한다. 본 연구의 결과는 선제적 보수 작업 계획 정책 수립 시 활용될 수 있으며, 향후 제주도 도로 투자 계획 유지관리 등과의 연계 가능한 발전 방향을 제시할 수 있을 것으로 기대된다.
선행연구
Kwon et al.(2002)은 국도 아스팔트 포장의 파손 예측 모형을 추정하기 위한 데이터베이스를 구축하였으며, 장기 공용성 관측 구간을 신설 포장 구간과 덧씌우기 포장 구간으로 구분하고, 시간 및 교통량의 변화에 따른 포장 상태의 변화를 분석하였다. 이를 위해 국도 아스팔트 포장 형태 분포를 파악하고, 국도 데이터베이스 포함 변수들을 환경적 인자, 하중 관련 인자, 구조적 인자로 선정하였다.
Lee and Kim(2009)은 도로화물 물류 및 운송비의 절감을 위해, 화물 차량 운행 개선 방안을 제시하고자 하였으며, 화물차량 우대정책에 관련하여 화물차량 운전자, 지역주민, 공무원 등의 세 집단을 대상으로 설문조사를 수행하여 분석하였다. 특히, 해당 연구는 화물차량 운행에 따른 문제점을 정의하는 과정에서 등가단축하중(ESAL; Equivalent Single Axle Load)을 활용하여 2003년부터 2006년까지 화물차량 비중이 도로 파손에 미치는 이론적인 효과를 도로 유지공사비로 확인하였다.
Bae et al.(2012)은 서울시 도로포장 관리에 대한 분석을 위해 실무자 대상 FGI(Focus Group Interview)를 수행하였다. 해당 연구는 도로포장 관리 현황을 파악하기 위해 포장 파손을 조사 노선에 대한 평균 수치인 균열, 소성변형, 종단 평탄성으로 구분하여, 포장 파손 종류별 현황을 서울시 내 지역별로 분석하였으며, 2010년 서울시 일일 교통량 데이터 기반 생애주기 비용분석을 통하여 하부 구조의 문제점을 분석하였다. 아울러, 버스전용차로는 버스에 의한 중하중의 반복 및 버스정류장에서의 단속류로 인하여 도로 파손이 증가하는 점을 정성적으로 분석하였고, 국내 기후의 아열대화에 따라 수분에 의한 포장파손에 대한 대책 마련의 필요성을 제시하였다.
Kim et al.(2015)은 고속도로 포장의 공용수명 분석기법을 정립한 후, 고속도로 포장 시공 및 유지보수 관련 자료와 포장유지관리시스템(HPMS; Highway Pavement Management System)을 활용하여 교통 및 환경 변화에 따른 포장의 공용수명을 분석하였다. 고속도로 포장 형식을 4가지로 구분하고, 차로별 등가단축하중, 제설제 사용량 등 3개 영향인자를 정의하여 각각 3가지 단계(Low~Medium~High)로 구분하였다. 그 결과, 포장 형식에 관계없이 등가단축하중이 증가할수록 포장 공용수명이 감소하고, 제설제 사용량이 증가할수록 무근콘크리트포장의 공용수명은 감소하는 상관관계를 확인하였다.
Lee and Sun(2020)은 도로파손에 영향을 주는 변수들을 기존 문헌 고찰을 통하여, 등가단축하중 및 환경 변수 등의 총 7개의 입력변수와 고속도로 포장상태지수(HPCI; Highway Pavement Condition Index)를 종속변수로 데이터셋을 구축하였다. 이후, 구축된 데이터셋을 바탕으로 머신러닝(Machine Learning; ML) 분류 알고리즘을 활용하여, 고속도로 콘크리트 포장 파손 예측 모형을 구축하여 그 성능을 평가하였다. 추가로, 협력적 게임이론 기반 SHAP(SHapley Additive exPlanations)을 활용하여, 각 변수의 중요도를 분석한 결과, 공용년수, 등가단축하중을 포장 파손의 핵심 영향 요인으로 도출하였다.
Kim et al.(2021)은 부산항 신항 임항도로의 포장 파손 누적의 문제점 제시 및 원인 규명과 동시에 파손 최소화를 위한 최적 설계 단면을 도출하고자 하였다. 특히, 해당 연구는 교통량의 증가 및 기온, 강수량의 포장 파손 영향을 규명하고자, 2016~2020년 임항도로의 연평균 일 교통량, 2011~2020년 기온의 추이 및 강수량 총량 자료를 활용하였다. 분석 결과, 임항도로에 무거운 트럭 교통량이 증가할 경우, 일반적인 도로에 비해 피로균열은 5.5배, 소성변형 발생 위험은 1.8배가 높다는 결론을 도출하였다.
분석한 선행연구들은 크게 세 분류로 나뉜다. 먼저 포장 성능 저하 및 공용수명과 관련된 연구들은 교통 하중, 도로 구조, 공용 특성 등이 파손 누적에 미치는 영향을 검증하였다(Kwon et al., 2002; Kim et al., 2015; Kim et al., 2021). 이들 연구는 장기 공용성 관측구간, 고속도로 PMS/HPMS 또는 특정 사례 도로를 활용하여 하중 증가에 따른 공용수명 단축, 파손 위험 증가를 정량적으로 제시함으로써 하중과 열화의 관계를 설명하는 기반을 제공하였다. 다만, 기존 연구는 HPCI 등의 성능지표 또는 특정 도로체계 분석으로 집중되어, 유지관리 개입을 종속변수로 산정하고 링크 단위 입력변수와 결합하여 장래 유지보수 발생 가능성을 예측하는 관점은 비교적 제한되었다.
다음으로 기후·환경 요인 영향에 관한 연구들은 강수, 온도, 제설제, 해안 환경 등이 재료 열화와 파손을 가속화할 수 있음을 논의하였다(Bae et al., 2012; Kim et al., 2015; Kim et al., 2021). 특히, 수분 노출과 온도 조건이 포장의 취약성을 높일 수 있음을 제시하여 환경 요인의 중요성을 강조하였다. 그러나 다수 연구에서 환경 요인은 보조 변수로 국한되거나, 단일 사례 기반으로 분석되었다. 또한, 지역 단위에서 교통 하중·도로 특성·기상 환경을 함께 고려하여 구간별 유지 보수 위험을 선제적으로 예측 및 분석까지는 확장되지는 못한 것으로 검토되었다.
마지막으로 ML 기반 분류 예측 모형과 해석가능한 인공지능 기법인 SHAP을 결합하여 변수의 도로파손 기여도를 제시하는 연구가 수행되었다(Lee and Sun, 2020). 이는 예측 성능뿐만 아니라 해당 구간이 위험한 이유를 설명할 수 있다는 점에서 유지관리 의사결정 지원 측면에서의 잠재력이 클 것으로 판단된다. 다만, 기존 연구는 적용 사례가 고속도로 성능지표 중심이거나 변수 중요도를 제시하는데 그쳐, 변수 값 변화에 따른 변수 간의 상호작용 관계나 개별 구간 단위의 예측 근거가 충분히 설명되지 못한 한계를 가진 것으로 생각된다.
이상 선행연구는 교통 하중과 환경 요인의 중요성을 충분히 검증하였고, 일부 연구는 ML-SHAP을 통해 설명 가능성을 제시하였다. 하지만 교통 하중·도로 특성·기상 요인과 유지보수 기록을 활용하여 다음 해 유지보수 발생 가능성을 예측함과 동시에 상호작용을 설명하는 시도는 제한적이었다. 이에 본 연구는 제주도 내 국지도와 지방도를 대상으로 연간 링크 자료를 수집 및 통합하여 유지보수 발생 가능성을 예측하고, SHAP 기반 해석을 통하여 유지보수 발생에 기여하는 요인의 중요도와 변수 간의 상호작용을 해석하였다. 또한, 유지관리 우선순위 설정을 위한 정량적 근거를 제공하고, 이를 토대로 제주형 도로 포장 관리 및 장래 보수 소요 예측 모형 구축의 가능성을 제시함으로써 기존 도로 포장 관리 관련 연구를 지역 교통계획 및 유지관리 전략으로 긴밀히 연계하는 데 기여하고자 한다.
제주도 도로 교통 현황 검토
제주도는 철도 인프라가 부재하여, 항공·해운을 제외한 지역 내 모든 통행이 도로교통에 의존하는 도서 지역이다. 2025년 기준 제주도의 총 인구는 약 66만 5,610명이며, 자동차 총 등록대수는 71만 6,426대로 1인 당 1.07대를 보유한 것으로 조사되었다. 이는 전국 평균(0.52대/인)의 두 배를 웃도는 수준이다. 특히, 제주도는 관광산업의 비중이 높음에 따라 관광객 이동 수단의 상당 부분을 렌트카를 포함한 승용차가 차지한다. Yoon et al.(2025)에 따르면 제주 관광객의 70~80%가 렌터카를 이용하며, 2024년 기준 렌트카 등록 대수는 약 3만 대로 보고되고 있다. 이러한 구조는 도내 통근·통학 수요와 관광 수요가 자동차를 이용할 가능성을 상당히 높일 것이다. 최근, 제주도 내 도로 교통량은 꾸준히 증가하는 추세를 보이고 있으며, 이로 인하여 도로 혼잡과 주차난, 교통사고뿐만 아니라 포트홀 등의 포장 파손 문제가 빈번히 제기되고 있다(JTO, 2024; Kim, 2024).
도로망 측면에서 살펴보면, 제주도 지방도 포장도로는 국가교통 통계누리 도로현황조서(MOLIT, 2024b)의 2024년 말 기준으로 전체 약 약 730km이며, 전체 행정구역별 연장 중 차로별로 2차로 이하 424.3km, 4차로 이하 260.1km, 6차로 이하 45.2km, 미개통도 42.9km으로 조사되었다. 행정구역별 도로포장 연장(특·광역시 관리구간 제외) 18,132.6km 중 4.2%로, 전국 9개 자치 관리청 중 관리 연장이 가장 짧은 편이다. 반면에 제주도 면적은 약 1,850km2로 전 국토의 약 1.8%에 불과하여, 상대적으로 좁은 관할 면적에 비해 도로 관리 연장은 길어, 단위 면적당 도로관리 부담이 타 지역에 비해 큼을 알 수 있다.
다음으로, 교통량 측면에서는 2010년을 기준으로 2019년에는 제주도의 평균 일일 교통량이 약 42.4% 증가하여 전국 광역지자체 가운데 가장 큰 증가율을 기록한 바 있으며(KICT, 2022), 장기적으로 1일 평균 교통량이 지속적으로 증가하여 주요 간선도로와 관광 및 생활 거점 주변을 중심으로 교통량이 누적되고 있다. 교통량은 도로포장의 파손에 가장 큰 영향을 미치는 것으로 알려져 있으며, 이러한 교통량 누적은 구조적으로 취약한 도로에서의 포장 손상을 가속화할 가능성이 크다(MOLIT, 2025a).
기상 측면에서도 제주도는 다른 내륙지방과 뚜렷이 다른 특징을 가진다. 특히, Figure 1에서 나타나듯이 전국 평균보다 많은 강수량을 보이고 있다. 우리나라는 2000년대 이후 집중 호우(시간당 강수량 80mm 이상)의 발생빈도가 약 50% 증가하였으며(KICT, 2022), 제주지방기상청과 제주도 기상개황 자료에 따르면 제주·서귀포·성산·고산 등의 4개 주요 관측지점의 제주지역 연평균 강수량은 2017~2024년 기간 동안 대부분 1,400~2,100mm 범위로 전국 연평균 강수량(약 1,400mm)을 상회하는 수준을 유지하고 있다(JSSGP, 2024). 이러한 강수량은 특히 포트홀과 같은 포장파손을 발생시키는 직접적인 원인으로 지적되고 있다.
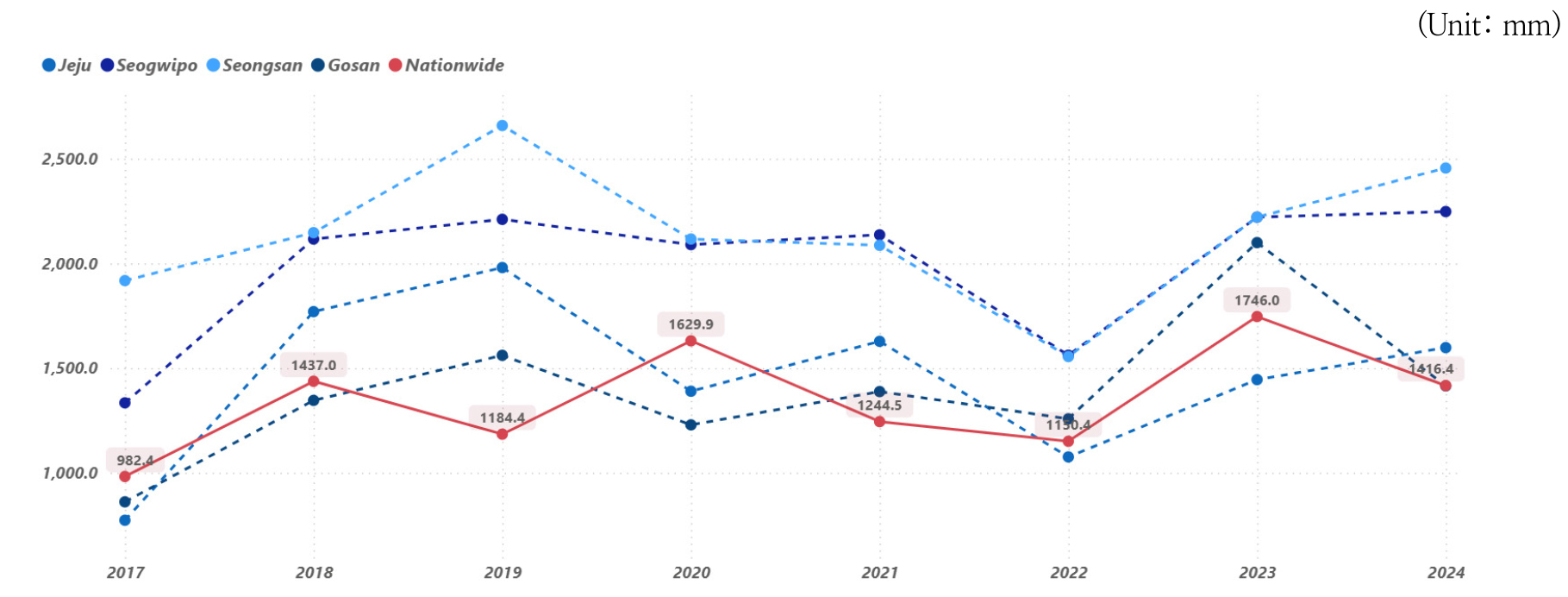
이상의 제주도 도로 특성을 종합하면, 1) 높은 단위 면적당 도로 연장, 2) 누적되는 교통량 증가율, 3) 높은 강수량에 의한 포장 약화 가능성 등 타 지역과 차별화된 교통, 도로, 기상 환경을 가지고 있음을 알 수 있다. 이러한 특성을 바탕으로 본 연구는 2023년 링크 단위 연간 자료를 활용하여, 교통·도로·기상 관련 요인으로 구성된 입력 변수 자료를 구축하고, 2024년 유지보수 기록을 관측 가능한 이벤트로 정의하여, 다음 해 유지보수 발생 가능성을 추정하고자 한다.
연구방법론
1. 데이터 수집 및 전처리
1) 교통 하중 변수 데이터 수집 및 링크 구축
본 연구는 View-T(KOTI, 2024) 자료를 활용하여 제주도 국지도 및 지방도를 대상으로 교차로 단위로 구획된 링크별 2023년 연간 교통자료를 수집하였다. 수집 항목으로는 링크별 연간 교통량(AADT; Annual Average Daily Traffic), 차종 구성 정보 등이 포함되었다. 교통량(변수명 : traffic_volume) 및 중차량 통행(변수명 : truck_ratio)은 반복 축하중 누적으로 인하여 포장 파손과 공용수명 단축에 영향을 미치는 핵심 요인으로 선행연구에서 검토되었으며, 이에 본 연구는 교통 하중 요인들을 입력변수로 포함하였다. 또한, 유지보수 이력과의 결합을 위해 도로 보수가 수행된 구간이 기 구축된 링크의 일부에 해당하는 경우에는 해당 링크를 추가로 세분화하여 유지보수 구간이 독립된 링크 단위로 반영되게 하였다. 최종적으로 2024년 1,136개의 분석 단위를 확보하였으며, 이 중 유지보수가 발생한 링크는 228개, 발생하지 않은 링크는 908개로 확인되었다.
한편, 본 연구에서 활용한 View-T 자료에서는 트럭이 3개 차종으로 통합되어 있어 ESAL 산정에 한계가 존재하였다. 따라서 본 연구는 링크별 트럭 차종 세분화 정보가 부재한 상황을 고려하여, 교통량정보제공시스템(TMS) (MOLIT, 2025b) 자료에서 제공되는 링크별 트럭 비율을 활용하여 트럭 교통량을 추정하였다. 이를 기반으로 산출된 링크별 ESAL(변수명 : esal)은 아스팔트 포장 기준의 축하중 환산계수를 적용하여 산출한 값이다. 포장 형식은 한국건설기술연구원의 제주형 도로포장 유지관리 개발 시 콘크리트 포장에 대한 별도 검토를 수행하지 않았다는 점(KICT, 2022)과 도내 공용 중인 고속도로가 부재하다는 점 등을 바탕으로 아스팔트 포장을 기본 형식으로 상정하였다.
2) 지역 도로 특성 변수 수집
도로 및 입지 특성은 링크 단위의 구조적·환경적 차이를 반영하기 위해 입력변수로 선정하였다. 도로 규모 및 운영 조건은 유지관리 개입 필요성과 연계될 수 있다는 점에서 링크 길이(변수명 : segment_length)와 차로 수(변수명 : num_lanes)를 도로 규모 변수로 포함하였다(Bae et al., 2012). 또한, 해안 인접 여부(변수명 : coastal_adjacent)는 제주 지역의 해풍 및 염분 노출 가능성을 반영하는 이진 변수로 정의하였다. 염분 및 해풍 등 해안 환경은 포장 열화를 가속화할 수 있는 조건으로 지적되어 왔다는 점에서(Famewo and Shokouhian, 2025), 제주 지역 특성을 반영하기 위한 입지 변수로 포함하였다. 추가로, 과거 유지보수 이력(변수명 : pre_maintenance)은 분석 시점 이전의 유지관리 이력 정보를 반영할 수 있는 변수로 본 연구에서 활용된 2024년 유지보수 이력의 전년도를 기준으로 구축하였다.
3) 기상 변수 수집 및 링크-관측소 매칭
기상 요인 관련 자료는 기상자료개방포털(KMA, 2024) 관측자료를 기반으로 2023년 연간 단위로 수집하였다. 강수 및 고온 노출이 도로 파손 발생 위험을 증가시킬 수 있다는 선행연구 결과를 고려하여(Kim et al., 2021; Famewo and Shokouhian, 2025), 본 연구에서는 강수량(변수명 : precipitation), 최고 평균기온(변수명 : high_temp_c), 최저 평균기온(변수명 : low_temp_c), 평균 일교차(변수명 : diurnal_temp_range_c)를 기상 변수로 설정하였다. 특히, 제주 지역의 공간적 기후 차이를 반영하기 위해, 제주도의 7개의 기상 관측·예보 권역(동부, 서부, 남부, 북부, 남부중산간, 북부중산간, 산지)을 기준으로 다음과 같이 총 14개의 관측소 자료를 수집하였다. 동부, 서부, 남부, 북부 권역에 해당하는 링크는 종관기상관측(성산, 고산, 서귀포, 제주) 자료를 할당하였으며, 그 외 남부중산간, 북부중산간, 산지는 해당 권역 내 근접한 방재기상관측(제주가시리, 한남, 서광, 새별오름, 유수암, 오등, 산천단, 송당, 어리목, 성판악) 자료를 할당하였다. Figure 2는 기상관측소와 도로 링크의 공간적 분포를 나타낸다. Table 1에서 이상의 입력변수들의 기술통계량을 제시하였다.
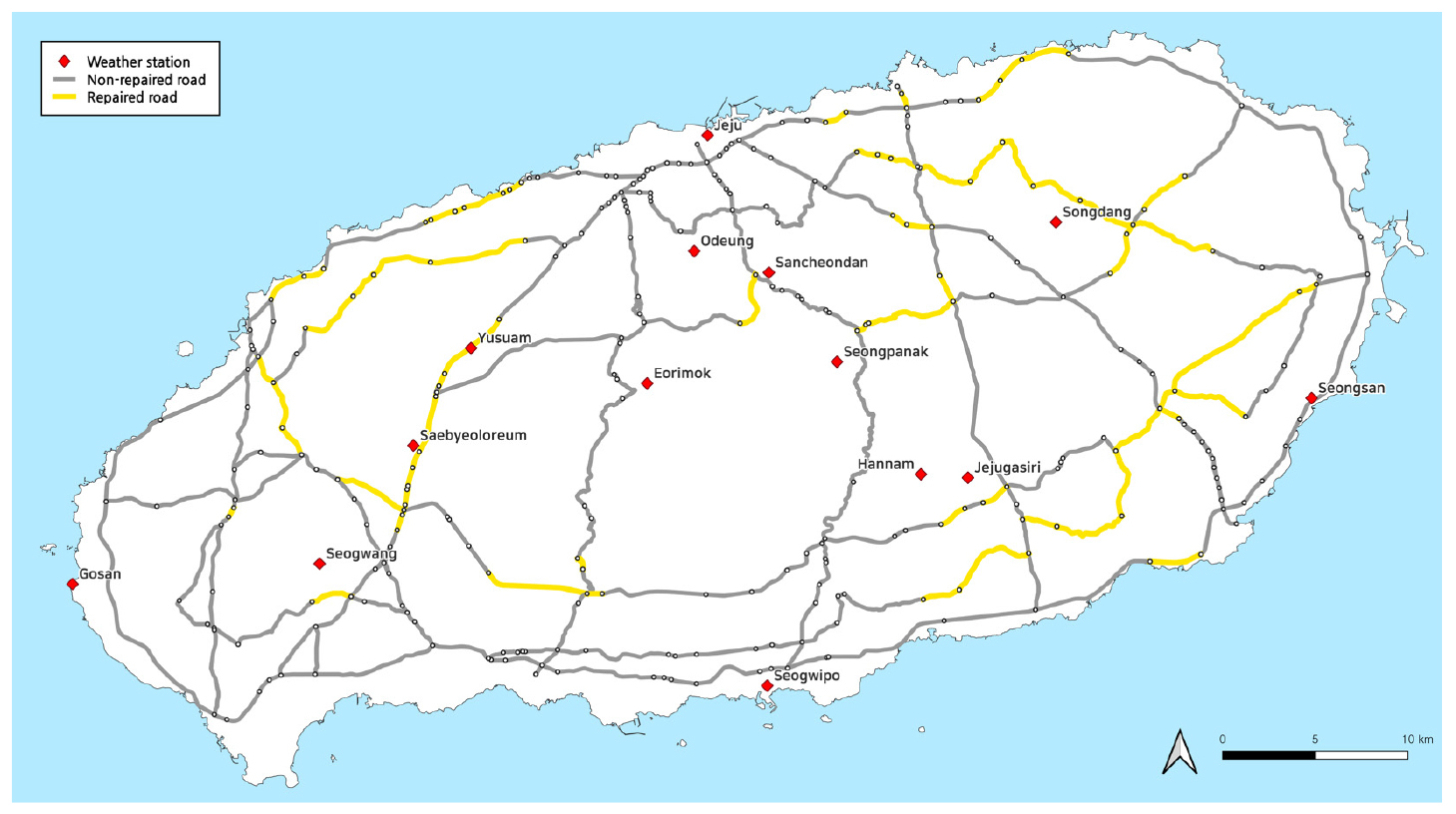
Table 1.
Input dataset construction
4) 종속 변수 정의
본 연구에서는 2024년 링크별 유지보수 여부를 나타내는 이진 변수를 종속변수로 정의하였다. 이는 포장 손상상태를 직접 측정한 지표는 아니지만, 손상 수준과 포장 관리 의사결정이 결합되어 발생하는 관측 가능한 개입으로 해석할 수 있다. 따라서, 본 연구는 2023년 교통 하중, 도로 특성, 기상 정보를 기반으로 다음 해 유지보수 발생 가능성이 높은 링크의 선제적 예측을 목표로 설정하였다.
2. 후보 모형 개요
본 연구와 같은 이진 분류형 종속 변수(보수 없음, 보수 있음)를 전통적인 로짓 모형으로 분석할 경우, 다수의 예측 변수 투입으로 인한 자유도 감소 문제가 발생할 수 있다(Lee and Kim, 2021; Yang et al., 2024). 또한, 본 연구의 링크 단위 연간 자료는 교통 하중·도로 특성·기상 요인이 복합적으로 작용하여 요인 간의 비선형 관계가 존재할 가능성이 크다. 이에 본 연구는 다양한 ML 분류 모형 중 분류 성능이 우수한 장점으로 널리 활용되고 있는 RF(Random Forest), SVM(Support Vector Machine), LightGBM(Light Gradient Boosting Machine), XGBoost(eXtreme Gradient Boost) 등 네 가지 모형에 기반하여 예측 모형을 구축한 뒤, 성능 평가를 수행하였다. 또한, ML 모형의 예측 과정을 설명하기 어려운 한계를 보완하고자 해석가능한 인공지능(XAI; Explainable Artificial Intelligence) 기법 중 하나인 SHAP(SHapley Additive exPlanations)을 활용하여 평가 결과를 바탕으로 최종 선택한 모형의 분석 결과를 해석하였다.
1) RF(Random Forest)
ML 앙상블 기법 중 하나인 RF는 의사결정나무를 여러 개 구축하여, 종속 변수를 예측하는 데 사용되는 기존의 의사결정나무(Decision Tree) 문제를 보완하기 위해 개발된 기법이다(Breiman, 2001). RF는 다수의 의사결정나무를 생성하되 개별 의사결정나무 내에서는 표본 및 변수 선택 과정에서의 무작위성을 최대한 부여함으로써 모형의 예측률을 높일 수 있다(Yoo et al., 2015). 또한, 무수히 많은 의사결정나무 구조를 갖고 있어도 무작위 중복표본 추출된 샘플이 서로 다른 특성 변수의 조합으로 구성되어 과적합과 다차원의 오류에 빠지지 않는다(Cho et al., 2023; Yang et al., 2024). 추가로 해당 기법은 범주형 변수뿐만 아니라 연속형 변수 예측에서도 높은 성능을 보여주기 때문에 다양한 분야에서 널리 활용되고 있다(Lin et al., 2017).
2) SVM(Support Vector Machine)
SVM은 데이터 포인트를 고차원 공간으로 매핑하여 선형 또는 비선형 결정 경계를 찾는 강력한 분류 기법으로 최대 마진을 활용하여 데이터의 경계를 찾는 것을 중점으로 일반화 능력을 향상시키고 과적합을 방지한다(Cherkassky and Ma, 2004; Yuan et al., 2010). 특히, SVM은 데이터 분포에 덜 민감한 장점을 갖고 있어 이상치를 가지는 데이터에 대한 신뢰할 수 있는 분류 결과를 도출할 수 있다(Jee et al., 2023). 해당 기법은 비교적 작은 표본에서도 양호한 성능을 보여주며(Yang et al., 2024), 선형 분류와 비선형 분류 모두에 활용될 수 있는 높은 범용성이 가장 큰 장점으로 평가되고 있다.
3) LightGBM(Light Gradient Boosting Machine)
LightGBM은 트리를 분할 할 때 전통적인 부스팅 알고리즘에서 흔히 사용하는 Level-Wise 방식과 달리 Leaf-Wise 방식을 사용한다. 즉, 다른 알고리즘은 손실 감소 극대화를 위해, 트리를 수평 방향으로 확장시키지만 해당 기법은 트리를 수직 방향으로 성장시킨다(Hajihosseinlou et al., 2023). 이러한 방식 덕분에 우수한 예측 성능을 지님과 동시에 시간 및 메모리 측면에서도 효율적인 알고리즘으로 평가 받고 있다(Ke et al., 2017). 아울러, LightGBM은 불균형 데이터셋을 효과적으로 처리하기 위한 여러 방안을 제공한다(Hajihosseinlou et al., 2023). 그 중 본 연구에서 활용한 ‘scale_pos_weight’은 클래스 가중치(Class weight)를 조정하여 데이터셋의 클래스의 비율로 파라미터를 설정함으로써 불균형 데이터셋 학습을 원활하게 수행할 수 있다.
4) XGBoost(eXtreme Gradient Boost)
XGBoost는 선형 모형이나 트리 기반 모형에서의 과적합 문제를 해결하기 위해 트리를 병렬처리(Parallel Processing)와 조기 중단(Early Stopping)으로 작동하도록 구성하여, 그래디언트 부스팅(Gradient Boosting)의 효율성을 개선한 알고리즘이다(Chen and Guestrin, 2016). 여러 개의 의사결정나무를 사용해 결과를 평균 내는 기법인 RF와 다르게 XGBoost는 동일 작동 원리를 적용하고, 여러 개의 결과를 검토하여 오답에 가중치를 부여한다. 이후, 가중치가 적용된 오답은 관심을 가지고 정답이 될 수 있도록 결과를 만들고 해당 결과에 대한 오답을 찾아 같은 작업을 반복하는 방식으로 작동한다(Yang et al., 2023). 또한, LightGBM과 같이 ‘scale_pos_weight’을 제공하여, 불균형한 데이터셋에서도 강력한 성능을 발휘하여 신뢰할 수 있는 결과를 도출할 수 있다.
3. 모형 성능 평가
1) 오차 행렬(Confusion Matrix) 기반 지표를 활용한 후보 모형 예측 성능 평가
앞에서 제시된 것과 같은 ML 분류 예측 모형에 사용되는 성능 평가 지표는 Table 2의 오차 행렬(Confusion Matrix)을 기반으로 산정이 가능하다(Lee and Sun, 2020). 오차 행렬은 학습된 모형의 예측 오류가 얼마인지, 어떤 유형의 예측 오류가 발생하는지를 나타내는 지표이다. ‘유지보수 없음’을 Negative(0), ‘유지보수 있음’을 Positive(1), 옳게 예측한 것을 True, 틀리게 예측한 것을 False라고 할 때 True Negative(TN), False Positive(FP), False Negative(FN), True Positive(TP)로 구성된다(Park and Park, 2024). 본 연구에서 모형 성능을 평가하기 위해 활용한 지표인 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 Score의 산출식은 Equation 1, 2, 3, 4와 같다.
Table 2.
Confusion matrix of the machine learning model
| Actual positive | Actual negative | |
| Predicted positive | True positive (TP) | False positive (FP) |
| Predicted negative | False negative (FN) | True negative (TN) |
아울러, 추가 평가 지표로 이진 분류 모형 예측 성능 평가에서 주로 활용되는 ROC(Receiver Operating Characteristic)_AUC(Area Under the Curve) Score를 산출하였다. 이는 모든 임계값(Threshold)에 대해 이진 분류기가 양성과 음성을 얼마나 잘 구별할 수 있는지를 평가할 수 있는 지표이다(Gope et al., 2024). 다만, 본 연구의 종속변수인 유지보수 발생이 상대적으로 낮은 불균형 데이터 특성을 가짐에 따라 ROC_AUC가 성능이 과대 평가될 우려가 있어, PR(Precision-Recall) 곡선 기반의 PR_AUC도 추가로 산출하여 활용하였다.
2) SHAP(SHapley Additive exPlanations)
SHAP은 협력 게임 이론(Cooperative Game Theory) 접근 방식을 기반으로 Shapley Value를 도출한다(Lundberg and Lee, 2017). 본 이론에서는 각 참여자가 연합 내에서 협력하여 전체 보상을 만들어 낼 때, 각자의 기여도에 따라 보상이 배분된다(Shapley, 1953). 특성 값 집합에 대한 Shapley Value는 다음의 Equation 5를 통해 도출된다.
여기서, 은 전체 입력변수의 개수를 의미하며, 는 특성 연합 의 임의의 부분집합으로서, 합은 입력변수 를 제외한 의 모든 부분집합 에 대해 계산된다. 함수 는 본 연구에서 보수 여부를 예측하는 데 있어 연합 의 기여도를 의미한다. 또한, 예측된 보수 여부 값과 평균 예측값의 차이는 데이터셋 내 모든 입력변수 값 조합에 대해 공정하게 배분된다(Ayoub et al., 2021).
SHAP은 대표적으로 세 가지 Plot을 출력하여 앞서 구축한 ML 모형의 결과를 해석할 수 있다. 먼저, SHAP Summary Plot은 SHAP 값을 사용하여 각 입력변수가 모형의 예측에 미치는 영향을 시각화할 수 있다. 다음으로 SHAP Dependence Plot은 특정 변수의 값과 이러한 변수가 모형의 예측에 미치는 영향 간의 관계를 보여준다. 또한, 특정 변수와 상호작용이 가장 큰 변수를 추출하여 변수 간의 영향 관계를 시각화할 수 있다. 마지막으로 SHAP Waterfall Plot은 데이터셋 내 하나의 개별 관측치에 대한 모형의 예측이 어떻게 이루어졌는지를 시각적으로 보여주는 그래프이다.
분석 결과
1. 모형 성능 평가 결과
본 연구에서는 과적합을 방지하기 위해 5-Fold Cross Validation을 활용하여 4가지의 예측 모형을 6가지의 지표로 평가하였다. 평가 결과, Table 3의 정확도와 정밀도 지표를 기준으로 LightGBM을 최종 모형으로 확정하였다. 최적의 조합 및 성능을 도출하기 위해 랜덤 서치(Random Search) 기법으로 설정한 LightGBM의 하이퍼파라미터(Hyper parameter) 설정값과 설명은 Table 4와 같다. 이후, 최종 모형으로 선정된 LightGBM에 SHAP을 적용하여 유지보수 발생 예측에 대한 변수 중요도와 기여 방향, 변수 간 상호작용, 개별 링크 단위의 예측 근거를 해석하였다.
Table 3.
Performance measures of models
Table 4.
Hyperparameter tuning for LightGBM
2. SHAP Summary Plot
SHAP Summary Plot은 SHAP 값을 사용하여 각 입력변수가 모형의 예측에 미치는 영향을 시각화한다. Figure 3의 오른쪽을 살펴보면 x축은 각 입력변수의 예측에 대한 기여도를 보여주며, 이는 유지보수 예측에 대한 해당 변수의 영향력을 양수 혹은 음수를 통해 표현한다. Figure 3 왼쪽의 SHAP Bar Plot은 해당 변수의 영향력을 절댓값으로 처리하여 영향력의 크기를 표현한 것을 알 수 있다. SHAP Summary Plot의 색상에서 빨간색은 각 변수의 예측값인 SHAP이 높음을 나타내고, 파란색은 반대로 예측값이 낮음을 나타낸다. 본 연구는 전술하였듯이 유지보수가 이루어진 것을 1로 이진 분류하였기에 x축의 0을 기준으로 오른쪽에 빨간색 점이 많이 분포한 변수 혹은 왼쪽에 파란색 점이 많이 분포한 변수가 유지보수 확률을 높이는 요인으로 해석할 수 있다. 반대로 x축의 0을 기준으로 오른쪽에 파란색 점이 많이 분포하거나 왼쪽에 빨간색 점이 많이 분포한 변수는 유지보수 확률을 낮추는 요인으로 해석할 수 있다.
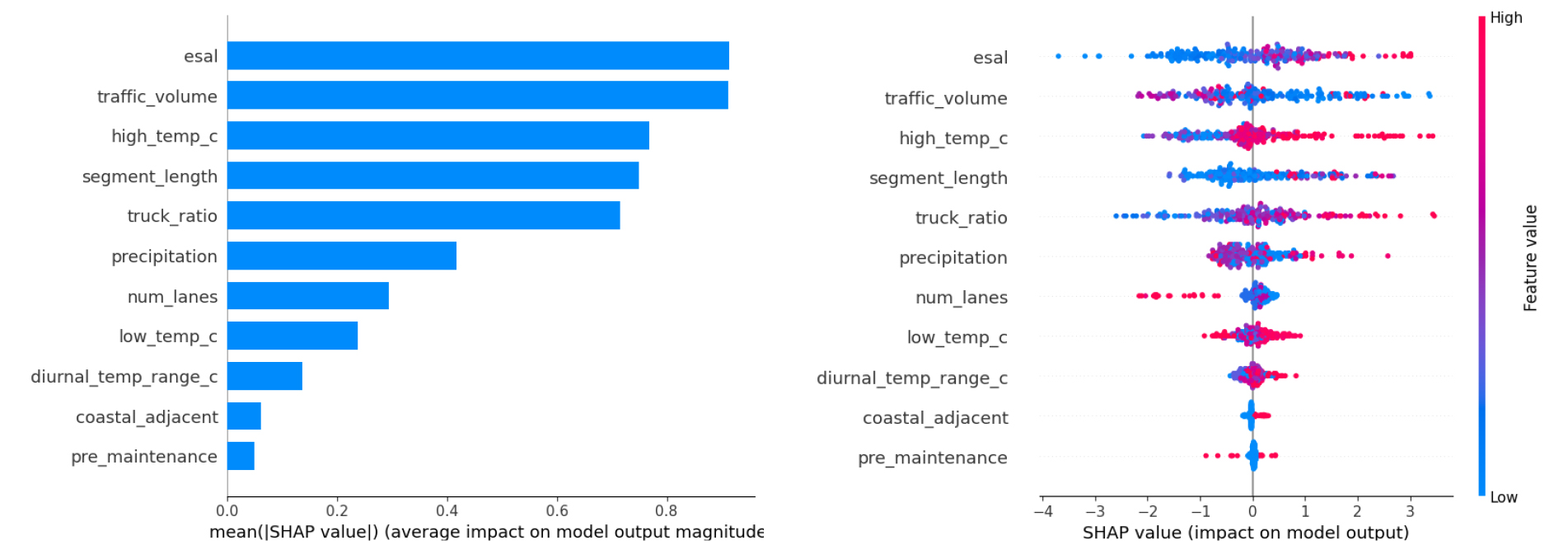
전반적으로 연구 결과를 살펴보면 변수 중요도는 ‘esal’이 가장 높게 나타났으며, 다음으로 ‘traffic_volume’, ‘high_temp_c’, ‘segment_length’, ‘truck_ratio’ 등의 순으로 확인되었다. 특히, ‘esal’인 등가단축하중과 ‘truck_ratio’인 중차량 비율은 값이 클수록 SHAP 값이 정(+)의 방향으로 이동하는 경향이 뚜렷하여, 축하중 누적 및 중차량 통행에 의해 대표되는 교통 하중이 다음 해 유지보수 발생 가능성을 증가시키는 핵심 요인임을 알 수 있다. 이는 포장 구조에 가해지는 반복 하중이 유지관리 개입과 밀접하게 연계된다는 기존 포장 성능 관련 선행 연구의 결과와도 부합한다.
다음으로 기상 요인 중 ‘high_temp_c’와 ‘precipitation’의 영향이 상대적으로 크게 나타났으며, 두 변수 모두 높은 값이 정(+)의 구간에 더 많이 분포하여, 고온 및 강수 노출이 유지보수 발생 가능성을 증가시키는 방향으로 작용함을 확인하였다. 반면, ‘low_temp_c’와 ‘diurnal_temp_range_c’는 상대적으로 영향력이 작거나 0 근처에 밀집된 분포를 보여 변별력을 확보하지 못함을 알 수 있다.
끝으로, 도로 특성 변수에서 ‘segment_length’는 높은 값이 정(+)의 구간에서 상대적으로 많이 관측되어, 구간 길이가 길수록 유지보수 발생 가능성이 증가하는 경향으로 분석되었다. 한편, ‘num_lanes’와 전년도 유지보수 이력인 ‘pre_maintenance’는 본 모형에서는 상대적으로 기여도가 낮은 변수로 확인하였다. 특히, 전체 교통량인 ‘traffic_volume’은 SHAP 값이 좌우로 혼재된 분포를 보였으며, 이는 단순 교통량이 많아도 파손을 일으킬 수 있는 하중의 강도가 포장의 수명 및 파손에 더 큰 영향을 미치는 선행연구(Gharaibeh and Darter, 2003; Lee, 2013)의 결론과 같은 방향으로 결과가 분석되었다.
3. SHAP Dependence Plot
SHAP Dependence Plot은 특정 변수의 값과 해당 변수가 모형 예측에 미치는 영향 간의 관계를 보여준다. 또한, 특정 변수와 상호작용이 가장 큰 변수를 추출하여, 변수 간의 영향 관계를 시각화할 수 있다. 해당 도표는 특정 변수의 값(x축)에 따라 해당 변수가 모형 출력에 기여하는 정도(y축)가 어떻게 변하는지를 알 수 있다. y축 SHAP 값이 정(+)이면 해당 변수가 유지보수 발생 예측을 증가시키는 방향으로 작용함을 의미하고, 부(-)이면 반대로 예측을 감소시키는 방향으로 작용함을 의미한다. 또한, 점의 색은 상호작용 변수의 크기를 나타내어 두 변수 간의 상호작용 가능성을 파악할 수 있다.
본 연구에서는 SHAP Bar Plot 기준 영향력이 높은 6개 변수의 SHAP Dependence Plot을 출력하여 각 변수와의 상호작용이 큰 변수를 파악하고 이들 간의 영향 관계를 분석하였다. 먼저 Figure 4의 좌측에서 보이듯이 낮은 ‘esal’ 구간에서 SHAP 값이 0 혹은 부(-)의 영역에 분포하였으며, ‘esal’이 증가할수록 SHAP 값이 동반 상승하는 경향을 나타났다. 또한, 동일한 ‘esal’ 수준에서도 ‘precipitation’의 높은 값이 정(+)의 SHAP 값 영역에 더 많이 분포하는 경향을 확인하였으며, 이는 하중 효과는 수분 노출 조건에서 더욱 강화될 가능성이 있음을 알 수 있다.
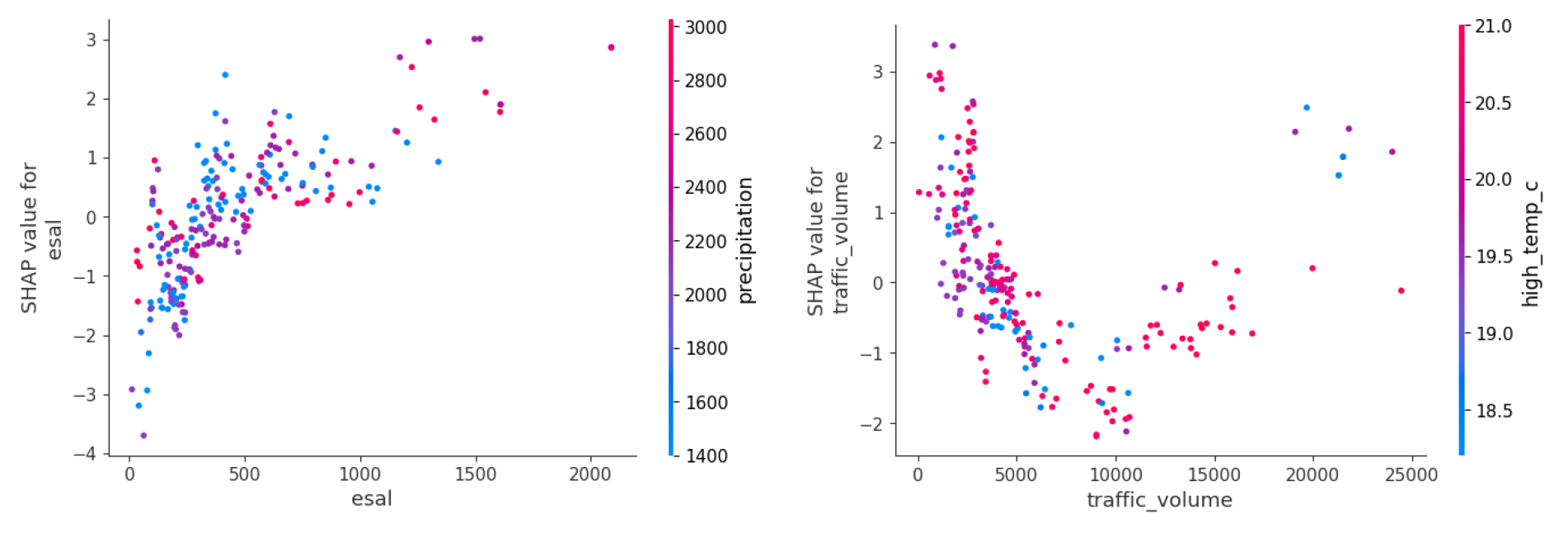
Figure 4 우측의 ‘traffic_volume’의 경우, 교통량이 작은 구간에서는 SHAP 값의 분산이 커 정(+)과 부(-) 값이 혼재하였다가 교통량이 증가함에 따라 SHAP 값이 부(-)의 방향으로 이동하는 경향을 알 수 있다. 이를 통해, 총 교통량이 포장 파손 혹은 유지보수 개입에 미치는 영향이 제한적임을 확인 가능하다. 또한, ‘high_temp_c’의 분포가 일부 구간에서 SHAP 값의 분포와 함께 변하는 양상을 파악할 수 있으며, 이는 교통량의 단독 변수로서의 영향력은 고온을 포함한 다른 변수들과 함께 해석해야 함을 시사한다.
Figure 5 좌측의 ‘high_temp_c’와 상호작용이 가장 큰 요인은 ‘traffic_volume’으로 분석되었다. 전반적으로 온도가 상승함에 따라, SHAP 값이 증가하는 경향을 확인할 수 있다. 즉, 고온 노출이 다음 해 유지보수 발생 예측을 증가시키는 방향으로 작용함을 알 수 있다. 또한, 동일한 온도 수준에서도 교통량이 높은 값에서 SHAP 값의 상단부가 상대적으로 크게 나타나는 양상을 확인하였으며, 이는 고온 환경에서 교통량이 많을 경우, 유지보수 발생 가능성이 높아질 수 있음을 시사한다.
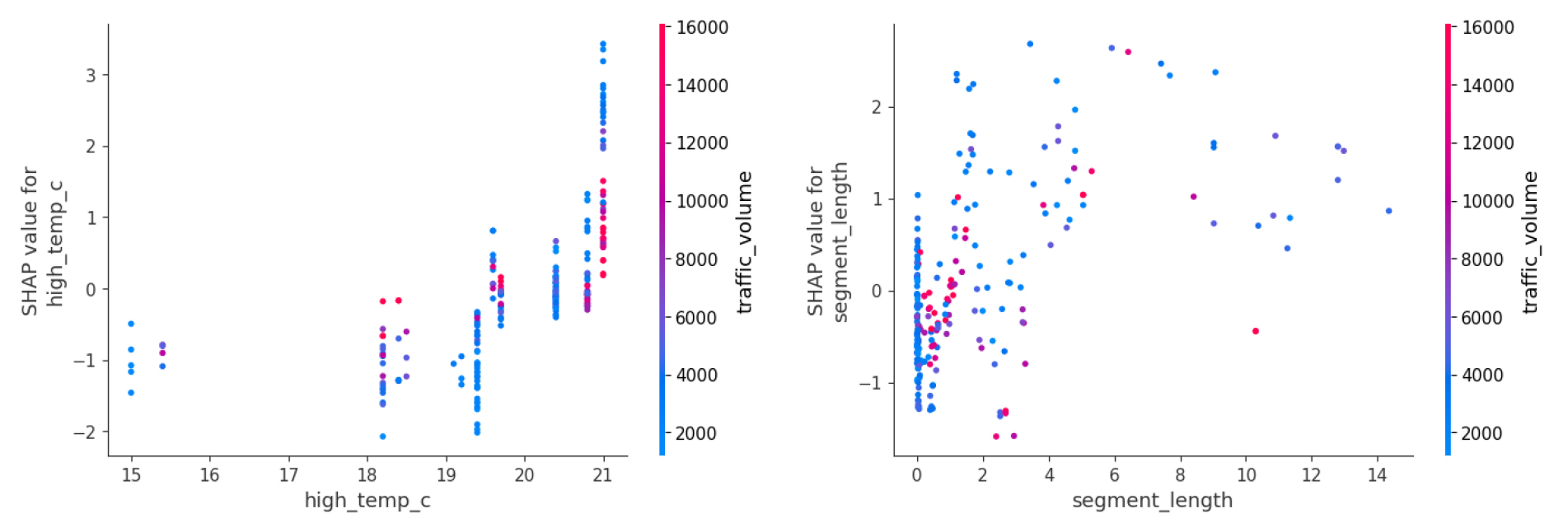
Figure 5 우측의 ‘segment_length’는 짧은 구간에서 해당 값이 밀집하여, SHAP 값이 주로 부(-)의 영역에 분포하는 반면, 일부 장거리 링크에서 정(+)의 SHAP 값이 관측되어, 구간 길이가 길수록 유지보수 발생 예측에 대한 기여도가 큰 것을 확인할 수 있다. 또한, ‘traffic_volume’과의 관계를 살펴보면, 장거리 링크에서도 교통량이 높은 값에서 반드시 SHAP 값이 커지는 형태로 뚜렷하게 분리되지 않았으며, 교통량이 낮은 값에서도 큰 정(+)의 SHAP 값이 분포되어 있다. 이는 링크 길이의 기여도가 교통량과 단순히 결합하기보다, 다른 조건에 따라 링크 길이의 예측에 대한 기여도가 달라질 수 있다고 해석할 수 있다.
Figure 6 좌측에서는 ‘truck_ratio’가 증가할수록 SHAP 값이 증가하는 뚜렷한 정(+)의 상관관계가 관측되었다. 이로부터 어떤 링크의 중차량 비율이 높아질수록 다음 해 유지보수 발생 예측을 증가시키는 방향으로 작용함을 알 수 있다. 추가로, 동일한 중차량 비율 수준에서도 ‘high_temp_c’의 높은 값들이 상대적으로 더 큰 정(+)의 SHAP 값으로 분포되어 있어, 중차량 비율의 영향이 고온 조건에서 강화될 가능성이 있음을 시사한다. 이는 앞선 선행연구의 결과와 같이 고온 환경에서 아스팔트 재료가 연화되어 반복 하중에 대한 취약성이 증가할 수 있다는 물리적 해석과도 정합성이 일치한다.
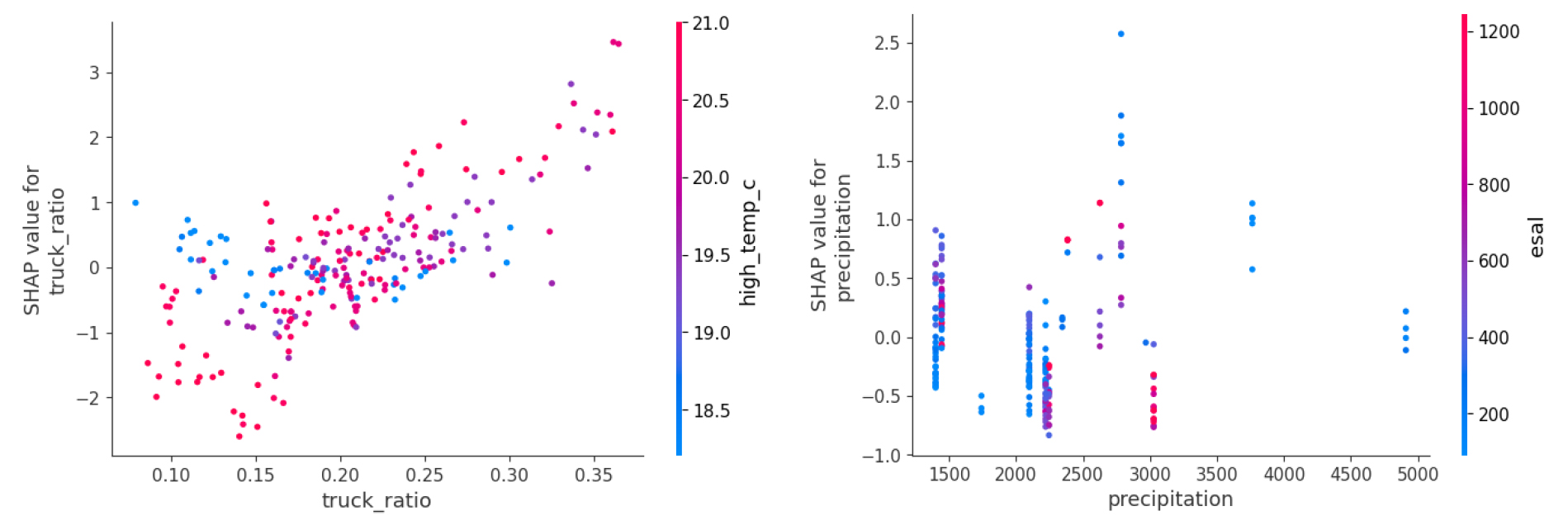
마지막으로, 우측의 ‘precipitation’은 특정 강수량 구간에서 SHAP 값의 분산이 큰 비선형적인 패턴을 관찰할 수 있다. 즉, 강수량은 단독 변수로서 유지보수 발생 가능성을 일관되게 증가시키지 않고, 다른 요인과 결합 되어 조건부 효과로 작용할 가능성이 큼을 알 수 있다. 추가로 ‘esal’ 분포를 검토하면, 동일한 강수량 에서도 ‘esal’이 높은 관측치에서 SHAP 값이 상대적으로 정(+)의 영역에 위치하였다. 이는 강수 노출이 ‘esal’과 같은 하중 조건과 결합할 때 유지보수 발생 가능성이 커질 수 있을 것으로 사료된다.
4. SHAP Waterfall Plot
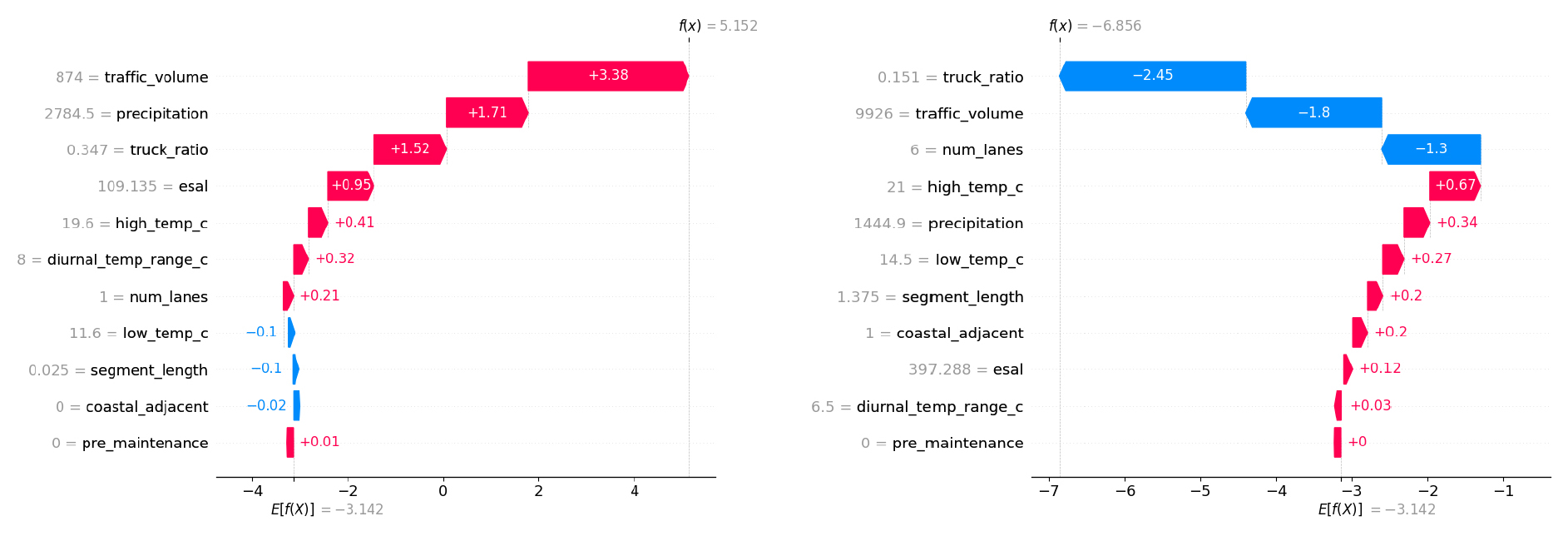
SHAP Waterfall Plot은 데이터셋 내의 하나의 개별 관측치에 대한 모형의 예측이 어떻게 이루어졌는지를 시각적으로 보여주는 그래프이며, 본 모형을 통해 구축한 기준값(base line)인 기준으로 Equation 6을 통하여 산출된다.
본 연구는 무작위로 선택되어 ‘유지보수가 예측된다’로 분류된 개별 관측치(0 이상)와 ‘유지보수가 예측되지 않는다’로 분류된 개별 관측치(0 미만)의 그래프를 도출하였다. 먼저, ‘유지보수가 예측된다’를 대상으로 한 Figure 7의 왼쪽 그래프에 따르면 개별 관측치의 예측값은 5.152로 도출되었으며, 예측값을 높이는 변수 및 값은 기여도가 큰 순으로 ‘traffic_volume’의 874, ‘precipitation’의 2784.5, ‘truck_ratio’의 0.347 등으로 나타났다. 반면에, ‘유지보수가 예측되지 않는다’로 분류된 개별 관측치의 예측값은 –6.856이 도출되었으며, 예측값을 낮추는 변수 및 값은 ‘truck_ratio’의 0.151, ‘traffic_volume’의 9926, ‘num_lanes’의 6으로 분석되었다.
결론
본 연구에서는 제주도의 지역적 특수성을 고려하여, 링크 단위 연간 도로·교통·기상 자료를 통합한 데이터셋을 구축하고 유지보수 기록을 관측 가능한 이벤트로 정의하여 다음 해 유지보수 발생 가능성과 영향 요인을 정량적으로 분석하였다. 이를 통해 제주 지역에서 유지보수 개입이 어떠한 요인 조합에서 증가할 수 있는지를 실증적으로 분석하고, ML 기반 제주형 장래 유지보수 수요 예측 모형 구축 가능성을 제시하였다.
모형 분석 결과, 축하중 누적 및 중차량 통행이 포장 열화 및 유지관리 수요 발생이 밀접히 연계됨을 확인할 수 있었다. 또한, 기상 변수 중 연간 강수량과 고온이 상대적으로 중요도가 큰 영향 요인으로 검토하였으며, 일부 결과에서는 ESAL 요인과 연계될 시 강수량의 영향력이 강화되었다. 또한, 도로 규모 특성은 상대적으로 중요도가 낮은 보조적 요인으로 분석되었다. 반면, 교통량은 단조 관계(Monotonic Relationship)가 명확하지 않고 비선형적 분포가 확인되었으며, 교통 하중 변수와의 중복 및 도로 운영 및 관리 요인의 대리변수(Proxy Variable)로서 검토될 수 있을 가능성을 확인하였다.
본 연구의 결과는 제주도와 같이 1) 교통 수요가 높은 수준으로 유지되고, 2) 강수량과 고온 수준이 상대적으로 높으며, 3) 상대적으로 좁은 면적에 도로망이 밀집된 지역에서, 교통 하중과 기후 요인 등을 통합적으로 고려한 도로 유지관리 의사결정 지원에의 활용 가능성을 제시한다. 특히, 구축된 예측 모형은 균열, 러팅 등의 상세한 도로 상태지표를 직접 활용하기 어려운 상황에서도, 연간 도로·교통·기상 특성만으로 다음 해 유지보수 발생 가능성이 높은 링크를 선제적으로 선별할 수 있다는 점에서, 제주도 도로 투자 예산 배분, 관광 성수기 교통관리, 도로 유지관리 계획을 연계한 우선순위 결정에 활용될 수 있을 것으로 기대한다.
다만, 본 연구에서 정의한 종속변수는 유지보수 유무로서 포장 손상 상태를 직접 측정한 지표가 아닌 손상 수준과 함께 관리·예산·우선순위 등 의사결정이 통합적으로 반영된 결과라는 한계를 가지고 있다. 향후 연구는 유지보수 유형을 구분하여, 보다 정밀한 분석이 필요할 것으로 생각된다. 아울러, 본 연구에서는 1년 시차의 예측 구조를 활용하였으나 도로 유지보수는 장기 누적 결과의 성격이 강하다. 따라서 다년의 데이터셋이 구축될 경우, 시간적 의존을 반영한 모형 또는 시계열 기반 예측 모형을 활용하여 보수 소요의 예측 가능성을 정교하게 규명할 수 있을 것으로 사료된다.
