

서론
선행연구
1. 사회경제지표를 활용한 교통량 예측 관련 연구
2. 교통량 기반 교통량 예측 관련 연구
3. 본 연구에 활용한 교통량 예측 방법론
4. 기존 연구와 본 연구의 차이점
데이터 분석
1. 데이터 및 분석방법
2. 세부 분석 방법론
3. 교통량 예측 결과
4. Transformer 모델의 Feature Importance 분석
결론
서론
현대 사회에서 도로 교통은 국가 경제의 근간을 이루는 중요한 요소로, 특히 고속도로의 원활한 교통 흐름은 여객 및 화물의 효율적인 이동을 보장하는 핵심적 역할을 한다. 한국도로공사(KEC; Korea Expressway Corporation)는 효율적 교통관리를 위해 교통 상황 및 소요시간 등 교통 예보 정보를 제공하며, 교통 혼잡을 최소화하고 안전한 운전을 돕는 데 주력하고 있다. 교통상황 및 소요시간 예측이 정확할수록 최적화된 실시간 교통관리를 수행할 수 있고, 이는 국민의 안전과 편의성을 높이는 결과로 이어지므로, 한국도로공사는 이러한 중요성을 인식하고, 교통상황을 정확히 예측하여 예보 정보를 제공하기 위해 노력하고 있다.
교통상황 및 소요시간 예측을 위한 가장 중요한 데이터는 일 교통량 예측값이다. 한국도로공사는 일 교통량 예측값과 기상, 요일 정보를 기반으로 K-최근접 이웃(KNN; K-Nearest Neighbors) 알고리즘을 적용하여 가장 유사한 과거 관측값을 기반으로 교통상황을 예측한다. 그리고, 이렇게 예측된 교통상황, 즉 시공도를 기반으로 출발지부터 목적지까지의 소요시간을 예측하고 있다. 따라서 일 교통량 예측값의 오차가 클 경우 교통상황 및 소요시간 예측 모두 오차가 커질 우려가 있다. 그리고 예측에 활용하는 기상 및 요일 조건은 외부 예측정보이거나 고정 요소이고, 교통상황, 소요시간 예측에 영향을 미치는 한국도로공사의 변동 요소는 교통량이므로, 예측 교통량이 교통상황과 소요시간 예측에 중요한 요소임을 알 수 있다.
한국도로공사도 정확한 일 교통량 예측의 중요성을 인지하고 있으며, 지속적 모델 개선 및 변수 추가를 통해 교통량을 정확히 예측하기 위한 노력을 하고 있다. 현재 한국도로공사는 요일 정보, 기상 정보를 기반으로 다중 선형 회귀 방식 및 K-최근접 이웃 알고리즘을 적용하여 교통량을 예측하고 있다. 한국도로공사의 모델은 시계열 자료를 기반으로 교통량을 예측하므로, 상당히 높은 정확도를 보여주고 있으나, 회귀 모델은 교통량이 매년 증가하게 되고, KNN 모델은 과거 교통량과 동일할 수 밖에 없는 한계를 가지고 있다. 고속도로 교통량이 줄어든 대표적 사례는 2008년을 들 수 있다. 2008년 상반기 유가는 1월 1,652원에서 7월 1,953원으로 급격하게 상승하였고, 하반기에는 세계금융위기로 인한 전 세계적 경기 침체가 있었다. 2001년부터 2007년까지 고속도로 일 평균 이용 차량은 252만대에서 332만대로 매년 4.7% 증가하였으나, 2008년에는 앞서 언급한 영향으로 인해 전년 대비 1.5% 감소한 327만대를 나타내었다. 이처럼 시계열 자료 기반 회귀 모델은 사회경제지표의 변화를 반영할 수 없기 때문에 예측 시 교통량이 증가할 수 밖에 없으며, 보다 정확한 교통량 예측을 위해 교통량에 영향을 줄 수 있는 다양한 사회경제지표를 기반으로 한 예측이 필요하다.
최근에 딥러닝과 같은 인공지능 기술과 모델이 개발 및 적용되고 있으며, 다양한 분야에서 활용되고 있다. 특히 기존의 통계적 모델과는 달리, 딥러닝 모델은 복잡한 비선형 패턴을 학습하고, 다양한 사회경제지표 및 기상 정보와 같은 데이터를 효과적으로 처리할 수 있는 장점을 지닌다. 이러한 배경에서 본 연구는 딥러닝을 활용한 사회경제지표 기반의 고속도로 교통량 예측 모델 구축을 제안하고자 한다. 본 연구의 목표는 시계열 및 기상지표 뿐만 아니라 사회경제지표에 기반한 정확한 교통량 예측 모델을 개발하여, 보다 정밀한 교통 예측 및 관리 체계 구축에 기여하는 것이다. 이를 통해, 교통류 관리의 효율성을 높이고, 고속도로 이용객의 편의성과 안전성을 증진시킬 수 있을 것으로 기대된다.
선행연구
연구 수행에 앞서 국내외의 교통량 예측 관련 연구 사례를 조사하였다. 조사 결과 사회경제지표를 활용한 교통량 예측 연구는 2건이었으며, 분기, 연단위 교통량을 예측하였다. 대부분의 연구는 60분 이내의 단기 교통량을 예측하였으며, 이 경우 사회경제지표나 기상지표 대신 교통량을 입력 데이터로 활용하여 교통량을 예측하고 있었다. 세부 조사 내용은 다음과 같다.
1. 사회경제지표를 활용한 교통량 예측 관련 연구
현재 한국도로공사는 회귀분석, KNN 모델을 활용하여 교통량을 예측하고 있다. 교통량 예측을 위한 변수로는 월, 수도권 기상, 요일 패턴을 사용하고 있다. 기상 요소는 강우/강설 유무와 강수/적설량을 사용하며, 요일 패턴은 월-금, 주말 외에 명절기간 인접요일을 활용하고 있다. 여기서 연도는 1개 변수, 월은 1-12월의 12개 변수, 요일 패턴은 예측일 및 예측일 전후의 평일/휴일/명절 패턴을 구분하여 사용하고 있다. 명절기간 교통량은 시스템으로 예측 가능하도록 구축되어 있으나 실제 예측정보로는 활용하지 않고 있으며, 실제 교통량은 도로교통연구원에서 별도로 예측하고 있다.
Jeong et al.(2012)은 고속도로 연장(한국도로공사 관리), GDP, 자동차 등록대수, 유가, 통행요금 계수 등을 회귀모형에 적용하여 고속도로 연간 이용차량 예측 모형을 구축하며, 분기단위 고속도로 이용차량을 예측하였다. Duraku et al.(2019)은 인구, 가구, 고용, 차량, 물가지수, 국내총생산, 국민소득, 휘발유 가격을 Neural PCA-RBF에 적용하여 연평균 일교통량(AADT; Annual Average Daily Traffic)을 예측하였다.
한국도로공사는 연, 월, 요일 등 시계열 데이터 및 기상 정보 외에 다른 지표를 사용하지 않고 있고, 명절기간 예측 교통량은 활용하지 않고 있는 단점이 있다. 그리고, 국내외 연구사례를 살펴보면, 다양한 사회경제 지표를 활용하여 교통량을 예측하나, 일단위 교통량이 아닌 분기 또는 연단위 교통량을 예측하였다. 즉 예측 목적이 다른 모형이며, 이 예측 정보는 매일 변하는 교통상황 예측에 활용할 수 없다.
2. 교통량 기반 교통량 예측 관련 연구
교통량을 기반으로 교통량을 예측한 연구는 시계열 분석, 기계학습, 딥러닝의 세 가지 방법론으로 나눌 수 있다. 국내외 주요 연구 현황은 Table 1과 같다.
Table 1.
Traffic volume-based traffic volume prediction study
| Author | Methodology | Prediction | |||
| Time series analysis | Machine learning | Deep learning | Target | Unit | |
| Chang et al.(2018) | KNN-NPR | TG Volume | 15/30/45/60min | ||
| Lee et al.(2018) | ARIMA | TG Volume | 5min | ||
| Lu et al.(2018) |
KNN SVR |
MLP Seq2Seq | TG Volume | 20min | |
| Baek et al.(2019) | ARIMA | TG Volume | 5min | ||
| Baek et al.(2020) | KNN-NPR | TG Volume | 5min | ||
| Han et al.(2021) | SARIMA | AVC Volume | 60min, day | ||
| Lee et al.(2021) | Singular linear model | TG Volume | 60min | ||
| Zheng et al.(2021) | CNN-LSTM | VDS Volume | 5/15/30/60min | ||
| Min et al.(2023) | Random forest XGBoost SVR | RNN | VDS Volume | 5/15/30min | |
| Lee et al.(2023) | LSTM | VDS Volume | 60min | ||
| Cho et al.(2023) | LSTM-GRU | VDS Volume | 60min | ||
| Ding et al.(2023) | FCN-LSTM | TG Volume | day | ||
| Das et al.(2023) | LSTM GRU | VDS Volume | 60min | ||
기존 교통량 기반 연구들은 특정 TG나 VDS 등 지점 교통량을 예측하고 있으며, 예측 단위는 대부분 60분 이하로 단기간 교통량 변화 예측에 초점을 맞추고 있다. 이로 인해 장기간의 시계열 변화와 사회경제지표 변화를 반영하기 어렵고, 기상 변화를 고려하지 못하는 한계가 있다.
3. 본 연구에 활용한 교통량 예측 방법론
본 연구의 목적은 시계열 데이터 및 기상 정보 뿐만 아니라 사회경제지표를 기반으로 모든 상황에서 적용 가능한 고속도로 일교통량 예측 방법론을 구축할 수 있음을 보이는 것이다. 일교통량은 다양한 요인에 의해 변하며, 대표적으로 계절성, 추세, 자기상관성, 이벤트 등의 특성을 포함한다. 요일에 따라 달라지는 요일 패턴이나 계절적 요인에 따른 변화는 계절성이라 할 수 있고, 경제 발전이나 산업 변화에 따른 장기적 변화는 추세의 예라 할 수 있다. 교통량은 이전 날짜, 특히 가까운 날짜와 강한 상관성을 가지는데, 이러한 것은 자기상관성으로 표현할 수 있다. 마지막으로 연휴, 폭우, 폭설 등 예외적 이벤트로 인해서도 교통량이 바뀌게 된다. 일교통량은 이러한 시계열적 특성과 패턴을 가지므로 회귀분석이나 Arima 모델로 예측해왔고, 최근에는 딥러닝 모델인 LSTM(Long Short-Term Memory)을 적용한 연구도 있다. 본 연구는 기존 연구에 적용된 회귀분석, LSTM 외에 Transformer를 추가하여 3가지 방법으로 교통량을 예측하였다.
회귀분석은 비결정론적 방식으로, 관련된 변수 간의 관계를 모델링하고 탐색하는 데 사용되는 통계 기법이다. 이러한 유형의 문제는 많은 엔지니어링 및 과학 분야에서 매우 자주 발생하기 때문에 회귀분석은 가장 널리 사용되는 통계 기법 중 하나이다(Montgomery et al., 2018). 사회경제지표들을 독립변수로 사용할 계획이므로, 단순 회귀분석, 다중 회귀분석 등 다양한 분석 방법 중 본 연구에서는 다중 회귀분석 모형을 적용하였다. 회귀분석은 다양한 독립변수를 고려할 수 있지만, 비선형적 관계를 효과적으로 반영하는 데 한계가 있다.
LSTM은 Hochreiter와 Schmidhuber에 의해 처음 제안된 신경망 구조로, 순환신경망(RNN; Recurrent Neural Network)의 변형된 형태이며, 장기 의존성 문제를 해결하기 위해 설계되었다. LSTM은 입력, 출력, 그리고 셀 상태로 구성되며, 이전 시간의 정보를 기억하고 중요한 정보를 선택적으로 업데이트한다(Hochreiter et al., 1997). LSTM은 과거의 정보를 일정 기간 동안 기억할 수 있는 메커니즘을 가지고 있어, 텍스트 생성, 음성 인식, 시계열 예측 등에서 자주 사용된다. 특히, LSTM은 기계 번역이나 음성 합성 같은 응용에서 탁월한 성능을 발휘하며, 데이터의 순차적 특성을 잘 반영하는 데 강점을 가진다.
Transformer 모델은 Vaswani et al.(2017)에 의해 제안된 모델로 자연어 처리에서 주로 사용되었으며, 기존의 순환 신경망과 같은 순차적 방식이 아닌 병렬로 입력 시퀀스를 처리한다. Transformer 모델은 입력 토큰 간의 관계를 직접 처리하고 이해할 수 있도록 하는 셀프 어텐션(Self-Attention)을 기반으로 하기 때문에, 모델이 재귀나 합성곱 연산 없이 입력 토큰 간의 관계를 직접 모델링할 수 있다. Transformer 모델 학습은 대용량 데이터세트에서 매우 효율적이며, 기계 번역, 언어 모델링, 텍스트 요약과 같은 장기적인 종속성을 포함하는 작업에 주로 사용되고 있다.
4. 기존 연구와 본 연구의 차이점
검토한 기존 연구와 본 연구의 차이점은 다음과 같다. 첫째, 입력 데이터는 시계열자료 뿐만 아니라 기상지표와 사회경제지표를 모두 활용하였다. 이를 통해 다양한 외부 요인을 반영하면서 장기 교통량을 예측할 수 있는 모델을 구축하고자 하였다. 둘째, 예측 데이터는 교통예보 등 교통관리에 직접적으로 활용할 수 있는 일교통량을 예측하였으며, 명절 등 특정 기간을 제외하는 것이 아닌 모든 기간의 교통량을 예측하였다. 셋째, 기상 지표를 반영하여 예측에 기상 상황이 반영될 수 있도록 하였다. 마지막으로 교통량 예측 모형에 기존 회귀분석이나 RNN 계열의 LSTM 모델 외에도 Transformer 모델을 적용하였다. 차이점을 정리하면 Table 2와 같다.
Table 2.
Differences between this study and previous studies
| Category | This study | KEC | Other studies (Socio- economic indicator base) | Other studies (Traffic volume base) |
| Input data |
Time series / Meteorological / Socio-economic indicator | Time series / Meteorological indicator | Socio-economic indicator |
Traffic volume (5–60 minutes) |
| Prediction data | Daily traffic volume (weekdays, weekends, traditional holiday) | Daily traffic volume (weekdays, weekends) | Quarterly/Annual traffic volume | Short-term traffic volume (5–60 minutes) |
| Weather impact consideration | Y | Y | N | N |
| Prediction methodology |
Time series analysis (regression analysis) Deep learning (LSTM, Transformer) |
Time series analysis (regression analysis) Machine learning (KNN) | Time series analysis (regression analysis) |
Time series analysis (ARIMA, etc.) Machine learning (KNN, SVR, etc.) Deep learning (LSTM, GRU, etc.) |
데이터 분석
1. 데이터 및 분석방법
연구를 위해 한국도로공사에서 일교통량으로 사용하는 고속도로 전구간의 영업소 출구교통량의 합을 예측 대상 교통량, 즉 종속변수로 선정하였다. 일교통량은 수백만 대로 값이 매우 크므로, 다른 변수와의 스케일 차이를 고려하여 단위를 ‘천대’로 설정하였다. 예를 들어 2024년 5월 31일의 일교통량은 5,683,000대이나, 5,683을 적용하였다. 그리고, 회귀분석, LSTM, Transformer 모델 구축을 위해 수집한 독립변수는 크게 시계열 정보, 기상지표, 사회경제지표로 나눌 수 있으며, Table 3과 같다.
Table 3.
Independent variables considered for prediction
| Variable | Data | Note | ||
| Form | Example(24.05.31.) | |||
| Time series | Year | 2023, 2024, … | 2024 | |
| Month | 1, 2, 3, … | 5 | One-hot Encoding | |
| Day pattern | W(Weekday), H(Weekend/Holiday), M(Traditional holiday) | W | One-hot Encoding | |
| Previous 3-day pattern | WWW, WWH, HWW, … | WWW | One-hot Encoding | |
| Subsequent 3-day pattern | WWW, WWH, HWW, … | HHW | One-hot Encoding | |
| Meteorological indicator | Lowest temperature | 00.0(℃) | 16.9 | |
| Highest temperature | 00.0(℃) | 25.4 | ||
| Precipitation (Y/N) | 0(N), 1(Y) | 1 | ||
| Precipitation amount | 0.0(mm) | 1.75 | ||
| Precipitation time | 0.0(hr) | 1 | ||
| Snowfall (Y/N) | 0(N), 1(Y) | 0 | ||
| Snowfall amount | 00.0(cm) | 0 | ||
| Cloudiness | 0.0(0-10) | 3.3 | ||
| Socio-economic indicator | Expressway length | 0000.0(km) | 4125.3 | |
| Consumer price indicies - Toll road fee | 00.00 | 97.28 | ||
| Population | 0000.0(Ten thousand people) | 5,127.7 | ||
| Number of cars owned | 0000.0(Ten thousand cars) | 2,609.6 | ||
| Gasoline prices | 0000.0(Won) | 1,697.5 | ||
| Nominal GDP (quarter) | 000.0(Trillion won) | 634.7 | ||
| Corona pandemic | 0(No-Pandemic), 1(Pandemic) | 0 | ||
시계열 정보는 교통량의 계절 및 요일 변동을 반영할 수 있도록 연, 월, 요일 패턴(해당일, 전3일, 후3일) 데이터로 설정하였다. 기상지표는 교통량 변화와 관련이 높다고 판단한 기온, 강우, 강설 관련 지표와 함께 날씨를 반영할 수 있는 운량을 포함하였다. 마지막으로 사회경제지표는 교통량과 연관성이 높은 고속도로 연장, 도로통행료, 인구, 자동차 보유대수, 유가, 명목 GDP, 코로나 팬데믹 여부로 설정하였다. 사회경제지표는 Jeong et al.(2012)의 연구에서 활용된 지표를 참조하였으며, 해당 연구의 지표 외에 통행에 큰 영향을 미쳤을 것으로 판단되는 코로나 팬데믹 지표를 추가하였다. 각 데이터는 2013년부터 2024년 5월까지 수집하였으며, 2013년부터 2023년까지 11년간의 데이터를 학습 데이터로 모델을 학습시키고, 2024년 1월-5월의 데이터로 교통량을 예측하였다. 성능 평가 지표는 MAPE(Mean Absolute Percentage Error)와 MAE(Mean Absolute Error)를 사용하였다. MAPE는 실제 교통량과 예측 교통량의 오차가 실제 교통량에서 차지하는 비율로 계산하고, MAE는 실제 교통량과 예측 교통량 차이로 계산하며, 두 지표 모두 0에 가까울수록 예측 정확도가 높다고 판단할 수 있다.
여기서, : 교통량 예측일 수
: 실제 일교통량
: 예측 일교통량
예측모형 구축을 위해 우선 데이터를 전처리하였다. 기상청에서 수집한 기상정보 중 2017년 10월 12일의 최고기온, 2022년 8월 8일의 최저기온은 데이터는 결측이었으며, 보간법을 활용하여 처리하였다. 월, 요일 패턴(해당일, 전3일, 후3일) 변수는 각 변수의 순서 정보가 중요하지 않으며, 시계열성은 보존하면서 비선형 관계를 반영할 수 있으므로 원핫인코딩(One-hot Encoding)으로 처리하였다. 그리고, 원핫인코딩으로 처리하지 않은 독립변수에 대해서는 데이터를 정규화한 경우와 정규화하지 않은 경우로 구분하였다. 데이터 정규화를 위해 MinMaxScaler를 적용하였으며, Case1 - 독립변수 정규화, Case2 - 독립변수 비정규화로 Case를 구분하였다. 구분된 2가지 Case 데이터를 활용하여 회귀분석, LSTM, Transformer 모델을 구축하여 데이터를 예측한 후, 실제 교통량(GT; Ground Truth), 한국도로공사에서 제공하는 예측 교통량(Base Line), 모델을 통해 예측된 교통량을 비교하였다. 예측 시스템/모델 간의 비교이므로, 한국도로공사의 예측 교통량에서 명절기간 교통량은 도로교통연구원의 예측값이 아닌, 한국도로공사의 시스템 예측값을 사용하여 분석하였다.
2. 세부 분석 방법론
교통량 예측을 위한 각 방법론별 세부 모델 구축 과정은 다음과 같다.
회귀분석은 상관분석, 다중공선성 제거, 정규화 순로 데이터를 처리하였다. 우선 Equation 3의 피어슨 상관계수 분석을 통해 각 독립변수들이 종속변수에 미치는 영향을 확인하였다. 강수여부, 강수량, 운량, 휘발유가격 변수는 상관계수의 절대값이 0.1 이하로 낮아 상관관계가 거의 없는 것으로 판단되어 제거하였다. 그리고, 코로나 팬데믹 변수는 상관계수 0.378로 교통량과 양의 상관관계가 있는 것으로 분석되었으며, 팬데믹으로 인한 이동 제한과 이로 인해 교통량이 감소했을 것이라는 추정과 상이하여 코로나 팬데믹 변수를 제거하였다. 다음으로 다중공선성 확인을 위해 Equation 4의 분산팽창계수(VIF; Variance Inflation Factor)를 산출하였다. 분산팽창계수가 10을 초과하는 경우 다중공선성이 존재할 가능성이 크고, 회귀모델의 불안정성을 초래할 수 있다. 따라서 분산팽창계수가 10을 초과하면서 가장 큰 변수를 제거하고, 다시 분산팽창계수를 산출하여 확인 및 제거하는 방법을 반복하였다. 이 때 원핫인코딩으로 처리한 범주형 변수는 이 과정에서 제거하지 않았으며, 동일 월에서 각 주차별로 동일한 교통량이 예측되는 것을 방지하기 위해 기온 변수 중 1개 이상은 남겨두었다. 이 과정을 통해 연, 인구, 고속도로 연장, 자동차 등록대수, 소비자 물가지수 - 도로통행료, 최고기온 변수를 제거하였다. 처리된 독립변수를 기반으로 앞서 언급한 2가지 Case로 모델을 생성한 후 교통량을 예측하였으며, 회귀모델은 Equation 5와 같은 형태로 도출된다.
여기서, : 독립변수 와 종속변수 간의 피어슨 상관계
: 독립변수 의 평균
: 종속변수 의 평균
여기서, : 독립변수 를 종속변수로 설정하고 나머지 독립변수들을 설명변수로 하는 보조 회귀모델의 결정계수
여기서, : 예측 교통량(종속변수)
: 절편(Intercept)
: 독립변수 의 회귀 계수(Regression Coefficient)
: 번째 독립변수
LSTM과 Transformer 모델 생성을 위한 데이터는 다음과 같은 방법으로 동일하게 처리하였다. 먼저 회귀분석 시 상관계수가 반대로 추정된 코로나 팬데믹 변수를 제거하였다. 그리고 회귀분석 시 다중공선성 분석을 통해 제거한 다른 변수는 제거하지 않았다. 다중공선성 문제는 회귀분석과 같은 선형 모델에서는 문제가 되지만, LSTM, Transformer와 같은 복잡한 비선형 모델에서는 다르게 다뤄질 수 있기 때문이다. LSTM은 여러 시점의 데이터를 입력으로 사용하므로 다중공선성이 있어도 그 정보가 모델 학습에 유용하게 사용될 수 있으며, LSTM은 비선형 관계와 복잡한 패턴을 학습할 수 있기 때문에, 변수들 간의 다중공선성을 적절히 처리할 수 있을 것으로 판단하였다. 그리고 Transformer 모델도 다중공선성이 있는 변수들을 포함함으로써 모델이 데이터 내의 상관관계를 학습할 수 있다. 또한 셀프 어텐션 메커니즘을 통해 입력 시퀀스의 각 부분에 가중치를 부여하며, 중요한 정보에 집중함으로써 다중공선성이 있는 변수들 중에서도 예측에 중요한 변수들을 자동으로 강조할 수 있다. 따라서 다중공선성이 있는 변수들을 제거하지 않더라도 모델이 중요하지 않은 정보를 무시하고, 중요한 정보에 집중할 수 있게 될 것이다.
LSTM 모델은 일반적인 순환신경망의 단점인 기울기 소실(Vanishing Gradient) 문제를 해결하기 위해 고안된 구조로, 입력 게이트(Input Gate), 망각 게이트(Forget Gate), 출력 게이트(Output Gate)를 포함하고 있다. LSTM 셀의 주요 연산은 다음과 같다.
망각 게이트는 이전 셀 상태 중에서 유지할 정보와 버릴 정보를 결정한다.
여기서, : 망각 게이트 값(0-1 범위)
: 현재 입력
: 이전 시점의 은닉 상태
: 학습 가능한 가중치와 편향
𝜎 : 시그모이드 활성화 함수
입력 게이트는 새로운 정보 중에서 현재 셀 상태에 추가할 정보를 결정한다.
여기서, : 입력 게이트 값
: 후보 셀 상태 값
출력 게이트는 최종적으로 출력될 은닉 상태를 결정한다.
그리고, 이러한 게이트들을 사용하여 셀 상태와 은닉 상태를 다음과 같이 업데이트 한다.
여기서, : 현재 셀 상태(이전 셀 상태 과 새로 추가된 정보의 조합)
: 출력 게이트 값
: 현재 은닉 상태(다음 시점으로 전달됨)
: 요소별 곱(Element-wise Multiplication)
LSTM 모델 구성은 다음과 같다. 모델 학습을 위해 시계열 데이터를 윈도우 방식으로 생성하였다. 윈도우 크기는 3으로 설정하였으며, 각 데이터 포인트에 대해 이전 3개부터 이후 3개 시간의 데이터를 기반으로 예측을 수행하였다. 데이터 포인트 이후의 3개 시간 데이터를 반영한 이유는 기상 예보 정보에 따른 교통량 변화를 반영하기 위해서이다. 이를 통해 시계열 데이터의 시퀀스를 모델에 입력하여 시간에 따른 패턴을 학습하도록 하였다. 모델 구조는 첫 번째 레이어로 200개의 유닛을 갖는 LSTM 레이어를 사용하였으며, 활성화 함수로는 ReLU를 적용하여 비선형성을 반영하였다. LSTM 레이어 이후에는 Dense 레이어를 추가하여 최종 출력값을 생성하도록 하였다. 출력 레이어의 노드 수는 1로 설정하여 단일 시점의 교통량을 예측하였다. 모델의 최적화 알고리즘으로 Adam 옵티마이저를 사용하였으며, Learning Rate은 0.001, 손실 함수로는 평균제곱오차(MSE; Mean Squared Error)를 채택하였다. 모델은 학습 데이터에 대해 1,000 에포크 동안 학습하였으며, 학습 Loss가 가장 낮은 모델을 최적 모델로 저장한 후, 이 모델을 예측에 적용하였다. 구성한 LSTM 모델을 도식화하면 Figure 1과 같다.

Transformer 모델의 주요 핵심 연산인 셀프 어텐션과 피드포워드 네트워크(Feed-Forward Network)이다. 셀프 어탠션 메커니즘은 시계열 데이터의 장기 의존성을 학습하기 위해 필요하다. 시계열 데이터에서 과거와 현재 간의 가중치 관계를 학습하는 것이며, 연산은 다음과 같다.
여기서, : 현재 시점의 입력 정보
: 과거 시점의 입력 정보
: 입력 데이터의 가중 평균
: 의 차원(Scaling Factor)
피드포워드 네트워크는 어텐션 레이어 이후 비선형 변환을 수행하여 모델의 표현력을 강화하는 역할을 위해 적용된다. Transformer의 피드포워드 네트워크는 입력 차원을 확장하여 더 복잡한 특징을 학습한 뒤, 다시 원래 차원으로 축소하는 역할을 한다. ReLU 활성화 함수를 사용해 비선형성을 추가하고, 각 입력 벡터에 독립적으로 적용된다는 점에서 셀프 어텐션과 상호 보완적인 역할을 하며, 연산은 다음과 같다.
여기서, : 입력 벡터
: 가중치 행렬
: 편향 벡터
Transformer 모델은 Transformer Encoder 구조를 적용하였으며, 세부 구성은 다음과 같다. 입력된 독립 변수들의 차원을 확장하기 위해 임베딩 레이어를 구성하였다. 이 레이어는 입력 데이터의 차원을 은닉 차원으로 변환하는 역할을 수행한다. 시계열 데이터의 순차적 특성을 반영하기 위해 Positional Encoding을 추가하였다. Positional Encoding은 입력 시퀀스에 위치 정보를 더하여 순서가 모델에 반영되도록 한다. Transformer 모델의 핵심은 Transformer Encoder로, 하나의 Transformer Encoder 레이어가 포함된다. 이 레이어는 멀티헤드 어텐션(Multi- Head Attention)과 피드포워드 네트워크로 구성되어 있으며, 입력 시퀀스 내에서 변수 간의 복잡한 상호작용을 학습한다. 본 연구에서는 은닉 차원을 128로 설정하였으며, 4개의 어텐션 헤드를 사용하였다. 마지막으로 최종 출력값을 생성하기 위해 은닉 차원에서 출력 차원으로 변환하며, 교통량 예측값을 생성한다. 모델의 최적화 알고리즘은 LSTM과 동일하게 Adam 옵티마이저를 사용하였으며, Learning Rate은 0.001, 손실 함수로는 평균제곱오차를 채택하였다. 3,000 에포크 동안 학습하였으며, 학습 Loss가 가장 낮은 모델을 최적 모델로 저장한 후, 이 모델을 예측에 적용하였다. 구성한 Transformer 모델을 도식화하면 Figure 2와 같다.

딥러닝 모델에서 Random Seed는 난수 생성기의 초기값을 설정하는 역할을 하며, 이는 데이터 분할, 가중치 초기화, 배치 샘플링 등 다양한 과정에서 영향을 미친다. Random Seed를 고정하면 실험을 반복할 때 동일한 결과를 얻을 수 있어 연구의 재현성이 보장되지만, 특정 Seed 값에서만 높은 성능을 보일 가능성이 있어 일반화 성능을 평가하는 데 한계가 있을 수 있다. 반면, Random Seed를 계속 변경하면 모델이 다양한 초기 조건에서 학습되므로 보다 다양한 분포를 반영할 수 있지만, 실험의 일관성이 떨어질 수 있고, 다수의 모델 학습 후 연구자에게 유리한 결과만 선택할 수 있는 우려가 있다.
따라서 본 연구에서는 실험의 일관성을 유지하고, 일반화 성능을 확인하기 위해 Random Seed를 41부터 45까지 고정하여 5개의 서로 다른 초기 가중치를 가진 모델을 학습하였다. 이를 통해 5개의 독립적인 모델을 생성하였으며, 이들 모델의 결과값을 평균하여 최종 예측값으로 사용하는 방법을 채택하였다. 여러 모델을 학습시키고 그 결과를 평균함으로써, 개별 모델의 예측이 가지는 불확실성을 줄이고, 예측의 안정성을 높일 수 있으며, Random Seed를 고정함으로써 모델 학습 과정의 재현성을 보장할 수 있다. 이는 동일한 환경에서 동일한 Random Seed를 사용할 경우, 일관된 결과를 얻을 수 있게 해주며, 연구 결과의 신뢰성을 높일 수 있다.
본 연구의 수행 절차 및 구축 모델별로 사용된 독립변수는 각각 Figure 3, Table 4와 같다.

Table 4.
Independent variables applied by model
| Category | KEC | Linear regression | LSTM | Transformer | |
| Time series | Year | ○ | × | ○ | ○ |
| Month | ○ | ○ | ○ | ○ | |
| Day pattern | ○ | ○ | ○ | ○ | |
| Previous 3-day pattern | ○ | ○ | ○ | ○ | |
| Subsequent 3-day pattern | ○ | ○ | ○ | ○ | |
| Meteorological indicator | Lowest temperature | × | ○ | ○ | ○ |
| Average temperature | ○ | × | × | × | |
| Highest temperature | × | × | ○ | ○ | |
| Precipitation (Y/N) | ○ | × | ○ | ○ | |
| Precipitation amount | ○ | × | ○ | ○ | |
| Precipitation time | × | ○ | ○ | ○ | |
| Snowfall (Y/N) | ○ | ○ | ○ | ○ | |
| Snowfall amount | ○ | ○ | ○ | ○ | |
| Cloudiness | × | × | ○ | ○ | |
| Socio-economic indicator | Expressway length | × | × | ○ | ○ |
| Consumer price indicies - Toll road fee | × | × | ○ | ○ | |
| Population | × | × | ○ | ○ | |
| Number of cars owned | × | × | ○ | ○ | |
| Gasoline prices | × | × | ○ | ○ | |
| Nominal GDP (quarter) | × | ○ | ○ | ○ | |
| Corona pandemic | × | × | × | × | |
3. 교통량 예측 결과
구축한 방법론에 따라 모델을 생성한 후, 일교통량을 예측하였으며, 모델별 교통량 예측 정확도를 비교하였다. 시계열 분석, 기계학습 기반인 한국도로공사의 교통량 예측 MAPE는 3.29%, MAE는 161.3을 나타냈다. 회귀분석 모델의 경우도 이와 유사한 3.20%와 154.0의 결과를 보였고, 독립변수 정규화 여부는 예측값에 차이를 보이지 않았다. LSTM, Transformer 모델의 경우 회귀분석 모델과 대비하여 상당히 개선된 결과를 보였고, 독립변수를 정규화한 경우(Case1) 예측 정확도가 더 향상되는 것을 확인할 수 있다. 특히 Transformer 모델의 경우 MAPE는 2.48%, MAE는 121.8로 가장 높은 예측 정확도를 보여, 예측력이 가장 우수한 것으로 나타났다. Table 5는 각 모델의 MAPE와 MAE를 나타낸 것이며, 가장 우수한 값은 진하게 표시하였다.
Table 5.
MAPE(%), MAE for each prediction model
| Model | MAPE | MAE | ||
| Case1 | Case2 | Case1 | Case2 | |
| KEC (Base Line) | 3.29 | 161.3 | ||
| Linear regression | 3.20 | 3.20 | 154.0 | 154.0 |
| LSTM | 2.58 | 2.71 | 125.4 | 129.9 |
| Transformer | 2.48 | 2.92 | 121.8 | 141.1 |
모델별 주요 시사점을 분석해 보면 다음과 같다. 먼저 회귀분석 모델의 결과와 각 변수가 교통량 예측에 기여하는 영향을 분석하기 위해 독립변수를 정규화하지 않은 회귀분석 모델(Case2)의 예측 결과를 확인하였으며, 결과는 Table 6과 같다. 수정된 결정계수가 0.848이고 F값이 432.4이므로 회귀모형은 높은 모델 설명력을 가지고 있다고 판단된다.
Table 6.
Result of the linear regression (Case2)
| Variable | 𝛽 | S.E. | p-value | Variable | 𝛽 | S.E. | p-value | |||
| Month | 1 | 148.666*** | 16.849 | 0.000 | Previous 3-day pattern | WHW | 288.693*** | 33.128 | 0.000 | |
| 2 | 222.151*** | 15.649 | 0.000 | WMM | 19.851 | 51.246 | 0.698 | |||
| 3 | 282.290*** | 12.697 | 0.000 | WWH | 37.749** | 18.593 | 0.042 | |||
| 4 | 346.019*** | 12.294 | 0.000 | WWM | 476.789*** | 66.335 | 0.000 | |||
| 5 | 388.609*** | 13.147 | 0.000 | WWW | 284.590*** | 17.204 | 0.000 | |||
| 6 | 284.255*** | 15.897 | 0.000 | Subsequent 3-day pattern | HHH | 369.532*** | 33.921 | 0.000 | ||
| 7 | 159.667*** | 18.567 | 0.000 | HHM | 247.263** | 98.805 | 0.012 | |||
| 8 | 261.637*** | 18.636 | 0.000 | HHW | 278.061*** | 18.392 | 0.000 | |||
| 9 | 289.077*** | 15.262 | 0.000 | HMM | 72.042 | 75.068 | 0.337 | |||
| 10 | 334.434*** | 12.661 | 0.000 | HWH | 316.600*** | 40.515 | 0.000 | |||
| 11 | 359.327*** | 13.438 | 0.000 | HWW | 366.532*** | 18.266 | 0.000 | |||
| 12 | 115.491*** | 16.696 | 0.000 | MHH | 590.092*** | 80.437 | 0.000 | |||
| Day Pattern | W | 844.445*** | 24.724 | 0.000 | MHW | 796.370*** | 77.487 | 0.000 | ||
| H | 1,215.359*** | 31.007 | 0.000 | MMH | -84.522* | 49.055 | 0.085 | |||
| M | 1,131.817*** | 22.526 | 0.000 | MMM | 268.717*** | 43.909 | 0.000 | |||
| Previous 3-day pattern | HHH | 170.117*** | 34.936 | 0.000 | MMW | -442.819*** | 87.355 | 0.000 | ||
| HHM | 639.289*** | 118.554 | 0.000 | MWW | 275.274** | 114.694 | 0.016 | |||
| HHW | 189.339*** | 19.216 | 0.000 | WHH | -85.323*** | 18.417 | 0.000 | |||
| HMM | 61.112 | 68.143 | 0.370 | WHM | 49.811 | 113.732 | 0.661 | |||
| HWH | 193.164*** | 40.069 | 0.000 | WHW | 0.757 | 34.061 | 0.982 | |||
| HWW | 217.823*** | 19.370 | 0.000 | WMM | 299.598*** | 52.630 | 0.000 | |||
| MHH | -156.083* | 81.129 | 0.054 | WWH | -73.368*** | 19.745 | 0.000 | |||
| MHW | 144.708* | 58.091 | 0.013 | WWM | -7.756 | 53.080 | 0.884 | |||
| MMH | -47.004 | 48.029 | 0.328 | WWW | -45.241** | 18.521 | 0.015 | |||
| MMM | -28.875 | 44.490 | 0.516 | Lowest temperature | 8.789*** | 0.911 | 0.000 | |||
| MMW | 77.136 | 98.968 | 0.436 | Precipitation time | -21.971*** | 0.755 | 0.000 | |||
| MWW | -141.623 | 99.089 | 0.153 | Snowfall (Y/N) | -28.024 | 24.909 | 0.261 | |||
| WHH | 219.188*** | 19.274 | 0.000 | Snowfall amount | -19.947** | 8.408 | 0.018 | |||
| WHM | 545.658*** | 119.802 | 0.000 | Nominal GDP | 5.543*** | 0.051 | 0.000 | |||
| Adj. Rsquared : 0.848, F-statistic : 432.4 | ||||||||||
그리고 각 변수들의 계수값을 통해 변수가 교통량 예측에 기여하는 정도와 영향을 알 수 있다. 예를 들어 일교통량은 최저 기온이 1℃ 상승하면 8,800대 증가하고, 비가 1시간 내릴 경우 21,970대 감소할 것으로 예상할 수 있다. 요일 패턴의 경우 명절이나 연휴의 교통량 변화를 확인할 수도 있다. 명절 당일 교통량은 매우 높은 교통량을 나타내며, 직전 3일 패턴이 HHM, WHM, WWM 등일 경우 이 변수의 영향만으로 교통량이 48-64만대가 더 많을 것으로 예상할 수 있다. 그리고 직후 3일 패턴이 MHH, MHW, MWW인 경우도 28-80만대의 교통량이 많아지게 된다. 두 변수는 독립적으로 영향을 미치므로, 명절 당일에는 요일 패턴 영향에 따라 76-144만대의 교통량이 증가하게 될 것이다. 연휴의 경우 연휴 전날과 첫날에 매우 높은 교통량을 나타내는데, 이 역시 직후 3일 패턴이 HHH, HHM, HHW인 경우를 통해 25-37만대 더 높은 교통량을 보일 것을 예상할 수 있다. 월 계수를 보면, 봄, 가을 행락철에 교통량이 증가하고, 겨울에 교통량이 감소하는 전형적인 패턴을 잘 나타내주고 있다. 그러나 이러한 패턴은 일반적 경우에 나타나는 것이며, 명절과 같이 일반적 패턴을 보이지 않는 경우는 설명력에 한계가 있다. 또한 명절은 음력으로 명절이 있는 달이 바뀌게 되므로 회귀식에서 변수의 영향력으로 반영되기에는 한계가 있을 것이다. 이러한 점은 명절과 같은 극단값 예측에 제한적일 수 밖에 없으며, Table 7의 요일 패턴별 결과에서도 확인할 수 있다.
Table 7.
MAPE(%), MAE for each prediction model by day pattern
| Model | Day pattern | MAPE | MAE | ||
| Case1 | Case2 | Case1 | Case2 | ||
| KEC (Base line) | Weekday | 2.47 | 126.4 | ||
| Weekend/Holiday | 4.70 | 215.5 | |||
| Traditional holiday | 9.55 | 527.7 | |||
| Linear regression | Weekday | 2.53 | 2.53 | 126.0 | 126.0 |
| Weekend/Holiday | 4.57 | 4.57 | 208.9 | 208.9 | |
| Traditional holiday | 4.96 | 4.96 | 277.1 | 277.1 | |
| LSTM | Weekday | 2.09 | 2.22 | 103.2 | 108.9 |
| Weekend/Holiday | 3.50 | 3.72 | 163.5 | 170.3 | |
| Traditional holiday | 5.36 | 4.13 | 302.4 | 230.1 | |
| Transformer | Weekday | 1.99 | 2.47 | 98.5 | 121.7 |
| Weekend/Holiday | 3.26 | 4.00 | 155.3 | 186.1 | |
| Traditional holiday | 7.09 | 2.04 | 405.1 | 118.0 | |
본 연구에서 구축한 회귀분석 모델의 경우 한국도로공사의 예측값과 비교하여 예측 정확도에 큰 차이를 보이지 않는다. 두 방법론은 독립변수의 종류 및 모델 구축을 위해 사용한 과거 자료의 기간이 서로 같지 않지만, 두 방법론이 유사하여 예측값도 큰 차이를 보이지 않았다고 판단된다. 따라서 회귀분석 모델에서는 예측 정확도를 크게 향상시키는 것이 쉽지 않을 것으로 생각된다.
그리고 LSTM, Transformer 모델은 독립변수 정규화 여부에 따른 예측 정확도 차이가 발생하는 것을 알 수 있다. 회귀분석의 경우 독립변수의 가중치를 학습하여 종속변수를 예측하는 모델로, 독립변수의 정규화 여부와 상관없이 독립변수와 종속변수 간의 선형 관계만을 학습하므로 동일한 결과가 도출된다. 그러나 LSTM은 시계열 데이터의 변동성과 추세를 학습하며, 정규화를 통해 입력값의 스케일을 일정하게 맞춰 주면 학습 과정에서 더 빠르고 안정적으로 최적의 파라미터를 찾을 수 있다. 또한 Transformer 모델은 어텐션 메커니즘을 사용하여 데이터 간의 상관관계를 파악하며 복잡한 비선형 관계를 학습하는데, 입력값이 정규화되지 않으면 값이 지나치게 크거나 작아져 학습의 안정성이 떨어질 수 있고 최적화가 제대로 이루어지지 않을 수 있다. 반면 정규화를 하면 Transformer 모델은 좀 더 일정한 분포의 데이터를 다루게 되어 학습 과정에서 일관된 성능을 보이며 예측값에 차이가 생긴다. 회귀분석은 독립변수 정규화 여부와 관계없이 동일한 값이 예측되는 반면, LSTM과 Transformer는 입력 데이터의 스케일에 민감하여 정규화 여부에 따라 예측값이 달라지게 되는 것이다.
다음으로 따른 예측 정확도를 세부적으로 분석하기 위해 요일 패턴별 정확도를 확인하였다. 한국도로공사의 Base Line과 회귀분석 모델의 경우 요일 패턴에 따른 결과도 유사한 결과를 보였다. 평일, 주말/공휴일, 명절의 예측 정확도 모두 딥러닝 방식인 Transformer 모델이 가장 우수하였다. Table 7은 요일 패턴별 MAPE와 MAE를 분석한 결과이며, 가장 우수한 값은 진하게 표시하였다.
회귀분석 예측 결과의 한계가 모델의 한계인지 딥러닝 모델과의 변수 차이에 의한 것인지 확인할 필요가 있다. 따라서 본 연구에서 제시한 회귀분석 절차를 따르지 않고 딥러닝 모델과 동일한 변수를 반영한 회귀분석 모델을 구축한 후 결과를 비교하였으며, 결과는 Table 8과 같다. 모든 변수를 포함한 모델을 통한 예측값의 MAPE와 MAE는 본 연구 절차에 따른 모델의 결과값과 유사하며, LSTM, Transformer 모델보다 예측 정확도가 떨어지는 결과를 보였다. 이를 통해 본 연구에서 수행한 회귀분석 결과와 딥러닝 모델의 예측 결과를 비교하는 것이 결과 해석에 영향을 미치지 않으며, 모든 변수를 반영하더라도 회귀분석 모델보다 딥러닝 모델이 더 우수한 결과를 보임을 알 수 있다.
Table 8.
MAPE(%), MAE for independent variables of linear regression
Figure 4는 각 모델의 예측 결과를 그래프로 나타낸 것이며, MAPE와 MAE가 가장 낮은 Transformer 모델은 진하게 표시하였다. 평일, 주말/공휴일, 명절 패턴에 따른 모델의 예측 차이를 확인할 수 있으며, 근로자의 날(5월 1일)은 현실적으로는 많은 기업이 업무를 하지 않으나, 법정공휴일은 아니기 때문에 평일로 분류되어 모든 모델에서 예측 오차가 크게 나타남을 확인할 수 있다.
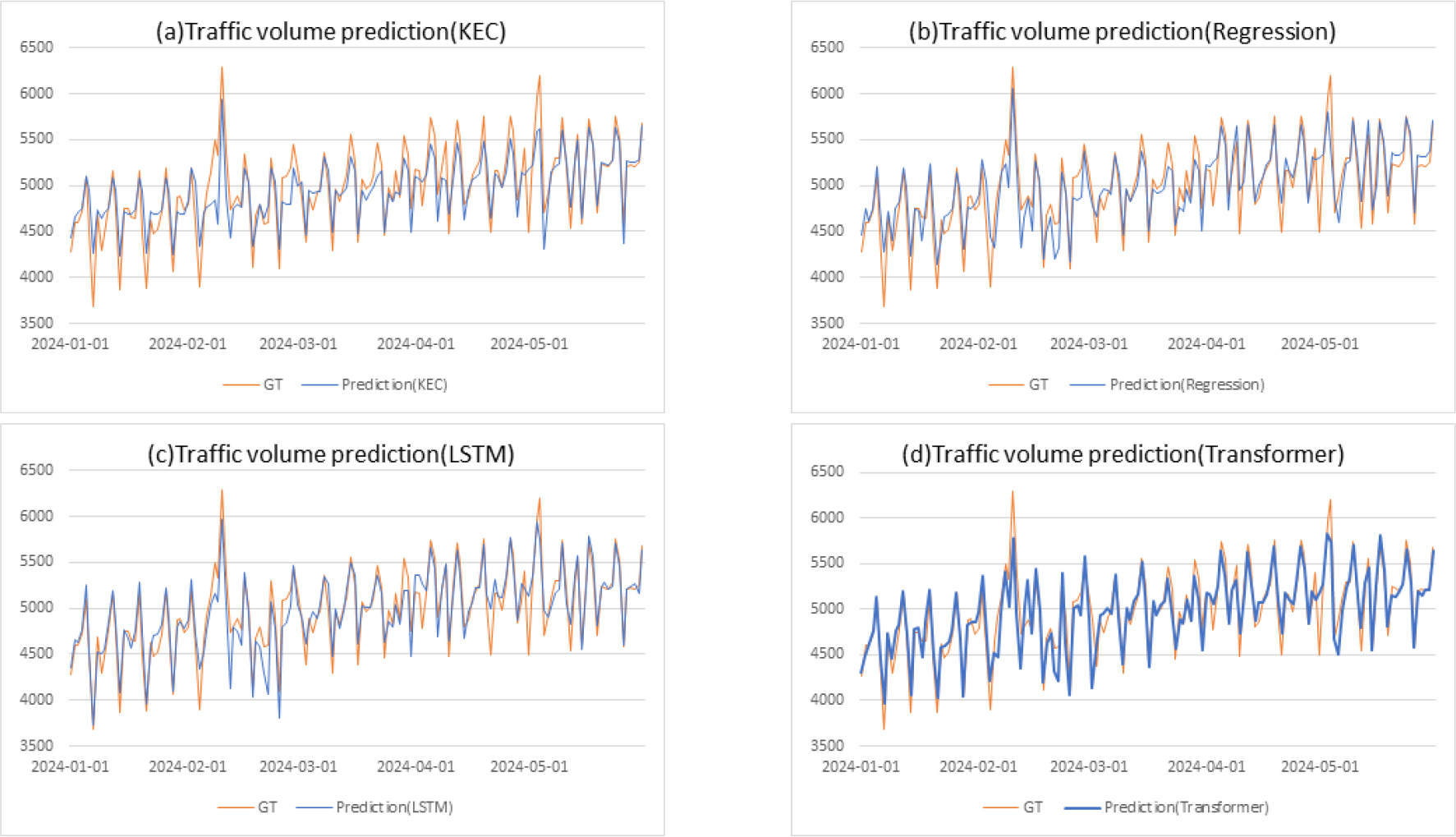
Figure 4.
Traffic volume prediction results ((a) Traffic volume prediction (KEC), (b) Traffic volume prediction (Regression),(c) Traffic volume prediction (LSTM (Case1)), (d) Traffic volume prediction (Transformer (Case1)))
※Vertical axis: Traffic volume (thousands), Horizontal axis: Days, GT: Ground Truth
Figure 4에 그래프로 나타낸 모델들의 일별 예측 오차를 분석한 결과는 Table 9와 같다. 각 모델별 예측 교통량과 실측 교통량 차이의 비율, 즉 예측 오차를 일자별로 확인한 후 비율 범위에 따른 일수와 누적 비율을 확인하였으며, 누적 비율이 가장 높은 값을 진하게 표시하였다. 예측 오차가 1.0% 이내인 일수는 Transformer 모델이 제일 많으며, 이후 오차 범위가 커질 경우에도 전반적으로 가장 우수한 예측 성능을 보인다. 또한 5.0%를 초과하는 오차를 보인 일수는 Transformer 모델이 23일로 가장 적으며, 이러한 결과들로 볼 때 Transformer 모델이 다른 모델에 비해 적은 오차 범위에서 안정적으로 예측이 가능함을 확인할 수 있다.
Table 9.
Number of days and cumulative percentage by prediction error
| Prediction error | Number of days | Cumulative percentage | ||||||
| KEC (Base Line) | Linear regression |
LSTM (Case1) |
Transformer (Case1) |
KEC (Base Line) | Linear regression |
LSTM (Case1) |
Transformer (Case1) | |
| 0.0-1.0% | 35 | 34 | 46 | 53 | 23.0% | 22.4% | 30.3% | 34.9% |
| 1.0-2.0% | 34 | 24 | 36 | 40 | 45.4% | 38.2% | 53.9% | 61.2% |
| 2.0-3.0% | 18 | 34 | 27 | 17 | 57.2% | 60.5% | 71.7% | 72.4% |
| 3.0-4.0% | 15 | 19 | 11 | 7 | 67.1% | 73.0% | 78.9% | 77.0% |
| 4.0-5.0% | 19 | 14 | 7 | 12 | 79.6% | 82.2% | 83.6% | 84.9% |
| 5.0%- | 31 | 27 | 25 | 23 | 100.0% | 100.0% | 100.0% | 100.0% |
4. Transformer 모델의 Feature Importance 분석
딥러닝 모델인 LSTM과 Transformer 모델의 요일 패턴별 결과를 보면, LSTM 모델은 독립변수 정규화 여부에 따른 결과 차이가 크지 않으나, Transformer 모델은 독립변수를 정규화한 경우(Case1) 평일과 주말/공휴일의 MAPE가 낮고, 독립변수를 정규화하지 않은 경우(Case2) 명절의 MAPE가 낮은 차이가 나타나는 것을 확인할 수 있다. 이러한 결과를 보이는 원인을 확인하기 위해 각 Transformer 모델별 Feature Importance를 분석하였다. 이를 통해 각 변수들이 예측에 얼마나 기여하는지를 확인할 수 있으며, 정규화된 데이터와 정규화되지 않은 데이터가 성능에 미치는 영향을 알 수 있다. 이를 위해 임베딩 가중치의 크기를 기반으로 Feature Importance를 산출하였다. 각 피처에 대해 학습된 임베딩 가중치가 모델의 예측 성능에 어느 정도 영향을 미치는지를 추정하는 방식으로, 가중치 크기가 클수록 해당 피처가 모델에 더 중요한 영향을 미친다고 간주한다. 임베딩 가중치를 기반으로 피처의 중요도를 계산하는 것은 매우 직관적이고 계산량이 적으며, 임베딩 레이어에서 직접 학습된 가중치만을 고려하므로, 모델이 특정 피처를 얼마나 중요하게 여기는지를 분석하는 데 유용하다. 그러나, 임베딩 가중치만을 사용하기 때문에, 모델이 예측을 위해 사용하는 모든 상호작용을 반영하지 못할 수 있다.
모델별로 피처에 부여하는 상대적 중요도가 다르기 때문에, Feature Importance의 합도 다르다. 따라서 Feature Importance 값을 직접 비교하는 것은 적절하지 않으며, 전체 대비 비율을 비교하여 각 모델별 상대적 중요도를 비교하였다. Feature Importance의 비율 값이 높은 상위 5개 피처 항목과 비율 값은 Table 10과 같다. 독립변수를 정규화한 모델(Case1)은 명절과 관련된 지표 2개 외에 휴일 관련 지표 및 사회경제지표 2개의 중요도가 높게 나타났다. 독립변수를 정규화하지 않은 모델(Case2)의 경우 중요도가 높은 피처에 기상, 사회경제지표는 포함되어 있지 않고, 명절(M)이 포함된 요일 관련 정보의 중요도가 높게 나타났으며, 명절 기간의 교통량 정확도가 높은 이유를 확인할 수 있다. 그리고, 이 결과는 기본 모델인 Transformer를 개선하거나, 입력 변수를 적절히 보완할 경우, 평일, 주말/공휴일, 명절 등 모든 기간에서 우수한 결과를 나타낼 수 있는 모델 구축이 가능하다는 것을 시사한다.
Table 10.
Feature importance(%) for each transformer model
결론
본 연구에서는 회귀분석, LSTM, Transformer 모델을 적용하여 기상 및 사회경제지표를 기반으로 교통량 예측 모형을 구축하였다. 그리고 구축 모형으로 교통량을 예측한 후, 한국도로공사의 교통량 예측 결과와 비교하는 사례분석을 실시하였다. 분석 결과 사회경제지표를 포함하는 모델이 기존 한국도로공사의 모델보다 MAPE와 MAE가 향상되는 결과를 보였다. 각 모델별 결과를 보면 회귀분석 모델은 한국도로공사 모델보다 약간(MAPE 2.7%, MAE 4.5%) 개선되는 결과를 보였으나, 딥러닝 모델의 경우 향상폭이 큰 것을 확인할 수 있다. 특히 가장 우수한 정확도를 보인 독립변수를 정규화한 Transformer 모델(Case1)의 경우 MAPE는 24.6%, MAE는 24.5%가 향상되었다. 따라서 보다 정확한 교통량 예측을 위해서는 사회경제지표를 포함하는 것 뿐만 아니라 딥러닝 모델 적용이 필요함을 확인할 수 있다.
Transformer 모델은 독립변수 정규화 여부에 따라 요일 패턴별 예측 결과가 상당히 차이가 나는 결과를 보였다. 이러한 결과가 나타난 원인을 확인한 결과 입력 변수의 정규화 여부에 따라 모델의 Feature Importance가 달랐는데, 이는 입력 변수의 스케일에 따라 데이터 간 상관관계를 파악하는 학습 방향이 달라짐을 의미한다. 이 결과는 모델의 입력 변수를 적절히 처리할 경우 모든 요일 패턴에서 우수한 성능을 보이는 모델을 구축할 수 있음을 의미한다.
향후 연구에서는 모델 개선 및 변수 조정을 통해 모든 기간에서 우수한 결과를 보일 수 있는 방법론을 구축하여 제시할 수 있을 것이다. 그리고 전구간 고속도로 일교통량 예측이 아닌, 고속도로 이외의 도로 교통량 예측에도 적용 가능성을 확인할 수 있을 것이다. 또한 일교통량이 아닌 시간대별, 일정 시간별 교통량 예측을 통해 다양한 미시적 분석 및 시뮬레이션에 활용할 수 있는 예측 데이터를 생성할 수 있을 것으로 기대한다.
