

서론
1. 연구의 배경 및 목적
2. 연구 대상 및 범위
3. 연구수행 방법
선행연구
연구 모형
1. 의사결정나무
2. CHAID 모형
3. CART 모형
모형설정
1. 변수선정
2. 모형설정
예측 및 정확도 비교
결론 및 시사점
서론
1. 연구의 배경 및 목적
글로벌 경제 성장과 세계무역기구(WTO)체제의 등장으로 항공운송산업이 지속적으로 성장하고 있는 가운데 항공운송 수요는 중간재적 성격과 파생수요라는 한계로 인해 국제 정세, 유가, 환율, 전염병 등 다양한 사회적 요인과 외부 환경적 요인에 따른 불확실성을 내포하고 있다(Min and Ha, 2020). 항공운송산업은 9.11 테러, SARS·신종플루·메르스 등 전염병의 유행, 글로벌 금융위기, 미중무역 분쟁 등 여러 사건에 영향을 받아왔다. 최근에는 COVID-19 대유행으로 인해 국제화물수송실적과 국제여객수송실적이 급감하면서 항공운송산업이 위축되는 모습을 보이기도 했다. 시간이 지나 국제화물수송실적은 2019년 이전 수준으로 회복됐고 향후 20년간 항공화물 시장은 RTK(유상톤킬로미터) 기준 연 평균 4% 성장할 것으로 예상된다(BOEING, 2020). 항공화물 시장은 사회적·환경적 요인에 따른 불확실성에도 불구하고 꾸준히 성장하고 있고 중요성은 증대되고 있다.
항공사 간 경쟁이 심화되면서 항공사 생존의 핵심 요소로 보유자원의 활용률 극대화를 통한 운영효율성 증대가 대두되고 있는데, 수요예측은 운영효율화 달성을 위한 핵심 분야 중 하나이며 항공수요예측은 항공산업 내 경제주체들의 의사결정에 기초자료 및 참고자료로 활용된다(Min and Ha, 2020). 항공수요예측은 예측 대상에 따라 항공여객에 대한 수요예측과 항공화물에 대한 수요예측으로 구분된다. 또한 항공수요예측은 예측기간에 따라 장기, 중기, 단기예측으로 구분할 수도 있다. 일반적으로 수요예측에서 장기예측은 2년 이상의 예측을 의미하고, 중기예측은 6개월에서 2년 사이의 예측, 단기예측은 6개월 이내의 분기별 예측, 월별 예측, 주별 예측, 일별 예측을 의미한다. 이외에도 항공수요예측은 예측 단위에 따라 연 단위의 예측, 분기 단위의 예측, 일 단위의 예측으로 구분할 수 있다.
일별 항공물동량 예측은 공항이나 항공사의 장비 또는 인력의 운용 계획, 재배치 등 세부적인 운영계획 수립을 위한 필수자료로 활용된다. 정확도 높은 일별 항공물동량 예측은 항공사·공항 등 항공운송산업 내 모든 경제주체들의 비효율성을 감소시킬 수 있고 대규모 투자가 수반되는 항공운송산업 특성상 비효율성의 감소는 대규모 비용절감으로 이어질 수 있다.(Min and Ha, 2020).
항공물동량 예측 기법으로 다중선형회귀, ARIMA, SARIMA 등 통계적 기법들과 서포트 벡터 회귀, 뉴럴 네트워크, 의사결정나무 등 머신러닝 기법들이 존재한다. ARIMA 모형은 과거 데이터를 기반으로 예측을 진행하기 때문에 과거의 추세가 예측 결과에 지배적인 영향을 미치고 예측 시차가 긴 예측 시에는 정확도가 떨어진다는 단점을 가지고 있다. 반면 의사결정나무 모형은 예정된 미래 사건들을 변수로 고려할 수 있어 단기 예측 시에 유리하다. 따라서 ARIMA 모형과 의사결정나무 모형을 결합하여 활용하면 두 모형 간 상호보완 효과로 인해 정확도 높은 일별 항공물동량 예측 결과가 기대된다. 의사결정나무 모형에는 여러 알고리즘이 존재하고 알고리즘 종류에 따라 서로 다른 특성을 가지고 있다.
본 연구에서는 ARIMA 모형과 CART를 결합한 일별 항공물동량 예측모형과 ARIMA 모형과 CHAID를 결합한 일별 항공물동량 예측모형을 생성하고 두 개 시점에서 두 모형의 예측정확도를 비교 분석하여 정확도 높은 일별 항공물동량 예측모형을 식별하였다. 또한 일별 항공물동량 예측모형 간 예측정확도 차이가 발생하는 원인에 대해 분석하였다. 최종적으로 예측 시점에 따라 적합한 모형을 식별하고 결론 및 시사점을 도출하였다.
2. 연구 대상 및 범위
본 연구에서는 K항공사의 인천공항발 일별 항공화물 수출 물동량 자료를 활용하였다. 연구에 활용한 데이터는 항공정보포털 시스템에 공개된 노선별 운송현황 실시간 통계 자료에서 수집하였다. 구체적인 기간은 2017년 1월 1일부터 2022년 9월 30일까지 총 2,099일이다.1) 첫 번째 시점에서 예측모형 생성에 활용한 training data의 기간은 2017년 1월 1일부터 2021년 12월 31일까지 총 5년이며 test data의 기간은 2022년 1월 1일부터 2022년 4월 1일까지 총 13주이다. 두 번째 시점에서 예측 모형 생성에 활용한 training data의 기간은 2017년 7월 2일부터 2022년 7월 1일까지 총 5년이며 test data의 기간은 2022년 7월 2일부터 9월 30일까지 총 13주이다.
3. 연구수행 방법
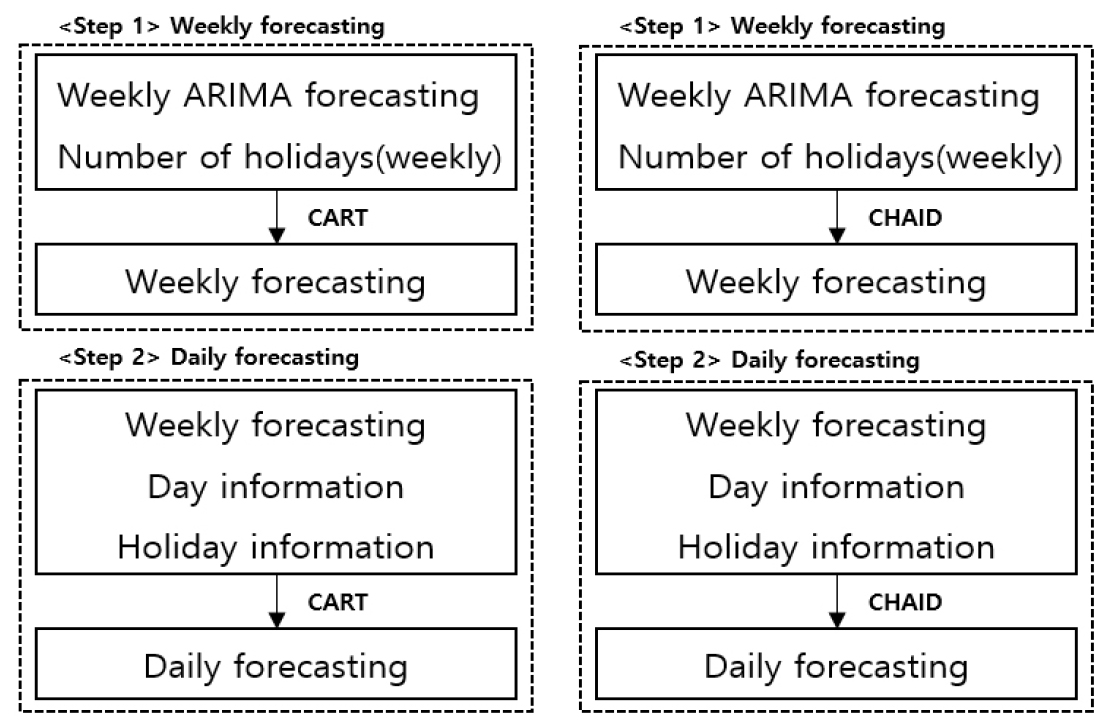
본 연구에서 사용된 일별 항공물동량 예측모형은 두 단계를 거쳐 생성된다. 예측모형을 두 단계로 구성한 이유는 정확도 높은 예측을 수행하기 위해서다. ARIMA 모형은 과거 시계열을 기반으로 예측을 진행하기 때문에 예측기간이 늘어날수록 정확도가 떨어진다. 따라서 주 단위의 ARIMA 예측치를 변수로 사용해 주별예측을 진행하고 이후 주별예측치와 다른 변수들을 사용하여 일별 예측을 진행하였다. 주별예측을 통해 주별 물동량 수준을 결정하고, 일별예측을 통해 요일, 주요국의 공휴일정보 등의 변수를 기준으로 세부적인 물동량 수준을 결정하여 정확도 높은 예측을 수행하였다. Figure 1은 예측모형 생성 단계를 도식화한 것이다.
첫 번째 단계에서는 주별 항공물동량 예측모형이 생성된다. 주별 항공물동량 예측모형에서는 주별 ARIMA 예측치, 주요국의 주별 공휴일 일수를 설명변수로 사용하였다. 주별 항공물동량 예측모형에는 의사결정나무 기법인 CART와 CHAID 방법론을 활용하였다. 두 번째 단계에서는 주별 항공물동량 예측모형을 통해 도출한 주별 예측치, 요일정보, 주요국의 공휴일 정보를 설명변수로 사용하였다. 일별 항공물동량 예측모형에는 첫 번째 단계와 마찬가지로 의사결정나무 기법인 CART와 CHAID 방법론을 활용하였다. 이를 통해 CART 방법론을 적용한 최종 일별 항공물동량 예측모형과 CHAID 방법론을 적용한 최종 일별 항공물동량 예측모형을 생성했다.
주요국의 주별 공휴일 일수, 요일정보, 공휴일 정보를 설명변수로 사용한 이유는 해당 변수들은 외부 설명변수에 대한 예측이 필요하지 않기 때문이다. ARIMA 예측치도 과거 관측값을 이용해 추세를 예측하기 때문에 외부 설명변수에 대한 예측이 불필요하다. 외부 설명변수를 이용할 경우 예측시점에 영향을 줄 것으로 생각되는 외부 설명변수의 정확한 값을 추정해야한다. 따라서 본 연구에서는 ARIMA 예측치, 주별 공휴일 일수, 요일정보, 공휴일 정보를 변수로 사용하였다. ARIMA 예측치를 이용해 추세를 구하고 의사결정나무 모형을 이용해 공휴일 일수, 요일정보, 공휴일 정보에 따른 물동량 예측을 진행하였다.
일별 항공물동량 예측모형을 통해 향후 91일간의 일별 항공물동량 예측치를 추정하고 실제 물동량 데이터를 통해 예측정확도를 도출하였다. 이후 전통적인 시계열 예측기법인 ARIMA 모형과 CART, CHAID 일별 항공물동량 예측모형 간 예측정확도를 비교하였다. 예측 정확도는 1월부터 91일간의 일별 항공물동량과 7월부터 91일간의 일별 항공물동량을 예측하여 비교하였다. 최종적으로는 일별 항공물동량 예측에 적합한 모형을 식별하고 결론과 시사점을 도출하였다.
선행연구
항공운송산업에서 항공수요의 불확실성은 효과적이거나 효율적인 운영을 방해하며 비용을 급격하게 증가시키는 요인이다. 불확실성을 내포하고 있는 항공운송산업에서 수요예측의 중요성은 매우 크다. 항공수요예측에 관한 연구는 오랜 기간에 걸쳐 광범위하게 진행되어왔다. 항공수요예측에 관한 선행연구들은 여객, 화물 등 여러 요인들을 대상으로 진행되었고 항공여객에 초점을 둔 연구들이 대부분을 이루고 있다. 항공수요예측에 관한 선행연구들은 중·장기적인 예측이 대부분이며 방법론으로는 시계열 모형, 다중선형회귀 등의 통계적 기법과 서포트벡터회귀, 뉴럴네트워크 등의 머신러닝 기법 같은 다양한 기법들이 활용되고 있다.
Chen et al.(2012)은 역전파신경망(BPN)을 이용해 일본발 대만행 항공여객과 화물에 대한 연간 예측을 진행했고 예측정확도를 향상시키는 방안을 제시했으며 여객과 화물에 영향을 미치는 요인들을 평가하고 분석했다. Lo et al.(2015)은 홍콩국제공항의 항공화물을 대상으로 회귀모형을 적용하여 수요·공급함수를 추정하고 2008년 발생한 글로벌 경제위기 이후에 항공화물 운임과 소득 탄력성 변화를 분석하였다. 분석결과 항공화물 수요가 가격에 음의 방향으로 반응하지만 민감하지 않게 반응하는 것으로 나타났다. Magaña et al.(2017)은 인터뷰, 문헌조사 등을 통해 항공화물 수요예측에 영향을 미치는 요인들을 식별하고 항공화물 취급회사의 운영성과 개선방안을 제시하였다. Shin and Lee(2019)는 중국, 일본, 태국, 필리핀 등 인트라 아시아 국가의 항공화물에 대한 수출입 항공화물 예측모형을 ARIMAX, SARIMAX 모형을 적용하여 제시하고 국가별로 항공화물 수요에 영향을 미치는 요인을 식별하였다. 모형 도출 결과 국가별로 수입 모형과 수출 모형이 서로 다르고 동일 국가 내에서도 모형 간 유효한 요인들이 다른 것으로 나타났다.
Min et al.(2013)은 ARIMA, SARIMA 모형을 적용하여 인천공항발 유럽항공노선의 분기별 항공화물 물동량 예측을 진행했고 방법론간 예측정확도를 비교하였다. 예측 결과 SARIMA 모형의 예측정확도가 ARIMA 모형의 예측정확도보다 높았다. Klindokmai et al.(2014)는 이동평균법, Holt-Winters, ARIMA 모형을 적용하여 항공화물 물동량의 예측정확도를 비교하였다. 예측결과 Holt-Winters 모형이 ARIMA 모형에 비해 높은 예측정확도를 보였다. Suh et al.(2017)은 SARIMA 모형을 적용하여 인천국제공항 미주노선을 통한 수출항공화물 물동량 예측 및 ARIMA 모형과의 예측정확도를 비교 분석하였다. 분석 결과 SARIMA 모형의 예측정확도가 ARIMA 모형에 비해 높게 나타났다.
Liu et al.(2020)은 ARIMA, 다중선형회귀 등 통계적 기법과 서포트벡터회귀, 뉴럴네트워크, Gradient Boosting Regression Tree 등 머신러닝 기법을 이용해 중국의 일별 항공화물 물동량 예측정확도를 비교 분석하고 항공화물 예측에 적합한 예측모형을 식별하였다. 연구 결과 단기항공화물 예측에는 ARIMA 모델이 적합한 반면 장기항공화물 예측에는 서포트벡터회귀 모델이 적합한 것으로 나타났다. Madhavan et al.(2020)은 ARIMA, Bayesian Structural Time Series(BSTS) 모형을 적용해 인도 항공 산업의 월별 항공여객 및 화물 수요 예측을 진행하였고 두 모형간 예측정확도를 비교하였다. 예측 결과 ARIMA의 예측정확도가 높았으나 BSTS 모형도 단기 항공예측에 적합한 것으로 나타났다. Chou et al.(2011)은 GDP를 주요 변수로 사용하여 대만의 수출 항공화물 물동량을 예측하기 위해 Fuzzy Regression Forecasting Model(FRFM) 예측기법을 이용한 예측모형을 제시하였다. Xu et al.(2019)은 SARIMA 모형과 서포트벡터회귀 모형을 함께 적용하여 중국의 항공여객 및 항공화물에 대한 예측을 진행하였다. SARIMA 모형을 통해 시계열을 분석한 후 SVR 모형으로 물동량 예측을 진행하였다. Min and Ha(2020)는 ARIMA, CHAID 모형을 함께 적용하여 인천공항발 K항공사의 일별 물동량 예측을 진행했고 방법론간 예측정확도를 비교하였다. 연구 결과 ARIMA 모형에 비해 ARIMA와 CHAID 모형을 함께 적용한 모형이 더 높은 예측정확도를 보였다. ARIMA와 CHAID 모형을 함께 적용한 모형은 시점 이동 후에도 예측정확도가 일정하게 유지되는 것으로 나타났다.
선행연구들은 대부분 중·장기적인 예측들이 대부분이었고 예측 방법론을 개별 적용한 연구들이 많았다. 최근 들어 비교적 짧은 예측 단위의 항공 수요예측 연구들이 진행되고 있지만 일 단위의 항공 수요예측에 대한 연구는 찾아보기 힘들다. 일 단위 항공 수요예측에 대한 연구가 적은 이유로는 일 단위 수요예측의 어려움과 적합한 방법론이 적었기 때문으로 생각된다. 수요예측은 예측 단위가 짧아질수록 예측이 어려워진다는 특징이 있고 예측 단위가 짧아지면 데이터 크기가 커져 예측에 필요한 컴퓨터 성능이 높아져야한다. 일 단위 항공화물 수요예측에 대한 연구가 거의 없는 상황에서 일 단위 항공화물 수요예측 방법론들의 예측정확도를 비교분석하는 것은 의미가 있다고 생각한다. 본 연구에서는 시계열 예측기법인 ARIMA 모형과 의사결정나무 모형인 CART, CHAID 모형을 결합하여 일 단위 항공화물에 대한 예측을 진행하였고 결합 모형들 간 예측정확도를 비교 분석하였다.
연구 모형
1. 의사결정나무
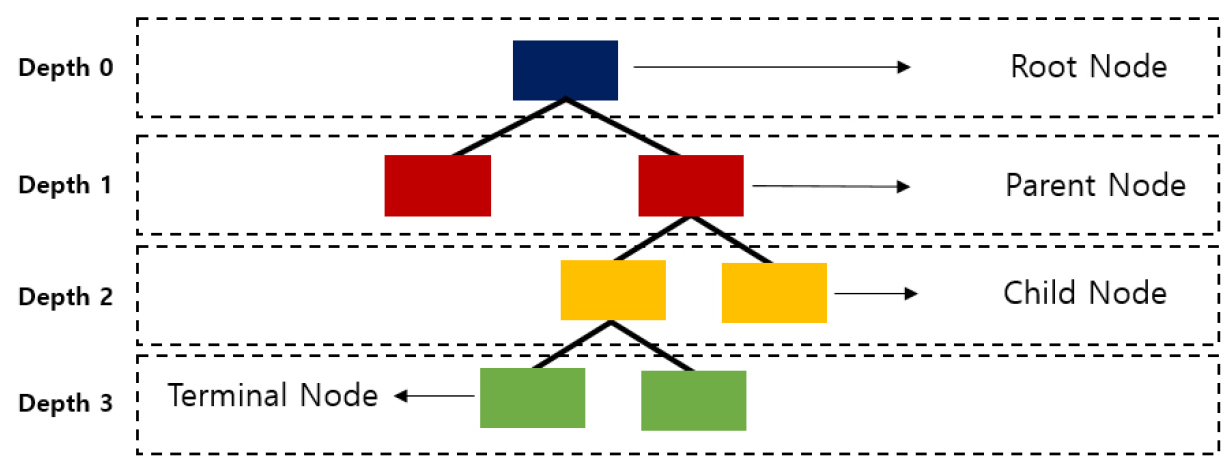
의사결정나무(Decision Tree)는 머신러닝 기법으로 의사결정 규칙을 나무구조로 나타내서 전체 집단을 여러 소집단으로 분류 또는 예측을 수행하는 분석기법이다. 분석결과의 형태는 ‘만약 A 조건을 만족하면서 B 조건을 만족하면 결과는 C다.’와 같이 일련의 규칙들로 표현되어 이해가 쉬운 장점이 있다. Figure 2는 의사결정나무의 구조를 표현한 그림이다. 의사결정나무 기법은 마케팅, 품질관리, 시장조사, 광고조사, 의학연구 등 여러 분야에서 활용되고 있다.
의사결정나무의 구조는 뿌리노드, 부모노드, 자식노드, 끝노드로 구성된다. 의사결정나무의 최상단에 위치한 노드를 뿌리노드라고 하는데 이는 분류대상이 되는 전체 집단을 의미한다. 의사결정나무는 뿌리노드부터 분류가 시작되어 하부의 노드로 분리가 진행된다. 이 때, 특정 노드의 상단에 존재하는 마디를 부모노드라고 부르고 특정 노드의 하단에 존재하는 노드를 자식노드라고 부른다. 의사결정나무의 최하단에 위치한 노드를 끝노드라고 부르며 끝노드에서는 더 이상 분리가 진행되지 않는다. 뿌리노드에서 최하단에 위치한 끝노드까지 분리가 몇 단계에 걸쳐 이뤄졌는지를 의사결정나무의 깊이라고 부른다.
의사결정나무는 종속변수가 범주형인 분류나무와 종속변수가 연속형인 회귀나무으로 구분된다. 그리고 의사결정나무에서는 일반적으로 3가지 종류(CHAID, CART, C5.0)의 알고리즘이 사용된다.
의사결정나무의 분석 과정은 의사결정나무 생성, 가지치기, 타당성 평가, 분류 및 예측의 4단계로 구성된다. 첫 번째 의사결정나무 생성 단계에서는 분석목적과 자료구조에 따라 적절하게 분리기준과 정지규칙을 적용해 의사결정나무의 구조를 작성하는 단계이다. 이 때 사용되는 분리기준은 의사결정나무의 종류(분류나무 또는 회귀나무)와 의사결정나무의 알고리즘에 따라 달라진다.
첫 번째 단계를 통해 생성된 의사결정나무는 오류 또는 과적합 문제(over-fitting)를 방지하기 위해 부적절한 가지를 제거하는 과정을 거친다. 이를 ‘가지치기(pruning)’라고 한다. 과적합이란 의사결정나무에서 학습데이터를 과도하게 학습한 경우 가지 수가 일정수준 이상으로 증가하여 의사결정나무의 예측정확도가 감소하는 현상이 발생하는 것을 말한다. 과적합 문제가 발생하면 학습데이터에서는 높은 예측정확도를 보이지만 실제데이터에서는 예측정확도가 떨어지는 현상이 발생한다. 따라서 과적합 문제를 방지하기 위해 적절한 수준의 가지 수를 유지하도록 가지치기를 진행한다. 가지치기는 일반적으로 비용함수를 통해 비용을 최소화시키는 수준으로 가지치기를 수행한다. 비용함수의 계산식은 Equation 1과 같다.
= 비용 복잡도
= 오분류율
= 끝노드(terminal node)의 수
= 가중치
가지치기 과정을 진행한 의사결정나무는 이익(Gain), 위험(Risk) 또는 비용(Cost) 등을 고려하여 의사결정나무 모형의 타당성을 평가하게 된다. 타당성 평가를 통과한 의사결정나무 모형은 분류 또는 예측에 사용된다.
2. CHAID 모형
CHAID(Chi-squared Automatic Interaction Detection)는 1975년 J.A.Hartigan에 의해 만들어진 알고리즘이다. CHAID는 종속변수가 범주형 또는 연속형인 경우 사용 가능한 알고리즘이다. CHAID는 부모마디에서 자식마디로 분리가 진행될 때 2개 이상의 자식마디가 생성되는 다지분리를 수행한다는 특징을 가지고 있다. CHAID는 의사결정나무 모형이 최적일 때 나무의 성장을 중단한다는 특징을 가지고 있어 가지치기를 진행할 필요가 없다. CHAID는 수평적 확장에 유용하고 해석이 쉽다는 장점이 있다. 하지만 나무구조가 깊지 않을 경우 오분류율이 높을 수 있다는 단점을 가지고 있다. CHAID는 종속변수가 범주형인 경우 카이제곱 통계량(Chi-Squared) 또는 우도비카이제곱 통계량(Likelihood Chi-Squared)을 분리기준으로 사용하고 종속변수가 연속형인 경우 F-검정 통계량을 분리기준으로 사용한다. 그리고 각 통계량 가운데 p-value가 가장 작은 예측변수를 통해 분리를 진행한다.
카이제곱 통계량은 Equation 2에 의해 정의되고 우도비카이제곱 통계량은 Equation 3에 의해 정의된다. 이 때 Equation 2와 Equation 3는 자유도가 (r-1)(c-1)인 카이제곱 분포를 따른다.
= 관찰치
= 기대빈도,
종속변수가 연속형인 경우 사용되는 F-검정 통계량은 Equation 4와 같이 정의된다.
= 설명변수의 수
= data의 수
MST = 처리평균제곱
MSE = 오차평균제곱
SST = 집단 간 편차의 제곱합
SSE = 집단 내 편차의 제곱합
3. CART 모형
CART(Classification And Regression Tree)는 1984년 Leo Brieman에 의해 만들어진 알고리즘이다. CART는 CHAID와 마찬가지로 종속변수가 범주형 또는 연속형인 경우 사용 가능한 알고리즘이다. CART는 부모마디에서 자식마디로 분리가 진행될 때 2개의 자식마디가 생성되는 이지분리를 수행한다는 점에서 CHAID와 차이가 있다. 또한 CART는 CHAID와 다르게 의사결정나무 모형을 최대로 성장시킨 후 가지치기를 통해 최적화를 수행하는 특징이 있다. CART는 수직적 확장과 변수의 중복사용으로 인해 오분류율이 낮아질 수 있다는 장점을 가지고 있다. 하지만 나무구조가 복잡해질 경우에는 해석이 복잡해질 수 있다는 단점을 가지고 있다. CART는 종속변수가 범주형인 경우 지니계수(Gini index)를 분리기준으로 사용하며 지니계수의 감소량을 최대화 시키는 예측변수를 통해 분리를 진행한다. 반면 종속변수가 연속형인 경우 분산의 감소량을 분리기준으로 사용하며 분산의 감소량을 최대화 시키는 예측변수를 통해 분리를 진행한다.
지니계수의 계산식은 Equation 5에 의해 정의된다.
분산과 분산의 감소량 계산식은 Equation 6, Equation 7과 같이 표현된다.
= 부모노드 관측치 수
= 자식노드 관측치 수
모형설정
1. 변수선정
본 연구에서는 사용한 일별 항공물동량 예측모형은 서론의 연구수행방법에서 제시된 절차에 따라 생성하였다. 두 단계에 걸쳐 예측모형을 생성하였는데 첫 번째 단계에서 주별 항공물동량 예측모형 생성하였다. 주별 항공물동량 예측모형에서는 주별 ARIMA 예측치와 주요국의 주당 공휴일 수를 설명변수로 사용하였다. 주요국으로는 중국, 미국, 일본을 선정했다. 두 번째 단계에서는 일별 항공물동량 예측모형을 생성하였다. 일별 항공물동량 예측모형에서는 첫 번째 단계에서 생성한 주별 항공물동량 예측모형을 통해 추정한 주별 예측치와 요일정보, 주요국의 공휴일 정보를 설명변수로 사용하였다.
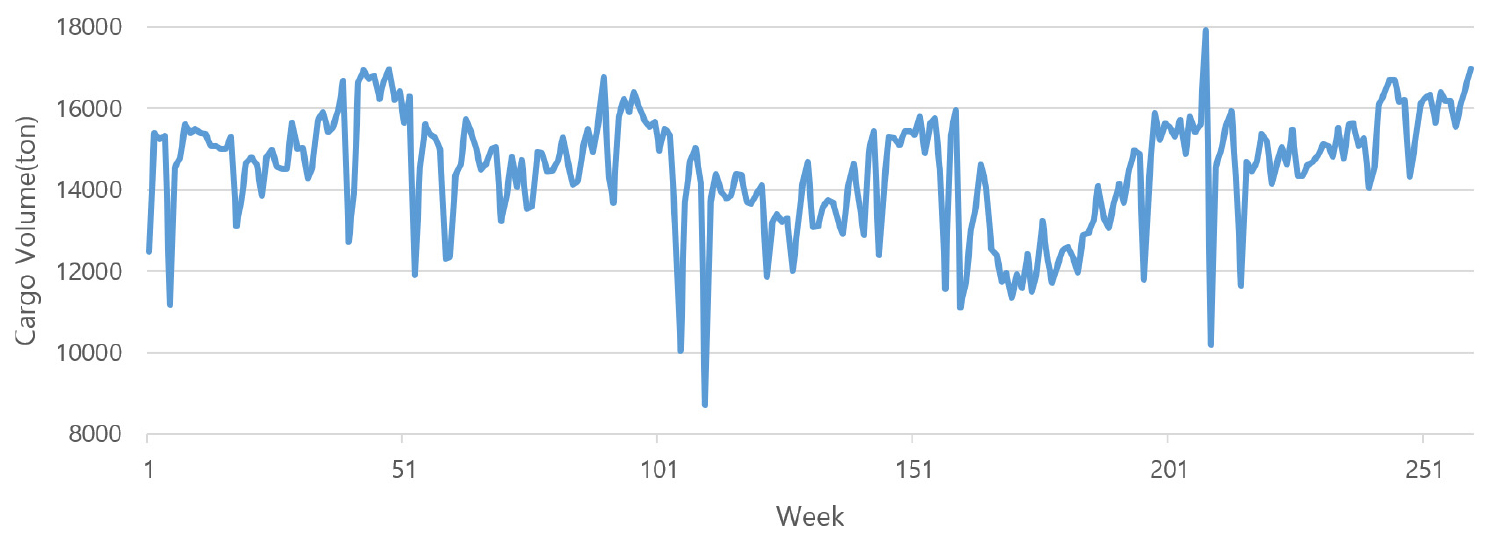
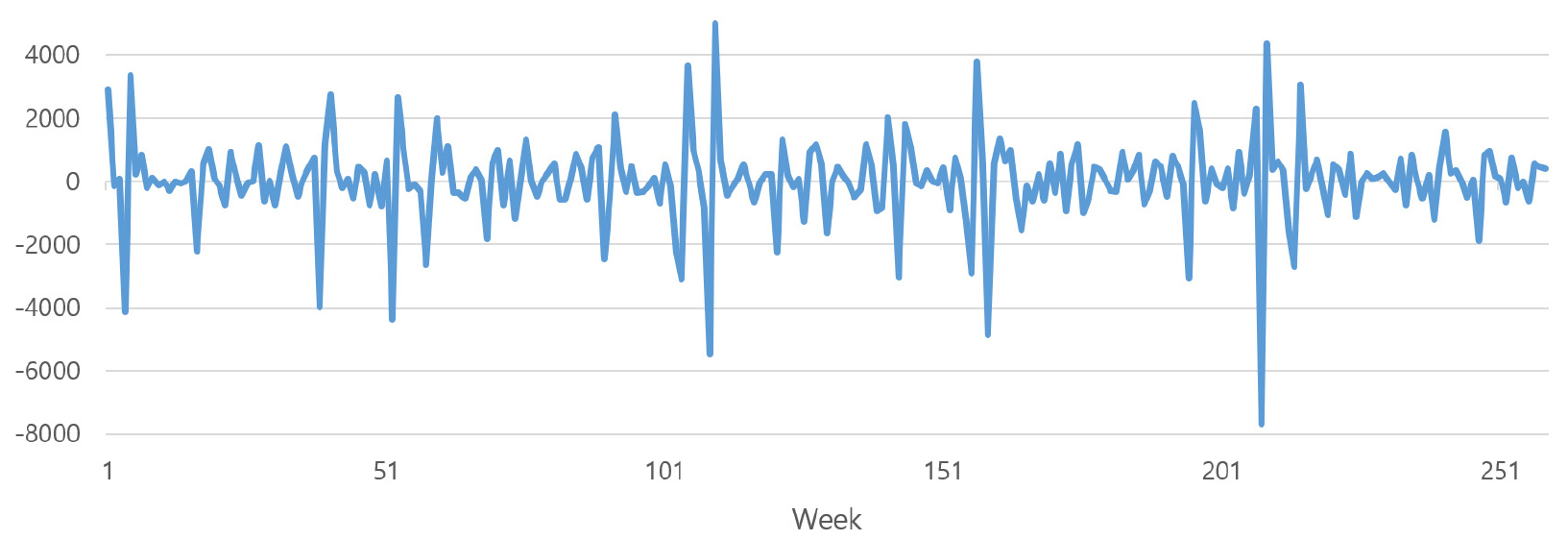
먼저 첫 번째 단계인 주별 항공물동량 예측모형의 설명변수로 사용될 ARIMA 예측치를 도출했다. Figure 3은 K항공사의 인천국제공항발 항공화물 수출물동량의 원시계열을 나타내고 있다. 원시계열은 시간에 따라 평균값이 증가 혹은 감소하는 모습을 보이고 있다. Figure 4는 원시계열 데이터를 1차 차분하여 안정적인 시계열로 변환한 것이다. 1차 차분 결과 평균이 일정하게 나타나는 안정적인 시계열로 변환되었다. 주별 항공물동량 예측모형의 설명변수로 사용된 주별 ARIMA 예측치는 시계열의 안정성을 위해 1차 차분한 뒤 AR 항의 차수는 2이고 MA 항의 차수는 2인 ARIMA(2,1,2) 모형을 통해 도출하였다.
첫 번째 단계에서 주별 ARIMA 예측치와 함께 설명변수로 사용된 주요국의 주당 공휴일 수는 2017년부터 2021년까지의 국가별 공휴일 정보를 정리하여 반영했다. 주당 공휴일 수에 반영된 국가별 공휴일 정보는 Table 1과 같다.
Table 1.
List of holiday information for weekly forecasting
두 번째 단계인 일별 항공물동량 예측모형에서는 첫 번째 단계를 통해 도출한 주별 예측치와 요일정보, 주요국 공휴일 정보를 설명변수로 사용하여 예측모형을 추정하고 일별 예측치를 도출했다. Table 2는 일별 항공물동량 예측모형에서 사용된 설명변수이다. 요일에 따른 항공물동량의 증감추이를 반영하기 위해 요일정보를 설명변수로 사용했다. 월요일부터 일요일까지 총 7개의 명목변수를 요일정보로 반영했다. 주요국의 공휴일 정보는 해당 일자가 공휴일인지 여부를 반영하여 설명변수로 사용했다.
Table 2.
List of variables for daily forecasting
| List | Description |
| Weekly forecasting volume | Using CART or CHAID |
| Day of the week | Monday , Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday |
| Holiday information | Korea, China, Japan, USA |
2. 모형설정
1) CART 예측모형
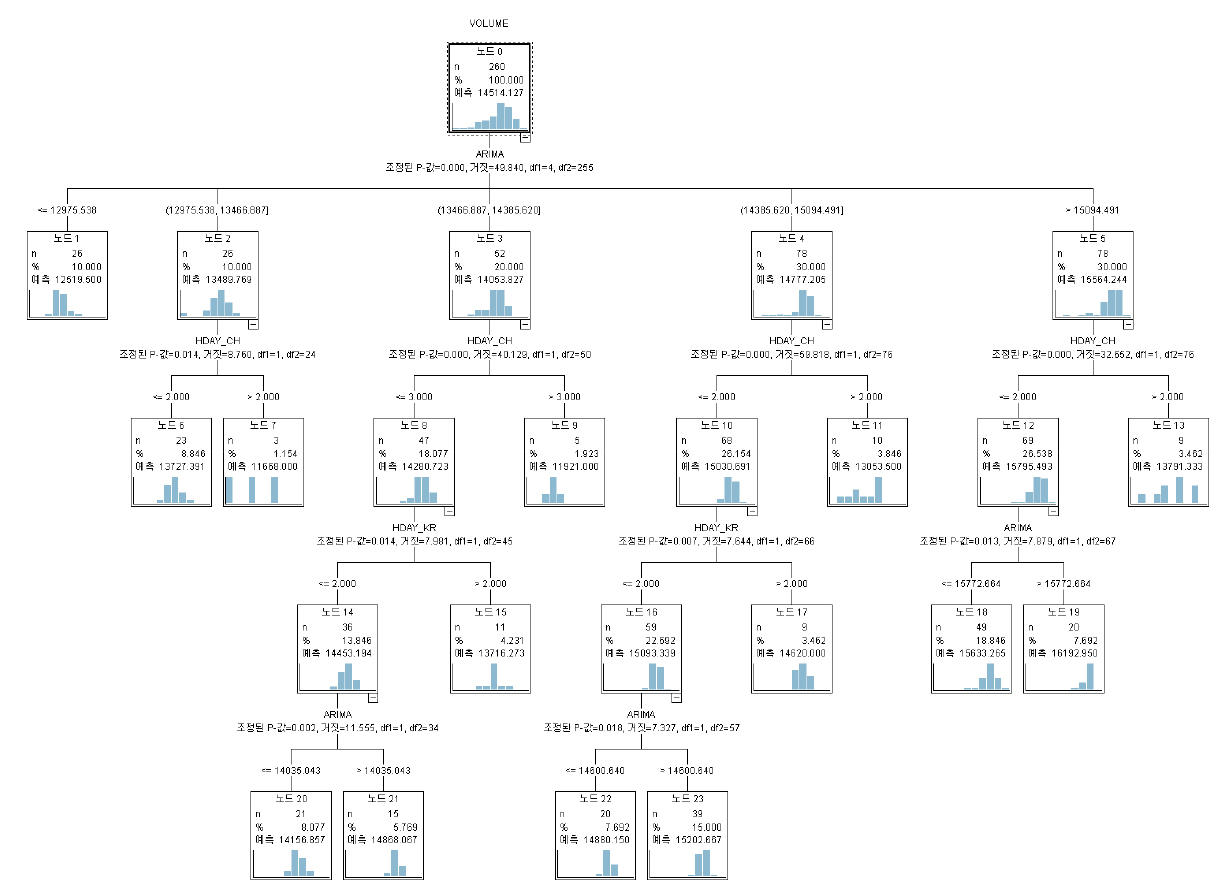
주별 예측모형은 일별 예측모형의 설명변수로 사용되는 주별 예측치 도출을 위한 모형이다. 예측모형의 생성 과정에서 과적합 방지를 위해 나무의 깊이는 최대 5단계로 정의했다. 설명변수로는 주별 ARIMA 예측치와 주요국의 주당 공휴일 수를 사용하였다. 주별 예측모형은 Figure 5와 같이 생성되었다. 주별 예측모형에서 첫 번째 분리기준은 주별 ARIMA 예측치로 나타났다. 뿌리노드의 분리기준은 의사결정나무 모형에서 가장 중요한 분리기준이 된다. 설명변수의 상대적 중요도는 Kim(2010)이 제시한 의사결정나무로부터 변수의 중요도를 산출하는 중요도 산출 수식을 사용하여 도출하였다.2)
주별 예측모형에서 사용한 설명변수의 상대적인 중요도는 Table 3과 같다. 설명변수 중요도를 살펴보면 ARIMA 주별 예측치 중요도가 0.7746으로 가장 높게 나타났다. 다음으로 중국의 주당 공휴일 수(0.1935), 한국의 주당 공휴일 수(0.0200), 미국의 주당 공휴일 수(0.0119) 순서로 나타났다. 이를 통해 주별 예측모형에서는 ARIMA 주별 예측치를 통해 각 주차의 물동량 수준을 결정하고 각 주차의 주요국 공휴일 수에 따라 세부적인 수준의 물동량을 결정한다는 것을 알 수 있다.
Table 3.
Variable importance of CART for weekly forecasting
| Variable | Importance |  |
| Forecasting result by ARIMA | 0.7746 |  |
| # of Holidays/week (China) | 0.1935 | |
| # of Holidays/week (Korea) | 0.0200 | |
| # of Holidays/week (USA) | 0.0119 |
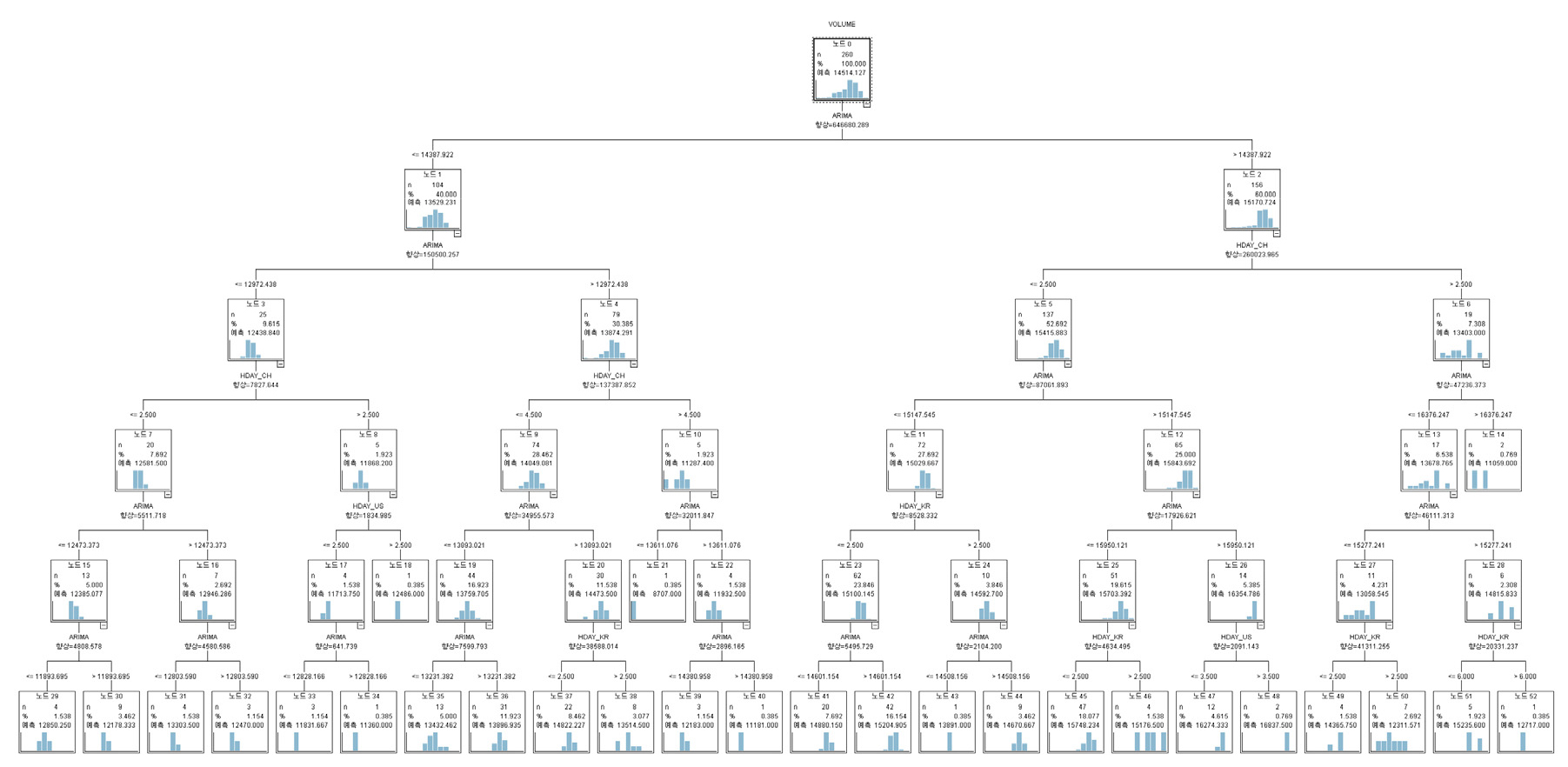
최종 일별 예측모형의 나무의 깊이는 주별 예측모형 추정 과정과 마찬가지로 최대 5단계로 정의했다. 설명변수로 이전 단계인 주별 예측모형을 통해 도출한 주별 예측치와 요일정보, 주요국 공휴일 정보를 사용하였다. 일별 예측모형은 Figure 6와 같이 생성되었다. 일별 예측나무는 총 50개의 노드로 구성되었고 최초의 뿌리노드는 1개, 중간노드 24개, 끝노드 25개로 구성되었다. 최초의 뿌리노드에서 요일정보가 분리기준으로 사용되었다.
일별 예측모형의 설명변수 중요도는 Table 4와 같다. 설명변수 중요도를 살펴보면 요일정보 변수 중요도가 0.5723으로 가장 중요한 것으로 나타났다. 다음으로 주별 예측치(0.3804), 중국 공휴일 여부(0.0352), 한국 공휴일 여부(0.0092), 미국 공휴일 여부(0.0029) 순으로 나타났다. 일별 예측모형은 요일정보와 주별 예측치를 통해 전반적인 물동량 수준이 결정된 후 주요국의 공휴일 변수들을 통해 세부적인 일별 물동량 수준이 결정되는 것으로 나타났다. 일별 예측모형에 사용된 설명변수 5개 중에서 요일정보 변수와 주별 예측치 변수의 중요도 합은 0.9527로 일별 모형에서 해당 변수들의 중요도가 절대적인 것으로 나타났다. 실제로 요일정보는 분리기준으로 7번, 주별 예측치 변수는 분리기준으로 13번 사용되었다. 주별 예측치 변수가 요일정보보다 분리기준으로는 더 많이 사용되었지만, 요일정보의 분리기준이 뿌리노드에서 사용되어 중요도가 높게 나타났다.
Table 4.
Variable importance of CART for daily forecasting
| Variable | Importance |  |
| Day of the week | 0.5723 |  |
| Weekly forecasting volume | 0.3804 | |
| Holiday (China) | 0.0352 | |
| Holiday (Korea) | 0.0092 | |
| Holiday (USA) | 0.0029 |
Figure 6에서 일별 예측을 위한 최초의 분리기준은 요일정보이다. 월요일인 경우와 월요일이 아닌 경우로 나누어 전체적인 물동량 수준을 결정했다. 일별 예측모형에서 월요일에는 물동량이 평균 대비 약 26.55% 감소하였다. 반대로 월요일이 아닌 경우에는 물동량이 평균 대비 약 4.43% 증가하였다. 일별 예측모형에서 월요일 여부에 따라 전체적인 물동량 수준을 결정한 이후에는 주별 예측치가 14,131톤 이하인 경우와 초과인 경우로 나누어 물동량 수준을 결정했다. 다음으로 주요국의 공휴일 정보, 주별 예측치, 요일정보 등을 기준으로 세부적인 물동량 수준이 결정되었다.
요일에 따른 물동량 변화수준은 Table 5와 같다. 일별 예측모형의 월요일과 일요일 효과는 training data에서 나타난 실제 월요일과 일요일 효과에 따른 물동량 변화수준과 비슷한 것으로 나타났다. 하지만 월요일과 일요일을 제외한 요일에는 실제 요일 효과에 따른 물동량 변화수준을 제대로 반영하지 못하고 있다. 실제 요일 효과에 따르면 수요일에는 물동량이 평균대비 12.43% 증가하는 것으로 나타났다. 하지만 일별 예측모형은 수요일에는 물동량이 평균대비 4.19% 증가한다고 예측하여 실제 수요일 효과와 차이를 보이고 있다. training data에 따르면 화요일, 목요일, 금요일, 토요일 효과로 물동량이 평균대비 증가하는 것으로 나타났는데 일별 예측모형에서는 화요일, 목요일, 토요일에는 물동량이 평균대비 감소하는 것으로 예측하였다.
Table 5.
Day of the week variable’s effectiveness analysis
| Day | CART Day effect | Actual Day effect |
| Monday | -26.55% | -26.6% |
| Tuesday | -1.83% | +0.59% |
| Wednesday | +4.19% | +12.43% |
| Thursday | -2.41% | +5.20% |
| Friday | +1.45% | +3.00% |
| Saturday | -1.04% | +6.74% |
| Sunday | -1.83% | -1.35% |
2) CHAID 예측모형
주별 예측모형은 일별 예측모형의 설명변수로 사용되는 주별 예측치 도출을 위한 모형이다. CART 예측모형과 동일하게 예측나무의 생성 과정에서 과적합 방지를 위해 나무의 깊이는 최대 5단계로 정의했다. 설명변수로는 주별 ARIMA 예측치와 주요국의 주당 공휴일 수를 사용하였다. 주별 예측모형은 Figure 7과 같이 생성되었다. 주별 예측모형에서 가장 중요한 분리기준이 되는 뿌리노드의 분리기준으로 주별 ARIMA 예측치가 사용되었다. 설명변수의 상대적 중요도는 CART 모형에서 중요도를 산출한 방식과 동일한 방식을 통해 도출했다.
주별 예측모형에서 이용한 설명변수들 사이의 상대적인 중요도는 Table 6과 같다. 설명변수 중요도를 살펴보면 ARIMA 주별 예측치 변수의 중요도가 0.6200으로 가장 높게 나타났다. 다음으로 중국의 주당 공휴일 수(0.2900), 한국의 주당 공휴일 수(0.0900) 순서로 나타났다. 이를 통해 주별 예측모형은 ARIMA 주별 예측치를 통해 각 주차들의 전체적인 물동량 수준을 결정하고 주요국의 주당 공휴일 수에 따라 세부적인 수준의 물동량을 결정한다는 것을 알 수 있다.
Table 6.
Variable importance of CHAID for weekly forecasting
| Variable | Importance |  |
| Forecasting result by ARIMA | 0.6200 |  |
| # of Holidays/week (China) | 0.2900 | |
| # of Holidays/week (Korea) | 0.0900 |
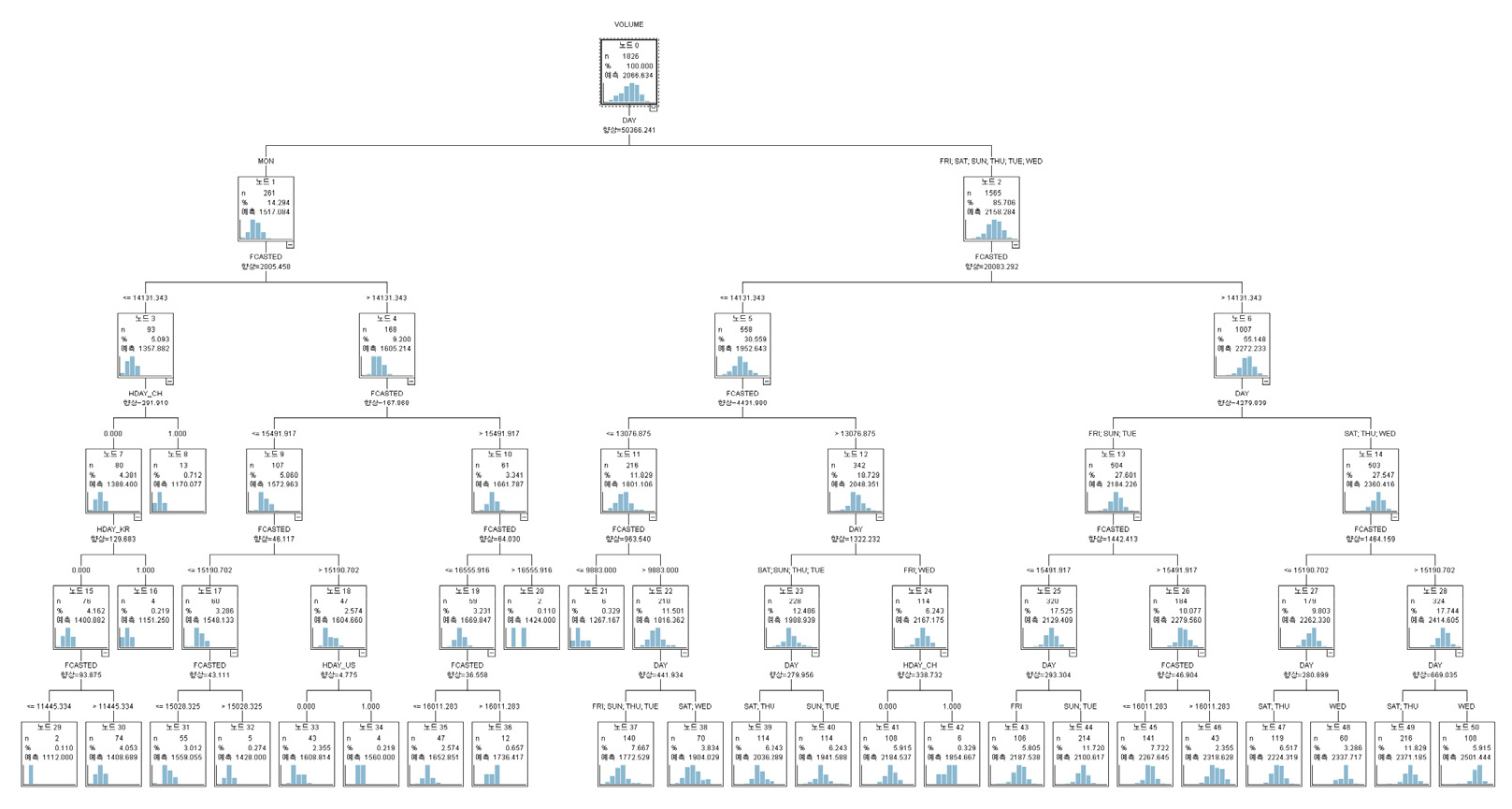
최종 일별 예측모형은 주별 예측모형 추정 과정과 마찬가지로 나무의 깊이는 최대 5단계로 정의했다. 설명변수로는 이전 단계인 주별 예측모형을 통해 도출한 주별 예측치와 요일정보, 주요국의 공휴일 정보를 사용하였다. 일별 예측모형은 Figure 8과 같다. 일별 예측나무는 총 37개의 노드로 구성되었고 최초의 뿌리노드는 1개, 중간노드 9개, 끝노드 27개로 구성되었다. 최초의 뿌리노드에서 요일정보가 분리기준으로 사용되었다.
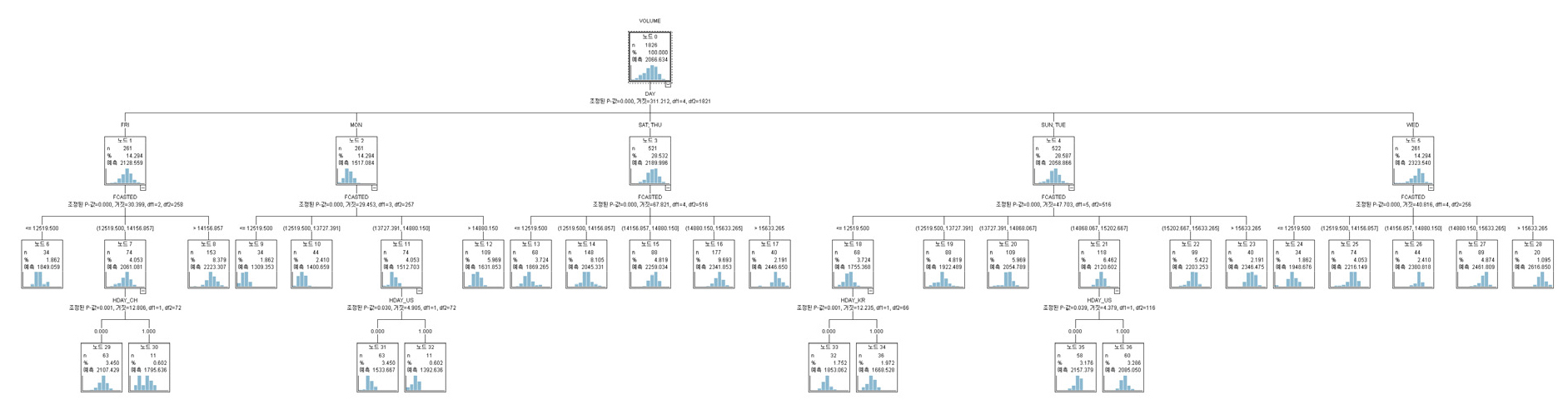
일별 예측모형의 설명변수들 사이의 중요도는 Table 7과 같다. 일별 예측모형에서 최종 선정된 설명변수는 총 5개로 나타났다. 설명변수 중요도를 살펴보면 요일정보 변수 중요도가 0.5715로 가장 중요한 것으로 나타났다. 다음으로 주별 예측치 변수(0.2857), 미국 공휴일 여부(0.0714) 순서로 나타났다. 중국, 한국 공휴일 여부 중요도는 0.0357로 나타났다. 이를 통해 일별 예측모형은 요일정보를 통해 전반적인 물동량 수준이 결정되고 이후 주별 예측치와 주요국의 공휴일 변수들을 통해 세부적인 일별 물동량 수준을 결정되는 것을 알 수 있다. 일별 예측모형에 사용된 설명변수 중에서 요일정보 변수와 주별 예측치 변수의 중요도 합은 0.8572로 일별 모형에서 해당 변수들의 중요도가 매우 높은 것으로 나타났지만 CART 모형에서 두 변수의 중요도 합인 0.9527보다는 낮은 것으로 나타났다. 요일정보는 뿌리노드에서 분리기준으로 1번 사용되었고 주별 예측치는 2단계 깊이에서 5번 사용되었다.
Table 7.
Variable importance of CHAID for daily forecasting
| Variable | Importance |  |
| Day of the week | 0.5715 |  |
| Weekly forecasting volume | 0.2857 | |
| Holiday (USA) | 0.0714 | |
| Holiday (China) | 0.0357 | |
| Holiday (Korea) | 0.0357 |
Figure 8에서 일별 예측의 최초 분리기준은 요일정보이다. CHAID 모형은 다지분리가 가능하여 뿌리노드에서 CART 모형에 비해 세분화된 요일에 의한 분리가 진행됐다. 일별 예측모형에서는 월요일, 화요일과 일요일, 수요일, 목요일과 토요일, 금요일 5가지 경우에 따라 전체적인 물동량 수준이 결정되었다. 예측모형에 따르면 월요일에는 물동량이 평균대비 약 26.59% 감소하는 것으로 나타났고 화요일과 일요일에는 약 0.38% 감소하는 것으로 나타났다. 수요일에는 물동량이 평균대비 12.43% 증가했고 목요일과 토요일은 5.97%, 금요일은 3% 증가하는 것으로 나타났다. 요일에 따라 물동량 수준이 결정된 후에는 중국의 공휴일 여부 또는 주별 예측치 수준에 따른 세부적인 물동량 수준이 결정되었다.
요일에 따른 물동량 변화수준은 Table 8과 같다. 일별 예측모형에서 화요일은 물동량이 평균대비 0.38% 감소하였지만 training data에서 나타난 실제 화요일 효과로 물동량은 평균대비 0.59% 증가했다. 일별 예측모형에서 화요일을 제외한 나머지 요일에 따른 물동량 변화수준은 실제 요일에 따른 물동량 변화수준과 비슷한 것으로 나타났다. 일별 예측모형에서 실제 요일 효과에 근접한 요일 효과가 도출된 이유는 CHAID 모형이 다지분리가 가능하여 첫 번째 분리기준에서 세분화된 요일 분류를 진행했기 때문으로 생각된다.
예측 및 정확도 비교
예측 및 정확도 비교 단계에서는 본 연구에서 사용한 모형 간 예측정확도를 비교하였다. 모형설정 단계에서 추정한 일단위 예측모형을 이용하여 향후 13주간의 일별예측치와 실제 물동량 데이터를 비교하여 예측정확도를 도출하였다. CART 모형과 CHAID 모형의 예측정확도와 대표적인 시계열 예측기법 중 하나인 ARIMA 모형의 예측정확도를 비교하였다. 예측시점은 1월과 7월 두 개의 시점을 설정했다.
Table 9은 1월 1일부터 4월 1일까지 13주간 본 연구에서 추정한 CART, CHAID 일별 예측모형을 통해 도출한 예측치, ARIMA(5,1,1) 모형을 통해 도출한 예측치와 실제 물동량 데이터를 비교한 표이다.
Table 9.
Forecasting Result of the estimated daily CART, CHAID and ARIMA (5,1,1) model
| Date |
Actual Volume1) | CART | CHAID | ARIMA | Date |
Actual Volume | CART | CHAID | ARIMA |
| D+1 | 1,579 | 1,904 | 2,045 | 2,320 | D+47 | 2,412 | 2,501 | 2,617 | 2,147 |
| D+2 | 1,723 | 1,773 | 2,055 | 2,032 | D+48 | 2,388 | 2,371 | 2,447 | 2,147 |
| D+3 | 1,519 | 1,170 | 1,534 | 1,883 | D+49 | 2,223 | 2,319 | 2,223 | 2,147 |
| D+4 | 2,010 | 1,773 | 2,055 | 2,239 | D+50 | 2,065 | 2,371 | 2,447 | 2,147 |
| D+5 | 2,295 | 1,904 | 2,216 | 2,364 | D+51 | 2,296 | 2,319 | 2,346 | 2,147 |
| D+6 | 1,892 | 1,773 | 2,045 | 2,090 | D+52 | 1,819 | 1,736 | 1,632 | 2,147 |
| D+7 | 2,375 | 1,773 | 2,107 | 2,154 | D+53 | 1,829 | 2,319 | 2,346 | 2,147 |
| D+8 | 2,121 | 2,371 | 2,447 | 2,196 | D+54 | 2,687 | 2,501 | 2,617 | 2,147 |
| D+9 | 2,274 | 2,319 | 2,346 | 2,063 | D+55 | 2,315 | 2,371 | 2,447 | 2,147 |
| D+10 | 1,556 | 1,736 | 1,632 | 2,072 | D+56 | 2,130 | 2,319 | 2,223 | 2,147 |
| D+11 | 2,353 | 2,319 | 2,346 | 2,204 | D+57 | 1,966 | 2,371 | 2,447 | 2,147 |
| D+12 | 2,384 | 2,501 | 2,617 | 2,171 | D+58 | 2,112 | 2,319 | 2,346 | 2,147 |
| D+13 | 2,137 | 2,371 | 2,447 | 2,137 | D+59 | 1,556 | 1,736 | 1,632 | 2,147 |
| D+14 | 2,253 | 2,319 | 2,223 | 2,174 | D+60 | 1,790 | 2,319 | 2,346 | 2,147 |
| D+15 | 2,098 | 2,371 | 2,447 | 2,155 | D+61 | 2,095 | 2,501 | 2,617 | 2,147 |
| D+16 | 2,288 | 2,319 | 2,346 | 2,109 | D+62 | 2,161 | 2,371 | 2,447 | 2,147 |
| D+17 | 1,955 | 1,736 | 1,632 | 2,137 | D+63 | 1,829 | 2,319 | 2,223 | 2,147 |
| D+18 | 2,046 | 2,319 | 2,346 | 2,159 | D+64 | 2,356 | 1,904 | 2,045 | 2,147 |
| D+19 | 2,148 | 2,501 | 2,617 | 2,145 | D+65 | 2,045 | 1,773 | 2,055 | 2,147 |
| D+20 | 2,835 | 2,371 | 2,447 | 2,150 | D+66 | 1,992 | 1,112 | 1,534 | 2,147 |
| D+21 | 1,893 | 2,319 | 2,223 | 2,161 | D+67 | 2,104 | 1,773 | 2,055 | 2,147 |
| D+22 | 2,285 | 2,371 | 2,447 | 2,144 | D+68 | 2,446 | 1,904 | 2,216 | 2,147 |
| D+23 | 2,469 | 2,319 | 2,346 | 2,137 | D+69 | 2,308 | 1,773 | 2,045 | 2,147 |
| D+24 | 1,683 | 1,736 | 1,632 | 2,147 | D+70 | 2,198 | 1,773 | 2,107 | 2,147 |
| D+25 | 2,412 | 2,319 | 2,346 | 2,147 | D+71 | 2,355 | 2,371 | 2,447 | 2,147 |
| D+26 | 2,560 | 2,501 | 2,617 | 2,145 | D+72 | 2,224 | 2,319 | 2,346 | 2,147 |
| D+27 | 2,629 | 2,371 | 2,447 | 2,151 | D+73 | 2,094 | 1,736 | 1,632 | 2,147 |
| D+28 | 1,651 | 2,319 | 2,223 | 2,151 | D+74 | 2,100 | 2,319 | 2,346 | 2,147 |
| D+29 | 2,219 | 1,904 | 2,045 | 2,145 | D+75 | 2,558 | 2,501 | 2,617 | 2,147 |
| D+30 | 2,120 | 1,773 | 2,055 | 2,145 | D+76 | 2,290 | 2,371 | 2,447 | 2,147 |
| D+31 | 1,355 | 1,170 | 1,534 | 2,147 | D+77 | 2,037 | 2,319 | 2,223 | 2,147 |
| D+32 | 1,845 | 1,773 | 2,055 | 2,146 | D+78 | 2,254 | 2,371 | 2,447 | 2,147 |
| D+33 | 1,743 | 1,904 | 2,216 | 2,146 | D+79 | 2,591 | 2,319 | 2,346 | 2,147 |
| D+34 | 1,997 | 1,773 | 2,045 | 2,149 | D+80 | 2,084 | 1,736 | 1,632 | 2,147 |
| D+35 | 1,274 | 1,773 | 1,796 | 2,148 | D+81 | 2,258 | 2,319 | 2,346 | 2,147 |
| D+36 | 1,741 | 2,371 | 2,447 | 2,146 | D+82 | 2,527 | 2,501 | 2,617 | 2,147 |
| D+37 | 2,191 | 2,319 | 2,346 | 2,147 | D+83 | 2,350 | 2,371 | 2,447 | 2,147 |
| D+38 | 1,558 | 1,736 | 1,632 | 2,147 | D+84 | 2,021 | 2,319 | 2,223 | 2,147 |
| D+39 | 1,850 | 2,319 | 2,346 | 2,146 | D+85 | 2,510 | 2,371 | 2,447 | 2,147 |
| D+40 | 2,406 | 2,501 | 2,617 | 2,147 | D+86 | 2,535 | 2,319 | 2,346 | 2,147 |
| D+41 | 2,142 | 2,371 | 2,447 | 2,147 | D+87 | 1,848 | 1,736 | 1,632 | 2,147 |
| D+42 | 1,965 | 2,319 | 2,223 | 2,147 | D+88 | 2,287 | 2,319 | 2,346 | 2,147 |
| D+43 | 2,344 | 2,371 | 2,447 | 2,147 | D+89 | 2,875 | 2,501 | 2,617 | 2,147 |
| D+44 | 1,811 | 2,319 | 2,346 | 2,147 | D+90 | 2,248 | 2,371 | 2,447 | 2,147 |
| D+45 | 2,100 | 1,736 | 1,632 | 2,147 | D+91 | 2,228 | 2,319 | 2,223 | 2,147 |
| D+46 | 1,902 | 2,319 | 2,346 | 2,147 |
Figure 9는 2022년 1월 1일부터 4월 1일까지 총 91일간 K항공사의 인천국제공항발 수출 물동량을 예측한 결과이다. 노란색 실선은 해당 기간 동안의 K항공사의 인천국제공항발 수출 물동량 실제 데이터를 나타내고 회색 실선은 CART 모형을 통해 예측한 예측치, 주황색 실선은 CHAID 모형을 통해 예측한 예측치, 파란색 실선은 ARIMA를 통해 예측한 예측치를 나타낸다. 예측한 기간의 K항공사의 수출 물동량 실제 데이터는 최저 1,274톤에서 최대 2,875톤을 기록했다. 이처럼 편차가 심한 K항공사의 수출 물동량을 정확하게 예측하는 것은 항공사의 운영효율성과도 직결된다. 전통적인 시계열 예측기법인 ARIMA 모형은 일정 시점이 지나면 실제 수출 물동량 데이터의 평균값에 근접한 수준의 예측치만을 도출했을 뿐 물동량의 등락에는 거의 반응하지 못하고 있다. 이는 과거의 값을 바탕으로 추세 예측을 진행하는 ARIMA 모형의 방법론적 특성 때문으로 생각된다.
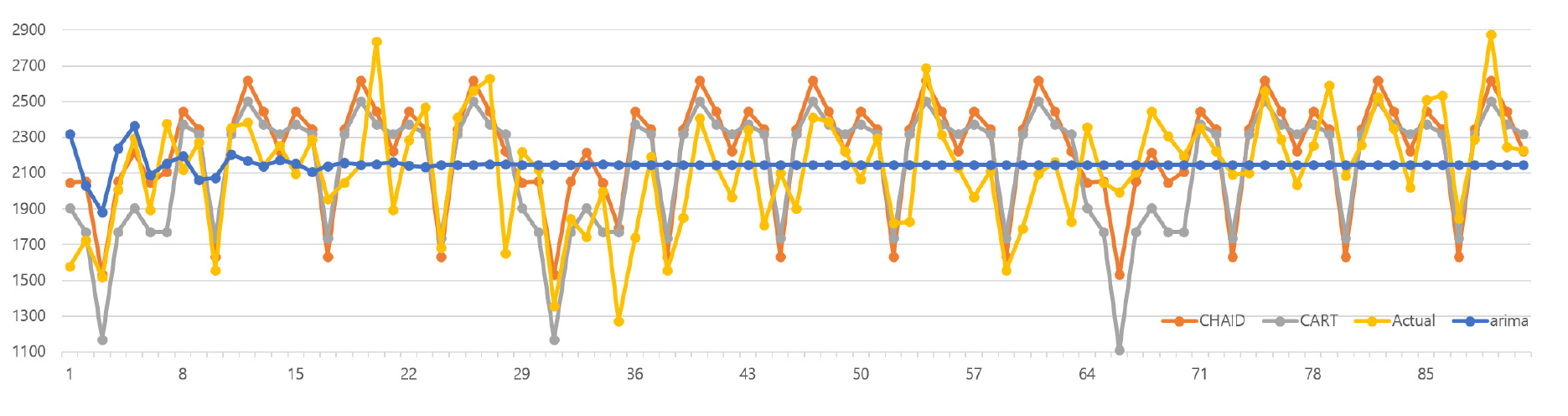
반면 CART나 CHAID 모형은 일별 수출항공 물동량의 증감 추이를 비교적 잘 따라가는 모습을 보이고 있다. 그래프를 통해 구간에 따라 CART, CHAID 모형의 정확도가 달라지고 있음을 확인할 수 있다. 보다 정확한 예측정확도를 확인하고자 예측정확도 측정에 자주 사용되는 지표인 MSE(Mean Squared Error), RMSE(Root Mean Sqaure Error), MAPE(Mean Absolute Percentage Error)을 활용하여 CART, CAHID, ARIMA 모형 간 예측정확도를 비교하였다. 예측정확도 비교 결과는 Table 10과 같다. 예측정확도는 CHAID, CART, ARIMA 순으로 나타났다. 예측정확도의 차이가 발생하는 이유는 CHAID 모형이 CART 모형에 비해 요일에 따른 물동량 변화수준을 충실하게 반영하였기 때문으로 생각된다.
Table 10.
Forecasting error of the estimated daily CART, CHAID and ARIMA (5,1,1) model
Table 11는 2022년 7월 2일부터 9월 30일까지 91일간 CART, CHAID 일별 예측모형을 통해 도출한 예측치, ARIMA(1,1,3) 모형을 통해 도출한 예측치와 실제 물동량 데이터를 비교한 표이다. Table 11를 통해 해당 기간의 예측에선 CART, CHAID, ARIMA 순서로 예측정확도가 높게 나타나는 것을 확인할 수 있다. CART 일별 예측모형의 경우 설명변수의 중요도가 요일 정보(0.5682), 주별 예측치(0.3988), 일본 공휴일 여부(0.0139), 한국 공휴일 여부(0.0110), 미국 공휴일 여부(0.0081)순으로 나타났다. CHAID 일별 예측모형의 경우 설명변수 중요도가 요일 정보(0.5714), 주별 예측치(0.2859), 중국 공휴일 여부(0.1429) 순으로 나타났다. CHAID 일별 예측모형은 주요국 가운데 중국의 공휴일 여부만을 고려하여 세부적인 물동량 수준을 정하고 있다. 반면 CART 일별 예측모형의 경우 일본, 한국, 미국의 공휴일 여부를 고려하여 세부적인 물동량 수준을 정하고 있다. 이러한 차이로 인해 CART와 CHAID 일별 예측모형 간 성능차이가 발생한 것으로 생각된다.
Table 11.
Forecasting error of the estimated daily CART, CHAID and ARIMA (1,1,3) model
예측결과 본 연구에서 설정한 CART, CHAID 모형은 예측시점에 따라 예측정확도가 달라지는 것으로 나타났다. CART 모형은 CHAID 모형에 비해 구조가 복잡하여 해석이 어렵다는 단점을 가지고 있지만 두 번째 예측시점에서 CHAID에 비해 예측 정확도가 높은 것으로 나타났다. 따라서 K항공사의 일별 수출물동량 예측에는 시점에 따라 두 가지 모형을 모두 적용해보고 예측정확도를 비교하여 예측정확도가 높은 모형을 선택하는 것이 적절하다고 판단된다.
결론 및 시사점
앞으로도 항공화물시장은 지속적으로 성장할 것으로 예상된다. 항공화물시장은 산업 특성상 외부 환경에 의해 많은 영향을 받아왔다. 이러한 불확실성은 항공화물에 대한 예측을 어렵게 만드는 요소이다. 정확한 수요예측을 통해 항공산업 내 다양한 경제주체들의 비효율성을 줄일 수 있다. 특히 일별 항공화물 수요예측은 항공사나 공항의 인력 또는 장비의 세부 운영계획에 관련된 비효율성을 줄이는데 도움을 줄 수 있다. 항공화물 예약시스템과 일별 항공화물 수요예측 모형을 적절하게 활용하면 일별 항공화물의 불확실성에 대해 어느 정도 대처가 가능할 것으로 생각된다.
본 연구에서는 K항공사의 인천국제공항발 일별 항공화물을 예측하기 위해 의사결정나무 방법론인 CART, CHAID 방법론과 공휴일 변수들을 활용하여 일별 항공화물 예측모형을 제시하고 예측정확도를 비교하였다. 예측시점에 따라 CART와 CHAID 모형의 예측성능이 다르게 나타났다. 첫 번째 시점에서는 CHAID 모형이 높은 정확도를 보였고 두 번째 시점에서는 CART 모형이 높은 정확도를 보였다. 두 모형 간 예측정확도 차이가 발생하는 원인으로는 요일에 따른 물동량의 변화수준과 주요국의 공휴일 여부에 따른 세부적인 물동량 결정 여부 때문으로 생각된다. 따라서 K항공사의 일별 항공물동량 예측에는 두 가지 예측모형 모두를 활용하여 예측한 후 예측정확도가 높은 모형을 선택하는 것이 적절하다고 판단된다. ARIMA 모형은 일정 시점이 지나면 실제 수출 물동량 데이터의 평균값에 근접한 예측치를 도출하여 일별예측에는 적합하지 않다. 반면 CART와 CHAID 모형은 ARIMA 모형에 비해 예측시점이 길어져도 추세를 따라가는 것으로 나타나 일 단위 항공물동량 예측에 적합하다고 생각된다.
항공화물 수요예측과 관련된 선행연구들에 의하면 항공화물 수요는 여러 변수들에 의해 영향을 받는다. 대표적으로 GDP, 수출입액, 유가, 항공운임, 환율, 화물의 특성 등의 변수들이 항공화물 수요에 영향을 미치는 것으로 나타났다. 외부 설명변수를 이용한 수요예측을 진행할 경우 예측시점에 영향을 줄 것으로 생각되는 외부 설명변수의 정확한 값을 추정해야한다. 타당한 예측모형을 추정하였다고 하더라도 설명변수의 값이 정확하지 않으면 왜곡이 발생하여 예측정확도는 떨어지게 된다. 또한 외부 설명변수의 추정에는 시간과 비용이 추가적으로 발생하기 때문에 예측효율성이 떨어진다는 문제점이 발생한다. 본 연구에서 활용한 모형은 외부의 설명변수를 이용하지 않았다는 장점이 있다. 따라서 외부 설명변수에 대한 예측이 필요하지 않다. 본 연구에서는 설명변수로 공휴일 변수와 ARIMA 주별 예측치를 활용하였다. 공휴일 변수의 경우에는 미래에 예정된 값이기 때문에 예측이 불필요하다. ARIMA 주별 예측치의 경우에도 외부 설명변수에 대한 예측이 불필요하며 과거의 관측값들을 이용하여 추세를 예측할 수 있다. 만약 외부 설명변수에 대한 합리적인 예측이 가능하다는 전제 하에 외부 설명변수들을 추가로 고려하여 예측모형을 생성한다면 보다 정확한 항공화물 예측이 가능할 것이다. 특히 본 연구에서 사용된 설명변수 외에 돌발변수를 고려한다면 정확도 높은 항공화물 예측이 가능할 것으로 생각된다.
본 연구는 실제 K항공사의 일 단위 항공 수출물동량 데이터를 사용하였기 때문에 본 연구의 일별 예측모형은 K항공사의 세부 운영계획에 직접적인 참고자료로 활용될 수 있을 것으로 기대된다. 연구 결과 K항공사의 일별 수출 항공물동량은 요일에 따른 편차가 큰 것으로 나타나 요일별로 인력 또는 장비의 투입수준을 조정하여 운영효율성을 제고하는 방안을 고려해볼 수 있을 것으로 생각된다. 마지막으로 본 연구에서 활용된 예측모형들을 이용하여 편차가 심한 K항공사의 수출 물동량의 증감추이를 예측하고 인력의 재배치를 고려한다면 수요예측의 어려움으로 인한 인력관리의 복잡성을 줄일 수 있을 것으로 기대된다. 수출 물동량 외에도 수입 물동량을 고려한 연구를 진행한다면 여러 시사점을 도출할 수 있을 것이다. 이외에도 다른 국가 주요 항공사들의 물동량 데이터를 대상으로 여러 예측모형들을 적용하여 일별 예측을 진행하면 의미있는 연구가 될 것이다. 항공 외에도 철도, 항만 등 다양한 물류 분야에서 본 연구에서 활용한 예측모형들을 활용할 수 있을 것으로 기대된다.
