

서론
기존 연구 고찰
1. 잠재 계층 분석 및 데이터 샘플링 관련 선행연구
2. 사고 심각도 모형 관련 선행연구
3. 기존 연구와의 차별성 및 의의
분석 데이터
방법론
1. 잠재 계층 분석(Latent Class Analysis)
2. ROSE(Random Over-Sampling Examples)
3. 랜덤 파라미터 이항 로짓 모델(Random Parameter Binary Logit Model)
4. 평가 지표
분석결과
결론
서론
현대 도시의 급속한 성장과 차량 보급률의 지속적인 증가는 도심부 교통안전 문제를 중요한 사회적 과제로 부각시키고 있다. 국토교통 통계누리에서 제공하는 자동차등록현황보고에 따르면 최근 5년간(2019년~2023년) 국내 승용차 등록대수는 2019년 약 1,918만대에서 2023년 약 2,139만대로 연평균 2.77%의 지속적인 증가 추세를 보이고 있다. 이와 같은 차량 증가는 교통혼잡 가중화와 더불어 교통사고 발생 가능성을 증대시키는 주요 요인으로 작용하고 있다. 기존 연구들은 주로 보행자 및 자전거 이용자 등과 같은 취약 도로 이용자(Vulnerable Road Users, VRU)의 안전성 확보에 초점을 맞춰 진행되어 왔다(Lee and Park, 2024; Seiniger et al., 2013). 그러나 도심부 교통량의 증가는 취약 도로 이용자뿐만 아니라 차량 간 충돌사고의 위험성도 동시에 증가시키고 있다(Kim et al., 2021). 도로교통공단의 통계자료에 의하면, 2023년 특별광역시도에서 발생한 차대차 사고는 58,888건으로 전체 차대차 사고의 38.5%를 차지하여 도시부 차대차 사고의 심각성을 보여주고 있다. 이러한 문제의식 하에 국내외에서는 도심부 차대차 사고예방 및 심각도 감소를 위한 다양한 연구가 진행되고 있다. Ko et al.(2021)은 C-ITS 환경에서 차량 내 경고 정보 제공에 대한 효과를 교통안전 측면에서 정량적으로 평가하고 경고 제공 정보 시 순응률이 안전성 개선효과에 미치는 영향을 분석하였다. 교통안전공단은 센서융합기술을 기반으로 차량 주변 환경을 인식하여 운전자에게 알림을 주는 기술인 능동안전장치를 활용하여 연구를 진행하였다. 또한, 능동안전장치를 활용해 충돌 직전에는 차량의 안전 시스템이 작동하고, 충돌 직후엔 차량의 안전지원장치가 작동하는 통합안전시스템에서 피해 심각도를 평가하는 충돌평가시험을 연구하였다(Korea Transportation Safety Authority, 2017). 치안정책연구소에서는 교통사고 감소를 위해 경찰 부문의 차세대 지능형교통시스템(C-ITS)에 기반한 적용 서비스를 선정하고 단계적 로드맵을 도출하여 C-ITS의 체계적인 도입방안을 연구하였다(Police Science Institute, 2013).
도심부에서 발생하는 차대차 사고 중 왕복 4~5차로 도로는 도시 간선도로의 핵심 구성요소로서 높은 교통량과 복잡한 교통 패턴을 나타낸다. 이러한 구간에서는 진출입로와 교차로, 엇갈림 구간 등 다양한 기하 구조적 요소가 복합적으로 작용하여 차량간 상호작용이 빈번하게 발생한다(Won et al., 2009). 특히, 높은 주행 속도와 빈번한 차선 변경 행태는 사고 발생 시 심각도를 증가시키는 주요 위험 요인으로 작용하였다. Chen et al.(2022)는 인천시 도심부 도로에서 발생한 교통사고 심각도 요인을 분석한 결과, 빈번한 차로 변경으로 인해 차로 수가 많을수록, 속도가 높을수록 사고 심각도가 증가함을 확인하였다. 또한 Kim et al.(2024)의 연구에서는 미국 오리건주에서 발생한 사고 데이터 중에서 왕복 4차로 사고가 전체의 41.8%로 가장 높은 비율을 차지하는 것으로 나타났으며 SPF(Safety Performance Functions) 분석을 통해 차로 증가가 초기에는 안전성 개선 효과를 가져올 수 있으나, 교통량 증가와 차로 변경 빈도 증가로 인해 사고 발생 가능성 또한 증가하는 것을 확인하였다.
본 연구에서는 이러한 복합적인 요인들을 고려하여 도심부의 왕복 4~5차로 도로에서 발생한 차대차 사고의 특성을 심층적으로 분석하고, 심각도에 영향을 미치는 요인들을 통계적으로 식별하고자 한다. 이를 위해 잠재 계층 분석(Latent Class Analysis)을 활용하여 차대차 사고의 잠재적 동질 집단을 식별하고 각 집단의 특성을 파악하였다. 교통사고 데이터의 희소성과 무작위성 등을 해결하기 위해 ROSE(Random Over-Sampling Examples) 기법을 활용한 데이터 증강을 수행하였다. 마지막으로 증강한 데이터를 바탕으로 관측되지 않은 이질성을 고려하기 위해 랜덤 파라미터 이항 로짓 모델(Random Parameter Binary Logit Model)을 통해 사고 심각도 요인을 분석하였다. 교통사고는 본질적으로 희소하고 무작위적인 특성을 가지며, 특히 중상 이상의 심각한 사고는 상대적으로 발생 빈도가 낮아 충분한 표본 확보에 어려움이 존재한다. 제한된 표본으로 분석을 수행하면 통계 모델의 추정 정확도와 분석의 신뢰성을 저해할 수 있으므로, 본 연구에서는 데이터 증강 기법 중 하나인 ROSE기법을 활용하여 모델의 예측 성능과 신뢰성을 향상시키고자 한다. 이를 통해 도심부 왕복 4~5차로 도로의 교통안전 개선을 위한 전략 수립에 기여하고자 하며, 연구의 전체적인 흐름은 Figure 1과 같다.
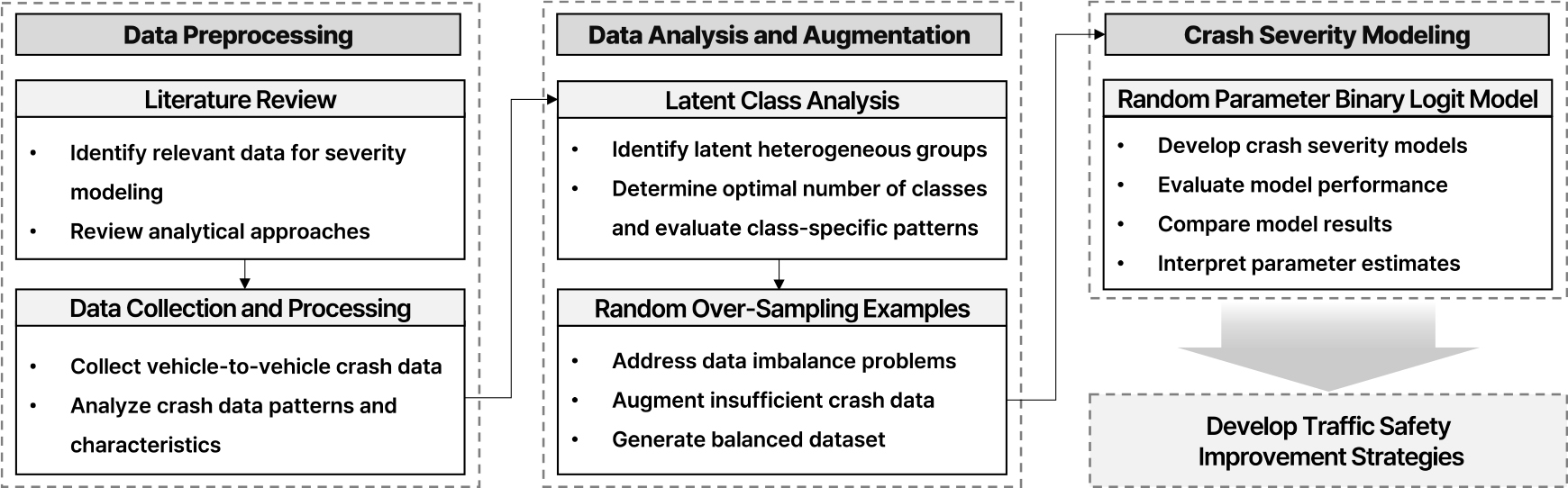
기존 연구 고찰
1. 잠재 계층 분석 및 데이터 샘플링 관련 선행연구
Li et al.(2019)은 운전자 사고 심각도에 영향을 미치는 요인을 식별하기 위해 혼합 로짓 모델으로 사고 심각도 모형을 개발하였다. 잠재 계층 분석을 통해 계층을 나눠 분석한 결과, 농촌지역과 젖은 노면 상태 구간에서 심각도가 높은 것으로 나타났다. Cho et al.(2022)은 분석 데이터의 이질성을 고려하기 위해 잠재 계층 분석을 수행하여 교통사고 특성을 분류하였다. 판단지표로 AIC(Akaike Information Criterion)와 BIC(Bayesian Information Criterion)를 사용하여 6개의 최적 계층 수를 도출하였다. 6개의 계층 간 사고 특성은 정차 중 추돌사고, 이상기후, 노면 상태가 젖거나 결빙인 상태, 주행차로 내 차로변경 사고, 터널, 다중사고, 좌 곡선부 등이 계층의 분류항목으로 분석되었다.
교통사고는 발생빈도가 낮고 예측이 어려운 특징을 가지고 있기 때문에 정확한 분석을 위해서는 충분한 데이터가 필요하다. Kim et al.(2023)은 항만 터미널에서 발생한 사고에 대해 전통적인 통계분석과 머신러닝을 함께 적용하여 방법론별 예측 성능을 비교하였다. 사고 데이터를 증강하기 위해 ROSE 기법을 사용하였으며, 기존 수집한 데이터 451건의 5배인 2,255건으로 데이터를 증강하였다. Man(2022)은 실시간 교통사고 예측 모델을 개발하는 데 있어 발생하는 데이터 불균형 문제를 해결하기 위해 WGAN(Wasserstein GAN)을 사용하였다.
2. 사고 심각도 모형 관련 선행연구
Fountas et al.(2018)은 미국 워싱턴주 고속도로에서 수집된 데이터를 통해 사고 발생에 영향을 미치는 동적 및 정적 요인들을 분석하였다. 동적 요인은 습도와 노면의 얼음 두께와 같이 실시간으로 수집된 데이터이며, 정적 요인은 차로 수 및 너비와 같이 도로 설계 요소와 교통량 등을 의미한다. 이러한 요인들을 고려한 랜덤 파라미터 이항 로짓 모델을 통해 습도가 60%를 초과할 때 사고 발생 확률이 3.57% 증가함을 확인하였다. Abdel-Aty.(2003)는 미국 플로리다 중부 지역에서 발생한 교통사고 데이터를 통해 도로 위 다양한 위치(기본 구간, 신호 교차로, 톨게이트 등)에서 발생하는 사고에 대해 심각도 모형을 개발하였다. 사고 심각도 수준을 분석하기 위해 순서형 프로빗 모형을 사용하였으며, 운전자의 나이, 성별, 안전벨트 착용 여부, 속도, 충돌 지점 등의 요인이 모든 위치에서 심각도에 유의미한 영향을 미치는 것을 확인하였다. Wu et al.(2014)은 뉴멕시코 주의 2차로 고속도로 사고 데이터를 통해 단일 사고와 다중 사고에서 운전자의 사고 심각도 영향을 미치는 요인들을 확인하였다. 혼합로짓모형을 적용하여 분석한 결과, 차량의 유형, 안전벨트 착용, 음주 운전, 도로 조건 등이 운전자의 사고 심각도에 영향을 미치는 것으로 나타났다. Cho et al.(2022)은 구분한 6개의 군집에 대해 이항 로짓 모델을 통해 기존 데이터를 학습하여 새로운 데이터를 검증하는 방법으로 군집별 사고 심각도를 예측하였다. 사고 심각도 모형의 예측 성능을 평가하기 위해 혼동행렬(Confusion Matrix)기반의 정확도(Accuracy)와 재현율(Recall), 정밀도(Precision)를 계산하였다. 사고 심각도가 높은 군집에서 정확도는 81.6%, 재현율 및 정밀도는 각각 92.3%, 87.6%로 나타났다. Ko et al.(2020)은 3년간 발생한 사고 데이터를 바탕으로 교통사고에 영향을 미칠 수 있는 각종 요인들을 파악하고, 사고 심각도를 예측할 수 있는 모형을 연구하였다. KNN(K-Nearest Neighbor), LR(Logistic Regression), NB(Naive Bayes), DT(Decision Tree), RF(Random Forest), GB(Gradient Boosting) 모형을 이용하여 심각도 예측 모델을 학습하고 성능을 비교 분석하였다. 경미한 상해의 경우 GB 모델이 가장 잘 예측하였으며, 중간 상해는 LR 모델이, 심각한 상해는 DT 모델이 우수한 성능을 보여주었고 피해 차량이 승용차인지에 대한 여부가 가장 큰 영향을 미쳤다. Park et al.(2019)은 기상상태에 따른 도로기하구조가 교통사고 심각도에 미치는 영향을 분석하기 위해 위계적 순서형 로짓 모형을 활용하여 연구를 수행하였다. Jo et al.(2022)은 C-ITS 자료를 이용하여 위험구간을 식별하는 주행안전성 평가지표 우선순위를 제시하였다. 주행안전성 평가지표는 사고건수와 상관분석을 통해 선정하였으며, 랜덤포레스트(random forest) 기법을 활용하여 사고발생 개연성이 높은 위험집단을 분류하였다. 분석결과 중요도가 상위 3개의 평가지표는 spacing 변동성, SDI 기반 상충건수, headway 지표로 분석되었다.
3. 기존 연구와의 차별성 및 의의
본 연구는 도심부 왕복 4~5차로 구간에서 발생한 차대차 사고를 대상으로 분석을 수행하였다. 이는 복잡한 교통환경, 높은 통행량, 차로 변경 등이 복합적으로 작용하는 구간으로, 기존의 도심부 보행자 사고 또는 고속도로의 차대차 사고를 대상으로 한 사고 심각도 연구와는 분석 대상 면에서 차이를 보인다. 특히 도심부 다차로 환경에서는 차량 간 상호작용이 빈번하고 다양한 위험 요소가 동시에 존재하기 때문에, 사고 발생 메커니즘이 상이하며 이를 반영한 맞춤형 분석이 필요하다. 또한 본 연구에서는 블랙박스 영상을 기반으로 구축된 실제 사고 데이터를 활용하였다. 기존 연구들이 주로 공공 통계자료나 경찰 사고 기록 등 정형화된 이차 데이터를 활용한 반면, 본 연구는 사고 당시의 차량 움직임, 충돌 각도, 도로 환경 등을 직접 관찰할 수 있는 블랙박스 데이터를 통해 보다 정밀하고 실질적인 분석이 가능하였다. 이는 단순한 사고 결과 중심의 분석이 아닌 사고 발생의 상황을 함께 고려할 수 있다는 점에서 실증적 의의를 가진다.
분석 데이터
본 연구에서는 도심부 교통사고의 분석을 위해 교통사고 블랙박스 영상 데이터를 활용한 상세 분석을 수행하였다. 연구의 시ㆍ공간적 범위는 2021년 전국 왕복 4~5차로 도로에서 발생한 차대차 교통사고이며, 블랙박스 사고 데이터의 수집 및 가공 절차는 Figure 2와 같다. 블랙박스 영상을 수작업으로 분석하여 사고 발생 전후의 세부적인 교통상황과 주행행태 등을 추출하였다. 특히 기존 데이터에서는 제공되지 않는 충돌 각도, 차량 간 상호작용, 사고 직전의 주행행태 등을 영상을 통해 확인하였다. 사고 심각도와 시간대 정보는 별도로 정리되어 있는 항목을 통해 수집하였다. 수작업으로 수집한 데이터에서 발생할 수 있는 일관성 문제를 해결하기 위해 2명의 연구자가 독립적으로 분석하고 결과를 교차 검증하여 신뢰도를 향상시켰다. 수집한 데이터를 바탕으로 체크리스트 항목에 알맞게 작성하고 이를 정형화하여 분석 데이터로 활용하였다. 수집된 사고 데이터는 크게 4가지의 범주로 구분할 수 있는데 가해 및 피해 운전자의 연령 및 성별 등의 인적 요인, 노면 상태, 평면/종단선형, 교차로 형태 등의 도로 요인, 주행행태, 상충유형 등과 같은 사고 요인, 기상 조건, 사고 발생 시간대 등의 기타 요인이다. 각 사고 데이터는 사고 발생 당시의 포괄적인 상황 정보를 포함하고 있으며, 세부 내용으로 사고 유형, 운전자 정보 및 과실 여부, 주행행태, 도로의 기하구조, 주행환경, 사고원인, 기상 조건 등의 변수들로 구성되어 있다. 다양한 요인 중에서 사고 심각도(Wound), 사고 유형(Type of crash), 기상 상태(Weather), 노면 상태(Road surface), 교차로 형태(Intersection type), 시간대(Time period) 변수를 분석에 활용하였다. 사고 심각도 변수는 본 연구의 종속변수로서, 한정된 데이터를 고려하여 이분형 변수로 구성하였다. 구체적으로 중상 이상의 사고를 1, 경상 사고를 0으로 가공하였다. 데이터 전처리 과정에서 이상치 제거 및 결측치 처리를 수행한 결과, 최종적으로 총 212건의 사고 데이터를 분석에 활용하였으며, 데이터 구성은 Table 1과 같다.
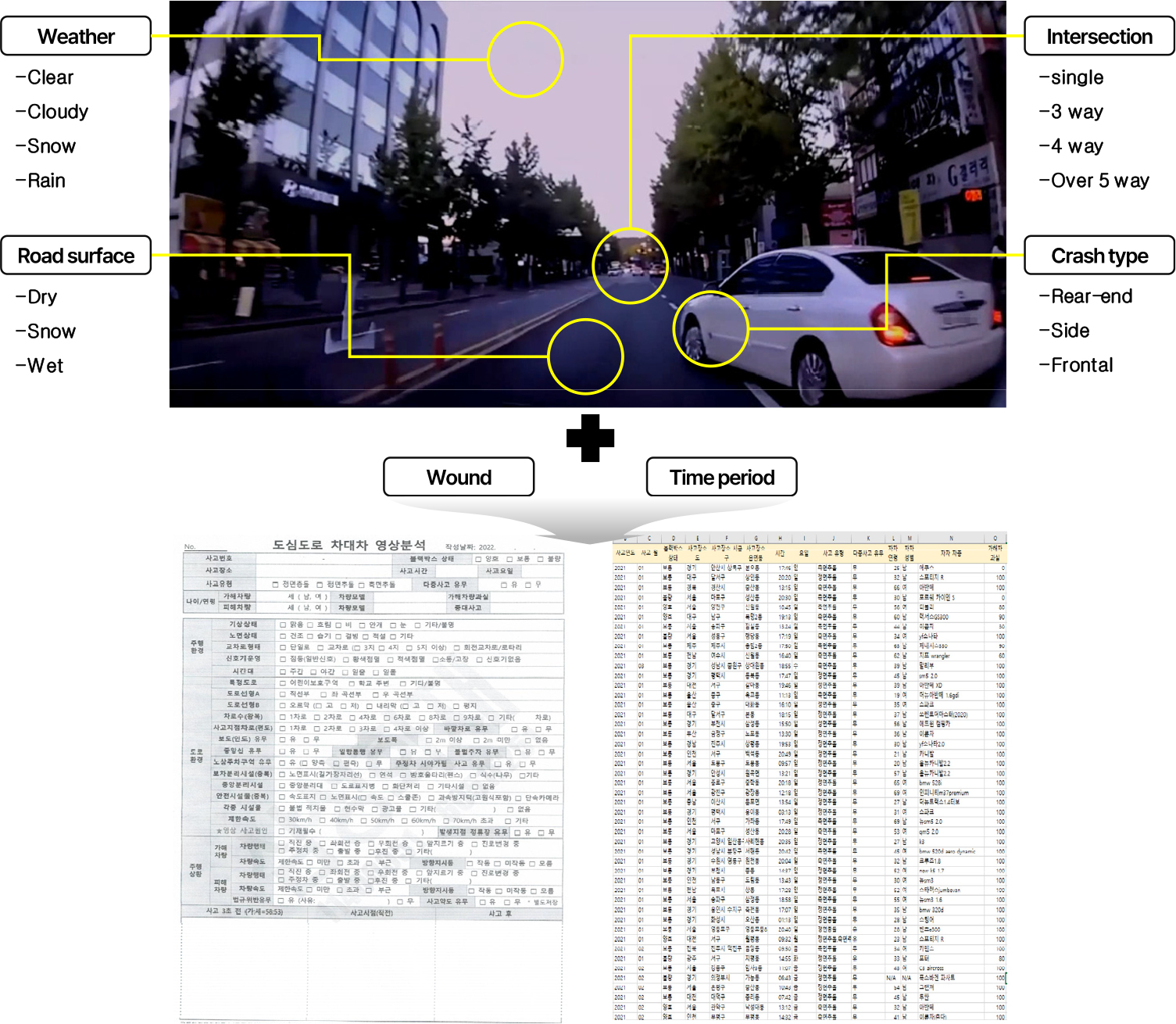
Table 1.
Data statistics
방법론
본 연구에서는 사고 유형별 잠재 계층을 식별하기 위해 잠재 계층 분석을 활용하였으며, 제한된 데이터를 보완하기 위해 ROSE 기법을 활용하여 데이터를 증강하였다. 마지막으로, 사고 심각도에 영향을 미치는 요인의 이질성을 반영하기 위해 랜덤 파라미터 이항 로짓 모델을 사용하였다.
1. 잠재 계층 분석(Latent Class Analysis)
잠재 계층 분석은 관측된 변수들의 패턴에 기반하여, 관측되지 않은 동질적인 하위 집단을 식별하는 통계적 기법이다. 또한 이질적인 모집단 내에서 유사한 특성을 공유하는 집단을 추론함으로써, 잠재적 이질성을 반영한 집단 간 차이를 통계적으로 분석하는 데 활용된다. 교통사고 데이터는 본질적으로 이질적인 특성을 지니고 있어, 전체 데이터를 단일 집단으로 분석할 경우 일부 변수 간의 통계적 관계가 왜곡되거나 식별되지 않을 수 있다(Depaire et al., 2008). 잠재 계층 분석은 이러한 한계를 극복하고, 복잡한 구조를 갖는 사고 데이터에서 내재된 사고 메커니즘의 유형을 규명하기에 적합하다. 잠재 계층 분석에 관한 수식은 Equation 1과 같이 표현할 수 있으며, 여기서 는 번째 잠재 계층의 사전 확률, 는 주어진 잠재 계층 에서 번째 변수의 조건부 확률을 의미한다.
본 연구에서 활용하는 도심부 왕복 4~5차로 사고의 복합적인 특성을 고려하여 잠재 계층 분석을 수행하였다. 수집된 212건의 블랙박스 사고 데이터는 사고 유형(정면 충돌, 후미 추돌, 측면 추돌), 기상 상태(맑음, 흐림, 눈, 비), 노면 상태(건조, 적설, 습기) 등의 변수가 다양하게 조합되어 나타난다. 이러한 조합별로 보이는 특성을 식별한 후 집단별 특성을 분석하고자 잠재 계층 분석을 활용하였다. 사고 유형, 기상 상태, 노면 상태, 교차로 형태, 시간대 변수를 계층 분류 변수로 활용하여 최적 계층 수를 결정하고, 각 계층의 주요 특성을 파악하였다.
2. ROSE(Random Over-Sampling Examples)
ROSE 기법은 소수 클래스의 데이터 희소성 문제를 해결하기 위한 확률 기반의 데이터 증강 기법으로, 부트스트랩에 기반한 조건부 확률 분포를 활용하여 가상의 데이터 샘플을 생성한다. ROSE 기법은 단순 복제나 선형 보간을 사용하는 기존 오버샘플링 기법들과 달리, 스무딩된 조건부 부트스트랩 방식을 적용하여 클래스 내 확률 분포를 따르면서도 데이터의 구조를 유지할 수 있도록 설계되었다. 또한 최근접 이웃 기반의 선형 보간 방식을 활용하는 SMOTE(Synthetic Minority Over-sampling Technique)와 달리, 커널 기반의 확률적 생성 방식을 사용함으로써 기존 데이터에 대한 의존성을 줄이고, 소수 클래스의 분산을 보다 정교하게 반영한다. 이러한 특성은 분류 모델의 일반화 성능을 높이고, 편향 문제를 완화하는데 기여할 수 있다(Kim et al., 2023). 다만 ROSE 기법은 클래스 불균형이 극심한 상황에서는 성능 평가 지표가 과도하게 낙관적으로 추정될 수 있어 신중한 적용이 필요하다(Menardi and Torelli, 2014).
본 연구에서 수집된 사고 데이터는 212건으로 사고 심각도 모형의 신뢰성 있는 결과를 도출하기에는 샘플 크기가 제한적이었다. 교통사고의 본질적 희소성과 블랙박스 영상의 수작업 분석이라는 한계가 존재하였고, 이를 해결하기 위해 ROSE 기법으로 원본 데이터의 분포를 반영한 데이터를 생성하였다. 증강 과정에서는 각 변수별 분포 비율을 유지하여 실제 도심부 사고 특성을 왜곡하지 않도록 하였으며, 증강된 데이터를 심각도 모형 분석에 활용하였다.
3. 랜덤 파라미터 이항 로짓 모델(Random Parameter Binary Logit Model)
랜덤 파라미터 이항 로짓 모델은 종속변수가 이산형 형태를 가질 때 개별 관측치 간의 이질성을 고려하여 선택 확률을 추정하는 확률적 선택 모형이다. 기존의 고정 효과를 갖는 이항 로짓 모델과 달리, 본 모형은 설명변수의 계수가 변수별로 확률적으로 분포한다는 가정을 통해 잠재적 이질성을 반영한다. 이항 로짓 모델의 기본 수식은 Equation 2와 같다.
여기서 는 주어진 설명변수 에서 종속변수 가 1의 값을 가질 확률을 의미하며, 𝛽는 추정해야할 계수 벡터이다. 해당 확률은 로짓 변환을 통해 Equation 3과 같이 표현할 수 있다.
로짓 변환은 확률을 실수 전체 범위의 지표로 변환하는데 사용되며, 모수의 추정은 우도함수를 최대화하는 방식인 최대우도추정법을 통해 이루어진다. 우도함수와 로그우도함수는 Equation 4, Equation 5와 같다.
기존의 고정 효과를 갖는 이항 로짓 모델은 모든 변수들에 대해 동일한 계수 𝛽를 가진다고 가정하지만, 현실적으로 계수에 영향을 미치는 관측되지 않은 이질성이 존재할 수 있다. 이를 반영한 확장 모델이 랜덤 파라미터 이항 로짓 모델이며, 각 개인 이 대안 를 선택할 때의 효용은 Equation 6과 같이 표현된다.
여기서 는 설명변수, 은 개인 에 대한 계수 벡터, 는 오차항을 의미한다. 계수 벡터 은 Equation 7과 같이 평균 𝛽와 개인별 편차 으로 구성된다.
랜덤 벡터 은 평균이 0이고 공분산 행렬이 𝛺인 정규분포를 따른다고 가정하며, 이러한 가정 하에서 개인 n이 대안 i를 선택할 확률은 Equation 8과 같이 표현된다.
여기서 는 계수 벡터 의 분포 함수이며, 위 적분은 닫힌구간으로 계산이 불가능하기 때문에 시뮬레이션을 통한 최대우도추정법을 활용하여 근사치를 추정한다.
본 연구에서는 동일한 사고 유형이라도 개별 사고 상황마다 심각도에 미치는 영향이 상이할 수 있다는 점을 고려하여 랜덤 파라미터 이항 로짓 모델을 적용하였다. 변수의 계수가 관측치별로 다를 수 있다고 가정하고, 각 계수가 평균과 분산을 갖는 정규분포를 따른다고 설정하였다. 관측되지 않은 이질성을 반영하기 위해 랜덤 효과를 설정하였으며, 최대우도추정법을 활용하여 개별 사고별 계수 분포를 추정하여 신뢰도 높은 모델을 구축하고자 하였다.
4. 평가 지표
본 연구에서는 모형의 적합도와 설명력을 정량적으로 평가하기 위해 AIC, BIC, Log-Likelihood, Gamma 지표를 종합적으로 활용하였다. AIC는 우도함수에 기반한 모형의 적합도를 평가하는 지표로, 모형의 복잡성과 데이터 적합도 간의 균형을 고려하며 Equation 9와 같이 표현된다. 여기서 은 최대 로그우도값이며, 는 추정된 모수의 수로 정의된다. 일반적으로 AIC의 값이 작을수록 모형이 사고 데이터에 적합한 모형으로 판단한다.
BIC는 AIC와 유사하지만 표본의 크기를 고려하여 모형의 복잡성에 대해 더 큰 페널티를 부여하는 지표다. BIC는 Equation 10과 같이 계산할 수 있으며 여기서 은 관측치의 수를 의미한다. BIC 지표 또한 값이 작을수록 사고 데이터에 더 적합한 모형임을 나타낸다.
Log-Likelihood는 데이터가 특정 모형 하에 관측될 확률의 로그값을 의미하며, 모형의 적합도를 나타내는 지표로 활용된다. 이 값은 추정된 확률값이 실제 관측값과 얼마나 일치하는지를 나타내며, 그 정의는 Equation 11과 같다. 여기서 는 종속변수의 관측값, 는 설명변수, 는 설명변수 에 대한 사건 =1의 추정 확률을 의미하며, Log-Likelihood 값이 0에 가까울수록 모형이 실제 데이터를 잘 설명하는 것으로 판단한다.
Gamma는 모형이 산출한 사건 발생 확률과 실제 관측값 간의 차이를 기반으로 계산되는 예측 오차 기반의 지표로 Equation 12와 같은 수식으로 정의된다. 여기서 은 전체 관측값의 수, 는 번째 사례의 실제 사고 심각도 값, 는 해당 사고에 대해 모형이 추정한 사건 발생 확률을 의미한다. Gamma 지표의 값이 0에 가까울수록 예측 정확도가 높고, 1에 가까울수록 예측 성능이 낮은 것을 의미한다.
분석결과
본 연구는 도심부 왕복 4~5차로에서 발생한 차대차 사고를 대상으로, 사고 심각도에 영향을 미치는 요인을 계층별로 분석하기 위해 잠재 계층 분석을 수행하였다. 분석 결과, Table 2와 같이 계층이 2개일 때 AIC의 값이 1,761.274로 가장 작게 나타났다. BIC 또한 2개의 계층에서 1,885.467로 가장 작게 나타났으며 두 지표 모두 계층의 수가 증가할수록 값이 커지는 것으로 나타났다. 이를 통해 계층의 수가 증가할수록 추정해야 할 파라미터 수도 증가하고, 이로 인해 모형 복잡성 또한 증가하는 것으로 해석된다. 212개의 한정적인 사고 데이터임을 고려하였을 때, 본 연구에서는 2개의 계층일 때가 가장 적합한 것으로 판단하였다.
Table 2.
Calculating the number of classes
| Number of classes | AIC | BIC |
| 2 Classes | 1,761.274 | 1,885.467 |
| 3 Classes | 1,761.819 | 1,949.788 |
| 4 Classes | 1,779.888 | 2,031.632 |
| 5 Classes | 1,798.403 | 2,113.922 |
2개의 계층으로 분석을 수행한 결과, Table 3과 Figure 3과 같이 특성들이 분류되었다. 사고 유형의 경우 계층 1은 후미 추돌 사고(0.7701, rear-end)의 비중이 높았으며, 계층 2는 후미 추돌(0.4576, rear-end)과 측면 추돌(0.4295, side)이 유사한 수준으로 나타났다. 기상 조건에서는 계층 1이 눈(0.5213, snow), 흐림(0.1644, cloudy), 비(0.1563, rain) 등의 악천후에서 사고가 발생한 반면, 계층 2는 맑은 날씨(0.8867, clear)에서 사고 발생 확률이 높게 나타났다. 노면 상태의 경우, 계층 1은 적설(0.7029, snow)과 습윤(0.2971, wet) 노면에서 사고 발생 비중이 높아 겨울철 도로 환경이 주요한 위험 요인으로 작용하는 것으로 분석되었다. 계층 2에서는 건조한 노면에서의 사고가 0.9543으로 대다수를 차지하였다. 교차로 형태에서는 계층 1이 단일로(0.4966, single)와 3지 교차로(0.3649, 3 way intersection)에서, 계층 2에서는 단일로(0.4796, single)와 4지 교차로(0.2818, 4 way intersection)에서의 주로 사고가 발생하였다. 시간대 변수에서는 두 계층 모두 주간과 야간 시간대에 사고가 집중되었으며, 일출 및 일몰 시간대의 사고 비중은 상대적으로 낮아 해당 시간대 특성 반영에 한계가 있었다. 이러한 한정된 원본 데이터의 문제를 극복하기 위해 ROSE 기법을 활용하여 데이터를 약 10배 수준인 2,120건으로 증강하였다. 데이터 증강 결과는 Table 4와 같이 구성되어 있다.
Table 3.
Probabilities of variables by class
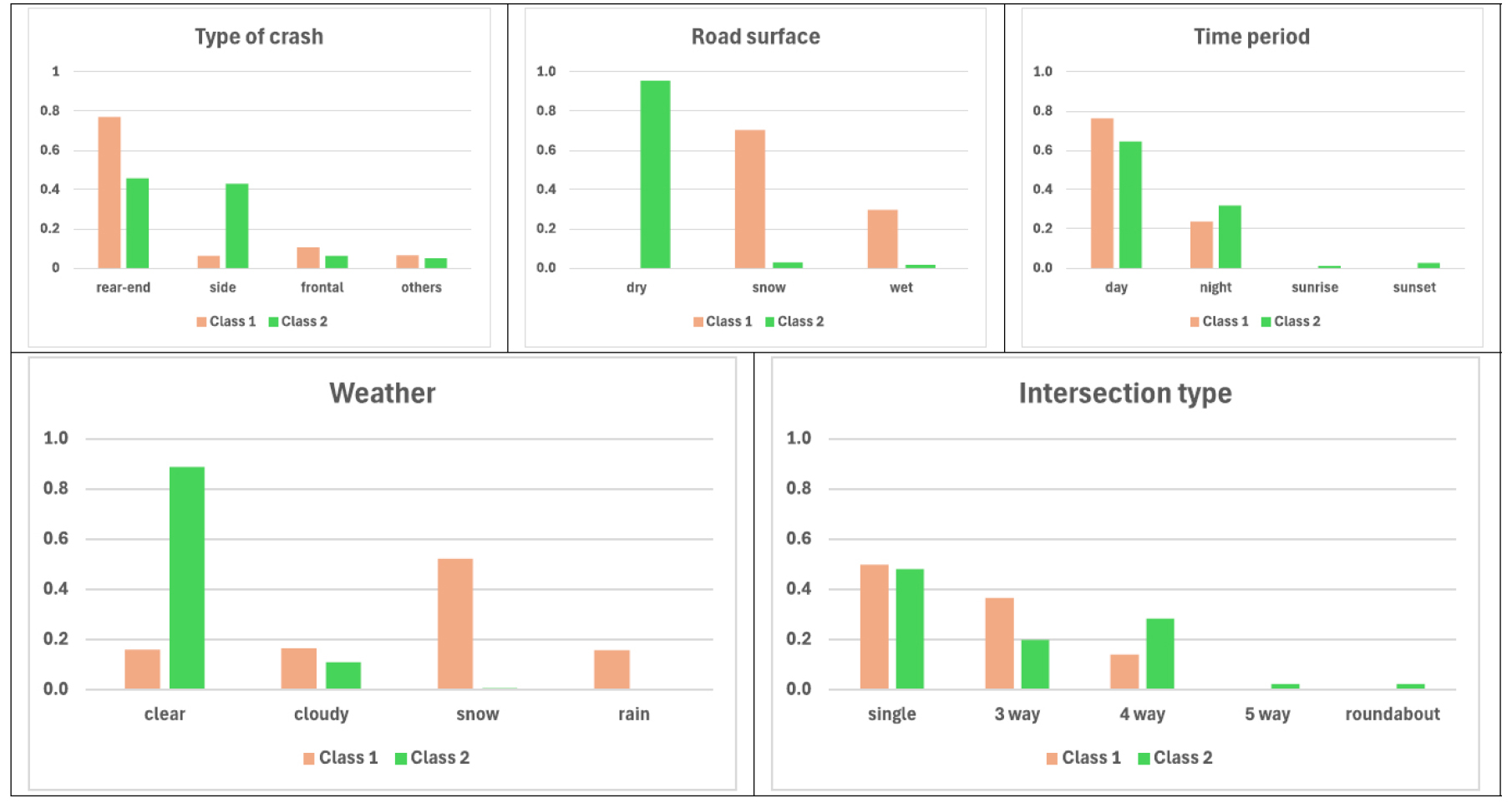
Table 4.
Data sampling results
원본 데이터의 표본 수가 분석에 충분하지 않아 ROSE기법을 활용한 데이터 증강을 통해 10배 증가한 사고 데이터를 확보하였다. 본 연구에서는 실제 도심부 교통사고 데이터의 고유한 특성과 분포를 유지하는 것이 연구의 실용성과 타당성 확보에 중요하다고 판단하여, 데이터 증강 과정에서 원본 데이터의 분포를 유지하여 증강을 수행하였다. Zarei and Hellinga(2021)는 데이터 증강 기법을 통해 생성된 데이터의 분포가 실제 데이터의 분포와 밀접하게 일치할 때 모델의 예측 성능이 향상된 것을 확인하였으며, Chen et al.(2024) 또한 CTGAN 기반 데이터 증강에서 원본 데이터와 합성 데이터의 분포 일치성이 모델 성능 향상에 영향을 미치는 것을 검증하였다.
증강한 데이터를 바탕으로 사고 심각도에 영향을 미치는 요인을 도출하기 위해 이항 로짓 모델과 랜덤 파라미터 이항 로짓 모델을 비교 분석하였다. 이항 로짓 모델을 통한 분석 결과는 Table 5에 제시되어 있으며, 변수별 추정 계수, 표준 오차, 유의확률을 통해 사고 심각도에 영향을 미치는 주요 요인을 도출하였다.
Table 5.
Binary logit model results
사고 유형 변수에서는 정면 충돌(𝛽=-1.264, p<0.0001, frontal)과 측면 추돌(𝛽=-0.544, p=0.0183, side)이 사고 심각도를 유의하게 낮추는 것으로 나타났다. 정면 충돌의 경우 도심부 도로 특성상 중앙 분리대와 같은 충격 완화 시설이 정면 충돌 시 충격량을 줄이는 역할을 하기 때문으로 해석할 수 있다. 측면 추돌은 동일 방향으로 주행하는 차량이 차선 변경, 유출입부 환경 등의 이유로 사고가 발생한 것이기 때문에 두 차량간 속력 차이가 크지 않아 심각도가 높지 않은 것으로 파악하였다.
기상 상태 변수에서는 맑음(𝛽=1.425, p<0.0001, clear), 비(𝛽=2.370, p<0.0001, rain), 흐림(𝛽=1.287 p=0.002, cloudy)일 때 통계적으로 유의한 것을 확인하였다. 기상이 맑거나 흐린 날씨 조건에서 사고 심각도가 유의하게 증가하는 경향이 확인되었는데, 이는 운전자가 기상 상태를 비교적 안전하다고 인식하여 주의력 저하 또는 감속 부족 등 일반적인 주행 습관을 유지하려는 경향이 사고의 심각도로 이어질 수 있음을 의미한다. 또한 비가 오는 조건에서의 추정 계수가 가장 높게 도출되었는데, 이는 시야 저하, 제동거리 증가 등의 복합적인 위험 요인이 심각도 증가에 영향을 미쳤을 가능성을 시사한다.
노면 상태 변수 중에서는 습윤(𝛽=0.796, p=0.0027, wet)일 때 통계적으로 유의미한 것을 확인할 수 있었다. 젖은 노면에서는 수막현상으로 인해 차량의 제동거리가 증가하기 마련인데, 운전자들은 주행할 때 이런 위험에 대한 경각심이 낮아 충분한 감속이 이루어지지 않은 채 평상시와 유사한 주행 속도가 유지되어 사고 심각도가 증가하는 것으로 분석되었다.
교차로 형태 변수에서는 4지 교차로(𝛽=-0.051, p<0.0001, 4 way intersection)에서 사고 심각도가 낮게 나타났으며, 이는 교차로 내 신호 통제, 복잡한 구조로 인한 운전자의 저속 주행 등으로 인한 것으로 판단되었다.
사고 심각도에 영향을 미치는 요인의 이질성을 반영하기 위해 랜덤 파라미터 이항 로짓 모델을 적용하였으며, 사고 유형 변수 중 측면 추돌과 후미 추돌을 랜덤 효과 변수로 설정하였다. 이는 동일한 사고 유형이더라도 운전자, 주행 환경, 사고 당시 상황 등에 따라 사고 심각도에 미치는 영향이 상이할 수 있다는 점을 고려하였다. 모델의 추정 결과는 Table 6에 제시되어 있으며, 기상 상태, 노면 상태, 교차로 형태, 시간대 변수 등이 사고 심각도에 통계적으로 유의한 영향을 미치는 것으로 나타났다.
Table 6.
Random parameter binary logit model results
기상 상태 변수에서는 맑음(𝛽=163.527, p=0.0226, clear), 비(𝛽=183.931, p=0.0166, rain), 흐림(𝛽=171.083, p=0.0235, cloudy)일 때 통계적으로 유의한 것을 확인하였다. 이는 이항 로짓 모델 결과와 마찬가지로 기상이 맑거나 흐린 날씨에서 사고 심각도가 유의하게 증가하는 경향이 확인되었는데, 이는 운전자가 맑은 날씨를 비교적 안전하다고 인식하여 일반적인 주행 습관을 유지하려는 경향이 사고의 심각도로 이어질 수 있음을 의미한다. 이는 악천후 상황에 더 조심스럽게 운전하는 주행행태와 달리 경각심 감소가 위험 증가의 요인으로 작용한다고 분석한 논문과 유사하였다(Tefft, 2016; Redelmeier and Raza, 2017). 비가 오는 조건에서의 추정 계수 또한 가장 높게 도출되었는데, 이는 시야 저하, 제동거리 증가 등의 요인이 심각도 증가에 영향을 미쳤을 가능성을 시사한다.
노면 상태 변수 중에서는 적설(𝛽=42.632, p=0.0475, snow)일 때 통계적으로 유의미한 것을 확인하였는데 적설된 노면에서는 사고 심각도가 증가하는 것으로 분석되었다.
교차로 형태 변수에서는 4지 교차로(𝛽=-27.066, p=0.0305, 4 way intersection), 5지 교차로 이상(𝛽=-289.881, p=0.0405, more than 5 way)에서 사고 심각도가 낮게 나타났으며, 이는 교차로 내 신호 통제, 복잡한 구조로 인한 운전자의 저속 주행 등으로 사고 심각도가 낮게 나타난 것으로 판단되었다.
시간대 변수에서는 일몰(𝛽=50.821 p=0.0364, sunset)과 주간(𝛽=-10.008, p=0.0431, day)일 때 통계적으로 유의미한 것을 확인하였다. 이는 일몰 시 태양의 위치가 운전자의 시야와 비슷한 위치에 존재하기 때문에 눈부심으로 인한 시야 확보의 어려움이 존재한다. 반면 주간 시간대에는 전방 시야가 확보되기 때문에 사고 심각도가 감소하는 것을 확인하였다. 한편, 기상 상태 변수 중 비, 흐림 조건과 교차로 형태 변수 중 5지 교차로 이상과 같은 일부 범주에서는 데이터 증강을 수행하였음에도 불구하고 여전히 관측치가 적어 추정 계수가 크게 나타난 것으로 해석될 수 있다.
모형의 예측력 및 적합도를 비교하기 위해 AIC, BIC, Log-Likelihood, Gamma 지표를 활용하였으며, 각 모형의 결과는 Table 7에 제시하였다. 분석 결과, 랜덤 파라미터 이항 로짓 모델이 전반적으로 이항 로짓 모델보다 우수한 성능을 보이는 것으로 나타났다. 값이 작을수록 모델의 적합도가 우수한 것으로 판단되는 AIC와 BIC 지표의 경우, 두 지표 모두 랜덤 파라미터 모델이 더 낮은 값을 기록하였다. 또한 값이 0에 가까울수록 좋은 모델로 해석되는 Log Likelihood 지표와 Gamma 지표 모두 랜덤 파라미터 모델이 우수한 것으로 나타났다. 이와 같은 결과는 개별 사고 간 이질성을 반영한 확률 기반 접근이 사고 심각도 분석에 있어 더욱 적절한 방법임을 확인할 수 있었다.
결론
본 연구는 기존 연구와 달리 차로 변경과 진출입이 복합적으로 작용하는 도심부 왕복 4~5차로에서 발생한 차대차 사고의 특성 및 사고 심각도에 영향을 미치는 요인을 식별하고, 이질적 사고 특성에 기반한 분석 프레임을 제시하는 것을 목적으로 하였다. 이를 위해 전국 교통사고 블랙박스 영상을 수작업으로 수집 및 분석하였으며, 사고 특성에 대한 계층 간 차이를 고려할 수 있는 통계적 분석 기법을 적용하였다. 먼저 사고의 특징을 고려하기 위해 잠재 계층 분석을 수행한 결과, 4~5차로에서 사고가 두 가지 패턴으로 구분되었다. 계층 1은 적설 노면에서의 후미 추돌이 주를 이루고, 계층 2는 건조한 노면에서 측면 추돌이 집중되는 특성을 보였다. 이는 사고 유형에 따라 이질성이 존재하며, 기상 및 노면 상태에 따라 위험 요인이 달라질 수 있음을 보여준다. 악천후 및 적설 노면에서 사고가 집중된 계층 1의 경우에는 속도 단속 강화와 미끄럼 방지시설 확충 등이 필요하며, 맑은 날씨 및 건조한 노면에서 집중된 계층 2의 경우에는 교차로 시야 확보와 같은 물리적 개선을 통해 사고를 예방할 수 있을 것으로 판단된다. 이후 사고 심각도 모형 개발을 위해 데이터 부족 문제를 해결하였다. 소수 클래스의 비중이 낮은 문제를 해결하고 모델 학습의 안정성을 확보하기 위해 ROSE 기법을 활용하여 데이터를 약 10배 수준인 총 2,120건으로 증강하였다. 증강된 데이터를 바탕으로 이항 로짓 모델과 랜덤 파라미터 이항 로짓 모델을 비교 분석하였다. 이항 로짓 모델은 모든 변수에 동일한 계수를 가정하는 반면, 랜덤 파라미터 모델은 동일한 변수더라도 개별 상황에 따라 심각도에 미치는 영향이 다를 수 있음을 반영한다. 이를 통해 사고 심각도 분석에서 개별 이질성의 중요성을 검증하고자 하였다. 이항 로짓 모델에서는 정면 충돌 및 측면 추돌이 사고 심각도를 유의하게 낮추는 요인으로 나타났으며, 이는 도심부 도로의 중앙분리대 설치나 동일 방향 주행 상황에서 속도 차이가 크지 않은 점 등에 기인하는 것으로 해석할 수 있다. 기상 상태에서는 맑음, 흐림, 비의 조건 모두 유의하게 사고 심각도를 증가시키는 요인으로 도출되었다. 본 연구에서는 수집된 사고 데이터가 모두 1월~3월 기간에 발생한 사고로 구성되어 있어, 계절적 특성을 고려해 눈 상태를 기준 범주로 설정하여 분석을 수행하였다. 특히 주목할 점은 비가 올 때 사고 심각도가 가장 높게 나타났는데, 이는 단순한 시야 저하나 제동거리 증가뿐만 아니라, 차로변경이 빈번한 다차로 환경에서 습윤 노면이 사고의 위험을 크게 증가시키기 때문으로 해석된다. 또한 4~5차로에서는 인접 차로 간 복잡한 상호작용으로 사고 결과에 직접적인 영향을 미친 것으로 판단된다. 노면 상태 중 습윤 조건에서도 사고 심각도가 유의하게 높게 나타났으며, 이는 수막 현상에 대한 운전자의 경계심 부족으로 사고 심각도가 증가한 것으로 확인하였다. 교차로 형태 변수에서는 4지 교차로에서 사고 심각도가 낮게 나타났는데, 이는 교차로 내 신호 통제 및 복잡한 구조로 인한 저속주행 등과 관련된 결과로 볼 수 있다. 랜덤 파라미터 이항 로짓 모델에서는 사고 유형 중 측면 및 후미 추돌 변수를 랜덤 효과로 설정함으로써 사고 유형별 이질성을 반영하였다. 모델 결과, 기상 상태(맑음, 흐림, 비), 노면 상태(적설), 교차로 형태(4지 교차로, 5지 교차로 이상), 시간대(일몰, 주간)가 사고 심각도에 유의미한 영향을 미치는 것으로 나타났다. 특히 적설 시 심각도가 유의하게 증가하였고, 일몰 시간대 역시 운전자의 시야 확보에 어려움이 존재해 사고의 심각도가 높아지는 경향을 보였다. 반면 주간 시간대에는 전방 시야 확보로 인해 사고 심각도가 유의미하게 낮게 나타났다. 이러한 분석 결과는 도심부 왕복 4~5차로 도로가 단순히 차로 수만 많은 것이 아니라, 차로변경과 진출입이 복합적으로 작용하는 환경임을 규명했다는 점에서 기존 연구와 차별화되는 의의가 있다.
모형 성능 평가 결과, 랜덤 파라미터 모델은 AIC, BIC, Log-Likelihood, Gamma 등 모든 지표에서 고정 효과 모델보다 우수한 성능을 보였으며, 이는 사고 심각도 분석 시 관측되지 않은 이질성을 반영한 접근이 더 효과적임을 나타한다.
이러한 분석 결과는 사고 발생 조건에 따라 서로 다른 사고 메커니즘이 존재할 가능성을 보여주며, 이를 반영한 교통안전 정책 수립이 필요성이 제기된다. 특히 다양한 기상 및 노면 상태, 사고 유형, 시간대에 따라 사고 심각도의 경향이 상이하게 나타난 점은 도심부 교통 환경의 복합성을 고려한 맞춤형 전략이 필요하다는 점을 시사한다. 본 연구의 분석 결과는 노면 상태별 차별화된 속도 관리 전략이나 시간대별 사고 대응 체계 등과 같은 정밀한 교통안전 대책 수립에 실질적인 근거로 활용될 수 있을 것으로 기대된다. 아울러, 사고 데이터 내의 이질적 구조를 고려하지 않고 단일 집단으로 가정할 경우, 사고 유형별 대응 전략 수립에 오류가 발생할 수 있다는 점도 확인할 수 있었다.
본 연구의 한계점으로는, 블랙박스 영상 자료를 기반으로 사고 사례를 수작업으로 수집하였기 때문에 제한된 데이터를 활용하였다는 점이 존재한다. 특히 수집된 사고 데이터가 모두 1월에서 3월 사이에 발생한 사고로 구성되어, 계절적 편향이 존재한다. 이에 따라 기상 상태 분석에서 겨울철 특성을 반영하여 눈인 변수를 기준으로 분석하였으나, 해당 범주의 사례 수가 11건으로 적어 통계적 안정성에 한계가 있었다. 향후 연구에서는 연중 고른 시기의 사고 데이터를 수집하여 기상 상태의 영향을 보다 정확하게 분석할 필요가 있다. 또한 ROSE 기법을 통한 데이터 증강 과정에서 발생할 수 있는 데이터의 편향성이 존재할 수 있다. 본 연구에서는 실제 도심부 교통사고 데이터의 고유한 특성과 분포를 유지하는 방향으로 증강을 수행하였다. 다만 이러한 접근법이 일부 변수의 비대칭적 분포를 반영함으로써 모델의 예측 성능에 영향을 미칠 수 있는 한계점이 존재한다. 향후 연구에서는 데이터의 비대칭성을 보정하는 다양한 증강 기법을 활용하여 분석 결과의 변화를 검토할 필요가 있다. 그리고 본 연구에서는 사고 심각도를 경상과 중상 이상 두 가지로 분류하여 사고 결과의 세분화가 미흡하였지만 향후 연구에서는 더 상세한 분석을 위해 분류를 경상, 중상, 사망 등으로 분류하거나 EPDO(Equivalent Property Damage Only, 대물피해환산법) 방법론 등을 적용해보고자 한다. 또한 여름철 폭우, 겨울철 강설 등 계절적 요인과 교차로, 곡선부, 엇갈림 구간 등 도로 기하구조별 특성을 고려한 세분화된 분석을 추가로 수행할 계획이다. 이를 통해 기상 상태 및 기하구조 특성에 따른 사고 패턴을 면밀하게 분석하고, 상황별 맞춤 교통안전 정책 수립 및 사고 관리 체계 개선에 실질적인 기초 자료를 제공하고자 한다.
