

연구배경 및 목적
선행연구 검토
1. 실시간 신호 제어 체계
2. 강화학습을 이용한 신호 제어 체계
3. 기존 연구의 한계점 및 본 연구의 차별점
연구 방법론
1. 모형 구축
2. 시뮬레이션 분석의 범위
3. 비교 모형 설정
연구 결과
1. 강화학습 결과
2. 모형 간 비교분석 결과
연구 요약 및 결론
연구배경 및 목적
최근, 전 세계의 완성차 업체는 자율주행차량 상용화를 목표로 V2X 기술 개발에 박차를 가하고 있다. V2X 기술은 도로 위의 시설 및 차량의 다양한 정보를 수집하고, 차량 탑승자에게 안전하고 효율적인 통행을 가능하게 한다. 이러한 자율주행차량이 상용화된다면 도로 네트워크를 이용하는 대부분의 차량이 자율주행차량이 될 것이다. 도심부 신호교차로 등 단속류 교통 환경에서는 차량의 출발과 정지를 신호를 통해 제어하기 때문에 신중한 신호 운영이 요구되지만, 설치 ‧ 관리에 있어 용이한 정주기식 신호 제어 체계가 주를 이루고 있어, 교차로 지체를 최소화할 수 있는 효율적인 신호 운영이 어려운 실정이다.
한편, Google에서 개발한 알파고가 인간과의 바둑 경기에서 승리함으로써 기계학습 분야에 대한 관심이 늘어나고 있다. 알파고의 핵심 알고리즘인 강화학습은 다른 기계학습 방법론과는 달리 빅 데이터를 요구하지 않고 스스로 데이터를 생성해내고 이를 기반으로 학습하며, 달성해야할 목표를 설정하여 학습을 통해 문제를 해결한다는 특징이 있어(Sutton and Barto, 1998), 실시간으로 차량 정보를 수집하고 이를 통해 교차로 지체를 최소화하는 신호 운영 체계를 개발시키는 학습에 적용하기에 적합하다고 할 수 있다.
알리바바 그룹의 알리바바 클라우드는 2018년 1월, 말레이시아의 쿠알라 룸푸르에 City Brain 솔루션을 적용하였다. City Brain은 대규모 컴퓨팅 엔진을 기반으로 영상 및 이미지 인식, 데이터 마이닝 및 인공지능을 통해 도시 공간에서 생성되는 다양한 빅 데이터를 수집, 분석하고 Smart City를 구현할 수 있도록 의사결정을 돕는다. 특히, 쿠알라 룸푸르의 AI 신호 제어 체계를 도입하여 교차로에 접근하는 차량 대수 및 교차로까지의 접근 시간을 계산함으로써 신호 시간을 최적화하여 단속류 흐름을 개선한다. 또한, City Brain은 승용차뿐만 아니라 특수 목적 차량이 감지되면 신속한 현장 도착을 위해 가장 빠른 경로를 제공하는 등 여러 목적을 달성할 수 있는 것이 특징이다(Zhang et al., 2019).
끊임없이 빅 데이터를 생산해내는 도시 교통 문제 해결을 위해서는 기존의 정적인 시스템에서 벗어나, 발생 가능한 문제를 예측하고 대처할 수 있는 자동화된 시스템이 요구된다. 이에 본 연구에서는 미시적 교통 시뮬레이션 프로그램인 Vissim을 이용하여 교통정보를 실시간으로 제공받아 강화학습을 실시하여 4지 교차로에서 차량의 지체를 최소화하며, 특히 긴급차량의 접근이 감지될 경우 긴급차량을 빠르게 통과시킬 수 있도록 최적 신호를 표출하는 신호체계를 개발하고자 한다.
선행연구 검토
1. 실시간 신호 제어 체계
Park and Jeong(2016)은 통행시간을 통해 대기행렬 길이를 산정하고, 최종적으로 포화도를 산정하는 프로세스를 개발하였으며, 이를 루프검지기를 통해 수집된 포화도 정보와 결합하여 신호시간을 산정하였다. 지점 검지의 문제점을 구간 검지를 통해 극복하였으며, 비포화 및 과포화 상태에서도 원활한 신호운영이 가능하도록 하였다. 그러나 주기 길이 및 현시 녹색시간 배분의 변동은 가능하나 현시체계가 고정되어, 불필요한 이동류에 현시에 배분되는 문제점이 존재할 수 있다.
Lee(2017)는 평균 통행시간 정보를 통해 신호교차로의 방향별 평균 지체시간을 산정하였으며, 이를 통해 교통량을 추정 모형을 개발하였다. 방향별 평균 지체시간과 추정된 교통량을 통해 다음 분석주기에 예상되는 지체변화량을 산정하고, 현시시간 및 주기길이를 조정하여 최적의 신호시간을 결정하고자 하였다. 그러나 기초 정보로 사용하는 평균지체시간이 5분 간격으로 수집되므로, 실시간으로 수집되는 더욱 짧은 시간간격의 정보를 사용한다면 더욱 정밀한 신호 운영이 가능할 것이다.
Han et al.(2016)은 V2X 환경에서 수집되는 교통정보인 차량의 위치 및 속도를 이용하여 주기, 현시, 현시 순서를 결정하는 신호최적 제어 알고리즘을 개발하였다. 그러나 알고리즘에 사용되는 변수로 단순히 정지하고 있는 차량의 대수를 통해 산정한 정지지체 만을 고려하였기 때문에, 제어 지체 등을 고려하지 못해 정밀한 운영이 불가능하다는 한계점이 있다.
Alvarez et al.(2007)은 교차로에서의 혼잡을 해결하기 위해 비협력 게임 이론을 적용하였으며, 두 개의 일방통행 도로가 만나는 교차로에서 두 행위자가 -Nash 평형을 찾아 각각의 도로의 대기행렬 길이를 최소화하려는 방법론이다.
James and Daniel(1997)은 도로 네트워크 상의 교통량을 통해 근사시킨 각 교차로의 대기행렬 내 차량 수 및 주기 당 도착 교통량, 이전 최적 신호 전략 등의 정보를 입력하는 인공 신경망을 구성하여 9개의 신호 교차로를 최적화하였으며, 기존 고정식 신호 제어에 비해 도로 네트워크 내 평균 차량 대기시간에 10%의 감소가 있었다.
Jan-Dirk et al.(2007)은 fuzzy logic 알고리즘의 membership function을 유전자 알고리즘에 적용하기 위해 유전자 정보로 변화하였으며, 이를 신호제어를 위한 최적 파라미터의 탐색에 이용하였다.
Lee and Lee(1999)는 검지기를 통해 교통량 정보를 수집하여 현시 순서 및 시간을 최적화하는 퍼지 이론을 적용하였으며, 차량의 평균 지체시간을 최소화하는 신호 제어 체계를 개발하였다. 개발한 신호 제어 체계를 모의 네트워크에 적용한 결과, 감응형 신호 체계에 비해 균일 교통량 상황에서는 3.5%에서 8.4%, 교통량이 변동하는 상황에서는 4.3%에서 13.5%의 지체 시간 개선이 이루어졌다.
Jian et al.(2011)은 신호 제어의 효율성과 교차로의 공평성 측면을 동시에 고려하는 2단계로 이루어진 퍼지 논리 신호 제어 체계를 개발하였다. 시뮬레이션 결과, 개발한 신호 제어 체계가 감응형 신호 제어 체계에 비해 낮은 차량 당 지체 시간을 보였다.
Mingming et al.(2009)은 도심부 신호제어를 위해 Multi-objective Discrete Differential Evolution(MDDE) 알고리즘을 사용하여 신호 현시 및 주기를 실시간으로 최적화하는 알고리즘을 개발하였다. 시뮬레이션 결과, 도심부 교통 체증을 완화하고 차량의 대기시간을 감소시키는 효과를 보였다.
Choy(2006)는 complex hybrid evolutionary fuzzy NN을 이용한 계층적, 분산적 다중 행위자 기반 신호 제어 체계를 개발하였으며, 각각의 행위자는 fuzzy 시스템의 추론 가능성과 인공 신경망의 학습 가능성을 통해 독립적인 실시간 의사 결정을 내린다. 또한, 행위자의 인지 과정은 실시간 강화학습을 통해 조정되었다. 게임 이론은 다중 행위자 강화학습에 필수적인 요소로써 기여하였으며, 게임 도중 학습하는 원리를 통해 상호작용하는 다중의 행위자의 보상치 최대화에 대한 이론이다.
Cheng et al.(2006)은 CoSign이라는 평행 연동 신호 방법론을 적용하여 게임 도중 Nash 평형을 계산하며, 각 의사 결정자는 신호 지속시간을 제어하는 행위자로 간주하였다. 시뮬레이션은 Michigan주 City of Troy의 75개 신호 교차로에 적용되었으며, 그 결과 현실 세계로의 확장이 가능함을 보였다.
2. 강화학습을 이용한 신호 제어 체계
Baher et al.(2003)은 Q-학습을 이용하여 독립 교차로에서 강화학습을 사용한 신호제어 체계의 이점을 소개하고, 간단한 네트워크에서 적용한 결과를 나타내었다. 그러나 2현시로 구성된 간단한 네트워크에서 Q-학습을 구현하여 최적 신호를 표출하는 신호체계를 개발하였기 때문에, 더 많은 연산을 필요로 하는 복잡한 교차로 네트워크에서는 정밀한 신호 현시의 구현이 불가능할 수도 있다는 점이 존재한다.
Chen et al.(2009)은 강화학습 및 적응 동적 프로그래밍 기반 신호 제어 체계를 개발하여 고정식 신호 제어 체계를 통해 도출한 최적 제어전략에 비해 상당한 차량 지체의 감소를 보였다. 그러나 적응 동적 프로그래밍만을 적용한 강화학습 방법론은 기존 강화학습 방법론에 비해서는 복잡한 문제를 해결할 수 있지만, 여전히 복잡한 상태에 대한 까다로운 수렴 조건 및 긴 계산 시간을 보인다는 단점이 존재한다.
Elise van der(2016)는 심층 강화학습(Deep Reinforcement Learning)을 이용하여 독립 교차로 및 연동 교차로에 대한 신호 제어 체계를 개발하였다. 그러나 교차로가 단순히 모든 방향에 대해 직진 1차로로만 구성되어 있으며, 교차로의 상태 정보를 입력함에 있어 차량의 위치를 0 또는 1로 나타내는 이진 위치 행렬(Binary position matrix)로 나타내어 교차로의 형태가 복잡해졌을 때에는 실제적인 적용이 힘들 수 있다.
Enrique and Pradeep(2000)은 다중 행위자를 통한 모형 기반 강화학습을 실시하였으며, 여러 개의 신호 교차로를 각각의 행위자가 제어하며 다른 행위자와 교통 상황 정보를 공유하는 등 연동을 거쳐 독립적인 의사 결정을 내리는 신호 제어 시스템을 개발하였다.
3. 기존 연구의 한계점 및 본 연구의 차별점
기존 실시간 신호 제어 체계 연구에서는 정보 수집 간격, 지체 산정 방안 등에 있어 한계점이 존재한다. 또한 기존 연구에서는 간단한 교차로 네트워크를 대상으로 하였기 때문에, 보다 정밀한 신호 현시를 필요로 하는 복잡한 교차로 네트워크에서는 구현이 불확실하다는 점이 존재하였다. 본 연구에서는 이를 해결하기 위해 모든 방향의 접근로에서 각각 좌회전, 직진, 우회전 이동류가 접근하는 시뮬레이션 환경을 구현하고, 차량의 정보를 연속적으로 수집하는 모듈을 개발하여 미시적 시뮬레이션 환경에서 지체시간을 연속적으로 수집하였으며, 이는 예측값이 아닌 시뮬레이션 상의 실측값이 실시간으로 입력되기 때문에 보다 정확한 신호 운영이 가능할 것으로 예상된다.
기존 강화학습을 이용한 실시간 신호 제어 체계 연구는 행위자의 빠른 학습을 위한 학습 파라미터 설정 등에 치중되어 있어 적절한 학습 목표 설정에 한계점을 보였다. 신호 운영 교차로의 효과척도는 차량의 지체시간으로, 강화학습에서 학습의 방향을 결정하는 보상치 또한 차량의 지체 시간을 비교하여 산출한 값으로 설정하는 것이 타당하다. 따라서 본 연구에서는 수집된 차량 정보를 입력값으로, 교차로 네트워크의 지체 시간을 최소화하기 위한 신호 현시를 출력값으로 하는 강화학습 모형을 포함하는 모듈을 개발하였다. 개발한 강화학습 모형은 신호 현시 표출 전후의 지체 시간을 비교하여, 이를 최대화하는 것을 학습의 목표로 하였다.
마지막으로, Alibaba Cloud의 City Brain과 같은 긴급차량 우선 신호 제어 체계를 구현하기 위해 긴급 차량의 네트워크 진입을 파악하고, 긴급차량에 우선 신호를 부여하는 모듈을 추가하였다. 앞서 설명한 교차로의 지체 시간을 최소화하는 강화학습 모형은 교차로 네트워크 내 긴급차량이 감지되지 않았을 때 작동하며, 긴급차량이 진입하면 긴급차량에 우선 신호를 부여하는 모듈이 작동을 시작한다.
연구 방법론
1. 모형 구축
1) 알고리즘 개발
실시간 신호제어를 위해 Python을 사용하여 알고리즘을 개발하였다. 알고리즘은 크게 5가지의 모듈로 구성되어 있으며, 모듈의 전반적인 구성은 Figure 1과 같다.
먼저, VissimEnv 모듈에서 시뮬레이션 환경을 초기화하기 위해 네트워크를 불러오고 랜덤 시드(Random Seed)를 초기화한다.
Vissim 모듈은 시뮬레이션에 필요한 함수와 변수를 정의하며, 차량 정보 수집 함수, 각 이동류별 지체시간 산정 함수, 신호 변경 함수 및 시뮬레이션 실행 함수가 포함되어 있다. 또한, 긴급 차량에 대한 우선 신호 부여를 위해 긴급 차량의 네트워크 진입 인식 및 긴급 차량의 희망 경로 정보를 수집하는 함수를 설정하여 긴급 차량 우선 신호 부여에 대한 시뮬레이션을 가능하게 하였다.
Simulation 모듈에서는 VissimEnv 모듈에서 불러온 네트워크를 사용하여 시뮬레이션을 실행한다. 차량 정보 수집 함수 및 각 이동류별 지체시간 산정 함수를 통해 수집한 정보를 바탕으로 신호 현시를 바꾸며, 달라진 지체시간을 토대로 보상을 산정한다. 시뮬레이션 단계에서는 긴급 차량 유무에 따라 DDQN 모듈과 Emergency 모듈의 작동이 선택된다.
교차로 네트워크 내 긴급 차량이 없을 때 작동하는 DDQN 모듈에서는 Double Deep Q Network를 구성하고 학습 파라미터를 정의하며 수집된 자료를 토대로 최적 신호 현시를 예측한다. 반대로 긴급 차량이 존재할 때는 Emergency 모듈이 작동하여 긴급 차량의 희망 경로를 파악하고, 해당 경로와 조합 가능한 이동류 중 가장 높은 지체 시간을 갖는 이동류와 조합하여 신호 현시를 선택하고 우선 신호를 부여한다.
정해진 학습 시간이 끝나면 학습된 행위자가 단독으로 신호 운영을 실시하며, 검증 시뮬레이션동안 얻은 보상치를 토대로 행위자의 점수(Score)를 산출한다.
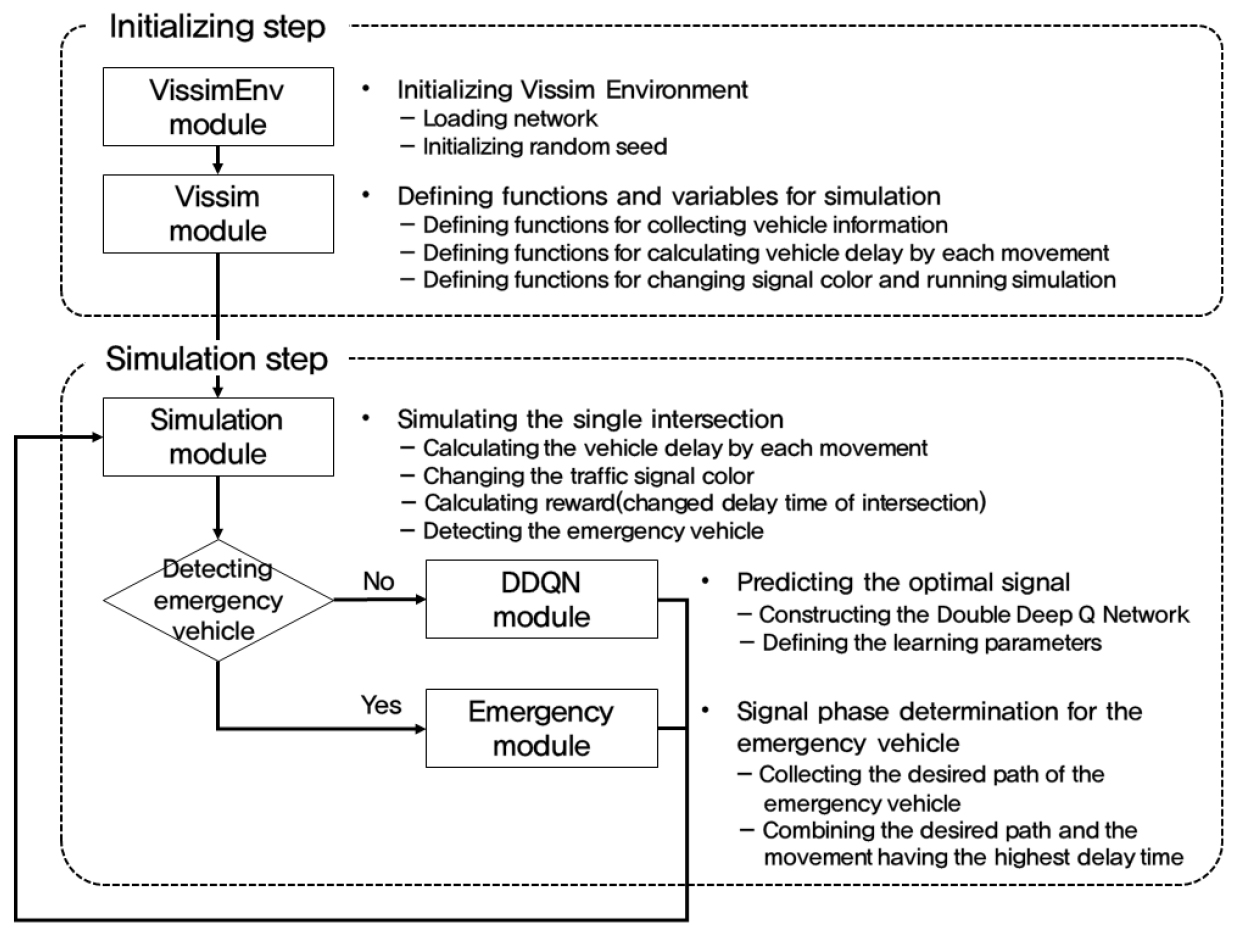
2) 강화학습 방법론을 이용한 Double Deep Q Network(DDQN) 모듈
강화학습은 행위자(Agent)가 환경(Environment)의 상태(State)를 인식하여 특정한 행동(Action)을 취하고 그 결과로 달라진 미래 상태 및 행위자에게 주어지는 보상(Reward)을 받게 되며, 장기적으로 누적되는 보상을 최대화하는 방향으로 학습을 진행한다(Sutton and Barto, 1998).
강화학습의 한 종류인 Q-학습에서는 주어진 상태 에서 어떤 행동 전략 에 속하는 행동 를 취했을 때의 가치인 기대 보상치를 추정하게 되며, 환경의 역학이 알려져 있지 않거나 상태-행동쌍가 무한히 많을 경우, 시뮬레이션을 통한 표본 추출을 사용한다. 행위자가 경험한 상태-행동쌍과 이에 상응하는 보상치가 저장되며, 연속적인 상태 에서의 기대 보상치 는 지도학습을 통해 Q-함수에 대한 함수 추정으로 행위자에게 학습된다. 그러나 이 과정에서 기대 보상치의 편향 문제가 생길 수 있으며, 이를 최소화하기 위해 모든 행동의 기대 보상치를 예측하는 평가 함수와 최적 행동을 선택하는 조정 함수(선택 함수)를 분리하여 최적화를 실시하는 Double Q-학습을 사용할 수 있다.
Double Q-학습은 와 라는 두 가지 Q-함수를 사용한다. 두 함수 모두 평가 함수와 조정 함수를 포함하고 같은 문제에 대한 최적화를 진행하지만, 두 함수에 저장되는 상태-행동쌍과 이에 따른 보상치의 집합이 서로 다르고 하나의 Q-함수를 갱신할 때 반대편 함수로부터 얻어진 값을 이용하여 과대 추정과 같은 편향을 줄일 수 있다(Van Hasselt et al., 2016).
한편, 기존의 Q-학습은 수렴 조건이 까다롭고 지체 시간과 같은 연속적 변수에서는 이에 따른 상태 표현과 상태-행동쌍이 무한히 많아져 모든 행동의 기대 보상치 예측 시간이 길어진다는 단점이 존재한다. Deep Q Network는 Q-함수의 학습 시 딥 러닝(Deep Learning)을 이용하는 방법으로 Q-함수에 대한 함수 추정 시 빠르고 정확한 최적 행동 결정을 가능하게 한다(Mnih et al., 2015). Double Q-함수의 갱신은 Equation 1, Equation 2와 같으며, Double Q-함수를 Deep Q Network의 손실 함수에 적용하면 Equation 3과 같이 나타낼 수 있다.
여기서, : 시간 에서의 상태
: 시간 에서 취한 행동
: 할인율을 포함한 미래 기대 보상치 함수
: 보상치의 장기적/단기적 고려를 위한 할인율 변수
: Q-함수의 함수 추정시 이용되는 파라미터
: Q-함수의 갱신에 사용되는 학습율
손실 함수()는 어떤 상태()에서 얻을 수 있는 보상치()가 최대인 특정 행동()을 취했을 때의 예측 보상치와 실제 관측된 보상치의 차이를 나타내며, 최적화를 통해 손실 함수의 수치를 최소화하여 특정 상황에서 어떤 행동을 취해야 최대 보상치를 얻을 수 있는지 예측하는 방향으로 학습한다.
강화학습에서 행위자의 학습 목표는 장기적으로 누적 보상치를 최대로 하는 것으로, 보상치를 어떻게 설정하느냐에 따라 행위자의 학습 결과가 달라질 수 있다. 따라서 행위자의 행동으로 인해 변화하는 상황에 따른 보상치를 적절하게 설정하여 행위자에게 부여하여야 한다. 환경의 상태 는 모든 이동류 중 가장 큰 평균 지체 시간을 보이는 이동류의 평균 지체시간으로, 행동 는 표출할 신호 현시로 설정하였으며, 독립 신호교차로를 개선할 때의 주요 평가지표가 차량 지체시간이므로 행위자의 행동 결정 기준이 되는 보상치 는 신호 현시 표출 후의 네트워크 상의 이동류별 지체 시간의 변화량으로 설정하여 이 보상치를 최대화하는 최적 신호 현시를 표출할 수 있도록 하였다. 따라서 신호 제어 체계는 신호 현시 표출을 통해 개별 이동류의 지체 시간을 감소시키려고 하며, 그 결과 교차로 전체의 지체 시간을 최소화하려고 한다. 상태 와 보상치 의 설정은 Equation 4, Equation 5와 같다.
여기서, : 시간 에서의 상태
: 이동류 의 각 차량
: 각각의 이동류
: 시간 에서 이동류 에서의 각 차량 의 지체 시간
: 이동류 의 차량 대수
: 시간 에서의 상태 에서 행동 를 취했을 때 얻게 되는 보상치
행위자에게 주어지는 신호 표출 이전 상태()와 표출한 신호 현시(), 보상치(), 신호 표출 이후 상태()는 누적되었다가 일정 시뮬레이션 시간 이후 무작위로 추출되어 학습에 사용되며, 행위자는 추출된 정보를 일정 횟수만큼 학습하여 실시간으로 표출할 신호 현시를 결정한다. 선택 가능한 8가지 신호 현시는 Table 1과 같으며, 최종적으로 8개의 신호 현시 중 1개의 신호 현시를 선택하여 표출한다. 또한, 지체 시간 최소화를 위한 실시간 신호 제어 체계 알고리즘의 전반적인 흐름도는 Figure 2와 같다.
Table 1.
Selectable traffic signal phase
| Traffic signal phase | |||
| #1 (EB/WBTH) | #2 (EBTH/LT) | #3 (WBTH/LT) | #4 (NB/SBTH) |
 |  |  |  |
| #5 (SBTH/LT) | #6 (NBTH/LT) | #7 (EB/WBLT) | #8 (NB/SBLT) |
 |  |  |  |
행위자의 탐색과정(Exploitation & Exploration)을 위해 학습 초반에는 임의의 신호 현시가 확률적으로 더 많이 표출되어 이에 따른 보상치 목록이 구성되며, 학습이 진행됨에 따라 더 높은 확률로 행위자의 결정이 선택된다. 이를 통해 어떤 상태에서 다양한 행동과 그에 따른 보상치 목록을 활용하여 최적의 행동을 도출할 수 있기 때문에 지역해에 빠지는 것을 방지할 수 있다. 또한, 인공 신경망 구조 내의 임의의 노드를 일정 비율에 따라 학습에서 배제(Drop out)하여 과적합 문제를 방지하였다. 마지막으로, 보상치에 할인율(Discount factor)을 적용하여 현재의 즉각적인 보상과 미래의 장기적인 보상 간에 적절한 선택이 가능하도록 하였다.
앞서 설정한 보상치는 지체 시간이 어느 정도 감소하는 효과가 있었는지를 나타내며, 지체 시간을 많이 감소시킬수록 다음 상태에서 높은 보상이 주어진다. 그러나 교차로 접근로에 정지하거나 대기하는 차량이 줄어드는 방향으로 학습이 진행되며 신호가 안정적으로 운영되기 때문에 높은 보상을 기대할 수 없다. 이러한 보상치 설정은 강화학습의 학습 척도로 타당할 수 있으나, 학습이 진행될수록 의도적으로 교차로에 접근하는 차량을 정지시킨 뒤 이를 한 번에 처리하여 높은 보상치를 얻으려는 행위가 일어났다. 따라서 학습 과정에서 이러한 행태를 보이지 않는 범위에서 어느 정도 학습 속도를 보장하는 방향으로 휴리스틱 탐색을 통해 학습 파라미터를 조정하였다. 학습 과정 및 시뮬레이션 수행에 사용한 파라미터는 Table 2와 같다.
Table 2.
Parameters used for learning and conducting simulation
3) 긴급차량 우선 신호 부여 모듈
긴급 차량 우선 신호 부여를 위해 긴급 차량이 통행을 희망하는 경로가 포함되는 이동류에 우선적으로 신호를 부여하는 Rule-based 모듈을 개발하여 추가하였다.
구체적으로, 긴급 차량이 교차로 네트워크에 진입하면 긴급 차량의 희망 경로 정보를 수집한다. 동시에 실시간 신호 제어 체계의 운영이 중지되고 긴급차량 우선 신호 부여 모듈을 통해 신호를 운영하며, 긴급 차량의 통행 시간이 최소화되도록 희망 경로가 포함되는 이동류에 신호를 부여한다. 따라서 선택될 수 있는 신호 현시는 2개이며, 이 중 더 높은 지체 시간을 가지는 이동류 조합으로 구성된 신호 현시를 표출한다. 만약 긴급 차량이 교차로 네트워크를 빠져나갔다면, 실시간 신호 제어 체계의 운영이 재개된다.
긴급 차량의 희망 경로와 조합 가능한 이동류 중 더 높은 지체 시간을 가지는 이동류에 현시를 부여하여 긴급 차량의 통행 시간을 최소화하되 교차로 네트워크의 지체 시간 또한 감소시키려 하였다. 긴급 차량 우선 신호 부여 모듈의 작동(예)은 Figure 3과 같다.

2. 시뮬레이션 분석의 범위
본 연구에서 개발한 알고리즘은 미시적 교통 시뮬레이션 프로그램인 VISSIM을 통해 구현하였다. VISSIM은 COM Interface 기능을 제공하여 다양한 개발언어를 통해 직접 시뮬레이션 환경을 제어할 수 있다. 본 연구에서는 Python으로 개발한 소스 코드를 COM Interface 기능을 사용하여 구현하였다. COM Interface 기능을 사용할 경우, 시뮬레이션 환경의 다양한 정보를 실시간으로 수집하는 것이 가능하며, 수집된 차량 및 네트워크 정보를 바탕으로 새로운 정보로 가공하여 조건에 따른 시뮬레이션 제어가 가능하다. 따라서 VISSIM을 이용하여 차량의 정보를 실시간으로 수집하는 것을 V2I 환경으로 가정하였다.
VISSIM 시뮬레이션에 사용하기 위해 구성한 네트워크는 toy network이며 좌회전 전용차로를 포함한 4지 교차로로, Figure 4와 같다.
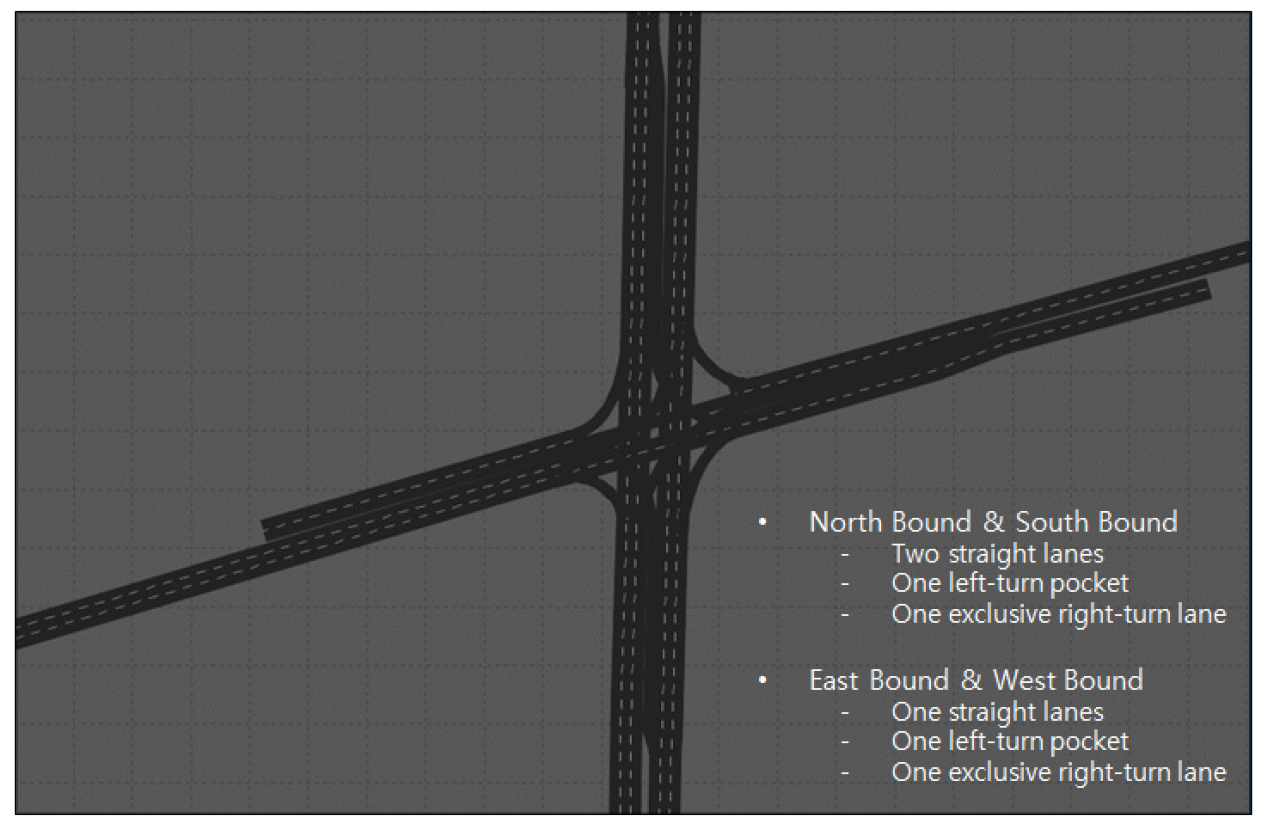
북측/남측 방향 접근로는 2개의 직진차선, 1개 차선의 좌회전 포켓과 1개의 우회전 도류화 차선으로, 동측/서측방향 접근로는 1개의 직진차선, 1개 차선의 좌회전 포켓과 1개의 우회전 도류화 차선으로 구성되어 있다. 행위자에게 주어지는 상태는 각 이동류별 총 지체시간으로 표현하였다. 네트워크 구성에 따른 이동류는 동서남북 네 방향에 각 방향당 직진과 좌회전 이동류로 구성되어 NBTH, NBLT, SBTH, SBLT, EBTH, EBLT, WBTH, WBLT 등 총 8개의 이동류를 이룬다. 따라서 상태는 8개 이동류별 평균 지체시간으로 주어진다. 각 이동류는 각각 다른 교통량을 가지며, 신호 운영 시 선택될 수 있는 신호 현시는 각 이동류 별 조합으로 구성된다. 또한, 강화학습 모형의 학습을 다양한 교통량 수준에서 실시하여 교통류 상황의 변화에 대처할 수 있도록 하였다. 강화학습 모형의 학습에 사용된 접근로별 교통량 수준에 따른 좌회전, 직진, 우회전 교통량은 Table 3과 같다.
Table 3.
Traffic volume of each movement flow in the network
3. 비교 모형 설정
미시적 교통 시뮬레이터 상에서 구현한 동일한 단일 교차로에 대해 본 연구에서 개발한 실시간 신호 제어 체계와 기존 전통적 신호 제어 체계와의 비교를 실시하였다. 모형 1은 실험군으로, 본 연구에서 개발한 실시간 신호 제어 체계이다. 모형 2는 대조군으로, 신호 최적화 패키지인 Passer Ⅴ를 통해 대상 네트워크에 대해 도출한 최적 신호 현시를 적용하였다. 두 모형의 실행 시간(에피소드), 교통량, 보상치 산정법은 모두 동일하게 설정하였다. 마지막으로 긴급 차량에 우선 신호를 부여하는 신호 제어 체계의 효과를 알아보기 위해, 긴급 차량 우선 신호 제어 체계를 모형 3으로 설정하고 모형 1 및 모형 2와 긴급 차량의 교차로 통과시의 평균 지체 시간을 비교하였다.
연구 결과
1. 강화학습 결과
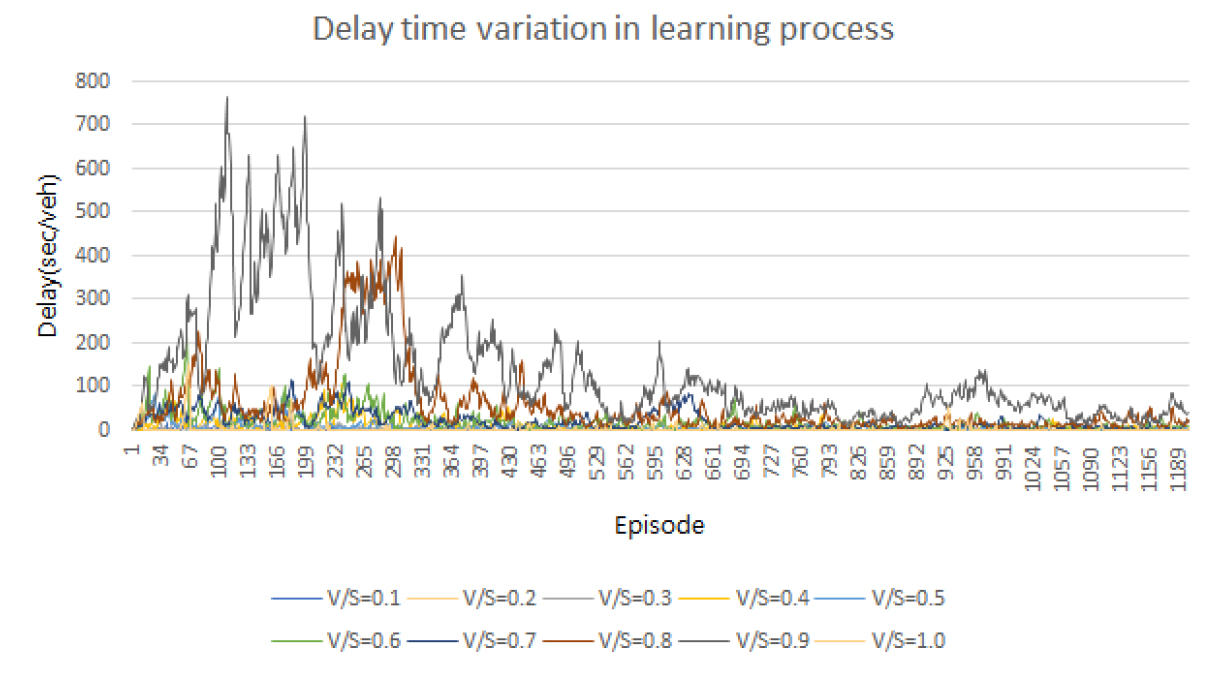
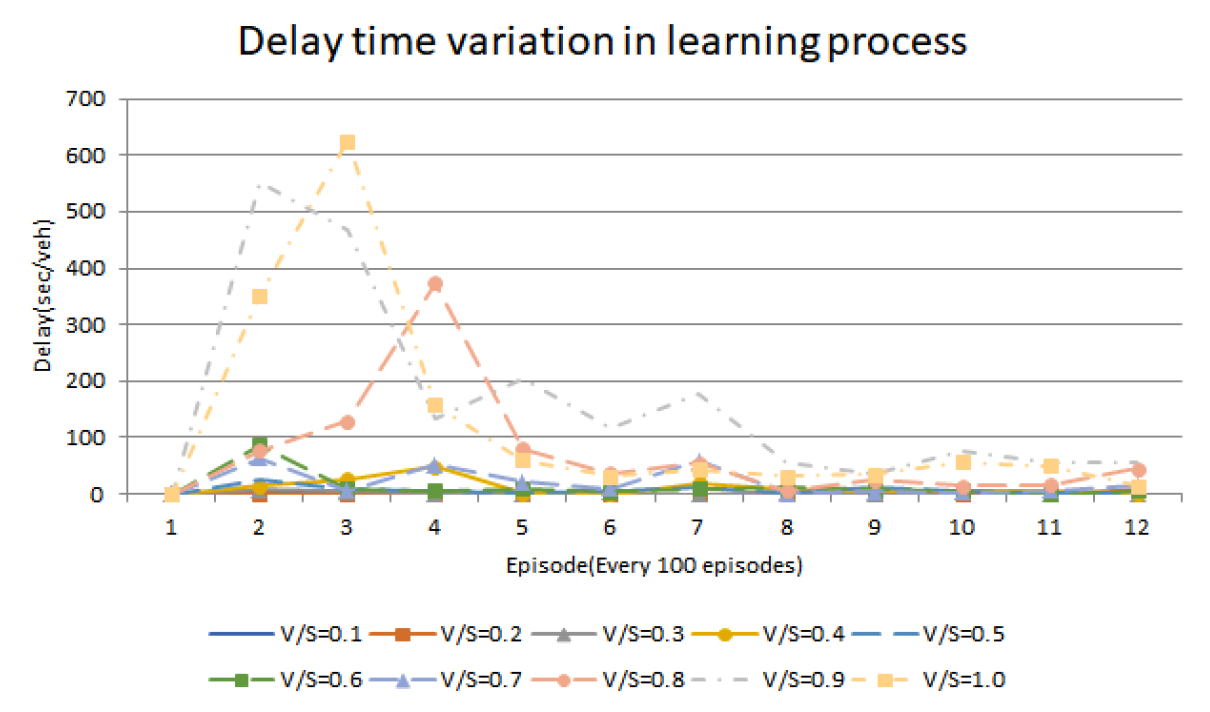
Double Deep Q Network 강화학습 모형을 1,200회 동안 학습하였으며, 강화학습이 적절히 이루어졌는지 알아보기 위해 다양한 교통량 수준에서의 학습 도중 교차로의 지체 시간을 분석하였다. 분석 결과, 모든 교통량 수준에서 학습이 진행될수록 교차로 내의 지체 시간은 감소하여 안정적인 교차로 신호운영이 가능함을 알 수 있다. 특히, 처음 800회 동안의 신호 운영 결과 지체 시간과 나중 400회 동안의 신호 운영 결과 지체 시간을 비교했을 때, 마지막 400회 동안의 지체 시간이 낮은 것으로 나타나 지체 시간을 낮추는 방향으로 학습이 진행된 것으로 분석되었다. 그러나 V/S가 0.8-1.0에서는 지체 시간이 다른 교통량 수준의 지체 시간에 비해 높은 수준으로 나타나 지체 시간을 감소시키는 방향으로 학습이 진행된 것으로 분석되었다. 본 연구에서 개발된 신호 제어 체계의 교통량 수준별 지체 시간 변화는 Table 4 및 Figure 5, Figure 6과 같다.
Table 4.
Average delay time variation in learning process
2. 모형 간 비교분석 결과
1) 지체시간 비교
본 연구를 통해 개발된 지체시간 최소화를 위한 실시간 신호 제어 체계를 대상 신호 교차로에 적용했을 때(모형 1)와 신호 최적화 패키지인 Passer Ⅴ를 이용하여 도출한 신호 현시를 적용하였을 때(모형 2)에서 나타난 지체시간을 비교 분석하여 구체적인 효과를 알아보았다. 동일한 시뮬레이션 조건에서 1시간 동안 신호를 운영했을 때 두 모형의 평균 지체시간을 비교하였으며, 어느 정도의 교통량 수준일 때 본 연구에서 개발된 신호 제어 체계가 기존 신호 제어 체계에 비해 나은 성능을 보이는지 분석하였다.
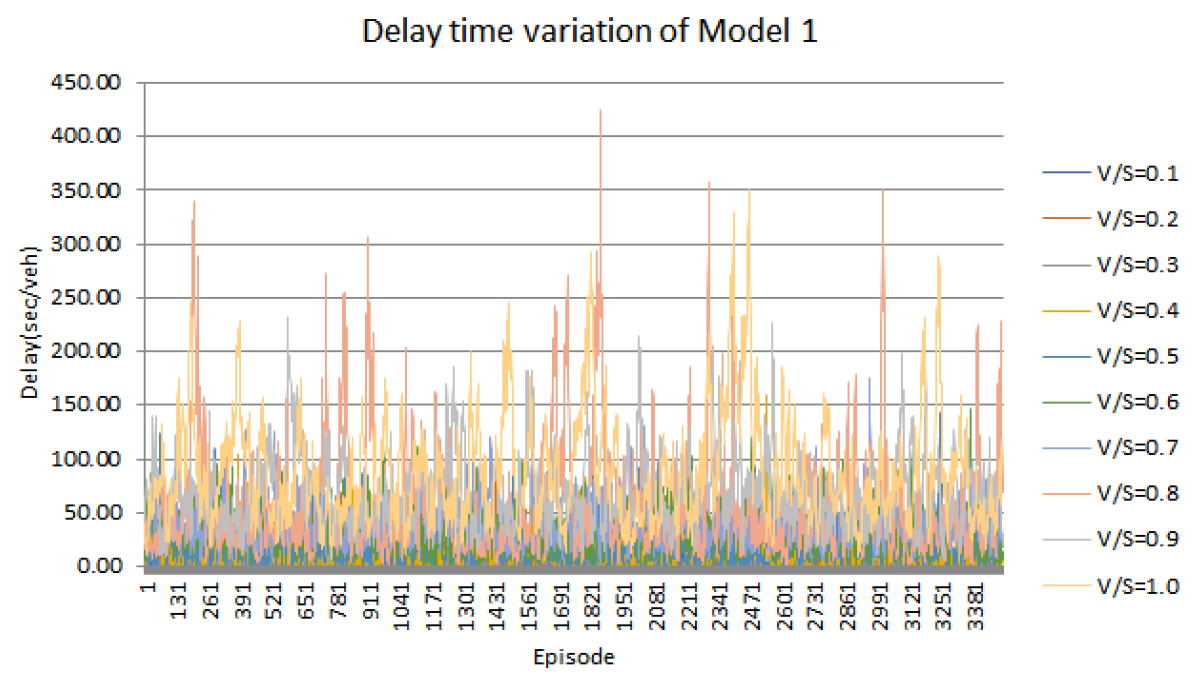
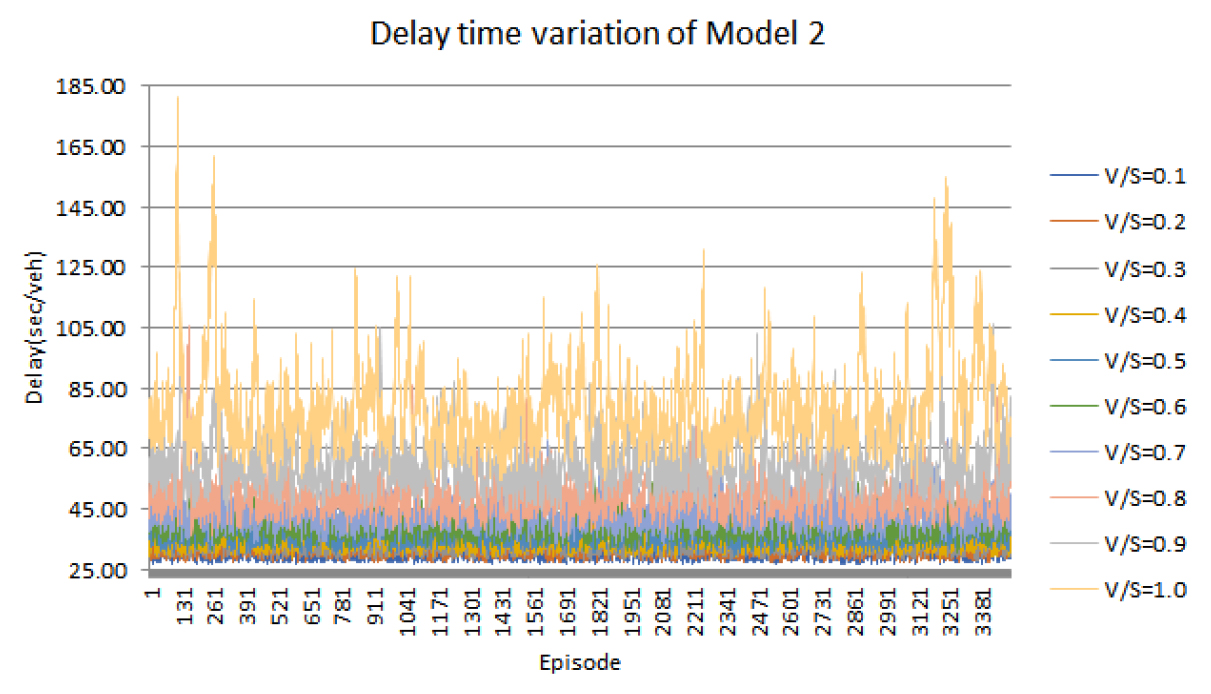
먼저 모형 1을 통해 신호 교차로를 운영했을 때 각 교통량 수준별 지체 시간은 Figure 7과 같다. 모형 1은 V/S가 0.7 까지는 낮은 지체 시간을 보였으나, V/S가 0.7을 초과하면 지체 시간이 높은 수준을 나타내어 적절한 신호 운영에 어려움을 보였다. 모형 2에서의 각 교통량 수준별 지체 시간은 Figure 8과 같다. 모형 2는 교통량 수준이 높아질수록 대체로 높은 지체 시간을 보이는 것으로 나타났으며, V/S가 0.8-0.9부터 지체 시간이 급격히 증가하는 것으로 분석되었다.
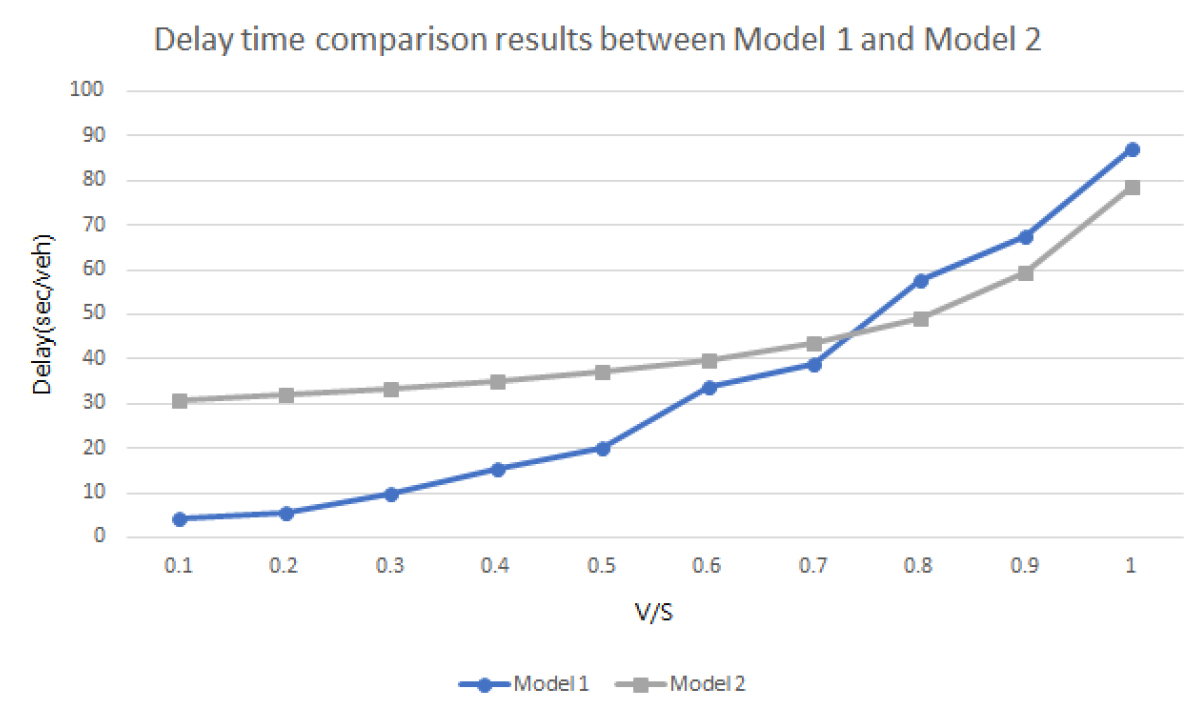
다음으로, 모형 1과 모형 2의 각 교통량 수준별 지체 시간 변화를 비교 분석하였다. 모형 1은 모형 2에 비해 V/S가 0.7까지는 낮은 지체 시간을 보였으나, V/S가 0.7을 초과할 경우 모형 1이 모형 2에 비해 높은 지체 시간을 보여 높은 교통량 수준에서는 정주기식 신호 제어 체계가 우수한 성능을 보이는 것으로 분석되었다. 따라서 교통량 수준이 높을 때에는 정주기식 신호 제어 체계를 적용하는 것이 적절하지만 낮은 교통량 수준에서 본 연구에서 개발된 실시간 신호 제어 체계는 정주기식 신호 제어 체계의 단점인 불필요한 신호 대기 시간을 감소시켰다고 할 수 있다. 모형 1과 모형 2의 다양한 교통량 수준에서의 지체 시간 비교는 Table 5 및 Figure 9와 같다.
Table 5.
Comparison between delay times of the Model 1 and 2
2) 긴급 차량 우선 신호 운영 결과
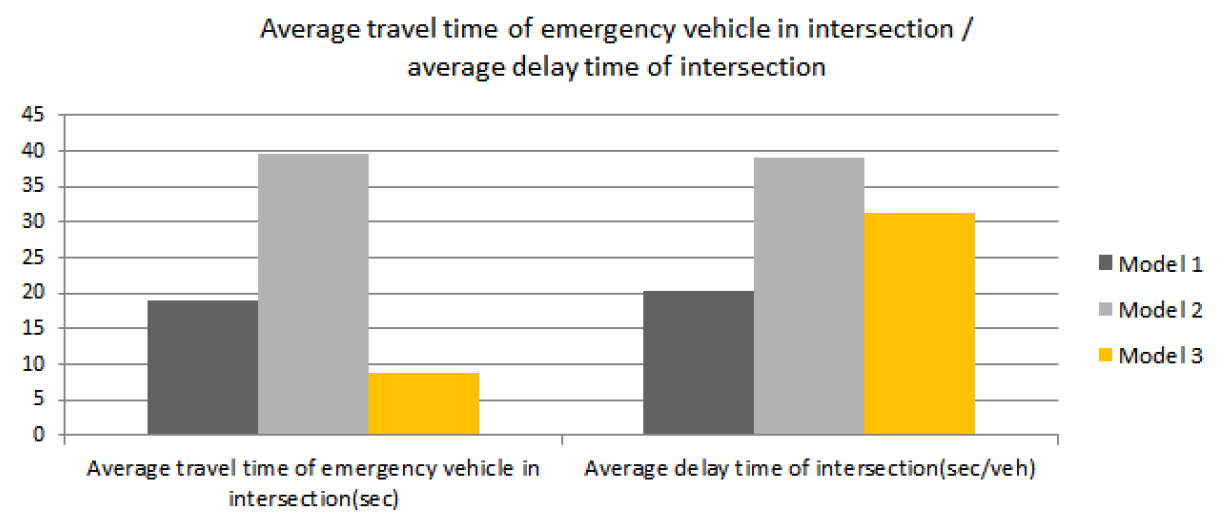
긴급 차량에 우선 신호를 부여하는 신호 제어 체계의 효과를 알아보기 위해, 긴급 차량 우선 신호 부여 모듈이 포함된 실시간 신호 제어 체계를 모형 3으로 설정하고 모형 1 및 모형 2와 비교하였다. 교통량 수준은 세 모형 모두 동일하게 V/S가 0.5인 수준으로 설정하였으며, 긴급 차량의 교차로 통과시의 통행 시간 및 교차로의 평균 지체 시간을 비교하였다. 비교한 내용은 Table 6 및 Figure 10과 같다.
비교 결과, 모형 3의 긴급 차량의 교차로 통과시의 통행 시간은 모형 1 및 모형 2에 비해 모두 짧았으며, 모형 1에 비해서는 46.8%, 모형 2에 비해서는 22.5% 수준인 것으로 분석되었다. 또한, 모형 3의 교차로 평균 지체 시간은 모형 1에 비해 높았으나 모형 2에 비해서는 낮은 것으로 분석되었다. 결론적으로, 모형 3이 모형 1에 비해 낮은 수준의 긴급 차량의 교차로 통과 시의 통행 시간을 보였으므로 긴급 차량에 대해 우선 신호를 부여하는 신호 제어 체계는 긴급 차량의 신속한 현장 도착을 도울 수 있으며, 모형 2에 비해 교차로 지체 시간이 낮아 기존 정주기식 신호 제어 체계에 비해서도 어느 정도의 교차로 지체 감소 효과가 있다고 할 수 있다.
연구 요약 및 결론
본 연구에서는 Double Deep Q Network(DDQN)를 이용하여 단일 신호 교차로에 대해 행위자의 단독 신호 운영이 가능하도록 강화학습을 실시하였다. 강화학습 시의 목적은 교차로 네트워크 내 차량의 평균 지체시간의 최소화였으며, 개별 차량의 정보는 VISSIM의 COM Interface 기능을 이용하여 실시간으로 수집하고 처리하도록 하였다. 실시간으로 수집된 개별 차량의 정보를 이동류 별로 가공하여 강화학습 모형에 입력하였으며, 강화학습 모형은 교차로 차량의 지체 시간을 최소화하는 방향으로 학습이 진행됨을 확인할 수 있었다.
본 연구에서 개발한 신호 제어 체계와 신호 최적화 패키지인 Passer V를 통해 도출한 신호 현시를 적용한 신호 제어 체계를 비교한 결과, 본 연구에서 개발한 신호 제어 체계는 지체 시간 측면에서 개선된 신호 운영이 가능하였다. 특히, 교통량 수준이 높을 때에 비해 교통량 수준이 낮을 때에 더욱 효율적인 신호 운영이 가능했으며 교통량 수준이 높을 때에는 오히려 기존의 정주기식 신호 제어 체계가 보다 나은 성능을 보이는 것으로 분석되었다. 이에 대한 결과 고찰을 수행한 결과는 다음과 같다. 본 연구에서 개발한 신호 제어 체계는 높은 평균 지체 시간을 보이는 이동류를 포함하는 신호 현시를 표출하여 교차로 전체 지체 시간을 줄이려고 한다. 하지만, 많은 교통량이 교차로 네트워크에 진입하게 되는 높은 V/S 수준에서는 기존에 형성된 차량의 대기행렬로 인해 새로운 차량이 도착하여 정지할 경우 해당 이동류의 평균 지체 시간이 일시적으로 낮아질 수 있으며, 최적 신호를 표출하지 못할 수 있다. 따라서 높은 V/S 수준에서는 지체 시간만을 통해 신호를 운영할 경우 교차로 네트워크의 상태를 표현하는 데 어느 정도 한계점이 존재할 수 있으며, 강화학습 모형의 입력값으로 차량 대기행렬 길이나 포화도 등 네트워크의 현재 상황을 보다 정확히 설명할 수 있는 변수를 추가하는 것을 고려할 수 있다.
지체 시간 최소화를 위한 강화학습 기반 실시간 신호 제어 체계에 긴급 차량 우선 신호 부여 모듈을 추가하여 운영했을 때, 기존 신호 제어 체계에 비해 어느 정도의 긴급 차량 통행 시간 감소 효과가 있는지 비교하였다. 비교 결과, 긴급 차량 우선 신호 부여 모듈이 추가된 모형의 긴급 차량의 교차로 통과 시간은 기존 정주기식 신호 제어 체계 및 실시간 신호 제어 체계에 비해 낮고, 교차로 평균 지체 시간은 기존 정주기식 신호 제어 체계에 비해 낮아 긴급 차량의 우선 통행을 보장하면서 어느 정도의 효율적인 교차로 신호 운영을 가능하게 한 것으로 분석되었다.
하지만 본 연구에서는 다음과 같은 한계점이 존재한다. 먼저, 본 연구에서 적용한 DDQN을 개선한 새로운 강화학습 방법론을 제시하여 더욱 효율적인 모형의 학습을 도모하여야 한다. DDQN은 기존 실시간 신호 제어 체계와 비교했을 때 해결 대상으로 하는 문제에 대해 명확한 목적을 설정하여 최적화가 가능하며, 기존 Q-학습에서의 기대 보상치 예측의 편향 문제와 학습 시간의 단점을 각각 Double Q-학습과 딥 러닝 방법론을 결합한 방법론이다. 그러나 강화학습 모형은 현재 활발한 연구가 이뤄지고 있는 분야로, DDQN을 개선한 새로운 방법론에 대한 탐색이 필요하며 본 연구에서 개발한 모형과의 비교를 통해 계량적인 분석을 수행한다면 교차로 지체시간 최소화에 있어 더욱 효율적인 학습을 달성할 수 있을 것이다.
또한, 학습 파라미터인 하이퍼 파라미터 설정에 한계점이 있었다. 딥 러닝의 하이퍼 파라미터 설정에는 격자 탐색(grid search), 랜덤 탐색(randomized search), 베이지안 최적화(bayesian optimization) 등이 사용될 수 있으나, 본 연구에서 개발한 모형은 입력값과 결과값이 단순해 직관과 경험에 기반한 휴리스틱 탐색을 통해 하이퍼 파라미터를 설정하였다. 휴리스틱 탐색은 개발한 모형을 적절하게 수행된다면 다른 방법론에 비해 빠른 학습 시간을 보일 수 있으나, 학습 모형의 규모가 커지면 알고리즘 기반 탐색법이 정확도 면에 있어 이점이 있기 때문에 학습 효율을 증진할 수 있을 것이다. 향후 연구에서는 베이지안 최적화과 같은 알고리즘에 기반한 방법론을 적용하여 학습 모델 간 성능을 비교하고 하이퍼 파라미터를 설정한다면 모형의 학습 및 최적화에 있어 이점이 있을 수 있을 것이다.
본 연구에서는 실제 교차로가 아닌 toy network에서 수행되었다. 비록 더욱 현실과 가까운 시뮬레이션 환경을 구축하기 위해 Vissim에서 교차로 네트워크를 구성하였으나, 강화학습 기반 모형은 한 번 학습된 모형을 재사용하여 환경에 구애받지 않고 다양한 환경에서 최적의 성능을 낼 수 있다는 강점이 있기 때문에 다양한 기하구조와 실제적인 교통량 수준을 가지는 여러 실제 교차로 네트워크에서의 성능을 분석한다면 개발된 모형의 효과를 더욱 정확히 분석할 수 있을 것이다. 또한 본 연구에서는 동일 시간 동안 일정한 수준의 교통량을 이용하여 성능을 분석하였다. 실제 교차로 환경에서는 다양한 교통량 수준이 혼재하기 때문에, 이를 반영하여 분석한다면 더욱 현실에 가까운 분석이 가능할 것이다.
마지막으로, 앞서 고찰한 바와 같이 높은 교통량 수준에서는 오히려 기존 정주기식 신호 운영 체계가 더 좋은 성능을 보이는 것으로 나타났다. 이는 V/S가 높은 상황에서도 지체 시간만을 입력값으로 설정하였고, 교차로의 상황이 강화학습 모형에 정확히 전달되지 읺았기 때문일 수 있다. 따라서 지체 시간 외에도 차량의 대기행렬 길이, 통행 속도, 포화도 등 단속류 환경의 다양한 상황을 보다 잘 설명할 수 있는 입력값을 추가로 조사한다면 보다 효율적인 교차로 운영이 가능할 것이다.
향후 본 연구를 발전시킨다면 다음과 같은 목표를 이룰 수 있을 것이다. 먼저, 교차로 네트워크의 오염물질 배출량 감소를 위한 신호 제어 체계를 개발할 수 있다. 본 연구에서는 지체 시간만을 최소화하기 위해 보상치를 설정하고 신호 제어를 최적화하였다. 그러나 지체 시간뿐만 아니라 오염 물질 배출량을 보상치 설정에 결합하여 학습을 진행한다면 여러 목적을 동시에 달성할 수 있는 다목적 신호 제어 체계를 개발할 수 있다. 구체적으로, 실시간으로 수집되는 차량 정보를 통해 교차로 네트워크의 오염물질 배출량을 추정하는 함수를 구축한 뒤 오염물질 배출량을 최소화하되 지체 시간은 서비스 수준 C 정도로 유지할 수 있다면 기존 내연기관 차량이 도로 인프라를 이용할 때의 오염물질 배출량을 감소시킬 수 있을 것이다.
또한, 전기차 또는 자율주행차량의 시장 점유율에 따른 지체 시간과 오염물질 배출량에 대한 연구가 진행될 수 있다. 이들 차량이 시장에 도입된다면 기존 내연기관 차량 및 V2X 기술 미탑재 차량과 혼재하여 도로 인프라를 이용하기 때문에, 새로운 기술이 도입되었을 때의 시장 점유율에 따른 신호 제어 체계의 효과에 대해 면밀히 분석한다면 보다 정확한 효과 분석이 가능할 것이다.
