

서론
기존연구고찰
1. C-ITS 기반 사고개연성 추정 관련 연구
2. 주행안전성 평가지표 관련 연구
3. 랜덤포레스트 기법 관련 연구
4. 시사점
분석방법론
1. 주행안전성 평가지표 선정
2. 주행안전성 평가지표와 사고건수 간의 상관분석
3. 랜덤포레스트 기법
데이터
1. C-ITS 자료
2. 고속도로 교통사고 자료
분석 결과
1. 주행안전성 평가지표와 교통 사고건수 간의 상관관계 분석 결과
2. 주행안전성 평가지표 우선순위 도출 결과
결론 및 향후 연구과제
서론
실시간으로 변화하는 도로교통환경 및 차량간 상호작용으로 인해 불가피하게 발생하는 교통사고를 근본적으로 해결하기 위하여 도로, 차량, 관제센터가 연계된 통합 시스템의 필요성이 대두되고 있다. 교통운영센터에서는 교통정체를 유발하는 요인을 분석하고, 돌발상황 발생 시 사고대응 시간을 단축하여 사고심각도를 감소키시고자 노력하고 있다. 흔히 커넥티드 차량(connected vehicle) 시스템이라고 불리는 cooperative-intelligent transport system(C-ITS)은 vehicle-to-vehicle(V2V) 및 vehicle-to-infrastructure(V2I) 통신을 기반으로 전방 돌발상황에 신속하게 대응할 수 있는 서비스를 제공하는 시스템이다. C-ITS의 이점은 전방 충돌 경고시스템을 통해 선행차량과의 차간거리, 충돌예상시간을 포함하는 advanced driver assistance system(ADAS) 데이터 수집이 가능하다는 점이다. 또한 C-ITS 환경에서 수집된 probe vehicle data(PVD)는 개별차량의 사고개연성을 추정하는데 활용되며, 추정된 사고개연성을 도로 구간 단위로 집계할 경우 도로위험구간 식별이 가능하다(Jang et al., 2020; Jo et al., 2021; Kamrani et al., 2017). 사고개연성이 높은 도로위험구간을 효과적으로 추출하는데 있어서 다양한 주행안전성 평가지표를 대상으로 중요도를 정량적으로 산출할 수 있다면 C-ITS 기반 교통안전 모니터링을 위한 실효성있는 지표 선정 및 개발이 가능할 것으로 기대된다.
C-ITS 환경에서 차내 경고정보 제공 및 교통안전 모니터링을 위해서는 실제 사고위험도를 효과적으로 계량화할 수 있는 주행안전성 평가지표 선별이 요구된다. 기존 연구에서 보고된 다양한 평가지표를 활용하기에 앞서 도로위험구간 식별이 가능한 주행안전성 평가지표 중요도 도출 방안이 필요하다. 따라서 본 연구의 목적은 C-ITS 자료를 이용하여 도로 위험구간을 효과적으로 식별하는 주행안전성 평가지표 우선순위를 도출하는 것이다. 본 연구에서는 실제 C-ITS 환경에서 도출된 종‧횡방향 주행안전성 평가지표와 차량간 상호작용 기반 안전성 평가지표를 고속도로 이정 단위로 집계하였다. 총 22가지의 주행안전성 평가지표는 교통 사고건수와 상관분석을 통해 통계적으로 유의미한 상관관계가 성립되는 후보지표(significant indicators) 선정을 목적으로 사용되었다. 또한 머신러닝 기반 분류 모델 중 하나인 랜덤포레스트(random forest) 기법은 사고발생 개연성이 높은 위험집단(risk class)을 효과적으로 분류하는 후보지표들 간의 중요도를 도출하기 위하여 활용되었다. 최종적으로 significant indicators를 대상으로 도로위험구간을 식별하는데 우수한 평가지표 우선순위를 제시하였다. 본 연구의 결과는 C-ITS 환경에서 실시간으로 운전자 주행행태 분석기반의 효과적인 도로위험구간 식별을 위한 신뢰할 수 있는 교통안전 모니터링 지표로 활용될 것으로 기대된다.
본 연구의 구성은 다음과 같다. 2장에서는 C-ITS 기반 사고개연성 추정 및 평가지표 개발에 관한 기존 연구동향을 파악하고 본 연구의 시사점을 제시하였다. 3장에서는 C-ITS 자료를 활용한 주행안전성 평가지표 우선순위 도출 방법론을 제시하였다. 4장에서는 본 연구에서 활용한 데이터셋에 대해 서술하고, 5장에서는 significant indicators를 대상으로 랜덤포레스트 기반 평가지표 우선순위 도출 결과를 제시하였다. 마지막 장에서는 본 연구의 결과를 요약하고, 연구의 활용방안 및 향후 연구과제에 대해 서술하였다.
기존연구고찰
본 연구는 C-ITS 자료를 이용하여 효과적인 도로위험구간 식별을 위한 주행안전성 평가지표 우선순위를 도출하고자 한다. 이와 관련하여 C-ITS 환경 개별차량 단위 사고개연성을 추정한 연구를 고찰하고, 도로위험구간을 식별하는데 있어 주로 활용된 평가지표를 조사하였다. 또한 교통사고 및 사고위험도에 영향을 미치는 요인들 간의 중요도를 도출하는데 있어 머신러닝 기법 중 하나인 랜덤포레스트 기법을 적용한 관련문헌을 고찰하였다.
1. C-ITS 기반 사고개연성 추정 관련 연구
도로에 설치된 루프검지기, CCTV 등 인프라로부터 수집된 자료를 이용하여 지점 단위의 사고개연성을 추정한 연구가 수행되었으나(Abdel-Aty et al., 2012; Jo et al., 2019; Xu et al., 2013), 최근에는 차량의 주행궤적자료를 수집할 수 있는 기술이 발달함에 따라 개별차량 단위 주행안전성 평가에 대한 연구가 활발히 진행되었다(Njobelo et al., 2018; He et al., 2018; Sakhare et al., 2021). 이에 C-ITS로부터 수집된 데이터는 과거 이력자료를 보완할 수 있으며, 충돌 직전 주행 특성의 변동성이 높은 구간을 능동적으로 식별하는데 도움이 된다(Kamrani et al., 2017). Arvin et al.(2019)은 주행 변동성(driving volatility) 개념을 적용하여 개별 차량의 주행행태 변화를 정량화하는 방법론을 제시하였다. 불규칙한 종‧방향 주행 변동성이 높을수록 후미추돌사고 개연성이 증가하는 것으로 분석되었으며, 특히 횡방향 주행 변동성은 측면추돌 사고와 유의한 양의 상관관계가 존재하는 것으로 도출되었다. C-ITS 자료는 위험상황 식별을 목적으로 차량간 상호작용 기반의 안전성을 평가하는데 활용될 수 있다(Xie et al., 2019). Time to collision with disturbance(TTCD)은 후미추돌 사고개연성을 추정하는 지표로, TTCD 기반 위험지점이 실제 교통사고가 잦은 지점과 유사한 것으로 분석되었다. 또한 C-ITS 환경에서 추정된 crash potential index(CPI)는 실시간 교통안전 모니터링을 위한 지표로 적용성이 검토되었다(Jo et al., 2021). 고속도로 1km 단위별 집계된 CPI와 사고건수 간에 통계적으로 유의한 상관관계가 존재하며, 추정된 CPI의 90 percentile에 해당되는 32곳의 도로위험지점이 추출되었다. 또한 Jang et al.(2020)은 C-ITS 자료를 이용하여 전방 위험상황 경고정보 제공에 따른 정량적 교통안전 효과를 평가하였다. 선‧후행차량 간의 후미추돌 사고위험도 관점에서 경고정보 제공시 안전성이 개선되는 것으로 분석되었다. C-ITS 자료는 선제적 교통안전관리 관점에서 사전에 사고발생 가능성이 높은 시 ‧ 공간을 식별하는데 활용될 수 있으며 교통사고를 예방하기 위한 대응책 마련에 기여할 수 있을 것으로 예상된다.
2. 주행안전성 평가지표 관련 연구
개별차량 단위 주행행태를 평가하고 차량간 상호작용을 분석하여 사고개연성을 추정하는 것은 교통안전관리전략을 설계하는데 중요한 요소로 활용될 수 있다. 안전성 증진을 위하여 개별차량 및 차량간 상호작용 단위의 위험 정도를 정량적으로 판단할 수 있는 기준 및 지표 개발에 관한 연구가 활발히 수행되었다(Kim et al., 2021; Wang et al., 2021; Zheng and Sayed, 2019). 개별차량 단위 종방향 주행안전성을 평가하기 위한 지표는 주로 속도 표준편차, 가속도 표준편차, peak-to-peak jerk가 활용되었다(Bagdadi and Várhelyi, 2013; Ko et al., 2022; Zheng et al., 2018). 횡방향 주행안전성 평가지표는 횡방향 가속도 표준편차, yaw 속도가 있으며 도로구간 단위 집계를 통해 도로위험구간 식별이 가능한 것으로 보고되었다(Jung et al., 2021; Mauriello et al., 2018; Wang et al., 2015). 또한 개별차량의 주행행태 변화 정도를 반영하는 time-varying stochastic volatility(VF)는 시간의 흐름에 따른 평가지표의 불규칙한 변화 행태를 정량적으로 산정하는데 활용되었다(Kamrani et al., 2018; Mahdinia et al., 2021). 교통사고 발생 개연성을 계량화하여 나타낼 수 있는 교통안전 대체평가 지표인 surrogate safety measure(SSM)가 개발되었으며, 대표적으로 time-to-collision(TTC), stopping distance index(SDI), deceleration rate to avoid crash(DRAC)가 있다(Cooper and Ferguson, 1976; Hayward, 1971, Oh et al., 2006). TTC는 두 차량이 현재 주행상태와 같은 방향 및 속도로 주행할 경우 충돌이 발생하기까지 남은 잔여시간으로 1.5초 미만일 경우 심각한 상충이 발생한 것으로 판단한다(FHWA, 2003). SDI는 선후행차량의 최소 정지거리 차이에 따라 상충을 판단하는 지표로 선행차량보다 후행차량의 정지거리가 긴 경우 위험상황이 발생한 것으로 간주한다(Oh et al., 2006) DRAC은 후행차량이 전방 위험상황을 인지하고 감속하기 시작할때의 충돌 회피 감속도로 3.35m/s2를 초과할 경우 상충으로 해석한다(Archer, 2005). 또한 후행차량의 DRAC이 차량 고유의 최대 감속도 보다 클 확률을 의미하는 CPI가 보고되었다(Cunto and Saccomanno, 2008). C-ITS 환경에서 도로위험 지점 및 구간을 식별하는데 있어 CPI의 적용성이 검토된바 있다(Jang et al., 2020; Jo et al., 2021).
3. 랜덤포레스트 기법 관련 연구
교통사고는 발생 빈도가 낮고(rare event) 임의적(random event)인 특성을 가지고 있기 때문에 통계모델링을 통한 사고건수에 영향을 미치는 요인을 규명하는데 있어 대규모의 데이터셋이 요구된다. 랜덤포레스트는 다수의 의사결정나무 모델로부터 분류 결과를 취합하여 결론을 얻는 방식의 머신러닝 기법 중 하나로(Abdel-Aty and Haleem, 2011; Haleem et al., 2010; Harb et al., 2009), 데이터 수집 노력을 줄여 변수의 중요도 결과를 기반으로 우선순위를 지정하는데 주로 활용된다(Saha et al., 2016). Abdel-Aty et al.(2008)은 루프검지기 데이터를 이용하여 랜덤포레스트 기반 실시간 사고위험도 분류 모델을 개발하였으며, 제안된 모델은 시공간 단위의 속도 및 밀도 변화량이 사고개연성과 관련이 높은 것으로 분석되었다. 교통사고에 영향을 미치는 주요 요인을 파악하는 것은 안전성 증진을 위한 대응책 마련에 기여할 수 있다. Saha et al.(2016)은 5개년의 교통사고 자료를 이용하여 사고발생에 영향을 미치는 요인의 우선순위를 도출하였다. 교통량, 노변장애물, 상업 및 주거 진입로 관련 변수는 교통사고에 영향을 미치는 요인으로, 해당 영향요인이 도로안전도 평가항목에 우선적용 되어야 한다고 보고하였다. 또한 도로기하구조 특성, 운전자 특성, 교통 환경이 사고심각도에 미치는 영향을 분석하기 위하여 랜덤포레스트 기법이 적용되었다(Haleem and Gan, 2013). 심각한 부상을 구분하는 변별력 높은 변수는 교통량, 중차량 비율, 운전자 연령으로 도출되었다. 실시간 교통안전 영향요인의 중요도를 추정하기 위하여 랜덤포레스트 기반 도로혼잡도 분류 모델이 개발된 바 있다(Shi and Abdel-Aty, 2015). 고속도로에 설치된 검지기로부터 수집된 교통자료를 이용하여 37개의 변수 중 도로혼잡도를 구분하는데 변별력 높은 상위 20개의 변수를 도출하였다. 제안된 모델은 모니터링 측면에서 도로혼잡도 분류를 통한 교통안전 및 운영정보 제공 시점을 결정하는데 활용될 것으로 보고되었다. 랜덤포레스트는 교통사고 및 사고위험도에 영향을 미치는 요인들 간의 중요도를 도출하는데 효과적인 기법으로, 본 연구에서는 사고발생 가능성이 높은 도로위험구간 식별이 가능한 평가지표들 간의 우선순위를 도출하기 위하여 랜덤포레스트를 활용하였다.
4. 시사점
개별차량 주행정보 수집이 가능해짐에 따라 다양한 주행안전성 평가지표 개발에 대한 연구가 지속적으로 수행되고 있으나, 사고발생 가능성을 효과적으로 계량화할 수 있는 평가지표 선별을 위해서는 사고발생 개연성에 영향을 미치는 요인들 간의 중요도 도출이 요구된다. 따라서 본 연구의 시사점은 3가지로 정리될 수 있다. 첫째, 기존 연구에서는 주로 단일 평가지표를 이용하여 사고개연성을 추정하였으나 본 연구에서는 다수의 평가지표를 기반으로 종‧횡방향 주행행태 및 차량간 상호작용을 분석하고자 한다. 둘째, 주행안전성 평가지표와 실제 교통사고 간의 상관분석을 통해 통계적으로 유의미한 상관관계가 성립되는 significant indicators를 선정하고자 한다. 마지막으로 significant indicators를 입력변수로 설정하여 위험집단을 구분하는 변별력 높은 평가지표를 도출하고자 한다. 따라서 본 연구에서는 C-ITS 환경에서 효과적인 도로위험구간 식별이 필요함을 인지하고, 이를 위하여 C-ITS 데이터 기반의 주행안전성 평가지표 우선순위를 제시한 점에서 기존 연구와 차별화된다.
분석방법론
본 연구에서는 C-ITS 자료를 이용하여 통계적 및 휴리스틱 접근 방식의 주행안전성 평가지표 우선순위를 도출하는 방법론을 개발하였다. 연구의 수행 절차는 Figure 1에 제시하였다. 주행안전성 평가지표 산출 단계에서는 C-ITS 자료를 수집하고 사고개연성 추정을 위한 데이터 처리‧가공 과정을 포함한다. 그리고 기존 문헌에서 보고된 주행안전성 평가지표를 대상으로 고속도로 이정별 사고개연성을 추정하는 단계이다. 상관분석 단계에서는 고속도로 이정별 집계된 평가지표와 사고건수 간의 상관관계를 분석한다. 주행안전성 평가지표 중 사고건수와 통계적으로 유의미한 상관관계가 성립되는 평가지표를 significant indicators로 정의한다. 마지막 단계에서는 앞서 정의된 significant indicators를 대상으로 랜덤포레스트 기반 평가지표 우선순위를 도출한다.
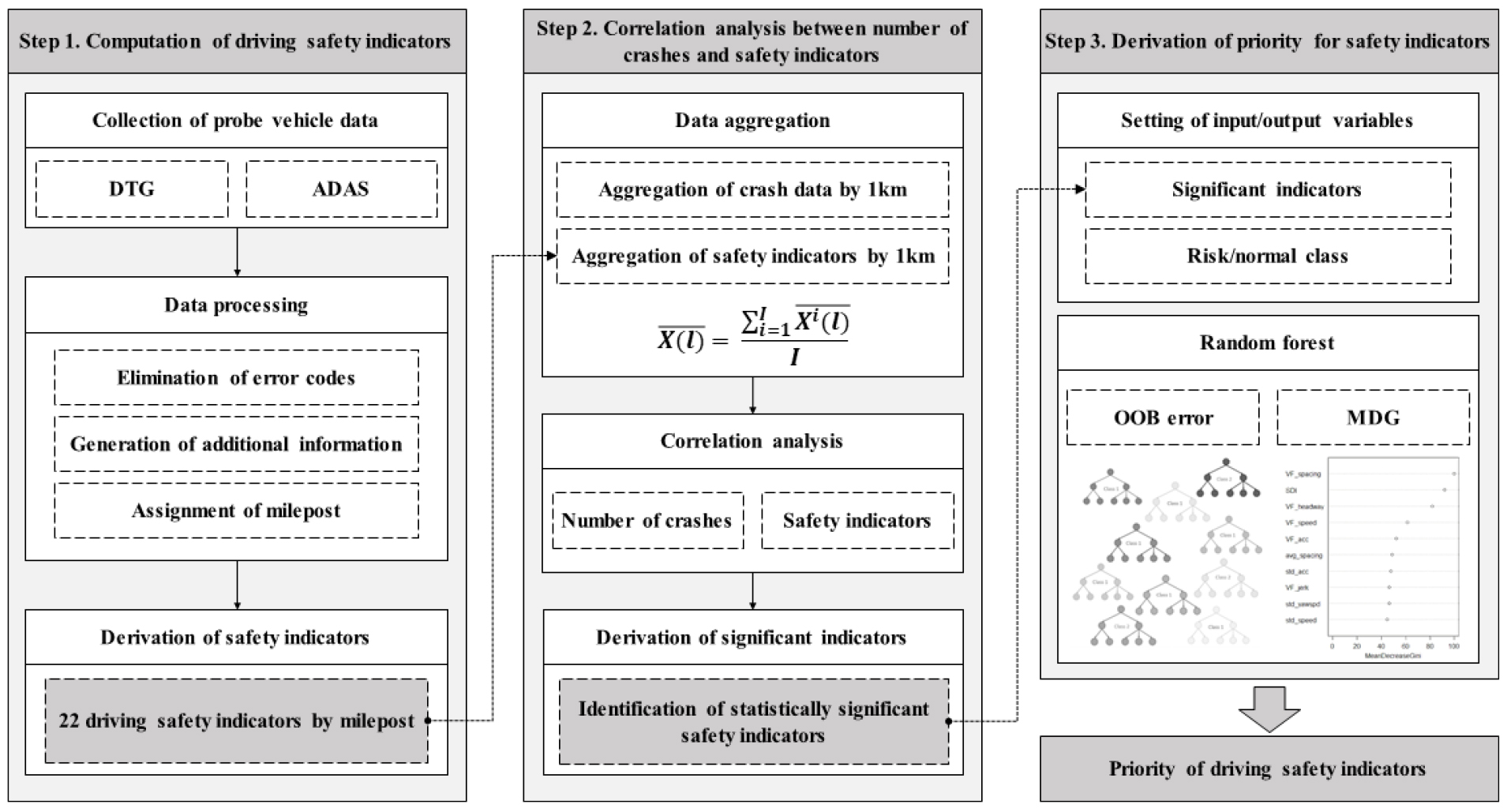
1. 주행안전성 평가지표 선정
본 연구에서는 개별차량의 주행정보를 이용하여 사고개연성 추정을 위한 3가지 관점의 주행안전성 평가지표를 제시하고자 한다. 종방향 및 횡방향 주행안전성 평가지표는 개별차량의 주행행태 변화를 정량적으로 산정할 수 있는 표준편차와 변동성(VF)을 기반으로 선정하였다. 차량 간 상호작용 기반 안전성 관련 지표는 후미추돌 사고개연성을 계량화하여 나타낼 수 있는 SSM 기반 상충건수를 활용하였다. 이에 따라, 종방향 안전성 관련 지표로 속도 표준편차, 가속도 표준편차, jerk 표준편차, peak-to-peak jerk, 그리고 VF 기반 속도, 가속도, jerk를 선정하였다. 종방향 주행안전성 평가지표 값이 클수록 사고개연성이 증가하는 것으로 해석할 수 있다(Ko et al., 2022). 또한 횡방향 가속도 표준편차, yaw 속도 표준편차, VF 기반 횡방향 가속도 및 yaw 속도는 횡방향 주행안전성 평가지표로 정의하였다. 횡방향으로 불규칙한 변화 행태가 증가할수록 측면추돌 사고가 발생할 가능성이 높은 것을 의미한다(Arvin et al., 2019). 마지막으로 차량 간 상호작용 기반 안전성 평가지표는 spacing 및 headway 표준편차, DRAC 평균 및 상충건수, SDI와 TTC 상충건수, CPI, VF 기반 spacing 및 headway로 선정하였다. 기존 연구를 참고하여 본 연구에서 활용한 주행안전성 평가지표는 Table 1에 제시하였다.
Table 1.
Lists of driving safety indicators
2. 주행안전성 평가지표와 사고건수 간의 상관분석
본 연구에서는 22가지의 주행안전성 평가지표 중 사고건수와 통계적으로 유의한 상관관계가 성립되는 평가지표인 significant indicator를 선정하기 위하여 상관분석을 수행하였다. 상관분석은 통계적으로 두 변수 간에 어떠한 선형적 관계가 존재하는지 분석하는 방법이다. 두 변수는 서로 독립적이거나 상관된 관계일 수 있으며 상관관계의 정도를 파악하는 상관계수는 두 변수 간의 연관된 정도를 나타낸다. 이때 상관계수가 0보다 크고 1 이하일 경우에는 두 변수가 양의 상관관계, 반면에 상관계수가 –1 이상이고 0보다 작을 경우에는 두 변수가 음의 상관관계가 존재한다고 해석한다. 고속도로 이정 단위로 집계된 사고건수와 평가지표 간의 상관분석 결과는 교통안전 모니터링을 위한 실효성있는 지표를 선정하고 C-ITS 데이터의 적용성을 검토하는데 활용될 수 있다(Jo et al., 2021).
3. 랜덤포레스트 기법
본 연구에서는 교통 사고건수와 통계적으로 유의미한 상관관계가 성립되는 significant indicators를 대상으로 도로위험구간을 효과적으로 분류할 수 있는 평가지표를 식별하고자 한다. 대표적인 분류 기법으로 랜덤포레스트, K-NN(K-nearest neighbor), SVM(support vector machine), 인공신경망(neural network)이 주로 활용된다. Boateng et al.(2020)에 따르면 랜덤포레스트는 적은 데이터 샘플만으로도 SVM 및 인공신경망 보다 예측 정확도가 우수하다는 장점이 있다. 특히 SVM은 다양한 커널(kernel) 함수를 기반으로 모형이 구축되기 때문에 모델의 이식성 및 일반화 성능이 랜덤포레스트 보다 낮다. K-NN의 경우는 모델의 구현 및 이해가 쉽지만 이상적인 k 값을 설정하기 어렵고 데이터 샘플수가 많아질수록 학습 속도가 현저히 떨어지는 단점이 있다. 또한 인공신경망은 다양한 매개변수를 조정하기 위한 학습시간이 오랜시간 소요되는 반면에 랜덤포레스트는 빠른 훈련속도로 높은 정확도를 도출하는데 우수하다고 보고되었다(Boateng et al., 2020).
랜덤포레스트 학습 과정에서 각 트리는 학습 데이터 중 중복을 허용하여 랜덤하게 선택된 붓스트랩 샘플(bootstrap sample)에 기반하여 생성된다. 본 연구는 분석가가 미리 설정한 500개의(T=500) 트리를 임의적으로 생성하였으며, 각 트리에서 출력된 일반집단(normal class)과 위험집단(risk class) 분류 결과를 바탕으로 개별 트리의 결과에 대해 다수결 투표방식으로 최종 분류결과를 도출하였다. 붓스트랩 샘플링을 통한 랜덤포레스트 학습과정은 다음과 같은 단계로 진행된다.
1) 주어진 훈련 데이터셋에서 붓스트랩 방법을 통해 T개의 훈련 데이터셋을 생성한다.
2) T개의 기초 트리를 훈련시킨다.
3) 기초 트리들을 하나의 분류기로 결합한다.
4) 다수결 투표를 통해 최종 결과값을 결정한다.
랜덤포레스트는 개별 트리를 학습하는 과정에서 사용되지 않은 관측치를 out-of-bagging(OOB)으로 구분한다. OOB는 범주별 예측 확률을 추정하고 비정상의 원인이 되는 변수를 확인하는 데에 사용된다. 전체 의사결정나무에서 OOB로 선택된 횟수는 개별 트리마다 상이하며 선택되었을 때 분류되는 값도 트리마다 상이하게 예측된다. 범주 k에 속하는 각각의 관측치에 대한 OOB 관측치를 원래의 범주로 올바른 분류를 할 확률은 Equation 1과 같이 산출된다.
는 괄호 안이 참(true)일 때 1을 나타내고, 거짓(false)일 때 0을 나타내는 표시(Indicator)함수이며, 는 예측된 범주를 의미한다. 는 생성된 의사결정나무의 번째 의사결정나무를 의미한다. 는 bagging을 이용한 학습 과정에서 관측치를 사용하지 않은 의사결정나무의 집합이다. 학습할 때 가 사용되지 않은 의사결정나무의 집합에서 을 범주 k로 예측하는 의사결정나무 개수의 비율이 이 된다(Deng et al., 2012). 다시 말해서, 는 OOB error로 정의되며 OOB error가 낮을수록 개발된 랜덤포레스트 모형의 성능이 우수함을 의미한다(Breiman, 2001). 또한 본 연구에서는 랜덤포레스트에 적용된 주행안전성 평가지표의 중요도를 분석하기 위한 지표로 mean decrease gini(MDG)를 사용하였다. MDG는 모든 트리에서 특정 설명변수의 GI지수 감소량을 평균한 값으로 GI지수 감소량이 높을수록 MDG는 증가한다. 분류범주가 개, 즉 인 경우 GI지수는 Equation 2와 같이 산출된다. 는 범주 에 대해 올바르게 분류한 비율이고, 는 범주 를 다른 범주로 분류한 비율이다. MDG는 0에서 100 사이의 값으로 산출될 수 있으며 0이면 해당 변수가 분류에 전혀 사용되지 않음을, 100에 가까울수록 해당 변수가 관측치를 완벽히 분류하였음을 의미한다. 본 연구에서는 특정 주행안전성 평가지표의 MDG 값이 높을수록 도로위험구간을 식별하는데 중요한 변수로 해석하였다. 따라서 본 연구는 significant indicators의 MDG 값을 기준으로 주행안전성 평가지표 우선순위를 도출하였다.
데이터
1. C-ITS 자료
차내 전방 충돌 경고시스템이 장착된 C-ITS로부터 수집된 PVD는 차량 원시 자료와 ADAS 자료로 구성되고 자료 수집주기는 1초이다. 차량 원시 자료는 주행속도(km/h), 가속도(m/s2), yaw 속도(deg/s), 위도 및 경도(deg) 등을 포함한다. 또한, ADAS를 통해 전방차량과의 차간거리, 충돌예상시간에 대한 자료 수집이 가능하다. 본 연구에서는 국내 고속도로 C-ITS 실증사업 구간 중 경부고속도로 양재IC-기흥동탄IC 구간과 수도권제1순환 고속도로 조남JC-상일IC를 분석구간으로 설정하였으며 Figure 2와 같다. 수집된 데이터의 시간적 범위는 2020년도 10월이며, 개별차량에 대해 총 1237만 4222개의 데이터 샘플이 수집되었다. PVD 기반 고속도로 이정 단위 주행안전성 평가지표 산출 절차는 Figure 3에 제시하였다. 본 연구에서는 PVD에 포함된 위도 및 경도 정보를 고속도로 이정으로 변환하였으며, 이는 이정 단위로 집계된 평가지표와 교통 사고건수 간의 상관분석을 수행하는데 있어 분석의 용이성을 높이기 위함이다.
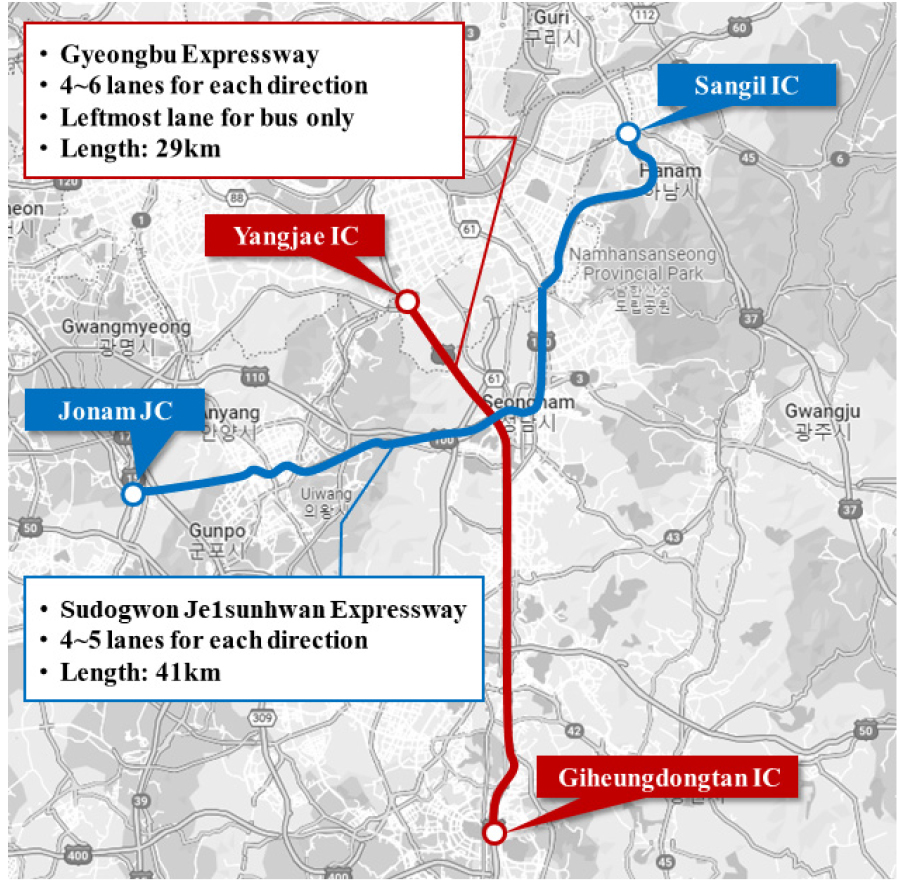
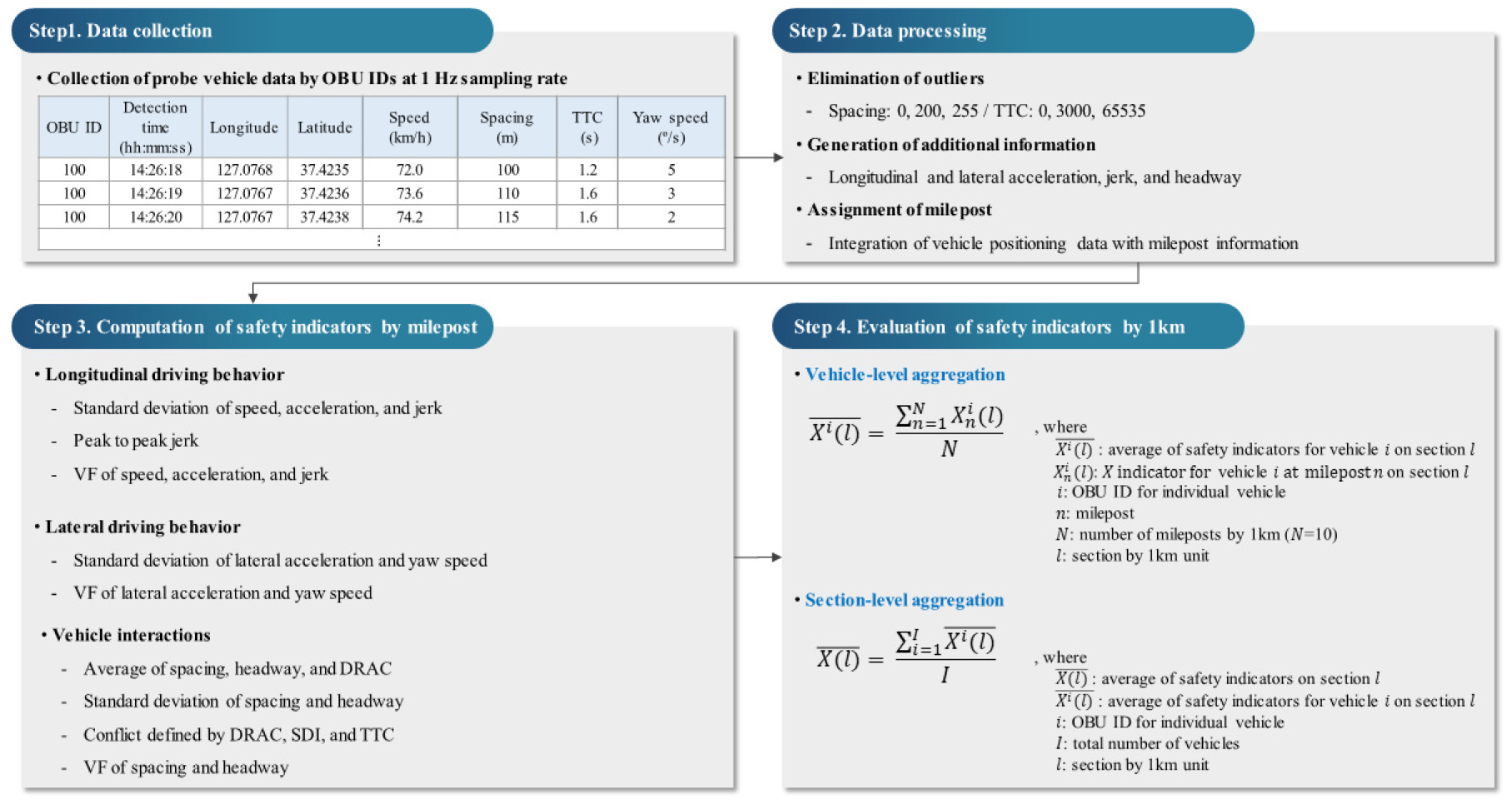
2. 고속도로 교통사고 자료
C-ITS 자료 수집 범위와 동일한 구간에서 2017년 6월부터 2022년 5월 동안 발생한 교통사고 자료를 수집하였다. 고속도로 본선에서 발생한 사고건수는 양재IC-기흥동탄IC 구간에서 308건, 조남JC-상일IC 구간에서 565건으로 집계되었다. 사고자료는 C-ITS 데이터로부터 추정된 주행안전성 평가지표와 상관분석을 수행하기 위하여 활용되었다. 또한 본 연구에서는 분석대상 범위에서 발생한 사고건수의 평균 값을 기반으로 데이터셋을 두 개의 집단(class)으로 구분하였다. 분석 범위 내 발생한 1km 단위 평균 사고건수는 12.4건으로 평균 사고건수보다 높은 구간을 위험집단(risk class), 그렇지 않은 구간을 일반집단(normal class)으로 정의하였다. 분석 구간별 1km 단위로 집계된 교통사고 건수는 Figure 4와 같다.
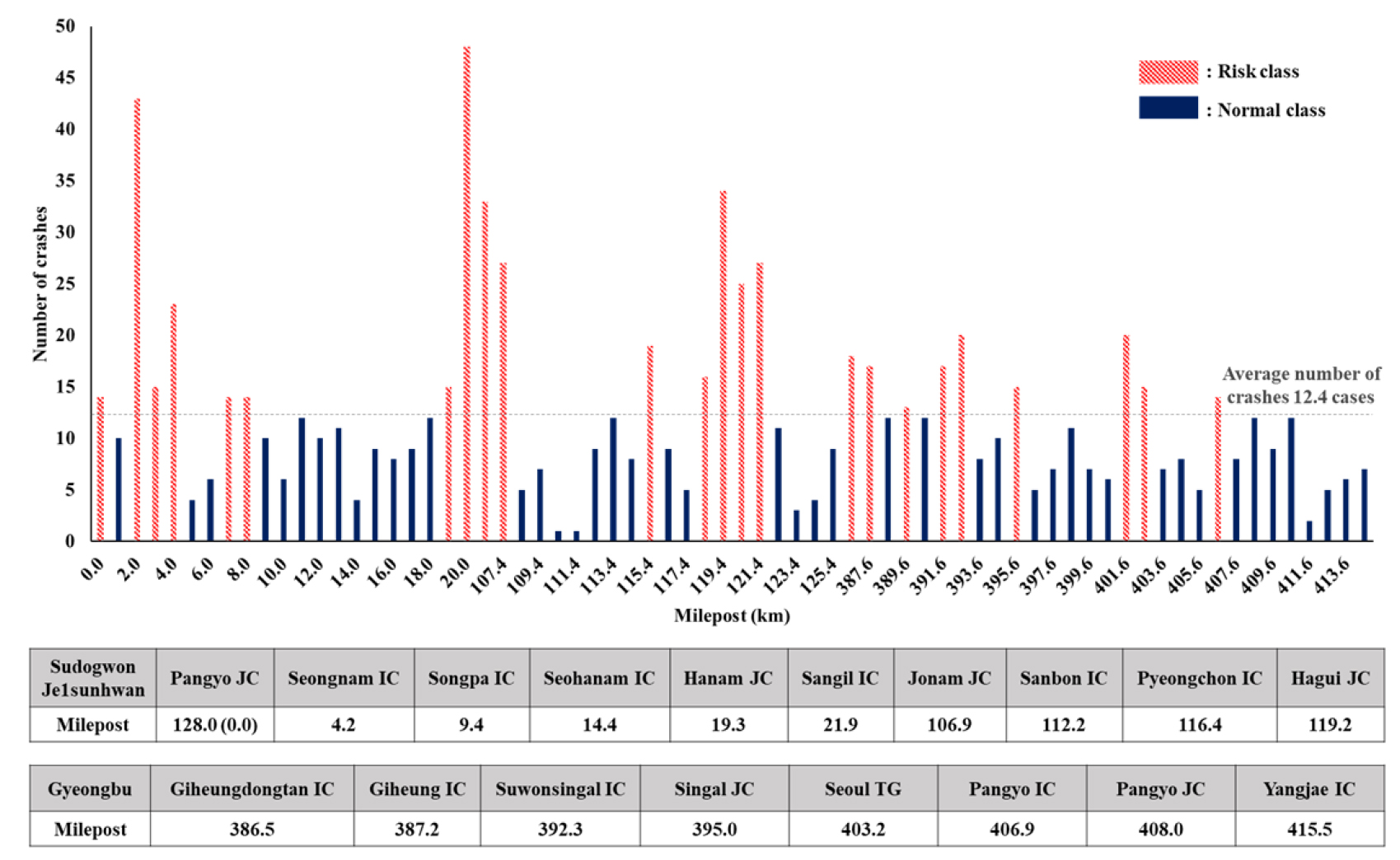
분석 결과
1. 주행안전성 평가지표와 교통 사고건수 간의 상관관계 분석 결과
본 연구에서는 기존 연구에서 보고된 22가지의 주행안전성 평가지표를 대상으로 실제 사고건수와 통계적으로 유의한 상관관계가 성립되는 significant indicators 선정을 목적으로 상관분석을 수행하였다. 상관분석 수행 시 분석구간 1km 단위로 집계된 평가지표와 사고건수 데이터셋을 활용하였다. 교통사고는 발생 빈도가 낮고 임의적인 특성을 가지고 있기 때문에 1km 단위의 공간적인 범위로 집계하였다. 분석구간을 대상으로 1km 단위로 자료를 집계할 경우 경부선과 수도권제1순환선의 데이터 샘플 수는 각각 29개, 41개(총 70개)이다. 상관분석에 앞서, 개별 평가지표가 정규성을 따르는지 검증하기 위하여 Kolmogorov-Smirnov(K-S) 분석을 수행하였다. K-S 분석 결과는 Table 2에 제시하였으며, 각 평가지표에 대해 정규성이 있을경우 Pearson 상관분석, 그렇지 않을 경우 Spearman 상관분석을 수행하였다. 정규성 검정 결과에 따른 Pearson 상관분석 대상 지표는 SD_yaw, AV_spc, SD_spc, AV_hdwy, NC_DRAC, CPI, VF_jerk, VF_yaw, VF_spc이다. 반면 Spearman 상관분석의 대상이 되는 지표는 SD_speed, SD_acc, SD_jerk, P2Pjerk, SD_lacc, SD_hdwy, AV_DRAC, NC_SDI, NC_TTC, VF_speed, VF_acc, VF_lacc로 해당 지표들은 정규성을 따르지 않는 것으로 분석되었다.
본 연구의 분석대상 구간에서 발생한 사고건수와 통계적으로 유의한 상관관계가 성립되는 10개의 significant indicators를 도출하였으며, Table 3에 제시하였다. VF_hdwy와 사고건수는 90% 신뢰수준(p<0.1)에서 통계적으로 유의한 양의 상관관계가 있는 것으로 분석되었다. 상관계수는 0.488로 다소 높은 상관관계가 존재하는 것으로 나타났으며, 1km 단위 VF_hdwy와 사고건수를 매칭한 결과는 Figure 5에 제시하였다. VF_hdwy는 시간의 흐름에 따른 headway의 불규칙한 변화행태를 정량적으로 산정하는 지표로, 차량추종 상황에서 선‧후행차량의 빈번한 가감속도 조정은 차두시간 변화량을 증가시킬 것으로 예상된다. 따라서 VF_hdwy의 증가는 차량간 상호작용 안전성이 저하됨을 의미하며, 후미추돌 사고발생 가능성이 증가한다고 해석할 수 있다. 추가적으로 종방향 주행안전성 측면에서 속도, 가속도, jerk의 변동성과 속도 및 가속도의 표준편차는 사고건수와 양의 상관관계가 성립되었다. 그리고 횡방향 주행안전성 측면에서는 yaw 속도 표준편차가 사고건수와 양의 상관관계가 존재하는 것으로 분석되었다. 운전자의 빈번한 조향 조정은 횡방향 주행안전성을 저하시킴에 따라 측면추돌 사고발생 개연성이 증가할 것으로 예상된다. 차량간 상호작용 기반 안전성에 대해서는 평균 spacing은 사고건수와 음의 상관관계, spacing 변동성과 SDI 상충건수는 사고건수와 양의 상관관계를 가진다. 예를 들어, 유출입 연결로 구간에서 진출입 차량 간의 상호작용은 이격거리 변화량과 후미추돌 상충 건수를 증가시킬 것이다. 결론적으로 VF_spc와 NC_SDI 값이 커질수록 차량간 상호작용 기반의 후미추돌 사고개연성이 증가함을 의미한다.
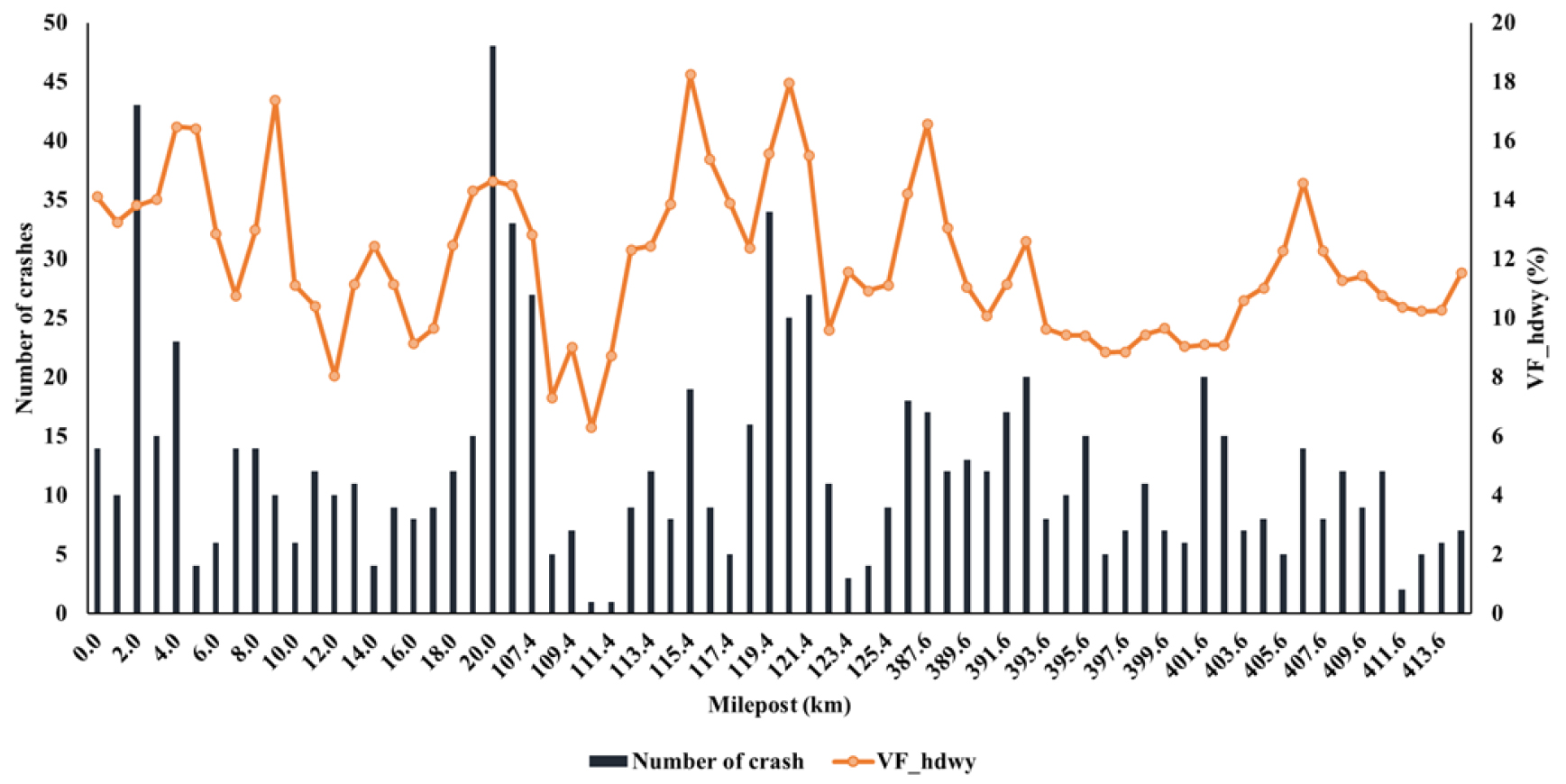
Table 2.
One-sample Kolmogorov-Simirnov test of driving safety indicators
Table 3.
Correlation between driving safety indicators and number of crashes
2. 주행안전성 평가지표 우선순위 도출 결과
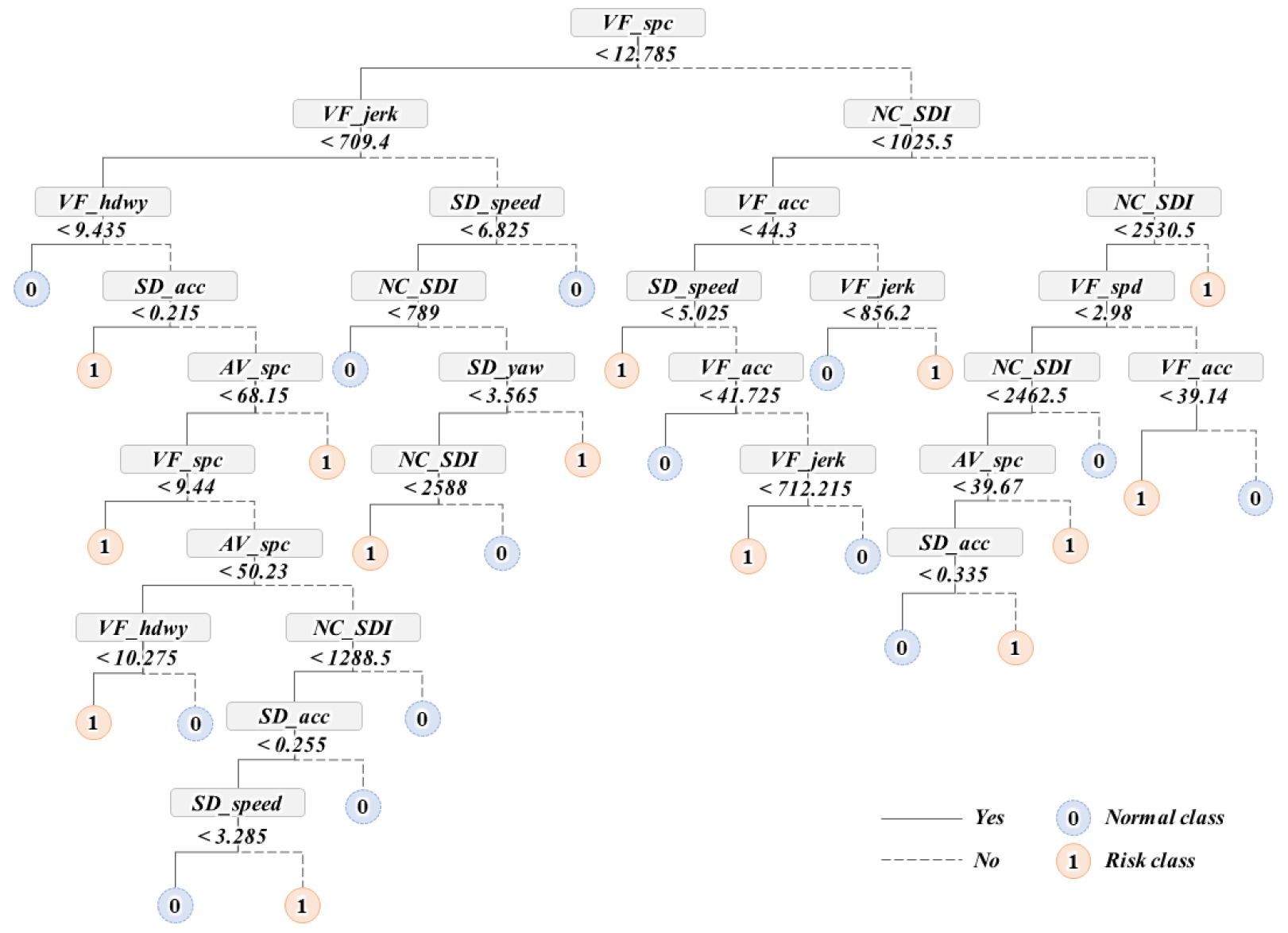
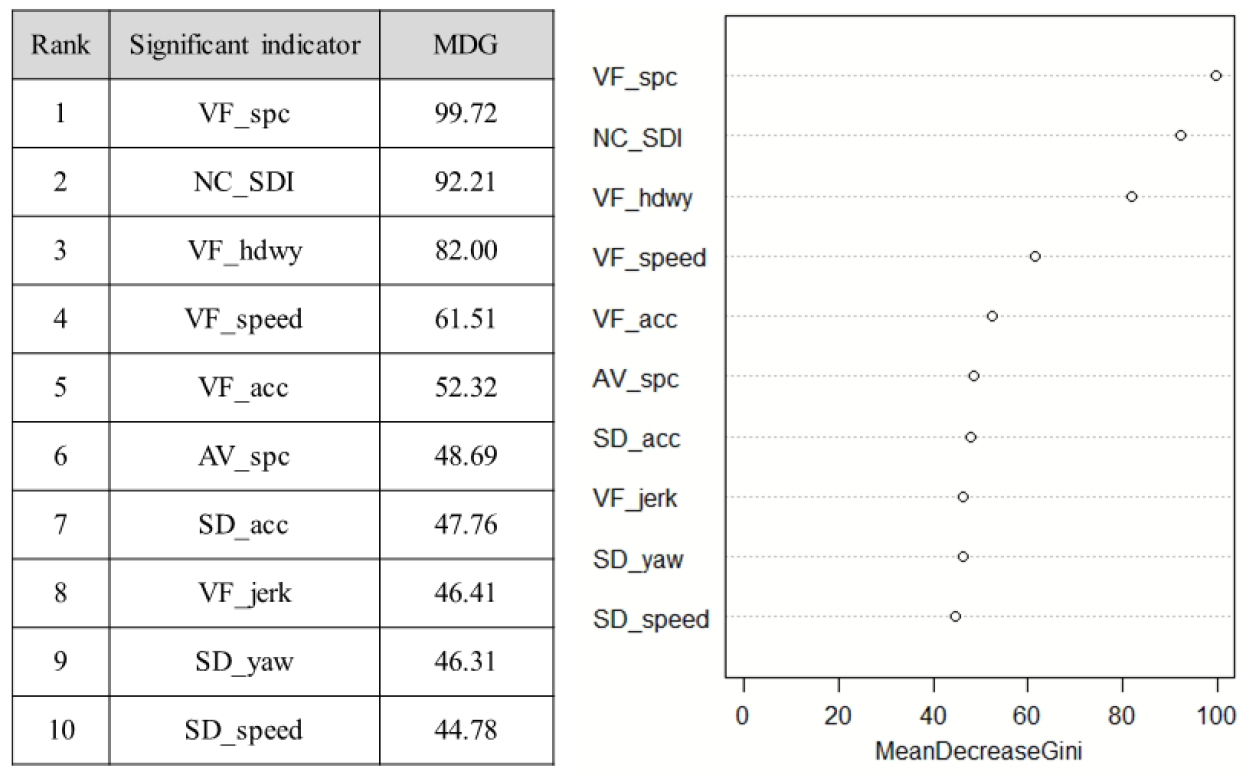
본 연구에서는 상관분석을 통해 선정된 significant indicators를 대상으로 위험집단을 분류하는 변별력 높은 평가지표 도출을 목적으로 랜덤포레스트를 적용하였다. 랜덤포레스트 기법을 활용한 기존 연구를 검토한 결과 최소 1,200개의 데이터 샘플이 적용된 것으로 보고되었다(Shi and Abdel-Aty, 2015). 본 연구에서는 랜덤포레스트 수행 시 시‧공간적 범위로 데이터셋을 확장하여 일별(31일), 구간별(70개)로 집계된 데이터 샘플 총 2,170개를 분석에 적용하였다. 랜덤포레스트 학습을 위하여 트리의 총 개수를 500개로 설정하였으며 각 트리마다 무작위로 3개의 변수를 사용하여 모델을 구축하도록 설정하였다. 구축된 모델의 OOB error는 16.13%로(분류정확도 83.87%) 분석되었다. 랜덤포레스트 기반 위험집단 분류 모델의 임의의 개별 트리에 대한 예시는 Figure 6과 같다. MDG 값을 기준으로 위험집단을 분류하는 평가지표들 간의 중요도 평가 결과는 Figure 7에 제시하였다. 분석 결과, 위험집단을 분류하는데 효과적인 상위 3개의 지표는 VF_spc, NC_SDI, VF_hdwy 순으로 도출되었으며, 차량 간 상호작용 기반 안전성 지표가 도로위험구간 식별에 비교적 큰 영향을 미치는 변수로 분석되었다. 특히 VF_spc의 MDG 값이 99.72로 가장 높은 것으로 도출되어 spacing의 변동성은 위험집단 분류에 가장 변별력있는 지표로 선정되었다. VF_spc는 시간의 흐름에 따른 spacing의 불규칙한 변화행태를 정량적으로 산정하는 지표이다. 예를 들어, 차량추종 상황에서 선‧후행차량의 빈번한 가감속도 조정은 이격거리 변화량을 증가시킬 수 있다. 또한, 유출입 연결로 부근에서는 진출입 차량의 차로변경으로 인해 이격거리 변화량이 증대될 것으로 예상된다. 결론적으로 VF_spc 값이 커질수록 차량간 상호작용 기반의 후미추돌 및 측면충돌 사고개연성이 증가함을 의미한다.
결론 및 향후 연구과제
C-ITS를 기반으로 실시간으로 변화하는 도로교통환경 및 운전자의 주행정보 수집이 가능함에 따라 개별차량 단위 사고개연성 추정을 통한 도로위험구간을 식별하기 위한 노력이 요구된다. 이를 위해서는 실제 교통사고와 유의미한 상관관계를 나타내는 주행안전성 평가지표를 선정하고, 도로위험구간을 구분하는데 변별력있는 평가지표를 도출해야 한다. 따라서 본 연구에서는 C-ITS 자료를 이용하여 보다 과학적인 교통안전 평가를 가능하게 하는 주행안전성 평가지표 우선순위를 제시하였다. 우선, 기존 연구를 참고하여 종‧횡방향 주행행태 및 차량 간 상호작용 기반 안전성을 평가하는데 주로 활용되는 22가지의 지표를 선정하였다. C-ITS 기반 주행안전성 평가지표는 실제 교통사고 건수와 상관분석을 수행하는데 적용되었으며 유의미한 상관관계가 성립되는 10개의 significant indicators를 도출하였다. Significant indicators는 랜덤포레스트를 기반으로 위험집단을 구분하기 위한 입력변수로 활용되었다. 최종적으로 도로위험구간 식별이 가능한 변별력 높은 주행안전성 평가지표 우선순위를 도출하였으며, 중요도가 높은 상위 3개의 평가지표는 spacing 변동성(VF_spc), SDI 기반 상충건수(NC_SDI), headway 변동성(VF_hdwy)로 분석되었다.
국내에서는 자율주행 시대를 대비하여 2014년 7월부터 C-ITS 시범사업이 수행되고 있다. C-ITS 환경에서 능동적이고 선제적인 교통안전정보가 제공되기 위해서는 교통운영센터의 역할이 중요하다. 사고예방 측면에서 교통운영센터의 운영자는 실시간으로 수집되는 C-ITS 자료를 이용하여 경고정보 제공 및 모니터링을 수행하고자 할 것이다. 본 연구에서 제시한 주행안전성 평가지표 우선순위는 교통 운영자 관점에서 실효성있는 안전지표를 선정하기 위한 기초 연구자료로 활용될 수 있다. 또한 랜덤포레스트를 기반으로 도출된 평가지표 중요도(MDG)는 통합 주행안전성 평가지표를 개발하는데 활용될 수 있으며, 개발된 통합지표를 이용하여 도로위험구간 식별이 가능할 것으로 예상된다. 추가적으로 향후 C-ITS 환경에서 새로운 서비스 도입 이전 및 초기 단계에서 시뮬레이션을 기반으로 안전성 효과평가 수행 시 제안된 지표를 우선 적용하기 위한 기초연구 자료로 유용하게 활용될 것으로 기대된다.
본 연구에서 제시한 C-ITS 자료를 이용한 주행안전성 평가지표 우선순위 도출에 대한 신뢰도를 높이기 위해서는 다음과 같은 추가적인 연구가 필요하다. 첫째, C-ITS 기반의 추가적인 PVD 수집이 요구된다. 본연구에서 활용한 C-ITS 자료는 한달 동안 수집된 샘플 데이터이기 때문에 추정된 평가지표의 신뢰도 저하가 문제가 야기될 수 있다. 추가적인 데이터 수집을 통해 도로위험구간 뿐만 아니라 시간대 식별이 가능할 것으로 기대된다. 둘째, 횡방향 주행행태 관점의 측면추돌 사고개연성 추정이 가능한 지표선정이 요구된다. 본 연구에서는 수집된 데이터 항목의 한계로 횡방향 가속도와 yaw 속도에 대한 평가지표를 산출하였으나, 조향각 및 lane position 등 횡방향 주행행태를 분석할 수 있는 평가지표 도출에 대한 연구가 지속적으로 수행되어야 할 것이다. 셋째, 고속도로 교통 조건과 사고 특성을 고려한 주행안전성 평가지표 선정이 요구된다. 본 연구는 기존 연구에서 주로 활용된 평가지표를 대상으로 사고건수와의 상관관계를 분석하였으나, 선정된 평가지표와 밀접한 관련이 있는 교통사고 유형을 고려할 필요가 있다. 이에 따라, AHP(analytical hierarchical process) 기법 등 전문가 설문조사를 통해 평가지표 선정기준을 마련하고 관련 교통사고의 상관관계에 대한 전문가 검토가 수행되어야 한다. 마지막으로, 도로위험구간 식별을 위한 서포트벡터머신, 인공신경망 기반 모델 개발이 필요하다. 머신러닝 모델의 파라미터 최적화를 통해 정확도가 우수한 도로위험구간 분류 모델이 개발될 수 있다. 또한 랜덤포레스트 모델의 목적변수인 위험집단과 일반집단 설정 시 사고심각도, 사고율, 사고유형 등을 고려할 필요가 있다. 예를 들어, 1건의 단일 교통사고에 대해 부상사고 보다 사망사고에 더욱 큰 가중치를 적용하여 인적피해 요소가 고려된 위험집단 구분이 가능할 것이다. 추가적으로 사고위험도에 따른 효과적인 교통안전 모니터링을 위하여 위험정도를 여러 집단으로 식별할 수 있는 모델 고도화가 요구된다. 향후 연구내용에 대한 체계적인 분석을 통해 실질적으로 적용 가능한 결과 도출을 위한 다각적인 노력이 필요할 것이다.
