

서론
Digital TachoGraph(DTG) 및 교통사고 데이터
분석 방법
1. 음이항 회귀모형(Negative Binomial Regression Model)
2. 졸음운전 위험 구간 분석
결론
서론
지난 10년 간 졸음운전은 전체 고속도로 사고건수의 약 23%로서 교통사고 사망원인 중 가장 높은 비중을 차지하고 있다. 한국도로공사에서 제공하는 사고속보자료에 의하면 고속도로 전체 교통사고는 2011년부터 2015년까지 감소추세를 보이고 있으나, 졸음운전에 의한 사망사고 비율은 증가하고 있는 실정이다. 졸음운전은 과속, 주시태만 등 운전자의 과실이 주요원인인 일반적인 사고유형과 달리, 졸음이라는 불가항력적 원인에 의해 발생한다는 점에서 타 사고유형과 차별화된 접근이 요구된다. 그 동안의 졸음운전 감소대책은 일반적인 교통사고 대책과 마찬가지로 사고다발지점과 같은 특정지점(Spot)에 집중하였으나, 도로구간 또는 시간구간의 특성을 고려한 감소대책이 필요함에 따라, 본 연구에서는 시·공간적으로 확대한 구간(Link) 개념을 도입하였다. 본 연구의 목적은 사고가 일어난 지점 분석이 아닌 졸음운전의 근본적인 대책을 강구하기 위해서 잠재적인 위험 구간을 도출하는데 있다. 특히 상대적으로 장시간 운전환경에 노출된 화물차 통행을 대상으로 분석하였으며, 화물차 digital tacho graph(DTG) 자료를 이용하였다. 본 과업의 공간적 범위는 한국도로공사에서 관리하는 고속도로 전체 노선을 대상으로 하며, 시간적 범위는 2015년으로 설정하였다. 본 연구의 구성은 다음과 같다. ⅰ)수집된 DTG 데이터 및 교통사고자료에 대한 기술통계분석, ⅱ)본 연구의 방법론 및 졸음사고 예측모형 추정결과, ⅲ)고속도로 네트워크 적용을 통한 위험구간 도출이 순차적으로 제시된다, 마지막으로 결론 부분에 연구결과의 활용방안 및 향후 연구과제가 제시된다.
Digital TachoGraph(DTG) 및 교통사고 데이터
Digital tacho graph(DTG)는 차량운행기록을 실시간으로 저장하는 기기로 차량의 GPS 위치, 주행속도, 분당엔진회전수(RPM), 자동차상태, 브레이크 신호, 방위각, 가속도 등을 기록하는 장치이다. 이를 활용하여 사업용자동차 운전자의 과속, 급정지, 급차로변경 등 난폭운전 습관에 대한 과학적 분석을 통해 교통사고를 예방하기 위한 목적으로 교통안전공단에서 운행기록분석시스템(digital tachograph analysis system)이 구축되었다. DTG를 통하여 차량번호, 시간, 거리, 평균속도, 일 운행 시간, 과속, 위험과속, 장기과속, 급가속, 급감속, 급출발 급제동, 공회전수와 같은 정보를 추출할 수 있다. 교통안전공단이 제공하는 운행기록분석시스템에서 정의하는 위험운전 행동 기준의 정의는 교통안전공단 홈페이지(http://www.ts2020.kr)에 자세히 기술되어 있다.
디지털 운행 기록계(DTG) 자료는 과속, 급가속, 급출발, 급감속, 급정지, 급좌회전, 급우회전, 급유턴, 급앞지르기 및 급차로변경의 위험한 행태가 나타난 경우에 한해 추출되었으며, 본 연구에서는 2015년 1월에서 3월까지 자료를 사용하였다. 교통사고의 자료는 2015년 1년간 고속도로 상에서 발생한 졸음운전 사고자료(전차종 대상)를 사용하였다. 사고자료는 구간별로 수집되었으며, 전체 사고건수, 전체 사망자수, 전체 중상자수, 전체 경상자수, 졸음운전 사고건수, 졸음운전 사고 사망자수, 졸음운전 사고 중상자수 및 졸음운전사고 경상자수를 포함하고 있다. 본연구에서는 한국도로공사가 관리하는 고속도로 전체 인터체인지간(IC-IC) 구간(1,127 구간)을 분석대상으로 설정하였으며, Table 1은 각 구간별로 수집된 DTG 데이터의 기술통계량을 보여준다.
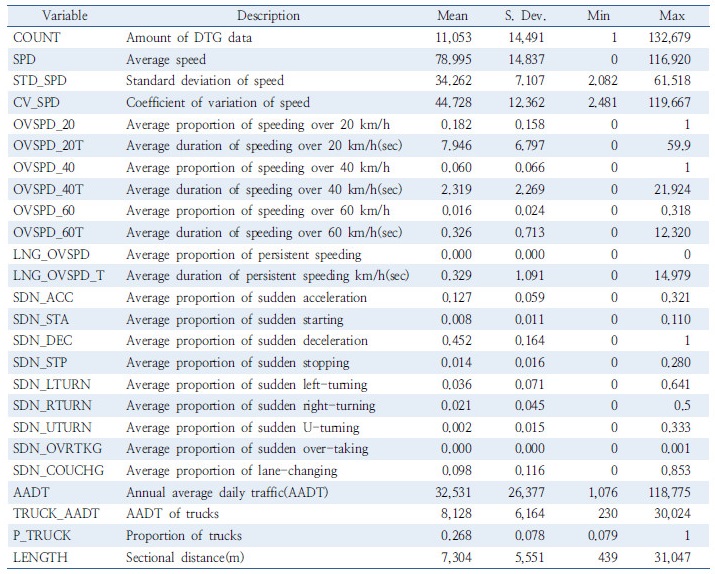
이벤트를 발생시킨 차량 중 6.0%는 제한속도 기준 40km/h를 초과하고 있으며 평균 2.3초의 과속시간을 보이고 있다. 이벤트 발생 차량 중 1.6%는 제한속도 기준 60km/h를 초과하며 평균 0.329초의 과속시간을 보인다. 이벤트 발생 차량 중 45.2%에서 급감속 행태가 나타났지만 급정지는 1.4%에 불과한 것으로 드러났으며, 평균 급죄화전, 급우회전 및 급 유턴은 각각 3.6%, 1.5% 및 0.2%으로 매우 드문 행태가 나타났다. 평균 급앞지르기는 그 최대값이 0.1%일 정도로 매우 드물었고, 급차로 변경은 평균 약 7.3%로 분석되었다. 인터체인지 간 평균 연장은 7.304km 였으며, 가장 짧은 구간은 0.439km 그리고 가장 긴 구간의 연장은 31.047km로 나타났다.
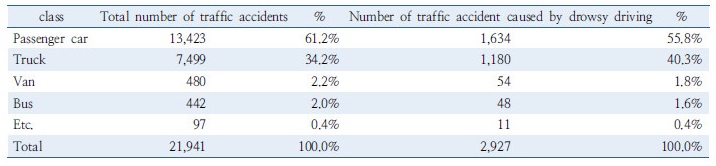
Table 2는 전체사고와 졸음운전 사고간의 차종별 분석 결과값을 보여준다. 두 종류의 사고 모두 승용차의 비율이 가장 높은 것으로 나타났다. 하지만 전체사고에서의 승용차의 비율이 61.2%로서 졸음운전사고의 승용차 비율인 55.8%보다 다소 높았게 나타났다. 화물차의 경우는 이와 반대의 경향을 보이는데, 화물차의 전체사고에서의 비율은 34.2%이지만 졸음운전사고에서는 이보다 현저히 높은 40.3%로 나타났다. 이는 화물차 운전자의 졸음운전 사고의 빈도가 높음을 시사한다. 승합차의 경우 전체사고에서의 비율이 2.2%, 졸음운전 사고에서의 비율이 1.8%로서, 전체사고의 비율이 다소 높게 났다. 마지막으로 버스의 비율 역시 전체사고에서 2.0%로서 졸음운전 사고에서의 비율인 1.6%보다 약간 높은 것으로 나타났다.
분석 방법
1. 음이항 회귀모형(Negative Binomial Regression Model)
본 연구의 주요목표인 디지털 운행 기록계 자료에서 수집된 운전자의 행태와 고속도로 구간에서의 사고 발생건수와 관련이 있는지 분석하기 위해 음이항 회귀모형(negative binomial regression)을 사용하였다. 사고건수는 비음정수(non-negative integers)이며 일반적으로 정규분포를 따르지 아니하는데, 이는 사고발생이 매우 드문 사건이기 때문에 구간별 사고가 대부분 0이나 1등 작은 값을 갖기 때문이다. 포아송이나 음이항 회귀모형 모두 독립변수를 이용하여 사건 건수를 추정할 수 있지만 포아송 모형의 경우 평균과 분산이 같은 값을 갖는다는 제약된 가정을 내포한다. 이와 같은 가정은 특히 사고 자료에서 유효하지 않은 경우가 많이 발생하는데, 사고건수 자료에서는 대부분 분산이 평균보다 매우 큰 것으로 나타나기 때문이다. 이를 과분산(overdispersion)이라고 하며, 음이항 회귀모형은 Equation(1)과 같은 평균-분산 관계를 갖기 때문에 포아송 회귀모형의 가정을 완화한다.

여기서, 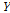 는 종속변수,
는 종속변수, 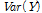 는
는 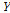 의 분산,
의 분산, 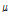 는 평균 그리고
는 평균 그리고 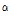 는 과분산계수(overdispersion parameter)를 나타낸다.
는 과분산계수(overdispersion parameter)를 나타낸다.
위의 식에서 보듯이 과분산계수의 값이 0에 수렴할 경우 이는 포아송 모형의 가정과 같이 분산과 평균이 동일하게 된다. 본 분석에서 추정된 평균 졸음 사고건수는 Equation(2)와 같이 독립변수와 로그선형 관계를 갖는 것으로 설정하였다.
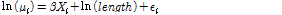
여기에서 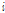 는 각각의 자료,
는 각각의 자료, 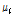 는 추정된 사고건수,
는 추정된 사고건수, 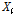 는 독립변수,
는 독립변수, 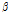 는 계수,
는 계수, 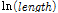 는 구간의 연장의 로그변환 값으로서 사고건수를 일정한 연장 단위로 분석할 수 있게 하며, 마지막으로
는 구간의 연장의 로그변환 값으로서 사고건수를 일정한 연장 단위로 분석할 수 있게 하며, 마지막으로 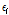 는 감마분포를 따르는 오차항이다. Equation(3)은 음이항 분포의 확률 분포를 보여주는데,
는 감마분포를 따르는 오차항이다. Equation(3)은 음이항 분포의 확률 분포를 보여주는데, 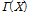 는 감마 함수이며 과분산분포 계수인
는 감마 함수이며 과분산분포 계수인 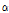 는 반드시 0보다 큰 값을 가져야 한다.
는 반드시 0보다 큰 값을 가져야 한다.
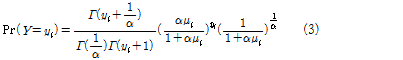
Lord & Mannering(2010)에 따르면 음이항 회귀모형은 추정하기 쉬우며 과분산을 고려할 수 있는 반면, 과소분산(underdispersion)은 통제할 수 없으며 작은 평균값 및 적은 표본수에 의해 편의가 발생할 수 있다는 단점이 있다고 설명하였다. 그럼에도 불구하고 최근에도 미국의 highway safety manual (AASHTO, 2010)을 포함한 많은 교통안전 연구에서 음이항 회귀분석을 널리 사용하고 있다(Daniels et al., 2010; Cafiso, 2010; Siddiqui et al., 2012; Abdel-Aty et al., 2011; Abdel-Aty, 2013; Lee et al., 2013).
통계 S/W SAS를 활용하여 음이항 회귀모형을 추정하였으며, Table 3과 Table 4는 각각 전체 사고건수 및 졸음운전 사고건수에 대한 추정 결과를 나타낸다. 전체 사고의 경우 본 연구와 직접적인 관련은 없으나 졸음 사고가 일반적인 사고에 비해 어떠한 차별성을 갖는지 비교하기 위해 분석하였다.
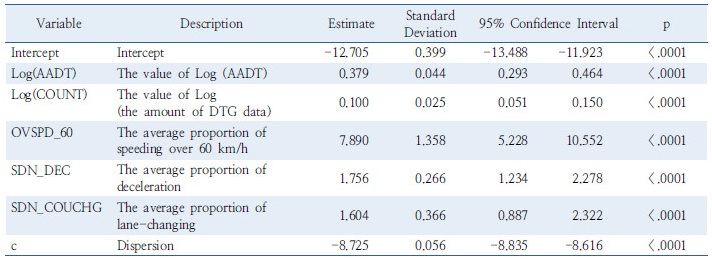
Table 4. Results in traffic accidents caused by drowsy driving using negative binomial regression model  |
전체사고건수의 경우, 연평균 일교통량, DTG 수집 자료건수, 평균 과속비율(60km/h 초과), 평균 급감속비율 및 평균 급차로변경비율의 증가가 전체 사고건수의 증가를 유발하는 것으로 나타났으며, 졸음사고 건수의 경우, 연평균 일교통량, 화물차 비율, DTG 수집 자료건수, 속도, 평균 과속비율(20km/h 초과), 평균 급감속비율, 평균 급좌/우회전비율 및 평균 급차로변경비율이 늘어날 경우 졸음운전 사고건수 역시 증가하는 것으로 분석되었다. 특히 화물차 비율과 평균 과속비율(20km/h 초과)이 전체사고건수 대비 졸음운전 사고건수에 큰 영향을 주는 것으로 나타났다.
추정된 모형에 포함된 독립변수 간 상관관계가 클 경우 해당 변수가 실제로 유의미한 것인지 확신할 수 없게 되며, 이를 위해 피어슨 상관계수 분석을 수행하였다. 피어슨 상관계수는 두 변수의 선형관계를 파악하기 위한 것으로서 Equation(4)에 의해 계산된다.
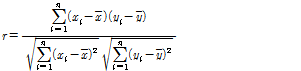

Table 6. Pearson correlation coefficient analysis using estimated parameter in the accident cuased by drowsy driving 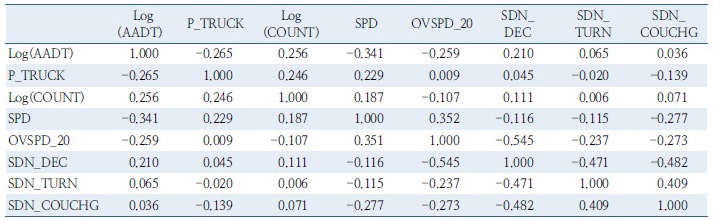 |
분석 결과, 평균 급감속비율(a)과 평균 20km/h 초과 과속비율(b), 평균 급좌/우회전비율(c), 평균급차로변경비율(d) 간의 상관지수가 각각 -0.545(a vs. b), -0.471(a vs. c), -0.482(a vs. d)로 도출되었으나, 그 절대값이 크지 않고 각 변수가 졸음운전 행태를 나타내는 중요한 설명변수라고 판단되어 모형에 반영하였다.
2. 졸음운전 위험 구간 분석
미국의 highway safety manual (AASHTO, 2010)에서는 사고 위험구간(hotspot)을 선정하는 다양한 기법이 제시되어 있으며 단순한 방법으로는 간단히 사고건수를 기준으로 위험구간을 선정하는 방법, 사고건수를 교통량으로 표준화한 사고율을 기준으로 선정하는 방법 등이 있다. 그러나, 관측된 사고건수는 사고발생 본연의 임의적 변동성(Random fluctuation)에 따라 평균 회귀(regression-to-the-mean) 등으로 인한 편의가 나타날 수 있다. 이러한 편의을 극복하기 위해본 연구에서는 경험적 베이즈(empirical Bayes: EB) 추정법을 사용하였다. 경험적 베이즈 추정법에 의한 사고건수는 Equation(5)와 같다.
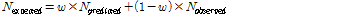
 는 경험적 베이즈 추정법을 통해 계산된 사고추정 건수이고,
는 경험적 베이즈 추정법을 통해 계산된 사고추정 건수이고, 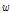 는 가중치,
는 가중치,  는 모형에서 예측된 사고건수,
는 모형에서 예측된 사고건수,  는 관측된 사고건수이다.
는 관측된 사고건수이다.
위 식에서 알 수 있듯이 경험적 베이즈 추정 사고건수는 관측된 사고건수와 모형 예측 사고건수의 가중평균에 의해 계산되며, 가중치(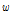 )는 Equation(6)에 의해 계산된다. 여기서,
)는 Equation(6)에 의해 계산된다. 여기서, 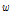 는 가중치,
는 가중치, 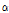 는 과분산계수, 그리고
는 과분산계수, 그리고  는 모형에서 예측된 사고건수를 나타낸다.
는 모형에서 예측된 사고건수를 나타낸다.
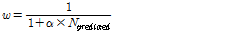
구간에서의 과분산계수(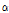 )는 특정한 값이 아닌 구간 연장의 함수로 정의되는데 Equation(7)을 통하여 산출할 수 있다.
)는 특정한 값이 아닌 구간 연장의 함수로 정의되는데 Equation(7)을 통하여 산출할 수 있다. 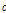 는 과분산계수를 위한 파라미터로서 Table 3, 4에 제시되어 있으며,
는 과분산계수를 위한 파라미터로서 Table 3, 4에 제시되어 있으며, 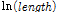 는 구간의 연장의 로그변환 값이다.
는 구간의 연장의 로그변환 값이다.
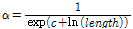
잠재적 안전개선 지수(PSI: Potential for Safety Improvement)는 경험적 베이즈 추정 건수를 신뢰할 수 있는 관측값으로 가정하여 모형에서 예측된 사고 건수에 비해 얼마나 많은 사고건수가 개선될 수 있는지를 나타내는 지표로서 해당 구간이 동일한 조건을 가진 다른 구간의 평균적인 사고건수에 비해 얼마나 많은 사고가 추가로 발생하는지를 나타내는 지표이다. 따라서 이 지수가 양의 값을 갖는 경우 해당 구간은 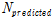 보다 많은 사고가 발생하고 있음을 나타내며, 이 지수가 음의 값을 갖는 경우 해당 구간이
보다 많은 사고가 발생하고 있음을 나타내며, 이 지수가 음의 값을 갖는 경우 해당 구간이 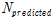 보다 적은 사고가 발생함을 나타낸다. 잠재적 안전개선 지수는 Equation(8)을 통해 계산된다.
보다 적은 사고가 발생함을 나타낸다. 잠재적 안전개선 지수는 Equation(8)을 통해 계산된다.
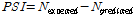
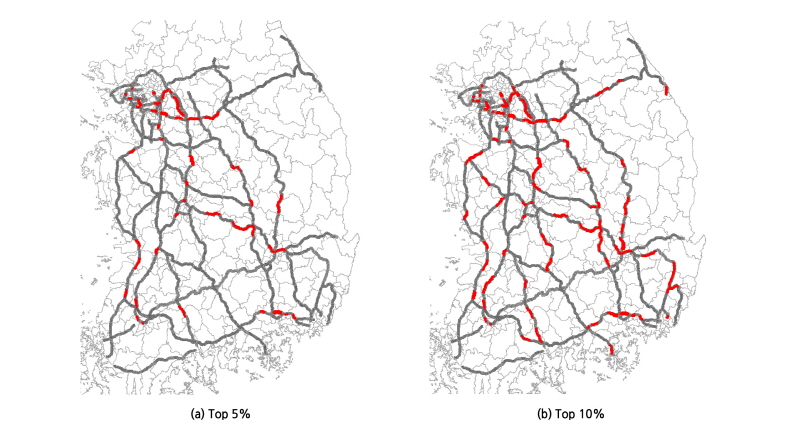
Figure 1는 잠재적 안전개선 지수를 기준으로 졸음운전 위험구간을 분석한 결과로서 상위 5%와 상위 10%에 해당하는 잠재적 안전개선 지수를 가진 구간을 나타내고 있다. 분석 결과 가장 위험한 구간은 경부고속도로의 금호JC-칠곡물류IC구간으로서 연간 13건의 졸음 운전사고가 발생하였다. 경험적 베이즈 추정법에 의한 사고건수( )는 약 8.65건이며 예측 건수(
)는 약 8.65건이며 예측 건수( ) 2.761건에 비해 현저히 높은 것으로 나타났으며, 잠재적 안전개선 지수(PSI)는 5.888건으로 나타났다. 그 다음으로는 경부고속도로 상 서초IC-반포IC 구간으로 선정되었다. 경험적 베이즈 추정건수(
) 2.761건에 비해 현저히 높은 것으로 나타났으며, 잠재적 안전개선 지수(PSI)는 5.888건으로 나타났다. 그 다음으로는 경부고속도로 상 서초IC-반포IC 구간으로 선정되었다. 경험적 베이즈 추정건수( )는 약 4.26건으로 다소 낮게 나타났지만 이 값이 모형에서 추정된 예측건수(
)는 약 4.26건으로 다소 낮게 나타났지만 이 값이 모형에서 추정된 예측건수( ) 0.48건에 비해 현저히 높기 때문에 잠재적 안전개선 지수는 매우 높은 3.779건으로 나타났다.
) 0.48건에 비해 현저히 높기 때문에 잠재적 안전개선 지수는 매우 높은 3.779건으로 나타났다.
PSI 지수는 개선사업 시행에 따른 잠재적인 편익을 의미하며, 투입예산 대비 편익의 효율을 판단하는 요소가 된다. 따라서 고속도로 유지관리 주체는 개선사업(휴게소 및 졸음쉼터의 확충 등)의 후보군을 판단 하는데 Table 7의 결과를 활용할 수 있다.
결론
본 연구는 교통사고자료와 디지털 운행기록계(digital tacho graph: DTG) 데이터를 이용한 거시적 모형을 추정했다는데 의의가 있다. DTG 자료는 2015년 1월에서 3월까지 3개월 간 자료가 수집되었고, 사고건수는 2015년 1월에서 12월까지 1년간의 자료가 수집되었다. 두 가지 자료는 IC구간을 기준으로 통합되었으며, 이를 바탕으로 전체사고 및 졸음사고에 대한 모형을 추정하였다. 졸음사고 모형 추정 결과, 연평균 일교통량, 화물차 비율, DTG 수집 자료건수, 평균 과속비율(20km/h 초과), 평균 급감속비율 및 평균 급차로변경비율이 늘어날 경우 졸음운전 사고건수 역시 증가하는 것으로 분석되었고, 특히 화물차 비율과 평균 과속비율(20km/h 초과)은 일반 사고가 아닌 졸음 운전 사고에 큰 영향을 주는 것으로 나타났다. 이를 바탕으로 경험적 베이즈( empirical Bayes: EB) 추정법과 잠재적 안전개선 지수(potential for safety improvement: PSI)를 이용하여 위험구간을 분석하였다.
현재 DTG 데이터는 화물차 전체에 대한 전수화가 어렵다는 한계점이 존재한다. 예컨대, 졸음사고 예측모형에 사용된 Log(COUNT) 변수는 해당 구간의 위험운전의 절대적 크기만을 의미하기 때문에 구간별 화물차 통행량에 따른 편의가 발생할 수 있다. 따라서 향후 전수화된 데이터 대비 위험운전의 비율 등이 추가적으로 고려되어야 한다. 본 연구에서는 위험운전 행태에 대한 졸음사고의 위험성을 DTG 데이터로부터 추정된 예측모형을 통해 설명하고 있으며, 모형화되지 않은 그 밖의 위험요인(기하구조, 노선특성, 휴게시설 여부 등)은 PSI 지수로 제시하고 있다. 향후 이 두 가지 범주의 위험요인에 대한 종합적 평가가 시행된다면 개선사업의 공간적 범위를 설정하고 예산투자를 시행하는 데 명확한 근거자료가 될 것이다.
