

서론
교통수요 분석에서 랜덤효용이론(Random utility theory)을 기반으로 한 Random Utility Model(RUM) (Manski, 1977)은 다양한 교통 분야의 의사결정분석에 널리 활용되어왔다. 이용 가능한 대안들에 대한 이용자의 선호를 효용(utility)이라는 정량적 단위를 통해 파악하고 이를 통해 장래 이용행태를 예측하는 것이 주된 목적이며, 교통수요 추정에서는 매우 중요한 요소이다. RUM의 대표적인 알고리즘인 로짓모형은 효용이론과 모수적(parametric) 가정(예: 선형효용함수)을 통해 직관적인 해석이 가능하다는 큰 장점이 있어서 수요 예측 및 정책 평가에 널리 활용되어왔다. 특히, 다항로짓모형(multinomial logit model, MNL)의 경우의 프로빗이나 혼합 로짓과 비교하여 추정 비용이 매우 적어 교통 수단선택 분석에 널리 활용되어져 왔다.
하지만, MNL은 알고리즘의 특성상 각 대안들의 오즈 비율(odds ratio)이 다른 대안의 확률과 무관해야 하는 가정-IIA(Independence from Irrelevant Alternatives) 속성-이 존재하며, 이를 만족하지 못할 때 편향된 예측 결과를 도출할 수도 있다는 한계를 가지고 있다. 또한, 대안 및 이용자의 특성을 설명하는 속성들의 복잡한(예: 비선형 혹은 결합 관계) 관계들은 선형가정에서 무시되기 쉽다. 물론, 주어진 데이터의 속성들에 대해 분석가가 가능한 모든 비선형 및 결합 조합을 고려하거나 경험 지식(domain knowledge)을 통해 최적의 효용함수(modeling specification)을 파악할 수 있다. 하지만, 복잡하고 다양한 형태의 데이터가 존재하는 현시대에서 이는 거의 불가능한 경우가 많다. 특히 통행 인구 자료가 광범위한 경로를 통해 수집되어 대규모 데이터베이스의 형태를 띠게 될 경우, 광역단체 범위의 수요 모형을 고려한 통행 수단선택 모형을 구축하기 위해서는 모형 구축을 위한 입력 자료 준비에 지나친 자원 소모가 발생하고, 정책 수립이나 대안 제시를 위한 민첩한 모형 구축, 적용, 및 갱신이 어렵게 된다. 이러한 문제점을 극복하기 위해 혼합분포(mixing distribution)를 다양한 형태로 가정하여 IIA 속성을 비교적 완화한 혼합로짓모형도 최근 많은 연구가 이루어지고 있지만, 복잡하고 다양한 변수들의 관계를 모두 파악하여 이상적인 선형효용함수 형태를 예측하기에 여전히 어려움이 남아있다. 또한, 모형의 추정과정(estimation)이 통계적 샘플링 기법을 활용한 근사적 추론 방식(예: maximum simulated likelihood)에 기반하고 있어 오랜 연산 시간이 소요된다.
최근 이러한 모수적 방법론의 대안으로 다양한 비모수 통계적 기계 학습법(이른바 Machine Learning, ML)이 제시되고 있는데, 알고리즘을 기반으로 한 머신러닝 기법들은 높은 기계적 계산 성능을 활용하여 복잡한 알고리즘과 하부 모형들을 계산할 수 있게 함과 동시에 자료에 대한 통계적 가정 없이 자료들의 관계들을 학습하기 때문에 기존의 모수적 접근법에 비해 뛰어난 예측 성능과 모형 추정 시 높은 효율성을 보여주고 있다(Robert, 2014; Golshani et al., 2018; Lee et al., 2018; Wang and Ross, 2018). 이러한 높은 수준의 예측 능력은 이미 컴퓨터 공학이나 정보통신 분야에서는 널리 입증되었으며, 실제 많은 기업은 많은 양의 데이터를 머신러닝 기법을 통해 가공 및 예측하여 사용하고 있다.
하지만, 컴퓨터 공학이나 물리학 분야에서 주로 높은 예측 성능만을 목표로 개발 및 활용되어 온 머신러닝 기법들은 교통 분야와 같은 사용자 선호 문제를 다루는 데에 있어서는 문제에 대한 해석적 방안을 제시하지 못하는 경우가 많았다. 예를 들어 교통 정책 분석을 위해 마련된 정책 대안에 따른 사용자의 선택 결과에 대한 예측은 높은 정확도를 보일 수 있었으나, 선호 변화에 대한 분석이나 해석에 대한 요구에 있어서는 그간 머신러닝 기법의 해석 한계로 인해서 충분히 납득할 만한 분석 방법이나 지표를 제시하지 못하여, 사회과학이나 도시 관련 연구에서 Blackbox 추정이라는 비판을 피할 수 없었다.
따라서 본 연구에서는 교통 수단의 선호 예측과 정책 대안 분석이라는 두 가지 요구를 모두 만족하는 머신러닝 기법의 활용 가능방안에 대해 살펴보고자 하였다. 부산광역시에서 실시한 한일해저터널 기초연구를 위해 수집된 장래 여객 수요에 대한 Stated Preference(SP) 설문조사 자료를 활용하였으며, 한일 해저터널을 통해 예상되는 부산-후쿠오카 구간의 고속철도 수단 도입에 따른 이용자들의 수단간 선호 예측을 머신러닝 기법 중에서 모형 해석법(model agnostic method)과 부스팅(boosting) 기법을 결합한 XGBoost 기법의 모형을 통해 살펴보고, SHAP(SHapley Additive exPlanations) 기법을 활용하여 장래의 수단간 정책 분석의 가능성을 살펴보고자 하였다. 본 연구를 통해 검증된 교통행태분석 방법론은 머신러닝의 장점인 예측력 확보와 동시에 학습된 머신러닝의 해석을 통한 정책 분석에 활용 가능한 방안을 제공함으로써 교통수요 분석 및 정책 평가 방법론의 새로운 대안으로 머신러닝의 활용 가능성을 높이고자 한다.
선행연구
국내의 통행 수단 선택 모형에 관한 연구들에서 가장 활발하게 이용되고 있는 분석 도구는 다항로짓모형이라고 할 수 있다. 서울과 일산 신도시의 출근 통행행태를 분석하고 모형의 지역 간 이전 가능성을 모색하는 연구에서 다항로짓모형이 활용되었으며(Cho and Kim, 1998), 대구광역시 취업자들의 교통수단 선택의 행태 분석에도 다항로짓모형이 이용되었다(Kim et al., 1999). 또한, 부산 울산권의 가구 통행실태조사 자료를 활용한 수단선택 행태와 수단 분담률 예측 가능성에 관한 연구에도 다항로짓모형(기본 로짓모형)과 두 가지의 개선된 로짓모형, 그리고 네스티드 로짓모형이 활용되었다. 이처럼 국내의 교통수단 선택 모형의 연구는 다항로짓모형을 통해서 설명변수들의 영향력을 파악하고 교통수단 이용자들의 행태 분석 결과와 여러 정책적 대안들과 적용 가능성을 제시하고 있다. 최근, Lee and Hong(2019)의 연구에서 서포트 벡터 머신과 의사결정나무 모형을 다항로짓과 비교하여 머신러닝 기반 모형의 더 높은 예측력에 관한 연구 결과를 제시한 바 있으나, 정책 평가를 위한 해석적 방법에 관한 부분은 안타깝게도 제시되지 않고 있다.
해외에서도 전통적인 로짓모형 기반의 교통수단 선택 모형은 학술연구에서 뿐만이 아니라, 각 지방 자치 단체별로 운영 중인 수요 모형을 통해 정책 수립 및 분석 단계에서 활발히 이용되고 있다. 하지만, 다양한 정보처리(data science) 기법들이 알려지면서 보다 광범위한 분야에서 새로운 기법들이 소개되고 있으며, 교통 및 도시 문제의 분석이나 설계에 관한 문제들에도 그 적용이 점차 확대되고 있다(Derrible and Ahmad, 2015; Ahmad et al., 2016; Ahmad et al., 2017; Akbarzadeh et al., 2017; Golshani et al., 2018; Lee and Derrible, 2020; Wisetjindawat et al., 2018). 특히 머신러닝과 데이터 마이닝 기법들이 통행 설문 자료를 활용하여 모형을 구축하고 다양한 교통 특성들을 예측하는데 활발히 적용되고 있다(Ghasri et al., 2017). 모형의 적용과 비교에 있어서는, 로짓계열 모형의 가정의 한계와 해석의 복잡성을 해결하고자 의사결정나무와 인공신경망 모형(Xie et al., 2003), 그리고 서포트 벡터 머신(Xian-Yu, 2011)을 다항로짓 모형 혹은 네스티드 로짓 모형과 비교하여 뛰어난 예측력이 확인되었으며, 랜덤포레스트 기법을 활용한 모형이 다항로짓보다 더 나은 정확도를 가지며, 특히 대규모 데이터베이스에서 효율적으로 실행된다는 점을 확인한 바 있다(Sekhar et al., 2016). 그리고 종합적인 비교 제시를 위해 일곱 가지의 머신러닝 모형을 통해 결과를 비교하여, 의사결정 나무 기반 모형들의 예측력이 뛰어나고 교통수단 선택을 예측하는 데에 가장 적합하다고 제시하였다(Hagenauer and Helbich, 2017). 최근에는 다항로짓 모형과 네 가지의 다른 인공신경망 모형을 비교하여 머신러닝 기반의 인공신경망 모형이 다항로짓 모형과 비교해서 더 나은 예측력을 나타낸다는 것이 확인된 바 있다(Lee et al., 2018).
머신러닝 기반으로 교통수단 선택에서 가장 나은 예측력을 보여주는 의사결정 나무 모형 접근법 중에서 Gradient Boosting Model(GBM)은 머신러닝 분야에서 이미 활발히 활용되고 있는 모형이지만 교통 분야에서는 최근 그 관심과 적용사례가 늘어나면서 여러 연구 결과들이 소개되었다. Semanjski and Gautama(2015)는 크라우드 소스 통행 행태 자료를 활용하여 수단선택을 예측하면서 GBM을 활용하여 향후 스마트 교통에 있어서 필수적인 예측 기법이 될 것이라는 제안을 내놓았으며, Zhang and Haghani(2015), Lee and Min(2017)과 Lee et al.(2019)은 수단선택 예측과 교통류를 분석함에 있어서 GBM을 통한 모형의 예측력이 뛰어나다는 것을 밝혔다. 또한 Wang and Ross(2018)는 GBM이 MNL 보다 높은 수단선택 예측 정확도를 가진다는 것을 미국의 가구 통행 설문 자료(National Household Travel Survey)를 통해서 비교하였다. James et al.(2013)은 병렬학습이 불가능한 GBM의 특성상 상대적으로 긴 학습 시간을 지적하면서, 이 부분이 개선된 XGBoost Model을 활용하여 더 빠른 모형 성능과 높은 예측력을 보여주었다.
지금까지 로짓 기반 모형을 통해 활발하게 이루어져 온 교통수단 선택 모형의 구축과 분석은, 다양한 정보처리 기법들의 발전으로 인해 머신러닝 기법을 통한 모형의 구축과 분석 가능성이 확인되었고 이의 적용을 위한 단계에 많은 연구자의 관심이 몰리고 있다. 본 연구는 현재까지 제시된 머신러닝 기법 중에서 교통수단 선택 모형으로 가장 적합하다고 판단되는 XGBoost 모형을 이용하여 SP 설문 자료로 부터 확인되는 개인의 수단선택 선호에 대한 모형을 구축하고 예측력을 검증하고자 하였다. 또한, 통행자들의 수단 선택 선호를 분석하고 정책 분석의 가능성을 살펴봄으로써 기존의 예측력 중심의 연구 범위에서 확장된 논의를 제시하고자 하였다.
분석 데이터
본 연구에서는 모형 구축과 분석을 위해 부산광역시에서 실시한 한일해저터널 기초연구를 위해 수집된 여객 수요 설문 조사 자료를 활용하였다(Pusan Metropolitan City, 2018). 해당 기초연구는 한일 간 해저 터널의 현실화에 따른 대안 교통 수단으로 등장할 해저 터널을 통과하는 고속 철도에 대한 국내 여객 수요를 살펴봄으로써 장래 수요에 대한 예측과 분석에 대한 방안을 제시하기 위한 목적으로, 여러 대안 노선들 중에서 부산과 후쿠오카를 연결하는 노선을 연구 대상으로 한정하여 2018년 1월 23일 부터 2월 2일 까지 김해 국제공항 및 부산항 국제 여객터미널을 이용하는 여행객 300명을 대상으로 면접 설문을 통해 수집된 SP(Stated Preference) 자료를 수집하여 활용하였다. 다만, 기초 연구 결과와 중복되는 분석 및 정책 제안을 피하기 위해서 기초연구의 자료보다는 집합적인 형태의 자료로 변경하여 분석에 활용하였으며, 자료 변경 부분에 대해서는 본 장의 마지막 부분에 상술하였다.
기초연구에서 수집한 변수들 중에서, 목적 변수는 현재 운행 중인 항공과 고속 페리, 그리고 가상의 교통 철도 수단으로 구성되어 있으며, 특성으로는 편도 이용 요금과 탑승 대기시간, 그리고 일일 운행 횟수가 고려되었다. 각 변수들의 수준과 특성에 대해서 살펴보면, 항공 요금은 부산-후쿠오카 구간을 기준으로 현재 운항 중인 대한항공, 진에어, 에어부산 세 항공사의 평균 운임인 200,000원을, 고속 페리 요금은 부산-후쿠오카 구간을 운행 중인 쾌속선 비틀의 평균 운임인 약 115,000원을 기준 요금으로 설정하였다. 고속철도 요금은 약 250km로 사정한 해저터널 연장에 KTX와 신칸센의 평균 운임을 적용하여 약 150,000원으로 설정하였다. 다만 해저터널을 통과하는 고속철도의 도입으로 경쟁력 확보를 위해 항공과 고속 페리 요금 수준은 기준 요금에 약 15-20%의 운임 할인을 적용하고, 고속철도의 요금 수준은 건설 공사비 등을 고려해 설정 요금의 120%로 조정하여 수단별 운임 수준을 설정하였다. 하루 평균 운행 횟수는 항공은 약 8회, 고속 페리는 2회로 조사되었으나 고속철도와의 경쟁력 향상을 위해 각각 10회와 4회로 상향 조정하였다. 고속 철도의 경우에는, 부산과 오송을 기준으로 KTX 및 SRT가 일일평균 약 45회 운행되고 있는 반면, 신칸센의 경우 해당 기초연구 조사에서 제시한 연장길이와 유사한 구간인 하치노헤 역에서 신 하코다테 역을 기준으로 현재 12회 운행되고 있다. 한일간의 고속 철도 운행 횟수 차이와 수요를 고려하여, 한일 해저터널의 고속철도 운행횟수는 10회로 설정되었다. 탑승 대기시간은 터미널에 도착하여 실제 교통수단에 탑승하는데 까자 소요되는 대기시간으로, 항공은 90-120분, 고속 페리는 60-90분, 고속철도는 60-90분으로 설정하였다. 목적 변수로 설정한 수단별 편도 요금, 일일 운행 횟수, 그리고 탑승 대기시간의 설명 변수를 두 개의 수준으로 설정할 때 27가지의 조합이 가능하지만, 설문의 응답 수준 향상을 위해 직교 배열표를 활용하여 12가지의 시나리오를 마련하여 조사표를 작성하였다.
응답자들의 특성으로는 성별, 나이, 직업, 공항 및 여객 터미널 접근 교통수단, 일본과 후쿠오카 및 대마도 방문 횟수, 일본 방문 교통수단, 방문 목적, 방문 형태, 그리고 해저터널 건설 시 고속철도 이용 의사에 대한 선호/비선호에 대해서 택일 형태의 질문을 마련하여 설문조사를 실시하였다. 응답자 특성 중에서 나이와 방문 횟수, 선호/비선호 속성에 대한 자료를 제외하고는 모두 명목형(nominal) 자료이기 때문에 모형 구조에 맞추어 더미 변수로 변경하였다. 설문지 원본에서 10가지의 유형으로 수집된 직업군은 모형의 단순화를 위해 직장인과 학생, 그 외의 세 가지 항목으로 축소하였으며, 11가지 유형의 공항 및 여객 터미널 접근 교통수단에 관한 응답은 승용차, 버스, 택시, 지하철, 그 외의 다섯 가지 항목으로 축소하여 자료를 수정하였다. 이 외에도 일본의 재방문 선호와 터널 이용의 선호/비선호 속성에 대한 자료는 원본 설문 자료의 이용 의사의 유무와 이유에 대한 응답을 잠재 변수로 변환하여 마련하였다. 이상의 연구에서 사용된 변수들의 구성과 기술 통계량을 정리하면 Table 1과 같이 정리할 수 있다.
Table 1.
List of variables and descriptive statistics
분석 방법론
1. 모형 알고리즘
의사결정나무(Decision Tree) 모형은 규칙 기반(rule-based)의 비모수 추정 기법으로 학습을 통해 자료의 패턴을 찾아내고 의사결정 트리의 형태를 추정하는 방법이다. 이름에서 예측할 수 있듯이 전체 자료를 가지를 치듯이 분류를 하고 나뭇가지 끝에 해당하는 추정값을 결정하는 모형인데, 분류의 조건이 많아질수록 많은 하부 나무 구조(sub-tree)가 생성되고 세밀한 예측할 수 있지만, 과도하게 깊은 트리 구조는 예측력의 저하, 모형 추정결과의 일관도 결여, 과적합(overfitting)이나 out-of-sample 문제를 유발하는 큰 단점이 있다(Friedman et al., 2001).
이러한 의사결정나무 기법이 가진 한계를 극복하는 방안으로 Hastie et al.(2009)이 제시한 알고리즘이 앙상블(Ensemble Learning) 기법이다. 앙상블 기법은 기계의 반복적 연산 능력을 활용하여 의사결정나무가 가진 단점인 예측력 저하 및 추정결과의 일관성 문제를 해결할 수 있다는 큰 장점이 있다. 또한 다계층(multi-level) 데이터에서 생길 수 있는 관측되지 않은 개인 또는 집단 간의 이질성(heterogeneity) 문제 등에서 비교적 자유로울 수 있다는 장점이 있다. 이러한 앙상블 알고리즘에는 크게 배깅(bagging)과 부스팅(boosting) 기법이 있다. 배깅은 데이터의 샘플링(bootstrapping) 과정에서 여러 개의 결정 나무를 추정하고 이를 합하여 결과를 제시하는 알고리즘이고(Breiman, 2001), 부스팅은 결정 나무의 잔차를 순차적으로 갱신하여 최적화된 결정 나무를 결정하는 알고리즘 구조를 갖는다(Friedman et al., 2001; Chen and Guestrin, 2016).
본 연구에서 활용하고자 하는 부스팅 알고리즘에서는 관측치와 예측치 간의 잔여 오차(residual error)를 최소화하도록 규칙을 설정하고 있는데, 부스팅 모형을 일반화하여 수식으로 나타내면 Equation 1과 같이 주어진 x에 대한 y를 추정하는 순차적인 결정나무들의 합으로 도출된다.
여기서, b : 나무의 개수(1-N)
: 매 단계 순차적으로 갱신되는 새로운 결정나무
: 최종적으로 추정되는 결정나무
2. 머신러닝 모형의 해석 방법론
예측 모형에서 독립 변수의 변화에 따라 예측값의 오차가 클수록 해당 독립 변수의 중요도가 높다는 것을 의미하며 이것을 상대적 변수 중요도(Variable Importance, VI 혹은 Feature Importance, FI)라고 표현한다(Hastie et al., 2009). 이는 의사결정 나무 모형의 분류 단계에서 중요한 변수임를 의미하며, 머신러닝 기법을 통한 분석 결과의 해석 과정에 큰 역할을 한다. 상대적 변수 중요도는 모든 독립 변수를 비교하고 전체 분산의 감소에 기여하는 변수의 순위에 따라 결정된다. 일반적으로 상대적 변수 중요도는 0에서 1사이의 지표로 제시되며, 기여도가 없을 경우에는 0으로 표시된다. 상대적 변수 중요도는 종속 변수에 영향을 미치는 독립 변수의 영향을 나타내며, 중요도가 높은 변수가 종속 변수에 중요한 역할을 한다는 것을 의미한다.
추가적으로 독립 변수의 한계 효과를 통해 모형에 대한 추가적인 해석이 가능하다. 평균 한계 효과란 독립 변수와 예측 반응 사이의 관계를 설명하는 것으로 학습된 모형의 예측 반응에 대한 선택적 특성의 한계 효과를 의미한다(Friedman, 2001). 따라서 독립 변수의 서로 다른 값에 대한 평균 한계 변화율을 측정하여 인과적 해석을 제공할 수 있도록 Partial Dependence(PD) plot을 통해 시각화가 가능하며, 이는 변수의 영향을 예측함에 있어 중요한 근거가 될 수 있다. 독립 변수의 평균 한계 변화율은 Equation 2를 통해 측정된다.
여기서, xs는 선택된 독립 변수이며, xc는 xs를 제외한 독립 변수들의 집합이다. 모든 변수들이 모형의 학습에 사용되며, 예측값에 대한 xs의 평균 한계 변화율은 Equation 3과 같이 다른 독립 변수들에 대한 예측값을 한계화하여 구할 수 있다. 평균 한계 변화율은 독립 변수의 한 단위 변화가 종속변수에 미치는 영향을 표현하는 지표가 된다.
이러한 변수들 사이의 관계들을 시각적 표현을 통해 보다 직관적으로 이해하도록 하기 위해서 Shapley value를 활용하여 머신러닝 기반 모형의 결과값을 설명하는 SHAP(SHapley Additive exPlanations) 접근법이 Lundberg and Lee(2017)에 의해 소개되었다. Shapley value는 게임이론을 바탕으로 특정 변수의 중요도를 알기 위해 여러 특성들의 조합을 구성하고 해당 특성의 예측치와 평균 예측치 간의 차이 변화를 통해 변수의 기여도를 예측하며, 이 기여도 값을 통해 변수의 중요도를 파악하고자 한 것이다. 선택된 독립변수 xs의 기여도를 𝜙s라고 하고 자료의 관측갯수를 m으로 한다면 Shapley value는 Equation 4를 통해 구할 수 있으며, 모든 변수들의 기여도는 Equation 5와 같이 정리할 수 있다.
상대적 변수 중요도는 모형 전체의 중요도(global importance)를 찾기 위해 전체 자료에서 변수 별 Shapely value의 절대값 평균으로 나타내며 Equation 6과 같다.
상대적 변수 중요도와 변수 특성을 결합하여 각 변수의 기여도를 나타낼 수 있는데, 변수의 관찰값과 Shapely value관측치를 각각 다른 색과 x축의 값으로 변수 중요도에 따라 정렬하여 나타내어, 모형에 대한 변수의 영향과 관계를 시각적으로 표시할 수 있다. 그리고 평균 한계 변화율을 통해 변수의 한계 변화에 따른 선택 선호의 변화를 확인할 수 있다.
따라서 본 연구에서는 모형 결과를 해석하기 위한 지표로서, SHAP을 통해 얻어지는 상대적 변수 중요도와 수단별 변수 기여도, 그리고 평균 한계 변화율에 대한 시각적 분석 결과를 통해, 전체 모형과 수단 선택 선호에 대한 독립 변수의 중요도 순위를 확인하고, 각 독립 변수가 종속 변수에 미치는 영향의 정도를 확인하여, 부산-후쿠오카 간 수단 선택에 대한 선호 패턴를 분석하고자 하였다.
모형분석 결과
본 연구에서는 설문조사를 통해 관찰된 3,600개의 자료 중에서 무작위로 선택된 70%에 해당하는 2,520개의 자료를 XGboost 모형의 학습(Train)에 사용하고 나머지 30%의 자료인 1,080개의 자료를 검증(Test)에 사용하여, 모형을 통한 교통수단 선택의 예측치와 검증 자료의 실제 설문 결과를 비교하였다. 머신러닝 기반 알고리즘의 과적합(overfitting)과 out-of-sample 문제를 해결하기 위해 Figure 1과 같이 자료의 분리를 여러 차례 반복하여 검증하는 교차검증(Cross-Validation, CV)을 통해 자료의 구분이 중복되지 않는지 예측하였다. 또한, 무작위 추출을 통한 교차검증이 유발할 수 있는 선택 대안별 불균형 샘플링 문제를 해결하기 위하여 stratified cross-validation(stratified CV) 방법을 적용하였다. 부스팅 알고리즘의 최적 알고리즘 파라미터 결정(hyper-parameter tunning) 과정도 stratified CV를 통해 수행하였다. 5-fold 교차검증 결과(Table 2 참고), 모형 학습의 일관성이 매우 높게 나타난 것을 확인할 수 있었다.
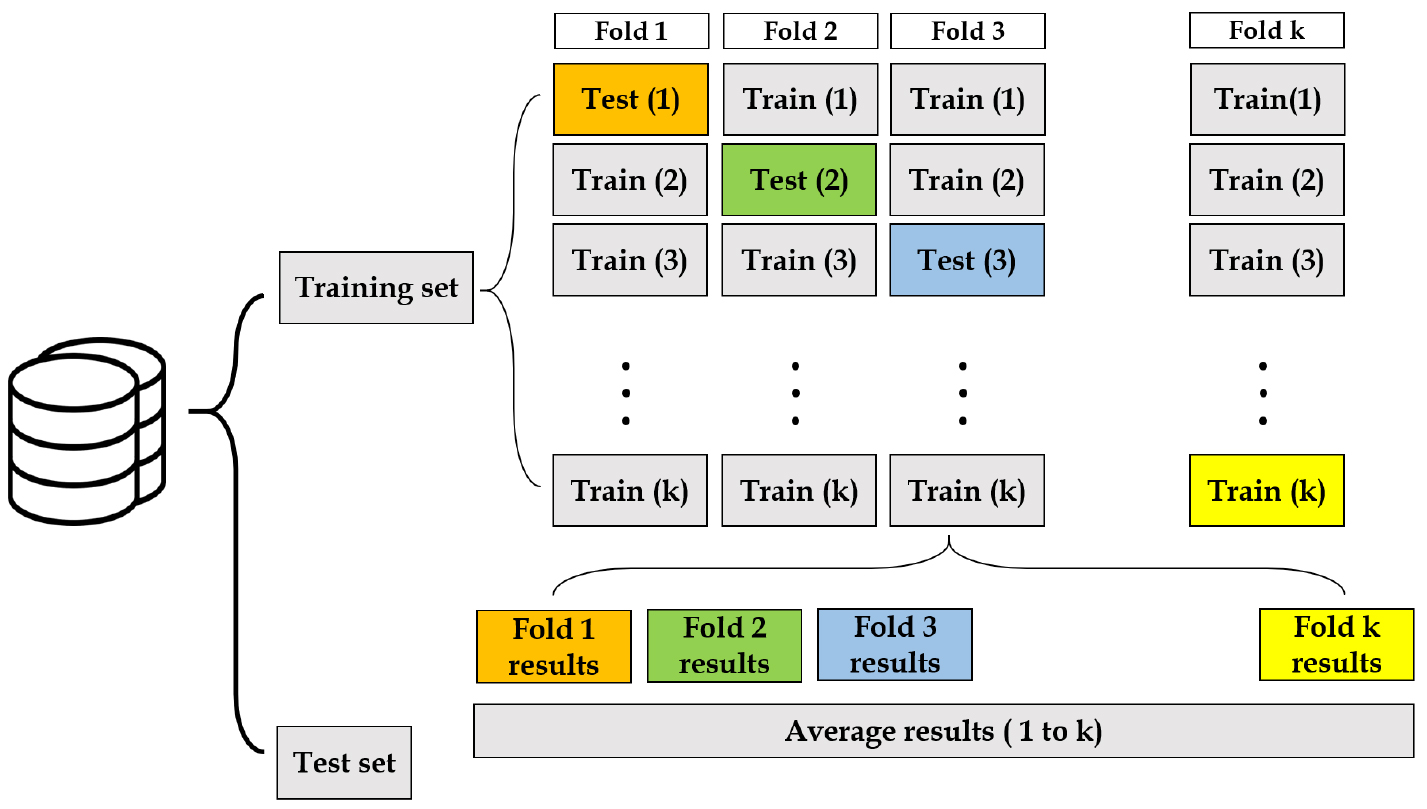
Table 2.
Cross-validation
| Item | 1 | 2 | 3 | 4 | 5 | Mean | S.D.* |
| Cross-validation score | 0.947 | 0.876 | 0.966 | 0.985 | 0.990 | 0.953 | 0.041 |
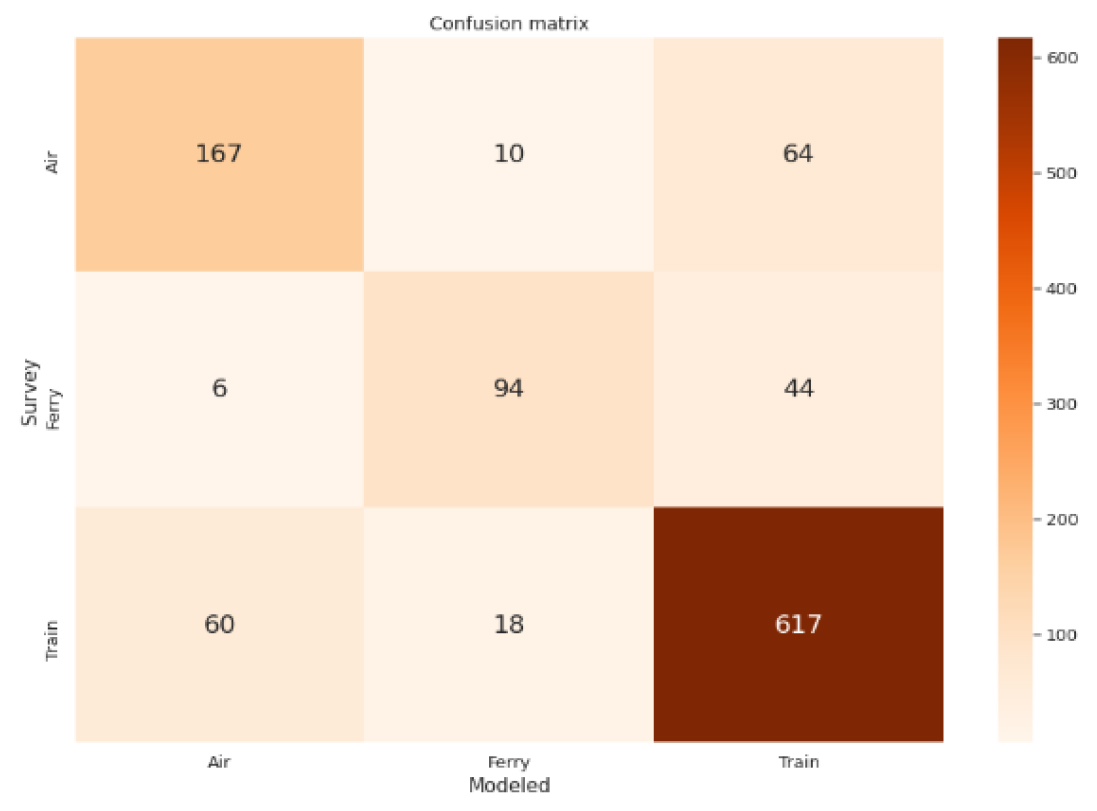
모형의 전체 결과는, 예측 선택 값과 실제 선택 값을 비교하여 나타내는 Figure 2의 Confusion matrix에서 확인할 수 있듯이, 예측된 수단선택과 설문 응답 수단선택을 비교했을 때 수단별로 항공 69.2%, 페리 65.2%, 고속철도 88.8%의 정확도로 예측과 실제 선호 응답이 일치하는 결과를 보였으며, 전체 모형의 예측력은 약 81.3% 정도로 나타나 Test set의 실제 결과치를 높은 정확도로 예측하는 것을 확인할 수 있었다.
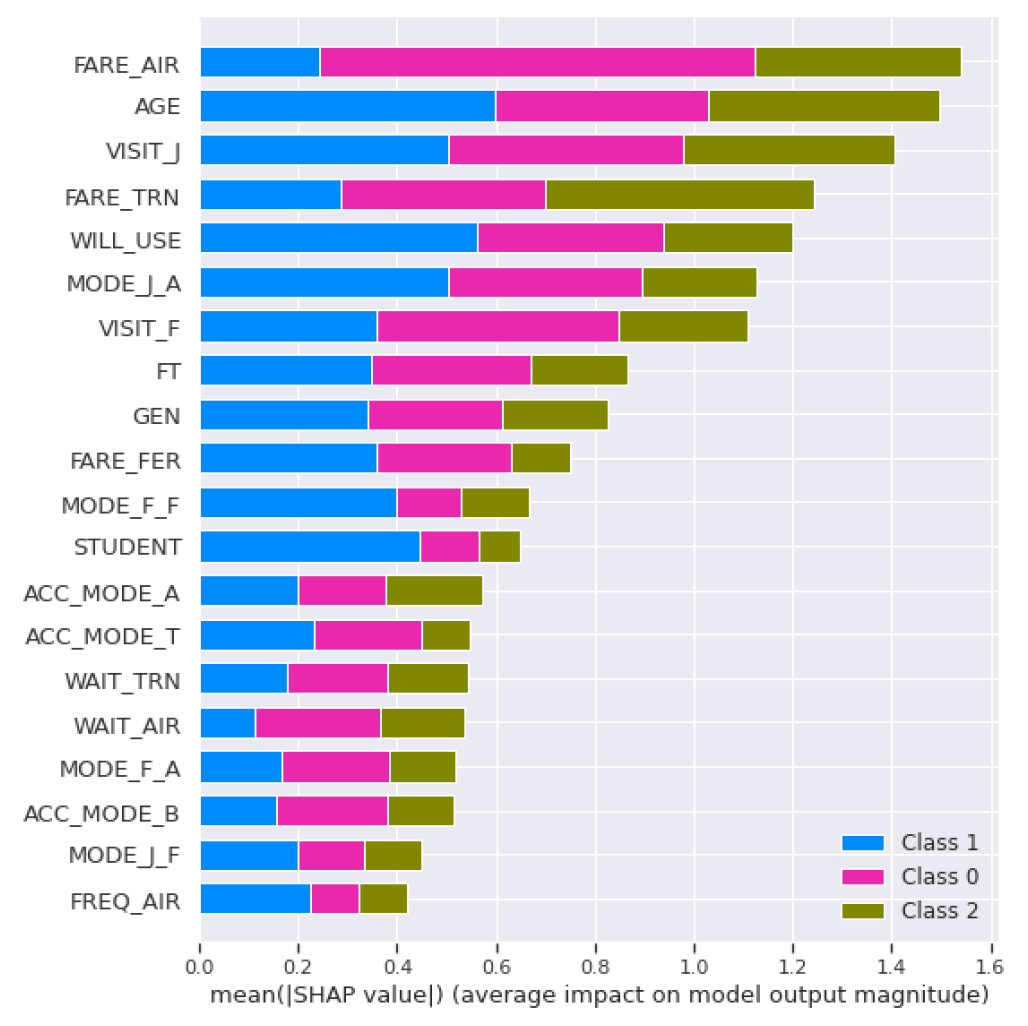
상대적 변수 중요도(Variable Importance)는 앞에서 언급하였듯이, 결정 나무 기반의 모형에서 모든 예측 변수를 비교하고 전체 분산의 감소에 기여하는 변수의 순위를 매겨 산정하는 것으로, 해당 변수가 전체 모형의 잔차제곱합(SSR)의 감소에 얼마나 많은 영향을 미쳤는지를 상대적으로 계량화한 것이다. 교통수단 선택 모형 예측 결과 수단선택 선호에 있어서는 전체적으로 Figure 3의 막대그래프의 전체 크기를 통해 알 수 있듯이 항공 요금, 나이, 일본 방문 빈도, 고속철도 요금 순으로 주요하게 영향을 미치는 것으로 확인되었다. 하지만 수단 그룹별로는 각 수단선택에 영향을 미치는 요인이 다른 것으로 나타났는데, 항공 수단(Class 0)을 선택하는 데에는 항공 요금, 일본 및 후쿠오카 방문 빈도와 연령순으로 중요 요인이 확인되고, 고속 페리(Class 1)을 선택하는 데에는 나이와 해저터널 이용 의사, 일본 방문 빈도, 일본 방문 때 항공 이용을 선택한 경험 순으로 중요도 순위를 확인할 수 있다. 고속철도(Class 2)의 경우에는 항공 수단과 마찬가지로 고속철도 요금과 나이, 일본 방문 빈도순으로 중요도가 산정되었다.
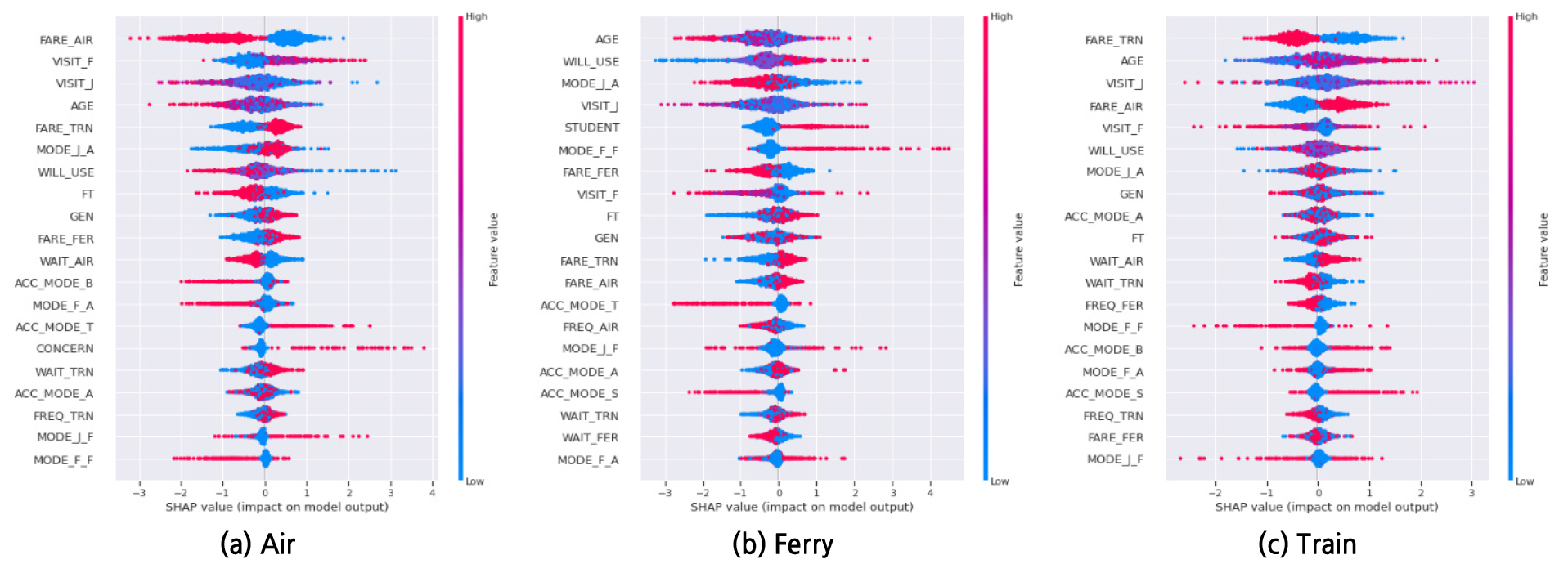
수단별 변수 중요도를 변수 간의 결합 요인을 고려하여 확인한 이른바 Summary plot(Figure 4)를 통해 제시하였다. 좌측에 나열된 변수들이 위에서부터 아래로 중요도의 순위로 정열 되어 있으며, 각 변수의 색이 그래프 우측의 적색-청색 gradient bar에서 나타난 바와 같이 붉을수록 높고 푸를수록 낮은 변수 값을 나타낸다. 수단 선택 별 변수 중요도를 살펴보면, 항공 수단을 선택하는 그룹에서는 항공 요금과 후쿠오카 및 일본 방문 빈도, 연령순으로 수단선택 선호도에 영향을 미치는 것으로 확인할 수 있다. 다음으로 각 변수가 수단선택에 미치는 선호 관계를 알 수 있는데, 예를 들어 FARE_AIR의 적색 부분이 Shaply value에서 음의 영역에서 확인되는 것을 통해 항공 요금이 높은 경우 수단선택 확률이 감소함을 확인할 수 있다. 같은 방법으로, 후쿠오카 방문 빈도가 높고, 일본 방문 빈도와 연령대가 낮은 경우 항공 수단선택에 더 긍정적인 영향을 미치는 것으로 해석할 수 있다. 고속 페리 수단을 선택하는 요인은 앞서 변수 중요도 막대그래프에서 확인한 바와 같이, 나이와 해저터널 이용 의사, 일본 방문 때 항공 이용, 일본 방문 빈도순으로 나타나며, 수단선택에 미치는 중요도의 우선순위를 Figure 4에서도 같은 순위로 확인할 수 있다. 항공 수단과는 달리 고속 페리의 요금은 그 중요도가 상대적으로 낮게 나타났으며, 일본 방문 때 항공 수단을 이용할 때는 부정적으로, 학생인 경우와 후쿠오카를 페리를 이용해 여행할 때는 고속 페리 수단선택에 긍정적인 영향을 미치는 것으로 나타났다. 고속철도의 경우에는 항공 수단과 마찬가지로 해당 수단(고속철도)의 요금과 나이, 일본 방문 빈도순으로 수단선택에 대한 중요도를 확인할 수 있으며, 철도 요금은 낮고, 나이와 일본 방문 빈도, 그리고 항공 요금이 높은 경우 고속철도 선택에 긍정적인 영향을 미치는 것으로 확인되었다.
다음으로, 각 변수의 변화에 따른 수단선택 선호 패턴의 변화는, 앞서 설명한 독립 변수 한 단위 변화에 따른 종속변수의 변화를 나타내는 평균 한계 변화율(Partial Dependence, PD)을 통해 확인할 수 있다. 지면 관계상 전체 변수 중요도에서 우선순위가 높게 나타난 항공 요금(FARE_AIR), 고속철도 요금(FARE_TRN), 나이(AGE), 그리고 일본 방문 빈도(VISIT_J)에 대해서 Figure 5를 평균 한계 변화율을 시각적으로 나타내었다. 그림은 항공, 고속 페리, 고속철도의 세 가지 수단에 대한항공 요금, 고속철도 요금, 나이, 일본 방문 빈도에 대한 평균 한계 변화율이며, 각 그래프 간의 비교와 이해를 돕기 위해, 수단선택 별 SAP value를 항공은 주황색, 고속 페리는 청색, 그리고 고속철도는 붉은색으로 나타내었다. 항공 요금이 증가하는 경우, 항공 수단선택에는 부정적으로, 고속철도 수단선택에는 긍정적으로 선호의 변화가 명확하게 변화되는 것을 확인할 수 있다. 하지만 고속 페리 수단을 선택할 때 있어서는 항공 요금의 증가가 그래프의 형태상으로 고속 페리 수단선택으로의 변화가 명확하게 나타나지도 않을 뿐만 아니라, y축에 나타난 종속변수의 척도 크기 또한 다른 수단선택의 경우에 비해 그 수준이 낮은 것으로 볼 때, 그 영향이 크지 않은 것을 확인할 수 있다.
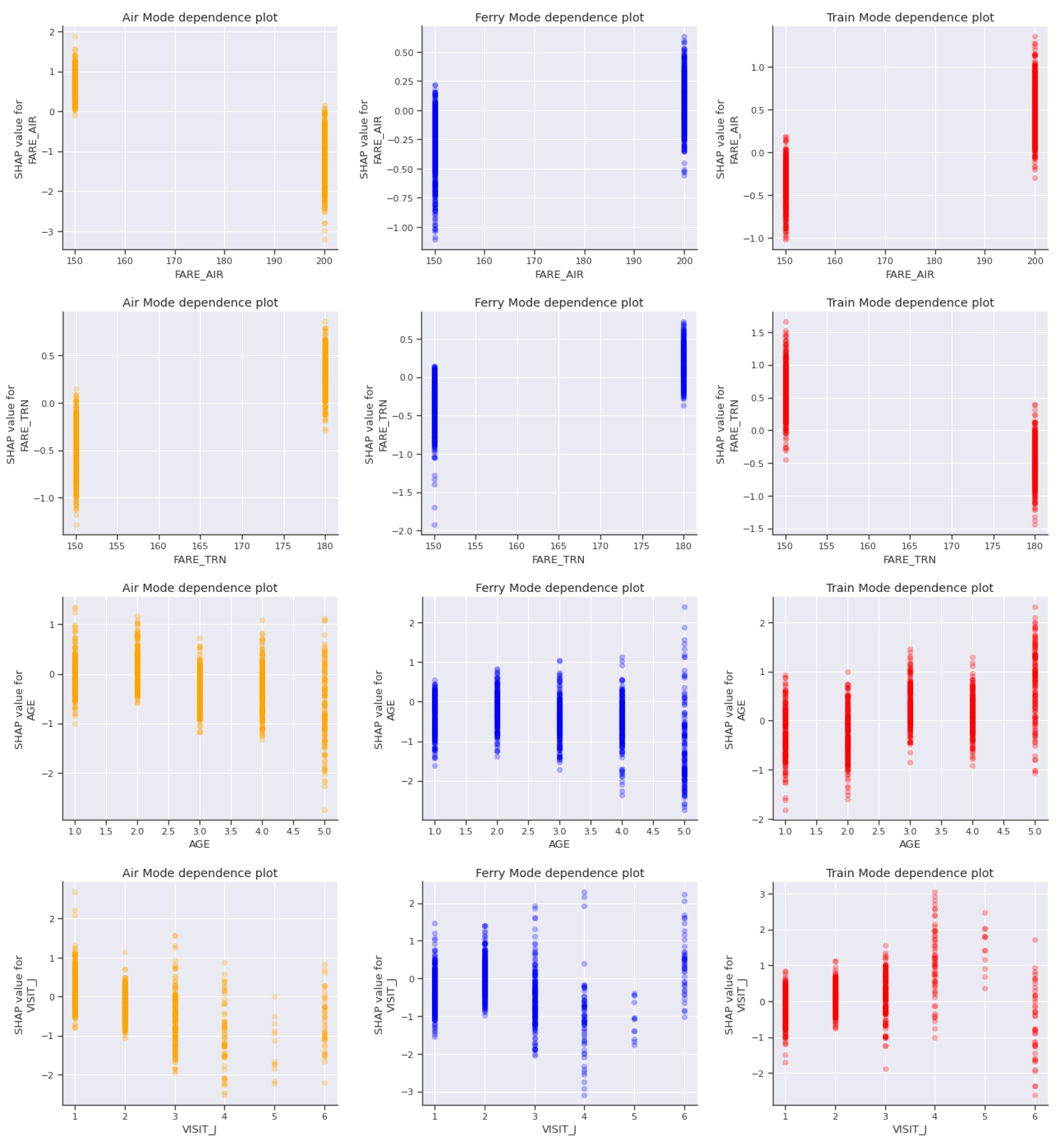
고속철도의 요금이 증가하는 경우, 해당 수단인 고속철도에 대한 선호가 그래프의 형태 뿐만 아니라 종속변수의 척도를 고려했을 때 부정적으로 바뀌는 것을 확실히 목격할 수 있으며, 항공 수단선택에서도 이보다는 적은 변화이지만 확실한 형태로 항공 수단선택에 긍정적인 영향을 미치는 것으로 나타났다. 다만 고속 페리 수단을 선택하는 경우, 고속철도 비용의 감소는 그 영향이 있기는 하지만 그 크기가 작은 그것으로 보인다. 이는 수단별 변수 기여도를 통해서도 확인한 바와 같이 항공 수단에서는 다섯 번째, 고속 페리 수단에서는 열한 번째로 중요한 변수로 나타난 것과 함께 비교했을 때 전체적으로 분석 결과가 일치함을 알 수 있다. 연령대의 변화에 관련해서도 각 수단선택의 선호에 차이가 있음을 확인할 수 있다. 먼저 항공 수단의 경우, 낮은 연령층일수록 항공 수단에 대한 선호가 확실하게 나타나며, 나이가 증가할수록 낮은 선호 수준을 보이는 것으로 나타났다. 고속 페리 수단의 경우에는 30-40대(Age 2.0-3.0)의 연령대에서 20대보다 높은 선호를 보이고, 이후 연령대가 증가할수록 분산의 정도가 커지기는 하지만 수단 선호가 감소하는 것으로 확인되었다. 고속철도의 경우에는 연령대가 높아질수록 수단에 대한 선택 선호가 증가하는 것으로 확인할 수 있다. 일본 방문 빈도에 있어서도, 방문 횟수가 점차 늘어 갈수록 항공 수단에서 고속 페리, 그리고 계획안으로 제시된 고속철도에 대한 수단 선호도가 높아지는 것으로 확인되었다.
이러한 특성들을 바탕으로 후쿠오카를 방문하는 수단별 선호 특성을 정리해 보면, 항공의 경우 요금이 저렴할수록, 그리고 일본 다른 지역과 비교해 후쿠오카를 자주 방문하는 낮은 연령층일수록 선택 확률이 높은 것으로 나타났고, 고속 페리는 요금은 상대적으로 덜 중요하지만, 학생층에서 후쿠오카를 고속 페리를 이용해 방문한 경험이 많은 층에서 선택 확률이 높은 것으로 확인되었으며, 터널 이용에 대한 의사가 두 번째로 중요한 수준으로 확인된 것으로 판단했을 때, 고속철도로의 수단 전환은 고속 페리보다는 항공 수단 이용자들로부터 이루어질 것으로 예상된다. 가상의 수단인 고속철도를 이용하여 후쿠오카를 방문하는 경우는 요금이 항공 요금보다 상대적으로 낮다고 판단되고, 연령층과 일본 방문 빈도가 높을수록 선택 확률이 높은 것으로 나타났다. 다만 항공과 고속철도의 요금이 증가하면 각각 고속철도 선택 확률과 항공 선택 확률이 증가하며 항공 수단과 비교해서 고속철도의 요금 증가에 따른 수단 변화가 좀 더 두드러질 것으로 예상된다. 연령대에 따라서도 수단 간 선호의 차이를 보였는데, 20대에서는 항공 수단 선호가 두드러지게 나타났으며, 연령대가 증가함에 따라 고속 페리와 고속철도로의 수단선택 선호 수준이 변화하는 것으로 알 수 있었다. 그리고 일본 방문의 빈도가 늘어날수록 고속 페리나 고속철도로의 수단선택 선호 형태가 변화되는 것을 확인할 수 있었다.
결론 및 시사점
본 연구에서는 부산-후쿠오카 구간의 한일 해저터널을 통과하는 고속철도 수단이라는 대안을 고려한 여객 수요에 대한 여객 통행 수단 선택 모형을 머신러닝을 활용한 앙상블 기법인 XGBoost를 적용하여 예측하였다. 또한, 머신러닝 기반 모형 기법이 가진 한계점인 해석력(interpretability) 한계점을 상대적 변수 중요도, 변수 기여도, 그리고 평균 한계 변화율을 SHAP value를 활용한 시각화 기법을 통해 극복함으로써, 수단선택 모형의 정책 분석에서의 머신러닝의 활용 가능성을 높이는 방안을 제시하였다.
모형의 결과로는, 설문 이용자의 장래 수단선택 예측 결과가 81.3%로 확인되어 높은 수준의 모형 예측력을 보였으며, 각 수단 간 예측 결과도 항공 69.2%, 고속 페리 65.2%, 고속철도 88.8%의 높은 수준으로 확인되었다. 상대적 변수 중요도를 통해 이용자의 수단선택 선호에 영향을 미치는 요인들은 항공 요금, 고속철도 운임, 나이, 그리고 일본 방문 빈도순으로 나타났으며, 수단별로 항공은 항공 요금, 후쿠오카 방문 빈도, 일본 방문 빈도순, 고속 페리는 나이, 터널 이용 의사, 일본 방문 때 항공 수단 이용 순, 고속철도는 운임, 나이, 일본 방문 빈도의 순으로 해당 수단선택에 큰 영향을 미치는 것을 확인하였다. 추가로 게임이론 기반의 대리모형 해석 기법인 SHAP value와 평균 한계 변화율을 통해, 각 변수의 변화에 따른 수단선택 변화의 선호 패턴 변화들을 분석할 수 있었다.
교통과 도시 문제에 관한 선호 분석 모형에서는 예측의 정확도와 함께 정책적으로 활용 가능한 분석 결과의 제공 또한 중요한 과제이다. 기존의 통계 및 계량 경제 모형 방법론은 수학적 가정(예: 함수의 형태)과 모수 추정 방식(예: 모형 파라미터 제공)을 통해 모형 결과에 대한 해석이 용이하여 여전히 정책적 분석에서 활용 가치가 매우 높지만, 상대적으로 예측력이 낮으며 빅데이터 환경에서의 추정과정이 효율적이지 못하다는 한계를 가지고 있다. 특히, 데이터가 구조가 복잡해지고 기록의 양이 많아질 경우, 사용자 선호와 행태에 영향을 미치는 변수의 관계를 분석가가 직접 파악하여 최적의 모형 식을 추정하는 과정은 분석 자원의 손실이 지나치게 크며, 시의적절한 대안 제시가 어렵다. 기계 학습 기법은 지난 수십 년간 컴퓨터 기술의 진보로 인해 많은 분야에서의 활용성과 높은 예측 정확도를 보여주고 있다. 대부분 자료 분포의 함수 형태에 대한 가정이 없는 비모수 추정 방식과 기계의 반복적인 연산 능력을 활용하므로, 머신러닝 기반의 통계 모형은 복잡한 데이터의 패턴이나 변수 간의 관계를 자동적으로 파악하여 정확한 예측을 제공한다는 점이 큰 장점으로 부각되어 왔지만 복잡한 모형 구조와 기계의 반복적인 연산을 통한 추정 방식으로 인한 결과 해석 가능성(interpretability)의 한계가 지적되어 왔다. 따라서 본 연구에서는 머신러닝의 장점인 높은 예측력을 극대화하고, 단점으로 지적되어 온 모형 및 추정 결과의 해석(interpretability) 가능성을 제시하여 향후 정책적 분석 도구로서의 활용 가능성을 제시했다는 데 의의가 있다. 다만, 본 연구에서 활용된 자료를 활용하여 이산선택모형을 바탕으로 한 관련 연구의 결과와의 비교는 변수 수준의 설정 차이 등으로 인해 모형의 차이점을 직접 비교하기에는 상이함이 있고, 한일해저 터널 개통과 관련하여 부산-후쿠오카 간의 고속철도 수단만 고려한 제한적인 시나리오 가정하에 모형 예측이 이루어 졌다는 점도 향후 연구의 확장이 필요하다고 판단된다. 또한 머신러닝 모형의 특성을 극대화 할 수 있는 관측자료가 아닌 SP 설문 자료를 분석하였다는 점도 연구 자료의 폭넓은 활용 가능성을 제시하지 못한 아쉬운 부분이라고 할 수 있다. 하지만, 향후 다양한 형태의 자료를 통합한 big-data 자료를 활용하여 교통 수단 선택 모형에 적용함으로서, 수단 선택 예측력과 광범위한 정책 대안 제시의 가능성을 확장 할 수 있기를 기대한다.
