

서론
선행연구
1. 교통 분야 도로 구성요소 및 노면 상태 검출 연구
2. GAN 기반 데이터 증강 방안 연구
3. 소결
방법론
실험
1. 데이터셋 구축
2. 모델 설계 및 학습
학습 결과 및 토의
1. 학습 결과
2. 토의
결론 및 향후 연구
서론
최근 인공지능 분야는 소프트웨어 및 하드웨어의 발전과 다양하게 수집되는 빅데이터를 통해 급속도로 성장하고 있다. 인공지능의 하위분야인 딥러닝은 인공신경망의 구조를 활용하여 데이터의 특징을 스스로 학습하는 알고리즘으로 자연어 처리, 음성인식, 컴퓨터 비전 등 다양한 분야에서 활용되고 있다. 특히 딥러닝은 컴퓨터 비전 분야에서 두각을 드러내고 있으며, 매년 진행되는 이미지 인식 경진대회인 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)를 통해 사람의 인식률을 뛰어넘는 수준으로 진화하였다. ILSVRC는 10,000,000개 이상의 대용량 데이터셋을 활용하여 이미지를 분류하는 대회이며, 이 대회를 통해 합성곱 신경망(Convolution Neural Network, CNN)기반의 AlexNet(Krizhevsky et al., 2012), VGGNet(Simonyan and Zisserman, 2014), GoogLeNet(Szegedy et al., 2015), Resnet(He et al., 2016) 등 정확도가 높은 알고리즘이 제안되었다. 나아가 이미지 분류에서 높은 정확도가 도출됨에 따라 여러 객체의 위치와 레이블을 예측하는 Mask R-CNN(He et al., 2017), Faster R-CNN(Ren et al., 2015), YOLO(Redmon et al., 2016) 등 이미지 분할과 객체 검출 알고리즘이 개발되었다. 이처럼 CNN의 높은 성능을 위해서는 대용량의 데이터셋이 구축되어야 한다. 만약 데이터셋이 부족한 경우 정확도가 낮게 도출되는 언더피팅 현상과 학습 데이터셋을 과도하게 학습하여 새로운 데이터를 대상으로 정확도가 낮게 도출되는 오버피팅 현상이 나타난다. 실제 컴퓨터 비전 분야에서는 이를 방지하기 위해 CIFAR-10, Fashion MNIST, MS-COCO, Cityscapes 등 대용량 오픈 데이터셋을 공개하여 이를 활용하고 있으며, 추가적인 대용량 데이터셋을 구축하기 위한 노력이 이루어지고 있다. 그러나 데이터 수집에는 많은 시간과 비용이 소모됨에 따라 이를 보완하는 방안으로 데이터 증강 기술이 활용되고 있다.
데이터 증강은 한정된 데이터를 다양한 알고리즘에 적용하여 데이터의 양을 늘리는 기술로 자르기, 뒤집기, 회전시키기, kernel filter 등 이미지의 색상, 밝기, 노출 등을 조절하는 방식과 Autoencoder, 생성적 적대 신경망(Generative Adversarial Network, GAN) 등 딥러닝을 활용하는 방식이 있다. 이러한 데이터 증강 기법을 통해 부족한 데이터의 양을 보완할 수 있으며, 이는 언더피팅과 오버피팅을 방지하여 객체 인식률의 향상에도 도움이 된다. 특히, 교통 분야에서는 교통사고를 예방하기 위해 대용량 데이터셋인 BDD100K, Cityscapes 등을 활용하여 자동차, 보행자, 교통표지판 등 도로 구성요소와 포트홀, 도로 균열 등 도로 노면 상태를 인식 및 분류하는 연구가 수행되고 있다. 그러나, 블랙 아이스의 경우 교통사고 심각성이 높음에도 불구하고 시간 및 비용 등 현실적인 문제로 인해 데이터셋을 구축하는데에 한계가 존재한다. 블랙 아이스는 비와 눈이 먼지와 같은 오염물질과 결합하여 도로에 형성되는 얇은 얼음으로 운전자의 눈에는 도로에 얼음이 없는 건조한 상태로 보여 인식하기 힘들다는 특징이 있다. 또한, 주로 다리 위, 터널의 출입구, 그늘진 도로 등에서 형성되는 지리적 조건과 도로 표면의 온도가 대기 온도보다 낮을 때 형성되는 기상 조건을 모두 충족해야 하는 까다로운 형성조건으로 인해 데이터 수집에 어려움을 겪고 있다. 특히 블랙 아이스는 차량 조작기능을 저하시키기 때문에 겨울철 대형 사고의 원인으로 지목되고 있으며, 2019년 12월 미국 버지니아 고속도로에서 발생한 69중 추돌 사고와 상주, 영천고속도로에서 발생한 43중 추돌 사고 등 블랙 아이스 사고는 지속적으로 발생하고 있다. 이에 따라 블랙 아이스 사고는 이미지 인식 기술을 통해 블랙 아이스가 형성된 구간을 파악하고 사전에 사고를 예방해야 할 필요성이 존재한다. 그러나, 형성조건의 특이성으로 인해 블랙 아이스 이미지 데이터가 부족함에 따라 대용량 데이터셋을 구축하는 것에 한계가 존재한다.
이에 본 연구는 블랙 아이스를 대상으로 이미지를 생성하는 딥러닝 알고리즘 GAN의 한 종류인 Pix2Pix를 활용하여 블랙 아이스 이미지 데이터의 증강 방안을 제시하고자 하며, 이를 통해 블랙 아이스 이미지 인식을 위한 데이터셋을 구축하는 것에 그 목적이 있다.
선행연구
1. 교통 분야 도로 구성요소 및 노면 상태 검출 연구
전 세계적으로 자동차 보급률이 높아짐에 따라 교통사고는 지속적으로 발생하고 있으며, WHO 보고서에 따르면 매년 100만 명 이상의 사망자가 꾸준하게 발생하고 있다. 이는 연간 범죄로 인한 사망자 수가 약 50만 명인 것과 대비하여 매우 높은 수치이다. 이처럼 심각한 인적 피해를 일으키는 교통사고를 예방하는 것은 매우 중요하고 이를 예방하기 위한 다양한 노력이 이루어지고 있다. 특히 교통사고는 인적요인에 의해 90% 이상 발생하기 때문에 인간의 주행을 보조하는 ADAS(Advanced Driver Assistance System)의 개발, C-ITS(Cooperative Intelligent Transport Systems) 인프라 구축 등이 진행되고 있다. 이러한 시스템의 일환으로 이미지 인식 및 분류 기술이 활용되고 있으며, 자율주행자동차의 교통사고를 예방하기 위해 도로 구성요소와 도로 노면 상태 데이터셋 기반의 이미지 인식 및 분류 연구가 수행되고 있다. 도로 구성요소로는 자동차, 보행자, 표지판 등을 검출하는 연구가 진행되고 있었으며, 도로 노면 상태로는 도로 균열, 노면 표시 등을 검출하는 연구가 수행되고 있었다.
Yang et al.(2013)은 wavelet transformation과 SVM(Support Vector Machine)을 활용하여 도로 표면 상태를 분류하는 연구를 수행하였다. 도로 표면 상태를 4개의 클래스(마름, 젖음, 눈, 얼음)로 분류하였으며, wave transformation을 활용하여 특징을 추출하고, 이를 바탕으로 SVM을 통해 도로 표면 상태를 분류하였다. 성능을 평가하기 위해 k-means 알고리즘과 비교를 진행하였으며 연구 결과 모든 클래스에서 SVM의 분류 정확도가 높게 도출되는 것을 확인하였다. 그러나 SVM의 평균 정확도는 87%가 도출되어 절대적인 수치로는 분류 정확도가 낮다는 한계가 존재하였다. Muñoz-Bulnes et al.(2017)은 데이터 증강 기법을 활용한 도로 객체 검출 연구를 수행하였다. 위 연구는 데이터 증강 기법으로 시점 변환, 이미지 자르기, 왜곡, 색 변환 등 기하학적 증강과 pixelwise changes를 적용하여 훈련 데이터의 증강을 수행하였다. 객체 검출 모델은 CNN 기반의 ResNet-50과 ResNet-101을 채택하였으며, 객체 검출 지표로 F-measure를 활용하였다. 연구 결과, 데이터 증강과정을 활용한 데이터셋의 객체 검출 정확도가 향상되었고, 이를 통해 데이터 증강과정이 객체 검출 정확도에 영향을 미치는 것을 시사하였다. Maeda et al.(2018)은 도로 파손 검출을 위한 대규모 데이터셋을 구축하였고, 도로 파손의 종류를 분류하는 연구를 수행하였다. 총 8개의 클래스로 구분하였으며, SSD Inception V2와 SSD MobileNet를 활용하여 성능 평가를 진행하였다. 연구 결과 0.75 이상의 recall과 precision이 도출되었으며, 스마트폰에서 1.5초 이내에 검출이 가능한 것을 확인하였다. 또한, 위 연구는 약 16만장의 도로 이미지에서 9,053개의 대용량 도로 파손 데이터셋을 구축한 것에 의의가 있다. Wang et al.(2019)은 데이터 증강을 통해 자동차, 집, 철탑, 와이어 등 도로 구성요소의 데이터셋을 구축하였고, 이를 활용한 객체 검출 연구를 수행하였다. 데이터 증강 기법으로는 다양한 시점을 제공할 수 있는 perspective transformation을 선정하였으며, 자르기, 뒤집기, 노이즈 형성, 무작위 지우기 등을 진행한 데이터셋과 mAP(mean Average Precision)를 비교하였다. 실험 결과, perspective transformation과 자르기 기법을 활용한 데이터셋의 mAP가 가장 높게 도출되었다. 위 연구는 데이터 증강 기법을 활용하여 객체 검출 모델의 학습 데이터셋을 구축한 것의 그 의의가 있으며, 이를 통해 mAP가 향상된다는 것을 확인하였다. 향후 연구로는 작은 객체를 대상으로 한 데이터 증강 및 객체 검출 연구를 제시하였다. Li et al.(2020)은 CNN을 활용하여 도로의 균열을 분류하는 연구를 수행하였다. 위 연구는 데이터 전처리를 통해 512×512px 크기의 패치를 생성하고, 5개의 클래스로 분류하여 CNN 학습을 진행하였고, 제안한 모델의 성능 평가를 위해 기존의 CNN 분류 모델과 비교 ‧ 분석을 수행하였다. 실험 결과, 연구에서 제안한 모델의 정확도는 94%를 기록하여 다른 CNN 모델과 대비하여 정확도가 떨어졌지만, 이진 분류(균열, 비균열)가 아닌 5개의 범주를 분류한 것에 그 의의가 있다. Chung et al.(2020)은 드론으로 촬영한 이미지 데이터를 활용하여 YOLOv3 기반의 객체 검출연구를 수행하였다. 객체는 자동차, 트럭, 버스, 이륜차로 설정하였으며, 데이터 증강 기법을 활용하여 부족한 데이터의 양을 보완하였다. 데이터 증강 기법으로 자르기와 무작위 회전을 진행하였으며, 이를 통해 AERIAU 데이터셋을 구축하였다. YOLOv3 학습결과, 기존 데이터셋과 대비하여 정확도가 10%p 상승하는 것을 확인하였다. 또한, 한 가지 증강 기법을 활용하는 것보다 두 가지(자르기, 무작위 회전) 기법을 활용한 경우 정확도가 더욱 높게 도출되는 것을 확인하였다. 위 연구는 데이터 증강 기법을 두 가지만 활용하였다는 한계가 존재하였지만, 데이터 증강을 통해 객체 인식률의 향상이 가능하다는 것을 시사하였다. Alzraiee et al.(2021)은 Faster R-CNN을 활용하여 도로 마킹 결함을 검출하는 연구를 수행하였다. 위 연구는 구글 맵 이미지 데이터를 활용하였으며, 도로 마킹 결함을 총 9개로 분류하여 데이터 라벨링을 진행하고, Faster R-CNN의 학습을 진행하였다. 실험 결과 43-99%의 신뢰 범위로 도로 마킹 결함을 성공적으로 식별하는 것을 확인하였다.
2. GAN 기반 데이터 증강 방안 연구
다수의 데이터를 구축하는 것은 딥러닝 알고리즘의 학습을 통한 객체 인식 과정에서 매우 중요하다. 데이터의 수가 부족하면 객체 인식 정확도가 낮게 도출될 수 있으며, 학습 데이터를 과도하게 학습하여 새로운 데이터를 정확하게 예측하지 못하는 과적합 현상이 발생하기 때문이다. 이로 인해 부족한 데이터의 수를 늘리기 위한 데이터 증강 방안으로 다양한 방법론이 활용되고 있으며, 주로 GAN을 활용한 연구가 활발하게 수행되고 있었다. GAN의 종류는 DCGAN(Deep Convolutional GAN), CycleGAN, SRGAN(Super Resolution GAN) 등이 있으며, 주로 GAN, DCGAN, CGAN(Conditional GAN), Pix2Pix를 활용하여 데이터 증강 연구가 수행되고 있었다. 또한, GAN 알고리즘을 기반으로 새로운 구조를 제안하는 연구도 수행되고 있었다.
Madani et al.(2018)은 GAN 기반의 데이터 증강을 진행하고 CNN 학습을 통해 심혈관 이상 이미지를 분류하는 연구를 수행하였다. 위 연구는 NIH PLCP 데이터셋을 활용하였으며, GAN을 통해 정상과 비정상의 흉부 x-ray 이미지 500장을 생성하였다. 이후 증강을 수행하지 않은 데이터와 뒤집기, 자르기, 확대/축소하기 등을 활용한 증강 데이터와 GAN을 활용한 증강 데이터로 데이터셋을 구축하여 이미지 분류 성능을 평가하였다. GAN을 활용한 증강 데이터의 분류 정확도가 84.19%로 가장 높게 도출되어 증강 데이터가 우수한 품질의 이미지인 것을 확인하였다. Tanaka and Aranha(2019)는 데이터 불균형 문제를 해결하기 위해 GAN을 활용하여 이미지를 증강하는 연구를 수행하였다. 총 3개의 데이터셋을 활용하였으며, Original, SMOTE, ADASYN, GAN을 활용한 데이터 증강을 수행하였다. 알고리즘의 성능 평가는 의사결정나무를 활용하였으며, 실험 결과 GAN의 성능은 SMOT, ADASYN 보다 낮았지만, 기존 대비 높은 정확도(accuracy)와 재현율(recall)이 도출되었다. 또한, GAN은 다른 알고리즘과 달리 규칙이나 제약조건을 적용할 필요가 없다는 이점이 존재한다는 것을 시사하였다. Fang et al.(2018)은 DCGAN을 활용하여 부족한 날씨 데이터셋을 보충하고 CNN을 활용한 이미지 분류 연구를 수행하였다. 라이다 데이터를 대상으로 4개의 클래스를 분류하였으며, DCGAN을 활용하여 클래스별 1,000장의 이미지를 증강하였다. 증강 데이터를 활용한 CNN 학습 결과, 기존 데이터셋과 비교하여 정확도가 향상됨에 따라 데이터 증강을 통해 분류 정확도가 상승하는 것을 확인하였다. Fang et al.(2019)은 DCGAN을 활용하여 손 제스쳐 이미지를 증강하고 이를 활용하여 제스쳐를 인식하는 연구를 수행하였다. 위 연구는 숫자, 감정, 알파벳을 표현하는 손 제스쳐 이미지를 활용하여 DCGAN 기반의 데이터 증강을 수행하였다. 연구 결과, 증강 데이터를 활용한 것이 기존과 비교하여 정확도의 향상이 나타났으며, 실시간으로 제스쳐 인식이 가능한 것을 확인하였다. Xing et al.(2019)은 Pix2Pix를 활용하여 흉부 x-ray 이미지를 증강하는 연구를 수행하였다. 위 연구는 Atelectasis, Cardiomegaly, Effusion, Infiltration, Pneumonia, Pneumothorax에 해당하는 흉부 x-ray 이미지를 증강하였으며, StarGAN을 통해 생성된 이미지와 비교분석을 진행하였다. 전문가 평가를 통해 Pix2Pix 기반의 생성 이미지가 더 우수한 품질인 것을 확인하였으며, 추가적으로 Faster R-CNN 기반의 객체 검출 연구를 수행하였다. 실험 결과, 기존의 데이터를 활용한 것보다 Pix2Pix의 증강 이미지를 추가한 것의 성능이 우수한 것으로 나타남에 따라 Pix2Pix를 통해 우수한 품질의 이미지를 생성할 수 있다는 것을 확인하였다. Tran et al.(2018)은 GAN의 문제점인 모드 축소와 기울기 소실을 완화하기 위해 Dist-GAN이라는 새로운 구조를 제시하였다. 제안한 Dist-GAN 모델의 생성자에는 Autoencoder를 추가하고, distance constraints를 사용하였다. Dist-GAN의 성능 평가를 위해 다양한 데이터셋(MNIST-1K, VelebA, CIFAR-10 등)을 활용하여 기존의 GAN 방법론(MDGAN, WGAN-GP, VAEGAN 등)의 FID score를 도출하였다. 연구 결과, Dist-GAN의 모드 축소가 매우 감소하였으며, FID score가 낮게 도출됨에 따라 제안한 Dist-GAN이 이미지를 우수하게 생성하는 것을 확인하였다. Ali-Gombe et al.(2019)은 MFC-GAN(Multiple Fake Classes GAN) 구조를 제안하여 얼굴 이미지를 증강하는 연구를 수행하였다. 위 연구는 제안한 방법론과 ACGAN(Auxiliary Classifier GAN)을 통해 안경 쓴 사람과 염소수염을 가진 사람의 얼굴 이미지를 생성하였으며, 이미지의 평가 지표로 CNN 기반의 분류 결과와 FID score를 활용하였다. 실험 결과, MFC-GAN을 기반 데이터셋의 CNN 분류 정확도가 높았으며, FID score는 ACGAN과 비교하여 낮게 도출됨에 따라 MFC-GAN으로 생성한 이미지의 품질이 우수한 것을 확인하였다.
3. 소결
졸음운전, 과속, 운전미숙 및 부주의 등의 인적요인과 자동차 보급률의 증가로 인해 교통사고는 지속적으로 발생하고 있으며, 이로 인해 생기는 인적 피해가 심각함에 따라 교통사고를 예방하는 것은 매우 중요하다. 이를 위해 인공지능 기반의 이미지 인식 기술을 활용되고 있으며, 도로 구성요소와 도로 노면의 상태를 인식 및 분류하는 연구가 활발하게 수행되고 있었다. 특히 도로 노면의 경우 데이터가 부족함에 따라 데이터 증강 기법을 활용하여 데이터셋을 구축하는 연구가 존재하였으며, 이를 활용한 객체 검출을 통해 객체 인식률의 향상이 가능한 것을 확인하였다. 그러나, 활용하는 데이터 증강 기법이 다양하지 않았으며, 주로 자르기, 뒤집기, 회전등이 활용되고 있었다. 다음으로 GAN 기반의 데이터 증강 관련 연구를 고찰한 결과, DCGAN, Pix2Pix 등 다양한 알고리즘을 활용하여 데이터 증강 연구가 수행되고 있었다. 특히 Pix2Pix를 활용한 경우 직접 라벨링을 진행하여 객체의 위치에 따라 적절한 이미지가 생성 가능하였고, 이를 활용한 객체 검출 결과 객체 인식률의 향상이 가능한 것을 확인하였다. 또한, Pix2Pix는 다른 방법론과 대비하여 실제 이미지를 기반으로 객체의 위치와 형태를 파악할 수 있는 라벨 이미지를 제공하여 안정적인 학습이 가능하였으며, 학습이 완료된 모델에 실제 이미지가 존재하지 않는 새롭게 생성한 라벨 이미지를 입력하여 원하는 모양과 원하는 위치에 존재하는 객체가 포함된 이미지를 생성 가능하다는 장점이 존재하였다. 그러나, 블랙 아이스의 경우 생성 조건이 까다롭고 육안으로 확인하기 힘든 특성으로 인해 데이터 수집 및 증강에 한계가 존재함에 따라 이와 관련된 연구는 미비하였다. 본 연구는 Pix2Pix를 활용하여 블랙 아이스 이미지 데이터의 증강 방안을 제시하는 것에 그 차별성이 있으며, 이를 통해 블랙 아이스 객체 인식을 위한 데이터셋을 구축하는 것에 그 의의가 있다.
방법론
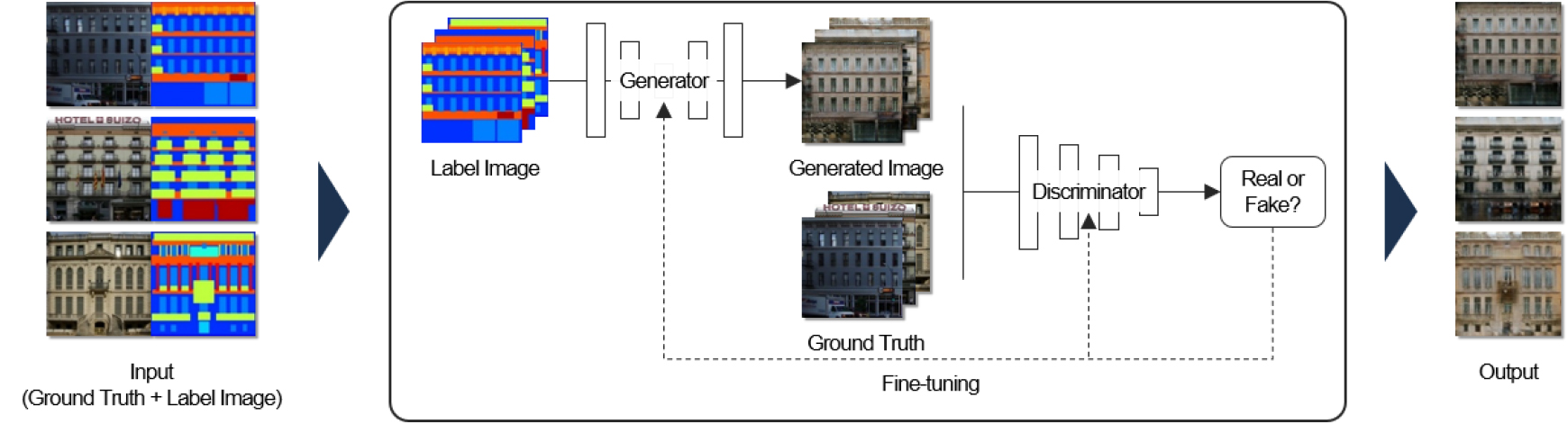
Pix2Pix는 CGAN의 일종으로 이미지를 생성하는 비지도 학습 딥러닝 알고리즘이다. 이는 하나의 이미지를 입력하는 GAN과 달리 두 개의 이미지를 입력하여 안정적인 학습이 가능하다는 장점이 있다. 또한, 창문, 문, 벽면 등 객체의 종류와 위치를 지정하는 라벨링을 진행하여 새로운 이미지를 생성할 수 있다. Pix2Pix의 입력 이미지는 256×256px 크기의 정답 이미지(Ground Truth)와 라벨 이미지(Label Image)를 합친 512×256px 크기의 이미지이며, 이를 활용하여 정답 이미지와 유사한 새로운 이미지를 생성한다. Pix2Pix의 구조는 Figure 1과 같이 생성자(Generator)와 판별자(Discriminator)로 구성되어있다. 생성자는 이미지의 크기를 줄였다가 늘리는 Enconder-Decoder 구조이며, 라벨 이미지를 활용하여 진짜 같은 가짜 이미지를 생성한다. 이후 생성자가 생성한 이미지(Generated Image)는 정답 이미지와 함께 판별자에 입력된다. 판별자는 PatchGAN 구조이며 30×30px 크기의 patch를 생성한다. 생성된 patch는 정답 이미지를 기반으로 생성 이미지의 진위여부를 판별하고 patch가 입력 이미지보다 작게 생성되기 때문에 두 이미지를 세부적으로 비교할 수 있다는 장점이 있다. Pix2Pix의 학습이 진행되면서 생성자와 판별자는 미세조정을 진행하며, 이를 통해 정답 이미지와 비슷한 이미지를 생성한다. 위와 같은 과정을 통해 학습이 완료된 Pix2Pix 모델에 라벨 이미지를 입력하면 각 객체의 형태 및 위치를 반영한 이미지를 생성할 수 있다.
요약하면, Pix2Pix는 GAN의 일종으로 비지도학습의 알고리즘이지만 정답 역할을 하는 라벨 이미지를 제공하여 안정적인 학습이 가능하고, 학습이 완료된 모델에 라벨 이미지를 입력하면 새로운 이미지를 생성할 수 있는 장점이 존재한다. 그러나, 라벨 이미지를 전처리하여 입력 데이터로 제공해야 하는 단점이 존재한다. 이에 본 연구는 Pix2Pix 방법론을 활용하여 블랙 아이스 이미지 데이터의 증강을 진행하고자 한다.
실험
1. 데이터셋 구축
본 장에서는 Figure 2와 같이 Pix2Pix 학습에 필요한 데이터를 수집하고 전처리를 진행하여 학습에 필요한 데이터셋을 구축하였으며, 데이터 수집 및 크롭(Data Collecting & Data Crop), 데이터 라벨링(Data Labeling), 데이터 결합 및 데이터셋 분할(Data Combining & Dataset Split)을 진행하였다.

1) 데이터 수집 및 크롭
본 연구에서 활용하고자 하는 블랙 아이스 이미지의 대규모 데이터셋은 구축되어있지 않다. 이에 따라 우선 Pix2Pix 학습에 필요한 블랙 아이스 이미지 데이터를 수집하였다. 이는 구글과 유튜브를 활용하였으며, 검색을 통해 블랙 아이스 이미지와 블랙 아이스 실험 영상 및 사고 영상을 확보하였다. 영상의 경우 프레임 단위로 이미지를 추출하였으며, Figure 3과 같이 블랙 아이스 이미지로 구성된 Original Data를 확보하였다. 다음으로 Original Data를 대상으로 데이터 크롭을 진행하였다. 이미지의 크기를 256×256px로 설정하였으며, 무작위 크롭(random crop)을 진행하여 Crop Data를 확보하였다. 무작위 크롭을 통해 256×256px 크기의 이미지를 확보하였으나, 이들 중 학습에 불필요한 이미지가 존재하였다. 본 연구는 블랙 아이스 이미지를 생성하는 것이 목적이므로 블랙 아이스가 포함된 이미지만을 선별하였으며, 위와 같은 과정을 통해 총 388장의 Crop Data를 확보하였다.

2) 데이터 라벨링
Pix2Pix는 라벨 이미지를 입력하여 학습에 활용한다. 이는 객체의 위치를 라벨링한 이미지를 통해 각 객체의 특징을 학습시킴으로써 실제와 비슷한 이미지를 생성하기 위함이다. 이에 본 장에서는 라벨 이미지를 만들기 위해 데이터 라벨링을 진행하였다. 앞서 데이터 크롭을 통해 확보한 Crop Data에는 블랙 아이스, 도로뿐만 아니라 하늘, 차량, 교통콘 등 외부가 포함되어 있다. 본 연구는 도로 위에 생성된 블랙 아이스 이미지를 확보하는 것이 목적이기 때문에 블랙 아이스와 도로의 경우 반드시 라벨링을 진행하여 객체별 특징을 학습시켜야 한다. 그러나 외부의 경우 많은 객체가 포함되어 있으며, 블랙 아이스와 관련이 없는 부분이다. 또한, 388장의 Crop Data에서 외부를 세분화한다면 객체에 대한 학습 데이터 수가 적어지기 때문에 객체의 특징을 학습할 가능성이 낮아진다. 이러한 이유로 이미지를 블랙 아이스, 도로, 외부로 나누었으며, 라벨링을 진행하였다. 우선 하늘, 차량, 교통콘 등 외부를 파란색(#2400ff)으로 라벨링 하여 Out-label Data를 구축하였으며(Figure 4), 이는 향후 Pix2Pix 학습에서 정답 이미지로 활용될 예정이다. 다음으로 Out-label Data에 도로와 블랙 아이스를 각각 노란색(#ff0000), 빨간색(#ff0006)으로 라벨링 하여 Label Data를 구축하였다(Figure 4).

3) 데이터 결합 및 데이터셋 분할
다음으로 Pix2Pix의 데이터와 형태를 일치시키기 위해 데이터 결합을 진행하였고, 데이터셋 분할을 통해 train data와 test data를 지정하였다. 앞서 데이터 라벨링을 통해 정답 이미지로 활용되는 Out-label Data와 객체별 위치 및 특징을 표시하는 Label Data를 확보하였다. 데이터 결합에서는 256×256px 크기인 두 이미지를 이어 붙여 512×256px 크기의 Combination Data를 구축하였다(Figure 5). 다음으로 Figure 6과 같이 데이터셋 분할을 진행하였다(Figure 6). 우선 Combination Data에서 무작위로 350장을 추출하여 train data로 지정하였다. 다음으로 Combination Data에서 남은 38장의 데이터를 test data로 지정하였으며, 추가적인 이미지 확보를 위해 50장의 New Label Data를 생성하였다. 우선 원하는 위치에 다양한 형태의 블랙 아이스를 라벨링 하였고, 도로와 외부의 라벨링을 진행하였다. New Label Data는 새롭게 만든 이미지이기 때문에 정답 이미지를 빈 사각형으로 채웠으며, 두 이미지를 결합하여 데이터를 생성하였다. 이러한 데이터셋 분할 과정을 통해 350장의 train data와 88장의 test data를 확보하였으며, 데이터의 현황은 Table 1과 같다.
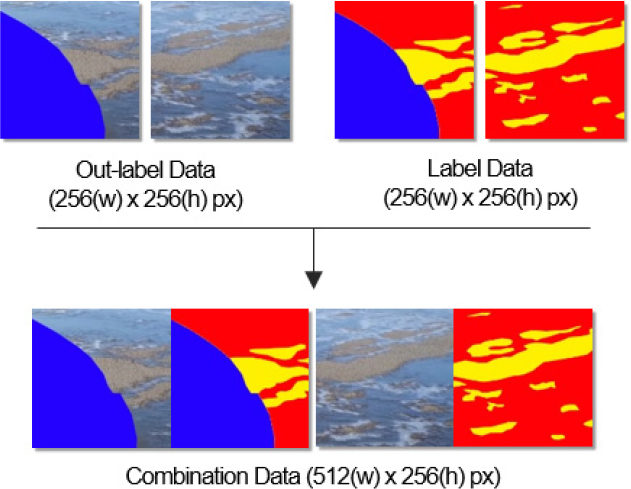
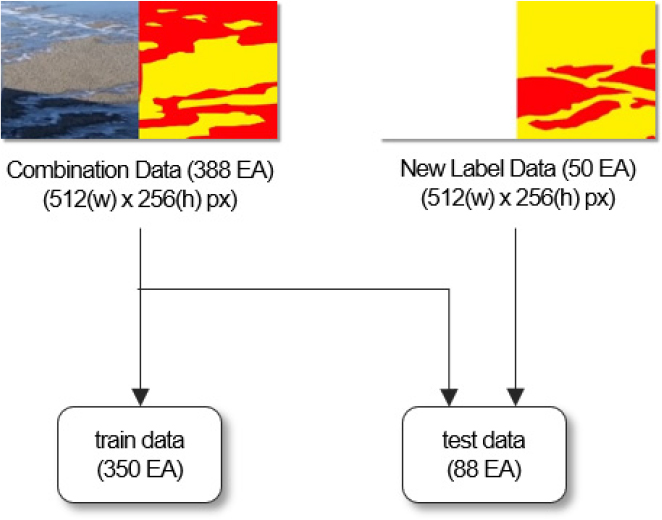
Table 1.
A number of data
| Dataset | Number | |
| Train data | Combination data | 350 EA |
| Test data | Combination data | 38 EA |
| New label data | 50 EA | |
2. 모델 설계 및 학습
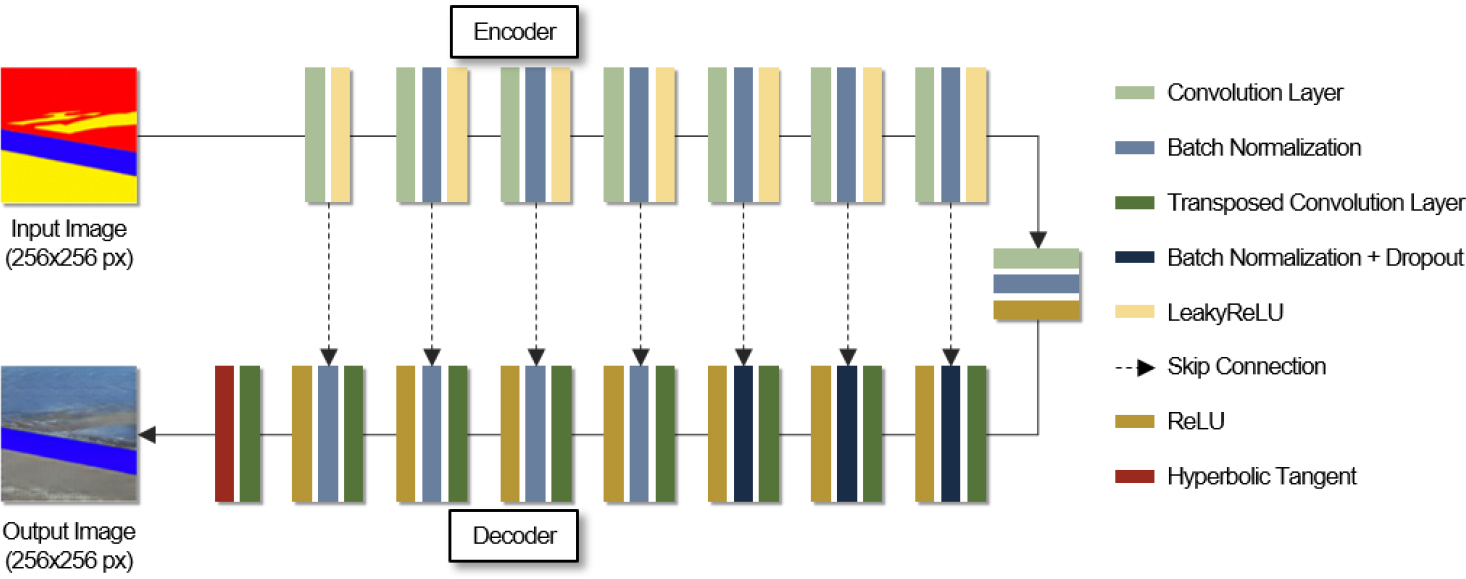
Pix2Pix의 생성자(Generator)와 판별자(Discriminator)는 모델을 처음 제안한 Isola et al.(2017)의 구조를 활용하였다. 이미지를 생성하는 생성자의 구조는 Figure 7과 같다. 생성자는 라벨 이미지를 입력하여 새로운 이미지를 생성한다. 이는 이미지의 크기가 줄었다가 커지는 encoder-decoder 구조이며, encoder에서는 convolution layer를 활용하여 이미지의 크기를 줄이면서 핵심 특징만을 추출하는 다운샘플링을 진행한다. 또한, 과적합을 방지하고 기울기 소실 문제를 해결하기 위해 batch normalization을 진행하였으며, 활성화 함수는 LeakyReLU를 적용하였다. decoder의 경우 encoder에서 추출한 특징을 활용하여 각 라벨에 맞는 객체를 생성한다. decoder에서는 transposed convolution layer를 활용하여 이미지의 크기를 키우면서 이미지를 복원하는 업샘플링을 진행한다. 또한, batch normalization을 진행하였으며, 활성화 함수는 ReLU와 hyperbolic tangent를 적용하였다. 그러나, 생성자는 이미지의 크기를 줄였다가 늘리기 때문에 특징이 손실된다는 단점이 존재한다. 이를 보완하고자 encoder의 결과를 decoder에 concatenate하는 skip connection을 적용하여 특징의 손실을 최소화하였다.
다음으로 생성된 이미지의 진위여부를 판별하는 판별자(Discriminator)의 구조는 Figure 8과 같다. 판별자는 PatchGAN 구조를 활용하는 것이 특징이다. 이는 전체 이미지를 한 번에 검토하는 방식이 아니라 특정 크기의 patch를 단위로 하여 이미지의 진위여부를 판별한다. 판별자는 256×256px 크기의 생성자가 생성한 이미지(Generated Image)와 정답 이미지(Ground Truth)를 활용한다. 처음에는 stride가 2인 convolution layer를 활용하여 이미지의 크기를 줄이고 batch normalization을 적용하며 활성화 함수는 LeakyReLu를 적용한다. 마지막 2개의 convolution layer는 stride를 1로 적용하고, 특징의 손실을 막고자 zero padding을 진행한다. 출력 직전의 활성화 함수는 Sigmoid를 적용하였으며, 최종적으로 30×30px 크기의 결과를 출력한다. 이는 patch 단위로 적용되며, 입력 이미지의 70×70px 영역에 해당된다. 출력된 output은 sliding 방식의 연산을 통해 생성된 이미지의 진위여부를 판별하고, 이로 인해 정답과 유사한 이미지가 생성된다. 위와 같이 생성자와 판별자를 설계하였으며, 학습 횟수는 200회로 설정하여 Pix2Pix의 학습을 진행하였다.

학습 결과 및 토의
1. 학습 결과
본 장에서는 Figure 9와 같이 Pix2Pix 모델의 학습 결과를 분석하였다. 우선 학습 과정에서 도출되는 l1-loss, 생성자 loss, 판별자 loss의 추이를 살펴보고 분석을 진행하였다. 다음으로 train data를 입력하여 생성된 이미지와 test data를 입력하여 생성된 이미지의 정량적 평가를 진행하였으며, 추가적인 분석을 위해 정성적 평가를 진행하였다.

1) loss 변화
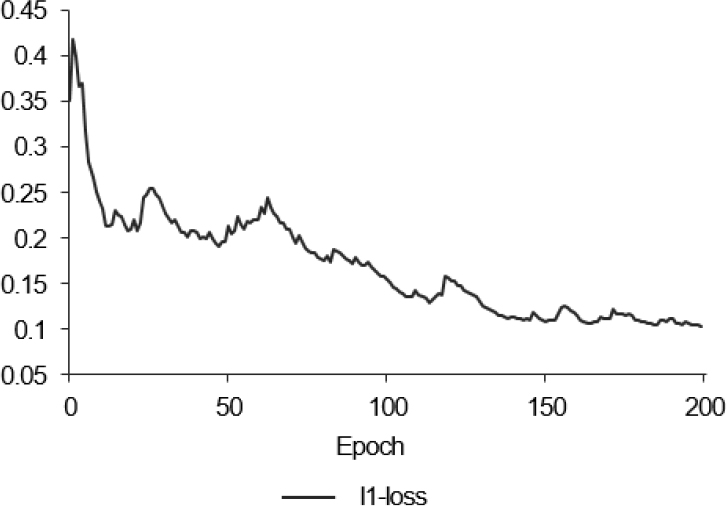
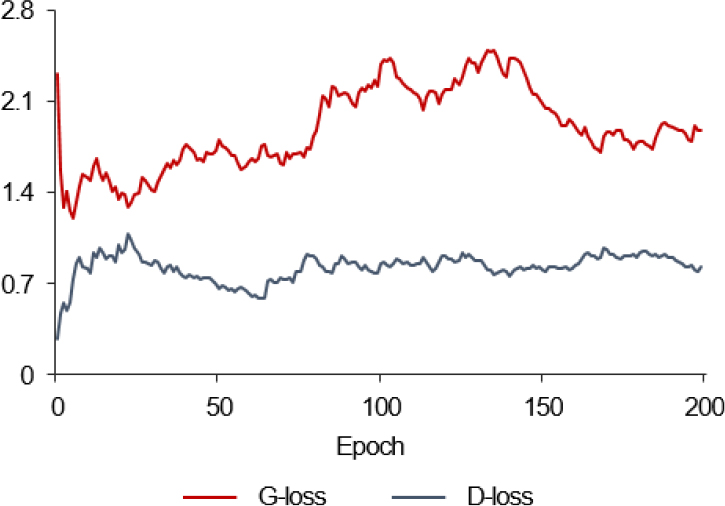
loss는 l1-loss, 생성자 loss(G-loss), 판별자 loss(D-loss)를 도출하였으며, smoothing 값을 0.95로 설정하여 loss의 추이를 살펴보았다. l1-loss는 생성자가 생성한 이미지와 정답 이미지의 각 픽셀 간 평균제곱오차(Mean Absolute Error, MAE)를 계산한 값이며, epoch 별 l1-loss의 변화는 Figure 10과 같다. l1-loss의 경우 학습이 진행될수록 우하향하는 이상적인 형태를 보이는 것으로 확인되었다. 다음으로 epoch 별 생성자 loss와 판별자 loss를 도출하였으며, 이는 Figure 11과 같다. G-loss는 Equation 1과 같이 l1-loss에 LAMBDA를 곱한 값과 생성된 이미지와 1의 배열의 이미지의 sigmoid cross entropy loss를 더한 값으로 구할 수 있다. LAMBDA를 l1-loss에 곱해줌으로써 흐릿한 결과물을 뚜렷하게 도출할 수 있으며, 해당 값은 Isola et al.(2017)의 연구를 참고하여 100으로 설정 하였다. D-loss는 Equation 2와 같이 정답 이미지와 1의 배열의 이미지의 sigmoid cross entropy loss인 real loss와 생성된 이미지와 0의 배열의 이미지의 sigmoid cross entropy loss인 generated loss의 합으로 구할 수 있다. Figure 11은 epoch 별 G-loss와 D-loss의 변화이며, 두 loss 중 하나가 급격하게 증가하거나, 감소하는 경우 한 모델이 학습을 지배하는 것을 의미한다. 학습 결과, G-loss는 epoch 1에 2.31로 도출되었고, 학습 마지막인 epoch 200에 1.876이 도출되었으며 D-loss는 epoch 1에 0.277로 도출되었고, epoch 200에 0.8252가 도출되었다. 또한, 학습이 진행되면서 G-loss와 D-loss가 급격하게 증가하거나 감소하는 경우가 없었기 때문에 생성자와 판별자는 안정적으로 학습하는 것을 확인하였다.
2) 정량적 평가
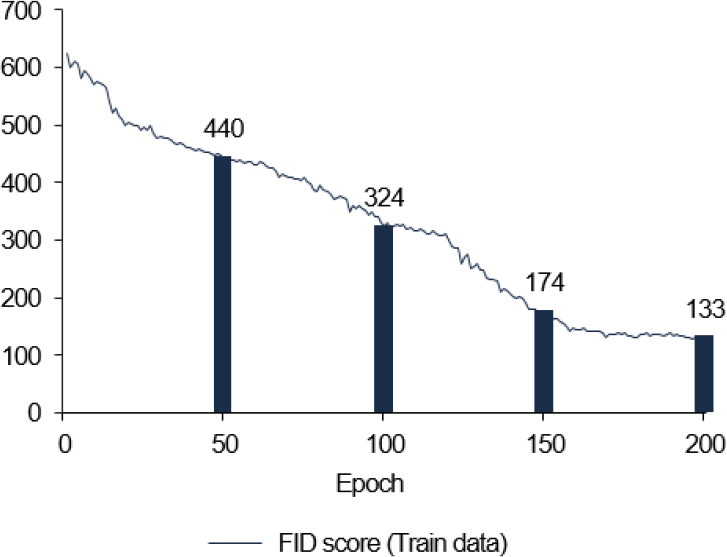
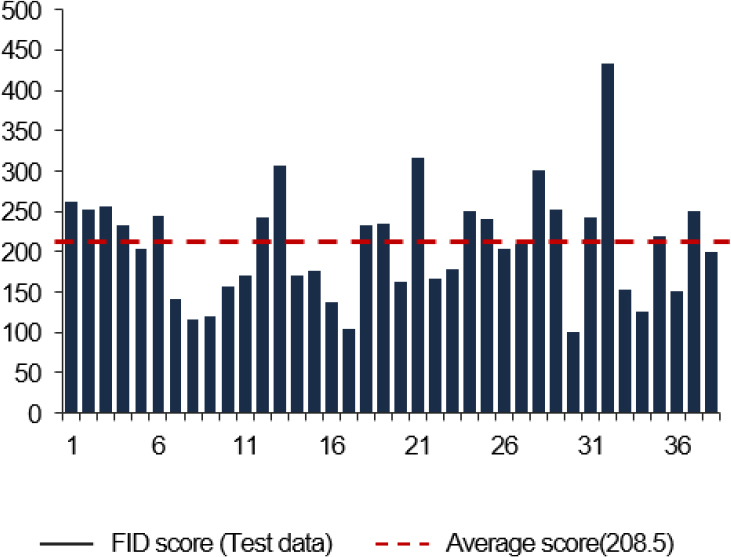
다음으로 train data와 test data를 대상으로 정량적 평가를 수행하였다. 이는 정답 이미지와 생성된 이미지를 비교하는 지표인 FID(Frechet Inception Distance) score를 통해 수행하였으며, 정답 이미지가 존재하는 Combination Data를 대상으로 진행하였다. FID score는 Heusel et al.(2017)에 의해 제안되었으며, 사전 학습된 Inception v3를 활용하여 정답 이미지와 생성 이미지의 유사도를 측정하는 지표이다. FID score가 낮은 것은 두 이미지 분포의 거리가 가까우며, 두 이미지가 유사하다는 것을 의미한다. 그러나 FID score는 이미지 왜곡에 민감하고(Borji, 2019) 학습 데이터 수가 적거나(Lucic et al., 2017) Inception v3 모델에 포함되지 않은 클래스를 대상으로 점수가 높게 형성될 수 있다는 단점이 존재한다. Figure 12와 같이 Train data의 FID score 경우 학습이 진행되면서 감소하는 것을 알 수 있다. 다음으로 test data의 FID score는 Figure 13과 같다. 평가 결과, 38개 이미지의 평균 FID score는 208.5가 도출되었으며, 이미지 별로 FID score의 편차가 큰 것을 확인하였다.
3) 정성적 평가
정량적 평가를 통해 train data는 학습이 진행될수록 FID score가 감소하는 경향을 보였지만 test data는 이미지 간의 편차가 큰 것으로 확인되어 추가적인 평가가 필요할 것으로 판단된다. 또한, test data로 활용한 New Label Data는 직접 라벨링을 진행하여 정답 이미지가 없기 때문에 정략적 평가가 불가능하였다. 이러한 이유로 인해 생성된 이미지를 육안으로 판단하는 정성적 평가를 진행하였다(Xing et al., 2019). Table 2는 학습 과정에서 추출한 라벨 이미지(Input Image), 정답 이미지(Ground Truth), 생성된 이미지(Output Image)이다. epoch 1과 2일 때 생성된 이미지는 객체별 특징이 제대로 학습되지 않았으며, 노이즈가 많은 것을 확인할 수 있다. 그러나, 학습이 진행될수록 생성된 이미지는 선명해지며 정답 이미지와 비슷한 이미지가 생성되는 것을 확인할 수 있다.
Table 2.
Train data result (combination data)
| Epoch | Input image | Ground truth | Output image |
| 1 |  |  |  |
| 2 |  |  |  |
| 94 |  |  |  |
| 153 |  |  |  |
| 199 |  |  |  |
| 200 |  |  |  |
다음으로 학습이 완료된 모델에 test data를 입력하여 이미지 생성 결과를 확인하였다. Test data로 지정한 Combination Data와 New Label Data 각각 5개 이미지의 결과는 Table 3을 통해 알 수 있으며, Combination Data의 경우 평균값보다 FID score가 낮은 이미지를 선별하였다. 이미지 생성 결과, Combination Data는 도로, 블랙 아이스, 외부 라벨링의 위치에 맞게 정답 이미지(Ground Truth)와 비슷한 이미지가 생성되는 것을 확인하였다. 다음으로 New Label Data의 생성된 이미지(Output Image)는 도로, 블랙 아이스, 외부를 라벨링한 위치에 객체가 생성되는 것을 확인하였다. New Label Data의 경우 정량적 평가가 불가능하였지만, 정성적 평가를 통해 향후 블랙 아이스 학습 데이터셋으로 활용이 가능할 것으로 판단된다.
Table 3.
Test data result (combination data and new label data)
| Combination data | New label data | |||
| Input image | Ground truth | Output image | Input image | Output image |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
2. 토의
본 장에서는 FID score가 높은 이미지를 대상으로 정성적 평가를 진행하여 점수가 높게 도출된 원인을 파악하고, FID score를 포함하여 생성된 이미지의 품질을 측정하는 척도를 비교 ‧ 분석하고자 한다. Table 4는 Combination Data에서 평균값보다 FID score가 높게 도출된 이미지이며, 생성된 이미지의 블랙 아이스 부분은 대부분 정답 이미지(Ground Truth)와 비슷하였다. 그러나, Image 1, 2의 경우 블랙 아이스가 빛에 반사되는 특징이 생성된 이미지(Output Image)에 반영이 되지 않은 것을 확인할 수 있으며, 이로 인해 FID score가 높게 도출된 것으로 판단된다. 다음으로 Image 3, 4의 경우 Ground Truth와 비교하였을 때 도로의 차선과 그림자가 제대로 표현되지 않은 것을 볼 수 있다. 이는 그림자, 차선 등의 라벨링을 따로 진행하지 않고 도로라는 하나의 객체로 라벨링 하였기 때문에 추가적인 특징을 추출하지 못함에 따라 점수가 높게 도출된 것으로 파악된다. 마지막으로 Image 2, 5의 경우 Ground Truth와 Output Image의 도로 재질이 다른 것을 알 수 있으며, 이로 인해 FID score가 높게 도출된 것으로 파악된다.
Table 4.
Test data result (combination data with high FID score)
| Image | Input image | Ground truth | Output image | FID score |
| 1 |  |  |  | 252.7 |
| 2 |  |  |  | 433.6 |
| 3 |  |  |  | 244.6 |
| 4 |  |  |  | 209.8 |
| 5 |  |  |  | 251.8 |
| Average | 208.5 | |||
앞서 FID score가 높은 이미지를 대상으로 정성적 평가를 진행한 결과, 도로에 차선, 그림자 등이 제대로 표현되지 않았으며, 도로의 재질이 다르기 때문에 점수가 높게 도출되는 것으로 판단된다. 이처럼 이미지의 FID score가 높게 도출되는 원인이 블랙 아이스를 제외한 도로와 외부에 기인한 것인지 확인하고자 Combination Data를 블랙 아이스와 외부가 차지하는 비율에 따라 두 개의 그룹으로 분리하였다. 두 그룹의 이미지 개수를 비슷하게 맞추기 위해 기준을 70%로 설정하였으며, 평균 FID score와 P value는 Table 5와 같다. Group A는 블랙 아이스와 외부가 차지하는 비율이 70% 이상인 이미지로 구성되어있으며, Group B는 비율이 70% 미만인 이미지로 구성되어있다. 그룹별 평균 FID score는 각각 189.2, 225.9를 기록하였다. 다음으로 두 그룹의 점수 차이가 유의미한지 파악하기 위해 P value를 도출하였다. 두 그룹의 분산의 차이가 없었기 때문에 등분산 t-test 분석을 진행하였으며, P value는 0.039가 도출됨에 따라 두 그룹의 평균값은 통계적으로 유의한 차이가 있는 것을 확인하였다. 즉, 본 연구에서 얻고자 하는 블랙 아이스의 이미지가 좋은 품질이어도 FID score가 높게 도출될 수 있기 때문에 정량적 평가와 더불어 정성적 평가를 통해 생성된 이미지의 품질을 평가하고 선별해야 한다고 판단된다.
Table 5.
Comparison of status by group (combination data)




본 연구에서 활용한 FID score와 더불어 GAN을 통해 생성한 이미지의 품질을 측정하는 척도는 Table 6과 같이 Inception Score, MS-SSIM(Multi-scale Structural similarity)가 있다. MS-SSIM은 생성 이미지를 Ground Truth와 비교하여 유사도를 측정하는 지표로 GAN의 단점인 불안정성을 발견하기 쉽지만 작은 loss를 파악하기 어려운 단점이 있다. 또한, 생성 이미지의 품질을 단독적으로 평가하는 지표로는 Inception Score가 있다. 이는 이미지의 품질과 다양성을 측정하는 지표로 사전학습된 Inception-v3 모델을 활용하기 때문에 ImageNet이 아닌 다른 데이터셋을 활용한다면 점수의 신뢰도가 떨어지며, 다양성을 파악하기 어려운 단점이 존재한다. 이러한 단점으로 인해 FID score가 제안되었으며, 이는 식별성 및 계산 효율성 측면에서 우수한 성능을 발휘한다(Borji, 2019). 이로 인해 GAN을 통해 생성된 이미지의 품질을 측정하는 척도로 FID score를 많이 활용하는 추세이다. 요약하면 블랙 아이스 특성상 빛 반사 등의 미세한 변화를 식별해야하며, 생성되는 이미지의 다양성 측면에서 노이즈에 강하고, 식별성이 우수한 FID score를 측정 지표로 활용하는 것이 적절하다고 판단된다.
Table 6.
Comparison of status by group
결론 및 향후 연구
딥러닝을 활용한 객체 검출 및 분류는 대용량의 데이터셋을 활용하여 학습을 진행해야 높은 인식률이 도출된다. 이러한 대용량 데이터셋을 구축하기 위해 다양한 데이터 증강 기법이 활용되고 있으며, GAN 기반의 여러 알고리즘을 통한 데이터 증강 연구가 활발하게 수행되고 있다. 특히 Pix2Pix는 기존 GAN 알고리즘의 문제점이었던 불안정성을 보완한 알고리즘으로 원하는 위치에 원하는 객체의 이미지를 생성할 수 있다는 장점이 있다. 이에 본 연구는 Pix2Pix를 활용하여 블랙 아이스 이미지를 증강하는 연구를 수행하였다. 구글과 유튜브를 활용하여 현존하는 블랙 아이스 이미지 데이터를 구득하였고, Pix2Pix 학습을 위한 데이터 전처리 및 데이터셋 분할을 진행한 이후 200회의 학습을 진행하였다. 학습 결과, l1-loss는 감소하였으며, 생성자 loss와 판별자 loss는 큰 증감 없이 안정적으로 학습하는 것을 확인하였다. 또한, FID score 지표를 활용하여 정량적 평가를 진행하였으며, 추가 분석을 위해 정성적 평가를 진행하였다. 정량적 평가 결과, FID score의 단점이 존재함에 따라 전체적으로 높은 FID score가 도출되었지만, 학습이 진행되면서 FID score가 감소하는 것을 확인하였다. 또한, test data의 평균 FID score는 208.5가 도출되어 원인을 분석하기 위해 생성된 이미지를 확인하는 정성적 평가를 수행하였다. 정성적 평가 결과, 블랙 아이스가 빛에 반사되는 특징을 파악하지 못한 경우가 존재하였으며, 도로 부분의 다양한 특징으로 인해 FID score가 높게 도출되는 것을 확인하였다. 다음으로 GAN을 통해 생성된 이미지를 측정하는 지표인 FID score, MM-SSIM, Inception Score의 장단점을 고찰하였으며, 블랙 아이스의 특성을 고려하였을 때 FID score를 측정 지표로 활용하는 것이 적절한 것을 확인하였다.
본 연구는 부족한 블랙 아이스 이미지 데이터를 증강함으로써 향후 블랙 아이스 객체 인식 모델을 구축하는데 필요한 학습 데이터셋을 구축하였다. 또한, 라벨링을 진행하여 실제 존재하지 않는 블랙 아이스 이미지의 생성을 통해 이미지의 다양성을 확보한 것에 그 의의가 있다. 본 연구는 학습을 위한 데이터 수가 부족하였으며, 외부에 해당하는 부분을 세부적으로 라벨링을 진행하지 않아 FID score가 높게 도출되는 한계가 존재하였다. 이에 향후 더 많은 데이터를 수집하고 세부적인 라벨링을 진행하여 데이터 증강 연구를 수행할 필요가 있으며, 인공지능 학습용 빅데이터 구축을 위한 증강 연구의 일환으로 객체 검출 결과를 활용한 정량적 평가를 수행해야 할 것으로 판단된다.
