

서론
기존 문헌 고찰
연구 방법론
1. Simulation Setting
2. Problem Formulation
3. 시뮬레이션 분석
분석 결과
1. 이동성
2. 안전성
3. 혼재 상황에서의 전략 평가
결론
서론
자율주행차량이 미래 모빌리티의 핵심으로 부상하면서 자율주행차량에 관한 연구와 개발은 꾸준히 지속되어 발전하고 있다. 자율주행차량은 운전자의 인적요인을 제거하여 보다 이상적이고 일정한 주행행태를 교통류에 반영하고 이를 통해 교통류에 긍정적인 영향을 미칠 것으로 기대되고 있다. 하지만 활발한 기술 개발에도 불구하고 차량 중심 자율주행의 한계로 인해 자율주행차량은 다양한 돌발상황에서 적절한 대처를 하지 못하고 교통류에 악영향을 끼치며 이와 더불어 사고 또한 끊이지 않고 있다. 이에 따라 자율주행차량이 기대됐던 만큼의 긍정적인 영향을 교통류에 미치기 위해서는 V2X(Vehicle to Everything, V2X) 통신 기반 도로 인프라의 지원을 통한 자율주행차량의 자율협력 주행의 필요성이 강조되고 있다.
교통사고, 공사 등으로 인한 차로 통제상황의 경우 운전자들은 통제차로 회피를 위해 무질서한 차로변경을 실시하고 이에 따라 교통류 안전과 운영성에 큰 악영향을 미치며 병목현상 및 사고를 유발한다. 사전에 통제 구간에 대한 정보를 제공받고 이를 통해 통제차로 도달 전 개방 차로로의 적절한 차로변경 지점을 찾을 수 있다면 앞서 말한 통제차로 회피를 위한 무질서한 차로변경에 따른 문제점을 개선하고 교통류의 안전과 운영성을 증대시킬 수 있을 것으로 기대된다. 향후 LV4+ 자율주행 상황에서 인프라 지원을 포함한 자율협력주행차량(Connected Automated Vehicle, CAV)의 경우 V2X 통신을 통해 인프라로부터 사전에 통제 구간의 정보 획득이 가능하며 이를 활용하여 개방 차로로의 적절한 차로변경 지점을 찾기 위한 CAV의 거동 제어가 가능할 것이다. 이에 따라 본 연구는 적절한 차로변경 지점을 찾아 개방 차로로의 안전한 합류를 위한 CAV 거동 제어 알고리즘을 개발하고 해당 알고리즘을 통한 통제차로 회피 전략의 평가를 목표하였다.
강화학습은 큰 차원의 다양한 상태 공간을 고려할 수 있어 다양한 제어 문제를 효과적으로 해결할 수 있는 유망한 프레임워크로써 부상하고 있고 다양한 연구에서 강화학습을 활용하여 자율주행차량의 문제를 해결하고자 하는 시도가 많아지고 있다. 이에 따라 본 연구에서는 CAV 거동 제어 알고리즘 개발을 위해 강화학습 접근법을 선택하였다. 본 연구에서는 강화학습 알고리즘으로 DQN(Deep Q Network)을 활용하였고 강화학습 기반 CAV 거동 제어 알고리즘을 개발하기 위해 본 연구에서는 미시교통시뮬레이션 VISSIM을 활용하여 V2X 환경에서의 차로 통제상황을 구현하였다. 시뮬레이션 내에서 강화학습 에이전트는 교통 환경과의 상호작용을 통해 최적의 제어 전략을 학습하였고 여기서 에이전트는 학습의 주체를 의미한다. 학습된 에이전트를 기반으로 CAV 거동 제어 알고리즘을 개발하였으며 이를 일반 상황, 단순 규칙 기반 통제차로 회피 전략, 강화학습 기반 통제차로 회피 전략 총 세 가지 상황으로 나누어 시뮬레이션을 수행하였으며 안전성과 이동성 측면의 교통류 영향을 평가하였다. 또한 다양한 교통상황과 혼재 교통상황을 고려하여 시뮬레이션을 수행하기 위해 LOS(Level Of Service, LOS) 및 CAV의 MPR(Market Penetration Rate, MPR)을 다양하게 설정하여 시나리오를 구성하였고 시나리오별 교통류 영향을 분석하였다. 이를 통해 차로 통제상황에서 강화학습 기반 거동 제어를 통한 통제차로 회피 전략에 대한 효과를 제시하고 향후 LV4+ 자율주행 환경에서의 통제 차로 회피 전략의 기초 자료로서 역할을 목표하였다.
본 연구는 다음과 같이 구성되어 있다. 2장에서는 시뮬레이션 활용 자율주행 환경에서의 교통류 분석 연구 및 강화학습 기반 교통 시스템 최적화 연구에 대하여 기존 문헌을 검토하였고, 3장에서는 CAV 거동 제어 알고리즘 개발을 위한 강화학습 방법론을 제시하고 시뮬레이션 설정 및 수행 방법을 제시하였다. 4장에서는 본 연구에서 제시한 세 가지 상황에 따른 시뮬레이션 결과를 제시하였으며, 마지막 장에서는 본 연구 결과를 요약하고 결론 및 한계점을 정리하여 향후 연구 방향을 서술하였다.
기존 문헌 고찰
본 연구는 미시교통시뮬레이션을 활용하여 강화학습 기반 CAV 거동 제어 알고리즘을 통한 통제 차로 회피 전략의 효과를 교통류 측면에서 제시하고자 한다. 본 장에서는 시뮬레이션 활용 자율주행 환경에서의 교통류 분석과 강화학습 기반 교통 시스템 최적화에 관한 기존 연구를 검토하였다.
Chen et al.(2021)은 CAV 연구와 관련하여 CAV에 접근할 수 없는 많은 연구자에게 시뮬레이션은 실용적인 선택이며 적절한 시뮬레이션 모델 보정을 통해 CAV의 주행행태를 구현할 수 있다고 제시하였다. 이처럼 자율주행 환경에서 CAV 및 AV 관련한 많은 기존 연구가 시뮬레이션을 활용하여 수행되고 있다. Park et al.(2021)은 자율주행차량의 보급(Market Penetration Rate, MPR)에 따른 도심부 네트워크의 교통용량에 대하여 분석하였다. 이들은 VISSIM내 Wiedemann74모형과 차선변경 제어, 운전자 특성 제어 파라미터 등을 이용하여 자율주행 자동차 Level4에 해당하는 수준의 자율주행차량을 구현하였고 MPR에 따른 영향을 분석한 결과 MPR이 증가할수록 통행시간과 지체시간이 감소하고 통행속도가 증가하는 결과를 나타냈다. Mark Mario et al.(2018)은 VISSIM을 이용하여 Level4 수준의 자율주행차량 비율에 따른 회전교차로에서의 안전성을 분석하였다. VISSIM 상에서 자율주행차 매개변수로서 Atkins(2016)과 PTV에서 제시하는 매개변수를 채택하여 자율주행차량을 구현하였다. 상충 분석 소프트웨어인 SSAM(Surrogate Safety Assessment Model, SSAM)을 활용하여 TTC와 PET를 통해 안전성을 분석하였고, 그 결과 자율주행차량 비율이 25%에서 75% 사이에서 충돌 횟수가 꾸준히 감소함을 확인하였고, 자율주행 차 비율이 늘어남에 따라 안전성이 높아짐을 검증하였다. 본 연구에서는 미시교통시뮬레이션 VISSIM을 활용하여 VISSIM내 파라미터 보정을 통해 자율주행차량을 구현하고 시뮬레이션 분석을 수행하였다. 이처럼 다양한 AV 및 CAV 관련 연구가 시뮬레이션을 활용하여 진행되고 있다(Granà et al., 2024; Chen et al., 2021).
교통 문제들을 해결하기 위한 교통 지원 알고리즘 개발에 관한 연구가 VISSIM을 활용하여 수행되고 있다. Jo(2023)은 V2X 기반 자율협력주행 상황에서의 선제적 안전관리 전략을 설계 및 평가하였다. VISSIM을 활용하였으며 VISSIM내에 VISSIM COM API를 활용하여 자율협력주행 기반 차로변경 지원 알고리즘을 개발하고 해당 알고리즘의 효과를 분석하였다. 차로변경 지원 알고리즘을 통한 선제적 안전 관리 전략 도입 시 교통류의 통과교통량과 평균 속도가 75%, 63% 증가하는 결과를 도출하였다. Ma et al.(2021)은 VISSIM을 활용하여 비신호교차로에서 CAV를 위한 우선권 판단 모델을 수립하였다. 속도 유도 알고리즘을 개발하고 이에 따라 교차로 내 상충 예상 지점을 핵심 제어 지역으로 선정하여 집중적으로 관리하였다. 본 연구에서 해결하고자 하는 교통 문제는 차로 통제상황이며 차로 통제상황에서 자율주행차량의 자율협력주행을 통한 현장 대응 전략의 중요성과 효과는 많은 연구에서 제시되고 있다(Uhlemann, 2015; Jo, 2023; Wang et al., 2023; Suh et al. 2022; Guériau et al., 2016). 본 연구에서는 VISSIM을 활용하여 차로 통제상황에서의 통제 차로 회피 전략 알고리즘을 개발하였다.
최근 강화학습은 시뮬레이션과 컴퓨팅 능력의 발전과 함께 다양한 분야에서 최적화 및 제어 전략의 방법론으로서 다양한 분야에서 적용되고 있으며, 교통 분야에서 또한 강화학습을 활용한 교통류 알고리즘 연구가 활발히 진행되고 있다. Jung et al.(2021)은 VISSIM을 이용하여 강화학습 기반 지체시간 최소화 실시간 신호 제어 체계를 개발하였다. 실시간 교통정보를 활용하여 4지 교차로에서 차량의 지체를 최소화하며 긴급차량의 접근이 감지될 경우 긴급차량의 통과를 우선할 수 있도록 하는 최적 신호를 표출하는 신호체계를 강화학습(DDQN)을 통해 개발하였고 개발된 신호 제어 에이전트를 통한 신호제어 체계와 기존 신호 최적화 패키지 Passer V를 통해 도출한 신호 현시를 적용한 신호 제어 체계와 비교하여 교통량 수준이 낮을 때 개발한 신호체계의 신호 운영이 효율적임을 확인하였다. Park et al.(2022)은 VISSIM을 이용하여 강화학습(DQN) 기반의 VSL 효과평가를 수행하고, 링크별 안전권고 속도를 도출, 이를 기반으로 사고위험도 수준과 교통 조건에 따른 VSL 운영 전략을 도출하였다. 이처럼 국내 교통 분야에서도 강화학습을 활용한 교통류 알고리즘 연구는 활발히 진행되고 있으나 교통 시스템 제어에 치우쳐져 있다. LV 4 자율주행환경에서는 개별 CAV의 거동을 제어 및 지원할 수 있으며 이를 바탕으로 국외에서는 강화학습을 기반으로 CAV의 거동을 제어 및 지원하여 다양한 교통 문제를 해결하고자 하는 다양한 연구가 수행되고 있다. Ren et al.(2020)은 VISSIM을 이용하여 강화학습 기반의 work zone 제어 알고리즘을 개발하고 이를 통한 협력 주행을 기반으로 고속도로 work zone 합류 제어 전략을 제시하고 평가하였다. 차량들이 work zone을 회피하여 개방 차로로의 빠른 합류를 목표로 알고리즘을 설계하였다. Zhou et al.(2022)은 Gym highway env 환경에서 강화학습 기반의 협력 차선변경 주행 알고리즘을 개발하였고, CAV의 협력 차선변경의 가능성 및 효과를 제시하였다. 이처럼 기존 국내 연구에서는 강화학습을 교통 시스템에 적용해 문제를 해결하고자 하였고 개별차량의 제어를 다룬 연구는 부족한 상황이다. 제어 알고리즘 관련 연구에서는 알고리즘 개발에만 치우쳐 교통류에 미치는 전반적인 효과에 대한 평가는 간과하였다.
이에 따라 본 연구에서는 미시교통시뮬레이션 VISSIM을 활용하여 강화학습 기반의 CAV 거동 제어 알고리즘을 개발하고 이를 활용한 통제 차로 회피 전략을 제안하고자 하며 해당 전략의 교통류 영향 평가를 목표한다.
연구 방법론
최근 하드웨어의 컴퓨팅 능력이 향상됨에 따라 큰 상태 공간을 고려하는 것이 가능해져 강화학습은 다양한 분야에서 적용되고 있다. 강화학습은 큰 상태 공간을 고려할 수 있어 다양한 현실의 복잡한 제어 문제를 해결할 수 있는 효과적인 프레임워크로써 이는 실시간으로 연속적인 다양한 상태가 존재하는 교통상황에 유용하게 적용될 수 있음을 시사한다. 특히 실시간 동적으로 변하는 교통상황에 따라 유연하게 대응할 수 있어야 하는 CAV에게 효과적인 거동 제어 방법론이 될 수 있다. 이에 따라 본연구에서는 통제 구간에서 발생할 수 있는 다양한 교통상황을 Trial-and-error를 통해 학습하고 통제 차로 회피를 위한 CAV의 종방향 제어 문제를 해결할 수 있는 강화학습을 채택하여 회피 전략을 설계 및 개발하고자 하였다. 강화학습 알고리즘으로는 DQN을 사용하였으며 이를 추가적인 두 가지 상황과 비교하여 효과를 평가하였다. DQN은 높은 성능과 안정성을 제공하며(Minh et al., 2013), 다양한 환경에 적응할 수 있는 범용성을 가지고 있어 복잡한 교통상황에서도 적절한 대응이 가능하여 CAV의 동적 주행 시나리오에 효과적이다. 이를 바탕으로 다양한 연구들에서 DQN을 활용하여 교통 문제들을 해결하고자 하였다(Kang et al., 2024; Kim et al., 2024; Roy et al., 2022). 총 네 가지 단계로 연구는 수행되었으며 먼저 첫 번째로 시뮬레이션 분석을 위해 VISSIM 상에 가상의 도로 네트워크를 구축하고 세 가지 시뮬레이션 상황을 정의하였다. 다음으로 강화학습 기반 CAV 거동제어 알고리즘을 개발하기 위해 VISSIM COM을 활용한 강화학습 프레임워크를 구축하였고 통제 차로 회피를 위한 거동 제어 알고리즘 문제상황을 State, Action으로 나누어 정의하고 보상함수를 설계하였으며 정의된 강화학습 환경을 기반으로 CAV 거동 제어 에이전트를 학습시켰다. 앞서 개발한 강화학습 기반 CAV 거동 제어 알고리즘을 단순 규칙 기반 전략, 일반 차로변경 모형 두 가지 상황과 안전성, 이동성 측면에서 비교 평가하였다. 안전성 분석은 차량들의 주행궤적 데이터를 활용하여 미국 FHWA에서 개발한 상충 이론을 기반으로 상충의 발생을 분석하는 소프트웨어인 Surrogate Safety Assessment Model(SSAM)을 통해 상충 분석하여 안전성을 분석하였고, 이동성은 차량 단위의 평균 지연시간, 속도, 통행시간을 지표로 추출하여 평가하였다. 본 연구의 분석 개요는 Figure 1에 제시하였다.
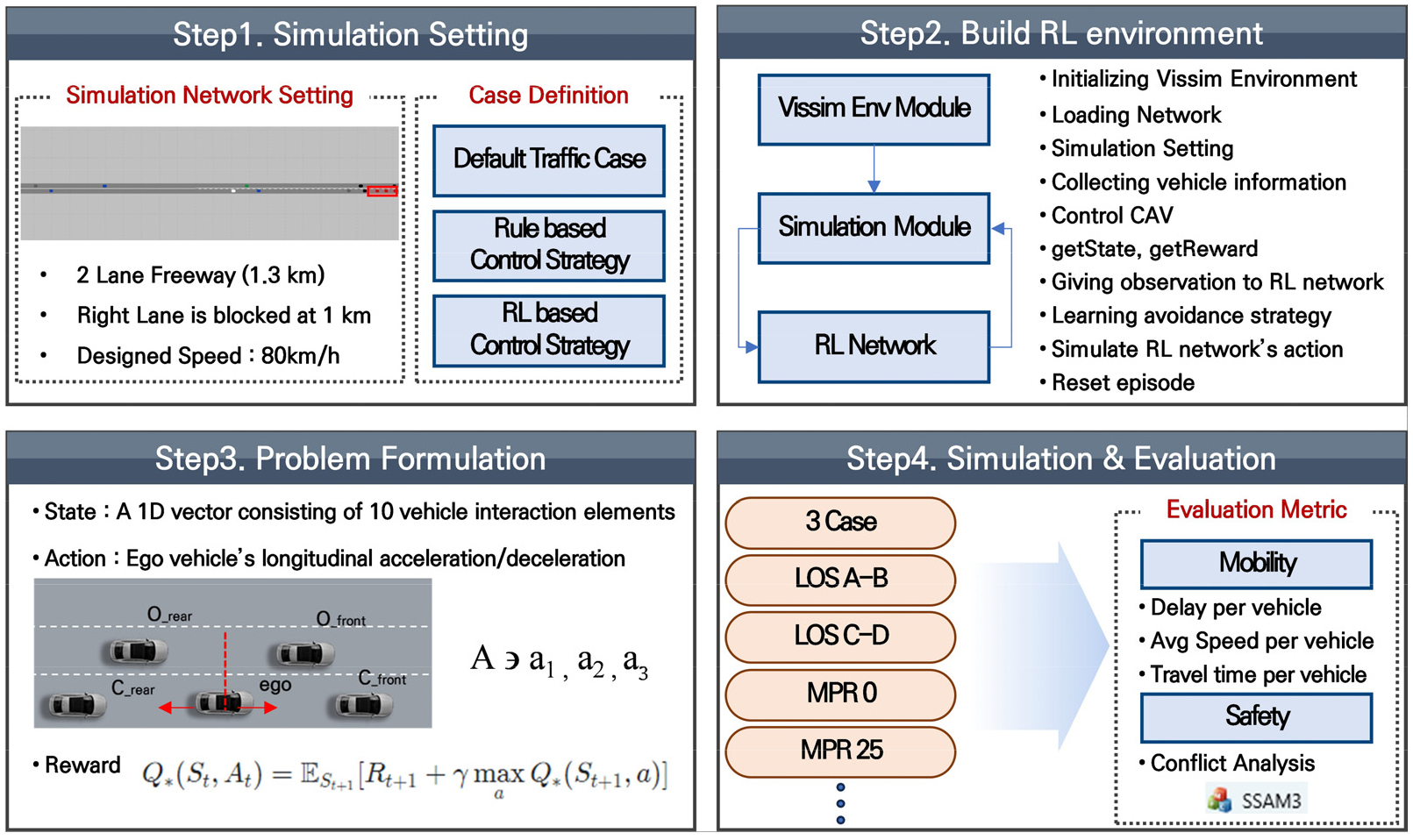
1. Simulation Setting
1) Network Setting
본 연구에서는 2차로 도로 토이 네트워크를 사용하여 시뮬레이션 분석을 수행하였다. 1.3km의 2차로 도로이며 설계속도는 80km/h로 지정하였다. 도로 시작점으로부터 1km 떨어진 지점에서 우측 차로를 폐쇄하여 통제 차로를 구현하였다. 구축한 네트워크는 Figure 2에 제시하였다. 교통량은 도로용량편람을 참고하여 설계속도 80km/h LOS 교통량에 따라 LOS(A-B) 1650 veh/h, LOS(C-D) 2000 veh/h 두 가지로 구성하였다.

2) 시뮬레이션 상황 정의
본 연구에서는 총 세 가지 케이스로 나누어 시뮬레이션 분석을 진행하였다. 먼저 강화학습 기반 통제 차로 회피 전략의 경우 일부 차로 통제 상황은 교통류 측면에서 통제 차로와 개방차로 모두 동일한 속도와 유량으로 주행하는 것이 이상적이라는 주장(Ren et al., 2020)을 바탕으로, 2차로 도로의 용량을 최대로 사용하면서 이동성을 향상하는 것을 목표로 하였다. 이를 위해 Figure 2의 노란색으로 표시된 차로변경 구간 에서만 차로변경이 가능하게 하였다.
파란색 제어 구간에서는 거동 제어 알고리즘에 의해 CAV의 종방향 거동을 제어하여 차로변경 구간 도달 시 개방 차로로의 즉각적인 차로변경을 위한 최적의 종방향 위치를 찾을 수 있도록 하였다. 이를 통해 CAV는 제어 구간에서 통제 차로에 대한 정보를 사전에 수집하고 주변 차량과의 상호작용 데이터를 State로 활용하여 종방향 거동을 제어하고 협력형 자율주행을 실현함으로써 차로변경 구간에서 빠르고 안전한 개방 차로로의 합류를 유도 시켜 통제 차로를 회피할 수 있도록 하였다. State에 대한 자세한 내용은 Problem Formulation 장에서 자세히 다루고자 한다.
단순 규칙 기반 통제차로 회피 전략의 경우 C-ITS 상황을 가정하여 통제 차로 도달 전 500m 지점에서 통제 구간에 대한 정보를 획득 가능하다고 가정하였으며, 이에 따라 일괄적으로 차량들이 개방 차로로의 차로변경을 실시하도록 하였다. 일반 차로변경 모형의 경우 VISSIM내 내장된 기본 모듈에 따라 주행하도록 하였고 이는 Table 1에 제시하였다.
Table 1.
Strategy case description
2. Problem Formulation
1) State & Action
본 연구에서는 거동 제어되는 대상 ego 차량을 기준으로 목표 차로 선/후행 차량 현재 차로 선/후행 차량을 포함하여 총 다섯 대의 차량을 포켓(Jang and Yu, 2021)으로 지정하여 포켓 내 차량 간의 상대 속도 및 간격을 통해 state를 구성하였다. 포켓 내 ego 차량 제외 차량들과 ego 차량과의 종방향 간격 및 상대 속도 총 8개 요소가 state를 구성하며 ego 차량의 속도 및 통제 지점까지의 거리 총 2개 요소를 포함하여 총 10개의 요소로 이루어진 1차원 벡터를 state로써 활용하였다. 본 연구에서 설정한 포켓은 Figure 3에 제시하였다.
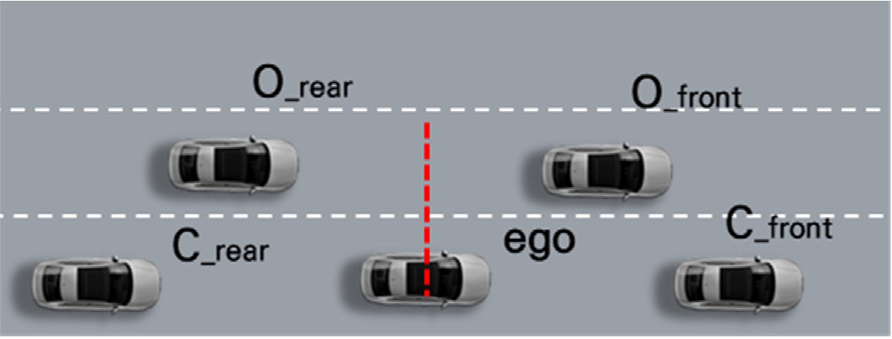
본 연구에서는 CAV 거동 제어를 통한 통제 차로 회피 전략을 목표하였고 이에 따라 제어 대상인 ego 차량의 종방향 주행 제어를 위해 가감속도를 action으로 설정하였다. 본 연구에서 사용한 강화학습 알고리즘 DQN의 경우 이산적인 액션만을 다루므로 본 연구에서는 가감속량을 으로 고정하여 연구를 수행하였다.
2) Reward
본 연구에서 제안하는 강화학습 기반 통제 차로 회피 전략의 목표는 도로 용량을 최대화하면서 이동성을 증가시키는 것이며 이를 위해 종방향 위치 제어를 통해 적절한 차로변경 지점을 조정함으로써 차량이 통제 차로 회피를 위한 개방 차로로의 합류 과정에서 차로변경으로 인한 개방 차로 차량들의 정지 및 주행 변화를 생성하지 않고 합류하도록 하는 것을 목표하였다. 이는 통제 차로에서 개방 차로로 CAV가 합류할 때 주변의 차량들이 가속이나 감속 없이 원활하게 주행행태를 유지할 수 있도록 하여 교통류의 이동성 및 안전성을 향상할 수 있다.
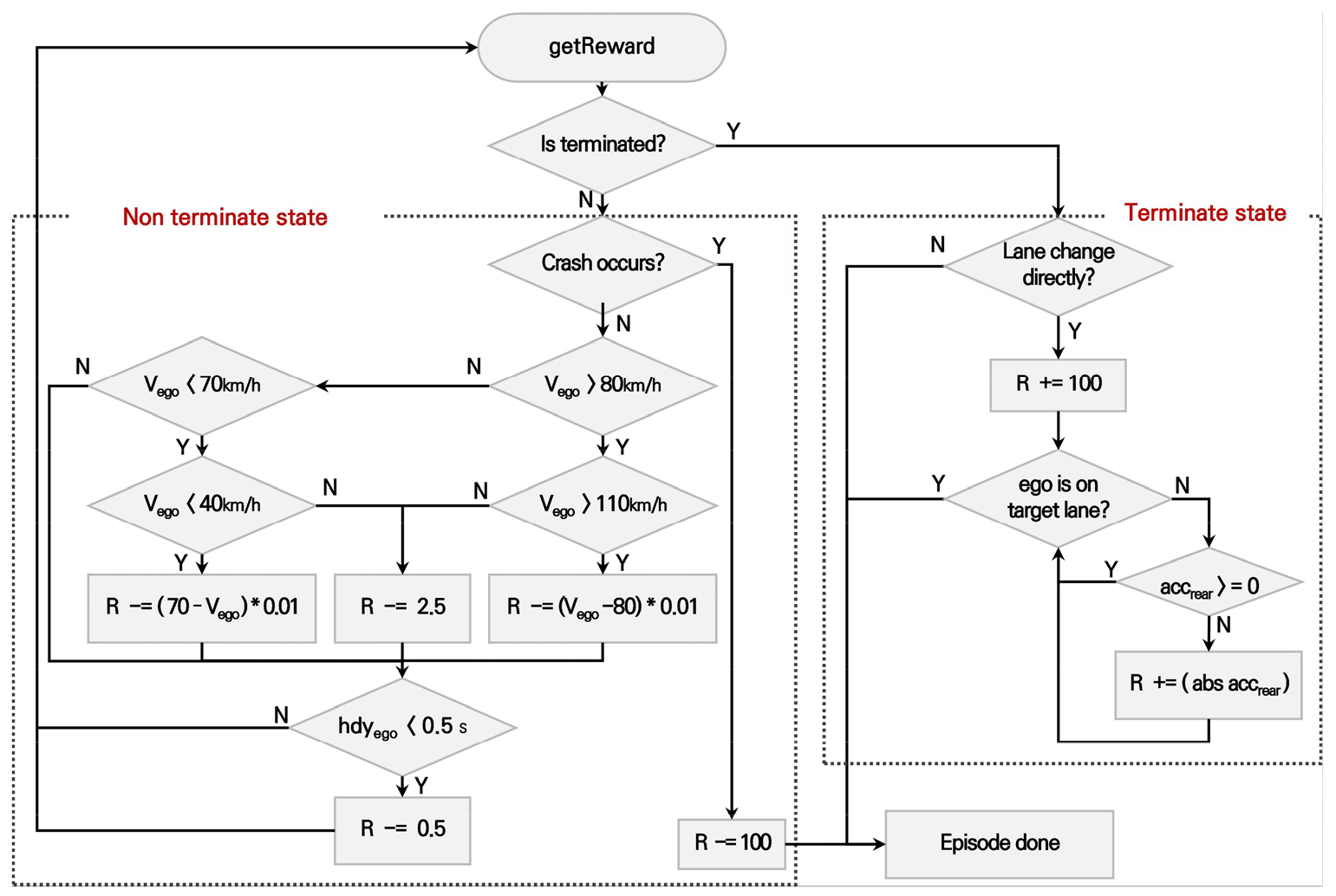
이를 위해 본 연구에서는 보상함수를 다음과 같이 설계하였다. 먼저 차로변경 구간에 들어올 경우를 Terminate State로 정의하였고, 차로변경 구간 전에 제어 구간에서 에이전트에 의해 제어를 받는 경우를 Non terminate State로 정의하였다. Non terminate State에서 CAV는 다른 차량과 충돌을 피해야 한다. 이에 따라 CAV가 에이전트의 거동 제어로 다른 차량과 충돌할 때 –100의 패널티를 부여하고 에피소드가 종료되도록 하였다. 이는 Equation 1과 같이 나타낼 수 있다.
CAV의 종방향 거동이 제어될 때 설계속도 80km/h를 고려하여 과속 및 저속 주행 시 차량 속도에 따른 패널티를 부여 하고 위험 주행을 방지하기 위해 ego 차량과 선/후행 차량간 headway의 임계값을 두어 패널티를 부여하였다. 거동 제어 시 ego 차량의 속도 및 headway에 관한 보상 설계는 Equation 2, Equation 3과 같다.
여기서,
ego 차량의 빠른 합류를 유도하기 위해 ego 차량이 Terminate State에 도달하였을 때 즉각적으로 차로변경이 가능할 경우 Equation 4와 같이 보상을 주어 즉각적인 차로변경을 유도하였다.
차로변경 시 목표 차로에 가해지는 충격파를 최소화하는 차로변경 지점을 찾을 수 있도록 유도하기 위해 ego 차량의 차로변경 시간 동안 후행 차량의 감속량을 패널티로 부여하여 Equation 5와 같이 보상을 설계하였다.
여기서,
위와 같이 설계한 보상함수에 따라 보상이 산출되는 과정을 Figure 4에 흐름도로 제시하였다.
3. 시뮬레이션 분석
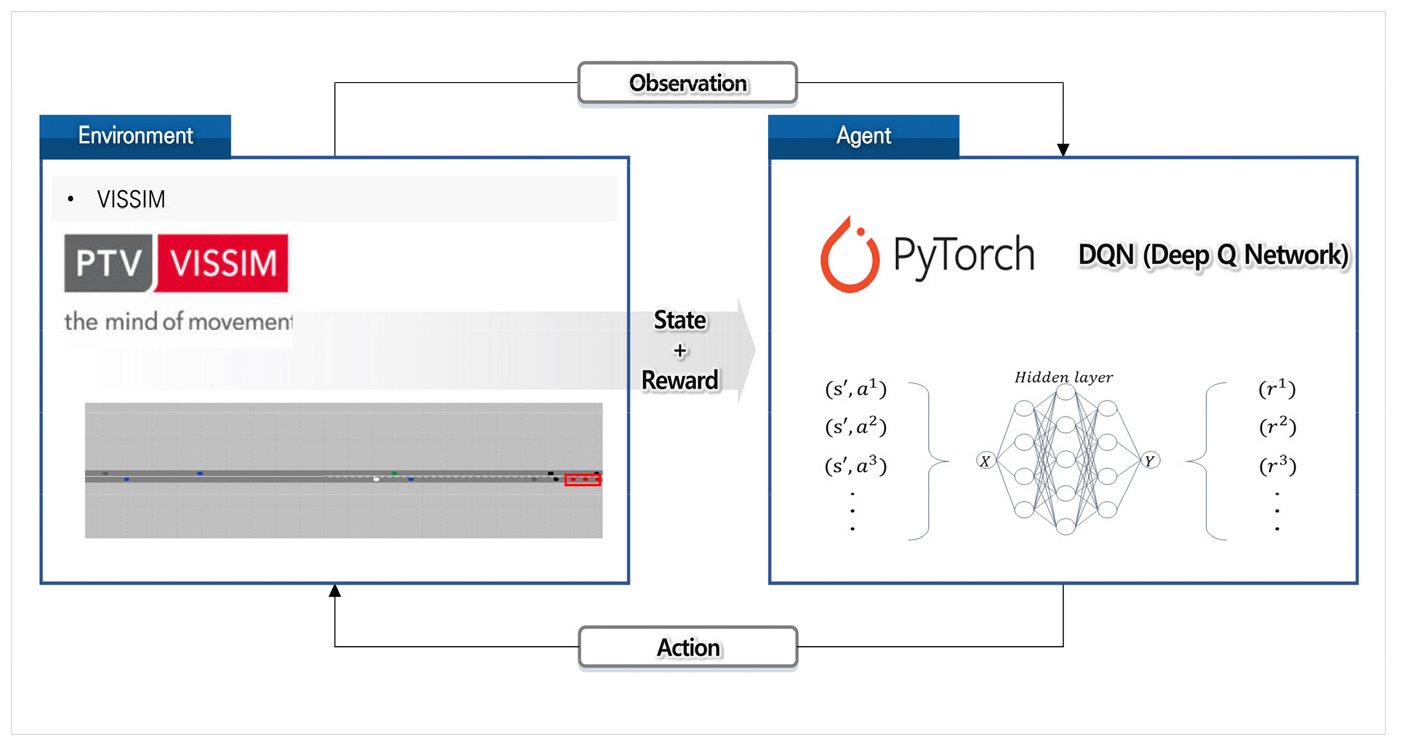
본 연구에서는 미시교통시뮬레이션 VISSIM을 활용하여 강화학습 프레임워크를 구성하였으며 이를 Figure 5에 제시하였다. VISSIM의 VISSIM COM API를 통해 0.1s 단위의 실시간 교통정보를 수신하고 개별차량의 정보를 통해 강화학습을 진행하였다. 파이썬 딥러닝 라이브러리 PyTorch를 활용하여 학습 네트워크를 설계하였으며 네트워크는 3중 선형 레이어로 구성하였으며 활성화 함수로 ReLU를 사용하였다. DQN 하이퍼 파라미터는 gamma 0.99, buffer size 50000, batch size 32, learning rate 0.005로 구성하였다.
본 연구에서는 Table 2와 같이 교통량은 LOS(A-B), LOS(C-D) 두 가지 상황을 고려하고 회피 전략 케이스를 세 가지로 나누어 총 여섯 가지 시나리오를 통해 시뮬레이션 분석을 수행하였으며 추가로 혼재 교통상황에서 본 연구에서 제시한 전략의 효과를 알아보기 위해 강화학습 전력에 대하여 총 다섯 가지의 MPR 시나리오를 사용하여 시뮬레이션 분석을 수행하였다. 시뮬레이션을 통해 나온 차량 궤적 데이터를 활용하여 안전성 평가지표와 이동성 평가지표를 산출하고 교통량에 따른 세 가지 케이스의 효과를 비교 분석하고 MPR에 따른 제안한 전략의 효과를 분석하였다. 각 평가지표는 Table 3에 제시하였다.
분석 결과
1. 이동성
본 연구에서 설정한 시나리오에 따라 시뮬레이션 분석을 수행하였으며 각 케이스에 따른 교통류 이동성 영향을 비교 분석하였다. 먼저 케이스별 차량들의 주행궤적을 분석하여 케이스별 이동성 영향 원인을 파악하기 위해 시뮬레이션 중간 1800초부터 2000초 사이의 24대의 차량을 랜덤 샘플링하여 시공도로 나타내었고 이는 Figures 6, 7과 같다. 시공도에서 빨간 부분은 개방 차로에 있음을 뜻하며 초록 부분은 통제 차로에 있음을 뜻한다.
차로 통제상황에서는 통제 차로에 있는 차량들이 개방 차로로 합류하는 과정에서 많은 혼잡이 발생하고 이에 따른 이동성 저하가 발생 된다. 이러한 특징은 특히 Figure 6를 통해 LOS C-D 상황 일반 케이스에서 두드러지게 나타남을 확인할 수 있다. 통제 차로의 차량이 합류 지점에서 대기 후 합류를 시도함으로써 무분별한 차로변경으로 인해 개방 차로에 있는 차량의 감속 및 지연을 발생시키고 이는 Figure 6의 일반 케이스에서 합류 지점 부근의 개방 차로 차량과 통제 차로 차량 그래프의 휘어짐을 통해 알 수 있다. 이를 통해 일반 케이스가 통제 차로에 대한 사전 정보가 없어 통제 차로의 차량은 통제 지점에 다다르고 나서야 통제상황을 인식하고 개방 차로로 합류를 시도하는 현실 교통상황을 잘 반영함을 나타내고 이는 앞서 얘기한 것과 같이 전체 교통류의 이동성 저하로 이어진다.
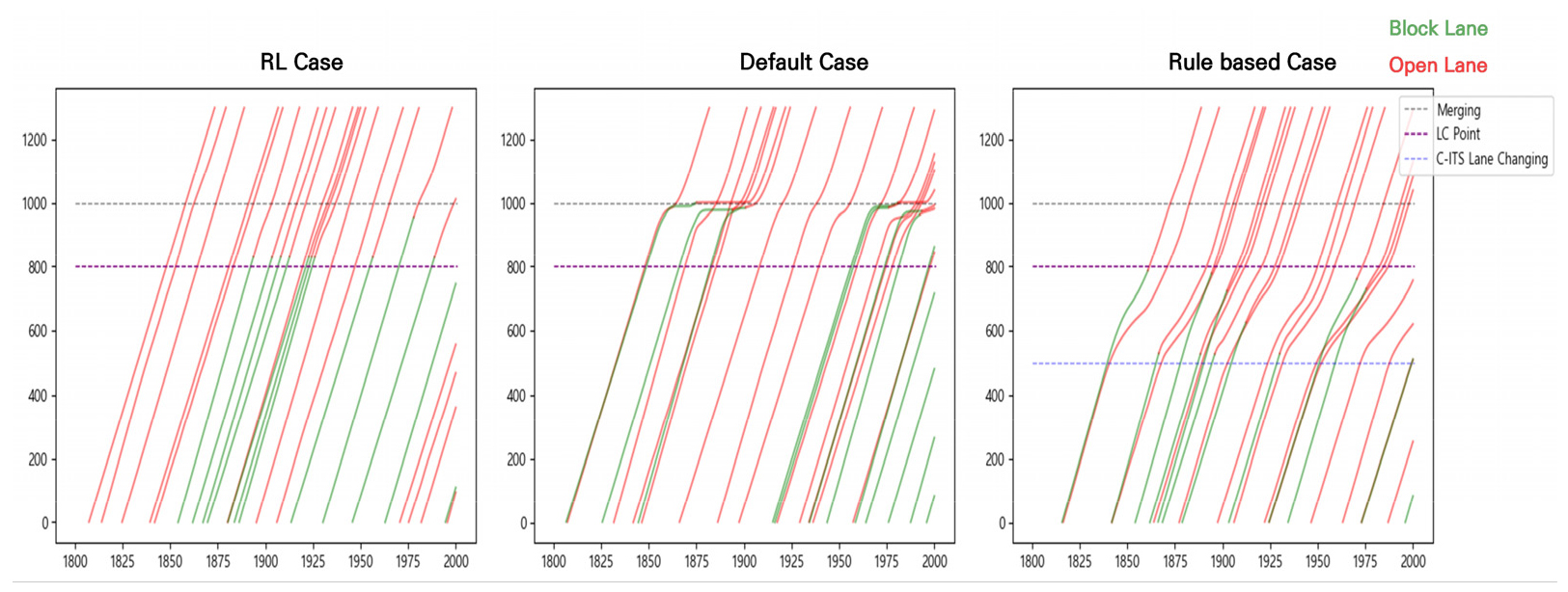
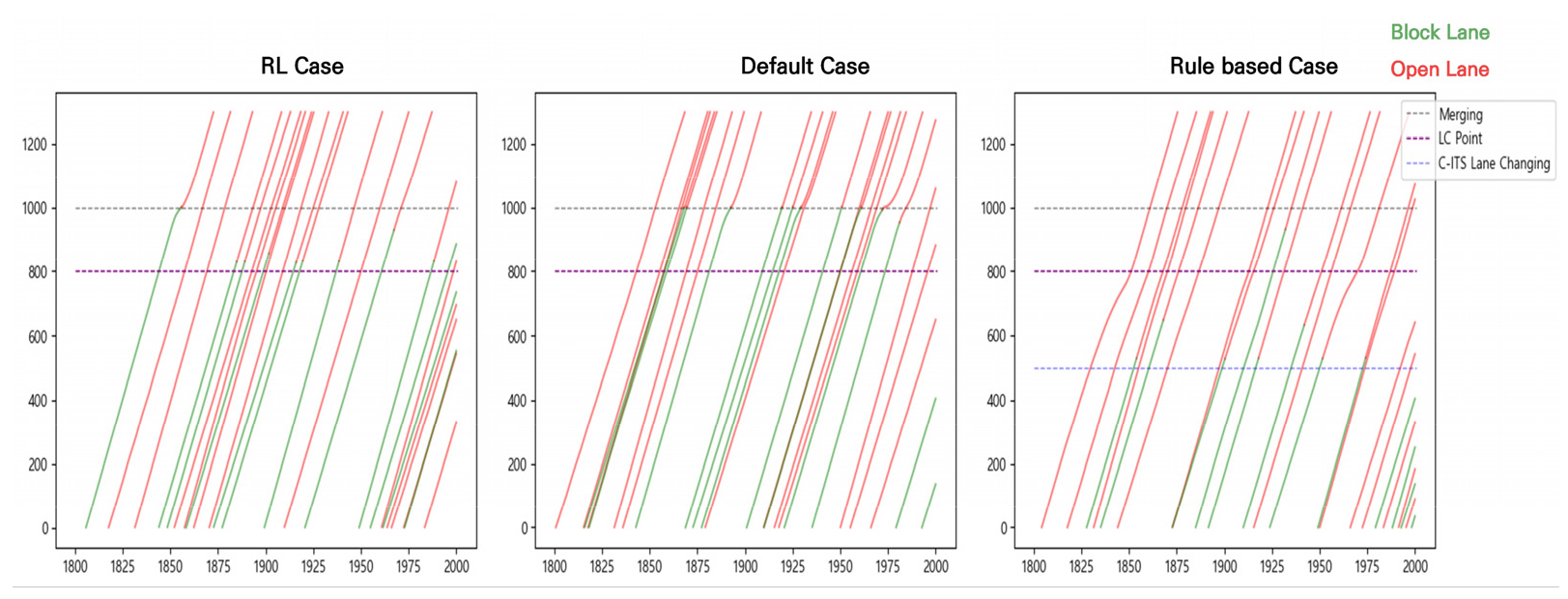
이와 달리 나머지 두 케이스에서는 통제 차로에 대한 사전 정보를 통해 사전에 조치함으로써 통제 구간 합류 지점에서 통제 차로 차량의 대기가 현저히 적어짐을 확인할 수 있다. 그러나 규칙 기반 케이스의 경우 500m 지점에서 차로변경을 일괄적으로 수행함에 따라 개방 차로 차량과 차로변경 차량 모두 지연이 발생하고 감속이 유발됨을 확인할 수 있다. 하지만 강화학습 케이스의 경우 대부분의 차량이 차로변경 구간에 들어서 즉각적인 차로변경을 수행하고 차로변경 시 사전의 적절한 거동 제어를 통해 개방 차로의 차량에 최소한의 영향을 주며 차로변경을 수행함을 확인할 수 있다. 이는 전체 교통류의 이동성에 긍정적인 영향을 가져올 수 있음을 의미한다. 케이스별 교통류 이동성에 미치는 실제 영향 효과를 비교 분석하기 위해 이동성 평가지표를 산출하였고 이를 Tables 4, 5에 제시하였다.
Table 4.
Result of mobility LOS C-D
| Evaluation index | RL case | Rule based case | Default case |
| Delay | 1.65 | 12.52 | 5.46 |
| Speed | 68.41 | 61.98 | 60.44 |
| Travel time | 34.85 | 45.35 | 40.35 |
Table 5.
Result of mobility LOS A-B
| Evaluation index | RL case | Rule based case | Default case |
| Delay | 0.69 | 2.19 | 1.85 |
| Speed | 70.35 | 65.74 | 67.04 |
| Travel time | 33.30 | 34.67 | 35.29 |
Tables 4, 5의 결과를 통해 강화학습 케이스가 나머지 두 케이스에 비해 지연시간과 통행시간이 감소하고 평균 속도가 늘어나 이동성 측면에서 우수함을 확인하였다. 앞서 주행궤적 분석을 통해 파악한 사실과 같이 일반 케이스의 경우 차량들이 통제 지점에 도달해서야 차로변경을 실시하게 되고 이는 통제 차로 차량들의 대기열을 발생시켜 차량들의 지연시간을 증가시키고 통행시간을 증가시킨다. 또한 통제 차로 차량의 대기 후 합류시 무분별한 차로 변경으로 인해 개방 차로 차량의 감속 및 지연을 유발함으로써 결과적으로 전체 교통류의 이동성이 저하됨을 Tables 3, 4의 명시된 평가지표 값을 통해 나타낸다.
규칙 기반 케이스의 경우 앞서 살펴본것과 같이 통제 지점 전 500m 지점에서 일괄적으로 차로변경을 실시함으로써 차로변경을 시도하는 차량들로 인해 개방 차로에 있던 차량들의 감속을 유발하고 이에 따라 전체 교통류의 지연시간이 증가하고 통행시간이 증가하였다. 하지만 원활한 교통상태를 띄는 LOS A-B 상황에서는 500m 지점에서 개방 차로의 차량에 대한 영향을 크게 주지 않고 합류에 성공하는 경우가 많아져 전체 교통류의 통행시간이 낮아져 차량들이 통제 구간을 빠르게 통과함을 알 수 있다.
강화학습 케이스는 통제 구간 도달 전 통제 구간 정보 및 주변 차량의 정보를 활용하여 강화학습 모형에 의해 CAV가 적절한 거동 제어를 유도하고 이에 따라 통제 구간에서 원활한 합류를 수행함으로써 두가지 케이스에 비해 이동성 측면에서 모든 평가지표에서 우수함을 확인할 수 있다. 이는 강화학습 기반 통제 차로 회피 전략을 실행할 경우 교통류의 이동성 향상을 기대할 수 있음을 의미한다.
2. 안전성
본 연구에서는 안전성 분석을 위해 SSAM 소프트웨어를 사용하여 상충 분석을 실시하였고 그에 따른 결과를 Tables 6, 7에 제시하였다.
Table 6.
Result of Safety LOS C-D
| Conflict | RL case | Rule based case | Default case |
| Rear end | 9 | 4 | 278 |
| Lane change | 4 | 1 | 128 |
| Crossing | 0 | 0 | 0 |
Table 7.
Result of Safety LOS A-B
| Evaluation index | RL case | Rule based case | Default case |
| Rear end | 1 | 0 | 134 |
| Lane change | 2 | 1 | 80 |
| Crossing | 0 | 0 | 0 |
Tables 6, 7의 결과는 강화학습, 규칙 기반 케이스 모두 안전성에 문제가 없음을 보여준다. 이에 반해 일반 케이스의 경우 두 가지 케이스와는 대조적으로 상충의 발생히 현저히 높음을 확인할 수 있다. 상충 분석을 통해 일반 케이스의 경우 통제 지점에 도달해서 대기열을 발생시킨 후 대기열에 있는 차량들이 무분별한 차로변경을 실시함으로써 개방 차로에서 접근하는 차량과 Lane change 상충을 발생시키고 대기열에 접근하는 통제 차로 차량은 Rear end 상충을 발생시킴을 확인하였다. 이는 통제 구간 발생 시 사전 정보의 부재로 인해 체계적이지 않은 차량들이 주행행태를 보임으로써 빈번하게 상충이 발생할 수 있음을 시사한다.
3. 혼재 상황에서의 전략 평가
본 연구에서는 혼재 상황에서의 제안한 회피 전략의 효과를 알아보고자 MPR에 따라 다섯 가지 혼재 상황 시나리오를 설정하여 시뮬레이션 분석을 진행하였다. MPR은 0에서부터 25%씩 증가하도록 하였으며 회피 전략을 채택한 CAV의 증가에 따른 효과를 평가하였고 이를 Table 8과 Figure 8에 나타내었다.
Table 8.
Result of MPR
| Evaluation index | MPR 0 | MPR 25 | MPR 50 | MPR 75 | MPR 100 |
| Delay | 5.46 | 4.91 | 3.05 | 2.53 | 1.65 |
| Speed | 60.44 | 60.86 | 63.09 | 64.95 | 68.41 |
| Travel time | 40.35 | 39.75 | 36.84 | 35.76 | 34.85 |
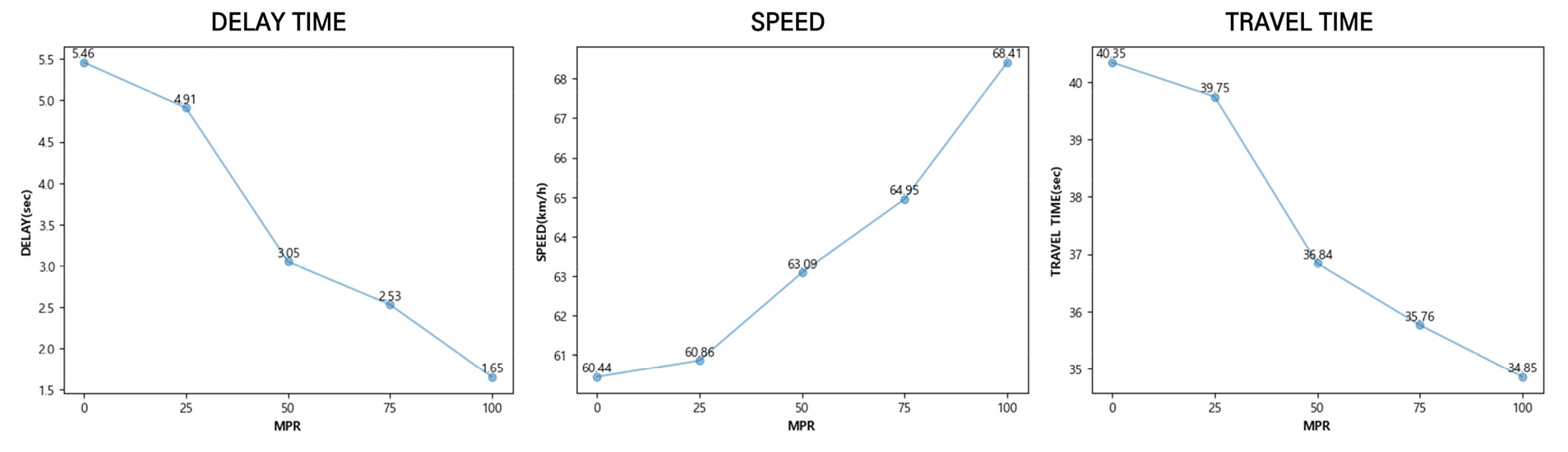
위 결과를 통해 MPR이 늘어남에 따라 제안한 회피 전략을 채택한 CAV의 비율이 늘어날수록 그에 따른 이동성이 증가하는 경향이 있음을 확인할 수 있다. 특히 MPR 25구간까지는 그 효과가 미미하게 드러나지만, 혼재 상황에서 CAV가 일반 차량과 동등한 비율을 차지하는 MPR 50구간부터 그 효과가 급격히 증가함을 확인할 수 있는데 이는 MPR 25와 같은 CAV의 혼재율이 낮은 교통류에서는 회피 전략에 따라 움직이는 CAV의 비율이 낮고 일반 차량이 다수를 차지하기 때문임을 나타낸다. 사전 정보를 획득하지 못한 일반 차량들의 통제 구간에서의 이동성 저하 주행 패턴 및 무분별한 차로 변경은 교통류에 혼란을 발생시키고 사전에 합류한 CAV의 이동성 저하도 유발함으로써 전체 교통류의 이동성을 저하시켜 회피 전략의 효과를 미미하게 만든다. 반면 혼재 상황에서 CAV가 일반 차량과 동등한 비율을 차지하기 시작하는 MPR 50구간부터는 본 연구에서 제시한 전략에 따라 체계적으로 통제 차로를 회피하여 통과하는 CAV가 다수를 차지하면서 CAV가 통제 구간 도달 전 교통류에 영향 없이 원활히 합류함으로써 일반 차량의 대기열 길이 또한 줄어들며 차로 변경 또한 수월해져 그 효과가 급격히 증가함을 확인할 수 있다.
결론
본 연구에서는 향후 LV4 자율주행 상황에서 CAV의 통제 구간 제어 전략의 기초 자료로서의 역할을 목표하였으며 이를 위해 미시교통시뮬레이션 VISSIM을 활용하여 강화학습 기반 CAV 거동 제어 알고리즘을 통한 통제차로 회피 전략을 개발하고 이에 따른 교통류 영향 효과를 분석하였다. VISSIM의 COM Interface를 활용하여 개별 차량의 정보 및 통제 구간 정보를 실시간으로 수집하여 V2X 통신 환경 및 CAV의 connected 상황을 구현하였으며, 실시간으로 수집된 개별 차량 정보를 활용하여 강화학습 환경을 구축하고 학습을 진행하였다.
본 연구에서 개발한 통제차로 회피 전략은 도로 네트워크의 용량을 최대화하면서 통제차로 회피 시 원활한 개방 차로로의 합류를 유도함으로써 이동성을 증가시키는 것을 목표하였다. 이를 위해 종방향 거동 제어를 통해 CAV의 종방향 위치를 조정하여 적절한 차로변경 지점을 찾도록 하였으며, 이를 통해 제어 차량이 통제 차로 회피를 위한 개방 차로로의 합류 과정에서 차로변경으로 인한 개방차로 차량들의 정지 및 주행 악영향을 유발하지 않고 합류하도록 거동 제어 에이전트를 학습시켰다.
강화학습 기반 통제차로 회피 전략의 효과를 분석하기 위해 일반 차로변경 모형, 단순 규칙 기반 제어 전략 상황 두 가지 상황을 가정하여 VISSIM 상에 구현하고 비교 분석하였다. 그 결과 이동성에서 두 가지 케이스 보다 큰 향상 효과를 보였으며 이는 해당 전략을 통해 통제 차로를 회피할 경우 통제 구간에서 차량들이 원활하게 개방 차로로의 합류를 진행하면서 이러한 효과가 나타났음을 알 수 있으며 이를 차량들의 시공도를 통해 확인하였다. 상충 분석을 통한 안전성 비교 평가에서 또한 해당 전략을 실시할 경우 상충 발생이 현저히 적어 문제가 없음을 확인하였다.
또한 혼재 상황에서의 해당 전략의 효과를 분석하기 위해 MPR에 따른 다섯 가지 혼재 상황 시나리오를 설정하였고 각 시나리오를 따라 시뮬레이션 분석을 진행하였다. 그 결과 해당 전략을 채택한 CAV가 증가함에 따라 이동성 향상 효과가 있음을 확인하였고 특히 MPR 50을 기점으로 효과의 상승 폭이 커짐을 확인하였고 이는 해당 전략을 채택한 CAV가 늘어날수록 통제 구간 교통류에 긍정적인 효과를 가져올 수 있음을 시사한다.
본 연구에서 제시한 통제 차로 회피 전략을 발전시키기 위해 다음과 같은 추가 연구가 필요하다. 본 연구에서는 2차로 도로만을 대상으로 연구를 진행하였다. 하지만 실제 현장에서는 2차로 도로보다 크고 다양한 네트워크에서 차량들이 주행하기 때문에 이에 따라 다차로 도로에 대한 추가연구를 통해 해당 전략의 범용성을 확보가 필요하다. 본 연구에서는 강화학습 시 도로 네트워크를 세 가지 구간으로 나누어 강화학습을 진행하였다. 세 가지 구간의 연장에 따라 결과가 크게 달라질 수 있어 구간 길이에 따른 추가 분석이 필요하다. 본 연구에서는 DQN 알고리즘을 사용하여 이산적인 액션만을 고려했지만, 실제 차량의 가감속량은 연속적임을 고려했을 때 폴리시 기반의 강화학습 알고리즘을 활용하여 연속적인 액션을 고려한 추가 연구가 필요하다.
