

Introduction(서론)
Literature Review(선행연구)
Methodology(방법론)
1. Main Concepts and Assumptions(주요 개념 및 가정)
2. Algorithm for Mobile Phone Data Processing(모바일기지국 데이터 가공 알고리즘)
A Case Study of Verification(사례 검증)
1. Mobile Phone Data and GPS Survey(모바일기지국 데이터와 GPS 조사)
2. Verification Results(검증 결과)
Discussions(논의 사항)
1. Improvement of Spatial Resolution(공간적 해상도 개선)
2. Analysis of Various Commuting Trips(다양한 형태의 출퇴근 통행 분석)
3. Adjustment of Travel Times(통행시간 보정)
Conclusions and Future Work(결론 및 향후 연구과제)
Introduction(서론)
교통 분야에서는 다양한 모빌리티 데이터가 존재하는데, Kim et al.(2018)은 차량, 대중교통, 사람의 통행 정보를 파악할 수 있는 차량내비게이션, 대중교통카드, 모바일기지국 데이터가 대표적이라고 언급하고 있다. 그중 모바일기지국 데이터는 휴대폰과 통신 기지국 간의 일정한 간격 또는 휴대폰 사용 시 기록되는 신호 정보를 말한다. 이러한 데이터는 신호의 기록 주기 및 포함하고 있는 속성 정보에 따라 Sighting 정보와 CDR(Call Detailed Recorder) 정보로 구분된다. Sighting 정보는 휴대폰을 사용하지 않더라도 일정 시간 간격으로 기지국과 송 ‧ 수신할 때 기록되는 정보로, 단말기가 특정 기지국의 수신범위에 진입하면 일정 간격으로 정보를 생성하다가 수신범위를 벗어나면 기록이 중지된다. CDR 정보는 통화, 문자, 인터넷 등 휴대폰을 사용할 때 기록되는 정보로, Sighting 정보보다는 기록 주기와 빈도가 낮지만, 사용자가 실제로 휴대폰 단말기를 사용하는 패턴 및 시간을 정확하게 파악할 수 있는 정보이다.
교통 분야 통행 분석에 있어서 모바일기지국 데이터의 장점은 높은 시 ‧ 공간적 표본 비율과 항시성이다. 먼저, 국내 스마트폰의 보급률은 95%에 육박하며, 그 중, SKT와 KT가 전체 점유율의 71.6%를 차지한다(Kim et al., 2018). 그러므로 국내 최대 2개의 통신회사의 데이터를 분석하면, 전 국민 모빌리티의 71.6%를 분석할 수 있는 것을 의미하며, 이것은 차량내비게이션 데이터(승용차 수송 분담률 약 54.0% 중 차량내비게이션 보급률 약 20%)와 대중교통카드 데이터(대중교통 수송 분담률 약 43.2% 중 대중교통카드 이용률 약 99%)와 비교해도 월등히 높은 표본 비율이다(Kim et al., 2018). 또한, 차량내비게이션이나 대중교통카드 데이터가 차량 또는 대중교통 수단을 이용했을 때만 그 정보가 기록되지만, 모바일기지국 데이터의 경우에는 차량과 대중교통은 물론, 자전거거나 도보 등 어떠한 통행을 하거나 심지어 통행하지 않을 때도 이용자의 정보를 수집한다는 측면에서 그 표본의 크기와 활용범위가 매우 넓다. 이미 국내외에서는 이러한 모바일기지국 데이터를 이용하여 개별통행DB와 통행사슬(Trip Chain)DB를 구축하고, 유동 인구 분석, 목적통행 분석, 출퇴근 분석, 대중교통 취약지역 분석, 사회 및 경제 여건 변화(경기침체, 코로나19, 교통재난 등)에 따른 통행패턴 분석 등 다양한 방법으로 활용되고 있다(Kim et al., 2018, 2019a, 2019b; Won, 2020).
그럼에도 불구하고, 1) 불규칙성(무작위성)을 가지는 모바일기지국 신호의 전처리 문제; 2) 개별 통행 특성 및 지역별 기지국 거리를 고려하지 못하는 이동/체류 구분의 모호한 기준값; 3) 야간 및 저녁 근무 등 비주류 통행 추정에 대한 문제; 4) 기지국으로 대표되는 공간적 저해상도 문제; 5) 공간적 저해상도로 인한 이동 경로 및 수단 추정의 문제; 6) 일부 고도화된 알고리즘의 컴퓨팅 타임에 대한 문제 등, 더 정확하고 신뢰성 있는 통행 분석을 위해 해결해야 할 문제들이 남아 있다(Chen et al., 2014, 2016; Won, 2020).
그러므로 본 연구는 모바일기지국 데이터를 이용하여 더 정확하고 정밀한 출퇴근 목적의 개별 통행 정보를 추정하기 위한 알고리즘을 개발하였다. 제시된 알고리즘은 실제 GPS 다이어리 조사 자료를 통해 그 성능과 정확도를 검증하였다.
Literature Review(선행연구)
모바일기지국 데이터는 기지국에서 통행자의 신호를 감지하여 해당 기지국에서 최초로 식별된 시점과 최종적으로 식별된 시점이 기록된 자료이다. 이러한 모바일기지국 데이터의 통신 범위는 지형, 기상 등과 같은 주변 환경과 운영의 목적에 따라 그 영역이 시시각각으로 변화하는데, 이러한 현상에 의해 휴대폰 사용자의 실제 위치를 왜곡하는 현상이 발생하게 된다(Chen et al., 2016). 대표적인 것이 핸드오버(Handover) 현상인데, 통행자가 정지해 있음에도 불구하고 여러 기지국에 반복적으로 연결되는 Ping-pong Handover와 물리적으로 신호를 감지할 수 없는 먼 기지국에 연결되는 Signal Jump Handover가 대표적인 현상이다(Chen et al., 2016; Kim et al., 2019a; Won, 2020).
이러한 신호 왜곡 현상을 보정하고 개별 통행에 대한 정보를 추출하기 위하여 다양한 방법이 적용되고 있는데, 그 중 대표적인 것이 신호 간 이동 속도를 이용하는 방법(Iovan et al., 2013)과 신호 간 기록 패턴을 이용하는 방법(Lee and Hou, 2006; Kim et al., 2019a; Bayir et al., 2010)이다. 하지만 이러한 방법들의 이슈는 신호 왜곡 현상을 구분하기 위한 속도 기준 및 패턴을 어떻게 정의할 것인가이다. 왜냐하면, 이러한 기준값들에 따라 반복적인 단거리 이동 등 자칫 정상적인 이동과 체류를 신호 왜곡 현상으로 잘못 인식할 수 있기 때문이다. 또한, 속도 기준과 패턴인식 방법을 동시에 이용하여 각 방법의 한계점을 해결하고자 한 연구도 있다. Wang(2014)은 먼저, 패턴인식을 통해 신호 왜곡 현상이라고 판단되는 신호 정보들을 선별하고, 다음 단계에서 이러한 신호들의 속도를 계산하여 특정 기준을 벗어나는 신호 정보들을 보정하여, 더 정확하게 신호 왜곡 현상을 보정하고자 하였다.
다음으로, 모바일기지국 데이터만으로는 이동과 체류에 대한 정보를 알 수 없다(Chen et al., 2016; Kim et al., 2019a). 그러므로 이러한 이동 및 체류를 구분하기 위하여, 특정 체류시간(e.g., 20분, 30분 등)을 이용하거나(Yuan et al., 2012; Kim et al., 2019a), CDR 정보의 시간대 발생 빈도(Wang, 2014), 또는 다양한 클러스터링 방법(Clustering Methods)을 적용하여 이동 및 체류를 구분하고 있다(Ester et al., 1996; Fraley and Raftery, 2002; Ye et al., 2009; Calabrese et al., 2010; Chen et al., 2014). 클러스터링 방법은 각 클러스터링 알고리즘의 장단점에 따라 Distance-based clustering(Ye et al., 2009; Calabrese et al., 2010), Density-based clustering(Ester et al., 1996), Model-based clustering(Fraley and Raftery, 2002; Chen et al., 2014) 등 다양한 방법이 적용되고 있는데, 특히 Chen et al.(2014)은 Gaussian Mixture Model(GMM)기반 클러스터링 방법을 이용하여 이동과 체류를 효과적으로 구분하였다.
마지막으로, 이렇게 구분된 이동과 체류 정보를 바탕으로 각 체류지의 유형 및 통행목적 정보를 추출하여야 하는데, 모바일기지국 데이터는 위치 정보와 체류시간 정보밖에 포함하고 있지 않기 때문에, 가구통행조사에서 요구하는 다양하고 상세한 목적통행 정보를 파악하는 것이 쉽지 않다(Chen et al., 2014; Gong et al., 2016; Won, 2020). 가장 간단한 방법은 밤과 낮에 체류한 빈도를 기준으로 집과 직장을 구분하거나(Phithakkitnukoon et al., 2010; Alexander et al., 2015; Kim et al., 2019a), 실제 체류정보(i.e., Ground Truth)를 알고 있다면 통계적 모형(Chen et al., 2014) 등을 이용하여 각 체류지의 유형을 구분한다. 또는, 각 체류지 위치에 대한 속성 정보(e.g., Point of Interests: POIs)를 활용하여 체류지 유형을 구분하는 연구도 있다(Xie et al., 2009; Huang et al., 2010; Spinsanti et al., 2010; Gong et al., 2016).
Methodology(방법론)
1. Main Concepts and Assumptions(주요 개념 및 가정)
본 연구에서는 모바일기지국 데이터의 Sighting 정보와 CDR 정보 중, 표본의 수가 더 많고 체류와 이동의 추적이 더 용이한 Sighting 정보(Chen et al., 2016)를 이용한 개별 출퇴근 통행 추정 알고리즘을 개발하였다. 선행연구에서 밝혔듯이, 모바일기지국 데이터를 이용하여 통행을 분석하기 위한 데이터 전처리 방법은 다양한데, 해당 연구에서는 다음과 같은 사항을 고려하여 알고리즘을 개발하였다.
먼저, 기지국과 단말기 간 발생하는 불규칙한 신호 왜곡 현상(e.g., Signal Jump and Handover)을 보다 효과적이고 효율적으로 처리할 수 있어야 한다. 왜냐하면, 기존 연구에서 보듯이, 대부분의 연구들이 불규칙한 신호 왜곡 현상을 정형화 또는 패턴화하여 데이터를 전처리하였으나(Lee and Hou, 2006; Iovan et al., 2013; Kim et al, 2019a, 2019b), 모바일기지국 데이터의 무작위적으로 발생하는 신호 패턴을 정형화하는 것이 불가능하고, 경우의 수가 너무 많아 기존의 접근 방법이 효과적이고 효율적이지 못하기 때문이다(Won, 2020). 두 번째로, 개별통행 특성 및 지역별 기지국 특성을 고려한 이동 ‧ 체류 구분 및 체류지 유형 구분 알고리즘이 필요하다. 기존에는 특정 체류시간(e.g., 25분 or 60분) 또는 특정 시간대(e.g., 출근: 9시, 퇴근: 18시)를 가정하여 통행행태를 분석하였다(Kim et al., 2018, 2019a, 2019b). 하지만, 이러한 기존의 방법은 도심과 비도심의 기지국 간 간격의 차이(e.g., 수도권 평균 0.7km, 비수도권 평균 2.9km)를 고려하지 못하고, 야간 근무 및 주 3회 근무 등 우리가 보통 시행하고 있는 정기 근무시간(9시 출근, 18시 퇴근; 이하 ‘9-to-6’)에 해당하지 않는 출퇴근 통행에 대해서는 분석할 수 없기 때문이다(Won, 2020). 세 번째로, 모든 위치가 기지국 위치로 대표되는 모바일기지국 데이터의 공간적 해상도를 극복할 수 있는 방법이 필요하다. 앞에서 설명하였듯이, 모바일기지국 데이터는 기지국과 단말기 간의 신호 정보이기 때문에 정확한 단말기의 위치를 추정하기 어렵고, 모든 단말기의 위치를 기지국의 위치로 대표한다. 그렇기 때문에 추정된 단말기의 위치 정보는 실제 위치 정보와 기지국 간 거리만큼 오차를 가지며, 이러한 공간적 저해상도로 인해 이동 경로 및 수단을 파악하거나, POI(Points of Interest) 정보 등을 활용한 통행목적 추정이 불가능하다(Won, 2020). 마지막으로, 실행 가능한 빅데이터 처리 알고리즘이 필요하다. 기존의 일부 연구에서는 인공지능 또는 머신러닝 기법 등을 이용하여 데이터를 전처리하고 통행을 분석하는 방법을 제시하였다(Chen et al., 2014). 하지만, 국내 특정 모바일 회사의 모바일기지국 자료는 하루 약 60억 건이 발생하고(Kim et al., 2019a), 이러한 데이터를 전국을 대상으로 1년을 분석하기에는 적합한 방법이 아니다. 그러므로 이렇게 매일 발생하는 대규모의 모바일기지국 빅데이터를 효과적으로 처리 ‧ 가공할 수 있는 실행 가능한 알고리즘의 설계가 필요하다.
마지막으로, 모바일기지국 데이터 가공 ‧ 분석 알고리즘 개발을 위하여 다음과 같은 모바일기지국 데이터와 통행행태에 대한 3가지 기본 가정을 정의하였다: 1) 단말기는 위치가 가까운 기지국과 더 오래 또는 자주 통신할 것이다; 2) 누구나 집은 있다; 3) 집 다음으로 오래 또는 자주 가는 곳은 직장이다. 먼저, 첫 번째 가정은 단말기와 기지국 간의 모바일기지국 신호가 왜곡되는 현상(e.g., Signal Jump and Handover)이 발생할 수 있으나, 전체적으로 긴 시간을 놓고 보면 단말기와 가장 가까운 기지국 간의 통신 시간과 빈도가 더 높다는 것이다. 두 번째 가정은 개인별로 매우 다양한 형태의 활동과 통행패턴을 가지더라도 기본적으로 주로 숙식을 해결하는 집이라는 장소가 모두 있다는 것이다. 마지막 세 번째 가정은 집 다음으로 오래 체류하거나 자주 방문하는 곳은 직장이라는 것이다. 기본적으로 직장보다는 집에서 체류하는 시간이 더 길 것이며, 경우에 따라 하루 중 직장에 더 오래 있을 수 있지만, 일주일 이상의 시간을 놓고 보면, 누구나 하루쯤은 집에서 휴식을 취할 것이기 때문에 집의 방문 빈도가 더 높을 것이라는 것을 의미한다.
2. Algorithm for Mobile Phone Data Processing(모바일기지국 데이터 가공 알고리즘)
본 연구에서는 앞에서 제시된 주요 고려사항과 가정을 바탕으로 Figure 1과 같이 주요 3가지 단계로 구성된 모바일기지국 데이터 가공 알고리즘을 개발하였다. 해당 알고리즘은 개별 통행에 대한 모바일기지국 데이터를 일주일 단위로 분석하여 집과 직장을 추정하고 출퇴근 통행을 추출한다.
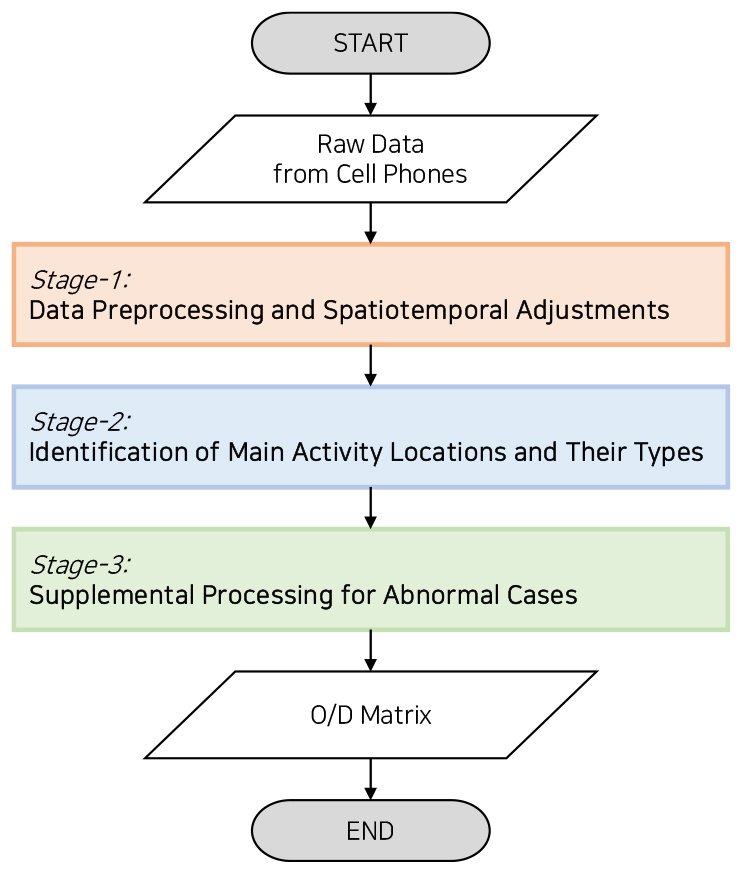
Stage-1: Data Preprocessing and Statiotemporal Adjustment(데이터 전처리 및 시공간적 보정)
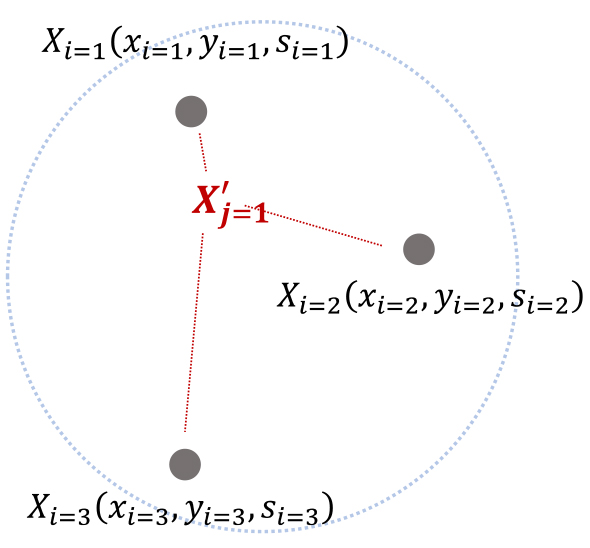
∙ Step-1: (시간적 보정) 특정 시간 단위 로 각 시그널 정보 를 그룹화한 후, Equation 1을 이용하여 Figure 2와 같이 각 그룹별 시그널 정보의 위치(, )와 체류시간()을 가중치로 통행자의 실제 위치 를 추정. 단, 은 각 시간 단위 안에 있는 시그널 로그 순서(), 은 보정된 로그 순서().
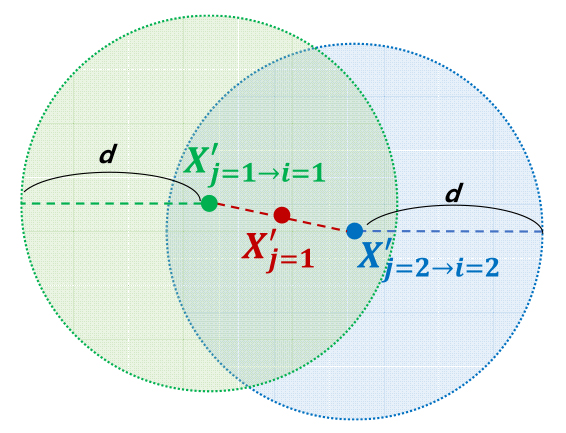
∙ Step-2: (공간적 보정) 특정 시간 단위 로 보정된 각 시그널 정보 의 위치가 최소 이동 속도 기준 시간 안에 도달할 수 있는 거리 보다 작으면(Figure 3), Equation 1을 이용하여 위치를 다시 보정.
개발된 알고리즘의 첫 번째 단계는 모바일기지국 데이터의 신호 이상현상(e.g., signal handover and jump)을 효과적으로 처리하기 위하여, 이벤트별로 발생한 각 신호 정보를 특정 시간 단위 로 평활화(i.e., smoothing)하고, 이렇게 집합화된 신호 정보 중 각 신호의 발생 및 점유 빈도를 이용하여 통행자의 실제 위치를 추정하였다. 왜냐하면, Liu et al.(2018)의 연구에서도 밝혔듯이 모바일기지국 데이터의 신호 정보는 약 7.5분 단위로 집합하여도 개별 통행에 대한 특성 및 궤적을 판단하는데 문제가 없으며, 신호 이상 현상을 고려하더라도 단말기와 기지국의 거리가 가까울수록 발생 및 점유 빈도가 높기 때문에(Reades et al., 2009; Kang et al., 2012; Deville et al., 2014), 이러한 정보를 이용하여 휴대폰의 실제 위치를 추정할 수 있다. 단, 해당 연구에서는 Liu et al.(2018)의 7.5분 보다 작은 5분을 시간 보정 단위()로 설정하였다.
두 번째로, 이렇게 보정된 위치들이 최소 이동 속도 (해당 연구에서는 평균 도보 속도 5km/h 이용. Levine and Norenzayan, 1999; Browning et al., 2006; Mohler et al., 2007)로도 이동하지 않았을 것으로 판단되면(i.e., ), Step-1과 같은 방법으로 각 위치를 다시 보정하였다. 왜냐하면, 해당 알고리즘에서는 특정 시간 단위 로 각 위치를 보정하였기 때문에, 이러한 작은 시간 단위 안에서 최소 이동 속도 이하로 움직이는 것을 이동으로 볼 수 없다. 또한, 30분, 1시간, 6시간 이상 등, 실제로는 한 장소에 체류했음에도 불구하고, 주변 기지국 간 신호 빈도 및 간섭에 의해 짧은 시간 단위 에 의해 보정되는 각 위치는 조금 다를 수 있는데, 이러한 점들이 결국은 하나의 동일한 체류 위치라고 판단하기 위해서는 Step-2와 같은 공간적 보정 단계를 통해 최소 속도 기준으로 각 위치를 집합화하여야 한다.
Stage-2: Identification of Main Activity Locations and Types(주 체류지 식별 및 유형 구분: 집, 직장 추정)
∙ Step-1: (첫 번째 주 체류지 식별) 각 보정 위치 별 점유시간 를 이용하여 최장 체류지 를 식별(Figure 4).
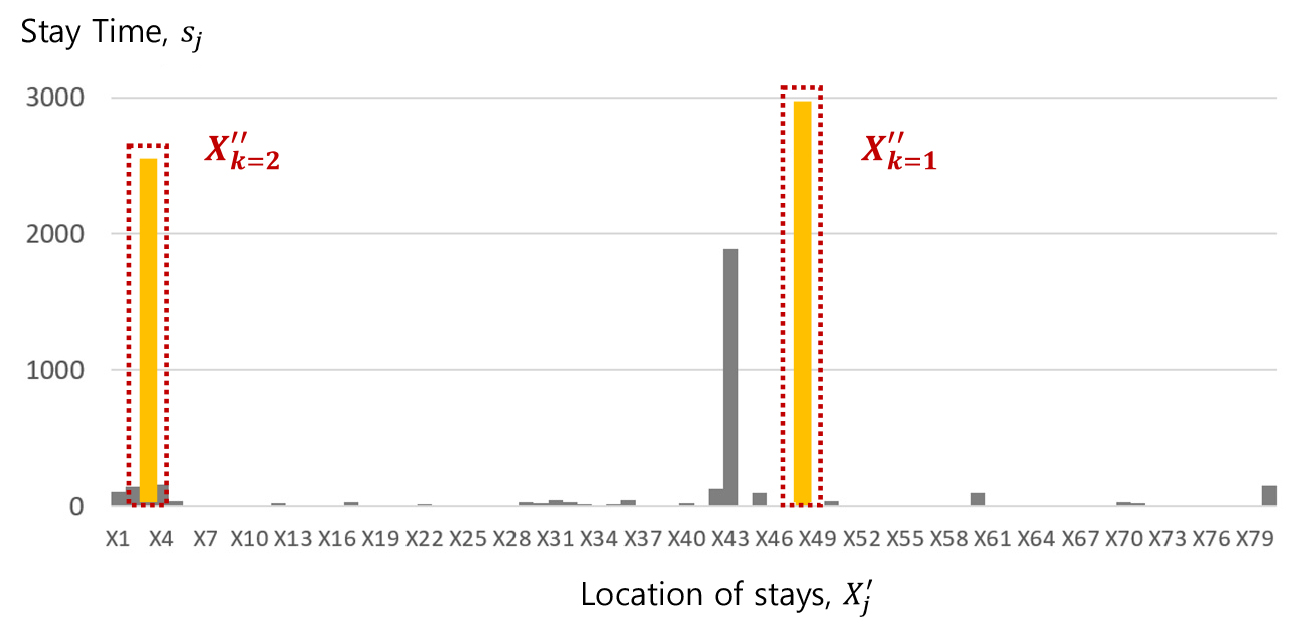
∙ Step-2: (첫 번째 주 체류지의 실제 점유시간 추정) 하루 24시간 중, 첫 번째 주 체류지 이외의 점유시간 중 최장 점유시간만 남겨놓고 나머지 시간을 첫 번째 주 체류지의 점유시간으로 산정(Figure 5).

∙ Step-3: (두 번째 주 체류지 식별 및 실제 점유시간 산정) 첫 번째 주 체류지 와 그 점유 시간 의 영역을 제외하고 Step-1과 Step-2를 시행하여 두 번째 주 체류지 와 그 실제 점유시간 를 산정(Figure 6).
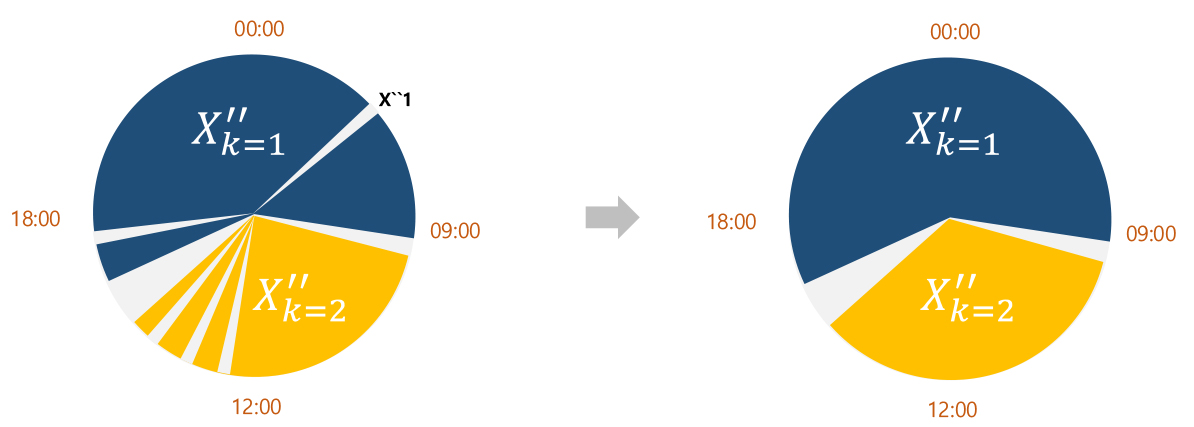
∙ Step-4: (각 주 체류지의 유형 구분) 각 주 체류지 과 에 대한 일주일 기준 방문 빈도 과 를 비교하여, 더 높은 것을 집으로, 그 외를 직장으로 구분. 단, 방문 빈도가 동일 할 경우에는 일주일 총 점유시간 과 중 더 큰 것을 집으로 산정.
개발된 알고리즘의 집과 직장(i.e., 주 체류지) 식별 방법은 앞에서 언급한 ‘누구나 집은 있으며, 직장보다 오래 또는 자주 방문할 것이다’라는 두 번째와 세 번째 가정에 기반한다. 먼저, 신호 이상이 처리된 데이터에서 일주일 기준 가장 오래 있었던 최장 체류지 를 집과 직장의 후보지로 설정한다. 다음으로 이러한 주 체류지의 일별 점유시간을 확인하여 실제로 첫 번째 주 체류지에 있었을 것으로 예상되는 점유시간 을 재산정한다. 즉, 고객이 첫 번째 주 체류지에 있는 동안 신호 이상에 의해 다른 기지국 위치가 매칭되었거나, 또는 중간에 다른 부수적 활동을 했더라도, 출퇴근 통행을 구분하기 위한 집 또는 직장의 시공간적 체류 영역 및 시간대를 정의하기 위해서이다. 예를 들어, 어떠한 사람이 퇴근하여 집에 19시에 도착하여 다음 날 8시에 다시 출근한 경우, 19시 이후 운동, 쇼핑 등 다른 활동을 하거나, 신호 이상에 의해 다른 기지국의 신호가 매칭될 수 있지만, 출퇴근 통행을 분석하기 위한 집 체류의 범위는 19-8시가 될 것이며, 이것은 최장 체류지의 주요 점유시간과 그 시간의 최장 시간 차이(i.e., 8-19시, 예를 들어, Figure 5의 )를 이용하여 찾을 수 있다는 것을 의미한다. 직장의 경우에도, 어떠한 사람이 직장에 9시에 출근하여 18시에 퇴근하였고, 중간에 점심, 외근, 또는 다른 기지국의 신호가 매칭되었더라도, 주 체류지의 주요 점유시간과 그 외 시간의 시간 차이를 이용하여 9-18이라는 직장 체류 시간대를 정의할 수 있다는 것이다. 마지막으로, 해당 알고리즘의 목적이 집과 직장이라는 두 가지 주 체류지를 식별하고 출퇴근 통행을 분석하는 것이기 때문에, 위와 같이 첫 번째 주체류지와 그 시간 영역이 정의되면, 해당 주 체류지를 제외하고 두 번째 주 체류지와 그 시간 영역을 같은 방법으로 찾는다.
다음으로, 이렇게 선정된 두 개의 주 체류지 중에 직장의 유무를 포함하여 어떠한 곳이 집이고 직장인지를 구분한다. 본 연구에서는 직장보다 집에 오래 또는 자주 방문할 것이라고 정의했기 때문에, 각 주 체류지별 일주일 기준의 방문 빈도 를 확인하여 한 번이라도 더 많이 방문한 곳을 집으로 정의한다. 왜냐하면, 일일 기준으로 보면 집이나 직장에 더 오래 있을 수 있으나, 일주일 방문 빈도로 보면, 주말 또는 휴무일 때문에 직장보다는 집에 하루는 더 있을 확률이 높기 때문이다. 마지막으로, 직장으로 구분되었음에도, 잠재체류지(e.g., 정기적인 운동, 여가, 쇼핑 등)와 장거리 출장 통행(e.g., 일주일 2회 이상 반복되지 않을 것으로 예상되는 장거리 출장 통행)을 제외하기 위하여, 동 시간대 3시간 이상 주 2회 이상 체류하지 않았거나 출퇴근 통행이 주 2회 미만이면 직장에서 제외하도록 하였다(Kim et al., 2019a, 2019b; Won, 2020). 단, 이러한 파라미터 조건은 분석 결과의 정확도에 따라 변경될 수 있다.
Stage-3: Supplemental Processing for Abnormal Cases: 이상치 처리를 위한 예외 조건
∙ Step-1: 두 주 체류지 간 이동 속도가 최소 이동 속도 보다 작으면, 이상치로 처리
∙ Step-2: 두 주 체류지 간 이동 속도가 최대 이동 속도 보다 크면, 이상치로 처리
마지막 단계는 Stage-1과 Stage-2에 의한 데이터 전처리 및 통행 구분 알고리즘에도 불구하고 발생할 수 있는 비상식적 통행행태를 제외하기 위한 조건이다. 그 첫 번째는 이동 속도가 최소 이동 속도 보다 느린 경우이며, 두 번째는 이동 속도가 실제 현실에서 가능하다고 판단되는 이동 속도 보다 빠른 경우이다. 이러한 현상은 데이터 기록 또는 퀄리티에 대한 이슈로 판단되어, 통행분석에서 제외하도록 한다. 해당 연구에서는 과거 동일한 통신회사의 데이터로 분석되었던 연구의 결과(Kim et al., 2019a, 2019b; Won, 2020)를 바탕으로 최소 이동 속도은 앞에서 언급한 평균 도보 속도 5km/h로 설정하였으며, 최고 이동 속도 는 200km/h로 설정하였다.
A Case Study of Verification(사례 검증)
1. Mobile Phone Data and GPS Survey(모바일기지국 데이터와 GPS 조사)
본 연구에서는 개발된 알고리즘의 성능을 평가하기 위하여 개인정보제공 및 활용 동의를 받은 1,000명의 모바일기지국 데이터와 GPS 통행다이어리 수집 정보를 이용하였다. 조사대상은 2020년 06월 22일부터 28일까지 서울과 충북에 거주하고 있는 20-59세대까지의 사무직, 영업직, 프리랜서, 학생, 주부, 무직 등 다양한 직업을 가지고 있는 사람들을 대상으로 조사 참여 전 개인정보 제공 및 활용에 대한 동의를 얻어 실시하였다. 모바일기지국 데이터는 대상자의 통행에 대해 기지국 기반으로 수집된 자료로써, Table 1과 같이 기지국의 위도 ‧ 경도 좌표 기준으로 휴대폰 신호가 진입 ‧ 진출한 시간 정보가 날짜, 시간 순서로 구성되어 있다. GPS 통행다이어리 조사 자료는 자기 기입식으로 조사 기간동안 첫 번째 통행부터 마지막 통행까지의 모든 통행에 대해 일기형식으로 기록한 통행일지와 휴대폰 GPS로부터 1분 단위로 수집되는 통행자의 실제 위치를 시점별로 매칭하여 구축한 자료로 개인 특성 및 통행 정보를 포함하고 있다. 개인 특성 정보로는 성별, 직업, 근무 형태, 집과 직장의 주소가 있으며, 통행 특성 정보로는 통행 단위별 출발지, 목적지, 출발시간, 도착시간, 통행목적, 교통수단, 동반 인원에 대한 정보가 포함되어 있다. 수집 데이터에 대한 기초 정보 및 상세 내용은 Table 2와 같다.
Table 1.
Descriptions of mobile phone data
Table 2.
Descriptions of GPS survey data
2. Verification Results(검증 결과)
GPS 정보와 함께 조사된 1,000명 중, 모든 응답에 응한 836명의 실제 GPS 조사 정보와 본 연구에서 개발한 알고리즘을 적용한 결과의 집/직장 식별 정확도, 집/직장 위치 정확도를 비교 ‧ 분석하였다.
먼저, Table 3에서 보듯이, 집 식별 정확도는 100%이다. 왜냐하면, 본 연구에서 제사한 알고리즘은 ‘모든 사람은 집이 있다.’라는 가정하에 모든 통행자에 대하여 집의 위치를 지정하기 때문에, 그 위치 정확도를 논외하더라도 식별 정확도은 100%가 되는 것이다. 또한, Table 4에서 보듯이, 이렇게 식별된 집의 위치 정확도도 1km 이하가 전체의 약 90%일 정도로 매우 정확한 것을 알 수 있다. 실제로 국가교통OD자료를 구축하기 위한 가구통행실태조사의 기본 공간 단위인 읍면동 평균 반경 약 3km와 통신 기지국 위치를 이용한 통신 폴리곤 평균 반경 약 2km(Kim et al., 2018)를 고려하더라도, 거리오차 1km 이하 약 90%, 평균 거리오차 1.59km는 매우 정확하다고 할 수 있다.
Table 3의 직장 식별 정확도를 살펴보면, 직장 추정의 전체적인 식별 정확도(Accuracy)는 80.4%((93+579)/863)이며, 정밀도(Precision)은 0.91, 민감도(Sensitivity)는 0.85이다. 즉, 실제로 직장이 있는 사람들의 약 85%를 정확하게 직장으로 식별하였으며, 제시된 알고리즘에서 직장이라고 추정하였을 경우 실제 직장일 정확도는 약 91%라는 의미이다. 또한, Table 4에서 보듯이, 이렇게 식별된 직장의 위치 정확도도 거리오차 1km 이하 약 85%, 평균 거리오차 1.57km로 매우 정확한 성능을 보여주고 있다.
Table 3.
Confusion matrix for verification results
Table 4.
Ratio of accumulated customer by distance error range
Table 5와 같이, 직종별 식별 정확도 및 위치 정확도를 분석하였다. 결과를 보듯이, 비교적 정기적인 통행을 하는 사무직과 영업직의 직장 식별 정확도는 각각 86.79, 85.09%, 집 추정 위치 정확도는 각각 2.26km, 0.67km, 직장 추정 위치 정확도는 1.31km, 1.41km로 로그 식별 정확도와 추정 위치의 정확도가 상대적으로 높게 나타나는 것을 확인할 수 있다. 반면에, 통행패턴이 상대적으로 비정기적이라고 예상되는 프리랜서와 기타 그룹에 대해서는 직장 식별 정확도가 각각 55.17%, 59.32%, 집 추정 위치 정확도는 각각 0.21km, 1.73km, 직장 추정 위치 정확도는 각각 4.75km, 2.72km로 상대적으로 그 식별 정확도와 위치 정확도가 높지 않은 것을 확인할 수 있다. 마지막으로 주로 거주지에서 시간을 보낼 것으로 예상되는 주부와 무직의 경우에는 집 추정 위치 오차가 작아 상대적으로 정확하게 추정되는 것을 확인할 수 있다.
Table 5.
Accuracies on classification and estimated locations of each types of stays
Discussions(논의 사항)
1. Improvement of Spatial Resolution(공간적 해상도 개선)
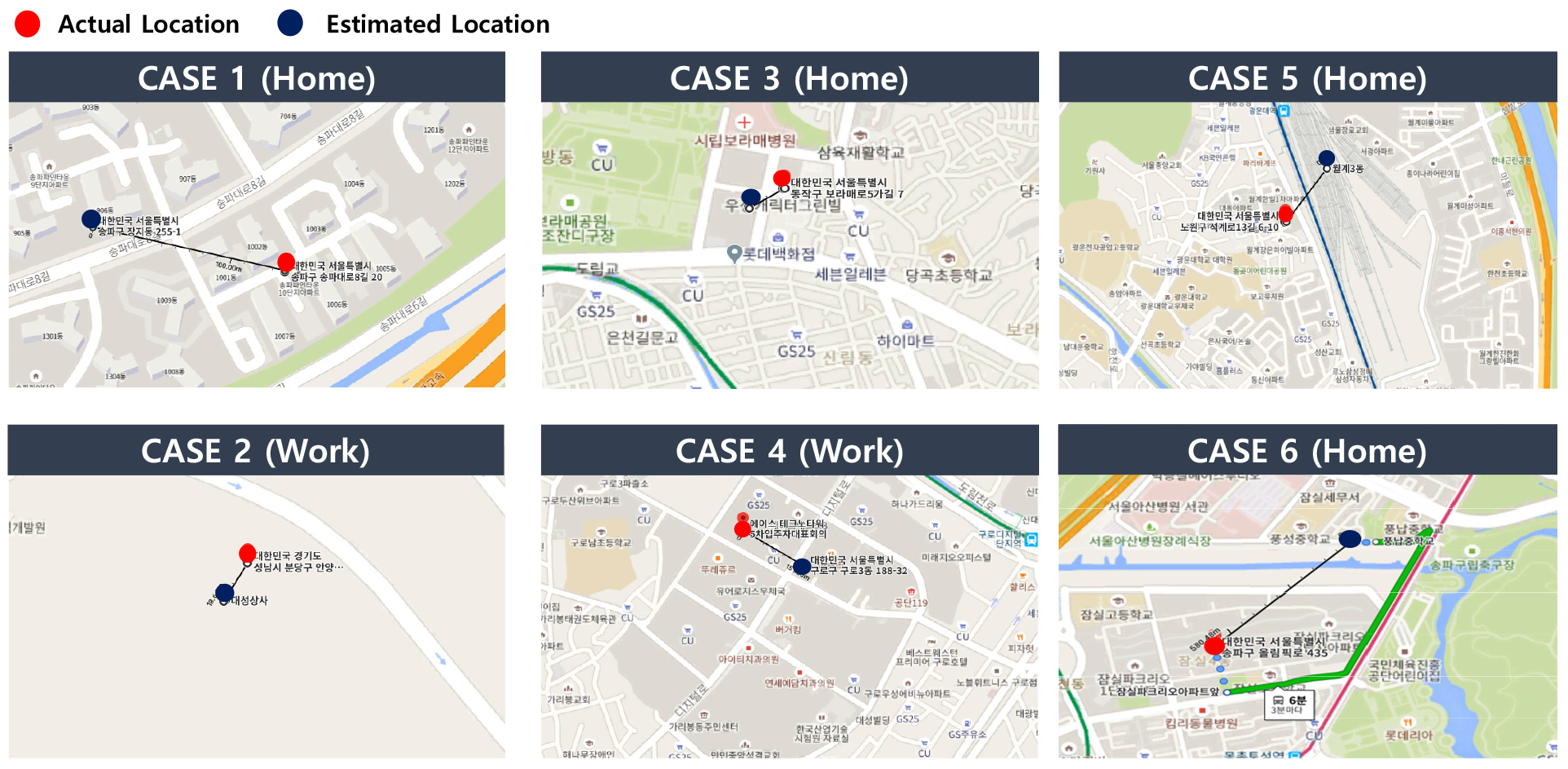
서두에서 언급하였듯이, 모바일기지국 데이터의 한계점 중의 하나는 기록되는 위치 정보가 실제 단말기(i.e., 휴대폰 사용자)의 위치가 아니라 인근 기지국의 위치라는 것이며, 그렇기 때문에, 차량내비게이션, 대중교통카드 데이터 등의 다른 모빌리티 데이터보다 공간적 해상도가 낮다는 것이다. 그러므로 이러한 저해상도의 공간 정보를 이용하여 이동 경로 및 교통수단을 추정하고 토지용도 및 건물과 같은 POI 정보를 활용할 수 없다는 단점이 있다. 과거에는 통신 폴리곤을 이용하여 기지국 간 거리와 반경으로 임의의 공간을 정의하였으나, 여전히 GPS와 같은 점추정(Point Estimate)의 장점을 활용할 수 없었다. 그러나 본 연구에서 제시된 알고리즘은 인근 기지국과의 통신 시간 및 빈도를 이용하여, 실제 단말기 사용자의 위치를 추정함으로써, 공간적 정밀성 및 정확성과 그 활용성을 높였다는 점에서 큰 의미가 있다.
실제 Table 4에서 보듯이, 집과 직장의 평균 추정 위치 정확도는 각각 1.59km와 1.57km에 해당하며, 전체의 약 90%와 85%가 1km 안에 들어온다. 이러한 위치 정확도는 Figure 7의 Case 1-4에서 보듯이, 대부분의 거리오차가 같은 아파트 단지나, 상업지구 내, 한 블록 정도의 차이로 매우 정확하게 추정되는 것을 확인할 수 있다. 단, Figure 7의 Case 5-6과 같이 대형 기지국(i.e., 통신 범위가 상대적으로 넓은)을 포함하고 있는 큰 지하철역이 있거나, 강이나 하천처럼 통신 신호가 장애물 없이 널리 도달할 수 있는 곳에서는 그 거리오차가 다소 증가하지만, 기존 면단위(e.g., 읍면동, 집계구, 통신폴리곤 등)의 위치 정보를 GPS와 같은 점 단위의 정보로 전환했다는 측면에서 그 활용성이 매우 높아졌다고 할 수 있다.
2. Analysis of Various Commuting Trips(다양한 형태의 출퇴근 통행 분석)
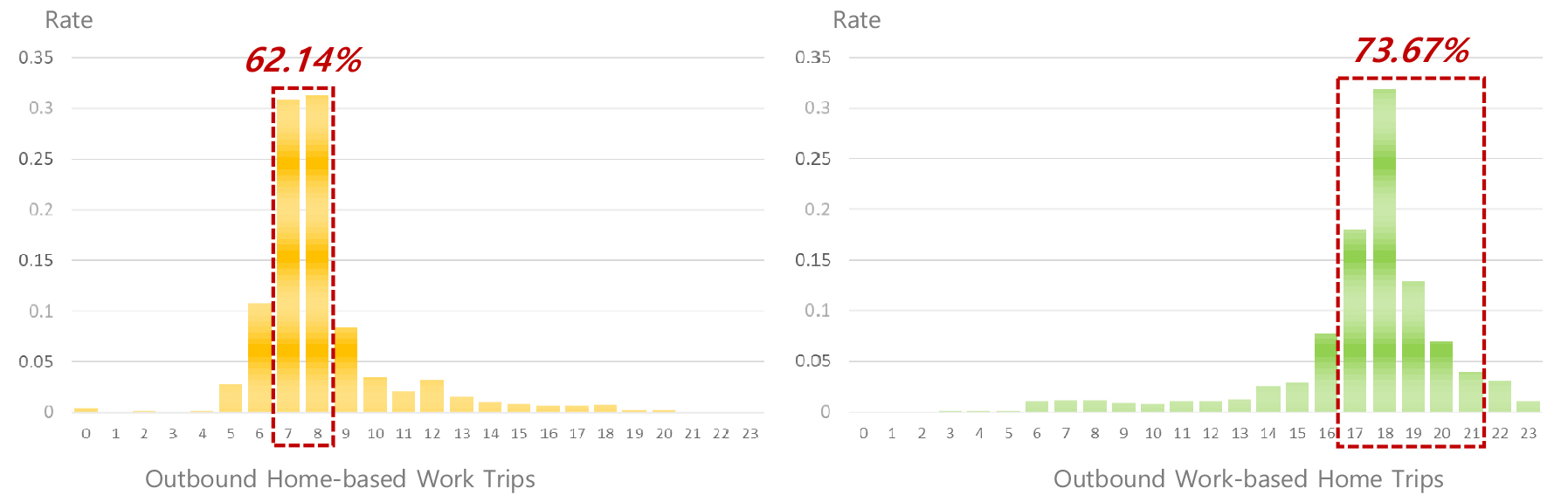
선행연구에서 언급하였듯이, 일부 연구에서는 모바일기지국 데이터를 이용하여 출퇴근 목적통행을 구분하기 위하여 9-to-6에 해당하는 통행패턴을 기준으로 알고리즘과 판별규칙(Clalssification Rules)을 만들었다(Kim et al., 2018; 2019a; 2019b). 그러나 통계청에 밝혔듯이, 실제 9-to-6에 해당하지 않은 야간 및 저녁 근로자는 전체 고용 형태의 약 30% 이상에 해당하며(Han, 2016), 특정 시간대(e.g., 출근 7-9시, 퇴근 17-22시 등)를 기준으로 출퇴근 목적통행을 구분하는 기본 방법으로는 이러한 야간 및 저녁 근무에 대한 비주류 통행을 분석하는데 한계가 있다. 그러므로 본 연구에서는 이러한 한계점을 극복하고 교통 취약 계층 및 비주류 통행 분석에 대한 활용성을 높이기 위하여 새로운 개별 통행 분석 알고리즘을 제안하였고, Figure 8에서 보듯이, 시간대별 출퇴근 통행 비율을 확인할 수 있다. 836명을 대상으로 9-to-6에 해당하는 출퇴근 통행(해당 연구에서는 출근 7-9시, 퇴근 17-22시로 정의)은 전체의 약 62%와 74%에 해당하며, 그 외의 시간대에 출퇴근 통행하는 비율은 약 38%와 26%에 해당한다. 즉, 본 연구에서 제안한 알고리즘 및 방법론은 이러한 야간 및 저녁 근무에 대한 출퇴근 통행을 구분하고 그 통행패턴을 효과적으로 분석할 수 있다는 점에서 그 의미가 크다.
3. Adjustment of Travel Times(통행시간 보정)
본 연구에서 제시한 방법론은 통행의 출발 및 도착 위치를 효과적이고 정확하게 추정한다는 것을 Table 3, Table 4, Table 5와 Figure 7을 통해서 확인할 수 있었다. 그럼에도 불구하고, 통신 기지국 수신 범위를 기준으로 기록되는 모바일기지국 데이터의 특성 때문에 통행시간 추정에 관해서는 다음과 같은 이슈 사항을 고려해야 한다.
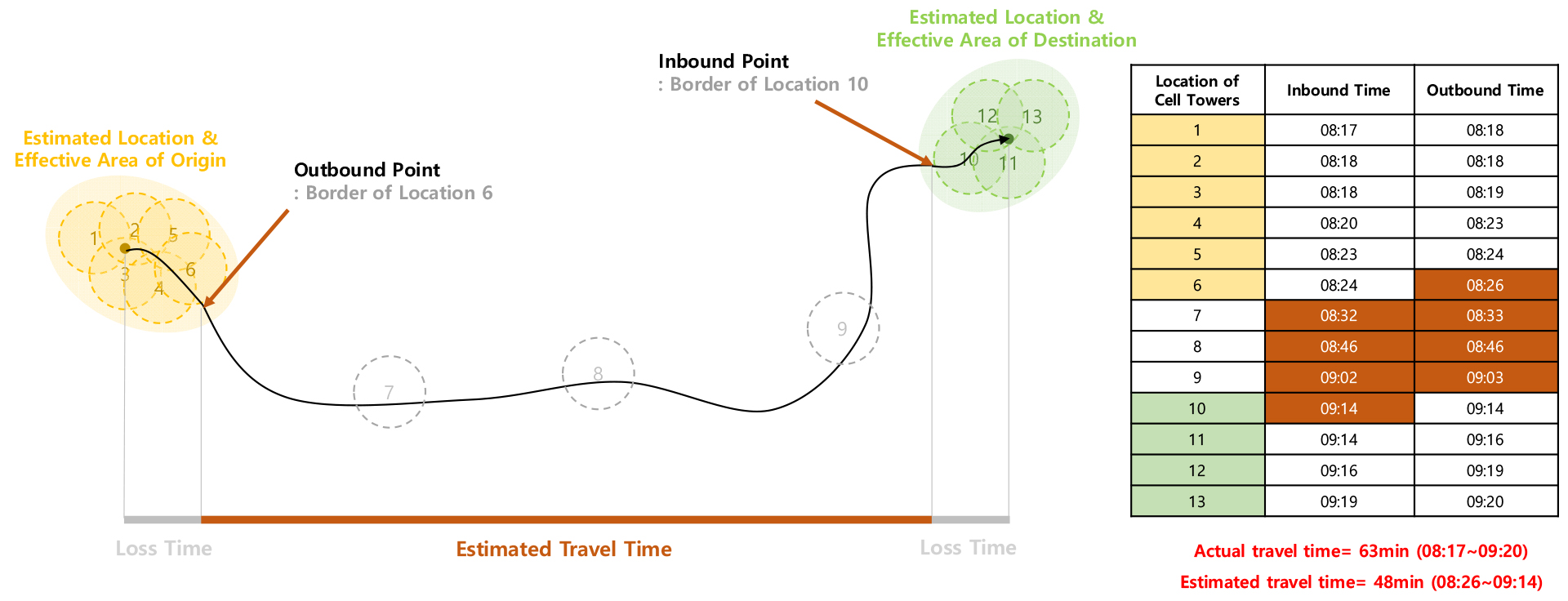
기존의 Yoo(2005)의 연구에서도 밝혔듯이, 모바일기지국 정보는 기지국 통신 반경에 들어오고 나가는 시점에 시간이 기록되기 때문에 이러한 정보를 이용한 통행시간은 과소추정(Underestimated)되는 경향이 발생한다. 마찬가지로 본 연구에서 제시한 방법론도 Figure 9에서 보듯이, 주변 기지국 체류시간 및 빈도를 이용하여 위치를 추정하게 되고, 이렇게 대표된 기지국의 이탈 및 진입 시간은 실제 출발 ‧ 도착지의 추정 위치인 기지국 1-6과 10-13의 중심 위치가 아닌, 각 이동 방향의 가장 끝과 처음에 존재하는 기지국 6과 10의 진출 ‧ 진입 시간이기 때문에, 출발 ‧ 도착지에서 손실시간이 발생하게 된다. 그러므로 이러한 기지국 정보의 시간 기록 방식 및 특성을 고려하여, 과소추정되는 통행시간을 보정하는 방법이 추가적으로 고안되어야 한다.
Conclusions and Future Work(결론 및 향후 연구과제)
본 연구의 아이디어는 기존의 가구통행실태조사를 기반으로 구축되는 국가교통DB를 개선하고 모바일 기지국 데이터를 활용한 개별 단위의 통행사슬(Trip Chain)정보를 구축하는 것을 목표로 시작하였다. 해당 논문은 이러한 일련의 연구 과정 중에서 가장 기본이 된다고 할 수 있는 출퇴근 통행을 중심으로 집과 직장을 추정하고 개별 통행 정보를 추출하는 것에 그 목적이 있었다.
본 연구의 서두에서도 밝혔듯이, 모바일기지국 데이터는 사람의 이동 및 체류를 판단하여 개별 통행에 대한 다양한 정보를 수집할 수 있는 매우 중요한 모빌리티 데이터이다. 기존 많은 연구를 통해서 그 가능성이 검증되었으나, 1) 모바일기지국 데이터의 신호 왜곡 현상; 2) 이동/체류 구분의 모호한 기준값; 3) 야간 및 저녁 근무 출퇴근 등, 비주류 통행 추정에 대한 한계; 4) 공간적 저해상도 문제; 5) 이동 경로 및 통행수단 추정의 한계; 6) 일부 알고리즘의 컴퓨팅 타임 한계 등이 존재하고 있다. 그러므로, 본 연구는 모바일기지국 데이터를 이용하여 더 정확하고 정밀한 출퇴근 목적의 개별 통행 정보를 추정하기 위한 알고리즘을 개발하고 약 1,000명의 GPS 다이어리 조사 자료를 이용하여 검증하였다.
분석 및 검증 결과, 집과 직장의 식별 정확도는 각각 약 100%와 80.4%이었다. 또한, 집과 직장 추정 위치의 정확도는 위치오차 1km 이하가 전체의 약 90%와 85%일 정도로 매우 정확한 성능을 보여주었다. 기존의 국가교통조사사업에서 실시하고 있는 가구통행실태조사의 기본 공간 단위인 읍면동 평균 반경 약 3km와 기존 통신 폴리곤의 평균 반경 약 2km를 고려하더라도 해당 연구의 알고리즘은 매우 정확하다고 할 수 있다. 특히, 직종별로는 사무직 및 영업직의 식별 정확도와 위치 정확도가 상대적으로 높았으며, 비정기적 통행이 예상되는 프리랜서와 기타 그룹의 식별 정확도와 위치 정확도가 상대적으로 낮은 것을 확인할 수 있었다. 이러한 결과는 기존 면 단위(Area-based estimates) 또는 기지국의 위치로 대표되는 모바일기지국 데이터 기반 통행 정보를 GPS와 같은 점 단위(Point-based estimates)의 정보로 더 정확하고 정밀하게 추정함으로써, 향후 목적별 통행뿐만 아니라 이동 경로 및 통행수단 추정을 위한 모바일기지국 데이터의 공간적 해상도를 크게 높였다는 점에서 큰 의의가 있다. 또한, 기존의 알고리즘에서는 효과적으로 분석할 수 없었던, 전체 통행의 약 30% 이상에 해당하는 9-to-6 이외의 야간 및 저녁 근무자의 출퇴근 통행을 분석하였다는 점에서도 큰 의미가 있다고 할 수 있다. 특히, 해당 연구는 궁극적으로 전 국민의 90% 이상이 사용하고 있는 모바일폰 정보를 이용하여 기존 가구통행실태조사의 한계점을 극복하고, 국가 개발 사업 및 정책 결정을 지원하기 위한 기초 데이터를 보다 신뢰성 있게 구축할 수 있다는 측면에서 큰 의미가 있다.
그럼에도 불구하고, 해당 연구에서 제안하고 있는 모바일기지국 데이터를 이용한 통행OD 구축은 기존 가구통행실태조사와 다음과 같은 차이점과 한계점을 가지고 있다. 먼저, 설문조사 방법인 가구통행실태조사는 개별 통행에 대한 목적과 수단뿐만 아니라, 가구 구성원을 포함한 다양한 개인정보가 포함된 능동적 정보(Active Information)인 것에 비해, 모바일기지국 데이터는 시간별 위치 정보와 제한된 개별 속성 정보만이 포함된 수동적 정보(Passive Information)이다. 그러므로, 모바일기지국 데이터에서는 가구통행실태조사에서 알 수 있는 다양한 종류의 통행목적과 수단 정보를 직접적으로 알 수 없고, 가구 구성원 정보 등을 이용한 수요추정 모델링을 할 수 없다는 한계점이 있다. 특히, 20대 이상에서의 출근과 등교, 기타 통행에서의 여가, 쇼핑, 학원, 업무 등 가구통행실태조사에서 세세하게 구분하고 있는 통행목적을 모바일기지국 데이터에서는 파악하기 어렵다. 또한, 몇몇 연구에서 모바일기지국 데이터에서 수단OD를 구축하려는 시도가 있으나, 복잡한 도심에서의 이동, 승용차와 같은 도로를 이용하는 대중교통, 접근 수단의 구분, 다 수단 이용에 대한 정보 등, 모바일기지국 데이터를 이용하여 상세한 교통수단을 구분하는 것은 여전히 어렵다. 두 번째로, 전국 1-3%의 인구를 대상으로 실시하는 가구통행실태조사에 비해 전 국민 90% 이상이 사용하는 모바일폰을 이용한 통행OD 구축은 샘플 확보 측면에서 매우 큰 장점이 있지만, 여객 통행 분석의 대상이 되는 통행 정보 이외에도 화물, 택배, 배달, 상업용 차량, 승객이 없는 택시 등의 통행도 포함되어 일반적으로 여객 통행량이 과대추정(Overestimated)될 수 있다. 반면에 앞의 논의 사항에서도 언급하였듯이, 모바일기지국 정보의 기록 방법과 공간적 해상도에 의해 통행시간은 과소추정(Underestimated)될 수 있다. 마지막으로 모바일기지국 데이터의 수집 및 관리 주체는 민간이기 때문에 데이터 확보 및 활용이 쉽지 않고, 개별 통행 정보를 더 정교하게 추정할수록 개인정보 수집 및 활용에 대한 이슈가 발생할 수 있다.
향후 연구과제로는 먼저, 모바일기지국 데이터 기록 방법과 기지국 반경 등을 고려하여 정확한 통행시간을 추출하여 모바일기지국 데이터 기반 통행OD의 신뢰성을 확보하는 것이 필요하다. 또한, 개선된 공간적 해상도를 이용하여 이동 경로를 추정하고 이동 궤적 및 POI 정보 등을 활용하여 각 통행에 대한 교통수단 정보를 추출하는 것이 필요하다고 판단된다. 마지막으로, 본 연구에서 제시한 알고리즘을 전국 단위 모바일기지국 데이터에 적용하여 지역별, 연령별, 시간대별 출퇴근OD를 구축하고, 기존 가구통행실태조사의 결과와 비교‧분석하여 제시된 알고리즘의 성능을 다각적으로 평가할 필요가 있다.
