

서론
방법론
1. GIS 사고데이터 시각화
2. 사고심각도 가중치 기반의 평가지표 개발
분석 데이터
분석결과
1. 사고심각도 분류분석 결과
2. GIS 기반 세부위험구역 분석 결과
결론 및 토의
서론
도시부 도로에서 발생하는 교통사고에 의한 사망자는 국내 전체 교통사고 사망자의 약 70%에 달하는 것으로 알려져 있다. 이러한 사고 중에서도 교차로, 환승시설과 같은 도시부 교통 시설 인프라에서 발생한 사고는 그 시설의 활용목적과 고유 특성에 따라 사고의 원인이 관련될 수 있다. 가장 대표적인 도시부 인프라로 교차로를 예를 들 수 있으며, 교차로에서 발생한 사고는 도시부에서 발생한 사고의 대부분을 차지하고 있다.
일반적으로 교차로에서 발생한 사고의 예방과 대응전략 수립을 위해 다양한 교차로 안전관리 연구가 수행되고 있다. 사고가 빈번하게 발생하는 사고위험구간을 선정하는 Network screening 기법을 활용한 hotspot identification 연구가 대표적이다(Son et al., 2022). 이러한 방법론은 교차로에서 발생한 사고를 집계하여 통계적으로 분석하는 방법으로 사고데이터의 누적 빈도와 통계적 분포를 고려하여 예측모형 및 통계적 비교분석 방법론을 통해 안전성 분석이 수행된다.
통계적 데이터 분석과 달리 교차로를 통과하는 차량 간의 교통상충(Traffic confilct)을 대리안전지표(Surrogate safety measure, SSM)로 정량화하여 분석하는 시뮬레이션 또는 영상 기반의 연구 또한 다양하게 수행되고 있다. 실제 차량의 주행궤적을 기반으로 통행을 시뮬레이션으로 구현하여 분석한다는 점에서 미시적인 실제 통행을 모사할 수 있기 때문에 위험상황을 직관적으로 이해할 수 있으며, 원하는 교통조건을 분석가의 의도에 따라 구현할 수 있다는 장점이 있다. 그러나 일부 연구에서는 해당 분야의 연구가 실제 사고가 아닌 예상되는 사고 상황을 가정하여 분석하기 때문에 직접적으로 측정된 데이터가 아니라는 점에서 회의적이라는 의견이 있다(Tarko et al., 2009).
마지막으로 GIS 환경에서 데이터를 활용한 분석방안이 있다. 사고데이터 및 구간 통행데이터, 교통량 데이터 등 다양한 데이터를 입력변수로 설정하고 GIS 배경 레이어에 투영하여 특정 구간 또는 지점에 공간적 가중치를 고려한 분석이 가능하다(Pulugurtha et al., 2007). 본 연구에서는 이러한 방법론 중 GIS 환경에서의 사고데이터를 활용한 분석을 수행하고자 계획하였으며, 이를 위해 관련 분야에서 수행된 기존 연구를 고찰하였다(Sabel et al., 2005; Anderson, 2009; Plug et al., 2011; Truong and Somenahalli, 2011; Bíl et al., 2013; Xie and Yan, 2013; Kabir et al., 2021; Hazaymeh et al., 2022; Hussain et al., 2022; Karimzadeh et al., 2022; Le et al., 2022).
먼저 GIS 데이터를 활용한 밀도 기반의 대표적인 분석 방법론으로 커널밀도추정(Kernel density estimation, KDE)이 있으며, 본 연구에 활용하기 위해 KDE 기법을 활용한 연구를 고찰하였다.
Anderson(2009)은 영국 런던의 도로에서 발생한 사고의 공간적 패턴 분석을 위해 GIS 및 커널밀도추정 방법론, 추가적으로 환경데이터를 결합한 클러스터링 방법론을 제안하였다. 다양한 셀 밀도를 설정하여 커널 윈도우를 설정하여 분석하고 클러스터링을 거쳐 5개의 그룹과 15개의 클러스터를 식별하였다. Bíl et al.(2013)은 체코 남부 모라비아 지역을 대상으로 KDE 방법론을 활용하여 교통사고 클러스터를 분석하고, 중요도에 따른 분류 절차를 제안하였다. 클러스터의 중요성을 검증하였으며 KDE 기반의 위험한 장소 식별 결과를 제시하였다. Xie and Yan(2013)은 Network KDE와 Local Moran’s I를 통합하여 사고위험지역을 식별하였다. Network KDE 시각화 방법론을 통해 얻은 밀도값을 근거로 Local Moran’s I와 같은 지역통계 접근방식을 활용하여 유용한 통계적 접근절차가 될 수 있음을 결론으로 제시하였다. Truong and Somenahalli(2011)는 사고에 취약한 버스정류장을 식별하기 위해 보행자-차량 사고데이터를 활용하여 공간적 자기상관 분석을 수행하는 GIS 접근 방식을 제안하였다. 공간적 패턴 분석을 위해 Xie and Yan(2013)의 연구와 마찬가지로 Moran’s I 통계량을 활용하였으며 Getis-Ord Gi 통계량의 인덱스 값을 근거로 보행자 사고에 취약한 버스정류장을 식별하였다. Hussain et al.(2022)의 연구에서는 기존 위험지역 식별 연구와 다르게 시간적 위험지역과 나아가 사고심각도까지 고려한 위험지역 식별 연구를 수행하였다. 보행자 사고위험지역을 식별하기 위한 3단계 방법론을 제안하였으며, 공간적 자기상관 툴을 활용하여 1차적인 위험지역을 식별하고, 이어서 시공간적 큐브와 신규 핫스팟 분석을 연계하여 링크 단위의 위험지역을 식별, 마지막으로 사고심각도를 기반으로 링크의 순위를 지정하는 방안을 제안하였다. 그 밖에 다양한 연구에서 KDE 기법을 활용한 사고발생에 취약한 시설 및 지점, 지역을 식별하기 위한 연구가 수행되었다(Hussain et al., 2022; Le et al., 2022).
KDE 기법은 전통적으로 GIS 환경에서의 핫스팟 식별에 널리 활용되고 있지만 보행자, 자전거, 이륜차, 자동차, 화물차와 같은 다양한 유형의 교통이용자가 혼재하는 교차로 내부에서의 세부적인 위험도 분석을 위해 사고데이터를 활용하여 세부위험구역을 식별하기 위한 연구는 수행되지 않은 것으로 확인되었다. Hussain et al.(2022)의 연구에서는 시공간적 위험구역과 사고심각도를 같이 고려하였으나, 이러한 세부위험구역에 대해서는 연구가 수행되지 않았다. 따라서 본 연구에서는 사고데이터가 갖는 통계적 장점을 미시적 수준(Micro-level)에서의 도시부 인프라인 교차로 단위 연구에 활용하여 GIS 데이터를 활용한 교차로 세부위험구역 식별 방법론을 제안하였다. 기존 연구(Son et al., 2022)에서 식별된 위험교차로를 분석 대상으로 선정하였으며 사고심각도 분류분석 결과를 가중치로 개별 사고단위에 반영하여 산출한 개별 사고심각도 score를 GIS에 맵핑하여 이를 고려한 미시적 수준에서의 세부위험구역을 식별하였다. 마지막으로 시각화 단계에서 심각도 score를 정확하게 표출하기 위한 기법으로 역거리 가중치 보간법(Inverse distance weighted interpolation, IDW)을 활용하였다. 본 연구에서 제안하는 사고심각도 분류분석 기반의 심각도 score를 시각화하기 위해 기존 KDE 기법의 단점을 보완할 수 있는 기법으로 IDW 기법을 활용하였으며 이에 대한 설명은 이어지는 방법론 장에서 작성하였다. 또한 본 연구에서 활용된 GIS 기반 시각화 방법론과 사고심각도 score 산출에 활용된 사고심각도 분류분석 방법론, 그리고 지표 산출 절차를 제시하였으며 이어지는 분석 데이터 장에서는 연구에 활용된 사고심각도 데이터셋과 분석대상 교차로의 연도별 데이터를 제시하였다. 분석결과 장에서는 분석된 시각화 결과 및 GIS 사고 포인트에서 식별된 사고심각도 요인에 따른 해석결과를 제시하였으며, 추가적으로 연도별 변화까지 분석하였다. 마지막으로 결론에서는 본 연구의 요약 및 향후 연구계획, 미흡한 점에 대해서 서술하였다.
방법론
1. GIS 사고데이터 시각화
본 연구에서는 개발한 사고심각도 가중치 평가지표를 활용하여 교차로 세부위험구역을 분석하기 위해 다음 2가지의 GIS 시각화 방법론을 활용하였다. 제안한 방법론을 통해 기존 방법론을 통해 식별할 수 없는 새로운 세부위험구역 분석 방법을 설명하였다.
1) 커널밀도추정(Kernel density estimation, KDE)
GIS 관점에서의 밀도(Density)는 단위 면적당 features 또는 events의 양을 의미하며, 밀도 추정(Density Estimation)은 수집된 데이터로부터 밀도함수를 개발하는 것을 의미한다(Silverman, 2018). KDE는 포인트 개념의 1차적인 속성을 분석하는데 널리 활용되는 대표적인 기법이다. 특히 교통사고의 포인트 단위 분석으로 적용이 가능한 사고위험지역 식별 연구에 빈번하게 활용되고 있다. KDE에서 커널(Kernel)은 임의의 위치에서 밀도 추정에 사용되는 관측(수집)된 데이터의 비율을 결정하기 위해 설정된 Window function이다. 본 연구에서는 KDE 기법을 활용하여 교차로 내 세부위험구역을 일반적으로 식별할 수 있는 포인트 기반의 시각화 방법을 수행하였다. KDE를 수식으로 표현하면 다음과 같다(Equations 1, 2).
where, : The estimates of kernel density
: Weighting factor
: A distance between the location of kernel function and each observed value
2) 역거리 가중치 보간법(Inverse distance weighted interpolation, IDW)
역거리 가중치 보간법은 GIS 분야에서 표준 공간보간 절차 중 하나로 활용되는 방법론이다(Burrough et al., 2015). 표본의 포인트에만 값이 위치하여 제한된 시각화가 표현될 경우에 활용되며, 포인트 값을 중심으로 거리당 가중치가 계산되어 주변 지표면을 생성할 수 있는 기법이다(Lu and Wong, 2008). 본 연구에서는 사고심각도 가중치 평가지표를 거리당 가중치로 표현하여 기존 KDE 기반 시각화 절차에서 식별되지 않은 새로운 사고심각도 기반의 교차로 내 사고위험구역을 특정하였다. IDW의 수식은 다음과 같다(Equations 3, 4).
where, : 와 의 선형결합 기반 예측값
: 에서 까지의 역거리
: 지리적 가중치 지표(geometric weighted index)
: 1
KDE는 설정한 커널 윈도우의 크기에 따라 내부에 포함되는 포인트가 얼마나 집중되어 있는지를 밀도로 접근하는 분석 방법으로서 설정한 커널 크기에 따라 목적에 맞는 우수한 결과를 도출할 수 있다. 하지만 개별 사고단위에 집중했을 때 각각의 사고가 갖는 사고내용과 심각도를 포함하여 시각화를 수행하고자 할 경우, 커널 안에 수치적으로 집중되는 합계만 표현할 수 있다는 한계가 존재한다. 본 연구에서는 개별 사고마다 갖는 사고심각도 가중치 기반의 평가지표를 표현하기 위해 IDW를 활용하였다. 본 연구에서는 사고심각도 가중치 평가지표를 거리당 가중치로 표현하여 기존 KDE 기반 시각화 절차에서 식별되지 않은 새로운 사고심각도 기반의 교차로 내 사고에 취약한 세부위험구역을 특정하여 시각화 결과로 제시하였다.
2. 사고심각도 가중치 기반의 평가지표 개발
본 연구에서는 데이터 마이닝 기법인 랜덤포레스트(Random forest, RF)를 활용하여 사고심각도 분류 모형을 개발하여 사고심각도 가중치 평가지표를 추정하였다. 추정된 평가지표를 활용하여 GIS 기반의 시각화 기법에 적용하여 교차로 내 세부위험구역 분석 절차에 활용하였다. 기존 연구에서 활용되는 단순 사고건수 기반의 지표는 단순히 발생한 사고의 포인트로서 심각한 사고와 그 내용을 포함하지 못한다. 심각한 사고의 경우에는 EPDO(Equivalent property damage only) 등 심각한 사고를 중심으로 설정된 지표를 통해 포인트 지표로 활용이 가능하지만 이는 각 사고의 세부내용과 원인을 포함하지 못한 단순 집계지표이다(Son and Park, 2022). 본 연구에서는 이러한 기존 단순 사고 포인트 지표의 단점을 보완할 수 있는 사고심각도 가중치 기반의 평가지표를 연구에 활용하였으며, 활용을 위해 기존 선행연구에서 수행된 사고심각도 분석 주제의 다양한 연구를 참고하였다(Choi et al., 2013; Park et al., 2016; Yoon et al., 2016; Son and Park, 2022). 기존 연구에서 사고심각도 가중치 기반의 집계 평가지표를 활용하여 Network screening 절차를 적용한 위험교차로 식별 연구가 수행되었다(Son et al., 2022). 본 연구에서는 Son et al.(2022)과 Son(2022)의 연구에서 활용된 사고심각도 score 산출 방법론을 활용하였다. 국내 도시부 교차로에서 발생한 사고를 대상으로 사고심각도 분류분석을 수행하여 심각한 사고에 미치는 요인을 도출하였으며, 도출된 요인의 변수 중요도에 따라 각 사고의 심각도 기반 점수를 계산하여 GIS 분석에 필요한 위치좌표 기반의 포인트로 데이터셋을 준비하였다. 사고심각도 분류분석 기반의 사고점수 산출을 위한 심각도 분석 방법론으로 머신러닝 기법인 RF 기법을 활용하였다. RF는 사고심각도 분석 연구분야에서 다양하게 활용되고 있다(Ijaz et al., 2021; Yan et al., 2021). RF 기법은 Breiman(2001)이 제안한 성능이 우수한 머신러닝 방법론 중 하나이다. 랜덤 포레스트를 구성하고 있는 각 트리는 무작위로 선택된 표본과 트리 특성을 바탕으로 생성된다. 최종적으로 트리 중 투표 방법에 의해 최적 모형이 결정된다. Single classifier인 의사결정나무(Decision tree)의 국소 최적화 및 과적합 문제를 효과적으로 극복할 수 있는 것으로 알려져 있다. Bootstrap sampling을 이용하여 트리 분류기 모음을 확장하고 이후에 트리의 결과를 사용하여 트리 모델링에 사용된 변수의 중요성을 평가할 수 있도록 알고리즘이 구성되어 있다. RF 분류 모형의 변수 중요도 산출 지표는 MDA(Mean Decrease Accuracy), MDG(Mean Decrease Gini)이다. 본 연구에서는 이 지표를 표준화하여 가중치로 환산하여 심각도 Score 산출에 활용하였다.
RF 기법을 활용하여 국내 교차로 사고심각도 데이터셋을 대상으로 사고심각도 분석을 수행하였으며, 분석의 수행 결과로 도출한 RF 모형 개발 결과에 따라 KA 사고와 BC 사고를 분류하는데 크게 기여한 변수의 영향이 반영된 개별 사고단위의 사고점수를 추정하였다. 추정된 사고점수에 Shim et al.(2016)에서 제시한 사고비용을 기준으로 계산한 가중치 점수를 기본적인 사고심각도 분류에 따라 곱하여 최종 GIS 환경에 시각화 할 사고점수를 추정하였다. 심각도 분류에 따른 사고비용은 Table 1에 제시하였으며, 사고심각도 분류분석 기반 사고점수의 수식은 다음과 같다(Equation 5).
where, : 사고 의 사고심각도 분류분석 기반 사고점수
: 사고번호(=1, 2, ..., )
: 변수 의 값
: 변수 의 weight
: 사고 n의 심각도 구분별 사고비용 weight(severity=K, A, B, C)
: 개별 사고의 변수번호(=1,2,...,)
분석 데이터
본 연구에서는 2가지의 데이터셋이 활용되었다. 첫 번째는 서울시내 교차로에서 발생한 사고의 심각도 분류분석을 위한 사고심각도 데이터셋이다. 기간은 2017년부터 2019년까지 발생한 사고로 한정하였으며 총 49,397건의 사고로 구성된다. 사고데이터는 도로교통공단 교통사고분석시스템(Traffic Accident Analysis System, TAAS)에서 수집되었으며, 분류분석의 종속변수로 설정되는 사고심각도는 사망(K), 중상(A), 경상(B), 부상(C)의 4가지로 구분하였다. 사고심각도 데이터셋에는 인적요인, 차량요인, 환경요인의 3가지 대구분 하에 개별 사고의 원인이 될 수 있는 설명변수가 포함되어 있다. 사고심각도 분석을 위해 활용된 데이터의 독립변수에 대한 이해를 위해 변수별 심각도 수준에 해당하는 통계량과 내용을 Table 2에 정리하여 제시하였다. 독립변수 중 차종의 화물차(Freight car) 변수는 일반적으로 정의될 수 있는 모든 수준의 화물차를 대상으로 하였으며, Special vehicle은 특수차량으로 구난차, 견인차 등을 의미한다. 또한 이륜차(Two-wheel)는 원동기 및 오토바이 등 동력 이륜차를 의미하며, 자전거(Bicycle)는 자전거와 PM(Personal mobility)를 대상으로 설정하였다. 이어서 연령 기준은 기존 연구(Hazzard et al., 2022)에서 정의한 연령대 기준을 근거로 Youth, Younger, Middle-aged, Older의 4가지 구분으로 설정하였다. 그밖에 데이터 전처리 과정에서 적은 표본 수로 인해 분석에 유의하지 않을 것으로 판단되는 일부 Outlier 변수에 한해서는 제외하거나 Unclassified로 정리하였다.
두 번째는 분석 대상교차로인 교보타워교차로에서 발생한 사고데이터의 위치좌표와 내용을 집계한 GIS 데이터셋이다. 여기서 분석 대상교차로인 교보타워교차로는 기존 연구(Son et al., 2022)를 통해 사고위험지점으로 선정된 교차로이며, 이 교차로 내에서 2016년부터 2020년까지의 5년간 발생한 199건의 사고와 사고의 위치좌표는 사고심각도 데이터셋과 마찬가지로 도로교통공단 교통사고분석시스템(Traffic Accident Analysis System, TAAS)에서 수집하였다.
Table 2.
Variable definitions and descriptions for crash injury severity analysis (1)
분석결과
1. 사고심각도 분류분석 결과
본 연구에서는 교차로 내에서 발생한 사고의 위치좌표 포인트 기반의 사고심각도 가중치 평가지표 개발을 위해 사고심각도 분류분석을 수행하였다. 데이터 마이닝 기법인 RF를 활용하였으며, 분류 모형의 종속변수는 사망 및 중상사고(KA)와 부상 및 경상사고(BC)를 분류하는 모형을 개발하여 사망 및 중상사고 분류 예측에 영향을 미치는 변수를 도출하였다. 분석을 통해 총 82개의 변수 중 상위 20개 변수의 표준화된 변수 중요도(Standardized MDG)를 Table 3에 제시하였다.
Table 3.
Variable importance of top 30 variables (random forest)
사고심각도 분류분석 모형의 분석 결과에 따르면 피해차종-승용차(0.0351), 피해자 연령-56세 이상(0.0289), 시간대-낮(0.0263), 계절-가을(0.0263), 계절-여름(0.025947), 계절-봄(0.025923), 가해자연령-36세 이상 55세 미만 사고의 변수 중요도가 높은 것으로 나타났다. 이러한 변수에 해당하는 사고는 상대적으로 높은 심각도 Score가 반영되었다고 볼 수 있다. 앞서 제시한 수식 Equation 5에 따라 사고별로 세부 독립변수의 값에 적용하여 사고심각도 가중치 기반의 Score를 산출하였다. 최종적으로 199건의 사고에 사고비용 가중치까지 적용된 사고심각도 가중치 평가지표의 통계량은 Table 4에 제시하였다.
Table 4.
Statistics summaries of crash severity measures (random forest)
| Crash score based on severity classification analysis by each crash | |||||
| Crash score | n | Mean | S.D. | Min | Max |
| 199 | 0.2126 | 0.1307 | 0.6627 | 0.0487 | |
| 199 | 0.8001 | 1.4066 | 6.9587 | 0.0682 | |
2. GIS 기반 세부위험구역 분석 결과
앞서 사고심각도 분류분석 결과를 활용하여 추정한 개별 사고단위의 사고점수를 추정하였으며, 이를 GIS 환경에서 시각화하여 교차로 내 세부위험구역을 분석하였다. 본 연구에서는 분석결과의 직관적인 이해와 비교분석을 위해 폴리곤 그리드 단위 분석, 그리고 접근구역별로 구분한 12개 레이어 단위 분석을 선행연구로 진행하였다. 이어서 본 연구에서 제안하는 사고점수 기반의 세부위험구역 분석을 위해 GIS 환경 시각화 기법인 커널밀도추정(KDE)과 역거리 가중치 보간법(IDW)을 활용하여 신규 위험구역을 분석하였다.
폴리곤 그리드 단위 시각화 분석을 위한 폴리곤의 크기는 5-30m까지 다양한 크기를 분석에 적용하기 위해 검토하였다. 도시부 교차로를 통과하는 차량 중 가장 크다고 볼 수 있는 시내버스의 평균길이는 10.923m이고(Kang and Shin, 2019) 기타 대부분의 차량은 이 수치보다 작다. 본 연구의 분석이 사고의 포인트, 즉 지점 단위로 수행되기 때문에 차량의 크기가 직접적으로 연관성이 있는 것은 아니지만, 교차로 이용 차량에 의해 발생하는 사고 지점을 분석하는 연구이기 때문에 유의미한 분석을 위한 기준 값으로 10m를 선정하였다. 추가적으로 이보다 큰 폴리곤의 역할을 대체, 통합하기 위해 교차로를 12개의 접근구역별 레이어 단위로 구분하여 분석을 수행하였다.
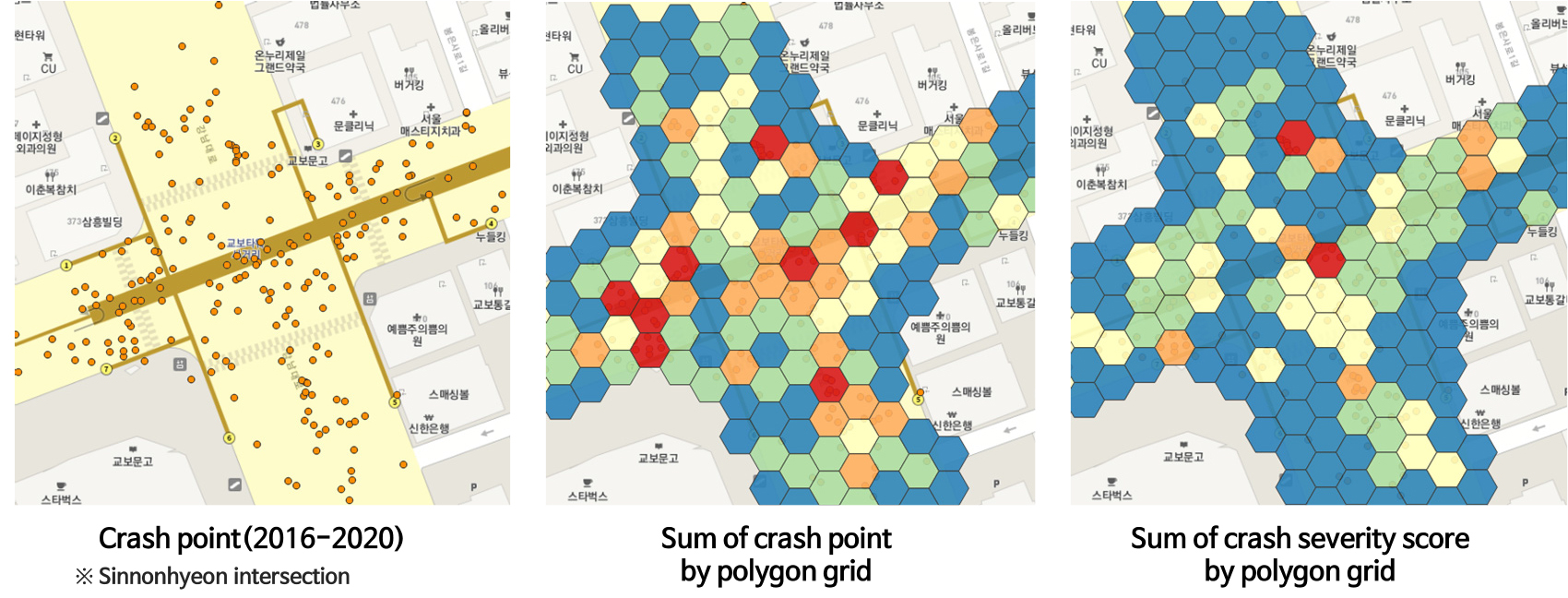
1) 반경 10m의 폴리곤 그리드 단위 시각화 결과
단순 사고건수를 기준으로 폴리곤을 식별하였을 때 교차로 좌측, 중심부, 우측 접근로에서 사고가 집중된 것으로 확인되었으며, 사고심각도 기반 사고점수를 적용한 시각화 결과에서는 교차로 중심 및 상단에서의 세부위험구역이 특정되는 것으로 확인되었다(Figure 1).
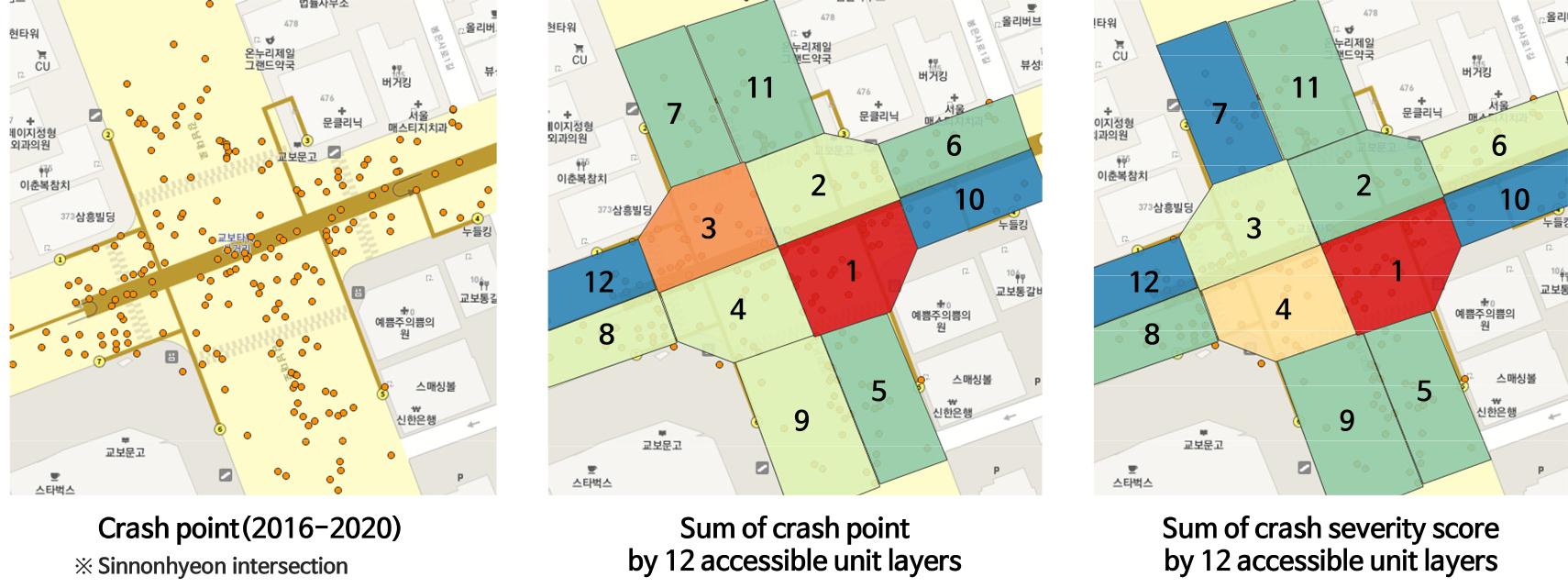
2) 교차로 내 차량 기준 접근가능한 12개 구역별 레이어 단위 시각화 결과
교차로 내부를 12개의 접근가능한 구역으로 레이어를 설정하여 분석을 수행하였으며, 단순 사고건수를 기준으로 시각화하였을 때 그림의 1번 구역이 가장 위험한 것으로 나타났으며, 심각도 기반 사고점수를 적용했을 때도 1번은 동일하게 위험한 구역으로 식별되었다(Figure 2). 그러나 심각도 기반 사고점수의 집계 차이에 기인하여 분석한 결과에 따르면 3번과 4번 구역의 순위 변화가 있는 것으로 확인되었으며 이는 추가적인 분석을 위한 중요한 요인이 될 수 있다.
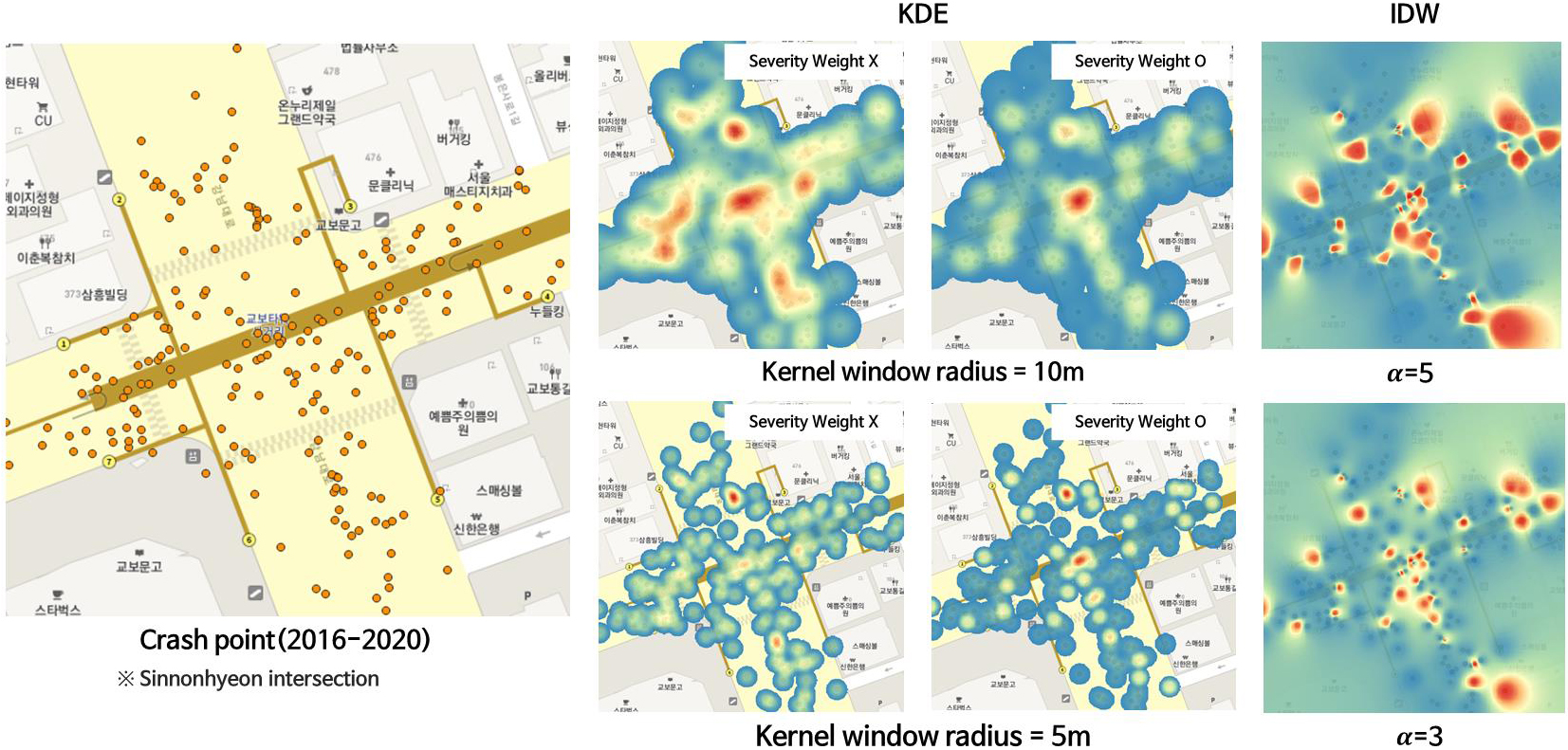
3) 커널밀도추정(KDE) 및 역거리 가중치 보간법(IDW) 시각화 결과
GIS 기반 Hotspot 식별 연구에 대표적으로 활용되는 KDE 기법을 활용하여 교차로 세부위험구역을 분석하여 시각화 결과로 제시하였다(Figure 3). 커널 윈도우 반경을 10m로 설정하였을 때 Figure 1에서 제시한 반경 10m의 폴리곤 그리드 단위 시각화 결과와 유사한 결과가 나타났다. 교차로 중심 및 좌측, 상단, 하단, 우측 부에서 사고가 많이 발생한 곳이 결과에서 확인되었다. 마찬가지로 사고심각도 가중치를 적용했을 때 커널 윈도우의 크기에 상관없이 교차로 중심부 등 사고가 반복적으로 집중되는 곳에 대한 시각화 결과가 분석되었다. 이는 KDE 기법이 심각도 기반 사고점수를 시각화 결과로 나타내는 것에 제한사항이 있다는 것을 의미한다. 반면에 IDW를 적용한 결과에서는 교차로 내에 보간 범위인 α에 따라 심각한 사고가 발생한 포인트를 중심으로 새롭게 식별된 시각화 결과가 확인되었다. 남쪽 하단의 접근로와 우측 접근로에서 발생한 사고의 높은 점수에 기인하여 넓은 범위의 세부위험구역이 표현되었다. 단순히 사고가 집중되는 곳이 아닌 심각한 사고가 발생한 위치를 중심으로 시각화 결과가 GIS 화면에서 확인되었다. 이는 KDE 기법에서 커널 윈도우 내 사고건수 밀도 기반 분석이 갖는 한계점을 보완하기 위한 대안으로서 IDW가 검토될 수 있다는 것을 의미한다.
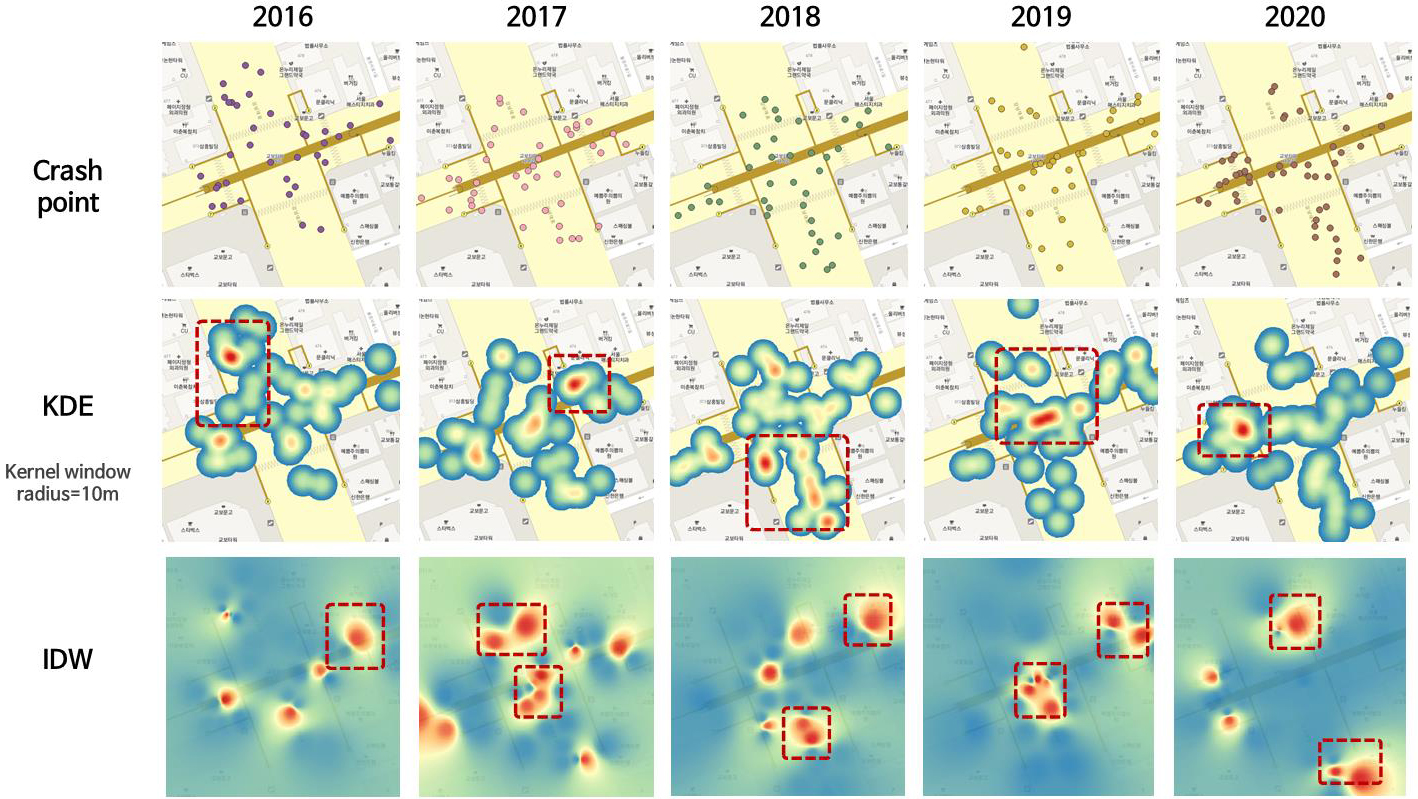
4) 연도별 추이 분석(Point, KDE, IDW) 결과
제안한 KDE, IDW 기법을 활용하여 연도별 시각화 결과를 제시하여 사고가 집중되는 세부위험구역과 심각한 사고가 발생하는 구역을 분석하였다(Figure 4). KDE 결과에 따르면 연도별로 사고가 집중되는 위치가 지속적으로 변화한 것이 확인되었다. 단순히 집계된 사고의 커널 윈도우 내 밀도 기반 시각화 결과로서 추후 연계분석을 통해 사고가 집중적으로 발생한 원인을 추정할 수 있다. IDW 결과도 마찬가지로 연도별로 식별되는 위험구역이 변화하는 것으로 시각화 결과에 나타났다. 다만 우측 접근로와 교차로 중심부에서는 반복적으로 결과가 표현된 것이 확인되었으며, 연도별 추이 분석에서 식별된 이러한 결과는 추가적인 안전시설물 설치 또는 안전개선사항 검토의 근거자료로 활용이 가능할 것으로 판단된다.
결론 및 토의
본 연구에서는 사고심각도 분류분석 결과를 적용한 사고점수를 활용하여 GIS 환경에서의 도시부 인프라 내부 세부위험구역 분석 방법론을 제안하였다. 사고심각도 분류분석 기반의 사고심각도 점수가 GIS 시각화 대상변수로 설정되었으며, 총 4가지 종류의 시각화 방법이 연구에 활용되었다. 먼저 사고심각도 분류분석은 2017년부터 2019년의 3년간 서울시 교차로에서 발생한 49,397건의 사고를 대상으로 수행되었다. 우수한 분류성능을 갖춘 것으로 알려져 있는 랜덤포레스트 기법을 연구에 활용하였으며 모형 최적화 과정을 거쳐 변수중요도를 도출하였다. 모형의 변수 중요도를 활용하여 개별 사고단위의 사고점수를 추정하였으며, 여기서 사고점수를 추정하는 대상은 기존 연구를 통해 사고위험교차로로 식별된 서울시 신논현역 교보타워교차로에서 2016년부터 2020년에 발생한 199건의 사고를 대상으로 하였다. TAAS에서 제공하는 사고위치정보를 분석에 활용하였으며, 개별 사고단위로 추정한 사고점수를 GIS 환경에서 시각화 기법으로 분석을 수행하였다. 단순 사고건수 시각화를 기준으로 1) 10m 반경의 폴리곤 그리드, 2) 교차로 내 차량 접근가능한 12개 구역별 레이어, 3) 커널밀도추정(KDE) 및 역거리 가중치 보간법(IDW), 4) 연도별 추이 분석의 방법 기반 시각화 분석 결과가 제시되었다. 분석결과를 근거로 사고심각도 점수를 시각화했을 때 기존 분석방법에서 식별할 수 없는 새로운 세부위험구역을 식별할 수 있음을 입증하였으며, 특히 효과적인 시각화를 위한 IDW 기법의 활용방안을 제시하였다.
본 연구는 기존 GIS 기반 사고위험구역 식별 연구에서 흔히 다룬 지역단위의 Macro-level 사고위험구역 연구에서 다루지 않은 도시부 인프라 내에서 발생한 Micro-level에서의 세부위험구역을 사고데이터로 분석한 연구로서 학술적, 실용적 의미를 갖는다. 또한 세부위험구역에서의 심각한 사고발생을 분석하기 위해 사고심각도 분류분석 결과를 개별 사고단위의 점수 지표로 개발하여 연계분석을 수행하였으며, 효과적인 시각화를 위해 기존 연구에서 사용되지 않은 IDW 기법의 활용방안을 제시하였다는 점에서 의의가 있다. 나아가 분석을 통해 새롭게 식별된 인프라 내 세부위험구역은 사고심각도 분류분석 결과가 반영된 결과로서 안전개선을 위한 계획 수립단계에서 우선대상으로 설정될 수 있음을 시사한다(Son, 2022). 향후 연구로서 분석 대상으로 설정된 도시부 교차로 뿐만 아니라 도시부 주요 교통인프라 시설인 환승시설, 이면도로, 합분류부 등에서의 세부위험구역 분석에 활용할 수 있을 것으로 기대된다.
다만 본 연구는 몇가지 한계점을 갖고 있다. 먼저 세부위험구역 분석에 활용한 데이터는 과거에 발생한 사고기록 데이터이다. 실제 교통이용자에 의해 발생된 사고를 기록한 데이터로서 실제 도로행태를 반영한다고 볼 수 있으나, 운전자 부주의 등 일부 특수한 상황에서 사고가 발생한다는 점에서 판단하면 모든 사고데이터가 일반적인 교통류 통행특성을 반영하고 있다고는 볼 수 없다. 따라서 실제 차량 궤적 데이터, 신호데이터, 차로별 교통량, 보행교통량 등의 통행 행태를 정확하게 반영할 수 있는 데이터 기반의 추가 연계분석이 수행된다면 식별된 위험구역과 위험 요인에 대한 이해, 개선사항 도출이 가능할 것으로 기대된다. 나아가 현재 사고기록 수준에서 집계가능한 사고심각도 요인 기반 분석에서 그치지 않고 향후 자율주행 및 C-ITS 등이 도입된 첨단 교통환경에서 발생한 사고데이터와 그 당시의 차량 및 인프라 환경 데이터, 교통류 특성 데이터가 분석에 반영된다면 미래 교통안전 및 사고데이터 분석 연구의 중요한 부분이 될 수 있을 것으로 기대된다.
