

서론
자연어처리 기술을 활용한 도로교통사고 판결예측 시스템
1. 도로교통사고 판결예측 시스템
2. 데이터 수집 및 전처리
3. 단어사전 구축 및 FastText 임베딩
4. Traffic Violation Insight Net(TVIN)
실험 및 실험 결과
1. 성능 평가지표
2. 실험 결과
3. 실험 결과 논의
결론 및 향후연구
서론
국내에서 발생하는 교통사고 중, 공소권이 없는 경우를 제외하고, 신호위반 및 지시위반, 과속, 음주운전 등 주요 12개 항목을 위반한 사고의 경우는 그 원인을 분석하여 재판을 통해 과실비율에 따른 상계와 판결을 받게 된다(Yoon, 2016). 그러나, 교통사고 상황은 대개 복잡하여 사고의 원인, 경위, 결과 등을 포함한 다양한 정보가 텍스트 형태로 기록되기에, 이러한 정보를 수작업으로 처리 및 분석하는 것은 높은 시간비용이 요구될 뿐만 아니라 개인적 판단에 따른 오류의 가능성 또한 배제할 수 없다(Graham et al., 2023; Noh and Yeo, 2021). 따라서, 이러한 텍스트 정보를 보다 객관적으로 분석하고 이해하는 것이 필요하다.
재판을 받는 피고의 입장에서 살펴보면, 대부분은 법적 지식이 부족하기에, 교통사고 발생 시 법적 대응에 어려움을 겪는 것이 일반적이다(Hwang, 2009). 특히, 법률은 매우 복잡하고 전문적인 지식을 필요로 하는 분야이기 때문에, 일반인이 법률을 이해하고 적용하는 것은 쉽지 않다. 이에 따라, 교통사고 상황에 대해 관련 법률을 이해하고, 객관적으로 분석하여 판결을 예측할 수 있는 시스템의 필요성이 점점 커지고 있다(Kim, 2022b).
한편, 최근 몇 년간 인공지능(Artificial Intelligence, AI)과 머신러닝의 발전은 다양한 분야에서 혁신적인 변화를 가져왔다(Choung, 2023). 특히, 자연어처리 분야에서 텍스트 데이터를 분석하고 이해하는 데 있어 중요한 도구로 자리잡았으며, 법률 분야에서도 그 가능성이 조명되고 있다(Kim, 2021; Kim et al., 2022).
그 예로써, 유럽에서 진행된 유럽 인권 협약 위반 여부를 예측하는 머신러닝 모델 연구를 꼽을 수 있다(Medvedeva et al., 2020). 이 연구에서는 유럽 인권 재판소의 판결문을 분석하여 판결을 예측하였다. 유럽인권협약에 규정된 다양한 권리의 침해에 대한 판결 데이터를 바탕으로 Support Vector Machine(SVM)을 사용하였다. 이 연구에서는 n-gram 사용, 판사의 이름만 사용하여 예측하는 등의 다양한 실험을 통해 평균 75%의 정확도로 판결을 예측하였다. 또 다른 예로써, 아랍어 법률 문서를 분석하여 법원 판결을 예측하는 연구(Zahir, 2023)에서는 모로코 대법원 판결문 데이터를 활용한 연구를 진행하였으며, 최근 자연어처리 문제에서 널리 활용되는 'Global Vectors for Word Representation'(Glove) 모델(Pennington et al., 2014)과 FastText 모델(Bojanowski et al., 2017)을 학습하여 예측을 진행하였다. 이 연구에서는 다양한 전략을 수립하여 성능을 비교하였으며, 그 결과 Glove와 Convolutional Neural Network(CNN)(Lecun et al., 1998) 기반의 아키텍처가 정확도 80%로 우수한 성능을 도출하였다. 국내의 사례를 살펴보면, 양형 기준이 적용된 판결문에서 인자값을 추출하여 판결을 예측한 형태의 연구도 이루어졌다(Byun et al., 2018). 이 연구에서는 각 판결문에 대해 죄 유형, 양형 인자, 집행유예 인자등의 값을 직접 추출하여, 선형 회귀를 통해 형량을 예측하거나, 주성분 분석을 이용해 유사 판례를 탐색하여 형량을 예측하는 방법을 제안하였다. 그러나, 선술한 연구들은 범용적 범위를 다루거나 특정 요인에 대한 영향만을 고려한 판결 분석 및 예측을 수행하였기에, 교통사고와 같은 비교적 좁은 범위에서의 사건의 현장이나 상황을 종합적으로 고려하기에는 한계가 존재한다.
사고 상황 텍스트를 활용한 부상 요인 분류에 관한 연구도 진행된 바 있다(Goldberg, 2022). 이 연구는 단어 임베딩을 통해 자동화된 사고 상황 분류를 목표로 하며, 건설 업계 사고 데이터인 미국 직업안전보건국(OSHA) 데이터와 브라질 회사 IHM Stefanini의 광업 및 금속 산업 사고 데이터를 활용하여 실험을 수행하였다. 연구는 부상당한 신체 부위, 부상 원인, 사고 유형, 입원 여부, 절단 여부를 분류하는 데 초점을 맞췄으며, 단어 임베딩 모델을 통해 기존의 Tf-idf 접근법을 능가하는 성과를 보였다. 미국 OSHA의 건설 업계 사고 데이터와 IHM Stefanini의 광업 및 금속 산업 사고 데이터는 산업 현장에서 발생하는 사고의 특성을 담고 있다. 이러한 데이터는 작업 현장에서 발생한 부상과 사고의 원인을 파악하고, 작업 환경 개선을 위해 수집된 것이다. 해당 데이터는 산업 현장의 구조적 특성과 작업 환경의 위험 요소에 집중하며, 사고 원인을 분석하고 부상 요인을 분류하는 데 사용된다.
그러나 도로교통사고는 산업 현장 사고와는 성격이 다르다. 도로교통사고는 도로에서 운전자와 보행자의 상호작용에 의해 발생하며, 교통법규 위반, 과속, 음주운전 등 다양한 요인으로 인해 발생한다. 관련 판결문에는 사고 경위, 원인, 결과 등에 대한 텍스트 정보가 기록되어 있으며, 도로교통법 위반에 따른 법적 대응의 복잡성을 고려할 때 일반 시민은 교통사고 판결을 이해하고 대비하는 데 어려움을 겪을 수 있다.
따라서, 본 연구에서는 도로교통사고 도로교통법 위반에 관한 판결예측을 위한 자연어처리 시스템을 제안한다. 제안하는 시스템은 자연어처리 모델을 활용하여 교통사고 상황에 관한 텍스트 정보로부터 도로교통법(National Law Information Center, 2024a) 및 교통사고처리 특례법(National Law Information Center, 2024b) 등 교통법규 관련 정보를 분석하여 해당 상황에 대한 형량 정보(집행유예 여부 및 벌금액 등)을 예측한다. 제안하는 시스템은 크게 1) 데이터 수집 및 전처리, 2) 단어사전 구축 및 임베딩, 3) 판결예측의 세 과정으로 구분된다.
먼저, 데이터 수집 및 전처리 과정에서는 다양한 법률 데이터베이스 및 공식 문서로부터 도로교통사고 관련 판결문을 수집한다. 수집된 판결문은 전처리 과정을 통해 불필요한 정보의 제거, 텍스트의 정규화, 문장의 토큰화 등을 수행하며, 이를 통해 데이터의 질을 향상시키고 분석에 적합한 형태로 가공할 수 있다. 또한, 징역 및 집행유예 여부, 벌금액 등과 같은 판결문 내의 중요 정보를 추출하고, 이를 분석 가능한 형태로 구조화한다.
다음으로, 단어사전(Vocabulary) 구축 및 임베딩 과정에서는 전처리된 텍스트 데이터를 바탕으로 도메인(본 연구에서는 교통사고 판례)에 특화된 단어사전을 구축하고, 임베딩을 통해 주어진 단어를 벡터의 형태로 변환한다. 판결문으로부터 구축된 단어사전은 교통사고와 관련된 전문 용어, 법률 용어, 일반적인 언어 사용 패턴을 포함하며, 구축된 단어사전은 FastText와 같은 임베딩 기법을 사용하여 단어 벡터의 형태로 변환된다. FastText는 문자 수준의 N-gram을 활용하여 단어사전 내 포함되지 않는 새로운 단어의 처리(Out of Vocabulary, OOV) 문제를 일부 해결할 수 있으며(Lee, 2023), 주어진 단어를 문장 내 의미적 특성을 반영한 벡터의 형태로 표현할 수 있다. 이 과정을 통해, 판결문의 핵심 내용과 패턴을 반영한 임베딩 벡터를 획득할 수 있다.
마지막으로 판결예측 모델에서는 위 과정에서 생성된 임베딩 벡터를 학습하여 판결문으로부터 형량을 예측한다. CNN(Lecun et al., 1998) 기반의 모델을 구성하고 이를 바탕으로 징역, 집행유예 여부, 벌금을 예측한다.
본 연구에서는 FastText 임베딩을 이용하여 판결문 내의 핵심 단어의 특징을 분석하고, 이를 바탕으로 CNN 기반의 판결예측 모델을 이용해 형량 정보를 예측하는 시스템을 제안한다. 제안한 시스템은 법률 전문가들의 판결문 분석 과정을 간소화하고, 법적 지식이 부족한 사법 취약계층에게 법적 지원을 제공하는데 기여한다.
자연어처리 기술을 활용한 도로교통사고 판결예측 시스템
1. 도로교통사고 판결예측 시스템
본 연구는 자연어 처리 기술을 활용하여 도로교통사고 관련 판결문을 분석하고, 이를 통해 판결예측의 정확성을 제고하는 시스템 개발을 목표로 한다. 제안하는 도로교통사고 판결예측 시스템의 전체 구조는 Figure 1과 같다. 먼저 데이터 수집 및 전처리 과정에서는 분석에 필요한 다양한 판결문 데이터들을 수집 및 가공한다. 가공된 데이터셋을 바탕으로 단어사전 구축 및 FastText 임베딩을 수행하고, Traffic Violation Insight Net(TVIN)을 활용하여 도로교통사고에 대한 법원의 판결을 예측하여 도출한다.
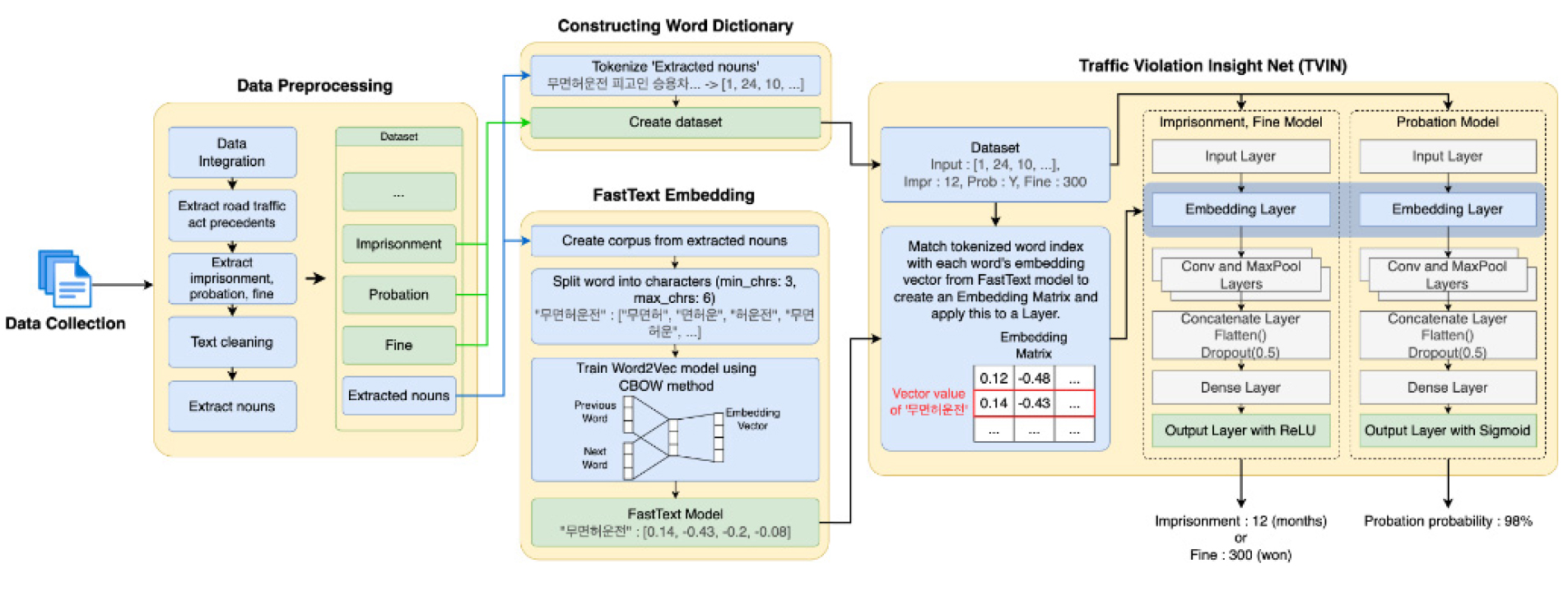
2. 데이터 수집 및 전처리
판결문은 법원이 판단한 법적 사실과 근거, 그리고 판결의 종류와 내용을 포함할 뿐만 아니라, 사건의 배경과 상황, 적용된 법류 조항, 제출된 증거와 증언, 법원의 해석과 판단 과정 등 다양한 정보를 담고 있다. 이러한 정보는 도로교통법 위반 사건의 특성과 경향을 파악하고 분석하는 데 유용한 특징으로 활용될 수 있다.
본 연구에서는 판결문 제공 서비스 LBox(LBox, 2023)를 통해 도로교통법 위반 사건에 대한 판결문을 전국의 지방법원 약 18곳 중 다양한 행정구역 별 데이터를 수집한다. 이를 위해 서울 및 수도권(의정부) 지역의 지방법원들과 광역시 중 한 곳인 울산의 지방법원 그리고 특례시 중 한 곳인 창원지방법원에서 수집한다. 이들 지역은 교통 밀도와 사고율이 높은 도시로, 다양한 교통 사례가 발생하는 경제 활동의 중심지이다. 이러한 특성은 판결문 데이터의 다양성과 복잡성을 포괄적으로 반영하는 데 유리하며, 연구 데이터의 포괄성을 보장한다. 서울과 수도권은 인구 밀도와 교통량이 많아 사고 사례가 풍부하며, 울산과 창원은 각각 동남권의 주요 산업 도시로서 다른 지역적 특성을 보여준다. 판결문은 2020년 11월부터 2023년 9월까지 총 37,406건을 수집하였으며, 판결이 선고된 지방법원별로 구분한다. Table 1은 수집한 판결문에 대한 지방법원 목록이다.
Table 1.
local courts conducted data collection
판결문 내에 포함된 사건의 배경과 상황을 서술하는 복잡한 내용은 모델 학습 과정에서의 효율성과 정확도에 있어 불리한 요소로 작용할 수 있다. 이러한 문제를 해결하기 위해 데이터 전처리 과정에서 데이터 정제 단계와 특징 추출 단계를 거쳐 데이터셋을 구축한다. 데이터 전처리 과정은 Figure 2와 같다.
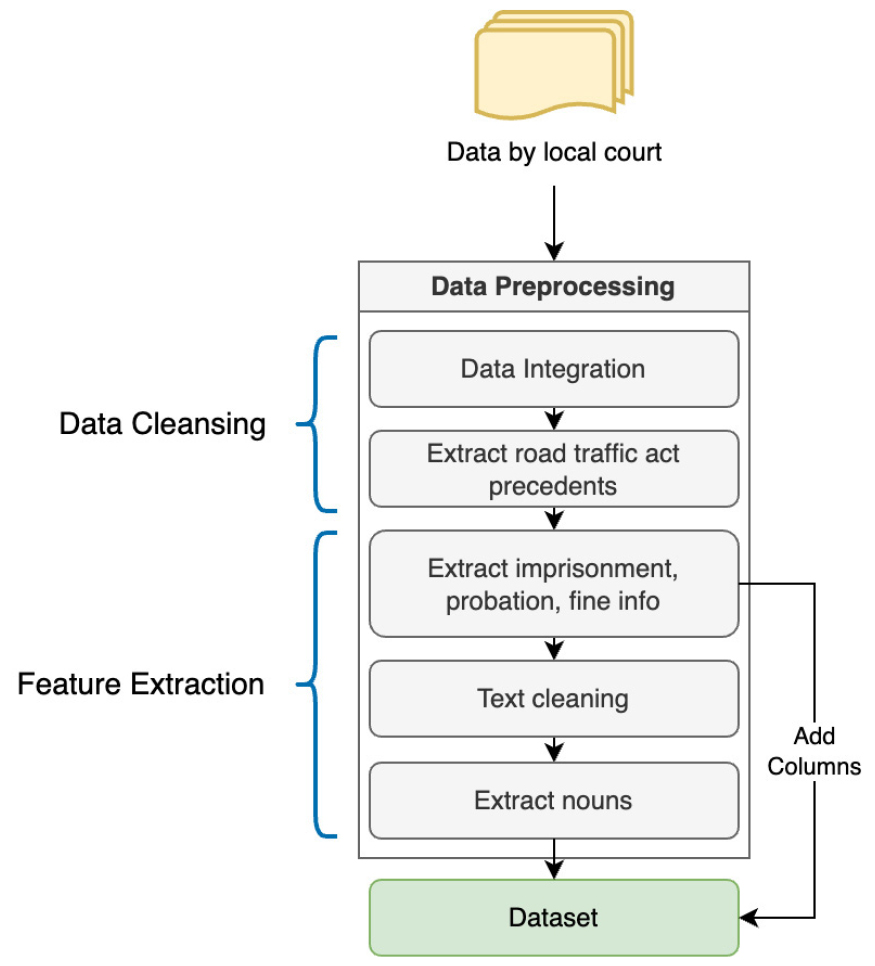
데이터 정제 과정에서는 여러 지방법원으로부터 수집한 판결문 데이터를 통합한 후, 도로교통법 위반 사례에 초점을 맞추어 교통사고와 관련 없는 판결문을 선별적으로 제거한다. 이는 도로교통법 위반과 무관한 선고 이유를 기준으로 이루어진다.
특징 추출 단계에서는 판결문으로부터 징역(imprisonment), 집행유예(probation), 벌금(fine) 정보를 추출해 해당 변수에 저장한다. 판결문의 요지 부분은 특수문자와 불용어를 정제한 후 처리되며, 이 과정을 통해 정제된 텍스트에서 핵심 단어를 추출하기 위해 명사만 추출하여 extracted_nouns 변수에 할당한다. 그러나 해당 과정에서 "사고 후 미조치"와 같은 복합명사가 "사고", "후", "미조치"로 분리될 수 있기 때문에, 사전에 도로교통법 판결문 내에서 빈번하게 사용되는 복합명사에 대한 단어사전을 구성한 뒤 복합명사가 분리되는 문제를 해결한다. 이렇게 수집된 명사는 판결문의 핵심 내용을 대표하는 중요한 요소로 활용된다. 데이터 전처리 완료 후 데이터셋 구조는 Table 2와 같다.
Table 2.
Dataset structure
3. 단어사전 구축 및 FastText 임베딩
본 절은 제안하는 TVIN 모델에 입력될 명사 데이터셋을 위한 단어사전 구축과 모델 내에서 사용될 임베딩 행렬을 생성하기 위한 FastText 임베딩 과정을 설명한다.
단어사전 구축 과정에서는 판결문에서 추출된 명사를 토큰화한다. 토큰화는 문자 형태의 단어를 수치화된 인덱스로 변환하는 작업이다. 토큰화된 명사는 해당 단어를 나타내는 인덱스로 변환되며, 이 인덱스들의 집합이 모델 입력으로 사용된다. 토큰화를 진행하기 위해 Keras의 토크나이저를 활용한다. 이 토크나이저는 텍스트 형식의 데이터를 각 단어의 인덱스가 담긴 시퀀스로 변환한다. 위 과정을 통해 생성된 토큰 데이터는 imprisonment, probation, fine의 타깃 변수와 결합하여 데이터셋을 재구성한다. 단어사전 구축 과정은 Figure 3과 같다.

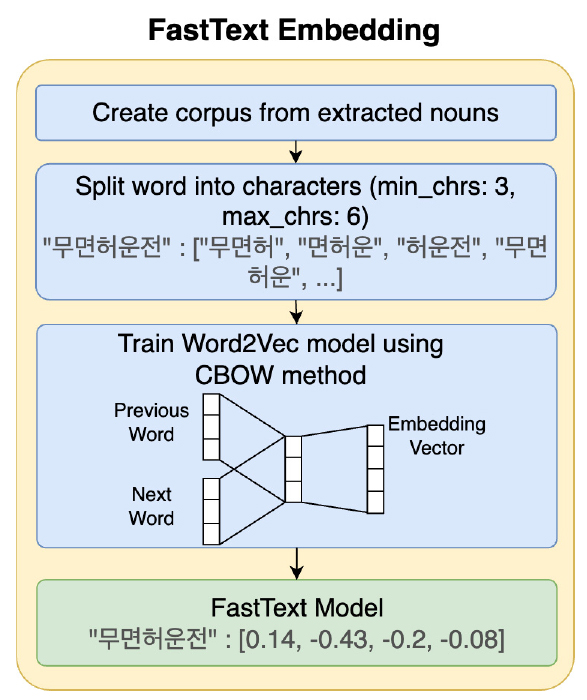
FastText 임베딩 과정은 FastText 모델을 활용하여 데이터를 벡터 형태로 변환한다. 이 모델은 Word2Vec의 확장으로, 단어를 문자 수준 N-gram의 집합으로 표현하고, 이 N-gram을 기반으로 단어 간 유사도를 계산하여 임베딩 벡터를 생성한다(Lee et al., 2019). 이 접근법은 말뭉치에 존재하지 않는 단어들에 대해서도 임베딩 벡터를 생성할 수 있으므로, Out of Vocabulary(OOV) 문제에 대한 해결책을 제공한다(Lee, 2023).
본 연구에서는 각 단어들을 최소 3개 이상의 문자를 가진 문자열로 분할하기 위해 FastText 모델의 N-gram의 N을 3으로 설정하며, 주변 단어들을 통해 중심 단어를 예측하는 Continuous Bag of Words(CBOW) 방식으로 학습을 진행한다. FastText 임베딩 과정은 Figure 4와 같다.
4. Traffic Violation Insight Net(TVIN)
본 절에서는 단어사전 구축과 FastText 임베딩 과정을 통한 결과를 바탕으로, 도로교통사고 관련 법원 판결을 예측하는 Traffic Violation Insight Net(TVIN) 모델을 설명한다. Figure 5는 본 연구에서 제안하는 Traffic Violation Insight Net(TVIN) 모델의 구조이다. 모델 내의 임베딩 레이어에 탑재될 임베딩 행렬을 생성하는 전처리 과정과 입력 데이터로 징역, 집행유예 여부, 벌금 정보를 예측하는 CNN 기반의 판결예측 모델로 구성된다. 사전 과정에서는 이전 단어사전 구축과정에서 생성한 토큰 데이터와 학습된 FastText 모델에서 생성된 각 단어에 대한 임베딩 벡터를 매칭시켜 임베딩 행렬을 생성한다(Umer et al., 2023). 임베딩 행렬은 모델 내의 임베딩 레이어에 탑재되며, 모델에 입력되는 토큰들이 해당 레이어로 입력될 때 각 토큰을 해당하는 단어의 임베딩 벡터로 변환하는 역할을 수행한다.
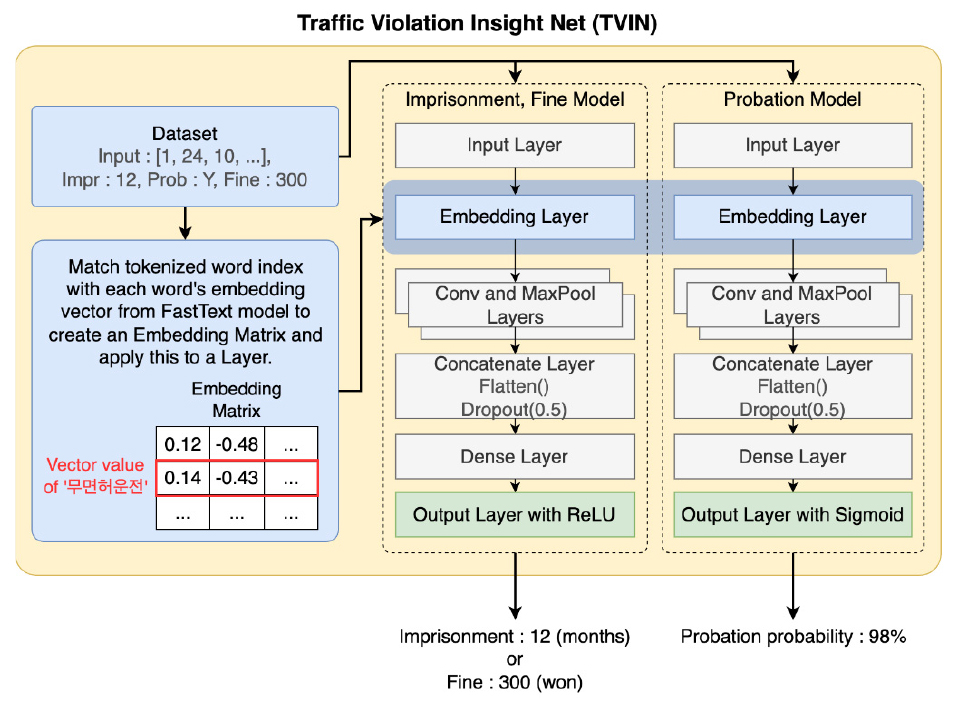
판결예측 모델은 CNN 구조를 기반으로, 판결문 내에서 핵심 단어의 특징을 추출하여 징역, 집행유예, 벌금의 판결을 예측하는 세 개의 서브 모델로 구성된다. 각 서브 모델의 구조는 Figure 6, Figure 7과 같다. 판결을 예측하기 위한 세 개의 서브 모델은 징역, 집행유예, 벌금의 특성에 맞게 서로 다른 활성화 함수를 사용하여 예측 결과를 나타낸다.
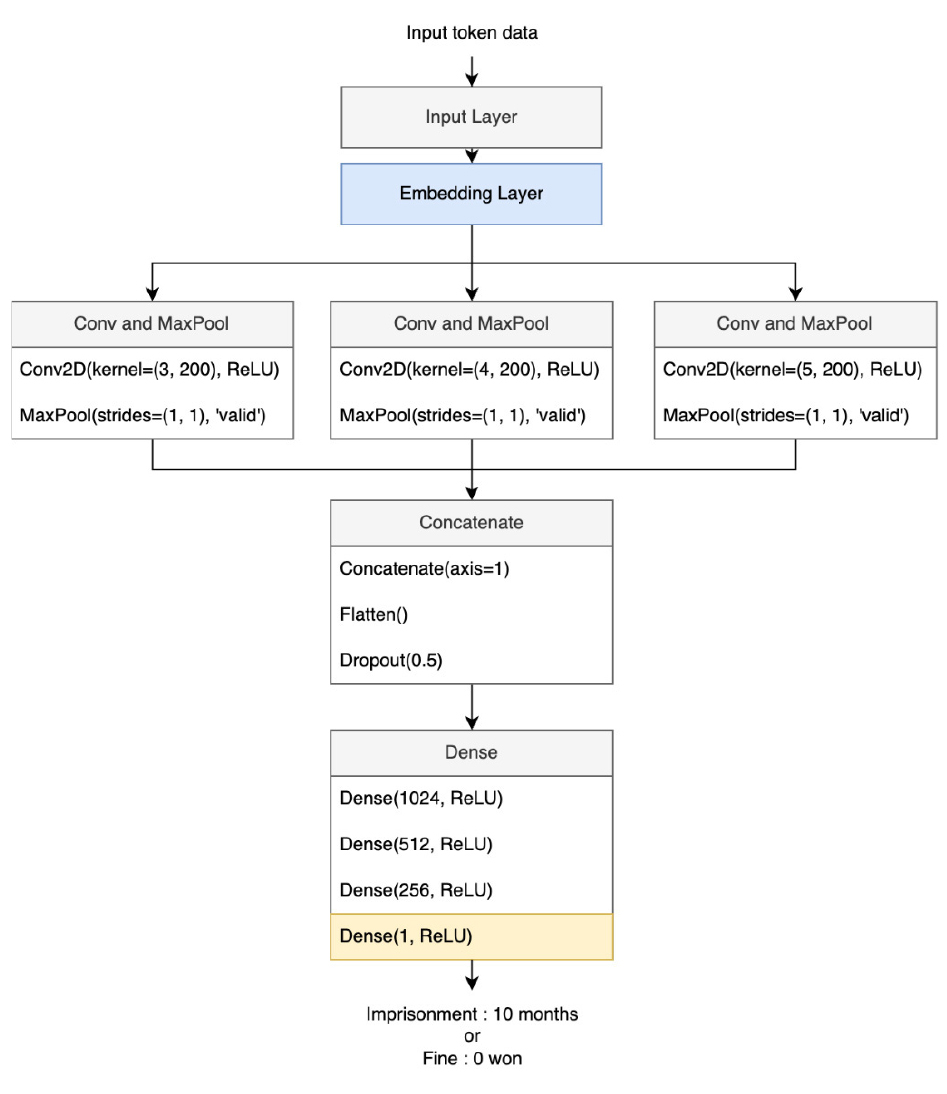
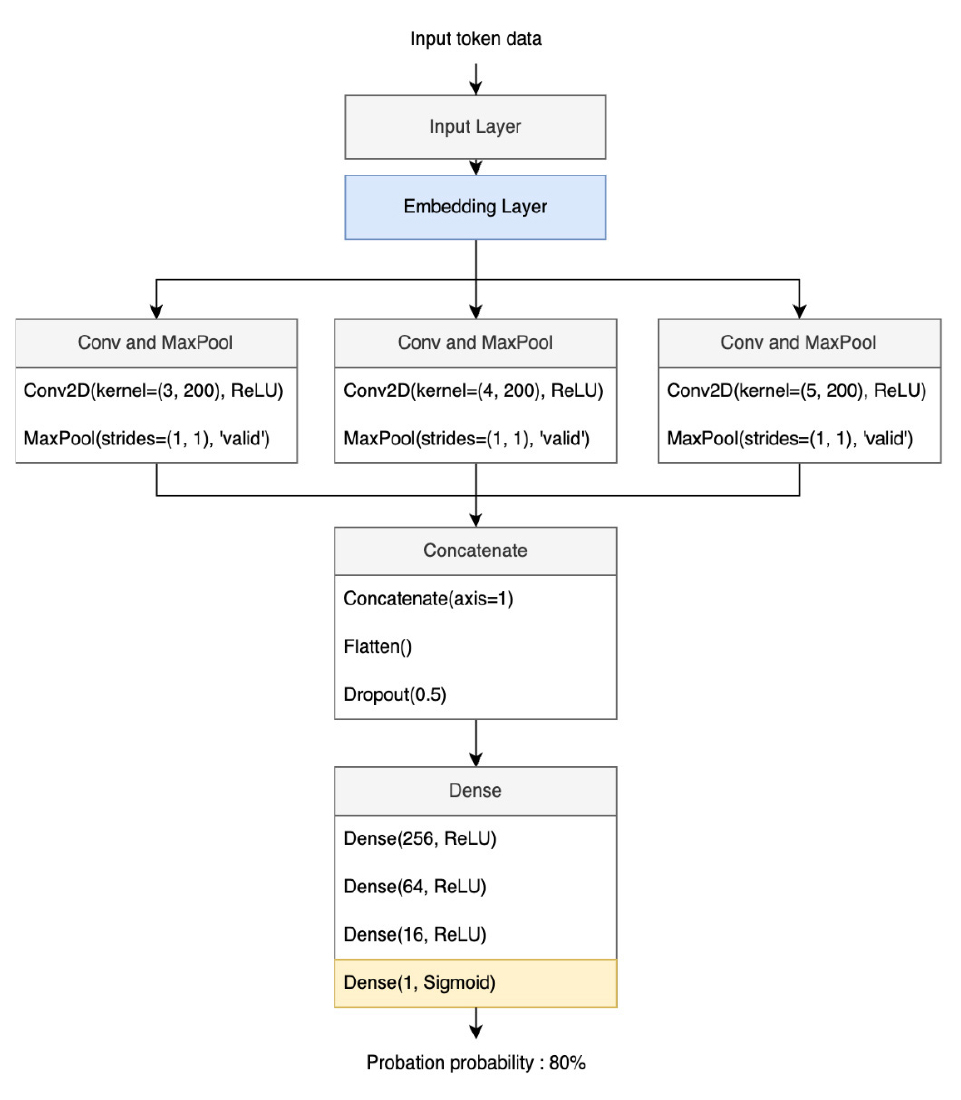
본 연구에서 제안한 판결예측 모델은 다음과 같은 구조를 가진다. 초기 단계에서, 입력 레이어는 토큰화된 데이터를 수용한다. 이어서, 임베딩 레이어는 사전에 정의된 임베딩 행렬을 참조하여 각 토큰을 해당하는 벡터로 매핑한다. 이 변환 과정을 거친 벡터들은 서로 다른 설정을 가진 다수의 Convolutional 레이어와 MaxPooling 레이어로 병렬적으로 이동한다. 병렬 레이어는 판결문 내 핵심 단어의 특성을 다양하게 추출하며, 깊게 구성된 Hidden레이어와 대비하여 ReLU나 Sigmoid 함수로 인해 학습률이 저하되는 현상을 줄여 더욱 높은 학습효과를 얻을 수 있다(Kim, 2022a). 추출된 특성들은 Concatenate 레이어를 통해 결합되어 하나의 1차원 벡터로 재구성된다. 이 벡터는 이후 여러 Dense 레이어를 통과하여 최종적인 예측 결과로 변환된다. 징역 및 벌금 예측 모델에서는 최종 결과가 수치형으로 제시되므로, 마지막 Dense 레이어에 ReLU 활성화 함수를 적용한다. 반면, 집행 유예 예측 모델에서는 집행 유예 발생 확률을 도출해야 하므로, Sigmoid 활성화 함수를 사용하여 결과값을 0과 1 사이 확률값으로 출력한다.
이 모델 구조는 판결문 분석에 있어서 핵심적인 단어 특성의 포괄적 추출을 가능하게 하며, 징역, 집행유예, 벌금 등 서로 다른 법적 판단 기준을 갖는 판결 유형마다 각각의 특성에 맞추어 최적화된 예측 결과를 제공한다.
실험 및 실험 결과
1. 성능 평가지표
본절에서는 연구에서는 제안한 모델의 다각적인 성능 비교를 위해 다음과 같이 정의된 징역 오차율 지표(Imprisonment Error Rate)(1), 집행유예 오차확률 지표(Probation Error Probability), 벌금 오차율 지표(Fine Error Rate)(2)를 설명한다. 양형 기준은 법관이 판결을 내릴 때 다양한 요소를 고려하여 일관되고 공정한 결정을 내리기 위해 마련된 주요 가이드라인이다. 이는 범죄의 유형, 가해자의 전과 여부, 피해자에 대한 보상 등을 포괄하는 다양한 요소들을 고려함으로써 동일한 범죄에 대한 처벌이 적절하게 이루어지도록 한다. 그러나 실제 판결에서는 사건별 특수성이 존재하고, 판사의 재량과 경험이 중요한 요소로 작용하기 때문에 양형 기준과 실제 판결 간의 차이가 발생한다. 또한, 교통범죄 중에서도 유형에 따라 양형 기준이 다르게 정의되기 때문에 모델의 다각적인 성능 비교를 위해서는 다양한 양형 기준을 포괄적으로 수용할 수 있는 새로운 평가지표가 필요하다. 각 지표는 모델의 예측 결과에 대한 허용 오차를 정의하며, 오차 범위 내에 존재하는 예측값은 정답이라 간주한다. 오차 범위는 교통범죄의 유형에 따라 크게 변동되는 양형기준을 유연하게 반영할 수 있도록 여러 교통범죄 유형 중에 받을 수 있는 최대 형량과 벌금액을 기준으로 한다. 그리고 통상적으로 사용되는 유의수준 0.05를 적용하여 다양한 교통범죄에 대한 유연한 평가가 가능하도록 지표를 정의한다. 유의수준이 적용된 성능평가지표는 Table 3와 같다.
징역 오차율 지표(Imprisonment Error Rate)(1)는 교통사고 치사 후 유기 도주 사례에 적용되는 최고 가중형 징역 기간인 12년(144개월)(Sentencing Commission, Sentencing Guidelines for Traffic Crimes, 2023)의 5%에 해당하는 7.2개월을 오차 범위로 설정한다. 이 지표는 징역 기간 예측 모델이 징역 기간을 얼마나 정확하게 예측하는지를 평가하는 역할을 한다. 징역 기간 예측 모델의 예측이 오차 범위 안에 들어오면, 모델의 예측이 옳은 것으로 간주한다.
집행유예 오차확률 지표(Probation Error Probability)는 집행유예 모델의 출력 확률과 실제 집행유예의 부여 여부를 0과 1로 표현한 값에 대한 허용 오차확률을 나타낸다. 예측 확률과 실제 확률에 대한 오차가 5% 이내이면 정답이라 간주한다.
벌금 오차율 지표(Fine Error Rate)(2)는 위험운전 교통사고, 어린이 교통사고, 교통사고 후 도주 사례에 부과될 수 있는 최대 벌금 3000만원(Sentencing Commission, Sentencing Guidelines for Traffic Crimes, 2023)의 5%, 즉 150만원을 오차 범위로 정한다. 이 지표는 벌금 예측 모델이 벌금 금액을 얼마나 정확하게 예측하는지를 평가하는 데 사용된다. 예측된 벌금 금액이 5% 오차 범위 이내이면 정답이라 간주한다.
Table 3.
Performance evaluation index
| Evaluation index | Tolerance |
| Imprisonment error rate | 7.2 months |
| Probation error probability | 5% |
| Fine error rate | 1,500,000 KRW |
2. 실험 결과
본 연구에서 제안한 판결예측 모델은 세 가지 중요한 법적 판단 요소(징역 기간, 집행유예 여부, 그리고 벌금 금액)를 예측하기 위해 세 개의 독립적인 모델로 구성된다. 이 모델들의 성능은 연구에서 제시한 성능 평가지표를 기반으로 평가하였다. 본 연구에서 제안한 모델의 성능은 Table 4와 같다.
징역 기간 예측 모델은 0.9613의 정확도로, 이는 모델이 제안한 예측값이 실제 징역 기간과 7.2개월 이내의 오차 범위에 있을 확률이 약 96%임을 의미한다. 이는 교통사고 치사 후 유기 도주와 같은 심각한 범죄에 대하여 권고되는 최대 가중형 징역 기간 12년의 5% 범위 내에서 모델이 상당히 정확한 예측을 제공함을 시사한다.
집행유예 확률 예측 모델은 0.9485의 정확도를 보여, 예측된 확률값과 실제 집행유예 부여 사이의 오차가 5% 이내에 있는 경우가 전체 예측의 약 95%를 차지함을 나타낸다. 이는 모델이 집행유예 여부를 결정하는 데 높은 신뢰도를 가짐을 나타낸다.
벌금 예측 모델은 0.9549의 정확도로, 이는 모델이 예측한 벌금 금액이 실제 금액과 150만원 이내의 오차를 보이는 경우가 전체 예측의 약 95%임을 의미한다. 이 결과는 모델이 위험운전 교통사고, 어린이 교통사고, 교통사고 후 도주 사례에 부과될 수 있는 최대 벌금 3000만원의 5% 범위 내에서 정확한 예측을 제공함을 시사한다.
이러한 평가 결과는 본 연구에서 제안한 판결예측 시스템이 각 법적 판단 요소에 대해 높은 정확도를 나타냄을 의미한다.
3. 실험 결과 논의
본 연구에서 제안한 판결예측 시스템은 징역 기간, 집행유예 여부, 및 벌금 액수를 예측하는 세 개의 서브 모델을 포함하고 있다. 이 모델들은 높은 정확도를 달성함으로써, 판결예측 분야에서 신뢰성을 입증하였다. Table 5에서는 도로교통법 위반에 관한 실제 판결문 데이터를 본 시스템에 입력했을 때 얻어진 실제 판결 결과와 예측 결과를 비교하여 나타내고 있다. 표 내의 Actual은 실제 해당 판례가 선고받은 형에 대한 데이터이고, Predicted는 본 시스템이 예측한 결과이다. Actual와 Predicted의 각 열은 해당 판례가 받은 징역 개월 수, 집행유예를 받을 확률, 천 원 단위의 벌금을 나타낸다. 이 데이터는 대부분의 예측 결과가 본 연구에서 제시된 성능 평가지표의 허용 오차 범위 내에 위치함을 보여주며, 양형위원회의 양형 기준에 모두 부합한 것을 확인할 수 있다. 그러나 Case 4의 경우 판결문에 접촉 사고, 사고 후 미조치, 음주운전 등 다양한 유형의 교통범죄에 대한 명사가 포함되어 있기 때문에 모델이 객관적인 예측을 하지 못한 것으로 사료된다. 그러나 교통사고 치상 후 도주의 경우 감형이 되는 경우 최소 6개월의 징역을 받을 수 있는 유형이기 때문에 다른 판결문에 비해 오차가 크지만, 양형 기준에 부합한 것을 확인할 수 있다. 따라서 실제 형량과 예측된 형량 모두 양형 범위에 부합하며, 이는 예측 결과가 실제 판결 결과와 밀접하게 일치함을 보여 준다. 이러한 일치는 모델이 실제 법률적 상황에서 유효하게 작동할 수 있음을 시사하는 긍정적인 지표로 해석된다.
비교 연구로서, Glove와 FastText 임베딩을 활용하고 원문의 특정 단어를 의미적으로 유사한 다른 단어로 대체하는 방법을 적용한 데이터 증강 기법과 CNN을 사용한 실험(Zahir, 2023)에서는 75.49%의 정확도를 기록했으며, Glove 임베딩 모델을 적용한 최고 정확도는 80.51%에 이른다고 보고되었다. 그러나 이 연구는 어근과 어간이 어미와 함게 변형되는 언어적 특징을 가지고 있는 아랍어에 초점을 맞추고 있다. 반면 한국어의 경우 복잡한 형태소 구조와 다양한 조사 및 어미 변형을 보이며, 동음이의어나 한자어의 영향으로 다양한 표현이 존재한다. 이러한 이유로 문자 단위의 서브 단어 분할 방식을 사용하는 FastText 임베딩 모델이 한국어의 의미와 문맥을 효과적으로 포착하는 데 적합하다. 본 연구에서 제안한 모델은 FastText 임베딩을 활용함으로써, 한국어 법률 텍스트의 복잡한 구조와 다양한 표현을 세밀하게 분석할 수 있다. 이는 법률 용어의 특수성을 이해하고 법률 텍스트의 복잡한 구조를 보다 정확하게 파악할 수 있는 모델 구축에 기여한다. 이를 통해 비교 연구에서 다루지 못한 한국어의 언어적 특성을 반영함으로써 더 정확하고 신뢰할 수 있는 예측을 제시하는 모델을 구축했다는 점에서 본 연구의 의의가 있다.
본 연구에서 제안한 접근 방식은 법률 분야에서 자연어처리를 위한 임베딩 선택 시 고려해야 할 요소를 명확히 규명하였다. 제안한 모델은 실제 법률 상황의 복잡한 요소를 효과적으로 반영해 판결예측의 정확도와 신뢰성을 향상시켰으며, 법률적 판단의 예측 가능성을 높이는 데 중요한 역할을 한다.
Table 5.
Predicted results of actual precedents
결론 및 향후연구
본 연구에서 제안한 판결예측 시스템은 사법 취약계층을 대상으로 한 도로교통사고 상황 속 도로교통법 위반에 대한 판결예측을 목적으로 하고 있으며, 총 37,406건의 ‘도로교통법’ 관련 판결문 데이터를 기반으로 구축되었다. 이 시스템은 자연어처리 기술을 활용한 TVIN(Traffic Violation Insight Net)모델을 통해 징역, 집행유예, 벌금 예측을 수행하고 있으며, 각 모델은 각각 약 96.13%, 약 94.85%, 약 95.49%의 높은 정확도를 달성했다. 이러한 성능은 법률적 상황에서의 유용한 적용 가능성을 보여주며, 인공지능 기술이 법률 분야에서 중요한 역할을 할 수 있음을 시사한다. 본 연구는 징역 오차율 지표, 집행유예 오차확률 지표, 벌금 오차율 지표를 성능 평가지표들을 사용했다. 이 지표들은 모델의 예측 정확도를 객관적이고 실제 법률적 상황에 맞게 평가하는 데 중요한 역할을 한다.
그러나 모델의 성능평가를 위해 도로교통법 위반 판결에 대해 받을 수 있는 최대 형량 및 벌금을 기준으로 오차범위를 산정했기 때문에 모델 평가지표의 허용 오차범위가 넓어진다는 한계가 존재한다. 실제로 교통사고는 위험운전, 어린이 교통사고, 무면허운전 등 다양한 유형이 존재하고, 각 유형마다 선고되는 형량의 범위가 다르기 때문에 추후 연구에서는 각 교통사고 유형별로 허용 오차범위를 달리하여 이를 모델 성능평가에 반영해야 할 것이다.
이러한 연구 결과를 바탕으로, 향후에는 사법 취약계층을 세밀하게 정의하고 이들에게 특화된 지원 방안을 개발하며, 도로교통법의 복잡한 부분을 해석하고 적용하는 기술을 연구하여 일반 시민들의 법률 이해력을 증진시키는 한편, 법률 분야에서 인공지능 기술의 응용 범위를 확대하고 사법적 불평등 해소를 위한 연구를 지속적으로 진행할 것이다. 이러한 다방면의 연구를 통해, 법률 분야에서 인공지능의 응용을 더욱 확대하고, 사법 접근성 향상과 법률적 지원의 개선을 통해 사법 취약계층의 권익 보호에 중요한 역할을 할 것으로 기대된다.
