

서론
선행 연구
1. 통행 생성 정의
2. LLM 기반 통행행태 예측
3. 선행 연구와의 차별성
방법론
1. 데이터 정의 및 전처리
2. 통행 생성 프롬프트 설계
3. LLM 생성 전략에 대한 비교 분석
4. 통행 생성 정확도 평가
분석 결과
1. 통행 생성 정확도 평가
2. Tail 영역 분포 정확도 평가
결론 및 향후 연구과제
APPENDIX (LLM prompt in this research)
서론
도시 환경의 급격한 변화와 더불어, 개인의 일상적 활동(Activity)과 이에 따른 통행(Trip) 패턴을 정교하게 이해하고 예측하는 것은 도시 계획, 설계 등 여러 분야 전반에서 핵심적인 과제로 자리 잡고 있다(Barbosa et al., 2018; Li et al., 2021). 이러한 예측을 위해 전통적으로 활동 기반 모델(Activity-Based Models: ABM)이 사회경제적 특성을 기반으로 일상 활동을 시뮬레이션함으로써 사람들의 통행과 그 수요에 대한 이해를 증진시켰다. 특히 정부 기관과 같은 정책 의사결정권자들은 교통 분석, 도시 계획, 상업 전략 개발 및 세금 정책 평가를 포함한 다양한 응용 분야에 ABM들을 채택해 왔다(Bhat and Koppelman, 1999; Goulias et al., 2011). ABM은 복잡한 통행 수요들을 효과적으로 생성하지만, 높은 과거 통행 데이터 의존성과 복잡한 보정(calibration) 비용이 수반되는 한계가 존재한다(Zhang and Levinson, 2004; Gonzales et al., 2025). 이에 모바일 기기, GPS 등에서 수집된 대규모 시공간 데이터를 활용하여 인공지능 모델 또는 클러스터링을 활용한 이동 패턴 모형화 시도로 확장되어 왔다(Huang et al., 2018; Tang et al., 2015). 그러나 이러한 접근법들 또한 정밀한 개인 통행 일지(travel diary) 데이터의 확보가 필수적이고, 인간 의사결정 속 내재된 유연성과 불확실성을 포착하기 어려운 한계를 지닌다(Prelipcean et al., 2018; Chakraborty et al., 2017; Pellungrini et al., 2017).
최근 자연어 처리 분야에서 급속도로 발전한 거대 언어 모델(Large Language Models, LLM)은 교통 분야에서 새로운 가능성을 제시하고 있다(Liu et al., 2025; Hassan et al., 2025). LLM은 방대한 텍스트 데이터를 사전 학습하여 언어적 패턴뿐만 아니라 다양한 지식과 맥락적 추론 능력을 내재화한 모델로 이러한 특성은 기존 교통 예측 모델의 한계를 보완할 수 있는 여러 장점을 제공한다(Ma et al., 2024). LLM은 이미 다양한 분야의 대규모 데이터로 사전 학습되어 있어, 특정 분야 적용을 위해 추가적인 대규모 학습 데이터를 수집하거나 모델을 처음부터 학습시킬 필요가 없다. 대신, 적절한 프롬프트(prompt) 설계를 통해 모델을 즉시 활용할 수 있으며, 이는 데이터 수집 및 전처리 비용을 크게 절감한다(Ying et al., 2025). 또한 LLM은 텍스트 기반의 비정형 정보를 자연스럽게 처리하고 이해할 수 있으며 이벤트의 성격, 규모, 시간대 등을 맥락적으로 파악하여 이어지는 이벤트 예측에 유의미한 정보를 제공할 수 있다(Liang et al., 2024). 또한, LLM은 복잡한 인과 관계와 시나리오를 추론할 수 있어, 단순한 패턴 인식을 넘어 논리적 판단을 요구하는 의사결정 문제에 적용 가능하다(Masri et al., 2024). 그리고 LLM은 검색증강생성(Retrieval-Augmented Generation, RAG)을 통한 지식 확장이 가능하다. RAG는 LLM이 외부 지식 베이스나 문서를 동적으로 검색하여 참조할 수 있도록 하는 기법으로 이를 통해 LLM의 사전 학습 시점 이후의 최신 정보나 사전 학습되지 않은 특정 분야의 지식을 보완하여 지역별 특성이나 최신 정책 변화를 반영하는데 유용하다(Lewis et al., 2020). 따라서 LLM의 추가 학습 없이도 활용 가능한 범용성, 텍스트 기반 맥락 이해 및 추론 능력, 외부 지식 연계를 통한 확장성이라는 장점을 바탕으로, 본 연구는 LLM의 이러한 특성을 통행 생성 문제에 접목하여 그 적용 가능성을 검증하고자 한다.
본 연구에서는 LLM의 자연어 기반 추론 능력을 활용하여, 통행 생성 체계의 새로운 접근법을 제안하고자 한다. 기존 복잡한 모형 설계 또는 대규모 학습 과정 없이도, LLM이 언어적 지식과 추론을 통해 활동 기반 통행 일정을 생성할 수 있다는 가능성을 검증하고자 한다. 본 연구는 (1) LLM 통행 생성에 필요한 통행 인구 추출 및 참고 데이터 정의, (2) LLM 기반 통행 생성 프롬프트 설계 및 LLM 통행 생성 전략 제안, (3) LLM 통행 생성 전략별 통행 생성 결과의 정확도 평가로 구성된다. 따라서 데이터가 희소한 환경에서도 사전 학습된 LLM이 통행 시나리오 생성 도구로서 효과적일 수 있는가를 검토하고, LLM 사용 방법에 따라 통행 생성 품질에 미치는 영향을 분석함으로써, LLM 기반의 통행 생성 가능성 및 적절성을 평가하고자 한다.
선행 연구
1. 통행 생성 정의
통행 발생(Trip Generation)은 특정 공간 단위에서 발생·유입되는 통행량을 추정하는 과정으로, 전통적으로 4단계 교통 수요예측 모형의 출발점이자 교통 수요분석의 기초 단계이다(Bhat and Koppelman, 1999). 초기 통행 발생은 Trip-based 구조를 기반으로 발전해 왔는데, 이는 생성(Production)과 유인(Attraction)의 개념에 기반해 거주지에서 발생하는 출발 통행과 다양한 목적지로의 도착 통행을 구분하여 이후 통행 분포, 수단 선택, 통행 배정 단계에 체계적으로 활용될 수 있도록 통행 방향성과 목적을 명확히 한다(Ben-Akiva and Bowman, 1998). 또한 통행을 활동의 파생수요(derived demand)로 바라봄으로써, 단순히 통행 발생량을 산정하는 수준을 넘어, 누가 언제 어디에서 어떤 활동을 수행하며 그 결과 어떤 통행이 발생하는지까지 일상적 의사결정의 흐름 속에서 설명하는데 초점을 두었다(Bowman, 1995; McNally, 1996). 그러나 Trip-based 구조는 사람들의 통행 패턴을 사실대로 묘사하지 못하는 한계가 존재한다. 통행은 단순히 한 사람에 의해 만들어진 결과물이 아니기에 하나의 목적지에서 다른 목적지까지 독립된 단위로 가정할 수 없으며, 이는 가구 구성원들 또는 각 개인이 참여하여 이루어지는 복합적인 의사결정이자 일련의 쇠사슬처럼 서로 연결된 더 높은 차원으로 정의될 필요가 있다(Lim et al., 2013).
이에 통행 행위자를 정의하고 해당 행위자의 행동을 안내하고 규제하는 전략을 바탕으로 교통 네트워크, 토지이용, 이용 교통수단과 같은 변수를 포착하는 물리적 환경 기반 시뮬레이션인 ABM이 등장하였다(Arentze et al., 2000). Kulkarni and McNally(2000)에 따르면, ABM은 개인의 활동 선택, 활동 지속시간, 방문 순서, 공간적 분포 등을 통합적으로 고려하며, 일일 활동 스케쥴(Activity Schedule)과 통행 사슬(Trip chain)을 기반으로 통행(Trip) 단위의 패턴을 모형화하였다. Zhao et al.(2019)에 따르면 통행 설문조사 데이터와 도로망 데이터를 바탕으로 개별 에이전트의 움직임과 상호 작용을 시뮬레이션하였다. 그러나 ABM은 정확한 통행 생성을 위해 정교한 모델 구조 설계와 파라미터 보정이 진행되어야 하며, 이는 고해상도 활동 일지 데이터가 필수적이고 특정 지역과 시점에 최적화된 모델이 다른 환경에 적용될 때 제약이 따른다는 한계를 나타내었다(Joubert and De Waal, 2020; Molla et al., 2017). 또한 많은 에이전트 간 상호 작용을 시뮬레이션하려면 상당한 계산 자원이 소요되며, 이는 실시간 또는 대규모 통행 생성에 한계를 나타내었다(Zhao et al., 2019).
2. LLM 기반 통행행태 예측
최근 인공지능 기술의 발전과 함께, 다양한 데이터 소스에 기반하여 사전 학습된 LLM이 기존 접근법의 한계를 극복할 수 있는 강력한 대안으로 부상하였다. Generative Pre-trained Transformer(GPT)와 같은 LLM은 트랜스포머(Transformer) 아키텍처를 기반으로 구축되어, 개인 비서, 법률 자문, 차량 운전 지원 등 다양한 분야에서 우수한 성능을 발휘하고 있다. 방대한 규모의 데이터로 학습된 LLM의 높은 유연성과 일반화 능력은 추가적인 데이터 입력이나 학습 없이도 새로운 상황에 빠르게 적응할 수 있음을 보여준다(Achiam et al., 2023).
LLM을 활용한 초기 연구들은 LLM이 보유한 언어 기반 추론 능력과 사전지식을 활용하여 이동성 패턴을 해석하거나 예측 가능한지에 대한 가능성을 확인하였다. Liang et al.(2024)은 뉴욕 바클레이스 센터를 대상으로 과거 행사 정보와 택시 이동 데이터를 기반으로 앞으로 개최될 행사 당일에 발생할 통행 수요를 GPT-4 모델에 Few-shot 기법을 활용하여 예측하였다. Wang et al.(2023)은 GPT-3.5 모델에 Few-shot 기법을 활용하여 개인의 다음 목적지, 체류 지속시간 예측을 통해 LLM이 개인 통행을 모델링 할 수 있음을 확인하였다. Wang et al.(2024)은 과거 개인 활동 스케쥴 데이터를 바탕으로 가상의 프로필 유형을 설정하여 도시 내 개인 이동 경로(trajectory)를 GPT-3.5 모델에 추가학습을 통해 생성하였고, Li et al.(2024b)은 GPT-4 모델과 DeepSeek모델을 활용하여 별도의 추가학습 없이 Zero-shot 기법을 통해 생성하였다. Beneduce et al.(2025)은 LLaMA-2, LLaMA-3, GPT-3.5, GPT-4 와같은 다양한 LLM들을 Zero-shot 기법을 통해 다음 목적지에 대한 예측 정확도를 비교‧분석하였다. 그 결과 사전 학습 데이터양이 많고 최신에 배포된 모델일수록 더 좋은 예측력을 보여주었다.
이러한 기존 연구들을 통해 LLM의 사전 학습 지식과 실데이터에 대한 맥락 이해를 바탕으로 LLM이 실제 통행 패턴과 통행목적을 이해하여 사람들의 일상적인 이동 경로를 보다 정확하게 재현할 수 있는지 확인할 수 있었다(Liang et al., 2024; Wang et al., 2023; Beneduce et al., 2025). 이는 이용자 그룹의 일반화된 이동 특성을 반영할 수 있다는 장점이 있었으나, 특정 프로필 유형에 국한되어 개별 사용자 특성에 따른 세세한 통행 차별성을 설명할 수 없거나(Wang et al., 2024; Li et al., 2024a), 특정 시공간 범위에 한정되어 하루 또는 도시 전체 범위의 통행을 분석하는데는 한계가 존재하였다(Liang et al., 2024).
3. 선행 연구와의 차별성
기존 통행 생성 연구는 전통적으로 4단계 교통 수요예측 모형부터 ABM까지 다양한 방식으로 발전해 왔다(Molla et al., 2017). 4단계 모형은 각 통행 의사결정 과정을 분절하고, 통행 발생 단계에서 통행량 생성 또는 추정에 초점을 두고 있으며(Lee and Choi, 2006), ABM은 통행 과정 전반을 연계 및 모형화함으로써 보다 정교한 통행 재현을 가능하게 하였다(Zhang et al., 2018).
그러나 이러한 방법들은 고해상도의 통행 일지 데이터에 대한 의존성, 데이터 요구량 증가에 따른 높은 모델 구축·보정 비용 등 한계점을 가지고 있다(Zhang et al., 2018). 즉, 새로운 지역에 조사된 과거 데이터가 존재하지 않거나 조사된 데이터가 부족한 환경에서는 적용이 어려우며, 다양한 개인의 통행 패턴을 모사하기 위한 개별 단위 모형 확장에도 한계가 있다(Bowman and Bradley, 2017).
최근 나타난 LLM 기반 이동성 예측 연구는 이러한 한계를 완화할 수 있는 대안으로 제시되었으나, 대부분의 기존 연구는 가상의 페르소나 또는 그룹 단위 이동성을 모델링하였고, 다음 방문지·특정 목적지 수요 등 단편적 이동성 예측에 집중하였다. 이에 본 연구는 개인통행실태조사 자료를 활용하여 개인 단위의 하루 동안 발생할 수 있는 연속적 활동인 일일 통행 사슬(Trip Chain)을 생성하고 개인의 실제 통행 패턴을 재현하고자 하였다.
따라서 본 연구는 실제 통행자료인 개인통행실태조사 데이터를 활용하여 개인통행실태조사와 동일한 인구학적 특성을 유지한 상태에서 Zero-shot, Few-shot, Few-shot with statistics, RAG 기반 네 가지 LLM 활용 방식을 비교하여 LLM 활용 방법에 따른 통행 생성을 진행하고 생성 데이터에 대한 정확도를 정량적으로 비교·검증함으로써 LLM 기반의 통행 생성 가능성 및 적절성을 평가하고자 한다.
방법론
본 연구에서는 Figure 1과 같이 세종시 개인통행실태조사 원시 데이터를 기반으로, LLM이 제한된 표본 데이터 환경에서도 현실적인 일일 통행을 생성할 수 있는지를 검증하고자 한다.
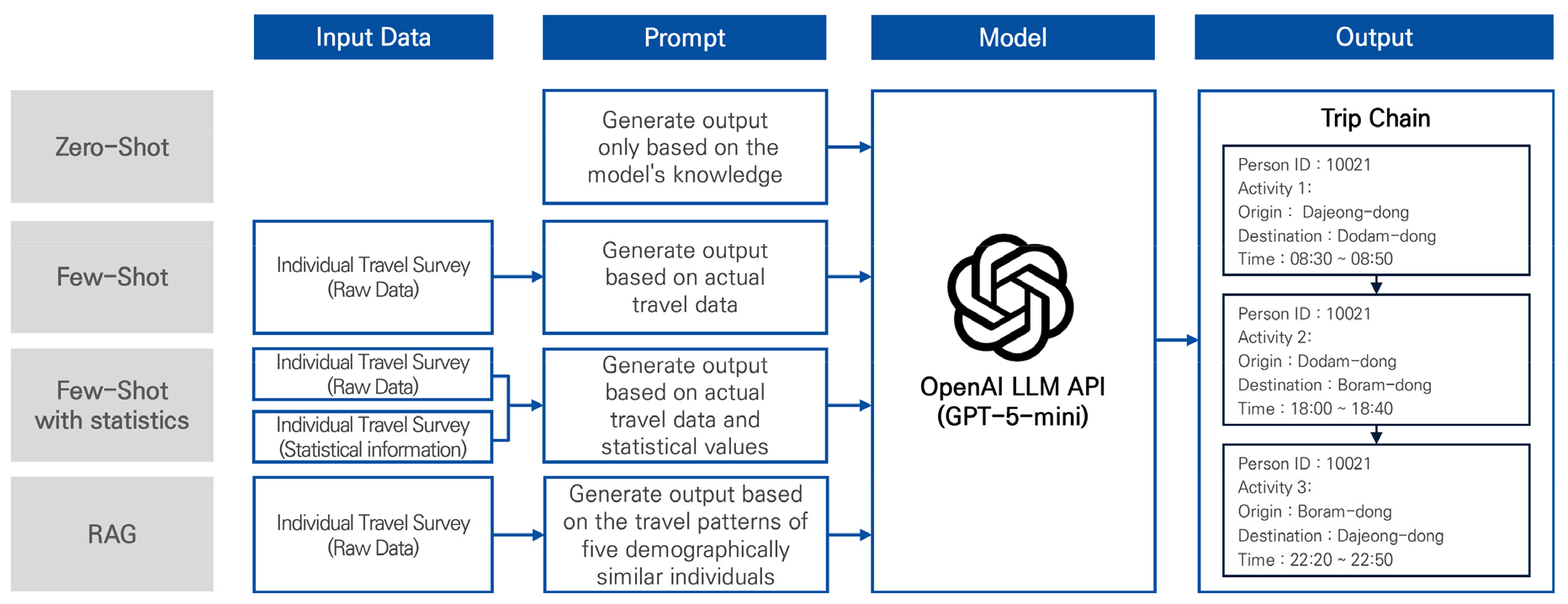
본 연구는 개인통행실태조사 데이터 전처리, 통행 생성을 위한 LLM Prompt 설계, LLM Prompt 설계 유형별 일일 통행 생성, 통행 생성 유사도 평가의 순서로 진행되었다. 먼저 분석에 활용되는 입력 데이터인 개인통행실태조사 데이터 중 출·도착지가 세종시 지역인 데이터를 추출하였다. 이후 입력 데이터 변수 정의, 통행 생성 규칙, 모델 출력 형식을 기반으로 LLM Prompt를 설계하였으며, Zero-Shot, Few-Shot, RAG와 같이 LLM 사용 방식에 따른 통행 생성 비교·분석을 OpenAI사에서 제공하는 GPT-5-mini 모델의 API를 사용하여 진행하였다. 각 유형은 LLM에 제공되는 정보의 수준과 성격이 서로 다르도록 설계되어, 모델이 어떤 조건에서 가장 합리적이고 현실적인 결과를 생성하는지를 비교할 수 있도록 하였다. 생성된 결과는 Jensen–Shannon Divergence(JSD) 기반의 분포 유사성 평가를 통해 비교·분석하였으며 이를 통해 본 연구는 LLM의 언어적 추론 능력을 활용하여, 별도의 추가 학습 없이도 실제 통행자료와 유사한 개인별 일일 통행(Trip Chain)을 생성할 수 있는지를 검증하였다.
1. 데이터 정의 및 전처리
본 연구는 개인의 일일 통행 특성을 반영하는 2021년 개인통행실태조사 원시 데이터를 활용하였다. 개인통행실태조사는 국가통합교통체계효율화법에 근거하여 5년 주기로 시행되는 전국 단위 표본조사로, 개인의 하루 활동 및 통행 일지를 수집하여 국가 교통정책 및 교통 수요 모델링의 기초자료로 활용된다(Korea Transport Database, 2025). 개인통행실태조사는 2021년 10월 14일~21일간 이루어졌으며 만 5세 이상 국내 거주 국민을 대상으로 조사하여, 가구 특성 - 개인 특성 - 통행 특성의 3계층 구조로 이루어져 있다. 응답자는 하루 동안 수행한 모든 통행에 대해 출발 시각, 도착 시각, 이동 목적, 이동 거리, 이용 교통수단 등 상세 정보를 기록하게 된다.
본 연구는 해당 조사자료 중 출발지 또는 도착지가 세종시인 사례만을 추출하여 가장 표본수가 많은 10월 21일 하루에 대한 분석 데이터셋을 구축하고 데이터 전처리 과정을 수행하였다. 먼저 공간 정보는 세종시 행정동 주소 체계를 기준으로 읍·면·동 단위로 표준화하였으며, 세종시 외부 지역은 단일 범주(세종시 외부)로 통합하였다. 다음으로, 출발·도착 시각은 24시간제 형식으로 통일하고, 통행시간(Travel Time)은 분 단위로 변환하였다. 이러한 데이터 전처리 과정을 통해 Table1과 같은 형태로 총 501명의 응답자와 1,427건의 Trip으로 구성된 통행일지 데이터셋을 도출하였다.
Table 1.
Data description
LLM 기반 통행 생성을 위해, 응답자별 사회인구학적 정보는 Agent 프로필 입력 변수로 재구조화하였으며(예: 연령, 성별, 면허 보유 여부, 직업, 가구원 수, 차량 보유 여부, 가구소득), 각 Trip은 Trip Chain 구조에 맞게 통행 순서 순으로 정렬하였다.
2. 통행 생성 프롬프트 설계
LLM은 방대한 자료를 기반으로 사전 훈련된 모델을 뜻하며, 본 연구에서는 OpenAI에서 개발한 GPT의 다양한 버전 중 하나인 GPT-5-mini 모델을 OpenAI API를 통해 활용하였다. OpenAI의 GPT 모델은 사전 훈련된 정보들을 기반으로 언어 이해, 논리적 추론, 수치 분석, 설명 가능성 측면에서 탁월한 능력을 제공한다는 특징이 있다(OpenAI, 2025).
LLM의 성능은 모델 자체의 파라미터뿐 아니라, 프롬프트(Prompt) 구성 방식에 크게 좌우된다. 프롬프트란 LLM에 수행할 작업과 조건을 전달하는 입력 명령문으로, LLM은 프롬프트에 포함된 정보와 사전 학습된 지식을 바탕으로 응답을 생성한다. 특히 구조화된 출력 형식, 데이터 정의, 제약조건, 예시 제공 여부는 생성 결과의 논리성·일관성·사실성에 중대한 영향을 미친다(Achiam et al., 2023). 본 연구에서는 통행 데이터를 생성하는 작업의 특성을 고려하여, 프롬프트 내부에 데이터 스키마 정의, 제약규칙, 공간 범위, 시간 범위, 생성 데이터 출력 형식을 명확히 명시하는 설계를 적용하였다.
LLM 기반 Trip Chain 생성 프롬프트는 Table 2와 같이 세 가지 요소로 구성되었다:
Table 2.
Contents of trip generation prompt
3. LLM 생성 전략에 대한 비교 분석
LLM을 활용한 통행 생성의 성능은 모델 자체의 성능뿐만 아니라, 프롬프트에 어떠한 정보와 조건을 제공하는지에 따라 크게 달라진다. 특히 LLM은 사전 학습 과정에서 방대한 언어적·사회적 지식을 내재하고 있지만, 외부 정보 없이 생성하는 경우와, 예시·통계·검색 기반 정보를 조건부로 제공하는 경우 간 생성 품질의 차이가 존재한다. 따라서 본 연구는 LLM이 통행을 생성할 때, 입력 정보 수준에 따라 결과가 어떻게 달라지는지를 검증하기 위해 Table 3과 같이 네 가지 프롬프트 전략을 비교하는 실험 구조를 설계하였다.
Table 3.
Comparative framework of LLM prompting methods
먼저, Zero-shot은 사전 예시나 추가 데이터 없이, 프롬프트 지시만으로 모델이 작업을 수행하도록 하는 방식으로. LLM 사전 학습 지식에 전적으로 의존하는 가장 쉬운 활용 전략이다. 본 연구에서는 사회인구학적 속성만 제공한 상태에서, LLM이 스스로 출발 시각·도착 시각·통행 횟수·공간 분포 등을 얼마나 현실적으로 재현할 수 있는지를 평가하였다.
Few-shot의 경우 모델이 따라야 할 예시를 일부 제공하여, LLM이 패턴을 귀납적으로 학습하도록 유도하는 방식으로 모델 파라미터 수정 없이 맥락적 학습 효과를 유발한다. 본 연구에서는 실제 세종시 통행 표본 전체를 예시로 제시하여, LLM이 통행 순서·시간 패턴·공간적 경향성을 학습하도록 하였다. 이를 통해 LLM이 실데이터의 구조를 인식하고, 이에 기반한 통행을 재현할 수 있는지를 평가하였다.
Few-shot에 더해 분포·평균·왜도 등 통계 정보를 직접 계산을 통해 제공함으로써, LLM이 Few-shot을 통해 원시 데이터의 전체적 구조를 잘 이해하는지, 입력 데이터를 어떤 형태로 제공해야 하는지 차이를 비교해 보고자 하였다. 본 연구에서는 출·도착 시각, 통행시간, 체인 길이(Trip count) 등의 분포 통계(평균, 분산, 왜도, 빈도)를 프롬프트 내에 명시하여, 모델이 보다 현실적인 통행 분포를 재현할 수 있도록 하였다.
마지막으로, RAG를 활용하여 모델이 출력 생성 전, 외부 데이터베이스에서 관련 정보를 검색해 참조하도록 하는 방식을 택하였다. RAG는 LLM이 텍스트를 생성하기 전, 외부 지식 베이스로부터 관련 정보를 검색하여 입력 데이터로 활용함으로써 응답의 정확성과 사실성을 향상시키는 접근 방식이다(Gao et al., 2023). 본 연구에서는 동일한 LLM 모델 내에서 RAG 모듈을 활용해, 각 Agent와 가장 유사한 5명의 실제 사례를 검색하여 Few-shot 예시로 제공함으로써, 개인 특성 반영에 따른 통행 재현 성능을 평가하였다.
4. 통행 생성 정확도 평가
본 연구는 LLM이 생성한 통행 데이터의 정확성을 정량적으로 검증하기 위해, 원본 데이터(개인통행실태조사)와 생성 데이터 간 확률분포 유사도를 비교하였다. 정량적 평가 지표로 하나의 확률분포를 기준으로 다른 분포가 얼마나 많은 정보 손실을 가지는지를 측정하는 Kullback–Leibler Divergence(KLD) (Kullback and Leibler, 1951) 기반의 비대칭성 문제를 보완한 대칭적(symmetric) 지표인, 데이터 간 분포 비교에서 널리 사용되는 JSD를 활용하였다. JSD는 실제 데이터 분포 𝑃와 생성 데이터 분포 𝑄간의 차이를 측정하는 척도로, 0에서 1 사이의 값을 가지며 값이 0에 가까울수록 두 분포가 유사함을 의미한다. JSD는 Equation 1과 같이 정의되며 Equation 2에 정의된 두 분포의 평균 분포와 Equation 3에 나타낸 두 확률분포 간의 상대적 엔트로피를 측정하는 KLD를 기반으로 한다(Lin et al., 1991).
본 연구에서는 통행의 시간적·공간적·구조적 특성을 종합적으로 평가하기 위해, 다음 여섯 가지 항목에 대해 JSD를 산출하였다.
•Origin Address(출발지 주소, 행정동)
•Destination Address(도착지 주소, 행정동)
•Departure Time(출발 시각, 시간)
•Arrival Time(도착 시각, 시간)
•Travel Time(통행시간, 분)
•Daily Trips per Person(1인당 일일 통행 수)
•Trip Purpose(통행목적)
추가적으로, 단순 평균 분포 유사도만으로는 LLM이 분포의 양 끝단에 있는 사례들까지 잘 생성하였는지 직관적으로 확인할 수 없는 한계가 존재한다. 이를 보완하기 위하여, 전체 분포에 대한 JSD 외에도 하위 15% 및 상위 85% 분위 수 영역에 대한 부분 JSD를 산출하였다. 이는 장·단거리 통행, 비정형 출·도착 시각, 드문 활동-통행 구조 등 분포의 꼬리(tail) 영역에서의 재현도를 평가하기 위한 것으로, 생성 모델이 평균적 이동 행태 재현 말고도 표본이 적은 특수한 상황에 대한 이동 행태 재현이 가능한지에 대한 검증을 수행하였다.
분석 결과
1. 통행 생성 정확도 평가
네 가지 LLM 생성 전략(Zero-shot, Few-shot, Few-shot with statistics, RAG)을 대상으로, 대상 인원 수, 총 통행량, 그리고 1인당 평균 통행 수를 먼저 비교하였다. 모든 생성 전략은 원본 통행 데이터와 동일한 501명에 대한 인구정보를 기준으로 생성하였기에 대상 인원수는 모두 동일하며, 이를 통해 통행 생성 전략에 따른 개인 단위 통행의 차이를 직접적으로 비교할 수 있다.
LLM 생성 전략에 따른 생성 통행량을 비교한 Table 4에 따르면, 원본 통행 데이터의 경우 총 1,427회의 통행이 관측되어 1인당 평균 통행 수는 약 2.85회로 나타났다. 반면 Zero-shot 방식은 총 통행량이 2,619회로 크게 증가하여, 1인당 평균 통행 수가 약 5.23회로 나타났다. 이는 원본 대비 약 두 배 수준으로, Zero-shot 방식이 개인 단위 통행을 전반적으로 과대 생성하는 경향을 보였다. Few-shot 방식에서는 총 통행량과 평균 통행 수가 각각 1,846회, 3.68회로 감소하여 Zero-shot 대비 통행 과대 생성 현상이 일부 완화되었다. 그러나 여전히 원본 데이터 대비 높은 통행 수준을 보이며, 예시 제공만으로는 개인 단위 통행 강도를 충분히 제어하기 어렵다는 점을 확인할 수 있다. 이에 비해 Few-shot with statistics 방식과 RAG 방식은 각각 1인당 평균 통행 수가 약 2.89회와 2.97회로 나타나, 원본 데이터의 평균 통행 수준과 유사한 값을 보였다. 특히 Few-shot with statistics 방식은 총 통행량 측면에서도 원본 데이터와 거의 동일한 수준을 유지하며, 통계 정보 제공이 현실적인 통행 생성에 효과적으로 작용함을 나타낸다.
Table 4.
Descriptive statistics of daily trip generation results
Figure 2는 원본 통행 데이터와 각 LLM 생성 전략을 비교한 1인당 일일 통행 수 분포를 나타낸다. 원본 데이터의 경우 중앙값이 약 2회로 나타나며, 다수의 개인이 하루동안 적은 숫자의 통행을 수행하는 동시에 일부 통행자가 높은 빈도로 통행하는 분포 특성을 보인다. 반면 Zero-shot 방식은 중앙값이 약 5회로 상승하고 분포 전체가 상향 이동한 양상을 보이는, 개인 단위 통행 수를 전반적으로 과대 생성하는 경향이 관찰된다. 이는 외부 예시 없이 일반적인 일상 이동 패턴에 대한 사전지식만으로 개인 통행 특성을 온전히 복원하는데 한계가 있음을 보여준다. Few-shot 방식에서는 Zero-shot 대비 중앙값과 분산이 감소하여 통행 과대 생성 현상이 일부 완화되었으나, 여전히 원본 데이터 대비 높은 통행 빈도를 보여준다. Few-shot with statistics 방식의 경우 약 3회의 중앙값 수준을 보이며, 원본데이터와 더 근접한 수준을 보여준다. 그러나 사분위 범위(IQR)가 매우 좁게 형성되어, 개인 간 통행 수의 변동성이 실제보다 작게 재현되었음을 확인할 수 있다. 이에 비해 RAG 방식은 중앙값과 사분위 범위가 원본데이터와 유사하게 나타나며, 개인 단위 일일 통행 횟수를 가장 정확하게 재현했음을 확인할 수 있다.
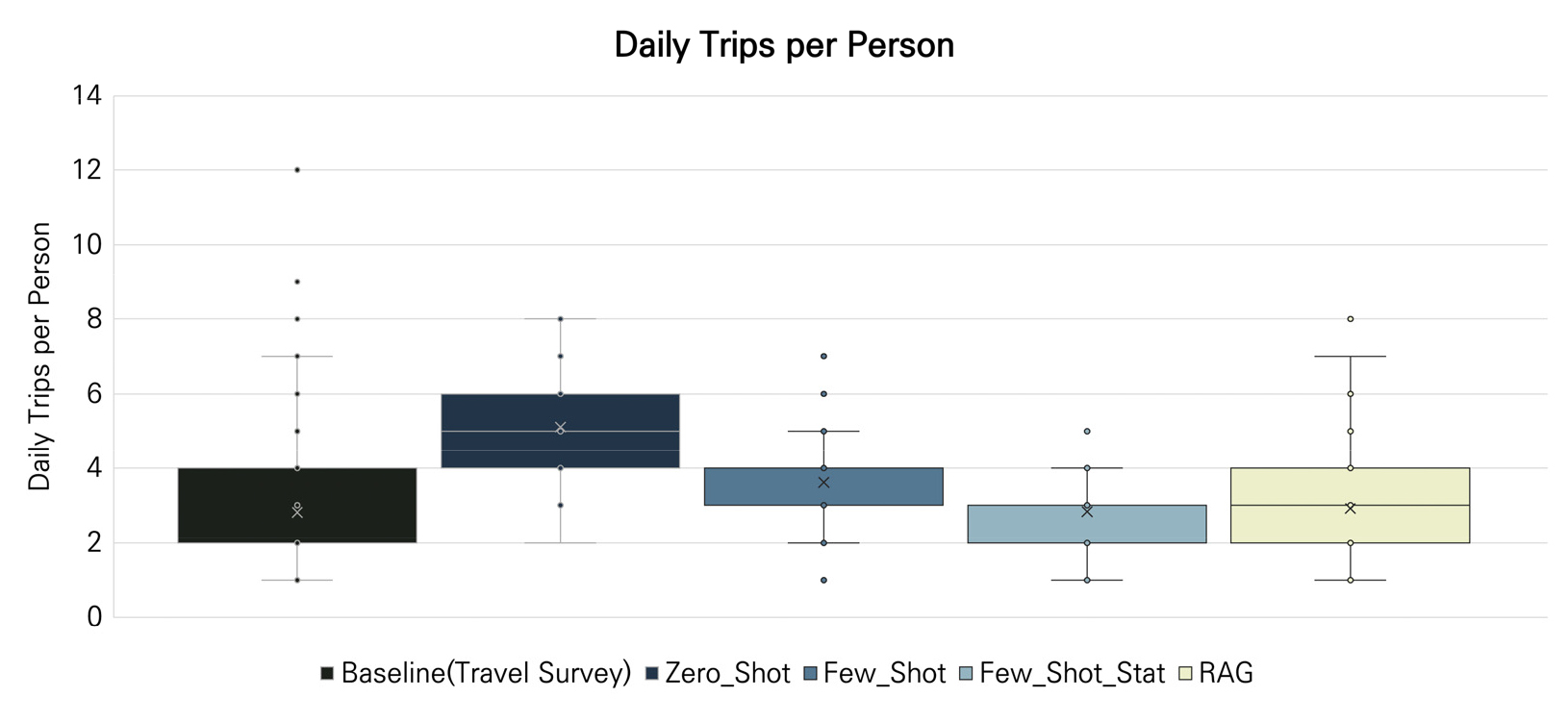
다만, 평균 통행 수나 분산과 같은 기초 통계량은 통행 생성 결과의 전반적인 경향을 파악하는 데 유용하나, 통행 데이터가 갖는 본질적인 분포 특성을 충분히 반영하는 데에는 한계가 있다. 통행 목적, 통행 수, 출발 시간 구간과 같은 주요 변수들은 연속형 정규분포를 따르기보다는, 이산적이고 범주형 특성을 갖는 다항분포의 형태를 보이는 경우가 많다. 이러한 자료에 대해 평균이나 MAE와 같은 단일 수치 기반 지표를 적용할 경우, 분포의 상대적 비중이나 형태적 차이가 충분히 반영되지 않을 수 있다. 이에 본 연구에서는 분포 전체의 유사성을 직접 비교할 수 있는 JSD를 활용하여 통행 생성 정확도를 평가하였다. JSD 값은 0~1 범위의 정량 지표이며 작은 값을 나타낼수록 원본 데이터와의 유사성을 알 수 있지만, 절대적 정확도가 아닌 분포 간 차이를 상대적으로 비교하기 위한 기수적(cardinal) 정확도 비교 지표에 해당한다. 따라서 JSD 값을 활용해 LLM의 여러 생성 전략 간 분포 재현성의 상대적 비교를 통해 각 LLM 생성 전략이 상대적으로 얼마나 실제 분포에 가까운 패턴을 생성했는지를 비교하였다.
JSD 분석 결과를 나타낸 Table 5에 따르면, Few-shot with statistics 방식과 RAG 방식이 전반적으로 0.1 미만의 JSD를 기록하며 가장 높은 분포 재현성을 보인 것으로 나타났으며. RAG 방식, Few-shot with statistics 방식, Zero-shot 방식, Few-shot 방식 순으로 높은 정확도를 기록하였다. 이는 단순 예시 제시(Few-shot)보다 통계 정보 제공(Few-shot with statistics) 또는 개인 유사 사례 기반 예시 제공(RAG)이 LLM의 통행 생성 성능 향상에 기여했음을 의미한다.
Table 5.
JSD based trip generation accuracy
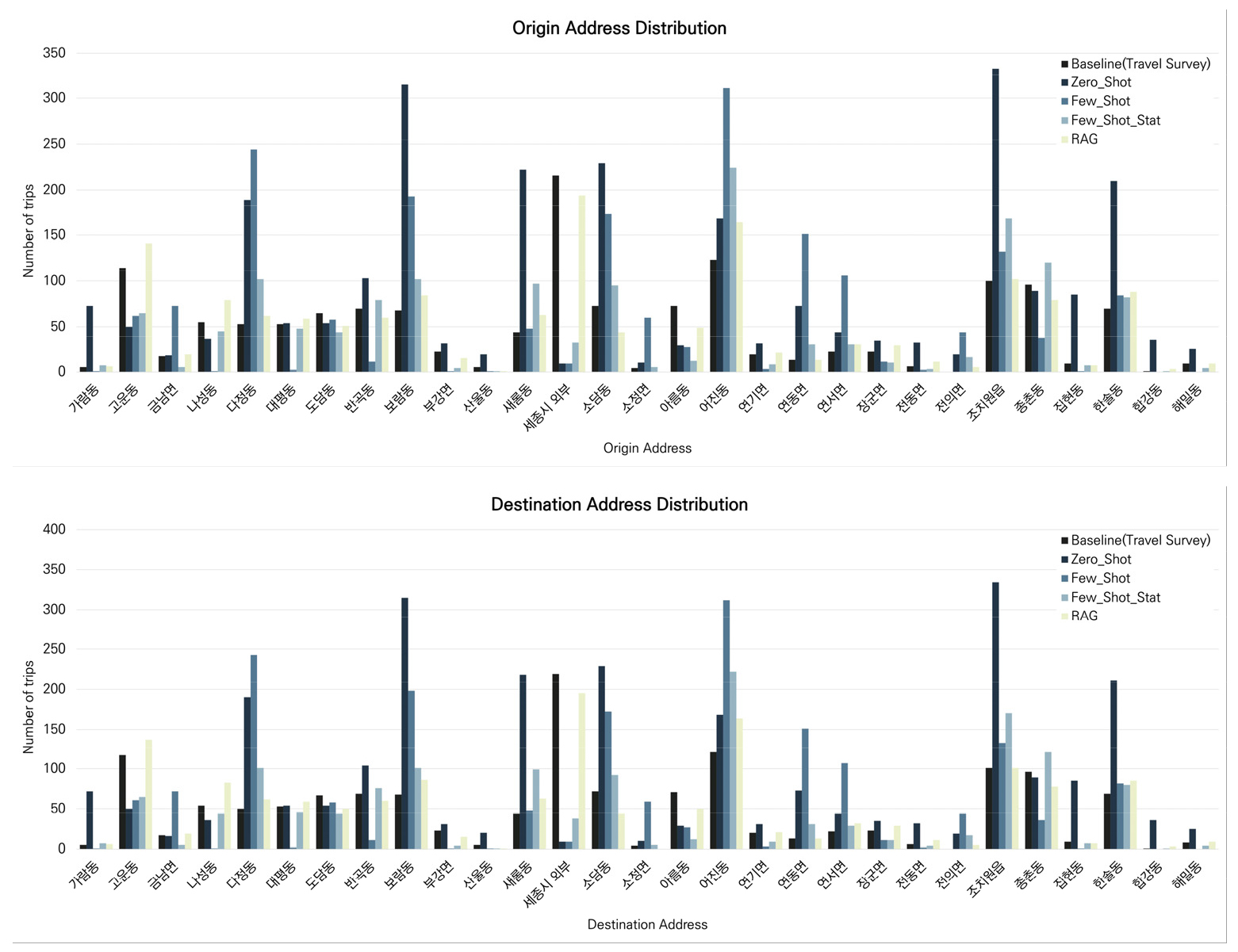
Origin Address(출발지 주소)의 경우 RAG 방식이 0.015의 JSD 값을 보이며 가장 우수한 결과를 나타내었다. 이후 Few-shot with statistics 방식이 0.096, Zero-shot 방식이 0.173, Few-shot 방식이 0.259의 JSD 값을 기록하였으며 RAG, Few-shot with statistics, Zero-shot, Few-shot 순으로 기준 데이터와의 높은 유사성을 기록하였다. Destination Address(도착지 주소) 역시 RAG 방식이 0.015의 JSD 값을 보이며 가장 우수한 결과를 나타내었으며, Few-shot with statistics 방식 0.095, Zero-shot 방식 0.175, Few-shot 방식 0.263 순으로 뒤를 이었다.
Figure 3는 Origin Address(출발지 주소) 및 Destination Address(도착지 주소) 분포를 시각화한 결과를 나타낸다. RAG 방식의 경우 전반적으로 기준 데이터의 출발지/도착지 분포와 유사한 분포를 생성했음을 확인할 수 있으며 고운동, 세종시 외부, 어진동과 같이 빈도수가 높은 지역, 가람동, 산울동, 해밀동과 같이 빈도수가 낮은 지역 모두 기준 데이터와 유사한 빈도를 나타내었다. Few-shot with statistics 방식의 경우 RAG 방식만큼 유사한 데이터를 생성하진 못하였으나, 다른 방식들에 비해 빈도수가 높거나 낮은 지역을 기준 데이터에 더 유사하게 생성하였음을 확인할 수 있다. Zero-Shot의 경우 일부 행정동의 출발 비중이 과대·과소 추정되는 경향이 뚜렷하게 나타났다. 예를 들어, 세종시 외부가 포함된 세종시 유/출입 통행에 대해서는 0에 가까운 비중으로 치우치는 큰 분포 차이를 보였으며, 이는 외부 예시 없이 사전지식만으로 지역적 통행 특성을 온전히 복원하는데 한계가 있음을 보여준다. 반면 Few-Shot 기법은 기준 데이터에 대한 전체 예시가 활용되었음에도 Zero-Shot 기법보다 좋지 않은 정확도를 나타내었다. LLM은 입력 데이터 예시를 수치적 확률분포로 해석하지 않고 자연어 형태의 서술 패턴으로 해석하기 때문에, 전체 예시가 제공되면 오히려 특정한 서술 구조나 반복되는 형태를 과도하게 학습했을 수 있다. 특히 공통적으로 자주 등장하는 단어열(특정 행정동 이름 등)을 중심으로 응답을 구성하게 만들 가능성이 있다. 이러한 점들을 고려했을 때 LLM이 전체 예시에 대한 데이터 형태 제시만으로는 통행행태의 공간적 맥락을 제대로 이해하지 못하는 것으로 파악된다.
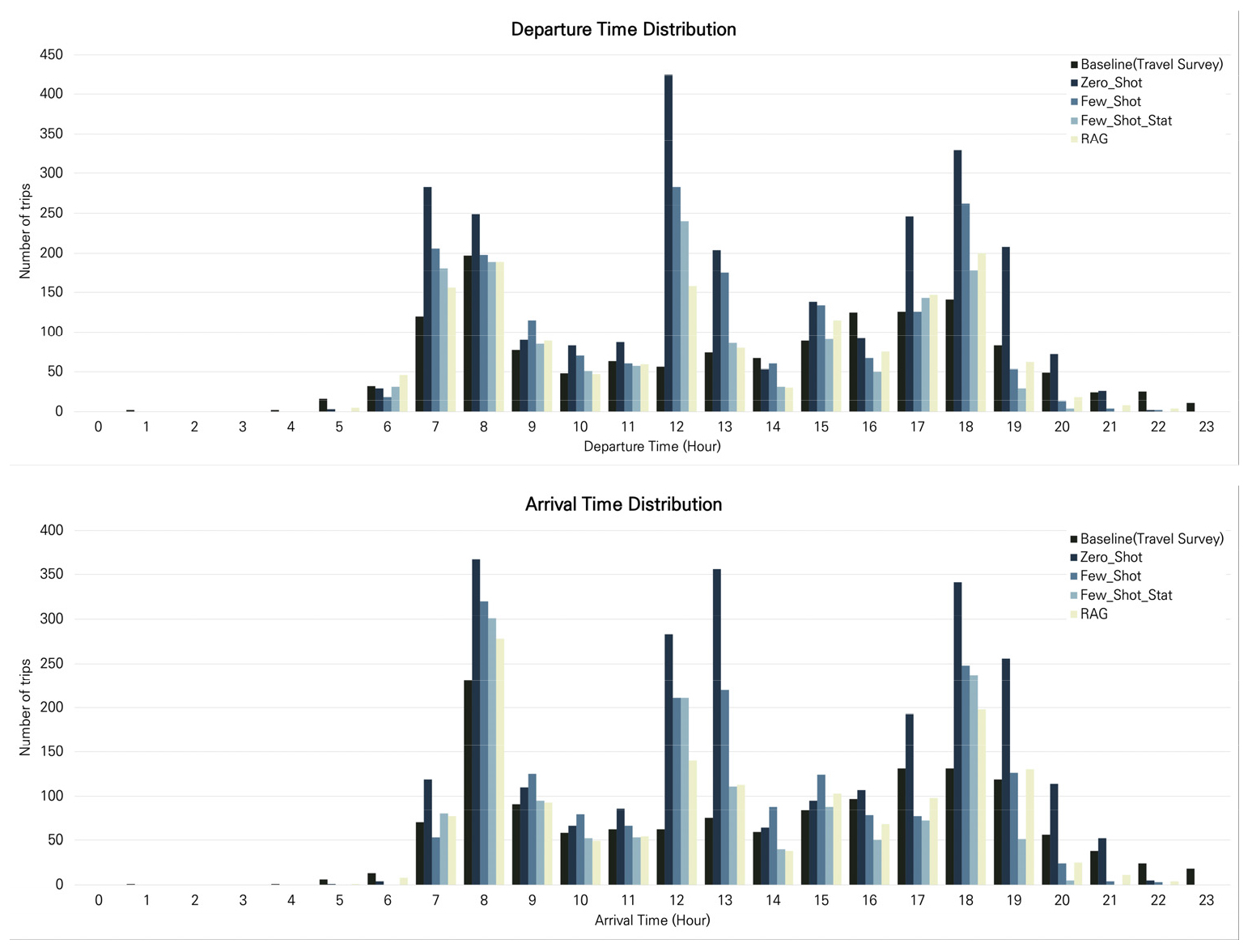
Departure Time(출발 시각)의 경우 RAG 방식이 0.042의 JSD 값을 보이며 가장 우수한 결과를 나타내었다. 이후 Zero-shot 방식이 0.070, Few-shot 방식이 0.082, Few-shot with statistics 방식이 0.093의 JSD 값을 기록하였으며 RAG, Zero-shot, Few-shot, Few-shot with statistics 순으로 기준 데이터와의 높은 유사성을 기록하였다. Arrival Time(도착 시각) 역시 RAG 방식이 0.037의 JSD 값을 보이며 가장 우수한 결과를 나타내었으며, Zero-shot 방식 0.054, Few-shot 방식 0.070, Few-shot with statistics 방식 0.098 순으로 뒤를 이었다.
Figure 4는 Departure Time(출발 시각) 및 Arrival Time(도착 시각) 분포를 시각화한 결과를 나타낸다. RAG 방식의 경우 전반적으로 기준 데이터의 출발 시각/도착 시각 분포와 유사한 분포를 생성했음을 확인할 수 있으며 빈도가 높은 7~9시 출근 시간, 17~19시 퇴근 시간 모두 기준 데이터와 유사한 빈도를 나타내었다. Zero-shot 방식의 경우 RAG 방식만큼 유사한 데이터를 생성하진 못하였으나, 다른 방식들에 비해 출퇴근 시간의 통행 패턴을 기준 데이터에 더 유사하게 생성하였음을 확인할 수 있다. 모든 모델 사용 방식에서 12시~13시 사이의 통행을 과도하게 생성하는 모습을 보였으며 이는 LLM의 사전지식에 점심시간에 발생하는 통행에 대한 부분이 내제되어 통행 생성에 반영되었을 것으로 추정된다.
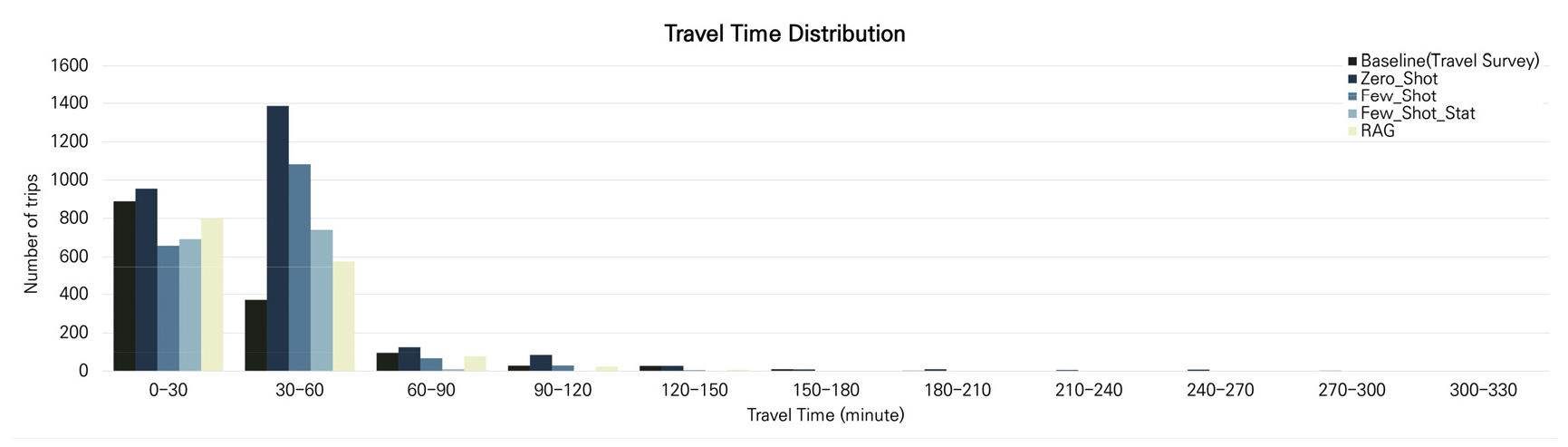
Travel Time(통행시간)의 경우 RAG 방식이 0.019의 JSD 값을 보이며 가장 우수한 결과를 나타내었다. 이후 Zero-shot 방식이 0.065, Few-shot with statistics 방식이 0.082, Few-shot 방식이 0.086의 JSD 값을 기록하였으며 RAG, Zero-shot, Few-shot with statistics, Few-shot 순으로 기준 데이터와의 높은 유사성을 기록하였다.
Figure 5는 Travel Time(통행시간) 분포를 시각화한 결과를 나타낸다. 통행시간의 경우 0~30분 사이의 시간이 소요된 빈도가 가장 높은데 RAG 방식의 경우 해당 통행시간 분포를 기준 데이터와 유사하게 생성하였음을 확인할 수 있으며 전반적으로 기준 데이터의 통행시간 분포와 유사한 분포를 생성했음을 확인할 수 있다. 모든 모델 사용 방식에서 30분~60분 사이의 통행을 과도하게 생성하는 모습을 보였으며 이는 LLM의 사전지식에 세종시 지역에서 발생하는 통행의 공간적 맥락을 고려하였을 때 30분에서 60분 사이의 통행시간이 걸릴 것이라는 부분이 내제되어 통행 생성에 반영되었을 것으로 추정된다.
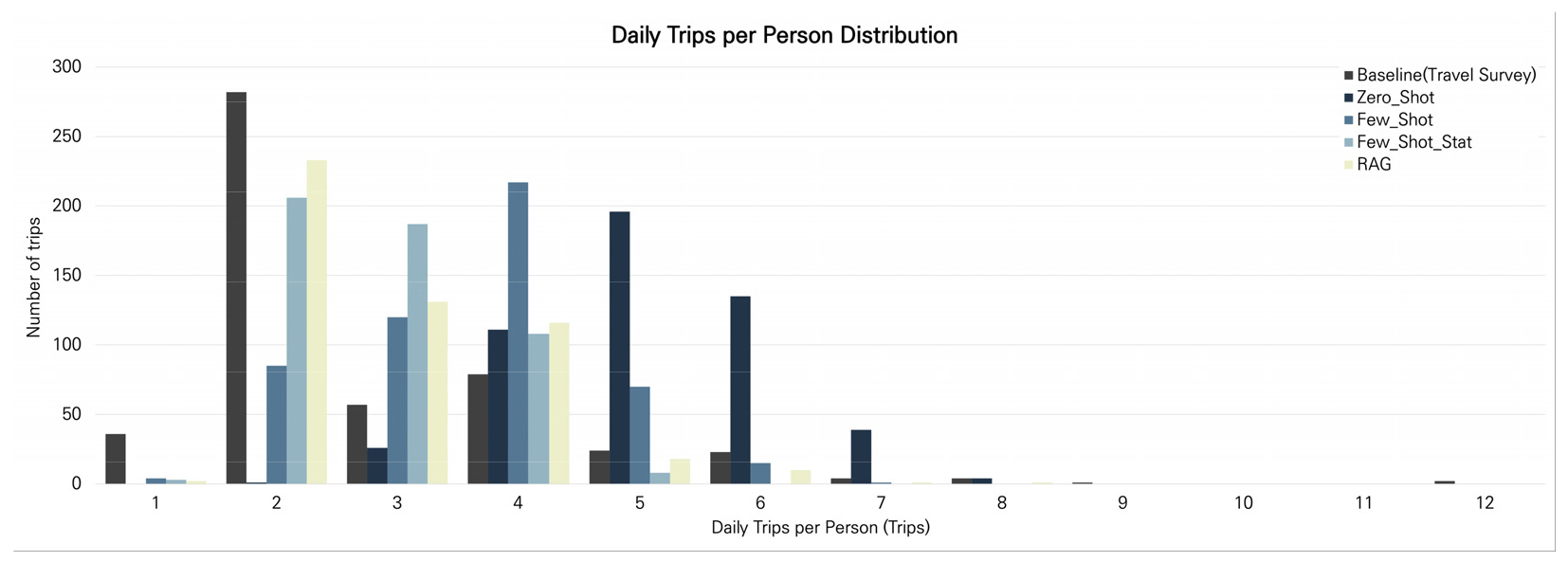
Daily Trips per Person(인당 일일 통행 횟수)의 경우 RAG 방식이 0.064의 JSD 값을 보이며 가장 우수한 결과를 나타내었다. 이후 Few-shot with statistics 방식이 0.123, Few-shot 방식이 0.190, Zero-shot 방식이 0.504의 JSD 값을 기록하였으며 RAG, Few-shot with statistics, Few-shot, Zero-shot 순으로 기준 데이터와의 높은 유사성을 기록하였다.
Figure 6는 Daily Trips per Person(인당 일일 통행 횟수) 분포를 시각화한 결과를 나타낸다. 인당 일일 통행 횟수의 경우 하루 2번의 통행한 빈도가 가장 높은데 RAG와 Few-shot with statistics 방식의 경우 해당 통행시간 분포를 기준 데이터와 유사하게 생성하였음을 확인할 수 있었다. Few-shot과 Zero-shot의 경우 분포의 형상이 Baseline과 다른 모습을 나타내며 두 방식 간 유사한 분포를 나타내었다. 두 방식 모두 실제 세종시 통행의 1인당 일일 통행 횟수를 반영했다고 보기 어려우며 그 중 Few-shot의 경우 예시 데이터를 반영해 Zero-shot보다 빈도수가 높은 2회 통행을 잘 반영한 모습을 나타내었다. Zero-shot의 경우 5~6회의 통행을 과도하게 생성하는 모습을 보였으며 이는 LLM의 사전지식에 세종시 지역에서 발생하는 통행은 1인당 5~6회의 통행이 발생할 것이라는 부분이 내제되어 통행 생성에 반영되었을 것으로 추정된다.
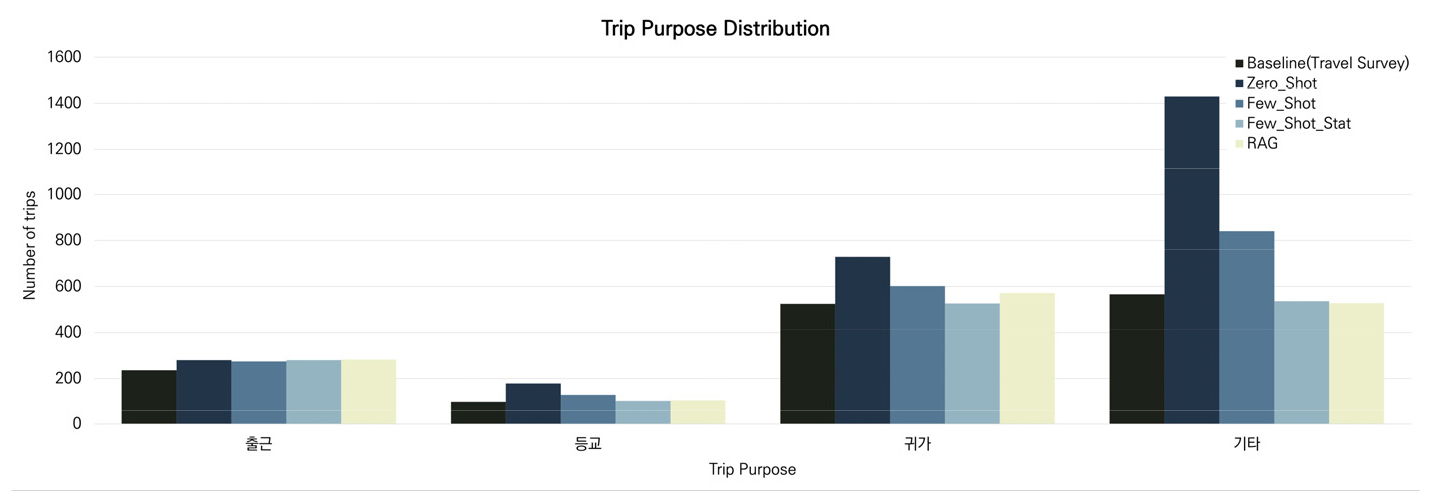
Trip Purpose(통행목적)의 경우 Few-shot with statistics 방식이 0.001의 JSD 값을 보이며 가장 우수한 결과를 나타내었다. 이후 RAG 방식이 0.002, Few-shot 방식이 0.003, Zero-shot 방식이 0.018의 JSD 값을 기록하였으며 Few-shot with statistics, RAG, Few-shot, Zero-shot 순으로 기준 데이터와의 높은 유사성을 기록하였다.
Figure 7는 Trip Purpose(통행목적) 분포를 시각화한 결과를 나타낸다. 통행목적의 경우 기타 통행의 빈도가 가장 높은데 Few-shot with statistics 방식과 RAG 방식의 경우 해당 통행시간 분포를 기준 데이터와 유사하게 생성하였음을 확인할 수 있다. 특히 Zero-shot 방식의 경우 기타 통행을 과도하게 생성하였음을 보였는데, 이는 통행목적에 대한 사전 분포 정보나 개인 특성이 프롬프트에 명시적으로 제공되지 않은 상태에서, LLM이 일반적인 일상 이동 행태에 대한 사전 지식에 의존하여 목적 분류가 불명확한 통행을 ‘기타’로 포괄적으로 생성한 결과로 추정된다. 반면, Few-shot with statistics 및 RAG 방식에서는 기준 데이터로부터 추출된 통계 정보 또는 유사 사례가 함께 제공됨으로써 통행목적 특성이 보다 명확히 반영되었고, 이에 따라 기타 통행의 과대 생성 현상이 완화된 것으로 파악된다.
2. Tail 영역 분포 정확도 평가
통행행태 데이터는 출·퇴근 시간과 같이 특정 분포에 집중되어 있어 단순히 평균적 분포의 적합도(JSD)만으로는 충분하지 않으며, 분포 양 끝 영역에서의 재현력을 별도로 검증함으로써 보다 정확한 재현 가능성 비교를 수행할 필요가 있다. 이러한 극단 영역은 실제 통행행태의 희소한 패턴을 반영하기 때문에, 모델이 인간적 이동 맥락을 얼마나 정교하게 이해하고 생성하는지를 평가하는 중요한 지표가 된다. 따라서 본 연구에서는 세종시 개인통행실태조사 원시 데이터의 하위 15% 값과 상위 15% 값을 사전에 규정하고, 해당 범위에 속하는 LLM 생성 데이터들을 비교함으로써 희귀 통행 분포에 대한 LLM 생성 정확도를 비교하였다.
Table 6과 같이 통행 분포 하위·상위 15% 구간에 해당하는 값을 기준으로 각 LLM 생성 기법별 분포 유사도(JSD)를 분석한 결과, RAG 기법이 전반적으로 가장 낮은 분포 차이를 보이며 가장 정확한 재현 성능을 보였다. 특히 시간 단위의 분석(출/도착 시각, 통행시간)에서 RAG가 높은 수준의 재현력을 보였으며 공간 단위의 분석(출/도착지, 통행 횟수)의 경우 Few-shot with statistics 방식과 RAG가 비슷한 수준으로 높은 재현력을 보여주었다. Few-shot with statistics는 기존 Few-shot보다 전반적으로 높은 재현력을 보여주었으며, 이는 LLM에 통계 정보를 제공하는 방법이 원시 데이터만 제공하는 것 보다 LLM이 실제 통행의 공간적 이해를 높이는 데 효과적이었음을 시사한다. 다음으로 Zero-shot 전략은 외부 예시 없이 사전지식만으로 통행 패턴을 생성해야 하므로, 세종시 외부와 같이 실제 분포에서 비중이 높음에도 불구하고 모델 내부 지식과 상이한 경우 분포 차이가 크게 나타났다. 이는 해당 지역에서 실제 통행 정보가 명시적으로 주어지지 않은 상태에서 모델이 일반화된 도시 이동 패턴을 재현해 현실과는 차이가 있었음을 시사한다. 한편, Few-shot의 경우 전체 예시 데이터를 그대로 제공하였음에도 Zero-shot보다 정확도가 낮게 나타났다. 예시를 단순 나열하는 방식인 Few-shot의 경우 모델에 분포 정보를 학습시키기보다는, 특정 지역명이 반복되는 패턴을 과도하게 인식하는 방향으로 작용했음을 의미한다. 따라서 동일한 데이터라도 어떤 구조로 참고 정보를 제시하는가에 따라 모델이 인식하는 맥락이 크게 달라질 수 있다.
Table 6.
JSD based areas of tails of distribution accuracy
종합적으로, 본 통행 분포 양 끝 패턴 분석 결과는 실제 개별통행을 명시적으로 제공한 RAG 방식과 예시 데이터와 통계 값을 같이 제시한 Few-shot with statistics 방식이 LLM의 통행행태 생성 정확성과 극단값 재현성을 잘 나타내었음을 시사한다. 이는 단순한 예시 제공 보다, 모델이 비슷한 구조적 맥락을 직접 찾아서 사용하도록 유도하는 RAG 설계가 실제 통행 분포의 양 끝 영역의 정확성까지 보여주는 데 더 효과적임을 의미한다.
결론 및 향후 연구과제
본 연구는 LLM의 사전 학습된 사회적·언어적 지식을 기반으로, 별도의 추가 학습 없이도 실제 개인 일일 통행 패턴(Trip Chain)을 어느 수준까지 재현할 수 있는지를 평가하였다. 세종시 개인통행실태조사 데이터를 기준으로 Zero-shot, Few-shot, Few-shot with statistics, 그리고 RAG 기반 네 가지 LLM 활용 전략을 비교하고, 각 전략이 공간적(출‧도착지), 시간적(출‧도착 시각, 통행시간), 1인당 일일 통행 횟수 분포를 얼마나 정확히 재현하는지 정량적으로 분석하였다. 실제 예시 정보 제공 방식 중 RAG 방식은 실제 데이터베이스로부터 유사 사례를 동적으로 검색하여 참조함으로써, 공간적 분포 및 시간대 패턴의 재현성 측면에서 가장 우수한 성능을 나타냈다. 통계 정보를 활용한 Few-shot with statistics 접근 역시 전체 분포 적합도와 통행 분포 양 끝 패턴 재현성 측면에서 높은 성능을 보였다. 이는 LLM이 단순한 언어적 지식뿐 아니라, 외부 정보를 구조적으로 결합하였을 때 실제 통행행태의 다양성을 효과적으로 반영할 수 있음을 보여주며 광범위한 예시를 직접 참조하는 것 보다 각 사례에 적합한 작은 규모의 예시를 LLM이 참조하는 것이 실제 예시를 LLM이 이해하는 데 도움이 됨을 확인하였다. 이를 통해, LLM은 복잡한 모형 구조나 추가 학습 절차 없이도 현실적인 통행 생성이 가능함을 확인하였다. 또한 LLM이 실제 예시 정보를 참고하는 데 있어 해당 정보들의 제공 예시를 어떻게 구성하고 어떤 형태로 제공하는지가 중요한 요소임을 확인하였다.
본 연구는 LLM이 데이터 희소 환경에서 데이터 추가 학습 없이도 활용 가능한 새로운 통행 생성 방법의 가능성이 될 수 있음을 확인하였으나 몇 가지 한계가 존재한다. 첫째, 세종시 개인통행실태조사 데이터를 활용하였으나 세종시 개인통행실태조사는 특정 시점에 수집된 제한적인 규모의 데이터로 더 큰 기간 동안의 실제 통행행태와 유사한지 검증이 필요하다. 둘째, 통행 생성에 있어 통행의 시간·공간·목적 분포를 고려하였으나, 통행수단과 통행사슬을 이루는 통행간의 연속적 흐름을 충분히 고려하지 못하였다. 셋째, 본 연구는 세종시 개인통행실태조사와 동일한 인구의 일일 통행을 재현하였으며 표본 인구에 대한 통행 생성만으로는 세종시 전체 인구의 통행을 설명할 수 없다. 따라서 향후 연구에서는 이러한 결과를 확장하여, 인구 센서스(Census) 기반의 세종시 거주 전체 인구 정보를 활용하여 세종시 전체 인구를 대상으로 한 통행 생성·검증 진행을 통해 LLM의 전수화된 통행 패턴에 대한 재현력까지 확인하고자 한다. 또한, 통행목적·수단·시간대 등을 고려한 다차원 모빌리티 지표 활용, 직장·학교 밀집 지역 제공, 주요 랜드마크 입지 정보 및 시설 접근성 등 다양한 참조 데이터 활용 등을 통해, 실제 통행행태의 맥락을 반영한 현실성 있는 도시 전체 통행 재현으로 확장해 보고자 한다.
