

서론
기존 연구 고찰 및 차별성
연구 방법
1. 데이터
2. 연구 수행 절차
3. 교통안전대체지표(SDI)
분석 결과
1. 기초 통계 및 상관 분석
2. 주행 안전성 평가 분류기
결론 및 향후 연구과제
서론
도로를 주행하는 차량은 선행 차량 또는 인접 차량과 끊임없는 상호 작용을 하며, 차량간에 발생하는 상호 작용의 결과는 차량들의 주행 안전성에 많은 영향을 미친다. 상호 작용은 주체 차량과 선행 또는 인접하는 관계에 있는 차량의 속도, 위치를 고려하여, 주체 차량의 움직임(속도, 가속도 등)을 조정하는 것을 의미한다. 따라서 차량간의 상호 작용이 원활하게 형성되어야만 차량의 주행 안전성에 대한 확보가 가능하다. 특히, 주체 차량과 동일한 차로를 주행하는 선행 차량의 움직임은 주체 차량의 움직임에 직접적인 영향을 미치므로, 주체 차량과 선행 차량의 상호 작용이 원활하게 형성하고 있는지 여부를 판단하는 것은 매우 중요하다.
차량간의 상호 작용을 평가하는 다양한 방법 중에서 교통안전대체지표(Surrogate Safety Measure, SSM)를 사용하는 것은 대표적인 평가 방법이다. Stopping Distance Index(SDI), Time to Collision(TTC)가 대표적인 교통안전대체지표이며, 각 차량들의 속도, 위치 등의 자료를 이용하여 주행 안전성을 평가한다. 특히, 이러한 교통안전대체지표를 이용하여 주행 안전성을 평가하기 위해서는 주체 차량과 상호 작용을 형성하고 있는 차량들의 주행 자료를 반드시 취득해야 한다. 최근에는 선행 차량의 주행 정보를 취득할 수 있는 기능을 보유한 차량의 보급량이 높아지고 있지만, 도로를 이용하는 모든 차량이 선행 차량의 정보를 취득할 수 있는 수준에는 다다르지 못하였다. 선행 차량의 주행 정보를 취득하지 못하는 상황에서는 주체 차량의 주행 안전성을 평가하는데 한계가 존재하므로, 주체 차량의 정보만을 이용하여 차량의 주행 안전성을 평가 할 수 있는 방법의 개발이 요구된다.
따라서 본 연구에서는 주체 차량의 주행 정보만을 이용하여 차량의 주행 안전성을 평가 할 수 있는 방법론을 개발하였다. 주체 차량과 상호 작용 하는 인접 차량을 선행 차량으로 한정하여 연구를 수행하였으며, 상충 유형을 후미 추돌로 한정하였다. 주체 차량의 주행 정보는 속도, 가속도, 차량의 위치를 사용하였으며, 특히, 가속도의 변화량을 의미하는 Jerk를 분석 변수로써 사용하여 주체 차량의 움직임을 보다 정밀하게 반영 할 수 있도록 하였다. 또한, 성별, 연령대를 고려한 20명의 피실험자가 연속류의 실도로를 주행하면서 취득한 데이터를 이용하여 분석하였다. 인접 차량 등에 의한 영향을 최소화하고 선행 차량만의 움직임을 고려하기 위하여 1차로를 주행하도록 시나리오를 구성하였으며, 인접 차로에서 1차로로 진입하거나 인접 차로로 진출하는 상황에 따라 선행 차량을 구분하여 분석하였다. 본 연구에서 사용한 교통안전대체지표는 차량 추종 관계에 있는 선행 차량과 주체 차량의 정지 거리를 비교하여 주행 안전성을 평가하는 SDI를 사용하였다. 기계 학습중 하나인 Support Vector Machine(SVM)을 위험 운전 행태를 판단하는 분류기로 사용하였으며, 피실험자의 속도, 가속도, Jerk 값을 입력 자료, SDI를 출력 자료로써 적용하였다. 또한, 본 연구에서 개발한 주체 차량의 주행 안전성을 평가하는 방법론에 사용된 분류기의 성능은 특이도, 정밀도, 재현율 및 분류 정확도를 고려하여 검증하였다.
본 연구에서 개발한 방법론은 주체 차량의 정보만을 이용하여 차량의 안전성을 평가하는 방법론을 제시했다는 점에서 연구의 의미를 가지고 있다. 또한, 주체 차량의 정보만을 이용하여 차량의 주행 안전성을 평가할 수 있는 방법론을 개발했다는 관점에서 본 연구의 결과가 유용하게 활용될 수 있을 것으로 기대된다.
기존 연구 고찰 및 차별성
본 장에서는 차량의 주행 안전성을 평가하기 위하여 사용된 교통안전대체지표, Jerk 및 기계 학습에 관한 주요 내용을 고찰하였다.
기존 연구에서는 교통사고를 유발하는 개연성이 높은 이벤트를 검출하는 교통안전대체지표로써, SDI, TTC, Acceleration Noise(AN), Deceleration Rate to Avoid the Crash(DRAC), Crash Potential Index(CPI), Deceleration-based Surrogate Safety Measure(DSSM)등을 사용하였다. SDI는 선행 및 후행 차량의 속도에 따른 정지 거리(Oh et al., 2006, 2009), TTC는 선 ‧ 후행 차량 속도, 이격 거리(Hayward, 1971; Vogel, 2003; Minderhoud and Bovym, 2011), DRAC, CPI, DSSM은 선 ‧ 후행 차량의 감속도를 이용하여 차량 간의 상충을 평가하였다(Cunto and Saccomanno, 2008; Kim et al., 2008; Cunto et al., 2009; Talebpour et al., 2014; Wu et al., 2014; Park et al., 2015; Tak et al., 2015).
또한, 주로 사용된 속도, 가속도 외에 가속도의 변화량을 의미하는 Jerk를 본 연구에서 활용하였으며, Jerk를 주행 안전성 평가에 적용한 연구를 고찰하였다. Jerk는 가속도 자체보다 더 민감하게 반응하는 변수로써, 차량의 주행 궤적과 운전자 행태를 분석하는 연구에 주로 활용되었다(Murphey et al., 2009; Bellem et al., 2016). 특히, 차량의 주행 안전성을 평가하는 방법으로써, 주행 차량의 가감속도 프로파일 및 Jerk의 프로파일을 동시에 활용하여 교통 상충을 검출하거나(Wahlberg, 2000; Othman et al., 2008; Bagdadi and Varhelyi, 2011), Peak to Peak Jerk를 이용하여 교통 상충을 검출하였다(Bagdadi, 2013). Jerk 값을 위험 운전을 판단하는 기준으로써, 시뮬레이션을 이용하여 차량의 주행 안전성을 분석하는 연구에 사용된 최대 Jerk는 2.1m/s3(Aycin and Benekohal, 2001), 실제 차량의 주행 궤적 자료를 이용한 연구에서는 감속 상황에 대한 평균 Jerk 값은 -8.0m/s3, 상충 상황시 Jerk 값은 -9.9~-12.6m/s3(Nygard, 1999)으로 제시했으며, 위험 상황을 판단하는 기준으로써 Minimum Jerk는 -7m/s3(Zaki et al., 2014), Critical Jerk는 -9m/s3(Bagdadi and Varhelyi, 2011)를 제시하였다.
본 연구에서는 기계 학습의 하나로써 많이 사용되고 있는 서포트벡터머신을 이용하여 주체 차량의 위험 운전을 평가하는 연구를 수행하였다. 기계 학습은 데이터 패턴을 자동으로 인지하여 분류하는 분석 기법으로써, 고차원의 공간에서 작은 트레이닝 세트 크기로 분류 문제를 해결하는데 적합한 지도 학습 방법이다(Vapnik, 1995; Kuhn and Johnson, 2018). SVM은 최적 분류 초평면인 결정 경계와 마진을 최대화하는 최적 가중치 파라미터(w)와 바이어스(b)를 찾아 데이터를 분류하며, Equation 1에 마진에 대한 산출식을 제시하였다.
where, : A point on the plus-plain
: A point on the minus-plain
: Constant
: Weight
마진의 최대화를 통해 초평면을 분류할 수 있으며, Equation 2에 제시한 라그랑지안 최적화 기법을 이용하면 선형 분류를 위한 최적화가 가능하다.
where, : The lagrange
: A point on plain
: A point on plain
: Constant
: Weight
: Bias
또한, 최종적으로 임의의 입력 값이 주어지는 경우, Equation 3의 판별 함수식을 이용하여 데이터를 분류한다.
where, : The optimal lagrange multiplier
: The optimal bias
: A point on plain
: A point on plain
선형 분리가 불가능한 데이터 집합의 경우는 커널 함수를 이용한다. 커널 함수는 Polynomial, Gaussian, Sigmoid 커널이 대표적이며, Equation 4에는 커널 함수를 이용한 판별 함수식을 제시하였다.
where, : The Kernel function
: Bias
: A point on plain
: A point on plain
기존 연구에서는 상호 작용 관계를 형성하는 모든 차량들의 주행 정보와 교통안전대체지표를 이용하여, 차량의 주행 안전성을 평가하였다. 그러나 현 시점에서는 주체 차량과 상호 작용 관계를 형성하고 있는 모든 차량들의 주행 정보를 취득할 수 없으므로, 교통안전대체지표를 이용하여 차량의 주행 안전성 평가하는데 한계가 존재한다. 따라서 주체 차량의 주행 정보만을 이용하여, 차량의 주행 안전성을 평가 할 수 있는 방법론을 개발했다는 점에서 기존 연구와의 차별성이 있다. 또한, 기존 연구에서는 차량의 감속 상황에 한정하여 차량의 주행 안전성을 평가하는데 Jerk를 사용하였지만, 본 연구에서는 모든 주행 상황에서 차량의 움직임을 분석하였으며, 이를 이용한 주행 안전성 평가 방법론을 개발했다는 점에서 기존 연구와의 차별성이 존재한다.
연구 방법
1. 데이터
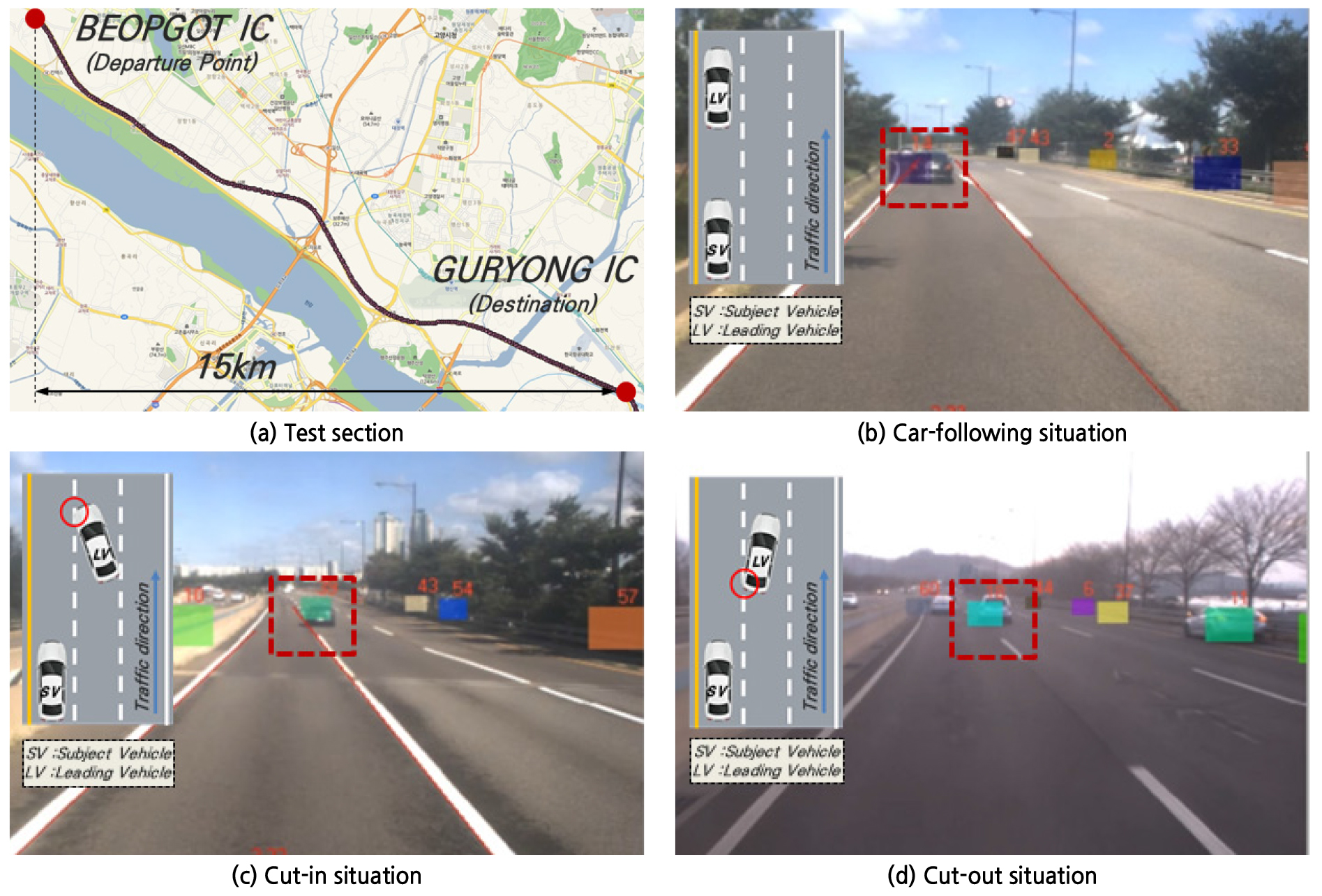
본 연구에서는 신호에 의한 지정체가 발생하지 않는 연속류 일부 구간(법곶 IC-구룡 사거리, 약 15km)을 분석 구간으로 선정하였다. 분석 구간의 제한 속도는 80km/h, 차로 수는 왕복 6차로이며, 3년간의 평균 교통량은 오전 3,137대/시, 오후 1,616대/시로 조사되었다.
성별(남, 여), 연령(20대, 30대, 40대), 운전 경력(1년 이상)을 고려하여 20명의 피실험자를 선정하였으며, 평소 주행 습관을 유지하여 분석 구간을 주행하도록 하였다. 주행 시간대는 오전 첨두시(7-9시)와 오후 비첨두시(13-17시)로 구분하여 피실험자의 주행 데이터를 취득하였다. 또한, 선행 차량의 움직임에 따른 주체 차량의 주행 안전성을 평가하기 위하여, 피실험자에게는 차로 변경을 하지 않고 1차로만을 주행하도록 하였다.
피실험자가 탑승한 주체 차량에는 주체 차량, 선행 차량 정보를 취득 할 수 있는 GPS(Global Positioning System)-IMU(Inertial Measurement Unit), 레이더 센서 등이 부착되어 있으며, 주체 차량의 속도, 위치 정보는 GPS-IMU, 선행 차량의 속도 및 위치는 레이더에서 수집되는 자료를 사용하였다.
주체 차량에 영향을 주는 인접 차량은 주체 차량과 추종 관계를 유지하고 있는 선행 차량으로 한정하였다. 특히, 본 연구에서 정의한 선행 차량은 주체 차량과 동일 차로를 주행하고 진행 방향과 가장 가까운 거리에 있는 차량만으로써, 레이더 센서의 물리적 검지 범위에 존재하는 차량을 의미한다. 또한, 인접 차로를 주행하는 인접 차량이 1차로로 진입하는 경우에는 인접 차량의 앞범퍼가 1차선을 통과하는 최초 순간, 인접 차로로 진출하는 경우에는 선행 차량의 뒷범퍼가 1차선을 진출하는 마지막 순간까지를 선행 차량으로 설정하였다. Figure 1에는 본 연구의 대상 구간 및 주체 차량과 선행 차량의 주행 데이터를 수집하고 있는 상황에 대한 사례를 제시하였다.
2. 연구 수행 절차
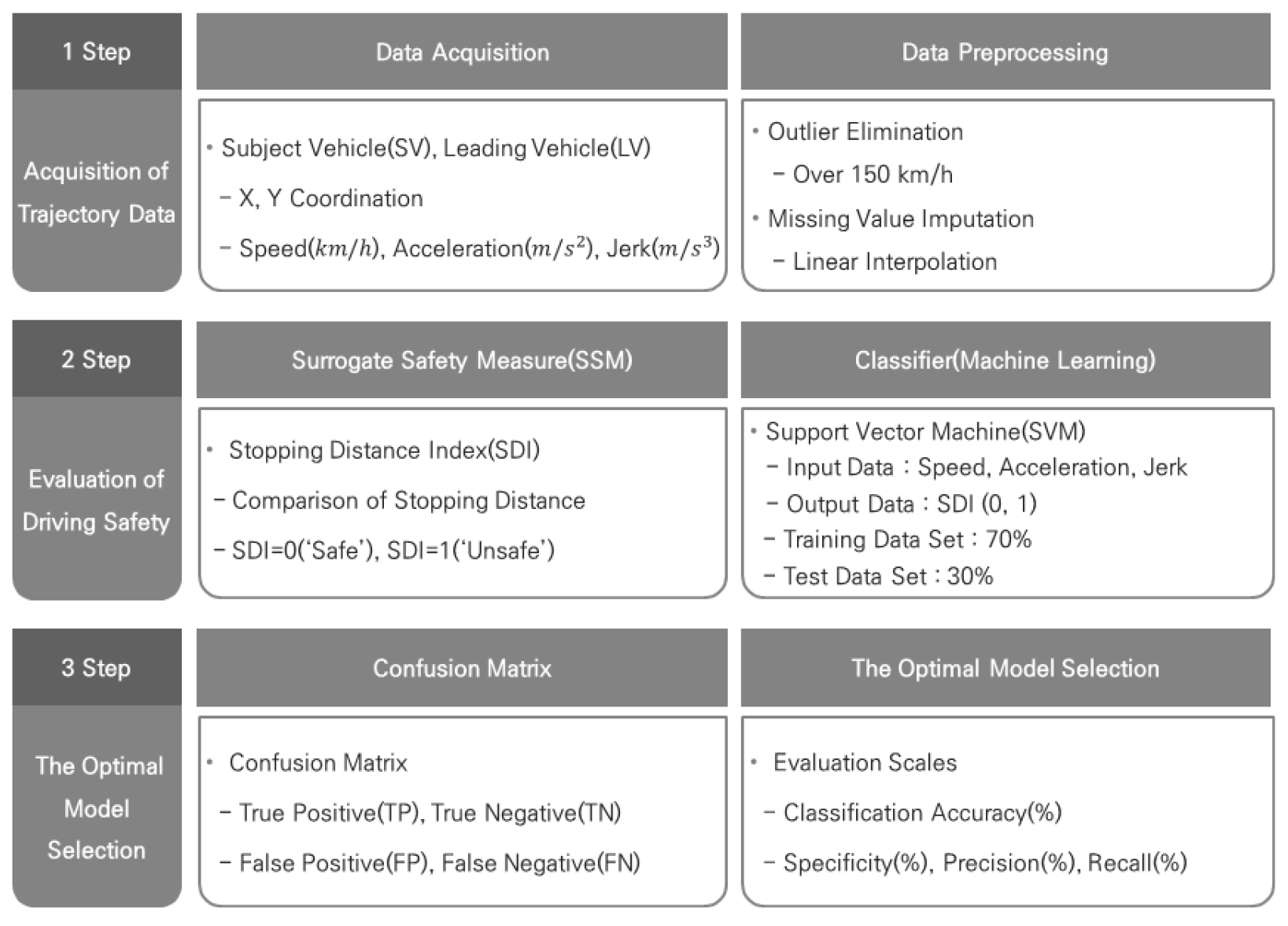
주체 차량의 주행 정보만을 이용하여 주행 안전성을 평가하는 방법론의 개발은 3단계로 구분하여 수행하였다.
1단계는 주체 차량 및 선행 차량의 데이터를 취득하는 단계이다. 주체 차량에 부착된 레이더, GPS-IMU 센서를 이용하여 주체 차량 및 선행 차량의 주행 정보를 수집하였다. 레이더와 GPS-IMU에서 수집된 데이터를 이용했으며, 수신기 자체에서 발생하는 결측치를 보정하기 위하여 1초 단위로 데이터를 집계화하여 분석에 사용하였다. 2단계는 차량의 주행 정보와 교통안전대체지표를 이용하여 주체 차량의 주행 안전성을 판단하는 단계이다. 주체 차량의 위험 운전을 판단하는 분류기는 서포트벡터머신을 사용하였으며, 피실험자를 통해 수집한 주행 데이터를 학습 데이터 집단(70%)과 평가 데이터 집단(30%)으로 구분하여 적용하였다. 또한, 입력 자료는 주체 차량의 속도, 가속도, Jerk, 출력 자료는 SDI를 이용하여 판단된 결과를 사용하였다. 3단계는 본 연구에서 개발한 분류기의 예측 성능을 평가하고, 차량의 주행 안전성을 평가할 수 있는 최적 모형을 선정하는 단계이다. 분류기에서 도출된 오차 행렬은 True Positive(TP), True Negative(TN), False Negative(FN), False Positive(FP)로 구분 될 수 있다. TP는 실제 안전한 상황을 안전하다고 예측한 케이스, TN은 실제 위험한 상황을 위험하다고 예측한 케이스를 의미한다. FN은 실제 안전한 상황을 위험한 상황으로 예측한 케이스, FP는 실제 위험한 상황을 안전한 상황으로 예측한 케이스를 의미한다. 본 연구에서는 이러한 평가 지표를 종합적으로 고려하여, 주체 차량의 주행 안전성을 평가 할 수 있는 방법론에 대한 검증을 수행하였다. Figure 2에는 본 연구의 연구 수행 절차를 제시하였다.
3. 교통안전대체지표(SDI)
주체 차량의 주행 안전성을 평가하는 교통안전대체지표로써 SDI를 사용하였다. SDI는 선행 차량 및 주체 차량의 속도, 가속도를 이용하여 차량의 정지 거리를 산출하고, 두 차량의 정지 거리를 비교함으로써 주행 안전성을 안전한 상황과 위험한 상황으로 평가한다. 후행 차량의 정지 거리가 선행 차량의 정지 거리보다 길게 나타나는 상황에서는 t초 후에 후미 추돌 사고가 발생하므로, 차량의 주행 안전성이 위험한 상황으로 평가될 수 있다. SDI의 산출에 필요한 인지반응시간 및 차량 길이는 운전자 반응 시간(2.5초)과 소형자동차(4.7m) 기준을 적용하였으며(MLTM, 2020), Equation 5에 SDI의 산출 식을 제시하였다.
where, : Speed of leading vehicle (km/h)
: Speed of subject vehicle (km/h)
: Acceleration of leading vehicle (m/s2)
: Acceleration of subject vehicle (m/s2)
: Stopping distance of leading vehicle (m)
: Stopping distance of subject vehicle (m)
: Perception and reaction time (2.5s)
: Vehicle length (4.7m)
: Headway (s)
분석 결과
1. 기초 통계 및 상관 분석
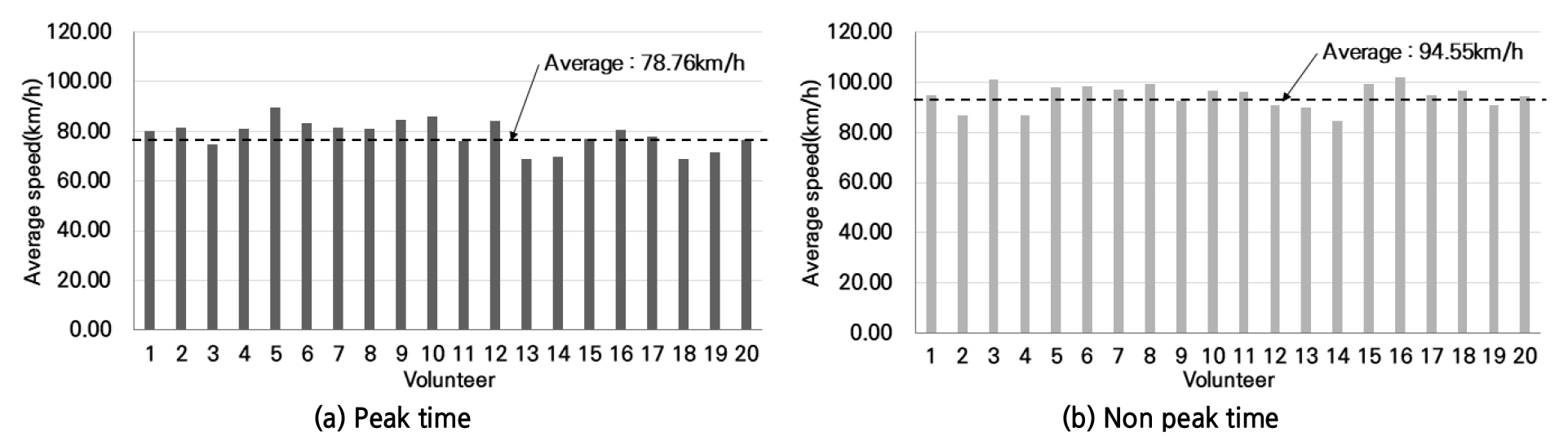
주체 차량과 선행 차량의 속도, 가속도, Jerk에 대한 기초 통계 분석을 수행하였다. 20명의 피실험자의 오전 시간대의 평균 속도는 78.76km/h, 오후 시간대의 평균 속도는 94.55km/h로 나타났으며, Figure 3에 결과를 제시하였다.
선행 차량과 피실험자가 주행한 주체 차량의 주행 평균 속도는 선행 차량 66.96km/h, 주체 차량 66.19km/h, 평균 가속도는 선행 차량 -0.39m/s2, 주체 차량 -0.50m/s2, 평균 Jerk는 선행 차량 -0.09m/s3, 주체 차량 -0.17m/s3로 나타났으며, Table 1에 결과를 제시하였다.
Table 1.
Result of descriptive statistics
선행 차량의 움직임이 주체 차량의 움직임에 영향을 미치는 정도를 분석하기 위하여 피어슨 상관 분석을 수행하였으며, 이격 거리, Headway, 상대 속도를 추가적으로 분석하였다. 분석 결과, 유의 확률 0.05 이하에서 주체 차량의 속도, 가속도, Jerk는 선행 차량의 속도, 가속도, Jerk 및 Headway, 상대 속도와의 상관성이 높게 나타났으며, Table 2에는 주체 차량 및 선행 차량의 주행 정보를 이용한 피어슨 상관 분석 결과를 제시하였다.
Table 2.
Result of correlation analysis
2. 주행 안전성 평가 분류기
주체 차량의 주행 안전성을 평가하는 방법론에 사용되는 분류기로써, 기존 데이터를 학습하여 새로운 데이터를 추가하였을 때, 데이터를 구분하는데 유리한 서포트벡터머신을 사용하였다. 서포트벡터머신에 사용된 입력 자료에는 선행 차량의 움직임과 상관성이 높은 것으로 나타난 주체 차량의 속도, 가속도, Jerk, 출력 자료에는 SDI를 사용하여 평가하였다.
20명의 피실험자를 통해 수집된 주행 데이터 중에서 이상치와 결측치를 제외한 데이터는 7,926개를 분석에 사용하였으며, 최종 데이터를 학습 데이터 집단(70%, 5,549개)과 평가 데이터 집단(30%, 2,377개)으로 구분하였다. 최적 모형 선정을 위한 최대 학습 횟수는 100회로 설정하였으며, 분류기 선정에 사용된 학습 데이터 및 평가 데이터는 무작위로 선정하였다. Table 3에는 주행 안전성 평가를 위한 데이터 구성을 제시하였다.
Table 3.
Data composition
| Total | SDI=0 (‘Safe’) | SDI=1 (‘Unsafe’) | |
| Total data set | 7,926 | 4,218 | 3,708 |
| Test data set | 2,377 | 1,265 | 1,112 |
| Train data set | 5,549 | 2,953 | 2,596 |
주행 안전성 평가 방법론에 사용된 분류기에 사용된 커널 함수는 Sigmoid Function, Gaussian Function, Polynomial Function을 검토하였으며, Gaussian Function이 최적의 커널 함수로써 선정되었다. 분석 데이터의 경계를 선정하는 Box Constraint는 88.8497, 커널의 행렬 계산을 위한 Kernel Scale은 4.9388로 나타났다. Gaussian Function에 포함되는 μ는 66.8842(속도), -0.3907(가속도), -0.0944(Jerk), σ는 36.3184(속도), 0.4182(가속도), 0.4647(Jerk)로 도출되었다. 또한, 최적 모형 구성을 위한 학습 횟수가 50회 이상인 경우에는 최소 목적 값의 변화가 없는 것으로 나타나므로, 100회 이상의 학습 횟수는 주행 안전성 평가 분류기의 성능 향상과 무관한 것으로 판단하였다. 또한, 주행 안전성 평가 분류기를 이용하여 나타난 속도, 가속도, Jerk의 예측 값과 참 값을 평균, 최대, 최소로 구분하여 비교한 결과를 Table 4에 제시하였다.
Table 4.
Comparison of the true value and the predicted value
주행 안전성 평가 분류기를 이용하여 나타난 오차 행렬과 분류 정확도, 특이도, 정밀도, 재현율을 산출한 결과를 Table 5에 제시하였다.
Table 5.
Confusion matrix
실제 주행 데이터가 안전한 상황으로 판단된 데이터 중에서 안전한 상황으로 예측된 데이터(TP)의 개수는 777개, 실제 주행 데이터가 위험한 상황으로 판단된 데이터 중에서, 위험한 상황으로 예측된 데이터(TN)의 개수는 1,126개로 나타났다. 또한, 분류기의 예측 성능을 나타내는 분류 정확도는 80.1%로 나타났으며, 특이도는 89.0%, 정밀도는 84.8%, 재현율은 69.9%로 나타났다.
도로의 돌발 상황 발생 또는 교통 사고 발생시 사고 심각도를 판단하거나 예측하는 연구에서 서포트벡터머신이 사용되었다. 특히, 기존의 유사 연구(Xiao and Liu, 2012)에서도 분류기의 성능이 80% 이상을 확보한 경우에는 분류기로써 의미를 가진다는 결론을 제시하였다. 따라서 기존의 연구 결과로써 제시한 분류 정확도의 성능과 비교시, 본 연구에서 개발한 주행 안전성 평가 방법론 및 주행 안전성 평가 분류기는 적절한 예측 성능을 확보한 것으로 판단이 가능하다.
결론 및 향후 연구과제
도로를 주행하는 차량은 인접 차량과의 상호 작용을 통해 차량의 주행 안전성을 확보 한다. 상호 작용을 이루고 있는 차량들의 안전성을 판단하는 방법에는 교통안전대체지표를 이용하는 방법이 대표적이다. 교통안전대체지표 사용을 위한 전제 조건은 상호 작용을 형성하고 있는 모든 차량의 주행 정보를 사전에 취득하고 있는 것이다. 그러나 실제 주행환경에서 모든 차량의 주행 정보를 수집하는 것은 한계가 존재하므로, 주체 차량의 정보만을 이용하여 차량의 주행 안전성을 평가할 수 있는 방법론의 개발이 요구된다.
본 연구에서는 주체 차량의 정보만을 이용하여, 차량의 안전성을 평가할 수 있는 방법론을 개발하는 연구를 수행하였다. 센서가 부착된 차량에서 수집된 실제 주행 데이터를 분석했으며, 속도, 가속도 및 가속도의 변화량을 의미하는 Jerk를 변수로써 사용하였다. 또한, 차량간의 정지 거리를 이용하여 주행 안전성을 평가하는 SDI를 주행 안전성을 평가하는 변수로써 선정하였으며, 주행 안전성을 평가하는 분류기로는 서포트벡터머신을 사용하였다. 본 연구에서 개발한 주행 안전성 평가 분류기의 분류 정확도는 80.1%로 나타났으며, 특이도는 89.0%, 정밀도는 84.8%, 재현율은 69.9%로 나타났다.
본 연구에서 제시한 연구 결과의 한계점을 보완하기 위하여 요구되는 향후 연구 내용은 다음과 같다.
첫째, 주행 안전성 평가 분류기에 입력 자료로써 사용된 피실험자의 주행 데이터에 대한 다양성이 확보되어야 한다. 연속류 도로에서 수집된 주행 데이터만을 사용했기 때문에, 교차로와 같이 신호의 영향이 존재하는 구간을 주행하거나, 유출입에 영향을 많이 받는 2차로, 3차로를 주행하는 경우는 본 연구의 결과에 대한 활용성이 낮을 것으로 예상된다. 또한, 피실험자의 구성이 전체 운전자의 운전 성향을 대표하기에는 한계가 존재한다. 따라서 단속류를 포함한 다양한 구간을 주행한 피실험자의 주행 데이터가 수집되어야하며, 운전자의 인적 특성을 다양화하여 본 연구에서 개발한 주행 안전성 평가 방법론에 대한 활용성을 높일 수 있도록 해야 한다. 둘째, 주체 차량과 상호 작용을 형성하는 차량을 선행 차량으로만 한정하여 분석하였다. 그러나 주체 차량과 동일한 차로를 주행하는 선행 차량뿐만 아니라, 인접한 차로를 주행하는 차량들도 주체 차량의 움직임에 많은 영향을 미친다. 따라서 주체 차량과 상호 작용을 형성하는 모든 차량들의 주행 데이터를 수집하고 분석함으로써, 주체 차량에 인접하여 발생할 수 있는 모든 상충 상황을 종합적으로 평가할 수 있도록 해야 한다. 셋째, 주체 차량의 주행 안전성을 평가하는 분류기의 예측 성능을 향상 시켜야 한다. 주행 안전성 평가 분류기로써 서포트벡터머신을 사용하였으나, 기계 학습에는 의사결정나무, 뉴럴네트워크 등이 존재한다. 또한, 교통안전대체지표로써 정지 거리를 비교하는 SDI만을 사용했으나, 충돌 시간을 계산하여 상충을 평가하는 TTC 등도 존재한다. 따라서 분류기 및 교통안전대체지표의 종류를 다양하게 검토해야 하며, 입력 자료 및 출력 자료의 구성도 변화시켜, 분류기의 예측 성능을 향상 시킬 수 있도록 해야한다. 넷째, 사업용 차량 운전자의 위험운전행동을 정의한 11가지 지표(Ministry of Land, Infrastructure and Transport, 2013)와 같이, 본 연구의 결과가 위험 상황을 정의하는 지표로써 활용될 수 있도록 추가적인 연구가 수행되어야 한다. 본 연구에서는 주행 차량의 정보만을 이용하여 차량의 주행 안전성을 평가할 수 있는 방법론을 제시하였다. 그러나 실제 상충 상황을 대표할 수 있는 데이터에 대한 분석이 충분하지 않으며, 본 연구 방법론에 의해 위험하다고 판단된 상황 및 구간 등에 대한 검증이 충분치 않은 한계가 존재한다. 따라서 이러한 한계를 극복할 수 있는 추가 연구를 수행하여, 본 연구의 결과가 주행 안전성을 평가할 수 있는 객관적인 지표로써 활용될 수 있도록 해야한다.
본 연구의 결과는 주체 차량의 주행 정보만을 활용하여 차량의 주행 안전성을 평가하는 방법론을 제시했다는 점에서 연구의 의의가 있다. 또한, 차량 센서에서 수집된 주행 자료를 이용하여 주행 안전성을 평가할 수 있는 기초 연구로써 활용될 수 있을 것으로 기대된다.
