

서론
선행연구
1. 운전면허시험 제도 변화와 그 효과에 대한 실증적 검토
2. 운전면허 학과시험 문항의 구성과 특성 분석
3. 선행연구와 차별성
연구 방법
1. 연구 분석 절차
2. 자료 수집 및 가공
3. 분류 체계 정의
4. LLM 기반 문항 분류 및 전문가 검증 절차
5. 문항 특성에 따른 수행 차이 분석
6. 연령집단 간 성취 격차의 정량적 평가
분석 결과
1. 문제 분류 결과
2. 인지 수준 및 내용 영역에 따른 정답률 차이 분석
3. 인지 수준 및 내용 영역에 따른 연령 집단 간 차이 분석(Cohen’s 𝒉)
결론
서론
자동차 운전면허 학과시험은 운전자가 도로에서 준수해야 할 교통법규와 안전운전 지식을 평가하는 중요한 제도적 장치이다(Lee and Son, 2025). 이 시험은 운전면허 취득 과정의 첫 단계로서, 응시자의 실제 운전 능력 평가에 앞서 기본적인 규범과 안전 지식을 체계적으로 학습하도록 설계되어 있다. 우리나라는 운전면허 보유율이 높은 국가로, 그 첫 단계인 학과시험은 국민 대다수가 경험하는 대표적인 국가 수준의 평가 절차이며, 그 결과는 교통사고율, 보험 제도, 사회적 안전 비용 등 다양한 사회적 지표와 밀접하게 연관된다. 특히 교통사고의 약 95%가 운전자 등 인적 요인에서 기인한다는 연구 결과(Baik, 2018; Lee, 2019)를 고려할 때, 법규 지식과 준법 의식을 갖춘 신규 운전자를 배출하는 과정으로서 학과시험의 중요성은 더욱 강조된다.
우리나라 운전면허시험 제도는 시대적 요구와 교통안전 여건의 변화에 따라 여러 차례 개편되었다. 특히 2010~2011년에는 응시자의 부담을 경감하고 면허 취득 절차를 간소화하는 정책이 시행되었다. 이러한 간소화 조치는 면허 취득 기간과 난이도를 크게 완화하여 국민의 부담을 경감하는 효과가 있었으나, 시험의 난이도와 변별력의 저하로 인해 교통안전에 부정적 영향을 미쳤다는 평가가 다수 제기되었다(Lee et al., 2020). 이에 정부는 2016년 말부터 면허시험을 전면적으로 강화하였으며, 특히 학과시험 문제은행 문항 수를 730문항에서 1,000문항으로 확대하고, 학과시험 문항에 사진·일러스트 형식을 추가하였으며, 위험인지 등 상황 판단 능력을 평가하는 내용을 강화하였다. 강화된 시험은 문제은행 문항 수를 늘리고, 다양한 문제 유형을 추가했다는 점에서 과거의 간소화된 시험과 구별되지만, 실제 운전에 필요한 지식 및 능력을 충분히 평가하고 있는지는 여전히 검토가 필요한 과제로 남아 있다.
현행 운전면허 학과시험은 한국도로교통공단이 공개한 문제은행을 기반으로 하는 객관식 평가 방식으로, 교통법규, 안전운전 지식, 자동차 구조 및 관리 등 다양한 영역의 내용을 대·중·소분류 체계에 따라 구분하여 출제한다. 그러나 실제로는 공개된 문제은행을 일부 암기하는 것만으로도 합격이 가능하다는 인식이 확산되어 있으며, 이로 인해 수험자가 교통법규를 심층적으로 이해하지 않은 채 피상적인 학습으로도 시험을 통과할 수 있다는 한계가 지적된다(Baik, 2018). 이러한 점에서 현행 학과시험은 운전에 필요한 실질적인 역량을 충분히 평가하지 못한다는 비판을 받고 있다. 따라서 학과시험의 타당성을 제고하기 위해서는 단순 암기 또는 구체적인 교통법규 지식 없이 풀이 가능한 문항 구성에서 벗어나, 복합적 사고와 상황 판단 능력을 요구하는 평가체계로의 전환이 필요하다. 실제로, 운전자의 안전 운전 능력은 다양한 주행 맥락을 해석하고 적절한 대응을 선택하는 인지적 판단 능력이 핵심 요소임을 알 수 있다. 이러한 관점에서 국제 운전면허 제도 또한 위험인지(hazard perception)와 상황 판단(situation judgment)을 독립된 평가 영역으로 포함하고 있으며(EU Directive 2006/126/EC), 이는 학과시험이 단순 지식 평가를 넘어 실제 운전 수행과 직결되는 인지 능력을 일정 수준 평가할 필요성을 시사한다. 따라서 학과시험의 타당성을 높이기 위해서는 규칙 기반 문항 중심의 평가를 보완하고, 실제 교통상황에서 요구되는 사고 과정과 위험 인지 능력을 반영한 문항 체계를 구축하는 것이 필요하다(Krathwohl, 2002; Fraade-Blanar et al., 2018).
현행 학과시험이 실제로 어떠한 인지 능력을 어느 수준에서 평가하고 있는지, 그리고 이러한 평가 요구가 연령별 인지 특성과 얼마나 정합적인지에 대해서는 명확히 규명되지 않았다. 이러한 한계는 인구 고령화로 인해 교통안전의 불확실성이 증가하는 현시점에서 더욱 중요한 문제로 부각된다. 국제 운전면허 제도(EU Directive 2006/126/EC)가 위험인지(hazard perception)와 상황판단(situation judgment)을 독립된 핵심 평가 영역으로 규정하고 있듯, 실제 운전 수행은 단순 지식 재생을 넘어 다양한 정보를 통합하여 적절한 판단을 내리는 고차 인지 능력을 요구한다. 관련 선행연구는 연령 증가가 이러한 인지 능력에 구조적 변화를 초래함을 반복적으로 보고해 왔다. Salthouse(2019)는 중년 이후 정보 비교와 추론·통합 능력이 비선형적으로 저하된다고 밝힌 바 있으며, Lee et al.(2018)과 Depestele et al.(2020) 또한 고령자의 주의전환력 및 집행기능(executive function) 약화가 차로 유지 실패나 충돌 회피 실패 등 실제 운전 수행 저하로 직결될 수 있음을 제시하였다. 문제는 현행 학과시험이 이러한 연령별 인지 특성을 적절히 반영하도록 설계되었는지가 명확히 검증되지 않았다는 점이다. 만약 시험 문항이 단순 암기 중심으로 구성되어 있거나, 실제 운전 능력과 무관한 인지 부담을 과도하게 요구한다면 이는 고령자의 실제 위험성을 과소평가하거나, 반대로 불필요한 진입 장벽을 야기할 가능성이 있다. 따라서 시험 문항이 요구하는 인지적 복잡성(cognitive complexity)을 체계적으로 분석하고, 그것이 연령대별 수행과 어떤 방식으로 상호작용하는지 규명하는 연구가 필요하다.
이러한 문제의식에도 불구하고, 기존 연구들은 주로 제도 변화 전후의 합격률이나 사고율 같은 거시적 성과 지표 분석(Yoo and Jo, 2020; Lee et al., 2020)에 집중해 왔으며, 문항 자체에 대한 분석 역시 언어적 편향성이나 형식적 구조를 파악하는 수준(Lee and Son, 2025; Kim and Lee, 2025)에 머물러 왔다. 실제로 1,000문항에 달하는 방대한 문제은행의 특성상, 문항 전수에 대해 응시자가 거쳐야 할 인지적 사고 과정(cognitive process)을 체계적으로 분류하고 검증한 연구는 부족한 실정이다. 본 연구는 이러한 공백을 보완하기 위해 대규모 언어모델(Large Language Model, LLM)의 자동 분류 역량과 출제위원의 전문 판단(Human-in-the-loop)을 결합한 하이브리드 문항 분류 체계를 제안한다. 구체적으로, 교육학적 인지 목표 분류인 SOLO(Structure of Observed Learning Outcomes)와 교통공학적 운전 역량 영역을 통합한 이중 분류 프레임워크를 적용하여 문항 전수에 대한 인지 수준과 내용 영역을 구조화하였다. 이는 전통적 수작업 분석으로는 사실상 불가능했던 대규모 문항의 체계적 분석을 가능하게 하고, 향후 AI 기반의 지능형 문항관리 시스템으로 확장될 수 있는 기반을 마련한다는 점에서 방법론적 의의가 있다.
본 연구의 궁극적 목적은 구축된 문항 분류체계를 활용하여 문항의 인지 수준(cognitive level)과 내용 영역(content area)이 연령대별 수행 패턴의 차이를 분석하는 것이다. 이러한 접근은 다음과 같은 연구 질문을 중심으로 한다. (1) 현행 학과시험 문항은 어떤 인지적·내용적 구조를 갖는가? (2) 문항의 인지 수준과 내용 영역은 연령대별 수행에 어떠한 차별적 영향을 미치는가? (3) 이러한 차이가 시험의 타당성·공정성 측면에서 어떤 개선 필요성을 제기하는가? 이러한 연구 질문을 통해 본 연구는 초고령 사회로 진입한 한국에서 운전면허 학과시험이 단순 암기형 평가를 넘어 실제 위험 인지 역량을 공정하고 타당하게 평가하는 체계로 발전하기 위한 구조적 개선 방향을 제시하고자 한다.
선행연구
운전면허시험 제도의 변화와 그에 따른 영향에 대해서는 다양한 선행연구가 수행되어 왔다. 특히 기존 연구들은 크게 (1) 운전면허시험 제도 변화의 과정과 그 효과를 분석한 실증적 연구, (2) 학과시험 문항의 구성과 특성을 분석한 연구로 구분할 수 있다.
1. 운전면허시험 제도 변화와 그 효과에 대한 실증적 검토
우리나라는 2011년 6월 운전면허시험 절차를 대폭 간소화하면서 면허 취득이 이전보다 용이해지는 제도적 변화를 겪었다. 이에 따라 충분한 지식과 운전 기술이 부족한 초보 운전자들이 대거 배출되어 사고가 증가할 것이라는 우려가 제기되었다 (Yoo and Jo, 2020). 이러한 문제 인식에 따라 정부는 2016년 학과시험을 비롯한 운전면허시험 제도를 전면적으로 강화하는 개선안을 시행하였다. 2016년 면허시험 강화 조치의 일환으로 문제은행의 전면 개편과 문항 공개가 이루어진 것은 주목할 만한 변화로, 한국도로교통공단은 2017년 새롭게 시행된 학과시험에서 상황 판단형 문항과 위험예지형 동영상 문항의 비중을 높였고, 총 문항 수를 730문항에서 1,000문항으로 확대하였다. Lee et al.(2020)에 따르면, 2016년 면허시험 난이도 상향 이후 학과시험 합격률은 약 9.8% 감소한 반면, 면허시험 강화 전후 동일 기간(약 17개월)을 비교했을 때 교통사고 발생 건수는 25.4%, 사망자 수는 15.7% 감소한 것으로 분석된다. 더 나아가 2017년 강화 조치 이전 연습면허 취득자 261,543명을 제외하여 간소화 정책의 영향을 배제하고 재분석한 결과, 초보운전자의 교통사고 발생 건수는 35.4%, 사망자는 28.6% 감소하여 제도 강화가 초보운전자 안전 향상에 기여했음을 보다 명확히 보여준다. 이러한 개선에도 불구하고, Baik(2018)은 현행 운전면허 학과시험의 한계로 선진국에 비해 상대적으로 낮은 합격기준, 재응시 제한기간의 부재, 오답 문항 열람 시스템 미비 등을 지적하였으며, 이에 따라 합격 기준 점수를 기존 70점에서 90점으로 상향하고, 재응시 제한기간 도입 및 오답 확인 시스템 구축 등을 제안하였다.
한편 Lee(2019)가 운전면허 재취득자 158명을 대상으로 실시한 체감도 조사에 따르면, 현재 면허시험 제도에서 가장 개선된 점으로는 ‘공정성’이 52.5%로 가장 높게 나타난 반면, 가장 개선이 필요하다고 인식된 분야는 ‘실효성’이 69.6%로 압도적인 비중을 차지하였으며, 그 다음이 ‘난이도’(20.9%)로 나타났다. 반면 ‘공정성’을 개선이 필요한 요소로 지목한 응답은 2.5%에 불과하였다. 이러한 결과는 면허시험 제도의 공정성은 일정 수준 확보되었으나, 실제 운전 능력 향상과 직결되는 실효성 측면에서는 여전히 한계가 인식되고 있음을 시사한다. 이와 같은 실효성에 대한 문제의식은 시험 구성요소별 체감 난이도 평가에서도 간접적으로 확인된다. Lee(2019)는 이러한 결과를 바탕으로 문제은행 중심의 학과시험 출제 방식이 실제 운전 능력 향상이라는 시험의 본래 목적을 충분히 담보하지 못하고 있을 가능성을 지적하며, 교통안전 향상을 위해 시험 체계 전반, 특히 학과시험의 역할과 실효성에 대한 조속한 보완이 필요하다고 평가하였다. 이를 종합하면, 2016년 면허시험 강화 조치는 난이도와 공정성 측면에서는 일정 수준의 성과를 거두었으나, 학과시험의 실효성 제고는 여전히 중요한 정책적 과제로 남아 있다고 볼 수 있다.
2. 운전면허 학과시험 문항의 구성과 특성 분석
운전면허 학과시험 문항을 인지 수준의 관점에서 살펴보면 여러 한계가 드러난다. 종래의 운전면허 학과시험 문제은행은 상당수가 교통법규 조항이나 운전 상식의 단순 암기형 질문으로 구성되어 있다는 지적이 제기되어 왔다(Baik, 2018). 예를 들어, 도로교통법상의 벌금액이나 처벌조항의 수치를 그대로 묻는 문항은 단순한 사실 기억(factual memory)만으로도 정답을 도출할 수 있어, 실제 운전에 필요한 사고력이나 판단력을 충분히 평가하지 못한다. 반면 복잡한 교통상황에서의 우선순위 판단이나 위험 예측을 요구하는 문항은 응시자의 적용 및 분석 능력을 검증할 수 있으나, 과거 시험에서는 이러한 고차원 인지 능력을 평가하는 문항이 상대적으로 부족하였다. 또한 낮은 합격 기준 점수와 제한된 문항 수로 인해 응시자의 법규 이해 수준을 충분히 변별하지 못한다는 비판도 제기되었다. 이러한 한계는 학과시험 성취도가 실제로 면허 소지자의 교통법규 준수율이나 교통사고 감소와 유의미한 상관관계를 보이지 못하고 있었다는 기존 연구결과와도 일맥상통한다(Lee and Lee, 2018).
최근 연구에서는 운전면허 학과시험이 실제 법규 이해보다는 언어적 단서나 구조적 편향에 따라 정답을 유추할 수 있는 한계를 지니고 있음을 지적하였다. 이러한 인식에 기반하여, 자연어처리(Natural Language Processing, NLP) 기법을 활용해 시험 문항의 언어적 편향성을 정량적으로 분석하려는 시도가 이루어지고 있다. Lee and Son(2025)은 이러한 문제의식을 다루며, TF-IDF와 SBERT 기반 의미 유사도 분석을 통해 1,000문항의 선택지를 정량적으로 평가하였다. 그 결과, 일부 문항에서는 안전지향적 키워드가 정답과 높은 연관성을 보였으나, 전체적으로는 통계적으로 유의하지 않아 학과시험이 일정 수준의 공정성을 유지하고 있음을 확인하였다. 다만 연구진은 이러한 결과가 문항의 언어적 구성과 선택지 표현 방식이 응답 행태에 영향을 미칠 수 있음을 시사한다고 지적하였다. 이후 Kim and Lee(2025)은 해당 연구를 확장하여, 운전면허 학과시험의 구조적 편향 가능성을 GPT 기반 프롬프트 시뮬레이션을 통해 분석하였다. 이들은 문항의 정답 위치, 선택지 길이, 안전지향적 표현 등 형식적 요소가 응시자의 반응에 미치는 영향을 실험적으로 검증하였다. 그 결과, 특정 문항에서 안전 관련 키워드가 포함된 선택지가 정답으로 선택될 확률이 높게 나타났으며, 이러한 경향은 응시자가 교통법규 지식 없이도 직관적 추론만으로 정답을 선택할 가능성을 높이는 구조적 요인으로 작용할 수 있음을 확인하였다. 이는 향후 시험의 공정성과 인지적 타당성을 높이기 위해 문항의 표현 방식, 의미 균형, 선택지 구조 등을 체계적으로 관리할 필요성을 제시한다.
실제로 다양한 자격시험을 대상으로 교육심리학과 심리측정학에 기반한 문항 분석 연구가 활발히 이루어져 왔다. 예를 들어 교원임용시험이나 의사국가시험, 간호학 시험 문항 등의 문항을 Bloom의 교육목표 분류 체계(Bloom’s Taxonomy)에 따라 분석한 연구들은 대부분의 문항이 ‘기억’과 ‘이해’ 수준에 편중되어 있으며, ‘적용’이나 ‘분석’을 요구하는 문항은 상대적으로 부족하다는 점을 공통적으로 보고하였다(Thompson et al., 2008; Lee, 2020; Yang, 2023). 이러한 교육학적 분석 틀은 운전면허 학과시험에도 직접적으로 적용될 수 있다. 운전면허 학과시험 문항이 단순 암기형 지식 평가에 치중되어 실제 교통상황 판단 능력을 변별하지 못한다는 지적에 따라, 한국도로교통공단은 2016년 이후 위험예지형 동영상 문항과 상황판단형 문항을 도입하였다. 이는 시험이 요구하는 인지 수준을 ‘분석’과 ‘평가’ 단계로 확장하려는 제도적 개편으로 평가된다.
한편 해외에서도 운전면허 학과시험의 신뢰도와 타당도를 검증하거나(Henriksson et al., 2004), 학과시험 점수와 면허 취득 후 사고율 간의 예측타당도를 분석하여 시험의 실효성을 분석한 연구가 이루어져왔다(Curry et al., 2017; Stefan et al., 2025). McKnight(2003)은 초보 운전자 사고의 주요 원인이 위험인지 실패(hazard perception failure)에 있음을 밝혔으며, Horswill et al.(2015)은 운전면허 취득 시 시행되는 위험인지 시험 점수가 이후 사고율과 유의미한 상관이 있음을 실증하였다. 또한 Habibzadeh et al.(2023)은 문화적·법적 맥락의 차이에 따라 위험인지 및 판단 관련 문항의 구성과 표현을 조정해야 한다고 제안하였다. 이러한 선행연구들은 운전면허 학과시험의 문항이 단순한 법규 지식 암기를 넘어, 실제 운전상황에서의 인지·판단 능력과 위험 인식 역량을 얼마나 반영하고 있는지를 평가하는 것이 중요함을 시사한다.
3. 선행연구와 차별성
기존 연구들은 주로 운전면허시험 제도 변화가 초보 운전자의 사고율에 미친 영향이나, 시험의 난이도·합격률 등 거시적 지표에 초점을 맞추어 왔다(Yoo and Jo, 2020; Baik, 2018). 이러한 접근은 학과시험의 독립적인 영향을 분리하여 평가하지 못했으며, 학과시험 문항과 응시자 성취 간의 구조적 관계를 직접적으로 규명하지 못했다는 한계를 지닌다. 일부 연구에서 문항의 언어적·형식적 편향성을 정량적으로 진단하려는 시도가 이루어졌으나(Kim and Lee, 2025; Lee and Son, 2025), 이는 주로 문항의 표현 방식과 의미적 편향성에 초점을 두었을 뿐, 문항이 요구하는 인지 수준에 따른 응시자 성취도의 체계적 차이를 분석하지는 않았다. 특히 연령에 따른 인지기능 변화가 운전 수행 능력에 직접적인 영향을 미친다는 실증 연구들이 반복적으로 보고되고 있음에도 불구하고 (Salthouse, 2019; Lee et al., 2018; Depestele et al., 2020), 이러한 특성 차이가 학과시험 수행에 어떤 영향을 미치는지는 충분히 검토되지 않았다.
이에 본 연구는 기존의 통계적·언어적 분석을 넘어, 운전면허 학과시험의 문항을 인지적 복잡성과 내용 영역에 따라 이원적으로 분류하고, 문항 특성과 응시자 연령대별 정답률 차이를 종합적으로 분석함으로써, 시험이 실제로 어떤 인지 수준의 사고력을 요구하고 있으며, 연령 간 수행차이가 어떤 문항에서 발생하는지를 실증적으로 검토하고자 한다. 특히 학과시험 문제은행이 실제 교통 상황에서 필요한 정보 통합, 위험 인지, 상황 판단 등의 인지 과정과 얼마나 정합적으로 설계되어 있는지를 문항 특성과 응시자 수행을 연계하여 실증적으로 분석하였다. 이를 통해 학과시험이 실제로 어떤 수준의 인지적 사고과정을 요구하는지, 그리고 연령 간 수행 차이가 어떤 유형의 문항에서 발생하는지를 규명하였으며, 특정 응시자 집단이 어떤 지식 유형과 어떤 인지 수준에서 상대적으로 어려움을 겪는지를 밝혀 학과시험이 타당하게 설계되어 있는지를 재평가하였다. 이러한 접근은 단순한 정답률이나 난이도 지표를 넘어, 인지과정 기반의 문항 분석 틀을 운전면허 평가체계에 적용함으로써, 시험의 공정성 제고와 맞춤형 운전자 교육 설계를 위한 실증적 근거를 제시한다는 점에서 기존 연구와 차별성을 갖는다.
연구 방법
1. 연구 분석 절차
본 연구의 전체 분석 절차는 Figure 1에 제시된 바와 같이 네 단계로 구성된다. 첫째, 데이터 수집 단계에서는 한국도로교통공단이 제공한 운전면허 학과시험 문제은행 문항(총 1,000문항)과 연령별 정답·오답 응답 데이터를 확보하였다. 이 중 정답률 데이터가 수집되지 않은 11문항을 제외하고, 총 989문항에 대해 분석용 데이터베이스를 구축하였다. 둘째, 분류체계 정의 단계에서는 문항을 인지적 복잡성과 내용적 범주에 따라 체계적으로 분류하기 위해, SOLO 분류체계(Cognitive Level)와 운전 역량 내용 영역(Contents Area)을 통합한 이중 분류 스키마를 정의하였다. 셋째, 문항 분류 수행 단계에서는 대규모 언어모델(LLM, Gemini 1.5 Flash)을 활용한 자동 분류 결과와 전문가의 수기 분류 결과를 비교·보완하여, 각 문항에 대해 인지 수준 및 내용 영역을 부여하고, 연령대별 정답률 정보를 포함한 통합 데이터베이스를 생성하였다. 넷째, 통계 분석 수행 단계에서는 일원분산분석(One-way ANOVA)과 Tukey’s HSD를 통해 분류체계별 정답률 차이를 검정하고, 연령 집단 간 정답률 격차는 Cohen’s 효과크기를 통해 정량화하였다. 이를 통해 문항의 인지 수준 및 내용 영역이 응시자 성취에 미치는 영향을 실증적으로 분석하였다.
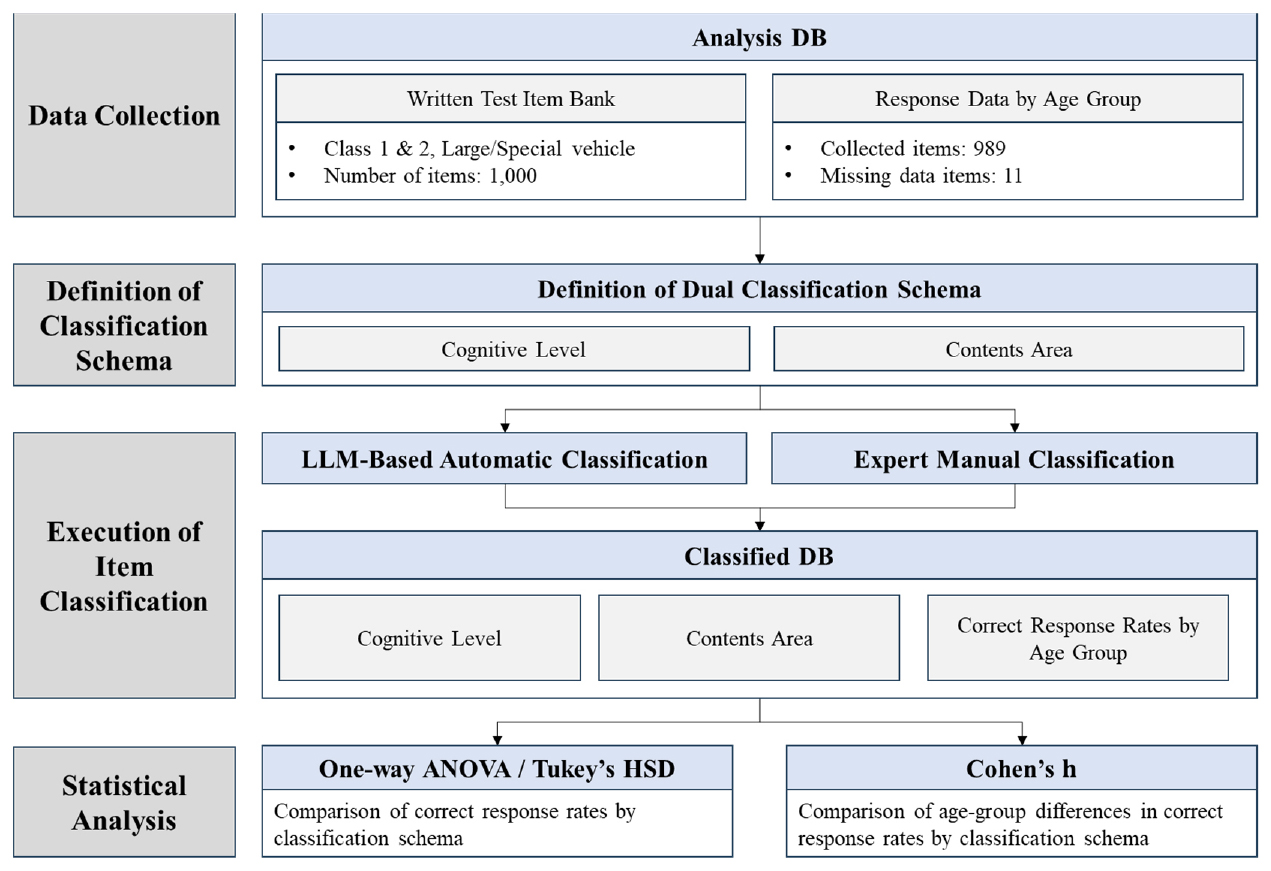
2. 자료 수집 및 가공
본 연구는 한국도로교통공단에서 공개하는 운전면허 학과시험 문제은행 중 1·2종보통, 대형·특수면허에 해당하는 1,000개 문항을 분석 대상으로 하였다. 이 문제은행은 2025년 2월 24일부터 8월 25일까지 약 6개월 간 출제에 활용된 공식 문항으로, 각 문항의 텍스트, 정답 및 오답 선택지, 해설 정보를 포함하고 있다. 문항 유형은 교통법규 지식을 확인하는 텍스트형 문항부터 실제 도로 상황 사진이나 교통표지를 활용한 시각 자료형 문항까지 다양하게 구성되어 있다. 또한 인지적 복잡성과 내용 영역에 따른 응시자들의 성취도 차이 분석을 위해 한국도로교통공단의 협조를 받아 대분류·중분류·소분류 등 기존 문항 분류 정보와 2025년 2월 24일부터 7월 2일까지의 문항별로 정답자·오답자 수 데이터를 함께 활용하였다. 전처리 과정에서는 관련 법규 개정 등으로 인해 미출제되어 정답률 데이터가 없는 11문항은 제외하였으며, 최종적으로 989개 문항을 분석 데이터베이스로 구축하였다, 이 데이터베이스는 문항별 인지 수준 분류 및 정답률 산출의 기초 자료로 활용되었으며, 구체적인 구성은 Table 1과 같다.
Table 1.
Variables included in the dataset
3. 분류 체계 정의
본 연구에서는 운전면허 학과시험 문항을 체계적으로 분류하고 평가하기 위해 본 연구는 이중 분류 스키마를 적용하였다. 첫 번째는 SOLO 분류 체계에 기반한 인지적 복잡성 차원이고, 두 번째는 운전 역량 범주에 따른 내용 영역 차원이다. 이러한 분류 기준은 교육학적 이론과 선행연구에 근거하며, 국제적인 운전면허 평가 표준에도 부합한다. 인지적 복잡성 차원의 분류체계는 Biggs and Collis(1982)가 제안한 SOLO taxonomy에 근거한다. 인지적 복잡성 차원은 문항이 요구하는 인지 처리 수준을 의미하며, SOLO는 학습자의 이해 깊이를 전구조(Pre-structural), 일구조(Unistructural), 다구조(Multistructural), 관계적(Relational), 확장된 추상(Extended Abstract)의 다섯 단계로 구분하지만, 전구조 단계는 학습자가 문제를 의미 있게 이해하지 못한 수준이므로 평가 문항 분류에서는 제외하였다. 이러한 SOLO 분류체계(Biggs and Collis, 1982)는 학습자의 이해 깊이를 정밀하게 구분할 수 있는 틀을 제공한다(Brabrand and Dahl, 2009; Hodges and Harvey, 2003). 각 단계에 대한 정의는 다음 Table 2과 같다.
Table 2.
SOLO taxonomy: levels, definitions, and examples
또한 내용영역 차원의 분류체계를 정의하기 위해 Hatakka et al.(2002)의 Goals for Driver Education model (GDE model), Fisher and Strayer (2014)의 Scanning, Predicting, Identifying, Decision making, and Executing a Response (SPIDER) model, EU 운전면허 지침(Directive 2006/126/EC)의 요구 사항을 검토하였으며, 이를 토대로 안전운전을 위해 필요한 운전 역량을 법규·표지·신호(Traffic Regulations, Signs, and Signals), 운전기술·차량안전(Driving Skills and Vehicle Safety), 위험인지·상황판단(Hazard Perception and Situation Judgment), 운전자 상태·태도(Driver Condition and Attitude) 네 가지로 구성하였다. 해당 분류체계는 문항이 다루는 지식 또는 기능의 주제 범주를 의미하며 각 분류에 대한 정의는 다음 Table 3과 같다.
Table 3.
Content areas of driving competence
4. LLM 기반 문항 분류 및 전문가 검증 절차
본 연구에서는 다양한 LLM 모델 중 Gemini 1.5 Flash 모델을 활용하여 운전면허 학과시험 문항의 인지 수준과 내용 영역을 자동 분류하였다. 모델에는 SOLO 분류체계의 단계 정의와 각 내용 영역의 설명 및 예시를 포함한 고정형 프롬프트를 입력으로 제공하였다. LLM은 각 문항의 전체 텍스트를 분석하여 인지 수준과 내용 영역을 예측하고, 분류 근거와 신뢰도 점수를 함께 산출하였다.
문항 분류의 신뢰성을 확보하기 위해, LLM 자동 분류와 전문가 검토를 결합한 반자동화 2단계 절차를 적용하였다. 먼저 LLM이 생성한 전체 분류 결과 중 총 300개 문항을 최종 분석 표본으로 선정하였으며, 이는 Cohen’s κ 추정의 안정성을 확보하기 위한 최소 기준(N≥30)을 충족하고, 항목별 비중을 고려하여 통계적 검정력을 확보하기 위함이다. 이후 운전면허 학과시험 출제위원인 연구진 2인이 독립적으로 표본을 수기 분류하였고, 의견이 불일치한 문항은 상호 논의를 통해 최종 전문가 분류 결과를 확정하였다.
LLM과 전문가 간 분류 결과의 일치도, 즉 평가자 간 신뢰도를 정량적으로 측정하기 위해 Cohen’s κ 계수를 주요 지표로 사용하였다. Cohen’s κ는 두 평가자 간 범주형 분류 결과의 일치도를 측정하는 지표로, 단순 일치율과 달리 우연에 의해 발생할 수 있는 합치 가능성을 보정한 값이다. κ 값은 −1에서 1 사이의 범위를 가지며, 0은 우연 수준의 일치를, 1은 완전한 일치를 의미한다(Landis and Koch, 1977). 단순 일치율(percent agreement)은 우연에 의한 합치 가능성을 보정하지 못해 실제 일치도를 과대평가할 위험이 있으므로, 본 연구에서는 우연에 의한 합치를 보정한 Cohen’s κ 값을 최종 지표로 채택하였다. 이 절차를 통해 LLM의 자동 분류 효율성과 전문가 판단의 정확성을 문항 분류 결과의 일관성과 재현성을 동시에 확보하였다. 나아가 본 연구는 향후 운전면허 시험 문항의 자동 분류 시스템 개발 및 평가 타당성 검증의 기초 자료로 활용될 수 있다.
5. 문항 특성에 따른 수행 차이 분석
문항 분류체계(인지 수준, 내용 영역)에 따른 문항별 평균 정답률의 차이를 검정하기 위해 일원분산분석(One-way ANOVA)을 실시하였다. 종속변수는 각 분류체계의 평균 정답률, 독립변수는 인지 수준과 내용 영역으로 설정하여, 문항 분류체계에 따라 평균 정답률에 차이가 있는지 분석하였다. 그러나 ANOVA는 차이가 존재한다는 사실만 제시할 뿐, 어떤 집단 간 차이가 실제로 유의한지까지는 구분하지 못한다. 이에 본 연구는 Tukey’s HSD 사후검정을 적용하여 각 집단쌍의 평균 정답률 차이가 통계적으로 유의한지를 추가적으로 확인하였다. Tukey’s HSD는 모든 집단쌍을 동시에 비교하면서도 제1종 오류를 효과적으로 통제한다는 점에서 적합한 방법이다. ANOVA와 Tukey’s HSD를 연속적으로 적용한 이유는, 문항의 인지적·내용적 특성이 응시자의 수행에 어떤 방식으로 구체적인 차이를 만들어내는지 확인하기 위함이다. 즉, ANOVA로 전체적 차이의 존재를 검증하고, HSD로 세부 차이의 패턴을 식별함으로써 문항 분류 체계가 정답률에 미치는 영향을 평가적으로 해석할 수 있다.
6. 연령집단 간 성취 격차의 정량적 평가
본 연구에서는 문항의 인지수준과 내용 영역에 따라 연령집단 간 정답률이 어느 정도 차이를 보이는지를 정량적으로 비교할 필요가 있었다. 이러한 비율 기반 차이를 단순한 통계적 유의성으로만 판단할 경우, 집단 간 표본 수의 불균형이나 대규모 표본에서의 과도한 민감성 때문에 실제로는 미미한 차이도 유의한 것으로 나타날 수 있다. 따라서 연령별 정답률 차이가 실질적으로 의미 있는 수준인지를 평가할 수 있는 지표가 요구된다. 이러한 목적에서 본 연구는 Cohen(2013)이 제안한 효과크기 지표인 Cohen’s 를 도입하였다. Cohen’s 는 Equation 1과 같이 두 비율의 차이를 아크사인(arcsin) 변환 후 비교하는 방식으로 정의되며, 비율 간 차이의 크기를 표본 크기와 독립적으로 해석할 수 있다는 점에서 다양한 분야에서 활용되어 왔다. 본 연구와 같이 문항 수가 많고, 문항별 정답률이 이산적이며 분포의 범위가 제한적인 상황에서는 단순 유의성 검정보다 비율 차이의 실질적 크기를 해석하는 접근이 더 타당하다. 이에 Cohen’s 는 각 문항에서 연령집단 간 정답률 격차가 교육적·평가적으로 의미 있는 수준인지 식별하는 데 적합한 지표라 판단하여 채택하였다.
where, is arcsine square-root transformation of the probability for group ,
is the probability for group , and
is the Cohen’s
Cohen(2013)은 제시한 지표의 해석을 위한 경험적 기준선을 제시하였다. 일 때는 작은 차이, 일 때는 중간 수준의 차이, 일 때는 큰 차이로 정의하였다. 본 연구에서는 Cohen’s 해석 기준에 근거하여, 정답률 수준 간의 차이를 일 때 차이 없음, 일 때 작은 차이, 일 때 중간 차이로 구분하였다.
결과적으로, Cohen’s 분석은 연령대가 높을수록 고차 인지 수준(다구조적·관계적 사고)과 상황판단·위험인지 영역에서 큰 성취 격차가 나타나는지를 검증하기 위한 정량적 근거로 사용되었다.
분석 결과
1. 문제 분류 결과
인지 수준과 내용 영역을 결합한 이중 분류 체계를 적용하여 LLM을 통해 분류 후 전문가가 검증하였다. 다음 Table 4는 LLM과 전문가의 분류 결과를 인지 수준과 내용 영역별로 비교한 결과를 제시한 것이다. 각 항목에 대해 LLM과 전문가가 분류한 문항 수, 일치율 및 Cohen’s κ 값을 함께 나타내었다.
Table 4.
Counts of LLM- and expert-labeled Cohen’s κ by cognitive level and content area
인지 수준별로 살펴보면, 일구조적 문항과 다구조적 문항에서 각각 77.1% 및 67.0%의 비교적 높은 일치율을 보인 반면, 관계적 문항 및 확장된 추상 문항에서는 각각 38.2%, 0.0%로 일치율이 크게 낮았다. 전반적인 인지 수준의 평균 일치율은 64.0%, Cohen’s κ는 0.4561로 중간 수준의 일관성을 보였다. 이는 LLM이 문항의 주제적 범주를 정확히 파악하는 데 강점을 지니는 반면, 관계적·추상적 사고와 같은 고차 인지 수준의 판단에는 여전히 한계가 있음을 보여준다. 한편, 내용 영역별로는 모든 범주에서 86.2%의 높은 일치율이 나타났으며, 특히 법규·표지·신호 영역에서 91.3%로 가장 높았다. 내용 영역의 Cohen’s κ는 0.8111로, 두 분류체계 간 강한 일치(strong agreement)를 나타낸다. 이러한 결과는 LLM 기반 분류가 전반적으로 전문가 판단과 높은 수준의 일관성을 보이지만, 인지 수준이 높아질수록 분류 난이도가 증가함을 시사한다.
최종적으로 산출된 인지수준 및 내용영역별 문항 수는 Table 5 및 Figure 2에 제시하였다. 인지수준 분류 결과, 다구조적 문항이 587문항(59.4%)으로 가장 높은 비중을 보였고, 일구조적 문항은 355문항(33.9%), 관계적 문항은 66문항(6.7%)으로 나타났다. 특히 확장된 추상 단계 문항은 단 1문항(0.1%)에 불과하여, 고차원적 사고를 요구하는 문항이 사실상 거의 포함되지 않은 것으로 확인되었다. 내용영역별 분류에서도 법규·표지·신호 영역이 640문항(64.7%)으로 절대적으로 높은 비중을 차지하였으며, 위험인지·상황판단 196문항(19.8%), 운전기술·차량안전 114문항(11.5%), 운전자 상태·태도 39문항(3.9%) 순으로 구성되어 있었다.
Table 5.
Number of items by cognitive level and content area
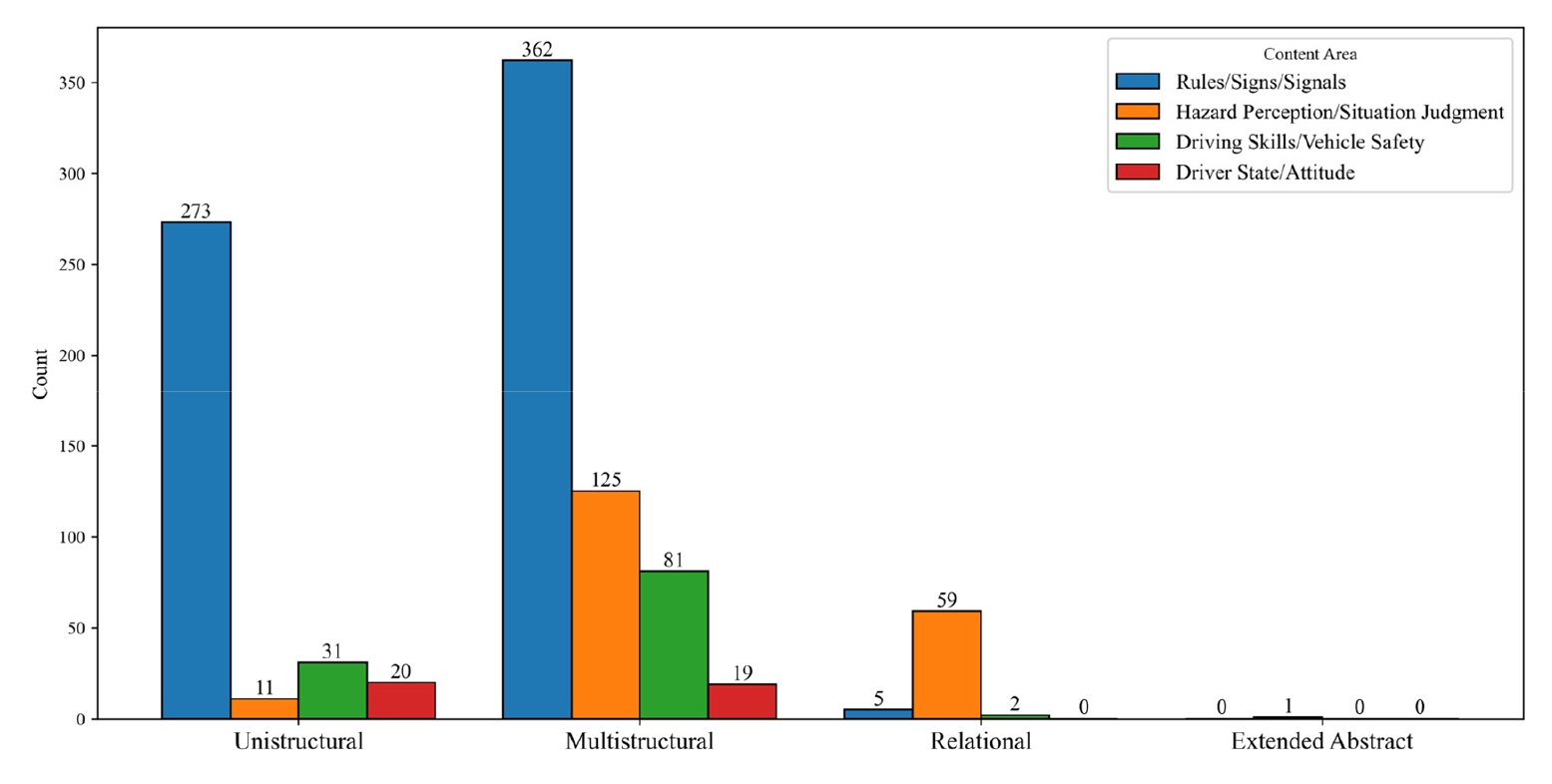
분석 결과, 운전 수행 능력에서 인지적 판단이 갖는 중요성에도 불구하고, 현행 학과시험은 실제 주행 상황에서 요구되는 고차 인지 능력을 충분히 반영하지 못하고 있다. 본 연구의 문항 분류 결과에서도 관계적 문항 6.7% 및 확장된 추상문항 0.1%로 비중이 극히 낮게 나타났으며, 이는 시험이 대부분 단일 정보 처리나 단순 규칙 적용에 머물러 있음을 의미한다. 이러한 구조적 제약은 학과시험이 실제 운전 수행에서 요구되는 복합적 사고 과정과 판단 능력을 적절히 평가하지 못하게 하고, 결과적으로 시험의 타당성을 저해하는 요인이 될 수 있다. 또한 내용영역 측면에서도 문항이 특정 지식 범주(법규·표지·신호)에 과도하게 집중되어 있어, 다양한 운전 역량을 균형 있게 평가하기 어렵다는 편중 현상이 확인되었다.
2. 인지 수준 및 내용 영역에 따른 정답률 차이 분석
인지수준 및 내용영역에 따른 정답률은 Table 6 및 Figure 3에 제시하였다. 인지 수준별 평균 정답률은 일구조적 63.9%, 다구조적 64.2%, 관계적 71.9%로 나타났다. 인지 수준이 높아질수록 정답률이 낮아질 것이라는 일반적 예상과 달리, 관계적 문항에서 오히려 높은 정답률이 확인된다. 이러한 경향은 운전면허 학과시험이 실제 교통상황과 유사한 맥락에서의 판단을 요구하는 문항에서는 응시자가 법규 지식보다 ‘안전지향적 선택’을 직관적으로 활용해 정답을 도출하는 경향이 있다는 해석과 부합한다. 이는 시각 자료 기반 문항에서 법규 이해가 부족하더라도 안전한 선택지를 통해 정답을 유추할 수 있다는 기존 연구의 지적과도 일치한다(Lee and Son, 2025; Kim and Lee, 2025). 이러한 결과는 고차 인지 문항의 비중 부족뿐 아니라, 존재하는 고차 문항조차 기대된 인지 부담을 충분히 유발하지 못하고 있음을 보여준다.
Table 6.
Accuracy by cognitive level and content area
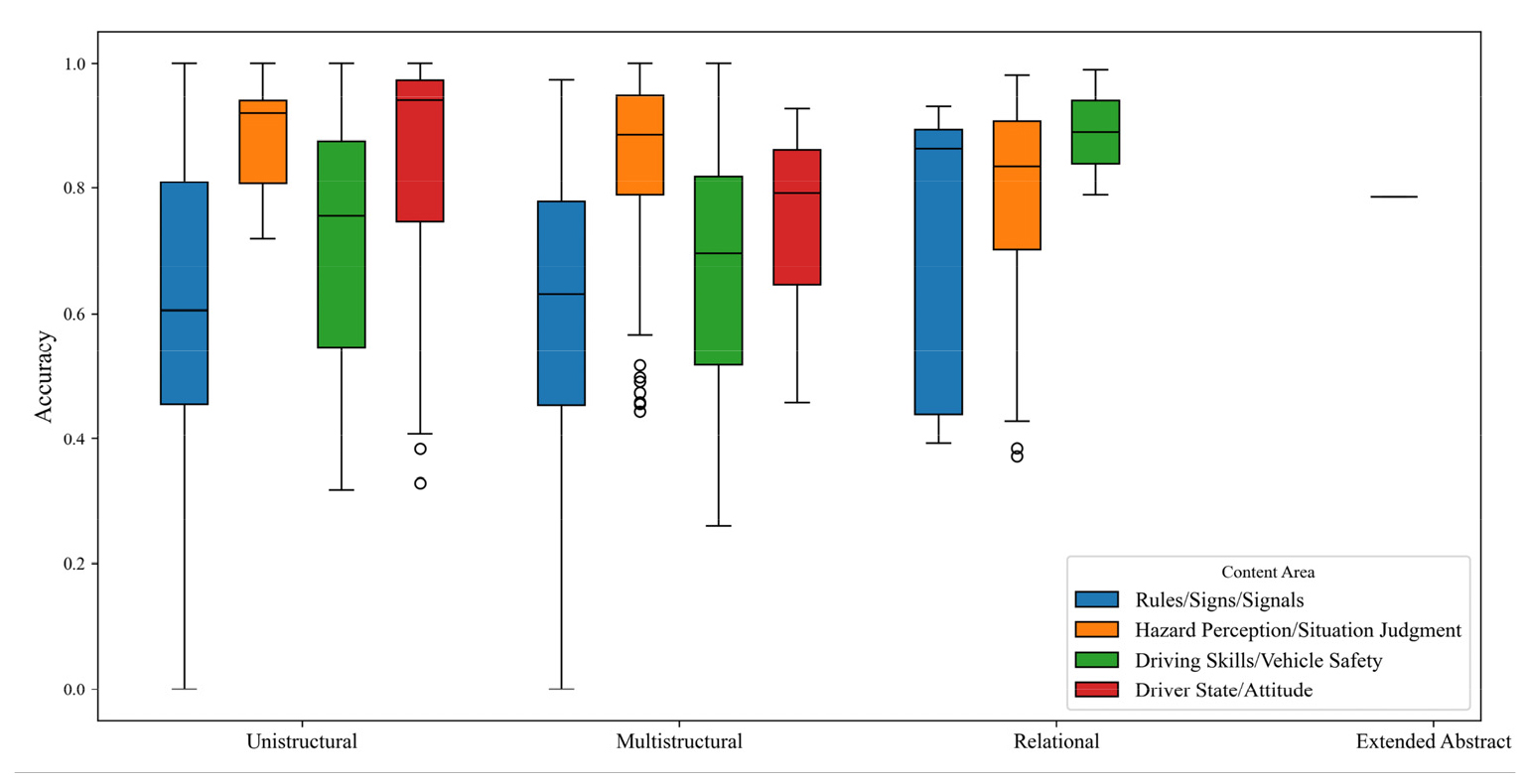
내용영역별 정답률을 살펴보면, 위험인지·상황판단 영역이 77.3%로 가장 높았고 운전자 상태·태도 74.4%, 운전기술·차량안전 66.7% 순이었다. 반면 법규·표지·신호 영역은 59.8%로 가장 낮았다. 이는 학과시험이 특정 지식 영역에 과도하게 편중되어 있을 뿐 아니라, 실제 운전상황에서 요구되는 인지·태도 기반 능력을 충분히 평가하지 못하는 구조적·질적 한계를 동시에 지니고 있음을 시사한다. 특히 법규·표지·신호 영역의 낮은 정답률은 세부 조항 암기 중심의 문항 설계로 인해 실제 교통상황과의 연결성이 약하다는 구조적 특성을 반영한 것으로 보인다. 이러한 정답률이 특정 영역에서 과도하게 높거나 낮게 분포하는 현상은 문항이 평가해야 할 인지적·내용적 범주를 균형 있게 변별하지 못하고 있음을 의미하며, 이는 학과시험의 구성타당성 및 변별력 측면에서 중요한 개선 과제로 볼 수 있다.
이상의 분류 결과는 인지 수준과 내용 영역에 따라 정답률이 체계적으로 달라지는 경향이 존재함을 시사한다. 다만 이러한 차이가 단순한 변동인지, 실제 유의미한 성능 차이가 발생하는지를 확인하기 위해서는 통계적 검증이 필요하며, 이에 본 연구는 통계적 유의성을 확인하기 위해 일원분산분석을 수행하였다.
Table 7은 일원분산분석 결과를 제시한 것이다. 분석의 유의수준은 0.05로 설정하였다. 인지 수준에 대한 ANOVA 결과, p = 0.0262로 나타나 인지 수준 간 정답률 차이가 통계적으로 유의한 것으로 확인되었다. 이는 문항이 요구하는 인지적 복잡성 수준이 실제 응시자의 수행에 영향을 미쳤음을 의미한다. 또한 내용 영역에 대한 ANOVA 결과에서도 p-value가 0.001보다 작게 나타나, 영역별 평균 정답률 차이가 통계적으로 유의함이 확인되었다.
Table 7.
One-way ANOVA
일원분산분석 이후 문항 분류 간 차이를 보다 면밀히 비교하고자 Tukey의 HSD 사후분석을 실시하였으며, 그 결과는 Table 8에 제시하였다. 분석 결과, 인지 수준에서는 문항 수가 1문항에 불과한 확장된 추상 수준을 제외할 경우 관계적 문항이 다른 모든 인지 수준에 비해 유의하게 높은 정답률을 보였다. 내용 영역에서도 법규·표지·신호 영역과 타 영역 간 평균 정답률 차이가 통계적으로 유의한 것으로 나타났다. 이러한 결과는 앞서 기술통계 분석에서 나타난 경향이 통계적으로도 일관되게 검증되었음을 의미하며, 인지 수준과 내용 영역 모두에서 응시자 수행의 실질적 차이가 존재함을 뒷받침한다.
Table 8.
Tukey’s HSD results by cognitive level and content area
3. 인지 수준 및 내용 영역에 따른 연령 집단 간 차이 분석(Cohen’s 𝒉)
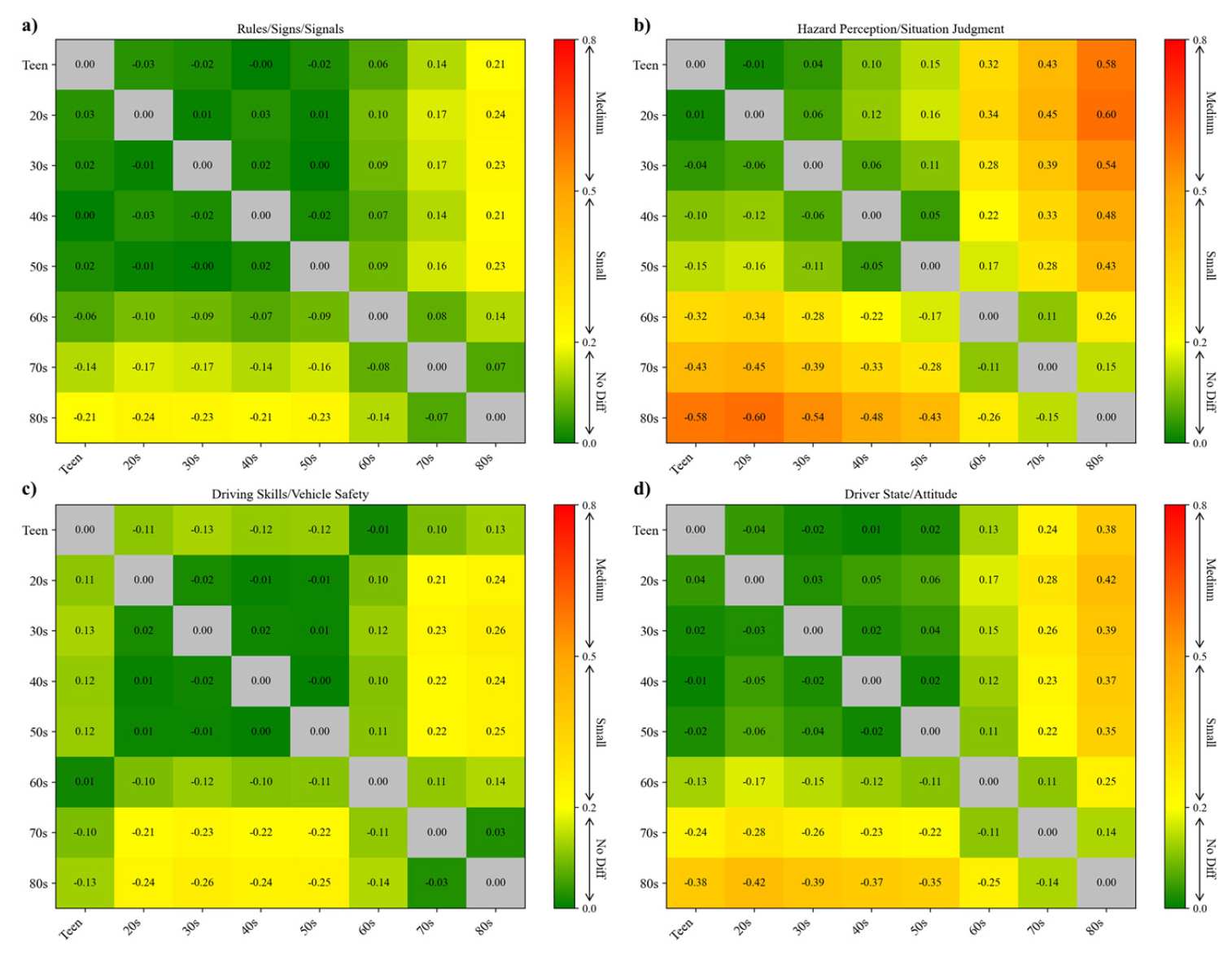
운전면허 학과시험의 989개 문항을 10대부터 80대까지 여덟 개의 연령집단으로 구분하여, 각 집단 쌍의 정답률 차이를 Cohen’s ℎ 효과크기로 산출하였다. Figure 4은 인지 수준별 문항에 대한 연령 집단 간 정답률 차이를, Figure 5는 내용 영역별 문항에 대한 차이를 시각화한 것이다. 두 그림에서 초록색은 연령 집단 간 차이가 거의 없는 경우()을, 주황색은 작은 정도의 차이()를, 빨간색은 중간 차이()를 의미한다.
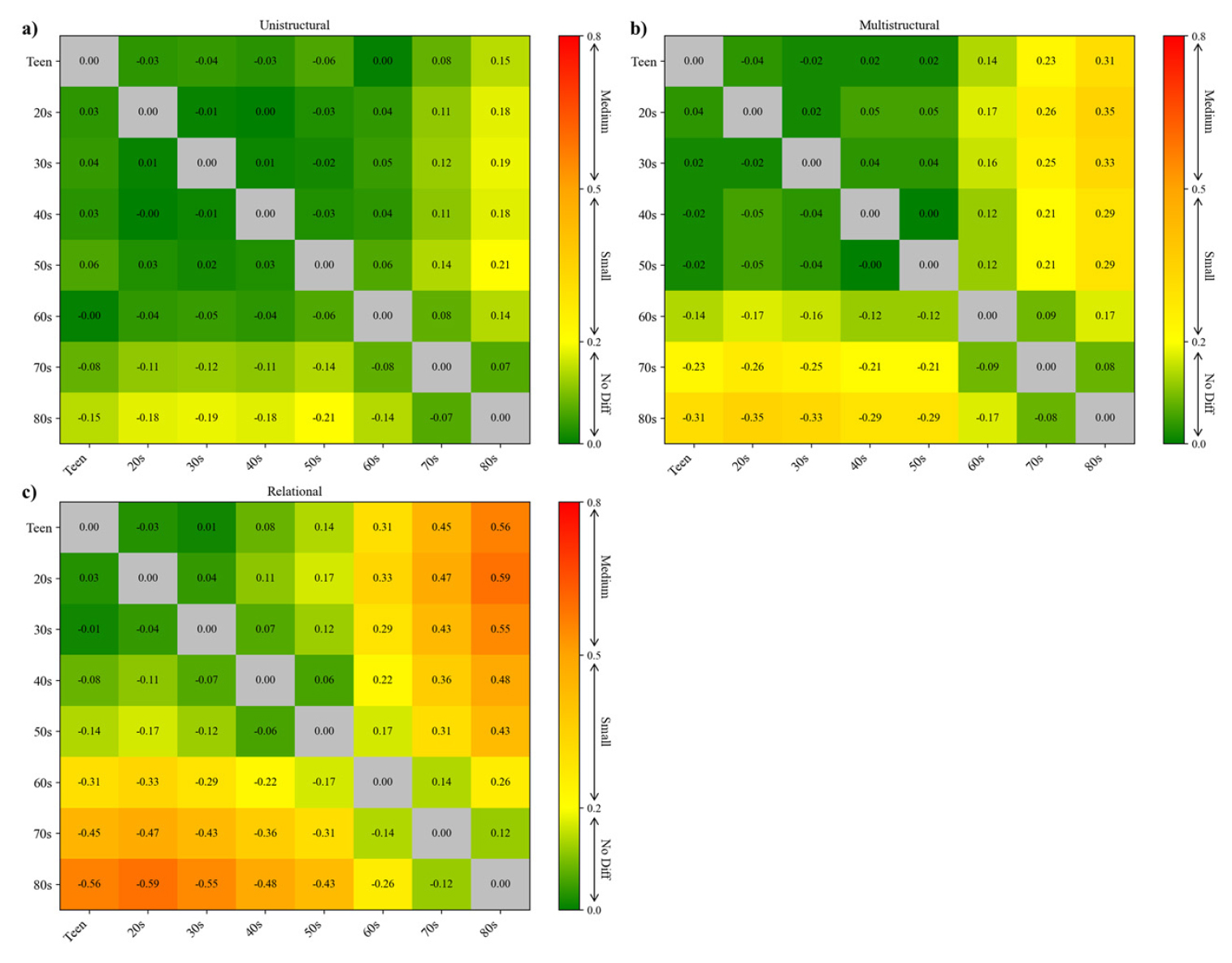
인지 수준 분석에서는 문항수가 적어 통계적으로 유의성을 검증하기 어려운 확장된 추상 단계의 문항(1문항)을 제외하고 분석을 수행하였다. 인지 수준별로 살펴보면, 일구조 문항에서는 전반적으로 연령 간 차이가 거의 없었다. 대부분의 연령대 비교에서 효과크기 ℎ 값이 0.00∼0.12 수준으로 연령 집단 간 차이가 거의 없는 것으로 나타났으며, 다만 80대가 50대와 비교될 때만 ℎ≈0.21로 약한 차이가 나타났다. 즉, 연령이 높더라도 단순 사실 인식 수준의 문항 수행력에는 뚜렷한 감소가 없었다. 반면 다구조적 문항에서는 연령이 높아질수록 집단 간 차이가 점차 뚜렷해졌다. 70대와 80대는 대부분의 젊은 연령층(10∼50대)과 비교할 때 ℎ≥0.20으로 작은 수준의 차이를 보였다. 이는 복수의 정보 요소를 조합해 의미를 이해해야 하는 문항일수록 고령층의 수행 저하가 뚜렷함을 의미한다. 마지막으로 관계적 문항에서는 연령 집단 간 차이가 가장 크게 나타났다. 60대와 70대는 10∼40대와의 비교에서 ℎ=0.22∼0.47로 중간 수준의 차이를 보였으며, 80대는 10∼30대와 비교할 때 ℎ≥0.50로 중간 차이에 해당하였다. 즉, 복합적인 관계 이해나 상황 추론을 요하는 문항에서 고령층의 인지적 부담이 증가하는 양상을 보였다.
종합적으로 볼 때, 요구되는 사고 수준이 높아질수록 세대 간 성취 차이가 급격히 확대되는 경향이 확인되었다. 이는 노년층의 인지적 저하가 복합적 사고와 추상적 개념화를 요하는 고차 인지 영역에서 두드러진다는 점을 시사한다. 이러한 결과는 고차 인지기능의 연령별 저하가 운전 수행 능력에 영향을 미친다는 기존 인지심리학 및 교통공학 분야의 연구들(Salthouse, 2019; Depestele et al., 2020)과도 일관된 양상으로 해석할 수 있다. 특히 본 연구에서 고령층의 관계적 사고 문항 정답률이 실제 운전 상황에 비해 시간적 제약이 크게 완화된 학과시험 환경에서도 체계적으로 낮게 나타난 점은, 고령자의 수행 저하가 단순히 시간 압박 하에서의 순간적 판단 실패 때문이 아니라 관계 기반 추론 과정 자체에서의 인지적 부담에 기인할 가능성을 시사한다. 아울러 이러한 수행 양상은 학과시험 문항이 일정 수준의 사고 복잡성을 반영하여, 연령에 따른 인지 능력 차이를 민감하게 식별할 수 있는 구조로 설계되어 있음을 뒷받침하는 결과로도 해석될 수 있다.
내용 영역별로 살펴보면, 법규·표지·신호 영역이 가장 연령별 차이가 적은 것으로 나타났다. 10대부터 60대까지의 비교에서는 ℎ 값이 대부분 0.00∼0.17 수준으로 거의 차이가 없는 수준이었으며, 80대가 10~50대와 비교될 때만 ℎ=0.21∼0.24로 작은 수준의 차이를 보였다. 즉, 기초적인 교통규칙 및 표지 인식 능력은 세대 간 차이가 거의 없는 것으로 나타났다. 반면 위험인지·상황판단영역에서는 연령이 높아질수록 차이가 급격히 확대되었다. 60대와 70대가 20∼50대와 비교될 때 ℎ=0.22∼0.45으로 작은 수준의 차이를 보였고, 80대는 10~30대와 비교할 때 각각 ℎ=0.58, 0.60, 0.54로 중간 수준의 차이를 나타냈다. 이는 주행 상황에서 위험 요소를 인식하고 판단하는 능력이 고령층에서 뚜렷하게 저하됨을 시사한다. 운전기술·차량안전 영역에서는 10∼50대 사이의 차이는 미미했으나, 70~80대는 20∼50대와 비교할 때 ℎ=0.21∼0.26으로 작은 차이가 확인되었다. 즉, 조작 능력이나 안전운전과 관련된 절차적 수행력에서도 고령층의 약화가 점진적으로 나타났다. 운전자 상태·태도 영역에서도 유사한 경향이 확인되었다. 70~80대는 10∼50대와 비교할 때 ℎ=0.22∼0.42로 작은 수준의 차이를 보였다. 이는 연령이 높아질수록 주의 집중, 위험 민감도, 운전 태도 등 내적 인지·정서적 요인의 약화가 두드러진다는 것을 의미한다.
종합적으로 볼 때, 기초적인 교통규칙 인식은 세대 간 차이가 거의 없으나, 실제 주행 상황 판단, 위험 인지, 태도 및 주의 유지 등 고차적·상황적 인지 능력에서는 연령이 높아질수록 성취 격차가 뚜렷하게 확대되는 경향이 확인되었다. 이는 고령층의 인지 저하가 단순 지식의 손실보다는 복합적 판단과 상황 통합 능력의 저하로 나타난다는 점을 시사하며, 향후 고령운전자 교육에서는 지식 전달보다는 상황판단·주의집중·위험예측 능력 향상에 초점을 둔 맞춤형 훈련이 필요함을 의미한다.
결론
본 연구는 운전면허 학과시험 문항의 인지적 타당성과 공정성을 검증하기 위해 SOLO 분류체계와 운전 역량 내용 영역에 따라 분류는 LLM(Genimi 1.5 Flash) 자동 분류 후 출제위원 2인의 독립 검토·합의로 확정하는 방법으로 989개 문항을 분류하고, 인지 수준별 분포 및 연령별 정답률 차이를 분석하였다. 이를 통해 현행 시험 문항이 요구하는 사고 수준의 특성과 집단 간 성취 격차를 규명하고, 향후 문항 개발과 출제 정책 개선을 위한 기초적 근거를 제시하고자 하였다.
문항 구성 측면에서는 다구조적 문항이 전체의 과반을 차지하는 반면, 관계적·확장된 추상 수준 문항의 비중은 극히 낮아 고차원적 사고를 요구하는 평가 구조가 충분히 확보되지 않은 것으로 나타났다. 내용영역 역시 법규·표지·신호 중심으로 과도하게 집중되어 있어, 실제 운전 수행에 요구되는 위험 인지력이나 상황 판단 능력을 반영하는 문항의 비중이 제한적이었다. 이러한 구조적 쏠림은 시험이 다양한 운전 역량을 균형 있게 평가하기 어렵다는 점을 보여준다.
정답률 및 ANOVA 분석에서도 이러한 편중이 응시자 수행에 유의한 차이를 초래함이 확인되었다. 관계적 문항의 정답률이 오히려 높게 나타난 것은, 일부 문항에서 응시자가 직관적 ‘안전지향 선택’을 통해 정답을 추론했을 가능성을 시사하며, 이는 문항이 의도한 인지적 복잡도가 실제로는 충분히 발현되지 않았음을 의미할 수 있다. 반면 법규·표지·신호 영역은 세부 규정 중심의 암기형 문항 구성으로 인해 오히려 낮은 정답률을 보였고, 위험인지·상황판단 영역은 비교적 높은 정답률이 나타나 문항 유형에 따라 요구되는 인지적 부담이 상이함을 알 수 있다.
연령대별 Cohen’s h 분석에서는 일구조·다구조 수준 문항에서는 세대 간 차이가 거의 없었으나, 관계적 사고와 위험인지·상황판단 문항에서는 고령층의 수행 저하가 체계적으로 나타났다. 이는 선행연구에서 제시된 연령별 인지 기능 변화가 시험 수행 과정에도 반영된 결과로, 시험 문항의 인지적 요구 수준에 따라 연령 집단 간 인지 부담이 달라질 수 있음을 시사한다.
종합하면, 현행 운전면허 학과시험은 법규·표지·신호 중심의 지식형 문항에 편중되어 있을 뿐 아니라, 고차원적 사고를 요구하는 관계적·추상적 문항의 비중이 매우 낮아 실제 운전 상황에서 필요한 사고 과정(정보 통합, 위험 예측, 상황 판단 등)을 충분히 평가하기 어렵다는 구조적 한계를 지닌다. 이러한 결과는 향후 학과시험 체계가 단순 암기형 문항 중심에서 벗어나, 실제 교통상황을 반영한 상황 중심 문항(scenario-based items)과 고차 인지적 추론을 요구하는 문항의 비중을 확대할 필요성을 시사한다. 또한 정답률이 과도하게 높은 문항의 경우 구체적 교통법규 지식을 요구하는 선택지 설계를 통해 변별력을 강화할 필요가 있다.
다만, 본 연구는 학과시험 응시자의 실제 운전 수행 자료나 사고율과의 연계 분석이 이루어지지 않았다는 한계를 지닌다. 향후 연구에서는 응시자 성취도와 실제 운전 행동 데이터를 결합한 분석을 통해, 시험 문항의 예측 타당성과 실질적 교육 효과를 심층적으로 검증할 필요가 있다. 또한 본 연구에서는 단일 LLM 모형을 활용하여 문항 분류를 수행하였기 때문에 분류 정확도 측면에서 한계가 존재한다. 향후 연구에서는 서로 다른 구조와 학습 특성을 지닌 복수의 LLM 모형을 병행하여 활용하고, 모형 간 결과를 상호 검증·조정하는 멀티에이전트(Multi-Agent) 기반 합의 모델(Consensus Framework)을 도입함으로써 분류 신뢰도와 일관성을 향상시킬 필요가 있다.
