

서론
선행연구
1. 개인정보 제도와 데이터 활용
2. 교통·민원 텍스트 연구 동향
3. 텍스트 데이터의 가명처리
4. 선행 연구의 한계 및 차별성
연구 방법론
1. 데이터 수집 및 연구 방향
2. 인공지능 활용 모형
3. 대규모 언어모델 프롬프트
4. 평가방법
분석 결과
1. 데이터 유용성(Data Utility)
2. 개인정보 보호(Personal Information Protection)
결론 및 향후 연구 방향
서론
도시화 과정이 급격히 이루어 짐에 따라 도시내 교통, 환경, 토지이용 등 다양한 문제와 갈등이 존재하며, 이러한 도시내 문제들을 사회 참여자들 중심으로 해결하고자 각 지자체와 공공기관에서는 온라인·오프라인 채널을 통해 민원을 체계적으로 수집하고 있다. 수집된 민원 데이터는 도시내 공공 서비스를 효율적이고 신속하게 제공하는 핵심적인 근거 자료라 볼 수 있으며, 빅데이터 시대가 도래하면서 온라인을 통해 접수되는 민원의 규모가 증가하고 있으며, 해당 데이터의 활용과 가치가 지속적으로 증가하고 있다(Won and Yoo, 2016; Park and Kang, 2024).
교통 데이터는 사람이나 차량 등의 통행 데이터와 통행 주체인 개인의 사회경제적 특성들이 주로 포함되어 있으며, 특정 개인을 식별하는데 악용 될 수 있다. 특히 민원 데이터에는 주소, 차량번호, 민원인, 담당자 이름 등의 민감한 정보가 텍스트 내 다수 포함하고 있어, 개인정보 보호에 대한 사회적 인식수준이 높아지고 있는 현시점에서 안전한 데이터 활용과 정보주체 보호라는 문제를 해결하는 데 있어 중요한 과제로 부각된다(Lee and Yoo, 2024).
정부에서도 안전한 데이터 활용을 위해 2020년 데이터 3법 개정을 통해 가명정보라는 개념을 도입하였으며, 정보주체의 동의가 없이도 통계적 목적, 공익적 기록, 과학적 연구 목적에 한해서 데이터를 활용할 수 있는 법제적 근거를 마련하였다(Hwang, 2020; Kim and Jang, 2023; KISA, 2024).
가명정보가 도입되고 테이블 형태의 정형 데이터는 가명처리가 널리 활용되고 있으나, 민원 자료와 같은 비정형 데이터는 온라인 소통 채널 확장에 따른 데이터 증가에도 불구하고, 가명처리 기술과 실증 연구가 충분하지 않은 상황이다. 이에 따라 그 동안 공공 분야에서는 문장의 의미가 훼손된 단어 기반의 토픽 모델링 분석, 감성 분석, 통계적 특성 분석 등의 연구가 주를 이루었다(Rakhimzhanov et al., 2025; Park, 2020, Won and Yoo, 2016).
과거 텍스트 자료의 가명처리 방법으로는 정규 표현식을 활용하여 개인정보로 추정되는 단어를 대체하거나 삭제하는 방식으로 주로 처리되었으며, 최근 인공지능 기술의 발전으로 한글의 품사에서 명사를 추출하여 대체하는 가명처리 기법인 개체명 인식이 일부 연구에서 수행되었으며, 현업에서 주로 활용되고 있다(Seo et al., 2020; Jang et al., 2024; Kim, 2024; Sang and De Meulder, 2003). 개체명 인식 처리는 속도나 일정 조건내에서는 목적을 달성할 수 있는 장점이 존재하나, 문맥적 의미와 자연어의 다양성을 충분히 반영하지 못하여 정보의 손실, 대체 처리의 불완전성 등의 한계를 가지고 있다. 특히 현장성, 맥락성, 다양한 표현, 시·공간적 관련 정보가 혼재하는 교통 민원 데이터의 특성상 개체명 인식의 가명처리 효과는 제한적일 수밖에 없으며, 이는 현장의 데이터 활용 저하로 이어지고 있다.
한편, 최근 생성형 인공지능 기술의 급격한 발전과 텍스트 자료를 기반으로 하는 대규모 언어모형(LLM, Large Language Model) 등장은 이러한 한계를 극복할 수 있는 새로운 방법으로 평가 받고 있다(Vaswani et al., 2017; Thetbanthad et al., 2025; Bae et al,. 2025; An et al., 2024; Yermilov et al., 2023; Wang et al., 2025; Rakhimzhanov et al., 2025; Wandelt et al., 2024). 대규모 언어 모형은 데이터를 동시에 처리할 수 있는 병렬구조, 복잡한 정보간의 관계 학습, 확장 가능한 특성으로 주목받고 있으며, 민원과 같은 텍스트의 미묘한 언어적 구조를 파악하고 처리하는데 있어 효과적인 모형으로 판단된다(Asimopoulos et al., 2024; Nahid et al., 2024). 그럼에도 도시내 교통 시스템에 대한 중요한 정보를 포함하고 있는 민원 데이터를 활용하여 대규모 언어모형 기반의 가명처리 효과성, 정책적 활용 가능성에 대한 연구는 부족하며, 다국어 학습 모형이 아닌 한국어 특화 모형을 기반으로 하는 실증적 연구와 공공 행정에 적용 가능성 여부 등의 다층적인 관점에서의 연구는 전무한 상황이다(Rakhimzhanov et al., 2025; Park and Kang, 2024).
이에 본 연구는 공간적 범위로 국내 광역도시 중 하나인 대구시를 기반으로 도시 민원 데이터 중 교통 관련된 민원 데이터를 수집하였으며, 인공지능 기반의 가명처리 기법인 개체명 인식 모형, 대규모 언어모형 중 다국어 모형과 한국어 모형을 비교 분석하고자 한다. 모형별 평가 방식은 개인정보 보호 분야(KISA, 2024)에서 일반적으로 활용되는 데이터 유용성과 개인정보 보호라는 두가지 측면에서 평가하고, 지자체 교통 정책 수립에 실질적으로 기여할 수 있는 가명처리 전략을 제언하는 데 목적이 있다. 이러한 연구 결과는 향후 지자체, 공공기관에서 시민들의 의견을 수렴하여 정책수립이나 연구를 하는데 있어 기초 자료로 활용될 것으로 판단되며, 기존의 제한된 데이터 활용 영역을 확장하여 공공데이터 활성화와 데이터 기반 행정 활성화 측면에서도 의미 있을 것으로 기대한다.
선행연구
1. 개인정보 제도와 데이터 활용
대규모의 개인 데이터를 활용하기 위해서는 개별 정보주체의 동의를 받아야 활용이 가능하나, 2020년 8월 데이터 3법이 개정되면서 정보주체의 동의 없이 통계작성·공익적 기록보존·과학적 연구 목적에 한하여 데이터 활용을 할 수 있는 법제적 기반이 마련되면서, 다양한 분야에서 가명정보 활용을 위한 후속 연구들이 이어지고 있다(Hwang, 2020; KISA, 2024).
국내 데이터 산업내 개인정보 비식별 초기 연구는 다양한 비식별화 기법(마스킹, 총계처리, 범주화, 라운딩 등)을 적용하여 완전하게 제거된 익명 데이터를 빅데이터 플랫폼을 통해 교환할 수 있는 실증을 수행하여, 데이터 유용성과 개인정보 재식별 가능성의 시사점을 제시하였고(KISTI, 2017), 기술과 제도의 개선 필요성을 제언하였다. 또한 데이터의 비식별화 정도가 높아질수록 데이터의 유용성은 낮아져 연구의 목적을 달성할 수 없는 상황이 발생하므로 연구의 목적을 고려한 데이터 비식별화와 보호조치가 유연하게 적용해야 한다고 도출하였다(Lee and Song, 2016). 최근 공공 부문에서는 이러한 후속 조치로 지자체, 공공기관은 의무적으로 매년 평가받는 “공공데이터 제공 및 데이터 기반행정 평가” 제도내 가명정보 제공과 합성데이터 개방 실적을 배점 항목으로 반영하면서 공공에서는 의무적으로 개인정보의 가명처리를 할 수 밖에 없는 정책적 환경이 조성되었다(Ministry of the Interior and Safety, 2025). 본 연구는 관련 제도 및 가명정보 활용 가이드라인, 선행 연구에 근거하여 데이터 유용성과 안전성 두가지 측면에서 모형별 평가를 수행하고, 이를 실험 설계단계에 반영하여 활용하고자 한다(KISA, 2024; Yermilov et al., 2023; Walter et al., 2023).
2. 교통·민원 텍스트 연구 동향
급격한 도시화로 도시 문제가 복잡해지고 동적으로 변화됨에 따라 이러한 문제를 효율적으로 해결하는 것이 중요하며, 다양한 이해관계자들이 동의할 수 있는 정책을 수립하기 위해서는 다양한 시민들의 질의를 데이터 기반으로 과학적으로 처리하고 정책에 반영하여 과정의 정당성을 확보하는 데 있어 중요한 역할이 있다(Kim et al., 2021). 전통적으로 민원 데이터를 활용하여 키워드 분석, 주제 도출을 위한 토픽모델링 분석 등이 추진되어 왔으며(Won and Yoo, 2016; Park, 2020), 최근에는 개체명 인식 모형을 활용하여 민원 텍스트 자료내 포함되어 있는 지명 정보를 추출하여 주소로 변환한 후 공간적 특성을 분석하는 연구가 수행된 바 있으나, 연구의 목적과 분석 결과가 민원 정보를 공간적으로 분석하여 특성을 살펴보는 데 국한되어, 데이터의 안전성과 유용성을 평가하는 연구는 체계적으로 논의되지 못하였다(Park and Kang, 2024). 특히 교통 민원의 특성상 주소·차량번호·이름·상호명 등의 개인을 식별할 수 있는 정보가 다수 포함됨에도 불구하고, 기술적 한계로 인해 현장에 적용은 부족한 상황이다.
교통 분야에서는 민원 자료와 같은 텍스트 자료 외의 차량 이동궤적 자료, 자동요금 징수시스템과 차량 번호판 인식 데이터를 활용한 가명처리 연구가 일부 존재하며, 해당 분야에서 K-익명성·일반화·노이즈·합성·차등 프라이버시 등의 다층적인 개인정보 보호 연구가 축적된 점을 감안하면(Nergiz et al., 2008; Ghasemzadeh et al., 2014; Chen et al., 2020; Bhati et al., 2021; Shafaeipour et al., 2024, Walter et al., 2023), 현 시점에서 텍스트 자료인 교통 민원 데이터에 대한 체계적이고 다층적인 가명처리 연구가 필요하다고 판단된다.
3. 텍스트 데이터의 가명처리
텍스트 데이터의 개인정보 처리 방법은 전통적으로 정규표현식, 사전기반 대체처리, 마스킹 등 규칙 기반의 방법이 적용 되었으며, 간단하고 효율적인 장점이 존재하나 문장의 의미가 훼손되거나 개인정보가 아닌 정보까지도 비식별 처리되어 데이터의 유용성을 저하시킬 수 있는 문제를 가지고 있다(Seo et al., 2020). 이를 개선하기 위해 인공지능 기반의 개체명 인식 모형 도입 연구가 추진되어 왔으나, 개체명 인식 모형은 주로 영어 데이터를 대상으로 대다수 개발되었으며, 이는 공개 데이터의 대다수가 영어로 구성되어 있고, 한국어의 경우 별도의 시간과 비용이 소요되는 라벨링 작업이 필요하기 때문이다. 따라서 일부 연구자들이 한국어를 기반으로 개인정보를 식별하기 위해 개인정보 항목을 선정하여 데이터 구축 후 학습한 연구가 존재하며, 이를 통해 기존 정규 표현식이나 영어 개체명 인식 모델보다 우수한 성능 결과를 도출한 바 있다(Jang et al., 2024).
개체명 인식의 연구 트랜드를 살펴보면 초기 연구인 CoNLL-2003(Sang and De Meulder, 2003)은 영어와 독일어 텍스트 자료에서 사람, 조직, 지명, 기타 개체를 인식하는 개체명 인식 모형을 개발하였으며, 초기 연구임에도 높은 성능을 달성하여 모형의 실증 가능성을 입증 하였다.
한국어 데이터 기반의 연구로는 한국어와 영어가 혼용된 국내 의료기관의 전자의무기록에 대하여 기존 영문 비식별화 알고리즘과 번역기를 결합하여 자동 비식별화 개체명 인식 파이프라인을 구축한 바 있으며, 정밀도와 재현율, F1 Score에서 높은 성능으로 나타났다(Kim, 2024). 또한 한국어 텍스트 자료로 33종의 개체명을 정의하고, BERT(Bidirectional Encoder Representations from Transformers) 기반의 개체명 인식모형을 개발한 연구도 있으며(Jang et al., 2024), 기존의 지도학습 기반의 모형을 개선한 자가지도 사전학습 모형 방식을 활용하여, 별도의 라벨링 작업 없이도 개체명 인식 모형을 적용할 수 있는 가능성을 제시한 연구도 있다(Conneau et al., 2019). Seo et al.(2020) 연구에서는 문장 전체가 민감한 내용인지 우선 판별하고, 그 결과를 단어 단위의 개체명 인식에 추가하는 방식을 제안하였으며, 맥락에 따라 불필요한 가명처리를 줄이고 민감한 표현만을 우선 처리할 수 있도록 수행하여, 높은 성능을 달성하였다. 본 연구에서도 해당 선행연구의 아이디어를 바탕으로, 문장 의도를 기반으로 한 대규모 언어모델 합성데이터 생성 방식에 적용하여 새로운 가명처리 방법론을 제시하고자 한다.
최근 인공지능 발전에 따라 Vaswani et al.(2017)의 “Attention Is All You Need” 연구를 기점으로 트랜스 포머 기반의 대규모 언어모델과 관련된 가명처리 연구가 증가하고 있으며, 대규모 언어모델은 다양한 자연어 처리 과제에서 높은 성능을 나타내지만, 개체명 인식에서는 여전히 지도학습 보다 성능이 낮게 나타나, 이를 개선하기 위해 GPT-NER 모형을 제안한 연구가 존재하며, 이는 문장 생성시 개체명 앞뒤로 특수 토큰으로 마킹함으로써 라벨 정보를 출력 형식에 직접 반영하는 방식이다. 이는 기존의 개체명 인식 모형과 대규모 언어모형을 결합한 하이브리드 구조라는 점이 차별성으로 존재한다(Wang et al., 2025). Asimopoulos et al.(2024)는 CoNLL-2003 벤치마크에서 전통 모델과 트랜스포머(GPT-2)를 비교 분석하였으며, 분석결과 트랜스 포머 계열의 모형이 가장 높은 성능으로 나타났다. 반면 GPT-2와 같은 대규모 언어모델은 문맥은 잘 이해하지만 정밀도가 낮아 오탐 위험이 높은 것으로 나타났으며, 대규모 언어모델 기반의 가명처리시 주의와 추가 개선의 필요성을 도출한 바 있다.
대규모 언어모델을 활용한 합성데이터 생성 기술이 발전함에 따라 개인정보를 포함한 텍스트 데이터를 보다 안전하게 생성할 수 있는 연구도 증가하고 있으며, 텍스트 합성시 차등프라이버시 메커니즘을 결합하여, 민감 정보에 대규모 언어모델이 접근하지 않고도 합성 데이터 생성할 수 있는 프레임워크를 제안하여 대규모 언어모델 기반의 가명처리의 잠재적 가능성을 검증하였다(Nahid et al., 2024). 그 외에도 민감 정보가 다수 포함되어 있는 의료 분야에서는 미세 조정된 학습 모형으로 가명처리하여 성능 저하가 낮지 않음을 확인 하였고, 사전 학습 모델의 경우도 가명처리로 인한 성능 저하가 관찰되지 않은 것으로 나타났다(Vakili et al., 2023).
본 연구에서는 민원 데이터의 특수성을 고려할 때 한국어 데이터의 특성과 실제 지자체, 공공기관에서 활용될 경우 외부 데이터 반출이 없는 온프레미스(On-premise) 환경에서 수행되거나, 검증된 외부 연구기관에서 대다수 활용될 것을 감안하여, 대규모 언어모델 중 내부적으로 추론할 수 있는 소형 모델을 중심으로 검증하고자 한다. 언어적으로는 한국어 모형(An et al., 2024; Bae et al., 2025)과 다국어 모형간 비교 분석을 통해 민원 데이터 가명처리시 지명, 이름, 주소 체계 등에서 세부적으로 살펴볼 필요가 있을 것으로 판단되며, 모형별 비교 평가지표는 데이터 유용성과 개인정보 보호라는 두가지 측면에서 계량화 하여 살펴보고자 한다. 본 연구의 활용된 가명처리 모형의 주요 특징과 장단점은 Table 1에 요약하였다.
Table 1.
Comparison of text pseudonymization methods
4. 선행 연구의 한계 및 차별성
도시 내 교통 민원 데이터를 활용한 선행연구 대다수는 단어 기반 토픽모델링, 키워드 분석, 공간분석 등으로 지자체·공공기관 정책을 제언하는 연구가 수행되어 왔으나(Won and Yoo, 2016; Park, 2020, Park and Kang, 2024), 데이터 3법 개정 이후 데이터 개방 및 제공을 전제로 하는 비식별 처리 방법에 대한 본격적인 연구는 매우 제한적이다. 교통 분야의 가명처리 연구 또한 차량 이동 궤적이나 통행 데이터에서 특정인 식별을 방지하는 데 일부 연구가 수행되었을 뿐(Nergiz et al., 2008; Ghasemzadeh et al., 2014; Chen et al., 2020; Bhati et al., 2021; Shafaeipour et al., 2024; Walter et al., 2023), 도시 내 교통 민원 텍스트 자료에 대한 가명처리 연구에 대한 체계적이고 다층적인 논의는 부족하다고 판단된다. 또한 텍스트 마이닝 분야에서도 가명처리의 방법이 정규표현식이나 개체명 인식을 활용한 비식별화 연구는 축적되어 있고 현업에서 널리 활용되고 있지만, 최근 주목받고 있는 대규모 언어모델 기반의 가명처리 시도는 제한적이며, 특히, 한국어 특화 모형과 다국어 모형을 비교한 민원 데이터 적용 사례는 부족하다. 이에 본 연구에서는 Seo et al.(2020)이 제시한 문장 의도 판별 결과를 개체명 인식에 적용하는 아이디어를 교통 민원 데이터의 대규모 언어모델 기반의 가명처리 방법에 응용·확장하여, 서로 다른 가명처리 기법을 비교·평가하고, 도시 내 교통 민원 텍스트의 안전한 데이터 활용을 위한 가명처리 프레임 워크와 방법론을 제언하는 점이 차별성이라 할 수 있다.
연구 방법론
1. 데이터 수집 및 연구 방향
본 연구에서는 공간적 범위를 대구광역시로, 시간적 범위는 2023년 12월부터 2025년 3월까지 16개월로 설정하고, 도시 내 시민들이 접수한 교통 민원 텍스트 자료 4,889건을 대상으로 인공지능 기반의 가명처리 기법의 성능을 데이터 유용성과 개인정보 보호 측면에서 비교·분석하고자 한다. 연구의 절차는 데이터 수집, 전처리, 모형별 가명처리, 성능 평가로 구성되며, 데이터 전처리는 원활한 분석을 위해서 텍스트 내 특수문자와 공백을 제거하였다. 텍스트 길이는 민원 내용의 토큰(Token) 수 기준으로 중위값은 47개, 제3사분위수(75%)는 149개로 나타나며, 대다수가 짧은 단문 또는 중문 형태로 구성되어 있다. 반면 토큰 수가 400개를 초과하는 데이터는 외부 보도자료나 법령 등을 단순 인용하거나 붙여넣은 사례가 대부분인 것으로 파악되어(전체 데이터의 약 6.1%), 이를 이상치(Outlier)로 간주하여 분석 대상에서 제외하였으며, 연구의 절차는 Figure 1와 같이 수행하고자 한다.
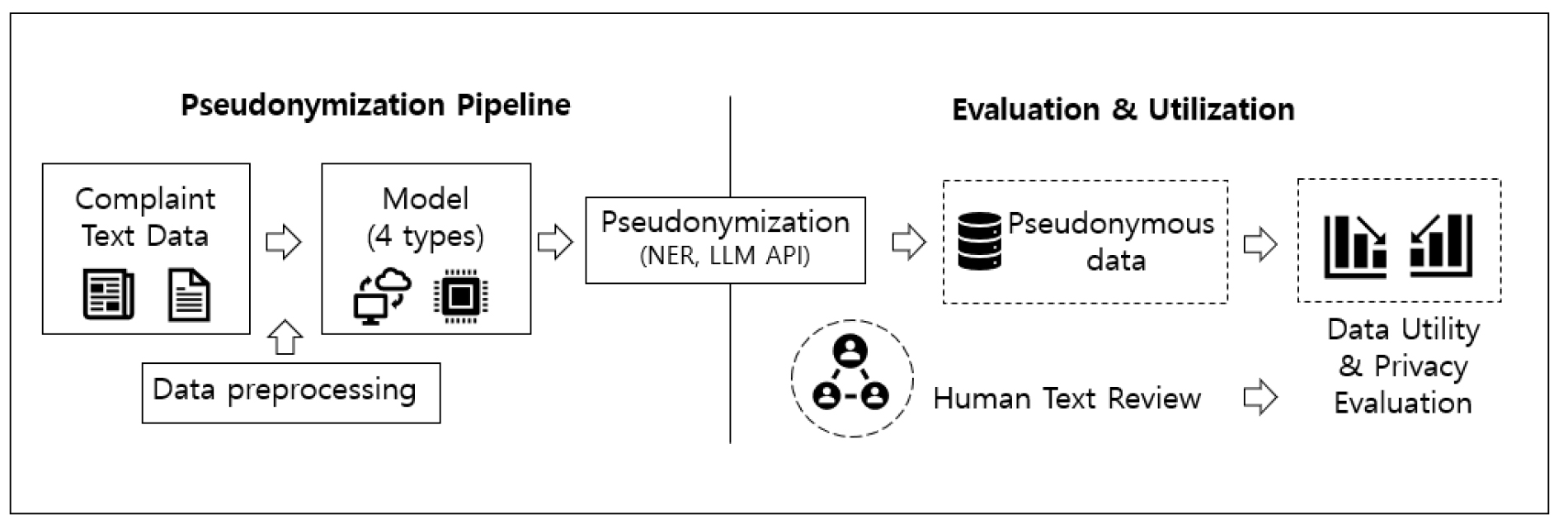
2. 인공지능 활용 모형
가명처리에 활용된 모형은 총 네가지 이며 세부적으로는 개체명 인식 모형, 대규모 언어모델 기반의 합성데이터 생성(다국어 언어 모형, 한국어 특화 모형, 한국어 특화 모형 기반 의도 기반 재조합)으로 구성되며, 세부적인 내용은 다음과 같다. 첫째, 개체명 인식 모형은 다국어 사전학습 언어모델을 기반으로 AI-Hub 플랫폼(aihub.or.kr)에 공개되어 있는 한국어 데이터로 파인튜닝한 세부 모형을 활용하였다. 해당 모형의 개체 인식의 범주는 PER(인물/이름), LOC(지명/지역), ORG(기관/단체/회사), MISC(기타 고유명사) 네 가지로 구성되어 있으며, 인식된 개인정보의 이름은 ‘홍길동’, 주소는 ‘OO구’, 전화번호는 ‘000-0000-0000 대표번호’와 같이 치환 된다. 이와 같은 방식은 텍스트 구조와 단어의 의미를 보존하면서 빠르고 효율적인 처리가 가능하다는 점에서 장점이 존재한다. 하지만 개체가 과대 또는 과소 마스킹 될 수 있으며, 문맥과 의도를 반영하지 못해 문장의 흐름이 어색하거나, 비속어·정치적 표현 등 추가적인 비식별 요소를 탐지하지 못하는 한계가 존재한다.
둘째, 대규모 언어모델을 기반으로 원본 텍스트의 사건·시간·공간·맥락을 유지하면서 프롬프트 엔지니어링을 통해 개인정보나 민감정보, 비속어 등을 제거하여 의미가 유사한 형태의 합성 데이터로 생성하도록 구성하였으며, 이에 적용된 모형은 중국 대규모 언어모델인 Qwen 2.5(7B 파라미터)와 한국어 특화 모델인 EXAONE 3.5(2.4B 파라미터)를 적용하고자 한다. Qwen은 Alibaba Cloud에서 개발하여 다국어 대응 능력이 뛰어나고, 대화형 자연어 처리에 특화되어 있으며, EXAONE은 LG AI Research에서 개발한 모델로, 대규모 한국어 데이터를 기반으로 문장 생성 및 의도 파악에 높은 성능을 보인다. 해당 모형들은 민원 원문을 입력하면, 문장의 흐름을 유지하면서 개인정보, 비속어, 정치·종교 표현 등 민감 표현을 제거하거나 치환하여 재작성 하게 된다. 예를 들어 “김철수씨가 대구 수성구 노변로 50에 자주 불법 주차했는데, 야! OOO”와 같은 문장을 “홍길동씨가 대구 수성구 인근에 반복되는 불법주차 하고 있다”는 식으로 의미는 유지하되 비속어와 개인정보가 제외된 표현으로 자연스럽게 변환하여 합성데이터를 생성하게 된다. Qwen과 EXAONE 모형은 상대적으로 모형 크기가 소규모 단위의 sLLM(Smaller Large Language Model)으로 공공기관, 지자체 내부 로컬 환경에서도 처리 가능하여 실제 현장에서 활용 가능할 것으로 판단되어 해당 모형을 적용하였다.
마지막으로 본 연구에서 제안한 모형인 “의도 재조합” 방법은 민원 제목을 작성자의 의도라 판단하고 원본 텍스트에서 핵심정보인 명사와 동사를 순서대로 추출한 다음, 작성 의도에 맞게 대규모 언어모델 기반의 프롬프트 엔지니어링을 통해 순서대로 문장을 재조합하여 합성데이터를 생성하는 방식이다. 이러한 과정에서 주소·이름 등의 개인정보와 비속어, 혐오표현 등을 처리하고 안전한 합성데이터를 생성 한다. 명사와 동사를 별도로 추출한 의도는 최대한 비속어와 혐오표현을 제거하기 위한 방법으로 이에 대한 검증도 동일한 한국어 모형을 통해 비교 분석하고자 한다. 본 연구에서 활용된 가명처리 모형의 특징은 Table 2와 같다.
모형의 성능평가는 데이터 유용성과 개인정보 보호의 두가지 관점에서 평가하고자 하며, 이는 정부의 가이드라인과 선행 연구에서 일반화되어 평가되는 요소이다. 세부적인 평가 방법은 유용성 측면에서는 원본 텍스트와 가명처리된 텍스트의 문장 단위의 의미 유사도를 파악하기 위해 문장 임베딩을 통해 텍스트를 벡터로 변환하여 코사인 유사도로 계산하여 비교하였으며, 단어 표현의 유용성은 단어 확률 분포를 기반으로 코사인 유사도 분석을 하였다. 개인정보 보호 측면에서는 별도의 모형을 통해서 평가하는 것은 기술적으로 한계가 존재하는 바, 정확한 성능 평가를 위해 관련 데이터 전문가 5인이 원본 텍스트와 가명처리된 텍스트 내 잔존 개인정보와 비속어, 혐오표현 등을 건별로 상호 확인하여 성능평가를 수행하고자 한다. 이를 통해 교통 민원 텍스트의 가명처리 성능을 비교 분석하고, 정책·실무 적용을 위한 시사점을 도출하고자 한다.
Table 2.
Comparative overview of models
3. 대규모 언어모델 프롬프트
대규모 언어모델은 모델의 성능뿐만 아니라, 프롬프트(Prompt) 구조와 설계 방식에 따라 출력되는 결과 품질에 큰 영향을 미치게 된다. 따라서 본 연구의 목적인 교통 민원 텍스트 자료의 원활한 가명처리를 위해 Table 3과 같이 프롬프트를 구성하였으며, 후속 연구의 재현성을 위해 공개하고자 한다. 두가지 처리 방식은 대규모 언어모델을 기반으로 한다는 점에서는 동일하나, 데이터의 구조와 목적에 따라 구분된다. 첫번째 방식은 민원 원문 전체를 입력하여 개인정보와 비속어, 혐오표현을 제거하거나 치환하면서 원본 텍스트의 주요 정보를 최대한 유지한 채 자연스러운 합성데이터 문장이 생성되도록 설계하였다. 이러한 프롬프트 설계는 연구자가 초기에 설계하고 결과물의 품질을 재확인하는 과정을 수차례 반복하여 최적의 프롬프트로 도출한 것 이다. 두번째 방식은 본 연구에서 제안하는 “의도 재조합” 방법으로 기존의 프롬프트를 데이터의 특성과 목적에 맞게 일부 변형한 것이다. 앞서 설명한 바와 같이 민원 제목을 작성자의 의도라 판단하고, 민원 텍스트로부터 명사와 동사를 순서대로 재조합하여 개인정보가 제거되고, 비속어 및 혐오표현 등이 제거된 새로운 합성 데이터 문장을 생성하는 프롬프트이다. 일반적인 문장 재생성 방법에 비하여 명사와 동사 추출시 불필요한 단어들이 소실되어 재구성할 때 한단계 안전한 내용으로 구성될 수 있을 것으로 판단하였다. 두가지 방식 모두 공통적으로 프롬프트 설계단계에서 개인정보 처리 원칙을 따르도록 되어 있으며, “의도 재조합”의 경우 명사와 동사를 순차적으로 재조합 할 수 있도록 역할을 추가로 부여하였다. 공통적인 프롬프트 내용을 살펴보면 (1) 민원 데이터의 주요정보(시간, 위치 등)는 보존 하며, (2) 주소는 “OO구”까지만 표기하고, 세부 주소는 제거한다. (3) 이름은 “홍길동”으로 치환하고, (4) 전화번호는 “000-0000-0000 대표번호”로 대체 처리하고, (5) 욕설 및 과격한 표현은 정중한 표현으로 순화하며, (6) 출력 문장은 원문과 유사한 길이로 유지 되도록 하였다. 마지막으로 (7) 결과 문장만 출력하도록 하여 불필요한 제목이나 부가 설명이 포함되지 않도록 제한하여 원본 데이터와 유사한 형태의 가명정보가 생성될 수 있도록 프롬프트 설계를 하였다.
Table 3.
Prompt design for LLM model
4. 평가방법
인공지능 기반 가명처리 방법에 대한 비교 분석은 데이터 유용성과 개인정보보호 관점에서 정량적으로 수행 하고자 하며, 여기서 데이터 유용성은 교통 민원 데이터 원본의 의미가 가명 처리 이후에도 어느 정도 보존되는지의 정도로 정의한다. 이를 위해 사전 학습된 다국어 문장 임베딩 모델을 활용하여 원본 텍스트와 가명 처리된 텍스트의 문장을 벡터로 변환한 뒤, 문장 단위의 의미와 단어 사용 분포를 코사인 유사도(Cosine Similarity, 이하 CS)로 비교·분석 하고자 한다. CS는 각 문장을 컴퓨터가 이해할 수 있는 벡터 형태로 표현한 후, 이를 정규화된 내적으로 계산하는 지표로, 텍스트 간 내용 유사성을 평가하는 대표적인 방법으로 널리 활용되고 있다(Kim and Lee, 2014). CS 값이 1에 가까울수록 원문과의 유사성이 매우 높은 것으로 해석되며, 선행연구에서는 일반적으로 0.6 이상일 때 동일 이슈·주제에 밀접하게 연관된 것으로 판단하는 기준으로 활용된 바 있다(Chibelushi et al., 2005). 세부적인 CS 계산 수식은 아래와 같다.
- u : 첫 번째 벡터
- v : 두 번째 벡터
- , : 각 벡터의 i번째 원소
- n : 벡터의 차원 수
※ 두 문장(원문, 가명정보) 벡터로 변경했을 때 방향이 얼마나 유사한지 평가(평균, 중위값 등)
- p : 첫 번째 문서의 단어 분포(벡터)
- q : 두 번째 문서의 단어 분포(벡터)
- , : 단어 t에 해당하는 빈도
- V : 단어 집합
※ 두 문서(원문, 가명정보)가 같은 단어(토큰) 비슷한 비율로 사용되는지 평가
개인정보 보호 관점에서 개인정보 잔여 검출 모형을 활용하여 평가하는 것이 기술적으로 한계가 존재하고, 결과가 왜곡될 것으로 판단되어, 데이터 관련 업무를 수행한 전문가 5인이 원본 데이터와 가명처리된 데이터를 건별로 상호 검수하는 과정을 통해 민원 텍스트 자료 내 잔여 개인정보(이름, 주소, 전화번호 등), 비속어 및 혐오표현, 정서적으로 불쾌하거나 부적절한 표현, 문장의 의미가 상실된 내용 등을 전반적으로 검토하여 이를 전체 비율로 계산하여 평가하고자 한다. 평가자의 수는 가명정보 처리 가이드라인(KISA, 2024)의 적정성 검토 권고 기준(최소 3명)을 상회하는 수준으로 구성하여 평가의 신뢰도를 확보하였다. 구체적으로는 지역 가명정보 활용지원센터 담당자 3인과 빅데이터 센터 내 공공데이터 활용 인력 2인을 포함한 총 5인의 전문가가 참여하였으며, 표본 조사가 아닌 전수 조사를 수행함으로써 분석 결과의 정확성을 확보하고자 하였다.
분석 결과
1. 데이터 유용성(Data Utility)
데이터 유용성 측면에서 가명처리된 민원 텍스트를 평가하기 위해 문장 의미 보존도와 단어의 표현 다양성을 지표로 활용하였다. 의미 보존도는 문장 임베딩 간 CS를 계산하였으며, 단어 표현 유사도는 단어 분포간 CS를 측정하여 비교·분석 하였다. 분석 결과, Table 4와 같이 개체명 인식 기반의 모델 1(RoBERTa) 문장 임베딩 유사도는 0.9845, 단어 분포 유사도는 0.9588로 가장 높게 나타났으며, 이는 원본 텍스트와 가명처리된 텍스트의 문장의 의미와 표현된 단어의 분포가 거의 동일함을 알 수 있다. 모델 3(Qwen 2.5)은 문장 임베딩 유사도가 0.9735, 단어 분포 유사도는 0.8610으로 대규모 언어모델 기반의 모형들 중에서는 가장 유사한 것으로 분석 되었으며, 한국어를 기반으로 하는 모델 2와 모형4는 각각 문장 임베딩 유사도 0.9476, 0.9388로 나타났으며, 단어 분포 유사도는 0.5857, 0.5102로 분석되었다. 이는 문장의 의미는 대체로 원문과 유사하게 생성 되었으나, 단어 분포에 있어 문장 표현이 적극적으로 재구성되어 단어의 분포가 변형되었음을 알 수 있다. 이를 통해 문장의 의미는 네가지 모형 모두 대체로 원본 텍스트와 유사하게 생성되는 반면, 한국어 기반의 대규모 언어모델인 EXAONE은 문장내 개인정보, 혐오표현, 비속어 등을 의미를 유지하면서 재표현하여 생성하는 과정에서 단어 표현의 다양성이 변형되는 것을 알 수 있다.
Table 4.
Data utility metrics (cosine similarity)
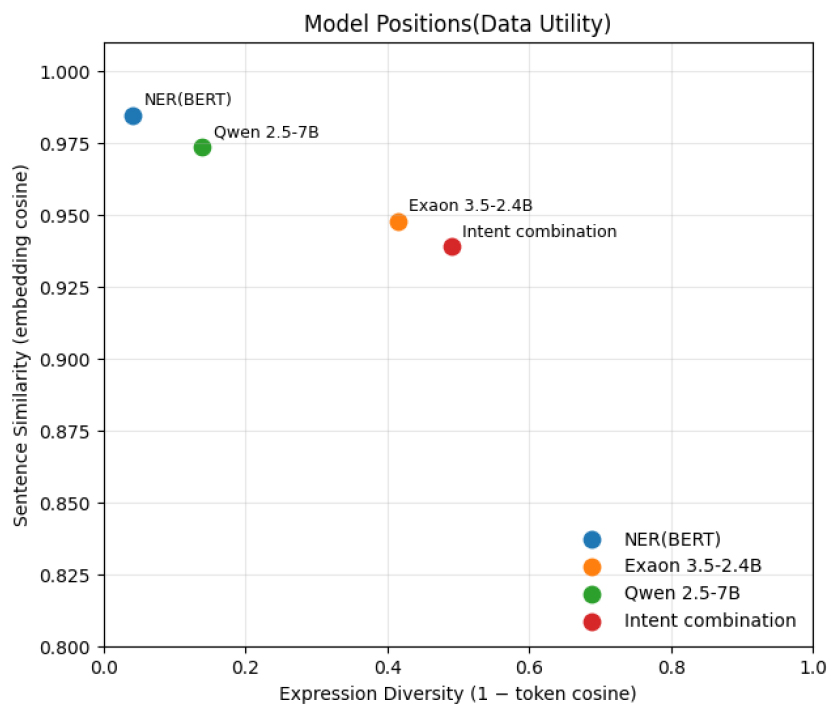
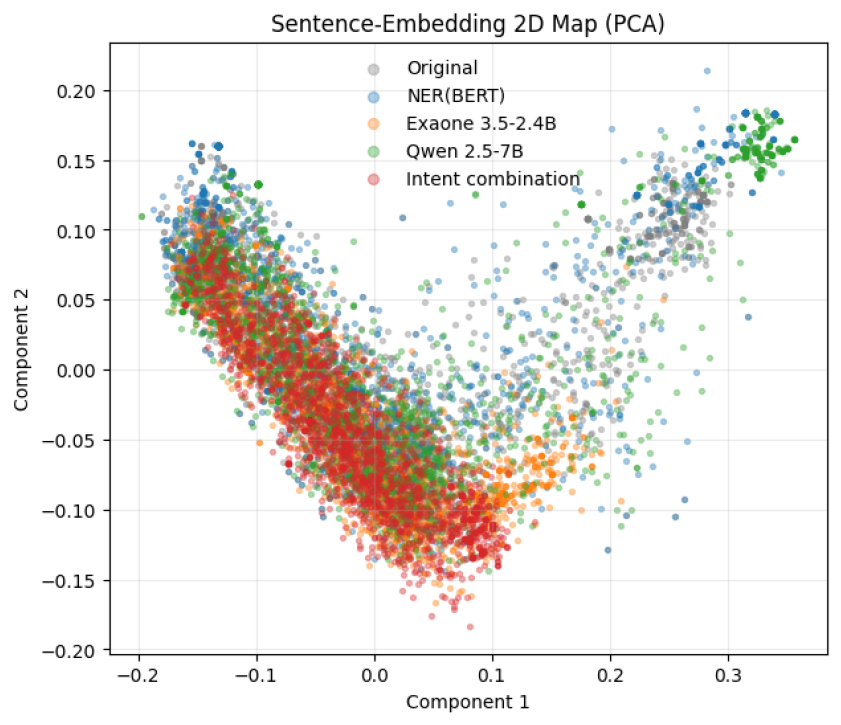
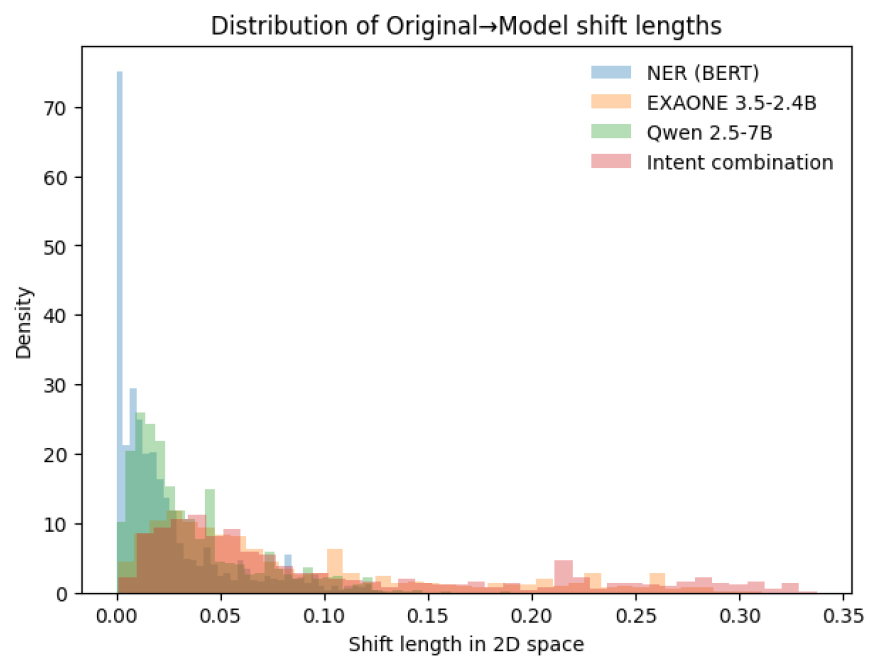
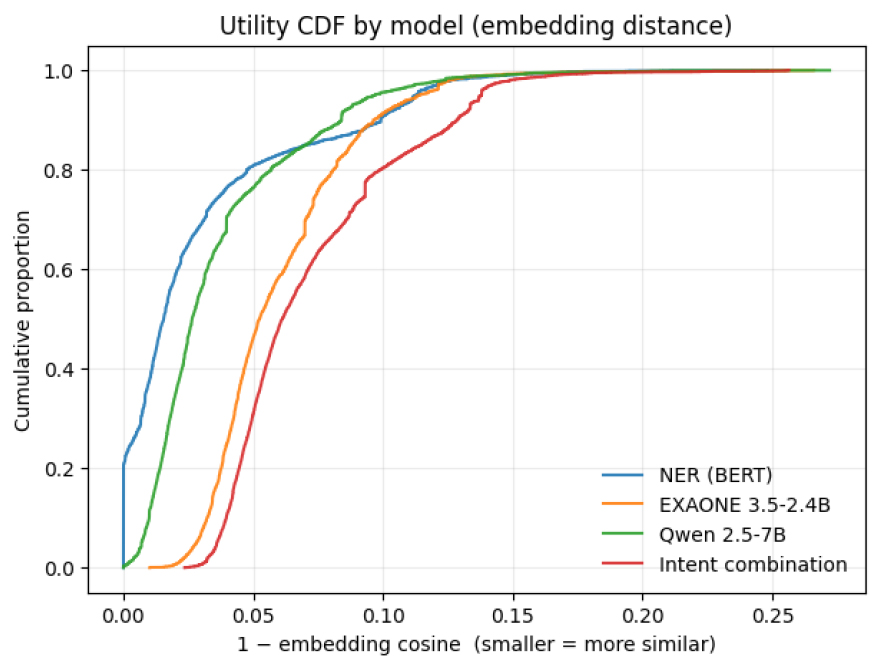
모형별 데이터 유용성을 시각적으로 표현하기 위해 아래 Figures 2, 3, 4, 5에 제시 하였으며, Figure 2은 문장 임베딩 유사도(세로축)과 단어 분포 유사도(가로축을) 통해 각 모형의 데이터 유용성을 시각화 한 것으로 모델 1(RoBERTa)와 모델 3(Qwen 2.5)의 경우 좌측 상단에 위치하여 문장의 의미와 단어 표현 모두 원본 텍스트와 동일하게 유지되는 반면, 모델 2(EXAONE 3.5)와 모델 4(EXAONE 3.5, 의도 재조합)의 경우 문장의 의미는 원본 텍스트와 유사하게 유지되는 반면, 표현 단어는 크게 재구성되는 경향을 확인하였다. 이러한 경향은 Figure 3의 문장 임베딩 2차원 분포 시각화에서도 유사하게 분석 되었으며, 원본 텍스트(회색)와 가장 인접한 영역에 모델 1, 3이 집중되는 반면, 모델 2, 4의 경우 보다 넓게 분산되어 시각화 되는 것을 알 수 있다. Figure 4 원본 텍스트 대비 각 문장이 얼마나 이동 하였는지를 2D 공간상 거리로 측정한 시각화 분포로, 모델 1은 0.05 이내의 근접 이동이 대부분을 차지하는 반면 모델 2, 4의 경우 이동폭이 상대적으로 크며, 이는 단어의 표현 다양성 확보가 크게 이루어 졌음을 재확인할 수 있는 자료로 판단된다. 마지막으로 Figure 5의 임베딩 유사도 기반 누적 분포에서도 모델 1이 가장 가파른 곡선을 보이며, 원본 텍스트와 유사도가 가장 높았으며, 모델 2, 4는 의미는 유지하면서도 단어 표현을 적극적으로 변경하는 방향으로 생성된 것을 확인할 수 있다. 또한 모델 3(Qwen 2.5)은 상대적으로 높은 의미 보존도로 분석되었으며, 한국어 모형 EXAONE을 기반으로 하는 모델 2, 4는 의미를 유지하면서도 단어 표현을 적극적으로 변경하는 방향으로 생성되는 것을 확인할 수 있다.
2. 개인정보 보호(Personal Information Protection)
개인정보 보호 측면에서는 인공지능 기반의 모형으로 평가를 수행하기에는 기술적 한계가 존재할 것으로 판단하였으며, 본 연구에서는 데이터 활용 전문가 5인이 가명 처리된 민원 텍스트를 건별로 상호 검토하는 방식으로 검증을 수행하였다. 평가내용으로는 (1) 잔여 개인정보, (2) 비속어·혐오표현, (3) 개인정보와 비속어·혐오표현이 함께 존재하는 경우, (4) 그 외 문맥이 불완전 하거나, 외국어 혼합 생성으로 문장을 이해하기 어려워 데이터 활용이 불가능한 경우로 분류 하였다. 연구의 책임자는 분류한 작업자들 간의 편차를 보정하기 위해 사전 교육 및 별도의 품질 검사를 수행하여 인적 오류를 최소화 하고자 하였다. 분석 결과, Table 5와 같이 모델 4(EXAONE 3.5, 의도 재조합)는 총 잔여 비율 5.27%(242/4,589)로 가장 낮게 나타나 개인정보 보호 측면에서 가장 우수한 것으로 분석 되었다. 그 다음으로 모델 2(EXAONE 3.5) 8.15%(374/4,589), 모델 1(RoBERTa) 8.54%(392/4,589) 성능을 보였다. 반면, 다국어 언어모형인 모델 3(Qwen 2.5)의 경우 총 잔여 비율이 17.67%(811/4,589)로 가장 성능이 낮았으며, 최근 개발된 대규모 언어모델 기반이라도 다국어 모형의 경우 한국어 가명처리에 있어 낮은 성능으로 분석되었다.
항목별로 살펴보면 개인정보 잔여율은 모델 4(EXAONE 3.5, 의도 재조합)가 5.01% 가장 낮았으며, 모델 2(EXAONE 3.5), 모델 1(RoBERTa), 모델 3(Qwen 2.5) 순으로 나타났다. 비속어·혐오 표현 잔여율은 모델 4(EXAONE 3.5, 의도 재조합)가 0.07%로 대다수 제거된 반면, 모델 3(Qwen 2.5) 1.11%, 모델 1(RoBERTa) 1.79%로 다국어 모형과 개체명 인식 모형은 한국어의 낮은 문맥 이해도와 규칙 기반의 처리로 인해 낮은 성능을 보였다. 또한 기타 범주(문맥 불완전, 외국어 생성 등)에서는 모델 3(Qwen 2.5)이 10.68% 기록하며, 다른 모델 대비 차이를 보였는데, 이는 민원 데이터가 모델 3을 통해 중국어로 변형되어 생성되거나, 문장의 의미를 알아볼 수 없는 형태로 생성되어 데이터 활용이 불가능한 것으로 분석되었다. 이상의 결과를 통해 한국어 대규모 언어모델을 기반으로 하는 EXAONE 모형이 가장 높은 성능을 보여주는 것을 알 수 있으며, 본 연구에서는 제안한 모델 4(의도 재조합) 방식이 추가됨으로써 개인정보와 비속어 처리에 더욱 효과적임을 확인할 수 있다. 반면, 다국어 언어모델인 모델 3(Qwen 2.5)는 언어 혼합 및 맥락 불완전성으로 인해 가장 낮은 성능을 보여주었으며, 모델 1(RoBERTa) 개체명 인식의 경우도 한국어 모형에 비하여 상대적으로 낮은 성능과 문장 표현에 있어 한계가 존재함을 알 수 있다.
Table 5.
Privacy preservation metrics (residual rates)
결론 및 향후 연구 방향
본 연구는 대구광역시 교통 민원 텍스트 자료를 대상으로 개체명 인식 모형과 다국어·한국어 대규모 언어모델을 활용하여 가명처리 방법을 비교·분석함으로써 지자체·공공기관에서 활용 가능한 교통 민원 데이터의 가명처리 전략을 제시하고자 하였다.
첫째, 데이터 유용성 관점에서 개체명 인식 모형(모델 1)과 다국어 모형(모델 3)은 문장 임베딩과 단어 분포 CS 유사도에 있어 가장 높게 나타나, 원문의 의미와 표현 유사성이 가장 높은 것으로 분석되었다. 이는 개체명 인식의 단어 치환 특성상 원문의 의미와 단어 표현을 대다수 유지하는 것으로 판단되며, 다국어 언어모형의 경우 한국어에 대한 미세한 특성을 인식하지 못하여 재표현하는 데 있어 한계가 존재하는 것으로 판단된다. 반면, 한국어 특화 모델인 EXAONE 기반의 모델 2, 4는 문장 의미는 대체로 유지하면서 단어 분포가 적극적으로 재구성되는 경향으로 보여, 개인정보나 비속어 등의 문맥에 맞게 재표현하는 과정에서 표현 다양성이 높은 것을 확인하였다. 둘째, 개인정보 보호 관점에서는 본 연구에서 제안된 모형(모델 4, 의도 재조합)은 잔여 개인정보·비속어 비율이 가장 낮게 나타나, 안전성 측면에서 가장 우수한 성능을 보였다. 동일한 한국어 모형(모델 2)의 경우도 개체명 인식 모형(모델 1)보다 낮은 잔여율로 분석 되었으며, 한국어 기반의 대규모 언어 모델의 문맥 이해도가 개인정보 및 비속어, 공격적 언어 표현 처리에 유리한 것으로 판단된다. 반면, 다국어 언어 모형(모델 3)은 개인정보·비속어 등 잔여율과 더불어 중국어 혼합 생성, 의미 왜곡 등의 문제가 존재하여 실제 현장에 적용하는 것은 어려울 것으로 분석되었다. 이상의 연구 결과를 종합하면, 개체명 인식 모형은 원문 구조와 통계적 특성을 보존한다는 점에서 장점이 존재하지만, 개인정보 및 비속어, 혐오표현 등의 의미적 처리에는 한계가 명확하다. 반대로 대규모 언어 모델 기반의 합성데이터 생성 방식은 표현 재구성을 통해 개인정보 보호 수준을 높이면서 원문의 의미를 상당 수준 유지할 수 있음을 확인하였다. 특히 본 연구에서 제안한 ‘의도 재조합’ 방법은 민원의 핵심 내용인 작성 의도와 주요 정보(시간·위치)를 중심으로 문장을 재구성한다는 점에서 중요한 의의를 가진다. 이는 시·공간적 정보와 정보주체의 활동 맥락이 포함되어 있어 재식별 위험이 높은 교통 민원 데이터의 특성을 효과적으로 처리할 수 있으며, 나아가 불필요한 개인정보나 비속어, 혐오표현 등을 선별적으로 제거하여 실무적 관점에서 데이터의 안전성과 활용성 간 균형을 확보한 대안으로 평가된다.
그럼에도 불구하고, 본 연구에서는 일부 한계를 가진다. 첫째, 데이터 유용성 평가에 있어 문장 임베딩 및 단어 분포 기반 CS 유사도 지표를 활용하였으나, 실제 정책 활용 과정에서 맥락 해석과 서비스 연결 등의 질적 요소를 충분히 반영하지 못한 것으로 판단된다. 둘째, 개인정보 보호 평가에 있어 기술적 한계로 인해 데이터 전문가를 활용하여 잔여 개인정보 등을 확인하였으나, 이는 평가자의 주관성이 개입될 여지가 있으며, 통계적으로 일반화하기에는 평가 인원이 제한적이라는 한계가 존재한다. 또한 비정형 텍스트 데이터의 특성상 정량적 지표(K-Anonymity)를 적용하여 위험도 산출함에 있어 방법론적 제약이 존재하여 이를 산정하는 추가 연구가 필요하다. 셋째, 본 연구에서 적용한 모형은 지자체·공공기관의 내부 인프라 환경을 고려하여 sLLM 모형을 적용하여 비교하였으며, 그 외에도 고성능 인프라가 구축된 중·대 규모의 대규모 언어모델(20~120B 이상)과 비교가 이루어지지 못하였으며, 한국어 특화 모형과 한국어 처리에 최적화 되지 않은 다국어 언어 모형을 직접 비교함으로써 모델 간 명확한 성능 비교에는 구조적인 한계를 가진다. 넷째, 연구의 목적에 따라 가명처리의 수준이 정해지며 세부 주소가 반드시 가명처리의 대상이 아닐 수 있으며, 불법 주정차 단속 등의 목적으로 주소 데이터가 활용될 경우 이에 대한 프롬프트 설계와 별도의 전처리가 필요할 것으로 판단된다. 마지막으로 분석 데이터는 시·공간적 특성을 포함하는 교통 데이터에 국한하여 연구가 수행되었으며, 도시내 다른 분야로 확장 가능성에 대한 추가 검증은 필요할 것으로 보인다. 따라서 향후 연구에서는 지자체 정책 담당자 평가를 결합한 질적 분석, 인공지능 기반의 잔여 개인정보 검출 도구 연계, 다양한 유형과 규모의 대규모 언어 모델과의 추가 비교, 교통 분야 이외의 도메인으로 확장 가능성을 검증함으로써 공공 부분에 있어 안전한 데이터 활용이 가능한 가명처리 프레임워크로 발전시킬 필요가 있을 것으로 판단된다. 특히 본 연구에서 제시한 한국어 특화 대규모 언어모델 기반의 “의도 재조합” 방법으로 가명처리에 대한 추가 연구가 진행된다면, 실무적으로 매년 시행되는 ‘공공데이터 제공 운영실태 평가’ 및 ‘데이터 기반행정 실태점검’의 가명정보 활용 및 합성데이터 생성 지표를 달성하는데 지자체와 공공기관에게 큰 도움이 될 것으로 기대하며, 공공 데이터를 활용한 거브테크(GovTech) 창업 및 산업 진흥에 있어 주요한 역할을 할 것으로 판단된다.
