

서론
선행연구
1. 코로나19와 회복탄력성에 관한 연구
2. 코로나19와 이동성에 관한 연구
3. 동적 시간 왜곡(DTW)과 응집형 계층적 군집화(AHC)를 활용한 연구
연구의 차별성
연구 영역 및 자료
그룹 및 단계 구분
1. 그룹 구분
2. 단계 구분
분석 방법
1. 동적 시간 왜곡(Dynamic Time Warping)
2. 응집형 계층적 군집화(Agglomerative Hierarchical Clustering)
3. 실루엣 스코어(Silhouette Score)
그룹별, 단계별 동적 시간 왜곡(DTW) 값 분포
결과 분석
1. 클러스터 범례
2. 그룹별, 단계별 클러스터의 평균 이용자 수 감소율
3. 그룹별, 단계별 클러스터의 지하철 역 분포 비율
4. 적용 방안
결론 및 한계점
서론
코로나19(코로나바이러스감염증-19) 발생으로 국경 폐쇄, 등교 중단 및 재택근무, 물리적 거리두기 등의 정책이 세계 각국에서 시행되었다(McKenzie and Adams, 2020). 국내의 경우, 2020년 2월 29일 외출 및 이동 자제, 타인과 접촉 최소화 등 사회적 거리두기를 시작으로 등교 인원 제한 및 원격 수업, 재택근무의 시행을 권고하였다(KDCA, 2023; Welfare News, 2020). 이에 따라, 코로나19 발생 초기에 사람들의 대중교통 이용량 및 통행량이 사상 최저 수준으로 감소하였다(OECD, 2020). 서울의 경우, 코로나19 초기 2020년 3월-4월에서 전년 동기간 대비 도로교통 약 8.8%, 지하철 약 40.8%가 감소하였으며(Cho et al., 2020b), Cho et al.(2020a)에 따르면 코로나19 초기 2020년 3월 전년 동기간 대비 평일 기준 도로교통 약 8.4%, 지하철 약 35.1%, 버스 약 27.5%가 감소하였다.
지하철은 서울 내 사람들이 이동을 위해 가장 많이 활용하는 수단으로, 2019년 기준 전체 통행의 약 41.6%가 지하철을 사용한다(Seoul Metropolitan Government, 2020). 이러한 통계를 종합하면, 가장 높은 수단 분담률을 가지는 지하철이 코로나19 기간을 거치며 가장 큰 이용자 감소율을 보여준다는 것을 알 수 있다. 이에 따라, 지하철을 중심으로 코로나19 기간 동안 사람들의 이동성 변화를 파악하는 것은 지속가능하고 회복력 있는 도시관리를 위해 중요할 것이다. 이에, 본 연구에서는 코로나19 유행 동안 서울 지하철 역을 중심으로 사람들의 이동성 회복 정도를 분석하고자 한다.
선행연구
코로나19 기간 동안 통행 변화에 관한 연구는 세계 각국에서 진행되어오고 있다. 본 연구는 서울 지하철 이용자 수의 장기적인 변화를 시계열로 분석함으로써 코로나19 유행 동안 사람들의 이동성 회복 정도를 역을 중심으로 평가하는 데에 목적이 있기에, 코로나19와 회복탄력성, 코로나19와 이동성, 동적 시간 왜곡(Dynamic Time Warping)과 응집형 계층적 군집화(Agglomerative Hierarchical Clustering)에 관한 연구를 중심으로 관련 문헌 고찰을 수행한다.
1. 코로나19와 회복탄력성에 관한 연구
코로나19와 회복탄력성 관련 연구로, Liu et al.(2023)는 중국 베이징의 모바일 통신 데이터를 활용하여 코로나19 동안 인간 이동성의 회복탄력성을 정량화하는 통합 프레임워크를 제시하며, 성별과 연령층별 통행의 회복탄력성 차이를 분석하였다. 해당 연구에서 코로나19 동안 이동성의 회복탄력성은 여성이 남성보다 지속적으로 낮은 것을 보여주며, 중국의 엄격한 통행 제한 정책이 해제된 후 고령층에서 가장 낮은 회복탄력성을 나타내는 것을 보여준다. Choi et al.(2024)는 코로나19 동안 스마트카드 데이터를 활용하여 서울 지하철의 회복탄력성을 월 단위로 분석하였는데, 해당 연구는 코로나19로 인한 대중교통 이용률의 충격 및 회복 패턴이 지역의 사회경제적 특성에 따라 차이가 존재함을 보여준다. Wang et al.(2024)는 코로나19 동안 미국 시카고의 승차 공유 데이터를 활용하여 서비스 이용의 회복력과 회복양상의 지역별 차이와 영향 요인을 인구 조사 구역(census track) 단위와 O-D 쌍 단위로 분석하였는데, 승차 공유 사용은 지역 간 불균형이 존재함을 보여주었다. 해당 연구에서, 높은 회복탄력성과 빠른 회복을 나타내는 지역은 주로 외곽지역으로, 거주지 밀도가 높고, 도로 밀도는 낮으며, 소수민족 비율이 높은 것으로 나타났고, 해당 지역은 다른 대안의 교통수단이 존재하지 않아 자동차에 의존적인 특징이 있는 것으로 나타났다. Wang et al.(2022)는 중국 쿤밍의 지하철 스마트카드와 결제 플랫폼 데이터로 지하철 이동성 회복 정도를 코로나19 기간을 3단계로 구분 후, 직장인, 노인, 학생, 기타 그룹으로 통행 그룹을 구분하고 개별통행을 추적하여 각 그룹의 회복 정도를 비교하였는데, 직장인 그룹은 이동 빈도와 거리가 회복되나, 노인 그룹은 이동 빈도가 감소하지만 활동 공간은 유지함을 보여준다. 연령대별로 4개의 그룹으로 세분화하여 코로나19로 인한 서울 대중교통 이용자들의 패턴 및 목적 변화를 분석한 연구인 Kim et al.(2023a)에서는 코로나19 전후 노인 그룹을 제외한 모든 그룹에서 통행량이 감소한 것을 보여주며, 노인 그룹의 경우 고령화로 인한 노인 승객의 절대적인 수 증가로 인한 것임을 보여준다.
2. 코로나19와 이동성에 관한 연구
코로나19와 이동성 관련 연구로, Niu and Zhang(2023)는 통신사 데이터를 활용하여 중국 선전시 지역 내 코로나19 이동성 개입 정책과 코로나19의 최초 감염 사례 공표일에 따른 4단계로 나누어 내부 이동량 변화를 비교하였다. 해당 연구는 코로나19의 첫 개인 간 감염 사례를 공표함으로써 상당한 통행량 감소가 발생했음을 보여주며, 봉쇄정책(lockdown intervention)과 2차 직장 복귀 명령(return-to-work order) 시행은 각각 즉각적인 통행량 변화 효과를 나타내었으나, 1차 직장 복귀 명령의 효과는 감염 공포로 인하여 미미하였음을 보여준다. 뿐만 아니라, 해당 연구는 이동성 개입 정책 효과의 지역별 차이를 보여주는데, 인접한 지하철 역이 환승에 편리할수록, 공항과의 거리가 가까울수록 이동성 개입 정책의 효과가 크게 나타났고, 도로에 대한 접근성은 이동성 개입 정책에 영향을 미치지 못하는 것으로 나타났다. Cho et al.(2020b)은 변화점 감지(Change Point Detection)와 접촉 지점의 위상학적 거리를 통해 팬데믹 초기 27주를 6가지 단계로 정의하였고, 서울의 시간 교통량 및 지하철 교통량, 코로나19 확진자 수, 마스크 착용률 데이터를 활용하여 도로교통과 지하철 이용량 감소율, 마스크 착용률 변화를 단계별로 분석하였다. 해당 연구는 코로나19 초기 지하철 이용 감소율이 도로교통 이용 감소율보다 최대 약 4배 더 높은 것을 보여주며, 이러한 통행 감소는 이동 제한 정책 시행되기 이전인 것을 고려할 때, 감염 위험으로 인한 자발적인 통행 감소의 결과인 것을 보여준다. 또한, 해당 연구는 감염으로부터 개인을 보호하는 수단으로, 초기 확산 단계에는 통행 감소를 사용하였다면, 재확산 단계에서는 마스크 착용으로 변화하였음을 보여준다. McKenzie and Adams(2020)는 구글 커뮤니티 이동 데이터로 국가별 코로나19 정책의 엄격지수, 6가지 장소 기반의 활동 패턴 변화를 분석하였는데, 교통시설과 거주지 인근 장소가 통행 제한, 경제적 지원, 백신 접종 등과 같은 코로나19 정책에 가장 기민하게 반응하는 장소로 나타났으며, 공원과 식료품 및 의약품 범주의 장소는 가장 둔감하게 반응하는 것으로 나타났는데, 이는 후자의 장소가 폐쇄 의무 장소에 해당하지 않아 방문 시간의 자율성이 확보되기 때문이다. 또한, 해당 연구는 장소 기반 활동 패턴 변화가 코로나19 확진자 수나 사망자 수보다 정부의 개입으로 더 크게 반응하는 것을 보여주었다. Joh et al.(2023)은 경기도 버스카드 데이터, 주간 코로나19 신규확진자 수, 인구, 사회 경제지표를 활용하여 대중교통 이용과 코로나19 확진자 수 변화 추이의 일치 정도를 측정하고, 일치 정도에 따른 지역별 차이를 분석하였다. 해당 연구는 경기도에서 인구 밀도가 높고, 유치원생 수가 많은 동에서 코로나19 확진자 수에 더욱 민감하게 반응함을 보여준다. 경기도 정류소별 교통카드 데이터를 활용하여 지역 특성과 통행 변화의 상관성을 분석한 Bhin et al.(2021)은 코로나19 초기 집단감염일을 중심으로 3단계(3일)로 구분하여 분석하였는데, 지역 특성 영향요인으로 총인구수가 많고, 면적이 좁고, 사업체 수가 많고, 상업 비율의 면적이 클수록 통행량이 감소함을 보여준다. 또한, 통행 변화 영향은 대규모 환승이 이루어지는 정류소에 집중적으로 나타나는 것을 보여준다. Nikiforiadis et al.(2022)는 웹 기반 설문조사와 인구, 면적 등의 데이터를 활용하여 그리스 도시 전역의 청년층을 대상으로 코로나19 단계별 통행수단 사용 빈도 변화와 영향요인을 분석하였고, 1차 봉쇄 전·후에서 대중교통 이용 빈도가 큰 폭으로 감소하였고, 보행 통행 빈도가 가장 높은 수준으로 증가하였음을 보여준다. 또한, Kim et al.(2023b)은 차량 개별 통행 데이터, 버스 통행 데이터, 코로나19 확진자 수 데이터, 토지이용 데이터를 활용하여 팬데믹 단계에 따라 코로나19 확진자 수가 개별 차량과 버스 통행 이동 패턴에 미치는 영향을 통행수요, 엔트로피, 모듈성 측면에서 분석하였는데, 해당 연구는 3가지의 이동성 패턴(통행 수요, 엔트로피, 모듈성)과 코로나19 확진자 수 사이에 멱법칙(power-law) 관계가 있으며, 코로나19가 진행됨에 따라 자가용과 대중교통 통행량이 처음 팬데믹에 직면했을 때만큼 많이 감소하지 않았음을 보여준다. 위의 연구들을 종합하면, 코로나19 초기 통행량 변화는 감염 위험으로 인한 자발적 감소와 정부의 이동 제한 정책에 큰 영향을 받으며, 팬데믹 유행이 지속될수록 정부의 이동 제한 정책 효과가 미미하여 짐을 시사한다.
3. 동적 시간 왜곡(DTW)과 응집형 계층적 군집화(AHC)를 활용한 연구
DTW와 AHC를 활용한 연구로, Lee and Leung(2023)는 시티바이크(Citi Bike) 모바일 어플리케이션 데이터를 활용하여 뉴욕시의 자전거 공유 시스템의 수요 패턴을 시공간적으로 분류하였고, AlMahamid and Grolinger (2022)는 가구의 에너지 소비량 데이터로 가전용 전력 부하 곡선을 군집화하여 고객 분류 활용방법론을 제시하였으며, Fransiska(2021)는 일별 코로나19 확진자 수를 활용하여 인도네시아 각 지역을 군집화하였다. Suris et al.(2022)는 대기 질 데이터로 지역별 PM10 패턴의 유사성을 DTW와 4개의 군집화 기법(K-means, Partitioning Around Medoids, Hierarchical, Fuzzy K-means)을 적용하여 분석하였는데, 계층적 군집화(Hierarchical Clustering)와 DTW를 결합하여 활용하였을 때 이상 관측소를 더욱 잘 구별함을 발견하였다. Radovanović et al.(2020)는 전력 시스템 데이터와 신경 과학 데이터에서 AHC와 다양한 거리 측정 방식을 결합하여 각 데이터에 가장 적절한 거리 측정 방식을 분석하였는데, 전력 시스템 데이터는 유클리드 거리(Euclidean Distance)와 피어슨 상관 계수(Pearson's Correlation Coefficient)를 AHC와 결합하여 사용하였을 때 좋은 성능을 보였고, 뉴런이 자극에 반응하는 스파이크 형태의 신경 과학 데이터(spike-train data)는 DTW와 AHC를 결합하는 방식을 활용하였을 때 좋은 결과를 보였다. 이처럼 기존 연구들에서 DTW와 AHC를 함께 활용하였을 때 우수한 결과를 나타냈고, 특히, 반응 시간이 상이한 특징을 갖는 데이터에서 DTW가 우수한 성능을 나타냈음을 확인할 수 있다.
연구의 차별성
세계 보건 기구(World Health Organization)는 2023년 5월 5일 코로나19의 국제적 공중보건 비상사태 종료를 선언하였고(WHO, 2023), 한국은 2023년 5월 11일 코로나19 심각 경보를 해제하며 일상 회복을 되찾게 되었음을 선언하였다(Office of The President Republic of Korea, 2023). 코로나19로 인한 비상사태 종료까지 전체 기간은 국내 첫 확진자가 발생한 2020년 1월 20일부터 2023년 5월 11일까지 약 3년 4개월이다. 하지만, 기존의 코로나19와 이동성, 회복탄력성을 주제로 수행한 연구 대다수는 코로나19의 전체 기간 중 일부만 진행되었다(Liu et al., 2023; Wang et al., 2024; Wang et al., 2022; Cho et al., 2020b; McKenzie and Adams, 2020; Joh et al., 2023; Nikiforiadis et al., 2022; Kim et al., 2023b; Lee and Leung, 2023; Fransiska, 2021; Bhin, 2021; Kim et al., 2023a; Cho et al., 2020a). 코로나19와 이동성, 회복탄력성에 관한 대부분의 연구에서 분석 기간은 최소 1주일에서 최대 1년 2개월이다. 이에 따라, 코로나19가 장기화됨에 따라 장기적인 관점에서 사람들의 이동성 회복과 변화에 대한 분석이 필요하다.
국내를 분석지역으로 분석한 연구 중 Choi et al.(2024)는 스마트카드 데이터로 기능적 주성분 분석(Functional Principal Component Analysis)과 AHC를 활용하여 서울 지하철역을 군집화하여 회복탄력성을 분석하였는데, 코로나19 발생 초기부터 2023년 5월까지 장기적으로 분석한 연구이다. 해당 연구는 코로나19의 장기간을 분석 대상 기간으로 설정하여, 군집화를 통해 분류된 지하철 역의 특성을 회귀분석을 활용하여 도출하였다는 의의를 갖는다. 하지만, 해당 연구는 월 단위로 데이터를 응집하여 코로나19 영향으로 인한 사람들의 이동성 변화 양상을 세밀하게 파악하지 못하는 한계가 있다. 코로나19 유행 동안 일별 지하철 이용자 수 변동성이 크게 나타나는데, 월 단위의 데이터 응집을 통해서는 이러한 변동성을 확인하기 어렵다. 또한, 주중과 주말의 분류 없이 하루 중 시간(Time Of Day)에 대한 월 단위의 데이터로 군집화함에 따라, 평일과 주말에서의 주된 이동성 양상 변화의 차이를 추출하지 못하는 한계를 가지며, 군집화 결과의 품질을 평가하는 지표가 부재하여 결과의 신뢰성을 설명하기 어려운 한계를 갖는다. 뿐만 아니라, 해당 연구는 이용자 규모를 고려하지 않고 역 전체를 군집화함에 따라, 이용량 차이가 발생시킬 수 있는 이용량 증가율의 특성을 고려하지 못하고 있으며, 분석 기간 전체를 AHC에 적용함으로써 해당 연구에서 분류한 팬데믹 단계에 따른 군집별 이동성 변화의 특징을 나타내지 못하는 한계를 지닌다.
이에, 본 연구에서는 서울 지하철 역을 중심으로 장기적 관점에서 코로나19 시기의 적정 단계를 정의하고, 단계별 및 지하철 이용자 규모별로 코로나19로 인한 사람들의 이동성 변화를 분석하고자 한다. 또한, 본 연구에서는 군집화 품질 측정 지표를 도입하고, 필수적인 통행이 가장 많이 발생하는 주중의 출근시간대(08-10시)를 분석 시간대로 설정하여 사람들의 이동성 변화를 일 단위로 세밀하게 파악하고자 한다.
연구 영역 및 자료
코로나19 동안 사람들의 행동 변화를 살펴보기 위해, 코로나19 발생 이전 연도(2019년 1월 1일)부터 사회적 거리두기가 전면 해제된 이후 시기(2023년 4월 30일)까지 서울교통공사에서 제공하는 서울 지하철 1-8호선의 일별 역별 시간대별 승·하차 인원 데이터를 사용하였다(Seoul Metro, 2023). Table 1에 나타난 바와 같이, 본 데이터의 시간대는 06시 이전, 06-07시, 07-08시, …, 22-23시, 23-24시, 24시 이후로 나뉘며, 1시간 간격으로 승차 및 하차 인원수를 나타낸다.
Table 1.
Example of data on the number of passengers boarding and alighting by station and time slot per day (Seoul Metro, 2023)
서울특별시는 2023년 1월 20일 의료기관, 약국, 사회복지시설 및 대중교통수단 내에서는 마스크 착용 의무를 유지하되, 그 외 실내 공간은 마스크 착용 권고로 전환하는 첫 실내 마스크 착용 의무 조정안을 발표하였고, 2023년 3월 20일 대중교통수단 및 약국, 마트, 역사 내 마스크 착용 의무를 해제하였다(Seoul Metropolitan Government, 2023). 이는 평균 확진자 수와 신규 위중증 환자 수가 대폭 감소하고 안정적 방역상황이 유지되고 있는 배경에서 시행되었다(Seoul Metropolitan Government, 2023). 이에 따라, 본 연구는 서울에서 대중교통수단을 포함한 실내 마스크 착용 의무가 전면 해제된 시기의 약 1달 후인 2023년 4월 30일까지를 분석 기간으로 설정하였다.
시간대별 승·하차 인원 데이터의 시간대별 이용자 수의 승차 인원과 하차 인원을 더하여 해당 역을 해당 시간대에 이용한 총인원을 분석에 사용하였으며, 본 연구에서 ‘이용자 수’란 승차 및 하차 인원을 더한 승객 수로 정의한다. 분석 기간인 2019년 1월 1일부터 2023년 4월 30일까지의 공통역은 232개소로, 본 연구에서는 232개의 역을 분석 대상 역으로 사용하였다.
그룹 및 단계 구분
1. 그룹 구분
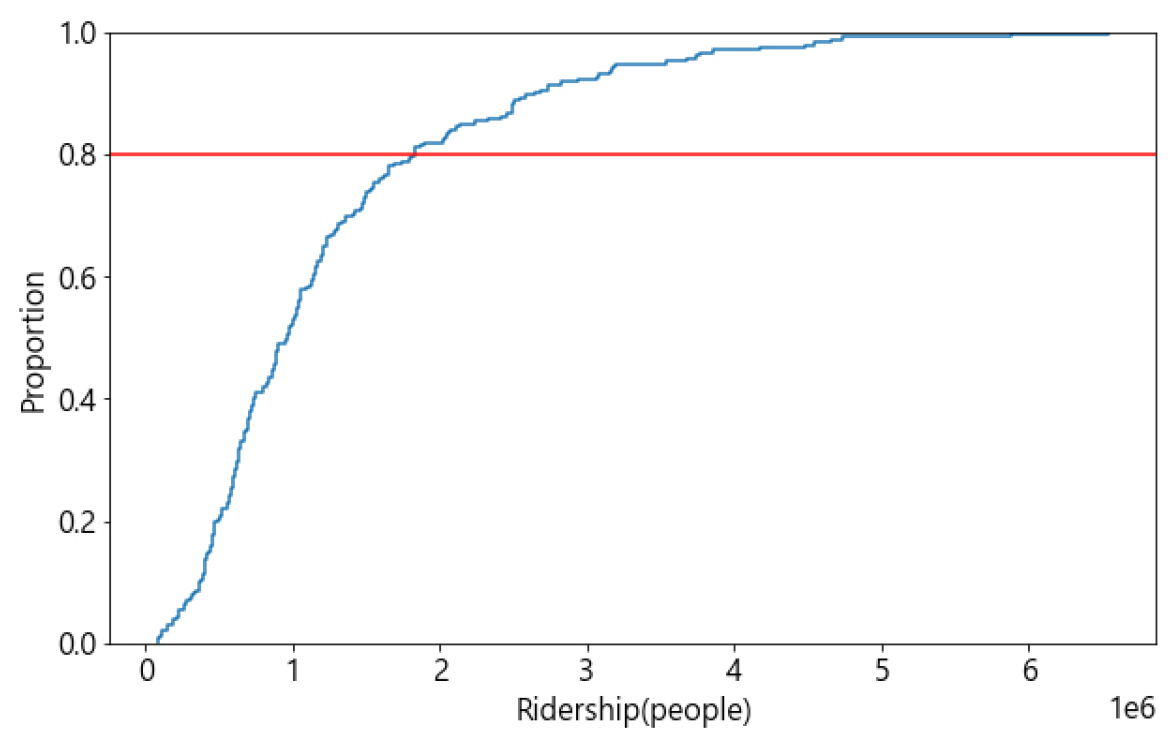
2019년 4월의 지하철 이용자 수 합의 상위 10개소와 하위 10개소를 비교해보면, 최소 18배, 최대 79배의 차이가 존재한다(Table 2). 본 연구에서는 통상 이용량의 차이가 감소율 산정 과정에 주는 영향을 최소화하기 위해, 지하철 이용자 수 규모에 따라 그룹을 나누어 역을 세분화하였다. Figure 1은 각 역의 2019년 4월 지하철 이용자 수의 합을 기준으로 나타낸 누적 분포 그래프로, x축 단위는 백만() 명이다. 지하철 누적 이용자 수의 기울기가 약 0.8에서 변화함에 따라, 지하철 이용자 수 기준 상위 20%에 해당하는 역(47개소)을 상위그룹으로 지정하고, 상위그룹 비율과 동일하게 하위 20%에 해당하는 역(47개소)을 하위그룹으로, 나머지 중위 60%(138개소) 역은 중위그룹으로 구분하여 분석을 진행하였다.
Table 2.
Top 10 stations (left), bottom 10 stations (right) by subway ridership in April 2019
2. 단계 구분
1) 이용자 수 감소율 시계열
이용자 수 감소율 시계열은 국내 코로나19 첫 확진자 발생일인 2020년 1월 20일(Infectious Disease Portal, 2023)을 시점으로 2023년 4월 30일까지의 평일의 기간을 코로나19 확진자 발생 이전 연도인 2019년의 날짜, 요일 및 공휴일을 고려하여 2019년의 가장 가까운 날짜와 매칭 및 나열하여 Equation 1, 2와 같이 산정한다. 예를 들어, 2020년 2월 7일 금요일, 2021년 2월 5일 금요일, 2022년 2월 11일 금요일, 2023년 2월 10일 금요일은 2019년 2월 8일 금요일과 매칭된다.
s.t. ,
여기서, 는 분석 대상 지하철 전체역을, 는 2020년 1월 20일부터 2023년 4월 30일까지의 일자 중 평일 일자의 집합을 나타내며, 와 는 각각 집합 와 에 속한 하나의 지하철 역과 하나의 일자를 나타낸다.은 역에서 일 08-10시의 지하철 이용자 수, 은 역에서 일과 매칭된 2019년도 날짜의 08-10시의 지하철 이용자 수를 나타내며, 는 역의 일 오전 출근 시간대(08-10시)의 이용자 수 감소율(%)을 나타낸다. 는 를 일자 순서로 나열한 역의 이용자 수 감소율 시계열이다.
2) 단계 구분
코로나19가 장기화되고, 시간이 흐름에 따라 이용자 수 감소율의 패턴도 변화한다. 이에 따라, 본 연구에서 설정한 분석 기간을 세분화하여 분석을 진행하는 것이 적절할 것이다. 팬데믹 기간을 세분화한 기존 연구로써, Joh et al.(2023)는 주간 코로나19 신규 확진자 수를 기준으로 팬데믹 기간(2020.01.20.-2021.04.18)을 6단계로 구분하였고, Kim et al.(2023b)는 해당 분석 기간(2020.02.18.-2020.12.31)에서 확진자 수의 급격한 증가가 나타나는 3개의 팬데믹 파동과 2개의 안정기로 구분하였다. 또한, Cho et al.(2020b)는 코로나19 신규 확진자 수를 활용한 변화점 감지(CPD)분석과 위상학적 거리를 활용하여 팬데믹 기간(2020.1.20.-2020.7.27)을 6단계로 구분하였다. 정부 정책이나 제한 명령에 따른 코로나19의 기간을 구분한 기존 연구로는, Nikiforiadis et al.(2022)가 국가적 봉쇄 조치에 따른 폐쇄 기간을 기준으로 해당 분석 기간(2020.3.23.-2021.5.14)을 3개의 기간으로 구분하였고, Wang et al. (2022)는 비약리학적 개입의 제한(재택 명령) 체계에 따라 분석 기간(2020.01.06.-2021.11.15)을 5단계로 구분하였다.
본 연구에서는 사회적 거리두기 세부 방침이 변화되는 시기와 월평균 지하철 이용자 수의 감소율의 변화를 바탕으로 분석 기간(2020.01.20-2023.04.30)을 Figure 2과 같이 3단계로 구분하였다. Figure 2는 분석 대상역의 지하철 이용자 수의 감소율을 월 단위로 나타낸 그래프로, 검정색 실선은 231개 역의 월단위 지하철 이용자 수 감소율 시계열의 평균값을 나타낸다. 지축역은 이용자 수 감소율이 약 –400%까지 도달하는 이용자 수 급증 양상을 보임에 따라 단계 구분에 있어서 제외하고 진행하였다. Figure 2에서 사회적 거리두기의 강화 및 완화 시기는, Table 3에 따라 사회적 거리두기가 이전보다 강화된 경우 해당 시기에 화살표와 (+)로 나타내었으며, 사회적 거리두기가 이전보다 완화되었을 경우 해당 시기에 화살표와 (-)로 나타내었다.
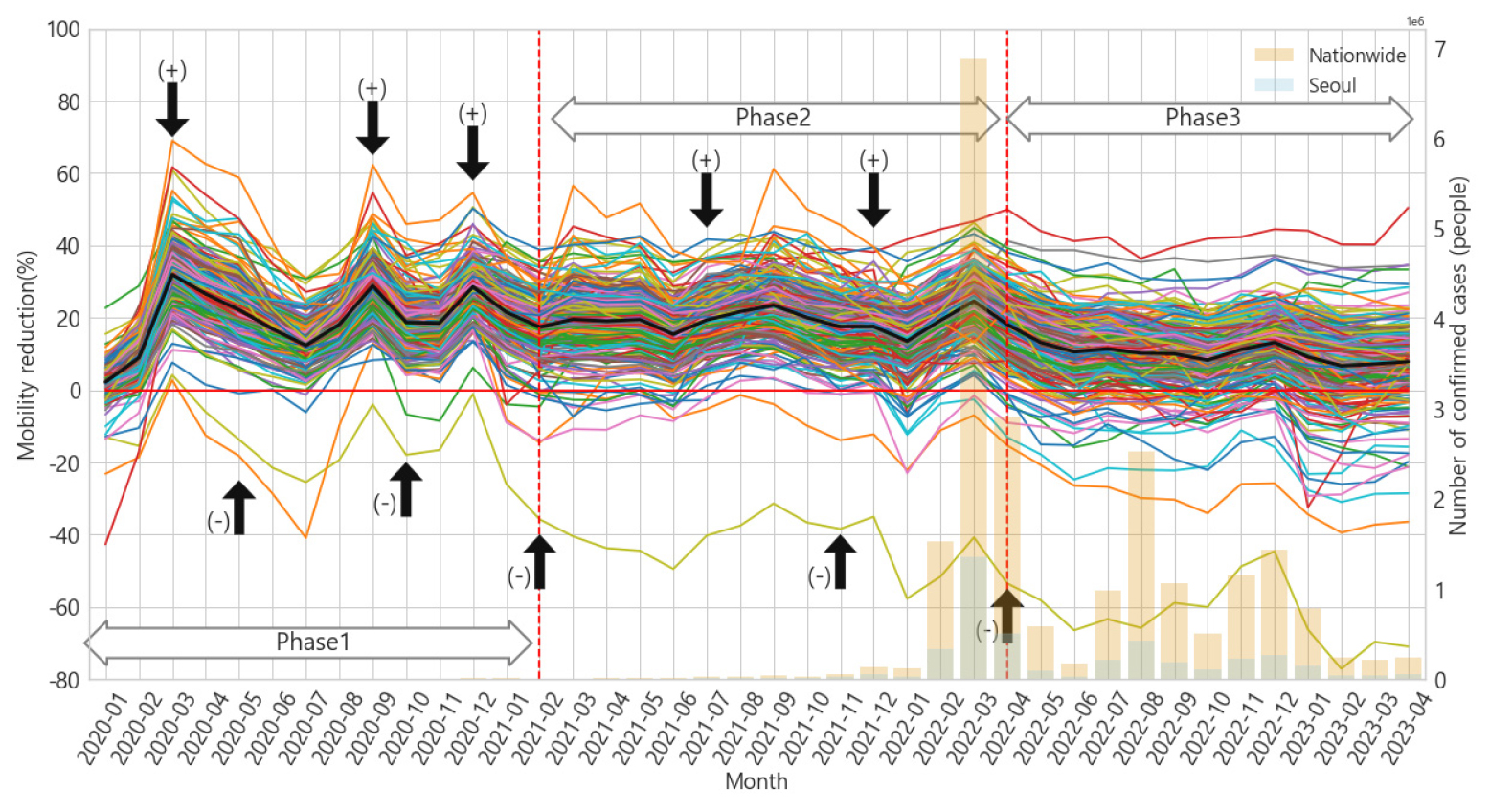
1단계(불안정기)는 2020년 1월부터 2021년 1월까지의 기간으로 사회적 거리두기 정책이 강화되고, 완화되면서 이용자 수 감소율이 거리두기 정책에 비례하여 큰 폭으로 변동하는 단계이다. 2단계(안정기)는 2021년 2월부터 2022년 3월까지의 기간으로 사회적 거리두기의 강화 및 완화에 따라 이용자 수 감소율이 비례하여 변화하지만, 사회적 거리두기 정책에 따른 이용자 수 감소율의 변동폭이 1단계(불안정기)에서처럼 큰 폭으로 나타나지 않는 단계이다. 3단계(회복기)는 2022년 4월부터 2023년 4월까지에 해당하며, 이 기간은 사회적 거리두기가 완전히 해제(2022년 4월)된 이후로, 점차 이용자 수 감소율이 회복되는 단계이다.
Table 3.
Social distancing policy changes (KDCA, 2023)
분석 방법
본 연구는 평일 아침 출근 시간대(08시-10시)의 지하철 이용자 수 감소율 시계열에 대하여, 단계별(1-3단계), 그룹별(상위, 중위, 하위그룹)로 DTW를 거리 측정 척도로 사용하여 AHC를 진행하였으며, 이용자 수 감소율의 일별 변동폭이 심하므로, 이를 완화하기 위해 5일 이동평균을 적용하여 DTW를 도출하였다. 평일 아침 출근 시간대(08-10시)는 퇴근 시간대와 함께 가장 많은 통행이 발생하는 시간대로, 퇴근 시간대는 여가 통행도 함께 발생하는 반면, 출근 시간대는 일상을 영위하기 위한 필수 통행이 주로 발생하는 시간대이므로 코로나19로 인한 파급 효과 파악에 적절하여 본 연구의 분석 시간대로 설정하였다.
1. 동적 시간 왜곡(Dynamic Time Warping)
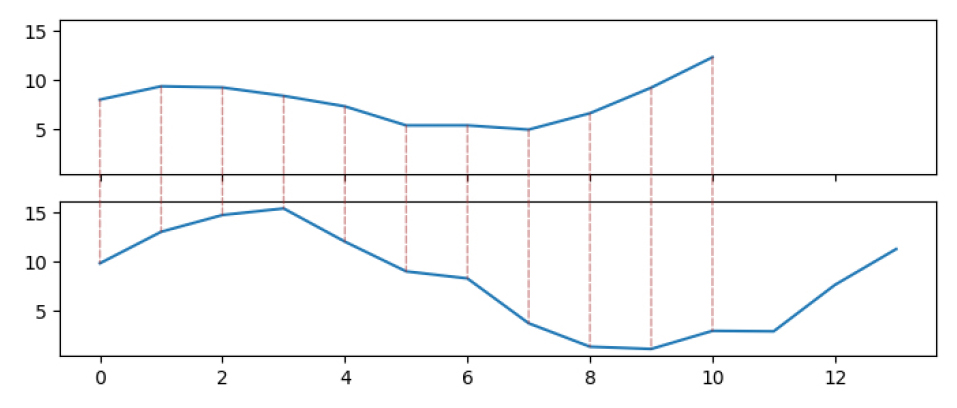
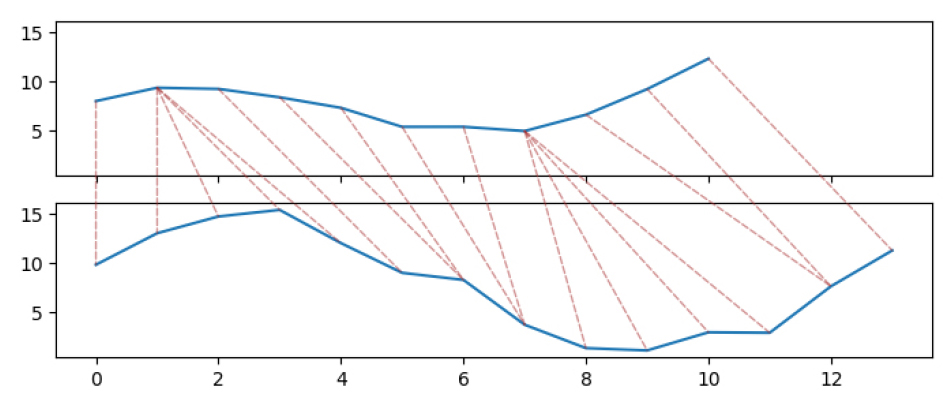
DTW는 핸드라이팅, 행동 인식, 음성 인식, 컴퓨터 비전과 같은 다양한 분야에서 사용되고 있다(Muller, 2007). DTW는 두 시계열(time series) 간의 특정 제약조건 아래에서 최적의 매칭 요소를 찾아 두 시계열 사이의 거리를 계산하는 방법이다. DTW는 두 배열 또는 시계열 사이의 거리를 계산하거나, 두 시계열의 길이가 다르더라도 유사성을 비교할 수 있으며, 시계열에 시간적 차이가 존재하더라도 유사한 패턴을 비교할 수 있다. 즉, 이벤트로 인한 영향이 시차를 두고 발생한 두 시계열의 패턴 비교가 가능하다. 또한, 1:1 매칭을 기반으로 하는 유클리드 거리보다 시계열의 모양을 더욱 잘 고려한다. Figure 3은 유클리드 거리를 활용하여 두 이용자 수 감소율 시계열(이대역, 한양대역)의 유사성을 측정하기 위해 매칭시킨 그래프이며, Figure 4는 DTW를 활용하여 매칭 시킨 그래프이다. 유클리드 거리는 시계열 요소 간의 엄격한 일대일 매칭을 하지만, DTW에 근거한 매칭은 두 시계열의 위상 변화를 고려하여 가장 유사한 요소와 매칭되는 것을 확인할 수 있다. 코로나19로 인한 지하철 이용량 변화 영향은 모든 역에서 동일한 시기에 발생하지 않고, 역마다 시차를 두고 이용량 변동이 발생한다. 이에 따라, DTW를 사용하면 지하철 역 간의 유사성을 더 정확하게 계산할 수 있다.
DTW는 두 시계열 사이의 최적 왜곡 경로 를 구성하는 것을 목적으로 하며, 는 최적 왜곡 경로 의 k번째 요소로, 두 시계열의 매칭 위치(i,j)까지의 최소 누적 거리를 의미한다. DTW의 계산과정은 다음과 같다. 길이가 같거나 다른 두 시계열 와 가 있을 때, 먼저 두 시계열 X, Y의 두 요소 와 의 거리 를 Equation 3을 통해 계산하고, Equation 4를 통해 N×M 비용 행렬(Cost matrix) 를 구성한다.
여기서, 를 초깃값으로 가지며, 두 시계열 사이의 최소 누적 거리(비용)를 도출하는 최적 왜곡 경로 는 다음과 같은 제약조건을 만족해야 한다:
끝점 제약(Endpoint constraint) : 왜곡 경로의 첫 번째 요소와 마지막 요소는 비용 행렬의 첫 번째 요소와 마지막 요소와 같다.
연속성 제약(Continuity constraint) : 왜곡 경로는 오직 한 번에 한 단계 만큼만 이동할 수 있다.
단조성 제약(Monotonicity constraint) : 왜곡 경로의 탐색 과정은 단조 증가해야 한다.
위 제약조건에 따라 동적 시간 왜곡 경로는 에서 시작하여 에 도달할 때까지 한 번에 한 단계 만큼만 양의 방향으로 움직이며, 왜곡 경로 중 비용을 최소로 하는 경로는 Equation 5와 같은 DTW를 도출한다.
subject to :
여기서, 는 가능한 모든 왜곡 경로 집합을 나타내며, 는 하나의 왜곡 경로를, 는 왜곡 경로 의 k번째 요소로 두 시계열의 매칭 위치(i,j)를 나타내고, 는 시계열 X의 매칭 위치 i, 는 시계열 Y의 매칭 위치 j, 는 왜곡 경로 의 길이를 나타낸다.
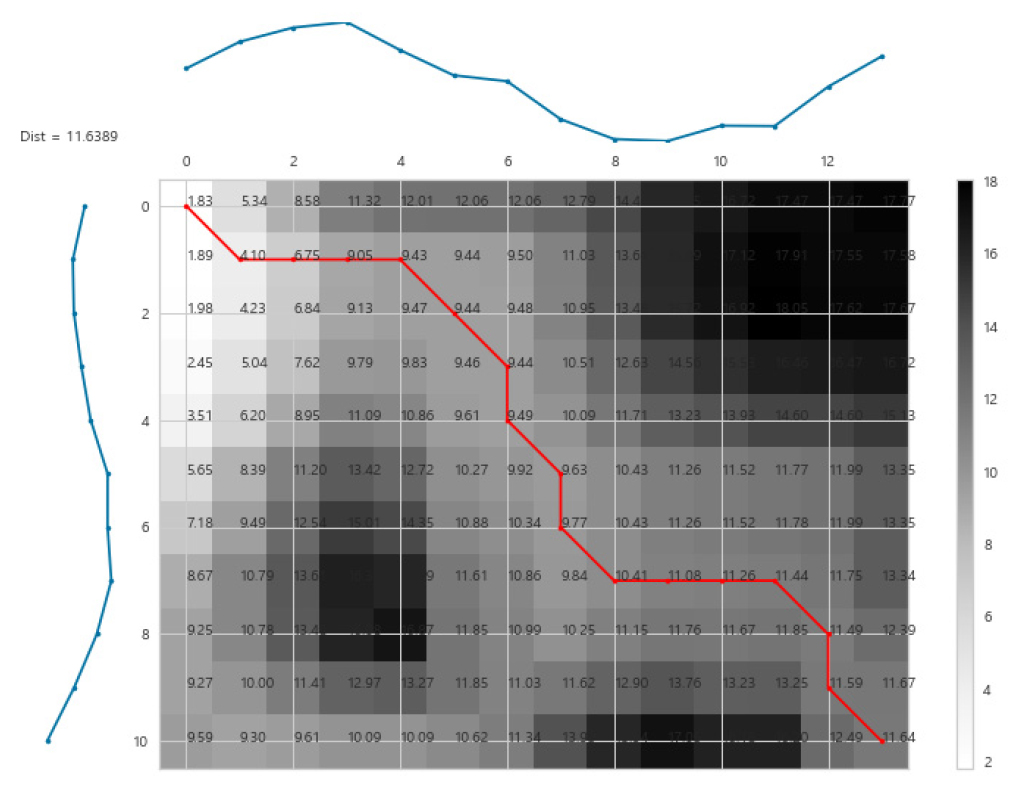
Figure 5는 두 시계열(이대역, 한양대역)의 비용 행렬과 동적 시간 왜곡 경로를 나타낸 것이다. Figure 5에서 각 셀의 숫자와 색상은 Equation 4를 통해 계산된 두 시계열(이대역, 한양대역) 요소까지의 누적 거리의 제곱근과 해당 값을 명암으로 나타낸 것으로, 비용 행렬 원소에 제곱근을 취한 값이라고 할 수 있다. 빨간색 선은 두 시계열(이대역, 한양대역)의 동적 시간 왜곡 경로(최적 왜곡 경로)를 나타내는데, 밝은 명암을 나타내는 셀을 중심으로 이동하는 것을 확인할 수 있다. 이는 동적 왜곡 경로가 두 시계열 사이의 거리를 최소화하며 이동하였음을 보여준다. 동적 시간 왜곡 경로의 마지막 값이 DTW로, 두 시계열의 유사성은 DTW 값인 약 11.64가 된다. Figure 5에서 이대역(좌측 시계열)의 첫 번째 요소와 한양대역(상단 시계열)의 첫 번째 요소가 매칭되며, 이대역의 두 번째 요소와 한양대역의 2, 3, 4번째 요소가 매칭됨을 알 수 있고, 이러한 시계열 요소의 매칭을 명확하게 시각화한 그래프가 Figure 4이다. Figure 4에서 동적 시간 왜곡을 통해 매칭된 그래프를 보면, 두 시계열의 모양(위상)을 따라 유사한 구간에서 최고점은 최고점과 매칭되고, 최저점은 최저점과 매칭되며 그 주변의 요소들은 시계열의 모양에 따라 비슷한 양상을 나타내는 요소와 매칭되는 것을 확인할 수 있다.
2. 응집형 계층적 군집화(Agglomerative Hierarchical Clustering)
군집화는 데이터를 유사한 군집으로 묶는 기법으로, 중심기반(centroid-based), 밀도기반(density-based), 연결기반(connectivity-based) 접근법 등 다양한 방법론을 활용한다. HC는 연결기반 군집화의 한 형태로, 사용자가 클러스터 개수 K를 미리 설정해야 하는 비결정적(nondeterministic)인 단점을 극복하기 위해 개발되었다(Charu and Chandan, 2013). HC는 데이터의 특정 분포를 가정하지 않으며, 사전에 군집 수(K)를 지정하지 않는 비모수적 군집화 기법으로, 데이터의 계층적 구조를 기반으로 군집화를 수행할 수 있어, 불균형 데이터에도 적용 가능하다(Jain et al., 1999). AHC는 HC 기법 중 하나로, 개별 데이터에서부터 시작하여 클러스터를 형성하는 상향식(bottom-up) 방법이다. AHC는 처음 각 개별 데이터를 개별 클러스터로 간주하며, 인접한 클러스터는 가장 큰 유사성(최소 거리)을 갖는 다른 클러스터와 병합하는 과정을 하나의 클러스터가 형성될 때까지 반복하며 수행한다(Malik and Tuckfield, 2019). 본 연구에서 하나의 데이터는 하나의 지하철 역에서 평일 오전 출근 시간대(08-10시)의 이용자 수 감소율을 일별로 나열한 시계열 데이터에 해당한다. AHC는 시계열 데이터 간의 거리행렬을 계산하여, 가장 가까운 거리를 갖는 두 개의 시계열 데이터를 병합하여 하나의 클러스터로 형성하며, 이후 새롭게 형성된 클러스터와 남아 있는 다른 시계열 데이터 간의 거리행렬을 갱신한다. 거리가 가장 가까운 두 클러스터를 병합하고 거리행렬을 갱신하는 과정을 반복한다. 이 과정에서 새롭게 형성된 클러스터와 시계열 데이터 사이의 거리 혹은 새롭게 형성된 클러스터 사이의 거리 계산을 위해 그룹 평균(Average linkage) 방법을 사용하였다. 그룹 평균은 서로 다른 두 클러스터에 포함된 모든 시계열 데이터 간의 거리 평균을 두 클러스터 간의 거리로 산정하는 방식이다(Malik and Tuckfield, 2019). 계산식은 Equation 6과 같으며, 는 시계열 데이터를, 는 클러스터를 나타내고, 이다. 는 각 클러스터 에 포함된 시계열 데이터의 갯수를 나타낸다.
DTW와 AHC를 함께 활용함으로써, 시계열 데이터(지하철 역) 간의 시차와 패턴을 고려한 유사성(거리) 측정이 가능하고, DTW로 계산한 유사성을 AHC에 직접 적용하여 차례로 병합해나가며 시계열 데이터를 군집화할 수 있다. AHC 없이 DTW를 단독으로 활용하면, 군집화 기법이 제외되게 되므로 비슷한 유사성을 갖는 지하철 역들을 군집화하지 못한다. 물론, 군집화 기법을 사용하지 않고, 시계열 데이터 간의 유사성을 기준으로 역을 정렬할 수도 있지만, 이를 위해서는 기준이 되는 역을 임의로 설정해야 하며, 분석자의 기준에 따라 임의의 척도로 그룹화해야 하는 문제가 발생할 수 있다. 본 연구는 이러한 임의성을 감소시키고 군집화하기 위해 DTW와 함께 AHC를 활용하였다.
3. 실루엣 스코어(Silhouette Score)
클러스터 품질 평가 지표로 실루엣 스코어(Silhouette Score)를 사용하였다. 실루엣 스코어는 1986년 Rousseeuw가 제안한 군집화 결과 평가 척도로, 군집 간의 분리 정도와 군집 내 응집도를 동시에 고려하여 시계열 데이터 X가 클러스터 그룹 내에 얼마나 잘 위치하고 있는지를 측정하는 지표이다.
는 시계열 데이터 가 그에 해당하는 클러스터에 얼마나 잘 할당되었는지를 보여주는 값으로, 클러스터 내부 평균 거리라고 할 수 있다. 여기서 는 시계열 데이터 가 속해있는 클러스터를 나타내며, 는 클러스터 에 속한 시계열 데이터의 갯수를 나타낸다. 는 시계열 데이터 와 가장 가까운 거리에 위치한 외부 클러스터에 소속된 시계열 데이터와의 평균 거리라고 할 수 있다. 여기서 , 는 시계열 데이터 가 각각 속해있는 클러스터를 나타내며, , 는 각 클러스터 , 에 속한 시계열 데이터의 갯수를 나타낸다. 는 시계열 데이터 의 개별 실루엣 스코어를 나타낸다.
군집화의 정확성과 품질 평가를 위해 시계열 데이터 전체의 평균 실루엣 스코어 를 지표로 사용하며, 군집화 품질 평가에서 실루엣 스코어는 시계열 데이터 전체의 평균 실루엣 스코어 를 의미한다. 실루엣 스코어 는 1에 근접할수록 잘 분할된 군집화를 의미하며, -1에 근접할수록 클러스터가 잘못된 방식으로 할당된 것을 의미하고, 0에 가까우면 클러스터가 특색이 없거나 클러스터 사이의 거리가 중요하지 않은 것을 의미한다(Rousseeuw, 1987).
여기서, R은 전체 시계열 데이터셋을, N은 전체 시계열 데이터의 갯수를 나타낸다.
실루엣 스코어 에 따른 클러스터의 품질과 정확성의 기준은 다음과 같다: 0.71 – 1.00(강력), 0.51 – 0.70(좋음), 0.26 – 0.50(약함), 0 – 0.25(나쁨) (Kaufman and Rousseeuw, 2009)
또한, 실루엣 스코어 는 군집화의 품질을 평가할 뿐 아니라, 적정한 클러스터의 개수를 알려주는 지표이기도 하다. 일반적으로 가장 큰 실루엣 스코어 를 나타내는 곳에서 최적 클러스터의 수로 고려할 수 있다.
그룹별, 단계별 동적 시간 왜곡(DTW) 값 분포
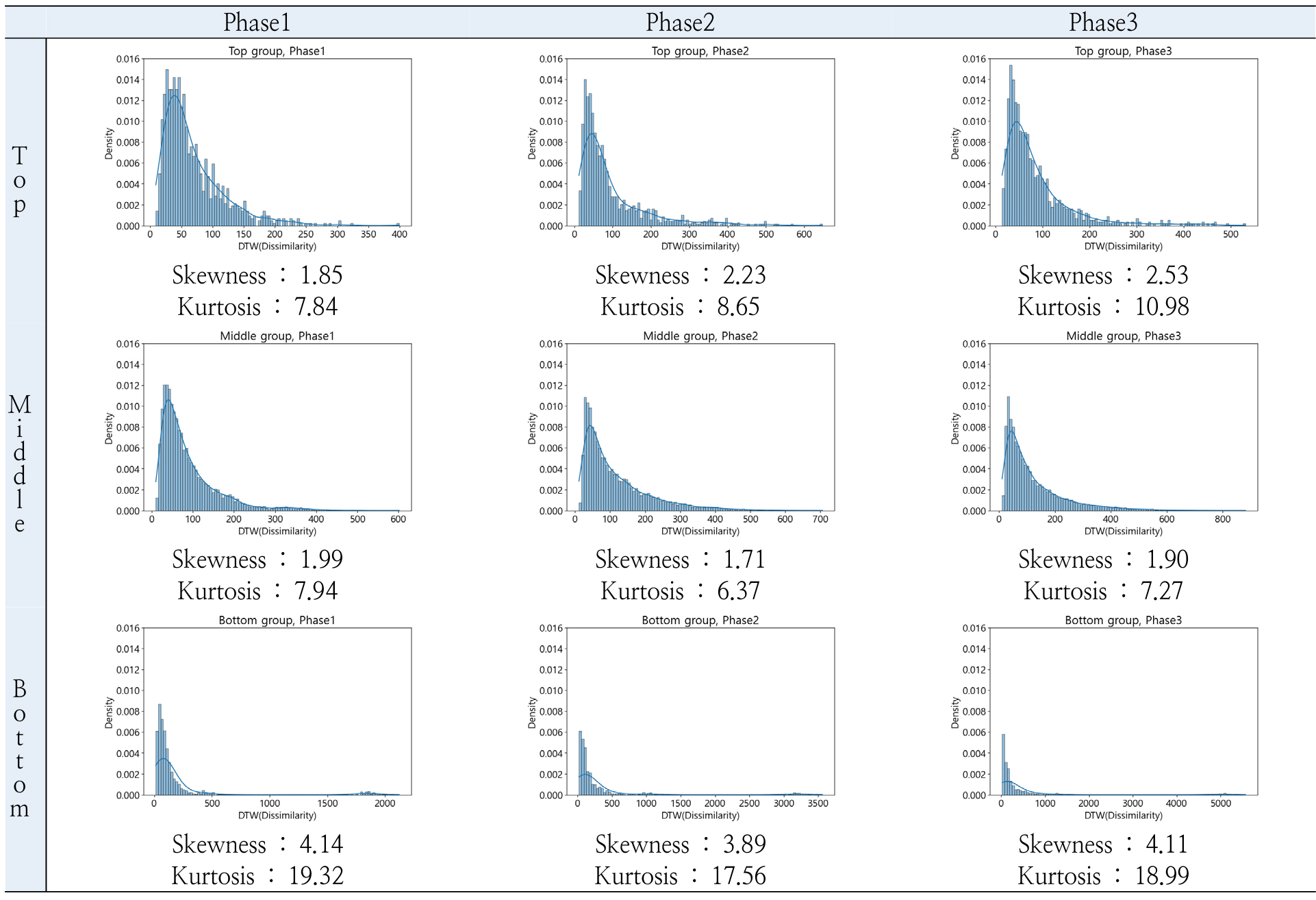
Figure 6은 각 그룹에 속하는 지하철 역 간의 DTW 값의 분포를 그룹별, 단계별로 나타낸 그래프이다. Figure 6의 DTW 값은 군집화 시행 이전, 각 그룹과 단계에서 시계열 데이터 간의 DTW 값을 의미한다. 각 그룹 및 단계에서 모두 양의 왜도(Fisher-Pearson coefficient of skewness) 값을 가지는 오른쪽으로 치우친 분포(right skewed distribution)를 나타내며, 이는 오른쪽 꼬리가 더 길고, 분포의 대부분이 그림의 왼쪽에 집중되어 있는 형태를 나타낸다. 세 그룹 중 하위그룹에서 왜도와 첨도(Pearson’s definition of kurtosis)가 가장 크며, 이는 하위그룹에서 DTW 분포의 오른쪽 꼬리 부분이 왼쪽에 비해 더 길게 늘어나 있고, 두꺼운 꼬리를 형성하고 있음을 나타낸다. 한편, AHC는 데이터의 특정 분포 형태를 가정하지 않으며, 불균형 데이터에도 적용 가능하므로 계산된 DTW 값을 변형없이 AHC에 적용하였다.
결과 분석
1. 클러스터 범례
그룹별(이용자 수 규모에 따른 상위, 중위, 하위그룹), 단계별(1단계, 2단계, 3단계)로 AHC를 수행한 결과 분석 대상 지하철역은 2-6개의 클러스터로 묶이며, 각 클러스터의 명칭을 Table 4와 같이 정의하였다. 클러스터 1은 평균 이용자 수 감소율이 20% 이상이고, 그룹 내 평균 이용자 수 감소율이 가장 높은 클러스터로 설정하였고, 그룹 내 평균 이용자 수 감소율이 20% 이상인 클러스터가 없는 경우, 그룹 내 가장 높은 평균 이용자 수 감소율을 갖는 클러스터를 클러스터 2로 정의하고, 평균 이용자 수 감소율의 크기를 기준으로 뒤를 잇는 클러스터를 각각 클러스터 3과 클러스터 4로 정의하였다. 이는 통행량이 20% 이상 감소하는 현상은 도로 구조나 운영 변경으로 인한 통행량 감소 효과를 넘어서는 수치로(Rapid Transition Alliance, 2019), 경제 및 환경 요인을 포괄하는 교통 정책의 전환이 필요한 중요한 지표로 해석될 수 있기 때문이다.
Table 4.
Cluster legend











2. 그룹별, 단계별 클러스터의 평균 이용자 수 감소율
1) 평균 이용자 수 감소율 크기 분석
Figure 7은 그룹별, 단계별로 클러스터 된 각 클러스터의 평균 이용자 수 감소율을 범례에 해당하는 색상으로 구분하여 나타낸 그래프이다. Figure 7을 통해 클러스터 1과 2는 평균 이용자 수 감소율이 0보다 월등히 크다는 것을 확인할 수 있는데, 이는 곧 지하철 이용자 수가 2019년도 수준으로 회복되지 못한 클러스터임을 나타내며, 그 심각도는 클러스터 1이 가장 높다는 것을 나타낸다. 클러스터 3과 4는 평균 이용자 수 감소율이 0에 근접하거나 0보다 작은 결과를 나타내고, 이는 각각 지하철 이용자 수가 2019년도 수준에 근접한 회복을 보인 클러스터와 2019년도 수준 이상으로 회복한 클러스터임을 나타낸다. Figure 8은 각 단계에서 그룹 간 클러스터 차이를 명확하게 파악하기 위해, 1단계 클러스터 1의 그룹 간 비교(a), 2단계 클러스터 1의 그룹 간 비교(b), 2단계 클러스터 3의 그룹 간 비교(c)를 나타낸 그래프이다. Figure 8에서 동일 클러스터의 그룹 간 비교를 위해 상위그룹은 실선, 중위그룹은 파선, 하위그룹은 점선으로 표시하였다.
상위그룹은 1단계에서 클러스터 1의 평균 이용자 수 감소율이 중위, 하위그룹보다 낮으며(2020.02월, 2020.08월, 2021.01월 제외)(Figure 8(a)), 다른 그룹과 달리 1단계에서부터 클러스터 3이 존재한다(Figure 7). 2단계에서 2021년 12월 이전까지 클러스터 1의 평균 이용자 수 감소율이 타 그룹보다 낮다(2021.02월, 2021.03월, 2021.08월 제외)(Figure 8(b)). 3단계에서는 평균 이용자 수 감소율이 20%를 넘는 클러스터 1이 존재하지 않고, 2019년 수준 이상으로 회복된 특성을 보이는 클러스터 4 또한 존재하지 않았다(Figure 7). 즉, 상위그룹은 다른 그룹들보다 팬데믹 전체 기간 동안 이용자 수 감소율이 높지 않고, 2019년도 수준 이상으로 초과 회복한 클러스터가 없다는 특징이 있다. 결국, 상위그룹은 코로나19 기간 동안 이용자 수 감소율이 타 그룹보다 높지 않으며, 코로나19 후반부(3단계)에서는 이용자 수 감소율이 큰 그룹도 없었으나, 2019년 수준을 초과하여 회복된 그룹도 없었다.
중위그룹은 1단계에서 클러스터 1의 평균 이용자 수 감소율이 세 그룹 중 가장 높으며(2020.02월, 2020.08월, 2021.01월 제외), 상위그룹보다 최대 약 24%, 평균 약 12% 높다(Figure 8(a)). 2단계에서는 2021년 11월 이전까지 클러스터 1의 평균 이용자 수 감소율이 세 그룹 중 가장 높았으며(2021.02월, 2021.07월, 2021.08월 제외), 상위그룹 대비 최대 약 14%, 평균 약 5% 높다(Figure 8(b)). 2단계에서 클러스터 3의 평균 이용자 수 감소율 또한 세 그룹 중 가장 높았으며, 상위그룹보다 최대 약 10%, 평균 약 5% 높은 것으로 나타났다(Figure 8(c)). 3단계에서는 2019년도 수준 이상으로 회복한 특징을 보이는 클러스터 4가 존재하며, 특이 패턴 클러스터가 존재한다(Figure 7). 3단계에서 중위그룹의 클러스터 1은 하위그룹의 클러스터 1보다 평균 이용자 수 감소율이 낮으며, 중위그룹의 클러스터 4는 하위그룹의 클러스터 4보다 평균 이용자 수 회복률(음의 방향 감소율)이 낮았다(Figure 7). 즉, 중위그룹은 1, 2단계(2단계는 2021. 11월 이전까지의 기간)에서는 클러스터 1의 평균 이용자 수 감소율이 세 그룹 중 가장 높았으며, 3단계에서는 하위그룹의 클러스터 1보다 평균 이용자 수 감소율이 낮아졌다. 중위그룹 3단계에서 20% 이상의 심각한 이용자 수 감소율을 보이는 클러스터 1은 하위그룹의 클러스터 1보다 평균 이용자 수 감소율이 낮고, 초과 회복한 특성을 보이는 클러스터 4가 존재하지만, 하위그룹의 클러스터 4보다 평균 이용자 수 회복률은 낮았다.
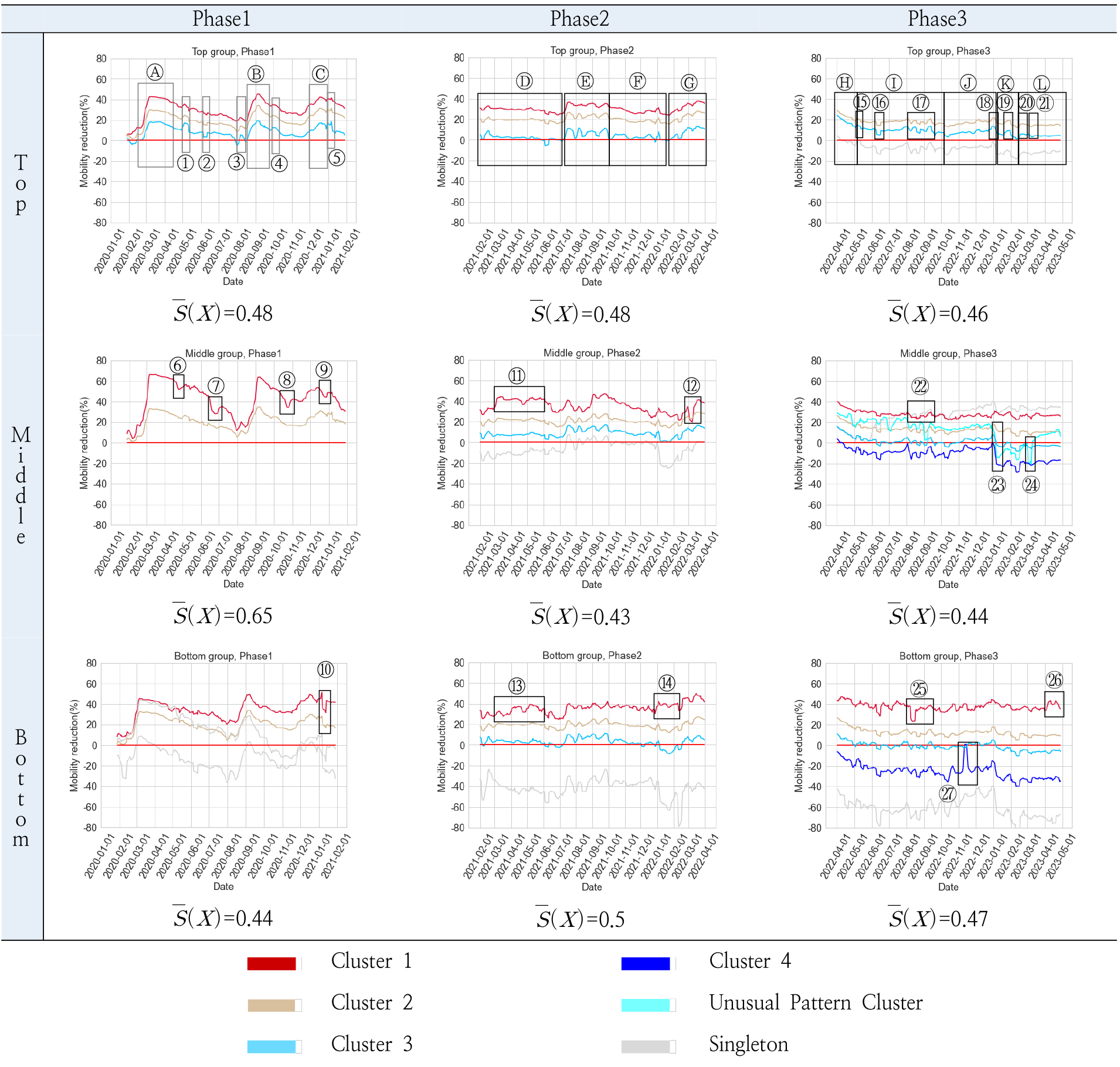
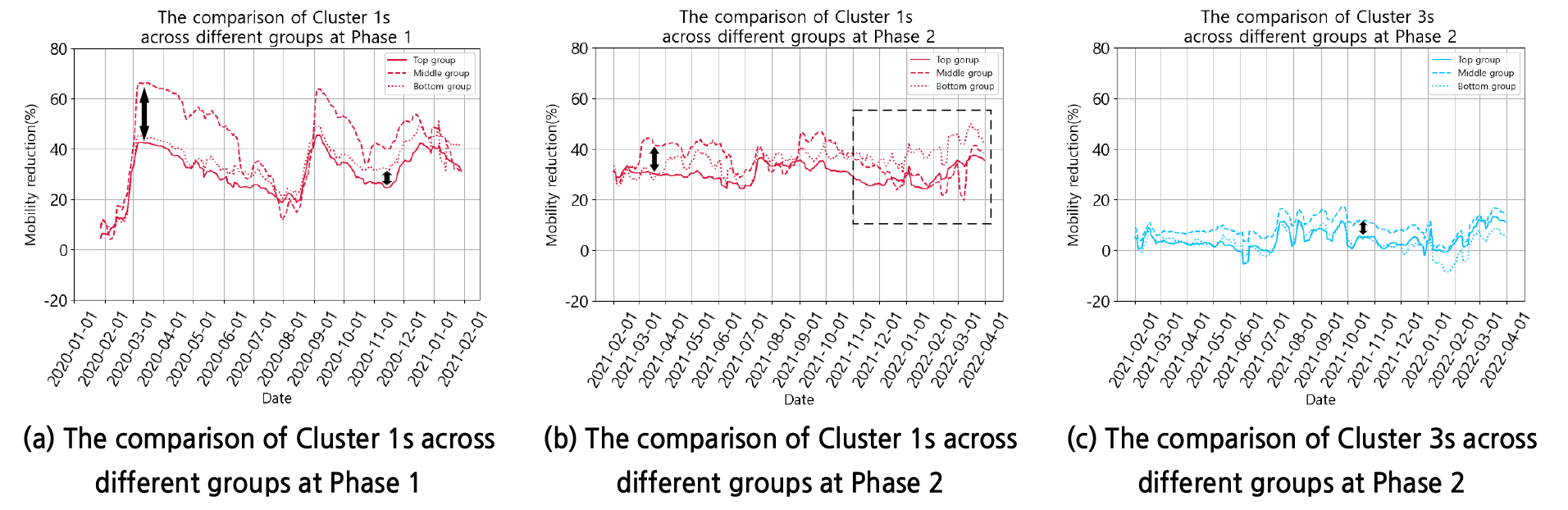
하위그룹의 경우 1단계에서 클러스터 1의 평균 이용자 수 감소율은 상위그룹과 중위그룹 사이의 감소율을 나타내는데, 상위그룹의 클러스터 1보다 최대 약 10%, 평균 약 3%로 근소한 차이만큼 높은 이용자 수 감소율을 보이며(Figure 8(a)), 산성역, 지축역, 마곡역이 각각 싱글톤으로 구성된다. 2단계에서는 2021년 11월부터 클러스터 1의 평균 이용자 수 감소율이 세 그룹 중 가장 높다(Figure 8(b) 네모). 2단계에서 지축역, 마곡역은 싱글톤으로 각각 구성된다. 3단계에서는 클러스터 1과 클러스터 4가 존재하는데, 클러스터 1의 평균 이용자 수 감소율은 중위그룹의 클러스터 1보다 높으며, 클러스터 4는 중위그룹의 클러스터 4보다 평균 이용자 수 회복률(음의 방향 감소율)이 높다(Figure 7). 즉, 하위그룹 3단계에서, 20% 이상의 심각한 이용자 수 감소율을 보이는 클러스터 1은 중위그룹의 클러스터 1보다 더 높은 이용자 수 감소율을 보이며, 초과 회복 특성을 보이는 클러스터 4는 중위그룹의 클러스터 4보다 회복된 정도가 더 큰 것으로 나타났다.
2) 평균 이용자 수 감소율 패턴 분석
이용자 수 감소율의 시기별 패턴을 살펴보면, 각 단계(Phase)별로 모든 그룹에 공통적인 이용자 수 감소율 패턴이 확인된다. 1단계(Phase 1)는 공통적으로 크게 3개의 위로 볼록한 파동이 나타나는 패턴이 존재한다. 구체적으로, 2020년 3월 초, 2020년 9월 초, 2020년 12월 중반부에서 3개의 큰 이용자 수 감소율의 정점이 형성된다(Ⓐ, Ⓑ, Ⓒ). 이는 사회적 거리두기가 처음 시행되거나 이전보다 강화된 시점과 맞물린다. 1단계에서 나타나는 세밀한 공통패턴으로는, 2020년 5월 초 이용자 수 감소율이 소폭 위로 솟는 형태가 나타나고(①), 2020년 6월 초 소폭 아래로 볼록한 형태를(②), 2020년 8월 초에는 소폭 위로 볼록한 형태를 나타내며(③), 2020년 10월에도 소폭 위로 볼록한 형태를(④), 2020년 12월 말에서 2021년 1월 초까지는 소폭 위로 볼록한 형태(⑤)가 나타난다. 이는 사회적 거리두기의 완화 및 강화에 따라 일치하여 큰 폭으로 변동함을 보여주며, 2020년 8월 초와 2020년 12월 말의 감소율 소폭 상승은 휴가철과 연말연시의 감염 우려로 인한 자발적 통행 감소로 추정된다.
2단계는 거시적으로 감소율이 아주 완만하게 감소 후 급증하며, 이후 다시 완만하게 감소하다가 증가하는 공통적인 패턴이 있다. 구체적으로, 2021년 2월 초기 이용자 수 감소율이 급감 후 회복하며 이후 2021년 7월 초까지 이용자 수 감소율이 서서히 감소하다가(Ⓓ) 2021년 7월 중순에 급증하여 2021년 9월 말까지 위로 볼록한 4개의 파동이 나타나며(Ⓔ), 2021년 10월에 급감 후 2022년 1월 중후반까지 천천히 이용자 수 감소율이 하락하며(Ⓕ), 이후 2022년 3월 말까지 이용자 수 감소율이 증가하는 양상으로 마무리되는 패턴이 나타난다(Ⓖ). 이는 2021년 2월 중순부터 7월 초까지 사회적 거리두기가 완화되고, 2021년 7월 중순부터 거리두기가 최고단계까지 강화되어 2021년 10월까지 유지되는 정책과 비례하여 이용자 수 감소율이 소폭으로 증감하는 것을 보여준다. 하지만, 2021년 11월에 단계적 일상 회복 정책이 시행되고 12월 중순부터 거리두기 정책이 다시 강화되는데 이 기간에는 거리두기 정책과 비례하여 감소율이 변동하는 모습을 보여주지 않는다. 2022년 2월과 3월에는 이용자 수 감소율이 급증하는 패턴이 나타나는데, 이는 해당 시기가 확진자 수의 최다 발생 기간으로 감염 우려로 인한 것으로 추정된다(Ⓖ). 즉, 2단계는 사회적 거리두기의 효과가 점차 옅어지며, 후반부에는 확진자 수 정보에 더 기민하게 반응함을 알 수 있다.
3단계에서도 모든 그룹을 아우르는 공통적인 패턴이 관찰되나, 상위그룹에서 하위그룹으로 갈수록 일별 변동성이 빈번하게 발생하여 매끄럽지 못한 패턴이 관찰된다. 3단계의 공통적인 특징은 2022년 4월 초를 시작으로 이용자 수 감소율이 완화되는 형태를 공통적으로 보여주는데, 이는 사회적 거리두기가 전면 해제된 시점으로, 이용자 수 감소율이 이와 함께 점차 회복됨을 알 수 있다. 구체적으로는 2022년 4월에서 5월 초까지 가파르게 감소하다가(Ⓗ) 2022년 5월 초부터 2022년 10월 초·중반까지는 완만하게 감소하는 패턴을 나타내며(Ⓘ), 2022년 10월 초·중반을 기점으로 2022년 12월 말까지 다시 완만하게 소폭 상승하는 패턴을 나타내며(Ⓙ), 2023년 1월부터 2월 중반부까지 급격히 감소하고(Ⓚ) 이후 소폭 증가하여 평탄한 패턴을 공통적으로 보여준다(Ⓛ). 3단계에서 하위그룹 클러스터 1의 경우 2023년 4월에서 2번의 위로 볼록한 파동과 함께 이용자 수 감소율이 40%에 달하는 양상을 보여주는데(㉖), 이는 3단계 하위그룹 클러스터 1에서 통행량의 영구적 손실이 발생한 것으로 볼 수 있다. 이러한 특이점은 동작(현충원)역의 영향으로 나타났다. 이 외 Figure 7에 숫자로 표시된 이용자 수 감소율 패턴 설명과 영향 요인은 Table 5에 정리되어 있다.
Table 5.
Explanation of the pattern of ridership decline rates indicated by numbers in Figure 7
|
Numbers in Figure 7 | Group-Phase-Cluster | Explanation of the pattern |
| ⑥, ⑦, ⑧, ⑨ | Middle-Phase1-Cluster 1 |
The mobility ridership decline rate in the latter halves of April, June, October, and December 2020 follows a concave pattern - The impact of in-person exam periods at Ewha Womans Univ. and Hanyang Univ. |
| ⑩ |
Bottom-Phase1-Cluster 1&2 |
The ridership decline rate experienced a sharp decrease and an increase in early to mid-January 2021 |
| ⑪ | Middle-Phase2–Cluster 1 |
Two upward convex waves in the ridership decline rate appeared from March to May 2021 – The impact of Hanyang Univ. |
| ⑫ | Middle-Phase2-Cluster 1 |
The ridership decline rate sharply decreased in early March 2022 - The impact of the first in-person semester at Hanyang Univ. |
| ⑬, ⑭ | Bottom-Phase2-Cluster 1 |
From March to May 2021, three upward convex waves appeared, and in January 2022, the decline rate remained high – The impact of Dongjak (Seoul National Cemetery) |
| ⑮ | Top-Phase3-All | At the beginning of May 2022, the ridership decline rate slightly increased |
| ⑯ | Top-Phase3-All | A slight reduction in the ridership decline rate was observed in mid-June 2022 |
| ⑰ | Top-Phase3-All |
From early August 2022 to mid-September 2022, the ridership decline rate showed four upward fluctuations |
| ㉒, ㉕ |
Middle&Bottom-Phase3- Cluster 1 | Four upward fluctuations, similar to pattern 17, occur but are not significant. |
| ⑱, ⑲, ⑳ | Top-Phase3-All |
At the end of December 2022, the end of January 2023, and the latter part of February 2023, the ridership decline rate showed upward fluctuations |
| ㉑ | Top-Phase3-All | At the beginning of March 2023, the ridership decline rate slightly decreased |
| ㉓, ㉔ | Middle-Phase3-U.P Cluster |
In early January 2023, the ridership decline rate sharply dropped by about 40%, and a similar sharp decrease of about 20% occurred in early March 2023, followed by a recovery |
| ㉕ | Bottom-Phase3-Cluster 1 |
The ridership decline rate sharply decreased in early to mid-August 2022 – The impact of Dongjak (Seoul National Cemetery) |
| ㉗ | Bottom-Phase3-Cluster 4 |
In mid-November 2022, the ridership decline rate sharply increased by over 20% – The impact of Geoyeo and Macheon |
3) 군집화 품질 분석
Kaufman and Rousseeuw(2009)이 제시한 실루엣 스코어의 군집화 품질 및 정확성 척도는 일반적인 저차원 데이터에 대한 기준에 해당한다. 본 연구에서 차원은 시계열의 기간에 해당하며, 이는 곧 나열된 평일의 수(1단계:253, 2단계:287, 3단계:270)이다. 차원이 증가할수록 데이터가 희소하게 존재하는 현상으로 인해(Bellman, 1961), 분석 기간이 길어질수록 차원이 증가하고, 데이터 간의 거리가 유사해져, 내부 클러스터의 평균 거리()와 외부 클러스터까지의 평균 거리()의 차이가 줄어들게 되고, 실루엣 스코어가 작아지는 결과를 초래하게 된다. 이에 따라, 해당 기준을 본 연구에 적용하기보다 차원을 고려한 완화된 기준을 적용할 필요가 있을 것이다. 본 연구의 그룹별, 단계별 평균 실루엣 스코어는 모두 0.43-0.65 사이에 해당하며, 본 결과는 고차원 시계열 데이터에 대한 실루엣 스코어임을 고려하였을 때 군집화 품질이 양호함을 내포한다.
3. 그룹별, 단계별 클러스터의 지하철 역 분포 비율
Figure 9는 그룹별, 단계별로 각 클러스터에 해당하는 지하철 역 수의 비율을 나타낸 그래프이다. 지하철 이용자 수가 2019년도 수준으로 회복되지 못한 클러스터(클러스터 1, 클러스터 2)에 속하는 지하철 역의 비율은 최소 64%로 나타나는데(Figure 9), 이는 2023년 4월까지도 사람들의 이동성이 서울 지하철 대부분의 역에서 회복하지 못하고 있음을 보여준다.
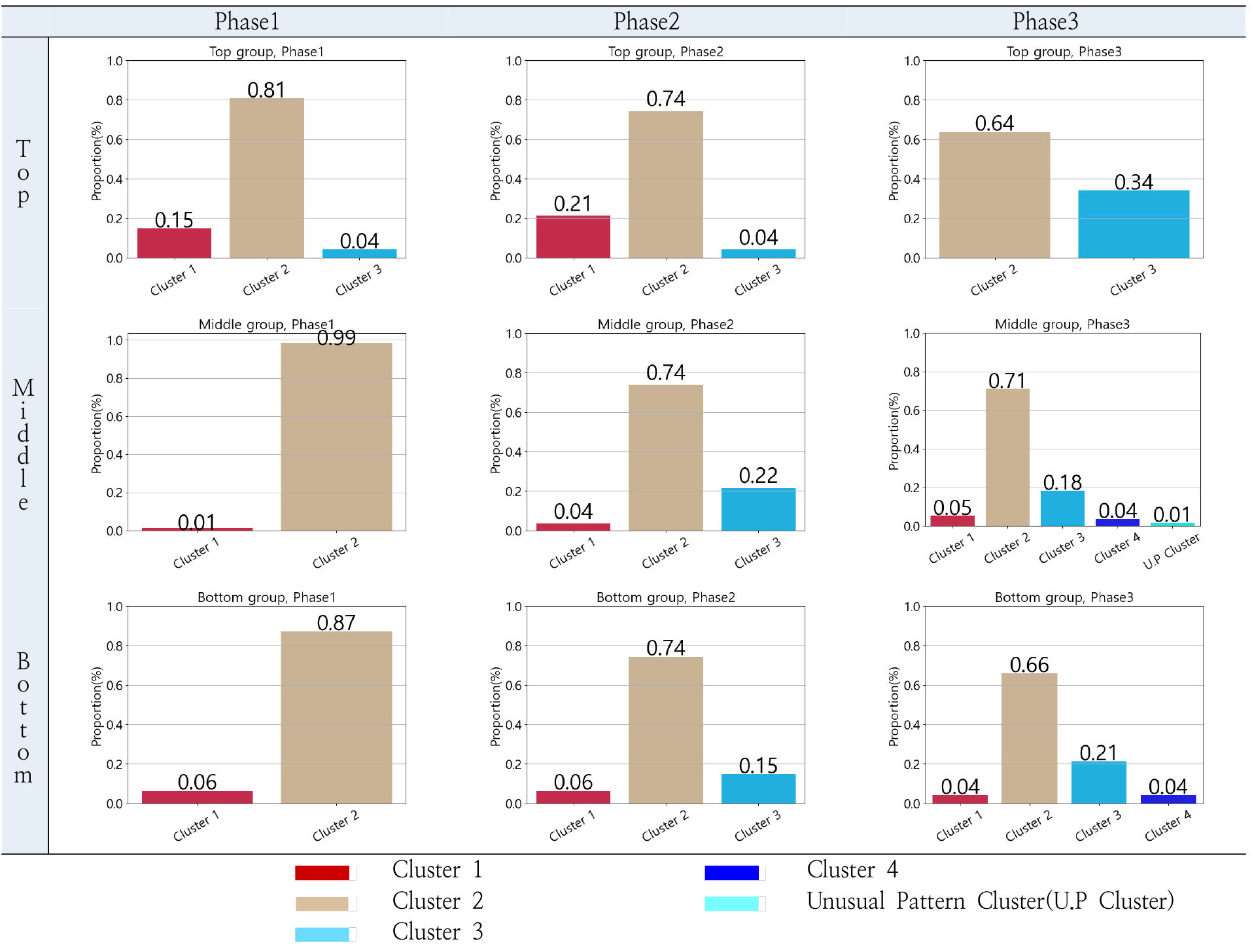
회복된 클러스터(클러스터 3, 클러스터 4)에 속하는 비율은 적지만, 모든 그룹에서 분석 기간 1단계에서 3단계로 갈수록 이용자 수가 2019년 수준으로 회복된 클러스터(클러스터 3, 클러스터 4)에 속하는 비율이 높아졌다. 그 중, 상위그룹 3단계에서 회복된 클러스터(클러스터 3)에 속하는 비율이 세 그룹 중 가장 높으며(0.34), 분석 기간 중 회복된 클러스터(클러스터 3, 클러스터 4)에 속하는 비율이 가장 먼저 큰 폭으로 상승하는 것으로 나타난 그룹은 중위그룹이다(2단계에서 0.22로 증가). 이용자 수 규모가 큰 상위그룹은 1, 2단계에서는 회복된 클러스터(클러스터 3)의 비율이 0.04로 미비하다가 3단계에서 0.34로 큰 폭으로 증가하는 양상을 보여주며, 중위그룹과 하위그룹은 회복된 클러스터(클러스터 3)의 비율이 2단계에서 각각 0.22와 0.15로 나타나는 바, 중위그룹과 하위그룹이 2단계에서 먼저 회복되는 양상을 보여주고, 상위그룹은 3단계에서 회복되는 양상을 보여준다. 이용자 규모가 큰 상위그룹에서 중요역들이 많이 포함되어 있기에 상위그룹이 다른 그룹보다 먼저 회복될 것이라는 예상과는 달리, 중위그룹과 하위그룹에서 먼저(2단계에서 회복) 회복되었다. 분석 기간 중 가장 먼저 큰 폭으로 회복된 그룹-단계-클러스터에 해당하는 역은 Table 6과 같다.
Table 6.
Stations corresponding to the group-phase-cluster that first experienced a significant recovery
평균 이용자 수 감소율이 2019년 수준 이상으로 회복된 특징이 있는 클러스터 4는 중위그룹과 하위그룹 3단계에서만 존재하는 클러스터이며, 클러스터 4에 해당하는 역들의 공통점은 크게 2가지로, 도시 외곽에 위치하여 도시 개발이 이루어진 역 이거나 도시 중심부에 위치하여 공원과 카페, 음식점이 밀집한 역이다. 중위그룹 3단계 클러스터 4에 속하는 역은 5개소이며, 이 중 발산역과 천왕역은 서울 외곽에 위치하며 도시 개발이 이루어진 특성이 있는 역이다. 이 두 역은 발산역 인근의 마곡지구 개발 및 천왕역의 천왕1지구 개발로 인한 도시 규모 확장 영향, 천왕역의 광역환승센터 및 경기도부터 운행하는 시내버스 개통으로 3단계(회복기)에서 이용량이 2019년도 수준 이상으로 회복된 것으로 추정된다. 나머지 3개의 역인 여의나루, 뚝섬, 을지로4가역은 초과 회복 서울 중심부에 위치하며, 공원 혹은 카페와 음식점 등이 밀집한 곳이라는 특징이 있다.
하위그룹 3단계 클러스터 4에 속하는 역으로 서울 남동쪽에 위치한 거여역과 마천역이 있으며, 이 두 역은 거여마천뉴타운의 도시재개발 사업으로 2020년부터 입주 시작 및 현재에도 입주 진행 및 예정으로, 도시 규모의 성장으로 인한 이용자 수 증가로 인한 것으로 추정된다.
20% 이상의 가장 높은 평균 이용자 수 감소율을 보이는 클러스터 1은 상위그룹 3단계를 제외한 각 그룹, 단계에서 모두 존재하는데, 클러스터 1은 하위그룹을 제외하고 주로 대규모 환승시설과 연결된 역, 대학 인근의 번화가, 대형 쇼핑시설, 경기장 및 체육시설 주변의 역이라는 특징이 있는 것으로 나타났다.
상위그룹 클러스터1에 해당하는 역은 대규모 환승시설과 연결된 역, 대학 인근의 번화가, 의류 및 쇼핑시설 주변이라는 특징을 보이며, 중위그룹 클러스터1에 해당하는 역은 대학 인근 혹은 경기장 및 체육시설 인근, 타 교통수단과의 대규모 환승이 발생하는 역, 전통시장 인근, 저소득층 밀집 지역의 특징이 있는 것으로 나타났다. 하위그룹에 속한 대다수의 역이 주거 지역에 해당하여 하위그룹 클러스터 1만의 뚜렷한 특징은 발견되지 않았다. 각 그룹의 단계별 클러스터 1에 해당하는 지하철 역은 Table 7과 같다.
Table 7.
Stations corresponding to Cluster 1 at each phase of each group
4. 적용 방안
코로나19의 장기적인 유행으로 인해, 1·2단계는 팬데믹의 공포와 정부의 거리두기 정책으로 인하여 필수적인 통행이 발생하지 않는 역에 대해서는 통행량 감소가 발생할 수 있을 것이다. 하지만, 코로나19의 후반부인 3단계는 사회적 거리두기가 전면 해제된 이후의 시점으로, 이 시기에도 이용자 수 감소율이 심각하게 회복되지 못한 지하철 역은 영구적인 통행량 손실이 있는 것으로 볼 수 있다. 따라서, 3단계 클러스터 1에 해당하는 중위그룹의 광명사거리, 청량리(서울시립대입구), 숙대입구(갈월), 종합운동장, 당고개, 복정, 송정역과 하위그룹의 잠원역, 동작(현충원)역은 유행병 중반기 이후부터 이동성 회복을 위해 우선적인 정책적 지원이 필요할 것이다.
한편, 1단계에서 클러스터 1에 속하는 지하철 역은 코로나19와 같은 유행병이 발생하였을 때, 가장 큰 이용자 수 감소율이 발생하는 역으로, 필수적인 통행이 이루어지지 않는 역으로 해석할 수 있다. 따라서, 상위그룹의 홍대입구, 고속터미널, 서울역, 신촌, 강변(동서울터미널), 명동, 혜화역과 중위그룹의 이대, 한양대역, 하위그룹의 개화산, 남태령역은 비필수적인 통행이 발생하는 역으로, 이 역들에 대해서는 유행병으로 인한 통행량이 크게 감소함에 따라 해당 역들의 주변 상권에는 경제적인 지원 정책이 유행병 초기 단계에서 우선적으로 필요할 것이다.
또한, 1단계임에도 2019년도 수준에 근접한 회복을 보이는 특성이 있는 클러스터 3은 상위그룹에서 단독으로 존재하는데, 가산디지털단지역과 성수역이 이에 해당한다. 해당 역들은 회사 밀집 지역이라는 공통적인 특징이 있으며, 코로나19로 인한 공포와 거리두기 정책이 시행되는 코로나19 초기에도 통행량이 상위그룹의 다른 역 대비 크게 감소하지 않는 것으로 나타난다. 따라서, 이 두 역은 필수적인 통행이 발생하는 역으로 해석될 수 있으며, 해당 역은 이용 규모가 크고 필수 통행이 발생하는 역에 해당하므로 방역 관리에 더욱 심혈을 기울여야 할 것이다.
결론 및 한계점
본 연구는 코로나19 동안 서울 지하철 이용자 수 감소율에 대해 DTW와 AHC를 활용하여 지하철 역을 중심으로 사람들의 이동성 변화를 분석하였다. 본 연구는 국내 코로나19 첫 확진자가 발생한 2020.1.20부터 2023.4.30까지의 장기적인 관점에서 지하철 이용자 규모별, 분석 기간의 단계별로 사람들의 이동성 회복양상을 시간 단위 이용량 정보에 기반한 시계열 분석을 수행함으로써, 이동성 회복 정도를 역을 중심으로 평가한다는 점에서 의의가 있고, 대부분의 역에서 사람들은 2019년도 수준의 일상적인 이동성을 회복하지 못했음을 발견했다.
주요한 발견으로, 사람들의 지하철 이용자 수는 2023년 4월에서도 대다수 역에서 2019년도 수준으로 회복하지 못하고 있으며, 중위그룹과 하위그룹에서 회복된 클러스터에 속하는 비율이 증가하는 시기가 상위그룹보다 이르게 나타났다. 또한, 평균 이용자 수 감소율 패턴은 코로나19 유행 후반부로 갈수록 사회적 거리두기 정책과 비례하여 변하는 변동 폭이 점차 줄어드는 것으로 나타났다.
본 연구에서 이용자 규모에 따른 그룹별, 단계별로 이동성이 회복되지 못한 역과 회복된 역을 선별하였는데, 이는 향후 코로나19와 같은 유행병이나 충격이 발생할 경우 지역적 필요에 부합하는 정책 지원에 활용될 수 있을 것으로 기대하며, 해당 정책 적용이 필요한 지하철 역의 우선순위를 선정함으로써, 한정된 자원을 효율적으로 활용할 수 있을 것으로 기대한다.
한편, 본 연구는 다음과 같은 한계점을 지닌다. 첫째, 지하철 이용자 수의 감소가 코로나19 영향 외의 요인이 존재할 수 있다는 점이다. 그 예로, 마곡과 지축역은 신도시 개발지구로 인하여 도시 규모의 발전으로 해당 역을 이용하는 이용자 수가 코로나19 기간 동안 2019년도 수준보다 월등히 증가하였다. 이처럼, 신도시 개발지구와 같이 도시 규모가 확장되면 코로나19로 인한 영향보다 도시 규모 확장으로 인한 영향이 더욱 크다. 둘째, 코로나19로 인하여 사람들이 일상으로 회복되지 못한 지하철역이 과반수를 차지함에 따라, 회복되지 못한 모든 역을 추적하기에는 한계가 있다. 이러한 대다수의 회복되지 못한 역들의 기저를 파악하는 연구를 향후 진행한다면 코로나19 이후의 지속가능한 교통과 회복력 있는 도시관리를 위해 중요하게 활용될 수 있을 것으로 기대한다. 셋째, 본 연구는 가장 많은 필수 통행이 이루어지는 평일의 출근 시간대를 기준으로 사람들의 이동성 회복양상을 분석하였는데, 평일의 다른 시간대(낮 시간대, 퇴근 시간, 밤 시간대)와 주말 각 시간대에서는 다른 양상을 보일 수 있을 것이다. 넷째, 본 연구는 승·하차의 총인원을 분석에 활용하였는데, 승차와 하차를 분리하여 분석을 진행한다면 이동의 방향성을 고려하여 이용자 수 감소율을 분석할 수 있을 것이다. 마지막으로, 본 연구는 사회적 거리두기의 강화 및 완화되는 시기와 월별 지하철 이용자 수 감소율의 변화를 바탕으로 분석 기간을 구분하였는데, 단계 구분에 있어 백신 접종 관련 요인을 추가하여 구분하는 방법도 고려할 수 있을 것이다. 백신 접종 전·후, n차 접종 완료 시점, 백신 접종 n% 달성 시점 등의 백신 접종 요인을 함께 고려하여 분석 단계를 구분한다면, 백신 접종 관련 시사점을 도출할 수 있을 것으로 기대한다.
