

서론
선행연구
1. Meta Heuristic Algorithm 기반 경로 탐색 선행 연구
2. Q-learning 강화학습 기반 경로 탐색 알고리즘 관련 연구
3. Deep Reinforcement Learning 알고리즘 관련 연구
4. 경로탐색 선행연구의 시사점
연구 방법론
1. 강화학습 알고리즘
2. DQN(Deep Q Network) 알고리즘
학습 데이터셋 설계 및 환경 구축
1. 강화학습 정책(Policy)
2. SPM(Shared Personal Mobility)데이터 분석
3. 강화 학습 환경 구성
4. Reward Function 정의
5. 게임 종료 조건
시뮬레이션 결과
1. 수요 시뮬레이션 결과
2. Q-learning 및 DQN 비교
결론 및 향후 연구과제
서론
대중들이 주로 이용하는 교통수단은 버스, 지하철, 택시 등이 있다. 버스와 지하철은 정해진 시각에 정해진 위치(예: 정류장, 역 등)에 직접 가서 타야 하는 불편함이 있고, 택시는 승객이 원하는 위치에 탑승하여 목적지까지 이동하지만 버스, 지하철에 비해 요금이 비싼 단점이 있다. 고령화·저출산 사회적 문제로 인하여 교외 지역 사람들은 하루 2-5회 운행하는 배차간격이 긴 대중교통을 이용해야 하는 불편함이 있다. 수요응답형 대중교통(DRT, Demand Responsive Transit)은 앞서 언급한 문제점을 해결하기 위한 교통수단으로 기존의 버스처럼 운행노선을 고정하지 않고, 승객의 수요에 따라 운행구간, 정류장 등을 탄력적으로 운행할 수 있고 버스와 택시의 장점을 결합한 교통수단이다(Park et al., 2022). DRT 서비스를 이용하는 방법은 이용자가 직접 콜센터에 예약하는 방법, 기사에게 직접 통화예약을 하는 방법, 스마트폰 앱 또는 인터넷을 이용하여 예약하는 방법 등이 있다. DRT 서비스 이용자들은 도착 시간, 출발지점, 목적지 등을 직접 예약 할 수 있으며, 일반 대중교통보다 유연(Flexible)하고 개인화된 서비스를 제공받을 수 있다. 이동수단과 이동 수요가 조합되어 형성되는 모바일 플랫폼의 혁신적인 발전으로 최근 카카오(Kakao)와 우버(Uber)와 같은 공유 택시 플랫폼이 등장함에 따라 실시간 호출 서비스가 가능하게 되었다. 이는 실시간자율주행 대중교통 모빌리티 서비스 연구가 활발히 진행되는 계기가 되었다.
실시간 자율주행 대중교통 모빌리티 서비스가 실현되기 위해서는 이용자들의 수요 기반을 통한 스케줄관리, 실시간 동적 노선을 고려한 최적 경로 생성 및 이용자의 실시간 예약에 따른 배차(Dispatching) 알고리즘 연구가 필요하다. 하지만 국내의 경우 배차알고리즘 연구보다 DRT 효과분석에 초점을 둔 한정된 연구가 진행되었다. Peng et al.(2020)연구는 차량 경로최적화(Vehicle Routing Optimization)와 호출운용(Order Dispatching) 및 차량 재배치(Vehicle Repositioning)등 다양한 주제에 대하여 강화학습(Reinforcement Learning)을 이용한 알고리즘 개발 연구가 진행되고 있다(Nazari et al., 2018). 최근 국내 연구 중 Q-learning 방법론을 이용한 수요대응 자율주행 대중교통 연구가 시도되었다(Kim et al., 2022). 하지만 도로 네트워크가 복잡하게 되면 Q-table에 저장해야 하는 메모리 용량이 기하급수적으로 증가하게 되는데, 상태(State)에 대한 Q-value 데이터를 불러올 때 지연시간(Latency) 발생하여 실시간성을 보장받지 못하는 한계를 가진다. 이러한 문제점을 보완하는 방법으로는 Deep Reinforcement Learning 모델중 하나인 DQN(Deep Q Network)을 이용하여 에이전트(Agent)의 현재 상태에 대한 Q-value값을 근사화하여 Q-table에 저장하지 않고 복잡한 네트워크에서도 실시간성을 보장받을 수 있다(Minih et al., 2015). 따라서 본 연구는 모든 상태와 행동에 대한 값을 Q-table에 기록하기 때문에 에이전트가 행동을 선택 할 수 있는 상태의 수가 많아질 경우 Q-table 데이터양이 기하급수 해지며, 순차적인 데이터간의 상관(Corelation)으로 인한 학습의 저하 등으로 인한 단점을 보완하고자 DQN를 이용하여 딥러닝 강화학습 기반 실시간 동적경로 알고리즘을 개발하고자 한다.
선행연구
1. Meta Heuristic Algorithm 기반 경로 탐색 선행 연구
TSP(Traveling Salesman Problem)문제는 여러 도시들이 있을 때, 한 도시에서 출발하여 모든 도시를 한 번씩 방문하고 다시 처음 도시로 돌아오는 최단 경로를 찾는 문제이다. 이 문제는 NP-hard으로 알려져 있어 정확한 해를 찾는 것은 어렵다. 이 문제를 해결하기 위해 Pihera et al.(2014)은 머신러닝과 메타 휴리스틱알고리즘을 사용하였으며 약 2000개 이상의 문제에 대해 다른 알고리즘과 성능 분석을 체계적으로 평가한 결과 다수의 문제에 대해 가장 좋은 성능을 보여주었다.
DARP(Dial A Ride Problem)는 택시, 버스, 자동차 등을 이용하여 여러 명의 승객을 수송하는 문제이다. 모든 승객이 출발지점에서 도착지점까지 이동하도록 경로를 계획하면서, 승객들이 출발 및 도착 시간과 같은 요구사항을 충족시키도록 한다. 주로 교통약자(노인, 장애인)를 대상으로 서비스를 제공하는 DARP는 차량 Pickup Delivery 경로 운행의 전반적인 성능을 향상시키는 것을 목표로 두고 있다. Belhaiza(2019)의 연구는 최소한의 운영 및 비용으로 가능한 많은 이용자를 수용하고자 하는 DARP 문제를 해결하기 위해 Adaptive Large Neighborhood Search(ALNS)와 Heuristic Algorithm을 결합한 하이브리드 알고리즘을 제시하였다.
Kim(2015)연구는 메타휴리스틱(Meta Heuristic) 방식으로 온라인 배송 차량의 최적 배차 및 경로를 정하였으며, 운영과 이용 측면을 고려하여 실시간 교통 정보를 이용한 최적 배송 차량 배차 및 동적 배송 경로 산정 방안을 제시하였다. 이 연구는 실시간 교통정보에 의해 경로가 동적으로 변화하는 Periodic Vehicle Routing Problem with Real Time Dependent(PVRP-RTD)를 정의하였으며, Tabu Search 알고리즘(Glover and Laguna, 1998)을 이용한 실시간 교통정보를 통해 교통 흐름에 영향을 미치는 사고 발생과 같은 통행 시간에 영향력이 큰 유고 정보 데이터 기반 경로를 재탐색을 통해 최적화된 배송 차량 시스템을 제안하였다.
2. Q-learning 강화학습 기반 경로 탐색 알고리즘 관련 연구
Kim et al.(2020)의 연구는 Q-learning 기반의 강화학습과 볼츠만 분포를 사용한 Softmax 정책을 사용하여 기존의 ε-greedy Policy 방법 보다 빠르게 보상 수렴을 하도록 하였으며, Open source 기반 시뮬레이터를 활용하여 동적 장애물이 존재하는 환경에서 강화학습을 이용한 드론의 장애물 회피 및 경로 계획 알고리즘을 개발하였다. 에이전트는 거리 센서를 활용하여 주변 환경과 동적 장애물을 거리에 따른 구분을 통해 부딪힘과 물체 감지 등을 감지하여 동적 장애물이 특정한 경로를 따라서 임의로 움직일 때 드론이 장애물을 피해 최종 목적지 까지 최적의 경로로 이동하는 알고리즘을 제시하였다.
Kim et al.(2022) 연구는 Q-learning을 이용한 실시간 대중교통 수요를 바탕으로 최적의 동적 경로를 생성할 수 있는 알고리즘을 이용하여 고정형 노선과 동적노선의 운영 효율성을 비교하였다.
3. Deep Reinforcement Learning 알고리즘 관련 연구
Sunwoo and Lee(2021)의 연구는 Deep Reinforcement Learning 모델중 하나인 DQN을 이용하여 기존의 강화학습 알고리즘인 Q-learning의 행동 가치 함수를 심층 신경망을 이용한 함수 근사를 통해 상태-행동 공간의 규모가 큰 환경에서도 학습이 가능하도록 하여 시뮬레이션 환경에서 로봇의 자율 경로 탐색알고리즘을 개발하였다.
4. 경로탐색 선행연구의 시사점
경로탐색 알고리즘 연구를 위해 Q-learning을 이용한 강화학습은 에이전트가 환경과 상호작용을 하여 경험을 쌓으며 학습을 진행하게 되는데 이 과정에서 환경이 변하거나, 다른 에이전트가 상호 작용하는 경우에는 학습된 가치함수가 유효하지 않을 수 있다. 또한 상태-행동의 가치를 추정하기 위해 메모리 문제 또는 비용(Cost) 문제 등이 발생할 수 있어, 테스트 환경이 커지거나 복잡한 도로 네트워크를 경험하지 않은 상태에서는 취약부분이 보일 수 있다는 문제점이 존재한다. 기존 Q-learning 알고리즘을 이용한 강화학습이 도로 네트워크가 범위가 확장됨에 따라 상태 공간, 행동 공간이 증가되어 Q-table의 Memory 증가로 인한 학습 속도 저하, 과도한 Exploitation을 방지가 필요하다.
따라서 본 연구는 앞서 언급한 문제점들을 해결하기 위해 다음과 같은 순서에 따라 개발하고자 한다. 첫째 강화학습 알고리즘을 테스트하고 평가할 수 있는 Open source 기반 OpenAI Gym을 이용하여 실시간으로 출발지(Origin)와 목적지(Destination) 수요를 생성하고 그리드 맵(Grid Map)기반 도로 네트워크를 구축한다. 다음으로 DQN 알고리즘을 이용한 실시간 수요를 반영한 최적의 경로 알고리즘을 개발하고자한다.
연구 방법론
1. 강화학습 알고리즘
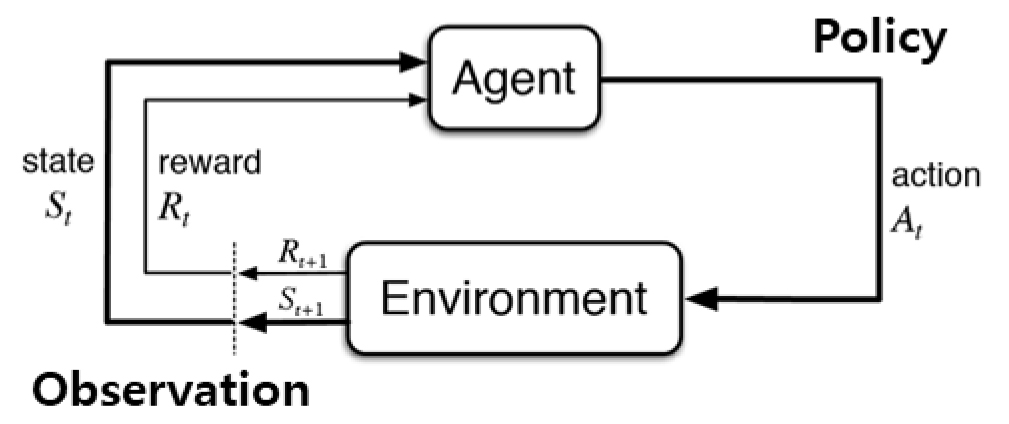
강화학습(Reinforcement Learning)은 인공지능 분야에서 사용되는 학습 방법 중 하나로 에이전트(Agent)가 특정 행동(Action)을 취해 환경(Environment)과 상호작용하여 변화되는 상태(State)에 대한 보상(Reward)을 최대화하기 위해 학습하는 것을 말한다. 강화학습의 구성요소는 Figure 1과 같이 구조화된 정의로 나타낼 수 있다. 에이전트는 환경과 상호작용하며 현재 상태를 관찰하여 특정 행동을 선택한다. 이 과정에서 환경은 다음 상태인 과 다음 보상 를 에이전트에게 제공한다. 에이전트는 이러한 피드백을 통해 최적의 행동을 선택하기 위해 반복 학습을 진행한다. 강화학습은 주로 게임이나 로봇 제어 등 다양한 분야에서 사용되며, 최근에는 자율주행차, 자원관리 등 다양한 분야에서도 활용되고 있다. 강화학습을 통해 인공지능이 현재 상태를 인식하고, 적절한 행동을 취하는 능력을 강화할 수 있으며, 이를 통해 보다 효율적인 시스템을 개발할 수 있다. 대표적인 모델로 MDP(Markov Decision Process)가 있으며 <S,A,P,R, >를 Tuple로 정의한다. 여기서, S는 가능한 상태, A는 행동의 집합, P는 전이 확률 Matrix, R은 보상, γ는 Decay-factor이다. MDP는 현재 상태에서 에이전트가 행동을 선택하는 경우, 다음 상태와 보상이 어떻게 결정되는지를 나타낸다. MDP는 현재 상태에서 에이전트가 행동을 선택은 다음 상태와 보상을 결정한다. 이러한 모델을 통하여 상태에 따라 어떤 행동을 선택하였을 때 보상을 최대로 받을 수 있는 함수를 정책(Policy)라고 하며, 최적의 정책을 찾기 위해 Q-learning 알고리즘을 사용한다(Sutton et al., 2018).
Q-learning 알고리즘의 핵심은 Q-function이다. 이 함수는 Equation 1과 같이 표현되며 상태와 행동을 입력으로 받아, 현재 상태에서 에이전트가 행동을 선택하였을 때 얻을 수 있는 가치를 출력하는 함수이다. 여기서 가치는 현재 상태에서 특정 행동을 취할 때 기대할 수 있는 총 보상(Discounted Reward)의 합을 나타낸다. 에이전트는 자신이 취할 수 있는 여러 가지 행동 중에서 보상 값을 최대화하는 것을 최적정책(Optimal Policy)이라 부른다. 현재까지의 경험 중 현 상태에서 가장 최대의 보상을 얻을 수 있는 행동을 수행하는 것을 탐사(Exploitation)라고 하고, 이러한 경험을 쌓기 위해서는 주어진 환경에서 무작위로 행동을 선택하여 새로운 경험을 얻어야 하는 데 이 과정을 탐험(Exploration)이라고 한다. 또한 Q-learning은 모델 없이(Model Free)학습이 가능하며, 에이전트가 학습하는 동안 얻은 상태, 행동 A에 대한 Q-value를 Q-table에 저장하게 되는데, 이것은 에이전트가 현재 상태에서 가능한 모든 행동의 Q-value를 비교하여 최적의 행동을 선택할 수 있도록 도와준다. Q-table은 학습이 진행됨에 따라 Equation 2와 같이 Q-value를 업데이트 하여 최적의 정책을 찾아가는 데 사용된다. 하지만 상태 공간(State Space)과 행동 공간(Action Space)이 커지면 Q-table에 저장해야 하는 데이터양 또한 증가하여 많은 메모리와 학습 시간이 필요하게 된다.
2. DQN(Deep Q Network) 알고리즘
앞서 언급한 문제점을 해결하기 위해 Minih et al.(2013) Deep Mind 연구팀에서 딥러닝(Deep learning)과 강화학습을 결합한 DQN 알고리즘을 발표하였으며, Q-learning 알고리즘의 단점인 Q-value 함수의 크기와 복잡도 문제를 딥러닝을 이용하여 Q-value함수를 근사화(Approximate)함으로써 상태, 행동의 공간이 증가하더라도 적은 양의 데이터로도 효과적인 학습이 가능할뿐더러 기존의 강화학습 알고리즘 보다 안정적인 학습과 높은 성능을 보여준다. 따라서 현재 DQN 알고리즘은 로봇제어, 자율주행 등 다양한 분야에서 활용되고 있다.
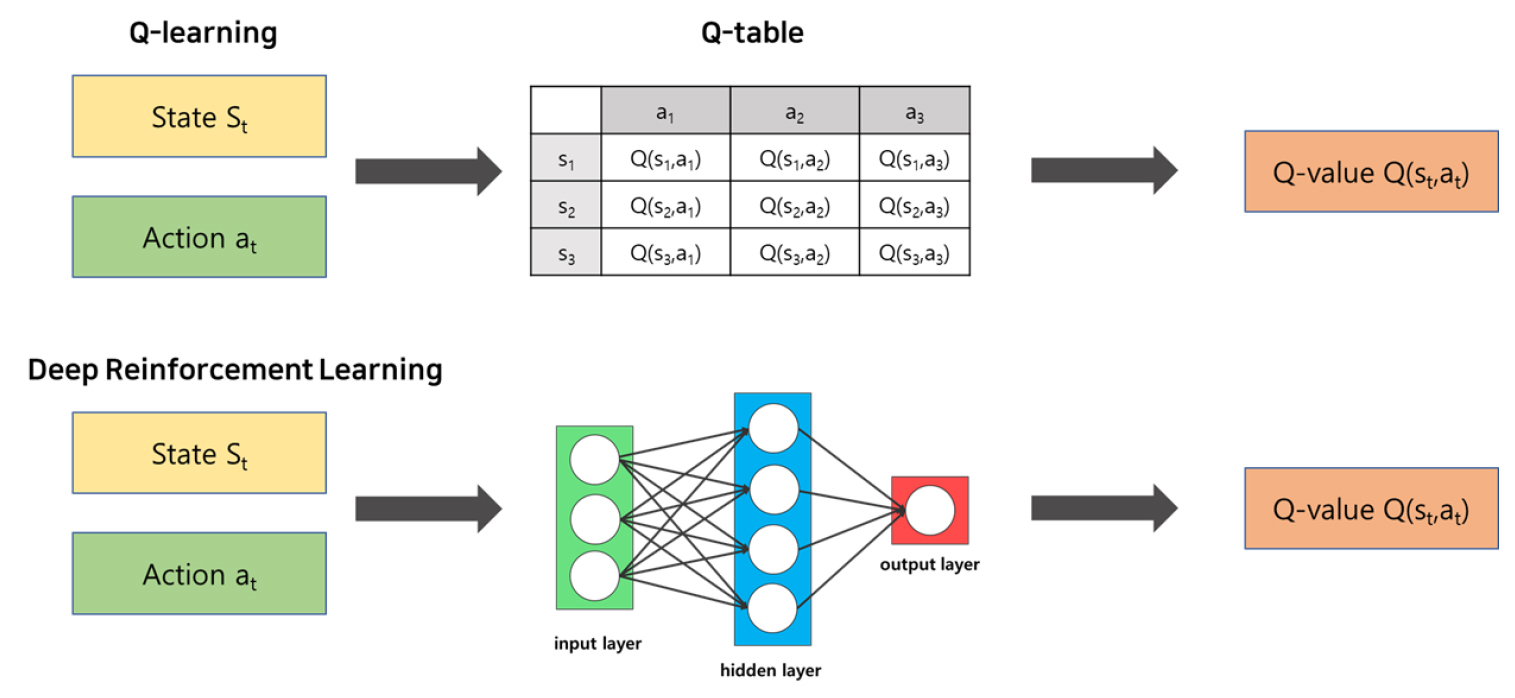
Figure 2는 Q-learning 과 DQN 모델의 특징을 나타낸다. Q-learning 기반 강화학습은 상태 에서 행동을 취했을 때 해당하는 Q-value값인 Q를 Q-table 테이블 형식으로 저장하여 학습한다. 처음 Q-table의 모든 값들은 0으로 초기화하여 학습과정 중 에이전트가 경험한 것을 바탕으로 Q-table에 업데이트되지만, 경험하지 못한 (s′, a′)에 대해서는 여전히 Q(s′, a′) = 0의 값이기 때문에 에이전트가 경험하지 않은 상태에 대해서는 어떤 행동을 취할지 판단하지 못하는 단점이 있다. 여기서 s′은 새로운 상태, a′은 s′에서 에이전트가 선택할 행동을 말한다. 반면에 심층강화학습인 경우 딥러닝의 신경망을 사용하기 때문에 이미 경험한 (s,a)에 대한 Q-value로부터 경험하지 못한 (s′, a′)의 Q-value를 예측할 수 있다. 심층강화학습 대표적인 모델은 DQN이 있으며, Q-function을 근사하는 가치 기반 TD(Temporal Difference) 알고리즘이다. DQN의 구조는 크게 신경망(Neural Network), Target Network, 경험적 재사용 메모리(Experience Replay Memory)으로 구성된다. DQN은 기존 강화 학습 Q-learning 알고리즘의 요소인 행동 가치 함수를 심층 신경망을 사용하여 함수 근사를 통한 값을 추정하기 때문에 행동, 상태 공간이 큰 환경에서도 학습이 가능하다. Equation 3은 DQN 알고리즘에 대한 벨만 방정식이다. Q-function의 벨만 방정식에서 θ가 추가되었다. 여기서 θ는 딥러닝의 가충치(weight)에 해당한다. 가중치를 업데이트하기 위해 Equation 4와 같이 loss function L(θ)을 정의한다.
이 부분은 학습의 안정성을 높이는 방법으로 Target network를 사용하였다. Target network는 Q-value 함수를 근사하는 신경망 중 하나로 학습에 사용되는 신경망과 동일한 구조로 가지로 있지만 주기 θ마다 현재 학습 중인 신경망의 가중치를 복사하여 업데이트 한다. 본 연구에서는 Target Network 주기를 에피소드 20번마다 업데이트를 진행하였다. 이를 이용하여 네트워크 파라미터를 업데이트하고, 최적의 Q-value를 학습하여 강화학습을 개선하는 방법은 Equation 5와 같이 표현한다.
경험적 재사용 메모리 알고리즘을 DQN에서 처음으로 도입되었으며, 에이전트가 이전 상태, 행동, 보상, 새로운 상태를 저장해두는 메모리 버퍼로 에이전트는 이 버퍼에서 일정 크기의 랜덤한 배치 크기(Random Batch Size)를 선택하여 학습에 도움을 주게 한다. 과거의 경험들을 재사용함으로써 데이터 간의 상관관계(Correlation)를 줄이고 효율적인 학습을 도와준다. DQN 알고리즘에 대한 Pseudocode는 Table 1과 같다.
Table 1.
Deep Q-learning with experience replay algorithm
|
Initalize replay memory D to capacity N Initalize action-value function Q with random weights for episode = 1, M do Initialise sequence = {} and preprocessed sequenced for t = 1, T do With probability ɛ select a random action othherwise select = Execute action in emulator and observe reward and image Set = and preprocess Store transition in D Sample random minibatch of transitions from D Perform a gradient descent step on( according to Equation 4 end for end for |
학습 데이터셋 설계 및 환경 구축
1. 강화학습 정책(Policy)
강화학습 Policy는 대표적으로 쓰이는 ε-greedy Policy를 사용하였다. 에이전트의 행동 선택은 Table 2와 같이 표현된다. 에이전트는 ε의 확률로 랜덤하게 행동을 선택하고, (1-ε)의 확률로는 Q-value 값이 가장 큰 행동을 선택하여 정의하였다. ε값이 너무 높을 경우 학습이 제대로 이루어지지 않고, 너무 낮으면 최적의 경로를 찾지 못 할 수 있기 때문에 초기 ε값은 1로 설정하여 많은 탐험을 하도록 하였으며, 매 에피소드 마다 0.09999값을 이전 ε값에 곱해서 점진적으로 감소하여 ε값을 업데이트한다. 에피소드 9000번 이상부터는 0.995가 곱해서 최종적으로 ε값이 0.01까지 급격하게 감소하여 탐험보다는 기존의 경험으로부터 최적의 Policy를 선택하도록 하였다. 에이전트는 우선적으로 승차와 하차 행동을 선택하도록 고려하였고, 이때 최소 승하차 시간은 6초로 가정하여 시간이 경과 후 에이전트는 승하차 행동을 제외한 현재 가능한 행동을 선택하도록 설계하였다.
Table 2.
Greedy action selection pseudocode
DQN을 이용한 동적 경로 알고리즘은 Q-function을 사용하여 차량의 이동경로를 결정하고 Equation 6와 같이 요청한 승객들의 대기시간(Waiting Time), 차량 내 탑승시간(In Vehicle Time)을 최소한 하는 것을 목적함수로 두고 있다. 이 목적함수는 승객의 탑승 대기시간, 승객의 전체 운행시간을 최소화하여 이용 승객의 불편함을 줄이고 편의성을 증대하는데 목적을 두고 있다.
where, : 차량 최대 수용인원(15명)
: k 승객이 차량에 탑승한 시간
: k 승객이 차량을 호출한 시간
: k 승객이 목적지까지 도착하는데 걸리는 시간
Kim et al.(2012)연구에 의하면 대중교통 이용자 측면에서 서비스 품질 평가를 통한 서비스 개선은 대중교통 이용을 지속적으로 활성화시키기 위한 반드시 필요한 요소라고 하였다. 이용자 서비스 관점에서 정류소 단위의 비용함수로 에서 으로 이동하는 승객의 traveling 비용은 Equation 7과 같이 표현하며, DRT 서비스를 이용하는 승객이 정류장까지 걸어가는 시간과 대기시간 그리고 탑승 내 시간 등 이동하는 비용을 계산한다.
where, : k 승객이 정류장 까지 걸어가는 시간
: k 승객이 정류장에서 버스를 기다리는 시간
: k 승객이 차량에 승차하는데 걸리는 시간
: k 승객이 목적지까지 도착하는 차내 시간
: k 승객이 목적지에 정차한 후 하차하는데 걸리는 시간
2. SPM(Shared Personal Mobility)데이터 분석
본 연구는 한국교통대학교 충주 캠퍼스 지역을 대상으로 연구를 진행하였다. Figure 3은 교통대학교 충주캠퍼스 지형과 지오펜싱을 나타내며 총 12개의 정류장을 선정하였다. 현재 교내에 운행 중인 고정형 노선 시내버스는 회차 지점 1번 정류장을 기준으로 상행 6, 7, 8, 9, 10번 정류장 순으로, 하행 2, 3, 4, 5번 정류장 순으로 운행하고 있다. 중간에 유턴구간 2곳을 추가하여 기존 고정노선에서 동적 노선 운행이 가능하도록 하였다. 선행연구와 달리 남/북행 정류장을 구분하지 않고 모든 정류장을 운행가능 지역으로 선정하여 Table 3과 같이 모든 정류장 간에 거리 행렬을 계산하였다.
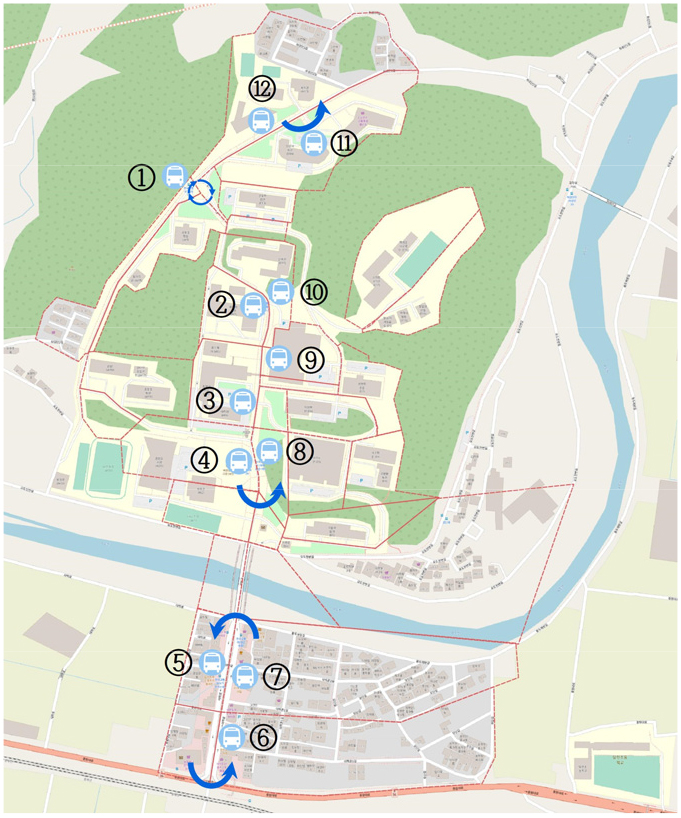
Table 3.
Origin-Destination distance matrix
본 연구에서는 현재 운행하지 않고 있는 DRT 버스를 사전에 승객들이 예상되는 탑승 지역에 미리 대기하여 시간대별, 요일별 등 예상되는 승객 수요에 따라 유동적으로 운행 패턴을 조정하여 효율적인 운영을 DQN 모델을 이용하고자 한다. DQN 모델을 학습하는 과정에서 각 승객들의 출발지와 목적지를 생성하는 수요데이터가 필요하다. 이 수요데이터를 이용하는 이유는 이용자 수, 이용자들의 출발지와 목적지 데이터를 분석하여 실현 가능한(Feasible) 수요데이터를 생성하기 위함이다. 하지만 테스트베드 지역에서 실험하기 위한 DRT버스 수요데이터가 부족한 상태이다. 따라서 이를 대체하기 위해 테스트베드 지역에서 유발되는 이용자 수요의 특성과 유사한 교통수단인 공유자전거 사용데이터를 이용하여 분석에 활용하고자 한다.
한국교통대학교에서 운영하고 있는 공유자전거는 대학교 캠퍼스 내 이동과 대학교 캠퍼스와 대학로 상가를 이용한 승객들의 출발지(Origin)와 목적지(Destination)데이터를 포함하고 있다. 실제 분석에 사용된 데이터는 2021년 9월에서 2022년 9월까지 한국교통대학교 캠퍼스타운에서 운영하였던 공유자전거 데이터를 사용하였고 공유자전거에 GPS센서가 탑재되어 있어 자전거를 빌린 이용자의 시간대별 대여위치와 반납위치의 데이터를 활용할 수 있다. 실제 공유자전거로 얻은 데이터는 지오펜싱을 통한 인접한 정류장에 그룹화 작업을 진행하였고 분석 과정에서 주말, 공휴일, 이용자 수가 급격하게 감소하게 되는 동·하계방학기간 그리고 COVID-19바이러스 확진자 수가 급격하게 발생한 기간 등 O-D데이터가 부족하여 다음 데이터는 제외하여 연구를 진행하였다. 실제 분석에 반영된 데이터는 학기 중 평일 163일 89,520 이용 건수의 데이터를 가지고 분석하였다.
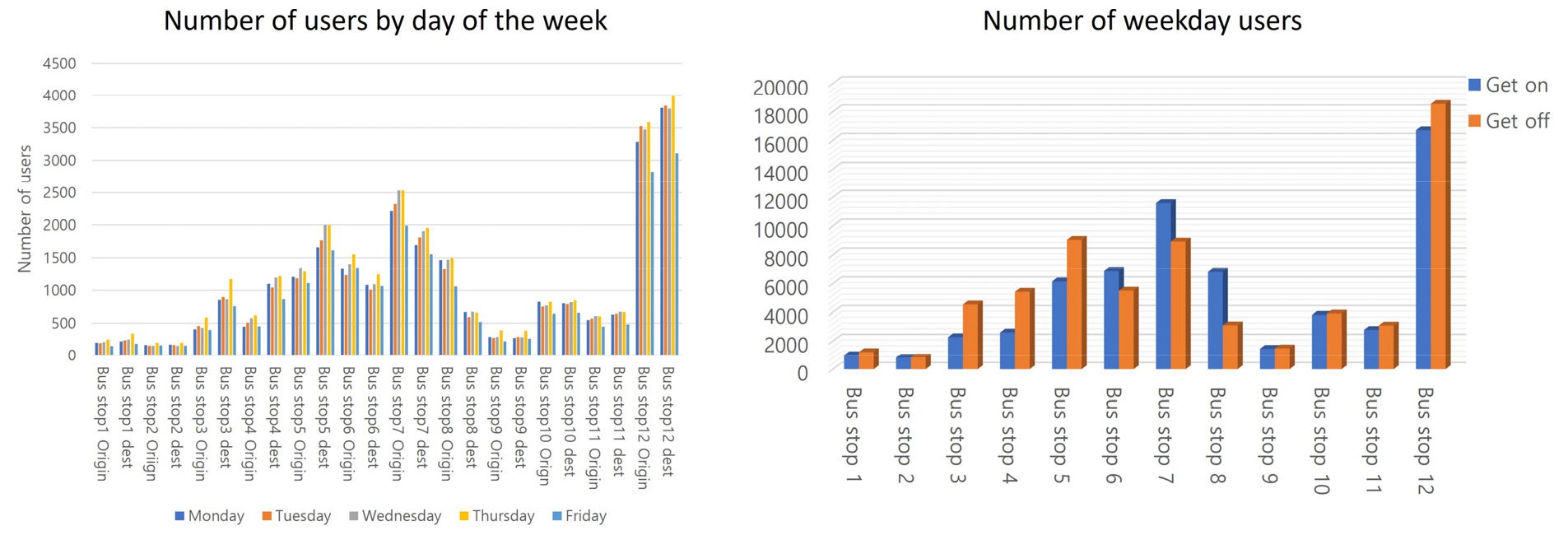
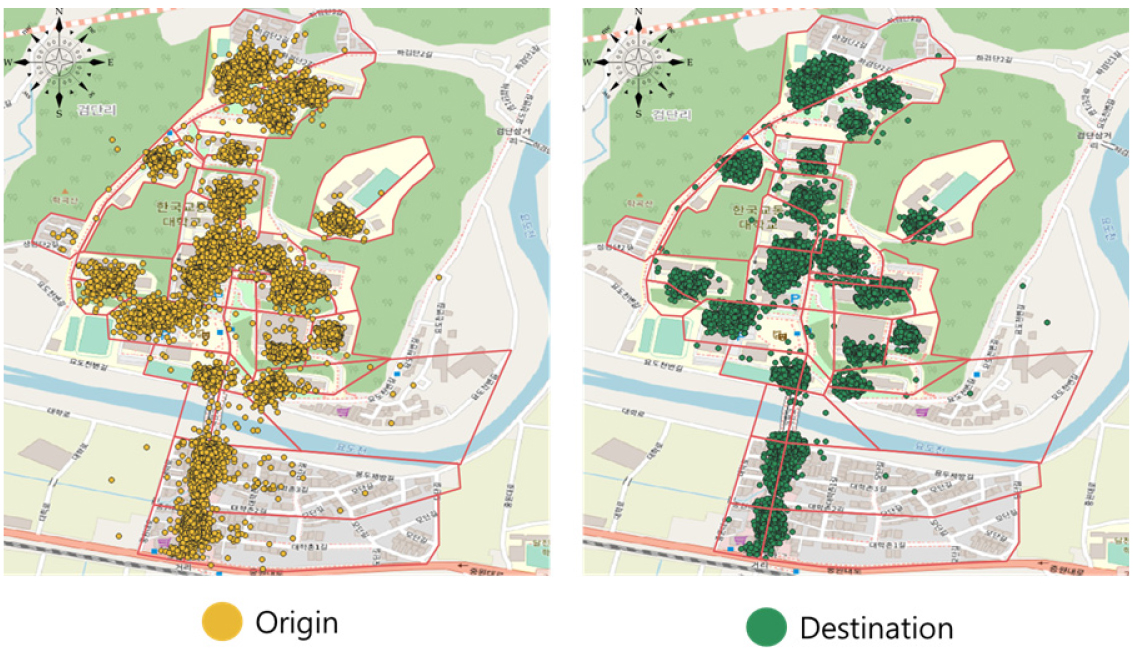
평일을 기준 가장 많은 이용객이 출발한 지역은 12번 버스 정류장(16,697명)과 7번 정류장(11,587명)이며, 가장 적은 이용객이 출발한 지역은 2번 정류장(822명)과 1번 정류장(997명)으로 분석되었다. 도착지역으로는 12번 정류장(18,541명)과 5번 정류장(9,041명)이 가장 많이 이용되었으며, 출발지역과 마찬가지로 1번 정류장(1234명)과 2번 정류장(834명)에서는 이용객이 적게 나타났다. 그 내용은 Figure 4와 같다. 캠퍼스 내에 기숙사, 이동하기 불편한 고지가 높은 지역에 위치한 건물, 상권이 있는 대학로 지역으로 공유자전거를 많이 이용한 것으로 분석되었다. 분석한 공유 자전거 데이터기반으로 일별 수요가 가장 많을 것이라고 예상되는 지역에 차량을 배차시키고, 해당 지역을 실시간 O-D 데이터를 생성하도록 반영하였다. 그 내용은 Figure 5와 같다.
3. 강화 학습 환경 구성
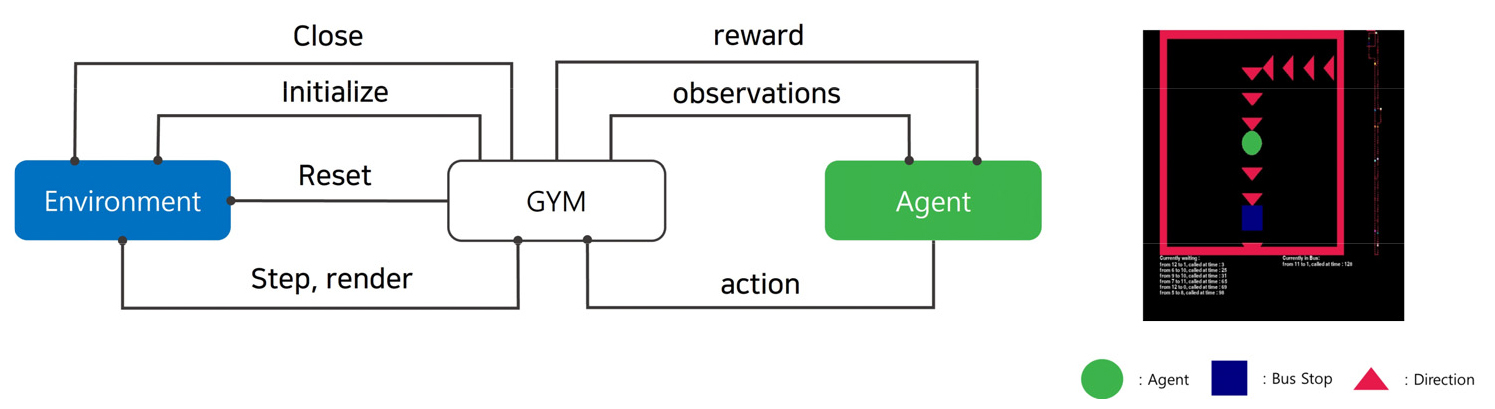
본 연구는 강화학습 환경을 OpenAI Gym(Brockman et al., 2016)을 이용하여 그리드 맵(Grid map)기반 한국교통대학교 도로환경을 구축하였다. OpenAI Gym은 오픈소스 기반 강화학습에 필요한 환경을 제공하여 강화 학습 알고리즘을 개발하고 테스트하는데 사용되는 도구로써 Gym을 사용하면 게임, 로봇제어, 자율주행자동차 등과 같은 다양한 환경에서 강화 학습 알고리즘을 시뮬레이션하고 평가할 수 있다. Gym에서는 환경과 에이전트 간의 상호작용을 처리하는 API(Feng, 2019)가 포함되어 있으며, 이용자는 이를 기반으로 자신만의 강화 학습 알고리즘을 구현할 수 있다. 또한 여러 가지 환경과 알고리즘 비교할 수 있는 벤치마크를 제공하므로, 이를 기반으로 강화 학습 알고리즘의 성능을 비교하고 개선할 수 있다.
Figure 6과 같이 환경 구성은 10 × 150 cell 으로 구성된 Grid Map에 승객을 태우는 초록색 원 셔틀 버스 에이전트 가 1대 있다. 각 색깔이 있는 사각형은 가상 Grid Map에 존재하는 버스 정류장이며 승객이 호출 시 승객의 기종점정보를 바탕으로 에이전트가 해당 정류장에만 승하차 하도록 설정하였다. 빨간색 삼각형은 현재 에이전트가 갈 수 있는 진행 방향으로 본 테스트베드 특성상 왕복2차선 도로가 빈번하기 때문에 갈 수 있는 진행 방향이 다소 제한적이다.
4. Reward Function 정의
강화학습은 에이전트가 주어진 환경 또는 상태에서 행동을 했을 때 보상을 얻고 이때 선택한 행동이 올바른 행동인지 옳지 않은 행동인지 피드백 및 반복을 통해 보상을 최대화하는 방향으로 스스로 학습하기 때문에 적절한 보상을 주는 것이 중요하다.
에이전트의 수용인원이 증가할수록 목표 지점으로 이동할 때마다 이용자의 서비스 비용이 누적으로 증가하게 된다. 만약 호출 승객의 이동거리에 따라 동일한 보상을 주어지게 된다면 현재 위치에서 가까운 수요 호출에 집중화될 수 있기 때문에 장거리 호출에 대해 상대적으로 큰 보상을 주어 효율적인 경로로 찾아 나아가도록 본 연구에서는 승객이 호출시 현재 에이전트의 위치에서 탑승하는 위치까지 거리 그리고 승객의 탑승 후 출발지에서 목적지 정류장간의 거리를 보상으로 주었다. 또한 에이전트가 최단거리 방향을 가도록 하기 위해 강화학습 환경 grid map 1개의 cell 거리 10만큼 승·하차가 아닐 경우 패널티를 부여하여 Equation 8과 같이 보상 값을 정의하였다.
where, N : 현재 서비스 이용 승객의 요청 수
: 에서 까지 travelling 비용
: k 번째 승객이 승·하차간의 거리
: 에이전트가 탑승, 하차가 아닌 행동을 취했을 때 보상
5. 게임 종료 조건
본 학습을 위한 1번 실행 시 Episode의 시간은 캠퍼스 정문에 위치한 6번 버스정류장에서 최정상에 있는 11번 버스정류장간의 거리를 바탕으로 왕복 도보 기준으로 40분이 걸리기 때문에 40분으로 설정하였고, 총 10,000번의 Episode를 학습하였다. 행동 정의는 크게 4가지로 승차, 하차 행동, 전진, 좌회전, 우회전으로 정의 하였으며 Observation 정보는 현재 차량의 위치 정보, 승객의 출발지와 목적지, 탑승여부, 현재 시간 순으로 정의되어 승객들의 대기시간 및 차량 내에 탑승 시간을 최소화 하도록 하였다. 셔틀버스가 최대로 수용할 수 있는 인원 15명이므로 현재 차내에 인원이 15명일 경우 승객의 호출을 받게 된다면 이때 일시적으로 콜을 받지 않는다. 에피소드의 게임은 종료됨과 동시에 셔틀의 전체 수요에 대비 90%이상 승·하차를 성공하면 다음 에피소드에 수용할 수 있는 인원을 점진적으로 증가시키게 하였다.
시뮬레이션 결과
1. 수요 시뮬레이션 결과
셔틀버스 차량이 이동 중 실시간으로 O-D 수요데이터를 받아 실험한 결과는 불특정 시간대에 랜덤 수요를 조건으로 Table 4와 같이 차량 운행시간 1시간 동안 셔틀버스를 운행하여 수요량별 대기시간과 차량 내에 소요된 시간의 결과값이다. 각 열은 호출 승객번호, 출발지와 목적지, 대기시간, 차내 이동시간을 나타내며 셔틀버스가 운행시간 내에 O-D 수요데이터를 출발지에서 목적지까지 운행이 불가능 할 것으로 판단이 될 경우, 이때부터 수요데이터를 받지 않고 현재 탑승한 인원들을 목적지까지 이동 후 운행이 종료된다. 중간에 대기시간 그리고 차내 이동시간의 이상치 결과값이 나타나는데, 이는 셔틀버스가 현재 탑승해야 하는 승객인원과 차내의 승객인원을 고려하여 동시다발적으로 최소 승·하차 과정을 진행하기 위한 과정에서 나온 결과값이다. 대기시간, 차내 이동시간은 초 단위로 실시간 호출수요의 평균 서비스 대기시간과 평균 차내 이동시간은 약 379초, 274초로 나타났다. 제안한 DQN 기반 경로탐색 알고리즘은 주어진 테스트베드 환경 내에서 경로 탐색이 가능한 것을 확인하였다.
Table 4.
Averages of services O-D waiting time and Invehicle time
2. Q-learning 및 DQN 비교
동적경로 생성 알고리즘 시뮬레이션 결과를 비교하기 위해 선행연구에서 사용한 수요데이터를 사용하였다. 그 이유는 선행연구에서 제시한 Q-learning 방법론과 DQN 방법론을 동일한 수요데이터에서 비교하고자 한다.
본 연구를 진행하는 순서는 다음과 같다. 첫째, 크게 2가지 정류장으로 구분하여 교내 정점에 위치한 12번 정류장에서 5번 정류장까지 가는 남행 정류장, 5번 정류장에서 12번 정류장으로 가는 북행 정류장으로 진행 방향 기준으로 승객의 탑승 가능한 기종점역이 정해져 있음을 가정하였다. 둘째, 승객 요청 가능한 인원수는 차량의 수요를 기준으로 최대 15명까지 설정하여 Q-learning 기반 경로 탐색 알고리즘, DQN 기반 경로 탐색 알고리즘의 에이전트인 셔틀버스는 12번 버스정류장을 기점으로 하여 동일한 수요를 가지고 수요 인원수를 증가하면서 경로 탐색 시뮬레이션 진행하였다. 셋째, Figure 7과 Table 5는 차량의 최대 수요 15명에 대한 경로 순서를 나타내며 각 번호는 셔틀버스가 방문한 순서를 나타낸다. Q-learning 기반 경로 탐색 알고리즘은 실시간 O-D 데이터를 한 번에 수신하여 이를 기반으로 최적 경로를 생성한다. 따라서 DQN 기반 알고리즘 또한 동일한 조건으로 실험을 진행하였다.
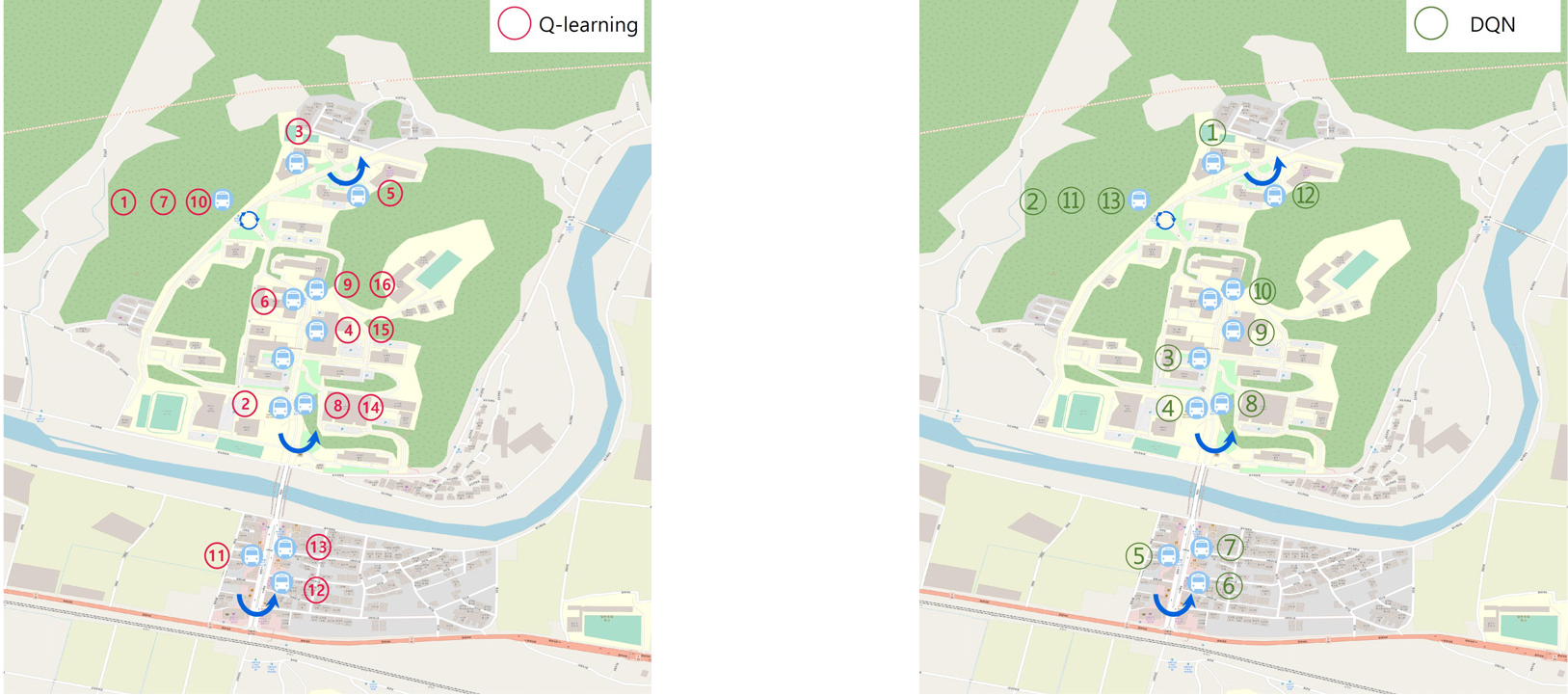
Table 5.
Route Optimization (Q-Learning vs Deep Q Network)
| Algorithm | Route Optimization | |||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |
| Q-learing | 1 | 4 | 12 | 9 | 11 | 2 | 1 | 8 | 10 | 1 | 5 | 6 | 7 | 8 | 9 | 10 |
| DQN | 12 | 1 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 1 | 11 | 1 | |||
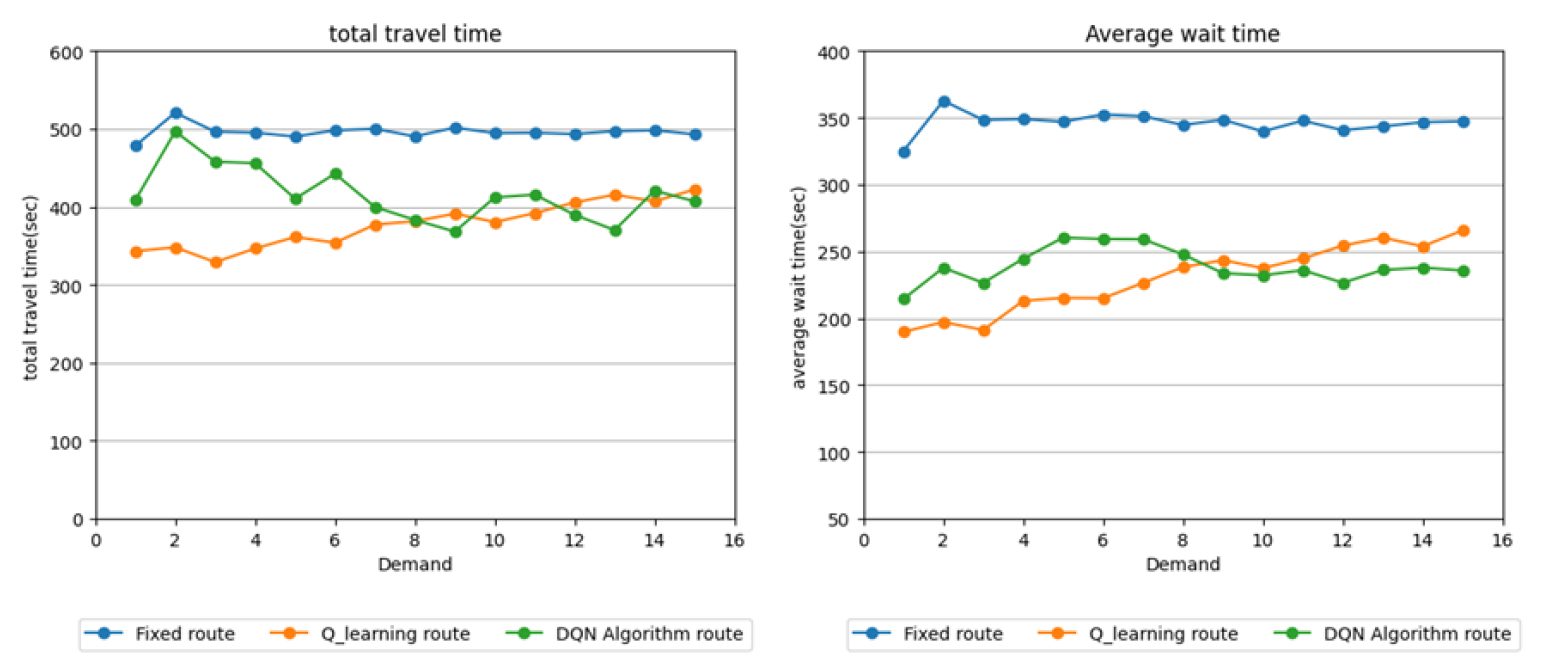
시뮬레이션 결과는 승객 수에 따른 셔틀버스 차량이 운행시간에 대해 결과와 각 승객 수요 인원별 평균대기 시간 결과를 Figure 8과 같이 나타났으며, 수요 인원이 적을 경우 해당 승객이 요청한 기종점 수요 정보는 기존 고정형 노선이 운행하는 경로로 이동하기 때문에 고정 버스노선과 운행시간이 비슷하였지만 수요가 증가함에 따라 고정형 노선에서 경로를 사용하지 않는 구간에 셔틀버스는 유동적으로 유턴이 가능한 경로를 사용하였기 때문에 점진적으로 운행시간이 줄어든 것을 확인하였고, 기존 선행연구 성능과 비슷하다는 것을 알 수 있었다. 또한 Q-learning 기반연구에서는 테스트베드의 지리적인 요인, 실시간 수요 O-D 데이터를 한 번에 수신하여 경로를 탐색, 상행선 하행선으로 구분하여 실험을 진행하였기 때문에 실시간 수요 O-D데이터를 일괄처리 하는 것이 아닌 실시간으로 O-D수요 데이터를 받아 실험을 진행하였다. 그 결과는 Table 5와 같이 수요가 증가하면 증가할수록 DQN 기반 경로 알고리즘의 결과 값은 Q-learning 기반 알고리즘에 비해 적은 동선으로 이동한 것을 확인할 수 있었지만 동적 노선 운영이 고정형 운영 경로로 수렴하게 되었다.
결론 및 향후 연구과제
본 논문은 기존 선행연구(Kim et al., 2022)의 Q-learning을 동적경로 생성 알고리즘 개선을 위해 DQN 동적 최적 경로 생성 알고리즘 개발 및 학습에 필요한 환경을 OpenAI Gym 라이브러리를 통해 가상 테스트베드를 구현하였다. Q-learning과 DQN의 동적 경로 생성 알고리즘 시뮬레이션 결과를 비교하기 위해, 선행연구(Kim et al., 2022)의 Q-learning의 수요 데이터를 사용하여 DQN 기반 경로 알고리즘, 고정형 노선운영, Q-learning 알고리즘을 비교 분석한 결과는 다음과 같다.
첫째, 대중교통 호출 수요가 낮은 경우도 Q-learning 방식은 경로 생성에 많은 탐색시간이 소요되었다. 반면 DQN 경로생성 알고리즘은 신경망 모델이 Q-value를 근사하여 학습을 진행하여 에이전트가 경험하지 않은 상태에 대해 최적 경로를 취할 수 있었다.
둘째, 호출 수요가 증가함에 따라 승객의 이동시간과 탑승 대기시간이 점차 고정형 운영노선으로 수렴하였다. DQN 동적 알고리즘은 동시 호출 수요가 8인으로 많아 질 경우 Q-learning 보다 승객의 이동시간과 탑승대기시간이 효율화되었다. 이는 테스트베드의 지리적인 요인, 상행선과 하행선을 구분하여 O-D 수요호출 등으로 인하여 호출수요량이 적을 때에는 고정형 보다 효율적인 경로 탐색이 가능하였지만 호출수요량이 증가에 따라 DRT를 운영하고자 하면 사전에 정류장을 지정하는 것이 아닌 첨두시간대, 비첨두시간대를 고려하여 동적 정류장 운영방안을 고려할 경우 승객 대기시간과 승객의 이동시간을 최소화시킬 수 있다.
마지막으로 앞서 언급한 첨두, 비첨두시간대 호출수요에 따른 DQN 기반 강화학습을 통해 상황에 맞는 효율적인 경로를 생성할 수 있다. 테스트베드 환경은 도로 네트워크가 단일 네트워크로 구성되어 있어 에이전트가 선택할 수 있는 행동들은 다소 제한적이었고, 보상 방식도 거리를 차량 평균 속도와 정류장 간의 거리를 활용하여 보상을 부여했기 때문에 실제 도로 네트워크를 접목시켰을 때 많은 시간이 걸릴 것으로 예상된다. 본 시뮬레이션의 환경은 단일에이전트에 대해 구축하여 제안하였기 때문에 에이전트가 증가함에 따라 경로 생성 방식이 달라질 것이라 생각된다. 추후 연구는 네트워크가 확장된 사례대상으로 수요응답형 서비스 데이터를 활용하여 다양한 환경에 부합되는지에 대한 평가가 필요하다.
