

서론
1. 연구의 배경 및 목적
2. 연구의 범위 및 방법
선행연구 검토
1. 도로결빙 교통사고 예방
2. 이미지 기반 공간학습 모형
3. 교통사고 심각도 요인 분석
4. 기존 연구와의 차별성
연구 방법론
1. 공간 유사성
2. 결빙 노면으로 인한 잠재적 사고 발생 가능성 예측 모형
사례 분석
1. 자료 수집 내용 및 방법
2. 자료 분석 결과
3. 사례 분석 대상 지역 선정 및 시사점 도출
결론
서론
1. 연구의 배경 및 목적
최근 도로결빙으로 인한 교통사고 심각성이 대두되면서 결빙 구간에 대한 사고 위험 빈도를 경감시키기 위한 노력이 이어지고 있다. 결빙된 노면은 일반 노면 상태에 비해 마찰계수가 낮아 차량의 제동거리가 증가하여 교통사고 유발 가능성을 크게 높인다(Lee, 2017). 결빙으로 인해 발생한 사고는 차가 미끄러지면서 연쇄적인 교통사고를 야기하기 때문에 한 번 사고가 나면 대형사고로 이어지기 쉽다(Kim et al., 2020). 실제 사고 자료를 기반으로 기록이 저장되어 있는 도로교통공단 교통사고분석시스템(TAAS)을 보면 최근 5년(2015-2019년)간 결빙 노면에서 발생한 교통사고의 100건 당 치사율은 3.23%1)로 일반 노면 상태에서 발생한 교통사고 치사율 대비 1.87배 이상 높다(Koroad, 2020). 결빙으로 인해 발생한 실제 사고 자료를 보면 2019년 12월 14일 새벽 4시 41분 경 상주영천고속도로 영천 방면 26.4km 지점에서 다중추돌 사고가 발생해 6명이 숨지고 25명이 다쳤으며, 곧이어 7분 후 같은 고속도로 상주 방면 31.4km 지점에서 다중추돌 사고가 발생하여 1명이 사망하고 16명이 다쳤다(Daegu District Prosecutors’ Office Uiseong District Office, 2020). 이처럼 도로결빙은 안전운전에 큰 위협을 주기 때문에 이를 예방할 수 있는 방법이 필요하다. 도로결빙을 물리적으로 제거하는 직접적 방법과 노면 상태 정보를 취득하여 취득한 정보를 활용하여 도로 정비의 우선순위를 정하거나 실제 주행에 참고하여 교통사고 발생 가능성을 감소시킬 수 있는 간접적 방법이 있다.
직접적 방법은 결빙으로 인해 발생하는 교통사고를 예방하는 방법으로 도로에 열선을 설치(Chea et al., 2014)하거나 제설제를 살포(Lee and Lee, 2007)하여 노면에 발생한 결빙을 직접적으로 제거하는 방법으로 교통사고 발생 가능성을 현저하게 낮출 수 있다. 간접적 방법은 센서 또는 예측 모형을 이용하여 취득한 노면 결빙 정보를 도로전광표지, 방송, 웹, 내비게이션 등을 통해 제공(Ko et al., 2012)함으로써 결빙으로 인한 교통사고를 예방할 수 있는 방법이다.
본 연구에서는 딥러닝을 활용하여 노면 결빙으로 인해 발생할 수 있는 잠재적 사고 발생 가능성을 예측하는 모형을 개발하고자 한다. 예측 모형의 학습, 검증, 테스트를 위해 실제 교통사고가 발생한 지점에 대한 정보(이하 사고 자료)와 정사영상(Orthophoto) 이미지를 수집하였다. 모형은 분할된 정사영상의 한 단편을 학습함으로써 지점이 아닌 범위 단위의 예측이 가능하도록 하였다. 또한 사고가 발생하지 않은 지역의 잠재적 사고 발생 가능성을 예측하도록 검증 및 테스트는 학습하지 않은 지역을 활용하였다. 마지막으로 다양한 종속 변수를 학습하여, 사고 발생 여부뿐만 아니라 예상되는 사고의 심각도 및 사고 발생 건수, 해당 지역에서 발생한 사고의 총 사상자 수 등을 예측하였다. 이러한 결빙 노면에 대한 사고 발생 가능성의 예측 결과는 대상 지역에 대한 선제적 대응을 가능하게 하여 교통사고 및 사회적 비용 감소에 기여할 수 있다.
2. 연구의 범위 및 방법
본 연구에서는 노면 결빙으로 인한 교통사고 발생 가능성을 판별하는 모형을 구축하기 위해 결빙 노면으로 인해 실제 사고가 발생한 지역의 정사영상 이미지를 학습한 딥러닝 모형을 개발하고자 하였다. 딥러닝 기반의 예측 모형은 이미지 클러스터 모형으로 Tensor flow 라이브러리2)를 활용하여 단일 입출력을 갖도록 구성하였고, 이미지 분류에 적합한 레이어 구성을 통해 정사영상을 효율적으로 학습할 수 있도록 하였다. 또한 모형의 자료 수가 부족하여 발생할 수 있는 과적합 문제를 해소하기 위해 이미지 증강 등의 최적화 기법을 적용하였다. 최종적으로 사고 발생 여부, 사고 다발지역에서 발생한 사고 건수(이하 사고 건수), 사고 다발지역에서 발생한 사고의 사상자 총수(이하 사상자 수), 사고 심각도를 예측하는 4개의 모형을 학습하였다. 4개의 모형은 사용 목적에 따라 사고 발생 가능성을 판별하는 모형과 연속형 종속변수를 이산형으로 치환하여 학습한 사고 발생 가능성 예측모형으로 나뉜다. 사고 건수, 사상자 수, 사고 심각도가 사고 발생 예측모형에 해당한다.
모형 학습에 사용된 정사영상 이미지는 대상 지역을 일정한 크기로 분할하여 데이터셋으로 활용하였다. 대부분의 모형에서는 실제 사고가 발생한 지역의 정사영상 이미지만을 학습하였다. 하지만 사고 발생 여부 예측 모형은 나머지 정사영상 이미지에서 실제 사고가 발생한 지역의 정사영상 이미지(True) 데이터셋의 수만큼 임의 샘플링하여 거짓(False) 데이터셋으로 활용하였다.
정사영상 이미지 데이터셋은 사고가 발생하지 않은 지역의 잠재적 사고 발생 가능성에 대한 예측 정확도를 검증하기 위해, 데이터셋을 학습, 검증, 테스트용 데이터셋으로 분할하였다. 모형을 학습하는 과정에서는 검증 데이터셋을 통해 모형의 정확도를 측정하였고, 모형 학습이 완료된 후에는 테스트용 데이터셋을 사용하여 모형의 예측 정확도를 최종적으로 측정하여 모형의 성능을 확인하였다.
본 연구에서 활용한 자료의 공간적 범위는 약 가로 20km, 세로 14km의 크기를 갖는 서울 일부 지역으로 수집한 정사영상 이미지의 크기로 한정하였다. 모형의 학습, 검증, 테스트에 활용한 사고 자료의 시간적 범위는 2013년부터 2019년까지이다. 예측 및 가시화를 위해 사용한 노면 센서 수집 자료의 시간적 범위는 2015년 11월부터 2016년 3월까지이다.
선행연구 검토
1. 도로결빙 교통사고 예방
결빙으로 인한 교통사고를 예방할 수 있는 방법에는 물리적으로 결빙 요인을 직접 제거하는 직접적 방법과 도로 노면 상태에 관한 정보를 제공하여 운전자의 사고발생 확률을 낮추는 간접적 방법이 있다.
직접적 방법은 결빙 지역에 제설제를 살포하거나 도로바닥에 열선을 설치하는 방법으로 노면에 발생한 결빙을 직접적으로 제거하여 도로면을 노출시킬 수 있다. 결빙으로 인한 교통사고 발생 가능성을 현저하게 낮출 수 있는 방법이다. 그러나 강설을 대비하여 미리 살포위치에 제설제를 적재해둬야 하고 열선 방식의 경우 고가의 시공비용 및 유지비용이 소요된다는 단점이 있다.
간접적 방법은 센서 또는 예측 모형을 이용하여 취득한 노면 결빙 정보를 도로전광표지, 방송, 웹, 내비게이션 등을 통해 도로결빙과 관련된 정보를 전달함으로써 결빙으로 인한 교통사고를 예방할 수 있는 방법이다. 간접적 방법은 정보를 전달하는 수단 및 대상에 따라 노면의 결빙 상태를 파악하는 방법이 달라지는데 이와 관련된 연구는 Table 1과 같다. 센서를 이용하면 약 87% 이상의 높은 정확도를 가진 노면 결빙 정보를 수집할 수 있다(Hippi et al., 2009; Kim et al., 2012). 이를 활용하여 실제 결빙으로 인해 사고가 자주 발생하는 지역의 노면 상태를 실시간으로 모니터링 할 수 있다. 센서를 이용하게 되면 높은 정확도는 확보할 수 있으나, 설치 지점의 노면 상태 정보만을 얻을 수 있기 때문에 넓은 지역에 적용하기 어렵다(Park et al., 2020). 또한 운영 ‧ 유지관리에 많은 비용이 소요되기 때문에 모든 구간에 설치하는 것은 현실적으로 불가능하다(Kim and Kim, 2010). 반면 예측 모형을 이용하여 노면 결빙정보를 예측하는 방법은 센서를 이용하는 방법에 비해 상대적으로 낮은 정확도를 갖지만 센서가 설치되지 않은 지역에 대한 예측이 가능하여 넓은 범위에 적용할 수 있다.
Table 1.
Frozen road identification method
2. 이미지 기반 공간학습 모형
대표적인 이미지 기반 공간학습 모형으로는 공간 분류와 공간 클러스터링 기법이 있다. 공간분류는 공간 이미지 단편의 공간적 특성을 학습하여 라벨링하는 학습 기법으로 객체의 일반 속성뿐만 아니라 객체들의 공간적 속성도 고려하여 객체를 분류할 수 있다(Koperski et al., 1998). 공간 클러스터링은 공간적 유사성을 지니는 공간 이미지들을 그룹화하여 특성을 부여하는 기법이다(Sander et al., 1998). 공간 클러스터링을 활용하면 예측하고자 하는 구간과 인접한 구간의 영향력은 반영하면서 속성정보가 크게 차이나는 인접 구간의 영향력은 감소시킬 수 있어 유사도를 갖는 공간을 예측할 때 보다 정확한 예측을 기대할 수 있다(Kim and Jung, 2020). Choe et al.(2017)은 신경망 알고리즘을 사용하여 위성영상 내의 지표면 온도를 예측하였으며 습도와 같은 기상 정보 특성을 모형의 입력 정보로 이용하지 않고 토지 피복 이미지 정보를 이용하여 유의미한 분석 결과를 도출하였다.
3. 교통사고 심각도 요인 분석
교통사고를 감소시키고 안전성을 확보하기 위해, 사고에 영향을 미치는 요인들을 분석하는 연구는 지속적으로 진행되고 있다. Lee et al.(2008)은 사고 심각도의 기준을 도로의 기하구조나 운전자 행태, 차종, 날씨 등에 대한 여러 요인들이 복합적으로 작용하여 사고를 일으키고, 사고의 심각도에 영향을 미칠 것으로 파악하고 도로 요인, 운전자 요인과 환경 요인 중 교통사고 심각도에 영향을 미치는 요인을 추정하기 위해 구조방정식을 이용하였다. 분석결과 환경 요인이 사고 심각도에 더 많은 영향을 미치는 것으로 나타났다. Jung and Kim(2020)은 의사결정나무 알고리즘을 이용하여 교통사고 심각도 요인을 분석하였으며, 피해자 차종이 교통사고 심각도에 영향을 가장 많이 준 것으로 나타났다. Qiu and Nixon(2008)은 날씨가 교통사고 발생 가능성에 미치는 영향성을 실제 사고 자료를 이용하여 분석하였으며 눈이 오는 날에 교통사고율이 일반적인 날씨 상태에 비해 높게 나타났다. 교통사고 심각도 분석의 연구동향을 살펴본 결과 시공간적 분석이 포함되어 있지 않으며, 교통사고를 시공간적으로 시각화하려는 연구의 경우 노면상태에 따른 교통사고 심각도를 분석하는 연구는 진행되고 있지 않는 실정이다.
4. 기존 연구와의 차별성
기존 연구에서는 도로 노면 상태가 변화하는 조건 및 과정에 대해 분석하고 분석 결과를 통해 도로 노면 상태와 교통사고와의 연관성을 검증하여 노면상태에 따른 교통사고 가능성 등을 도출하였다. 이는 교통사고가 발생했을 때 해당 지점의 노면상태 정보와 사망자, 부상자 수를 이용한 사고 심각도 정보만을 나타내고 있어 특정 노면상태일 때 어느 지점에서 교통사고가 주로 발생하는지, 사고 다발지역이 갖는 공간적 특징에 대해서는 연구가 이루어지지 않았다. 또한 사고 심각도를 추정할 때 도로 노면 정보를 고려하지 않고 운전자 정보, 도로 종단 ‧ 횡단 경사 등의 정보를 포함하여 분석함으로써 노면상태가 사고 심각도에 미치는 영향도만을 고려한 분석이 수행되지 않았다. 본 연구에서는 노면이 결빙 상태일 때 교통사고가 빈번하게 발생하는 지역을 정사영상 이미지 정보를 이용하여 판별하고 그 지역의 사고 심각도를 예측할 수 있는 모형을 개발하였다. 모형의 입력정보로 이미지를 활용하기 때문에 센서의 관측정보를 입력 정보로 활용하는 예측 모형에 비해 넓은 지역을 예측할 수 있다. 모형 구축에 사용한 자료 외에 예측용 데이터셋을 별도로 구성하여 노면 결빙시 사고 다발 지역을 판별하고 사고 심각도가 높게 나타날 곳으로 예측되는 지역들의 공간적 특징을 분석하였다.
연구 방법론
본 연구에서는 결빙 노면으로 인한 잠재적 사고 발생 가능성을 예측할 수 있는 모형을 개발하였다. 모형에 사용되는 정사영상 이미지는 대상지역의 공간적 특징을 반영하기 때문에 실제 결빙 사고 다발 지역과 다른 지역들과의 유사성을 비교할 수 있다. 모형에서 도출한 결과 값은 실제 결빙 사고 다발 지역의 값과 비교하여 신뢰도를 판단하였다.
1. 공간 유사성
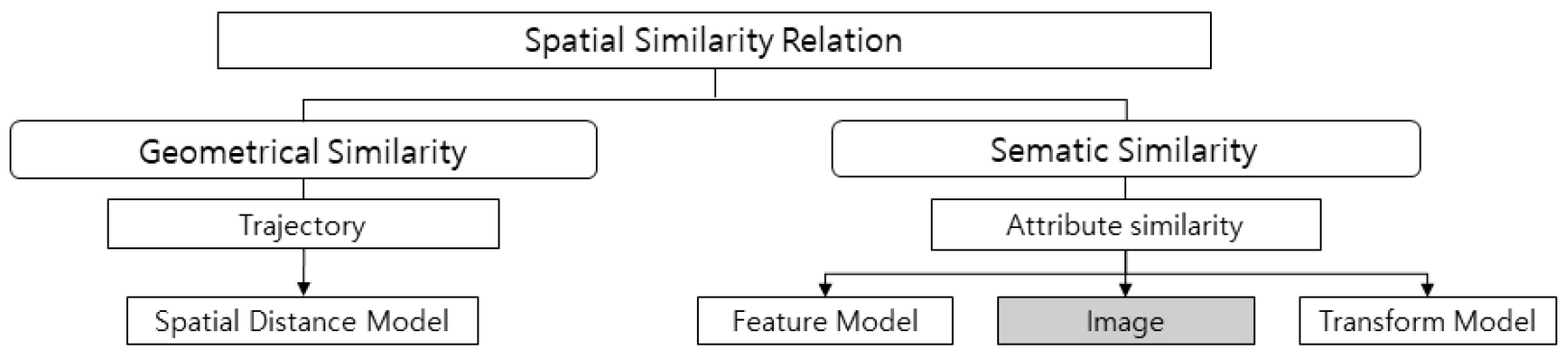
공간 유사성이란 공간 관계(Spatial Relation)중 하나로 시간, 공간 또는 축척이 다른 두 자료의 유사한 정도를 나타내며, 공간 관계는 거리나 방향, 위상적 관계 등을 포함하는 공간에서의 객체들 간의 관계를 의미한다(Hong, 1994). Yan and Li(2015)는 지리학적으로 공간 유사성에 대해 “A1과 A2가 지리학적 공간 상의 두 객체라고 가정할 때, 두 객체의 속성 집합은 C1과 C2이고 C1=∅, C2=∅이다. 만약 C1∩C2≠∅이라면, C∩을 두 객체 사이의 공간적 유사관계라 부른다.”라고 정의하였다. 지리학에서 사용하는 공간 유사성은 유사성 판별 대상과 축척에 따라 분류할 수 있다. 먼저 유사성을 판별하는 대상에 따라 기하학적 유사성과 속성 유사성으로 분류할 수 있고, 기하학적 유사성은 다시 단일 객체와 그룹 객체에 대한 공간 유사성으로 분류할 수 있다. 단일 객체 유사성은 차원, 크기, 모양, 면적, 길이를 기준으로 유사성을 판별하는 방식이며, 속성 유사성은 두 객체가 갖는 속성들 사이의 유사성을 판별하는 방식이다. 속성 유사성은 속성의 특성에 따라 의미론적 유사성, 시간 유사성, 이미지 기반 유사성으로 분류할 수 있는데, 이 중 이미지 기반 유사성은 두 이미지 사이 픽셀의 색상 값에 대한 유사 정도를 판별하는 기법으로 Kwak et al.(2017)은 위성 사진을 이용하여 접근이 불가능한 북한 대홍단 지역의 생산 작물을 분류하는데 공간 연속성을 통한 공간 유사성을 사용하였다. 본 연구에서는 이미지 기반의 유사성 판별 기법을 이용하여 실제 결빙으로 인한 사고 다발 지역과 유사한 지역들을 예측하고 사고 다발 가능 지역에 대해 분석하였다. Figure 1은 공간적 유사성을 판단하는 기준에 따른 분류도이며 본 연구에서는 이미지 기반의 유사성 판별 기법을 사용한다.
2. 결빙 노면으로 인한 잠재적 사고 발생 가능성 예측 모형
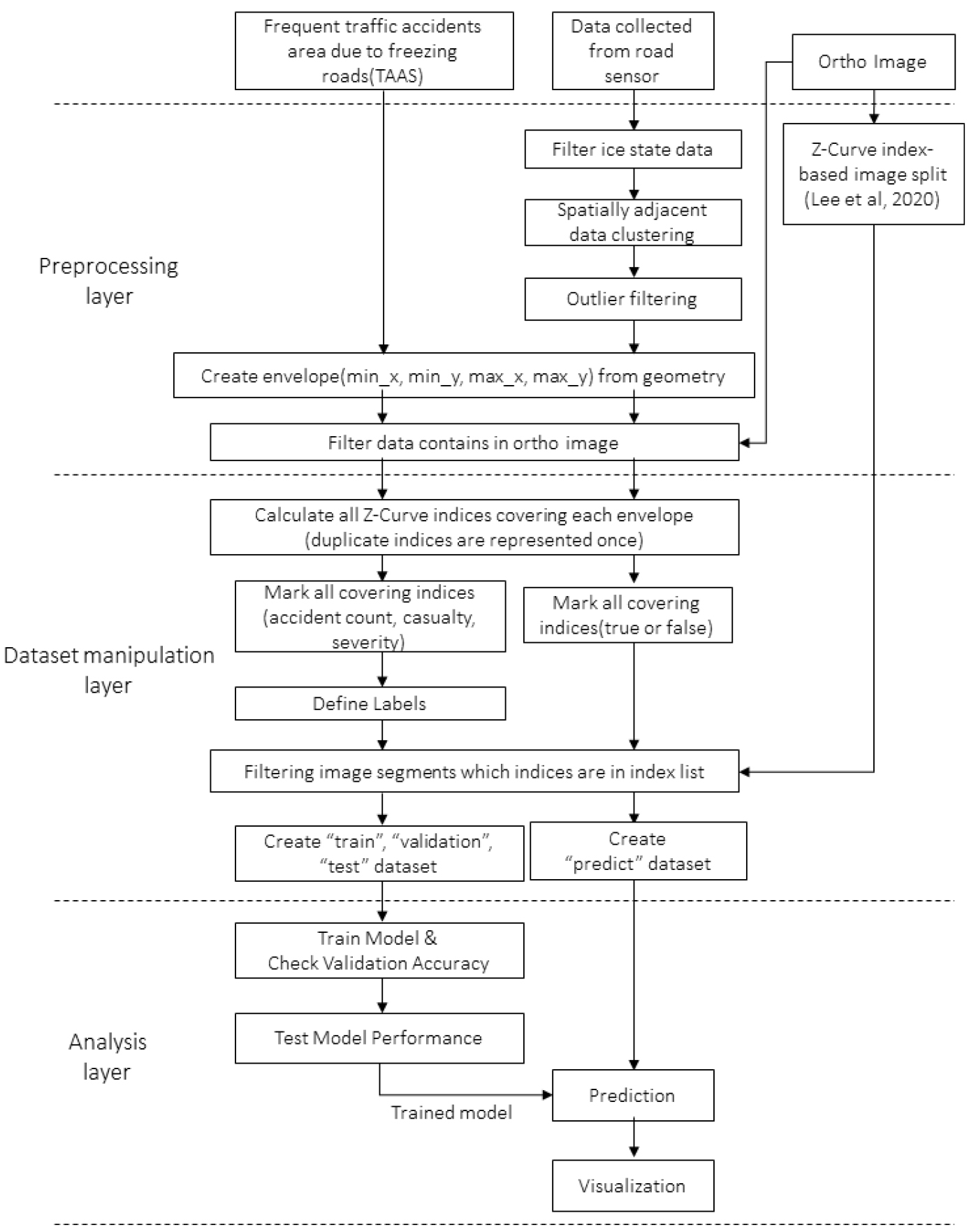
본 연구의 진행 과정은 Figure 2와 같이 크게 전처리, 데이터셋 가공, 분석의 단계를 거친다. 전처리 과정에서는 이미지 필터링, Boundary Envelope 생성, 정사영상 이미지 분할 등의 과정을 수행한다. 데이터셋 가공 단계에서는 이미지를 각 라벨별, 용도(학습, 검증, 테스트, 예측)별로 분류하여 모형 학습을 위한 데이터셋을 구성한다. 마지막으로 분석 단계에서는 데이터셋을 활용하여 모형의 성능 검증 및 최적화를 진행한다. 또한, 최적화된 모형을 사용하여 노면 센서에서 결빙 상태라고 수집된 지역들의 잠재적 사고 발생 가능성을 예측하고, 그 결과에 대한 기초 분석 및 가시화를 통해 시사점을 도출하였다.
1) 자료 전처리
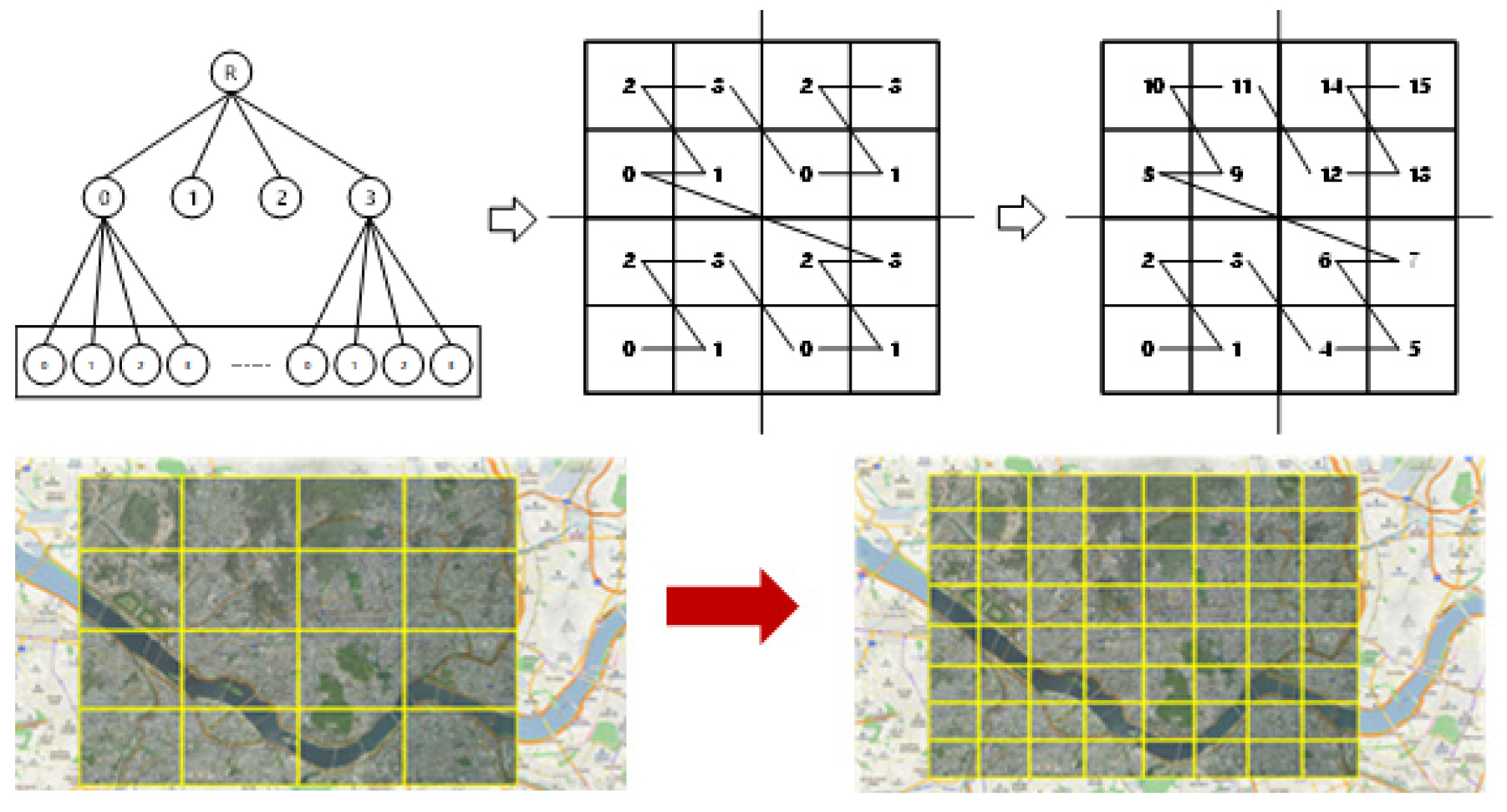
수집한 자료를 본 연구의 분석 자료로 사용하기 위해 이상치 제거 및 공간연산을 수행하였다. 사고 자료는 기초 전처리 과정을 마친 자료이기 때문에 별도의 전처리 과정을 진행하지 않았다. 노면 센서 자료의 경우 검출한 노면 상태가 결빙 상태인 자료만을 우선적으로 필터링하고 지역적으로 인접한 자료에 대해 DB Scan을 이용하여 클러스터링 과정을 수행하였으며 자료 사이의 시간적 거리가 1초 이하인 지역에 한하여 하나의 클러스터로 인정하였다. 클러스터 라벨이 -1로 형성된 자료는 군집이 1개의 자료로만 이루어졌다는 것을 의미하기에 이상치로 판단하여 제거하였다. 또한 클러스터별 평균 속도를 계산하여 5km/h 미만인 경우 한 곳에 일정 시간 이상 정차된 자료로 판단하여 제거하였으며, 평균 속도가 150km/h를 초과하는 자료도 이상치로 판단하여 제거하였다. 정사영상 자료는 Z-Curve Index 기반 정사영상 이미지 분할 기법을 활용하여 전처리하였다. Z-Curve Index는 속성 값을 가진 정보와 이미지 정보 간의 결합을 가능하게 하는 키 역할을 하고 대용량의 이미지 정보를 일정한 크기로 이미지를 분할함으로써 모형 학습 환경을 용이하게 구성할 수 있다. Z-Curve Index는 2차원의 좌표정보를 1차원으로 색인하는 알고리즘으로 Figure 3과 같이 특정 영역을 일정 크기의 격자로 나누고 왼쪽 아래 격자부터 Z 모양의 순서대로 색인 값을 정의한다. 만약 좌표정보가 특정 격자에 포함되면, 좌표정보는 해당 격자가 갖는 색인 값으로 표현할 수 있다(Lee et al., 2020).
개별 전처리 과정을 수행한 후에는 공간 연산을 통해 사고 자료 및 클러스터링된 노면 센서 자료에 대해 Boundary Envelope3)를 생성하였다. Boundary Envelope 생성에는 각 사고 자료의 위 ‧ 경도 최댓값, 최솟값과 각 클러스터의 위 ‧ 경도 값에 대한 최댓값, 최솟값을 사용하였다. 마지막으로 사고 자료와 클러스터 자료의 Boundary Envelope이 정사영상 이미지의 범위 밖에 있는 자료의 경우 제외하였다.
2) 데이터셋 가공
데이터셋 가공 단계에서는 전처리가 완료된 자료를 모형 학습, 검증, 테스트, 예측을 위한 데이터셋으로 가공하는 단계이다. 전처리 단계를 거쳐 Boundary Envelope가 생성된 사고 자료 및 노면 센서 자료는 하나의 점이 아닌 직사각형 형태의 객체 자료이다. Lee et al.(2020)에서 사용한 Z-Curve Index 기반 정사영상 이미지 분할 기법을 통해 분할된 정사영상은 Z-Curve Index 값으로 검색이 가능하기 때문에 정사영상 이미지를 불러오기 위해서는 그 지역의 Z-Curve Index 값을 알아야 한다. 객체 안에 여러 개의 인덱스를 포함하고 있는 경우를 고려하여 두 자료의 Boundary Envelope들이 포함하는 모든 Z-Curve Index를 계산하였다.
사고 자료와 클러스터링된 노면 센서 자료의 Boundary Envelope에 대한 Z-Curve Index를 계산하면, 계산된 Z-Curve Index에 포함되는 정사영상 이미지들에 값을 마킹하는 과정을 수행한다. 이 과정에서는 실제 이미지에 값을 마킹하는 것이 아닌, 이미지의 파일 이름과 종속 변수로 활용할 값이 마킹된 자료를 생성한다. 사고 자료는 각 모형에서 종속변수로 활용하는 사고 발생 여부(참/거짓), 사고 건수, 사상자 수, 사고 심각도를 마킹 값으로 활용한다. 노면 센서 자료의 경우, 활용 가능한 종속 변수가 없고, 예측만을 위해 사용하기 때문에 계산된 Z-Curve Index가 포함되는 경우 참, 아닌 경우엔 거짓을 마킹한다.
마킹이 완료된 자료는 필터링 과정을 거친다. 사고 건수, 사상자 수, 사고 심각도에 대한 마킹 자료는 값이 0보다 큰 정사영상 이미지만을 필터링하였다. 노면 센서 자료에 대한 마킹 자료의 경우 값이 참인 경우를 남기고 필터링하였다. 사고 발생 여부에 대한 마킹 자료의 경우 노면 센서 자료와 같이 참인 경우를 남기고 필터링하지만, 분류 모형을 학습하기 위해 참인 이미지 수와 동일한 수의 거짓 자료를 일부 샘플링하였다.
필터링이 완료되면 마킹 자료 중 사고 건수, 사상자 수, 사고 심각도를 연속형 변수에서 이산형 변수로 변환하고 값을 등급화한다. 사고 건수, 사상자 수, 사고 심각도 예측 모형은 범주화를 통해 사고발생 가능성을 표현하는 사고 발생 가능성 산출 모형이다. 따라서 사고 발생 가능성별로 자료를 출력하기 위해 분류 모형에 적합하도록 자료를 가공하였으며 사고 발생 가능성을 산출하는 방법은 Equation 1과 같다. 또한, 사고 발생 가능성 산출 모형용 데이터셋의 등급은 1부터 시작하도록 정의하였다. 사고 다발 지역 가능성 판별 모형에 해당하는 사고 발생 여부의 경우 종속 변수가 이미 참/거짓 값으로 분류되어 있기 때문에 별도의 변환 과정을 거치지 않는다.
: Traffic accident probability
: Number of accidents
: Number of casualties
: Accident severity
사고 다발 지역 가능성 판별 모형과 사고 발생 가능성 산출 모형의 학습을 위해 사고 자료를 이용하여 모형의 학습, 검증, 테스트 목적의 데이터셋을 생성하였다. 딥러닝 기반 이미지 분류 모형은 학습 자료를 하나의 파일로 구성할 수 없기 때문에, 각 라벨별 폴더에 이미지를 저장한 뒤 모형에서 학습 자료로 활용한다. 본 연구에서는 종속 변수로 치환한 마킹 자료를 이용하여 각 이미지의 저장 경로를 생성하고, 해당 경로에 같은 파일 이름의 정사영상 이미지를 저장한다. 이 과정에서 각 라벨별 이미지 파일은 7:1:2의 비율로 학습, 검증, 테스트 폴더의 각 라벨 폴더에 저장된다. 노면 센서 자료의 경우 마킹 값이 참인 자료만 예측 폴더에 저장하고 각 모형에서 값을 예측할 수 있도록 하였다.
3) 자료 분석
자료 분석 단계에서는 모형을 학습하고 정확도를 검증하며, 모형이 예측한 결과를 관찰하고 다시 분석하는 과정을 수행한다. 본 연구에서는 정사영상 이미지 학습을 위해 딥러닝 기반 이미지 분류 모형을 활용하였다. 모형은 단일 입출력을 갖는 모형으로 입력 자료로 정사영상 이미지를 사용하며, 각 모형별로 예측한 종속 변수를 출력 값으로 반환한다. 모형은 이미지 분류에 적합한 Convolution 층과 MaxPooling2D 층를 활용하였으며 각 층을 3개씩 활용하여 총 6개 층을 갖는 모형을 생성하였다. 활성화 함수는 ReLu(Nair and Hinton, 2010)를 적용하였으며, 손실함수로는 분류 모형을 생성하기 위해 Sparse Categorical Cross Entropy를 사용하였다. 최적화를 위해 학습마다 같은 이미지를 학습하지 않게 하여 과대 적합을 방지하는 데이터 증강 기법(Shorten and Khoshgoftaar, 2019)을 사용하였다. 또한 데이터 증강은 모형 학습에 사용되는 자료의 양을 증대시켜 모형 학습에 사용되는 자료의 양의 적은 경우에도 분류 정확도의 손실을 개선할 수 있다(Perez and Wang, 2017; Liu et al., 2019). 추가적으로 Dropout(Srivastava et al., 2014)을 통해 모형 학습 과정에서 중간 노드를 배제하고 학습을 진행하여 신경망의 크기를 조절하여 과대 적합을 방지하였다. 마지막으로 모형 학습 단계에서 가장 학습 효율이 높은 모형을 예측에 활용하기 위해 Model Check Point를 활용하여 검증 정확도가 가장 높은 모형을 저장하였다.
사고 발생 가능성 산출 모형의 경우, 등급 별 자료의 불균형이나 범주화에 대한 최적화를 위한 성능 테스트를 별도로 수행하였다. 불균형 자료의 경우에는 자료의 수가 적은 등급에 가중치를 주거나, 주지 않거나, 가중치의 제곱을 부여하는 3가지 방식으로 모형을 학습하였다. 범주화에 대한 최적화를 위해 각 종속변수의 라벨이 의미하는 범주를 다르게 하여 모형을 학습시킨 후, 사고 자료 기반의 테스트셋을 사용하여 모형의 성능을 시험했다.
본 연구에서 구축한 모형은 분류 모형이지만 모형의 예측 성능 테스트는 회귀 모형 테스트에 주로 사용하는 Mean Percentage Error(MPE)를 사용하였다. 모형의 예측 성능에 정확도 대신 MPE를 사용한 이유는 과소 예측을 최소화 할 수 있는 모형을 선정하기 위해서다. 의료분야에서도 질병 심각도에 대한 과소 예측으로 인해 발생할 수 있는 치료 실패를 방지하기 위해 과소평가 문제를 해결할 수 있는 연구를 진행하고 있다(McLaughlin et al., 2010). 사고 발생 가능성 등급이 3단계인 지역을 1단계로 예측한다면 예측 모형의 목적인 사고를 미연에 방지하는 기능을 상실하게 된다. MPE는 실제 값보다 높게 예측한 경우 음수의 값을 발생시킨다. 이를 이용하여 MPE 값이 양수인 모형은 우선순위에서 제외하였다. MPE가 음수인 모형은 전체 예측 정확도와 각 라벨별 예측 정확도(True Positive Rate, TPR), 과소 예측률(Underpredict Rate, UPR), 과대 예측률(Overpredict Rate, OPR)에 대한 평균값을 이용하여 최종적으로 선정한다.
모형 학습 및 성능 검증 단계가 끝나면, 최종적으로 선정된 4개의 모형으로 예측용 데이터셋을 활용하여 노면 센서에서 결빙 노면이 실측된 지역들의 사고 발생 가능성 등급 및 사고 발생 여부를 예측한다. 예측된 결과를 통해 가시화 및 필터링, 기초 통계 등의 분석결과를 해석하고 시사점을 도출한다.
사례 분석
1. 자료 수집 내용 및 방법
결빙으로 인한 교통사고 발생 가능성을 예측하기 위해 사고 자료, 노면 센서 자료, 정사영상 자료를 활용한다. 정사영상 이미지는 국토지리정보원에서 제공하는 이미지를 사용하며 정사영상 이미지의 한 픽셀이 포함하는 공간적 범위는 가로 51cm, 세로 51cm이다. 본 연구에서 활용한 정사영상의 공간적 범위는 Figure 4처럼 서울 일부 지역으로 한정하였다. 서울은 유동인구 및 교통량이 많고 전국에서 사고심각도법(Equivalent Property Damage Only, EPDO) 지수가 높은 지역으로 다양한 교통사고 정보를 확보할 수 있는 이점이 있다. 사례 분석을 위한 활용 자료의 공간적 범위도 정사영상의 공간적 범위로 한정한다.
사고 자료는 경찰청의 교통사고분석시스템(TAAS)에서 제공하는 매년 최근 3년간 결빙 노면으로 인해 발생한 사고에 대한 통계를 집계한 자료다. 본 연구에서는 2013년부터 2019년까지 집계한 통계 자료를 활용한다. 본 연구에서는 사고 자료로써 사고 건수와 사상자 수를 이용했다. TAAS에서 제공하는 자료에 대한 설명은 Table 2와 같다.
Table 2.
Accidents data column
노면 센서 자료는 택시에 부착된 RCM411을 이용하여 수집하였다. 수집 대상 지역은 택시의 영업활동 범위인 서울, 경기, 인천이며 자료수집 기간은 2015년 11월부터 2016년 3월까지 이다. RCM411의 제원은 Table 3과 같으며 다른 이동형 노면 센서에 비해 노면 결빙에 대해 관측 정확도가 높다는 이점이 있다(Wåhlin et al., 2016). 노면 센서 자료는 모형의 학습, 검증, 테스트에는 활용하지 않으며, 성능 검증까지 완료한 모형을 활용하여 사고 발생 가능성 등급 및 사고 발생 여부 등을 예측한다. 예측한 결과는 결과 분석을 진행한 후에 시사점을 도출하는 용도로 사용한다.
Table 3.
RCM411 specification

2. 자료 분석 결과
1) 자료 분석 환경
자료 분석을 위한 딥러닝 모형은 딥러닝 프레임워크인 Tensorflow로 구현하였다. 딥러닝 학습에 사용한 데이터셋은 각 모형별로 7:1:2의 비율로 학습, 검증, 테스트에 활용하였다. 사고 다발 지역 가능성 판별 모형의 경우 사고 자료를 이용해 마킹한 정사영상 이미지 344개를 참 값을 갖는 데이터로 활용하며 나머지 정사영상 이미지를 샘플링하여 거짓 데이터로 사용하였기 때문에 다른 모형에서 사용한 데이터셋 크기의 2배인 688개를 전체 데이터셋을 활용하였다. 본 연구에서 각 모형별로 사용한 학습, 검증, 테스트를 위한 데이터셋의 크기는 Table 4와 같다.
Table 4.
Number of data used to create the model
2) 모형 최적화 및 검증 결과
최종 선정된 사고 다발 지역 가능성 판별 모형의 테스트 정확도는 0.72이며, 사고 발생 가능성 산출 모형의 최적화 결과는 Table 5와 같다. 사고 발생 가능성 산출 모형은 레이블 수(num_class), MPE, UPR 평균(UPRA), TPR 평균(TPRA), OPR 평균(OPRA), 전체 평균 순으로 우선순위를 두고 최종 선정하였다. 모형 선정 우선순위에 따라 모형의 accuracy가 높지만 MPE가 양수로 나타나 예측 등급이 낮게 나타나는 모형 및 TPRA가 낮게 나타난 모형은 선정하지 않았다. 세 모형 모두 가중치를 적용한 모형을 선정하였다. 사고 건수 모형과 사상자 수 모형에서는 레이블의 범주가 5, 사고 심각도 모형에서는 레이블의 범주가 0.7인 모형을 최종 모형으로 선정하였다.
Table 5.
Risk rating model optimization results
3) 예측용 데이터셋에 대한 모형 예측 결과
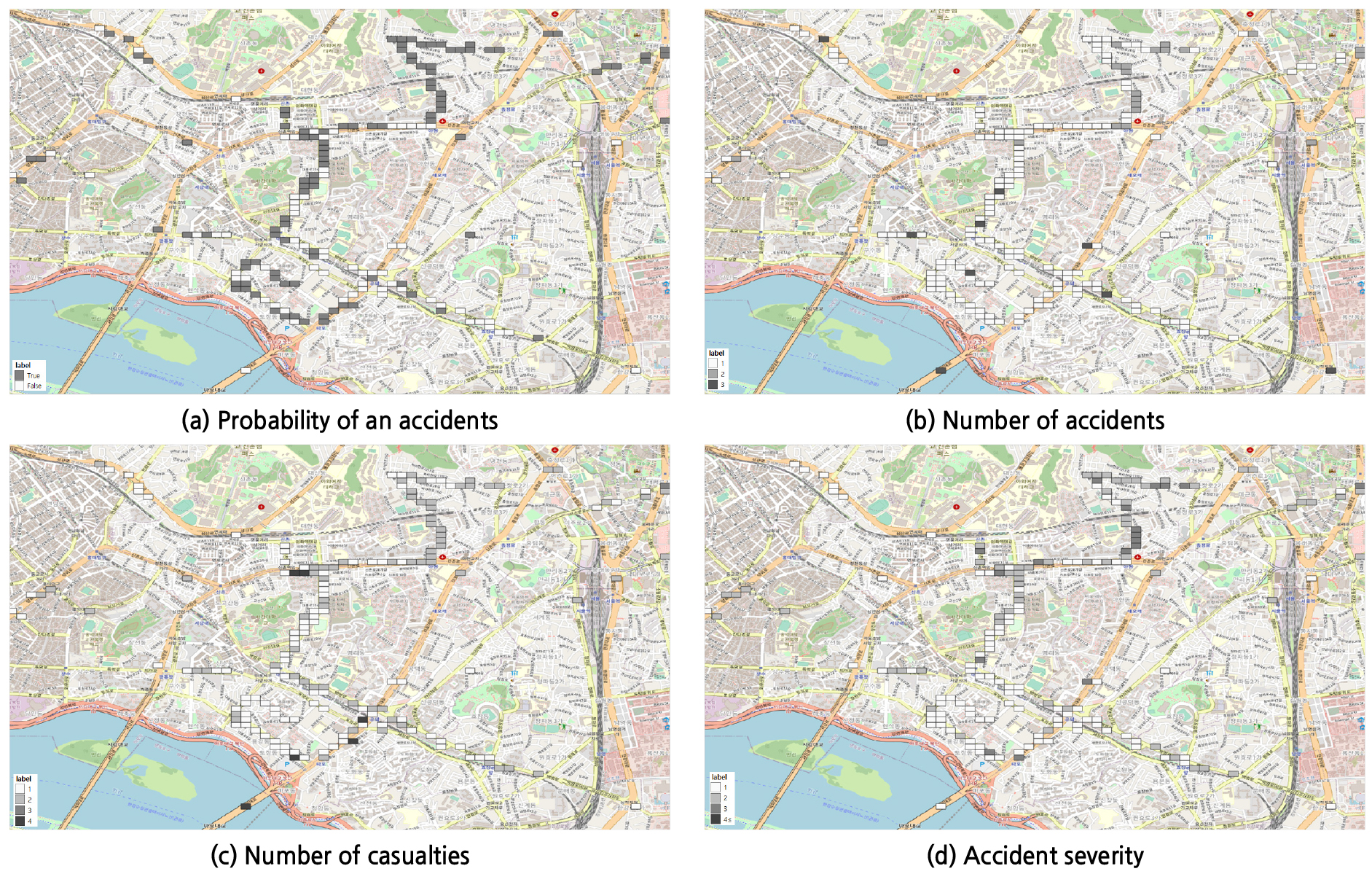
최적화 및 검증 단계를 마친 사고 다발 지역 가능성 판별 모형 및 사고 발생 가능성 산출 모형을 이용하여 노면 센서 자료 기반 예측용 데이터셋에 대한 사고 다발 지역 판별, 사고 건수, 사상자 수, 사고 심각도로 구성된 총 4가지 분석 유형에 따른 결과를 예측하였다. 판별 모형은 결빙 사고 다발 지역에 대한 판별 사고 가능성 유무에 따라 표현하였으며, 사고 발생 가능성 모형을 통한 예측 결과는 레이블 값을 이용하여 지도상에 표출하였다. 결빙 사고 다발 지역에 대한 판별 사고 가능성 유무를 나타낸 그림은 Figure 5(a)와 같으며, 사고 발생 가능성 등급 모형의 예측 결과는 Figure 5(b-d)와 같다. 사고 건수 라벨의 경우 회현역↔한국은행앞사거리, 광화문 일대가 높게 나타났다. 사상자 수 라벨은 올림픽대로↔영동대교 부근, 논현동↔한남대교 부근이 높았다. 사고 심각도 라벨은 북아현동, 광화문, 미아사거리 일대가 높게 나타났다.
3. 사례 분석 대상 지역 선정 및 시사점 도출
1) 사례 분석 대상 지역 선정
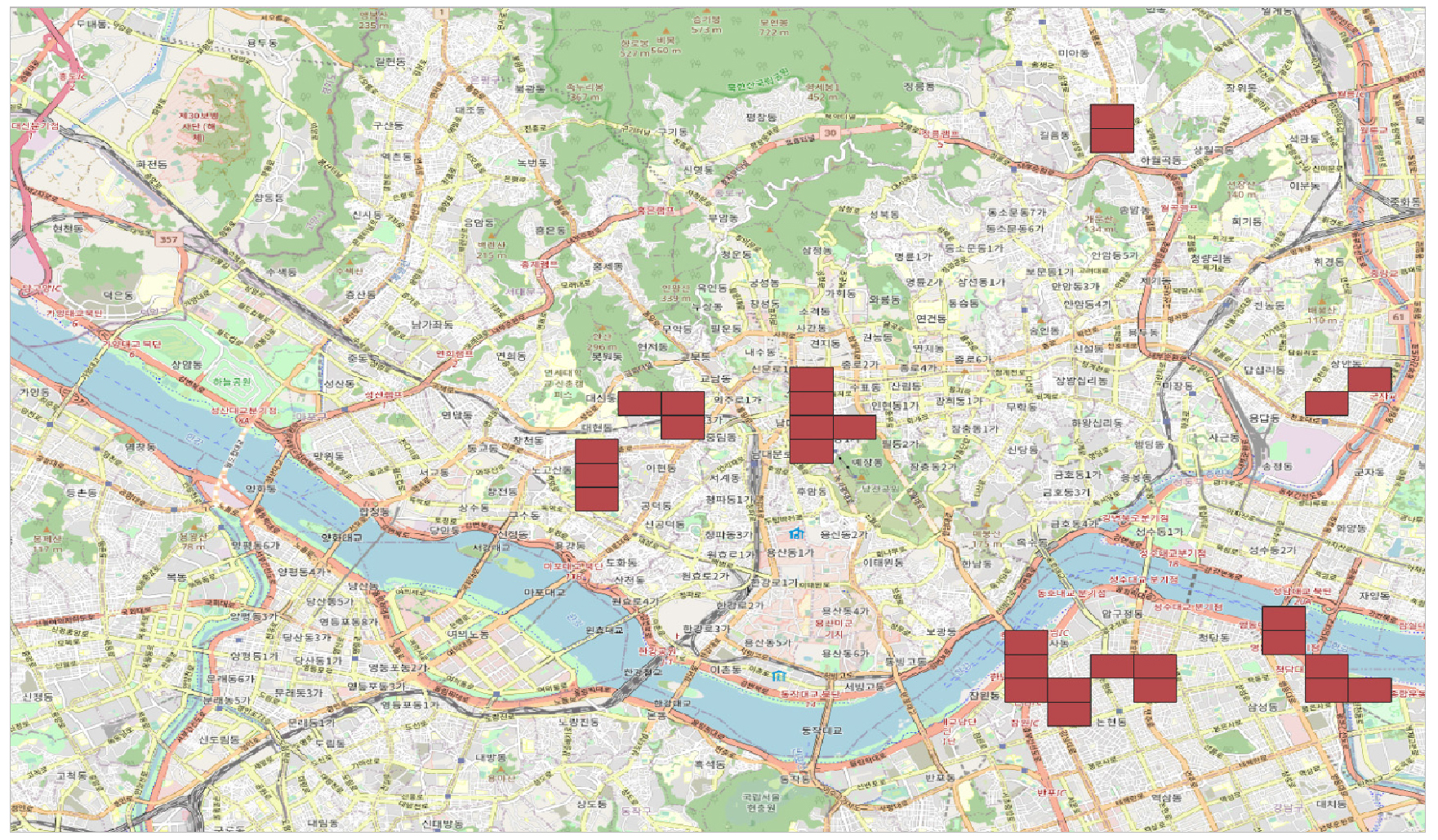
사고 발생 가능성 산출모형 예측을 통해 도출된 지역들 중 사고 건수, 사상자 수, 사고 심각도 라벨이 높게 예측된 지역을 사례 분석 대상 지역으로 선정하였다. 먼저 예측 모형을 통해 도출된 지역을 수치 비교 범위를 동일하게 설정하기 위해 사용한 정사영상 범위의 그리드화를 통해 동일한 크기(너비≒623m, 높이≒437m)의 사각형으로 분할하였다. 분석 대상 지역 선정시 그리드 필터링 기준을 적용하여 선정 지역에 대한 객관성을 확보하였다. 먼저 사고 다발 지역으로 예측된 지역만을 추출하기 위해 사고 다발 가능성 판별 모형으로 예측할 결과가 True인 그리드를 필터링 하였다. 그리드 간 연결성을 보이는 지역만을 선정하기 위해 영역 내에 방향에 상관없이 2개 이상의 자료가 포함되는 그리드만 추출하였다. 또한 그리드 내에 포함한 예측 자료가 2개 이상인 그리드를 필터링 함으로써 단일 자료가 대표성을 갖는 경우를 방지하였다. 마지막으로 사고 발생 가능성 등급이 높은 지역을 선정하기 위해 예측된 라벨 값이 전체 그리드 평균 라벨보다 높은 지역만 선정되도록 필터링하였다. 필터링 결과 Figure 6과 같이 사례 분석 대상지역으로 대흥역↔이대역 사거리, 북아현동, 회현역↔한국은행앞사거리, 광화문, 논현동↔한남대교, 올림픽대로↔영동대교, 미아사거리, 장한평역↔장한로 이상 총 9개 지역이 선정되었다.
2) 사례 분석 대상 지역의 시사점 도출
사례 분석 대상 지역에 대해 예측된 라벨의 평균은 Table 6과 같다. 이 중 사고 건수 라벨이 가장 높은 곳은 1.83으로 회현역↔한국은행앞사거리 지역으로 나타났다. 해당 지역은 사상자 수, 사고 심각도 라벨도 전체 평균보다 높게 나타난 지역으로 예측 라벨 수치상으로 봤을 때 결빙 사고 취약지역으로 판단할 수 있다. 사상자 수 라벨은 2.89로 올림픽대로↔영동대교에서 가장 높게 나타났다. 사고 건수, 사상자 수 라벨이 높은 곳이 대로부터 교량까지 길게 이어져 있다는 특징이 있다. 사고 심각도 라벨이 가장 높은 지역은 3.60의 값을 갖는 미아사거리로 나타났다. 미아사거리는 유동인구가 많은 대표적인 상권지역으로 지하철역, 버스 정류장, 백화점이 위치해있어 한 번 사고가 발생했을 시 대형 사고가 발생할 것으로 사료된다.
Table 6.
Prediction case study of area prediction label
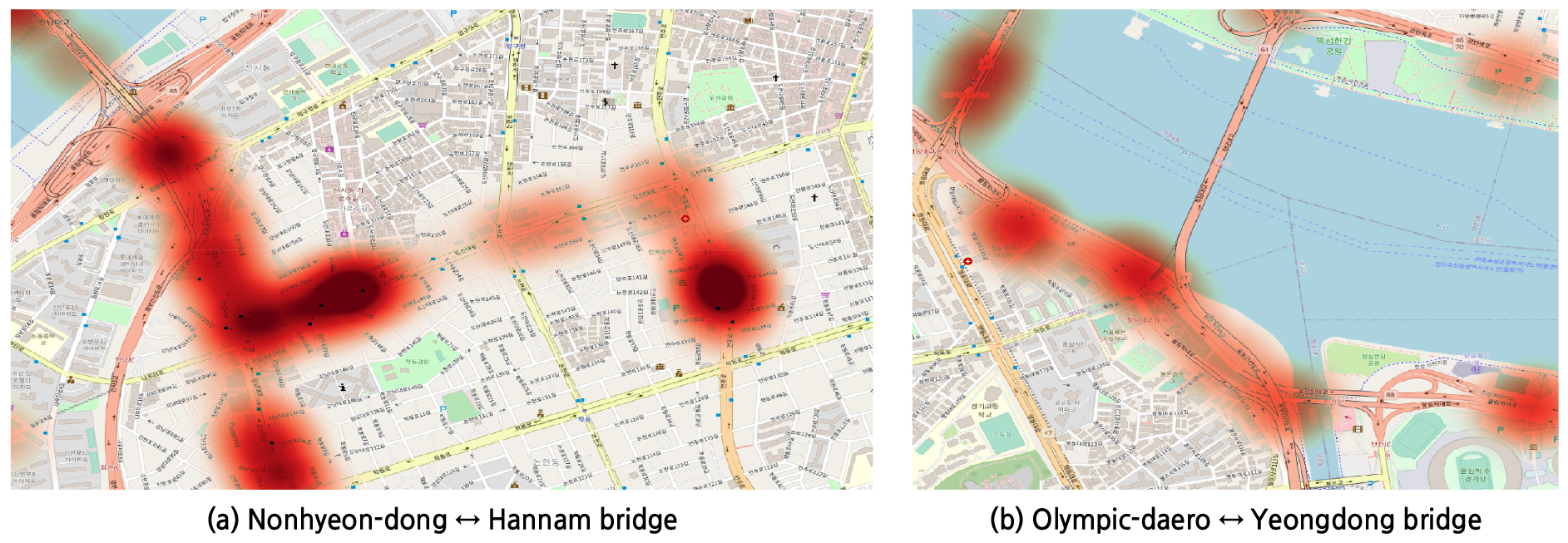
선정된 사례 분석 지역 중 가장 넓은 자료 분포 범위를 갖는 논현동↔한남대교, 올림픽대로↔영동대교 지역에 대해 열 분포 형태의 일정 범위를 가진 자료를 나타낼 수 있는 히트맵(Heat Map)을 이용하여 Figure 7과 같이 시각화하였다. 두 지역의 공통된 특징으로는 수변 지역이면서, 교량 진입 구간에 고가도로가 존재하며, 교량이 위치한다. 해당 특징들은 도로결빙 발생 및 유지에 간접적인 영향을 미칠 수 있는 환경적 특징을 나타낸다. 바다, 강, 댐 등 수변지역에서는 수증기의 공급이 활발하여 안개가 자주 발생한다. 빈번히 발생하는 안개는 지표 및 도로 노면 위에 떠 있는 지표에 얼어붙어 서리가 되거나, 도로 노면 결빙을 일으킬 수 있다. 교량 및 고가도로는 평지구간과 다르게 태양열에 의해서만 열을 받기 때문에 동절기에 노면에 결빙이 발생할 확률이 높다. 평지구간의 지열은 야간에 대기 온도가 낮아지더라도 결빙 가능성을 줄여주는 대 비해 교량의 경우 양측에서 공기와 접촉을 받기 때문에 열의 영향을 받는 영역이 평지구간보다 넓다. 그에 따라 일반 노면에 비해 표현 온도가 낮게 형성되기 때문에 결빙이 발생할 확률이 증가한다.
그 외 사례 분석 대상 지역의 특징을 보면 유동량이 많은 도심지역에 분포되어 있다. 도심지역은 고층건물이 많다는 특징을 갖는다. 고층건물로 인해 도로 노면 상태는 동일한 기하구조를 가진 도로더라도 온도 차이에 따른 증발산량에 차이가 발생한다. 도로 노면 온도는 음영변화에 따라 달라지는데 도로 구조물 또는 도로주변의 환경으로 인해 발생한 음영이 있는 공간에서는 증발산량이 낮아져 노면에 발생한 수분을 유지할 수 있는 시간이 증가한다. 도로 구조물로 인해 발생한 음역 지역으로 인해 도로 노면의 온도가 영하로 떨어지고, 노면상에 수분이 존재하는 경우 착빙이 발생할 수 있다. 이는 도로 노면 온도가 낮게 유지된다면 노면에 착빙이 발생할 가능성을 크게 증가시킨다.
결론
본 연구에서는 결빙 구간에 대한 사고 위험 빈도를 경감시키기 위해 결빙 노면으로 사고 발생 가능성을 판별할 수 있는 방법을 고안하였다. 딥러닝 기반의 결빙 사고 다발 지역 판별 모형 및 사고 발생 가능성 등급 산출 모형을 구현하기 위해 경찰청의 TAAS에서 제공하는 결빙사고 다발지역 정보 API, 노면 센서 자료, 정사영상 자료를 사용하였다. 활용 자료는 사용 목적에 따라 전처리 과정과 Z-Curve Index 계산, 종속변수로 치환하는 데이터셋 가공과정을 거쳐 모형의 입력 자료로 사용하였다. 모형 최적화를 위해 과대적합을 방지할 수 있는 Data Augment Layer와 Dropout 기법을 사용하였으며, Model Check Point를 이용하여 검증 정확도가 가장 높은 모형을 선정하였다. 또한 모형 학습 자료 라벨 비율에 따른 불균형 데이터셋 문제를 해결하기 위해 Class Weight를 적용하였으며, 각 라벨이 의미하는 범주를 다르게 하여 테스트 정확도를 검증하였다. 검증 결과로 결빙 사고 다발 지역 판별 모형은 0.72의 테스트 정확도를 가진 것으로 나타났다. 사고 발생 가능성 등급 산출 모형 선정은 MPE가 음수로 계산된 모형을 최우선적으로 선정함으로써 가장 사고가 발생할 가능성이 높은 등급을 낮은 등급으로 예측하는 경우를 최소화하고 불균형 자료에 대해서는 TPRA, UPRA, OPRA를 산출하여 검증하였다. 선정된 모형에 대해 노면상태 자료 기반 예측용 데이터셋을 이용하여 4가지 분석 유형에 따른 결과를 예측하고 지도에 매핑하여 사고 건수, 사상자 수, 사고 심각도 라벨을 예측하였다. 예측 결과 주로 유동량이 많은 도심지역과 수변 인근 교량 지역이 높은 라벨 값으로 예측되었다.
본 연구에서 제안된 결빙 노면으로 인한 사고 발생 가능성을 판별할 수 있는 모형은 정사영상 이미지 정보를 모형의 입력데이터로 활용함으로써 예측 범위가 지점이 아닌 구간을 예측할 수 있다는 점과 미계측 지역에서도 활용할 수 있다는 장점이 있다. 산출된 자료는 결빙 위험 정보를 제공하기 위한 기초자료로 사용할 수 있다. 도로관리 차원에서는 결빙 예방 시설 배치 시 우선순위를 결정하거나 도로안전 관련 제도 개선 및 정책반영에 활용할 수 있을 것으로 사료된다. 본 연구를 통해 몇 가지 주요한 시사점을 도출할 수 있었으나 분명한 한계점도 나타났다. 단일 PC의 처리량의 한계로 서울 일부 지역의 정사영상 이미지만 확보하여 모형 학습을 수행했기 때문에 학습에 사용한 자료의 수가 적었다. 정사영상 이미지의 경우 용량이 크기 때문에 처리에 오랜 시간이 소요되므로 고사양의 하드웨어가 필요한 경우가 대부분이다. 또한 노면이 결빙된 지역으로 관측된 지역으로 구분이 선행되어야 예측이 가능하다. 향후 연구에서는 빅데이터 시스템 기반 환경을 구성하여 보다 넓은 지역의 정사영상 이미지를 확보하고 노면 상태를 예측할 수 있는 모형을 개발하여 보다 명확한 예측 및 분석 결과를 도출할 예정이다.
