

서론
기존문헌고찰
1. 교통안전정책 관련 연구 동향 분석
2. 교통사고 분석을 위한 데이터 마이닝 기법 적용 사례
3. 기존 연구와의 차별성 및 의의
분석 방법론
1. 분석 개요
2. 변수 설정
3. 분석 방법론
분석결과
1. 기초통계 분석
2. 랜덤 포레스트 분석
3. 의사결정나무
4. MARS
5. 타당성 검토 및 최종 복합 영향요인의 선정
결론
서론
정부는 매년 「제8차 국가교통안전기본계획(2017-2021)」에 따라 소관부서별 국가교통안전 시행계획을 별도로 수립하여 추진하고 있으며 국민생명 지키기 3대 프로젝트의 일환으로 사망자 50% 감축을 목표로 설정하였다. 한국도로공사는 이러한 정부의 교통안전 시책을 적극적으로 고려하기 위해 별도의 고속도로 교통안전 종합대책 중 ‧ 장기 로드맵 수립이 필요한 실정이다. 현재 국내에서 발생한 전체 교통사고 발생건수는 지속적으로 감소하고 있는 추세이며 이는 최근 국가에서 교통안전에 대한 관심이 증대되어 다양한 안전개선대책 도입으로 인해 나타난 결과로 판단된다. 마찬가지로 고속도로에서 발생한 사망자 수 또한 지속적으로 감소하는 추세를 나타내지만 여전히 증감을 반복하고 있으며 주요 OECD 국가에 비해 높은 사망자 수가 발생하고 있다. 따라서 국내 고속도로의 심각한 사고를 감소시키기 위해서는 사망자 감축을 위한 중점적 노력이 필요하다. 최근 9년 동안 국내 고속도로에서 발생한 연장(100km)당 사망자 수의 평균 감소율은 약 7.91%이며 주요 OECD(7개국) 국가의 감소율은 약 2.5%로 3.2배의 차이가 나타났다. 한국의 경우 사망자 평균 감소율이 높게 나타났지만 여전히 사망자 수는 주요 OECD 국가에 비해 높은 편이다. 이는 국내 고속도로에서 발생한 사망자 수를 감소시킬 수 있는 개선 여지가 남아있으며 사망자 수 저감 목표 달성을 위해 사망자 수가 적게 발생한 국가의 교통안전정책을 우선적으로 검토하고 국내 실정을 반영한 도입 방안에 대한 고려가 필요하다.
국가 차원에서는 거시적 관점에서의 정책 수립을 위해 단순 기초통계 수준 내 교통사고 동향을 파악하고 분석을 수행하고 있다. 하지만 교통사고는 한 가지 이상의 요인이 복합적으로 결합되어 발생하며 메커니즘 또한 복잡하다. 기존 사고분석 방식은 사고 빈도를 감소시키기 위해 인적 요인, 도로 환경요인 등 특정 원인에 초점을 맞춰 주요 대책을 적용해왔으나 이러한 방식은 빈도를 감소시키기에는 효과적일 수 있으나 중상, 대형사고 등 심각한 사고를 감소시키기에는 실효성이 저하될 수 있다.
교통안전정책 수립 시 복합 영향요인을 파악하여 종합적 관점을 통한 사고분석이 필요함에 따라 본 논문에서는 다양한 방법론을 적용하여 고속도로 심각 사고 감소를 위한 복합 영향요인을 도출하였다.
기존문헌고찰
국내외에서 수행되고 있는 교통안전정책 수립을 위한 연구 동향을 파악하기 위해 교통안전정책 주요 부문 도출사례 및 사고분석을 위한 데이터 마이닝 기법 적용 연구에 대해 고찰하였다. 특히 빈도 및 심각도 측면에서 데이터 마이닝 기법을 적용하여 활용한 사례 분석을 통해 본 연구의 의의 및 차별성을 제시하였다.
1. 교통안전정책 관련 연구 동향 분석
Nam et al.(2016)은 자율주행자동차와 관련된 교통안전 정책과제 분석을 위해 Issue-Tree를 활용하였다. 선행 연구에서는자율주행자동차 도입에 따라 교통안전과 관련된 이슈를 해결하고 정책을 도출하기 위한 연계 키워드를 제시하였다. 또한 도출된 정책 과제의 필요성 및 기여도 등을 반영한 우선순위 도출을 위해 QFD(Quality Function Deployment) 방법론을 적용하여 중요도를 평가하였다. Lim(2018)은 지역별 특성에 따라 적용된 안전대책의 차이를 극복하기 위해 국가 차원에서 지역별 교통안전정책 수립을 위한 방향성을 제시하였다. 이를 위해 지역별 사고 발생 현황 분석을 통해 지역별 중대 교통사고의 차이가 있음을 밝히고 화물차의 차량 특성 별, 지역 물동량의 형태 등 지역별 특성에 따른 교통안전정책 도입 필요성을 제시하였다.
Kim and Kim(2018)은 빅데이터를 활용한 정책 이슈 도출을 위해 수원시를 대상으로 3년간 약 18만 건의 신문 기사를 분석하였다. 텍스트마이닝 분석을 통해 총 8가지 분야에서 110개의 이슈를 도출하였으며 정책 이슈의 중요도 도출을 위해 설문조사를 활용하여 IPA(Importance-Performance Analysis) 분석을 실시하였다. Oh et al.(2016)은 ITS와 관련된 정책 이슈 도출을 위해 경계분석 이론 및 텍스트마이닝 기법을 적용하여 감사이슈 분석 프레임워크를 제시하였다. 뉴스, 문헌 등의 정보를 바탕으로 정책 이슈를 발굴하였으며 부정적 견해를 반영하여 고위험 정책 이슈를 구분하였다. Kim and Yoon(2019)은 뉴스 및 신문 기사를 통해 도로 교통 서비스와 관련된 정책 이슈와 여론 변화를 파악하기 위해 오피니언 마이닝 기법을 적용하였다. 또한 감성분석을 통해 도로 이용자의 니즈를 파악하였으며 5년 단위 기간에 따라 정책 이슈가 변화함을 밝혔다. Oh(2015)는 텍스트마이닝 기법을 활용하여 교통 및 ICT 분야의 연구 동향을 정량적으로 분석하고 두 분야의 필요한 연구 영역을 도출하였다.
2. 교통사고 분석을 위한 데이터 마이닝 기법 적용 사례
Nam et al.(2004)은 의사결정나무를 이용하여 운전자의 인적 요인을 토대로 사고 영향요인을 도출하였다. 분석결과를 통해 변수 간 상호작용을 고려한 복합 요인의 경우 단일 요인과 상반된 결과가 도출될 수 있음을 제시하였다. Kang et al.(2017)은 사고를 심각도에 따라 분류하고 시공간적 특성 및 사고 영향요인을 도출하였다. 의사결정나무 분석을 통해 심각도 영향요인을 도출하고 사고 발생 개연성을 향상시키는 주요 규칙을 제시하였다. Lee et al.(2008)은 도로 기하구조 요인과 사고 간 관계를 파악하기 위해 CART(Classification and Regression Tree) 분석 모형을 개발하였다. 모형의 적합도 검증을 위해 다중 회귀모형, 포아송 회귀모형과 비교하였으며 CART모형의 경우 교통 사고율의 크기와 관계없이 우수한 성능을 보임을 밝혔다. 도출된 사고 영향요인은 구간 거리(km), 횡단보도폭(m), 횡단길어깨(m), 교통량 순으로 도출되었다.
Han et al.(2014)은 CART 모형을 통해 화물차 및 비화물차 사고를 구분하여 심각도 분석을 수행하였다. 화물차의 사고 심각도는 보호 장구 착용 여부, 운전 경력 등이 영향을 미치는 것으로 나타났다. Park et al.(2016)은 의사결정나무 분석 기법을 통해 공사구간과 일반구간에 대한 영향요인을 각각 도출하여 비교하였다. 분석결과, 트럭 비율이 공사구간 사고심각도에 큰 요인으로 작용하며 공사구간 안전 개선을 위해 트럭 비율에 따라 대책 수립을 다르게 적용할 것을 권장하였다. 또한 단순 의사결정나무 기법은 예측력이 저하되기 때문에 인공신경망, 다항 로지스틱 등 다양한 기법을 적용한 사고심각도 분석 연구가 필요함을 제시하였다.
Castro et al.(2015)은 베이지안 네트워크, 의사결정나무, ANN(Artificial Neural Network) 기법을 활용하여 사망 및 부상사고 영향요인을 도출하였다. 도로 유형, 조명 조건, 날씨, 차량 연식, 도로 포장 및 표면 상태에 대한 요인이 심각한 사고 발생에 영향을 미치는 것으로 도출되었다. Chung(2013)은 과분산 특성 및 비선형 특징을 갖는 사고건수를 예측하기 위해 BRT(Boosted regression trees) 모델을 제안하였다. 전통적 방식인 로지스틱 회귀모형과 CART 분석 간 사고 영향요인 도출 결과를 비교하였으며 기존에 도출되지 않았던 사고 특징을 설명할 수 있는 새로운 영향요인이 도출되었다. Prati et al.(2017)은 자전거 사고 중 심각한 사고에 영향을 미치는 요인을 도출하기 위해 베이지안 네트워크, CHAID(Chi-square Automatic Interaction Detector) 의사결정나무 기법을 적용하였다. 의사결정나무 분석 시 도로 및 사고 유형, 연령 등과 관련된 변수의 중요도가 높게 나타났으며 베이지안 네트워크 기법에서는 사고 및 도로 유형, 상대방 차종에 따른 영향이 큰 것으로 도출되었다. Zheng et al.(2018)은 화물차 사고 중 심각한 사고에 영향을 미치는 요인 도출을 위해 그래디언트 부스팅 기법을 적용하였다. 심각한 사고를 경미한 사고, 부상사고, 중상사고(1명, 2명 이상)로 구분하여 영향요인을 도출하였으며 그 결과, 주요 상위 11개 요인이 심각한 사고를 설명하는 주 변수로 설명되는 것으로 나타났다.
3. 기존 연구와의 차별성 및 의의
기존 교통안전정책 수립 방향성 및 정책과제 이슈 발굴을 위해 주로 정성적 요인을 고려한 텍스트마이닝 기법 등이 적용되고 있으나 복합 이슈를 고려한 정책 수립 방향성을 제시한 연구는 미흡한 실정이다. 또한 데이터 마이닝 기법의 적용을 통해 사고 영향요인을 도출한 연구는 다수 진행되었으나 변수 간 상호작용 효과를 고려하여 복합 영향요인을 고려한 연구는 미흡하였으며 대부분 의사결정나무 및 인공신경망 기법을 통해 영향요인을 도출하였다.
기존 선행 연구에 따르면 의사결정나무 기법은 단순하고 예측력이 저하된다는 문제점으로 인해 다양한 기법의 적용을 통한 심각도 분석 연구가 필요함을 제시하였다(Park et al., 2016). 다수의 선행 연구들은 정책 이슈를 도출하기 위해 단일 이슈에 기반하여 분석을 수행하였다. 그러나 본 연구에서는 고속도로 교통안전정책 수립 방향성 제시를 위해 복합 요인을 고려한 이슈를 도출하였다는 점에서 기존 연구와의 차별성이 있다.
따라서 본 연구는 고속도로 심각 사고 영향요인 도출을 위해 랜덤 포레스트, MARS(Multivariate Adaptive Regression Splines) 등 다양한 데이터 마이닝 기법을 적용하여 주요 복합 요인을 도출하여 최종 고속도로 교통안전정책 수립 방향성을 제시하는 데 의의가 있다. 본 연구의 결과는 향후 고속도로 교통안전 증진을 위한 로드맵 수립 시 심각한 사고를 감소시킬 수 있는 새로운 패러다임을 제공하고 정책 전개 방향을 제시하는데 기여할 수 있을 것으로 기대된다.
분석 방법론
1. 분석 개요
본 연구에서는 사망자 수 저감을 위한 교통안전정책 수립 방향성을 제시하기 위해 복합 영향요인을 도출하였다. 사고 기초통계, 데이터 마이닝(랜덤 포레스트, 의사결정나무, MARS) 기법을 적용하였으며 활용된 4가지의 방법론은 Figure 1과 같다.
본 연구에서 활용된 데이터 마이닝 기법은 분류에 최적화된 방법론으로 심각한 사고를 분류하기 위해 사용된 변수의 영향 정도를 추출할 수 있다. 의사결정나무 및 MARS 모형은 변수 간 상호작용 효과를 자동으로 나타내어 복합 영향요인의 도출이 가능하지만 랜덤 포레스트의 경우 단일 영향요인의 상대적 중요도를 나타낼 수 있어 기초통계 결과와 조합하여 상관분석을 실시하였다.
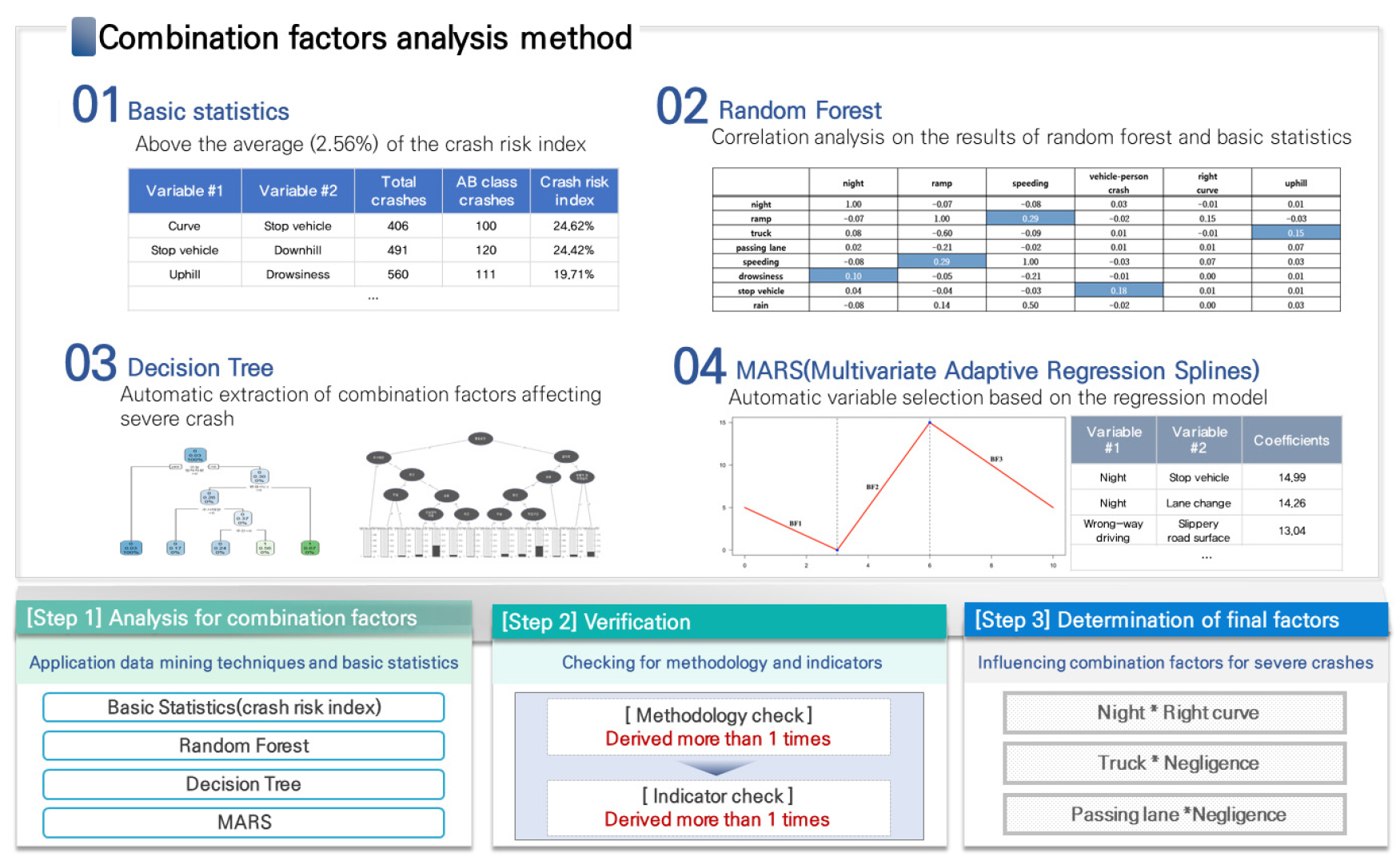
2. 변수 설정
최근 고속도로에서 5년간 발생한 사고 자료를 토대로 A등급 및 B등급 사고에 대해 심각한 사고로 정의하였다. 사고 심각도에 영향을 미치는 요인 도출을 위해 고속도로 사고 자료에 있는 항목을 고려한 변수는 Table 1과 같다. 이를 토대로 기초통계, 데이터 마이닝 기법(랜덤 포레스트, 의사결정나무, MARS)의 적용을 통해 복합 영향요인을 도출하였다. 본 연구에서는 사고 심각도에 영향을 미치는 요인의 명확한 구분을 위해 62개 변수에 대해 이항으로 구분했으며 종속변수는 심각한 사고 발생 여부(A, B등급=1, C, D등급=0)1)로 구분하여 분석을 수행하였다.
1) A등급: 사망 3명 이상/부상 20명 이상/피해액 1천만 원 이상B등급: 사망 1명 이상/부상 5명 이상/피해액 250만 원 이상C등급: 부상 1명 이상/피해액 30만 원 이상
Table 1.
Setting for variables
3. 분석 방법론
1) 사고통계 분석지표 정의
영향 요인별 타당성 검토 및 상대적 비교를 위해 사고위험도, 빈도, 심각도를 나타내는 3가지 지수를 정의하였다. 사고위험도 지수는 Equation 1에 제시하였으며 해당 요인의 전체 사고건수 중 심각한 사고가 차지하는 비율을 나타내는 지표로 사고 발생 시 심각한 사고 발생 개연성을 나타낸다. 빈도지수는 Equation 2에 나타냈으며 전체 62개의 단일 요인에 대한 전체 사고건수 대비 해당 요인의 사고건수로 영향요인 간 상대적 발생 빈도를 나타낸다. 심각도 지수는 Equation 3에 제시하였으며 전체 62개 단일 요인에 대한 심각한 사고건수 대비 해당 요인의 심각한 사고건수로 영향요인 간 상대적 심각도를 나타낸다.
2) 랜덤 포레스트(Random Forest)
랜덤 포레스트는 Breiman(2001)에 의해 제안되었으며 교통 분야에서 변수 중요도의 우선순위를 평가하는데 적용되고 있다(Abdel-Aty and Haleem, 2011; Ahmed and Abdel-Aty, 2011; Yu and Abdel-Aty, 2014). 여러 개의 의사결정나무를 구축하여 앙상블 기법을 통해 최종 결과를 도출하는 심화된 방법론으로 과적합 확률을 낮춰 결과의 정확도를 향상시킨다는 장점이 있다. 모형 개발을 위해 ntree 및 mtry 2개의 하이퍼파라미터에 대한 조정이 필요하다. 이때, ntree는 생성할 나무의 개수를 나타내며 mtry는 각 노드에서 랜덤하게 고려될 수 있는 변수의 설정을 나타내는 파라미터이다.
본 연구에서는 R randomForest 패키지를 활용하였으며 하이퍼파라미터는 기본값을 사용하였다. 또한 훈련 및 테스트 데이터는 7:3으로 구분하였으며 이는 분석자 주관에 따라 다르게 구분될 수 있다. 랜덤 포레스트 모형 구축 시 해당 결과를 도출하기 위해 사용된 변수의 중요도를 나타내는 MDA(Mean Decrease Accuracy), MDG(Mean Decrease Gini) 두 가지의 평가지표가 도출된다. 본 연구에서는 모형 구축을 위해 사용된 변수의 중요도를 나타내는 MDA를 활용하였으며 이는 해당 변수를 제거하여 모형을 재구축했을 때 감소되는 정확도 차이를 변수별로 평균화한 값으로 Equation 4와 같다. 랜덤 포레스트는 변수 상호작용 효과를 나타낼 수 없어 단일 변수 및 기초통계 변수를 조합하여 상관분석을 실시하였다.
여기서, : 트리의 개수
: 부트스트랩 샘플링 과정에서 추출되지 않은 관측치
: 관측치
: 레이블
: 변수 중요도 측정 전 예측된 레이블 값
: 변수 중요도 측정 후 예측된 레이블 값
3) MARS(Multivariate Adaptive Regression Splines)
MARS는 연속형 변수를 처리하는 데 효과적인 모형으로 자동으로 변수 간 상호작용 효과를 고려할 수 있는 특징을 가지고 있다. 이는 단계별 선형회귀 또는 의사결정나무를 비모수 회귀모형으로 확장한 것으로 고차원 회귀문제에 적합한 방법이며, 선형 스플라인을 사용하여 조각별로 선형인 연속함수로 추정한다. MARS는 각 모델의 결합 결과에 기초한 최적 변수 조합을 선택한다. MARS의 기본 형태는 Equation 5와 같이 나타낼 수 있다(Friedman, 1991).
여기서, : 기저함수
: 입력변수
: 상의 기저함수 혹은 에 속하는 둘 이상의 기저함수들의 곱
MARS는 일련의 절차에 따라 회귀모형을 적합 시켜 모델의 개선을 위해 변수 간 상호작용 여부를 반복적으로 확인하여 영향요인을 선택하는 방법론이다. 이는 기본 회귀모형에 잔차제곱합이 최소가 되도록 기저함수를 추가하는 원리이며 과적합 방지를 위해 GCV(Generalized Cross-Validation)값을 최소화하여 모형을 개발하며 Equation 6에 제시하였다.
모형 구축을 위해 R earth 패키지를 활용하였으며 훈련 및 테스트 데이터는 7:3으로 구분하였다. MARS는 모형 개발을 위해 별도의 가지치기 방법론 설정이 필요하며 본 논문에서는 교차검증 기법을 사용하여 변수에 사용될 수를 결정하였다. 교차검증은 모델을 학습 및 훈련하는데 데이터를 k개의 폴드로 구분된 검증 결과들을 평균하여 최종 결과를 도출하게 된다.
여기서, : 계수
: 경첩함수
4) 의사결정나무(Decision Tree)
의사결정규칙을 토대로 분류(classification) 또는 예측(prediction)을 수행하는 방법론으로 분석 과정이 나무 구조에 의해 도식화될 수 있어 직관적이고 쉽게 이해할 수 있는 장점이 있다. 의사결정나무는 분석의 정확도 보다는 분석 과정의 설명이 필요한 경우에 더 유용하게 사용될 수 있으며 활용 분야는 세분화, 분류, 예측, 변수선택, 상호작용 파악 등 다양하게 적용될 수 있다(Choi et al., 1998).
의사결정나무의 대표적 알고리즘으로 CHAID, CART 등이 있으며 본 연구에서는 의사결정나무 구축을 위해 R rpart 패키지 및 party 패키지를 활용하여 결과를 도출하였다. rpart는 CART 알고리즘을 구현한 대표적인 패키지로 모든 입력변수에 대해 모든 가능한 분할 지점을 조사하고 지니지수(Gini index)의 순수도를 증가시키기 위한 기준으로 사용한다(Therneau et al., 2015). 지니지수는 Equation 7과 같이 불순도를 측정하며 작은 값을 기준으로 분리하게 된다(Kang and Kim, 2013). party(Hothorn et al., 2015) 패키지는 조건부 추론방법에 이론적인 배경을 가지며 불편의 반복분할(unbiased recursive partitioning) 방법으로 반응변수와 설명변수들의 다중 검정 방법을 통해 유의확률을 보정하여 과적합 문제를 해결하고 변수의 측정 단위가 다르더라도 영향을 받지 않는다는 장점이 있다(Shin, 2016).
여기서, : 데이터셀
: 범주의 비율
: 범주의 개수
분석결과
1. 기초통계 분석
변수 조합을 토대로 사고위험도 지수를 산출하였으며 전체 단일 변수의 평균 2.56% 이상인 복합 영향요인을 Table 2에 제시하였다. 도출된 복합 요인 중 의미가 없는 조합에 대해서는 분석 대상에서 제외하였다. 상위 영향요인은 주로 정차차량과 연관된 복합 요인이 빈번하게 도출되었으며 주로 2차 사고와 연관성이 높은 것으로 판단된다. 다음 순으로 졸음과 관련된 요인이 도출되어 졸음 방지를 위한 시설물 설치 등 추가적인 노력이 필요할 것으로 예상된다.
Table 2.
Basic statistics analysis result by combination factor
2. 랜덤 포레스트 분석
복합 영향요인별 상대적 비교를 위해 MDA(Mean Decrease Accuracy) 지표를 사용하였으며 해당 값이 클수록 변수 중요도가 높은 것으로 해석할 수 있다. 랜덤 포레스트 분석 방법의 경우 변수 간 상호작용 효과를 도출할 수 없기 때문에 주요 변수 간 상관분석을 통해 도출된 복합 요인은 Table 3에 제시하였다. 상위 1위부터 10위까지 본선 및 미끄러운 노면 2가지 요인을 제외한 8가지 단일 변수를 토대로 변수 간 상호작용 분석을 위해 상관분석을 실시하였다.
Table 3.
single variable importance analysis result
변수 조합을 도출하기 위해 기초통계에서 도출된 5개의 단일 영향요인 및 랜덤 포레스트에서 도출된 8개의 단일 영향요인을 대상으로 상관분석을 수행한 결과를 Figure 2에 제시하였다.
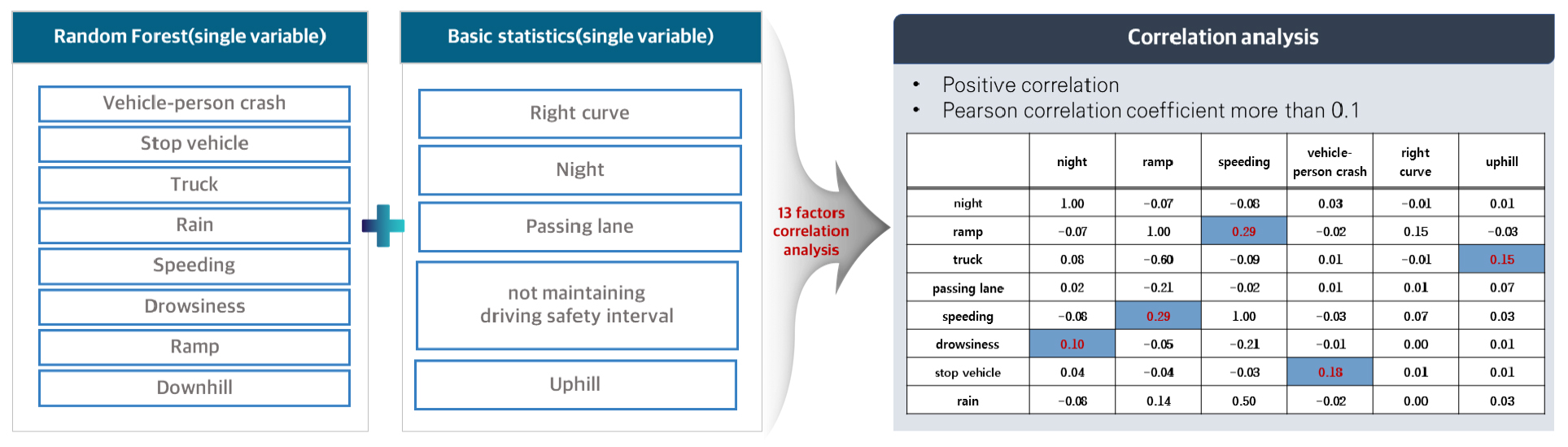
상관분석을 통해 최종적으로 도출된 복합 영향요인은 Table 4와 같다. 상관계수가 양수이며 0.1 이상인 변수 조합을 도출하여 9개의 복합 영향요인을 도출하였다. 상관분석을 통해 도출된 주요 복합 영향요인은 우천 시 과속으로 인해 발생한 사고, 추월차로 내 운전자의 주시태만 사고, 램프 과속사고 등의 유형이 도출되었다. 과속사고는 비, 램프와 연관될 경우 심각도가 높아지는 것으로 나타나 사고 예방을 위해서는 이에 대한 중점적 관리가 필요할 것으로 판단된다. 또한 추월차로 주시태만 사고 유형은 추월차로 내 차로변경 시 운전자의 주의가 요구되지만 주시태만으로 인해 사고가 발생한 것으로 판단된다. 정확한 사고 원인 분석을 통해 추월차로에서 발생한 사고를 감소시키기 위한 중점적 관리가 필요할 것으로 예상된다.
Table 4.
Pearson correlation coefficient between major variables
3. 의사결정나무
의사결정나무 구축을 위해 R의 party 패키지 및 rpart 패키지를 활용하였으며 분석결과를 각각 도출하였다. 또한 다양한 결과 도출을 위해 변수 간 상호작용 효과가 강하게 연관된 요인을 제외하고 추가 분석을 수행하였다.
rpart 패키지는 모든 입력변수에 대해 가능한 분할 지점을 조사하고 지니 지수의 순수도를 증가시키기 위한 기준을 활용한다. 반면 party 패키지는 p-test를 거쳐 변수를 결정하기 때문에 가지치기 작업이 불필요하다는 장점이 있다.
1) 영향요인 도출(rpart 패키지)
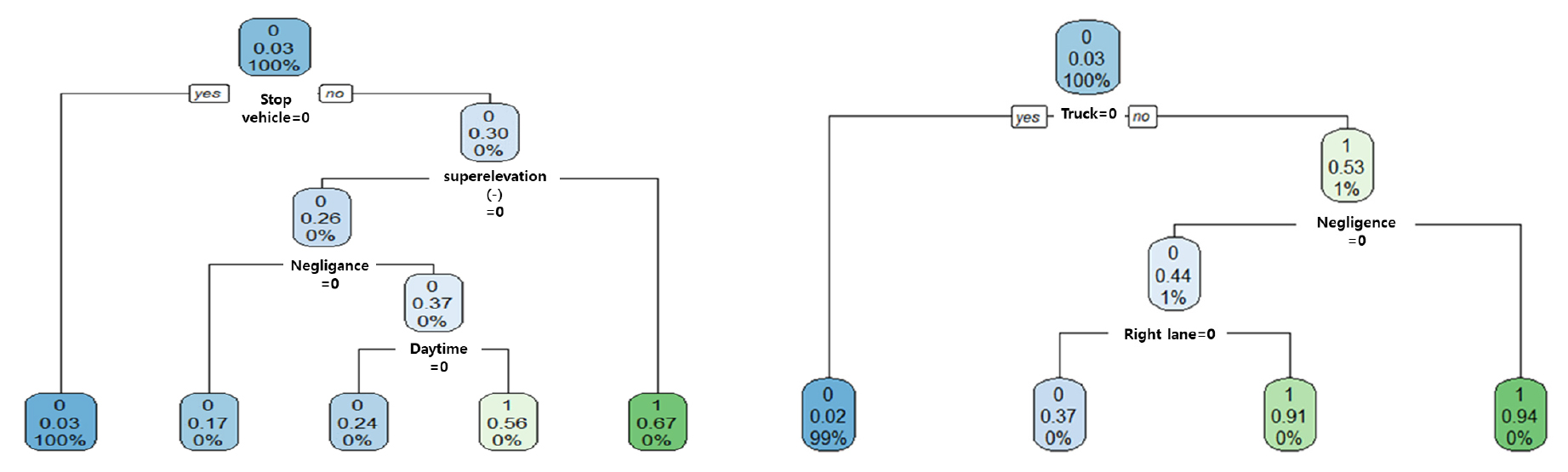
CART는 분류 수행 시 지니계수를 이용하여 이항 분리(binary split)를 수행하는 대표적 알고리즘으로 심각한 사고를 분류하기 위해 의사결정나무를 구축하여 도출된 주요 영향요인은 Figure 3과 같다.
변수 간 주요 상호작용 효과는 (정차차량*편경사(-)), (정차차량*주시태만)으로 나타났다. 이는 정차차량으로 인해 발생한 사고의 경우 심각도가 높은 것으로 판단되며 해당 사고 구간의 적정 편경사 설치 여부 검토 및 운전자 주의 환기를 위한 시설물이 필요한 것으로 판단된다.
다양한 결과 도출을 위해 정차차량을 제외하여 모형을 재구축하였다. 분석결과, (화물차*주시태만) 및 (화물차*우측차로) 2가지 변수 조합이 도출되었으며 주로 화물차와 연관된 요인이 도출되었다. rpart 패키지를 활용한 의사결정나무 분석을 통해 A등급 및 B등급에 해당하는 심각한 사고는 주로 화물차와 정차차량과 연관된 것으로 나타났으며 운전자의 인적요인 및 도로 환경요인이 결합될 경우 심각도가 증가한 것으로 해석할 수 있다.
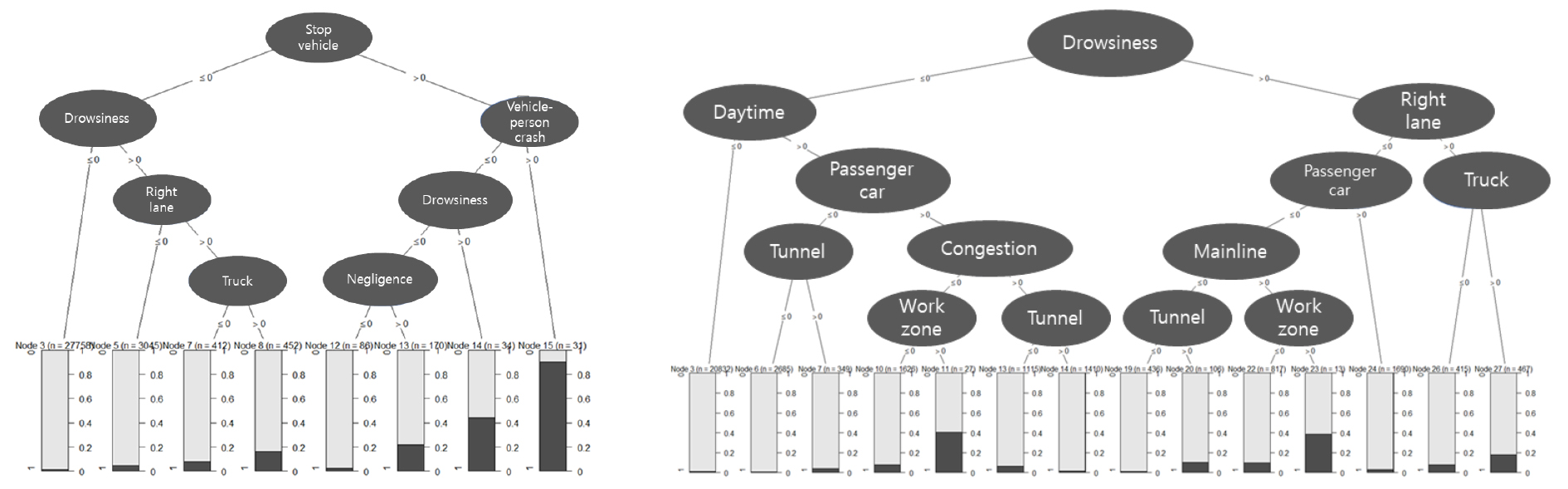
2) 영향요인 도출(party 패키지)
party 알고리즘은 조건부 분포에 따라 변수 간 상관관계를 고려하여 노드 분할에 사용하는 원리이며 기존에 존재했던 과적합으로 인한 데이터 편향 문제를 해결할 수 있다. 해당 알고리즘을 통해 구축된 의사결정나무는 Figure 4와 같다. rpart 패키지와 마찬가지로 다양한 결과 도출을 위해 정차차량을 제외하여 모형을 재구축하였다. 의사결정나무 분석을 통해 도출된 변수 간 주요 상호작용 효과는 (정차차량*차대사람), (정차차량*졸음운전), (정차차량*주시태만) 등이 도출되었으며 정차차량을 제외한 분석결과에서는 (졸음*우측차로), (터널*졸음), (터널*정체) 등과 같은 복합 영향요인이 도출되었다. party 패키지를 활용한 의사결정나무 분석결과는 주로 정차차량과 터널이 연관된 것으로 나타났으며 정차차량의 경우 rpart 패키지를 활용한 의사결정나무 분석결과와 유사하게 도출되었다. 이와 더불어 party 패키지를 활용한 의사결정나무는 rpart 패키지를 활용한 분석결과보다 다양한 변수 상호작용이 도출되었으며 이는 변수 간 상관관계를 고려하는 알고리즘 특성으로 인해 나타난 결과로 예상된다. 터널 사고의 경우 졸음운전, 정체 상황에서 심각도가 증가하는 것으로 나타나 이를 고려한 대책 마련이 필요할 것으로 판단된다.
4. MARS
MARS 모형을 통해 변수 간 상호작용을 고려하여 도출된 복합 영향요인은 Table 5에 제시하였다. 분석결과, 졸음운전 및 야간과 관련된 변수가 주로 도출되었으며 야간 정차차량 사고, 야간 차로변경 사고, 미끄러운 노면에서 발생한 역주행 사고 3가지 유형은 계수가 각각 14.99, 14.26, 13.04로 다른 복합 영향요인에 비해 크게 나타나 상대적으로 심각한 사고에 큰 영향을 미치는 것으로 나타났다. 주로 야간과 관련된 요인이 빈번히 도출되었으며 다른 방법론에서는 도출되지 않았던 역주행 사고 특성이 새롭게 도출되어 사고 감소를 위해 이에 대한 고려도 필요할 것으로 판단된다.
Table 5.
Coefficients for MARS model
5. 타당성 검토 및 최종 복합 영향요인의 선정
방법론별 도출된 복합 영향요인을 토대로 각 방법론에서 도출된 횟수를 고려한 중요성 검토, 3개 지수 검증을 통해 최종 복합 영향요인 선정한 내용을 Figure 5에 나타냈다. 방법론을 통한 중요성 검토는 본 연구에서 활용한 기초통계, 데이터 마이닝 기법(랜덤 포레스트, 의사결정나무, MARS)에서 2회 이상 도출되었는지 여부를 통해 검증을 수행하였다. 지표 검증의 경우 사고위험도 지수는 전체 단일 변수의 평균값을 기준으로 설정하였으며 빈도 및 심각도 지수는 상위 25% 내 포함 여부를 검토하였다. 즉, 본 연구에서는 방법론을 통한 중요성 검토를 통해 방법론별 2회 이상 도출 여부 및 3가지의 사고통계 분석지표가 지표별 기준 2회 이상 충족 여부를 종합하여 최종 7개의 복합 영향요인을 선정하였다. 고속도로 교통안전정책 수립을 위한 복합 영향요인은 정차차량, 야간, 졸음 및 주시태만과 연관된 세부 요인이 결합된 것으로 나타났다. 향후 국내 고속도로 교통안전 개선대책 도입을 위해 7개의 복합 영향요인에 대한 중점적 검토가 필요할 것으로 예상된다.

결론
국가 차원에서는 사고 현황분석 및 다양한 개선대책의 적용 등 사고 감소 도모를 위해 지속적인 노력을 수행하고 있다. 하지만 최근 고속도로에서 발생한 사망자 수 감소율은 주요 OECD 국가에 비해 높게 나타났으며 여전히 선진국에 비해 많은 사망자가 발생하고 있다. 따라서 국내 고속도로 교통안전 정책 수립을 위해서는 사망자 수 저감을 위한 중점적 노력이 필요하다.
교통사고는 한 가지 원인에 의해 발생하는 것이 아닌 여러 가지의 요인이 복합적으로 결합되어 발생하며 메커니즘 또한 복잡하다. 기존 사고분석 방식은 단순 기초통계를 통한 분석을 통해 특정 원인에 초점을 맞춰 주요 대책을 적용하는 등 편중된 대책 적용을 유도하였다. 하지만 이는 거시적 관점에서 사고 빈도를 감소시키는 데 효과적이지만 중상 및 대형사고 등 심각한 사고를 감소시키기 위해서는 실효성이 저하될 수 있다.
이에 따라 본 연구는 변수 간 상호작용을 파악할 수 있는 의사결정나무, MARS 등 다양한 데이터 마이닝 기법의 적용을 통해 심각한 사고에 영향을 미치는 복합 영향요인을 도출하였다. 각 분석 기법에 따라 도출된 복합 영향요인을 토대로 지표 검증 및 방법론별 도출 횟수 등 일련의 검토 과정을 통해 고속도로 교통안전정책 수립 방향성 제시를 위한 7개의 최종 요인을 선정하였다. 타당성 검토를 통해 최종적으로 선정된 복합 영향요인은 주로 정차차량, 야간, 주시태만 및 졸음과 연관된 요인과 세부 요인이 결합되어 나타났다. 심각한 사고를 감소시키기 위해서는 복합 영향요인에 대한 세부 분석과 안전 개선을 위한 대책 마련이 필요하다. 이와 더불어 본 논문에서 최종적으로 선정되지 않았지만 각 방법론을 통해 도출되었던 복합 영향요인을 추가적으로 검토하여 교통안전을 증진시키기 위한 지속적 노력이 필요할 것으로 판단된다.
본 연구의 한계와 이를 보완하기 위한 향후 연구과제는 다음과 같다. 첫째, 기존 연구에서는 다양한 분석 기법의 적용을 통해 도출된 복합 요인은 단일 요인과 상반된 결과가 도출될 수 있다는 점을 제시하였다(Nam et al., 2004). 본 연구에서 도출된 최종 복합 요인별 사고분석 내용은 단일 영향요인 분석을 통해 도출된 사고분석 내용과 비교 및 검증이 필요하다.
둘째, 의사결정나무, MARS 등 변수 간 단위를 통일하지 않더라도 유의한 결과 분석이 가능하다는 장점이 있으나 하이퍼파라미터에 따라 상이한 결과가 도출될 수 있다. 본 연구에서는 방법론마다 일반적으로 사용되는 값을 통해 결과를 도출하였으나 그리드 서치, 랜덤 서치 등 최적화된 결과 도출을 통해 추가적인 분석이 필요하다.
셋째, 의사결정나무, 랜덤 포레스트, MARS 3가지의 데이터 마이닝 기법을 적용하였으나 연관규칙 분석, 인공신경망 등 추가적인 분석 기법의 적용을 통해 새로운 분석 결과를 도출할 수 있을 것으로 기대된다.
