

서론
선행연구
1. 수요응답형 대중교통 수요 영향요인
2. 직접 수요예측 모형
3. 본 연구의 차별점
사용 자료
1. I-MOD 서비스 개요
2. I-MOD 서비스 자료 전처리
3. 교통존 구획
4. 독립변수 자료 수집
분석 방법론
분석 결과
결론
서론
수요응답형 대중교통은 고정된 운행계획에 따라 운행하는 전통적인 대중교통과 달리 이용자가 서비스를 호출할 때마다 노선과 운행계획을 실시간으로 조정하는 교통 서비스이다. 수요응답형 대중교통은 특유의 유동성을 바탕으로 이용자가 호출한 장소까지 이동하여 이용자의 접근시간을 줄일 수 있으며, 이용자 요청에 따라 경로를 최적화하여 불필요한 정류장을 거치지 않기 때문에 차내 이동시간을 줄일 수 있을 것으로 기대된다. 이러한 장점에도 불구하고 기술적인 한계에 부딪혀 수요응답형 대중교통은 한동안 주목받지 못하였다. 하지만, 정보통신기술의 발전으로 이용자가 스마트폰을 활용하여 간편하게 서비스를 호출할 수 있으며, 수요응답형 서비스 운영에 필요한 차량과 이용자 매칭, 실시간 경로 생성, 차량 재배치 등 알고리즘이 고도화되면서 수요응답형 대중교통이 전국 각지에서 도입되기 시작하였다.
국내에서 수요응답형 대중교통 서비스는 수요가 적어 대중교통 서비스가 닿지 않는 농·어촌지역에서 주민의 복지를 확보하기 위한 서비스로 도입되기 시작하였으며, 최근에는 도시 내에서 환승이 많이 필요한 경로 등 대중교통이 효율적으로 처리하지 못하는 경로를 처리하여 대중교통을 보완하는 성격의 수요응답형 대중교통 서비스 또한 도입되고 있다(Choi et al., 2022; Moon et al., 2021; Park and Jung, 2019; Park et al., 2022). 대표적으로, 현대자동차에서 운영하는 수요응답형 서비스인 셔클은 경기도 일부, 세종특별자치시 등 전국 각지에서 지역 특색에 맞춰 수요응답형 대중교통을 운영하고 있다.
수요응답형 대중교통 서비스가 다양한 지역에 도입되고 있으며, 이때 수요응답형 대중교통이 성공적으로 정착할 수 있도록 다양한 방안이 제시되고 있다. Park and Jung(2019)은 경상남도 창원시에 노선버스를 대체하는 수요응답형 대중교통을 도입하기 위해 39개 마을버스 이용자 164명에게 면접 조사를 시행하였다. 면접 조사 결과를 활용하여 수요응답형 대중교통 이용자 집단을 분석하여 창원시의 노선버스를 대체하는 수요응답형 대중교통 서비스 유형으로 다수의 기점에서 하나의 종점으로 이동하는 Many-to-one 형태와 이용자가 많은 시간대에 운행하는 Semi-dynamic 형태의 수요응답형 대중교통 운행을 제안하였다. Moon et al.(2021)은 도시 대중교통의 한계를 보완하는 첨두형 수요응답형 대중교통을 도입하기 위해 기존 대중교통의 기·종점 통행 중에 서비스의 질이 떨어지는 기·종점쌍을 식별하고 이러한 기·종점쌍을 클러스터링하여 수요응답형 대중교통의 경로를 생성하고 효과를 평가하였다. Choi et al.(2022)은 도농복합지역인 경기도 남양주시를 대상으로 K-means 클러스터링을 활용하여 수요응답형 대중교통의 승·하차 패턴을 분석하고, Density-based spatial clustering of applications with noise(DBSCAN) 클러스터링을 통해 승·하차지의 공간성을 분석하였다. 한편, Park et al.(2022)는 대기행렬이론 기반의 수요응답형 대중교통의 최적 차량 대수 산출 모형을 제시하였으며, 제시된 모형을 활용하여 인천 영종도에서 시범운영된 수요응답형 대중교통 서비스인 I-MOD의 최적 차량 대수를 밝혀냈다.
하지만, 교통 서비스 운영에 따른 기대효과를 평가하는데 기초적인 지표가 되는 수요에 관한 연구는 부족한 실정이다. 특히, 수요응답형 대중교통은 언제 어디서든 호출할 수 있으며 원하는 장소까지 데려다주는 서비스로, 수송 효율성이나 목적지까지의 접근성 등을 고려할 때 대중교통과 승용차의 중간적인 성격을 지니는 수단이다. 따라서, 이용자의 이용 패턴 또한 승용차나 대중교통과는 다를 수 있어 수요응답형 대중교통에 대한 별도의 수요예측 모형이 필요하다. 본 연구에서는 실제 운행되었던 수요응답형 대중교통 서비스인 I-MOD 이력자료를 활용하여 기·종점 통행량을 예측하는 모형을 개발하고 수요의 발생요인을 규명하고자 하였다. 앞으로의 논문 구성은 다음과 같다. 다음 장에서는 분석 대상인 수요응답형 대중교통의 수요에 영향을 미치는 요인에 관한 연구와 분석 방법론인 직접 수요예측 모형에 관한 연구를 고찰하였다. 사용 자료에서는 직접 수요예측 모형에 사용되는 독립변수와 종속변수를 수집하고 처리하는 과정을 설명하였다. 분석 방법론에서는 직접 수요예측 모형에 관해 설명하였으며, 분석 결과에서는 모형의 추정 결과를 제시하였다. 마지막으로 연구의 결론과 한계를 제시하였다.
선행연구
본 연구에서는 수요응답형 대중교통의 직접 수요모형을 개발하여 수요에 영향을 미치는 요인을 탐색하고자 한다. 본 연구의 목적을 고려하여 수요응답형 대중교통의 수요에 영향을 미치는 요인에 관한 연구와 직접 수요모형에 관한 연구를 중심으로 선행연구를 조사하였으며, 본 연구가 지니는 차별점을 제시하였다.
1. 수요응답형 대중교통 수요 영향요인
수요응답형 대중교통의 수요에 영향을 미치는 요인에 관한 연구는 크게 이용자에게 가상의 수단 선택 상황을 제시하여 수요응답형 대중교통의 선호도를 분석하는 수단 선택 기반의 연구와 교통존 단위로 집계된 수요를 예측하는 수요예측 기반의 연구로 분류할 수 있다. 수단 선택 기반의 연구에서는 수요응답형 대중교통이 다른 수단과 혼재된 상황에서 서비스 수용성이나 수단 선호에 영향을 미치는 요인을 탐색하였다. Lee et al.(2022)은 자율주행 수요응답 대중교통을 포함한 수단 선택 결과를 토대로 혼합 로짓 모형을 설계하여, 개인 성향과 대중교통 만족도가 자율주행 대중교통 선호도에 미치는 영향을 분석하였다. Go et al.(2022)은 설문조사 결과를 토대로 네스티드 모형을 설계하여 수도권 통근상황에서 연령이 낮을수록, 소득이 높을수록 수요대응형 서비스를 이용할 확률이 높은 것을 밝혀냈다. 한편, Seo et al.(2022)은 자율주행 수요응답 대중교통의 서비스 요소의 상대적 중요도를 비교하여 자율주행 수요응답 대중교통 이용에 영향을 미치는 요인의 중요도가 이동·배차 신속성, 플랫폼 편의성, 차량 편의성 순임을 밝혔다.
한편, 수요예측 모형을 설계하여 수요응답형 대중교통의 수요에 영향을 미치는 요인을 탐색하는 연구는 국내에서는 확인하기 어려웠으며 해외에서 일부 이루어지고 있었다. Yan et al.(2020)은 Random forest를 사용하여 미국 시카고에서 운영되는 승차 공유 서비스의 기·종점 간 수요를 예측하는 모형을 설계하였으며, 기·종점간 출퇴근 통근자 수, 기점의 고용자 수, 기점의 버스와 철도 노선 수가 수요예측에 중요한 변수임을 밝혀냈다. Wang et al.(2023)은 음이항 회귀분석을 활용하여 중국 북동부에 위치한 해안도시인 Dalian에서 운행된 호출 기반의 서비스인 Customized bus의 수요예측 모형을 추정하여 거주 인구가 많을수록, 고용 인구가 낮을수록, 도로 네트워크가 열악할수록 수요응답형 대중교통의 탑승이 많은 경향이 있다는 것을 밝혀냈다.
2. 직접 수요예측 모형
수요예측 모형은 통행을 통행 발생(통행 빈도 선택), 통행 분포(목적지 선택), 수단 선택이라는 연속적인 선택 과정으로 생각하는 순차적 접근방법(Sequential approach)과 위의 과정을 통합하여 수단별 수요를 직접 예측하는 직접 수요모형(Direct model)으로 구분할 수 있다(Ortúzar and Willumsen, 2011). 직접 수요예측 모형은 각각의 모형에서 발생하는 오차가 누적되는 등의 단점이 있는 순차적 접근방법의 문제를 해결할 수 있다는 점에서 널리 사용되고 있다(Choi et al., 2012).
Choi et al.(2012)은 승법 모형과 포아송 회귀분석 모형을 사용하여 지하철의 기·종점 통행량를 예측하는 모형을 개발하여, 오전 첨두시에는 출발지의 인구와 도착지의 고용 관련 변수가, 오후 첨두시에는 목적지의 고용과 인구 관련 지표가 수요에 영향을 미치는 주요한 변수임을 밝혀냈다. Zhao et al.(2014)은 위와 동일한 방법으로 중국 난징의 지하철간 기·종점 통행량 예측모형을 개발하였으며, 인구, 고용자 수, 사무실 면적, 도로 연장, 간선버스 노선 수 등 11개 변수가 유의함을 밝혀냈다. 한편, 최근에는 계량경제 모형 대신 머신러닝 모형을 사용하여 직접 수요모형을 개발하는 연구가 이루어지고 있다. 특히, 변수의 중요도를 계산할 수 있어 모형의 해석이 가능한 앙상블 기반의 의사결정 나무 모형이 많이 사용되고 있다. Gan et al.(2020)은 Gradient boosting decision tree를 설계하여 지하철의 기·종점 통행량을 예측하는 모형을 개발하였으며, 사회·경제적 변수가 모형 설명에서 절반 이상의 중요도를 가진다는 것을 밝혔다.
일반적으로 직접 수요모형은 기점과 종점의 특성을 나타내는 변수를 사용하여 수요함수를 추정하는 모형을 의미한다. 하지만 최근에는 수요응답형 서비스의 실시간 운영에 도움이 되도록 해상도 높은 수요를 예측하기 위해 과거 수요를 활용하여 현재 수요를 예측하는 모형이 딥러닝을 기반으로 개발되고 있다. Ke et al.(2017)은 Convolutional long short-term memory 모형을 기반으로 1시간 단위의 수요응답형 서비스의 승객 수요를 예측하는 모형을 개발하였다. Ay et al.(2022)은 수요응답형 서비스의 승객을 예측하기 위해 클러스터링 기반으로 교통존을 나누었으며, 시간 상관성과 공간 상관성을 처리하는데 뛰어난 Convolution neural network와 Long Short-term memory를 순차적으로 통과하는 딥러닝 모형을 개발하였다.
3. 본 연구의 차별점
정보통신기술의 발전에 따라 서비스 공급자와 이용자의 매칭, 실시간 경로 생성 및 차량 재배치 등 알고리즘이 고도화되어 수요응답형 대중교통이 세계적으로 주목을 받으면서, 국내·외에서 이와 관련한 연구가 이루어지고 있다. 수요응답형 대중교통이 성공적으로 정착하기 위한 전략을 수립하기 위해 수요를 예측하고 수요에 영향을 미치는 요인을 탐색하는 것은 중요한 일임에도, 관련된 연구는 부족한 실정이다. 본 연구에서는 수요응답형 대중교통의 직접 수요모형을 설계하고 수요에 영향을 미치는 요인을 식별하여, 수요응답형 대중교통이 포함된 수요응답형 대중교통의 도입과 활성화 등 교통계획 수립에 기여하고자 한다.
사용 자료
본 장에서는 인천 영종도에서 실제로 운행되었던 수요응답형 대중교통인 I-MOD 서비스에 관해 소개하고 운영 데이터의 처리 과정을 설명하고자 한다. 또한, 직접 수요모형의 독립변수로 사용된 각종 자료를 수집·처리하는 과정을 설명하였다.
1. I-MOD 서비스 개요
국토교통부가 주관하는 인천 스마트시티 챌린지 사업의 일환으로 시행된 수요응답형 대중교통 서비스인 I-MOD는 2020년 10월 26일부터 2022년 12월 31일까지 인천광역시 영종도, 송도국제도시 등에서 운행되었다. I-MOD 서비스는 정류장 기반의 수요응답형 대중교통으로 이용자는 서비스 운영자가 정한 정류장에서만 승·하차 할 수 있다. I-MOD 서비스가 최초로 도입되었던 인천광역시 영종도에는 평일에는 8대, 주말에는 4대의 차량으로 매일 오전 5시 30분부터 23시 30분까지 서비스를 운영하였으며, 23시 이후에는 더 이상 호출을 받지 않았다. 서비스 이용 요금은 성인 기준으로 기본요금이 1,800원이며 이동 거리가 7km를 초과하는 경우 추가 거리 1km마다 100원이 추가되었다. 한 번의 호출로 최대 6명의 일행이 함께 이동할 수 있으며, 한 차량의 최대 탑승 인원은 8명으로 제한하였다.
2. I-MOD 서비스 자료 전처리
본 연구에서는 2021년 7월 25일부터 2022년 7월 2일까지 약 11개월간 영종도에서 운행된 I-MOD 서비스의 이용자 호출 자료 3,194,945건을 사용하였다. 호출 자료는 서비스 호출 시각, 서비스 호출 위치, 출발 정류장과 도착 정류장, 동승 인원, 그리고 I-MOD 탑승 여부로 구성되어 있으며, 이용자에 관한 정보는 포함되어 있지 않았다. 하지만, 호출형 서비스의 특성상 한 건의 호출이 하나의 수요에 대응되지 않는다. 예를 들어, 차량을 탐색하는 시간이 길어져 호출을 취소하고 다시 호출하거나, 차량이 배차되지 않아 다시 호출하는 경우가 있다. 또한, 서비스가 매칭되어도 차량이 오는데 오래 걸리거나 예상보다 이동시간이 길어서 서비스를 다시 호출하는 경우도 있다. 즉, 서비스를 이용하기 위해서 여러 번 호출하는 경우를 고려하여 호출을 수요 단위로 변환해주어야 한다. 게다가, 서비스를 반복적으로 호출하였지만 서비스가 매칭되지 않거나 서비스가 만족스럽지 않아 서비스를 이용하지 않는 경우도 발생하게 된다. 실제로 서비스를 이용하지 않았더라도 서비스를 호출하는 행위로 이용 의사를 밝혔기 때문에 이러한 호출도 수요로 고려해야 한다.
본 연구에서는 호출형 서비스의 특성을 고려하여 호출을 수요로 변환하기 위해 같은 이용자의 연속되는 두 호출이 같은 통행을 위해 호출한 것인지 구분하기 위해 두 호출의 상이도를 제안하였다. 일반적으로, 호출 시간의 간격이 짧을수록, 기·종점이 유사할수록 같은 통행일 가능성이 높다. 이를 토대로, 두 호출이 같은 통행을 위해 발생한 호출인지를 구분하는 상이도를 두 호출의 시각 차이, 기점 정류장 간 거리 차이, 종점 정류장 간 거리 차이의 합으로 구성하였다. 서로 다른 두 기준을 더하기 위해 호출 시각 간격은 15분, 기점 정류장 간 거리와 종점 정류장 간 거리의 합은 1km를 기준으로 표준화하였다. 이때, 호출 시각 간격 15분과 기점 정류장 간 거리와 종점 정류장 간 거리의 합이 1km를 넘는 경우에는 값이 1이 되도록 하여 0과 1 사이의 값을 가지도록 표준화하였다. Equation 1은 두 호출 사이의 상이도 를 나타낸 식이다.
는 이용자 의 번째 호출을 나타낸다. 은 이용자 의 번째 호출의 호출 시각을 나타낸다. , 는 각각 이용자 의 번째 호출의 희망 출발 정류장과 도착 정류장을 나타낸다. 는 두 지점의 유클리디안 거리를 나타낸다. 즉, 와 는 각각 이용자 의 번째 호출과 그 다음 호출의 희망 출발 정류장 간의 거리와 도착 정류장 간의 유클리디안 거리를 나타낸다. , 는 각각 호출 시각의 차이와 호출 거리 차이의 가중치를 나타낸다. 본 연구에서는 , 를 모두 0.5로 설정하였다. 호출 시각과 호출 거리의 차이를 0과 1 사이의 값으로 표준화하였기 때문에, 거리 또한 0과 1 사이의 값을 나타낸다. 가 0에 가까울수록 두 호출은 같은 통행을 위한 호출일 가능성이, 1에 가까울수록 다른 통행을 위한 호출일 가능성이 높다는 것을 의미한다. 한편, 두 연속적인 호출이 같은 통행을 위한 호출인지를 구분하는 기준을 설정하는 것 또한 중요한 문제이다. 본 연구에서는 거리 의 누적확률분포를 크게 변화하는 지점을 탐색하여 그 기준을 0.5로 설정하였다. 그 결과, 3,194,945건의 호출이 290,158건의 통행으로 집계되었다. Figure 1은 거리 의 누적확률분포를 나타낸 그림이다. 마지막으로, 최초 호출시간을 기준으로 통행을 1시간 단위로 집계하였다. 이때, 운영시간을 고려하여 정각 기준이 아닌 30분을 기준으로 1시간 단위 수요로 집계하였다. 예를 들어, 오후 6시의 수요는 오후 5시 30분부터 오후 6시 30분까지의 1시간 수요를 집계하였다.
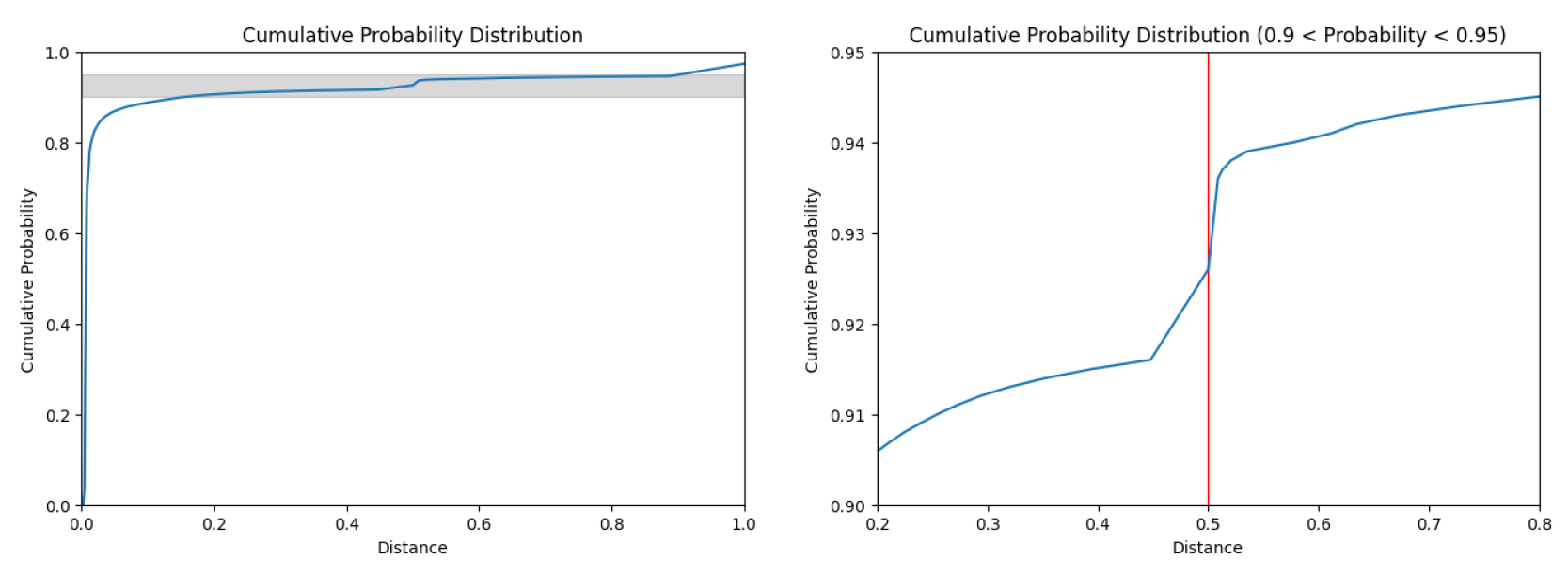
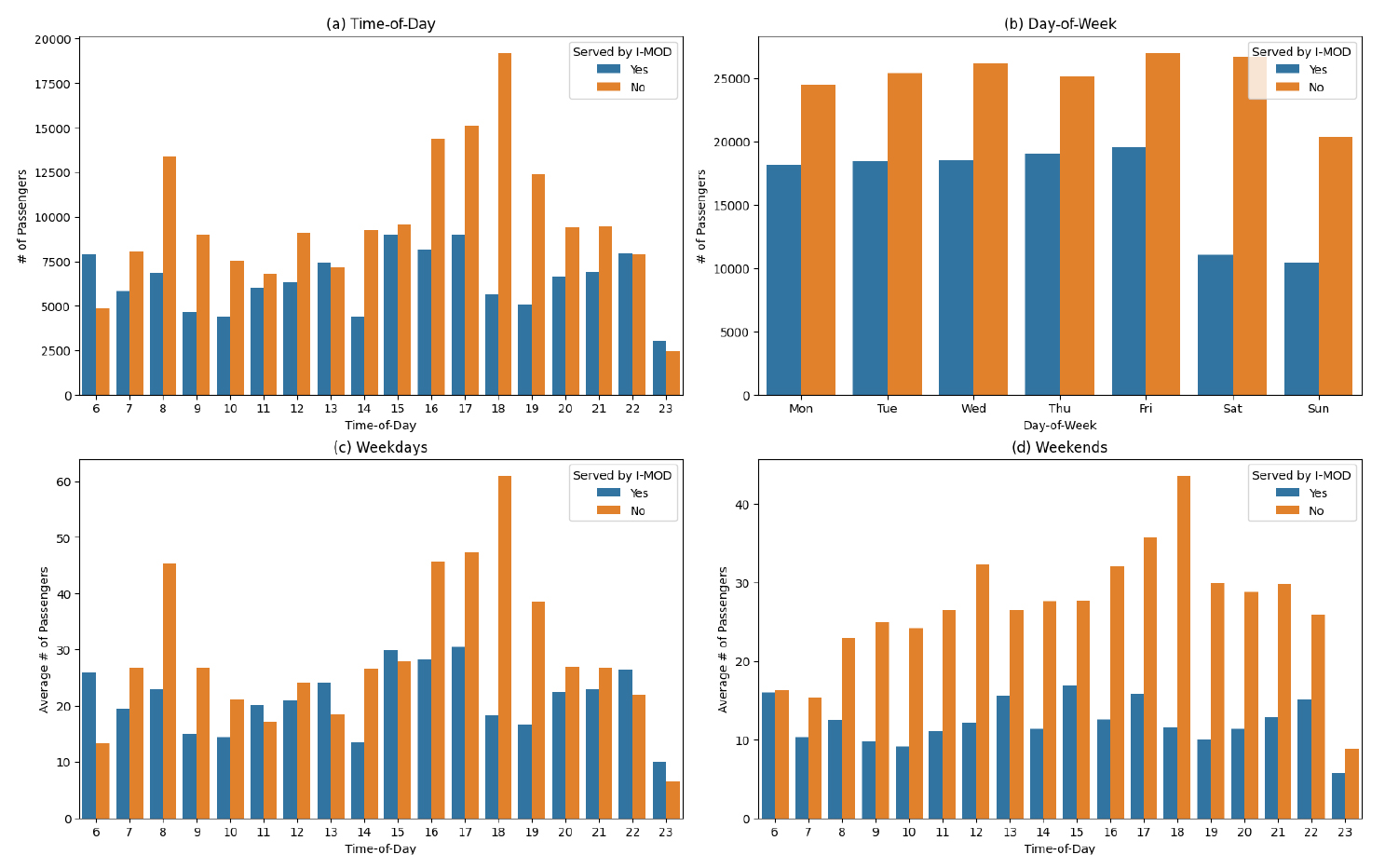
Figure 2는 집계된 수요를 시간대, 요일, I-MOD 서비스 탑승 여부를 기준으로 분류한 그래프이다. Figure 2(a), 2(b)는 각각 시간대와 요일을 기준으로 집계한 탑승 수요를, Figure 2(c), 2(d)는 각각 주중과 주말의 시간대별 평균 탑승 수요를 나타낸다. I-MOD 서비스를 이용하기 위해 한 번 이상 호출하였던 290,158 통행 중 115,188 통행(39.7%)은 I-MOD를 탑승하였으며, 174,970 통행(60.3%)은 I-MOD를 탑승하지 못했다. 즉, 하루 평균 I-MOD를 이용하고자 하는 수요는 일평균 848건이며, 그 중에서 I-MOD를 최종적으로 탑승한 수요는 약 337건이다. 기점과 종점이 같은 경우를 제외한 기·종점 쌍이 8,190개라는 점을 고려하면, 일부 기·종점간 통행을 제외하면 대부분의 기·종점 쌍에서 통행이 발생하지 않음을 알 수 있다. 평균적으로 주중보다 주말의 수요가 더 많으며, I-MOD 서비스를 호출한 뒤에 최종적으로 서비스를 이용하는 비율도 평일이 주말보다 더 높은 것으로 분석되었다. 또한, 주중의 경우 오전 첨두와 오후 첨두가 두드러지는 반면, 주말의 경우 상대적으로 첨두시가 두드러지지 않았다. 본 연구에서는 수요 분포를 고려하여 오전 7시 30분-8시 30분을 오전 첨두시로, 오후 16시 30분-18시 30분을 오후 첨두시로, 그 외 시간을 비첨두로 구분하였다.
3. 교통존 구획
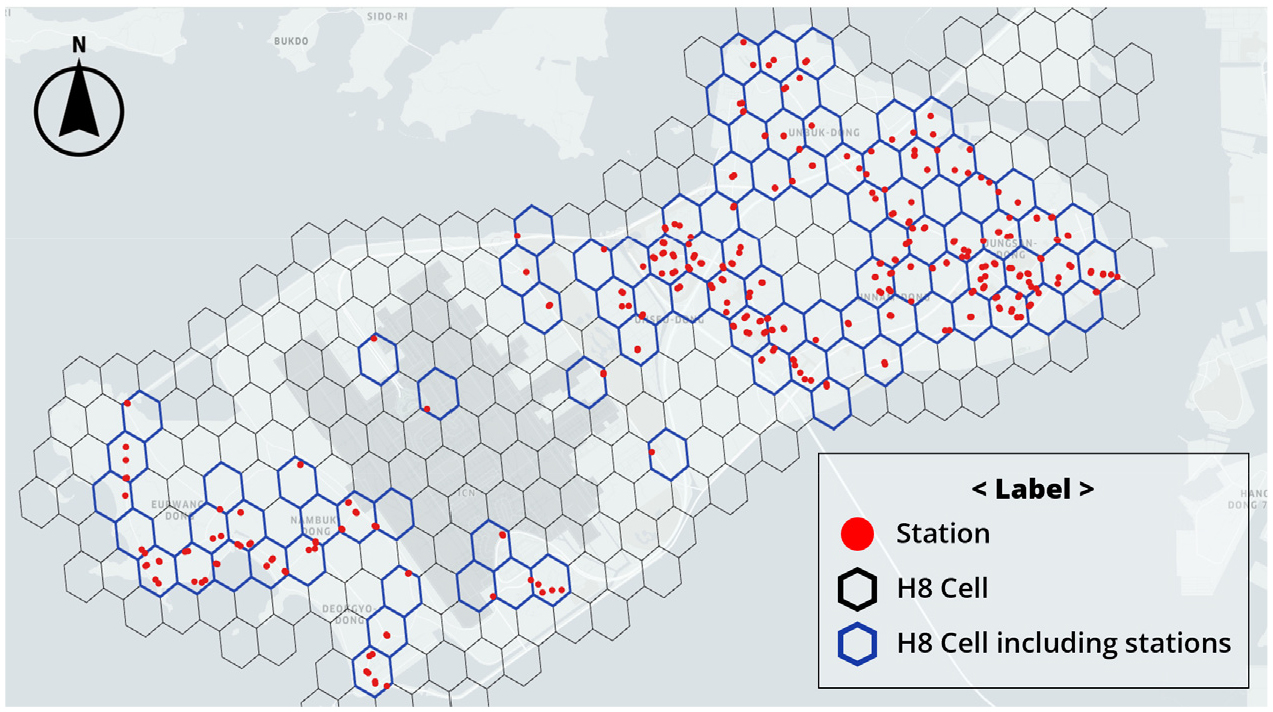
수요를 집계하고 독립변수를 설정하기 위해서는 교통존을 설정하여야 한다. 하지만 승·하차 정류장을 그대로 교통존으로 사용하는 경우 교통존의 영향권을 설정하는데 어려움이 발생할 수 있다. 정류장 밀도가 토지이용에 따라 크게 달라지기 때문에 정류장 반경으로 정류장의 영향권을 설정하는 경우 정류장 밀도가 높은 지역에서 영향권이 중첩되며, 중첩되지 않게 교통존을 나누는 경우에는 교통존의 크기가 위치에 따라 크게 달라질 수 있어 균일한 교통존을 만들 수 없다. 반대로 행정구역으로 교통존을 분할하게 되면 교통존의 개수가 너무 줄어들어 모형 추정에 어려움을 겪게 된다. 본 연구에서는 교통존을 균일한 크기로 설정하면서 중첩되지 않도록 Uber에서 만든 육각형 모형의 공간 단위인 H3 Cell을 수요예측의 공간적 단위로 설정하였다. 육각형은 중심으로부터 인접한 존이 모두 같은 거리에 있으면서 평면을 빈틈없이 채울 수 있다는 장점이 있다. 이때 H3 Cell의 해상도는 8로 육각형 변의 길이가 약 530m이며, 영종도 내의 319개의 이용 가능한 정류장을 포함한 교통존은 91개로 분석되었다. Figure 3은 I-MOD 서비스를 이용할 수 있는 정류장 319개소의 위치와 본 연구에서 설정한 교통존의 경계를 나타낸다.
4. 독립변수 자료 수집
본 연구와 유사한 방법으로 진행되었던 선행연구에서는 사회·경제적 속성이나 토지이용, 교통시설 등 건조 환경 변수를 주로 사용하였다(Choi et al., 2012; Zhao et al., 2014; Gan et al., 2020; Wang et al., 2023). 건조 환경이란 주거, 교통, 업무 등 사람의 이동이나 활동과 관련된 환경 중에서 인간이 만든 물리적인 요소로, 건축물, 토지이용, 교통체계 등을 포함하는 개념이다. 본 연구에서는 수요응답형 대중교통의 수요를 예측하기 위해 영종도의 환경, 육각 격자 모형이라는 교통존의 특성, 그리고 자료 수집 가능성을 종합적으로 고려하여 선행연구에서 사용되었던 건조 환경 변수 중에서 토지이용, 관심 지점(Point-of-Interest, POI), 그리고 교통시설 변수를 수집하였다. 영종도의 토지이용과 관심 지점은 국토교통부 국토지리정보원에서 제공하는 토지 특성정보와 국가관심지점정보 자료를, 교통시설에 관한 변수는 인천광역시가 공공 데이터 포털을 통해 제공하는 인천광역시 버스정보를 사용하였다.
토지이용은 국토계획법 제36조에 따라 도시지역인 주거지역, 상업지역, 공업지역, 녹지지역과 도시지역이 아닌 기타 지역(관리지역, 농림지역, 자연환경보전지역)으로 변수를 설정하였다. 한편, 토지이용 혼합도는 주거지역, 상업지역, 공업지역, 녹지지역, 도시지역이 아닌 기타 지역의 5개 지역의 면적 비율을 사용하여 엔트로피를 계산하였다(Gan et al., 2020; Wang et al., 2023). 교통시설 변수의 경우 영종도에서 운영되었던 I-MOD 서비스는 정류장을 버스 정류장과 공유하기 때문에, 버스와 관련 있는 변수를 중점적으로 수집하였으며, 환승과 관련된 요소인 지하철역까지의 거리를 반영하였다.
국토지리정보원에서 제공하는 국가관심지점정보의 경우 산업군을 기준으로 약 2,900개의 항목으로 관심지점을 세분화하여 관리하고 있다. 본 연구에서는 다른 변수인 토지이용과 교통시설에서 반영된 것으로 보이는 2차 및 3차산업과 관련된 관심지점과 교통시설과 관련된 관심지점을 변수에서 제외하였다. 나머지 관심지점 중에서 필수적인 통행인 통학과 연관성이 높을 것으로 예상되는 유치원 및 초·중·고등학교와 여가통행과 관련이 있을 것으로 보이는 관광지인 해수욕장을 변수로 설정하였다. 또한, 인천국제공항이라는 특수한 시설을 고려하여 공항을 변수로 반영하였다. Table 1은 사용된 변수에 관한 설명과 출처를 나타낸 표이다.
Table 1.
List of independent variables
Table 2는 독립변수의 기초통계량을 나타낸 것이다. 토지이용의 경우 평균적으로 녹지지역, 도시지역 이외의 기타지역, 주거지역, 상업지역, 공업지역 순으로 평균 면적이 큰 것으로 나타났다. 토지이용 혼합도는 1에 가까울수록 복합적인 토지이용을 나타내는 지표로, 평균은 0.373으로 조사되었다. 유치원과 학교의 경우 많은 존에서 발견할 수 없었으나, 하나의 존에 최대 2-4개의 유치원 또는 초·중·고등학교가 있는 등 일부 존에 밀집된 것을 확인하였다. 해변의 경우 을왕리 해수욕장, 용유 해변, 왕산해수욕장을 포함한 교통존이 하나씩 존재하였다. 공항을 포함한 교통존은 2개로, 각각 제1여객터미널, 제2여객터미널과 관련이 있었다. 교통시설의 경우 교통존의 버스정류장을 경유하는 평균 버스 노선 수는 간선 1.408개, 간선 1.477개, 기타 1.165개로 분석되었다. 한편, 교통존에서 가장 가까운 지하철역까지의 거리는 평균 2.483km로 나타났다. 각 존까지의 평균 거리는 6.834km이며, 최대거리는 18.813km로 조사되었다.
Table 2.
Descriptive statistics of independent variables
분석 방법론
선행연구에서 살펴보았듯이 수요 발생요인을 분석하는 방법으로는 수단 선택 모형을 구축하여 이용자의 선호도를 구분하는 방법과 이용자의 수요를 집계하여 수요모형을 설계하는 방법으로 구분할 수 있다. 본 연구에서 사용된 자료는 다른 수단에 대한 정보가 없이 수요응답형 대중교통에 관한 통행정보만을 포함하고 있으며, 이용자의 개인정보가 공개되지 않아 이용자 개별 단위로의 분석이 불가능하다. 따라서, 이용자의 수요를 집계하여 독립변수와 통행수요와의 관계를 설명하는 직접 수요예측 모형을 개발하였다. 직접 수요모형은 크게 승법 모형, 포아송 회귀분석 등을 활용한 계량경제 모형과 그라디언트 부스팅 기반 의사결정 나무 등을 활용한 머신러닝 기반의 연구로 분류할 수 있다. 최근에 많이 사용되고 있는 머신러닝 모형은 복잡도가 높아 자료의 양이 충분치 않은 경우 과적합될 우려가 있으며 모형을 해석하기가 어렵다는 한계가 있다. 따라서, 본 연구에서는 기·종점의 특성을 나타내는 독립변수와 통행량의 관계를 직관적으로 나타내는 계량경제 모형 중에서 널리 사용되고 있는 승법 모형을 사용하였다. 기·종점 교통량 을 구하는 승법 모형의 식은 Equation 2와 같이 정의할 수 있다.
는 독립변수들의 곱과 기·종점 통행량의 비율을 나타내는 계수이다. , 각각 기점 와 종점 의 번째 독립변수로 토지이용, 관심지점, 교통시설에 관한 변수를 나타낸다. 는 기점 와 종점 사이의 거리를 나타내는 impedance 변수이다. , , 는 각각 변수 , , 에 대응하는 계수를 나타낸다. Equation 2의 양변에 자연로그를 취하면 선형결합 형태로 변환되어 계수를 쉽게 추정할 수 있다.
한편, 본 연구에서는 분산 팽창 요인(Variance Inflation Factor, VIF)를 도입하여 수집한 자료끼리 상관성이 높아 발생할 수 있는 다중공선성을 진단하였다. 분산 팽창 요인은 하나의 독립변수를 종속변수로 나머지를 종속변수로 하는 다중회귀식의 결정계수를 활용하여 계산할 수 있다. 일반적으로 분산 팽창 요인값이 10보다 큰 경우에 다중공선성이 우려된다고 판단한다. 본 연구에서는 분산 팽창 요인값이 10이 넘는 독립변수가 있는 경우에 분산 팽창 요인값이 가장 큰 변수를 제외하는 과정을 반복하여, 모든 독립변수의 분산 팽창 요인값이 10이 넘지 않도록 통제하였다. 최종적으로 출발지와 도착지의 녹지 면적, 유치원 수, 중학교 수, 고등학교 수, 공항 수, 해수욕장 수 등 12개의 변수가 분석 모형에서 제외되었다. 이때, 분산 팽창 인자값은 초등학교 수가 7.198, impedance가 5.848 순으로 나타났으며, 나머지 변수는 5보다 낮은 값을 가진다.
분석 결과
Table 3은 오전 첨두시, 오후 첨두시, 비첨두시의 직접 수요모형 추정 결과를 나타낸 표이다. 8,281쌍의 기·종점 통행량 중 기점과 종점 정류장이 같은 91개 통행을 제외한 8,190쌍의 기·종점 통행량을 사용하여 22개의 계수를 추정하였다. 이때, 종속변수인 수요는 약 11개월의 분석 기간 동안의 오전 첨두, 오후 첨두, 비첨두시의 1시간 평균 기·종점 통행량이다. 모형 설명력을 나타내는 R2는 오후 첨두 0.280, 오전 첨두 0.192, 비첨두 0.169 순으로, 선행연구에 비해 상대적으로 낮은 것으로 나타났다(Choi et al., 2012; Zhao et al., 2014; Gan et al., 2020). 결정계수 R2가 낮다는 것은 종속변수의 분산보다 오차의 분산이 상대적으로 크다는 의미로 이는 추정된 계수의 통계적인 신뢰도에도 영향을 미치게 된다. 하지만, 표본이 충분히 많은 경우 계수 추정치의 편차가 줄어들어 관측되지 않은 변수가 많더라도 독립변수와 종속변수의 관계를 정확히 추정할 수 있다(Wooldridge, 2019). 다만, 결정계수 R2가 낮은 이유가 교통존 설정 때문에 사회·경제적 속성이 미반영되는 등 수요에 영향을 미칠 것으로 예상되는 변수를 반영하지 못했기 때문으로 보여 이러한 사항을 유의하면서 모형을 해석하였다.
Table 3.
Estimation results
| Independent Variables | Morning Peak | Evening Peak | Non peak | |||||
| Category | Variable | Coefficient | p-value | Coefficient | p-value | Coefficient | p-value | |
| Intercept | -5.186*** | 0.000 | -4.473*** | 0.000 | -5.093*** | 0.000 | ||
| Land use | Origin | Residential | 0.009*** | 0.000 | 0.007*** | 0.003 | 0.004 | 0.128 |
| Destination | Residential | 0.001 | 0.758 | 0.008*** | 0.001 | 0.004 | 0.106 | |
| Origin | Commercial | 0.024*** | 0.000 | 0.034*** | 0.000 | 0.033*** | 0.000 | |
| Destination | Commercial | 0.019*** | 0.000 | 0.042*** | 0.000 | 0.029*** | 0.000 | |
| Origin | Industrial | -0.003 | 0.123 | 0.006*** | 0.009 | 0.002 | 0.366 | |
| Destination | Industrial | 0.010*** | 0.000 | -0.001 | 0.815 | 0.003 | 0.226 | |
| Origin | Green | (VIF > 10) | ||||||
| Destination | Green | (VIF > 10) | ||||||
| Origin | Other land use | -0.009*** | 0.000 | -0.006** | 0.015 | -0.007*** | 0.008 | |
| Destination | Other land use | -0.002 | 0.489 | -0.007** | 0.010 | -0.006** | 0.024 | |
| Origin | Land use mix | 0.026*** | 0.003 | 0.005 | 0.546 | 0.007 | 0.497 | |
| Destination | Land use mix | -0.012 | 0.178 | 0.012 | 0.175 | 0.007 | 0.482 | |
| Point-of-Interest | Origin | Kindergarten | (VIF > 10) | |||||
| Destination | Kindergarten | (VIF > 10) | ||||||
| Origin | Elementary | 0.072*** | 0.000 | 0.062*** | 0.000 | 0.068*** | 0.000 | |
| Destination | Elementary | 0.042*** | 0.000 | 0.083*** | 0.000 | 0.055*** | 0.000 | |
| Origin | Middle | (VIF > 10) | ||||||
| Destination | Middle | (VIF > 10) | ||||||
| Origin | High | (VIF > 10) | ||||||
| Destination | High | (VIF > 10) | ||||||
| Origin | Airport | (VIF > 10) | ||||||
| Destination | Airport | (VIF > 10) | ||||||
| Origin | Beach | (VIF > 10) | ||||||
| Destination | Beach | (VIF > 10) | ||||||
|
Transportation Facility | Origin | Trunk | 0.023*** | 0.000 | 0.038*** | 0.000 | 0.018*** | 0.000 |
| Destination | Trunk | 0.034*** | 0.000 | 0.026*** | 0.000 | 0.019*** | 0.000 | |
| Origin | Feeder | -0.007* | 0.077 | -0.015*** | 0.000 | -0.007 | 0.128 | |
| Destination | Feeder | -0.029*** | 0.000 | 0.004 | 0.347 | -0.015*** | 0.001 | |
| Origin | Other buses | 0.026*** | 0.000 | 0.028*** | 0.000 | 0.033*** | 0.000 | |
| Destination | Other buses | 0.013*** | 0.000 | 0.040*** | 0.000 | 0.028*** | 0.000 | |
| Origin | Subway | -0.170*** | 0.000 | -0.191*** | 0.000 | -0.160*** | 0.000 | |
| Destination | Subway | -0.150*** | 0.000 | -0.159*** | 0.000 | -0.164*** | 0.000 | |
| Impedance | -0.030** | 0.033 | -0.085*** | 0.000 | -0.039** | 0.016 | ||
| Goodness-of-fit | Number of observation | 8,190 | 8,190 | 8,190 | ||||
| F-statistic | 92.0 | 150.8 | 79.1 | |||||
| R2 | 0.191 | 0.279 | 0.169 | |||||
| Adjusted R2 | 0.189 | 0.277 | 0.167 | |||||
상수(Intercept)는 독립변수의 곱과 기·종점 통행량의 비율을 나타내는 척도 계수와 비례하는 값으로 모든 모형에서 유의한 것으로 분석되었다. 토지이용의 경우 녹지는 다중공선성의 우려가 있어 분석에서 제외하였다. 상업지역은 기·종점에 관계 없이 모든 모형에서 양수로 유의미하게 나타났으며, 이는 기·종점의 상업지역 비율이 높을수록 I-MOD의 평균 수요가 많다는 것을 의미한다. 한편, 주거지역의 경우 오전 첨두시 모형에서는 출발지에서, 오후 첨두시 모형에서는 출발지와 도착지에서 양수로 유의하였다. 이는 오전 첨두시에는 주거지역에서 출발하는 통행 위주인 반면, 오후 첨두시에는 주거지역에서 출발하거나, 주거지역으로 향하는 통행이 혼재되어 있음을 의미한다. 산업 지역의 경우 오전 첨두시에는 도착지의 산업 지역 면적이, 오후 첨두시에는 출발지의 산업 지역 면적이 양수로 유의하였으며, 이는 산업 지역으로의 출·퇴근 흐름을 반영한 것으로 판단된다. 기타 토지이용은 대체로 통계적으로 유의하며 음수인 것으로 나타났으며, 이는 도시지역이 아닌 지역의 토지이용 비율이 높을수록 I-MOD 이용이 상대적으로 적은 것을 반영한 결과로 볼 수 있다. 토지이용 혼합도의 경우 오전 첨두시에만 통계적으로 유의하며 양수로 나타났다. 한편, POI의 경우에는 초등학교를 제외하고는 모두 다중공선성의 우려가 있어 분석에서 제외하였다. 초등학교의 경우 출·도착지 및 시간대와 관계없이 모두 통계적으로 유의하며 양수로 추정되었다. 초등학교에 유치원이 병설되는 경우가 많아 유치원과 초등학교의 상관계수가 0.612로 높으나 중학교나 고등학교와의 상관계수는 각각 0.009, -0.184로 낮은 것을 고려할 때, 이는 I-MOD를 활용하여 유치원이나 초등학교 등·하교를 하는 통행이 반영된 것으로 보인다.
교통시설과 관련된 변수는 대체로 유의한 것으로 분석되었다. 모든 시간대에서 간선버스의 수는 양수이며, 대체로 유의한 것으로 나타났다. 이는 간선 버스가 다니는 교통 허브를 중심으로 I-MOD의 통행이 이루어짐을 시사한다. 반면, 지선 버스의 경우에는 시간대에 따라 계수의 패턴이 극명하게 다른 것을 확인할 수 있었다. 오전 첨두시나 비첨두시의 경우 지선 버스의 계수가 도착지에서는 음수로 유의하였으며, 반대로 오후에는 출발지에서 음수로 유의하였다. 이는 지선 버스가 적은 지역과 관련된 통행에서 I-MOD의 이용 수요가 높으며, 시간대에 따라 흐름이 명확하다는 것을 나타낸다. 지하철역과의 거리는 시간에 관계없이 출발지와 도착지 모두 음수로 유의하였다. 이는 지하철역까지 거리가 가까운 정류장으로 통행하는 것을 나타낸다. 이를 종합해보면, I-MOD 서비스는 지선 버스가 적은 지역으로 접근하거나 영종도 내의 기존 버스와 지하철을 이용하기 위한 연계수단으로 활용되어, First- and Last-mile 문제를 해소하는 데 이바지하는 것으로 보인다. 마지막으로 두 교통존 간 거리는 시간대와 관계없이 통계적으로 유의하였으나, 오후 첨두시일 때 특히 영향이 큰 것으로 분석되었다. 이는 오후 첨두시에는 다른 시간대보다 단거리 통행 비중이 상대적으로 많다는 것을 의미한다.
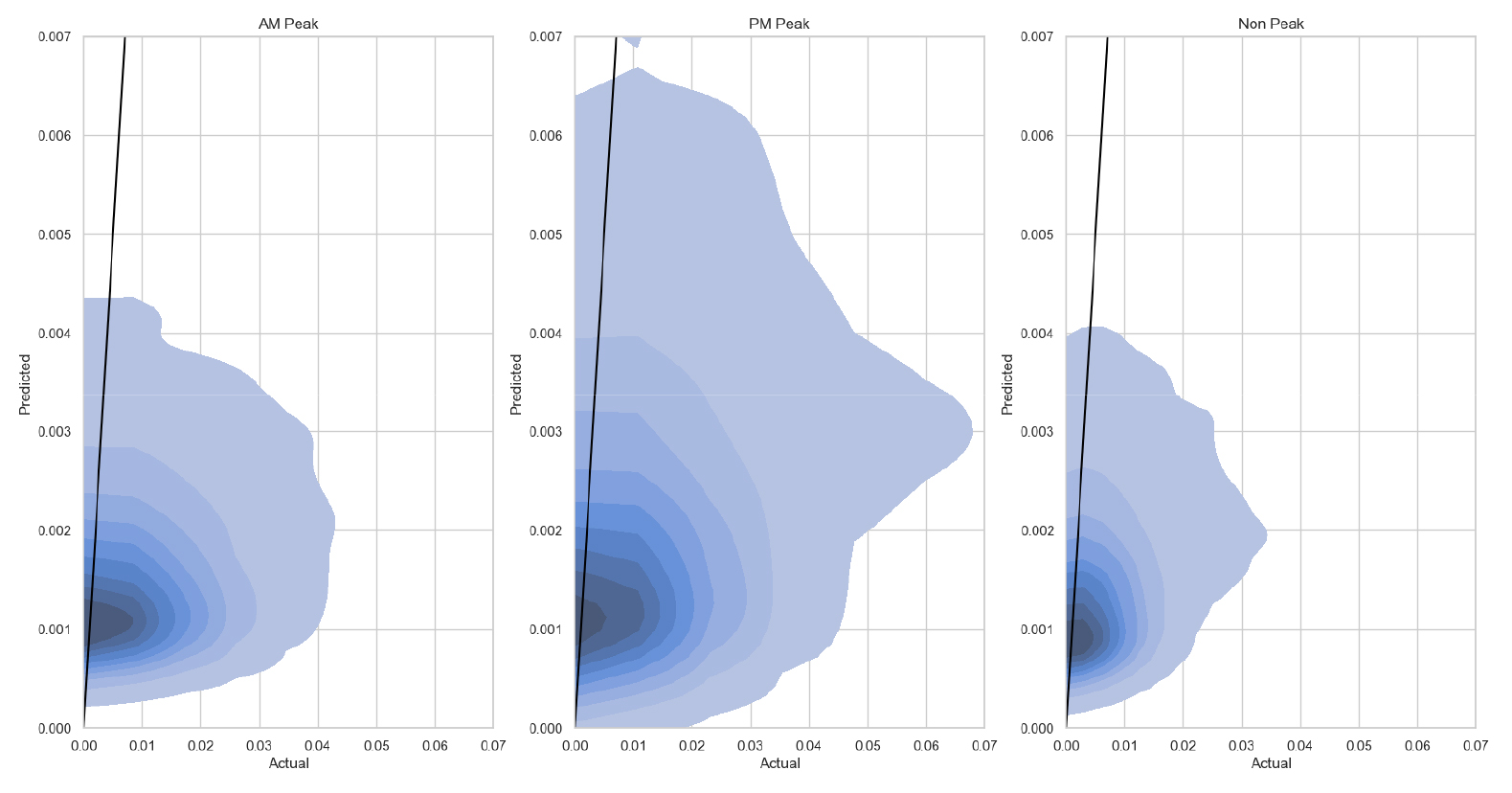
Figure 4는 실제 기·종점 수요와 예측 기·종점 수요를 비교한 그림이다. 그래프의 X, Y축은 각각 실제 수요와 예측 수요를 나타내며, 실제 수요와 예측 수요의 산포도를 커널 밀도 함수로 추정하여 표현하였다. 이때, 색상이 진할수록 실제 수요와 예측수요를 나타내는 점의 밀도가 높다는 것을 나타낸다. 한편, 그림의 검은 색 선은 실제 수요와 예측 수요가 같은 지점을 연결한 선이다. 커널 밀도가 검은색 선보다 대체로 밑에 쏠려 있는 것으로 보아 예측한 수요가 실제 수요보다 과소추정된 것으로 보인다. 이는 수요예측에 주된 변수인 사회·경제적 변수가 포함되지 않았으며 통행이 거의 발생하지 않는 기·종점 쌍이 많기 때문으로 보인다.
본 연구의 결과로 구축된 직접 수요모형의 모형 적합도는 다른 선행연구에 비해 상대적으로 낮으며 수요가 과소추정되어 활용에 유의하여야 하나, 다음과 같이 활용할 수 있을 것이다. 영종도 내에는 영종하늘도시 등 현재 개발이 진행되고 있는 지역이 존재한다. 이러한 지역이 개발이 완료되는 경우에 토지이용 변화에 따른 수요를 예측할 수 있을 것이다. 또한, 영종도에서 운행되었던 I-MOD와 유사한 성격으로 운행되었던 다른 지역의 수요응답형 서비스의 수요예측과 관련하여 추정된 계수를 직접 적용하기는 어려우나, 본 연구에서 사용된 방법론이나 영향이 있는 변수를 활용하여 모형을 구축할 수 있을 것이다.
결론
본 연구는 수요응답형 대중교통의 확산에 따라 중·장기적인 교통계획에 활용될 수 있는 수요응답형 대중교통의 수요모형을 설계하고 수요에 영향을 미치는 요인을 분석하고자 하였다. 이를 위해 인천 영종도에서 운행되었던 I-MOD 서비스의 자료와 토지이용, 관심 지점, 교통시설 등 변수를 수집하고 가공하였다. 수집된 변수를 활용하여 오전 첨두시, 오후 첨두시, 비첨두시의 직접 수요모형인 승법 모형을 추정하고, 추정된 모형을 비교·분석하였다.
본 연구에서는 직접 수요모형을 추정하여 토지이용, 관심 지점, 교통시설이 수요응답형 대중교통의 수요에 미치는 영향을 확인하였다. 토지이용의 경우 시간대와 무관하게 상업지역 비율이 높을수록 수요가 많았으며, 주거지역의 경우 오전 첨두시에는 출발지의 주거지역 비율이 높을수록, 오후 첨두시에는 도착지의 주거지역의 비율이 높을수록 수요가 많은 것을 확인하였다. 이는 출·퇴근이나 통학 교통량이 반영된 것으로 판단된다. 초등학교가 포함된 교통존에서 수요가 많이 발생한다는 점도 위의 사실을 뒷받침한다고 볼 수 있다. 대중교통 시설의 경우 지하철역과 가깝거나 간선 버스가 많이 다닐수록 기·종점에 관계없이 수요가 많이 발생한 반면, 오전에는 지선 버스가 적게 다니는 지역으로 향하는 수요가 오후에는 지선 버스가 적게 다니는 지역에서 출발하는 수요가 많은 것을 확인할 수 있었다. 이는 I-MOD 서비스가 지선 버스가 적어 접근하기 어려운 지역을 연계하거나, 지하철역이나 간선 버스가 많이 다니는 교통 결절점과 연계하기 때문으로 보인다.
이러한 연구 결과를 활용하여 도시에서 대중교통을 보완하는 성격의 수요응답형 대중교통 운영 전략을 수립할 수 있을 것이다. 특히, 본 연구에서 I-MOD를 이용하기 위해 서비스를 호출하였으나 최종적으로 서비스를 이용하지 못한 비율이 높았던 것을 고려할 때, 운영 전략을 개선하여 수요가 많이 발생할 것으로 예상되는 지역에 차량을 중점적으로 배차한다면 수요를 더 확보할 수 있을 것으로 기대된다. 예를 들어, 주거지역과 공업지역의 승·하차지 계수가 오전 첨두시와 오후 첨두시에 정확히 반대되어 오전에는 주거지역에서 공업지역으로, 오후에는 공업지역에서 주거지역으로의 수요가 두드러지는 점을 고려하여, 공업지역으로의 출·퇴근을 지원하는 수요를 집중적으로 지원할 수 있을 것이다. 또한, 지하철역 주변이나 간선버스가 많이 다니는 교통의 주요 결절점을 중심으로 수요응답형 대중교통을 집중적으로 배차하여 I-MOD 서비스와 간선 교통망을 연계하여 수요를 확보할 수 있을 것이다.
본 연구에서는 토지이용이나, 교통시설 변수 등이 수요응답형 대중교통의 수요에 미치는 영향을 밝혀냈지만 다음과 같은 한계가 존재한다. 첫째, 영종도에서 운행되었던 I-MOD 서비스는 대중교통을 보완하는 성격을 지는 서비스로, 농·어촌에서 주민의 이동권 보장을 위한 수요응답형 대중교통 등 성격이 다른 수요응답형 대중교통 서비스에는 본 연구 결과를 활용하기 어렵다는 한계가 있다. 또한, 본 연구에서는 교통존을 균등한 크기로 설정하고 일정 표본 수를 확보하기 위해 육각 격자 모형인 H3 Cell을 활용하였기 때문에, 수요에 큰 영향을 미쳐 많은 연구에서 사용되었던 인구, 고용자 수 등 지역의 사회·경제적인 속성을 반영할 수 없었다. 따라서, 모형 적합도를 나타내는 결정계수가 상대적으로 낮으며, 대체 변수의 효과가 혼재되었을 가능성이 존재한다. 향후 연구에서는 위의 한계를 개선하기 위해 사회·경제적 속성 등 다양한 변수를 반영하여 모형의 설명력을 높이거나, 수요응답형 대중교통의 유형에 따른 비교·분석을 시행할 수 있을 것이다.
