

서론
선행연구
1. 철도역 유형 분류 연구
2. 철도역 인근 지역 특성 분석 연구
3. 선행연구 검토 결과
연구방법
1. 데이터 수집
2. 변수 구축 및 상관분석
3. 유형 분석
4. 유형 검증 및 활용방안 제시
분석결과
1. 변수 기초통계 및 상관분석
2. 유형 분석
3. 유형 검증
4. 활용방안 제시
결론
서론
2018년 9월 정부는 수도권의 인구집중 문제 해소, 주택시장 및 서민 주거 안정을 위해 주택공급 확대방안을 발표하고 3기 신도시, 콤팩트시티, 중소 공공택지 사업을 통해 주택 30만호 추가 공급을 추진하고 있다(MOLIT, 2018). 이에 따라, 수도권은 서울 외곽의 택지개발에 따른 생활권이 광역화되고 인구집중이 심화되면서 광역교통 통행이 지속 증가하고 있는 상황이다(Korean Government, 2019). 광역교통 수요의 증가로 서울 도심 내 교통혼잡이 가중되고 있는 상황이며, 신도시 지역 확대로 해당 지역과 연계된 철도시설 혼잡이 심화되고 첨두시에 집중되는 수요로 인해 철도시설의 혼잡률이 매우 높은 상태이다(MOLIT, 2021a). 이에 대한 대안으로 정부는 광역교통수요를 효과적으로 처리하고 철도시설의 혼잡률을 완화하기 위해 대중교통 예산을 적극 투자하고 있다.
그러나 대중교통의 차내 혼잡도는 132~175% 수준으로 쾌적성이 낮게 나타나 이용자의 불편을 초래하고 있으며, 노선 굴곡도 증가, 통행속도 감소 등으로 인해 서비스 수준이 저하되고 있는 경향을 보이고 있다(Korean Government, 2019; Seoul Metropolitan Government, 2024). 또한, 환승 불편으로 대중교통망 구축에 따른 시간절감 효과가 감소하고 그 결과 예산 투자 대비 대중교통 수단분담률 제고 효과가 미미한 상황이다(MOLIT, 2021b). COVID-19 팬데믹 이후 철도시설의 이용자가 지속 증가하여 평시 수준을 회복하고, 신규노선 설치 및 연계에 따라 환승역의 통행수요 및 환승량은 증가하고 있는 상황이다.
광역교통 통행은 대부분 두 개 이상의 수단 또는 노선을 이용하는 장거리 통행 비중이 높아 전체 통행의 절반 가량은 수단 또는 노선 간의 환승이 발생하게 되는 특성을 지닌다(KRIHS, 2021). 이러한 특성 속에서 광역교통 통행의 편의성을 높이고 대중교통 수송분담률을 제고하기 위한 방안 중 하나로 환승 관리의 중요성이 더욱 강조되고 있다. 그 배경에는 대중교통 이용자 중 환승을 이용하는 비율은 66.6%로 나타났으고 이 중 버스-도시철도 간 환승 40.7%, 도시철도 노선 간 환승 12.7%로 나타나 도시철도 이용을 위한 환승통행 비중이 높은 것으로 조사되었으며, 서울시민 대상으로 실시한 대중교통 행복지수 민감도 분석 결과, 환승시간이 출근 시 중요 고려시간과 불만족 시간 분야에서 높은 순위로 나타나 환승 관리가 대중교통 이용자 만족도에 영향이 큰 것으로 조사됐다(KOTSA 2024; Seoul Institute, 2013). 또한, 최근 이태원 압사사고, 김포골드라인 안전사고 등으로 출퇴근시간에 많은 인파가 모여 혼잡도가 높은 환승역에 대한 안전 문제가 제기되어 환승역의 혼잡도 및 안전 관리의 필요성이 제기됐다(KOTI, 2023).
따라서 대중교통 이용자의 통행 편의를 제고하고 환승 불편과 혼잡 안전 문제를 개선하기 위해 도시철도 환승역의 관리와 운영에 대한 적극적인 논의가 필요한 시점이다. 이에 본 연구에서는 도시철도 이용자의 통행행태와 다차원 지역 특성 분석을 통해 환승역 유형을 분류하고, 전반적인 유형별 관리 및 운영 방안을 제시하고자 한다. 이를 바탕으로 환승역은 체계적인 관리와 운영이 가능할 것으로 사료되며, 더 나아가 혼잡도 및 수요 관리, 환승시설 개선계획, TOD 연계 개발 전략 등 정책 수립 검토자료로 활용하여 환승역을 이용하는 승객의 통행 편의를 도모하고 대중교통 수단분담률 제고에 기여할 것으로 기대된다.
선행연구
1. 철도역 유형 분류 연구
철도역의 체계적인 관리와 운영을 위해 다양한 변수를 활용하여 유형을 분류한 연구가 다수 진행되고 있다. Li et al.(2020)은 베이징 도시철도망 네트워크 구조와 교통카드 데이터를 기반으로 이용자의 시공간적 통행 흐름을 분석하여 교통허브, 상업, 주거, 사무 등 기능적 특성을 바탕으로 유형을 분류하였고, Shiran et al.(2024)은 역사 이용 목적, 철도 시스템, 역사 위치, 네트워크 내 위치, 고도 수준, 선형 배치, 서비스 제공 범위, 승강장 형태, 역사 건축 양식, 운영기간 등 역사의 위계와 구조적인 특징을 바탕으로 14가지 철도역 분류방법을 제시하였다. 또한, Zheng et al.(2024)은 철도역 인근에 입지한 교통수단, 주요시설과 인근 지역의 토지이용, 도시 경제지표 등 Node-Place- Network-City 변수를 활용하여 장강 삼각주의 123개 고속철도 역사 유형을 식별하였다. Hwang et al.(2024)은 도시철도 이용자 통행행태에 영향을 미칠 수 있는 용도지역을 기준으로 부산 도시철도 역사의 첨두/비첨두, 주중/주말 승하차 패턴 분석을 통해 철도역 및 역세권 유형을 분류하고 관리 방안을 제시하였다. 아울러, Cho et al.(2019)은 지하철 승차인원 예측을 위한 기초자료로 활용하기 위해 294개의 서울시 도시철도 역사를 환승 노선 개수, 출입구 개수, 버스정류장 개수, 백화점 개수, 병원 수, 날씨 등을 고려하여 군집 분석을 수행했고, 그 결과 3개의 유형을 도출하였다.
2. 철도역 인근 지역 특성 분석 연구
도시철도 환승역의 승객 흐름과 철도 이용자의 통행행태에 영향을 미칠 수 있는 철도역 인근 지역 특성 분석 연구에 대해 조사했다. Oh et al.(2019)은 밀도, 다양성, 도시설계, 대중교통 접근성, 도착지 접근성 등 5Ds RTOD (Rail-based Transit Oriented Development) 계획요소와 도시철도 승하차 인원의 관계를 분석을 진행하였고, 고용인구, 환승역 여부, 버스정류장 밀도 등이 도시철도 승하차 인원과 유의미한 관계가 있다 도출하였다. 다음으로 Kang et al.(2023)은 연계교통, 중심지 직선거리, 밀도, 다양성 등 철도역 인근 지역의 특성 데이터를 구축하여 변수간의 관계성을 분석하고, 수도권 TOD 유형 분류에 활용하고 Node-Place 모델이 균형이 이루는 철도역이 대중교통 수단분담률이 높은 것을 확인했다. Kim et al.(2015)은 교통카드 데이터를 활용하여 시간적 대중교통 통행행태을 기반으로 주거 중심 그룹, 활동 중심 그룹, 혼합형 그룹으로 분류하고, 토지이용, 인구 및 사회·경제적 요인, 대중교통 시설 등 철도역 인근 TOD 계획요소의 영향을 파악하기 위해 다중회귀분석을 통해 분석을 진행하였다. 분석 결과, 그룹별로 철도역 인근 지역 특성 요인이 승차량과 승객의 통행행태에 영향을 미쳤음을 확인했다.
3. 선행연구 검토 결과
선행 연구를 검토한 결과, 기존 연구에서는 이용자 통행행태, 철도역의 위계 및 구조, 철도역 인근 지역 특성 등을 기반으로 다양한 철도역 유형 분류 방법이 제시되었다. 아울러, 선행연구에서 철도역 인근의 밀도, 다양성, 대중교통 접근성 등과 같은 특성이 도시철도 승하차 인원과 대중교통 수송 분담률에 크게 영향을 미친다는 점을 확인하였다. 그러나 기존 연구에서는 철도역 인근의 지역 특성을 포함하여 고려한 유형 분류 연구가 상대적으로 부족했음을 확인했으며, 일부 연구에서 용도지역과 같은 지역 특성을 반영하여 유형화를 시도했으나 다양한 지역 특성 변수를 활용하지 않았거나 실제 철도 이용자의 통행행태까지 고려하지 못해 체계적인 유형화에는 한계가 있었다.
이에 따라, 본 연구에서는 교통카드 데이터를 활용하여 구축한 이용자의 통행행태과 Table 1과 같이 선행연구에서 검토된 다차원적인 지역 특성 변수를 연계하고, 이를 통해 환승역의 시공간적 이용자 통행행태, 대중교통 네트워크 접근성, 인구 및 종사자수 밀도, 토지이용 다양성 등 특성 지표를 기반으로 서울특별시 도시철도 환승역 유형화 연구를 진행하고자 한다.
Table 1.
Variable of previous researches
| Researcher | Dependent variable | Independent variable |
| Li et al.(2020) | Classification of station | Network structure, Time series, Passenger flow |
| Shiran et al.(2024) | Classification of station | Station usage, railway system, location, line geometry, architecture, etc. |
| Zheng et al.(2024) | Classification of HSR station | Transportation, network, vitality, GDP, etc. |
| Hwang et al.(2024) | Classification of station area | Ridership pattern, zoning |
| Cho et al.(2019) | Classification of station | Number of metro line/gate/bus stops/department stores/hospitals, weather, etc. |
| Oh et al.(2019) | Number of metro | Population density, LUM, road/intersection density, Transfer station, workers, etc. |
| Kang et al.(2023) | Classification of TOD type | Number of direction/frequency of rail/bus, distance to CBD, population, workers, land-use mix, intersection density, etc. |
| Kim et al.(2015) | Ridership patterns | Associative area per facility, land use entropy index, population density, car registrations, number of metro stations/bus stops, etc. |
연구방법
본 연구에서는 서울교통공사에서 운영하는 도시철도 환승역 67개소를 대상으로 이용자 통행행태와 다차원 지역 특성 분석 기반으로 유형을 분류하고 유형별 관리·운영에 활용하는 방안을 제시하는 것을 목적으로 한다. 여기서 철도역 인근 지역 특성은 「서울시 도시 및 주거환경정비 조례」 및 「서울시 역세권 장기전세주택 건립 운영기준」규정에 근거한 역세권 기준에 따라 환승역을 기준으로 반경 500m 이내로 정의하여 데이터 수집 및 전처리를 진행하였다(Korea Law Information Center, 2025; Seoul Metropolitan Government, 2025).
본 연구에서 제시한 연구방법은 4단계로 구성되며 전반적인 분석 흐름과 단계별 분석내용은 Figure 1과 같다. 먼저, 도시철도 이용자 통행행태과 다차원 지역 특성 데이터를 수집한다. 다음으로 수집된 데이터를 바탕으로 유형 분류를 위한 변수를 구축 및 정규화하고 상관분석을 통해 변수간 중복된 정보를 파악하고 상관관계가 높은 변수들은 통합하거나 제거하여 클러스터링 분석에 사용할 최종 변수를 추출한다. 세 번째 단계로 상관분석을 통해 추출한 변수를 PCA(Principal Component Analysis)를 실시하여 데이터 차원과 자료의 크기를 축소한 이후 클러스터링 분석을 실시하여 유사한 특성을 가진 역사들을 군집화하여 유형을 도출하고 정의한다. 마지막 단계에서는 클러스터링 분석 결과로 도출된 환승역 유형을 군집 간 차이, 해석력 평가지표를 통해 환승역 유형 분류의 적절성에 대한 평가를 진행한다. 아울러, 환승역 유형 도출 결과에 대한 활용방안을 제시하여 본 연구를 마무리한다.

1. 데이터 수집
서울특별시 환승역 유형을 체계적으로 분류하기 위해, 먼저 도시철도 이용자의 통행행태와 지역 특성 데이터를 Table 2과 같이 수집했다. 이용자 통행행태 분석을 위해 한국스마트카드사의 교통카드 데이터와 서울교통공사의 역별 환승인원 데이터를 활용했다. 다음으로 환승역의 지역 특성은 접근성, 밀도, 다양성의 세 가지 측면에서 데이터를 수집했다. 접근성 분석을 위해 한국철도공사와 서울교통공사에서 도시철도 노선 정보, 서울 버스 노선 및 정류소 데이터를 활용했다. 밀도 지표는 통계지리정보시스템의 인구수 및 종사자 수 데이터를 반영했으며, 다양성 지표는 V-WORLD에서 제공하는 토지이용현황, 건축물 GIS DB 데이터를 수집했다. 수집한 교통카드 데이터에서 승차 혹은 하차기록이 누락된 결측치는 제거하고, 환승역 반경 500m에 버퍼를 설정하여 지역 특성 데이터를 전처리했다.
Table 2.
Data collection
2. 변수 구축 및 상관분석
철도역 유형 분류 및 지역 특성 분석 관련 선행연구를 토대로 서울특별시 환승역 유형화에 필요한 변수를 Table 3과 같이 선정했다. 먼저 환승역의 네트워크 입지와 승객 흐름을 분석하기 위해 도시철도 이용자의 통행행태를 지표화했다. 이를 위해 일 평균 승하차 인원, 시도 간 광역 통행량, 출퇴근 시간대 승하차 비율을 주요 변수로 선정하고, 2020년 기준 한국스마트카드 교통카드 데이터를 전처리하여 데이터셋을 구축했다. 다음으로, 환승역의 접근성을 평가하기 위해 2024년 기준 한국철도공사·서울교통공사 도시철도 정보, 서울시 버스 노선 및 정류소 정보 데이터를 활용하여 연계교통 현황을 변수로 설정했다. 주요 변수로는 환승역에서 환승 가능한 도시철도 및 버스 노선 수, 고속철도·일반철도·고속버스 등 지역간 이동 교통수단 수, 환승역에서 도시철도나 버스를 이용해 이동할 수 있는 행정구역(시·군·구) 수, 그리고 환승역을 경유하는 도시철도·버스 노선의 운행 횟수를 변수로 구축했다. 세 번째로, 환승역 인근 지역의 밀도 특성을 검토하기 위해 환승역 반경 500m 범위와 통계지리정보서비스(SGIS)에서 구득한 2022년 기준 100m 격자 인구수 및 종사자수를 를 결합하여 변수로 구축했다. 이를 바탕으로 거주 인구 밀도 및 고용 밀도를 도출하여 환승역 유형 분류의 변수로 함께 활용했다. 마지막으로, 다양성 특성을 반영하기 위해 2024년 기준 토지이용현황을 엔트로피 지수로 나타내어 용도 혼합의 정도를 확인할 수 있는 토지이용 혼합도(Land Use Mixture, LUM)를 변수로 설정했다. 여기서 LUM 계산식은 Equation 1과 같다. LUM 값은 0에서 1 사이의 범위를 가지며 1에 가까울수록 용도 혼합이 높은 것을 의미한다(Cervero and Kockelman, 1997). 아울러, 2024년 기준 환승역 반경 500m 내 근린생활시설, 판매시설 등 상업용 건축물의 연면적을 변수로 포함하여 다양성 특성을 보다 정밀하게 반영하여 분석을 진행했다.
where, = Number of existing land use type,
= Specific land use type,
= Proportion of a specific land use type relative to total land use area
Table 3.
Building variables
유형화 및 분석 과정에서 변수의 크기와 단위 차이로 인해 발생하는 과대·과소 추정을 방지하기 위해 모든 변수는 z-score로 정규화를 진행하여 여러 변수 단위 차이를 제거하여 통합했다. 다음으로 이용자 통행행태와 지역 특성 변수 간의 상호작용이 있는지 확인하고, 변수 간의 관계성을 통계적으로 분석하기 위해 피어슨 상관분석(Pearson Correlation Analysis)을 수행하였다. 피어슨 상관분석은 상관분석에 널리 사용되는 방법으로 –1에서 +1 사이의 값을 갖는 피어슨 상관계수(R)을 통해 두 변수의 상관관계를 확인할 수 있다(Field et al., 2012). 피어슨 상관계수(R) +1은 완벽한 양의 선형관계, 0은 선형 상관관계 없음, -1은 음의 선형 상관관계를 의미한다. 이를 통해 구축된 변수의 중복된 정보를 파악하고 상관관계가 높은 변수들은 제거하거나 통합하여 자료의 크기를 축소하여 분석 속도를 개선하고 변수 간의 다중공선성 문제를 사전에 해결하고자 하였다.
3. 유형 분석
본격적인 유형 분석에 앞서 변수를 통합하거나 제거하였음에도 불구하고 변수가 많아 발생할 수 있는 과적합과 변수 간의 다중공선성을 축소하기 위하여 PCA(Principal Component Analysis) 분석을 진행하였다. PCA는 고차원의 변수들을 요약해서 노이즈를 줄여 더 명확한 클러스터링을 시도하게 하며, 축소된 데이터의 구조를 주성분을 이용해 보존하면서 차원을 줄여줄 수 있다. 또한, 상관성이 있는 변수 집합으로부터 선형 변환을 통해 독립적인 인공변수들을 도출하여 분석과 해석을 용이하게 하는 기법이다(Lee, 2015). 이에, 표준화된 변수를 PCA를 진행한 후 도출된 주성분이 전체 변수의 분산을 얼마나 설명할 수 있는지 누적 설명력 검토를 통해 확인하였고, 이를 기반으로 유형 분석에 적합한 주성분의 개수를 선정하였다.
다음으로 차원 축소된 이용자 통행행태과 지역 특성 변수들의 주성분을 기반으로 서울특별시 도시철도 환승역 유형을 파악하기 위하여 클러스터링 분석을 방법론을 선정하였다. 클러스터링은 비지도 학습의 일종으로서 레이블이 없는 데이터를 데이터 간 유사성을 바탕으로 자동적으로 특정 그룹으로 함께 묶거나 구분하는 데이터 분석기법이다. 본 연구에서는 정확한 환승역 유형 분류 결과를 확보하기 위해 적정 군집의 수를 결정하는 계층적 클러스터링 분석과 도출된 군집 해석에 용이한 k-means 클러스터링 분석을 결합한 혼합 클러스터링 기법을 사용하였다. k-means 클러스터링 기법은 주어진 데이터를 k개의 군집으로 묶는 알고리즘으로 군집 중심으로부터의 거리 측정값을 사용하여 데이터 요소를 군집으로 분류하는 방식으로 작동한다. 변수와 할당된 군집 사이의 유클리드 거리를 최소화하는 것을 개념으로 하며, 군집의 중심에 가까운 변수는 동일한 범주 내에 함께 그룹화하여 대표적인 유형 분류 기법으로 활용되고 있다. 각 군집의 중심은 해당 군집에 포함된 모든 패턴의 벡터 평균으로 계산되며, 계산식은 Equation 2과 같다.
where, = Centroid of patterns in cluster
= Patternsets in cluster,
= Specific patterns in cluster
그러나 k-means 클러스터링 기법은 정해진 군집의 수가 없이 임의로 군집 수를 추출하여 분석하므로 주어진 군집의 수가 원 데이터 구조에 적합하지 않거나, 초기 군집 중심의 위치가 적당하지 않은 경우 부적절한 결과를 도출한다(Lee et al., 2020). 이에 따라, 계층적 클러스터링의 기법 중 많이 활용되는 기법인 Ward법을 통해 최적의 군집 수를 파악하고, 이를 비계층적 클러스터링 분석 기법인 K-means 클러스터링 분석에 군집 수로 적용하여 환승역 유형을 분류하였고, 각 유형에 포함된 환승역의 이용자 통행행태와 지역 특성을 검토하여 분류된 유형을 정의하였다.
4. 유형 검증 및 활용방안 제시
혼합 클러스터링 분석 결과로 도출된 유형이 신뢰성이 있는지 검증하기 위해 군집 간 차이, 군집 해석력 측면에서 검토하였다. 먼저, 각 군집 간 특성이 실제로 유의미한 차이를 보이는지 확인하기 위해 3개 이상의 집단 간 연속형 종속변수의 분포 차이를 검정하는 분산분석(ANOVA)을 진행했다. 그리고 클러스터링 분석에 사용된 주성분의 성분적재값(Factor Loading)을 기반으로 실제 군집에 포함된 역사가 얼마나 적합한 지 검토하였다. 마지막으로 도출된 유형 결과를 기반으로 환승역 관리·운영 정책 수립을 위한 활용방안을 전반적으로 제시하고 연구를 마무리하였다.
분석결과
1. 변수 기초통계 및 상관분석
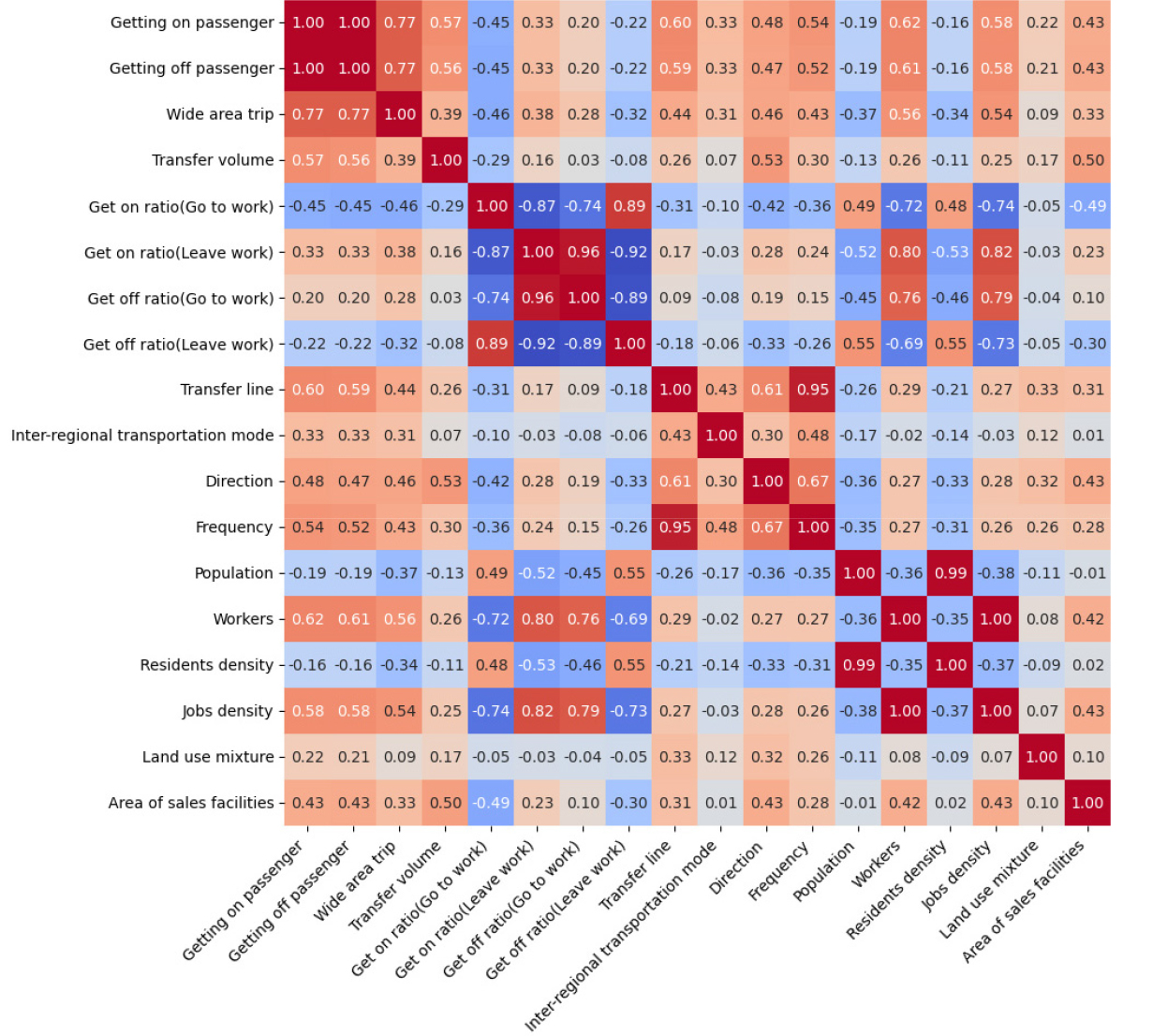
구축된 데이터를 z-score로 정규화하기 이전의 변수 기초통계는 Table 4와 같다. 분석대상 환승역 중 동작역은 역사 반경 500m 내 거주하고 있는 인구가 없어 인구수와 인구밀도가 0으로 나타났으나 자료의 분포에 큰 영향을 미치지 않는 것으로 판단되어 포함하여 분석을 진행했다. 모든 변수는 z-score로 정규화하고 이를 기반으로 피어슨 상관분석을 수행했다. 피어슨 상관분석을 수행한 결과는 Figure 2와 같으며, 승차인원-하차인원(R=1.00), 인구-인구밀도(R=0.99), 고용자수-고용밀도(R=1.00), 퇴근시간대 승차비율-승차시간대 하차비율(R=0.96)와 같이 상관계수가 0.9이상으로 높게 도출되어 거의 동일한 정보를 가진 변수로 확인되는 변수들은 통합 혹은 제거하여 향후 분석을 진행했다.
Table 4.
Basic statistics
2. 유형 분석
분석을 위한 변수가 많아 발생할 수 있는 과적합과 변수 간의 다중공선성 문제를 해소하기 위하여 PCA 분석을 수행하였다. 분석 결과 PCA의 누적 설명력은 Figure 3과 같이 도출되었으며, 이것은 각 주성분이 전체 데이터를 얼마나 설명하는지 누적 비율로 나타낸다. 클러스터링 분석을 위한 주성분 개수는 그래프에서 전체의 약 90% 이상 설명이 가능하여 구조적 분산을 유지하고, 엘보우(Elbow) 기법에 따른 설명력 증가가 급격히 완만해지는 지점인 6개로 설정하였다. PCA 분석의 적절성을 검토하기 위해 Eigenvalue, KMO, Bartlett 검토를 수행하여 Table 5와 같이 결과가 도출되었다. 먼저 도출된 6개 주성분의 Eigenvalue가 모두 1 이상으로 나타나 해당 주성분은 유의미하게 데이터를 설명한 것으로 나타났다. KMO 측도는 0.759로 나타나 주성분 분석에 적합한 수준임을 확인했으며, Bartlett의 구형성 검정 결과 p-value가 0.001보다 낮게 도출되어 변수 간 상관관계가 통계적으로 유의미하여 PCA 분석이 적절한 것으로 판단되었다.
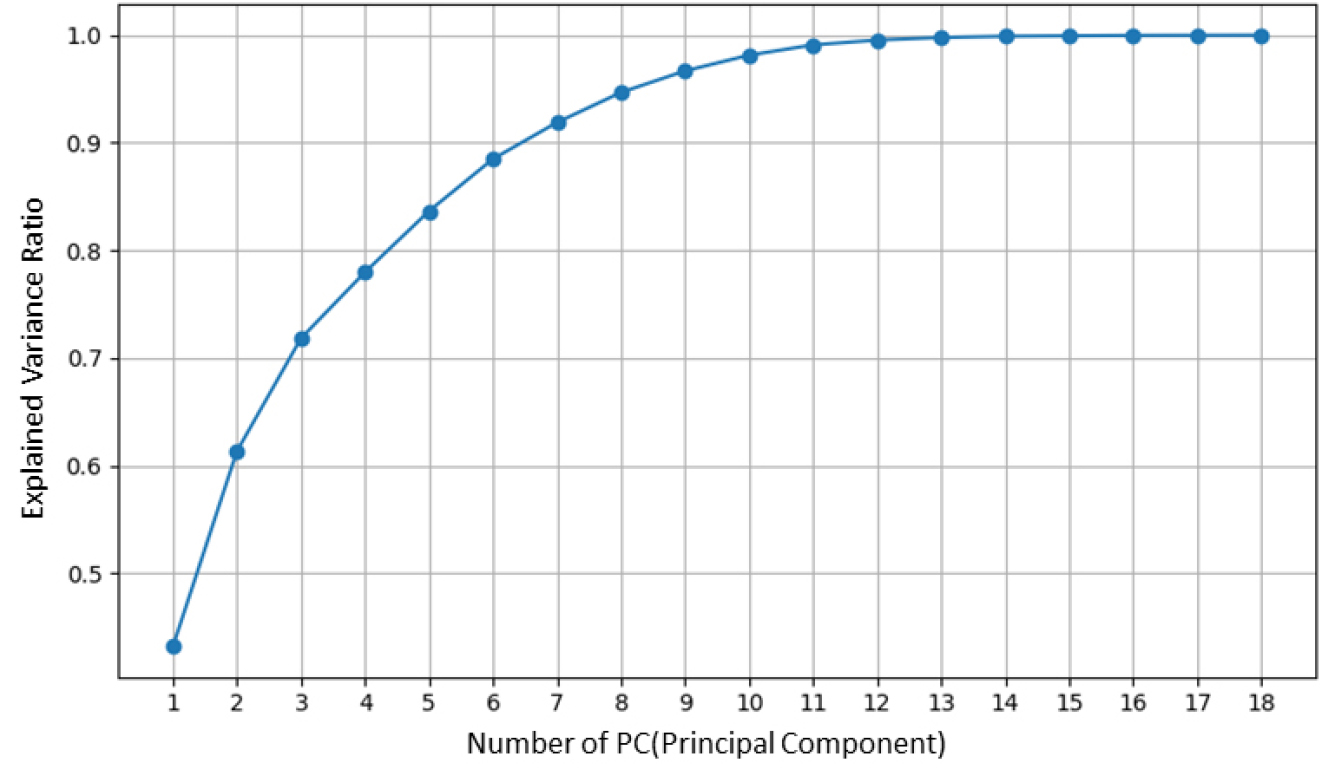
Table 5.
Results of assessing PCA suitability
| Index | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 |
| Eigenvalue | 7.78 | 3.26 | 1.89 | 1.10 | 1.03 | 1.00 |
| Index | KMO | |||||
| KMO | 0.713 | |||||
| Index | Chi-square | p-value | ||||
| Bartlett test | 1393.229 | 0.00000 | ||||
PCA에 따라 도출된 주성분 구성과 기존 변수의 관계에 대해 클러스터링 분석 결과 도출한 유형의 특성을 파악을 위하여 검토할 필요가 있다. 이에 따라, 기존 구축한 변수와 6개의 주성분 간의 관계를 나타내는 성분적재값(Factor Loadings)을 검토하였다. 성분적재값은 각 주성분(PC, Principal Component)이 원래 변수의 총 분산을 얼마나 설명하는지 나타내는 비율으로 PCA를 통해 도출한 주성분과 기존 데이터 변수와의 관계를 파악할 수 있다. PCA 결과 도출된 주성분의 성분적재값은 Table 6와 같이 제시하였다. 여기서 성분적재값이 양(+)인 경우 청색 음영 처리하고 음(-)인 경우 적색 음영 처리 하였으며, 성분적재값의 절대값이 0.25 이상인 변수에 대해선 볼드체 처리하여 나타냈다. 먼저 PC1의 변수 설명력 계수는 고용자수(-0.30), 출근시간대 승차비율(0.30), 퇴근시간대 승차비율(-0.29), 승차인원(-0.27)로 나타났으며 출근 수요가 많은 거주지 특성의 주성분으로 해석된다. 다음으로 PC2는 출근시간대 하차비율(0.35), 퇴근시간대 승차비율(0.30), 환승노선 수(-0.32), 운행 횟수(-0.29)로 도출되어 출근시간대 하차가 많고 퇴근시간대 승차가 많은 업무지구의 특성을 나타내는 것으로 보인다. PC3은 인구(0.46), 종사자수(0.24), 상업용 건축물 연면적(0.32)로 거주, 업무, 상업지구의 혼재된 특성을 보이는 것으로 나타난다. PC4는 운행방향(0.36), 환승통행량(0.34), 상업용 건축물 연면적(0.43), 토지이용혼합도(0.39)로 도출됐으며 연계교통이 좋고 상업적 이용도와 토지이용 혼합율이 높아 환승역의 상업 중심지적 복합기능을 나타내는 주성분으로 해석했다. PC5는 환승통행량(0.45), 광역통행량(0.27), 인구(-0.39)로 나타나 환승과 광역교통이 대량으로 발생하는 특성을 나타낸다. 마지막으로 PC6의 변수 설명력 계수는 토지이용혼합도(0.80)가 매우 높게 도출되었으며, 이것은 토지이용 혼합 중심으로 설명되는 주성분으로 단일 용도지역과 상업, 업무, 주거 둥 토지이용이 혼합된 지역을 구분하는 주성분으로 해석된다.
Table 6.
PCA result (factor loading)
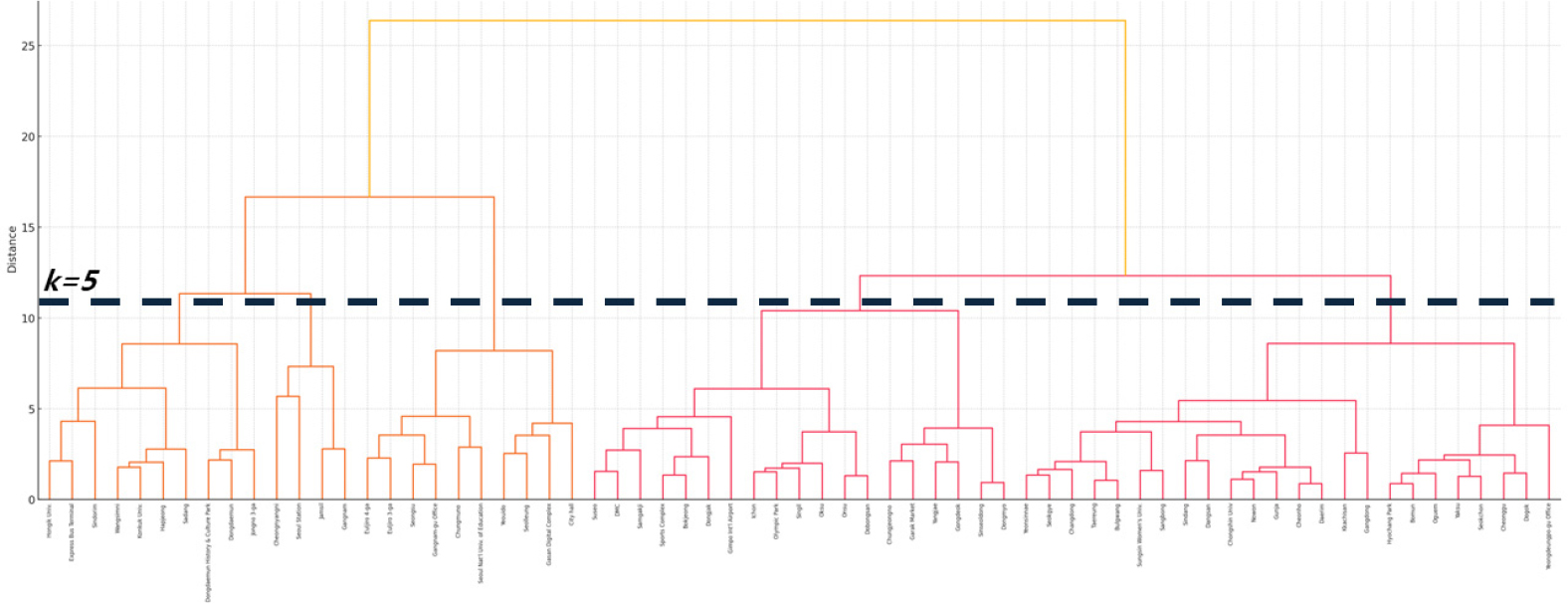
다음으로 적정 군집 수를 설정하기 위해 Ward법을 이용하여 계층적 클러스터링 분석을 수행하고, 시각화 한 결과를 Figure 4와 같이 덴드로그램을 제시하였다. 분석 결과, 최적의 군집의 개수가 3개 또는 5개가 도출되었으며, 본 연구에서는 상세하고 세부적인 유형 분류를 위해 군집 수를 5개로 설정하여 비계층적 클러스터링 분석 기법인 k-means 클러스터링 분석을 수행했다.
6개 주성분을 기반으로 군집 수를 5개로 설정하여 k-means 클러스터링 분석을 수행한 결과, 유형별 포함된 환승역 수는 군집별로 0번 군집 14개, 1번 군집 14개, 2번 군집 12개, 3번 군집 20개, 4번 군집 7개 환승역이 포함되었으며, Table 7과 같이 유형 분류 결과를 제시하였다. 도출된 군집을 바탕으로 유형 정의를 위해 각 군집의 이용자 통행행태와 지역 특성 데이터를 기반으로 Table 8과 같이 기초 통계량을 제시하였다. 여기서 유형 정의에 특성을 나타낸 변수는 볼드체 처리하였으며, 유형의 대표적인 특성을 나타내는 변수는 청색 음영 처리하였고 반대로 대조적인 경향을 보이는 변수는 적색 음영 처리하였다. 검토 결과, 먼저 0번 군집은 이용자 통행행태 측면에서는 출근 시간대 하차 비율(0.25%)이 높고 퇴근 시간대 승차 비율(0.27%)이 높은 업무지구 형태를 나타내고 있었으나, 지역 특성 검토 결과 인구(10,588.5명), 종사자 수(24,004.36명), 상업용 건축물 연면적(389,243.1㎡)이 균형된 수준으로 나타나, 업무, 상업, 주거 기능이 함께 나타나는 혼합형 중심지로 정의하였으며, 왕십리, 당산 등과 같은 역사가 포함되었다. 1번 군집은 출근 시간대 하차 비율(0.46%)과 퇴근 시간대 승차 비율(0.44%)이 모두 높은 특성을 보이며, 종사자 수(52,755.14명)와 고용밀도(5,132.54명/㎢) 또한 가장 높은 수준으로 나타났다. 이는 전형적인 업무지구 특성을 나타내는 가산디지털단지, 시청 등을 포함함에 따라 본 군집은 업무형으로 정의하였다. 다음으로 2번 군집은 출근 시간대 승차 비율(0.28%)이 높고 하차 비율(0.22%)이 비교적 낮으며, 승차인원(17,633.33명)과 상업용 건축물 연면적(42,209.33㎡) 또한 낮은 수준으로 나타났다. 인구 밀도(5,141.2명/㎢)는 중간 정도이지만 종사자 수(6,133.58명)는 매우 적은 편이며, 일정 수준의 환승통행량(42,363명)이 동반되는 특성이 나타나는 김포공항역, 수서역 등을 포함했다. 이에 따라 본 군집은 외곽 환승허브형으로 정의하였다. 3번 군집은 출근 시간대 하차 비율(0.2%)과 퇴근 시간대 승차 비율(0.18%)이 전반적으로 낮고, 승차인원(20,438.3명)도 낮은 수준을 보인다. 그러나 인구 밀도(15,390.44명/㎢)는 높은 편이며, 상업적 요소나 고용지표(종사자 수 10,500.3명, 고용밀도 12,444.91명/㎢)는 낮아 도심 내의 저밀도 주거지역의 특성을 보이는 것으로 해석되며 석촌, 천호 등 주거지역을 포함하고 있음에 따라 주거형으로 분류하였다. 마지막으로 4번 군집은 승하차 인원(승차 75,470.57명, 하차 77,109.57명)과 환승통행량(126,510.6명) 모두 가장 높은 수준으로, 매우 높은 유동성을 나타낸다. 출퇴근 시간대 승하차 비율은 균형되어 있으나, 상업용 건축물 연면적(533,895.5㎡), 광역 교통 접근성 지표(환승노선 40.71개, 지역간 교통수단 0.86개)가 높은 서울역, 잠실, 강남을 군집에 포함하고 있음에 따라 본 군집은 통근, 상업을 포함한 광역적인 통행이 집중되는 중심지-허브형로 제시하였다.
Table 7.
Result of clustering
Table 8.
Basic statistics of cluster
3. 유형 검증
클러스터링 분석 결과 도출된 군집 형성의 신뢰성을 검토하기 위해 군집 간 차이 측면에서 분산분석(ANOVA)을 실시하여 그 결과를 Table 9과 같이 제시하였다. 분석결과, 군집 간 평균 차이의 크기를 나타내는 F 값이 큰 것으로 나타났으며, 통행행태와 지역 특성 변수의 모든 p-value 값이 0.001보다 작게 도출되어 다수의 변수에서 군집 간의 차이가 통계적으로 유의미함이 확인되었다.
Table 9.
Result of cluster ANOVA
마지막으로 군집 해석력 검토를 위해 각 군집별 주성분 점수 평균값을 Table 10과 같이 제시하고 비교 분석하였다. 이는 주성분 기반 클러스터링 결과가 각 군집의 구조적 특성과 어떻게 연관되는지를 파악하는 데 유용한 접근법이다. 각 군집의 주성분 평균값과 성분적재값을 종합적으로 검토한 결과, 다음과 같은 해석이 도출되었다. 군집 0번 혼합형 유형은 대부분의 PC에서 중간 수준의 값을 나타내고 있으며, 특히 주거와 업무의 특성인 혼합된 PC3과 상업적 특성을 가진 PC4에서 균형 잡힌 값을 보여준다. 이는 업무, 주거, 상업 기능이 혼합된 도시 내 다기능의 특성을 반영하는 것으로 해석된다. 군집 1번 업무형은 PC1에서 두드러진 음의 값을 보이며, PC2에서 두드러진 양의 값을 보인다. 이것은 주거지 특성을 가지고 있는 PC1과 관계성이 낮음을 의미하며, 업무지구 출퇴근 흐름과 관련된 PC2에서 높은 적재값을 가진다. 이에 따라, 군집 1번 업무형은 출근 시간대 하차 비율과 고용 밀도가 높은 전형적인 업무지구 특성으로 해석된다. 군집 2번 외곽 환승허브형은 주거와 업무의 특성이 혼합된 PC3과 환승량 중심의 PC5에서 비교적 높은 값을 보이지만, 전체적으로 PC 점수의 분포가 두드러지지 않는다. 이는 명확한 기능성보다는 도시 외곽에서의 거점 기능 또는 도시 내에서 환승역으로서의 특성이 드러나는 군집으로 해석된다. 군집 3번 주거형은 주거지 특성을 나타내는 PC1에서 높은 값을 보여, 전반적으로 고용 밀도와 통행량은 낮지만 주거 밀도는 높은 도심 거주지역 특성이 두드러진다. 군집 4번 중심지 허브형은 주거 특성의 PC1과 상업 특성의 PC2의 값이 매우 낮고, 상업 특성의 PC4 매우 높은 수준이다. 이는 성분적재값 기준으로 승하차 인원, 환승통행량, 상업용 건축물 면적 등에 높은 값을 갖는 주성분이다. 따라서 해당 군집은 복수 노선 환승, 대규모 유동 인구, 중심지 기능이 집중된 중심지 허브형 환승역으로 해석됐다.
Table 10.
Descriptive statistics of clustering (mean)
위와 같이 군집 분류에 대한 검증을 진행한 결과, 분산분석을 통해 군집 간 차이를 검토한 결과 다수의 변수에서 통계적으로 유의미한 차이를 확인하였으며, 주성분 기반의 해석력 검토를 통해 각 군집 유형이 해당 데이터 구조와 적절히 군집을 형성하였음을 확인하였다. 또한, 각 유형 군집에 포함된 역사 간의 통행행태와 지역 특성을 검토하고 실제 환승역의 역할을 비교 검토한 결과 같은 유형에 포함된 역사와 특성이 유사했고 정의된 것과 같은 형태와 성격을 나타내고 있음을 파악하였다. 따라서 본 연구에서 혼합 클러스터링 분석을 통해 도출된 환승역 유형 분류는 해석 가능성과 구조적 타당성을 확보하고 있다 확인하였다.
4. 활용방안 제시
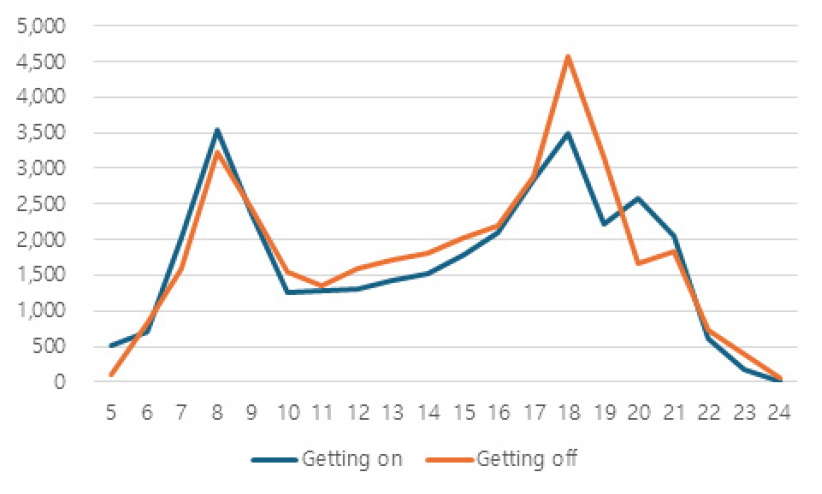
본 연구에서 도출한 환승역 유형은 실제 환승역의 관리·운영 측면에서 실질적인 정책 설계 및 시설 운영에 적용 가능한 기반 자료로 활용될 수 있을 것으로 기대된다. 특히, 시간대별 승하차 비율은 Table 11과 같이 주거형, 업무형 환승역에서 뚜렷한 차이를 보이며 혼합형과 중심지 허브형은 전 시간대에 걸쳐 높은 수준의 통행량을 보이며, 이를 반영한 맞춤형 혼잡도 및 수요 관리 정책 수립이 가능함을 시사한다. 주거형 환승역은 출근 시간대 승차 비율이 높아 아침 혼잡 대응 중심의 설계가 필요하며, 업무형 환승역은 출근 시 하차와 퇴근 시 승차가 모두 집중되어 이중 피크 대응 전략이 요구된다. 또한, 혼합형과 중심지 허브형은 전체적인 수요 관리 및 동선 정비가 필요한 것으로 사료된다. 이에 따라, 시간대별 통행 중방향을 고려하여 환승 및 이동통로의 가변적 배치 방안을 적용할 수 있다. 예를 들어, 주거형 환승역에서는 출근 시간대 승차 방향 통로를 넓게 확보하고 하차 방향은 축소하며, 업무형 환승역에서는 출근 시 하차 방향, 퇴근 시 승차 방향 통로를 중심으로 공간을 재배분하는 방식이 있다. 또한, 혼합형과 중심지 허브형 환승역은 시간대 전반에 걸쳐 통행량이 높게 유지되므로, 환승 동선 정비, 실시간 정보 제공, 교통수단 간 연계성 제고 전략 병행이 필요한 것으로 보인다.
Table 11.
Travel patterns over time by transfer station’s type
| Cluster 0 : Mixed centre | Cluster 1 : Business |
 < Konkuk Univ. > | 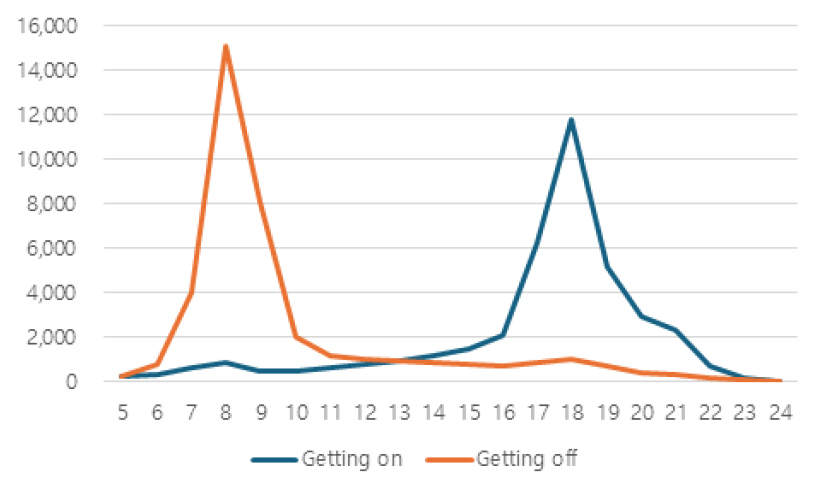 < Gasan Digital Complex > |
| Cluster 3 : Residential | Cluster 4 : Central-hub |
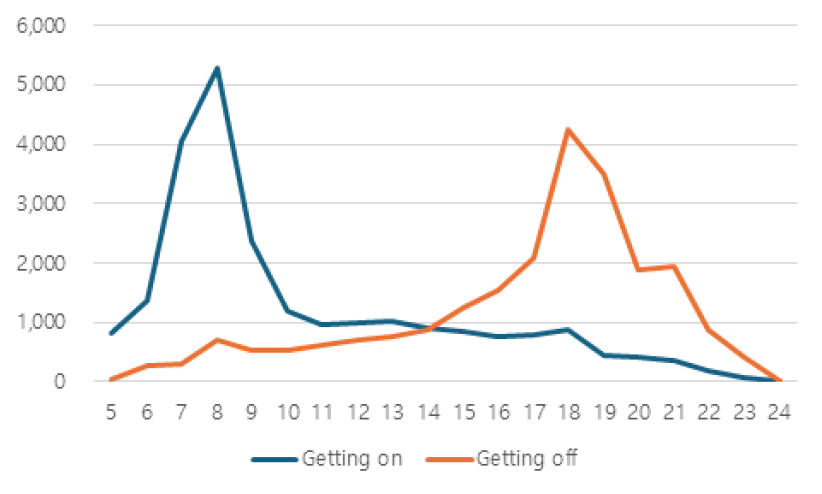 < Ggachisan > | 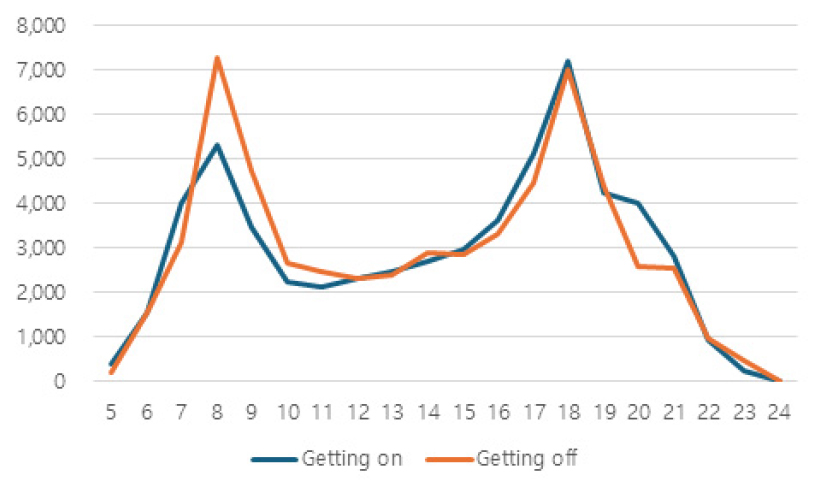 < Jamsil > |
또한, 이러한 유형 분류 결과는 단순한 수요 관리를 넘어, 환승시설 개선계획, TOD 연계 도시공간 개발 전략 등 다양한 정책 분야에 활용될 수 있다. 우선, 시설 측면에서는 업무형은 집중 동선 정비 및 배리어프리 설비 강화를, 주거형은 출근 대기 공간과 생활편의시설 확충을, 중심지 허브형은 전반적으로 승하차인원과 환승통행량이 많은 점을 고려하여 이용자를 위한 넓은 승하차 공간 및 대합실 확장을 요구한다. 외곽 환승허브형 환승역은 도심 접근 연계를 위한 간선-지선 체계 통합과 소형 환승거점화 전략이 적절하다.
나아가, 환승역 유형별 특성을 TOD 전략과 연계하여 지역 기능을 재정립할 수 있다. 예를 들어, 업무형 환승역은 직주근접을 고려한 업무지구 중심의 복합개발이, 혼합형 환승역은 상업·문화 중심 복합거점으로의 다기능 중심지 전략이, 외곽 환승허브형 환승역은 광역 환승 연계형 중간 거점으로의 조성이 필요함을 알 수 있다. 이러한 연계 전략은 도시 전체의 공간 구조 효율성을 제고하고, 환승역이 단순한 이동 공간을 넘어 지역의 핵심 앵커시설로 기능하는 데 기여할 수 있을 것이다.
이와 같이, 본 연구의 환승역 유형 분류 결과는 시설 관리 및 운영, 정책 설계, 도시공간 전략 등 다양한 측면에서 실용적 분석에 활용 가능한 기초자료로서의 역할을 수행할 수 있을 것으로 기대된다.
결론
본 연구는 서울특별시 도시철도 환승역을 대상으로 통행행태와 다차원 지역 특성을 종합적으로 고려하여 환승역의 유형을 분류하고, 그 유형에 따른 정책적 활용 가능성을 제시하였다. 교통카드 데이터를 활용하여 시간대별 승·하차 비율, 환승량, 광역통행 비율 등의 이용자 통행특성을 도출하였으며, 여기에 인구·종사자 밀도, 상업시설 연면적, 토지이용 혼합도 등 지역 특성을 통합하여 분석변수를 구축하였다. 이후 주성분 분석(PCA)을 통해 주요 요인을 추출하고, 계층적 군집분석과 K-means 군집화를 결합한 혼합 클러스터링 기법을 적용하여 총 5개의 환승역 유형을 도출하였다. 먼저, 혼합형은 출근 시간대 하차와 퇴근 시간대 승차가 균형을 이루며, 인구, 종사자, 상업시설 등 도시기능이 복합된 특성을 나타냈으며, 왕십리, 당산 등 14개 역이 포함되었다. 업무형은 출근 시 하차와 퇴근 시 승차가 뚜렷하게 집중되고 종사자 수 및 고용밀도가 높아 전형적인 업무지구의 통행 흐름을 보였으며, 가산디지털단지, 시청 등 14개 역이 포함됐다. 외곽 환승허브형은 중심지와의 접근성을 위한 중간 환승 기능이 강하고 승차 중심의 통행 흐름과 낮은 고용 밀도를 특징을 나타내며, 김포공항, 수서역 등 12개 역이 해당 유형으로 분류되었다. 주거형은 출근 시간대 승차가 집중되고 상업 및 업무 지표는 낮으나 인구밀도는 높은 주거지 기반의 특성이 뚜렷하여 주거지구에 위치한 석촌, 천호 등 20개 역이 분류됐다. 마지막으로 중심지 허브형은 시간대 전반에 걸쳐 승하차량과 환승량이 모두 높으며, 서울역, 잠실, 강남과 같은 광역교통 접근성과 다중 환승 노선이 결집된 고밀도 중심지로 확인되었으며 총 7개 역이 해당 유형에 포함됐다.
유형 군집의 타당성을 평가하기 위해 군집 간 차이, 해석력 측면에서 평가를 진행하였다. 분산분석을 통해 검토한 결과 대부분의 변수에서 군집 간 통계적 유의미한 차이가 확인되었으며, 주성분 기반 해석을 통해 각 군집의 구조적 특성과 변수 간 관계를 명확히 해석할 수 있었다. 또한 각 유형 군집에 포함된 역사 간의 통행행태와 지역 특성을 검토하고 실제 환승역의 역할을 비교 검토한 결과 같은 유형에 포함된 역사와 특성이 유사했고 정의된 것과 같은 형태와 성격을 나타내고 있음을 파악하였다. 이를 통해 본 연구의 유형 분류 결과는 군집 간의 실질적인 차별성과 해석력을 확보하고 있음을 입증하였다.
도출된 유형은 환승역의 운영 전략, 혼잡 대응 방안, 시설 정비계획, TOD 연계 개발 방향 등 다양한 분야에 적용될 수 있다. 예를 들어, 주거형 환승역은 출근 시간대 혼잡 대응 설계가 요구되며, 업무형은 이중 피크 대응 체계가 필요하다. 중심지 허브형은 실시간 환승정보 제공, 대규모 대합실 확보 등 다중 환승 흐름을 반영한 정비가 필요하며, 외곽 환승허브형은 도심 접근성과 환승 편의 강화를 위한 광역 환승 거점으로의 기능이 강조된다. 또한, 유형별 특성을 기반으로 한 환승거점 개발은 도시 전체의 공간구조 재편 및 대중교통 중심의 개발 전략 수립에 실효성 있는 기반이 될 수 있을 것으로 예상된다.
따라서 본 연구에서 제시한 환승역 유형 분류는 실질적인 정책 설계와 운영계획 수립, 공간 개발 전략 도출에 있어 기반으로 기능할 수 있으며, 향후 도시철도 환승체계의 통합적 운영관리 및 계획 수립을 위한 기초자료로 활용될 수 있을 것으로 기대된다.
