

서론
선행연구 조사
1. 강화학습 기반 배치 지역 연구
2. 공간정보시스템(Geographic Information System) 활용 연구
3. 선행연구 조사 결과 및 본 연구의 차별점
4. 문제상황 정의 및 해결방안
분석 방법론
1. 수집 데이터
2. 강화학습 환경 정의
분석 결과
결론
서론
도시는 거주민에게 모빌리티를 제공하여, 주거지역에 거주하고 업무 목적의 이동을 돕는다. 거주민은 대중교통을 이용하여 목적지까지 이동이 가능하며, 도시는 이용 요금, 세금, 교통혼잡 절감 편익 등을 통해 지속가능한 운영이 가능하다(Miller et al., 2016). 따라서 거주민의 모빌리티 제공은 도시의 지속성에 있어 중요한 역할을 하고 있다. 대중교통 접근성 및 배차간격 등 거주민의 mobility가 충분히 제공되어 있음에도 불구하고, 일부 지역은 목적지까지 접근하기 어려운 경우가 존재한다. 카카오 모빌리티에서 출간한 리포트에 따르면, 출퇴근 및 등교와 같은 특정시간대에 단거리 택시이용이 급증함을 확인하였다. 이는 대중교통 하차 후, 목적지까지 이동이 어렵기 때문이다(Kakao Mobility, 2017). 단거리 이동의 편의성을 제공하기 위한 대안으로, Personal moblilty(개인형 이동장치, PM)을 제안할 수 있다. PM은 개인이 운용할 수 있는 이동 장비로, 전기 자전거, 킥보드, 세그웨이 등이 포함된다. 공유 PM서비스는 빔모빌리티, 카카오 모빌리티, 지쿠터 등 여러 회사에서 운영되고 있으며, 따릉이와 같이 각 지자체에서도 공공자전거를 운영하고 있다. 공유 PM은 어디서든 승·하차가 가능한 스테이션리스 방식으로 운영되고 있다. 현재 공유 PM의 배치지역은 서비스 업체의 경험에 의존하고 있다. 공유 PM의 운영은 모빌리티 제공, 화석연료 감축 등 긍정적인 영향도 있으나, 공유공간 차지, 도로 안전 위험 등 부정적인 영향 또한 존재한다(Zagorskas and Burinskienė, 2019; Aziz et al., 2018). PM의 적절한 배치는 서비스의 운영효율성을 증대시킬 수 있으며, PM 이용객의 이동성을 향상할 수 있다(Radzimski and Dzięcielski, 2021). PM의 이용이 많을 것으로 예상되는 지역을 미리 확보 및 관리하여 PM이용 시 불편함 및 위험성을 감소시킬 수 있다(Oh and Kim, 2021). 본 연구는 공유 PM의 최적 배치지역을 찾을 수 있는 방법론을 개발하였다. 최적 배치지역의 시각화 결과를 통해, 서비스 업체의 운영효율성 및 서비스 이용자의 이동성을 향상 시킬 수 있으며, 정책개발자의 법적 근거 마련에 도움을 줄 수 있다.
선행연구 조사
PM의 최적배치 위치를 찾을 때 발생할 수 있는 문제상황을 고려하여, 선행연구를 조사하여 연구방법론 및 개선안을 참고하였다. 선행연구 중에서, 강화학습을 활용한 시뮬레이션 구축 및 활용방법, 그리고 공간분석을 활용한 연구를 조사하였다. 선행 연구 조사결과를 정리하고, 본 연구의 특장점을 정리한 내용은 “선행연구 조사결과 및 본 연구의 차별점”에 작성하였으며, 발생 가능한 문제상황 및 해결방안은 “문제상황 정의 및 해결방안” 에 정리하였다.
1. 강화학습 기반 배치 지역 연구
Wang et al.(2020)은 워게임에서 승리할 수 있는 인공지능 모형을 강화학습 환경에서 개발하였다. 워게임은 전장의 상황에 따라 결정이 달라질 수 있는 Multi-agent 실시간 전략게임을 의미한다. 해당 연구에서는 육각형의 격자 구조(헥사곤 그리드) 내 점령 가능, 통과 가능, 도로 여부, 은폐 여부, 진창 지대 여부와 같은 지리정보를 부울벡터 형태로 입력하였다. 헥사곤 그리드 내 지리정보 입력에 따라 인접한 지역에서 의사결정을 전략적으로 선택할 수 있다. Tong et al.(2021)은 호출에 응답할 수 있는 적절한 택시 배치를 위해, 강화학습 환경에서 최적 배치 알고리즘을 개발하였다. 해당 연구에서는 수요 및 공급의 복잡한 변동성, 이전 배치결정 위치로 인해 이후 배치 효율성에 영향을 미칠 수 있는 시간적 의존성으로 인해 강화학습 환경에서 분석을 수행하였다. 해당 연구에서 개발한 Learning to dispatch 알고리즘은 다른 강화학습 알고리즘에 비해 운영성 및 효율성을 3-40% 이상 증가시켰다. Luo et al.(2021)의 연구에서는 공유 Electric vehicle(EV)의 이용 후 재배치를 통한 수요 충족을 강화학습을 통해 수행하였다. 해당 연구에서는 EV의 충전시간 및 용량으로 인한 운영범위 제한, 공유 EV 충전 정류소 확장, EV 재배치 시 불균형을 막기 위한 재배치 인센티브 정책 등 복잡한 제한 조건 상황의 최적화를 위해 강화학습을 연구에 활용하였다. 또한 헥사곤 그리드 내에서 이동하는 강화학습 환경을 구축하여 무작위 배치 및 정류장 운영을 설정하였다. 선행연구를 참고하여, 강화학습 환경을 통해 현실적인 문제상황의 구현과 제약조건을 설정할 수 있음을 알 수 있었다. 그리고 분석 대상 지역을 격자구조로 세분화 하여 강화학습 환경 구축 및 부하 최소화가 가능함을 알 수 있었다. 본 연구에서는 기존 연구와 다른, 공유방식으로 운영되는 PM을 강화학습 환경 내에서 구축하였으며, 최적화 결과 선정된 지역 중 배치 대 수가 가장 많은 지역을 최적 배치지역으로 설정하였다. Kim et al.(2023)은 수요응답형교통(Demand Responsive Transit; DRT) 버스의 최적 경로 알고리즘을 Deep Q Network(DQN)를 활용하여 시뮬레이션 및 검증분석하였다. 해당 연구에서는 공유 PM의 출발, 도착지점 데이터를 활용하여, 운영되지 않는 DRT 버스의 이용이 많을 것으로 예상되는 지역으로 미리 대기할 수 있는 DQN 모델을 학습하였다.
2. 공간정보시스템(Geographic Information System) 활용 연구
공간분석을 활용한 연구 방법론으로, Son and Park(2022)는 지리정보시스템(Geographic Information System; GIS)를 활용하여 도시부 인프라의 세부 위험구역을 식별하였다. 해당 연구에서는 사고 심각도를 기준으로 사고유형을 분류하였으며, 추정된 결과를 GIS 환경으로 맵핑하여 세부 위험구역의 시각화 분석을 수행하였다. Kim and Lim(2024)은 교통소외지역의 공공형 택시 운행현황 및 특성을 분석하여 지속가능한 모빌리티 서비스 운영전략을 수립하였다. 수집된 공공형 택시 데이터를 ArcGIS를 통해 승하차지점, 수요 밀집 지역, 서비스 영역 분석을 수행하였다. 수요밀집지역 별 특성을 기준으로 클러스터 분석을 수행하여 개별 다른 운영방법을 제시하였다. Desai and Patel(2023)은 전기차량(electric vehicle; EV)의 충전소 배치를 GIS를 활용하여 도출하였다. 분석대상지역을 헥사곤 그리드로 세분화 하여, 입력된 인구밀도, 주유소, 공유공간여부 등과 같은 지리정보를 활용하여 공유 충전소의 수요를 계산하였다.
미국의 승차 공유 서비스회사인 Uber에서는 H3라 부르는 헥사곤 계층화 격자구조를 활용하여 지형공간을 분석하였다(Brodsky, 2018). 분석에 헥사곤 격자구조를 활용한 이유는 도시단위로 분석시 크기가 서로달라 동일한 기준으로 분석할 수 없으며, 도시의 경계 데이터에 대한 분석이 어렵기 때문이다. Zhang et al.(2023)은 GIS 기반 코로나 확산 효과 분석플랫폼을 개발하였다. 인당 통행 수, 자택 대기 비율, 장거리 통행 비율, 출근통행, 교통수단 등 여러 데이터를 수집하여 사회적 거리두기 지표(Social distancing index; SDI)를 개발하였으며, 그 결과를 지도상에 시각화 하였다. Koorey(2009) 또한 도로 경로를 제공할 수 있는 interactive display board를 헥사곤 격자구조를 통해 개발하였다. 헥사곤 격자구조 내에는 강, 언덕, 거주지 등이 공사비용으로 환산되어 입력되었다. Interactive display board를 통해 도로 건설시 소요되는 비용을 직관적으로 이해하여 새로운 최적 경로 생성을 판단하는데 도움을 줄 수 있다.
3. 선행연구 조사 결과 및 본 연구의 차별점
강화학습과 공간정보를 활용한 최적 배치지역 연구 사례를 조사한 결과, 대부분의 연구에서 격자구조 내 고정된 정보를 기준으로 강화학습 모형을 개발하였다. 본 연구에서 개발한 강화학습 모형은 지리정보, 대중교통, 토지용도와 같은 위치 및 시간이 고정된 정보 뿐 만 아니라, 생활인구 데이터를 활용하여 시간대 별 수요 발생 위치가 유동인구를 기준으로 변화할 수 있도록 격자구조 내 데이터를 입력하였다. 이를 통해 출퇴근 시간대와 같이, 시간대 별 변화하는 지점 별 수요를 강화학습 모형을 활용한 시뮬레이션 상에 반영할 수 있어 더 현실적인 시뮬레이션이 가능하다. 또한 강화학습 모형의 일관적인 예측이 가능하여 최적 배치지역의 예측 신뢰도를 높일 수 있다. 무작위 배치와 본 연구에서 개발한 시간대 별 수요변동이 적용된 강화학습 모형의 분석결과 차이를 비교하여 이를 증명하였으며, 본문의 “분석결과”에 해당 내용을 정리하였다.
4. 문제상황 정의 및 해결방안
선행연구를 참고하여, 본 장에서는 본 연구에서 예상할 수 있는 문제상황에 대해 정의하였으며, 이에 대한 해결방안을 제시하였다. PM의 배치 위치를 찾는 과정은 수많은 결정 상황을 요구하게 된다. 수집된 출발 및 도착지점(O/D) 데이터를 기준으로, PM의 이동은 1시간에 최대 4만 여대가 발생한다. 따라서 본 연구는 각 수요에 대응하는 PM의 배치를 위한 이동이나 주차 등, 수많은 의사결정 상황을 강화학습 환경으로 구현하였다. 선행 연구를 참고하여, PM은 헥사곤 그리드 환경에서 이동하도록 설정하였다. 헥사곤 그리드 환경으로 이동거리 계산 및 의사결정 상황을 단순화 할 수 있다. “분석방법론” 챕터에서 헥사곤 그리드 강화학습 환경 및 연구 진행과정에 대해 설명하였다. 다음으로 예상 가능한 문제점으로, 공유 PM을 이용하고자 하는 탑승객의 위치는 고정적이지 않으며, 시간에 따라 변화하게 된다. 따라서 본 연구는 시간단위로 생활인구 및 PM 탑승객의 위치 및 목적지를 수집 후 입력하였다. 분석방법론의 하위 챕터 “1. 수집데이터”에서 수집된 데이터의 출처, 구성, 세부 설명을 추가하였다. 마지막으로, PM의 잘못된 배치로 인해 운영 효율성이 저하될 수 있다. 만약 목적지로 이동한 PM이 다음 Time step에서 재배치를 위해 이동하는 거리가 증가한다면 과도한 노동력이 발생하게 된다. 따라서 본 연구에서는 강화학습 방법론을 적용하여, 재배치를 위해 이동하는 거리를 줄일 수 있도록 PM 배치위치를 학습하였다. 이는 “강화학습 환경 정의”에서 Reward function을 조정하여 학습할 수 있다. 본 연구에서 Reward function은 목적지까지 이동한 거리를 재배치 시 이동한 거리로 나눈 값으로 정의하였다.
분석 방법론
강화학습은 설정된 환경을 기준으로 상호작용하여 학습하며, 대부분의 문제에 적용할 수 있다. 또한 강화학습은 Reward Function을 기준으로 목표를 설정하며, 세부 정보 없이 문제를 해결할 수 있다(Silver et al., 2016). 강화학습 결과 도출된 최적배치지역은 GIS를 통해 서비스 지역에 시각화하였다. 수집된 데이터의 위치정보를 기준으로, 지리정보 데이터를 수정 및 편집할 수 있는 QGIS를 활용하여 지도상에 입력하였다. 분석대상지역을 헥사곤 그리드로 세분화 하였으며, 해당 셀에 ID를 배정하였다. 또한 헥사곤 그리드 별 위치에 해당되는 데이터를 모두 입력하였다. 시군구, 읍면동 지역 단위별 서로 다른 크기로 인해 GIS 분석이 어려우나, 헥사곤 그리드 세분화를 통해 같은 크기의 셀을 기준으로 분석할 수 있는 장점이 있다(Brodsky, 2018). 1km 이내의 단거리 이동을 주로 수행하는 PM이용객의 특성 상, 헥사곤 셀 하나의 크기를 보행자 이동거리 및 대중교통 접근성을 고려한 반경 100m로 설정하였다(Currie, 2010). 서울시 헥사곤 그리드는 전체 18045개의 헥사곤 셀로 구성되어 있으며, 2개의 좌표변수로 설정가능한 Offset coordinates 방식으로 좌표를 입력하였다. 이를 통해 좌표 내 데이터 배정 및 강화학습 분석 결과 도출되는 예상 배치지역의 좌표를 시각화할 수 있다(Luo et al., 2019).
강화학습 환경은 헥사곤 그리드 내에 배치된 PM이 인접한 셀로 움직이는 상황을 구현하였다. 헥사곤 그리드 환경은 간단한 강화학습 환경을 구현가능한 OpenAI GYM으로 구현하였다. PM 이용객 위치는 유동 인구수 및 집계된 O/D에 따라 무작위로 생성된다. 생성된 PM 이용객의 위치에 따라, PM 배치 및 이동 완료 후 Reward가 정의된다. 배치 지점의 가치에 따른 최적 배치 지점은 단순한 강화학습 알고리즘인 Q-learning 을 통해 예측된다. 강화학습을 통해 도출한 시·종점별 최적 배치 지점을 오픈소스 GIS 프로그램인 QGIS를 활용해 시각화 하였다. 본 연구의 전체 진행과정은 Figure 1에 제시하였다.
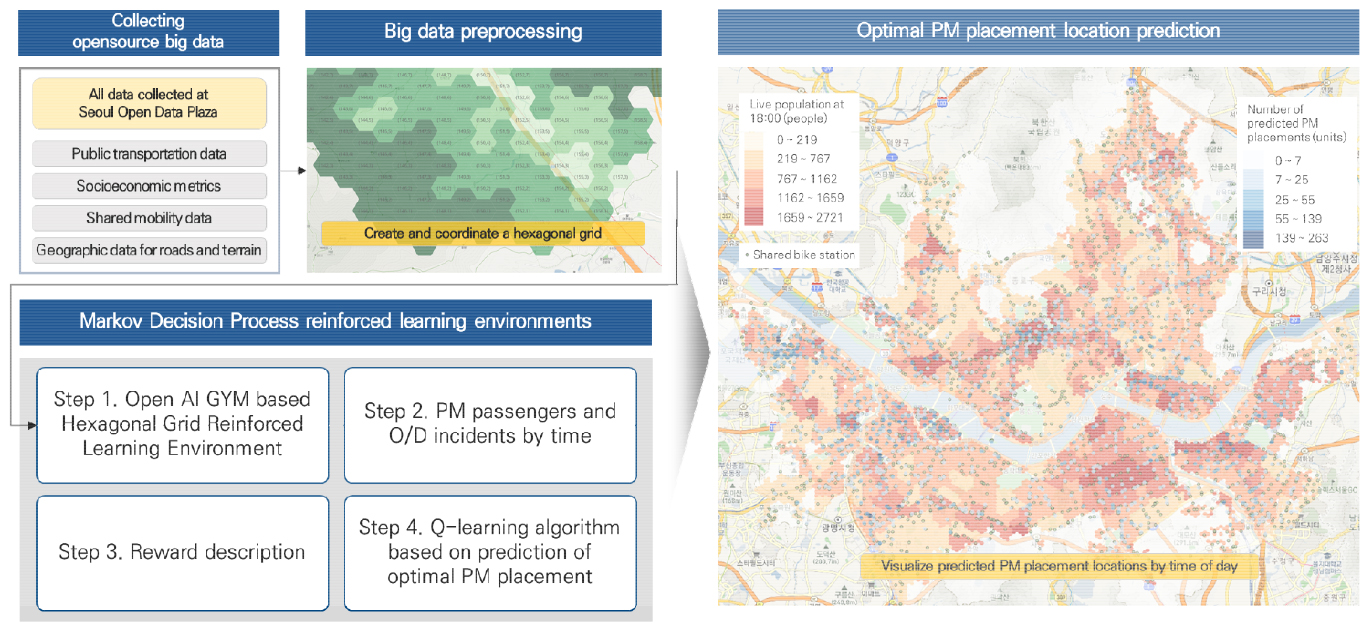
1. 수집 데이터
분석에 활용한 데이터는 2023년 10월 6일, 2023년 중 공유자전거 이용객수가 가장 많았던 일을 기준으로 수집하였다. 본 연구는 오픈 데이터 셋이 구축되어있으며, 타 지역에 비해 유동인구 및 PM 이용객 수가 많아 본 연구의 분석방법론을 적용하기 적합하다고 판단한 서울시를 기준으로 분석하였다. 연구를 위해 수집한 데이터는 버스 및 지하철과 같은 대중교통 수단과 관련된 데이터, 해당지역의 유동인구수, 거주인구수, 소득분위 등과 같은 사회경제지표, 차로 수와 도로폭, 경사도와 같은 도로 및 지형 관련 데이터와 공공자전거 따릉이의 스테이션 위치 및 시·종점이 포함된 공유모빌리티 관련 데이터를 수집하였다. 모든 데이터는 서울시에서 운영중인 “서울열린데이터 광장”에서 제공하는 오픈 소스 데이터를 수집하였다. 수집된 데이터에 대한 간략한 설명 및 구성은 Table 1에 제시하였다.
Table 1.
Discription of collected data
2. 강화학습 환경 정의
본 연구의 강화학습 구조는 주로 활용되는 Markov decision process(마르코프 결정 과정, MDP)로 구성하였다. MDP의 구성 요소 중, 상태(State), 행동(Action), 보상함수(Reward function), 전이확률(Transition Probability)을 정의 할 수 있다. MDP는 현재 State가 이전 State 및 Action에 독립적인 마르코프 특성(Markov property)를 충족한다. 즉, 현재 State와 Action만이 다음 State와 Reward에 영향을 미치며, 과거의 모든 State와 Action은 영향을 끼치지 않음을 의미한다(Sutton and Barto, 2018). Action을 선택할 확률을 결정하는 정책(Policy)는 현재 State와 Action에 따라 달라지며, Equation 1에 제시하였다.
여기서, Policy 는 시간단위 일 때 State 와 Action 를 선택할 확률을 의미한다. Policy 를 바탕으로 추정된 기댓값을 계산하는 가치함수 (value function)은 Equation 2로 정리할 수 있다.
여기서, 할인율(Discount rate)는 0에서 1사이의 값을 가지며, 모형의 과적합을 조정하기 위해 설정하는 변수이다. Reward function 은 환경에 따라 달라지며, 가치함수는 모든 반복횟수에서 얻어지는 R의 총합의 기댓값을 의미한다.
MDP의 구성 요소 중, 상태(State), 행동(Action), 보상함수(Reward function), 전이확률(Transition Probability)을 정의 할 수 있다. MDP는 임의로 설정된 초기 State에서 시작하며, 이를 기준으로 Action를 선택할 수 있다. Action을 선택하는 기준은 전이확률에 따라 달라지며, 동시에 Reward function에 따라 보상을 받게된다. MDP는 해당 과정을 반복하며 환경을 탐색하고, 전체 보상을 최대화 할 수 있도록 모델링된다(Howard, 1960; Garcia and Rachelson, 2013). 본 연구에서 State는 PM의 배치상태에 따라 점유, 배치, 주차(Occupy, Place, Parking)로 설정하였다. Action은 인접할 셀로 6개 중 하나로 이동할 수 있으며, 승객 주행, 배치 이동, 대기(Driving, Moving, Stand-by)로 정의한다. State가 Place, Parking일 경우 Action은 3개의 Action 모두 선택 가능하다. Moving을 선택할 경우 인접한 셀 중 하나로 이동하며, Stand-by를 선택할 경우 이동하지 않고 해당 셀에서 멈춘다. Driving을 선택할 경우, 따릉이 시·종점 데이터를 기준으로 설정된 목적지로 이동한다. Driving 경로는 최단거리로 이동하며, State는 Occupy로 설정된다. Occupy state는 목적지에 도착하기 전까지 다음 Policy를 정할 수 없다. Figure 2에 State에 따른 Action을 간략하게 묘사하였다.
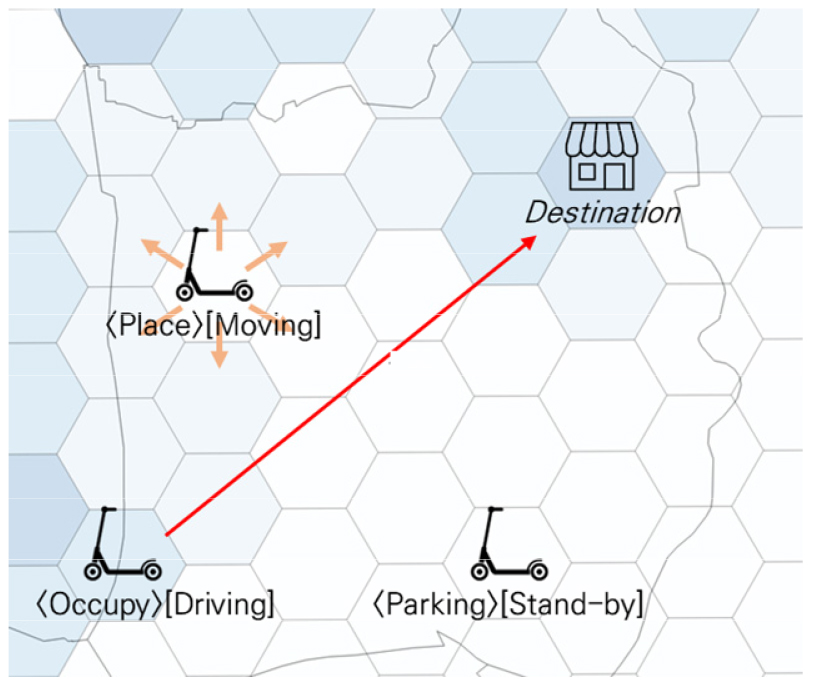
Reward function은 승·하차 지점을 기준으로, 승객이 탑승해서 목적지에 도착할 때 Reward를 부여한다. Reward는 승객이 주행한 거리가 길수록, 배치이동한 거리가 짧을수록 더 큰 Reward를 제공한다. 즉, Driving action에서 이동한 거리 를 Moving action에서 이동한 거리 으로 나누어 Reward function 을 설정하였다(Gao et al., 2018). 목적지 이동과 같이, 배치이동을 위해 이동하는 거리 또한 최단거리로 이동하도록 선정하였다. Equation 3에 Reward function에 대한 수식을 나타내었다.
본 연구에서는 Value function 의 최적화를 Q-learning algorithm을 통해 수행하였다. Q-learning algorithm은 간단하며 다양한 환경에 적용할 수 있고, Bellman optimality equation을 따르는 기초적인 강화학습 알고리즘 형태이다(Watkins and Dayan, 1992). Q-learning algorithm은 학습률 , 할인율 에 따라 반복적으로 Value function 를 업데이트 하며, Equation 4에 알고리즘을 제시하였다.
본 연구에서는 시간대 별 변화하는 수요를 MDP 내에서 구현하였다. PM 이용객은 시간대 별 집계된 O/D 및 생활인구 데이터를 통해 생성하였다. 시간대 별, 동별 PM 이용객 발생을 통해 실시간으로 변화하는 수요를 대응하여 PM을 배치할 수 있도록 설정하였다. PM 이용객은 동 별 생활인구수가 다른 동에 비해 많을수록 더 많이 생성되도록 유도하였다. 각 행정동에서 시간대 별, 구 별 집계된 총 수요 대 수를 동별 생활인구수 비율(동 별 생활인구수/ 구 별 생활인구수)로 곱한 값 만큼 PM 이용객이 무작위 위치에서 발생한다. 발생하는 PM 이용객 수는 Equation 5에 정의하였다.
여기서, : n 시간대일 때, i 구의 j 행정동에서 발생한 PM 이용객 수
: i 구에서 집계된 총 수요 대 수
: i 구의 j 행정동에서 집계된 생활인구수
: i 구의 총 생활인구수
수집된 데이터를 기준으로, 동에서 가장 많은 점수가 계산된 헥사곤 셀에서 PM이용객이 더 많이 발생하도록 설정하였다. 수집된 데이터인 경사도, 도로폭, 버스 노선 수, 용도지역, 지하철 영향권 내 이용객 수 데이터를 0-1사이 값으로 단위를 변환 한 후, 해당 값의 총합을 점수로 환산하였다. 이를 통해 강 한 가운데와 같은 PM이용객이 절대 발생하지 않는 지역으로 인한 오류를 제거할 수 있으며, 지역별 특성에 따른 수요 발생을 강화학습 시뮬레이션 상에 반영할 수 있다. 경사도는 0-2%, 2-7%, 7-15%, 15-30%, 30-60%, 60-100%, 기타로 구분되어 있으며, 각각 1, 0.83, 0.67, 0.5, 0.33, 0.17, 0으로 변환하였다. 도로폭, 버스 노선 수, 지하철 영향권 내 이용객 수는 min-max normalization을 통해 정규화하였다. 헥사곤 셀 내 데이터가 없어 0인 셀이 많아, 표준화 시 평균값이 0에 가까워 편향된 값으로 도출될 수 있기 때문이다(Singh and Singh, 2020). 용도지역은 녹지는 0으로, 나머지는 1로 값을 변환하였다. 변환된 데이터 중, 경사도 변환 값 및 비율은 Table 2에 제시하였다.
분석 결과
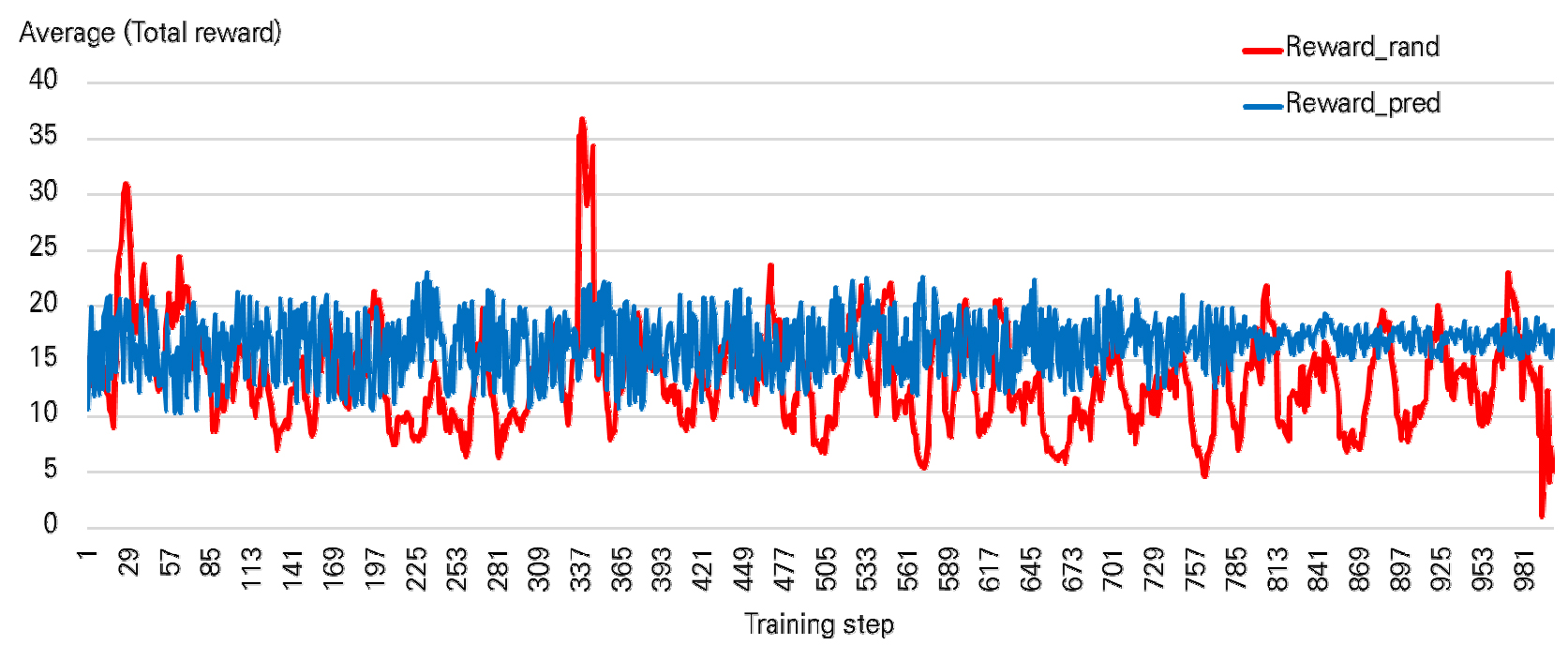
Q-learning algorithm에서, 학습률 는 0.1, 할인율은 0.99로 설정하였으며, 1000번의 학습을 수행하였다. PM의 시간대별 배치지역은 Reward가 가장 클수록, Moving 거리가 짧고 Driving 거리가 긴 지역으로 이동할 수 있도록 예측되었다. PM 배치가 많을 것으로 예상되는 지역에 PM을 배치한다면, 이용객의 이동성 향상 뿐 만 아니라 공유 PM 운영자의 운영 효율성 또한 증가시킬 수 있다. 본 연구에서 고려한 PM 수요 발생 방법론이 적절한지 확인하고자, 10명의 PM 이용객이 발생하였다고 가정하였을 때, 무작위로 발생한 PM 수요와 시간대 별 생활인구 비율 기준 PM 수요 생성 결과를 비교하였다. 수요 생성 결과는 10명의 Reward의 총합을 기준으로 비교하였다. Reward 총합이 클수록, 예측된 PM 수요에 더 가깝게 배치되었음을 나타낸다. 매 시간마다 변화하는 이용객의 O/D를 적용하여, 시간대별 학습결과 도출된 무작위 발생 및 시간대 별 생활인구 비율 기반 Reward 총합 평균을 그래프 형태로 Figure 3에 제시하였다. Figure 3에서 무작위 발생 Reward 총합은 적색으로, 시간대 별 생활인구 비율 기반 Reward 총합은 청색으로 나타내었다. 분석결과, 무작위 발생 Reward 총합의 평균은 13.36, 시간대 별 생활인구 비율 기반 Reward 총합의 평균은 16.52로 나타났다. Figure 3에서 제시한 Reward 총합의 시간대별 평균은 10개의 수요가 발생한 것으로 고정하였으나, 매 시간마다 O/D는 달라지도록 설정하였다. 즉, 시간마다 변화하는 통행이 반영되었으며, Reward의 총합이 클수록 주민의 이동성이 향상될 수 있는 방향으로 PM이 배치됨을 의미한다. 따라서, 본 연구에서 적용한 시간대 별 생활인구 비율 기반 PM 수요 생성이 더 효과적임을 알 수 있다. 그리고, Training step의 증가함에 따라, 무작위 발생 Reward 총합에 비해 헥사곤 셀 점수 기반 Reward 총합의 변동이 작아지는 것으로 나타났다. Training step의 증가할 때, Reward 총합이 달라짐은 최종적으로 예측된 지점 또한 달라짐을 의미한다. PM 예측지역은 Reward가 큰 지점으로 예측되기 때문이다. 따라서, 본 연구에서 적용된 방법론이 무작위 생성에 비해 예측 결과의 정확도 및 신뢰도가 더 높음을 의미한다.
전체 시간대 중, PM 배치 및 이용이 가장 많이 발생하였던 출근시간(8시) 및 퇴근시간(18시)을 검토하였다. 배치지역 결과는 생활인구수, 예측 PM 배치 대 수를 기준으로 시각화 하였다. 시각화 결과는 색의 채도가 진해질수록 더 큰 값으로 강조하였다. 시각화 구분 단계는 5개의 급간으로 구분하였으며, 그룹간 분산을 최대화 할 수 있고, 그룹 내 분산을 최소화할 수 있는 Natural break 방법으로 구분하였다. Natural break 방법을 통해 시각화 시, 다른 단계 구분 방법보다 더 직관적이고 명확한 시각화가 가능하다(Chen et al., 2013; Hadimlioglu and King, 2019). 강화학습을 통한 배치지역 예측 결과, 마곡나루역, 신도림, 구로·가산 디지털단지역 인근에 최소 139대 이상 배치가 필요할 것으로 예측되었다. 출근 및 퇴근시간 대 예측결과는 Figure 4에 제시하였다.
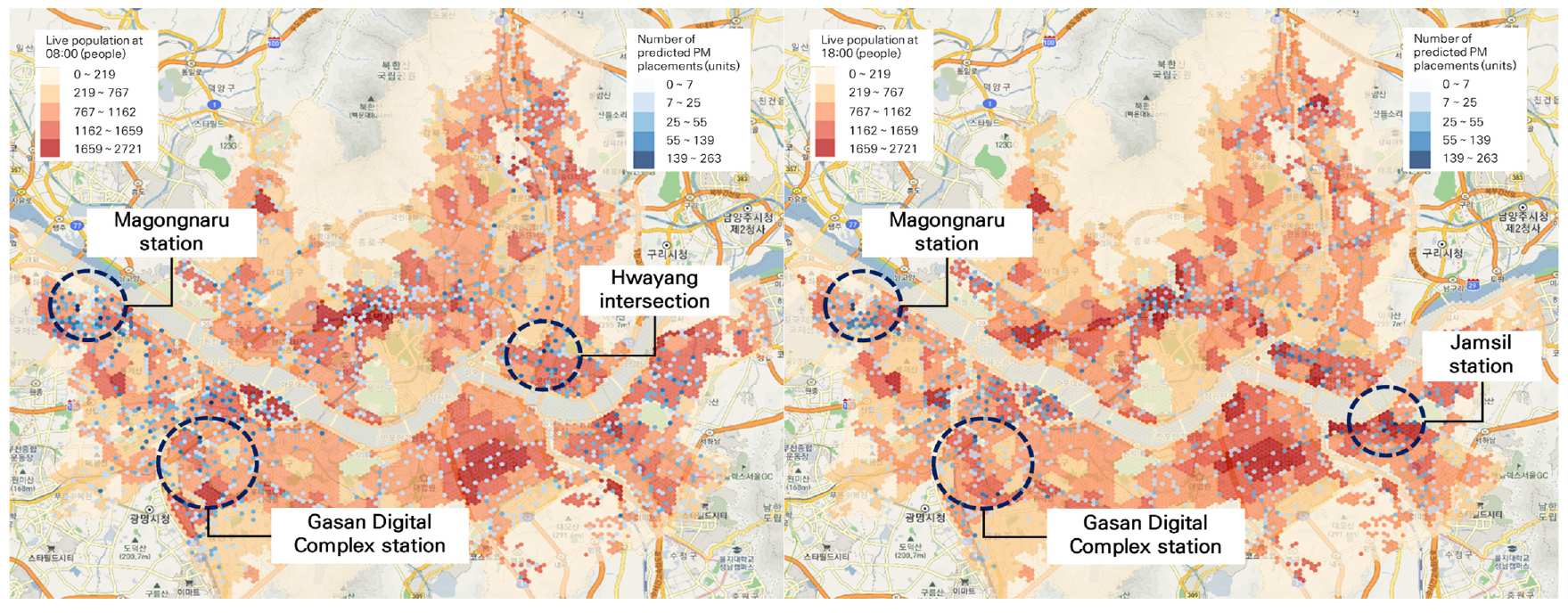
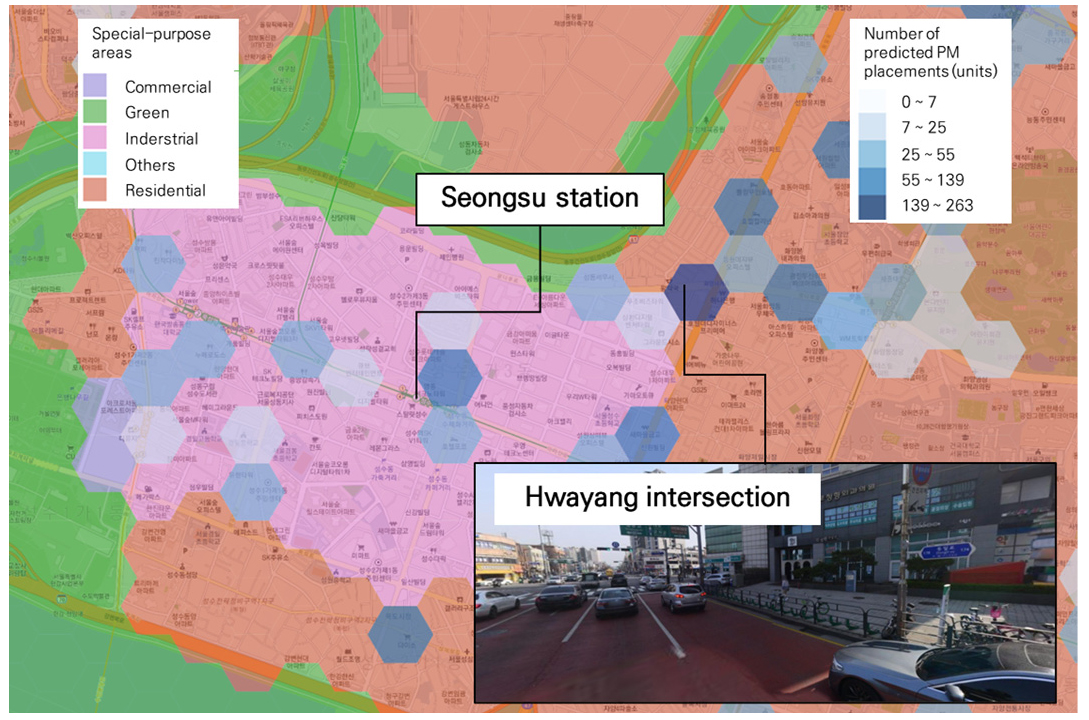
시간대 별 출근 및 퇴근 시간대 예측된 배치지역이 서로 다른 지역으로, 출근 시간대는 화양사거리에서, 퇴근 시간대는 잠실역에서 많이 배치될 것으로 예측되었다. 화양사거리는 인근에 성수 공업지역이 배치되어 있으며, 해당 지역으로 출근하기 위해 PM 이용이 많을 것으로 예상된다. 성수 공업지역은 영세기업이 주로 위치하고 있으며, 총 500여 업체가 밀집되어 있다. 공업지역 골목의 평균 도로폭은 9.45m로, 시내버스와 같은 대중교통의 통과가 어려워 공유 PM 운영 시 출퇴근 인구의 접근성이 향상될 것이다. 화양사거리 외, 공업지역 중앙에 배치 되어있는 성수역에도 PM이용이 많을 것으로 예측되었다. 성수역에 PM을 배치한다면 지하철 이용객과 연계되어 PM을 활용할 수 있다. 화양사거리 PM 배치지역 예측결과는 Figure 5에 제시하였다.
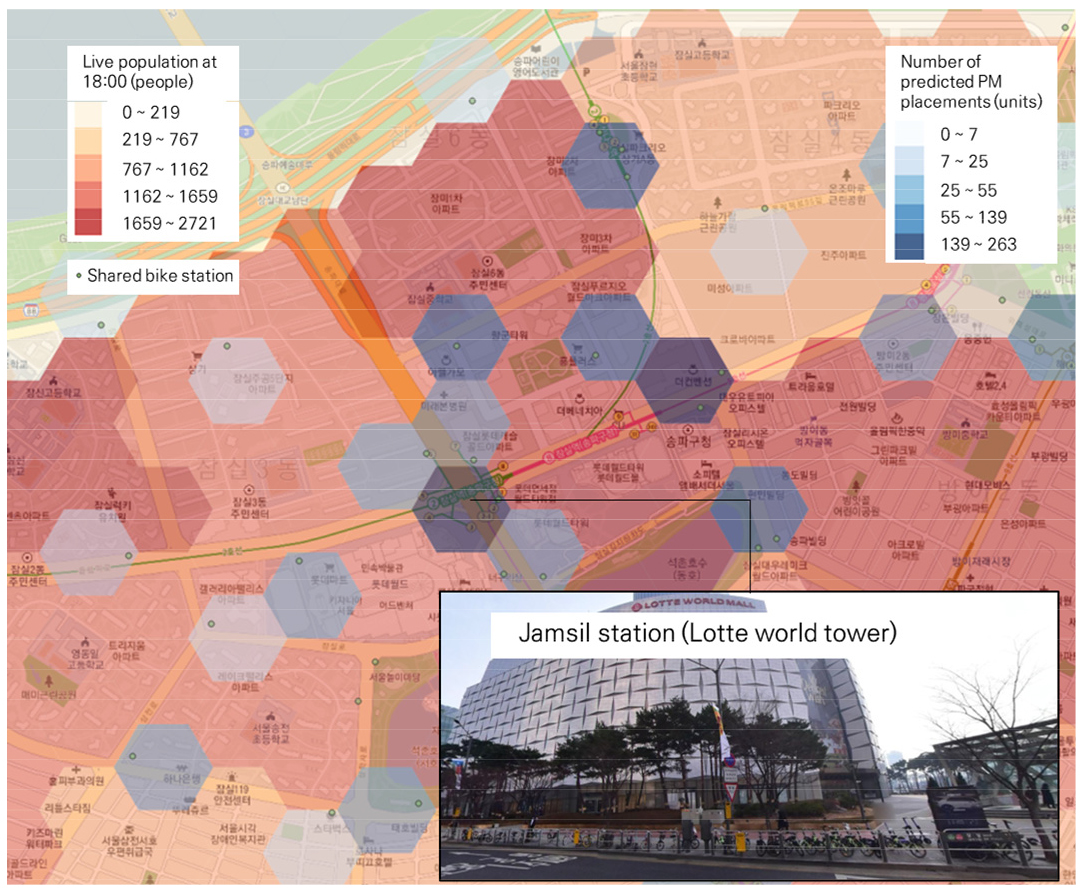
퇴근시간대 많이 배치될 것으로 예측되는 지역은 잠실역으로 나타났다. 잠실역 인근은 생활인구가 가장 높은지역으로, 인근 주거지역 거주민의 PM 활용이 가능할 것으로 예측된다. 그리고 롯데월드 및 석촌호수와 같은 유동인구가 많은 흡인요인이 다수 배치되어 있어, 여가목적의 PM 이용 또한 많을 것으로 예상된다. 잠실역 PM 예측결과는 Figure 6에 제시하였다.
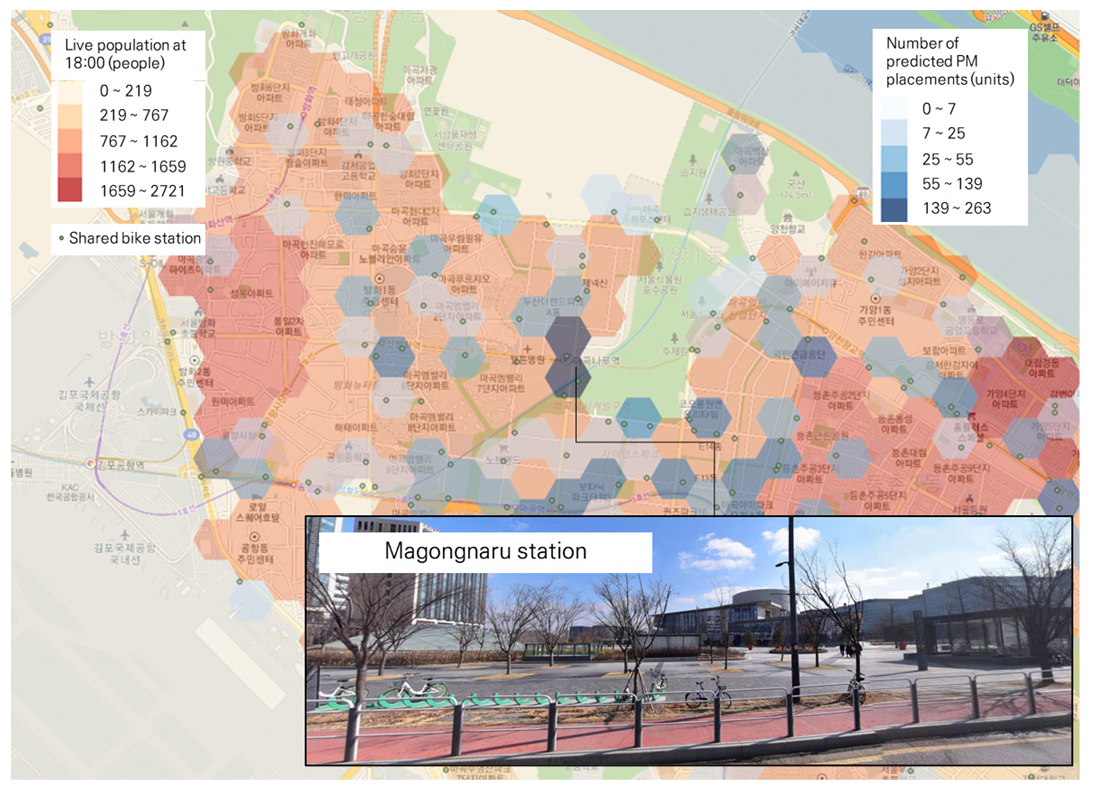
출·퇴근 시간대 공통적으로 많이 이용할 것으로 예측되는 마곡나루역의 PM 배치지역 예측 결과는 Figure 7에 정리하였다. 마곡나루역 3번출구 앞에는 서울식물원 공원 입구가 있어 여가목적의 PM이용이 가능할 것으로 예측되었다. 그리고 마곡나루역은 인근지역 대부분 인도에 자전거 도로가 설치되어 있어 안전하고 편리하게 PM 이용이 가능하다. 마곡나루역 인근은 공유 자전거 정류장 또한 100m 간격으로 1-2개 이상 설치되어 공유 PM 운영 시, 이용객은 탑승 이후 편리하게 주차할 수 있다.
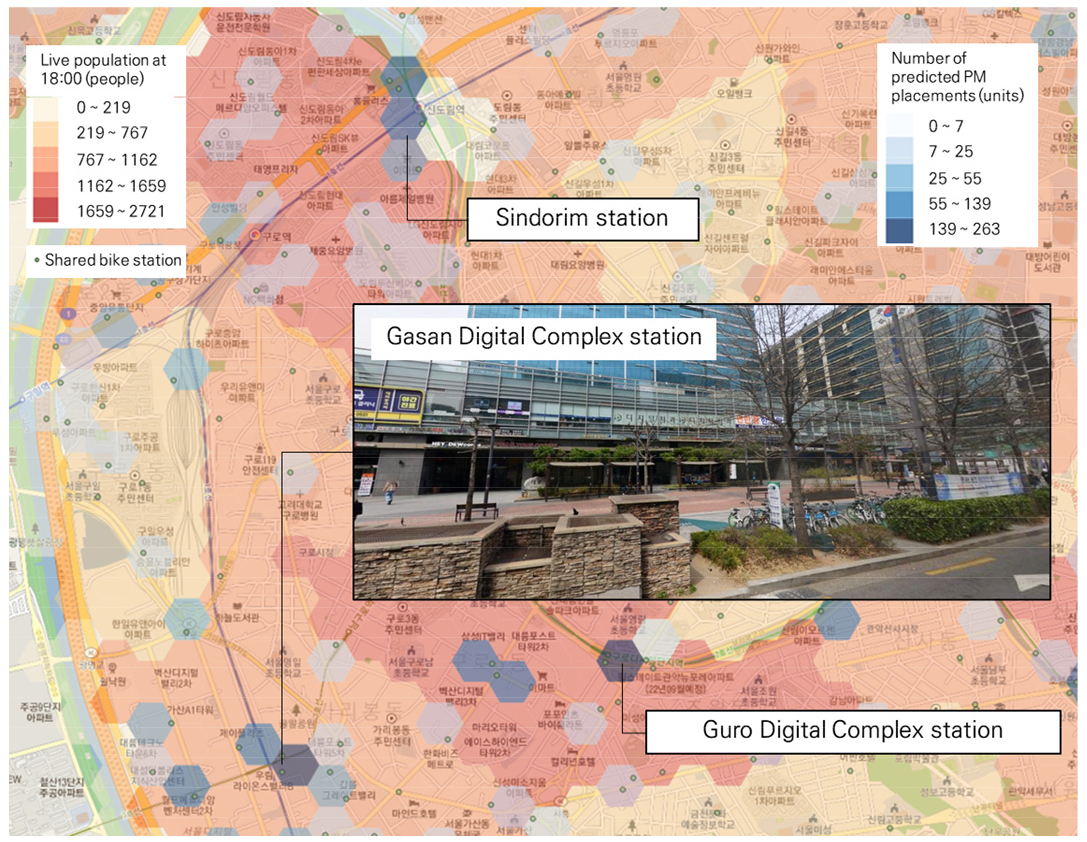
출·퇴근 시간대 공통적으로 PM 이용이 많을것으로 예측되는 지역은 신도림역과 구로·가산 디지털단지역 인근으로 나타났다. 3개 역 모두 공업지역과 가까운 곳에 위치하고 있으며, 역 인근에 PM 배치가 많을것으로 예측되었다. 역 인근에 PM 배치 시, 지하철과 연계하여 출·퇴근 인원의 PM 이용을 장려할 수 있다. 그리고 공통적으로 PM 정류장 및 자전거 정류장이 다수 배치되어 있어 스테이션 방식의 공유 PM 또한 운영이 가능하다. 스테이션 방식의 공유PM은 PM이용객의 승차 및 하차지점이 고정되어있어 이용가능지역이 한정되어 있으나, 공유 PM 운영자의 관리 편리성을 향상 시킬 수 있으며, PM을 이용하지 않는 보행자의 동선을 방해하지 않고 운영할 수 있다. 신도림역 및 구로디지털단지역, 가산디지털단지역의 시각화 결과는 Figure 8에 제시하였다.
분석결과, 출퇴근 시간 모두 역 인근에서 많이 이용할 것으로 예측되었다. 이는 공유 PM과 관련된 대부분의 연구에서 제시한 바와 같이, 공유 PM이 대중교통과 연계되어 단거리 통행에 대한 수요를 충족시키는 것과 같은 결과가 도출되었다(Radzimski and Dzięcielski, 2021; Lv et al, 2021; Zhao and Li, 2017). 다음으로 많이 이용할 것으로 예측된 지역은 공업지역, 주거지역 인근으로 나타났다. 이는 출퇴근 시간대의 특성 상, 직장 및 거주지로 이동하는 통행패턴이 반영되었기 때문이다. 공업지역 중에서도, 도로 폭이 좁아 대중교통 접근이 어려운 지역에서 많이 이용될 것으로 예측되었다. 그리고 자전거 정류장 및 자전거 전용도로와 같은 단거리 모빌리티 인프라가 구축된 지역, 공원과 놀이공원과 같은 유동인구가 많은 지역에서 PM 이용이 많을것으로 예측되었다. 이를 조합하여, 출퇴근 시간대는 도로폭이 좁은 공업지역과 모빌리티 인프라가 구축된 지역, 유동인구가 많은 지역과 가까운 지하철역에 공유 PM을 배치하여 거주민의 모빌리티를 증진시킬 수 있다. 출퇴근 시간 공유 PM 이용이 많을 것으로 예측되는 지역 4곳에 대한 특성은 Table 3에 정리하였다.
Table 3.
Prediction area summary (commute time)
결론
본 연구는 강화학습을 활용하여 공유 PM의 최적 배치지역을 도출하였으며, GIS를 활용하여 강화학습을 위한 데이터 입력 및 분석 결과 시각화를 수행하였다. 분석에 활용한 데이터는 대중교통 관련 데이터, 사회경제지표, 도로 및 지형 데이터와 공유모빌리티 데이터이며, 모든 데이터는 서울 열린 데이터 광장에서 제공하는 오픈 소스 데이터를 활용하였다. 강화학습 구조는 주로 활용되는 MDP로 구성하였으며, 무작위로 생성되는 PM 이용자 위치에 따라 배치 시 필요한 이동 거리가 최대한 작을수록 더 큰 Reward를 제공하도록 설정하였다. 가치함수의 최적화는 간단하고 다양한 환경에 적용가능한 Q-learning algorithm을 통해 수행하였다. 분석결과, 마곡나루역과 신도림, 구로·가산 디지털단지역 인근에 130대 이상 배치가 필요한 것으로 예측되었다. 그리고 출근시간대는 화양사거리, 퇴근시간대는 잠실역에서 PM 배치가 많을것으로 예측되었다. 해당 지역중, 가산디지털단지역, 화양사거리는 공통적으로 공업지역 인근에 있어 출·퇴근 시 이용이 많을것으로 예상되었다. 그리고 마곡나루역과 잠실역은 유동인구가 많고 여가시설이 인근에 배치되어 여가목적의 PM 이용이 많을것으로 예측되었다. 따라서, MDP 기반 출퇴근 시간대의 공유 PM 탑승지역 예측 결과, 도로폭이 좁은 공업지역과 모빌리티 인프라가 구축된 지역, 유동인구가 많은 지역과 가까운 지하철역으로 나타났다.
본 연구의 한계점은 다음과 같다. 연구에 활용한 공유 모빌리티 데이터는 스테이션이 있는 방식의 공유자전거 O/D 데이터로, 스테이션 리스 방식의 공유 PM의 성격과 다르다. 공유 PM의 O/D 데이터는 업체 내부 보안상의 이유로 제공받기 어려웠으며, 시에서 운영하는 공유자전거 데이터를 활용하였다. 향후 연구에서 업체 별 협력을 통해 공유 PM의 데이터를 제공받는다면, 더 정확한 PM 배치지역을 예측할 수 있을것으로 예상한다. 또한 본 연구에서는 강화학습의 가치함수 최적화 알고리즘으로, Q-learning algorithm만을 활용하였다. 향후 연구에서는 DQN, A3C와 같은 다양한 강화학습 알고리즘을 활용한다면 분석성능 비교를 통해 더 정확한 예측이 가능할 것이다.
