

Introduction
Literature Review
1. 코로나19의 교통사고 영향 연구
2. 시계열 모형을 활용한 교통사고 분석 연구
3. 시사점 및 연구 차별성
Data & Methodology
1. 연구지역 및 분석자료
2. 분석 방법론
Result
1. 전체 교통사고 분석결과
2. 차종별 교통사고 분석결과
Discussion
Conclusions
Introduction
2019년 12월 8일, 중국 우한에서 원인 미상의 폐렴 환자 발생과 함께 시작된 코로나19 바이러스는 전 세계적으로 수많은 인명피해를 발생시켰으며 이는 현재도 진행 중에 있다. 2023년 9월 현재, 전 세계 대부분의 국가에서 690만명 이상의 사망자와 6억 9천만명 이상의 확진자가 발생하였으며 한국 또한 지금까지 약 35,800명의 사망자와 3,400만명 이상의 확진자가 발생하였다.1)
2020년 1월 20일 첫 확진자가 발생한 한국을 포함, 최근까지 전 세계 많은 국가들이 코로나19 대응을 위해 막대한 의료 자원을 투입해왔다. 코로나19는 앞서 언급한 인명 피해 뿐만 아니라 경제, 고용, 돌봄, 교육 등 사회 전반에 큰 충격을 주었다. 각국 정부는 의학적 개입(medical intervention)과 비의학적 개입(non-pharmaceutical intervention), 두 가지 방식으로 감염병 확산에 대응해왔다(Lee, 2023). 의학적 개입으로는 백신 접종과 치료제 투입이 대표적이며 비의학적 개입으로는 개인의 자발적 거리두기와 정부의 사회적 거리두기를 들 수 있다.
이 중 사회적 거리두기는 각국에서 코로나19 초기부터 시행해온 정책으로 감염병의 확산 방지를 위해 개인 간 물리적 거리를 확보하는 정책이다. 이는 간단한 실행으로 상당한 방역 성과를 낼 수 있다고 평가되고 있으며(Hunter et al., 2021), 정책시행 이후 지금까지 분야별 연구들에서 이 효과가 분석되고 있다. 교통사고 또한 세계 각국 및 국가별 주요 도시를 대상으로 코로나19의 봉쇄정책에 따른 영향이 연구되었고 많은 연구들에서 코로나19 봉쇄정책으로 교통사고가 감소한 것으로 나타났다(Barnes et al., 2020; Huq and Islam, 2021; Saladié et al., 2020 etc).
한국 역시 여러 분야에서 사회적 거리두기의 영향 및 효과들이 연구되었으나(Kim et al., 2021; Kim and Park, 2022; Ha et al., 2023 etc), 아쉽게도 교통사고 관련 연구는 아직 이루어지지 않고 있다. 2022.7.8. 자 도로교통공단의 보도자료에서는 2020년 사고건수가 2019년 대비 8.7% 감소하였으며 이에는 코로나19에 의한 사회적 변화가 포함되었을 것으로 추측한 정도에 그쳤을 뿐이다. 또한, 코로나19가 교통사고에 미친 영향을 분석한 국외 연구들은 대부분 전체 사고를 토대로 코로나19 발생 전 후간 단순비교 위주로 수행되었으며 봉쇄정책이 교통사고에 미친 영향이 차종 특성에 따라 다양한 결과를 나타냈을 수 있음에도 불구하고 이에 관한 연구는 찾기 힘든 실정이다. 사회적 거리두기가 코로나19 뿐만 아니라, 향후 또 다른 팬데믹 상황에서도 충분히 적용 가능한 정책인 점을 감안할 때, 한국의 사회적 거리두기에 대한 교통사고 영향 분석은 그 필요성이 충분하다.
이에 따라, 본 연구에서는 코로나19 사회적 거리두기 정책의 교통사고 연관성을 분석하였다. 코로나19 및 사회적 거리두기의 영향을 분석한 국내외 많은 연구들은 분석결과를 인과관계(causal relationship)로 해석하였다. 하지만 인과관계가 타당성을 갖추기 위해서는 시간적 우선순위(time order), 동시발생조건(concomitant variance), 외생변수 통제(control extraneous variables)라는 세 가지 조건을 충족해야 하나 교통사고의 특성상, 이러한 인과관계를 현실적으로 증명해내기는 매우 어렵다.
따라서, 본 연구에서는 사회적 거리두기와 교통사고간 연관성을 분석하였으며 이를 위해 장기간에 걸친 교통사고 추세(trend)를 토대로 시계열 분석을 실시하였다. 시계열 분석으로 사회적 거리두기가 없었을 때의 교통사고 예측치와 사회적 거리두기 시행기간에 발생된 실제 교통사고를 비교함으로써 사회적 거리두기에 따른 교통사고의 변화를 살펴보았다. 연구를 위해 경기도에서 최근 10년간(2013-2022년) 발생되었던 교통사고 자료와 코로나19 기간 내 실시했던 사회적 거리두기 방역 자료가 수집되었으며 ARIMAX를 포함한 다양한 시계열 분석 모형이 사용되었다. 이러한 주제와 방법에 따라 본 연구는 다음 두 가지 문제(가설)에 초점을 맞추어 수행되었다.
· 한국의 사회적 거리두기 정책은 전체 교통사고 및 차종별 교통사고에 어느 정도의 연관성을 나타냈는가?
· 이러한 연관성은 사회적 거리두기의 기간(경과) 및 수준(강도)에 따라 그 결과가 어떻게 변화했는가?
Literature Review
1. 코로나19의 교통사고 영향 연구
대다수 연구에서 국가별, 지역별, 또는 도시별로 시행한 코로나19의 봉쇄조치(lockdown)로 통행량 및 교통사고가 감소한 것으로 나타났다.
미국 Louisiana에서는 코로나19 봉쇄조치로 사고건수가 47% 감소한 것으로 분석되었으며 여기에는 부상사고와 구급차사고 등이 각각 46% 및 41% 포함된 것으로 나타났다. 회귀불연속설계법(Regression Discontinuity Design, RDD)을 이용한 이 연구에서는 특히 남성 운전자, 25-64세 운전자 및 비백인 운전자와 관련된 사고의 변화가 크게 나타났으며 코로나19로 인해 교통량 또한 감소되었다고 밝혔다(Barnes et al., 2020).
호주 Sydney에서는 봉쇄기간에 자동차 사고건수 및 고장빈도가 50-60% 감소한 것으로 나타났다. 봉쇄기간 전후에 대한 사고자료를 카이제곱 검정(chi-square test)으로 비교한 연구 결과는 스페인, 그리스, 사우디아라비아 및 미국을 대상으로 했던 연구들과 유사한 결과를 나타냈다고 밝혔다. 하지만, 심각사고 등은 전체적인 사고 감소비율만큼 감소하지 않은 것으로 나타났다(Chand et al., 2021).
방글라데시에서는 봉쇄조치로 사고건수 58% 감소, 사망자수와 부상자수는 각각 58%, 82% 감소한 것으로 나타났다. BSTS(Bayesian Structural Time Seriese) 모형으로 봉쇄조치의 효과를 추정한 이 연구에서는 봉쇄조치 이후 사고가 다시 증가했지만 이전 수준까지는 아니었다고 밝혔다(Huq and Islam, 2021).
터키에서는 봉쇄기간에 교통사고 부문별로 20-60%의 사고 감소가 있었으며 포아송 모형을 통해 분석된 사망사고 등 일부 유형은 부정확한 결과가 나타났다고 밝히면서 봉쇄조치의 효과분석을 위해 이중차분법(Difference in Differences, DID)을 사용했다. 연구 결과 인적피해와 물적피해 사고건수는 각각 30% 및 32% 감소하였으며 부상자수는 19% 감소하였으나 사망자수 감소효과는 거의 없었던 것으로 나타났다(Oguzoglu, 2020).
스페인 Tarragona에서는 봉쇄기간 사고건수와 통행량이 각각 74.3% 및 62.9% 감소한 것으로 나타났다. Chand et al.(2021)의 연구와 같은 카이제곱 검정으로 전후 비교를 실시한 이 연구에서는 봉쇄조치 해제 후 교통사고가 지속적으로 증가하여 이전 수준과 유사해졌다고 밝혔다(Saladié et al., 2020).
네팔에서는 봉쇄조치로 인명 피해 사고건수가 21.8% 감소된 것으로 나타났다. 이 연구에서는 봉쇄조치 전후의 단순비교를 통해 봉쇄조치의 영향을 추론하였으며 오토바이 사고로 인한 교통사고가 전체 사망사고 중 큰 부분을 차지하게 되었으며 정부는 이를 주목해야 함을 주장했다(Sedain and Pant, 2020).
이 외에도 이탈리아에서는 봉쇄조치 기간 내 월별 교통사고건수 변화를 비교한 결과 최대 70% 감소한 월이 나타났으며(Valent, 2022), 세계 주요국의 사고자료로 봉쇄조치에 따른 월간 교통사고 변화 연구에서는 36개국 중 32개국에서 교통사고 사망자수가 감소했다고 밝혔는데 이는 12개국에서 50% 이상 감소, 14개국에서 25-49% 감소, 6개국에서 25% 미만 감소를 기록한 것으로 나타났다. 또한, 동일 연구의 연간 변화로는 42개국 중 33개국에서 교통사고 사망자수가 감소했으며 5개국 이상은 25%, 13개국은 15-24%, 15개국은 15% 미만의 감소를 기록한 것으로 나타났다(Yasin et al., 2021).
2. 시계열 모형을 활용한 교통사고 분석 연구
국외에서는 교통사고 분석에 다양한 시계열 모형을 적용한 연구들이 많이 존재하지만, 국내에서는 ARIMA 모형을 활용한 일부 연구만이 존재하는 것으로 파악된다.
먼저 시계열 분석에서 가장 많이 활용되는 ARIMA 모형 관련 연구이다. Ihueze and Onwurah(2018)는 나이지리아 Anambra주를 대상으로 교통사고 자료와 몇몇 설명변수들(인간, 차량 및 도로환경 요소)을 통해 교통사고를 예측하였으며 이 연구에서는 ARIMA와 ARIMAX간 성능을 비교하였다. 연구를 위해 2007년부터 2015년까지의 교통사고건수 자료가 월별로 구축되었으며(표본수 108개), 분석 결과 교통사고 자료만 활용한 ARIMA 모형 보다 ARIMAX 모형의 예측력이 우수하게 나타났다. Nassiri et al.(2023)은 이란의 지방부 고속도로를 대상으로 ARIMA와 ARIMAX에 계절성(seasonality) 요소를 추가한 SARIMA와 SARIMAX 모형을 포함하여 총 4개 모형으로 교통사고 발생추세를 예측하였다. 이 연구의 외생변수로는 교통량과 통행 속도가 사용되었으며 연구자료는 2016년 3월부터 2021년 8월까지 월별 교통사고 자료(표본수 55개)가 사용되었다. 분석 결과 전체사고와 심각사고, 그리고 외생변수들에 따라 다른 결과가 나타났지만 시계열 분석시 외생변수가 포함된 모형까지 함께 사용할 것을 제안하였다. 이란의 또 다른 연구로 Behzadi et al.(2023)은 이란 남동부에 위치한 Kerman주를 대상으로 Ihueze and Onwurah(2018)의 연구와 마찬가지로 설명변수(인간, 차량 및 도로환경 요소)를 고려한 ARIMAX 모형을 통해 교통사고를 예측하였다. 앞선 연구들과 마찬가지로 월별 교통사고 자료가 활용되었으며 2015년 3월부터 2021년 3월까지의 사고건수 자료(표본수 72개)를 통해 사고에 대한 속도와 평균 기온의 영향력을 밝혀냈다.
다음으로 ETS 모형 관련 연구이다. Ye et al.(2019)은 미국 Los Angeles를 대상으로 ARIMA와 ETS를 사용하여 교통사고의 추세, 계절성, 상관관계, 왜도 등의 통계적 특성을 분석하였다. 이 연구에서는 특히 Los Angeles의 교통사고가 연중 10월에 가장 높고 2월에 가장 낮다는 특성을 보이기 때문에 STL 분해법을 사용한 ETS 모형을 구축하였다.2) 연구자료로는 2010년부터 2019년까지의 월별 교통사고 자료(표본수 113개)가 사용되었으며 연구를 통해 시계열 분석시 다수의 모형을 통한 비교가 의미 있음을 주장하였다. 국내 연구로 Lee and Seong(2017) 또한, ARIMA와 ETS를 통해 한국의 2005년부터 2015년까지의 월별 교통사고 자료(표본수 132개)를 그룹별로 구분하여 계층적 시계열분석을 수행하였다. 분석결과 대상 그룹별 ARIMA와 ETS의 성능이 상이하였으나 전반적으로 ETS가 우수한 예측 결과를 나타낸 것으로 밝혀졌다.
다음으로 ANN 모형 관련 연구이다. Qian et al.(2020)은 중국내 교통사고 사망자수 자료를 통해 SARIMA와 ANN의 두 모형으로 단기 사망자수를 예측하였다. 연구자료로는 중국 교통국에서 집계된 2000년부터 2017년까지의 월별 사망자수(표본수 96개)자료가 사용되었으며 분석결과 타 연구에서는 SARIMA의 RMSE, MAE, MAPE가 ANN보다 훨씬 높게 나타났지만 이 연구에서와 같이 계절성이 강한 교통사고 패턴에서는 ANN이 SARIMA보다 근소하게 우수한 것으로 나타난 점을 밝히며, 연구자는 시계열 분석시 두 모형의 병행 사용을 제안하였다.
마지막으로 Prophet 모형 관련 연구이다. Feng et al.(2022)은 중국 동북부 지역을 대상으로 SARIMA, Prophet, LSTM의 세 모형으로 단기 사고예측 모형을 개발하였다. 이 연구에서는 교통사고 건수가 아닌 부상자수를 예측하였는데 연구자료로는 지린성(Jilin Provincial) 보건위원회가 집계한 지린성내 일반병원 입원환자(총 24,885명)에 대해서 2015년부터 2020년까지의 월별 입원자수(표본수 60개)가 사용되었다. 연구 결과 전반적 예측성능은 LSTM이 우수하였으나 부분적으로는 Prophet의 성능이 높게 나타났다.
이상과 같이 교통사고 시계열 분석에서는 다양한 모형들이 활용되고 있음을 알 수 있는데 이들은 각각의 특성을 가지고 있다. 이러한 모형들은 분석된 자료의 시계열적 패턴에 따라 상이한 결과가 나타나기도 한다. 모형별 주요 특성들을 정리하면 Table 1과 같다. ARIMA, ETS 및 ANN에 대한 상세한 내용은 Box et al.(2015), Enders(2014), Hyndman and Athanasopoulos(2021)에 제시되어 있으며 Prophet은 Taylor and Letham(2018)을 참고하면 된다.
Table 1.
Main characteristics by time series model
3. 시사점 및 연구 차별성
코로나19 봉쇄정책과 교통사고를 분석한 대부분의 연구들은 봉쇄정책 전후 단순비교 등으로 교통사고 감소 효과를 도출하였다. 그동안 거시적 차원의 사고 추세(trend)를 반영한 시계열 분석들이 주로 사용되었던 점과 코로나 팬데믹 특수성을 고려할 때, 기존 연구들은 이를 반영한 심도 있는 연구는 이루어지지 않은 것으로 보인다. 아울러, 팬데믹 상황에서의 사람 통행 특성을 파악할 수 있는 차종별 분석의 부재 또한 아쉬움이 남는다. 또한, Table 1에서 알 수 있는 바와 같이 분석 대상 자료에 따라 각각의 상황에서 적절한 시계열 모형이 필요할 수도 있다.
본 연구의 차별성이다. 첫째, 기존의 코로나19 봉쇄정책의 교통사고 연구방법과는 달리 교통사고의 추세(trend) 특성을 통한 시계열 분석을 실시하였으며 사회적 거리두기가 없었을 때의 시계열 예측값과 실제 교통사고 관측값을 비교하였다. 둘째, 이러한 분석은 기존 연구들에서 수행되지지 않았던 차종별 분석까지 수행하여 이들을 비교함으로써 의미 있는 시사점을 도출하고자 하였다. 셋째, 한국의 거리두기 정책 특성을 고려하여 거리두기 기간과 방역수준을 세분화하고 이에 따른 교통사고의 특성을 살펴보았다. 넷째, 분석 자료들의 시계열적 특성을 감안하여 보다 적절한 모형 탐색을 위해 단일 모형보다는 4개의 시계열 분석 모형을 적용하였다.
Data & Methodology
1. 연구지역 및 분석자료
본 연구는 경기도를 대상으로 한다. 경기도는 한국에서 사회적 거리두기가 비교적 안정적ㆍ효과적으로 시행된 수도권 지역 중 하나로 한국의 17개 광역지자체 중 규모가 가장 크다. 경기도는 2022년 말 기준, 인구수 13,680,911명(한국의 26.5%), 자동차등록대수 7,016,973대(한국의 23.9%), 운전면허소지자수 9,246,510명(한국의 27.1%), 도로연장 14,904km(한국의 13.0%), 2022년 발생 교통사고 52,968건(한국의 26.9%)을 차지하고 있다.
분석자료는 교통사고 자료와 코로나19 방역 대책 자료가 사용되었다. 교통사고 자료는 도로교통공단의 교통사고분석시스템(Traffic Accident Analysis System, TAAS)을 통해 경기도에서 최근 10년간(2013-2022년) 발생된 514,202건의 교통사고를 차종별 집계하였으며 거리두기 분석에서는 2022년을 제외한 9년간의 교통사고 461,454건이 사용되었다.3) 코로나19 방역 대책 자료는 질병관리청을 통해 거리두기 연혁 자료를 수집하였다.
또한, 본 연구에서는 수집된 사고자료를 주 단위로 구축하였다. 대부분의 선행 연구들이 교통사고 시계열 분석시 월 단위로 자료를 구축하였으나4), 본 연구에서는 한국의 사회적 거리두기 정책이 주 단위로 시행된 점과 보다 정교한 시계열 분석을 위해 국제 표준(ISO-8601) 날짜 산출 기준에 따른 주차를 산출하였다.
한국의 사회적 거리두기는 공식적으로는 2020년 3월 22일 시작되었지만 타인과의 접촉 최소화를 권장한 시점은 2020년 2월 29일부터였으며 전국적으로 주요 지역에서 감염이 확산되면서 지역에 따라 추가적 확산 방지를 위해 시설별 집합금지 행정명령, 선제검사 및 방역관리 강화를 실시하였다(Ha et al., 2023). 본 연구에서는 기간별 사회적 거리두기 단계의 지속적 변화와 체제 개편을 고려하여 경기도에서 기간별 실시되었던 방역 강도를 유사한 수준끼리 묶어 4단계로 단순화했다(없음, 낮음, 중간, 높음). Figure 1은 연구의 자료구축에 적용된 2년간(2020-2021년)의 주별 방역 수준과 해당기간의 경기도에서 발생된 주차별 전체 교통사고 발생건수를 함께 도식화하였다.
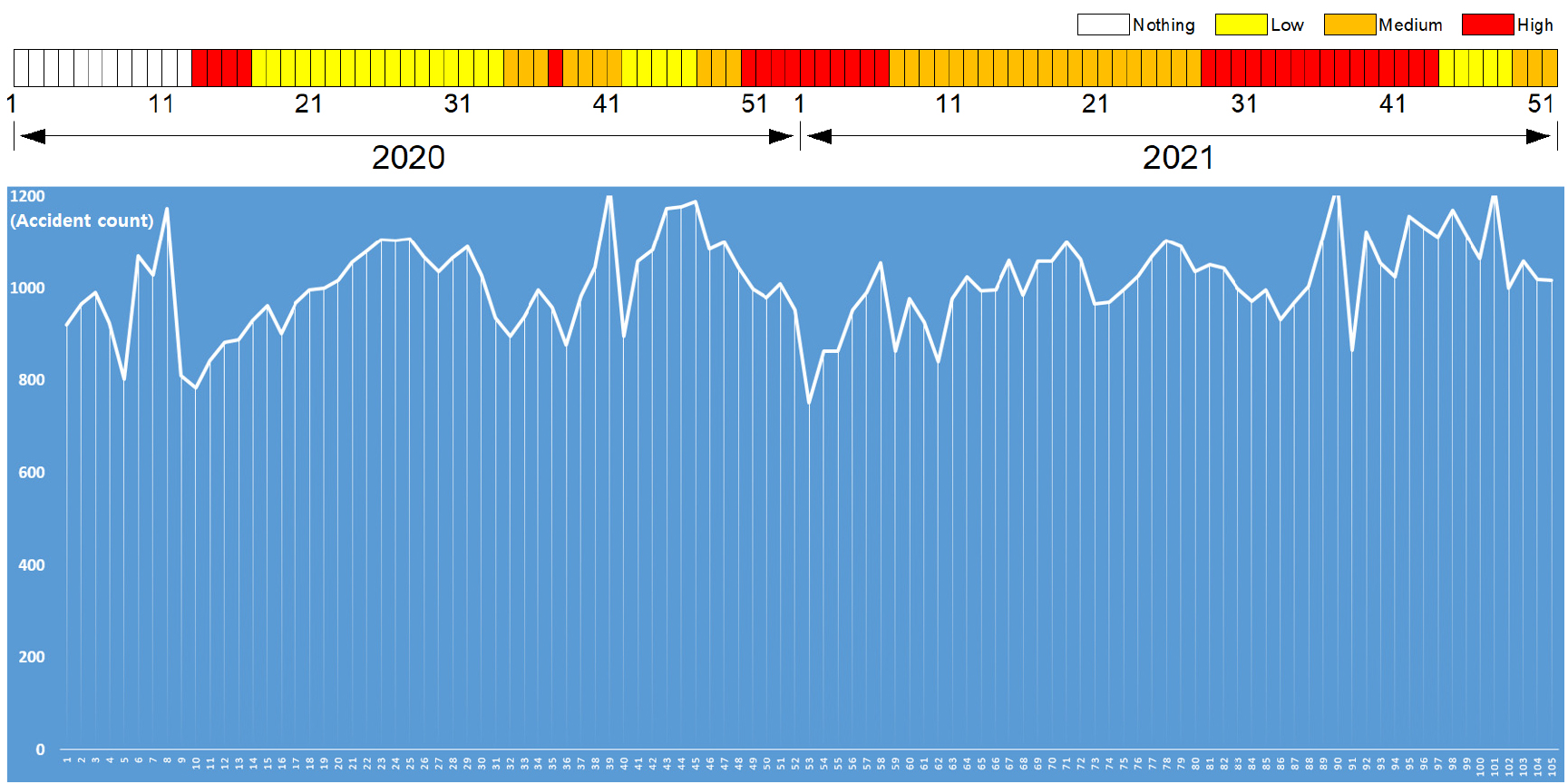
이와 같은 작업으로 총 470개의 표본(2015년과 2020년은 53주차까지 존재)이 구축되었다. Table 2는 본 연구를 위해 구축된 자료의 예시에 해당한다. 본 연구의 차종 구분은 경찰 교통사고 통계자료를 참고하여 총 5개로 구분(승용차, 승합차, 화물차, 오토바이, 기타)하였다. 오토바이에는 이륜차, 사륜오토바이, 원동기장치자전거가 포함되었으며 기타 차종에는 자전거, 건설기계, 특수차, 개인형 이동수단, 농기계, 기타 불명이 포함되었다. 거리두기 수준은 4단계(없음, 낮음, 중간, 높음)로 구분하였다.
Table 2.
Example of data set for the analysis (n=470, by weekly)
2. 분석 방법론
본 연구는 일정기간 발생된 교통사고의 추세를 바탕으로 특정기간에 시행된 사회적 거리두기 정책의 영향을 분석하기 위해 다양한 시계열 분석 모형들을 적용하였다.
1) ARIMAX(Autoregressive Integrated Moving Average X)
ARIMAX는 기존 시계열 분석모형인 ARIMA(autoregressive moving average) 모형에 회귀요소인 외생변수를 고려한 모형(autoregressive moving average model with exogenous inputs model)을 말한다.
ARIMAX의 기본 형태인 ARIMA는 Box-Jenkins가 개발한 모형으로 종속변수의 시계열 예측시 자기회귀(autoregressive, AR)와 이동평균(moving average, MA)을 함께 고려한다(Lee et al., 2023). AR과 MA 모형에 종속변수의 과거값 뿐만 아니라 백색잡음(white noise)의 과거값까지 포함된 모형이 ARMA 모형이며, 여기에 시계열 데이터의 정상성(stationary)을 위해 변수의 차분과정(differencing)까지 포함된 모형이 ARIMA 모형이다.
일반적으로 ARIMA 모형은 독립변수를 포함하지 않으므로 전통적 회귀분석에서의 관심사인 특정 독립변수와의 관계를 알아내기가 어렵다(Won et al., 2015). 이런 단점을 극복하기 위한 ARIMAX 모형은 기존 ARIMA 모형에 독립변수의 지체차수(lagged order)를 포함하여 ARIMAX(p, d, q, r)로 표현되며 수식은 Equation 1과 같다.
여기서, 는 시점 t의 주간 사고건수, 는 상수, 는 시점 t의 오차항, 는 자기회귀항, 는 자기상관계수, 는 이동평균항, 는 이동평균계수, 는 교통사고 자료의 계절성 옵션을 반영하기 위한 독립변수로 모형이 구성된다.5)
2) STL(Seasonal and Trend decomposition using Loess) & ETS(Exponential Smoothing)
STL(seasonal and trend decomposition using loess)은 Loess(locally estimated scatterplot smoothing) 평활화 기법을 사용한 시계열 분석 방법으로 계절성과 추세를 분해하는 방법이다(Cleveland et al., 1990).
Loess는 두 변수간 평활화된 함수를 각 시점별 주변 데이터를 d차 다항식으로 를 적합시키는 국지회귀분석법이다. 여기서 d값은 1또는 2이며 시점 의 주간 사고건수 에서 Loess 적합시 주변 시점 q개 데이터를 거리에 반비례하는 Equation 2의 가중치() 함수가 이용되며 평활화 모수 q가 커지면 시계열이 더 평활하게 적합된다(Lee, 2021).
STL은 계절변동과 추세순환변동을 추출하는 내부순환(inner loop)과 특이항의 영향을 줄이는 외부순환(outer loop)의 반복과정으로 구성된다. 이러한 계절조정법은 5단계의 내부순환 과정을 거쳐 추세순환을 산출하는데 이에 관한 자세한 내용은 Cleveland et al.(1990)과 Hafen(2010)을 참고하면 된다. 내부순환 과정 이후 외부순환 과정에서는 특이항 조정을 통한 불규칙 변동을 산출해 최종적으로 Equation 3이 도출된다.
여기서, 는 주간 사고건수 에서 잠정 계절변동 을 제거시킨 잠정 계절조정이다.
또한, 본 연구에서는 STL에 ETS를 결합한 모형을 사용하였는데 지수평활법으로 불리는 ETS(exponential smoothing)는 과거의 관측치에 시간의 흐름에 따른 가중치를 주고 합산하여 미래를 예측하는 방식이다. Equation 4는 단순 지수평활법(single exponential smoothing)의 수식을 나타낸 것이다.
여기서, 다음 예측치인 는 현재값 과 이전 예측치 의 합산으로 계산되며 는 0에서 1을 갖는 평활화 매개변수이다. 이러한 단순 지수평활법은 이중 지수평활법 등으로 추세를 보완한 모델링이 가능하다. ETS 모형은 시계열 자료가 가지고 있는 에러(error), 추세(trend), 계절성(seasonality)의 3가지 요소로 구성되며 시계열 자료의 추세 특성과 계절성을 각각 조합하여 12가지 유형을 상정할 수 있다. 아래는 모델의 형태를 의미하는데 예를 들어 에러, 추세, 계절성이 모두 가법적인 모델일 경우 ETS(A, A, A)로 표기된다. 계절성이 없는 가법 모델이라면 ETS(A, A, N)에 해당된다고 이해하면 된다.
· N: 상수 모델(constant)
· A: 가법 모델(additive)
· Ad: 감쇄하는 가법 모델(damped additive)
· M: 승법 모델(multiplicative)
· Md: 감쇄하는 승법 모델(damped multiplicative)
3) ANN(Artificial Neural Network)
ANN(artificial neural network)은 인간의 뇌에서 이루어지는 생물학적 학습과 지식전달 절차를 컴퓨터 공학적으로 응용시킨 알고리즘으로 인공신경망으로 불린다(Ryu et al., 2012). ANN의 구조는 입력층(input layer)과 출력층(output layer), 그리고 이 사이에 하나 또는 그 이상의 은닉층(hidden layer)으로 구성되어 있고 각각의 레이어들은 가중치인 연결강도에 의해 결정된다(Bishop, 1995).
가중치로 연결된 ANN의 레이어들 중 은닉층에서는 입력데이터별 가중치를 계산해서 합한 값을 활성화 함수로 출력후 결과를 반환하며 시계열 분석시 Equation 5와 같은 형태로 미래값을 예측한다.
여기서, 주간 사고건수 는 과거에 관측된 사고건수를 비선형 함수 로 맵핑하고 나온 결과값으로 가중치 를 수정한다. 결과값으로 이전의 값을 수정하기 때문에 ANN을 비선형 자기회귀 모형이라고도 한다(Che, 2018).
4) Prophet
Prophet은 2017년 Facebook에서 공개한 시계열 분석 라이브러리로 시계열 자료 입력으로 미래값을 예측할 수 있는 모형이다(Taylor and Letham, 2018). 현재까지 내부 알고리즘이 공개되지 않아 정확한 알고리즘을 알 수는 없으나, 시계열의 시간 종속적 특성을 고려하는 기존의 분석 방법론들과는 달리 curve-fitting(곡선 적합)으로 예측 문제를 해결한다(Kim and Ahn, 2023). Prophet에서는 일반화된 가법 모형을 채택하며 이는 요소의 분해와 새로운 요소의 추가가 쉽다는 장점을 가진다. 따라서 시계열 분석 방법론에 대한 지식이 많지 않더라도 도메인에 대한 경험과 이해를 알고리즘에 반영하기 쉽도록 설계되었다는 특징이 있다(Taylor and Letham, 2018).
Prophet 모형은 Equation 6과 같이 트렌드(growth), 계절성(seasonality), 휴일(holidays) 3가지의 기본 구성요소로 이루어져 있다.
여기서, 는 주간 사고건수, 는 비주기적 변화를 반영하는 추세 함수, 주기적 변화에 해당되는 는 주별 교통사고 변화량, 는 휴일과 같은 불규칙 이벤트의 영향력을 나타내며 는 정규분포를 가정한 오차항이다. 이러한 Prophet 모형은 현재 널리 사용되는 분석패키지 R과 Python에 대한 라이브러리가 공개됨에 따라 적용성이 쉽고 성능이 우수한 것으로 알려져 있다.
Result
앞선 자료와 방법을 토대로 전체 사고와 4개 차종(승용차, 승합차, 화물차, 오토바이)을 분석하였다. Table 3은 종속변수인 주간 사고건수에 대한 연도별(2013-2022년) 기술통계량이다. 2020년과 2021년에 대한 종속변수의 평균값을 살펴보면 코로나19 발생 직전인 2019년 대비 총계, 승용차, 승합차의 사고감소가 눈에 띄는 반면, 화물차는 큰 변화가 없으며 오토바이는 오히려 사고가 증가했음을 알 수 있다.
Table 3.
Descriptive statistics of dependent variable
또한, 본 연구에서는 2단계의 분석과정을 거치는데, 1단계에서는 2013-2018년까지의 자료로 코로나19 발생직전인 2019년의 교통사고를 모형별로 예측하여 실제 발생된 사고와 비교함으로써 예측성능이 가장 뛰어난 모형을 선정하였다. 2단계에서는 선정된 모형으로 2013-2019년까지의 자료를 통해 2020-2021년의 교통사고를 예측하여 실제 발생된 사고와 비교분석하였다.
본 연구에서 이루어진 모든 분석은 R프로그램의 시계열 분석 패키지들을 통해 이루어졌다. ARIMA와 ETS 모형은 시계열 분석에서 가장 많이 활용되는 forecast 패키지를 적용하였는데 이는 최적 ARIMA 모형을 스스로 결정해주는 auto.arima 함수를 보유하고 있다. ANN 모형은 nnet 또는 neuralnet 패키지가 많이 사용되는데 본 연구에서는 formula에 필요한 변수명을 직접 기재할 필요가 없는 nnet 패키지를 사용하였다. Prophet 모형은 prophet 패키지를 통해 분석되었다.
1. 전체 교통사고 분석결과
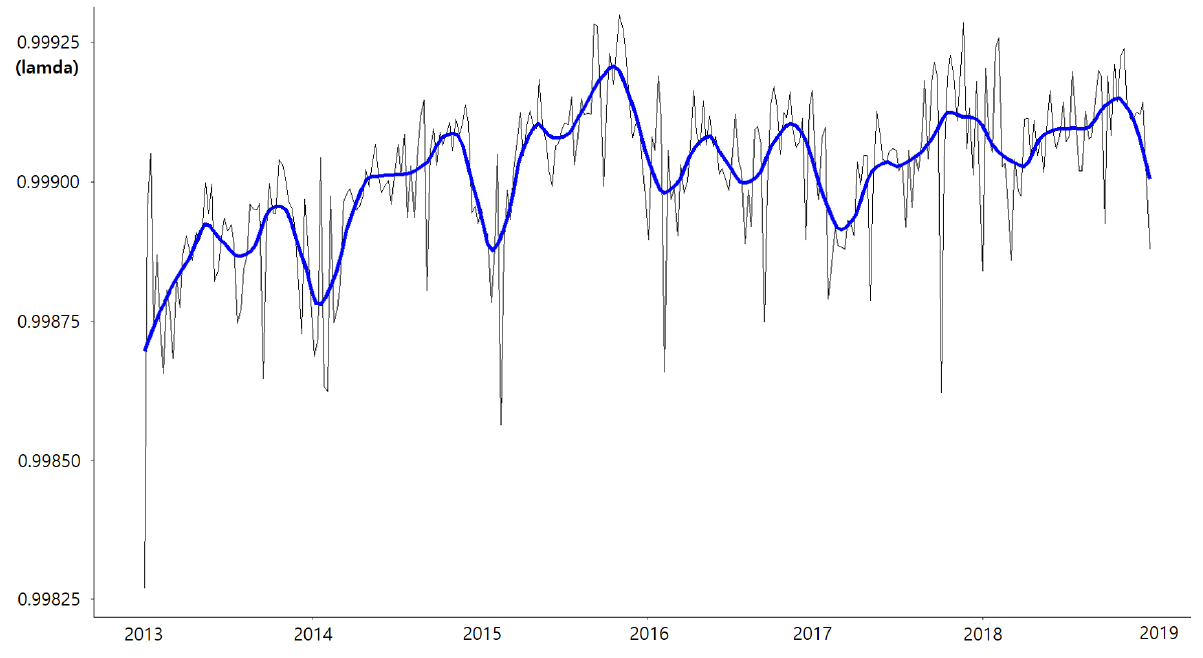
모형 적합을 위해 분석자료를 Box-Cox 변환 후, 2013-2018년 교통사고에 대한 탐색적 분석(Exploratory Data Analysis, EDA)으로 데이터 특성을 검토하였다. Box-Cox 변환은 정규분포가 아닌 데이터를 정규분포에 가깝게 만들거나 데이터의 분산을 안정화시켜 정상성(stationary)을 확보하는 변환기법으로 원데이터 를 로 변환하는 Box-Cox 수식은 Equation 7과 같다.
Equation 7로부터 도출된 값(-0.9999)을 통해 변환된 자료를 Dicky-Fuller test로 단위근(unit root) 검정한 결과, p-value는 0.01로 양호하게 나타났다. 이와 같은 과정을 거친 후 Loess 평활화 기법을 통해 데이터 특성을 검토한 결과 Figure 2와 같이 교통사고 자료에서 계절성과 추세성이 나타나는 것으로 확인되었다.
본 연구의 ARIMA 모형 적합은 R의 auto.arima( ) 함수를 사용하였다. auto.arima( ) 함수는 Hyndman and Khandakar(2008)의 변형된 형태를 사용하는데 이는 최적 ARIMA 모델을 얻기 위해 모형 식별단계의 단위근 검정 및 AIC(Akaike`s Information Criterion) 최소화, 모수추정 단계의 최대우도법(maximum likelihood method, MLE)을 결합해 사용한다. 이를 통해 계절성이 고려된 ARIMA(3,1,1)(0,0,2)[52] 모형이 도출되었다.6) STL+ETS 역시 R의 최적모형 선정 알고리즘에 따라 ETS(A,N,N) 모형이 도출되었다.
구축된 시계열 모형은 Ljung-Box test를 통한 잔차 진단이 이루어졌으며 ARIMA 모형의 p-value는 0.0723으로 정상시계열을 만족(잔차 간 자기상관 없음)하는 것으로 나타났다. Figure 3는 모형에 대한 잔차도이다.
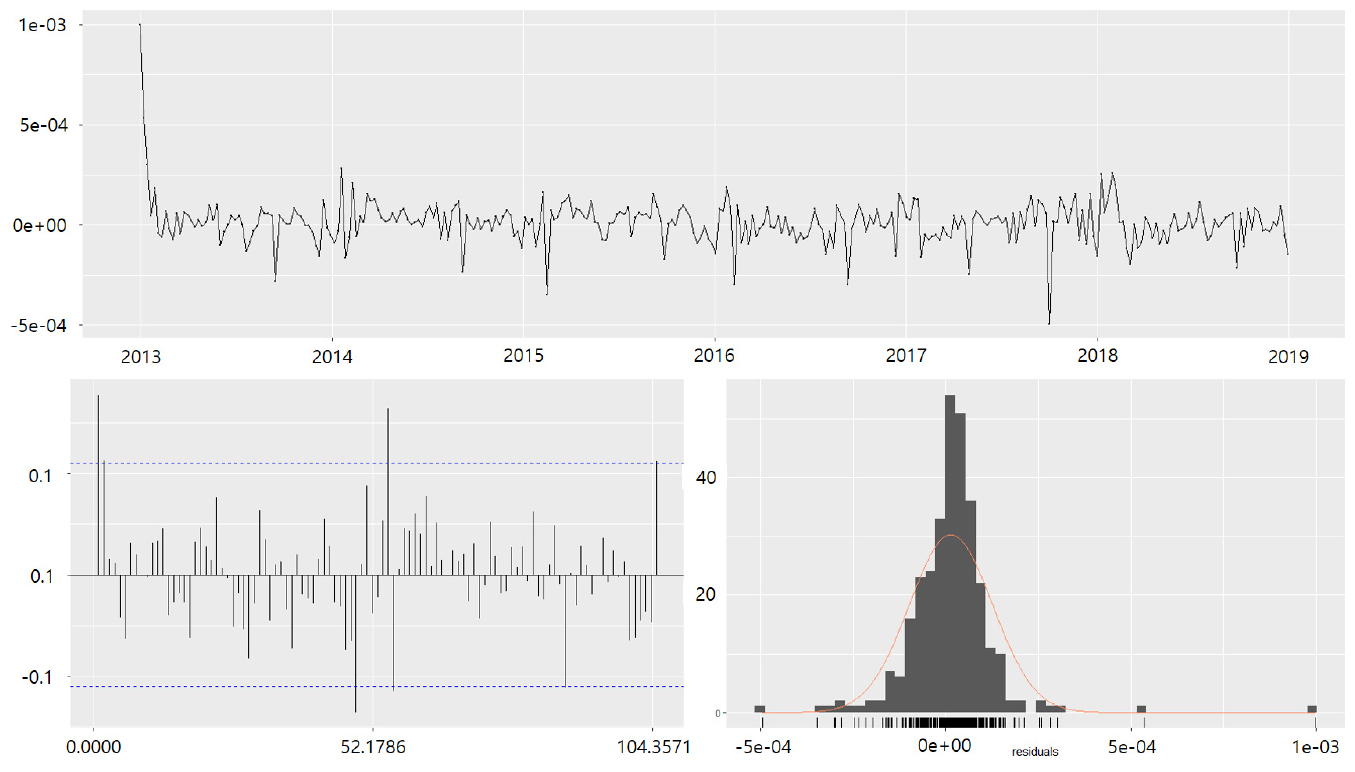
ANN 모형은 R의 nnetar( ) 함수를 이용하였다. 이 함수는 NNAR(p, P, k) m 모형을 선택하는데 p와 P값들을 설정하지 않으면 자동으로 선택된다. nnetar( ) 함수에서는 교통사고 자료와 같은 계절성 시계열에 대한 기본값은 P=1이고, p는 계절성으로 조정된 데이터에 맞춘 최적 선형 모형으로 선택되며 k값을 정하지 않으면 k=(p+P+1)/2로 산출된다. 분석에서 도출된 모형은 NNAR(8,1,10)[52] 이며, ARIMA 모형 등과 마찬가지로 잔차 진단이 수행되었다.
R의 prophet 함수를 적용한 Prophet 모형은 예측의 적합도를 높이기 위해 몇 가지 매개변수(parameter)를 선택적으로 조정할 수 있는 기능을 제공하는데(Rafferty, 2021), 본 연구에서는 교통사고 자료의 시계열적 변화를 반영하는 계절성 모드(seasonality mode)만 설정하였다. 그 외 자료의 변곡점 처리(changepoint prior scale) 등은 모형 자체적으로 수행하는 통제력 조정 기능을 기본적으로 적용시켰다.
앞서 밝힌 2단계의 분석과정 중, 1단계인 2013-2018년의 사고 자료를 통해 4개 모형이 예측한 2019년 교통사고의 모형별 예측 정확도 판단을 위해 다양한 평가지표들을 산출하였으며 결과는 Table 4와 같다. Table 4의 ME(mean error)를 통해 모형들이 예측한 교통사고는 실제 교통사고 대비 다소 낮게 예측된 것을 알 수 있으며 4개의 모형 중 ARIMA 모형의 성능이 가장 뛰어난 것으로 나타났다. Table 4의 Theil`s U 통계량은 분모의 예측값을 현재값 그대로 사용하는 단순예측치와 비교한 상대적인 예측 정확도를 나타낸 수치로, 이 값은 U=0(완전예측), U=1(단순예측치 수준의 정확도), U<1(단순예측보다 정확), U>1(단순예측보다 부정확)을 의미한다. Theil`s U 통계량 또한 ARIMA 모형이 가장 낮은 0.6637을 기록했다.
Table 4.
Performance evaluation results by model (overall traffic accidents)
Figure 4는 4개 모형이 예측한 2019년이 포함된 2013-2019의 교통사고 추이이다. 검정색선은 실제 교통사고의 추세선이며 Table 4의 결과를 통해 4개 모형 중 실제 교통사고와의 차이가 가장 작은 ARIMA 모형(Figure 4의 주황색선)이 2020-2021년 전체 교통사고 예측을 위한 최종 모형으로 선정되었다.
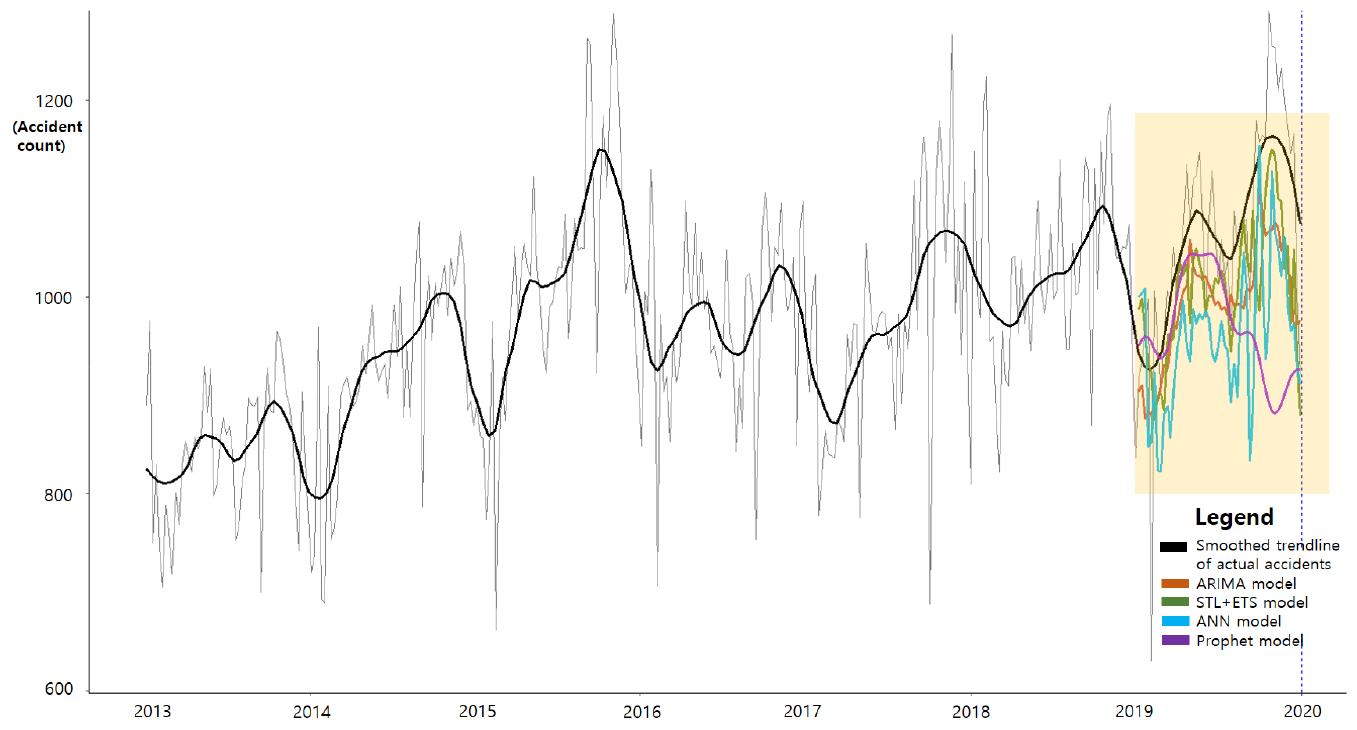
위에서 선정된 ARIMA 모형으로 동일한 방법에 따라 2013-2019년까지의 자료를 통해 2020-2021년 교통사고를 예측하였으며 이는 Figure 5로 표현되었다. 코로나19를 가정하지 않은 상황에서의 예측된 교통사고(주황색 선)는 실제 교통사고의 추세선(검정색 선) 대비 높게 나타난 것을 확인 할 수 있다.
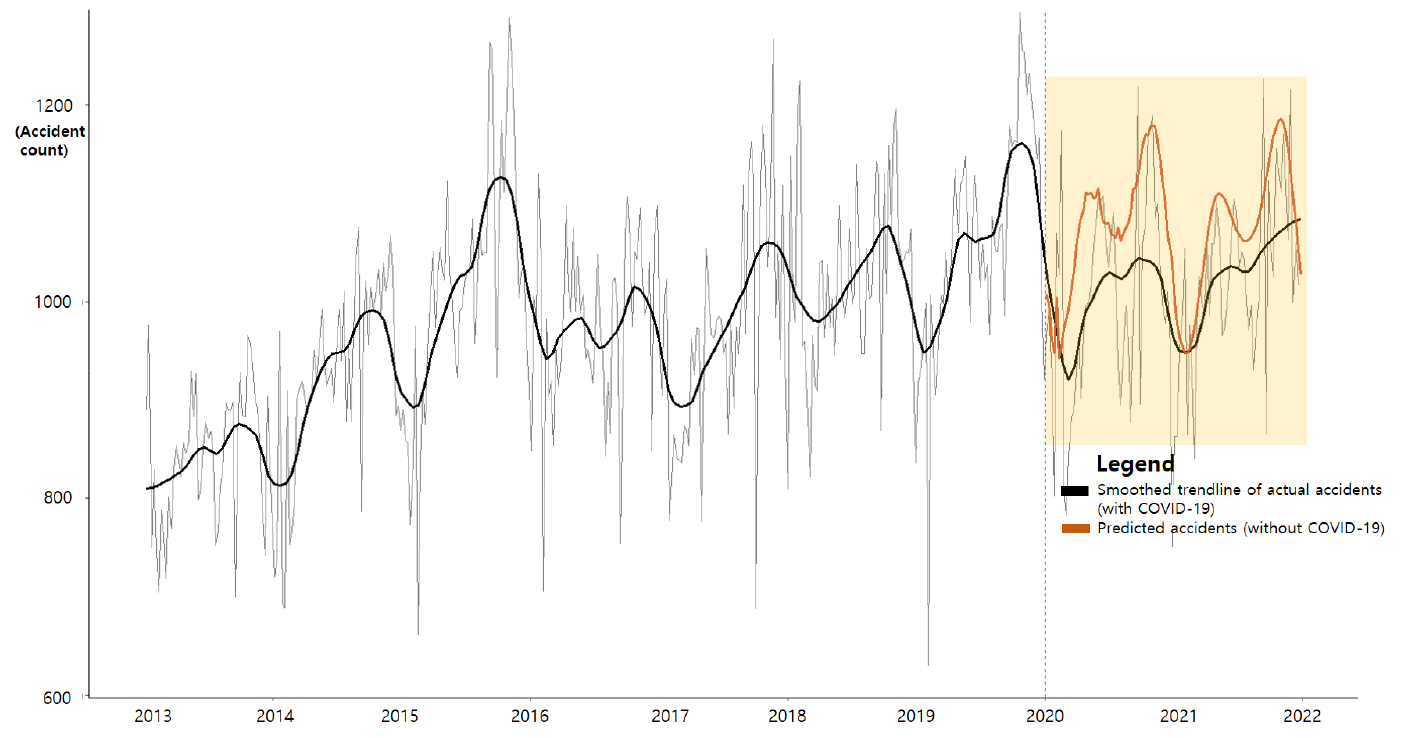
Table 5는 전체 교통사고에 대해 2020-2021년 분석된 결과이다. 본 연구 목적에 따라 자료 구축된 사회적 거리두기 단계는 2020년의 경우 낮음 단계 22주, 중간 단계 10주, 높음 단계 8주이며 2021년은 낮음 단계 5주, 중간 단계 25주, 높음 단계 22주로 이는 본 연구의 거리두기 단계별 표본수를 의미한다.
모형에서 분석된 예측값은 실제값과의 비교가 이루어졌으며 비교시 사회적 거리두기 기간과 수준으로 구분하였다. 이들 값은 각각 해당 표본 그룹의 평균값으로 주별 평균 교통사고 건수를 의미한다.
Table 5.
Results of overall traffic accidents for the COVID-19 period (2020-2021)
Table 5와 같이 코로나19를 가정하지 않은 상황에서 예측된 사고건수들은 모두 실제 사고건수 보다 높게 나타나 해당 기간 사고감소는 코로나19와의 연관이 있었던 것으로 추정된다. 2020년과 2021년의 2년 평균 사고건수 예측값은 1,098.6건/주이며 실제값은 1,027.3건/주으로 전체 –6.9%의 감소율을 나타냈다.
거리두기 기간별 변화 또한 두 개 년도에서 다르게 나타났다. 2년 평균 감소율(–6.9%)을 연도별로 각각 분석시, 2020년은 –9.9%(1,099.8 → 1,000.4건/주), 2021년은 –4.1%(1,097.3 → 1,054.2건/주)로 나타났다.
마지막으로 이 같은 사고감소는 거리두기 수준에 따라서도 다르게 나타났는데 Table 5와 같이 2020년과 2021년 모두 사회적 거리두기 수준이 높을수록 교통사고 감소가 크게 일어났다. 특히 2020년 높음 단계 기간에는 –14.3%(1060.8 → 928.0건/주)로 가장 큰 감소율을 기록했다.
2. 차종별 교통사고 분석결과
Table 6은 2013-2018년 사고 자료로 4개 모형이 예측한 2019년 교통사고에 대한 평가지표별 분석 결과이다.
Table 6.
Performance evaluation results by each model (traffic accidents by vehicle type)
Table 6에서와 같이 승용차(low occupancy vehicle, LOV), 승합차(high occupancy vehicle, HOV), 화물차(Truck)에서는 ARIMA 모형이 가장 뛰어난 예측력을 나타냈지만, 오토바이(Motorcycle) 사고는 STL+ETS 모형의 예측력이 ARIMA 모형 대비 근소하게 높은 것으로 나타났다.
ETS(Exponential Smoothing) 모형은 기본적으로 예측 시점을 기준으로 가장 최근의 관측치를 중요하게 다루기 때문에 그 이전 관측치는 미래에 대한 정보를 제공하지 않는다고 가정한다. 따라서, 모든 가중치가 마지막 관측치에 주어지는 가중 평균으로 계산된다는 점을 감안할 때, 타 차종 대비 한국의 오토바이 사고 특성(최근 높은 증가추세)을 STL+ETS 모형이 보다 정확히 분석한 것으로 판단된다.
또한, 문헌 고찰에서 살펴본 바와 같이 일부 선행연구에서 ANN과 Prophet 모형의 성능이 ARIMA 대비 높게 나타나기도 하였으나, 본 연구에서는 계절성(seasonality) 옵션을 반영한 ARIMAX 모형이 한국의 교통사고 특성을 보다 잘 예측한 것으로 나타났다.
Table 6의 결과를 토대로 승용차, 승합차, 화물차는 ARIMA 모형이, 오토바이는 STL+ETS 모형이 예측모형으로 선정되었으며 차종별로 2013-2019년까지의 자료를 통해 2020-2021년 교통사고를 예측한 사고 추이는 Figure 6과 같다. Figure 5와 마찬가지로 코로나19를 가정하지 않은 상황에서의 예측된 교통사고(주황색 선, 초록색 선)와 실제 교통사고의 추세선(검정색 선) 간 차이가 Figure 6을 통해 한눈에 파악되는데, 화물차와 오토바이의 경우는 승용차와 승합차 대비 상대적으로 그 차이가 크지 않음을 알 수 있다.
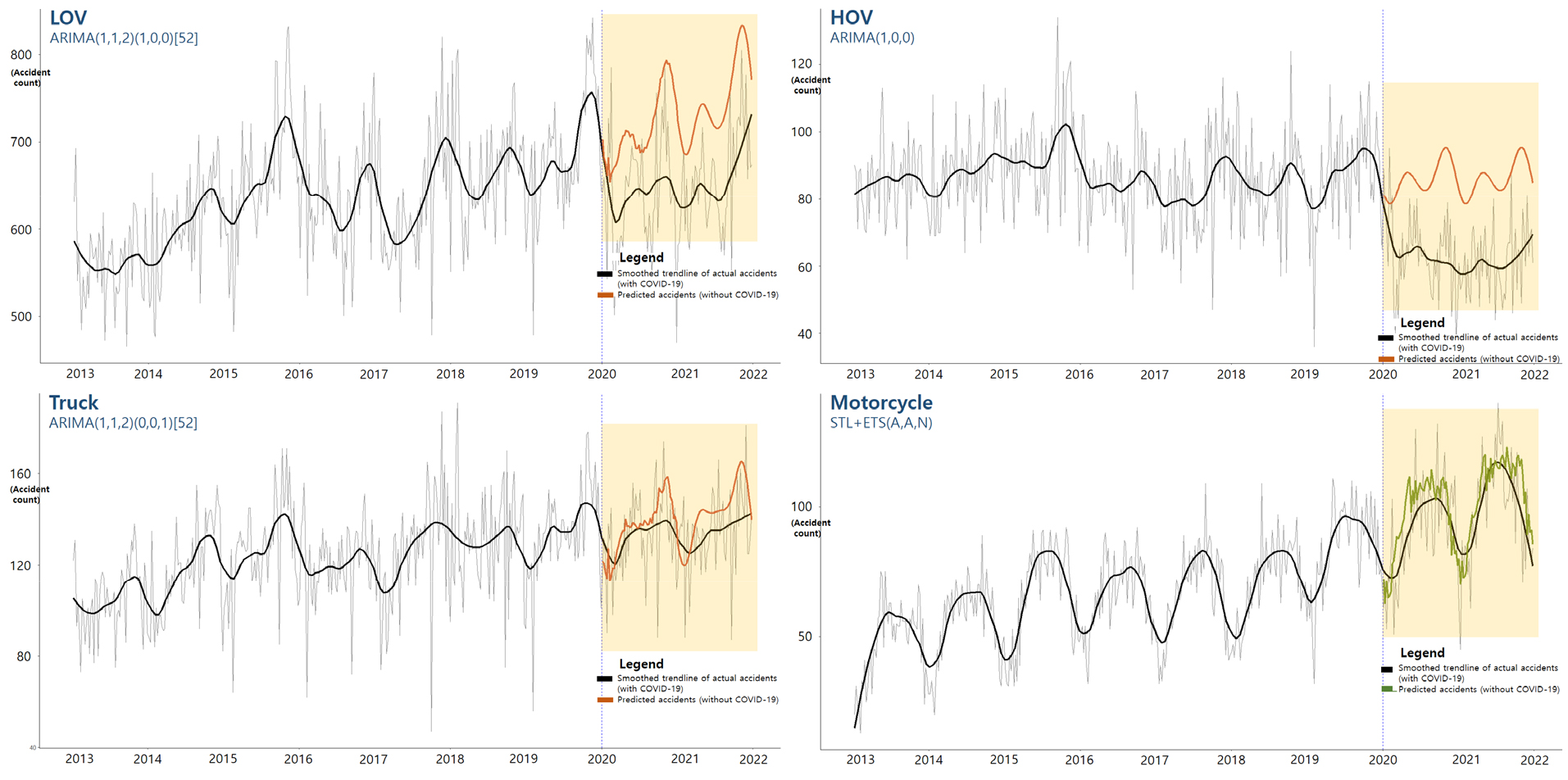
Table 7은 차종별 교통사고에 대해 2020-2021년 분석된 최종결과이다.
Table 7과 같이 차종별 분석결과에서도 예측된 사고건수들이 실제 사고건수 보다 높게 나타나 코로나19에 의한 사고감소 여부가 재확인되었다. 차종별 2년 평균 감소율은 승용차 –14.2%(749.8 → 656.8건/주), 승합차 –42.2%(88.1 → 61.9건/주), 화물차 –6.1%(144.9 → 136.5건/주), 오토바이 –3.8%(100.0 → 96.3건/주)로 차종간 큰 차이가 나타났다.
거리두기 기간별 감소율은 오토바이를 제외한 나머지 차종에서 2020년이 2021년 대비 높게 나타났으며 이는 전체사고와 같은 두 배 차이까지는 나지 않았다. 오토바이의 경우는 반대로 코로나19 2년차였던 2021년의 감소율(-6.1%)이 2020년 감소율(-1.6%) 보다 높게 나타났다.
마지막으로 사회적 거리두기 수준에 따른 결과이다. 승용차와 승합차의 경우 전체사고 결과와 마찬가지로 대체로 거리두기 수준이 높을수록 교통사고 감소가 크게 나타났으나, 화물차와 오토바이의 경우 사회적 거리두기 수준과는 큰 연관성을 보이지 않았다.
Table 7.
Results of traffic accidents by vehicle type for the COVID-19 period (2020-2021)
Discussion
4장의 분석 결과를 토대로 1장에서 제시한 두 가지 가설(two hypotheses)에 대한 논의이다.
먼저, 전제 가설(presupposed hypothesis)로 제시한 한국의 2020-2021년 교통사고는 정부의 코로나19 사회적 거리두기 정책과 연관이 있었던 것으로 나타났으며 이는 2장에서 살펴본 국외 주요 연구들의 결과와 맥락을 같이 하는 것으로 확인되었다. 다만 전체 교통사고 기준, 2년(2020-2021년) 평균 감소율은 약 –7%로 선행연구들 대비 상당히 낮은 수준을 기록했다.
이는 한국 정부의 코로나19 봉쇄정책(lockdown policy)에서 그 원인을 찾을 수 있다. 선행연구의 연구대상지가 대부분 전면봉쇄에 가까운 강력한 봉쇄정책을 펼친데 반해, 한국 정부는 사회적 거리두기라는 세분화된 단계구분으로 상황과 시기에 맞게 각종 제한조치의 수위를 조절해왔기 때문이다.
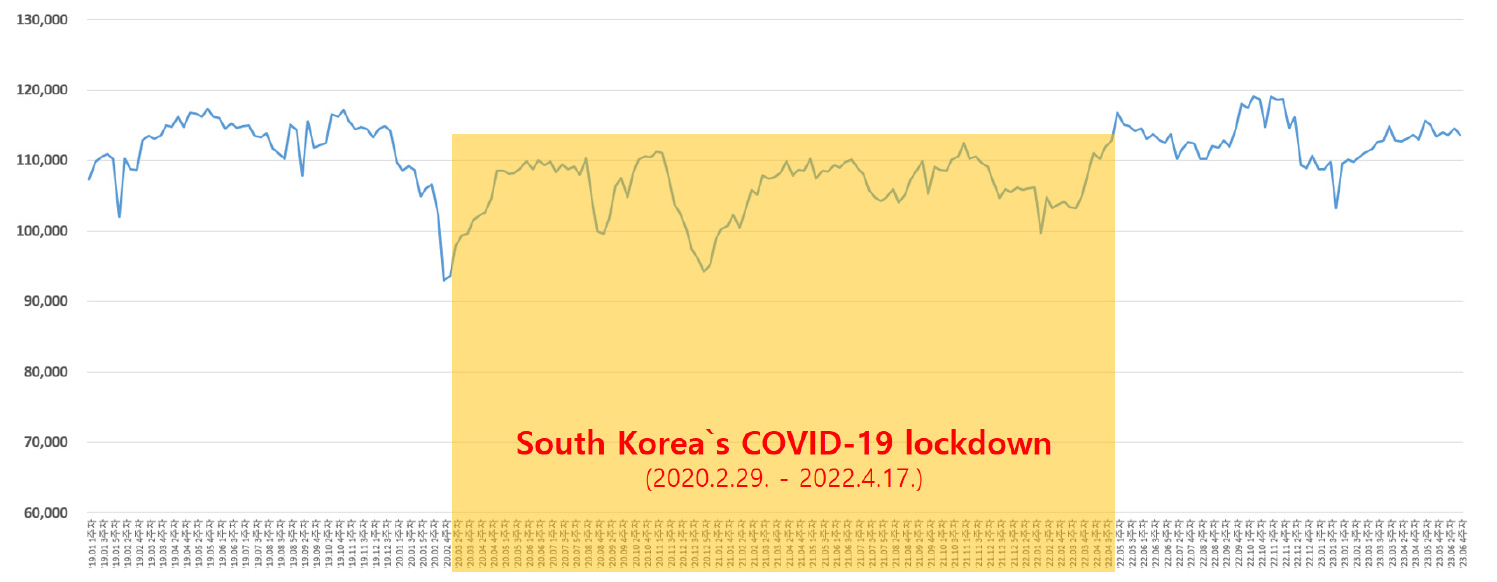
이는 인구이동량을 통해서도 유추 가능하다. 국외 주요 국가들은 봉쇄정책 기간내 이동량 및 통행량이 대폭 감소하였으나, 한국의 감소량은 상대적으로 크지 않았다. Figure 7은 국내 최대 통신사인 SK텔레콤에서 제공한 2019년 1월부터 2023년 6월까지 한국의 전국 인구 이동량 자료이다.7) 코로나19 발생전인 2019년의 전국 관내외 이동량은 115,000천명/일 수준이었으나, 코로나19로 사회적 거리두기 정책이 시행되었던 기간에는 전반적으로 약 10% 감소한 수준을 나타내고 있으며 거리두기가 종료된 2022년 4월부터는 다시 이전 수준으로 회귀하고 있다. 교통사고 발생빈도는 도로에 대한 이용자의 노출(exposure)과 깊은 관련이 있다. 노출이 사람의 통행(trip)에 직결된다는 점을 비추어 볼 때, 코로나19에 의한 통행량 감소가 결국 교통사고 감소에 영향을 미친 것으로 논의된다. 다만, 본 연구에서는 한국의 사회적 거리두기 정책으로 국외 주요국의 연구 결과 대비 확실히 감소량을 보였다.
또한, 차종별 분석 결과를 통해 교통사고 감소가 차종별 큰 차이를 나타내는 것으로 확인되었다. Table 7에서 알 수 있듯이 승합차8)의 경우 전반적으로 –40%의 사고감소가 나타난 반면, 화물차는 –6% 수준에 불과하였으며 오토바이는 분석 대상 차종 중 가장 낮은 수준을 기록했다.
Table 8은 2019년과 2020년에 대한 국토교통부 교통량 자료9) 및 이륜차 등록현황이다. Table 7의 2020년 분석결과를 Table 8의 YoY(Year over Year)와 함께 비교해보면 코로나19 전후 승용차 교통량 변화가 -1.7%인 반면, 교통사고는 –15.5%가 나타나 교통량 대비 훨씬 높은 사고감소가 있었던 것으로 추측된다. 승합차의 경우 버스 교통량 변화(-44.6%)와 본 연구에서 분석한 사고감소(-44.4%)가 거의 일치하였다. 화물차의 경우는 교통량 변화가 +3.0%인 반면 사고감소는 –6.2%가 나타났다. 마지막으로 오토바이는 이륜차 등록대수가 –2.3% 감소한 반면 사고감소는 –1.6%에 그쳤던 것으로 나타났다. 오토바이는 교통량이 아닌 등록대수를 근거로 판단하였으나, 원동기장치자전거 현황을 알 수 없는 관계로 정확한 논의는 어렵지만 분석대상 차종 중에서는 가장 낮은 감소율을 나타냈다. 이는 결국 코로나19에 의한 단체여행 수요의 급감, 그리고 택배사업 등 비대면 거래와 배달문화의 확대라는 한국 사회의 생활양식 변화를 암시한다. 교통량을 감안한 차종별 교통사고에서는 승용차가 코로나19에 의한 사고감소 영향을 가장 크게 받은 것으로 추측된다.
다음으로, 선행연구들과 차별화하여 주 가설(main hypothesis)로 제시한 교통사고 감소 정도는 사회적 거리두기 기간 및 수준에 따라 상이한 결과가 나타난 것으로 분석되었다. Table 5 및 Table 7을 통해 알 수 있듯이 오토바이를 제외한 나머지 차종의 교통사고는 코로나19 첫해였던 2020년에 더욱 크게 감소하였다. 이는 한국 정부의 사회적 거리두기 정책이 초기에는 큰 효과를 거두었으나, 시간이 흐를수록 코로나19에 대한 국민들의 인식 변화(두려움 감소)에 따라 그 효과가 낮아진 것으로 사료된다.10)
Table 8.
ADT status by vehicle & road type, and two-wheeled vehicle registration (2019-2020)
사회적 거리두기 수준에 따른 사고감소의 크기는 전체사고, 승용차, 승합차에서는 거리두기 강도가 높을수록 큰 폭의 사고감소가 나타난 반면, 화물차와 오토바이는 이와 연관성이 없는 것으로 나타났다. 이는 화물차와 오토바이의 주된 통행목적이 물류운송과 배달이기 때문인 것으로 생각된다. 한국 정부의 사회적 거리두기 단계 중, 고강도 제한조치가 교통사고 감소측면에서 만큼은 긍정적으로 평가 받을 수 있음을 시사한다.
Conclusions
본 연구에서는 한국에서 시행한 코로나19 사회적 거리두기와 교통사고의 연관성을 분석하기 위해 경기도에서 최근 10년간(2013-2022년) 발생되었던 교통사고 자료와 사회적 거리두기 자료를 수집하였다. 주 단위의 교통사고 자료구축을 통해 선행연구 대비 훨씬 많은 수준의 표본을 확보하였으며, 이를 통해 4개의 시계열 모형(ARIMAX, STL+ETS, ANN, Prophet)으로 전체사고뿐만 아니라 차종별 교통사고까지 분석하였다.
연구 결과, 선행연구들과 같이 한국에서도 코로나19 방역 정책에 의해 교통사고건수가 감소한 것으로 나타났으나 감소 효과는 전반적으로 선행연구 대비 낮은 수준을 기록했다. 또한, 최근 연구 동향에서 찾기 어려웠던 차종 및 거리두기 기간과 수준에 따른 분석으로 한국의 사회적 거리두기 정책 특성에 따른 교통사고 변화가 확인되었다.
본 연구의 결과는 당국의 정책결정권자와 실무자들에게 많은 도움이 될 수 있을 것이다. 특히, 향후 또 다른 팬데믹 상황에서 방역 정책 수행의 기초자료로도 활용 가능할 것으로 보인다. 아울러 시계열 모형을 통한 교통사고 분석에 관심이 있는 연구자들에게는 이와 관련한 통찰력을 제공할 수 것으로 기대된다.
상기와 같은 시사점에도 불구하고 본 연구는 다음과 같은 한계점들이 존재한다. 첫째, 본 연구의 시계열 분석에는 교통사고 자료만을 다룬 한계가 있다. 따라서, 이들 자료 외 도시부에서 수집 가능한 통행속도 자료 등이 추가된다면 더욱 의미 있는 연구가 이루어질 것으로 생각된다. 특히 도시부의 교통량 감소에 따른 통행속도 증가시의 사고심각도 변화, 사고 유형 중 후미추돌과 같은 유형의 교통사고 변화 등에 대한 연구가 가능할 것으로 보인다. 둘째, 시계열 자료의 자체적 특성에 따른 결과의 정확도를 위해 본 연구에서는 4개의 모형을 사용하였지만 보다 더 많은 모형들을 활용할 필요성도 있다. 특히 시계열분석법 중 최근 활용도가 높아지고 있는 머신러닝 기반의 causal impact 분석 모형인 BSTS(Bayesian Structural Time Seriese) 모형, 그리고 딥러닝 분야의 LSTM(Long Short-Term Memory) 모형을 통한 분석도 적용해 볼 필요가 있을 것으로 판단된다. 마지막으로 교통사고가 결국 교통량과의 밀접한 관계를 보이기 때문에 이 부분에 대한 심도있는 연구가 필요하다. 본 연구에서는 거시적인 교통량 자료를 활용했지만, 특정 지역을 대상으로 신뢰성 있고 상세한 교통량 자료를 활용한다면 교통사고와의 관계를 구체적으로 규명할 수 있을 것으로 판단된다.
