

서론
세계 무역의 약 90%가 항만을 통해 이루어지고 있다(Khan et al., 2022; Chauvin et al., 2013). 항만은 해상과 육상의 경로가 만나는 중요한 교차점으로서 대규모 화물 유통의 중심지 역할을 하며 국가 경제 발전에 크게 기여하고 있다. 그러나 이러한 중요성에도 불구하고, 항만에서 일하는 근로자의 안전은 여전히 사각지대로 인식되고 있다. 한국해양수산개발원(Korea Maritime Institute, KMI)에 따르면, 2019년 0.66%였던 항만 사고 재해율이 2020년 0.68%로 증가하였다. 특히, 2019년 전체 평균 산업 재해율이 0.50%, 2020년에는 0.49%로 나타나 항만 사고 재해율이 전체 평균 산업 재해율보다 매년 높은 수치를 보이는 것을 확인할 수 있었다. 이는 국가적인 차원에서 항만 안전에 대한 주의와 개선의 필요성을 강조하고 있다(Korea Maritime Institute, 2021).
기존의 대부분 항만 안전 연구는 주로 항만 사고를 실시간으로 예측하고 감지하는 데 중점을 두고 있다(Son et al., 2020; 2021, Kim and Kim, 2021). 이러한 연구들은 항만 내 위험에 선제적이고 즉각적으로 대응할 수 있도록 도와주지만, 항만에서 심각한 사고를 예방하기 위해서는 근본적으로 이러한 사고의 원인을 이해하고 잠재적인 위험 요소를 해결하는 것이 필요하다. 항만 사고 특성을 분석하는 대부분의 연구는 통계적 방법을 사용했다(Budiyanto and Fernanda, 2020; Zhang et al., 2016; Fuentes-Bargues et al., 2017; Azevêdo et al., 2021; Fabiano et al., 2010; Uğurlu et al., 2020; Qiao et al., 2020; Chin and Debnath, 2009; Zhang et al., 2018).
기계 학습은 인과 관계 이해를 방해하는 블랙 박스 특성 때문에 기존의 사고 요인 분석 연구에서 널리 사용되지 못했다. 그러나 최근 블랙 박스 모델을 해석할 수 있는 설명 가능한 인공지능(eXplainable Artificial Intelligence, XAI)의 등장으로 기계 학습이 사고 심각도 분석에도 사용되고 있다(Yang et al., 2021; Amini et al., 2022; Lee et al., 2023; Ahmed et al., 2023; Madushani et al., 2023, Min et al., 2023). Yang et al.(2021)은 XAI 기술인 Shapley additive explanation(SHAP)을 XGBoost 모델과 결합하여 트럭 사고와 관련된 주요 요인을 식별했다. Amini et al.(2022)은 랜덤 포레스트 기계 학습 알고리즘을 기본 모델로 하여 leave-one-column-out(LOCO) 및 TreeExplainer(TE)와 같은 XAI 기술을 탐구하여 사고 심각도에 영향을 미치는 요인을 식별했다. Lee et al.(2023)은 Light gradient-boosting machine(LightGBM)이라는 오픈 소스 그래디언트 부스팅 프레임워크를 기반으로 SHAP 및 local interpretable model-agnostic explanations(LIME)이라는 XAI 기술을 활용하여 보행자 사고에서 보행자 부상 심각도에 영향을 미치는 주요 요인을 식별했다. Ahmed et al.(2023)은 사고 심각도에 영향을 미치는 필수 요인을 식별하기 위해 SHAP 기반의 XAN(Explainable Analytics) 프레임워크를 제안했다. Madushani et al.(2023)은 SHAP 및 LIME이라는 XAI 기술을 기반으로 스리랑카 고속도로 사고 심각도에 영향을 미치는 고속도로 운영 조건 요인을 식별했다.
기계 학습은 예측 면에서 전통적인 통계 분석 방법보다 일반적으로 더 나은 성능을 보인다. 본 연구의 주요 목적은 이러한 기계 학습 기법을 활용하여 항만 터미널의 사고 데이터를 기반으로 사고 심각도 예측 모델을 개발하는 것이다. 또한, 설명 가능한 인공지능(XAI)을 사용하여 항만 사고의 심각도에 영향을 미치는 주요 요인을 추출하였다. 항만 터미널은 각 구역의 특성과 중장비의 종류가 다양하여, 이러한 이질성이 사고에 미치는 영향을 반영하는 것이 중요하다. 따라서 본 연구에서는 항만 사고의 이질적인 특성을 고려한 군집 기반 사고 심각도 예측 모델을 구축하는 것을 또 다른 목표로 삼았다.
본 논문의 나머지 부분은 다음과 같이 구성되어 있다. 2장 “방법론”에서는 연구에 사용된 방법론을 설명하며, 3장 “데이터 설명”에서는 항만 사고 데이터와 사용된 변수를 제시한다. 4장 “분석 결과”에서는 본 연구의 결과를 제시하며, 마지막으로 5장 “결론”에서는 연구 결과에 대한 논의와 향후 연구과제 및 기대효과를 제시한다.
방법론
1. 데이터 증강
본 연구는 데이터 구축, 변수 선택 및 군집화, 사고 심각도 분석의 세 가지 주요 단계로 구성되며, 전체적인 프레임워크는 Figure 1과 같다. 첫 번째 단계는 항만 사고 분석을 위한 사고 데이터를 구축하는 것이다. 사고 데이터는 예외적으로 희소하며 랜덤한 이벤트로 구성되어 있어 데이터 개수가 제한적이다. 이로 인해 사고 모델링 시 표본 크기 문제로 인한 오류가 발생할 가능성이 존재한다(Jeong et al., 2018; Zhu et al., 2024). 특히 항만의 경우 폐쇄적인 특성 때문에 사고 데이터를 얻기가 어려워, 사고 모델 구축 시 표본 크기를 늘리는 것이 필수적이다. 또한, 본 연구에서 수행한 군집화 과정에서 샘플 수가 감소한 점 역시 데이터 증강을 시도한 주요 이유 중 하나이다. 최근 연구들에서는 사고 데이터의 불균형 문제를 해결하고 사고 위험 예측 모델을 개발하며 고위험 지역을 식별하기 위해 데이터 증강 기법을 채택하고 있다(Ashraf et al., 2023; Morris and Yang, 2021; Islam et al., 2021). 이에 따라, 본 연구에서는 데이터 증강 기법인 random oversampling examples(ROSE) 기법을 사용하여 기존 사고 데이터를 증강했다.
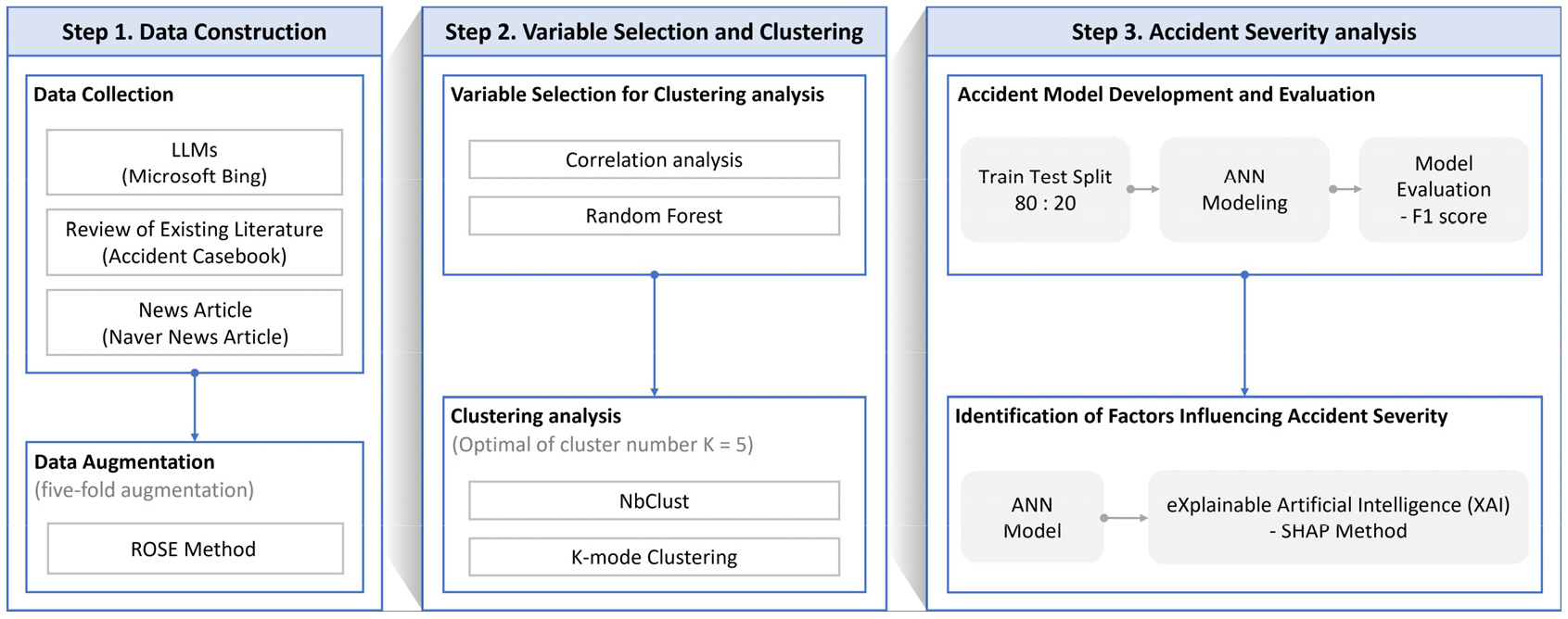
ROSE 기법은 데이터 불균형 문제를 해결하기 위해 Menardi and Torelli(2014)에 의해 고안되었다. 이 기법은 스무딩된 부트스트랩 기반 기술을 사용하여 데이터를 샘플링한다. 부트스트래핑은 새로운 샘플을 추출할 수 없을 때 사용하는 재샘플링 방법으로, 원본 데이터를 반복적으로 재샘플링하여 데이터를 생성하며 오버샘플링 기술의 기초를 형성한다. ROSE 기법에서 사용되는 스무딩된 부트스트랩 기반 기술은 전통적인 부트스트래핑의 통계적 유의성을 검증할 수 없다는 한계를 극복할 수 있다. 대표적인 오버샘플링 방법인 Synthetic Minority Oversampling Technique(SMOTE)은 입력으로 제공되는 기존의 소수 사례로부터 새로운 사례를 생성하여 데이터셋 내의 사례 수를 균형 있게 증가시키지만, ROSE는 SMOTE 보다 관측치에 덜 종속적인 특징을 가진다(Zhang and Chen, 2019). 따라서, 본 연구에서는 ROSE 기법을 사용하여 항만 터미널에서 발생한 물피 사고와 부상 사고 데이터를 원본 데이터 사고 심각도 비율을 유지하면서 증강하였다. 이때, 데이터 증강 배율을 5배, 10배로 각각 적용하여 모델 성능을 비교 분석한 결과, 5배 증강된 데이터셋을 활용한 모델이 더 우수한 성능을 보였다. 이에 따라, 최종적으로 5배 증강된 데이터를 사용한 모델 결과만을 제시하였다.
2. 변수 선택 및 군집화
항만 터미널에서 발생하는 사고는 날씨, 발생 시간, 발생 장소 등 다양한 요인에 의해 영향을 받는다. 즉, 하나의 모델을 사용하여 서로 다른 유형의 사고 심각도 요인을 예측하는 것은 예측 성능을 저하할 수 있거나 특정 변수에만 의존하는 모델을 초래할 수 있다(Park et al., 2023). 따라서 본 연구에서는 항만 사고 데이터를 증강하고 군집화하여, 군집 데이터와 비군집 데이터를 사용한 사고 심각도 예측 모델의 예측 성능을 비교 분석했다. 데이터 군집화를 위한 변수 선택에는 상관 분석과 Random Forest 기법을 사용했으며, NbClust 패키지를 활용하여 최적의 K를 도출한 후 K-modes clustering 기법을 통해 군집화했다.
1) 군집 분석을 위한 변수 선택
데이터 군집화를 위한 변수 선택을 위해 상관 분석과 Random Forest 분석을 수행했다. Pearson 상관계수는 Cauchy–Schwarz 부등식으로 인해 수학적으로 -1에서 +1의 범위로 제한되며, 절댓값이 1인 계수는 변수 간의 강한 상관관계를 의미한다(Cohen et al., 2009). Random Forest를 사용하여 변수 중요도를 도출할 때, 본 연구는 중요도 계산에서 발생할 수 있는 오류를 방지하기 위해 종속 변수(사고 심각도)와 최소 0.8 이상의 강한 상관관계를 가진 독립 변수를 제거했다.
Random Forest는 여러 학습 알고리즘을 활용하여 예측력을 향상시키는 앙상블 기계 학습 기법이다. 이는 동일한 알고리즘을 사용하여 여러 분류기를 생성하고 투표 시스템을 통해 최종 결정을 내리는 배깅 알고리즘에 속한다. Random Forest 알고리즘을 사용하면 원본과 동일한 여러 데이터셋이 생성되고, 각각의 구축된 의사 결정 나무에서 최적의 결과가 도출된다. Random Forest는 일반적으로 분류 및 회귀 모델을 구축하는 데 사용된다. 많은 나무를 생성하여 메모리 사용량이 많아지고 훈련 시간이 길어지는 단점이 있지만, 훈련 데이터의 과적합을 방지하며 변수 중요도 평가를 용이하게 할 수 있다는 장점이 있다(Rigatti, 2017). 본 연구에서는 Random Forest 평가 지표인 IncNodePurity를 사용하여 변수 중요도를 도출했다. IncNodePurity는 생성된 모든 의사 결정 나무에서 평균 제곱 오차의 감소를 나타내며, 값이 클수록 변수 중요도가 높음을 의미한다. 본 연구에서는 IncNodePurity 값이 급격히 변화하는 지점을 기준으로 상위 중요 변수를 도출하고, 이러한 변수들을 사용하여 군집 분석을 수행했다.
2) 군집 분석
군집 분석은 기존에 레이블이 없는 데이터를 유사한 특징을 가지진 데이터끼리 그룹화하는 대표적인 비지도 학습 기법이다. 항만 사고 데이터는 연속 변수가 아닌 이진 변수로 구성되어 있으므로, 본 연구에서는 이진 변수도 처리할 수 있는 K-modes clustering 기법을 사용했다. K-modes clustering 기법은 K-means clustering 기법과 유사하게 미리 정해진 클러스터 수를 설정하고, 각 클러스터의 중심을 결정하여 클러스터를 할당합니다. 본 연구에서는 변수들이 범주형이므로 각 클러스터의 중심은 평균 대신 최빈값을 사용하여 계산된다(Chaturvedi et al., 2001).
K-modes clustering 분석 전, 최적 클러스터 수 K를 결정하는 데 엘보우 방법 및 클러스터 내 제곱합 계산과 같은 여러 방법론이 사용될 수 있다. 본 연구에서는 최적 클러스터 수를 결정하기 위해 R 패키지인 NbClust를 사용했다. NbClust는 다양한 지표를 종합적으로 비교하여 최적 클러스터 수를 결정할 수 있게 하는 패키지로, CH, CCC, Pseudot2를 포함한 30개의 평가 지표를 제공한다(Charrad et al., 2014). 30개 지표 비교 결과, 본 연구는 최적 군집 수를 5개로 결정하고 군집 분석을 수행했으며, 군집 분류에 사용된 변수들의 빈도 분석을 통해 각 클러스터의 특성을 정의했다.
3. 사고 심각도 분석
본 연구에서는 사고 심각도 모델을 개발하기 전, Pearson 상관 계수 분석 결과를 바탕으로 상관 관계가 높은 변수(상관 계수 0.4 이상)를 제거하여 변수 간 높은 상관 관계로 인해 발생할 수 있는 모델 추정 오류를 방지했다. 기계 학습 기법으로는 인공 신경망(ANN)을 사용하여 비군집 데이터셋과 군집 데이터셋에 대한 사고 심각도 모델을 각각 개발하고 예측 성능을 비교했다. 모델의 예측 성능을 비교하는 것 외에도, 본 연구는 항만 사고의 심각도에 영향을 미치는 주요 요인을 도출했다. 기계 학습 기법은 모델 자체만으로는 해석하기 어려운 블랙박스 모델이기 때문에, 본 연구에서는 모델 개발에 사용된 주요 변수와 그 영향을 해석하기 위해 개발된 ANN 모델에 설명 가능한 인공지능(XAI) 기법을 적용했다.
1) 인공 신경망(Artificial Neural Network, ANN)
신경망(Neural networks)은 인간 신경계의 원리와 구조에서 영감을 받아 개발된 매우 정교한 분석 기법이다(Delen et al., 2006). 인공 신경망(ANN)은 사고 심각도 데이터를 모델링하는 데 여러 가지 장점을 제공한다. ANN은 높은 예측 정확도와 뛰어난 유연성을 자랑하며, 매우 복잡한 비선형 함수도 모델링할 수 있다. 그러나 ANN에 대한 일반적인 단점으로는 학습 시간이 길고, 모델 해석이 어려우며, 과적합의 위험이 존재한다는 점이 있다(Wen et al., 2021a). ANN 모델의 일반적인 수학적 표현은 다음 Equation 1과 같다:
여기서, : 모델의 정규화된 출력
: 활성화 함수
: 출력층 뉴런의 편향
: 출력층 뉴런과 은닉층의 k번째 뉴런 사이의 가중치
: 은닉층의 k번째 뉴런의 편향
: 입력층의 i번째 뉴런과 은닉층의 k번째 뉴런 사이의 가중치
: 입력층의 i번째 변수(뉴런)의 정규화 값
: 입력 변수의 수
: 은닉층의 뉴런 수
본 연구에서는 ANN 모델을 최적화하기 위해 layer를 조정하였으며, 도출된 하이퍼파라미터는 Table 1에 제시되어 있다.
2) 모델 성능 평가
본 연구에서는 혼동 행렬을 기반으로 정확도(Accuracy), 재현율(Recall), 정밀도(Precision), F1-score와 같은 평가 지표를 계산하여 모델의 예측 성능을 비교 및 평가했다. 혼동 행렬은 모델의 예측 성능을 다각도로 평가하기 위한 지표를 제공하며, 학습된 모델의 예측 결과와 실제 결과를 비교하여 모델의 유형별 성능을 파악할 수 있다. 본 연구에서는 물피 사고를 음성(0)으로 정의하고, 부상 사고를 양성(1)으로 정의했으며, 정확한 예측을 참(true), 잘못된 예측을 거짓(false)으로 정의했다. 혼동 행렬은 True Negative(TN), False Positive(FP), False Negative(FN), True Positive(TP) 결과로 구성되며, 평가 지표는 다음 Equations 2,3,4,5를 통해 도출할 수 있다(Caelen, 2017).
여기서, Accuracy는 실제 분류 범주를 올바르게 예측한 비율을 의미하며, Recall은 실제 양성 케이스 중에서 모델이 정확히 감지한 비율로, 2종 오류(실제로는 양성이지만 음성으로 잘못 분류한 경우)를 줄이는 데 중점을 둔다. Precision은 모델이 양성으로 예측한 것 중에서 실제 양성인 비율을 나타내며, 1종 오류(실제로는 음성이지만 양성으로 잘못 분류한 경우)를 줄이는 데 중점을 둔다. 그리고 F1-score는 Precision과 Recall의 조화 평균으로, Precision과 Recall의 균형을 고려하여 모델의 성능을 평가하는 지표이다(Caelen, 2017).
3) 모델 해석
모델의 예측 성능도 중요하지만, 결과의 해석 가능성도 중요한 고려 사항이다. 모델의 이해를 바탕으로 결과를 해석할 수 있어야 적절한 의사 결정을 할 수 있으며, 신뢰할 수 있는 모델을 생성하기 위해서 기계 학습 모델의 해석 가능성은 매우 중요하다. 기존의 기계 학습 방법론에서는 결과를 해석하고 그 이면의 이유를 밝히는 것이 어려웠다. 설명 가능한 인공지능(XAI)은 이 문제를 해결하기 위해 고안된 새로운 기법으로, AI가 내린 결정의 근거를 설명할 수 있도록 한다. 본 연구에서는 분석 결과에 영향을 미치는 주요 요인을 식별하기 위해 XAI 방법론 중 하나인 SHAP(SHapley Additive exPlanations) 기법을 적용했다. SHAP 기법은 게임 이론의 Shapley 값 개념을 사용하여 각 특성(feature)이 모델 예측에 얼마나 중요한지를 설명하는 방법이다(Wen et al., 2021b). SHAP 기법은 특정 예측과 관련하여 각 특징에 중요도 값을 할당하고, 다수의 독립 변수가 종속 변수에 미치는 결합 영향을 Shapley 값을 사용하여 분석하고 측정할 수 있다(Lundberg and Lee, 2017). Shapley 값은 Equation 6, 7로 도출할 수 있다:
여기서, : feature i의 기여도
: n개의 요인을 포함하는 집합
: feature의 부분 집합
: 집합 S의 크기
: 모든 feature의 수
: 부분 집합 S에 대한 가치 함수
여기서, 은 입력 feature의 개수를 나타내며, 은 에 속한다. feature가 관측되면 =1이 되고, 그렇지 않으면 =0이 된다(Guo et al., 2022). 본 연구에서는 SHAP 기법을 R의 DALEX 패키지를 이용하여 구현하였으며, 모델의 각 특성이 예측에 미치는 영향을 분석하고 해석하였다.
데이터 설명
1. 데이터 배경 및 수집
본 연구에서는 2017년부터 2022년까지 6년 동안 대한민국 항만 터미널에서 발생한 사고 데이터를 문헌 고찰과 데이터 크롤링을 통해 수집하였다. 데이터 수집은 부산, 여수·광양, 인천, 제주, 평택·당진항 총 5개의 항만을 대상으로 수행되었다. 부산항의 사고 데이터는 부산항 터미널 주식회사가 발행한 사고 사례집을 통해 수집하였다(Busan Port Terminal Co., Ltd., 2017; 2019). 부산항을 제외한 나머지 4개 항만의 경우 사고 사례집 접근이 어려워 Microsoft Bing을 이용하여 뉴스 기사를 크롤링하여 데이터를 수집하였다. Bing은 Google 검색을 기반으로 정보를 제공하며, 본 연구는 대한민국 항만 터미널에서 발생한 사고 데이터를 수집하는 것을 목적으로 하기 때문에 대한민국의 주요 검색 엔진인 네이버에서도 뉴스 기사를 검색을 통해 데이터 수집을 추가로 진행하였다. 크롤링 과정에서는 데이터 중복을 방지하기 위해 동일한 사고 발생 일자를 가진 기사들을 먼저 식별하였으며, 그 중 사고 내용을 가장 구체적으로 서술한 기사를 주 기사로 선정하고, 나머지 중복된 기사는 삭제하였다. Table 2는 이러한 데이터 수집 과정을 통해 확보된 각 항만별 사고 데이터 개수를 제시한다.
Table 2.
Accident data collected based on spatial background
| Category | Busan port | Other four port | Total |
| Property damage only | 387 | 0 | 387 |
| Injury | 53 | 11 | 64 |
| Total | 440 | 11 | 451 |
데이터 수집 결과, 총 451건의 사고 데이터를 수집하였으며, 그 중 물피사고는 387건, 부상 사고는 64건이었다. 부산항을 제외한 나머지 네 개의 항만 터미널에서는 물피 사고를 수집하지 못했는데, 이는 뉴스 기사가 주로 노동자 사망과 같은 중대한 사고만 보도하는 경향이 있기 때문인 것으로 판단된다.
2. 데이터 설명 및 통계
본 연구에서는 컨테이너 터미널을 세 구역으로 구분하고 있다(Figure 2 참고). 첫 번째 구역은 에이프런(Apron) 구역으로, 선석(Berth)을 따라 나란히 위치하여 정박한 선박이 컨테이너 하역을 할 수 있도록 관련 시설을 갖추고 있다. 이 구역에서 갠트리 크레인은 항만에서 바다에 가장 가까운 지점에 설치되어 컨테이너의 적재 및 하역을 가능하게 한다. 두 번째 구역은 야드(Yard) 구역으로, 적재 또는 하역 예정인 컨테이너들이 배열돼있는 공간이다. 이 구역에는 야드 내에서 컨테이너를 적재하고 하역하는 트랜스퍼 크레인이 위치 해있다. 세 번째 구역은 게이트(Gate) 구역으로, 컨테이너와 컨테이너 화물의 수령과 인도를 관리하는 장소이다. 이 구역에는 컨테이너 화물 조작장(Container Freight Station, CFS)과 게이트(Gate), 그리고 관리 사무소(administration office)가 위치해 있다.
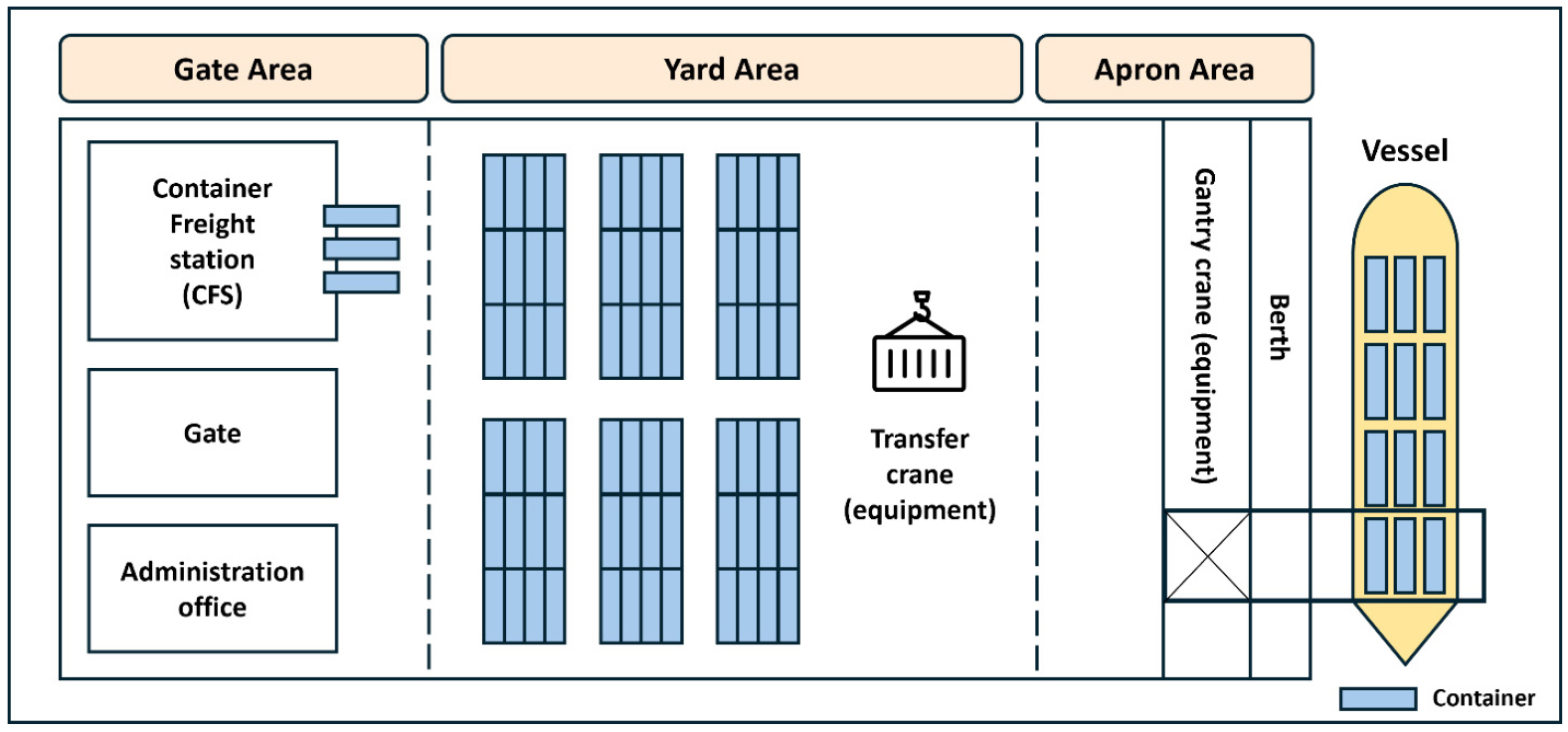
본 연구에서는 사고 분석을 위해 사고 위치를 야드, 에이프런, 선박, 기타 네 구역으로 나누었다. 이러한 분류 기준은 각 위치에 사고 수가 고르게 분포되도록 설정하였다. 야드에는 야드 구역에서 발생한 사고가 포함되며, 에이프런에는 에이프런 구역 중 선석을 제외한 공간에서 발생한 사고가 포함된다. 선박에는 터미널에 정박한 선박 위에서 발생한 사고가 포함되며, 기타는 야드, 에이프런, 선박을 제외한 구역에서 발생한 사고를 포함한다.
본 연구에서 선택된 도로 환경 특성 및 사고 정보에는 계절(봄, 여름, 가을, 겨울), 시간(주간, 야간), 위치(야드, 에이프런, 선박, 기타), 교차로 관련 여부(유, 무), 외부 차량 관련 여부(유, 무), 주요 피해 내용(부상, 시설, 외부 차량, 장비, 컨테이너), 사고 원인(근로자 과실, 기계적 원인, 자연적 원인, 기타), 사고 관련 장비(이동장비, 갠트리 크레인, 트랜스퍼 크레인, 외부 차량, 기타)가 포함된다. Table 3은 항만 사고 심각도 분석에 사용된 데이터셋의 변수와 변수의 기본 통계값을 제시하고 있다.
Table 3.
Variable set for port severity analysis
사고는 드물게 발생하는 이벤트이며 특히 항만은 폐쇄적인 특성으로 인해 사고 데이터를 얻는 것은 어려운 일이다. 이에 본 연구에서는 사고 데이터 부족 문제를 해결하기 위해 R의 ROSE 함수를 사용하여 오버샘플링을 수행했다. 사고 심각도 분석 시, 데이터셋의 불균형이 모델 결과에 미치는 영향이 적다는 점을 고려하여 본 연구에서는 종속 변수인 물피 사고와 부상 사고의 비율을 기존 데이터셋의 비율(1:0.14)과 동일하게 유지하며 데이터를 5배 증강하였다.
분석 결과
상관 분석을 통해 종속 변수인 사고 심각도와 상관계수가 0.8 이상인 독립 변수를 식별한 결과, 해당 기준을 충족하는 독립 변수인 "주요 피해 사항 - 부상" 변수를 모델 구축 시 제외하였다. 군집 분석 시 활용할 변수 선택을 위해 Random forest 변수 중요도 분석을 수행한 결과, "주요 피해 세부 사항 - 부상" 변수를 제외한 28개의 변수 중 8개의 변수가 높은 중요도를 가지는 것으로 확인되었으며, 해당 변수들에 대한 자세한 설명은 Table 4에 제시하였다.
Table 4.
Random Forest variable importance assessment results
군집 분석 전 NbClust 패키지를 사용하여 최적의 군집 개수 K를 도출하였고, 분석 결과 최적의 K는 5로 결정되었다. K=5로 설정하고 K-modes clustering을 수행한 결과, 총 2,255건의 사고 중 309건은 군집 1로, 881건은 군집 2로, 436건은 군집 3으로, 124건은 군집 4로, 505건은 군집 5로 분류되었다.
군집 별 핵심 특성은 빈도 기반 그래프 비교를 통해 도출하였다. 핵심 특성을 정의하기 위해, Figure 3(a) “주요 피해 내용”과 Figure 3(f) “심각도” 변수 그래프에서는 각 군집 내에서 가장 높은 빈도를 가진 특성을 핵심 특성으로 선택하였고, 나머지 변수 그래프에서는 해당 변수에서 5가지 군집 중 가장 높은 빈도를 보인 군집을 해당 군집의 핵심 특성으로 선택하였다.
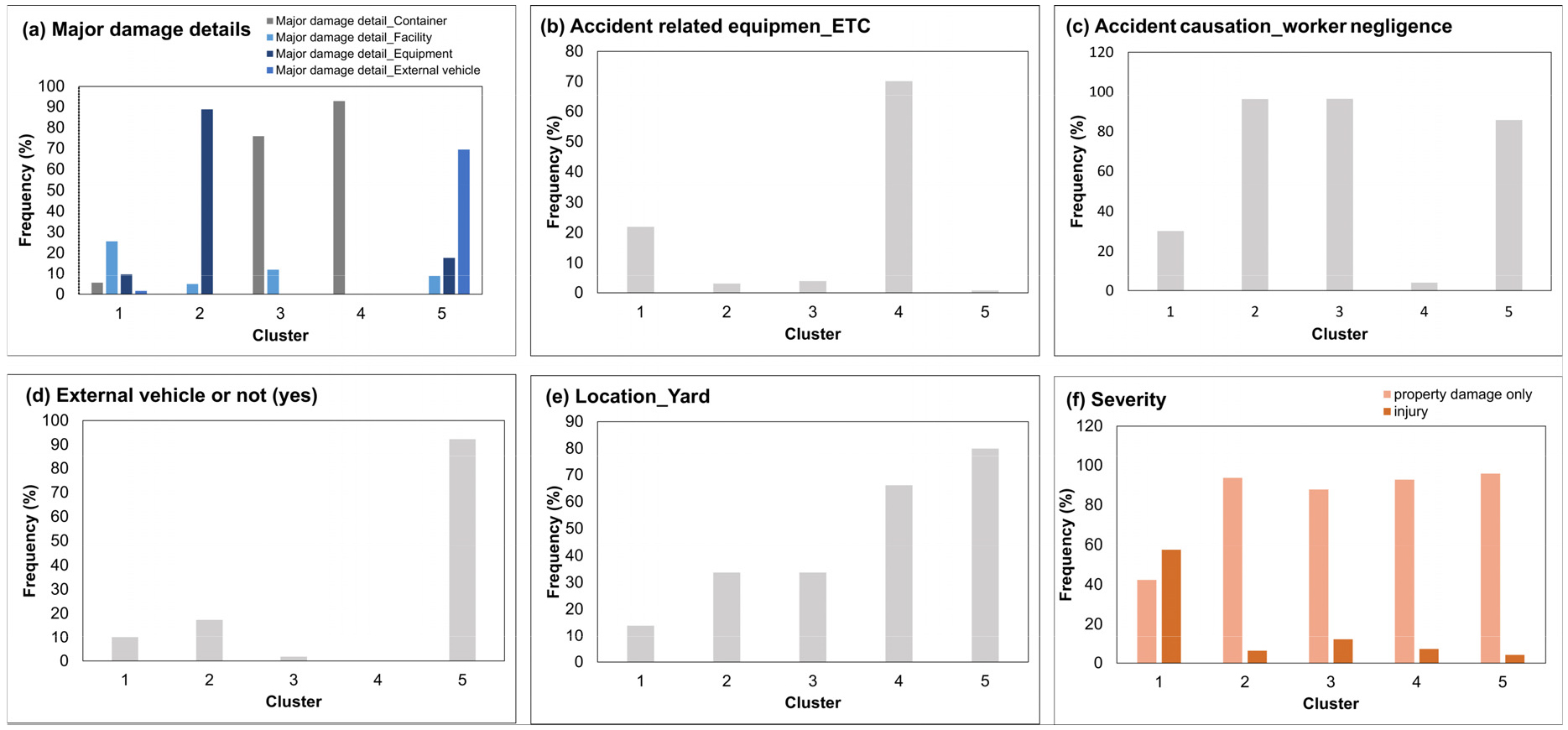
빈도 그래프 비교 및 분석을 통해 정의된 군집별 특성은 다음과 같다. 군집 1은 시설 피해와 부상을 초래하는 사고를 주요 특성으로 가지고 있다. 군집 2는 근로자 과실로 인한 장비 피해와 물피가 발생하는 사고를 주요 특성으로 가진다. 군집 3은 근로자 과실로 인한 컨테이너 피해와 물피가 발생하는 사고를 주요 특성으로 가진다. 군집 4는 이동 장비, 갠트리 크레인, 트랜스퍼 크레인, 외부 차량과 관련되지 않은 물피가 발생하는 사고를 주요 특성으로 가진다. 군집 5는 야드에서 발생하는 외부 차량 피해와 물피가 발생하는 사고를 주요 특성으로 가진다. 이와 같은 결과를 통해 각 군집의 특성을 명확히 정의할 수 있었으며, 군집 별 변수의 빈도 그래프는 Figure 3에 제시되어 있다.
군집 분석 수행 후, 군집 데이터와 비군집 데이터 모두에 대해 변수 간 상관 분석을 진행하여 사고 심각도 모델을 개발할 변수 선택을 진행했다. 상관 분석은 각 군집을 설명하는 핵심 변수를 제외하고 상관계수가 0.4 이상인 변수를 제거하는 방식으로 진행하였다. 그 결과, 비군집 데이터에서는 17개의 변수, 군집 1에서는 18개, 군집 2에서는 16개, 군집 3에서는 15개, 군집 4에서는 7개, 군집 5에서는 10개의 변수가 선정되었으며, 선택된 변수에 대한 자세한 설명은 Table 5에 제시하였다.
Table 5.
Non-clustered and clustered data final variables for accident severity analysis
본 연구에서는 ANN 모델을 대상으로 훈련 데이터(Train set)와 테스트 데이터(Test set)의 비율을 80:20으로 나누어 사고 모델링을 수행하였다. 혼동 행렬(confusion matrix)을 사용하여 사고 심각도 모델 예측 성능을 비교 및 분석했으며, 자세한 결과는 Table 6에 제시하였다. "All"은 비군집 데이터를 사용하여 구축된 모델의 결과를 의미하고, "Cluster_sum"은 각 군집에 대해 구축된 모델의 혼동 행렬 값을 평균낸 결과를 뜻한다. 본 연구와 같이 데이터가 불균형한 경우, 혼동 행렬 내에서 F1-score를 평가 지표로 사용하는 것이 권장된다(Jeni et al., 2013). 따라서 본 연구에서는 F1-score 값을 비교하여 비군집 데이터를 사용한 모델과 군집 데이터를 사용한 모델의 성능을 비교 및 평가하였다.
Table 6.
Predictive performance results by port accident severity model
| Category | Data | Accuracy | Recall | Precision | F1-score |
| ANN | All | 0.913 | 0.772 | 0.598 | 0.674 |
| Cluster_sum | 0.967 | 0.890 | 0.890 | 0.890 |
분석 결과, 비군집 데이터를 사용한 모델의 F1-score가 0.674, 군집 데이터를 사용한 모델의 F1-score는 0.890이 도출되었다. 이는 군집 데이터가 모델의 예측 성능을 향상시켰음을 나타낸다. 또한, Accuracy, Recall. Precision 등의 다른 평가 지표에서도 모두 비군집 데이터를 사용한 모델보다 군집 데이터를 활용한 모델이 더 높은 성능을 보였으며, 이는 군집 데이터가 모델의 정확성, 재현율, 정밀도 등 여러 측면에서 향상된 결과를 도출했다는 것을 의미한다.
본 연구에서는 ANN 기반 모델을 활용하여 항만 사고 심각도에 영향을 미치는 상위 10개 요인을 도출했다. 해당 결과는 전체 항만 사고 심각도에 영향을 미치는 요인을 도출하기 위한 것이므로, 비군집 데이터를 사용한 모델의 결과를 제시하였으며, ANN 모델을 기반 SHAP 분석 결과는 Figure 4에서 확인할 수 있다. x축은 SHAP 값(기여도)를 뜻하며, 각 특성이 모델의 출력에 미치는 영향을 나타낸다. 양수 값(녹색)은 예측 값을 높이고(심각한 사고가 발생할 확률이 높아짐), 음수 값(빨간색)은 예측 값을 낮춘다(심각한 사고가 발생할 확률이 낮아짐). y축 변수들은 모델의 종속 변수를 의미한다. Boxplot은 순열 특성 중요도(permutations of feature ordering)를 나타내며, 음영 처리된 막대 그림은 이러한 순열에서 파생된 평균 기여도를 강조하는 기능을 가진다(Alvarez et al., 2022).
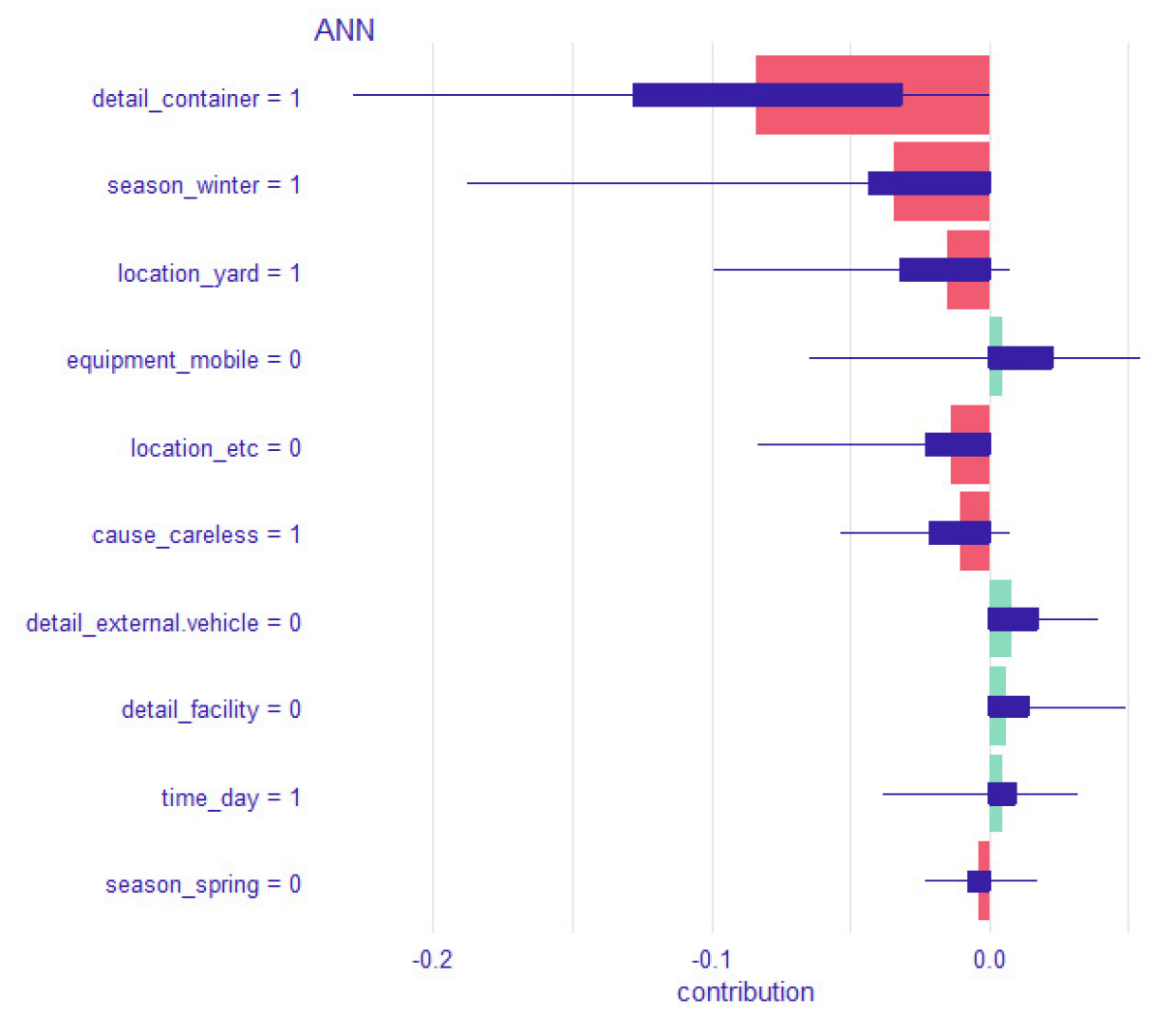
ANN 모델 기반 SHAP 분석을 통해 항만 사고 심각도에 영향을 미치는 요인들을 종합적으로 분석한 결과, 사고 심각도에 주요하게 영향을 미치는 요인은 사고 관련 장비, 주요 피해 내용, 시간, 계절, 위치, 사고 원인으로 나타났다.
사고 관련 장비 요인의 경우, “사고 관련 장비가 이동장비가 아닐 때” 부상 사고 발생 확률이 증가했다. 이는 이동장비가 주로 지상에서 사용하는 소형 장비이며, 갠트리 크레인이나 트렌스퍼 크레인과 같은 대형 장비에 비해 사고 발생 시 심각한 사고로 이어질 가능성이 상대적으로 낮기 때문으로 해석된다.
주요 피해 내용 요인의 경우, 부상 사고 발생 확률은 “주요 피해 내용이 외부 차량이 아닐 때”, "주요 피해 내용이 시설이 아닐 때" 증가했다. 반면, "주요 피해 내용이 컨테이너일 때" 물피 사고 발생 확률이 높아졌다. 이는 컨테이너 관련 사고 대부분이 컨테이너가 이동 및 적재되는 상황에서 발생하는 물적 피해로 이어지는 경우가 많기 때문이다. 이 결과는 외부 차량, 시설, 컨테이너보다 장비와 관련된 사고에서 부상 사고 발생 위험이 더 높아질 수 있음을 시사한다.
시간 요인의 경우, "사고 발생 시간이 주간일 때" 부상 사고 발생 확률이 증가했다. 이는 주간에는 야간보다 작업량이 많고 근로자들이 더 많이 활동하기 때문에 사고 발생 시 물피 사고보다는 부상 사고로 이어질 가능성이 더 높기 때문으로 판단된다.
계절 요인의 경우, "사고 발생 계절이 겨울일 때"와 "사고 발생 계절이 봄이 아닐 때" 물피 사고 발생 확률이 높았다. 겨울에는 일반적으로 날씨가 춥고 바닥이 미끄러운 등 작업 환경이 악화되기 때문에, 일반적인 상황에서 보다 작업이 신중하게 이루어지는 경향이 있어 사고 발생 시 부상으로 이어지지 않고 물피 사고로 그칠 가능성이 높다. 또한, 봄에는 날씨가 급격하게 변하는 경우가 많고, 큰 일교차로 인해 예상치 못한 기상 변화에 노출되기 쉬워 사고 심각도의 증가로 이어질 수 있다.
위치 요인의 경우, "사고 발생 위치가 야드일 때"와 "사고 발생 위치가 야드, 에이프런, 선박을 제외한 구역이 아닐 때" 물피 사고 발생 확률이 증가했다. 야드는 일반적으로 근로자의 도보 출입이 제한되어 있어, 사고 발생 시 근로자의 부상 확률이 낮을 수 있다. 또한, 야드, 에이프런, 선박을 제외한 다른 구역에서는 크레인 등의 중장비보다는 소규모 이동장비를 사용하는 작업이 주로 이루어지기 때문에, 사고가 발생해도 심각한 사고로 이어질 가능성이 낮다.
사고 원인 요인의 경우, "사고 발생 원인이 근로자 부주의일 때" 물피 사고 발생 확률이 높았다. 심각한 부상 사고는 고위험 작업이나 대형 장비가 연관된 상황에서 발생할 가능성이 크다. 그러나 일반적인 근로자의 부주의는 고위험 상황보다는 일상적인 작업에서 발생하기 쉬우며, 이 경우 사고가 발생해도 물피 사고로 끝나는 경우가 많다.
결론
본 연구는 머신러닝 기법 ANN을 사용하여 항만 내 심각도 예측 모델을 개발하고 사고 심각도에 영향을 미치는 요인을 도출했다. 항만 내 사고의 이질성을 고려하기 위해 유사한 특성을 가진 그룹을 군집화 했으며, 데이터 군집 여부에 따라 모델의 예측 성능을 비교 및 평가했다. 분석 결과, 비군집 데이터를 사용한 모델의 F1-score가 0.674, 군집 사고 데이터를 사용하여 개발된 모델의 F1-score가 0.890으로 도출되었으며, 비군집 사고 데이터를 활용한 모델보다 군집 사고 데이터를 활용한 모델이 0.216 더 높은 예측 성능을 보였다.
모델의 정확도와 관계없이, 사고 심각도에 영향을 미치는 주요 요인을 고려한 사고 예방 전략은 사고의 심각도를 줄이는 데 도움이 된다. 본 연구에서는 XAI 방법론 SHAP 기법을 활용하여 항만 사고 심각도에 영향을 미치는 요인들을 도출하였다. 분석 결과, 부상 사고의 발생 확률을 높이는 주요 요인으로는 “사고 관련 장비가 이동장비가 아닐 때,” “주요 피해 내용이 외부 차량이 아닐 때,” “주요 피해 내용이 시설이 아닐 때,” 그리고 “사고 발생 시간이 주간일 때”가 중요한 영향을 미치는 것으로 나타났다. 이러한 요인들을 항만의 안전성을 높이기 위해 고려해야 할 시사점과 개선 방안을 제시해준다.
부상 사고를 효과적으로 예방하기 위해서는, 우선 이동장비가 아닌 장비를 사용하는 작업 환경에 대한 철저한 안전 관리가 필요하다. 야드 트랙터나 리치 스태커와 같은 이동 장비에 비해 갠트리 크레인과 트렌스퍼 크레인과 같은 대형 장비는 사고 발생 시 심각한 사고로 이어질 가능성이 높다. 이러한 장비들은 규모와 무게로 인해 돌발 상황 발생 시 신속한 대응이 어렵기 때문에, 작업 전 철저한 장비 점검과 엄격한 안전 절차 준수가 필수적이다. 현재 항만 내 이동 장비에는 자동긴급제동장치를 설치하고 있는 추세지만, 크레인의 스프레더 반경을 고려한 제동장치 개발 및 설치는 미흡한 실정이다. 따라서, 크레인 특성을 고려한 자동긴급제동장치의 설치를 의무화 한다면 중대 사고를 예방하는 데 큰 도움이 될 것이다.
또한, 주요 피해 내용이 외부 차량이나 시설이 아닌 경우에도 근로자가 부상을 입을 가능성이 증가했다. 이는 근로자가 외부 차량이나 시설보다는 장비나 컨테이너 근처에서 작업할 때 위험이 증가한다는 것을 의미한다. 이러한 상황에서, 근로자와 장비 간의 물리적 접촉을 최소화하고, 컨테이너 추락 위험 구역에 접근하지 않도록 하여 위험 요소를 사전에 줄이는 것이 필수적이다. 이를 위해 작업 구역 내 안전 표지와 접근 제한 구역 설정 등의 예방 조치를 강화할 필요가 있다.
사고 발생 시간이 주간일 때 부상 사고의 위험이 높아지는 경향도 주목할 필요가 있다. 주간에는 작업량이 많아지고 다양한 작업이 동시에 이루어지기 때문에, 근로자 간의 상호 소통과 협력을 강화하는 안전 관리가 필수적이다. 이를 위해, 주간 작업 시 추가적인 안전 관리 인력을 배치하여 원활한 소통을 지원하고, 실시간 작업 모니터링 시스템을 구축하는 것이 필요하다. 또한, 작업 중 발생할 수 있는 근로자 부주의를 방지하기 위해 정기적인 휴식 시간을 제공하고, 작업 전후로 위험 요소에 대한 브리핑을 실시하는 것이 사고 예방에 효과적일 것이다.
본 연구의 향후 과제는 다음과 같다. 첫째, 본 연구는 인공지능 방법론인 ANN을 활용하여 모델을 구축하였다. 향후 연구에서는 다양한 머신 러닝 방법론 및 통계 기법을 활용한다면 항만 사고 심각도 예측 모델의 성능을 향상시킬 수 있을 것으로 기대된다. 둘째, 이 연구에서는 사고 데이터를 증강하여 분석을 수행했다. 데이터 증강 대신 더 많은 사고 데이터를 확보하고 분석을 위한 변수의 수를 늘림으로써 더 현실적이고 의미 있는 결과를 얻을 수 있을 것이다. 셋째, 본 연구의 데이터는 대한민국에 국한되어 있습니다. 연구 결과를 다른 나라에 적용하려면 향후 연구에서는 다른 나라의 항만 사고를 조사하고 이러한 연구 결과를 비교하여 연구 범위를 확장해야 할 것으로 보인다. 넷째, 본 연구에서는 항만별 물동량에 따른 사고 특성을 충분히 고려하지 않았다. 물동량과 밀접하게 관련된 항만 특성을 반영하여 보다 정밀한 분석을 수행하기 위해, 향후 연구에서는 이 점을 고려해야 할 것으로 판단된다. 다섯째, 본 연구에서는 항만 사고 데이터 부족 문제를 해결하기 위해 오버샘플링 기법을 적용하였다. 향후, 각 데이터를 활용한 모델의 성능을 비교 분석하여 증강된 데이터와 원본 데이터 간의 유사성 및 차별성을 평가함으로써 데이터 증강의 당위성을 강화할 필요가 있다.
본 연구는 항만 사고 심각도 분야에서 높은 성능과 해석 가능한 분석 모델을 제시한다. 연구 결과는 항만 사고 심각도에 영향을 미치는 주요 요인을 밝혀내어 항만 전문가들이 정보에 입각한 의사 결정을 내리는 데 중요한 통찰력을 제공할 수 있다. 또한, 항만 및 유사한 산업 환경에서 사고 심각도를 분석하기 위한 참고 자료와 연구 프레임워크를 제공할 수 있을 것으로 보이며, 항만 터미널에서 사고 심각도를 줄이고 안전을 증진하여 항만에서 발생하는 경제적 손실을 줄이는 데 중요한 역할을 할 수 있을 것으로 판단된다.
