

서론
선행연구
1. 가구통행실태조사자료와 모바일 통신데이터의 기종점 통행량 구축 방법
2. 조사자료와 모바일 통신데이터 기반의 통행 비교 연구
분석자료 및 방법
1. 분석자료
2. 분석방법
분석결과
1. 전체 통행 분석 결과
2. 통행목적별 분석 결과
결과 해석 및 논의
결론
서론
최근 가구통행실태조사자료와 이를 이용한 기종점 통행정보(OD)를 보완하는 방법으로 모바일 통신데이터 활용 필요성이 대두되고 있다. 모바일 통신데이터는 가구통행조사자료보다 표본률이 높고 통행량이 0인 제로셀(Zero-cell) 문제1)가 발생할 가능성이 낮아, 기존에는 확인할 수 없었던 시간대별 통행량, 특정 통행자(고령 통행자, 여성 통행자 등)와 같은 상세한 통행 정보를 확인할 수 있을 뿐만 아니라, 인력, 시간, 예산 등 다양한 측면에서 이점이 크기 때문이다.
그러나 아직 모바일 통신데이터에 대한 다각적인 신뢰도 검증이 이루어지지 않은 만큼 기존 가구통행실태조사를 대체하기에는 어려움이 있는 것이 현실이다. 모바일 통신데이터와 같은 passive information을 활용하여 구축·추정된 통행 정보, 특히 교통 수요분석에서 중요한 통행목적과 통행수단 정보의 추정 신뢰성을 담보할 수 없기 때문에 국가의 중요한 재정사업을 결정하는 기초자료로 공식화하기에는 한계가 있다고 할 수 있다.
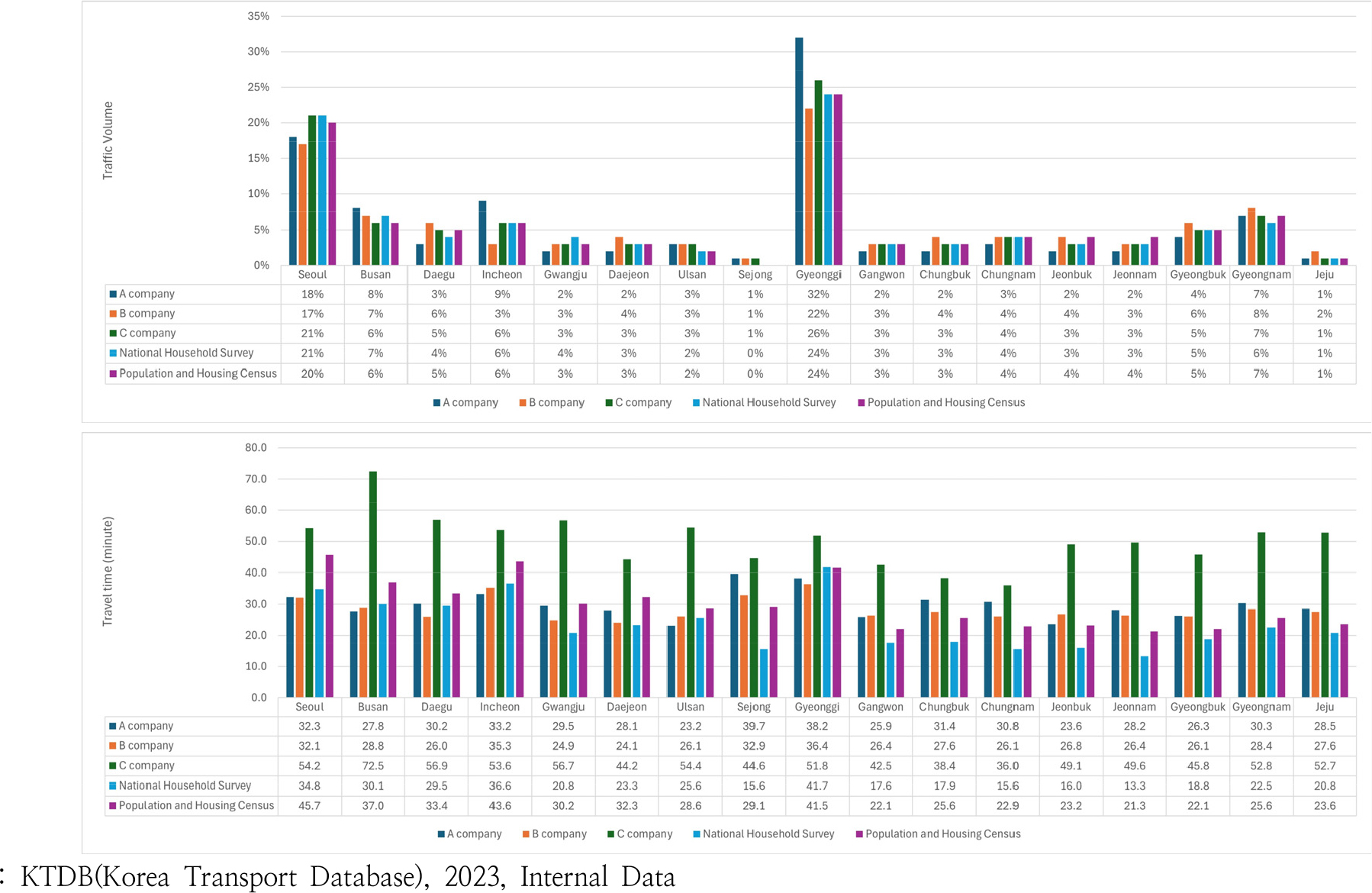
실제로 같은 종류의 모바일 통신데이터를 활용하더라도 데이터 공급자마다 상이한 가공 알고리즘을 적용하여 Figure 1과 같이 데이터 공급자별로 결과가 달라지는 것을 확인할 수 있으며, 이러한 데이터에 대한 일관성과 신뢰성 부족이 여전히 해결해야 할 과제로 남아있다.
그럼에도 불구하고, 모바일 통신데이터를 활용하여 모빌리티 정보를 생산·분석하는 기술이 나날이 발전하고 있고, 이러한 자료를 활용하여 기존 Korea Transport Database(KTDB) 및 관련 지표들을 고도화해야 하는 것은 당면 과제라고 할 수 있다. 특히, 향후 모바일 통신데이터와 같은 다양한 객체 단위 모빌리티 정보의 활용을 확대하고 기존 조사기반 구축 자료를 고도화하기 위해서는 현재 활발히 진행되고 있는 모바일 통신데이터를 활용하여 구축된 기종점 구축 자료의 특성을 면밀히 살펴볼 필요가 있다.
이에 본 연구에서는 가구통행실태조사자료와 모바일 통신데이터를 활용한 기종점 통행량 산출 절차 및 방식을 살펴보고, 기존 조사기반 기종점 통행량 자료와 모바일 통신데이터 기반 기종점 통행량 자료의 차이와 그 원인을 분석하고자 한다.
선행연구
1. 가구통행실태조사자료와 모바일 통신데이터의 기종점 통행량 구축 방법
1) 가구통행실태조사자료 기반의 기종점 통행량 구축 방법
가구통행실태조사는 만 5세 이상 국내 거주 인구 약 1%2)의 표본을 대상으로, 지난 통행(평일 하루)에 대한 통행정보를 조사한 것으로(The Korea Transport Institute, 2016), 구체적인 조사 항목과 내용은 Table 1과 같다.
Table 1.
Details of national household survey
가구통행실태조사는 수집의 용이성과 통계적 유의성을 종합적으로 판단하여 3%의 표본률로 수집한다. 이를 전 국민의 통행 결과로 확장하기 위해서는 Table 2와 같은 전수화 과정을 반드시 거쳐야 한다.
전수화 과정은 권역 내부 통행과 권역 외부 통행을 구분하여 이루어진다. 먼저, 권역 내부 통행의 경우, 가구통행실태조사자료를 기반으로 인구주택총조사의 가구 및 인구자료를 모집단으로 활용하여, 가구와 가구원에 대한 전수화를 수행한 후, 이를 바탕으로 수단별 통행 보정을 순차적으로 진행한다.
반면, 권역 외부 지역 간 통행은 수단별 교통량 또는 수송실적 자료 등을 모집단으로 활용하여, 수단별 통행에 대한 전수화를 먼저 수행한 후, 일부 통행을 보정하는 방식으로 전수화가 이루어진다(The Korea Transport Institute, 2017a).
이렇게 각각 별도의 전수화 과정을 거쳐 구축된 수도권 및 지방 5대 권역, 기타 권역 O/D와 전국 지역 간 O/D는 최종적으로 지역 간 통행량에 대한 상호 조절 과정을 거쳐 완성된다.
Table 2.
Expansion method of a national household survey
| Category | Details of process |
|
Seoul metropolitan area, 5 major regional areas, other areas |
ㆍStep 1: apply expansion factors for households and household members derived from the population and housing census data, using it as the base population for the household travel survey data ㆍStep 2: after converting to p/a trip purpose, adjustments are made using the statistical units for each city/county based on trip purposes. Additionally, the induced traffic for shopping, leisure, and work trips is further adjusted based on data from large-scale trip-generating facilities. ㆍStep 3: adjust traffic volume by public transportation mode based on transportation performance data ㆍStep 4: adjust car traffic volume based on observed traffic volumes at cordon/screenline points (excluding other areas) |
|
Inter- regional across the country |
1. Car O/D ㆍStep 1: after estimating trip production and attraction based on the traffic volume data from highways, other roads, and tcs (toll collection system) data, the inbound and outbound traffic, excluding through traffic, is calculated by applying the through traffic ratio (using navigation data) ㆍStep 2: expansion factors* are applied to the household travel survey data and long-distance travel survey data ㆍStep 3: after adjusting zero cells using navigation data, two-dimensional fratar model is applied to create the expanded o/d ㆍStep 4: the O/D is created by applying expansion factors based on toll collection system (tcs) survey data ㆍStep 5: the O/D created in step 3 is combined with the O/D created in step 4 2. Bus O/D ㆍStep 1: the intercity/express bus O/D is expanded by applying the departure/arrival location, purpose, and access mode ratios calculated using the passenger transportation facility utilization survey (for intercity/express buses) based on transportation performance data ㆍStep 2: the other buses O/D is expanded by distinguishing between commuting/school-related traffic volumes and traffic volumes for other purposes - Using population census data, commuting and school-related traffic volumes are expanded based on household travel survey data, while traffic volumes for other purposes are expanded using the travel distribution from charter bus survey data and general usage data of charter services |
|
Inter- regional across the country |
3. Rail, air, shipping, subway O/D ㆍThe expansion factors calculated using transportation performance data are applied to the passenger transportation facility utilization survey, and then the departure/arrival location, purpose, and access mode ratios are calculated. Based on this, the traffic volumes are estimated by the first departure to final destination, by purpose, and by access mode. (however, when expanding trips made by subway, the household travel survey data is used instead of the passenger transportation facility utilization survey data) 4. O/D adjustment using observed traffic volume data ㆍThe traffic volume is adjusted by comparing the observed traffic volume and assigned traffic volume at the screen lines, cordon lines, and cut lines |
2) 모바일 통신데이터 기반의 기종점 통행량 구축 방법
모바일 통신데이터는 휴대폰 기기와 기지국 간의 송·수신 이력으로, 휴대폰을 사용할 때만 기록되는 CDR(Call Detail Record) 데이터와 휴대폰 사용과 관계없이 일정 주기로 기록되는 Sighting 데이터로 구분되며(Won et al., 2021), 대개 교통수요 분석에는 시공간적 해상도가 높은 Sighting 데이터가 활용된다. Table 3은 밀리세컨드 단위로 휴대폰의 소지자의 위치가 기록된 닷(dot) 형태의 데이터를 이어서 선분 이력화 한 Sighting 데이터의 구조이다. Sighting 데이터에는 통행자를 구분할 수 있는 고객식별번호와 통행일시를 구분할 수 있는 기준일, 통행자의 위치를 추정할 수 있는 기지국의 위치정보(가상기지국 x좌표, y좌표), 통행자의 이동 및 체류 여부를 추정할 수 있는 체류시작시간(해당 기지국에서 로그가 기록되기 시작한 시간), 체류종료시간(마지막으로 로그가 기록된 시간), 체류시간(해당 기지국에 총 접속해 있었던 시간) 정보가 포함되어 있어 이를 기반으로 가공 과정을 거치면 출발지, 도착지, 출발시간, 도착시간 등의 통행정보를 추출하여 기종점 통행 OD를 구축할 수 있다.
Table 3.
Structure of mobile phone data
기종점 통행량 정보를 구축하기 위한 가공 절차는 표준화되어 있지 않으나, 대체로 데이터 전처리, 출발과 도착에 대한 정보 추정, 통행목적 추정, 통행량 집계 및 전수화 순서로 데이터 가공이 이루어지며, 각 단계별 가공 방법은 데이터 출처와 핵심 알고리즘에 따라 달라진다.
먼저 데이터 전처리 단계에서는 데이터 정렬 후 중복된 데이터3)와 일부 정보가 누락된 데이터를 제거하고, 통행량을 과대 추정할 가능성이 있는 데이터4)를 데이터 간의 시간 간격, 거리, 속도, 빈도 등의 정보를 활용하여 보정한다(The Korea Transport Institute, 2020). 또한 통행정보의 정확성을 높이기 위하여 통행자의 위치정보를 기지국 좌표 정보에서 통행자의 위치정보로 보정한다(The Korea Transport Institute, 2020).
다음으로 출발과 도착의 정보 추정 단계에서는 일련의 나열된 데이터 중에서 출발지와 도착지의 기준이 되는 체류지의 정보를 Table 4와 같은 방법으로 선별하고, 1일 기준(0시 0분부터 23시 59분까지) 내에서 선별된 체류지를 시간 발생 순서대로 정렬하여 출발과 도착을 구분한다.
Table 4.
Classification method of stay and movement using mobile phone data
| Researcher (year) | Method |
| Ester et al. (1996) | ㆍBy applying a density-based clustering method called DBSCAN, densely populated data points are defined as clusters and considered as stay locations |
| Calabrese et al. (2010) | ㆍBoth dwell time and distance changes are considered to distinguish between staying and moving. If the distance between the previous location and the next location exceeds a certain threshold, it is regarded as movement |
| Chen et al. (2014) | ㆍA Gaussian Mixture Model (GMM) is applied to identify clusters corresponding to stay locations. |
| Wang (2014) | ㆍIf the recording frequency at each location exceeds the threshold, it is considered a stay; if it does not exceed the threshold, it is considered a movement |
| The Korea Transport Institute (2017b) | ㆍA threshold for dwell time (e.g., 20 minutes) is established, with times exceeding the threshold classified as stays and those below it considered movements |
| Won et al. (2021) | ㆍBy measuring the cumulative dwell time at each location over a specified period (e.g., one week), stay locations are identified, and locations not identified as stay locations are considered movements |
다음으로 통행목적 추정 단계에서는 Table 5와 같이 데이터 통행자별 기록 패턴, 지역 특성을 기반으로 체류지를 유형화하거나 통행목적을 구분한다.
Table 5.
Methods for classifying stay location types using mobile phone data
| Researcher (year) | Method |
| Chen et al.(2014) | ㆍA statistical model is built based on the actual obtained stay information, and stay location types are classified based on this model |
| Alexander et al.(2015) | ㆍAssuming the potential stay characteristics for each location (home, workplace) such as dwell time periods, the stay location types are classified based on these criteria |
| Gong et al.(2016) | ㆍStay location types are classified based on POI (Points of Interest) |
| Won et al (2021) | ㆍStay location types are classified by comparing the observed frequency and total cumulative dwell time information over a specified period (e.g., one week). Locations with higher frequency are designated as home, while if the frequencies are the same, the location with the greater total cumulative dwell time is classified as the workplace |
마지막으로 통행량 집계 및 전수화 단계에서는 개인별(통행자별)로 구축되어 있는 DB를 개인의 통행을 식별하지 못하도록 비식별화 기술과 프라이버시 보호 모델을 적용한다.
비식별화 기술에는 가명처리(Pseudonymization), 총계처리(Aggregation), 데이터 삭제(Data Reduction), 데이터 범주화(Data Categorization), 데이터 마스킹(Data Masking) 등 크게 다섯 가지 방식이 있다(Ministry of the Interior and Safety, 2016). 모바일 통신데이터를 교통 패턴분석 등 공공목적으로 제공할 경우, 데이터 활용성을 고려하여 일반적으로 가명처리, 데이터 범주화, 데이터 마스킹 등의 기법이 우선 적용되며, 이후 일부 또는 전체 정보를 집계하는 총계처리 기술을 통해 1차 비식별화 처리가 이루어진다. 다음으로, 집합 내 최소 k명의 개체가 동일한 속성값을 갖도록 하는 ‘k-익명성(k-anonymity)’, 각 동질 집합이 최소 l개의 다양한 민감 정보를 포함하도록 하는 ‘l-다양성(l-Diversity)’, 각 동질 집합의 민감 정보 분포가 전체 데이터 집합의 분포와 유사하도록 하는 ‘t-근접성(t-Closeness)’ 과 같은 프라이버시 보호 모델을 적용하여 재식별 가능성을 더욱 낮춘다. 이러한 과정을 거쳐 개인정보보호 이슈가 없다고 판단된 데이터는 다시 통신사의 시장점유율, 개인의 휴대전화 이용 특성 등을 반영하는 전수화 과정을 거쳐 최종 DB를 구축한다.
3) 각 자료의 통행량 구축 방법 비교
전술한 내용을 토대로 가구통행실태조사와 모바일 통신데이터의 기종점 통행량 구축 방법을 Table 6과 같이 비교해 보면, 표본에서부터 기종점 통행량을 구축하는 기준 및 방법까지 크게 네 가지 측면에서 차이를 보이는 것을 알 수 있다.
Table 6.
Comparison of the criteria and methods for constructing O/D traffic volumes between a national household survey and mobile phone data
| Category | National household survey | Mobile phone data |
| Sample |
ㆍThe sampling rate is 1%, with an age restriction of 5 years and older ㆍBased on a sample deemed to be representative ㆍBased on travel information from a single weekday (Thursday) during the survey period |
ㆍThe sampling rate can vary between 20% and 50% depending on the market share of the telecommunications provider, with no age restriction. (Covering 98%* of the total population if data from all providers is used) ㆍThere may be biases due to regional subscriber ratios for each telecommunications provider, subscribers under another person’s name, and individuals using multiple phone numbers ㆍBased on travel information from all days |
| Method for collecting travel information | ㆍCollecting travel information by directly asking travelers | ㆍCollected via log collectors from signaling logs between mobile devices and base stations |
| Method for constructing travel information | ㆍTravel information is constructed based on the memory of the travelers | ㆍTravel information is estimated and constructed based on the criteria and methods established by the researchers (such as handover processing methods, traveler location correction methods, and stay location extraction methods) |
| Expansion method | ㆍExpansion factors are applied to households and household members based on population census data, and travel data is expanded using transportation performance and traffic volume data. |
ㆍExpansion is performed based on the market share of each telecommunications provider and resident registration population ㆍDepending on the researcher, factors such as the phone device ON/OFF ratio and the per capita line usage ratio are also taken into account |
첫째, 가구통행실태조사의 경우 모바일 통신데이터에 비해 표본률 자체는 매우 낮지만 모집단을 기반으로 표본을 설계하여 특정 집단에 편향되어 있을 가능성이 매우 낮은 반면, 모바일 통신데이터는 통행자가 가입한 통신사의 특성, 통행자의 휴대폰 이용 특성, 지역별 연령별 가입자 비율 등으로 인해 일부 데이터가 편향되어 있을 가능성이 존재한다. 예를 들어, CDR 정보를 활용할 경우 사용자의 휴대폰 이용패턴이 추정된 통행정보에 영향을 미칠 수 있다.
둘째, 모바일 통신데이터 기반 통행정보는 추정된 정보로써 조사기반 자료의 직접 수집 정보와는 차이가 있다. 가구통행실태조사와 같은 직접 설문기반 자료는 통행자의 통행 횟수, 통행목적, 통행수단 등이 설문으로 얻어진 직접적인 정보지만, 모바일 통신데이터 기반의 통행정보는 통신신호 변화로 추정된 정보이다. 그러므로, 수집 및 가공 알고리즘에 따라 통행 횟수, 통행목적, 통행수단 등의 통계가 달라질 수 있다.
셋째, 통행정보를 구축할 때 가구통행실태조사는 통행자의 기억에 의존하여 통행정보를 구축하고, 모바일 통신데이터는 연구자가 설정한 기준 및 방법에 따라 가공하여 구축한다.
넷째, 가구통행실태조사는 인구 특성과 통행 특성을 고려하여 전수화가 이루어지는 반면, 모바일 통신데이터는 인구 특성, 통신 특성을 고려하여 전수화가 이루어진다.
2. 조사자료와 모바일 통신데이터 기반의 통행 비교 연구
모바일 통신데이터에 대한 선행연구를 살펴보면, 대체로 모바일 통신데이터로부터 통행정보를 추출할 수 있는지 그 가능성을 확인하거나(Bolla and Davoli, 2000; White and Wells, 2002; Schlaich et al., 2010; Calabrese et al., 2011; Calabrese et al., 2013), 모바일 통신데이터별(GPS 데이터, CDRs, 모바일 네트워크 운영데이터) 데이터 특성에 따라 통행정보를 추정하는 방법에 초점을 맞추고 있다(Zheng and Xie., 2011; Jiang et al., 2013; Wang, 2014; Alexander et al., 2015).
반면, 모바일 통신데이터를 기반으로 산출된 통행량의 정확성 및 신뢰도를 검증한 연구는 상대적으로 드문 편이다(Table 7 참조). 특히 조사자료와 비교하여 모바일 통신데이터의 신뢰도를 확인한 연구는 많지 않다. 기존 연구들 또한 조사자료와의 차이보다는 유사성을 확인하는 데 목적을 두는 경향이 있으며(Calabrese et al., 2011; Becker et al., 2011; Lenormand et al., 2014; Bonnel et al., 2018; Imai et al., 2021), 비교 기준 또한 통행량이 아닌 인구 분포와 같은 간접 지표에 의존하거나(Calabrese et al., 2011; Becker et al., 2011; Lenormand et al., 2014), 통행량을 비교하더라도 지역 단위에 국한된 통행조사자료를 사용하는 경우가 많다(Bonnel et al., 2018; Imai et al., 2021). 일부 연구에서 비교 기준으로 활용한 인구 분포는 통행행태가 동질적일 수 있다는 전제 하에 비교한 것이나, 이는 광역적이고 이질적인 행태를 포함하는 분석에는 적합하지 않다. 또한 지역 단위에 국한된 자료는 지역 간 이동이나, 장거리 통행 행태에 대한 신뢰도를 평가하는 데 한계가 있다.
Table 7.
Summary of mobile phone data- based trip validation studies
|
Researcher (year) |
Country/ Region |
Reference data | Comparison criterion |
Analysis scope | Distance scale | Remarks |
| Calabrese et al.(2011) | Boston, USA |
Travel Survey (NHTS*), Census (CTPP**) |
Trip volume, residence distribution | Urban area | Short |
Included linear relationship with commuters |
| Becker et al. (2011) |
Morristown, USA | Census (CTPP) | Labor population distribution |
Within city (5-mile radius) | Short | Used contour plots and scatter plots |
| Lenormand et al. (2014) |
Madrid/
Barcelona, Spain |
Census (Spanish census survey) | Population density, OD matrices | Urban area |
Short/ Medium |
Compared population changes over time |
| Bonnel et al. (2018) |
Rhône-Alpes, France | Travel survey (EDR***) | Trip volume | Regional area | Medium |
Linear relationship analysis |
| Imai et al.(2021) |
Shizuoka, Japan | Person Trip survey (PT)**** | Travel distance distribution |
Urban/ subregional area (limited inter- prefectural coverage) |
Short/ Medium |
Included long-distance trip analysis |
본 연구는 이러한 한계를 보완하고자, 단·중거리 통행뿐만 아니라 장거리 통행까지 비교분석이 가능한 전국 단위의 통행조사자료를 활용하였으며, 직접적인 통행량 비교를 통해 통행패턴의 차이가 어떤 공간적 또는 구조적 조건에서 발생하는지를 정량적으로 분석하였다는 점에서 기존 연구와 뚜렷한 차별성을 갖는다.
분석자료 및 방법
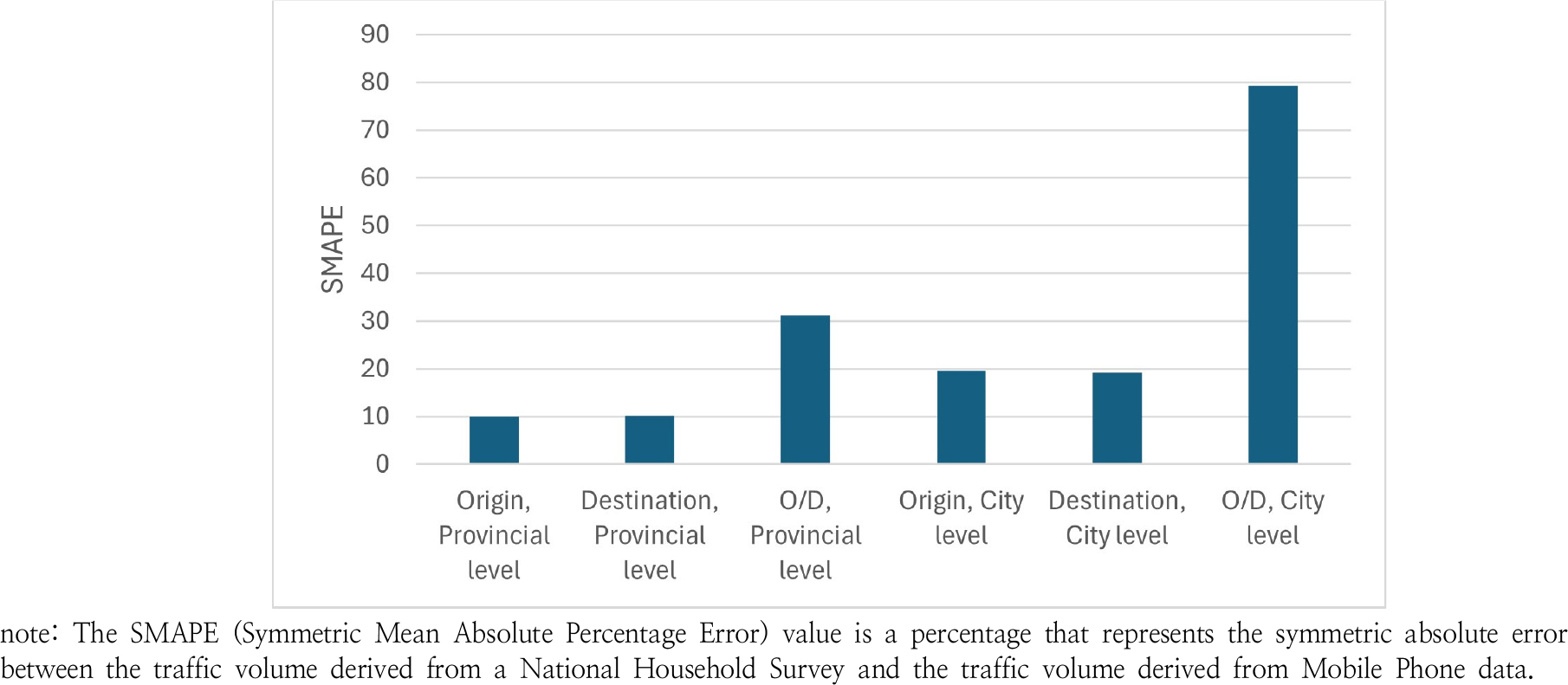
가구통행실태조사자료로 구축한 통행량과 모바일 통신데이터로 구축한 통행량은 Figure 2와 같이 시도 단위와 같이 큰 카테고리로 집계했을 때보다 시군구 단위, O/D 단위로 세분화하여 집계했을 때 그 차이가 두드러지게 나타난다. 따라서 본 연구에서는 세분화된 집계 단위인 시군구 단위의 O/D 통행량(분포량)을 기준으로 전체 통행량과 통행목적별 통행량에 대하여 통행량 차이가 나타나는 구간의 특성을 살펴보고자 한다. 통행목적은 가구통행실태조사자료와 모바일 통신데이터 모두 추정 가능한 통근, 통학 통행, 그리고 통근, 통학 통행을 제외한 나머지 기타 통행 총 세 가지로 한정하였다.
1. 분석자료
1) 모바일 통신데이터 기반의 통행자료
3사 통신사(SKT, KT, LG U+)에서는 각자 자사 통신데이터를 기반으로 자체 개발한 가공 알고리즘을 적용하여 통행 DB를 구축하고 있다. 이 중 A사 모바일 통신데이터 기반의 통행 DB는 한국교통연구원과 함께 개발한 가공 알고리즘을 적용하여 다른 통신사 기반의 통행 DB보다 결과를 해석하기에 용이하다는 장점이 있다. 따라서 본 연구에서는 A사 모바일 통신데이터를 기반으로 구축한 통행 DB를 분석자료로 선택하였다.
A사의 모바일 통신데이터는 Sighting 데이터5)로서, 다음과 같이 ‘데이터 전처리’, ‘체류지 유형 구분’, ‘통행량 집계 및 기타 정보 구축’, ‘통행 전수화’라는 총 네 단계의 가공 과정을 거쳐서 구축된다.
먼저 ‘데이터 전처리’ 단계에서는 Null값이 포함된 데이터, 기지국 좌표 정보와 행정동 정보가 매칭되지 않는 데이터를 제거하고, 개인별 로그 기록을 시간발생순으로 정렬한 다음 일주일 단위로 분할하여 1분 단위의 점 형태의 데이터로 변환한다. 또한 핸드오버로 인해 통행정보(통행자의 실제 위치)가 왜곡되어 있는 데이터를 보정하기 위해 시간(5분 단위), 속도(이웃한 행간 속도가 5km/h 미만), 공간(416m)에 대한 각각의 기준 두어 보정 대상을 추출하고 좌표를 가중 평균하여 통행자의 위치를 보정한다.
다음으로 ‘체류지 유형 구분’ 단계에서는 통행자가 체류한 위치가 집, 학교, 직장, 정기 잠재체류지, 기타 잠재체류지 중 어디에 해당하는지 체류 특성을 분석하여 구분한다. 이를 위해 일주일 단위로 개인별 최장 체류지(체류시간이 가장 긴 지점)와 두 번째 최장 체류지(최장 체류지를 제외한 나머지 지점 중에서, 첫 번째 주체류지의 점유시간을 제외한 시간대에서 가장 체류시간이 길게 나타난 지점)를 식별하며, 최장 체류지와 두 번째 최장 체류지의 발생 빈도를 비교하여, 발생 빈도가 높은 지점을 ‘집’으로, 발생 빈도가 낮은 지점은 ‘학교’ 또는 ‘직장’으로 구분한다. ‘학교’와 ‘직장’을 구분하는 기준은 통행자의 연령으로 20세 미만일 경우에는 ‘학교’, 통행자의 연령이 20세 이상, 60세 미만인 경우에는 ‘직장’으로 구분한다(단, 발생 빈도가 동시간대 3시간 이상 주 2회 기준을 충족하지 않을 경우 직장으로 구분하지 않는다). 또한 ‘집’과 ‘학교’, ‘회사’로 분류되지 않은 지점 중에 일주일 기준 주 2회 이상, 3시간 이상 체류한 지점은 ‘정기 잠재체류지’로, 그 외 구분되지 않은 지점은 ‘기타 잠재체류지’로 구분한다.
다음으로 ‘통행량 집계 및 기타 정보 구축’ 단계에서는 일별 통행 정보(출발 일자, 출발시간대, 출발 지역, 출발 체류지 유형, 도착 일자, 도착 시간대, 도착 지역, 도착 체류지 유형, 성, 연령, 통행수단)를 기준으로 그룹화하여 통행량을 집계한다. 체류지에서의 체류시간이 30분 미만인 체류지는 제외하고 집계되며, 집계한 통행량이 3 통행 이하인 경우 개인정보보호법에 의거하여 개인의 통행 정보를 추적할 수 없도록 3 통행으로 변환한다.
마지막으로 ‘통행 전수화’ 단계에서는 모든 개별통행 OD에 전수화 계수값을 반영한다. 전수화 계수는 시군구별 성별 연령대별 주민등록인구를 KT 모바일 통신데이터 기반 통행량 집계값으로 나눈 값을 의미하며, 통행자의 ‘집’을 기준으로 전수화 계수가 반영된다.
본 연구에서는 위와 같은 가공 과정을 거쳐서 구축된 통행 DB(Table 8 참조)를 수집하여 분석자료로 활용하였다.
Table 8.
Descriptions of mobile phone data from company A
해당 DB에는 A사 통신사를 이용하는 고객에 한해 통행량이 산출된 ‘Stay traffic volume’ 칼럼과 해당 칼럼을 이용하여 주민등록인구를 기반으로 전수화한 ‘Tpop weight’ 칼럼이 포함되어 있는데, 비교 대상인 가구통행실태조사자료가 전 국민의 통행을 대상으로 이미 전수화된 값이기 때문에 모바일 통신데이터 기반 기종점 통행량도 전수화 값을 기준으로 비교·분석하였다.
또한 모바일 통신데이터에서 추정한 통행목적(정기체류, 기타)은 가구통행실태조사자료의 통행목적(업무, 쇼핑, 여가/오락/친지방문, 기타)과 다르기 때문에 통행목적별 통행량을 집계할 때에는 출발 체류지 유형 칼럼인 ‘Origin type’과 도착 체류지 유형 칼럼인 ‘Destination type’을 활용하여 Table 9와 같이 통행목적을 구분하여 통행량을 집계하였다.
Table 9.
Standards for differentiating travel purposes
통행량은 평일 기준으로 조사하여 일평균값으로 공표되는 가구통행실태조사와 분석 조건을 동일하게 설정하기 위해서, 수집한 11월 한 달 치 모바일 통신데이터 자료(출발 일자와 도착 일자가 2022년 11월 1일에서 2022년 11월 30일 사이인 경우) 중에서 주말 8일을 제외하고 평일 22일 치 자료만 활용하였으며, 집계한 후 일평균값으로 환산하여 활용하였다.
2) 가구통행실태조사자료의 통행자료
모바일 통신데이터의 수집 시기에 맞춰 가장 가장 최근에 구축된 가구통행실태조사자료를 분석 대상으로 설정하고자 하였으나, 가장 최근에 구축된 2022년 기준의 가구통행실태조사는 이미 B사 모바일 통신데이터가 보정자료로 활용되어, 2019년 기준의 가구통행실태조사자료를 분석자료로 활용하였다.
가구통행실태조사자료는 Table 10과 같이 통행목적을 7가지(출근, 등교, 업무, 쇼핑, 귀가, 여가/오락/친지방문, 기타)로 구분하고 있으므로, ‘출근(통근)’, ‘등교(통학)’를 제외한 나머지를 ‘기타’로 간주하고 집계하였다.
Table 10.
Descriptions of a national household survey
3) 분석자료 비교
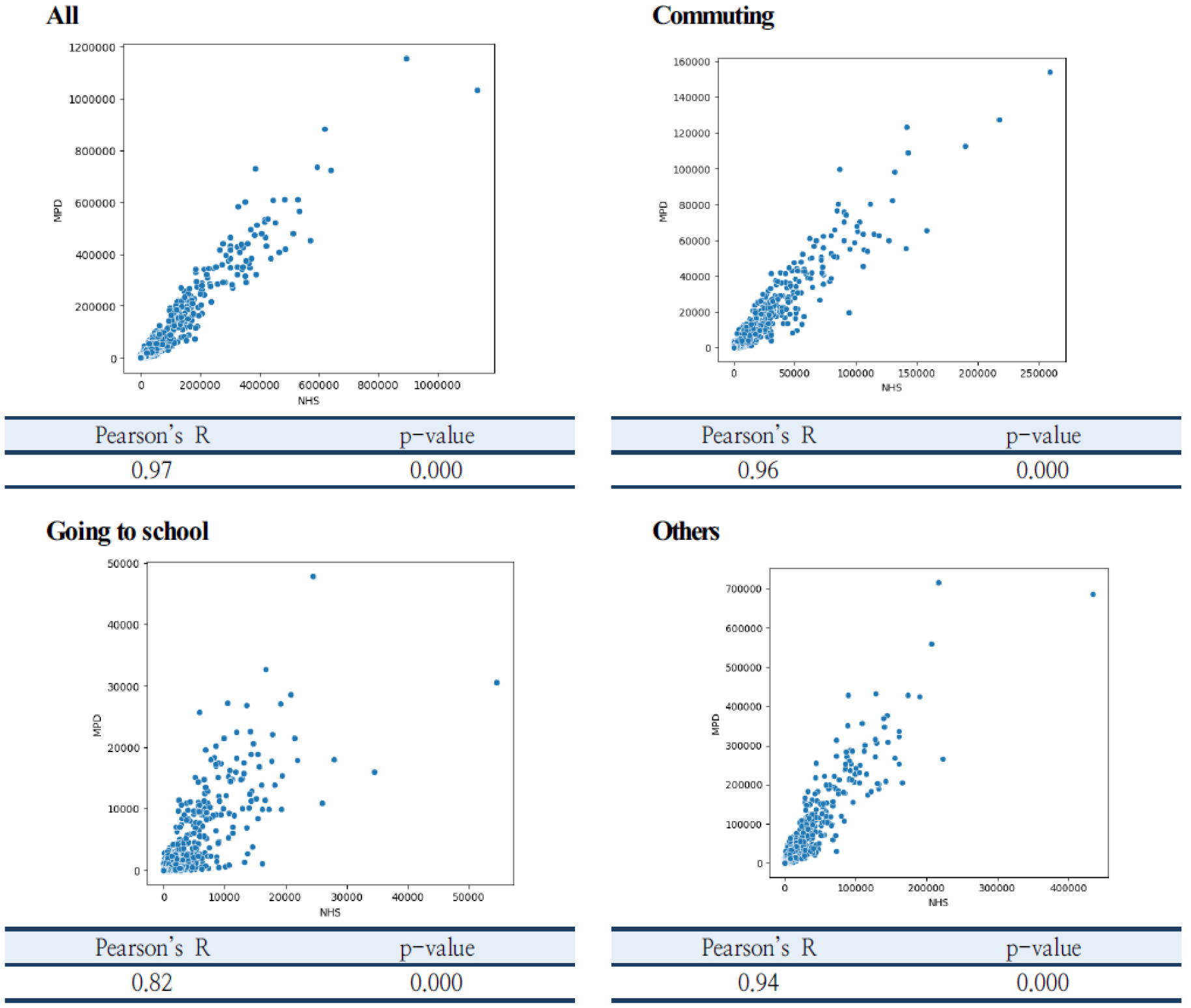
모바일 통신데이터의 통행량과 가구통행실태조사의 통행량의 통행패턴의 차이를 분석하기에 앞서, 데이터 간의 연관성을 확인하기 위해 시군구 단위의 O/D 통행량을 기반으로 상관분석을 수행하였다. 분석 결과 Figure 3과 같이 모바일 통신데이터의 통행량과 가구통행실태조사의 통행량 간의 상관계수는 0.97로, 매우 강한 양의 상관관계를 가지고 있는 것으로 분석되었으며, 통행목적별로 살펴봐도, 매우 강한 양의 상관관계를 갖는 것으로 분석되었다.
2. 분석방법
모바일 통신데이터와 조사자료 기반의 통행패턴 차이를 분석하기 위해 의사결정나무분석기법을 사용하였다. 의사결정나무분석기법은 의사결정 규칙을 도표화하여 관심대상이 되는 집단을 몇 개의 소집단으로 분류하거나 예측을 수행하는 계량적 분석방법이다(Jung, 2003). 의사결정나무분석을 수행하면 Figure 4와 같이 알고리즘에 따라 하나의 데이터(뿌리노드)가 동질의 성격을 가진 데이터로 분리되어 나무와 같은 구조를 띄게 되는데, 여기서 데이터의 분류하는 데 활용된 변수 및 절단값은 모바일 통신데이터와 조사자료의 통행패턴 차이를 해석하는 기준이 된다. 상위에 있는 변수일수록 종속변수에 더 큰 영향을 미치는 변수로 해석할 수 있으며, 최종노드까지 활용된 변수와 절단값의 조합으로 모바일 통신데이터와 조사자료의 통행패턴 차이에 대한 규칙을 정리할 수 있다.
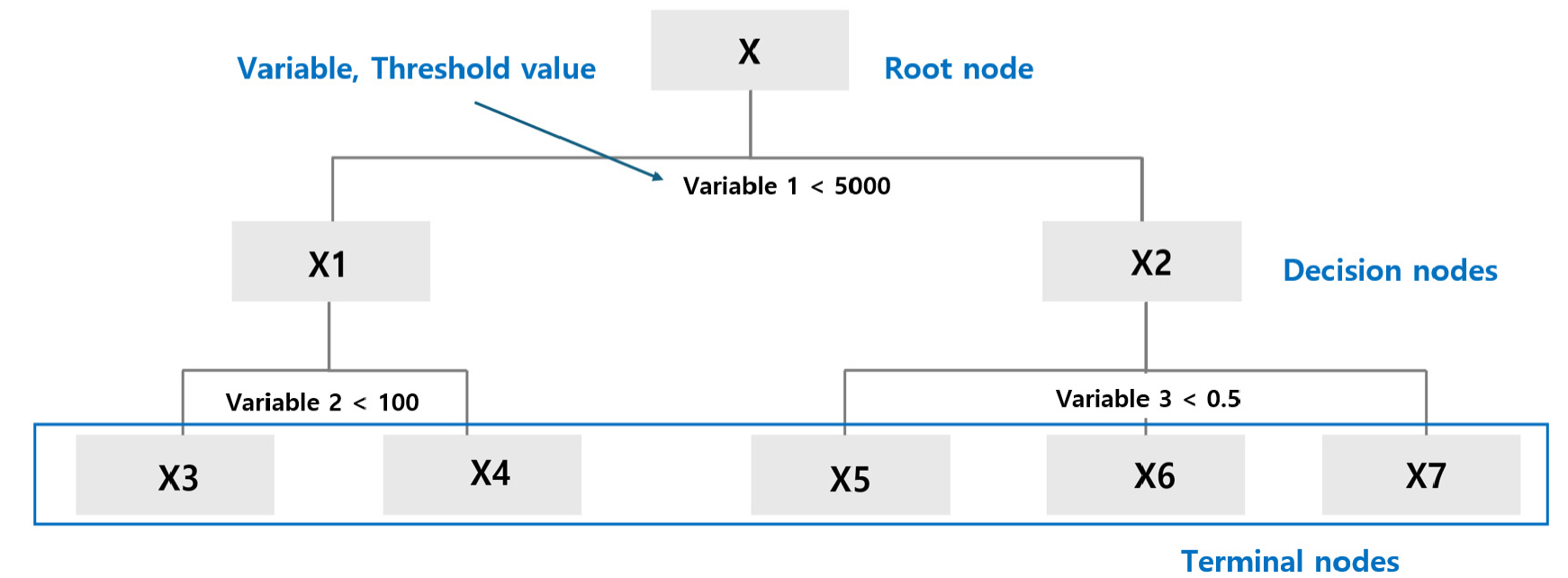
Table 11과 같이 데이터를 분리하는 기준은 알고리즘에 따라 달라지는데, 본 연구에서는 의사결정나무분석을 수행하는 네 가지(CHAID, QUEST, C5.0, CART) 알고리즘 중에서 종속변수의 형태와 해석의 용이성을 고려하여 CART(Classification And Regression Trees) 알고리즘을 선택하여 적용하였다.
Table 11.
Decision tree algorithm
R의 Rpart 함수를 사용하여 분석을 수행하였으며, 의사결정나무구조 모형 구축 시 과도하게 노드가 분리되지 않도록 노드의 관측치가 전체 데이터의 30% 미만일 때에는 노드가 분리되지 않도록 최소 분할 샘플 개수(minsplit)에 대한 기준을 설정하였으며, 최종노드 샘플 개수(minbucket)는 최소 분할 샘플 개수의 1/3로 설정하여 최종 노드가 최소 6,250개 이상의 관측치를 갖도록 하였다.
또한 나무모형 성장과정 중에 과적합(overfitting) 문제를 방지하기 위해 교차타당성(cross-validation) 방법으로 가지치기(pruning)를 수행하였다.
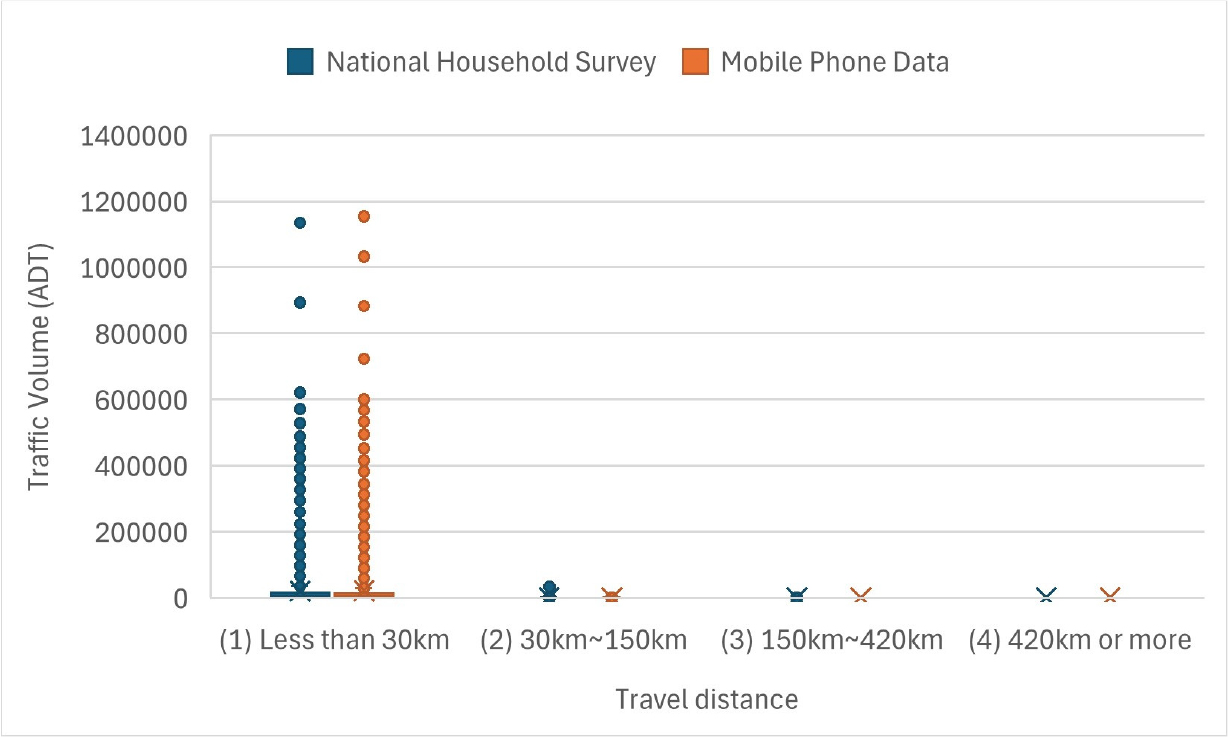
모바일 통신데이터와 조사자료 모두 Figure 5에서 보이는 것과 같이 30km 미만의 단거리 통행구간에서는 통행량이 매우 높고, 150km 이상 중·장거리 통행구간에서는 통행량이 매우 낮게 나타나 통행구간별로 통행량 차이가 크게 나타난다.
이러한 점 때문에 통행구간별로 각 데이터의 통행량 차이를 단순히 빼서 종속변수로 사용할 경우 데이터 간 스케일 문제로 인해 왜곡된 해석이 나올 수 있다. 따라서 본 연구에서는 동일한 기준으로 통행구간별 통행량 차이를 비교할 수 있도록 다음과 같이 스케일 차이를 보정한 상대적 차이를 계산하여 종속변수로 설정하였다.
여기서,
: 가구통행실태조사자료기반통행량
: 모바일통신데이터기반통행량
위와 같은 수식을 통해 계산한 종속변수(y) 값은 –1에서 1 사이의 값을 가지며, 상대적인 차이를 나타내는 정규화된 지표이므로 –1에 가까울수록 모바일 통신데이터의 통행량이 많고, 1에 가까울수록 가구통행실태조사자료의 통행량이 많은 것으로 해석할 수 있다. 또한 0에 가까울수록 두 자료의 통행패턴은 유사하다고 볼 수 있다. Table 12는 통행목적별 종속변수를 산출한 결과를 요약한 것이다.
Table 12.
Summary of the dependent variable (n=62,500)
다음으로 설명변수는 종속변수인 모바일 통신데이터와 조사자료 간의 통행량 차이를 설명할 수 있도록, 모바일 통신데이터는 통행량 구축 과정에서 핸드오버 데이터의 영향을 많이 받는다는 점과 가구통행실태조사자료는 모바일 통신데이터와 전수화 방법에 차이가 크다는 것을 고려하여, 핸드오버 데이터의 발생 빈도 및 비율에 영향을 주는 요인과 가구통행실태조사자료에서 전수화에 활용하는 사회경제지표를 종합하여 다음 10가지를 설명변수 대상으로 설정하였다.
첫 번째 설명변수는 ‘기지국 수(밀도)’이다. 지역 내 기지국 수가 많을수록, 즉 기지국 밀도가 높을수록 모바일 통신데이터에서 발생하는 핸드오버 데이터의 양이 증가할 가능성이 있다. 이는 핸드오버 데이터가 통행자의 이동을 추적하는 데 중요한 역할을 하기 때문에, 기지국 밀도의 변화는 모바일 통신데이터와 가구통행실태조사 자료 간의 통행량 차이를 초래할 수 있다.
두 번째 설명변수는 ‘인구수’이다. 지역 내 인구수가 증가하면, 통신 품질 개선을 위해 기지국이 추가로 설치되며, 이로 인해 기지국 밀도가 높아진다. 기지국 밀도의 변화는 핸드오버 데이터의 발생 빈도에 영향을 미칠 수 있으며, 이에 따라 모바일 통신데이터와 조사자료 간의 통행량 차이가 발생할 수 있다.
세 번째 설명변수는 ‘학령인구수’이다. 학령인구는 주로 통학 목적으로 이동하거나 체류하는 인구 군으로, 이들의 이동은 핸드오버 데이터를 발생시킬 수 있다. 따라서 학령인구수의 변화는 모바일 통신데이터에서의 통행량 변화와 관련이 있을 수 있으며, 이는 가구통행실태조사와의 차이를 유발할 수 있다.
네 번째 설명변수는 ‘수용학생수’이다. 수용학생수는 가구통행실태조사에서 통학 목적의 통행량을 보정하는 데 사용되는 사회경제지표로, 이 수치가 증가하거나 감소함에 따라 모바일 통신데이터와 가구통행실태조사 간의 통행량 차이가 발생할 수 있다.
다섯 번째 설명변수는 ‘학교수’이다. 학교수는 통학 목적의 통행의 도착량을 추정하는 지표로 활용될 수 있으며, 이를 바탕으로 핸드오버 데이터의 발생 가능성을 예측할 수 있다. 따라서 학교 수의 변화는 통학 목적 통행에 대한 핸드오버 데이터의 발생에 영향을 미칠 수 있다.
여섯 번째 설명변수는 ‘취업자수’이다. 취업자는 통근 목적의 체류 또는 이동을 하는 인구 군으로, 이들의 이동은 통근 목적 통행에서 핸드오버 데이터를 발생시킬 수 있다. 이에 따라 취업자수의 변화는 모바일 통신데이터와 가구통행실태조사 자료 간의 통행량 차이를 유발할 수 있다.
일곱 번째 설명변수는 ‘종사자수’이다. 종사자수는 가구통행실태조사에서 통근 목적의 통행을 보정하는 데 활용되는 사회경제지표로, 이 지표의 변화는 모바일 통신데이터와 조사자료 간의 통행량 차이를 발생시킬 수 있다.
여덟 번째 설명변수는 ‘생산인구수(비율)’이다. 생산인구는 고령인구에 비해 상대적으로 더 빈번한 이동을 한다. 이로 인해, 생산인구의 비율이 높을수록 이동 중 발생할 수 있는 핸드오버 데이터의 비중이 증가할 수 있다. 예를 들어, 시그널 점프와 같은 비현실적인 속도로 기지국 위치가 변환되는 데이터가 발생할 수 있으며, 이는 모바일 통신데이터와 가구통행실태조사 자료 간의 통행량 차이를 초래할 수 있다.
아홉 번째 설명변수는 ‘고령인구수(비율)’이다. 고령인구는 상대적으로 이동보다는 체류가 많기 때문에, 체류 중 발생하는 핸드오버 데이터의 비중이 높을 수 있다. 예를 들어, 핑퐁 핸드오버 데이터는 짧은 시간 동안 여러 기지국이 번갈아 기록되는 현상으로, 이는 고령인구가 이동하지 않고 체류하는 상황에서 자주 발생한다. 이로 인해 고령인구 비율의 변화는 모바일 통신데이터와 가구통행실태조사 자료 간의 통행량 차이를 유발할 수 있다.
열 번째 설명변수는 ‘통행거리’이다. 통행거리는 이동 수단의 선택에 영향을 미치며, 이동 수단에 따라 핸드오버 데이터의 유형과 발생 빈도가 달라질 수 있다. 예를 들어, 통행거리가 길어질수록 자동차나 기차 등의 이동수단을 이용하게 되고, 이에 따라 발생하는 핸드오버 데이터의 유형과 빈도가 달라지며, 이는 모바일 통신데이터와 조사자료 간의 통행량 차이를 초래할 수 있다.
설명변수별 수집 출처와 결과를 요약하면 Table 13과 같다.
Table 13.
Explanatory variable specification
| Variable (unit) | Classification | Statistics* | Data sources |
|
Number of base stations [Density (BS/km2)] |
0, ..., 25800 [0.0, ..., 907.1] |
M= 5652.86 SD= 3661.88 [M= 85.13] [SD= 133.09] | ㆍAfter aggregating the number of base stations by district and county from the Frequency Information System(the website known as Jeonpa Nuri), the total is divided by the area* of each district and county |
| Population | 8996, ..., 910814 |
M= 205756.1 SD= 167140.6 | ㆍAggregated the population data by district and county based on the resident registration population data from the KOrean Statistical Information Service (KOSIS, as of December 2022) |
| School-age population | 856, ..., 204426 |
M= 40216.06 SD= 35508.45 | ㆍAggregated the population data for individuals aged 5 to 24 from the KOrean Statistical Information Service (KOSIS, as of December 2022) |
| Number of accommodated students | 664, ..., 182568 |
M= 377729.06 SD= 35681.26 | ㆍAggregated the number of students by school type (kindergarten, elementary, middle, high school, and university) based on the Korean Educational Development Institute's education statistics database (as of October 2022) |
| Number of schools | 13, ..., 386 |
M= 90.92 SD= 54.24 | ㆍAggregated the number of kindergartens, elementary schools, middle schools, high schools, and universities based on the Korean Educational Statistics Service (KESS, as of October 2022) |
| Number of employed persons | 4226, ..., 461204 |
M= 107120.5 SD= 87131.59 | ㆍCalculated the population aged 15 and older by district and county by multiplying it with the provincial employment rates from the Korean Educational Statistics Service (KESS, as of 2020) |
| Number of workers | 4570, ..., 698840 |
M= 90886.38 SD= 87982.5 | ㆍAggregated the number of workers by district and county based on the employment data from the KOrean Statistical Information Service (KOSIS, as of 2020) |
| Working-age population [Rate] |
5940, ..., 666003 [0.50, ..., 1.41] |
M= 40216.06 SD= 35508.45 [M= 0.67] [SD= 0.08] | ㆍAggregated the population data for individuals aged 16 to 64 (KOSIS, as of 2022) and calculated the proportion of the working-age population within the total population |
| Elderly population [Rate] |
2511, ..., 125752 [0.08, ..., 0.44] |
M= 37230.04 SD= 23619.23 [M= 0.23] [SD= 0.09] | ㆍAggregated the population data for individuals aged 65 to 99 (KOSIS, as of 2022) and calculated the proportion of the elderly population within the total population |
| Travel distance (km) | 0.0, ..., 605.2 |
M= 178.08 SD= 98.69 | ㆍUtilized GIS to measure the straight-line distances between central points of districts and counties based on the administrative boundary data from the Statistical Geographic Information Service (SGIS, as of June 2022) |
분석결과
1. 전체 통행 분석 결과
전체 통행을 대상으로 한 의사결정나무 분석 결과, Figure 6과 같이 ‘도착지 기지국 밀도’가 최상위 분기 기준(뿌리노드)으로 작용하였으며, 이후 ‘출발지 기지국 밀도’로 분기되어 총 4개의 최종 노드가 형성되는 것으로 나타났다. 전반적으로 출발지와 도착지의 기지국 밀도가 높은 지역에서 가구통행실태조사와 모바일 통신데이터 간의 통행패턴이 유사하게 나타났으며, 출발지와 도착지의 기지국 밀도가 낮은 지역일수록 모바일 통신데이터의 통행량이 가구통행실태조사의 통행량보다 높게 집계되는 것으로 분석되었다.
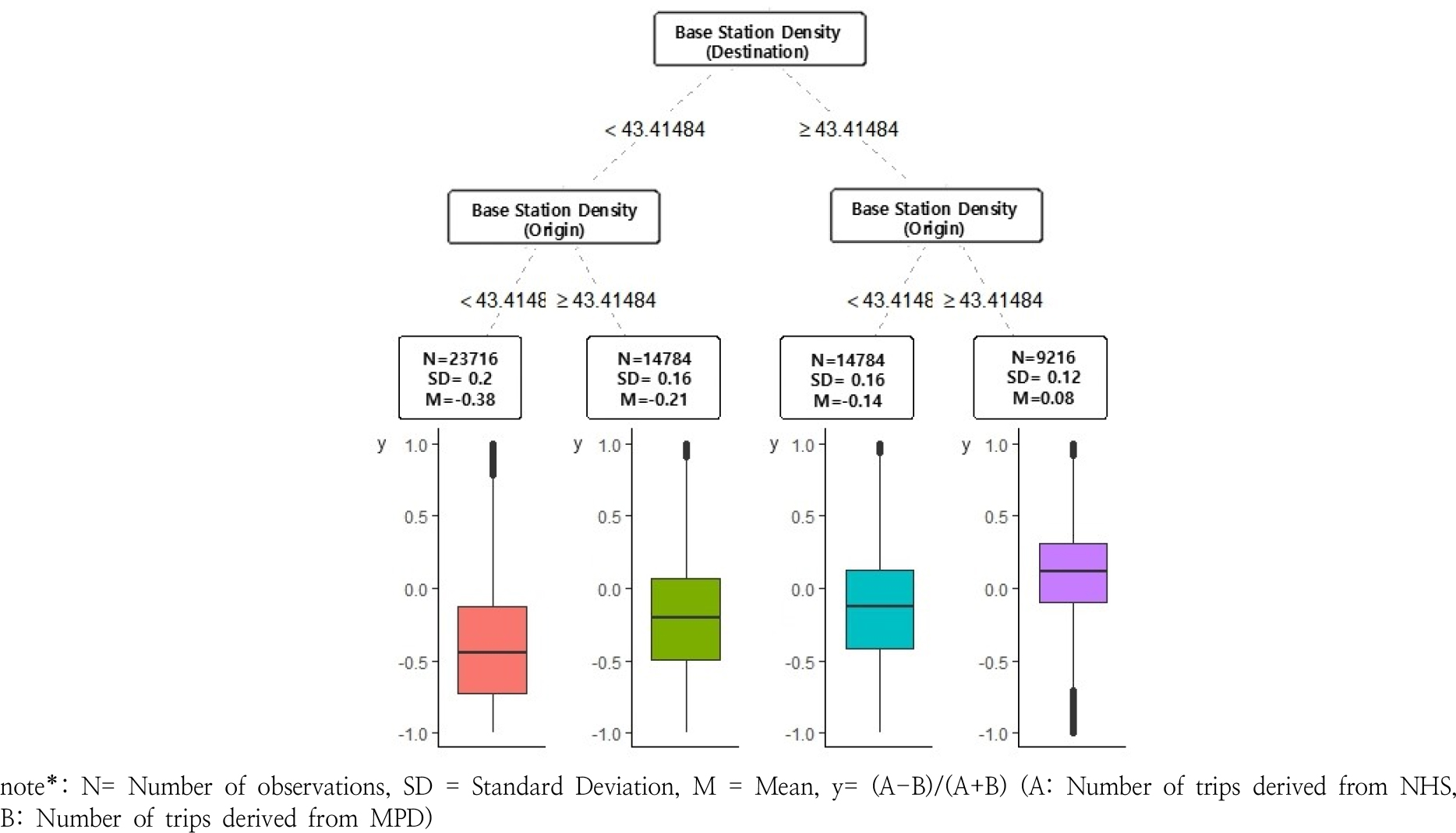
2. 통행목적별 분석 결과
분석 결과 모든 통행에서 ‘통행거리’가 뿌리노드에 설정되어 있어 모바일 통신데이터와 가구통행실태조사자료 간 통행패턴 차이를 결정짓는 가장 중요한 변수는 통행거리인 것으로 나타났다. 다만 통행목적별로 통행거리에 대한 기준과 최종 형성된 노드의 특성에는 차이가 있는 것으로 분석되었다.
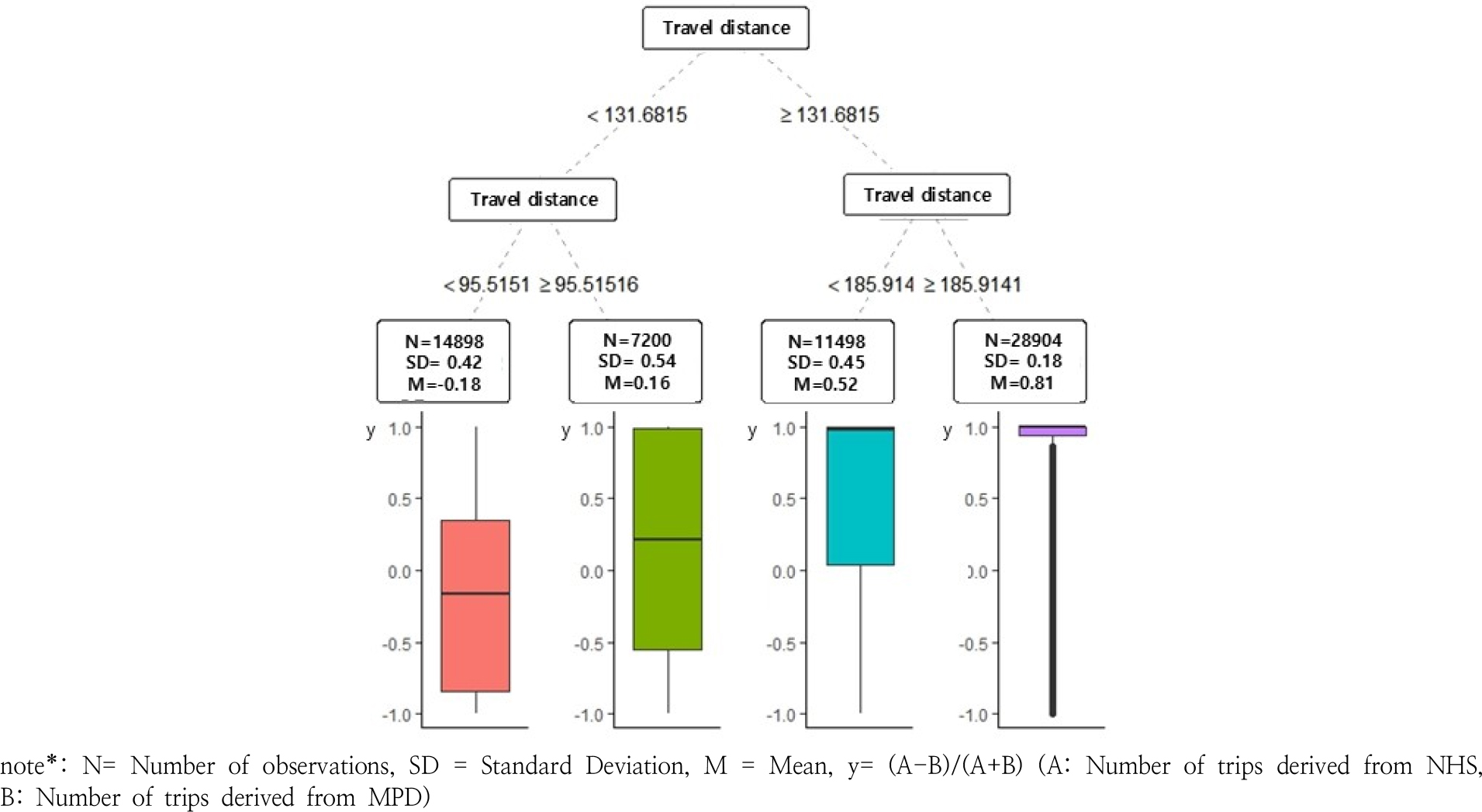
먼저 통근 통행은 Figure 7과 같이 모든 노드가 통행거리로만 분기되는 것으로 분석되었으며, 통행거리가 짧은 단거리 통행일수록 가구통행실태조사와 모바일 통신데이터의 통행패턴이 유사하게 나타나고 통행거리가 길어질수록 가구통행실태조사의 통행량이 절대적으로 많아지는 것으로 분석되었다.
다음으로 통학 통행은 Figure 8과 같이 통행거리로 1차 분기한 후, 출발지 종사자수에 따라 2차 분기하고 통행거리로 다시 한번 분기하여 총 4개의 최종노드가 형성되는 것으로 분석되었으며, 통행거리가 길수록, 출발지의 종사자수가 많을수록 가구통행실태조사의 통행량이 절대적으로 많은 것으로 분석되었다.
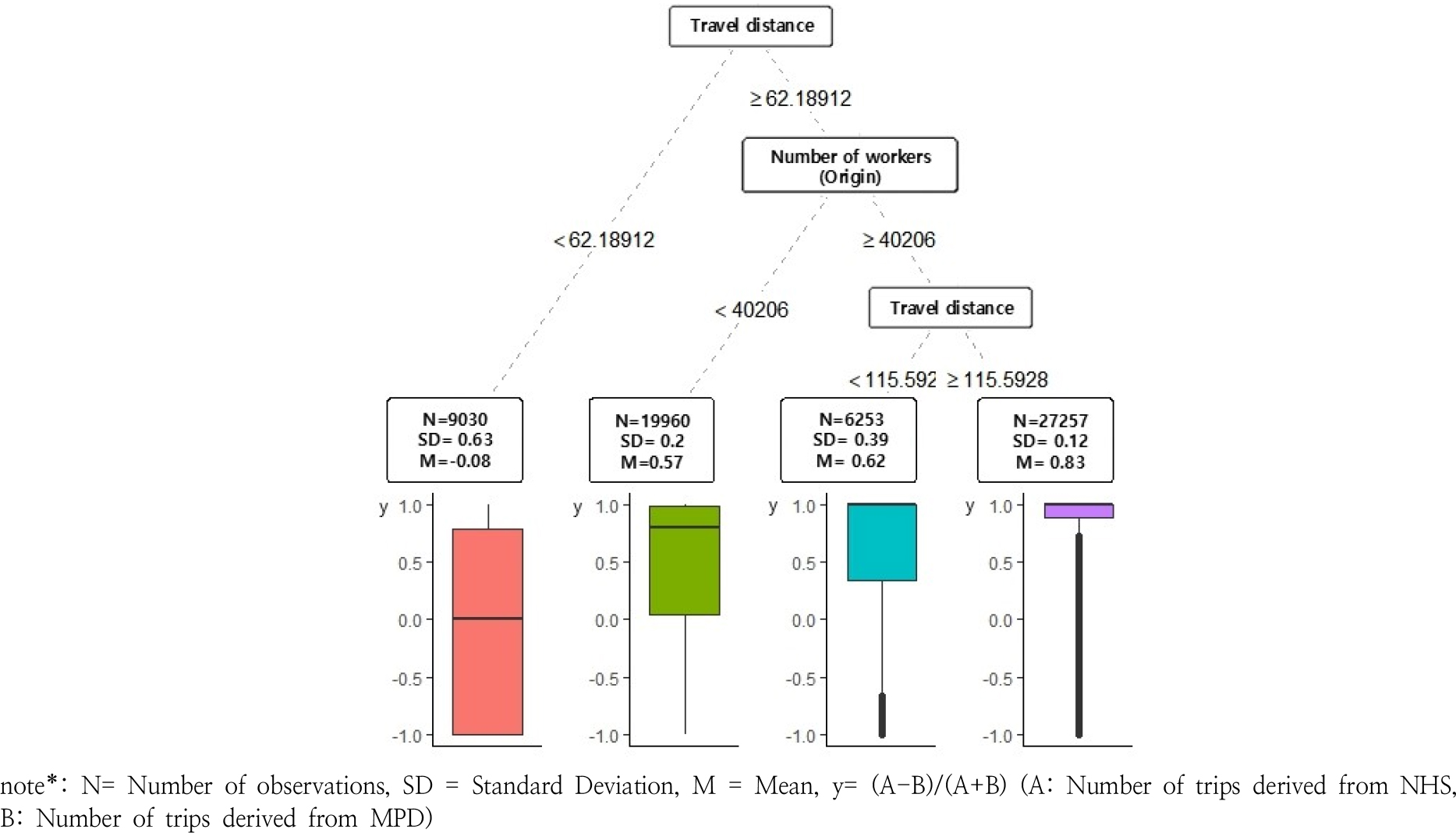
마지막으로, 기타 통행의 경우 Figure 9와 같이 통행거리를 기준으로 1차 분기한 후, 도착지 기지국 밀도를 기준으로 2차 분기, 출발지 기지국 밀도를 기준으로 최종 분기하여 총 4개의 최종 노드를 형성하는 것으로 분석되었으며, 단거리 구간에서 모바일 통신데이터의 통행량이 가구통행실태조사보다 더 많게 집계되는 경향을 보였다.
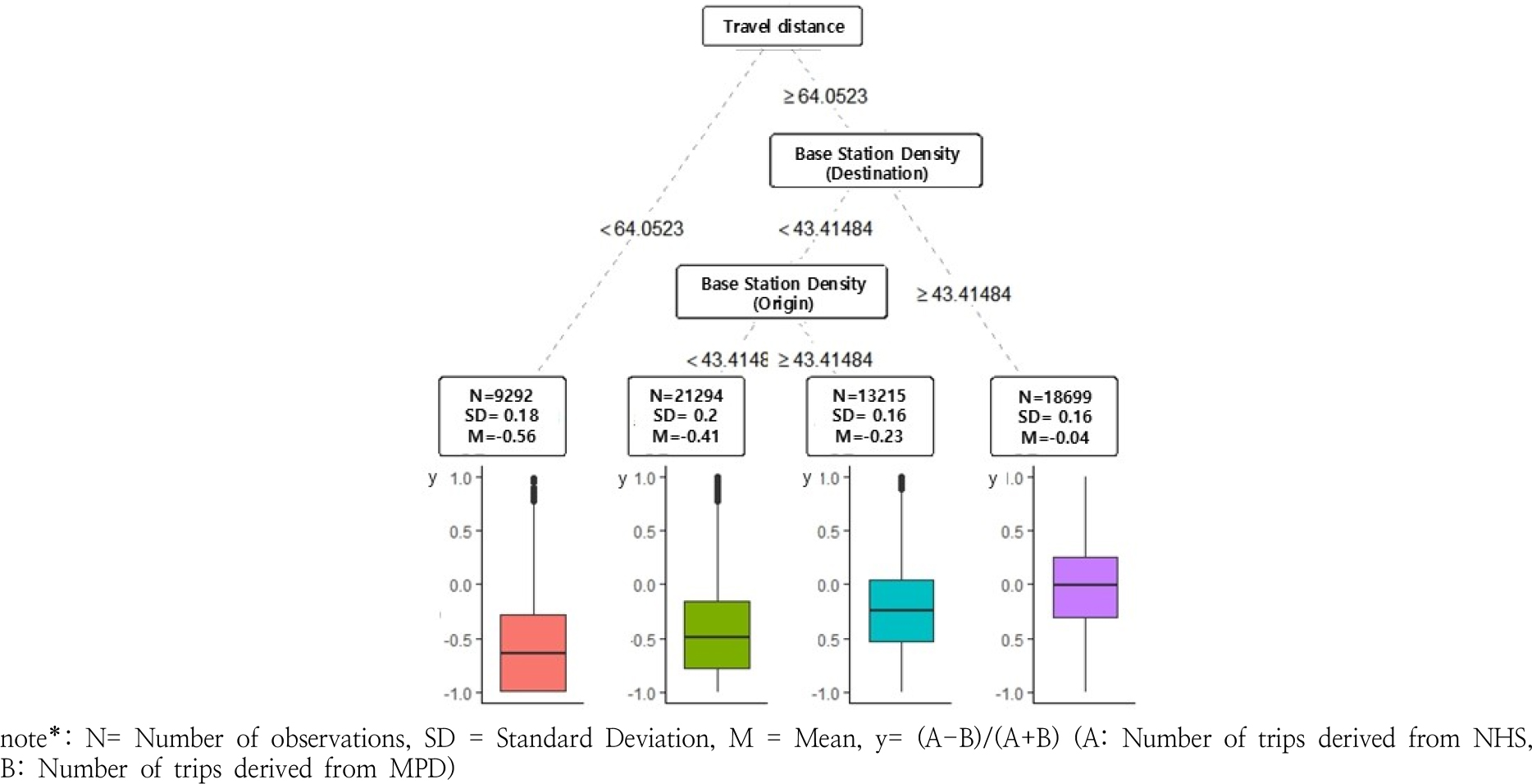
Table 14는 의사결정나무분석을 통해 도출된 분기 규칙을 통행목적별로 정리한 것이다.
Table 14.
Analysis results by purpose of travel
결과 해석 및 논의
의사결정나무분석에서 도출된 분석 결과를 바탕으로, 모바일 통신데이터와 가구통행실태조사 간 통행량 차이에 영향을 미치는 요인을 다음과 같이 해석할 수 있다.
우선 전체 통행의 경우, 출발지와 도착지의 기지국 밀도가 낮을수록 모바일 통신데이터의 통행량이 가구통행실태조사의 통행량보다 더 높게 나타나는 것으로 분석되었다. 이러한 결과는 모바일 통신데이터가 통행자의 이동 및 체류 여부를 기지국 간 신호 영역의 이동을 기준으로 판단하는 방식과 밀접한 관련이 있다. 기지국 밀도가 43.41개/km2 미만인 중소도시 및 농촌지역에서는 43.41개/km2 이상인 서울, 대전, 대구 등 대도시 지역보다 신호 영역의 크기가 상대적으로 크기 때문에, 두 기지국 간 이동하는 데 더 많은 시간이 소요된다. 이때 이동과 체류를 구분하는 기준 시간보다 기지국 간 이동 시간이 더 길어질 경우, 실제 이동임에도 불구하고 체류로 간주되어 별개의 통행으로 분리되어 인식될 수 있다. 이로 인해 하나의 통행이 복수의 통행으로 분절되며, 결과적으로 통행량이 과대 추정되는 현상이 발생할 수 있다.
다음으로 통근 통행의 경우, 장거리 통행일수록 가구통행실태조사에서의 통행량이 더 높게 나타나는 것으로 분석되었다. 이는 출·퇴근 시간대에 환승, 대기, 정체 등으로 인한 일시적 체류가 빈번하게 발생하며, 모바일 통신데이터에서는 이러한 체류 지점을 규칙 기반(rule-based) 처리 과정에서 기점 또는 종점으로 인식하는 경우가 있기 때문이다. 이로 인해 하나의 장거리 통행이 여러 개의 단거리 통행으로 분절되어 집계되며, 결과적으로 장거리 통행은 과소 추정되는 경향이 나타날 수 있다.
통학 통행의 경우, 통행거리가 길수록 그리고 출발지의 종사자 수가 많을수록 가구통행실태조사에서
집계된 통행량이 절대적으로 많은 것으로 나타났다. 이는 모바일 통신데이터의 처리 로직상, 통행자의 연령이 20세 미만인 경우에만 체류지에 ‘학교’가 부여되어 20세 이상 통행자의 통학 통행이 제외되기 때문으로 해석된다.
특히 20세 이상의 대학생은 주거지를 벗어나 장거리 통학을 하거나, 직장과 학업을 병행하는 경우가 많아 이러한 특성이 데이터에 반영되지 않았을 가능성이 높다. 결과적으로 모바일 통신데이터에서는 통학 통행이 과소 집계되고, 가구통행실태조사에서는 통행량이 상대적으로 많게 나타난 것으로 볼 수 있다.
또한, 출발지의 종사자 수가 40,206명 이상인 지역에서 두 자료 간 통행량 차이가 더 크게 나타난 것은, 해당 지역이 인구 밀도가 높고 통학 수요가 많은 도시 지역일 가능성이 크기 때문이다. 반면, 종사자 수가 40,206명 미만인 지역(예: 충북 보은군, 충남 계룡시, 전남 곡성군 등)은 고령화가 진행된 소도시 또는 농촌 지역으로, 전체 통행 중 통학 통행의 비중이 낮아 두 자료 간 차이도 상대적으로 작게 나타난 것으로 해석된다.
한편 기타 통행에서는 단거리 구간에서 모바일 통신데이터의 통행량이 가구통행실태조사보다 더 많게 집계되는 특징이 나타났는데, 이는 모바일 통신데이터와 가구통행실태조사의 통행 정의 및 포함 기준의 차이에서 기인하는 것으로 판단된다. 가구통행실태조사에서는 주유소, 편의점, 테이크아웃 등과 같이 최종 목적지로 가는 도중에 일시적으로 정차한 통행은 조사 대상에서 제외되는 반면, 모바일 통신데이터는 30분 이상 체류한 지점을 기·종점으로 간주하여 통행으로 집계한다. 이로 인해 동일한 이동이 모바일 통신데이터 상에서는 여러 개의 통행으로 분절되어 나타날 가능성이 높으며, 결과적으로 기타 통행의 경우 모바일 통신데이터의 통행량이 가구통행실태조사보다 더 많게 집계되는 현상으로 이어졌다고 볼 수 있다.
마지막으로 Table 15는 의사결정나무분석의 결과를 토대로 분기조건에 따른 통행패턴의 경향성을 정리한 것이다.
결론
본 연구에서는 의사결정나무분석방법을 활용하여 모바일 통신데이터와 조사자료의 통행량 차이가 나타나는 구간의 특성을 확인하고자 하였다. 이를 위해 A 통신사 자료로 구축한 22년 11월 기준의 통행량 자료와 2019년 기준의 가구통행실태조사자료를 수집하였으며, 상호 비교가 가능하도록 전체 통행과 통근, 통학, 기타 세 가지 통행목적 통행으로 구분하여 시군구 단위의 O/D 통행량으로 집계한 후 평일 일평균 통행량 값으로 환산하여 분석 DB를 구축하였다.
종속변수는 통행구간별 통행량 차이가 큰 점을 고려하여, 두 자료의 통행량 차이를 동일한 기준에서 비교할 수 있도록 각 통행구간별로 두 자료에서 나온 통행량의 합을 기준으로 하여, 그에 대한 두 자료의 통행량 차이를 비율 형태로 계산하여 설정하였으며, 각 자료의 통행량 구축 과정에서 통행량 차이에 영향을 줄 수 있다고 판단되는 기지국수(빈도), 인구수, 학령인구수, 수용학생수, 학교수, 취업자수, 종사자수, 생산인구수(비율), 고령인구수(비율), 통행거리를 설명변수로 선정하였다. 의사결정나무분석 알고리즘은 종속변수의 형태와 해석의 용이성을 고려하여 CART(Classification And Regression Trees)로 선택하였으며, 노드가 과도하게 분리되지 않도록 트리 중지 기준을 두었다.
분석 결과 전체 통행은 4가지, 통근 통행은 4가지, 통학 통행은 4가지, 기타 통행은 4가지의 규칙을 가지는 것으로 확인되었으며, 각 규칙에서 다음과 같이 공통된 특성을 보이는 것으로 분석되었다. 첫째, 가구통행실태조사자료와 모바일 통신데이터의 통행량 차이에 주요하게 영향을 미치는 변수는 ‘통행목적’, ‘통행거리’, ‘종사자수’, ‘기지국 밀도’로 나타났다. 둘째, 기점과 종점의 체류지 유형이 고정되어 있고, 다른 통행에 비해 정기적인 특성을 가지는 통근과 통학의 경우, 전반적으로 가구통행실태조사의 통행량이 많게 집계되는 경향을 보였다. 셋째, 기타 통행에서는, 단거리 통행이거나, 출발지 및 도착지의 기지국 밀도가 낮은 경우, 모바일 통신데이터의 통행량이 더 많이 집계되는 경향을 보였다.
이러한 결과는 모바일 통신데이터와 가구통행실태조사의 데이터 수집 방식과 처리 방식의 차이에서 비롯된 것으로 해석된다. 두 자료는 통행을 인식하고 분류하는 방식에서 근본적인 차이를 가지며, 이러한 구조적 차이가 통행량 집계 결과에 직접적인 영향을 미치기 때문이다.
구체적으로 살펴보면 우선, 모바일 통신데이터는 사전 정의된 규칙(rule-based)에 따라 데이터를 분류·가공하기 때문에 예외적인 상황에 유연하게 대응하기 어렵다는 특징이 있다. 특히 통근, 통학 통행의 경우, 모바일 통신데이터는 학교, 직장과 같은 체류지를 기반으로 통행목적을 판별하는 구조이므로, 통행자의 통근, 통학 행태가 비정기적일 경우 해당 체류지를 정확하게 인식하지 못해 일부 통행이 누락될 가능성이 있다.
또한, 모바일 통신데이터는 시간, 거리, 속도 등의 물리적 특성을 기반으로 통행을 추정하기 때문에 통신 인프라의 공간적 특성, 특히 기지국 밀도의 영향을 크게 받을 수 있다. 특히 기지국 밀도가 낮은 지역에서는 통행자의 실제 이동 여부를 정확히 판별하기 어려워, 하나의 연속된 이동이 다수의 단거리 통행으로 분절되어 과대 추정되는 경우가 발생할 수 있다.
반면 가구통행실태조사는 최종 목적지까지 이동하는 과정에서의 일시 정차 지점은 통행으로 간주하지 않고, 통행자의 기억에 따라 수집된 자료이기 때문에 일상 속에서 간헐적으로 발생하는 비정기적 통행은 가구통행실태조사보다 모바일 통신데이터의 통행량이 더 높게 집계될 수 있다.
향후 모바일 통신데이터 가공 알고리즘을 개발하거나, 조사자료를 대체하여 모바일 통신데이터를 활용할 때, 본 연구결과에서 제시한 이러한 특성이 반영된다면 보다 정확도 높은 통행량을 산출할 수 있을 것이다. 단, 본 연구의 결과를 활용함에 있어, 두 자료 중 어느 것이 참값(ground truth)인지 명확하지 않으므로, 어느 한쪽이 더 정확하다고 단정 지을 수 없음을 유의할 필요가 있으며, 자료 수집의 한계로 본 연구에서 활용한 가구통행실태조사 자료와 모바일 통신데이터의 시기가 일치하지 않으므로 해석 시 시기적 차이로 인한 영향을 염두에 둘 필요가 있을 것이다.
향후 연구에서는 이러한 한계를 보완하여, 핸드오버 데이터의 발생 조건에 따라 모바일 통신데이터와 가구통행실태조사 간 통행량의 차이를 보다 정밀하게 분석하거나, 랜덤포레스트와 같은 다른 분석기법을 적용하여 본 연구 결과의 일반화 가능성을 검토할 필요가 있다.
