

서론
선행연구
연구방법론
1. 변수 중요도 도출
2. 사고위험 예측모형
3. 모형성능평가
자료수집
분석 결과
1. First-stage; 변수 선택
2. Second-stage; 변수 조합 생성
3. Third-stage; 사고 위험 예측 모형 개발
결론 및 향후 연구과제
서론
교통사고는 사회적 경제적 측면에서 큰 손실을 초래하며, 사망을 초래한다. 세계보건기구에 따르면 교통사고는 전 세계 주요 사망원인 8위에 해당하며, 연간 135만 명이 교통사고로 사망하고 있다(WHO, 2019). 이에 따라 교통사고에 대한 대책을 마련하는 것이 필요하며, 과거 교통안전 관리는 이력 자료를 바탕으로 사고 위험 구간을 지정하여 관리하는 등 사후 대처에 초점을 맞추어 왔다. 하지만 최근에는 실시간으로 사고 발생 전 교통사고 발생확률을 예측하고 사전에 대응하는 교통안전 관리 전략의 필요성이 증가하고 있으며, 기술의 발전과 교통 빅데이터의 증가로 이를 활용한 실시간 교통사고 예측 연구들이 수행되고 있다(Yu and Abdel-Aty., 2013; Wang et al., 2015; Basso et al., 2018; Wang et al., 2019; Formosa et al., 2020; Huang et al., 2020).
실시간 교통사고 예측모형 개발에서 모형에 사용할 변수의 선택은 중요한 단계 중 하나이다. 예측모형에서 너무 많은 변수를 고려하게 되면 모형의 정확도는 높아질 수 있지만, 지나치게 과적합이 일어나거나 모형의 복잡성이 증가하는 문제가 발생할 수 있다. 따라서 적절한 수의 변수만을 사용하기 위해 사고 위험 예측에 핵심이 되는 중요 변수를 선택하는 절차를 거쳐야 한다. 본 연구에서는 이러한 변수 선택 과정에 있어 머신러닝 기법 중 지도학습과 비지도 학습 방법론을 동시에 고려한 Multi-stage 방법론을 제안하였으며, 이를 통해 사고위험 교통류를 잘 구분할 수 있도록 하는 안전 지표를 선택하고 정확도 높은 사고 위험 예측 모형을 개발하였다. Multi-stage 방법론에서 각 단계는 비지도 학습과 지도학습을 통한 주요 변수 선정, 선정된 주요 변수의 조합 도출, 도출된 변수 조합을 독립변수로 사용한 사고 위험 예측 모형 개발로 이루어져 있다. 첫 번째 단계인 핵심 변수 선별에서는 비지도 학습 방법론 중 K-means Clustering(KC)와 지도학습 방법론 중 Random Forest(RF) 방법론을 사용하여 주요 변수를 도출하였다. KC 방법론의 경우 주로 사고 심각도 모형 개발에 적용되어왔으며, 비지도학습을 통해 사고 데이터를 여러 개의 군집으로 분류함으로써 사고 모형 개발에 지도학습으로는 도출되지 않는 잠재적인 중요 요인을 반영할 수 있다는 장점이 있다(Mohamed et al., 2013). RF 방법론의 경우 학습 과정에서 생기는 노드 불순도를 활용하여 변수들의 중요도 순위를 도출할 수 있다는 장점을 가지고 있다. 두 번째 단계에서는 KC와 RF 방법론을 통해 도출된 변수들의 조합을 구성하였다. 마지막으로, 세 번째 단계에서는 회귀 및 분류모형에 주로 사용되는 머신러닝 기법 중 Support Vector Machine(SVM)을 사용하여 사고위험 교통류와 일반 교통류를 분류하는 사고 위험 예측 모형을 개발하였다. 모형 개발 과정에서 데이터는 사고위험 교통류와 일반교통류 정의에 따라 1:5 비율로 추출하여 사용하였으며, 오차 행렬표를 기반으로 RF로 핵심 변수를 도출하여 개발한 사고위험 예측모형과 KC로 핵심 변수를 도출했을 때의 사고위험 예측모형, RF와 KC 방법론으로부터 도출된 변수를 동시에 사용했을 때의 사고위험 예측모형의 성능을 평가하였다.
이전 연구들에서 검지기 자료 또는 개별차량 데이터를 사용하여 실시간 교통사고 위험을 포착하고, 이에 대응하려는 시도가 있었다(Formosa et al., 2020; Kim et al., 2021). 본 연구에서는 차량의 위험 주행행태를 잘 포착할 수 있도록 하기 위해 사업용 자동차 운행기록장치(Digital Tachograph, DTG)에서 수집된 주행궤적 데이터를 사용하였다. 주행궤적 데이터의 경우 일정한 시간 간격으로 수집된 평균적인 교통류 상태를 나타내는 검지기 데이터와 다르게 급감속, 급가속 등 차량의 불안정적인 주행행태를 포착할 수 있게 한다는 장점을 가지고 있다. 본 연구에서 활용한 DTG 데이터의 시간적 범위는 2017년 3월 5일부터 3월 14일, 12월 한 달. 그리고 2018년 3월 4일부터 3월 23일까지 총 61일이며, 공간적 범위는 한국의 고속도로 전체 범위이다. 1초 단위로 수집되는 DTG 데이터를 기반으로 다양한 변수를 산출했으며, 1분 단위로 집계하여 데이터의 실시간성을 반영하였다.
본 연구의 목적 및 목표는 다음과 같다. 첫 번째로, KC를 통해 사고위험 교통류 군집과 일반교통류 군집을 가장 명확하게 분류하는 핵심 변수를 도출하여 잠재적인 사고 발생 징후 인자(Crash precursor)를 도출하고자 하였다. 두 번째로, 개별차량 주행궤적 데이터를 가공하여 사용함으로써 주행행태 기반 안전 지표들을 사용해 사고위험을 예측할 수 있는 모형을 개발하였다. 세 번째로 RF, KC, RF-KC hybrid 방법으로 도출된 핵심 변수를 독립변수로 한 사고 위험 예측 모형을 개발하고 그 성능을 비교하여 변수 선택을 위한 최적의 방법과 정확도 높은 최종 사고 위험 예측 모형을 제안하였다. 본 연구에서 제안한 Multi-stage 방법론을 통해 보다 정확도 높은 사고 위험 예측 모형을 개발할 수 있다.
선행연구
교통 분야에서는 사전 예방 개념의 선제적 안전 관리 전략의 중요성이 대두되면서 사고위험 예측모형 개발과 관련된 연구들이 수행되어왔다(Abdel-Aty et al., 2004; Abdel-Aty and Pande, 2005; Abdel-Aty et al., 2005; Abdel-Aty et al., 2012; Ahmed and Abdel-Aty, 2013; Yu and Abdel-Aty, 2013; Xu et al., 2014; Lin et al., 2015; Shi and Abdel-Aty, 2015; Wang et al., 2015; You et al., 2017; Basso et al., 2018; Wu et al., 2018; Yang et al., 2018; Wang et al., 2019; Huang et al., 2020; Yuan et al., 2022). Yuan et al.(2022)은 고속도로 사고 위험 예측 모형 개발을 위해 20초 간격으로 수집되는 루프 검지기 데이터를 5분 단위로 집계해 사고 데이터와 매칭하였으며, 사고를 종속변수로, 다양한 교통변수를 독립변수로 한 Bayesian logistic 회귀모형을 개발하였다. 모형 개발 과정에서는 유의한 변수 선정을 위해 Logistic stepwise regression을 수행하였다. Cai et al.(2020)은 차량 검지기 데이터를 활용하여 고속도로 실시간 사고 예측모형을 개발하였다. 사고 예측모형으로 로짓모형(Logit model), SVM, Artificial Neural Network(ANN), Convolution Neural Network(CNN)를 사용하였다. 핵심 변수 선정을 위해서는 Pearson 상관분석과 RF 분석을 수행하였으며, 두 가지 분석 결과를 조합하여 사고 위험 예측 모형에 사용되는 변수를 선별하였다. Cheng et al.(2022)은 루프 검지기로부터 2분 간격으로 수집되는 속도, 교통량 등의 데이터를 활용하여 Extended logit 모형 기반의 사고 위험 예측 모형을 개발하였다. 개발된 로짓 모형의 매개변수 평가를 통해 사고위험 확률을 정량화하였으며, 핵심 변수 선정을 위해 카이 제곱 검정과 다중공선성 검정을 수행하였다. Lei et al.(2021)은 영상검지기로부터 수집한 데이터를 활용하여 머신러닝 기법으로 고속도로 사고를 예측하는 연구를 수행하였다. 모형 개발에 필요한 교통류 변수를 선정하기 위해 RF 기법을 사용하였으며, 사고 분류모형으로 SVM을 사용하였다. Kim et al.(2021)은 한국 DTG로부터 수집된 데이터를 활용하여 사고위험 예측모형을 개발하였다. 사고에 영향을 끼치는 교통류 변수의 우선순위를 도출하기 위해 Gradient Boosting(GB) 기법을 사용하였으며, Neural Network 기반의 사고 위험 예측 모형을 개발하였다. Ahmed and Abdel-Aty(2013)은 사고 위험 예측 모형 개발을 위한 주요 변수 선정을 위해 Stochastic Gradient Boosting(SGB) 방법론을 사용하였으며, 상대적 중요도가 25% 미만인 변수는 모델 개발 단계에서 제외하였다.
기존 연구들은 대부분 사고 위험 예측 모형 개발에 고속도로 등 교통 인프라에 설치되어 있는 검지기 데이터를 활용하였다. 루프 검지기와 같은 검지기 데이터의 경우 다량의 데이터를 수집할 수 있으며 교통류의 특성을 효과적으로 반영할 수 있다는 장점이 있다. 하지만 검지기 기반의 데이터의 경우 실시간으로 변화하는 차량의 주행행태와 위험 상황을 반영하는 데에 어려움이 있다. 따라서 최근에는 영상 자료, GPS 자료 등 개별차량 주행궤적 데이터를 활용하여 실시간으로 사고위험을 예측하는 연구들이 수행되었다. Formosa et al.(2020)은 실시간 Deep Neural Network(DNN) 기반의 사고 위험 예측 연구 모형을 개발하였으며, 차량 내 센서(In-vehicle sensor)로부터 수집되는 차량간 상호작용 정보를 사용하여 안전 대체 지표(Surrogate Safety Measures, SSM)를 산출하여 독립변수로 활용하였다. 그리고 모형 개발 과정에서 변수 선별 없이 26개의 독립변수를 모두 사용하였다. 또한, Kim et al.(2021)의 경우 버스, 택시 등 상업용 차량의 주행궤적 데이터인 DTG 데이터를 사용하여 실시간 사고위험을 평가하는 연구를 수행하였으며, 사고위험 예측에 핵심이 되는 변수 선별을 위해 앙상블 기반의 지도학습 방법론인 Gradient Boosting(GB) 방법론을 적용하였다. Xia et al.(2022)의 경우 영상 자료에서 추출한 차량 들의 주행궤적 데이터를 수집하고 Naive Bayes와 로지스틱 회귀분석, Gradient Boosting Decision Tree 기반의 교통 상충 예측모형을 개발하였다. 이 과정에서 사고위험 예측을 위한 변수로는 개별차량의 속도 기반의 데이터를 사용하였으며, 22개의 변수 후보 중 심각한 다중공선성이 존재하는 변수를 제외한 17개의 변수를 활용하였다. 본 연구에서는 실시간 주행궤적 데이터를 활용하여 사고위험 예측모형을 개발한 기존 연구들과는 다르게 개별차량의 주행 위험을 나타낼 수 있는 안전지표 뿐만 아니라 혼잡지표, 차선 수 등 교통류의 안전성을 나타내는 변수들을 함께 활용하였다. 또한, 고도화된 모형 입력 변수 선별 방법론을 통해 사고위험 예측모형에 핵심이 되는 변수들을 선정하였다.
사고 위험 예측에 관한 기존 연구들은 핵심 변수 선별을 위해 대부분 상관분석 또는 앙상블 기반의 머신러닝 방법론을 사용하였다. 하지만 교통사고는 사고위험 교통류 분류에 핵심이 되는 변수 중 지도학습을 통해 드러나지 않는 중요 변수가 있을 수 있으므로 비지도 학습 시 도출되는 안전 지표가 새로운 핵심 변수가 될 수 있는지 확인해 볼 필요가 있다. 본 연구에서는 고속도로 사고 위험 예측 모형 개발을 위하여 변수 선택과 변수 조합, 모형 개발의 3단계로 절차를 나누어 진행하였으며, 특히 변수 선정 과정에서 비지도 학습과 지도학습으로부터 도출된 주요 변수를 모두 고려하여 교통사고 발생과 관련된 잠재적인 요소를 고려할 수 있는 사고위험 예측모형을 개발하려고 시도하였다. 그리고 고도화된 핵심 변수 선별 방법론을 통하여 적은 입력 변수로도 사고위험 교통류를 정확도 높게 식별할 수 있도록 하는 사고위험 예측모형을 개발하였다. 사고위험 예측모형 개발 연구들에서 사용한 모형과 데이터, 변수 선택 방법론은 Table 1과 같다.
Table 1.
Previous studies in crash risk prediction
| Study | Variable selection | Crash prediction | Data |
| Ahmed and Abdel-Aty(2013) | SGB | SGB | AVI, RTMS |
| Yu and Abdel-Aty(2013) | CART | SVM | RTMS |
| Xu et al.(2014) | Pearson’s correlation test | Bayesian LR | Loop detector |
| Lin et al.(2015) | RF, Free-pattern tree | K-NN, Bayesian network | Traffic detector |
| Shi and Abdel-Aty(2015) | RF, Pearson’s correlation test | Bayesian LR | MVDS |
| Wang et al.(2015) | RF, Pearson’s correlation test | Multilevel Bayesian LR | MVDS |
| You et al.(2017) | RF | SVM | Weather data, Loop detector |
| Basso et al.(2018) | RF, Pearson’s correlation test | SVM, LR | AVI |
| Yang et al.(2018) | LR | Bayesian Dynamic LR | Loop detector |
| Wang et al.(2019) | Bayesian LR | SVM | MVDS |
| Cai et al.(2020) | Pearson’s correlation test | LR, SVM, ANN, CNN | MVDS |
| Huang et al.(2020) | - | CNN | Roadside radar sensor |
| Basso et al.(2021) |
Pearson’s correlation test, Boruta algorithm | CNN | AVI |
| Kim et al.(2021) | GB | Neural Network | Digital tachograph |
| Lei et al.(2021) | RF | SVM | Video detector |
| Cheng et al.(2022) | - | Extended LR | Loop detector |
| Formosa et al.(2020) | - | R-CNN, DNN |
In-vehicle sensor, Loopdetector, Camera |
| Li et al.(2022) | SHAP | XGBoost-Hybrid model | Traffic detector |
| Xia et al.(2022) | Multicollinearity diagnosis |
Naive Bayes, LR, GB, Decision Tree | Vehicle trajectory data |
| Yuan et al.(2022) | Stepwise LR | Bayesian LR, SVM | Loop detector |
*Automatic Vehicle Identification (AVI); Remote Traffic Microwave Sensors (RTMS); Classification And Regression Tree (CART); Rural Traffic Management System (RTMS); Logistic regression (LR); K-nearest neighbor(K-NN); Regional–Convolution Neural Network (R-CNN); Neural Network (NN); SHapley Additive exPlanations (SHAP)
연구방법론
본 연구에서는 고속도로의 실시간 사고위험을 평가하기 위한 Multi-stage 방법론을 제안하였다. 여기서 Multi-stage는 사고 위험 예측 모형에 입력 변수로 활용할 핵심 변수의 선별 과정에 비지도학습 방법론과 지도학습 방법론을 모두 사용한 것을 의미한다. 본 논문에서 Single-stage 방법론의 경우 핵심 변수의 선별 없이 전체 변수를 활용하여 사고 위험 예측 모형을 개발하는 것이고, Two-stage 방법론은 비지도학습 방법론 또는 지도학습 방법론 한 가지를 통해 핵심 변수를 선별하고, 해당 변수로 사고위험 예측모형을 개발하는 것이다. 본 연구에서는 Single-stage 방법론과 Two-stage 방법론, 그리고 제안된 Multi-stage 방법론 기반의 예측모형을 비교하였다. 본 연구의 전체적인 흐름은 Figure 1과 같다.

Multi-stage 방법론 기반의 사고 위험 예측 모형 개발 과정은 다음과 같다. 첫 번째로, 두 가지의 머신러닝 방법론을 사용하여 사고위험 예측모형의 핵심 안전 지표를 선별하였다. KC 방법론을 사용해서는 사고위험 교통류와 일반교통류 군집 분류 후 사고위험 군집과 일반 군집을 효과적으로 분류할 수 있는 변수를 핵심 안전 지표로 도출하였으며, RF에서는 모형 학습 과정에서 노드의 불순도에 따라 나타나는 변수 중요도 리스트를 통해 중요한 안전 지표를 선별하였다. 두 번째 단계는 주요 안전 지표들의 조합을 찾는 것으로, KC와 RF 분석 결과에 따라 도출된 안전 지표들의 조합을 도출하였다. 마지막으로 세 번째 단계에서는 SVM 기반의 사고 위험 예측 모형을 개발하고, 변수 조합별 예측 성능 비교를 통해 핵심 변수 선별에 있어 비지도 학습 및 지도학습의 기여도와 최적의 핵심 변수 조합을 도출하였다.
1. 변수 중요도 도출
본 연구에서는 군집분석 방법론 중 KC와 앙상블 기법의 하나인 RF 방법론을 사용하여 사고 위험 예측 모형 개발을 위한 주요 안전 지표들을 선별하였다.
1) K-means 클러스터링
군집분석은 머신러닝 비지도 학습 기법의 일종으로, 정답(label) 없이 유사한 특성을 갖는 데이터를 군집으로 묶는 방법론이다. 대표적인 군집분석 방법론에는 거리 기반의 군집 분류 방법론인 K-means clustering(KC)가 있다. KC는 주어진 데이터를 K개의 클러스터로 묶는 방법론으로, K는 클러스터의 개수를, means는 클러스터의 중심과 데이터 간의 평균 거리를 의미한다(MacQueen, 1967). 기존 연구에서는 주로 사고 심각도에 영향을 미치는 주요 요인을 도출하기 위해 클러스터링 기법을 사용하였다(Assi et al., 2020). 본 연구에서는 교통류 데이터를 위험 교통류와 일반교통류 두 가지로 구분하였으며, 두 집단을 잘 분류할 수 있는 잠재적인 안전 지표를 도출하기 위해 KC 방법론을 변수 선별 과정에 적용하였다.
KC의 원리는 다음과 같다. 초기에는 임의로 K개의 중심이 설정되어 데이터들을 가장 가까운 중심점이 속해있는 클러스터로 분류한다. 그리고 분류된 클러스터의 중심으로 중심점이 이동하며, 이 과정을 반복하여 결과적으로 K개의 클러스터를 생성한다. 이 과정에서 입력 변수와 각 클러스터 중심 사이의 거리를 계산해야 하며, Equation 1과 같이 유클리드 거리로 계산된다.
여기서, = 입력 변수
= 각 클러스터(군집)의 중심
= 변수의 개수
= 데이터 수
Objective function을 최소화하는 방향으로 클러스터 중심이 설정되며, Objective function은 Equation 2와 같이 표현된다.
여기서, = 입력 변수
= 각 클러스터(군집)의 중심
= 변수의 개수
= 클러스터(군집) 수
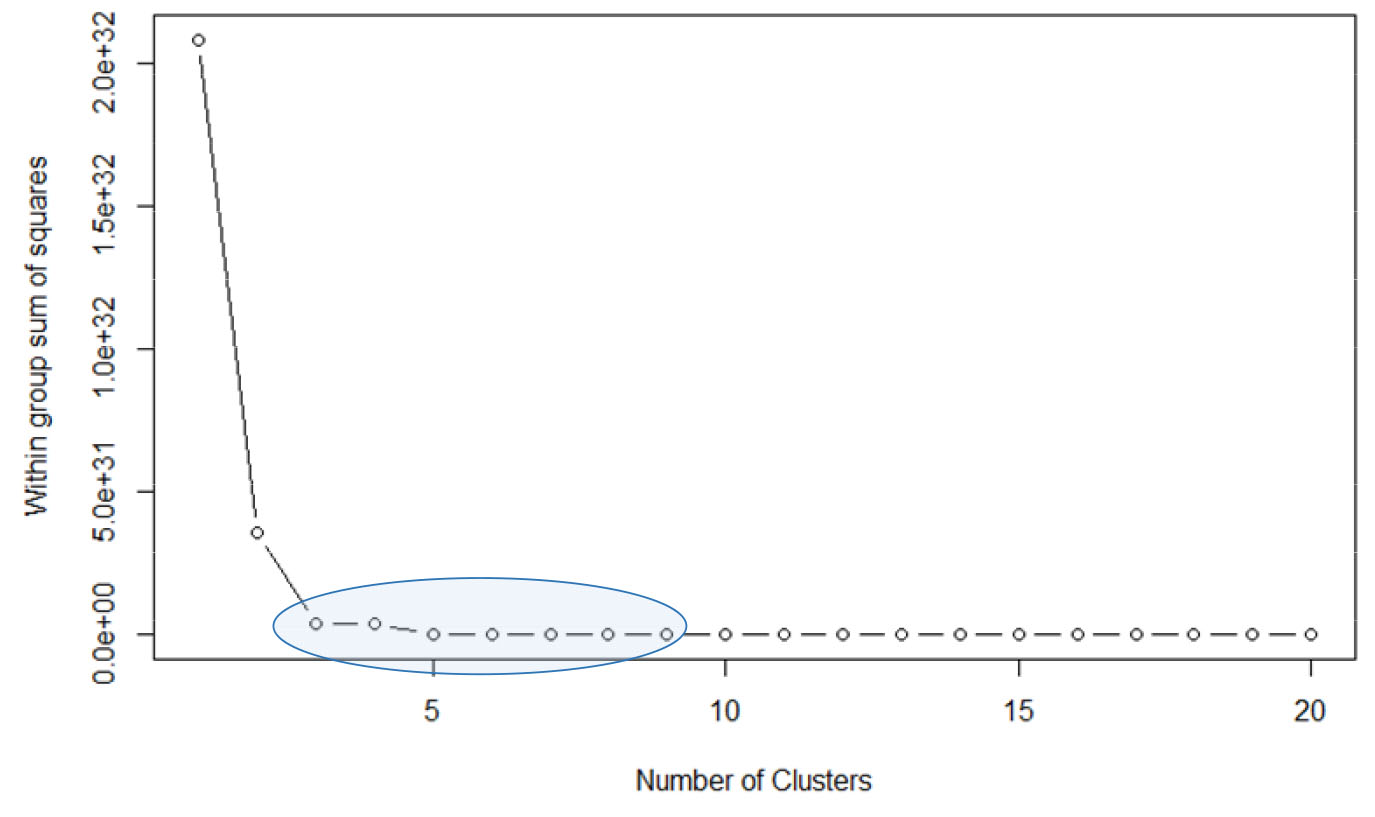
KC에서 K는 사전에 설정되어야 하는 값으로, 본 연구에서는 최적의 K값을 찾기 위하여 Cluster 간의 거리의 합을 나타내는 inertia가 급격히 떨어지는 구간을 찾아 K값을 설정하는 Elbow Method를 사용하였다(Cui, 2020). Elbow Method 결과, K=3부터 기울기가 급격하게 감소하였으며, 본 연구에서는 사고위험 교통류와 일반교통류를 잘 분류하는 최적의 군집 수를 찾기 위해 K=3, K=5, K=7, K=9로 군집 수를 변경하여 분석을 수행하였다.
2) 랜덤포레스트(Random forest, RF)
Random Forest(RF)는 머신 러닝 앙상블 기법의 하나로, 의사결정나무를 여러 개 구축하여 타겟 데이터를 예측하는 데 사용되는 기존 의사결정나무의 문제를 해결하기 위해 개발된 방법론이다(Breiman, 2001). RF 분석을 수행하면 모형 구축 결과와 변수 중요도를 평가하는 척도로 %IncMSE값과 IncNodePurity값을 구할 수 있다. %IncMSE는 해당 변수를 다른 값으로 대체했을 때 Mean squared error(MSE)의 증가 %를 의미하는 척도로, 값이 클수록 중요도가 높은 변수라고 할 수 있다. IncNodePurity는 노드 불순물(node impurity)과 관련된 척도로, node impurity가 증가하면 MSE가 증가한다. 즉, IncNodePurity가 클수록 중요도가 높은 변수이다. 기존 연구들에서 RF 방법론을 사용하여 사고 위험 예측 모형에 활용할 주요 변수를 도출하였으며(Lin et al., 2015; Shi and Abdel-Aty, 2015; Wang et al., 2015; You et al., 2017; Basso et al., 2018; Abou Elassad et al., 2020; Lei et al., 2021), 본 연구에서도 RF 모형 구축 결과 변수 중요도가 높은 안전 지표를 도출하였다.
2. 사고위험 예측모형
사고위험 예측모형으로는 사고위험 교통류와 일반교통류를 분류하는 이진 분류모형을 개발하고자 하였으며, 본 연구에서는 머신러닝 기법 중 서포트벡터머신(Support Vector Machine, SVM)을 활용하였다. SVM은 분류 또는 회귀 분석에 사용할 수 있는 머신러닝 기법으로, 라벨이 포함된 학습데이터를 학습시키는 지도학습 모형이다(Boser et al., 1992). SVM의 이해를 위해서는 초평면(Hyperplane)과 서포트벡터(Support Vector), 마진(Margin)의 개념을 이해해야 한다. 초평면은 데이터를 분류하는 평면이고, 서포트벡터는 이 초평면과 가장 가까운 포인트, 마진은 초평면과 서포트벡터 사이의 거리를 의미한다. SVM은 초평면을 기준으로 데이터를 분류하며, 분류 과정에서 마진을 최대화하는 초평면을 채택하여 데이터를 분류한다.
분석 정확도를 높이기 위해서는 SVM 하이퍼 파라미터 조정이 필요하다. 본 연구에서는 파이썬의 사이킷런(sklearn) 라이브러리를 활용하여 분석을 수행했으며, 그리드 서치를 통해 SVM 모형의 하이퍼파라미터 중 kernel, C, gamma값을 조정하였다. 또한, 모델 훈련과 검증을 위하여 전체 데이터를 훈련 데이터와 검증 데이터 7:3으로 나누어 분석을 수행하였다.
3. 모형성능평가
본 연구에서는 오차 행렬(Confusion matrix)을 기반으로 평가지표를 산출하여 모형의 예측 성능을 평가 및 비교하였다. 오차 행렬은 학습된 모형의 예측 오류가 얼마인지, 어떤 유형의 예측 오류가 발생하는지 나타내는 지표로, 일반교통류를 Negative(0), 사고 위험 교통류를 Positive(1), 옳게 예측한 것을 True, 틀리게 예측한 것을 False라고 할 때 True Negative(TN), False Positive(FP), False Negative(FN), True Positive(TP)로 구성된다.
자료수집
본 연구에서는 사업용 자동차의 운행기록장치(Digital Tachograph, DTG)에서 수집된 주행궤적 데이터를 사용하였다. DTG 데이터는 한국교통안전공단에서 관리하는 데이터로, 1초 단위의 주행궤적 데이터를 기록한다. 데이터 수집의 공간적 범위는 한국 고속도로 전체구간으로, DTG 데이터는 상업용 자동차의 데이터이기 때문에 고속도로 특성상 버스(시내버스, 농어촌버스, 마을버스, 시외버스, 고속버스, 전세버스)와 화물자동차(일반화물자동차, 개별화물자동차)가 각각 48.2%, 43.4%로 높은 비율을 차지하며, 택시(일반택시, 개인택시) 등 기타 차종은 8.4%의 비율을 차지한다. 데이터 수집의 시간적 범위는 2017년 3월 5일부터 3월 14일, 2017년 12월 한 달, 2018년 3월 4일부터 3월 23일까지로, 총 61일간의 데이터를 수집하여 사용하였다. 그리고 같은 기간에 발생한 190건의 고속도로 전체 교통사고를 수집하여 DTG 데이터와 매칭을 수행하였다. 교통사고 자료는 2017년 85건의 샘플과 2018년 105건의 샘플을 활용하였으며, 계절별로 다른 교통 패턴을 고려하기 위해 3월과 12월 자료를 수집하여 사용하였다.
DTG 원시 데이터는 차량 정보, 수집 시점, 주행거리, 속도, 차량 위치 등의 정보를 포함하고 있으며, 이를 가공하여 속도, 가속도, jerk, yaw와 같이 다양한 교통변수를 도출할 수 있다. 본 연구에서는 개별차량의 주행안전성을 평가하기 위해 안전 지표를 개발하고 평가한 이전 연구들(Dingus et al., 2006; Bagdadi and Várhelyi, 2013; Chevalier et al., 2017; Feng et al., 2017; Kamrani et al., 2018; Kim et al., 2018; Kim et al., 2021; Park et al., 2021)을 참고하여 4개의 교통변수를 활용해 산출할 수 있는 안전 지표(Safety indicator)를 산출하여 활용하였다. 한편, 대부분의 안전 지표는 개별차량의 주행 안전성을 나타내는 지표이므로 교통류 상황(특히 혼잡상황)을 반영하기 위해 혼잡지표(Congestion index)를 안전 지표에 추가로 포함했다. 또한, 도로 특성도 고려하기 위해 제한속도와 차선 수를 함께 고려하였다. 본 연구에서 사용한 변수들은 Table 2와 같다.
Table 2.
Variable set
| Category | Variable name | Description | Reference |
|
Traffic variables | Speed | - | |
| Acc | - | ||
| Jerk | - | ||
| Yaw | - | ||
|
Road variables | Lane | Number of lanes | - |
| Max_speed | Speed limit | - | |
|
Safety indicator | CI | Congestion index | Dias et al.(2009) |
| Peak to peak jerk | Peak to peak jerk | Bagdadi and Varhelvi(2013) | |
| SRI_x (x: speed, acc, jerk, yaw) | Safety reliability index | Kim et al.(2021) | |
| EDI_x (x: speed, acc, jerk, yaw) | Erratic driving indicator | Kim et al.(2018) | |
| Dangerous event | Dangerous driving event rate |
Korea transportation Safety authority | |
| RDEs | Rapid deceleration events | Chevalier et al.(2017) | |
| LNJ_x (x: 1.5, 2, 3, 4, total) | Large negative(-) jerk | Feng et al.(2017) | |
| LPJ_x (x: 1.5, 2, 3, 4, total) | Large positive(+) jerk | ||
| Rapid peak to peak | Rapid peak to peak jerk rate | Bagdadi and Varhelvi(2013) | |
| Yaw rate | Yaw rate | Dingus et al.(2006) Kamrani et al.(2018) | |
| S.D_x (x: speed, acc, jerk, yaw) | S.D (Standard deviation) | ||
|
TVSV_x (x: speed, acc, jerk, yaw) |
Driving volatility, TVSV (Time-varying stochastic volatility) |
사고위험 예측모형은 사고위험 교통류와 일반교통류를 분류하는 분류모형으로 구축된다. 기존 연구들에서는 사고 발생 시간대와 공간은 같지만 다른 날짜의 데이터를 비사고 데이터로 추출하거나(Abdel-Aty et al., 2008; Shi and Abdel-Aty, 2015; Zhai et al., 2020) 사고 발생 시점 전 시간대 범위를 설정하여 사고 데이터와 비사고 데이터를 추출하였다(Oh et al., 2005; Hossain et al., 2012; Kim et al., 2021). 또한 기존 연구들에서는 사고 위험 예측을 위해 예측 대상 데이터와 대조군 데이터 간의 비율을 1:5로 설정하여 분석하였다(Lei et al., 2021; Abdel-Aty et al., 2004). 본 연구에서는 사고위험 교통류를 사고 발생 시점에서 1분 전 교통류로, 일반교통류를 사고 발생 시점 10-15분 전 5분간의 교통류로 정의하고 데이터를 추출하였다. 추출된 데이터는 1분 단위로 집계하여 사고위험 교통류 190건, 일반교통류 831건의 분석 데이터를 구축하였다.
분석 결과
본 연구에서는 KC와 RF 분석 결과를 바탕으로 사고 위험 예측 모형의 핵심 변수를 선정하였으며, 이들 조합을 독립변수로 하고 사고위험 여부를 종속변수로 한 SVM 기반 사고 위험 예측 모형을 개발하였다. 본 장에서는 변수 선정 및 조합 결과와 예측모형의 비교 및 최적 변수 조합에 관하여 정리하였다.
1. First-stage; 변수 선택
1) K-means 클러스터링
KC 결과 군집 중 사고위험 교통류가 일반교통류보다 많이 존재하는 ‘사고 probability’가 0.5 이상으로 높은 군집을 사고위험 군집으로 정의하였다. 즉, 사고위험 군집과 일반 군집을 잘 나눌 수 있는 K값을 찾아 클러스터링을 수행하였으며, Elbow method 결과에 따라 K를 3, 5, 7, 9로 바꿔가며 클러스터링을 시행하였다(Figure 2). 이를 위해 38개의 전체 변수 set에서 변수를 하나씩 제거하며 분류된 군집을 확인하였으며, KC 분석 결과 K=7이고 5가지 변수를 사용했을 때 가장 사고위험 교통류 군집과 일반교통류 군집을 잘 분류하는 것으로 나타났다.
해당 5가지 변수는 3가지 안전 지표(Peak to peak jerk, RDE, CI)와 2가지 교통변수(Acc, Jerk)이다. Peak to peak jerk의 경우 가가속도(jerk)의 최댓값과 최솟값의 차이로, 해당 지표로 개별차량의 주행 안정성을 판단할 수 있다(Bagdadi and Várhelyi, 2013). RDE의 경우 7.35m/s2 이상의 급격한 감속 이벤트를 나타내는 지표로, 빠른 속도의 교통류가 저속 교통류를 갑작스럽게 마주하면 RDE 이벤트가 발생할 수 있다(Chevalier et al., 2017). 마지막으로 CI의 경우 혼잡지표로, 실제 속도와 자유속도로 정의할 수 있는 지표이다. 혼잡지표의 경우 지정체 상황 또는 혼잡상황을 반영할 수 있다는 장점이 있다(Shi and Abdel-Aty, 2015; Dias et al., 2009).
Table 3은 7개의 군집 별 사고위험 교통류와 일반교통류의 비율, 즉 사고 발생 가능성(Crash probability)를 보여준다. 즉, 군집 1-4의 경우 사고 발생 가능성이 0.5 이상인 사고위험 교통류를 나타낸다.
Table 3.
Risky and general traffic flow in each cluster
2) 랜덤포레스트(Random forest, RF) 결과
전체 데이터와 7개의 군집 별 데이터에서 RF 분석을 수행한 결과, 데이터 수가 매우 적어 RF 분석이 어려운 군집 1, 3, 4를 제외하고 Table 4 와 같이 핵심 변수들이 도출되었다. RF 분석에서 핵심 변수는 RF에서 도출할 수 있는 정확도(%IncMSE) 지표와 중요도(IncNodePurity) 지표를 확인하여 선정하였다. 분석 결과 각 군집 별 핵심 변수와 전체 데이터의 핵심 변수의 중요도 순위가 다르게 도출되었다.
Table 4.
Importance ranking of variables in each RF result
2. Second-stage; 변수 조합 생성
본 연구에서는 KC와 RF 분석 결과 도출된 핵심 변수들을 조합하여 사고 위험 예측 모형 개발을 위한 최적의 변수 집합을 찾고자 하였으며, Table 5와 같은 변수 조합에 따라 총 32개의 예측모형을 개발하였다. Table 5에서 Single-stage model의 경우 기존 문헌 고찰을 통해 선별한 38개의 안전 지표를 모두 독립변수로 하여 개발한 모델이고, Two-stage model의 경우 KC 또는 RF 결과 핵심 변수로 도출된 변수들의 조합을 독립변수로 하여 개발한 모델이다. 마지막으로 Multi-stage model의 경우 KC와 RF 방법론을 통해 도출된 핵심 변수들의 조합을 사용하여 개발한 모델로, 모델 13-22의 경우 KC을 통해 도출된 5개의 주요 변수와 RF를 통해 도출된 변수 중 높은 우선순위를 가지는 변수들의 조합으로 구성된다. 예를 들어, 모델 13의 경우, KC에서 도출된 5개의 핵심 변수와 군집 별 데이터에서 RF를 통해 도출된 핵심 변수 중 1순위로 중요한 변수들(Dangerous event, Yaw, SRI_speed, TVSV_speed)의 조합이다. 모델 23-32의 경우 사고위험 교통류 군집인 군집 2에서 RF 분석 결과 우선순위가 높게 도출된 변수와 KC을 통해 도출된 5개의 주요 변수의 조합으로 개발된 모델들이다. 예를 들어, 모델 23의 경우 KC를 통해 도출된 핵심 변수인 Peak to peak jerk, RDE, CI, Acc, Jerk와 군집 2 데이터에서의 RF 분석 결과 가장 중요도가 높은 것으로 도출된 Yaw 변수의 조합으로 개발된 모델이다.
Table 5.
Variable composition by model
3. Third-stage; 사고 위험 예측 모형 개발
Table 5에 정리된 변수 조합에 따라 SVM 기반의 사고 위험 예측 모형을 개발한 결과는 Table 6과 같다. 종속변수는 사고 위험(사고위험 교통류[1], 일반교통류[0])으로 설정하였으며, 정확도 높은 사고위험 예측모형 개발을 위해 사고위험 교통류를 판단하는 임곗값 기준인 cut-off point를 설정한 기존 연구(Ahmed and Abdel-Aty, 2013; Shi and Abdel-Aty, 2015)를 참고하여 본 연구에서는 default 값인 0.5 대신 다른 값을 사용하였다. 사고 위험 예측 모형 개발에서는 cut-off point가 낮을 때 실제 사고위험 상황을 사고위험 교통류로 예측하는 비율이 높아질 수 있으며, 즉, Recall 값을 높이기 위해 cut-off point를 낮게 조정할 필요가 있다. 예를 들어, 사고위험도가 0.4인 경우 통상적으로 0.5가 분류 기준으로 설정되기 때문에 해당 이벤트는 일반교통 상황으로 분류되지만, cut-off point를 0.3으로 낮출 경우 해당 이벤트는 사고위험 교통 상황으로 분류될 수 있다. 하지만 cut-off point가 너무 낮게 설정되면 실제 사고위험 상황이 아님에도 사고위험 교통 상황으로 분류하는 오경보율이 높아질 수 있으므로 적정한 cut-off point를 찾는 것이 중요하다. 기존 연구들에서는 실시간 사고 위험 예측 연구를 위해 cut-off point 값은 0.08에서 0.22까지 조정하였다(Wang et al., 2015; Shi and Abdel-Aty, 2015; Huang et al., 2017; Wu et al., 2019). 본 연구에서는 적정한 cut-off point를 찾기 위해 먼저 모형의 성능을 평가할 수 있는 Area Under the ROC Curve(AUC)를 산출하였다. 또한, AUC 산출 후 가장 성능이 높게 도출된 모델 7 (AUC 0.768)에 대하여 Figure 3과 같이 precision-recall graph를 도출하였다 (Figure 3). 결과적으로 도출된 모델 7의 precision-recall graph를 기준으로 Precision과 Recall 값의 조합으로 산출되는 F1-score가 급격하게 높아지는 지점인 0.18을 최종 cut-off point로 설정하였다.
Table 6은 각 변수 조합에 따른 사고 위험 예측 모형의 성능을 정리한 것이다. 본 연구에서는 모형 성능이 뛰어난 최적의 모델과 변수 조합을 찾기 위해 다음과 같은 기준을 세우고 가장 성능이 우수하게 도출된 모델을 도출하였다. 첫 번째로, 사고 위험 예측 모형은 일반 교통 상황을 옳게 분류하는 것 보다는 사고위험 상황을 사고위험으로 옳게 분류하는 것이 중요하기 때문에 recall 값이 0.6보다 큰 모델들을 선별하였다. 두 번째로, 모델의 전체적인 정확도가 0.6보다 큰 모델을 선별하였다.
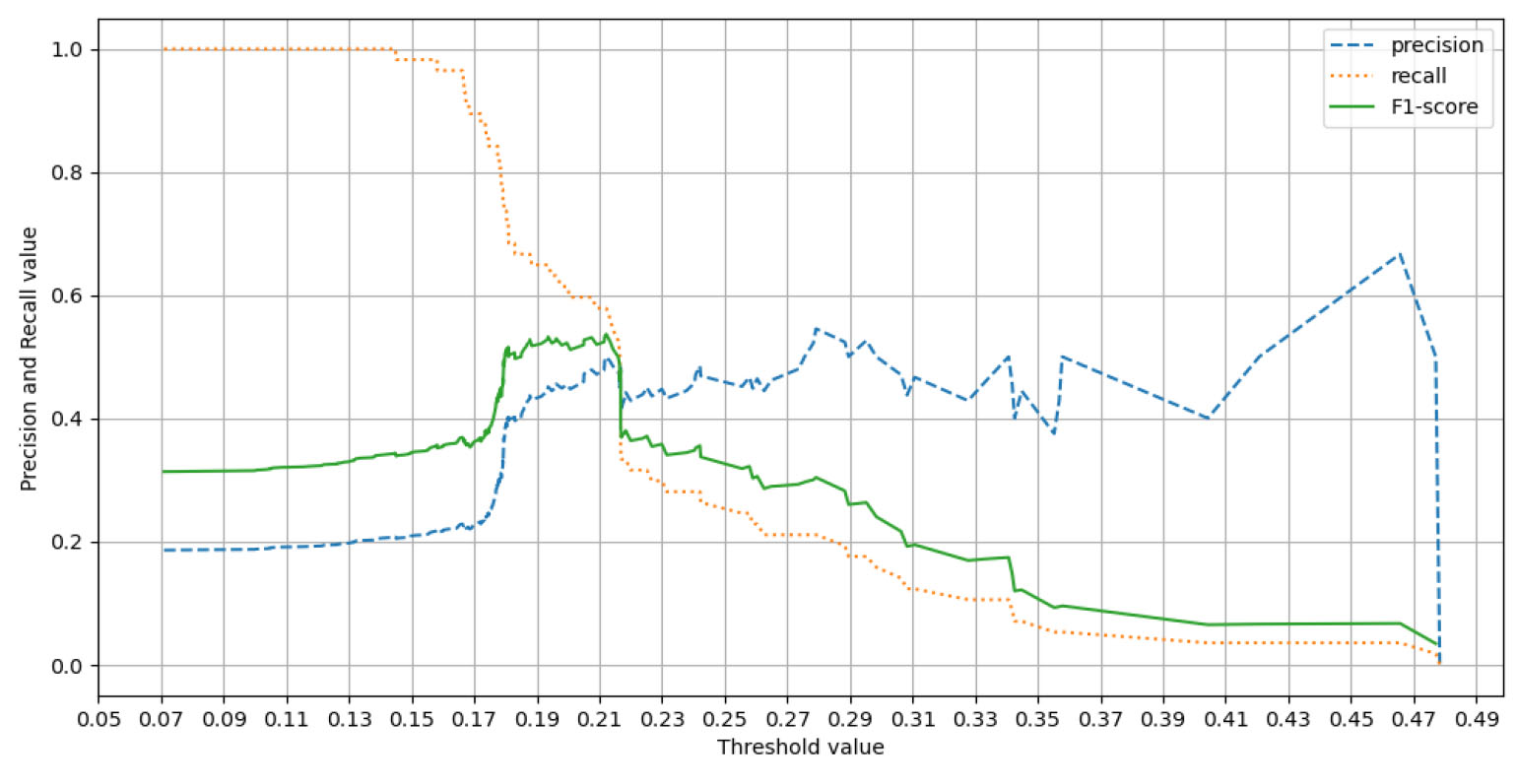
Table 6.
Model performance evaluation results
모델 개발 결과, 모델 15, 17, 27이 정확도와 recall 값 모두 0.6 이상으로 높게 나타나 최적 모형 중 하나로 선정되었다. 특히, 세 모델의 경우 recall 값이 각각 0.754, 0.772, 0.733으로 높게 나타났다. 모델 15와 모델 17의 경우 KC와 RF 분석 결과 도출된 핵심 변수 9개를 사용하여 개발된 모형이다. 이는 KC와 RF로부터 도출된 핵심 안전 지표들이 사고 위험 예측 모형의 성능을 높이는 데에 이바지했음을 의미한다. 모델 27의 경우 교통류 군집 중 군집 2에 해당하는 사고 위험 군집 데이터에서 도출된 주요 변수와의 조합으로 개발된 모델이다. 이 모델은 비지도 학습 군집분석을 통해 도출된 다섯 가지 주요 변수들과 사고 위험 군집인 군집 2에서 RF 분석을 수행한 결과 변수 중요도가 높게 도출된 변수를 함께 사용하여 개발되었으며, 모델 27의 recall 값은 모델 15와 모델 17에 비해 낮지만, 정확도와 정밀도 지표가 가장 높은 것으로 나타났다. 따라서 본 연구에서는 모델 27을 최적 모델로 선정하였으며, 해당 모델은 recall 값 0.733, 정확도 0.701의 높은 성능을 보였다.
모델 15의 경우 KC 결과 핵심 변수로 도출된 Peak to peak jerk, RDE, CI, Acc, Jerk와 RF 결과로 도출된 1-3순위의 변수들인 Yaw, Dangerous event, SRI_speed, TVSV_speed, EDI_speed, LNJ_total, LNJ_4, TVSV_jerk, SRI_jerk의 조합으로, 총 14개의 변수 조합으로 개발된 모델이다. 모델 17의 경우 마찬가지로 KC 분석 결과 핵심 변수인 5가지 변수와 RF 결과로 도출된 1-5순위의 변수 조합으로 개발된 모델로, 모델 15에 SRI_acc, EDI_jerk, EDI_acc가 추가된 예측모형이다. 두 모델 모두 속도와 가속도와 관련된 변수들이 다수 포함되었으며, 교통류의 혼잡 정도를 나타내는 혼잡지표 역시 주요 변수로 포함되었다. 모델 27에서 사용된 독립변수는 Dangerous event, Yaw, LNJ_4, Acc, Peak to peak jerk, Yaw, Jerk로, 급가속과 가속도의 변화 등 차량의 주행 안정성을 나타내는 지표들이 주요 안전 지표로 도출되었다. 또한, 한국교통안전공단에서 정의하고 있는 위험 운전 행동 이벤트인 Dangerous event가 주요 변수 중 하나로 나타나 사고 위험 예측에 있어 과속, 급가속, 급감속과 같은 차량 위험 운전 행동 이벤트를 고려할 필요가 있음을 시사하였다.
또한, 본 연구의 결과를 통해 Table 6과 같이 KC에서 선정된 핵심 변수와 RF 분석에서 도출된 중요도가 높은 변수를 결합할 때 모델의 성능이 향상되는 것을 알 수 있었다. 그뿐만 아니라 모델링 결과는 사고 위험 예측 모델 개발에 필요한 주요 변수를 도출하기 위해 사고위험 교통류 군집인 군집 2 데이터와 함께 RF 분석을 사용할 때 예측 모델의 성능이 향상되었음을 나타내었다. 즉, 본 연구에서 제안한 Multi-stage 방법론 기반의 사고 위험 예측 모델은 Single-stage 및 Two-stage 방법론 기반 모델보다 우수한 성능을 보인다.
결론 및 향후 연구과제
본 연구에서는 사고위험 예측모형 개발을 위해 사업용 개별차량 주행 궤적 데이터를 사용했으며, 사고위험 교통류와 일반교통류를 1:5 비율로 추출하였다. 주행궤적 데이터는 특정 시간 단위로 집계되는 검지기 데이터와 다르게 1초 간격으로 위치정보를 수집하기 때문에 Yaw, Jerk와 같이 보다 다양한 정보를 생성할 수 있다. 이러한 DTG 데이터를 활용해 기존 문헌에서 사용하던 총 38개의 안전 지표를 산출하였으며, 38개의 안전 지표 중 사고위험 예측모형에 독립변수로 사용할 핵심 변수를 도출하기 위하여 K=7로 한 KC와 앙상블 기법의 하나인 RF 분석을 수행하였다. 클러스터링 수행 결과 1-4번 군집은 사고위험 군집으로, 5-7번 군집을 일반교통류 군집으로 도출되었다. 클러스터링 결과를 바탕으로 사고위험 교통류와 일반교통류를 가장 잘 분류한 상황에서 사용된 변수, 각 군집 내에서의 핵심 변수, Random forest로 변수 우선순위를 도출했을 때의 중요도 높은 변수로 SVM 기반의 사고위험 예측(분류) 모형을 개발하고 그 성능을 비교하였다.
Accuracy와 Recall 비교 결과, 비지도 학습을 통해 도출한 변수들과 비지도 학습으로 도출된 군집 별 RF를 수행했을 때 우선순위가 높게 나온 변수들을 함께 사용한 모델 15, 17, 27의 성능이 우수한 것으로 나타났으며, 7개의 군집 중 사고위험군집(군집 2) 내에서 RF를 수행하여 우선순위가 높은 변수를 사용했을 때 Recall, Accuracy 값이 모두 0.7 이상으로 높게 나타났다. 이러한 결과를 통해 사고 위험 예측 시 모형의 성능을 높이기 위하여 군집분석을 통해 잠재적인 사고위험 특성과 사고위험 판단에 효과적인 변수를 도출하는 작업의 필요성을 확인할 수 있다. 비지도 학습 과정을 통해 잠재적 핵심 변수를 도출할 수 있다. 본 연구에서 개발한 방법론은 한국 고속도로의 실시간 사고 위험 예측에 활용할 수 있으며, 이를 통해 선제적인 안전 관리와 빠른 대응이 가능할 것으로 예상된다.
하지만 본 연구는 다음과 같은 한계점과 향후 연구과제가 존재한다. 첫 번째로 DTG 데이터 특성의 문제이다. DTG의 경우 공공기관에서 배포하고 있는 자료로, 자료의 구득이 비교적 쉽지만 사업용 차량에만 부착되어 차량 주행궤적 데이터를 수집하기 때문에 DTG 데이터는 교통류의 전체적인 특성을 반영하기 어렵다는 문제가 있다. 따라서 향후 민간 내비게이션 데이터 등 일반 차량의 주행 궤적 데이터의 구득이 가능하다면 함께 사용하여 사고위험 예측모형을 개발할 필요가 있다. 두 번째로 본 연구에서는 개별차량의 주행행태를 잘 포착하기 위해 DTG 데이터를 활용하였으나, 교통류의 사고위험과 무관한 졸음운전, 차량고장 사고 등으로 인한 사고위험까지 예측하기에는 한계가 존재할 수 있었다. 예를 들어, 예측하고 예방할 수 없는 사고에 대해서는 해당 사고 자체를 예측하는 것 보다는 그 사고로 인한 2차 사고 등을 방지하기 위해 노력하는 것이 더 중요할 수 있다. 따라서 향후 연구에서는 사고 유형을 구분하여 그에 맞는 사고위험 예측모형을 구축하고 안전 관리에 활용할 수 있는 방안을 제시할 필요가 있다. 또한, 우리나라의 전체적인 교통사고 특성을 반영할 수 있도록 사고 샘플링을 수행할 필요가 있다. 세 번째로 본 연구에서는 SVM을 사용하여 사고위험 교통류 분류 모형을 개발하였으나, Recall과 정확도 확인 결과 예측 성능이 뛰어나지 않은 것으로 나타났다. 따라서 보다 높은 정확도의 사고위험 예측모형 개발을 위해 신경망(Neural network), MARS 등 보다 다양한 모형을 개발하여 평가 및 비교해 볼 필요가 있으며, 변수 선택 과정에서도 모형이 과적합되거나 오류가 발생하지 않도록 변수 간 상관관계를 검토하고 모형 예측에 핵심 변수만을 사용할 필요가 있다. 네 번째로, 본 연구에서는 적절한 K값을 Elbow method를 통해 도출하고, 홀수개의 K를 사용하여 사고 군집을 분류하고, 사고위험 교통류에 해당하는 군집과 일반 교통류에 해당하는 군집을 결정하였으나, K값에 따라 군집의 특성이 달라질 수 있으므로 NbClust 등 다른 방법론을 사용하여 K값을 도출하고, 군집 분류를 수행할 필요가 있다. 마지막으로 본 연구에서는 COVID-19 발생의 영향을 받지 않는 연도의 약 2달간의 데이터를 사용하였으나, 더 많은 최신 데이터를 확보하여 정확성과 신뢰성 높은 모형을 개발할 필요가 있다.
