

서론
선행연구
1. 효율성의 개념
2. 효율성 분석방법론 고찰
3. DEA 기반 효율성 평가 연구 고찰
4. 기존 연구와의 차별성 및 의의
데이터 구축
1. 스마트카드 데이터
2. 환승통행 데이터 구축
방법론
1. 개요
2. 자료포락분석(Data Envelopment Analysis; DEA)
3. Tobit Regression
4. k-means++ clustering
분석 결과
1. 최종 데이터셋 및 효율성 분석 결과
2. 영향요인 분석 결과
3. 군집화 결과 및 군집별 효율성 개선방향 제시
결론
서론
수도권 지역의 대중교통 이용객 수는 지속적인 증가세를 보이고 있다. 2021년 대비 2023년까지 버스와 지하철 이용객 수는 약 8.8% 증가하였으며, 코로나19 팬데믹 이후에도 대중교통 수요는 안정적인 회복세를 나타내고 있다. 이러한 수요 증가는 도시화와 수도권 인구 집중 현상과 밀접하게 연관되어 있으며, 이에 대응하여 수도권 대중교통 네트워크는 지속적으로 확장되고 점차 복잡한 구조로 진화하고 있다. 그러나 대중교통 공급 확대만으로는 모든 이용자의 이동 경로를 직접 연결하는 데 한계가 존재하며, 결국 환승은 대중교통 이용 과정에서 필연적인 과정이 된다. Lee et al.(2019)는 서울시 대중교통이 전반적으로 높은 접근성을 제공하고 있음에도 일부 구간에서는 승용차 대비 경쟁력이 낮아질 수 있음을 지적하며, 대중교통 경쟁력 확보를 위해 환승 과정의 효율성 개선이 필요함을 강조했다. 대중교통 활성화를 위해 이용자의 서비스 만족도와 편의성을 높이기 위한 다양한 연구도 수행되어 왔다. Lee et al.(2024)는 도시철도 이용자의 대기 시간 수용 행태를 분석하고, 환승 과정에서의 대기 시간과 이동 편의성이 대중교통 이용 의사에 중요한 영향을 미친다는 점을 확인했다. 이는 복잡한 환승 동선과 부족한 시설 연계성이 환승 시간을 증가시키고, 대중교통 서비스 효율성뿐만 아니라 이용자의 경험에도 부정적 영향을 미칠 수 있음을 시사한다.
더불어, Cho and Park(2021)은 대중교통 혼잡과 환승 불편이 이용자의 행태 변화로 이어질 수 있음을 보여주었으며, 대중교통 서비스 개선이 수요 유지와 활성화에 매우 중요한 과제임을 강조하고 있다. 또한, Lee et al.(2024)는 수도권 광역버스를 대상으로 출근 시간대 이전 할인 정책의 효과를 분석하여, 요금 다양화가 혼잡 완화와 대중교통 활성화에 기여할 수 있음을 확인하였다. 뿐만 아니라, Hong et al.(2024)는 대중교통 이용 행태가 세대별로 차이를 보이며, 특히 고령층의 경우 젊은 층보다 환승 과정에서의 동선 복잡성과 시설 접근성 부족에 더욱 민감하게 반응하는 경향이 있음을 실증적으로 분석하였다. 이는 환승 효율성 평가 시 이용자의 특성을 반영한 맞춤형 개선이 필요함을 시사하며, 환승 편의성 향상을 위한 연구가 더욱 강화되어야 함을 의미한다. 이처럼 수도권 대중교통의 활성화를 위해 경쟁력 확보, 이용자 편의성 증대, 정책적 개선방안 등 다양한 측면에서 연구가 수행되어 왔다. 그러나 여전히 대중교통 시스템 구조적 한계로 인해 환승 과정에서 발생하는 물리적 환경의 제약과 동선의 불편함이 존재하며, 이는 이용자의 불편으로 이어지고 있다. 실제로, 수도권 전체의 평균 환승 소요시간은 2021년 7.94분에서 2022년 7.98분, 2023년에는 8.29분으로 증가하였다.1) 전년 대비 각각 약 0.5%, 3.9%의 증가율을 보이는 것으로, 매년 환승 소요시간이 점진적으로 증가하고 있는 것을 확인할 수 있다. 이러한 흐름은 다양한 교통수단 간의 원활한 연계를 보장하기 위한 효율적인 환승 시스템의 중요성을 부각시키며, 이는 단순한 물리적 연결을 넘어서 대중교통 네트워크 전체의 기능성과 이용자 만족도를 결정짓는 핵심 인프라로 작동하고 있음을 시사한다(Garcia-Martinez et al., 2018; Hwang et al., 2025).
이러한 문제를 해결하고 수단 간 연계를 강화하기 위한 방안으로 MaaS(Mobility-as-a-Service)와 같은 통합 서비스가 제안되고 있다. MaaS는 다양한 이동수단을 연계하여 이용자에게 하나의 통합된 플랫폼에서 효율적이고 편리한 이동 경험을 제공하는 것을 목표로 한다. 그러나 아직까지 대중교통 시스템은 수단 간 연계성이 부족하고, 환승 과정에서의 불편함이 지속되고 있어 MaaS의 실질적인 구현에 어려움이 따른다(Jittrapirom et al., 2017; Canca et al., 2012; Yen et al., 2018). 특히 환승 시스템의 비효율성은 MaaS가 전제로 하는 ‘수단 간 매끄러운 연계’를 저해하며 단순히 서비스 품질 저하를 넘어 시스템 전반의 통합 운영 가능성까지 저해할 수 있는 구조적 한계로 지적된다(Mao et al., 2023; Roquel et al., 2021). 그럼에도 불구하고 수단 연계 환승과정에서 발생하는 불편을 실증적으로 분석하고 정량적으로 평가하는 연구는 여전히 부족한 실정이다.
이에 본 연구는 서울시를 대상으로 수단 간 연계 환승 과정에서 발생하는 비효율성을 체계적으로 평가하고, 개선이 필요한 핵심 요인을 분석하고자 한다. 특히, 대중교통 시스템 내 수단 간 연계성이 집중되는 공간인 도시철도 환승역을 분석 단위로 설정하여 분석하고자 한다. 환승역은 서로 다른 도시철도 노선이 교차하여 이용자가 다른 노선의 열차로 갈아탈 수 있는 지점을 의미하며, 도시 대중교통 네트워크의 핵심 결절점으로 기능한다. 또한, 도시철도 환승역은 제도적으로 명확히 정의되어 있으며, 환승 통행량과 환승 시간 등 실증 분석에 필요한 통계자료가 정형화된 형태로 제공된다는 점에서 분석의 신뢰성과 일관성을 확보할 수 있다. 도시철도 환승역 중심으로 분석을 수행함으로써, 이용자 편의성과 시스템 효율성 개선을 위한 구체적인 방안 도출을 목표로 한다. 또한, 버스-지하철 간 환승과 지하철-버스 간 환승이라는 양방향 환승을 구분하여 분석하고자 한다. 이는 환승의 방향에 따라 이용자가 경험하는 통행 패턴과 환승 과정에서의 이동 특성이 달라지고 결과적으로 환승 효율성에 미치는 영향이 상이하게 나올 것으로 예상된다. 따라서 본 연구는 수단 간 연계 환승을 중심으로 분석함으로써, 대중교통 네트워크 내에서의 연계성을 강화하고, 이용자 편의를 개선하기 위한 구체적인 문제와 해결 방안을 도출하고자 한다.
선행연구
수도권 통합환승 할인제도와 복합환승센터는 각각 대중교통 이용 활성화를 위한 경제적 접근과 시설적 접근의 대표적인 사례로 평가된다. 수도권 통합환승 할인제도는 이용자의 경제적 부담을 줄이고 교통수단 간 연계를 유도하여 대중교통 이용을 촉진하였고, 복합환승센터는 환승에 필요한 물리적 동선을 개선함으로써 시설적 접근을 강화하였다. 그러나 이러한 제도들은 환승 과정의 시간적·공간적 비효율성까지 실질적으로 해소하지는 못했다는 한계를 가진다. 특히 혼잡 시간대의 과밀, 비효율적인 동선 설계, 시설 접근성 등으로 인해 이용자 불편이 지속되고 있다. 따라서, 본 연구에서는 기존 정책의 경제적·시설적 접근에서 더 나아가 환승 효율성을 종합적으로 평가하고자 한다. 운영자 관점의 효율성뿐만 아니라, 이용자 관점에서의 편의성과 효율성까지 종합적으로 분석하여 환승 시스템의 실질적인 개선 방안을 제시하고자 한다.
1. 효율성의 개념
효율성 분석 방법에 대한 고찰에 앞서 본 연구에서의 효율성에 대한 개념을 명확히 하고자 하였다. 경제학에서의 효율성은 일정한 산출물을 생산하기 위하여 투입물이 얼마만큼 효과적으로 사용되었는지로 정의된다(Farrell, 1957). 즉, 투입을 고정하여 가장 많은 산출물을 생산하는 능력 또는 동일한 산출물을 생산하기 위하여 투입물을 최소화하는 능력으로 볼 수 있다. 효율성은 이 외에도 사용에 따라 다양하게 정의되고 있으며, 특히 대중교통 분야에서의 효율성은 특히 공공자원의 제한성과 서비스 제공의 공공성이라는 특수성 아래, 효율적 자원 운용을 통해 서비스 품질을 유지하면서도 운영비용을 최소화하는 능력으로 간주된다. 기존 연구들은 주로 운영자 중심의 효율성 분석을 통해 비효율적인 단위를 식별하고, 투입 자원의 축소나 산출 성과의 증대를 통한 개선 방향을 제시하였다(Filippini et al., 1994; Johan Holmgren, 2013; Yi and Kim, 2013; Choi et al., 2024).
본 연구에서도 운영적 측면에서 효율성을 평가한다는 점에서 기존 연구와 유사하지만, 기존 연구와 달리 통행량과 통행시간을 동시에 고려하여 단순히 운영자의 효율성 평가를 넘어 이용자 관점에서의 편의성을 함께 고려한다는 점에서 차별성을 가진다. 본 연구의 ‘효율성’이란 환승역의 여러 인프라 요소가 수단 간 연계 환승 과정에서 얼마나 효과적으로 활용되는지를 평가하는 지표이다. 즉, 주어진 투입변수를 최대한 활용하여 해당 역에서 기대할 수 있는 최대 산출을 달성했는지를 나타내는 지표인 것이다. 각 역마다 효율성이 높다는 것은 동일한 인프라 및 시설 규모에서 더 많은 환승 통행량을 처리하고, 더 짧은 환승시간을 제공할 수 있다는 것을 의미한다. 환승 통행량을 더 많이 처리할 수 있다는 의미는 운영적 측면에서 효율성이 좋다는 해석을 할 수 있고, 더 짧은 시간에 환승할 수 있다는 것은 이용자 측면에서 효율성이 좋다는 의미이기에 두 측면 모두를 고려한 효율성 평가가 될 수 있다.
2. 효율성 분석방법론 고찰
위와 같이 정의한 효율성을 측정하기 위하여 효율성 분석 방법에 대해 고찰하였다. 효율성을 측정하는 방법은 Farrell(1957)에 의해 처음 소개된 이후 모수적인 방법론인 확률프론티어분석(Stochastic Frontier Analysis, SFA)과 비모수적인 방법론인 자료포락분석(Data Envelopment Analysis, DEA)로 나뉜다. 모수적 접근과 비모수적 접근의 근본적인 차이는 생산함수를 사전적으로 설정하는지 여부에 달려있다. 모수적 접근 방법은 사전적으로 생산함수가 특정 형태를 갖는다고 가정한 후 자료를 이용하여 이 함수의 알려지지 않은 모수를 추정하는 접근 방법을 취하나, 이와 달리 비모수적 접근은 생산함수의 형태 자체를 가정하지 않는다.
SFA는 오차항을 이용해 효율성을 추정하는 모수적 접근법으로, 크게 모형의 모수를 추정하는 단계와 추정된 모수와 오차항을 이용하여 효율성을 분석하는 단계로 진행된다. 모형의 함수형태는 시장의 생산기술과 관련 있으며, 생산량을 기준으로 하여 효율성을 실제 생산량과 최대 생산량 간의 비율로 산정할 수 있다. 효율성 점수는 0부터 1 사이의 값을 가지며, 최적의 효율성을 가지는 대상들이 효율성 프론티어를 형성한다. 여기서 효율성은 투입 요소와 산출 요소의 관계를 나타내는 함수로 정의되며, 산출 효율성의 경우 관측된 산출량이 최대 생산량에 얼마나 근접한 지를, 비용 효율성의 경우 관측된 비용이 최소 비용 수준에 얼마나 근접한지를 평가한다. 해당 과정에서 확률적 오차는 정규분포로, 효율성 손실을 나타내는 비효율성 항은 절단 정규분포로 가정되며, 이들을 바탕으로 최대우도추정법을 통해 매개변수를 추정한다. SFA는 무작위적 환경 요인과 비효율성을 분리함으로써 효율성을 보다 신뢰성 있게 평가할 수 있으며, 다양한 분야에서 생산성 및 비용 효율성을 분석하는데 활용된다. 다만, 특정 함수 형태를 미리 가정해야 하고 오차항의 분포를 추정해야 하고 생산함수를 이용하는 경우 다수의 투입변수와 산출변수를 모형 내에서 고려하기 어렵다는 단점이 있다.
DEA는 변수 간 상대적 효율성을 비교하는 분석기법으로 투입과 산출이 다수일 때, 이를 단일한 값으로 계산하여 상대적 효율성을 산출하는 비모수적인 방법론이다. 효율성을 측정하기 위한 대상으로 의사결정 단위(Decision Making Unit, DMU)를 설정하여 개별 DMU 중 가장 효율성이 높은 DMU를 기준으로 효율성을 평가한다. Charnes et al.(1978)에 의해 처음 개발되었으며, 투입물 대비 산출물을 산출하여 효율성이 높은 선(효율적 프론티어)을 도출하기 때문에 선형계획법이라고 일컫는다. DEA는 비모수적 방법론으로, 오차항의 확률분포에 대한 명시적 가정 없이도 효율성 분석이 가능하다. 이는 실제 데이터에서 나타나는 불확실성이나 복잡한 구조를 보다 유연하게 반영할 수 있다는 점에서 현실적인 분석 도구로 평가된다. 또한, 투입물의 가격 정보 없이도 다수의 투입물과 산출물을 고려해 기술적 효율성을 평가할 수 있다. 이러한 특성은 복합적인 요인이 작용하는 환승역의 효율성을 분석하는 본 연구의 목적과 부합한다. 특히, DEA는 효율성을 직관적인 점수로 제시하므로 연구자뿐 아니라 의사결정자에게도 이해와 활용이 용이해 본 연구의 분석 방법론으로 선정하였다.
3. DEA 기반 효율성 평가 연구 고찰
본 절에서는 DEA를 활용한 대중교통 시스템 및 환승역의 효율성 평가 관련 국내·외 선행연구를 Table 1과 같이 고찰하였다. 주요 연구들을 통해 대중교통 효율성 평가 시 어떤 변수를 투입·산출로 설정했는지, 어떤 공간 단위를 분석 대상으로 삼았는지를 중심으로 비교하였다. 이를 바탕으로 본 연구의 변수 설정과 분석 대상이 기존 연구와 어떻게 차별화되는지를 살펴보고자 한다. 대부분의 연구에서는 버스나 지하철 등 개별 교통수단 단위의 효율성을 평가하였으며, 이를 통해 대중교통 시스템의 운영 효율성을 평가하는 데 중점을 두었다. Filippini et al.(1994)는 스위스 버스 회사를 대상으로 운영비용, 인력, 연료비, 차량 수를 투입변수로, 승객 수, 운행거리, 서비스 범위를 산출변수로 설정하여 효율성을 측정하였다. Johan Holmgren(2013)은 스웨덴 자치구를 단위로 장기간의 패널 데이터를 활용해 대중교통 비용 효율성을 분석하였고, Yi and Kim(2013)은 서울 시내버스를 대상으로 공급자 중심의 효율성을 측정하였다. 이들은 대부분 공급자의 자원 활용 관점에서 효율성을 해석하며, 노선별 또는 사업자별 성과 향상을 위한 정책적 시사점을 제시하였다. Choi et al.(2024)은 16개 지방자치단체의 시내버스를 대상으로 효율성 분석을 수행하고, 이를 통해 지역별 운영체계와 성과 간 관계를 분석하였다.
Table 1.
Review of efficiency evaluation studies in public transportation sector
| Category | Analysis target | Analysis purpose | Input variables | Output variables |
| Filippini et al. (1994) | Swiss bus companies | Efficiency evaluation focusing on the performance of Swiss bus companies | Operating cost, Labor cost, Fuel cost, No. of vehicles | No. of passengers, Mileage, Service range |
| Sun et al. (2010) | 10 Transportation terminals in Beijing | Efficiency evaluation to provide potential improvements of each terminals | Transfer area, Operating expense, No. of staff, Capacity of bus |
Transfer safety, Average transfer time |
| Johan Holmgren (2013) | District | Efficiency evaluation of public transport cost structures using cost functions |
Capital, Labor cost, Fuel cost | Cost per passenger |
| Yi and Kim (2013) | Seoul city bus | Operational efficiency evaluation of bus routes | No. of passengers, Mileage, Operating revenues | Monthly passengers, Revenue, Mileage per kilometer |
| Nishiuchi et al. (2015) | Transfer stations in Kochi (Japan) | Evaluating efficiency of transfer nodes to understand the use of public transportation system | Frequency of bus/tram per day, No. of available route | Average of transfer time at the point |
| Guo et al. (2018) |
Tokyo Den-en Toshi line stations | Assess the efficiency of TOD | Population density, Land-use diversity, No. of bus stops, Road length, etc. | Average daily commuters per station |
| Lee et al. (2019) |
352 Subway stations in Seoul | Evaluate transit efficiency in Seoul | Population density, Land value, No. of households, No. of companies | No. of subway/bus/ transfer trips, Energy generation of trips |
| Lee and Jeong (2023) |
257 Subway stations in Seoul |
Evaluate equity of subway station regarding the installation of vertical transport system | Area, No. of floors, No. of trips, Walking time | No. of elevators, wheelchair lifts, escalators |
| Choi et al. (2024) | 16 Local government in Korea | Evaluation of the impact of city bus operation systems on operational efficiency |
No. of drivers, No. of vehicles, Operating cost, Financial burden rate |
No. of passengers, Revenue |
최근에는 대중교통의 거점인 환승역 또는 도시철도 중심 역세권을 분석 대상으로 하여 복합적인 공간 단위의 효율성을 분석하는 연구도 이뤄지고 있다. Sun et al.(2010)은 베이징 터미널의 이동 효율성을 평가하며, 면적, 인력, 운영비용, 버스 수용 능력을 투입으로, 환승 통행량과 안전성, 평균 환승시간을 산출로 설정하였다. Nishiuchi et al. (2015)는 일본 Kochi시의 환승역을 분석하여, 노선 수 및 이용량에 비해 환승시간이 과도하게 긴 역을 비효율적이라 판단하고 환승 동선 최적화 방안을 제시하였다. Guo et al.(2018)은 TOD(Transit-Oriented Development) 관점에서 역세권 27개 역을 분석하였으며, 인구밀도, 토지이용 다양성 등 지역 여건을 투입으로, 일일 승차 인원을 산출로 설정하였다. 역세권 개발 수준 및 주변 환경이 역의 이용 효율성에 영향을 미친다는 점을 실증하며, 도시개발과 대중교통이 상호 보완적으로 작동할 수 있음을 강조하였다. 이는 효율성 분석이 단순한 운영 지표만이 아니라, 도시공간 구조와도 연계될 수 있다는 가능성을 제시한 사례로 볼 수 있다. 또한, Lee et al.(2019)은 서울시 전체 환승역을 대상으로 노선 수, 버스 정류장 접근거리 등을 투입변수로, 통행량과 에너지 소비량을 산출로 설정해 효율성을 분석하였으며, 특히 지역 맞춤형 TOD 전략 필요성을 강조하였다. Lee and Jeong(2023)은 교통 약자를 고려한 수직 이동 편의성에 주목하여, 시설 접근성과 이동 시간, 이동 수단 수를 변수로 삼아 형평성 중심의 효율성 평가를 시도하였다.
4. 기존 연구와의 차별성 및 의의
선행연구들을 종합하면, 대부분의 효율성 분석은 운영 주체 또는 시설 공급자 중심의 투입 변수와 이용 실적 중심의 산출 변수로 구성되어 있으며, 분석 대상 역시 단일 수단 또는 정류장 단위에 머무르는 경우가 많았다. 환승이라는 복합적 이동 행위 자체를 중심에 두고 효율성을 분석한 연구는 제한적이며, 특히 수단 간 환승의 방향성과 행태적 특성을 동시에 고려한 정량적 분석은 미흡한 실정이다. 이에 비해 본 연구는 교통수단 간의 연계성에 주목하며, 환승역을 분석 대상으로 설정해 해당 역에서 발생하는 수단 간 연계 환승을 고려하고자 한다. 각 환승역은 서로 다른 교통수단을 연결하는 복합적 결절점으로서 기능하며, 버스에서 지하철로 환승하는 방향성과 이용자의 실제 행태를 반영하여 효율성 평가가 가능할 것이다. 또한 본 연구는 단순한 통행량 지표뿐 아니라, 이용자의 체감 불편을 직접적으로 반영하는 ‘환승 소요 시간’과 버스 정류장에서 지하철역 진입까지의 ‘환승 도보 거리’까지 변수에 포함함으로써, 운영자 중심의 효율성뿐 아니라 이용자 관점에서의 효율성까지 정량적으로 평가하였다는 점에서 차별성을 가진다. 이는 기존 연구들이 지니는 수단 단위의 정태적 평가라는 한계를 보완하고, 수단 간 연계성과 환승 편의성이라는 복합 요소를 반영한 동태적 분석 틀을 제시하였다는 점에서 의의를 가질 것으로 기대한다.
데이터 구축
1. 스마트카드 데이터
서울시를 포함한 수도권에서는 스마트카드 기반의 자동요금징수 시스템(Automatic Fare Collection, AFC)을 통해 대중교통 서비스를 운영하고 있다. 스마트카드 데이터의 경우, 버스의 차량 단말기나 지하철의 개찰구에 승객이 스마트카드를 태그할 때 생성된다. 발생되는 통행의 승·하차에 대한 정류장 및 시간 정보가 암호화되어 고유 정보로 수집된다. 이를 통해 역·정류장 단위로 개인의 이동 경로 추정이 가능하며, 98% 이상의 이용률로 전수에 가까운 대중교통 통행 기록이 수집된다. 본 연구에서는 수도권 전체 범위의 2023년 10월 19일(목요일) 1일치의 스마트카드 데이터를 활용하여 새로운 환승 데이터를 구축하였다. 통행 패턴의 일상성을 최대한 반영하기 위해 평일이면서 비정상적인 기상 상황이나 대중교통 파업 등의 특이사항이 없었던 일반적인 일자를 선정하였다. 해당 일자의 전체 수단통행은 20,509,781 통행이며, 수도권 내의 수단통행은 17,316,995 통행으로 약 84%의 통행이 해당된다.
스마트카드 데이터는 승·하차 및 이용 교통수단에 대한 정보가 하나의 통행이 한 줄씩 거래내역 데이터로 제공되며, 정류장 ID, 수단 ID 등 식별자 중심의 정보가 포함된다. 이에 따라 실제 정류장 명칭이나 교통수단 유형을 확인하기 위해서는 별도로 제공되는 노선, 정류장, 수단 등의 서브 데이터를 연계해야 한다. 본 연구에서는 거래내역 데이터와 서브 데이터를 연계하고, 승·하차 이력을 바탕으로 하나의 단일 통행 단위로 데이터를 재구성하였다. 더불어, 이용자의 통행패턴을 보다 정밀하게 확인하기 위해 환승 여부를 반영할 수 있는 통행사슬(trip chain) 형태로 데이터를 최종 구축하였다. 통행사슬은 이용자의 최초 출발지와 최종 목적지까지 환승을 포함한 개념으로, 특히 수도권 지역에서는 이를 고려한 분석이 매우 중요하다.
통합환승할인제도의 영향으로 수도권에서는 최소 1회 이상의 환승이 포함된 통행이 높은 비중을 차지하기 때문이며, 실제로 전국 평균 환승 통행률이 47.0%인 반면, 수도권의 환승 통행률은 90.5%에 달한다.2) 통합환승할인제도는 5개 수단 탑승 시까지 환승할인 혜택이 적용되고, 환승 유효시간은 07시부터 21시 사이에는 30분 내, 21시에서 07시 사이에는 60분 내로 제한되어 있다. 또한, 동일 노선 및 동일 차량 간 환승 시에는 환승할인이 불가하며 마지막 교통수단에서 하차 태그를 하지 않은 경우 다음 승차 시 환승할인이 적용되지 않는다. 본 연구에서는 이러한 환승 조건을 모두 고려하여 통행사슬 형태로 재구축하였으며, 환승 유효시간 내에 이루어진 연속 통행은 거래내역 데이터의 ‘트랜잭션 ID’ 항목을 통해 동일한 환승 통행으로 식별하였다. 구축된 데이터를 기반으로 이상치를 제거한 결과, 수도권 전체 거래내역 중 약 31%에 해당하는 4,195,178건의 환승 통행이 최종 분석 대상으로 추출되었다.
2. 환승통행 데이터 구축
본 연구에서는 환승역의 효율성을 평가하기 위해 수단 간 연계가 실제로 발생한 환승 통행 데이터를 기반으로 환승 경로 단위의 이동 특성과 인프라 요소를 통합적으로 반영한 데이터셋을 구축하였다. 특히 환승 과정에서의 공간 구조와 이용 행태를 함께 반영하기 위해, 수단 간 환승이 발생한 통행만을 추출하여 환승통행 데이터셋을 새롭게 구축하였다. 버스에서 지하철로 환승하는 경우는 1,343,401건, 지하철에서 버스로 환승하는 경우는 1,289,431건을 활용하였다. 버스 정류장과 지하철 역 간 실제 환승 행위가 스마트카드 상에서 확인된 경우에 한해 환승 경로로 정의하였으며, 이를 역별로 집계하여 ‘환승 경로 수(No. of transfer routes)’ 변수로 설정하였다. 또한, 환승 유형에 따라 이용자의 행태가 다르게 나타나는 점을 반영하여 버스에서 지하철로 환승하는 경우와 지하철에서 버스로 환승하는 경우를 나눠서 변수를 구축하였다. Table 2를 보면 버스에서 지하철에서 환승하는 경우의 경로는 22건, 지하철에서 버스로 환승하는 경로는 17건으로 나타난다. 이러한 차이는 이용자 행태에서 비롯된 것으로 판단되며 지하철에서 버스로 환승하는 경우에는 주로 더 가까운 버스 정류장을 선호하는 경향이 있어 경로 수가 상대적으로 적게 나타난다. 반면, 버스에서 지하철로 환승하는 경우에는 이용자가 원하는 목적지에 도달하기 위해 특정 노선에 맞는 역까지 이동해야 하기에 더 많은 통행경로가 발생하는 것으로 판단된다.
Table 2.
Transfer trip data example
환승 통행 데이터는 실제 환승 경로 단위로 재구성하였으며, 각 경로의 도보 이동 정보는 웹크롤링을 통해 조사하여 반영하였다. 환승 통행 경로별로 이용자 수가 10건 이하인 경우는 제외하여 분석하였으며, 경로별로 이동시간 및 이동거리 등 보행에 관련된 정보를 조사하였다. 버스 정류장부터 역까지의 거리는 정류장부터 최단에 있는 역 출입구까지의 거리를 기준으로 하였다. 각 역마다의 분석을 위해 역별로 환승 경로를 취합하였으며, 역별로 특성을 나타낼 수 있는 역 면적, 심도, 혼잡도, 출입구 수, 엘리베이터 수, 에스컬레이터 수 등을 서울교통공사에서 배포한 수송계획자료를 통해 추가하였다. 또한, 스마트카드 데이터를 기반으로 버스 정류장 수(No. of bus stops)와 버스 노선 수(No. of bus routes)를 역별로 실제 환승이 이뤄진 정류장 및 노선만을 집계하였다. 환승이 발생한 버스 정류장을 기준으로 해당 정류장을 경유하는 버스 노선 수를 파악하고, 이를 역별로 평균화하여 정량적으로 분석하였다. 또한, 환승 소요시간과 환승 통행량은 실제 이용자의 이동 행태와 체감 불편을 반영하는 요소로 인프라의 활용 성과를 나타내는 지표로 추가하였다. 구축된 데이터는 환승역의 공간 구조와 실제 환승 행태를 반영하는 다양한 변수로 구성되며, 효율성 분석을 위해 투입 변수와 산출 변수로 구분하여 적용하였다.
역의 심도, 출입구 수, 엘리베이터 및 에스컬레이터 수, 버스 정류장 수, 버스 노선 수, 환승 가능 노선 수, 혼잡도, 그리고 정류장부터 역까지의 평균 환승 거리는 모두 환승 과정에서 이용자가 직면하는 물리적·공간적 제약 요소로 간주하여 투입변수로 설정하였다. 이에 대응되는 산출변수는 해당 인프라가 실제로 얼마나 잘 활용되고 있는지를 나타내는 환승 소요시간과 환승 통행량으로 정의하였다. 이와 같은 변수 구성은 기존의 공급자 중심 평가를 넘어, 이용자의 실제 행태와 체감 불편을 반영한 정량적 효율성 평가라는 점에서 차별성을 갖는다. 특히, 두 환승 방향 간의 구조적·행태적 특성을 구분함으로써 보다 정밀한 효율성 해석이 가능하다. 실제로 평균 환승 소요시간에서도 이러한 차이가 분명하게 드러나는데, Table 2에서 버스에서 지하철로 환승하는 평균 환승시간은 4.83분, 지하철에서 버스로 환승하는 평균 소요시간은 7.21분으로 나타난다. 지하철에서 버스로 환승하는 경우의 평균 소요시간이 더 길게 나타나는 것을 볼 수 있는데, 이는 버스 대기시간이 추가로 고려되기 때문이다. 버스에서 지하철로 환승하는 경우 소요 시간은 조사한 도보이동시간과 출입구에서 개찰구까지의 수직 이동시간으로 구성되어있다. 반면, 지하철에서 버스로 환승하는 경우, 버스를 탑승할 때까지의 대기시간이 추가로 고려되기 때문에 버스에서 지하철로 환승하는 경우보다 큰 값을 갖게 된다. 이러한 특성을 반영하여 두 환승 방향을 구분함으로써, 보다 정교하고 행태 기반의 효율성 분석이 가능하도록 하였다. 그러나, 환승 소요시간 산정에는 한계도 존재한다. 스마트카드 기반 데이터는 개찰구 간 이동 시점을 중심으로 환승 소요시간을 측정하기 때문에 지하철 내부의 승강장, 계단 및 엘리베이터 등을 이용한 수평 또는 수직 이동과 같은 세부 동선은 포함되지 않는다. 반면, 이러한 내부 이동에 영향을 미칠 수 있는 요소인 역의 심도, 엘리베이터 및 에스컬레이터 수 등은 투입변수로 포함되어 있어, 산출변수와 투입변수 간에 공간적 범위의 차이가 발생할 수 있다. 이는 분석 결과의 해석에 있어 일정 수준의 유의가 요구되는 부분이기에, 본 연구에서는 이러한 한계를 인지하고 환승 과정에서의 공간적 제약이 실제 이용자 체감에 미치는 영향을 함께 고려하는 통합적 해석을 제시하고자 하였다.
방법론
1. 개요
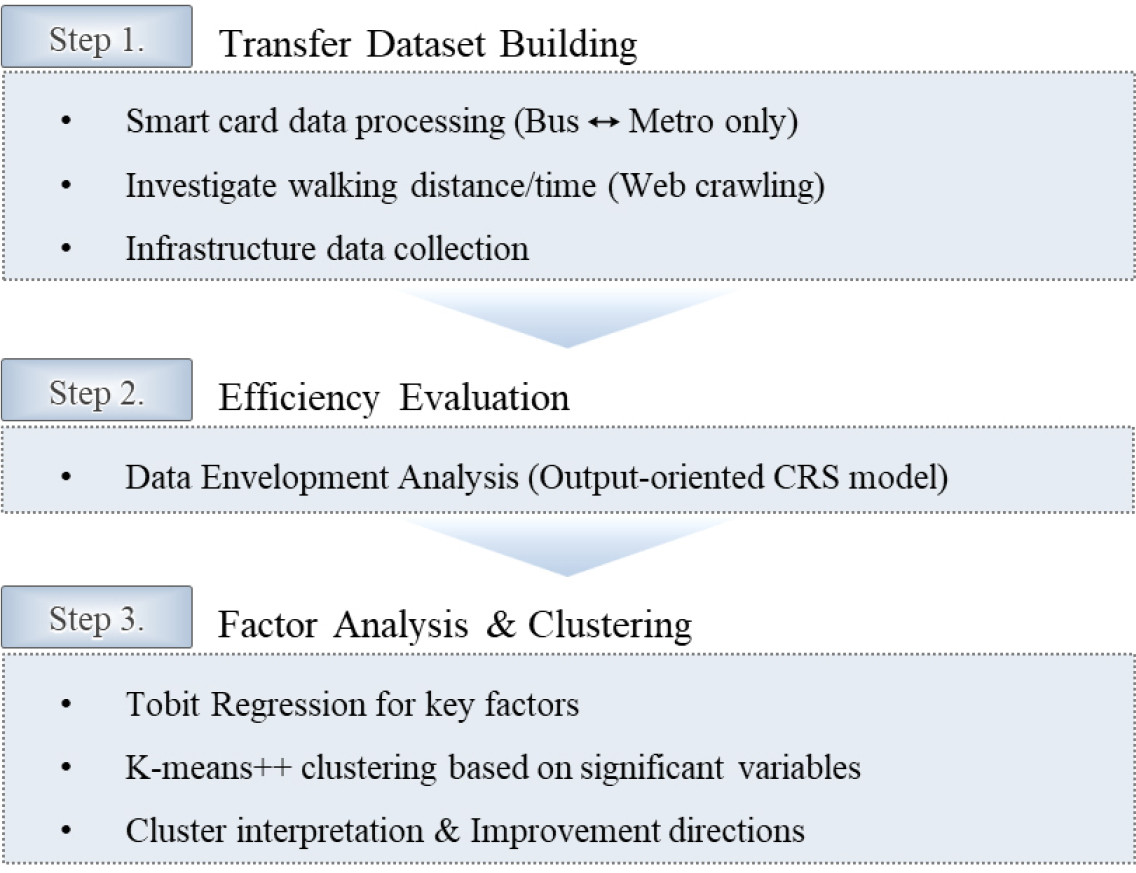
본 연구는 환승역 효율성 평가를 위해 Figure 1과 같이 크게 3단계로 방법론을 구축하였다. 1단계는 환승역의 물리적 인프라와 환승 특성을 나타낼 수 있는 데이터 구축방안을 제시하였으며, 2단계에서는 구축한 데이터를 바탕으로 자료포락분석을 활용하여 환승역 효율성을 평가하였다. 마지막으로 3단계에서는 효율성에 영향을 미치는 주요 요인을 분석하기 위한 Tobit Regression을 실시하였으며, 효율성에 주요 영향을 준 변수를 함께 고려하여 k-means++ 군집화를 통해 환승역을 그룹화하였다. 효율성에 영향을 미친 주요 변수를 기반으로 각 군집의 특성과 비효율성 요인을 종합적으로 해석하고 각 군집에 맞는 개선 방향을 제시하였다.
2. 자료포락분석(Data Envelopment Analysis; DEA)
앞서 구축한 데이터셋을 통해 환승역에 대한 효율성을 평가하기 위하여 본 연구에서는 자료포락분석(DEA)을 활용하였다. DEA는 특정 DMU가 다른 DMU에 비해 ‘상대적으로’ 얼마나 효율적인지를 측정하는 방법론이며, 본 연구에서의 DMU는 개별 환승역으로 볼 수 있다. DEA 모형에는 여러 종류가 있기에 개별 환승역의 환승 효율성을 평가하기 위한 최적의 모형을 선택하기 위해 다양한 요인을 고찰하였다. 우선 DEA 모형 중에 가장 널리 사용되는 것은 Constant Returns to Scale(CRS) 모형과 Variable Returns to Scale(VRS) 모형으로, 두 모형의 차이는 생산가능집합 혹은 효율경계를 정의할 때 사용하는 가정에 있다. CRS 모형의 경우 규모에 대한 수확불변을 가정하는데 비해 VRS 모형은 규모에 대한 수확가변을 가정하는 것이 가장 큰 차이이다. 적용 가능 상황을 나눠보면 모든 DMU가 동일한 규모에서 작동할 때는 CRS 모형을, DMU가 서로 다른 규모에서 작동하여 규모가 효율성에 영향을 미칠 때는 VRS 모형을 사용하는게 일반적이다. 본 연구에서의 DMU는 규모가 서로 다른 개별 환승역으로 구성되어 있어, 이론적으로는 규모에 따른 효율성 차이를 반영할 수 있는 VRS 모형을 적용하는 것이 타당하다. 그러나 연구의 목적과 분석의 실용성을 고려하여, 본 연구에서는 보다 명확하고 해석이 용이한 효율성 결과를 도출할 수 있는 CRS 모형을 적용하였다. CRS 모형은 VRS 모형에 비해 단순한 구조를 가지며 일반적으로 더 강한 효율성 경계를 형성하는 경향이 있다. 특히 DMU 간 규모나 특성의 이질성이 큰 경우, CRS 모형이 더 일관되고 신뢰성 있는 결과를 제공할 수 있다(Banker et al.,1984; Coelli et al., 2005).
규모수익을 가정한 이후에는 투입요소와 산출요소에 따라 투입지향 모형을 사용할지, 산출지향 모형을 사용할지 선택해야 한다. 투입지향 모형의 경우 산출요소의 수준을 유지하면서 투입을 최소화하여 효율성을 측정하며, 반대로 산출지향 모형의 경우 투입요소의 수준을 유지하면서 산출을 극대화하는 효율성을 측정한다. 본 연구에서 환승역의 효율성을 정의할 때, 평균 환승시간이 짧고 환승 통행량이 많은 경우를 효율적이라고 판단하였다. 주어진 시설 규모에서 더 많은 환승 통행량이 창출되고, 더 빠르게 환승할 수 있는 환승역이 효율적이라는 것을 의미한다. 이러한 목적을 달성하기 위해, 투입을 최대한 활용하여 산출을 극대화하는 산출지향(output-oriented) 모형을 선택하였다. 최종적으로 본 연구에서 활용한 모형은 산출지향 CRS 모형이며, 수식은 Equation 1과 같이 나타낼 수 있다.
여기서, 𝜙는 효율성 점수를 나타내며 ,은 각 DMU의 자원 투입량과 달성 산출량을 나타낸다. , 은 분석 대상 DMU()의 번째 투입값과 산출값을 나타낸다. 산출지향 CRS 모형은 주어진 투입값을 고정한 상태에서 산출을 최대화하는데 초점이 맞춰져 있으며, 첫 번째 제약함수는 분석 대상 DMU의 투입값()은 다른 DMU의 투입값()을 가중합한 값보다 크거나 같아야 함을 의미한다. 즉, 주어진 투입량에서 산출을 극대화하는 방향으로 평가가 이루어지며, 해당 DMU가 불필요하게 더 많은 투입을 하고 있는지 여부를 평가한다. 두 번째 제약함수는 분석 대상 DMU의 산출값 ()을 𝜙배 증가시킬 수 있도록 하여, 출력 극대화를 반영하는 조건이다. 해당 조건을 통해 각 DMU가 동일한 투입량을 유지하면서 얼마나 더 높은 산출을 달성할 수 있는지를 평가한다. 마지막 제약조건은 가중치()가 음수가 되지 않도록 제한하는 조건으로 기여도가 음수로 설정되는 것을 방지한다. 해당 모형으로 분석한 결과는 궁극적으로 평가 대상이 되는 DMU의 성과 개선을 위해 사용되어야 하기에 이에 대한 구체적인 설명이 필요하다. 즉, 벤치마킹해야 할 DMU는 어느 DMU인지, 효율성 점수가 왜 낮은지, 개선 가능한 DMU는 어디인지 등에 대한 정보를 제공해야 한다. 이를 위해 본 연구에서는 효율성이 1로 나타난 DMU를 벤치마킹 대상으로 설정하고, 효율성이 낮은 DMU에 대해서는 추가적인 분석을 통해 보다 구체적인 해석을 제시하였다.
3. Tobit Regression
DEA 분석은 주로 2단계 접근(two-stage approach)로 이뤄지며 1단계에서는 앞서 설명한 DEA를 활용한 효율성 측정을, 2단계에서는 효율성에 영향을 주는 설명변수를 확인한다. 추정된 효율성 값을 이용하여 통계분석을 수행할 때, 효율성 값이 0과 1 사이에 있는 절단(censored) 자료의 형태를 갖기 때문에 통상최소제곱법(Ordinary Least Square, OLS)에 기반한 회귀분석을 수행할 수 없다는 주장들이 제시되었다. 이러한 주장에 따라 본 연구에서는 Tobit Regression을 통해 효율성에 영향을 주는 변수를 확인하였으며, Equation 2와 같이 나타낼 수 있다. Tobit Regression은 종속변수 값의 절단된 형태에 따라 수정하여 회귀분석을 수행하기에 OLS를 이용한 해석과 큰 차이가 없다는 장점이 있다.
여기서, 는 잠재변수로 DEA 모형으로부터 도출된 효율성 점수이다. 는 독립 변수로 효율성에 영향을 미칠 수 있는 다양한 입력변수들을 포함한다. 𝛽는 추정된 회귀 계수로 각 독립 변수 가 효율성 점수에 미치는 영향을 나타낸다. 이는 해당 독립 변수와 효율성 점수 간의 관계를 정량적으로 나타내며, 양수일 경우 해당 변수는 효율성 점수를 증가시키는 방향으로 작용하고 음수일 경우 효율성 점수를 감소시키는 방향으로 작용한다. 마지막으로 는 오차항으로 평균이 0이고 분산이 인 정규분포를 따르는 확률 변수를 의미한다. 이는 각 DMU의 효율성 점수가 독립 변수에 의해 완전히 설명되지 않는 부분을 나타내며, 모델의 불확실성을 반영한다.
4. k-means++ clustering
분석 대상인 역은 각기 다른 특성과 운영 환경을 가지고 있기에 모든 역에 대해 개별적으로 해석을 제시하는 데 한계가 있다. 따라서, k-means++ 군집화를 통해 유사한 특성을 가진 역들을 그룹화하여 군집별로 공통적인 특성을 파악하고 이를 기반으로 보다 체계적인 개선 방향을 제안하고자 하였다. 우선 k-means++ 군집화의 기초가 되는 k-means 군집화 알고리즘은 비지도 학습 알고리즘으로 사전에 클러스터 개수 와 초기값을 입력하면 각 중심점과 군집 내 관측치 간의 거리를 비용함수로 하여, 해당 함수값이 최소화되도록 중심점과 군집을 반복적으로 재정의해주는 방식이다. 이때, 거리를 계산하는 방식은 유클리디안 거리(Euclidean distance)를 활용하였다. 이후 각 군집의 중심은 해당 군집이 속한 새로운 데이터 포인트들의 평균값으로 재설정되고 해당 과정은 군집 중점이 더 이상 변하지 않거나, 사전에 지정한 반복 횟수에 도달할 때까지 반복된다(Kim et al., 2023).
이는 중심점을 초기에 랜덤하게 위치시키기 때문에, 매번 결과가 달라질 수도 있고 한 번에 개의 중심점을 랜덤하게 생성하기에 각 중심점 사이의 거리가 짧으면 분류가 제대로 이루어지지 않을 수도 있다는 한계가 발생한다. 따라서, 본 연구에서는 이러한 한계를 해결하고자 k-means++ 군집화를 활용하였다. 이는 센트로이드를 한 번에 개 모두 생성하는 것이 아니라, 데이터 포인터 중에서 무작위로 1개를 선택하여 해당 데이터를 첫 번째 중심점으로 지정한다. 나머지 데이터 포인터들과 중심점 사이의 거리를 계산하고, 그 다음 생성할 중심점들의 위치는 데이터 포인터들과 계산한 중심점 사이의 거리를 최대한 멀리 위치시키는 방향으로 설정된다. 해당 과정을 번 반복하여 최종적으로 개의 클러스터를 만들어내는 것이다. 다만, k-means++는 분석자가 사전에 설정한 클러스터 수 𝑘를 기준으로 군집을 형성하기 때문에, 실제 데이터가 내포하고 있는 군집 구조를 완벽하게 반영하지 못할 수 있는 한계가 존재한다. 따라서 본 연구에서는 군집 수 결정 과정에서 Elbow Method 및 Silhouette Score와 같은 정량적 검증을 병행하여 그 타당성을 확보하였다. 그럼에도 불구하고 분석 결과는 설정된 군집 수에 따라 다르게 나타날 수 있음을 인지하고, 해석 시에도 특정 군집의 절대적 성격보다는 상호 비교를 통한 상대적인 특성 파악에 중점을 두어야 한다. 즉, 군집 결과는 고정된 절대값이 아닌, 유사한 특성을 가진 역들 간의 ‘상대적 구분’으로 해석될 필요가 있다.
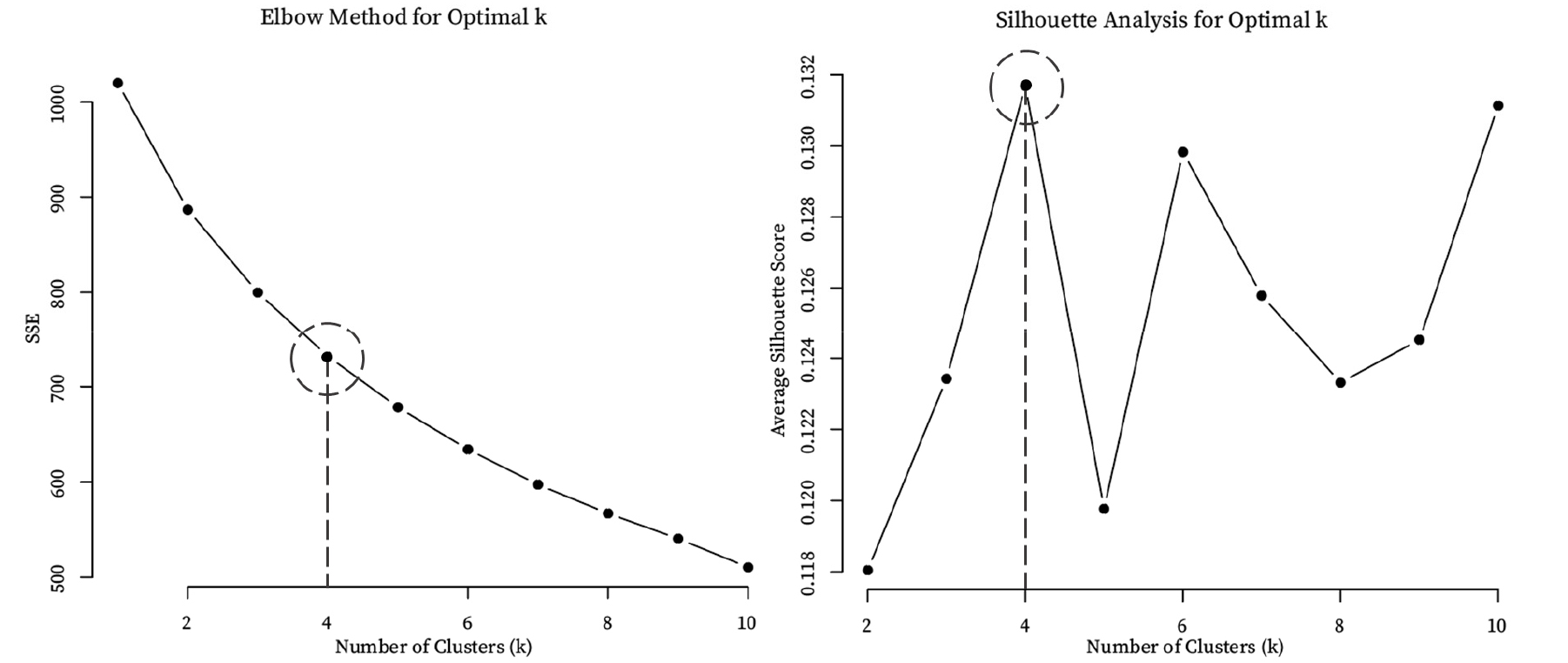
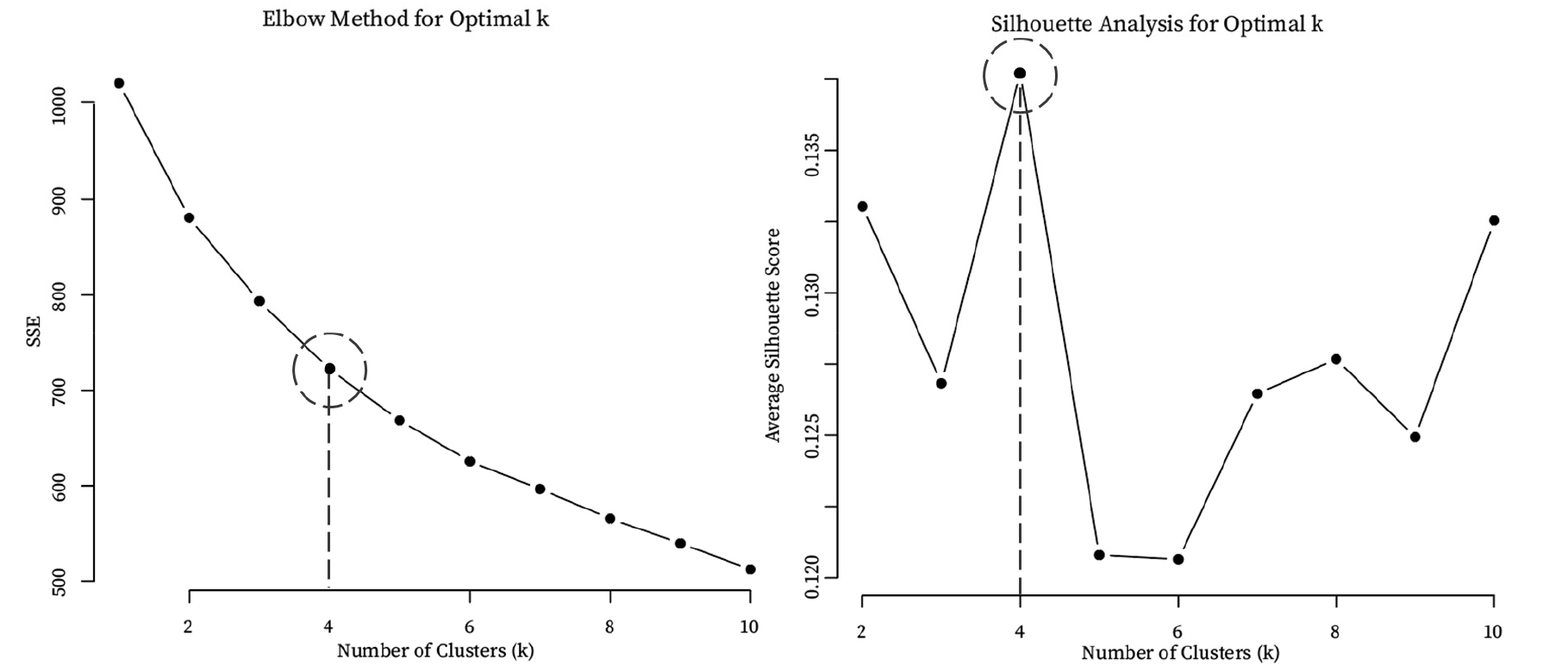
k-means++ 군집화에서 가장 중요한 것이 적절한 값을 설정해야 하는 것으로, 군집의 수는 모델의 성능에 결정적인 영향을 미친다. 본 연구에서는 최적의 값을 찾기 위하여 Elbow Method를 활용하였고 클러스터의 품질을 판단하기 위해 Silhouette Score를 함께 활용하였다. Elbow Method는 군집화를 통해 데이터 포인트가 군집 중심에서 얼마나 가까운지를 측정하는 군집 내 분산(Within-Cluster Sum of Squares, SSE)을 기준으로 한다. SSE는 각 데이터 포인트와 그 데이터가 속한 군집의 중심 사이의 거리 제곱합으로 군집 내 데이터가 군집 중심에 가까울수록 SSE는 작아지며 Equation 3과 같이 나타난다.
여기서, 는 군집 수,는 번째 군집, 는 번째 데이터 포인트, 는 번째 군집의 중심을 나타내며, 값이 증가하면 군집 수가 늘어나면서 데이터가 더 많은 군집으로 나뉘어 각 군집 내 데이터가 중심에 더 가까워져 SSE가 감소하게 된다. 하지만, 가 특정 지점 이상으로 커지면 SSE 감소폭이 점점 작아지고, 군집 수를 늘리는 것이 더 이상 유의미하지 않게 되는데, 이 감소폭이 급격히 줄어드는 지점의 값을 최적의 값으로 활용한다. Silhouette Score는 군집 간 분리도와 군집 내 응집도를 동시에 고려하는 지표로 각 데이터 포인트의 군집화 적절성을 수치화한다. 이 지표는 –1에서 1 사이의 값을 가지며, 1에 가까울수록 명확하게 군집화되었음을 의미한다.
Figures 2, 3에 나타난 Elbow Method 분석 결과, 군집의 수가 4개일 때부터 SSE 감소율이 미미해지는 것으로 나타났다. 이는 군집 수를 추가로 늘리는 것이 실질적인 성능 향상으로 이어지지 않음을 의미한다. 또한 Silhouette Score 분석에서도 군집 수가 4개인 경우에 평균값이 가장 높게 나타나, 해당 군집 수에서 군집 간 분리도와 군집 내 응집도가 가장 균형 있게 유지되고 있음을 확인하였다. 이에 따라 본 연구는 두 지표의 일관된 결과를 바탕으로 최적 군집 수를 4개로 결정하였다.
분석 결과
1. 최종 데이터셋 및 효율성 분석 결과
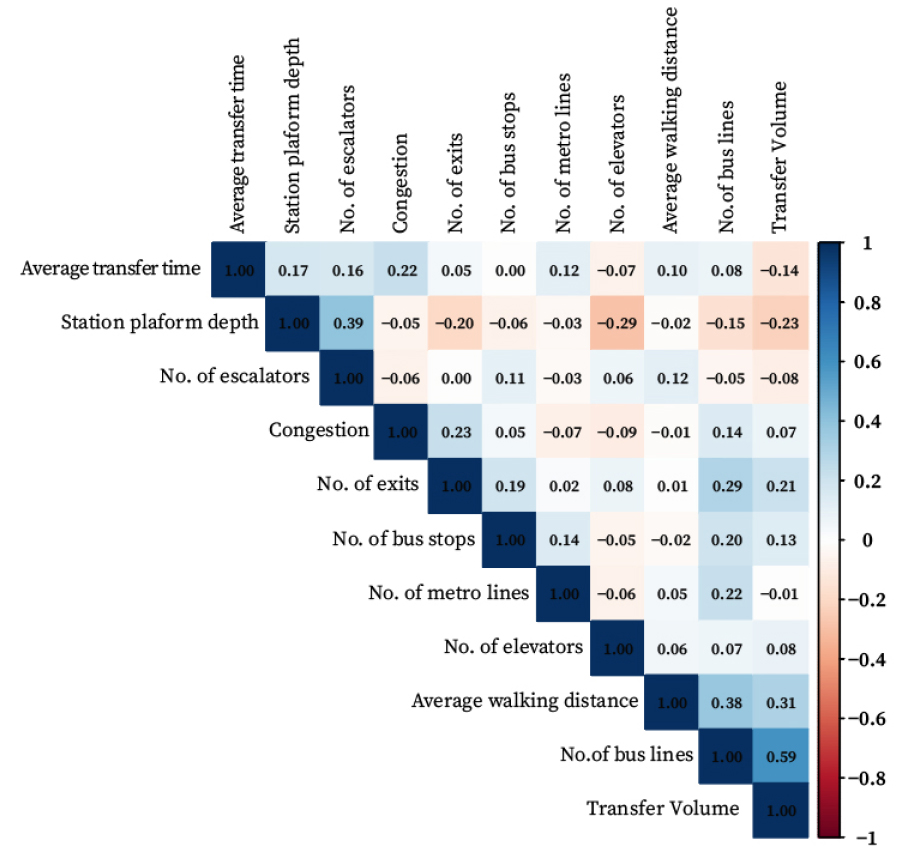
최종 투입변수 및 산출변수에 대한 기초 통계분석은 Table 3과 같이 정리된다. 본 연구에서는 평균 환승시간이 짧고 환승 통행량이 많은 역을 효율성 달성 기준으로 산정하였다. 모형에서의 ‘평균 환승시간’ 산출 변수를 역수로 변환하여 투입함으로써 해석의 일관성을 높였다. 이후 설정한 변수들 간의 상관관계를 확인하기 위해 피어슨 상관분석을 시행하였다. 상관관계가 높은 투입, 산출 변수를 사용할 경우 효율성 점수가 왜곡될 가능성이 있다. 0.5 이상의 상관관계를 보이는 경우 모형에 포함하지 않는 것이 좋기에(Cook and Zhu, 2008; Cooper et al., 2007; Dyson et al., 2001), Figures 4, 5와 같이 각 변수들의 상관관계를 파악하였다. 피어슨 상관분석을 통해 투입 및 산출 변수 간의 관계를 파악하고, 변수들 간의 중복이 없는지를 확인하여 최종 모형에 변수로 활용하였다.
Table 3.
Descriptive statistics of variables
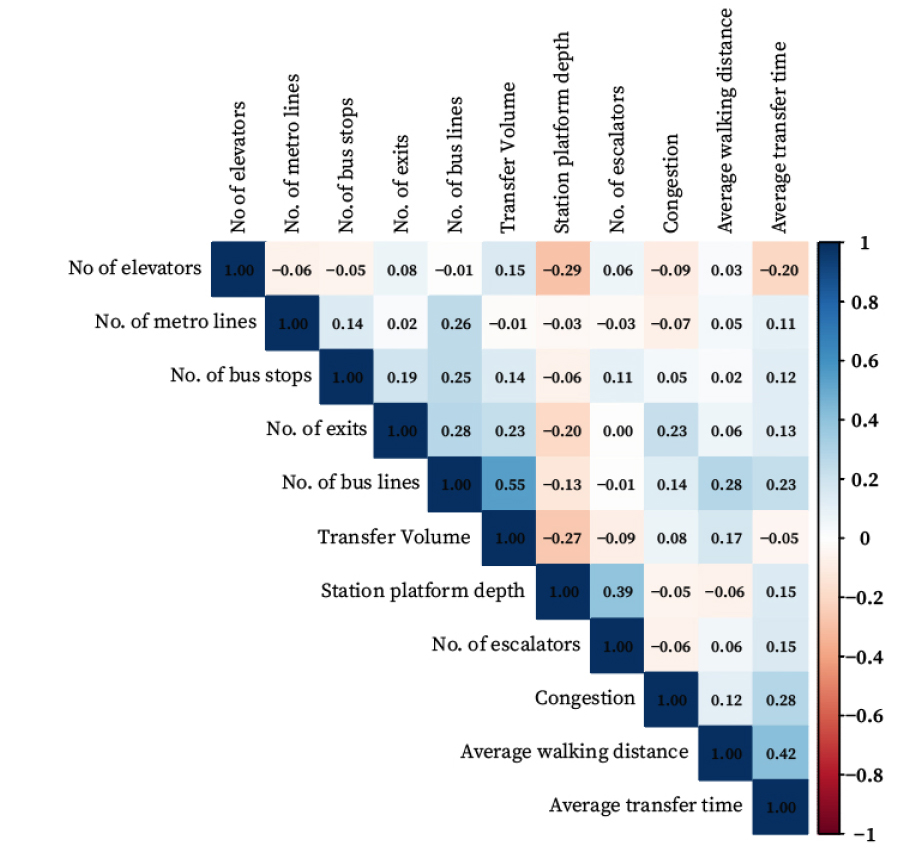
변수의 상관관계까지 확인한 후에 설정된 투입 및 산출변수를 기반으로 환승역의 효율성을 분석하여 각 역의 상대적 효율성 점수를 산출하였다. 분석 대상은 105개 역으로 호선에 따라 시설 특성을 구분하여 변수를 설정하였기에 서울교통공사에서 운영하는 역마다 호선별로 구분하여 DMU를 설정하였다. 분석 결과, 버스에서 지하철로 환승한 경우 전체 환승역의 CRS 기준 평균 효율성은 0.685, VRS 기준 평균 효율성은 0.704로 나타났다. 두 모형 간 평균값의 차이는 약 0.019, 즉 2.8% 수준으로, 해석상 유의미한 변동은 크지 않았다. 이러한 결과는 본 연구가 상대적 효율성 비교 및 클러스터 특성 도출에 초점을 두고 있다는 점에서 보다 단순하고 해석이 명확한 CRS 모형의 적용이 실용적인 선택이었음을 정당화할 수 있다. 또한, VRS 분석 결과와의 큰 편차가 없다는 점에서 분석 결과의 일관성과 신뢰성도 확보되었음을 시사한다.
지하철에서 버스로 환승한 경우를 살펴보면 전체 환승역의 CRS 기준 평균 효율성은 0.741, VRS 기준 평균 효율성은 0.754로 나타나, 두 모형에서도 큰 차이를 보이지 않음을 확인할 수 있었다. 또한, 버스에서 지하철로 환승하는 경우보다 평균 효율성이 좋게 나타나는 것을 확인할 수 있는데, 이는 버스 정류장의 선택 범위가 상대적으로 좁고 더 가까운 정류장에서 환승하려는 경향이 있기 때문이다. 동일하게 효율성이 좋은 역을 살펴보면, 평균 환승 통행량은 2,547통행이며 최대 통행량은 22,299통행, 최소 통행량은 21통행으로 나타났다. 환승 소요시간을 살펴보면 평균적으로 8.89분 소요되며, 최대 12.29분에서 최소 5.21분까지 나타나는 것을 확인할 수 있다. 두 모형의 결과를 통해서, 환승 통행량이 많거나 환승 소요시간이 적다고 해서 반드시 효율성이 높은 것은 아님을 알 수 있으며, 주어진 투입변수가 산출 변수를 충분히 뒷받침할 수 있을 때 효율성이 높게 평가되는 것을 확인할 수 있다. 효율성이 높은 환승역 대부분은 주요 환승 허브로서 여러 노선이 연결된 지역 중심부에 위치하고 있다. 예를 들어, 2호선 강남역이나 잠실역은 효율성이 1.00으로 나타났는데 이러한 역들은 높은 환승 통행량을 보이면서도, 투입된 시설이 충분히 활용되어 효율성을 유지하고 있음을 확인할 수 있다(Figure 6).
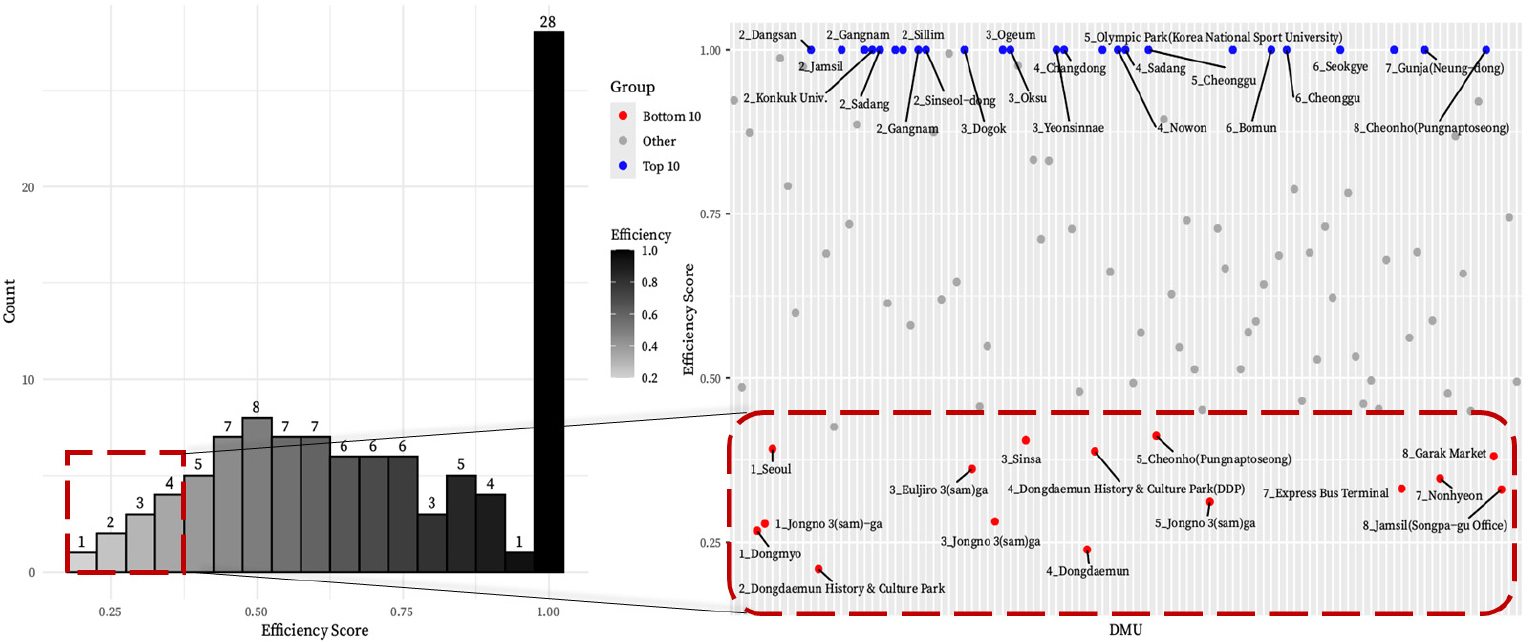
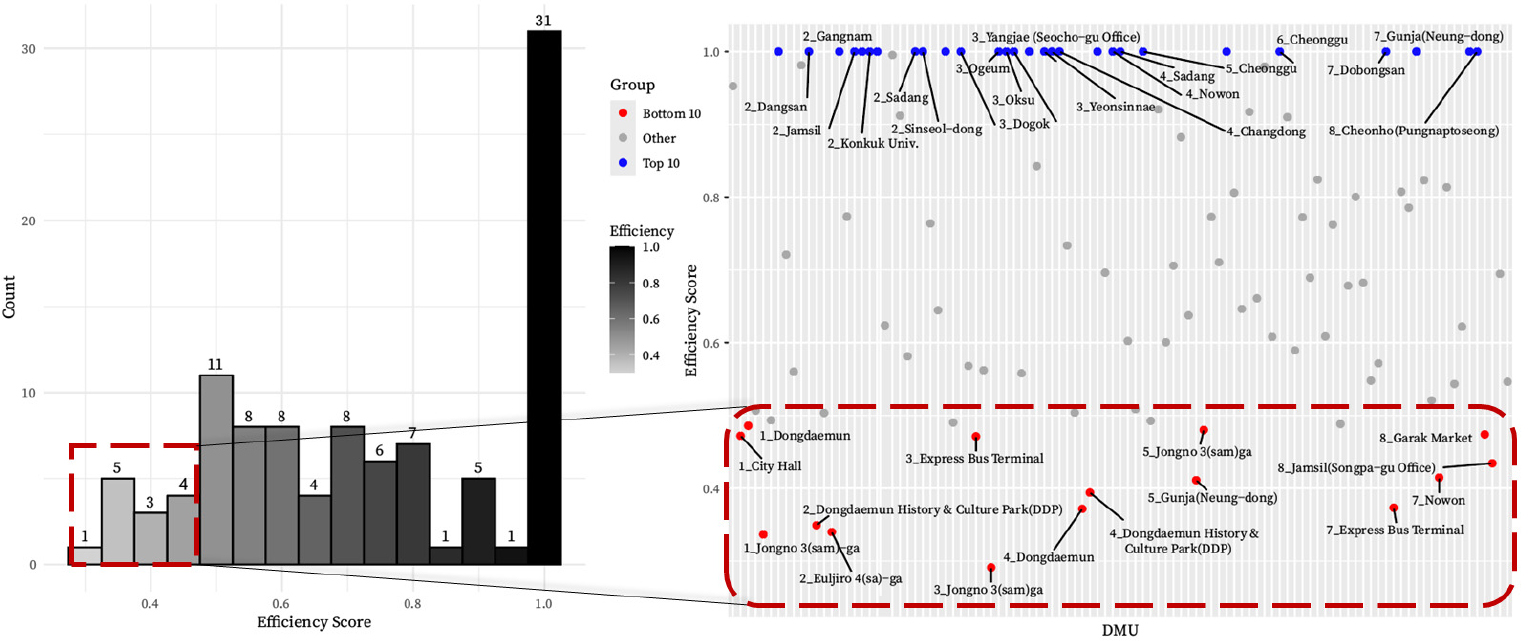
또한 같은 역이더라도 호선이 다른 경우 효율성의 차이가 나타나는 역이 존재하며, 대표적으로 2호선 잠실역과 8호선 잠실역이 그 예이다. 2호선 잠실역은 효율성이 1.00, 8호선 잠실역은 버스에서 지하철로 환승하는 경우 0.330(Figure 6), 지하철에서 버스로 환승하는 경우 0.434(Figure 7)로 매우 큰 차이가 발생한다. 실제로 대부분의 버스 정류장이 2호선 잠실역 근처에 위치하고 있는 것을 확인할 수 있으며, 버스에서 내린 이용자가 8호선 잠실역을 이용하기 위해 최소 10분 이상의 도보가 필요한 경우가 발생하기에 두 호선 간의 효율성 차이가 발생한다고 해석할 수 있다. 다만, DEA는 다수의 투입 및 산출 변수를 동시에 고려하여 상대적 효율성을 평가하는 다변량 분석 기법이므로, 잠실역 사례에서 나타난 효율성 차이는 버스 정류장 접근성과 같은 환승 동선의 물리적 제약이 영향을 미쳤을 가능성을 시사하는 것으로 이해할 수 있다. 이는 본 연구의 효율성 분석 모형이 단순한 수치 비교를 넘어 이용자 행태 및 공간 구조의 특성을 일정 수준 반영하고 있음을 보여주는 정성적 근거로 해석될 수 있다.
2. 영향요인 분석 결과
본 연구에서 설정한 효율성 평가 모형이 실제 이용자들의 행태를 잘 반영하고 있음을 확인하였으나, 효율성이 좋지 않은 역들의 경우 효율성 저하의 원인을 파악하는 추가적인 분석이 필요하다. 이를 위해 Tobit Regression을 활용하여 효율성에 영향을 미치는 요인을 Table 4와 같이 파악하였다. 분석은 전체 환승역을 대상으로 하였으며, 효율성 점수를 종속변수로 설정하고 DEA 분석에서 활용한 투입변수를 설명변수로 포함하여 분석을 진행하였다.
Table 4.
Result of Tobit regression models
효율성에 영향을 주는 변수를 확인한 결과, 공통적으로 역의 심도, 에스컬레이터 수, 평균 버스 노선 수, 혼잡도가 효율성에 부정적인 영향을 미치고 있는 것을 확인할 수 있다. 탑승 플랫폼이 깊이 위치한 역은 승강장 접근에 많은 시간이 소요되어 에스컬레이터 이용 빈도가 높아지며, 이는 환승 소요시간 증가와 관련되어 효율성 저하에 영향을 미치는 것으로 해석된다. 또한, 버스 노선 수가 많을수록 다양한 환승 가능성이 제공되지만, 선택지가 많아질수록 이용자의 경로 판단 부담이 증가하고 환승 동선의 복잡성도 높아질 수 있다. 또한, 역별 혼잡도가 효율성 저하에 영향을 미치는 것으로 나타났는데 이는 행태적 관점으로 보면 혼잡 회피를 위한 우회 동선 증가 가능성이 있음을 시사한다. 혼잡한 열차를 피하기 위해 일부 이용자는 특정 플랫폼 끝으로 이동하거나 다른 출구를 선택할 가능성이 있다. 이로 인해 환승 동선이 길어지고 소요시간이 증가함으로써 효율성이 떨어지는 경향이 발생할 수 있다.
모형별로 살펴보면, 버스에서 지하철로 환승하는 경우는 추가적으로 엘리베이터 수와 환승 가능한 지하철 노선 수가 효율성에 영향을 미치는 것으로 나타났다. 이는 지하철로 환승 시의 물리적 환경 특성과 노선 선택 과정의 복잡성 때문으로 판단된다. 지하철에서 버스로 환승하는 경우, 이용자는 지하철 역사 내에서 출구까지의 경로가 명확히 정해져 있어 이동 동선에서 큰 혼란이 없다. 그러나 버스에서 지하철로 환승할 때는 플랫폼까지 도달하는 경로를 결정해야 하며, 계단, 에스컬레이터, 엘리베이터 중 어떤 시설을 이용할지 선택에 따라 이동 시간이 달라질 수 있다. 또한, 여러 노선이 교차하는 환승역의 경우, 환승 가능한 경로가 많아짐에 따라 역사 내 구조적 복잡성이 증가한다. 이는 이용자 입장에서 경로 탐색 과정에서의 인지적 부담과 체류 시간 증가로 이어질 수 있다. 이러한 이유로, 엘리베이터 수와 환승 가능 노선 수가 버스에서 지하철로의 환승 시 효율성에 영향을 미치는 변수로 작용하는 것으로 해석할 수 있다.
지하철에서 버스로 환승하는 경우, 출구 수와 버스 정류장 수가 중요한 변수로 작용하는 것으로 나타났다. 이는 지하철에서 버스로 환승할 때 이동 경로의 선택지가 많아지는 환승 환경의 특성을 반영한 결과로 볼 수 있다. 지하철에서 버스로 환승하는 경우는 출구 선택과 그 이후의 버스 정류장 접근 경로가 다양하다. 특히, 다수의 출구와 버스 정류장이 존재하는 역에서는 이용자가 환승을 위해 선택해야 할 경로가 많아지며, 이러한 선택지가 환승 시간과 편리성에 영향을 미친다. 예를 들어, 주요 버스 정류장이 특정 출구에 집중되어 있는 경우, 그 출구로 가는 동선이 환승 효율성에 중요한 변수로 작용할 수 있다. 또한, 출구의 물리적 위치와 정류장과의 거리도 환승 과정에 영향을 미친다. 출구 수가 많더라도 주요 버스 정류장이 출구에서 멀리 떨어져 있거나 특정 출구에 집중되어 있다면, 이용자 입장에서는 이동 시간이 길어지고 환승 효율성은 낮아질 수 있다.
3. 군집화 결과 및 군집별 효율성 개선방향 제시
k-means++ 군집화를 통해 환승역들을 유사한 특성의 그룹으로 분류하여, 군집별 특징을 파악하고 보다 체계적인 개선 방향을 제안하고자 하였다. 앞서 설정한 최적의 값인 4개의 군집으로 분류된 결과를 분석한 결과, 버스에서 지하철로 환승하는 경우 각 군집별로의 주요 변수의 분포는 Figure 8, 지하철에서 버스로 환승하는 경우는 Figure 9와 같이 나타난다. Tobit Regression 분석 결과, 역의 심도, 에스컬레이터 수, 평균 버스 노선 수, 혼잡도가 효율성에 부정적인 영향을 미치는 변수로 확인되었다. 이 중 군집별로 큰 차이를 보이지 않는 혼잡도를 제외한 변수에 대해 각 군집의 분포를 시각화하였으며, 특성을 명확하게 확인하기 위해 효율성, 평균 환승시간, 환승 통행량, 정류장부터 역까지의 평균 도보거리에 대한 분포를 함께 Table 5와 같이 나타내었다. 이를 통해 군집화된 역들이 구조적, 운영적 특성에 따라 효율성에 어떤 영향을 미치는지 살펴보고자 하였으며, 해당 변수들은 환승역의 운영 효율성과 이용자 편의성을 반영하는 지표로 각 군집별로 개선이 필요한 요소를 식별할 수 있다.
Table 5.
Distribution of key transfer variables by cluster (bus→metro)
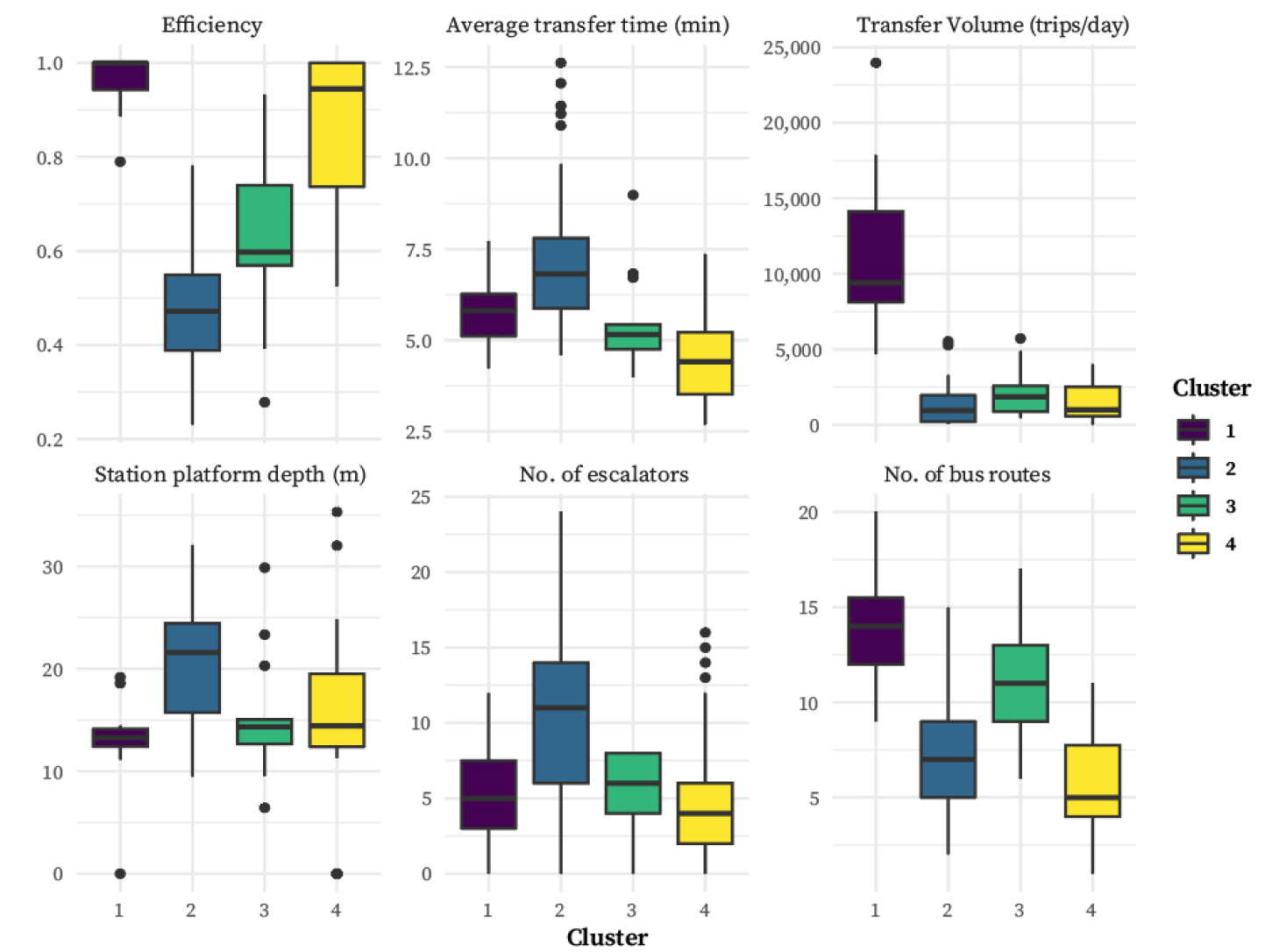
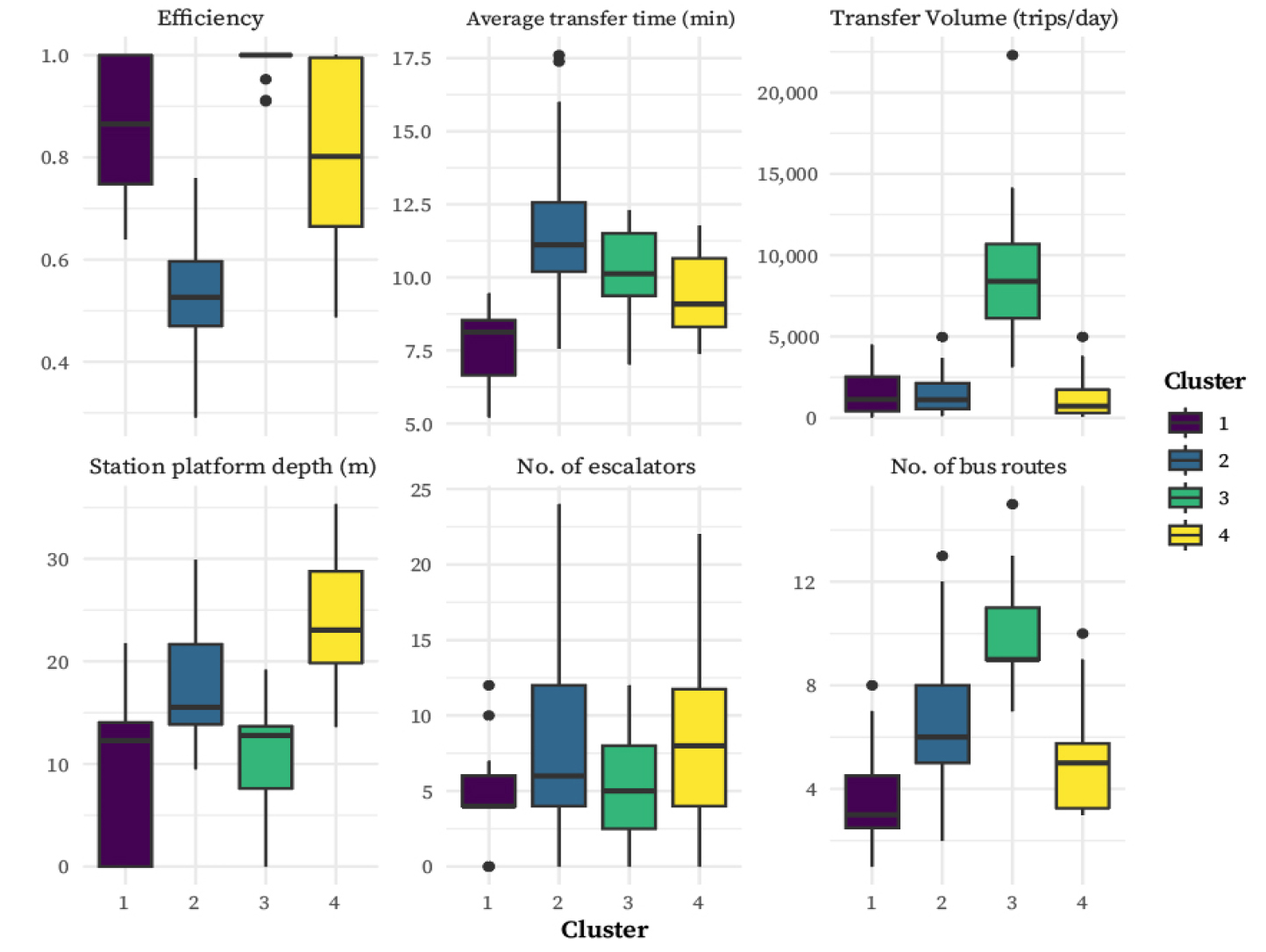
버스에서 지하철로 환승하는 경우를 살펴보면, 우선 Cluster 1은 단순하고 명확한 환승 동선을 갖춘 환승역들로 구성되어 있으며, 전반적으로 매우 높은 환승 효율성을 보인다. 해당 군집에는 2호선 강남, 2호선 잠실, 3호선 양재, 4호선 사당, 8호선 복정역 등의 역이 포함되며, 이들 대부분은 이미 복합환승센터가 구축되어 있거나 향후 조성이 예정된 거점 환승역이라는 공통점을 가진다. 이미 이용자 동선 최적화 및 수단 간 연계성 강화를 위한 시설 설계가 반영되어 있어 효율적인 환승 환경이 구축되어 있는 군집으로 볼 수 있다. Cluster 2는 전반적으로 환승 환경의 물리적 복잡성과 제약이 커 효율성이 가장 좋지 않은 역들로 구성된 군집으로 볼 수 있다. 특히 탑승 플랫폼이 깊이 위치해있고 이동 거리가 길며, 버스 노선이 적어 환승의 직관성과 접근성이 낮은 것으로 해석된다. 에스컬레이터 수가 평균보다 높은 것은 환승 편의성 제고를 위한 물리적 보완의 노력으로 볼 수 있으나, 플랫폼 심도나 복잡성으로 인해 여전히 시간이 오래 걸리는 구조적 한계를 극복하지 못하고 있는 상황으로 보인다. 해당 군집에는 1호선 시청, 3호선 을지로3가, 5호선 여의도, 5호선 종로3가, 6호선 동묘 등 개통된지 오래되었거나 초기 설계에서 환승 수요를 충분히 반영하지 못했던 역들이 포함되어 있다.
Cluster 3에는 1호선 서울역, 2호선 왕십리, 5호선 김포공항, 7호선 상봉 등이 포함되며, 이들 대부분은 중규모 이상의 환승 수요를 수용하는 주요 환승 거점역에 해당한다. 전반적으로 플랫폼 심도가 얕고, 에스컬레이터 수는 적정 수준이며, 버스 노선 수도 평균 10.62개로 다양한 환승 선택지를 제공하고 있다. 이러한 특성은 해당 군집의 역들이 복수의 교통수단 및 노선이 집적된 환승 허브로 기능하고 있음을 보여준다. 특히 서울역, 김포공항, 왕십리 등은 철도·공항·광역교통과의 연계가 가능하여 기능적 복합성이 높은 역으로 평가된다. 그러나 다중 노선과 수요가 집중된 구조로 인해 환승 경로 선택의 복잡성, 수평 이동 거리 증가 등은 환승 효율성에 부정적인 영향을 미칠 가능성이 있다. Cluster 4에는 2호선 선릉, 4호선 삼각지, 5호선 청구, 6호선 석계 등 다양한 환승역이 포함되어있다. 이들 역은 환승 이동거리가 짧고 동선이 단순한 편으로 환승 효율성 자체는 높게 나타난다. 버스 접근성이 낮고 환승 수요가 작아 전체적인 환승 거점 기능은 약한 것으로 해석되나, 본 군집의 효율성 변수에 대한 표준편차는 0.16으로 타 군집에 비해 상대적으로 높다. 동일 군집 내에서도 역 간 환승 효율성 수준에 상당한 편차가 존재함을 의미하며, 군집의 동질성이 상대적으로 낮을 수 있음을 시사한다. 따라서, 해당 군집에 속한 환승역들은 일률적인 해석보다는 개별 역의 구조적·운영적 특성을 고려한 세분화된 분석이 요구된다.
지하철에서 버스로 환승하는 군집 분석 결과는 버스에서 지하철 환승에 비해 군집 간 구조적 차이가 비교적 명확하지 않았다. Table 6을 보면 4개의 군집 모두 효율성, 환승시간, 통행량 등 주요 변수의 평균값은 일정 부분 차이를 보이나, 표준편차가 상대적으로 높아 군집 내 이질성 또한 크게 나타났다. 특히 효율성 지표의 경우 Cluster 3을 제외한 다른 군집에서는 유사한 수준의 평균값 대비 큰 분산이 나타나, 군집 간 실질적 구분이 상대적으로 불분명함을 시사한다. Cluster 3은 효율성이 가장 높은 군집으로 평균 5.10분의 짧은 환승시간과 9,205건의 높은 환승 통행량을 보이며, 환승거점으로 기능하는 일부 역이 포함된 것으로 추정된다. 그러나 Cluster 1, 2, 4는 효율성 및 환승시간, 버스노선 수 등에서 상호 유사한 분포를 보이며, 특히 Cluster 4는 효율성이 높은 편이지만 환승시간이 길고, 플랫폼 심도가 깊은 역들이 포함되어 있어 단일한 해석이 어렵다. 이는 해당 군집 내 역 간의 특성이 이질적이며, 효율성이 높은 경우에도 환승 동선이 비효율적으로 설계되었을 가능성을 내포한다. 또한, Cluster 2의 경우 효율성 버스노선 수가 낮은 편에 속하면서도 환승시간은 가장 길게 나타났다. 하지만 표준편차 또한 전반적으로 높아 군집 전체를 통일된 특성으로 해석하는 데 한계가 존재한다. 이러한 분석 결과는 지하철에서 버스로의 환승 특성에 있어 물리적 공간 구조나 시설 요소보다는 이용자 행태나 주변 교통환경 등 외부적 요인이 작용할 여지가 크다는 점을 시사하며, 향후에는 군집 간 차이를 보다 정밀하게 구분하기 위해 보다 다양한 설명변수를 보완하여 보다 명확한 군집화를 시도할 필요가 있음을 시사한다.
Table 6.
Distribution of key transfer variables by cluster (metro→bus)
이러한 군집화 결과를 통해, 환승 환경에서의 구조적 차이를 보다 명확하게 확인할 수 있었다. 특히, 환승 동선이 복잡하거나 이동 거리가 긴 역들의 효율성이 낮게 나타났으며, 이는 단순히 시설 개선만으로 해결할 수 있는 문제가 아님을 시사한다. 즉, 환승 동선의 직관성과 이동 거리, 이동 시간 등의 요소가 환승 효율성에 중요한 영향을 미치며, 이를 고려한 개선이 필요하다. 또한, 동일한 역이라도 수단 간 연계 환승(버스→지하철, 지하철→버스)에 따라 효율성 및 군집화 결과가 다르게 나타나기에, 이용자의 행태나 실제 이동 동선을 고려한 안내 시스템 개선, 보행 동선 최적화, 대기 시간 단축 등의 운영적 접근을 통해 환승역의 효율성을 개선시킬 수 있다.
본 연구에서는 환승 효율성에 영향을 미치는 구조적 요인들을 위와 같이 군집 분석을 통해 도출하였으며, 각 군집별 특성에 따라 환승 환경의 이질성과 효율성의 편차가 존재함을 확인하였다. 이러한 결과를 바탕으로 향후 환승 환경 개선을 위한 정책적 시사점을 다음과 같이 제안한다. 첫째, 환승 효율성이 낮은 군집의 경우 환승 동선이 복잡하거나 물리적 구조로 인해 직관성이 떨어지는 문제가 존재하였다. 이러한 경우 환승 유도선, 안내 표지판 등 물리적 시설 외에도, 실시간 환승 경로 정보 제공 시스템, 혼잡도 기반 플랫폼 분산 안내 시스템 등 디지털 기반의 이용자 중심 정보 제공 방식이 효과적일 수 있다. 특히 다중 노선 환승역의 경우, 경로 선택의 복잡성이 효율성 저하로 이어질 가능성이 높기 때문에 통행 경로 최적화를 지원하는 시스템 도입이 필요하다. 다양한 환승 선택지가 존재하는 구조적 특성상, 환승 동선의 직관성 확보가 중요하므로 시각적 정보 체계(UI/UX) 개선, 컬러라인 연계 안내 및 실시간 환승 정보 제공 장치 도입이 요구된다.
둘째, 버스에서 지하철로 환승하는 경우의 Cluster 1과 같은 군집에서는 기존 인프라를 유지하면서도 혼잡 시간대 수요 대응 중심의 관리 전략이 필요하다. 예를 들어, 출퇴근 시간대 에스컬레이터 방향 전환, 환승 통로 내 실시간 혼잡도 알림 시스템 도입 등을 통해 서비스 수준을 유지할 수 있다. 향후 수요 증가에 대비하여, 환승 유도 동선의 여유 공간 확보, 출입구 추가 설치 등 유연한 공간계획이 고려될 필요가 있다. Cluster 3과 같이 다중 수단이 연계되는 군집에서는 경로 선택의 복잡성이 효율성에 부정적 영향을 미칠 수 있으므로, 경로 안내의 명확성 확보가 중요하다. 또한, 다양한 교통수단 간 연계와 통합이 중요하기에 MaaS 기반 정보 통합 플랫폼을 도입하여 실시간 수단 간 이동 정보를 제공하고, 경로 선택을 지원하는 기능을 강화할 필요가 있다. 마지막으로, 장기적으로는 환승 기능이 미비한 일부 역사에 대해 역세권 구조 개편, 정류장 재배치, 환승 동선 재설계 등 환승 거점으로의 기능을 강화하기 위한 물리적·제도적 보완이 필요하다. 특히 초기 개통 당시 환승 수요를 반영하지 못했던 역의 경우, 기존 구조를 전제로 한 환승 동선 최적화뿐만 아니라 BRT 및 환승 전용 공간 도입 등 기능 재구성 차원의 접근도 검토되어야 한다. 본 연구는 구조적 변수 중심의 분석에 초점을 두었으나, 향후에는 이용자 행태 기반의 요인을 통합적으로 고려할 필요가 있다. 환승 회피 경향, 최적 경로 설정 기준, 실시간 경로 탐색 방식 등은 환승 효율성에 영향을 미칠 수 있는 주요 행태 변수이며, 이러한 요소를 설명변수로 반영함으로써 군집 간 실질적인 차이를 보다 정밀하게 구분하고 정책 설계의 타당성을 제고할 수 있을 것이다.
결론
본 연구는 자료포락분석을 활용하여 수도권 지하철 환승역의 효율성을 평가하고, 효율성에 영향을 미치는 요인을 분석함으로써 각 환승역의 개선 방향을 제시하였다. 특히, 수단 간 연계 환승(버스→지하철, 지하철→버스)에 따라 k-means++ 군집화를 통해 그룹별 특성을 구분하고, 군집에 맞는 효율성 개선 방안을 제시한 점에서 의의를 갖는다. 환승역 DB 구축을 통해 기존 연구와 달리 스마트카드 데이터와 다양한 관련 지표를 활용하여 환승역의 다각적인 특성을 반영하였다. 특히, 버스→지하철, 지하철→버스라는 환승 방향별 DB 구축을 세분화하여 환승 행태를 구체적으로 평가하고, 이를 토대로 효율성 분석의 정밀성을 높였다. Tobit Regression을 통해 효율성에 영향을 미치는 주요 요인을 도출한 결과, 심도, 혼잡도, 평균 버스 노선 수, 에스컬레이터 개수 등이 효율성을 저해하는 주요 변수로 확인되었다. k-means++ 군집화를 통해 4개의 군집으로 분류하고, 그룹별 특성을 분석하여 차별화된 개선 방안을 제시하였다. 환승역 군집 특성에 맞는 환승 동선 최적화, 혼잡 완화, 시설 개선 등의 개선 방향을 제안하였다. 본 연구에서 정의한 효율성 개념은 환승역의 인프라가 수단 간 연계 환승 과정에서 얼마나 효과적으로 활용되는지를 평가하며, 운영적 효율성과 이용자 편의성을 동시에 고려한 점에서 기존 연구와 차별성을 가진다. 투입 변수로는 환승역의 인프라와 시설 요소를, 산출 변수로는 환승 통행량과 환승 시간의 역수를 설정함으로써, 동일한 인프라에서 더 많은 환승 통행량을 처리하고, 더 짧은 환승시간을 제공할 수 있는 역을 효율성이 높은 역으로 평가하였다. 이러한 결과는 환승역 운영 정책 설계와 대중교통 계획 수립에 있어 실질적인 기초 자료로 활용될 수 있는 가능성을 제시하였다.
다만, 본 연구는 데이터 측면에서, 수도권 전체 환승역에 대한 DB를 구축하지 못하고, 서울교통공사에서 제공된 일부 환승역 데이터를 중심으로 분석이 진행되었다. 또한, 분석에 활용된 스마트카드 데이터는 특정일 하루치에 한정되어 있어 통행 패턴의 다양성과 시간대별·요일별 변동성을 충분히 반영하지 못하였다. 이는 연구 범위가 제한적이며, 다른 철도 기관이나 다양한 지역적 특성을 고려하지 못한 점에서 한계가 있다. 또한, 변수 설정의 측면에서, 수단 간 환승의 어느 측면에서 연계성이 부족하여 MaaS의 활성화가 되지 않는지에 대한 고려를 하고 싶었으나 타 수단을 고려할 수 있는 변수 설정을 하지 못하였다. 특히, 개인형 공유수단, 공공자전거 등 타 수단에 대한 고려나 ‘환승 대기 시간’과 같은 주요하게 영향을 줄 것 같은 변수를 구축하지 못한 점에서 한계가 있었다. 향후 연구에서는 다양한 교통수단 간 연계성을 반영하고, 타 수단과의 환승 효율성을 분석할 수 있는 변수를 추가하여 더 풍부한 해석을 하고자 한다. 마지막으로 개선방안 제시 측면에서, 환승 효율성에 영향을 미칠 수 있는 여러 요인을 충분히 고려하지 못했다. 본 연구는 환승 통행량과 환승 시간의 효율성 평가를 기반으로 제안된 개선 방향에 그쳤으며, 구체적인 실행 방안이나 정책적 실현 가능성을 다루지 않았다. 향후 연구에서는 배차 간격 조정, 혼잡 시간대 환승 경로 최적화, 이용자 행태 분석을 바탕으로 한 개선 방안을 세분화하여 제시할 필요가 있다. 이러한 한계를 보완하기 위해, 향후 연구는 데이터 수집 범위를 확대하고 다양한 변수를 추가하며, 분석 기법을 이에 맞게 수정하여 환승역 효율성 평가를 더욱 다각적으로 하고자 한다. 나아가, 정책적 실행 가능성을 고려한 구체적인 실행 전략을 제시함으로써 환승역 운영 효율화를 위한 실질적인 기여를 할 수 있을 것으로 기대된다.
