
-
Article
-
Economic Impacts of Urban Air Mobility Industry: an Input-Output Analysis Comparing the Seoul Metropolitan Area and Non-Metropolitan Regions
도심형 항공 모빌리티(UAM) 산업의 경제적 파급효과 분석: 수도권과 비수도권의 산업연관분석 비교
-
CHO, Jungwoo, MAENG, Kyuho
조정우, 맹규호
- This study evaluates the economic impacts of Urban Air Mobility (UAM) in Korea using the 2020 input–output table within a demand-driven framework. …
본 연구는 한국은행 2020년 산업연관표를 활용하여 도심형 항공 모빌리티(UAM)의 경제적 파급효과를 수요유도형 모형으로 추정하였다. UAM 산업은 항공기·부품 제조, 인프라 구축, 서비스 운영, …
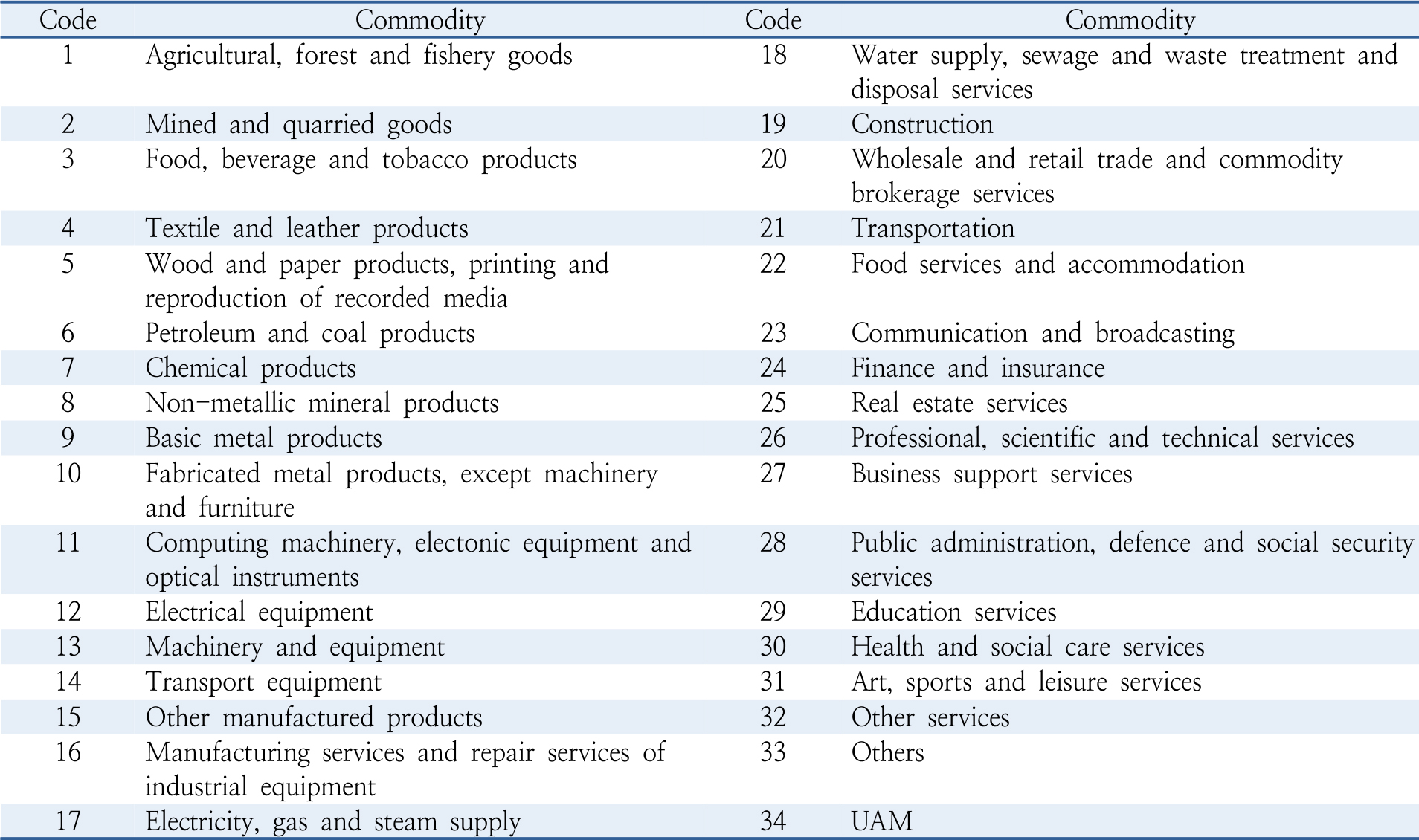
- This study evaluates the economic impacts of Urban Air Mobility (UAM) in Korea using the 2020 input–output table within a demand-driven framework. UAM is operationalized as an exogenous industry integrating aircraft and parts manufacturing, infrastructure construction, service operations, and digital traffic management. The analysis estimates production, value-added, and employment induction effects, and compares outcomes across nationwide, Seoul metropolitan, and non-metropolitan regions. The nationwide induction coefficients are 0.9905 for production, 0.3928 for value added, and 0.4139 employees per KRW 100 million of final demand. Sectoral results indicate that chemical products, basic metals, and professional scientific and technical services exhibit the strongest production linkages, while professional services, wholesale and retail, and business support services account for most value-added and employment effects. Regional disparities further reveal stronger value-added effects in the Seoul metropolitan area, driven by information and communication technology and high-skilled services, while non-metropolitan regions show higher production and employment effects associated with manufacturing and construction. By identifying UAM’s forward and backward linkages and region-specific structural characteristics, this study provides empirical evidence to guide policies that position UAM as a national growth driver and a catalyst for balanced regional development.
- COLLAPSE
본 연구는 한국은행 2020년 산업연관표를 활용하여 도심형 항공 모빌리티(UAM)의 경제적 파급효과를 수요유도형 모형으로 추정하였다. UAM 산업은 항공기·부품 제조, 인프라 구축, 서비스 운영, 디지털 관제의 외생부문으로 재정의하였으며, 생산·부가가치·취업유발효과를 중심으로 전국, 수도권, 비수도권 수준에서 분석하였다. 전국 기준 유발계수는 생산 0.9905, 부가가치 0.3928, 취업 1억원당 0.4139명으로 나타났다. 산업별로는 화학제품, 1차 금속제품, 전문과학기술 서비스가 가장 높은 생산 연계효과를 보였으며, 전문서비스, 도소매, 사업지원 서비스가 부가가치 및 취업유발효과를 주도하였다. 지역 비교 결과, 수도권은 ICT 및 고숙련 서비스 기반의 부가가치 창출 효과가 높게 나타난 반면, 비수도권은 제조업·건설업 중심의 생산 및 취업유발효과가 상대적으로 크게 나타났다. 본 연구는 UAM 산업의 전·후방 연계 구조와 지역별 산업 특성을 규명함으로써, UAM을 국가 성장동력 및 지역균형 발전의 매개로 활용하기 위한 정책적 근거를 제시한다.
-
Economic Impacts of Urban Air Mobility Industry: an Input-Output Analysis Comparing the Seoul Metropolitan Area and Non-Metropolitan Regions
-
Article
-
Segmenting Potential Users and Analyzing Acceptance Differences of Automated Demand-Responsive Transit: The Role of Digital Affinity and Technology Trust
자율주행 수요응답형 대중교통의 잠재 이용자 유형화 및 유형별 수용성 차이 분석 : 디지털 친화도와 기술 신뢰도를 중심으로
-
KIM, Hyunwoo, YOUM, Juhyoun, KIM, Jinhee
김현우, 염주현, 김진희
- Recent transportation systems are transitioning from traditional fixed-route public transit topersonalized mobility services based on user demand. In particular, autonomous demand- responsivetransit …
최근 교통체계는 고정 노선 기반의 전통적 대중교통에서 이용자 수요에 기반한 맞춤형 이동 서비스로 전환되고 있으며, 특히 자율주행 기술이 결합된 수요응답형 대중교통(ADRT)이 새로운 …
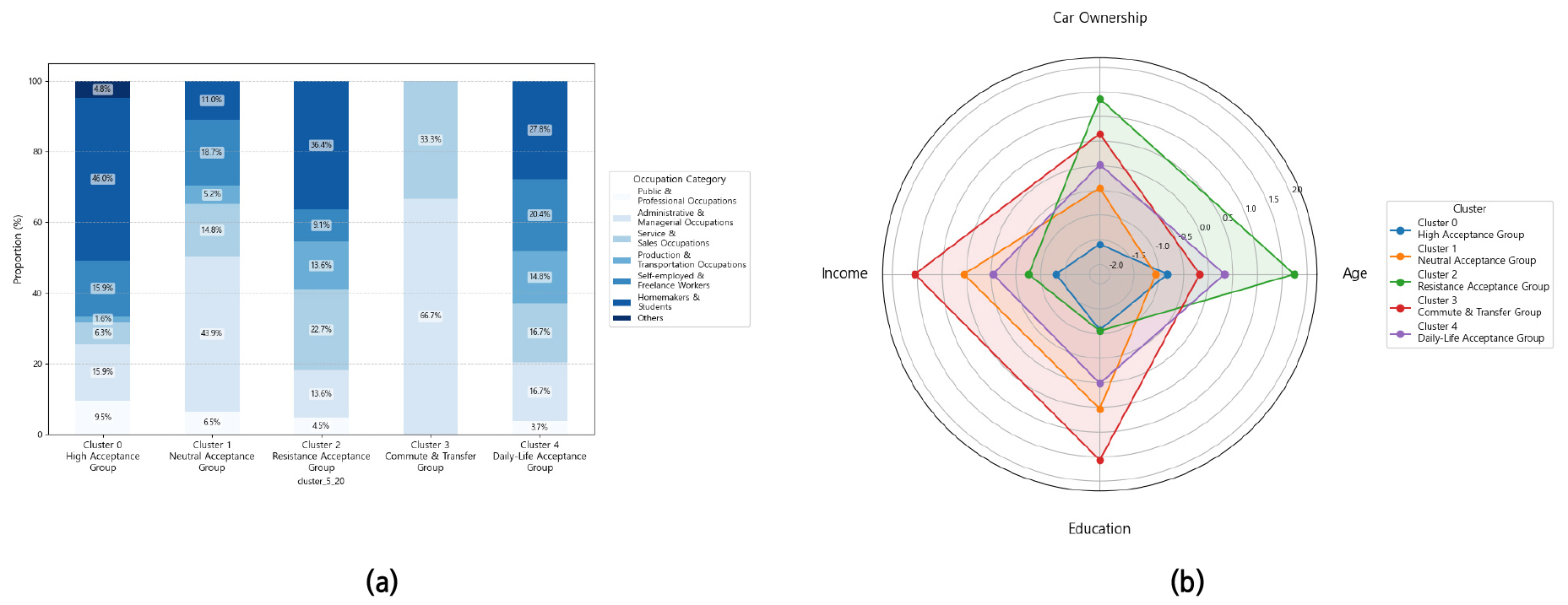
- Recent transportation systems are transitioning from traditional fixed-route public transit topersonalized mobility services based on user demand. In particular, autonomous demand- responsivetransit (ADRT), combining flexibility with automation, is emerging as a significant alternative.However, previous studies have predominantly focused on technological efficiency or macroscopicfactor analysis, leaving user-centric behavioral acceptance—crucial for successful ADRT adoption—relatively underexplored. This study aims to segment potential users of ADRT services based on theirfuture behavioral intentions (trip purposes) and to empirically analyze differences in digital affinity andtechnology trust among these segments, ultimately proposing customized adoption strategies. Toachieve this, a survey was conducted among 300 residents and workers in the Namyang-eup living labarea of Hwaseong-si, Gyeonggi- do. Using k-means cluster analysis on data regarding usage intentionsfor eight different trip purposes, five distinct potential user clusters were identified. The analysisrevealed statistically significant differences among these clusters not only in their usage intentions bytrip purpose but also in digital affinity, attitudes toward learning technology, trust in autonomous drivingtechnology, and socio-economic characteristics (age, occupation, income, car ownership, etc.). Thesefindings suggest that ADRT is not merely a technological innovation but an integrated transportationsystem that requires a multi-layered approach reflecting users’ behavioral characteristics and perceptionlevels. The study provides foundational evidence for developing customized strategies centered on userexperience and trust-building, thereby helping future ADRT service design and policy formulationmove beyond a purely technology-centric perspective and secure both academic and policy relevance.
- COLLAPSE
최근 교통체계는 고정 노선 기반의 전통적 대중교통에서 이용자 수요에 기반한 맞춤형 이동 서비스로 전환되고 있으며, 특히 자율주행 기술이 결합된 수요응답형 대중교통(ADRT)이 새로운 대안으로 부상하고 있다. 그러나 기존 연구는 주로 기술적 효율성이나 거시적 요인 분석에 집중되어 ADRT 도입 성공의 핵심인 이용자 중심의 행태적 수용성 분석은 상대적으로 미흡했다. 본 연구는 ADRT 서비스의 잠재 이용자를 장래 이용 의향에 따라 유형화하고, 각 유형별 디지털 친화도와 기술 신뢰도의 차이를 분석하여 맞춤형 도입 전략을 제시하는 것을 목적으로 한다. 이를 위해 경기도 화성시 남양읍 리빙랩 지역 거주자 및 근로자 300명을 대상으로 설문조사를 수행하였으며, 8가지 통행 목적별 이용 의향 데이터를 기반으로 K-means 군집분석을 적용하여 5개의 잠재 수용자 군집을 도출하였다. 분석 결과, 각 군집은 통행 목적 별 장래 서비스 이용 의향뿐만 아니라 디지털 친화도, 기술 학습 태도, 자율주행 기술 신뢰도, 그리고 사회경제적 속성(연령, 직업, 소득, 차량 보유 등)에서 유의미한 차이를 나타냈다. 이는 ADRT 서비스가 단일한 기술 혁신이 아닌, 이용자의 행태적 특성과 인식 수준을 고려한 다층적 접근이 필요한 통합 교통체계임을 시사한다. 본 연구 결과는 향후 ADRT 서비스설계 및 정책 수립 시, 기술 중심적 관점에서 벗어나 이용자 경험과 신뢰 형성을 중심으로 한 맞춤형 전략 마련의 기초 자료를 제공한다는 점에서 학문적·정책적 의의를 가진다.
-
Segmenting Potential Users and Analyzing Acceptance Differences of Automated Demand-Responsive Transit: The Role of Digital Affinity and Technology Trust
-
Article
-
Predictive Model for Extinction Risk Areas with Machine Learning
머신러닝 기법을 이용한 소멸위험지역 예측모델 구축
-
KIM, Jungyeon, DO, Myungsik
김정연, 도명식
- This study aims to build a machine learning-based predictive model to identify regions in South Korea at risk of local extinction. A …
본 연구는 한국의 지방소멸위험에 처한 지역을 식별하기 위한 머신러닝 기반 예측 모델을 구축하는 것을 목표로 하며, 전국 232개 시군구를 대상으로 랜덤포레스트(Random Forest) …
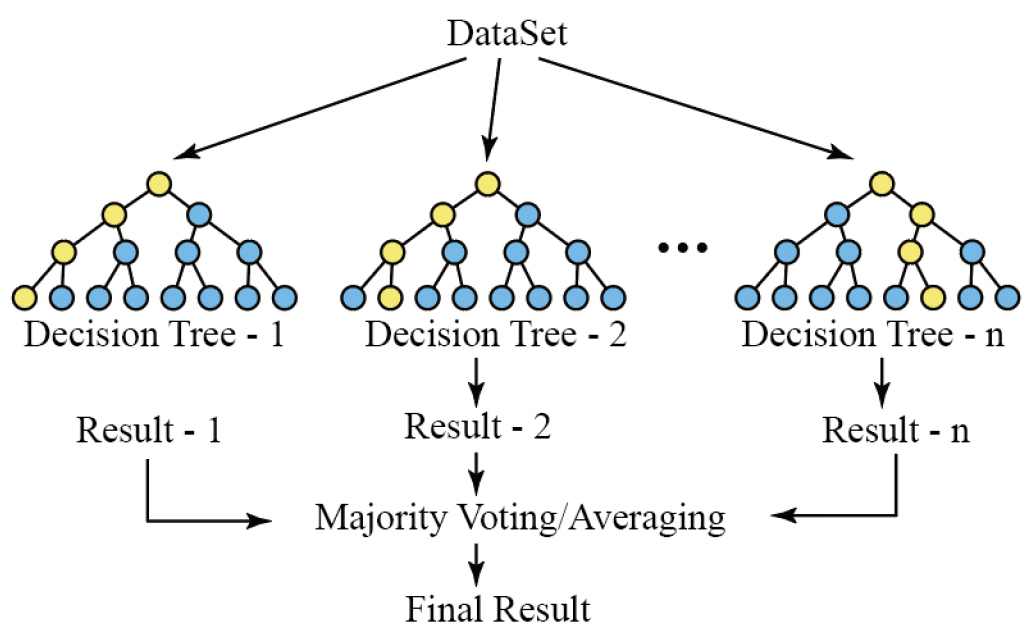
- This study aims to build a machine learning-based predictive model to identify regions in South Korea at risk of local extinction. A Random Forest algorithm was applied to data from 232 cities, counties, and districts across the country. The dependent variable, the local extinction risk index, was calculated by averaging three existing indices related to regional population decline. To ensure a comprehensive analysis, 17 independent variables were selected from six domains: population, economy and finance, housing and households, transportation, environment and health care. The dataset was divided into training and testing subsets, and hyperparameters were optimized Using 5-fold cross-validation. The model showed strong predictive performance, with an R² of 0.94 and a MAPE of 7.76%, indicating reliable generalizability. Variable importance analysis revealed that the percentage of elderly population, OD traffic volume, and GRDP were the most influential factors in predicting extinction risk. Furthermore, time-series prediction results from 2025 to 2050 showed a gradual expansion of extinction risk, particularly among small and mid-sized cities outside the capital region. By 2050, over half of the regions were predicted to fall into high-risk categories. The consistency between actual and predicted values, with differences generally within ±1 risk stage, further supported the model’s external validity. These findings suggest that the proposed model can serve as a valuable tool for supporting long-term regional policy planning. However, a limitation of this study is that only six variables were available for future projections, excluding other potentially influential factors such as social or institutional elements. Future research should consider expanding the range of forecastable variables to enhance the model’s comprehensiveness and accuracy.
- COLLAPSE
본 연구는 한국의 지방소멸위험에 처한 지역을 식별하기 위한 머신러닝 기반 예측 모델을 구축하는 것을 목표로 하며, 전국 232개 시군구를 대상으로 랜덤포레스트(Random Forest) 알고리즘을 적용하였다. 종속변수인 지방소멸위험지수는 지역 인구 감소와 관련된 세 가지 기존 지수를 활용하였으며, 인구, 경제·재정, 주택·가구, 교통, 환경, 보건, 의료 여섯 가지 분야에서 총 17개 독립변수를 이용하였다. 데이터 셋은 훈련데이트와 테스트 데이트로 나누어졌으며 하이퍼파라미터는 5겹 교차검증을 통해 최적화하였다. 그 결과, 모델의 R2값은 0.94, MAPE 값은 7.76%로 모델의 일반화 능력이 신뢰할 수 있다. 변수별 중요도 분석 결과, 고령인구비율, OD통행량, GRDP가 소멸위험예측에 가장 큰 영향을 미치는 변수로 나타났다. 또한 2025년부터 2050년까지의 시계열 예측 결과, 특히 수도권 외 중소도시에서 소멸위험지역이 확산되는 경향을 보였으며, 2050년에는 절반 이상의 지역이 고위험지역으로 분류될 것으로 예측되었다. 본 연구의 성과는 장기적인 지역 정책 계획수립에 중요한 도구로 활용될 수 있을 것으로 기대된다. 그러나 장래예측 가능한 변수들이 일부에 국한되어 있으며, 사회적 또는 제도적 요인과 같은 다른 잠재적으로 영향력 있는 요소들을 충분히 반영하지 못한 점은 한계로 남아있다.
-
Predictive Model for Extinction Risk Areas with Machine Learning
-
Article
-
An Ontology-based Method for Estimating Traffic Congestion Costs According to Autonomous Vehicle Operation
자율주행차량 운영을 통한 온톨로지 기반의 교통혼잡비용 감소방안 연구
-
KIM, Seunghyun, KIM, Jinyoung, PARK, Mingyu, KIM, Sujin
김승현, 김진영, 박민규, 김수진
- Recently, it has become possible to automatically create or expand ontologies using machine learning, natural language processing, and knowledge graphs. This helps …
최근 머신러닝과 자연어 처리, 지식그래프 등을 활용해 자동으로 온톨로지를 생성하거나 확장하는 것이 가능해졌다. 이를 통해 AI가 데이터를 더욱 효율적으로 활용하고, 복잡한 문제를 …
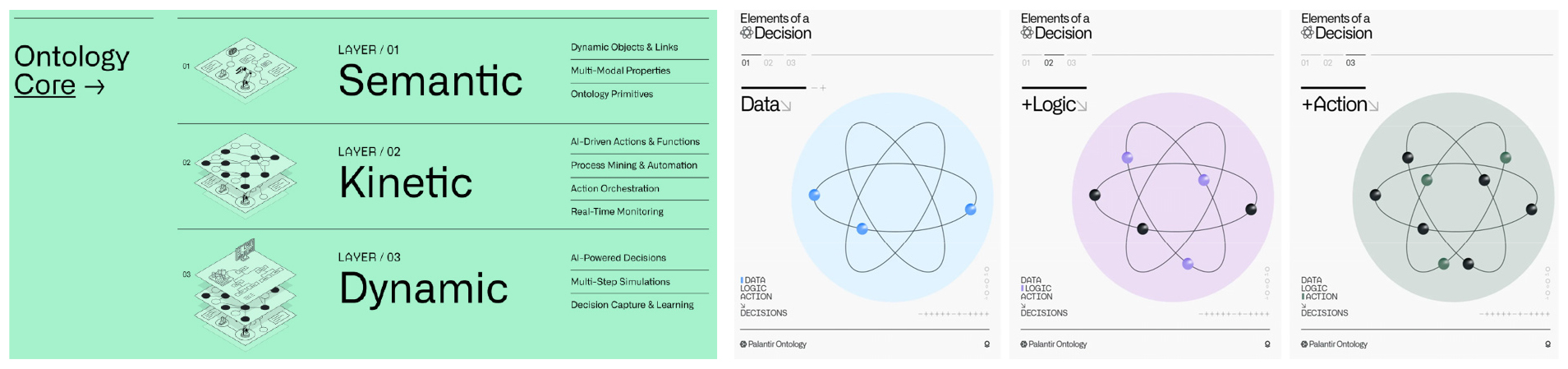
- Recently, it has become possible to automatically create or expand ontologies using machine learning, natural language processing, and knowledge graphs. This helps AI utilize data more efficiently and enhances its reasoning capabilities to solve complex problems. Ontology is an explicit formal specification of a shared conceptualization in terms of a computer engineering. In this study, we applied the 3-layer structure of semantic-kinetic -dynamic, one of the latest ontology techniques, to build a system that quantitatively calculates traffic congestion costs based on various traffic-related big data generated in the autonomous vehicle driving environment and analyzes the congestion reduction effect. For ontology design, we used the free, open-source ontology editor ‘Protégé’. The Semantic layer defines each data entity and defines its properties to calculate traffic congestion costs using the diverse data collected in autonomous vehicle environments. The Kinetic layer connects the entities and concepts defined in the Semantic layer to real-world data and defines the methods and logic for system operation. The Dynamic layer is a layer that predicts and simulates the behavior and interaction of objects, and implements the necessary functions by developing a smart mobility control system on the web. This program was used to structure data on traffic volume, speed, signal operation, and optimal routes, and to systematically define data flow and decision rules between systems. This provided an analytical framework for quantitatively and visually assessing the dynamic interactions that could occur in autonomous vehicle-based traffic operations. This study analyzed the results of the ‘Autonomous driving technology development innovation project’ test-bed installed in Siheung City and found that it reduced traffic congestion costs by approximately 20% compared to existing commercialized navigation guidance routes.
- COLLAPSE
최근 머신러닝과 자연어 처리, 지식그래프 등을 활용해 자동으로 온톨로지를 생성하거나 확장하는 것이 가능해졌다. 이를 통해 AI가 데이터를 더욱 효율적으로 활용하고, 복잡한 문제를 해결하는 추론 능력을 강화하도록 돕고 있다. 온톨로지는 컴퓨터 공학적 관점에서 일반적으로 개념화된 것을 형식적으로 명백하게 기술하는 명세라고 정의할 수 있다. 본 연구에서는 최신 온톨로지 기법중의 하나인 시맨틱–키네틱–다이내믹의 3-레이어 구조를 적용해 자율주행차 운행환경에서 발생하는 다양한 교통관련 빅데이터를 기반으로 교통혼잡비용을 정량적으로 산출하여 혼잡감소 효과를 분석하는 시스템을 구축하였다. 온톨로지 설계를 위해 무료 오픈소스 온톨로지 편집기인 ‘Protégé’ 프로그램을 사용하였다. 시멘틱 레이어는 논리적 추상화 계층으로 개체 또는 데이터가 무엇이며 어떻게 연관되어 있는지를 분석한다. 키네틱 레이어는 실행 및 동작 계층으로 데이터가 모델에 매핑되는 방식을 결정한다. 다이나믹 레이어는 개체의 동작 및 상호작용 방식을 예측하고 시뮬레이션하고, 웹 기반 스마트모빌리티 관제시스템을 구현해 필요한 기능을 구현하는 계층이다. 이를 활용해 교통량, 속도, 신호운영 및 최적경로 데이터를 구조화하고 시스템 간 데이터 흐름 및 의사결정 규칙을 체계적으로 정의하였다. 이를 통해 자율주행차 기반 교통운영 환경에서 발생 가능한 동적 상호작용을 정량적, 시각적으로 평가할 수 있는 분석 프레임워크를 마련하였다. 본 연구를 통해 시흥시에 설치된 자율주행기술개발혁신사업 테스트베드 실증결과 기존의 상용화된 네비게이션 안내경로 대비 약 20%의 교통혼잡비용 절감 효과가 나타나는 것으로 분석되었다.
-
An Ontology-based Method for Estimating Traffic Congestion Costs According to Autonomous Vehicle Operation
-
Article
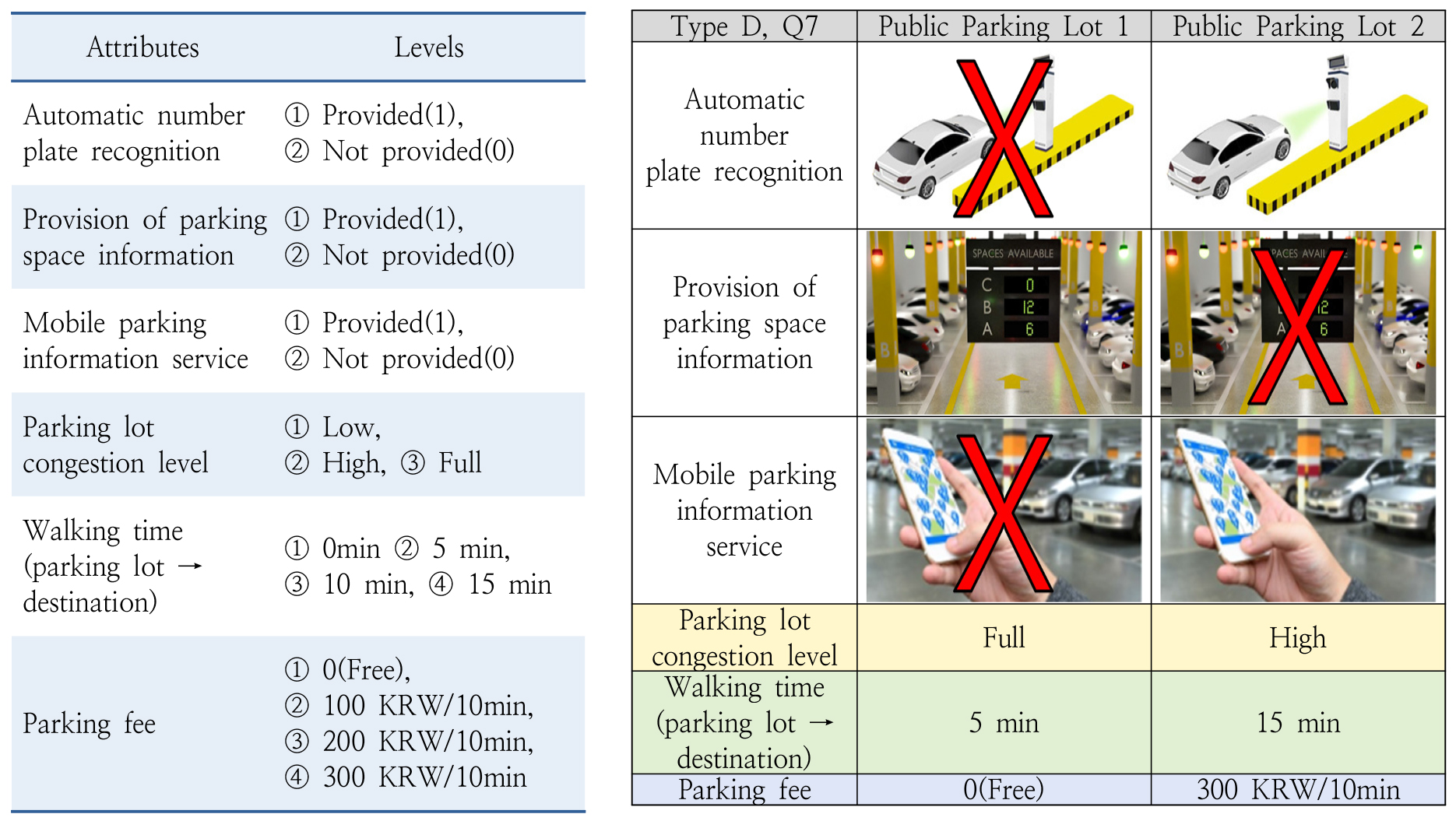
-
Preferences and Willingness to Pay for the Smart Parking System Attributes in Public Parking Lots: A Discrete Choice Experiment in Gyeonggi
공영주차장 스마트주차시스템 속성별 선호와 지불의사액 추정: 경기도 이용자 이산선택실험
-
KIM, Jeong-Min, LEE, Hoyoung, CHO, Shin-Hyung, KIM, Jooyoung
김정민, 이호영, 조신형, 김주영
- Rapid urbanization has intensified traffic congestion, increased parking demand, and raised land costs, making the efficient operation of public parking facilities a …
최근 도시의 교통혼잡 심화, 주차 수요 증가, 토지비용 상승으로 인해 공영주차장의 효율적 운영 방안 모색이 중요한 정책 과제로 부상하고 있으며, 특히 디지털 …
- Rapid urbanization has intensified traffic congestion, increased parking demand, and raised land costs, making the efficient operation of public parking facilities a critical urban policy challenge. Smart Parking Systems (SPS) have been promoted as an effective solution; however, their adoption in Korea remains limited. Moreover, conventional economic feasibility analyses of public parking projects tend to focus primarily on external traffic-related benefits, while overlooking improvements in user convenience within parking facilities. This study addresses this gap by examining user preferences and Willingness to Pay (WTP) for key SPS attributes among public parking users in Gyeonggi Province, Korea. The primary objective is to provide empirical evidence supporting the inclusion of service quality improvements in the benefit structure of public parking project evaluations. A Discrete Choice Experiment was conducted, and a Conditional Logit Model was employed to estimate attribute-specific utility parameters and corresponding WTP values. The results indicate that reductions in internal parking congestion, measured by parking search time, exert the strongest influence on user choice and WTP. In addition, shorter walking distances to final destinations and the provision of SPS services generate statistically significant positive utility. Among individual SPS components, Automatic Number Plate Recognition yields the highest WTP, followed by mobile parking information services and real-time parking availability information. An extended model further reveals that users traveling for commuting or transfer purposes exhibit higher preferences for SPS attributes. These findings demonstrate that user convenience benefits derived from SPS implementation should be incorporated into the benefit–cost analysis of public parking projects, alongside external benefits such as traffic flow improvements. From a policy perspective, the results provide a basis for prioritizing and phasing the introduction of Smart Parking Systems in public parking facilities.
- COLLAPSE
최근 도시의 교통혼잡 심화, 주차 수요 증가, 토지비용 상승으로 인해 공영주차장의 효율적 운영 방안 모색이 중요한 정책 과제로 부상하고 있으며, 특히 디지털 기술의 발전과 함께 스마트주차시스템이 주차장 운영 효율성 및 이용 편의성을 제고하는 방안으로 주목받고 있다. 그러나 국내 공영주차장에는 스마트주차시스템 도입이 아직 제한적인 수준이며, 관련 투자사업의 경제성 분석 시 주차장 이용 편의성 개선 효과는 편익 항목으로 충분히 반영되지 못하고 있다. 이에 본 연구는 경기도 공영주차장 이용자를 대상으로 스마트주차시스템의 주요 속성에 대한 선호와 지불의사액을 분석하고, 향후 공영주차장 투자사업의 경제성 분석에서 이를 편익으로 반영할 가능성을 검토하였다. 이를 위해 이산선택실험을 설계하고 온라인 설문조사를 통해 자료를 수집하였으며, 조건부 로짓모형을 활용하여 속성별 효용계수와 지불의사액을 추정하였다. 분석 결과, 주차장 내부 혼잡수준 완화가 이용자의 선택 확률과 지불의사액에 가장 큰 영향을 미치는 요인으로 나타났으며, 주차 후 최종목적지까지 보행시간 단축과 스마트주차시스템 제공 여부 또한 유의미한 수준의 선호 및 지불의사액이 확인되었다. 스마트주차시스템 속성별 지불의사액은 차량번호 자동인식, 모바일 주차정보, 주차공간 정보제공 순으로 높았으며, 개인특성을 반영한 확장모형에서는 업무 통근 및 환승 목적 이용자가 일부 스마트주차시스템 속성에 상대적으로 더 높은 가치를 부여하는 경향이 확인되었다. 이러한 결과는 차량 통행 개선과 같은 외부 효과뿐만 아니라 스마트주차시스템 제공 등 주차장 이용 편의성 개선 효과가 공영주차장 사업의 경제성 분석에서 편익으로 반영될 필요가 있음을 시사하며, 향후 스마트주차시스템 단계적 도입 시 투자 우선순위를 설정하는 정책적 근거로도 활용될 수 있다.
-
Preferences and Willingness to Pay for the Smart Parking System Attributes in Public Parking Lots: A Discrete Choice Experiment in Gyeonggi
-
Article
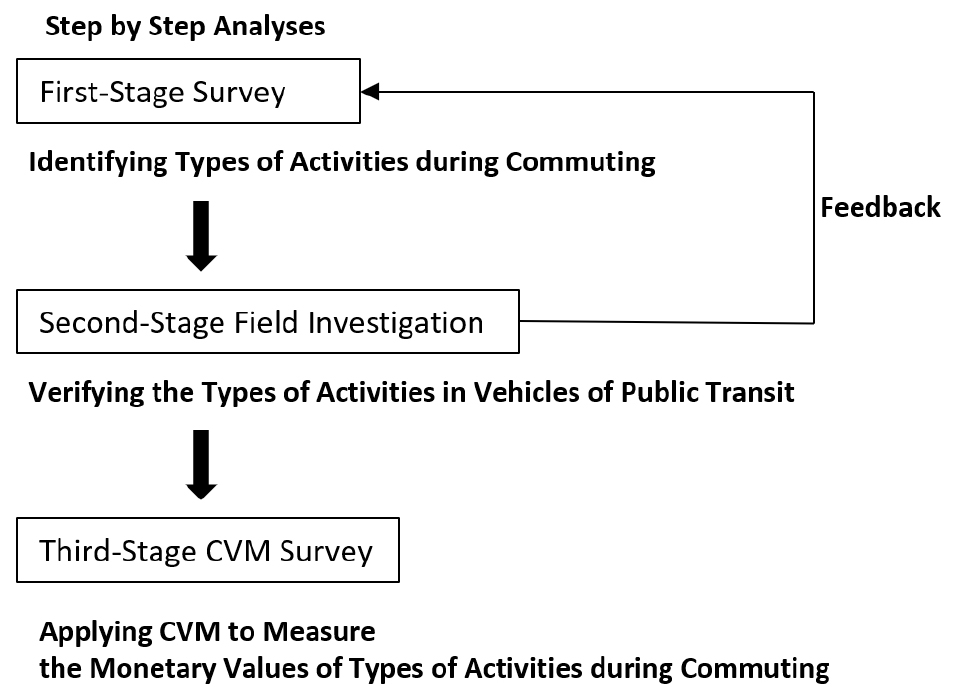
-
Predicting Monetary Value of Activities during Commuting
통행 중 활동의 금전적 가치 추정 연구
-
YI, Chang, JEONG, Sangmi, KIM, Youngbeom
이창, 정상미, 김영범
- Transportation planners consider travel as derived demand to execute various activities at destinations. Here what is important is ‘activity’. Travel is just …
교통계획 분야에서는 통행을 목적지에서의 활동을 수행하기 위해 발생하는 ‘파생수요’로 간주한다. 이러한 관점에서 통행시간은 기회비용으로 이해된다. 따라서 새로운 교통 인프라를 구축할 때의 주된 …
- Transportation planners consider travel as derived demand to execute various activities at destinations. Here what is important is ‘activity’. Travel is just a necessary act to perform the activity. Thus travel time is considered an opportunity cost, a time that is wasted. In that respect, the ultimate objective of building a new transport infrastructure is to shorten travel time. However, since everybody owns and uses smart phones these days, whether travelers can find some utilities while doing a range of activities during travel (such as reading news, watching dramas and listening to music) is controversial. In particular, if there are people who study or work during commuting, it means that commuting time can be productively used. That goes against the traditional assumption in transportation field that travel time is an opportunity cost. This study predicts monetary values of activities during commuting. Using the Contingent Valuation Method (CVM), the authors asked 1,000 residents of Seoul as to what they did while traveling to work and how much they would pay to continue their activities during commuting. Our analysis predicts that drivers, subway users and bus riders are willing to pay for 9,278, 7,963 and 5,475 Won/hour·month, respectively. For instance, a person who commutes for 2 hours every day using subway would be willing to pay for 16,000 Won a month. This result provides a useful information and insight to evaluate current transportation policies.
- COLLAPSE
교통계획 분야에서는 통행을 목적지에서의 활동을 수행하기 위해 발생하는 ‘파생수요’로 간주한다. 이러한 관점에서 통행시간은 기회비용으로 이해된다. 따라서 새로운 교통 인프라를 구축할 때의 주된 목표는 시민들의 통행시간을 단축하는 것이다. 물론 통행시간은 단축되는 것이 바람직하지만 통행시간이 단순히 기회비용이라는 가정에는 의문이 제기될 수 있다. 이를테면 통행자들은 대중교통이나 승용차로 이동 중에 뉴스 읽기, 드라마 시청, 음악 감상은 물론 공부나 업무까지 다양한 활동을 수행하고 있다. 이 연구는 통근 및 등하교 통행을 대상으로 통행 중 활동의 금전적 가치를 추정하였다. 조건부가치측정법(CVM)을 활용하여 서울 거주자 1,000명을 대상으로 출근길에 어떤 활동을 하는지, 그리고 이동 중 수행하는 다양한 활동에 얼마를 지불할 의향이 있는지 조사했다. 분석 결과, 1시간 통행 중 활동에 운전자는 매월 9,278원, 지하철 이용자는 7,963원, 버스 이용자는 5,475원을 지불할 의향이 있는 것으로 나타났다. 이 연구의 결과는통행 중 활동의 금전적 가치를 추정하여 통행시간 개념에 관한 새로운 시각을 제공한다. 본 연구 결과를 바탕으로 후속연구에서는 자율주행 차량 등에 관한 심도있는 논의가 가능할 것이라 기대한다.
-
Predicting Monetary Value of Activities during Commuting
-
Article
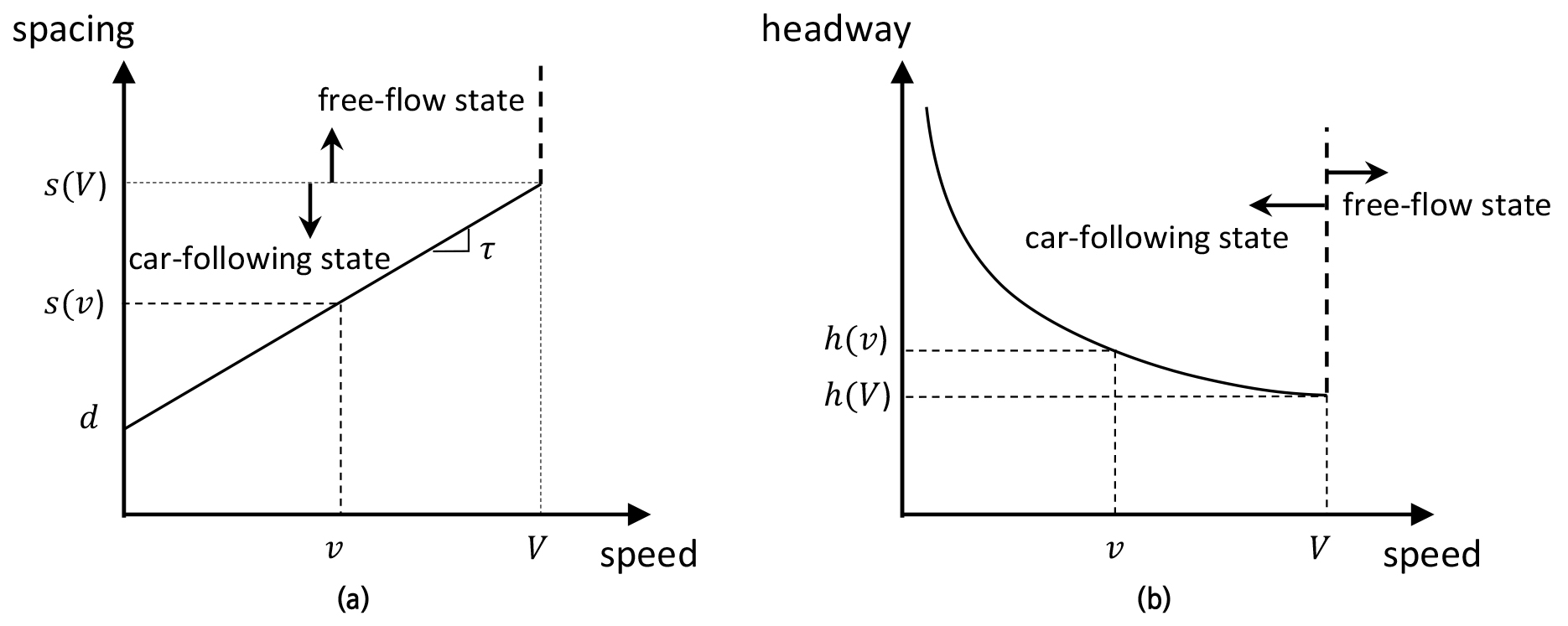
-
How Traffic Congestion Affects Driver Behavior: An Empirical Analysis Using Drone Data
교통 혼잡이 운전자 행동에 미치는 영향: 드론 데이터 기반 실증 연구
-
HAN, Youngjun, LEE, Jinhak
한영준, 이진학
- This study investigates changes in driver characteristics as a result of experiencing traffic congestion. Novel vehicle trajectory data were generated from drone …
이 연구는 교통 혼잡을 경험하면서 운전자 특성이 어떻게 변화하는지를 실증적으로 분석하였다. 교통 혼잡이 발생하는 시점을 드론으로 촬영하여 개별 차량의 궤적 데이터를 구축하고, …
- This study investigates changes in driver characteristics as a result of experiencing traffic congestion. Novel vehicle trajectory data were generated from drone videos that captured the onset of traffic breakdown, and an extended Newell’s car-following model adopting the dynamic driver characteristics was applied to describe the drivers’ response to traffic disturbances. Notably, this study compares two distinct sites where traffic flow evolves from a free-flow and a congested state, respectively, to identify behavioral differences across conditions. The results show that drivers generally maintain larger headways after experiencing congestion, indicating a change in driver characteristics toward more timid behavior. This behavioral change is more pronounced when the traffic initially evolves from a free flow state. Furthermore, the degree of characteristic change is positively correlated with the severity of congestion. These microscopic features of car-following behavior contribute to a diminished discharge rate following congestion, thus providing a microscopic explanation linking a macroscopic capacity drop phenomenon.
- COLLAPSE
이 연구는 교통 혼잡을 경험하면서 운전자 특성이 어떻게 변화하는지를 실증적으로 분석하였다. 교통 혼잡이 발생하는 시점을 드론으로 촬영하여 개별 차량의 궤적 데이터를 구축하고, 가변적인 운전자 특성을 반영한 확장된 Newell 차량추종모형을 적용하여 교통 혼잡에 대한 운전자 반응을 분석하였다. 특히, 교통류가 자유류 상태에서 혼잡 상태로 전이되는 지점과 이미 혼잡 상태에서 혼잡이 심화되는 지점을 비교함으로써, 기존 교통 상태에 따른 운전자 행태의 차이를 규명하고자 하였다. 분석 결과, 운전자는 혼잡을 경험한 이후 전반적으로 더 큰 차두거리를 유지하는 경향을 보였는데, 이는 운전자의 특성이 보다 보수적인 방향으로 변화함을 의미한다. 이러한 행동 변화는 교통류가 자유류 상태에서 혼잡 상태로 전이되는 경우에 더욱 뚜렷하게 나타났으며, 운전자 특성 변화 정도는 혼잡의 심각도와 양의 상관관계를 가지는 것으로 나타났다. 이러한 차량추종 행태의 미시적 특성은 혼잡 발생 이후 통과교통량 감소로 이어지며, 거시적 관점에서 관측되는 용량 감소(capacity drop) 현상을 설명하는 미시적 근거를 제공한다.
-
How Traffic Congestion Affects Driver Behavior: An Empirical Analysis Using Drone Data
-
Article
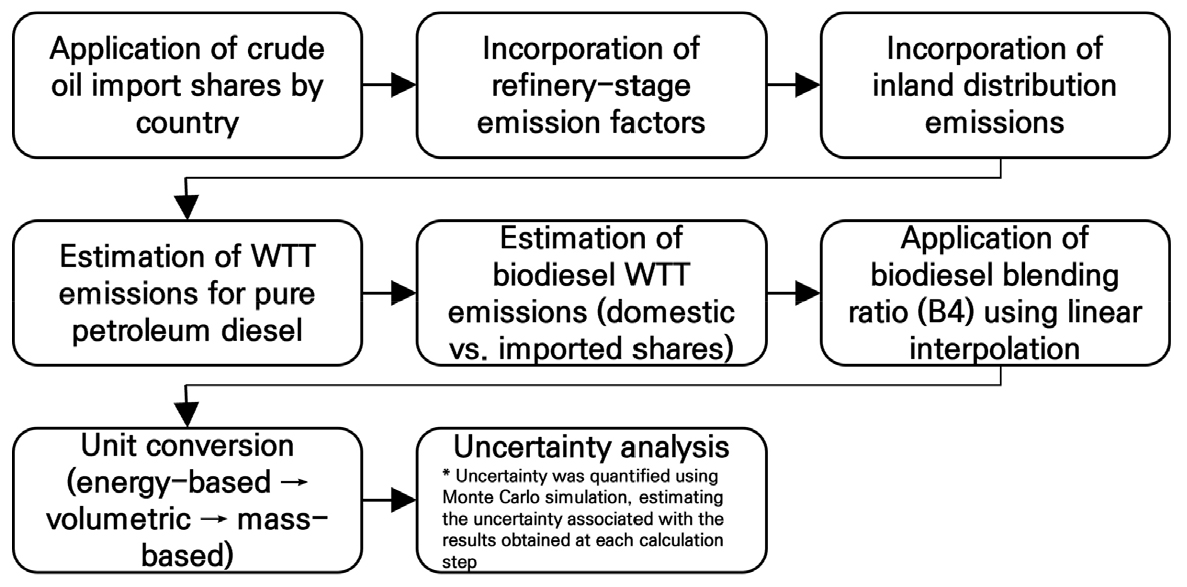
-
Estimation of Well-to-Wheel Greenhouse Gas Emission Factors for Road Freight Transport in Korea Considering Freight Transport Characteristics
한국 화물 운송 특성을 고려한 연료 전과정 (Well-to-Wheel) 온실가스 배출계수 산정 연구
-
OH, Gwanyong, KIM, Sung Min, KANG, Deokho, LEE, Soongbong, LEE, Jonghak, KIM, Daejin
오관용, 김성민, 강덕호, 이숭봉, 이종학, 김대진
- This study develops a Korea-specific Well-to-Wheel (WTW) greenhouse gas emission factor framework for the road freight transport sector by integrating emissions from …
본 연구는 국내 도로 화물운송 부문을 대상으로 연료의 생산·공급 단계와 차량 운행 단계를 통합한 전주기(Well-to-Wheel, WTW) 기반 온실가스 배출계수 체계를 구축하는 것을 …
- This study develops a Korea-specific Well-to-Wheel (WTW) greenhouse gas emission factor framework for the road freight transport sector by integrating emissions from fuel production and supply with vehicle operation. Previous inventories and studies have mainly focused on Tank-to-Wheel (TTW) emissions, insufficiently accounting for upstream emissions related to crude oil sourcing, refining, and fuel distribution, as well as logistical characteristics such as load factors and empty running. To address these limitations, this study follows international standards, including the GLEC Framework and ISO 14083, while incorporating Korea-specific conditions. Well-to-Tank (WTT) emission factors were estimated by reflecting country-specific crude oil import shares, domestic refinery efficiency, and the mandatory biodiesel blending ratio (B4). TTW emission factors were derived using real-driving emission data. Transport activity–based WTW emission intensity (gCO2e/t·km) was then calculated by incorporating vehicle-class fuel use, driving distance, load factors, and empty running ratios. The results show that WTW emission intensity is strongly influenced by logistical efficiency as well as fuel efficiency. The proposed framework provides a practical basis for policy evaluation and corporate ESG and Scope 3 emission management.
- COLLAPSE
본 연구는 국내 도로 화물운송 부문을 대상으로 연료의 생산·공급 단계와 차량 운행 단계를 통합한 전주기(Well-to-Wheel, WTW) 기반 온실가스 배출계수 체계를 구축하는 것을 목적으로 한다. 기존 국가 온실가스 인벤토리와 선행연구는 주로 차량 운행단계(Tank-to-Wheel, TTW)에 초점을 두어, 원유 도입 구조, 정유 공정, 연료 유통 과정에서 발생하는 간접 배출을 충분히 반영하지 못하였다. 또한 적재율과 공차율 등 화물운송의 물류적 특성이 배출량 산정에 체계적으로 고려되지 않았다. 이에 본 연구는 국제 기준(GLEC Framework, ISO 14083)을 준용하되, 한국의 원유 수입 구조, 정유 효율, 바이오디젤 혼합 의무비율(B4)을 반영한 한국형 WTT 배출계수를 산정하고, 실주행 배출가스 자료를 활용한 TTW 배출계수 산정 방법을 제시하였다. 나아가 차종별 연료 사용량, 주행거리, 적재율 및 공차율을 반영하여 운송활동량(t·km) 기준 WTW 배출강도를 도출하였다. 분석 결과, 차종별 WTW 배출강도는 연비뿐만 아니라 물류 효율에 의해 크게 좌우되는 것으로 나타났다. 본 연구는 정책 평가와 기업의 ESG·Scope 3 배출 관리에 활용 가능한 한국형 전주기 배출계수 체계를 제시한다는 점에서 의의가 있다.
-
Estimation of Well-to-Wheel Greenhouse Gas Emission Factors for Road Freight Transport in Korea Considering Freight Transport Characteristics
-
Article
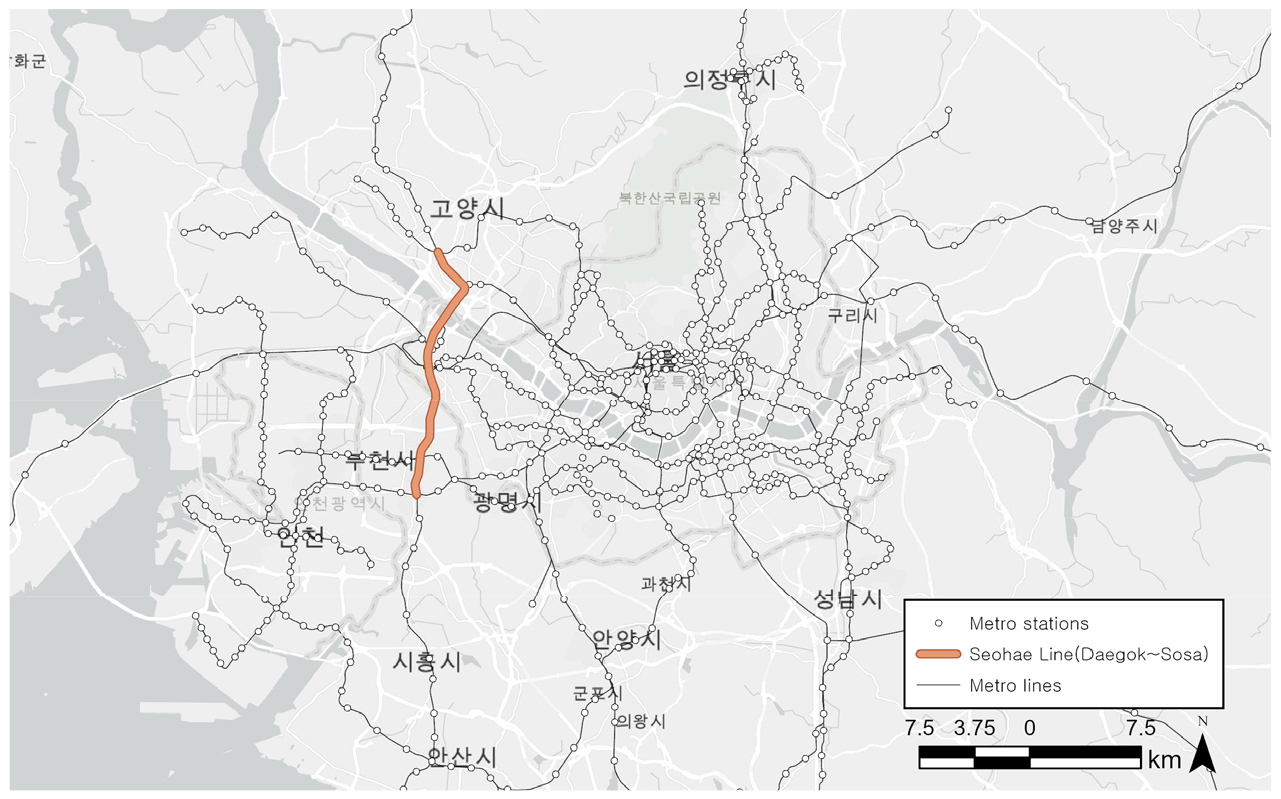
-
Determinants of Accessibility Changes Before and After the Opening of the Seohae Line(Daegok–Sosa): Network Centrality Measures and Spatial Regression Analysis
서해선(대곡~소사) 개통 전후 접근성 변화량의 결정요인 분석: 네트워크 중심성 및 공간회귀 활용
-
JANG, Seunghwa, KIM, Taewoo, KIM, Saehim, KO, Joonho
장승화, 김태우, 김새힘, 고준호
- This study analyzes the impacts of the introduction of a new urban rail line on public transport network structure and station-level accessibility …
본 연구는 수도권 광역철도 서해선(대곡~소사) 개통을 사례로 신규 도시철도 노선 도입이 대중교통 네트워크 구조와 도시철도 역 접근성에 미치는 영향을 교통 네트워크 관점에서 …
- This study analyzes the impacts of the introduction of a new urban rail line on public transport network structure and station-level accessibility from a transport network perspective, using the opening of the Seohae Line (Daegok~Sosa) in the Seoul Metropolitan Area as a case study. While previous studies have focused on changes in ridership performance at individual stations or along specific lines, this study considers both network structural changes and the spatial diffusion of accessibility improvement effects. To this end, rail networks before and after the opening of the Seohae Line are constructed using GTFS-based actual operational information, and network centrality measures, including betweenness centrality, along with a 60-minute cumulative opportunity accessibility indicator, are derived. In addition, spatial regression models are applied to analyze the spatial dependence and spillover effects of accessibility changes. The results show that the opening of the Seohae Line restructured the public transport network in the western Seoul metropolitan area and generated accessibility improvement effects. In particular, areas accessible within 30 minutes to the new line and changes in betweenness centrality within the network had significant impacts on accessibility improvement, and these effects exhibited spatial spillovers to neighboring areas. These findings suggest that the impacts of urban rail openings extend beyond individual station areas and can reshape regional accessibility patterns by altering network connectivity and potential mobility opportunities. The results further indicate that accessibility change analysis may support metropolitan transport planning by informing network-level decision-making, including route evaluation, transfer hub consideration, and integrated feeder service planning. This study provides academic and policy implications by demonstrating urban rail opening effects at the network level through the integration of GTFS-based network analysis and spatial econometric models.
- COLLAPSE
본 연구는 수도권 광역철도 서해선(대곡~소사) 개통을 사례로 신규 도시철도 노선 도입이 대중교통 네트워크 구조와 도시철도 역 접근성에 미치는 영향을 교통 네트워크 관점에서 분석한다. 기존 연구가 개별 역이나 노선의 수송 실적 변화에 초점을 맞추어왔으나 본 연구는 네트워크 구조 변화와 접근성 개선 효과의 공간적 전이를 함께 고려한다. 이를 위해 서해선 개통 전후의 GTFS 기반 실제 운행 정보를 활용하여 철도 네트워크를 구축하고 매개중심성을 포함한 네트워크 중심성 지표와 60분 누적 기회 접근성 지표를 산출하였다. 또한 공간회귀모형을 적용하여 접근성 변화의 공간적 상호의존성과 파급효과를 분석하였다. 분석 결과, 서해선 개통은 수도권 서부권역의 대중교통 네트워크 구조를 재편하며 접근성 개선 효과를 유발한 것으로 나타났다. 특히 신규 노선에 30분 이내로 접근가능한 지역과 네트워크 내 매개중심성 변화가 접근성 개선에 유의미한 영향을 미쳤으며 이러한 효과는 인접 지역으로 확산되는 공간적 파급효과를 보였다. 이러한 결과는 도시철도 개통 효과가 개별 역세권 수준의 변화에 국한되지 않고 네트워크 연결 구조의 재편을 통해 권역 전반의 잠재적 이동 기회를 변화시킬 수 있음을 시사한다. 또한 접근성 변화 분석이 향후 광역교통망 계획 과정에서 노선 검토, 환승 거점 고려, 연계 교통 서비스 평가 등 네트워크 차원의 계획 의사결정을 지원하는 분석적 근거로 활용될 수 있음을 보여준다. 본 연구는 GTFS 기반 네트워크 분석과 공간계량모형을 결합하여 도시철도 개통 효과를 네트워크 차원에서 규명하였다는 점에서 학술적·정책적 시사점을 제공한다.
-
Determinants of Accessibility Changes Before and After the Opening of the Seohae Line(Daegok–Sosa): Network Centrality Measures and Spatial Regression Analysis
-
Article
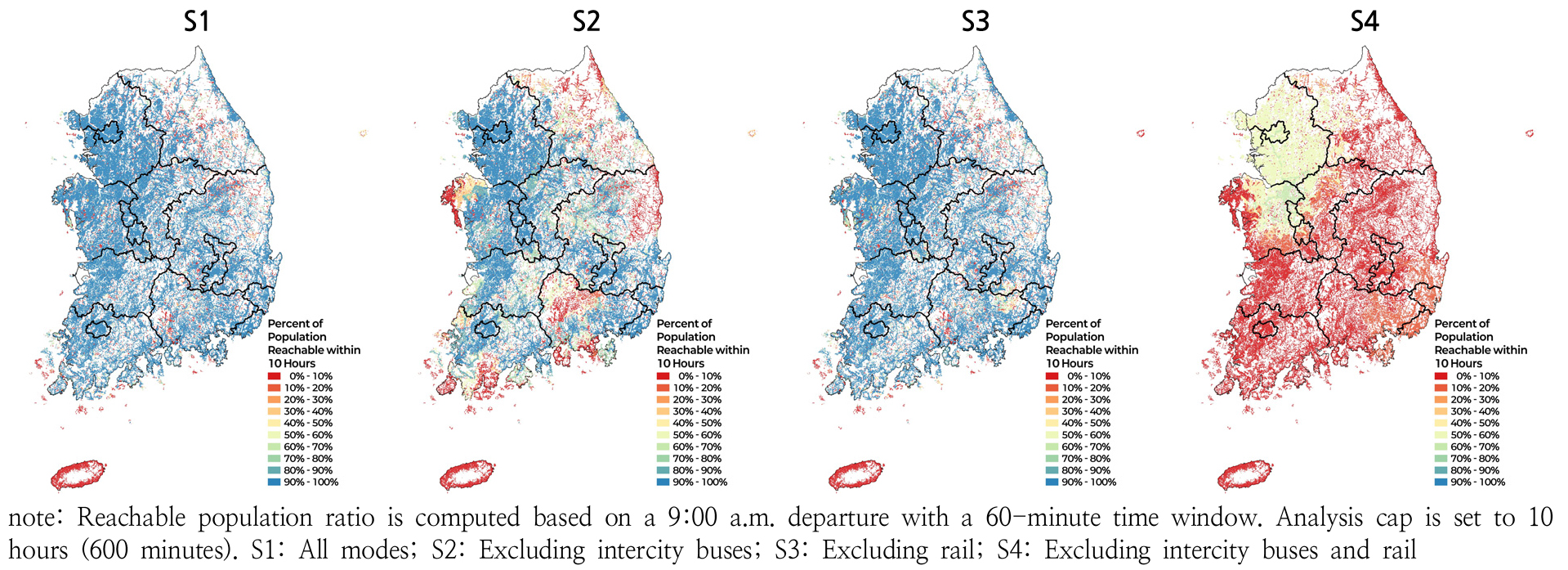
-
GTFS-Based Changes and Spatial Inequality in Interregional Public Transport Mobility-Based Accessibility: A Counterfactual Analysis of Rail and Intercity Bus Removal (2019–2024)
GTFS 기반 지역 간 대중교통 이동성 기반 접근성의 변화와 공간적 불균등성: 지역 간 수단 가상 제거 분석(2019–2024)
-
JANG, Dongik, HONG, Dahee
장동익, 홍다희
- This study examines changes in interregional public transport mobility in South Korea between 2019 and 2024 using nationwide General Transit Feed Specification …
본 연구는 2019–2024년 전국 General Transit Feed Specification(GTFS) 자료를 활용하여 지역간 대중교통 이동성의 변화를 분석하였다. 이동성 기반 접근성(mobility-based accessibility)은 대중교통으로 일정 시간 …
- This study examines changes in interregional public transport mobility in South Korea between 2019 and 2024 using nationwide General Transit Feed Specification data. Rather than measuring accessibility to specific facilities or activities, the study adopts a mobility-based accessibility approach, defining mobility-based accessibility as the share of the national population reachable by public transport within a given travel-time threshold. The analysis is conducted at a 500m × 500m grid level using Statistics Korea’s spatial grid system. Travel times are computed with the R5 routing engine via the r5r package, assuming a 9:00 a.m. departure with a 60-minute sampling window, accounting for scheduled services, transfers, and multimodal connections. Travel-time thresholds of 2.5 and 6.5 hours are empirically derived as the population-weighted median travel times of intra- and inter-municipal trips, respectively. To assess the structural role of different transport modes, a set of counterfactual scenarios is designed in which intercity buses and rail services are selectively excluded from the network. Air transport is excluded from the analysis due to its distinct network structure and usage characteristics in interregional travel. Results show that interregional public transport mobility declined overall during the study period, with substantial spatial heterogeneity. In 2024, the national average reachable population ratio under the full-mode scenario reached 83.9% within 10 hours, dropping sharply to 18.4% when both modes were excluded. The exclusion of rail services leads to the largest reduction at the 6.5-hour threshold (mean slope: -0.889 %p/year), highlighting the critical role of rail in maintaining long-distance mobility. Intercity bus services play a complementary role, but travel-time threshold curve analysis reveals their disproportionate importance in depopulation areas: when intercity buses are excluded, the median reachable population ratio in depopulation areas drops sharply to 16.8% at the 6.5-hour threshold, compared to 83.1% in non-depopulation areas. At the 6.5-hour threshold, the risk of extreme accessibility decline is disproportionately concentrated in depopulation areas (Extreme OR: 22.79), while an OR below 1 at the 2.5-hour threshold reflects a floor effect. These findings demonstrate that mobility losses tend to be concentrated in structurally vulnerable areas, with implications for regional equity and transport policy.
- COLLAPSE
본 연구는 2019–2024년 전국 General Transit Feed Specification(GTFS) 자료를 활용하여 지역간 대중교통 이동성의 변화를 분석하였다. 이동성 기반 접근성(mobility-based accessibility)은 대중교통으로 일정 시간 이내 도달 가능한 인구 규모를 전국 총 인구 대비 비율로 정의하였으며, 국가데이터처 500m×500m 공간격자 단위에서 R5 라우팅 엔진을 활용하여 산정하였다. 출발시각은 오전 9시 기점 60분 타임 윈도우 내 중앙값을 적용하였고, 시간 임계치는 시군구 단위 지역내·지역간 통행시간의 인구 가중 중앙값을 기준으로 2.5시간과 6.5시간으로 설정하였다. 수단별 구조적 역할을 평가하기 위해 고속·시외버스와 철도를 단계적으로 제외하는 가상 제거 실험을 설계하였다. 분석 결과, 해당 기간 동안 지역간 대중교통 이동성은 전반적으로 감소하였으며 그 영향은 공간적으로 불균등하게 나타났다. 철도 제외 시 도달 가능 인구 비율의 감소가 가장 크게 나타났는데(평균 기울기 –0.889%p/년), 이는 고속·시외버스가 지역간 이동을 전적으로 담당해야 하는 가상 상황에서 팬데믹 이후 고속·시외버스 공급 축소가 이동성 악화로 직결되었음을 보여준다. 고속·시외버스는 전반적인 기여도는 제한적이나, 철도역 접근이 어려운 인구감소지역에서는 사실상 핵심 연결 수단으로 기능하는 것으로 나타났다. 고속·시외버스 제외 시 6.5시간 기준 인구감소지역의 도달 가능 인구 비율 중앙값이 16.8%로 급감하여 비인구감소지역(83.1%)과의 격차가 두드러졌다. 본 연구는 GTFS 기반 이동성 지표와 가상 제거 실험을 결합하여 지역간 대중교통 이동성의 구조적 특성과 공간적 불균등성을 실증적으로 분석하였다는 점에서 의의를 가지며, 향후 지역 균형 및 대중교통 정책 수립을 위한 기초자료를 제공한다.
-
GTFS-Based Changes and Spatial Inequality in Interregional Public Transport Mobility-Based Accessibility: A Counterfactual Analysis of Rail and Intercity Bus Removal (2019–2024)

Journal Informaiton
 Journal of Korean Society of Transportation
Journal of Korean Society of Transportation
Journal of Korean Society of Transportation








Korean Society of Transportation
대한교통학회
Room 809, The Korea Science & Technology Center, 22,Teheran-ro 7 gil, Kangnam-Ku, Seoul 06130, KOREA
Tel: +82-2-564-9201-2 / Fax: +82-2-564-9203 / E-mail: journal@kst.or.kr Copyright© Korean Society of Transportation. Powered by APUB
대한교통학회
Room 809, The Korea Science & Technology Center, 22,Teheran-ro 7 gil, Kangnam-Ku, Seoul 06130, KOREA
Tel: +82-2-564-9201-2 / Fax: +82-2-564-9203 / E-mail: journal@kst.or.kr Copyright© Korean Society of Transportation. Powered by APUB